
 The W3C Internationalization (I18n) Activity works with W3C working groups and liaises with other organizations to ensure Web technologies work for everyone, regardless of their language, script, or culture.
The W3C Internationalization (I18n) Activity works with W3C working groups and liaises with other organizations to ensure Web technologies work for everyone, regardless of their language, script, or culture.
From this page you can find articles and other resources about Web internationalization, and information about the groups that make up the Activity.
Read also about opportunities to participate and fund work via the new Sponsorship Program.
What the W3C Internationalization Activity does
Selected quick links
Selected quick links
Selected quick links
New translation into Chinese
管理中文和日文中的行内空白 (Managing inline spaces in Chinese & Japanese)
Thanks to Fuqiao Xue for providing this translation.
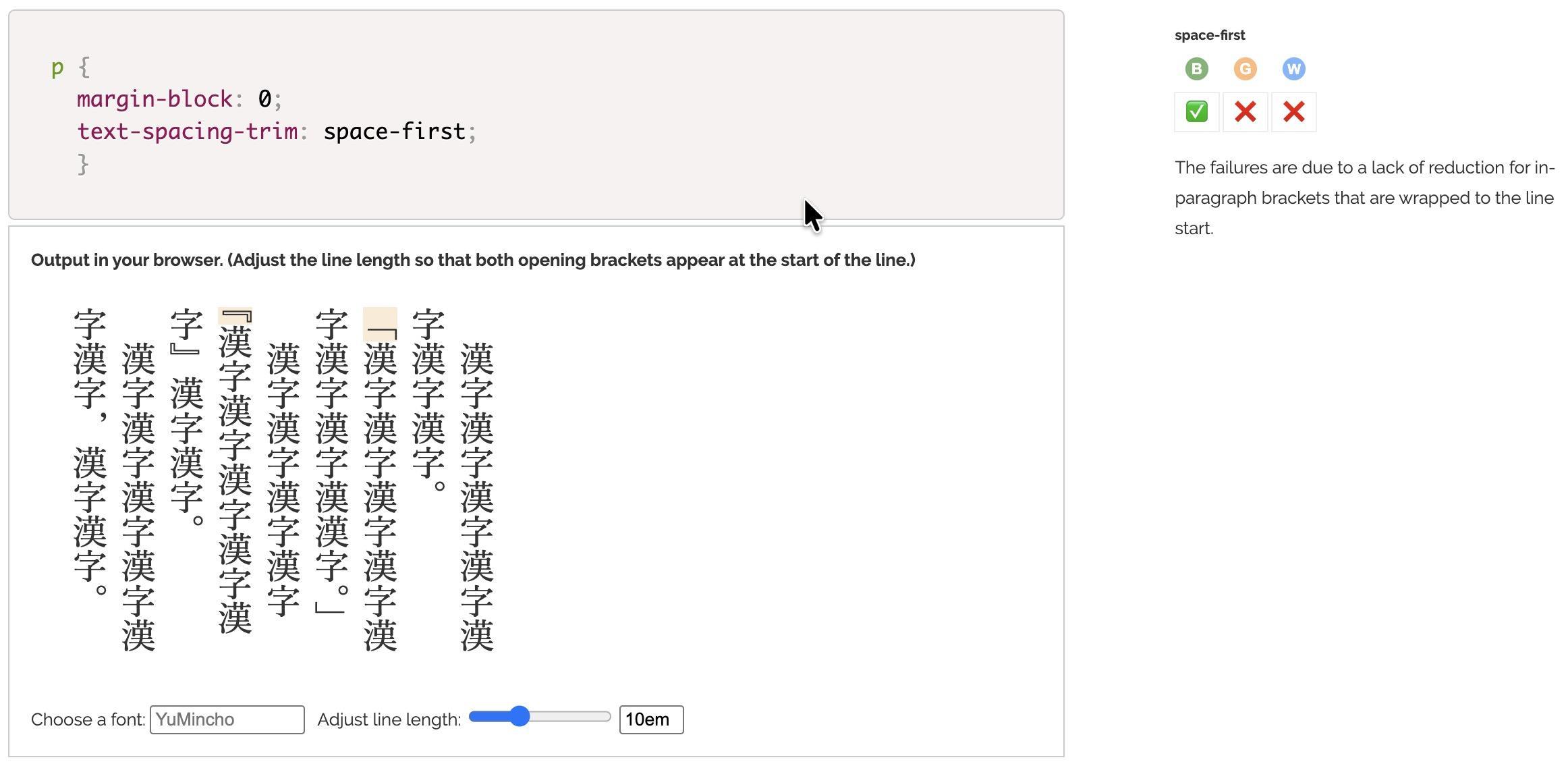
PUBLISHED! Managing inline spaces in Chinese & Japanese
The article Managing inline spaces in Chinese & Japanese looks at ways of using CSS to add gaps between certain types of text, to reduce gaps between punctuation marks, and to manage paragraph-initial spacing. It describes what currently does and doesn’t work.
