
 The W3C Internationalization (I18n) Activity works with W3C working groups and liaises with other organizations to ensure Web technologies work for everyone, regardless of their language, script, or culture.
The W3C Internationalization (I18n) Activity works with W3C working groups and liaises with other organizations to ensure Web technologies work for everyone, regardless of their language, script, or culture.
From this page you can find articles and other resources about Web internationalization, and information about the groups that make up the Activity.
Read also about opportunities to participate and fund work via the new Sponsorship Program.
What the W3C Internationalization Activity does
Selected quick links
Selected quick links
Selected quick links
WEB I18N GAP FIXED: Upright alphanumerics in vertically-set text

By default, in runs of Latin alphanumeric text the letters are rotated 90º and run down the page. However, in some instances the alphanumerics need to stand upright. For example, this is important for acronyms.
This is now supported, using CSS, in all 3 major browser engines.
See the Gap report.
New translations into French
L’indicateur d’ordre des octets (BOM) en HTML (The byte-order mark (BOM) in HTML)
Les langues qui s’écrivent de droite à gauche (Languages using right-to-left scripts)
Thanks to Gwendoline Clavé, Clavoline Traduction for providing these translations.
First Public Working Draft: Korean Layout Gap Analysis
This document describes and prioritises gaps for the support of Korean language on the Web and in eBooks. In particular, it is concerned with text layout. It checks that needed features are supported in W3C specifications, in particular HTML and CSS and those relating to digital publications. It also checks whether the features have been implemented in browsers and ereaders. This is a preliminary analysis.
The first public working draft is published to encourage users and experts to review the information it currently contains, and provide any additional information that may be relevant to supporting users of the Korean language on the Web.

We are looking for expert contributors who can help us move this work forward by answering questions, documenting other gaps in support, and creating tests. For more information about the program, see this 15 minute overview (slides), and see the Language Enablement overview page.
Updated: Ready-made Counter Styles

The Ready-made Counter Styles document provides ready-made definitions for counter styles and covers the needs of a range of cultures around the world. The code snippets provided in the document can be included in style declarations by simply copying and pasting, or they can be use as a starting point and modified as desired.
This update brings the total number of style templates to 177, covering 44 writing systems.
Substantial changes were also made to the styling and presentation. Each template is now accompanied by a set of examples, as well as an icon that copies the template to your clipboard in a single click. Another icon points to MDN’s roundup of browser support for named styles. Extensions to cover affix variants are now expressed in terms of the extends syntax.
Fixes were applied for tai-lue and warang-citi styles.
Finally, a button is provided to allow you to turn off all counter styling for the examples. That then allows you to see which styles have built-in support in the browser you are using.
WEB I18N GAP PROGRESS: N’Ko Unjoined font

Noto N’Ko Unjoined fonts in regular and bold are now available, making it possible to create unjoined headings in text.
WEB I18N GAP FIXED: N’Ko tone marks

N’Ko tone marks are now all at the same height in the Noto fonts as well as Ebrima and Kigelia.
First Public Working Draft: NʼKo Layout Requirements
This document describes requirements for the layout and presentation of text in the N’Ko script when used by Web standards and technologies, such as HTML, CSS, Mobile Web, Digital Publications, and Unicode. It is developed in conjunction with a document which summarizes gaps in Gurmukhi support on the Web and eBook technologies.
The first public working draft is published to encourage users and experts to review the information it currently contains, and provide any additional information that may be relevant to supporting users of the N’Ko script on the Web.

Please send comments by raising a GitHub issue for each point.
Updated article: How to use Unicode controls for bidi text
The W3C Internationalization Activity has updated the article How to use Unicode controls for bidi text.
This article looks at how content authors can apply direction metadata to bidirectional text when markup is not available. It was largely rewritten to incorporate more up to date information and improve the examples.
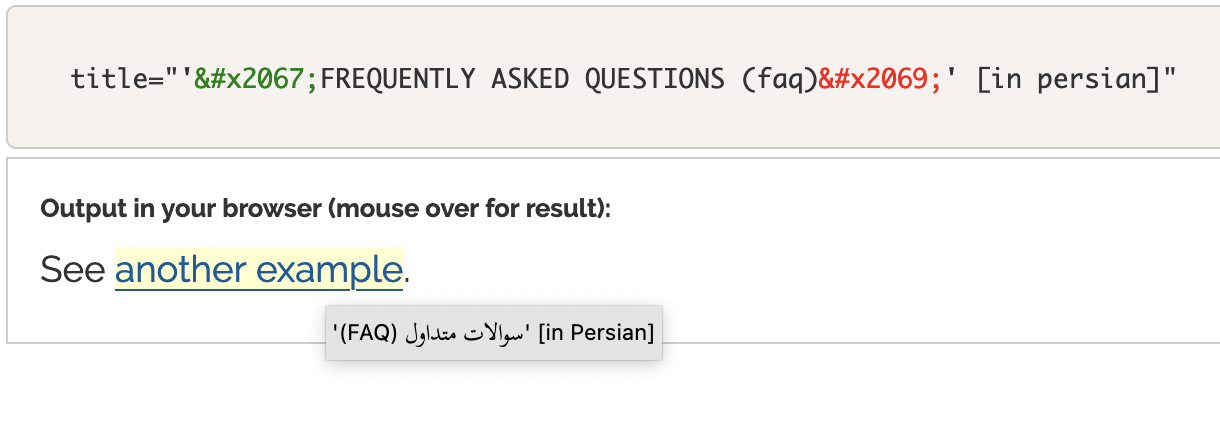
New article: Working with source code markup and code examples for RTL scripts
The W3C Internationalization Activity has published the article Working with source code markup and code examples for RTL scripts.
Editing markup for pages in Arabic, Hebrew, and many other languages poses challenges unless a specialized editor is available. For similar reasons, it is also difficult to include examples of bidirectional code in explainers. This page looks at some of the problems content developers and implementers of editors are likely to be faced with, and offers some advice, where possible.
For review: N’Ko Layout Requirements
N’Ko Layout Requirements is out for wide review in preparation for publishing as a First Public Working Draft. We are looking for comments by Wednesday 3 May.
The N’Ko script is used for a West African koiné register of Manding (called Kángbɛ).
The document describes requirements for the layout and presentation of text in Web standards and technologies such as HTML, CSS, & Digital Publications. It supports the N’Ko Gap Analysis.
Please send any comments as github issues.