New translations into Chinese
世界各地的地址格式 (Address formats around the world)
ECMAScript国际化API指南 (Guide to the ECMAScript Internationalization API)
数字、货币和单位格式化 (Number, currency, and unit formatting)
Thanks to Fuqiao Xue for providing these translations.
Requirements for Hangul Text Layout and Typography 한국어 텍스트 레이아웃 및 타이포그래피를 위한 요구사항
A NEW VERSION of Requirements for Hangul Text Layout and Typography
한국어 텍스트 레이아웃 및 타이포그래피를 위한 요구사항 has been published.
The content was rearranged to match the standard headings used for the W3C Language Enablement Framework. The document is still in English and Korean, with buttons to switch between.
New article: Number, currency, and unit formatting
The article Number, currency, and unit formatting has been published.
The formats used by numbers, including specialized formatting such as currencies and units, varies dramatically across cultures, regions, and languages. The web platform provides robust, standards-based solutions to navigate this complex landscape. This article will guide you, step-by-step, through leveraging JavaScript’s built-in Intl object to effortlessly adapt your web pages to varying international number, currency, and unit formats.

FOR REVIEW: Styling underlines
The article Styling underlines is out for wide review. We are looking for comments by Thursday 19 March, 2026.
This article explores various ways in which CSS can be used to manage underlines for non-Latin scripts.
Please send any comments as GitHub issues by clicking on this link, or on “Leave a comment” at the bottom of the article. (That will add some useful information to your comment.)
New translation into Chinese
HTTP标头、meta元素与语言信息 (HTTP headers, meta elements and language information)
Thanks to Fuqiao Xue for providing this translation.
New First Public Draft Note: Text-to-Speech Rendering of Electronic Documents Containing Ruby: User Requirements
The Internationalization Activity published Text-to-Speech Rendering of Electronic Documents Containing Ruby: User Requirements as a First Public Draft Note.
This document describes user requirements related to text-to-speech rendering of electronic documents containing ruby annotations. It examines the roles and practices of ruby in different writing systems and discusses the implications of various reading strategies for text-to-speech, without prescribing algorithms or implementation-specific behavior.
Comments welcome, via the GH links indicated at the top of it.
New articles have been published
Two articles have been published:
Address formats vary widely across the globe, with differences in structure, content, and the level of granularity. For authors and developers designing forms, databases, or systems that handle addresses, understanding these variations is crucial to avoid frustrating users from other countries. The first article will introduce some of the key differences in address formats around the world and provide guidance on how to design systems that can handle them effectively.
The second article will serve as a practical overview of the most essential parts of the Intl API, providing actionable examples you can use to internationalize your web applications today.

FOR REVIEW: Number, currency, and unit formatting
The article Number, currency, and unit formatting is out for wide review. We are looking for comments by Friday 20 February, 2026.
Hardcoding formats is a brittle and unsustainable approach. Fortunately, the web platform provides robust, standards-based solutions to navigate this complex landscape. This article will guide you, step-by-step, through leveraging JavaScript’s built-in Intl object to effortlessly adapt your web pages to varying international number, currency, and unit formats.
Please send any comments as GitHub issues by clicking on this link, or on “Leave a comment” at the bottom of the article. (That will add some useful information to your comment.)