
Paris Web presentation, Paris, France, October 2018
In its goal to create a Web for All, the W3C works in three principal areas:
We will visit each of these topic areas in turn during this presentation, and describe some typical issues, then show resources and processes that people can benefit from, and participate in developing, in order to support the goal of one Web for All. (See a 15 minute video version of this talk, without the background use cases found here, that was recorded during the W3C Developer Meetup at Lyon.)

The W3C Internationalization Initiative was recently set up to attract additional participation in the W3C's internationalisation work, and to attract sponsorship funding to increase the resources at the W3C dedicated to internationalisation.


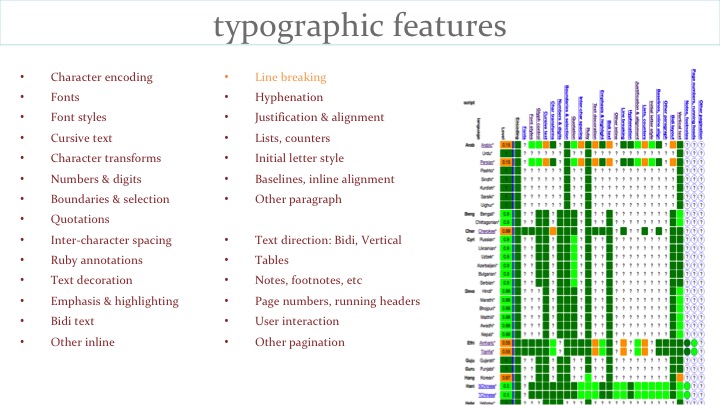
The language matrix is a recent innovation. We plan to use it as a heat map to show how well languages are supported on the Web. We started tracking around 80 languages, but are open to add others if there are experts available to provide the necessary information about them. The columns of the matrix represent various typographic features that need to be supported by Web technologies in order for people to use the Web. The matrix shows whether, for a given language, those features are well supported, need additional work for advance publications, need additional work for basic web use, or are problematic enough to make it difficult to use the Web in that language.
As of the snapshot on the slide, 33 language need work for advanced publishing; 25 need work for basic features, and 2 don't work well on the Web. However, 47% of the cells in the matrix carry question marks: indicating that we need to do some research in order to know the status for that feature.
The matrix should allow us to get an overall idea of how well the Web is supported for local users around the world, and help identify and prioritise areas where work is needed.

Let's look at one of the feature categories, to get an idea of why this information is needed. This will only be a cursory glance at some of the issues involved. (This material is a subset of that in the article Approaches to line breaking, which is itself only a high level summary).
The table on the slide shows a number of languages organised in two dimensions. Down the side of the table we list whether a language wraps words, syllables, characters; across the top we list whether the language uses a space as a word separator, some other word separator, a syllable separator, or no separator at all.
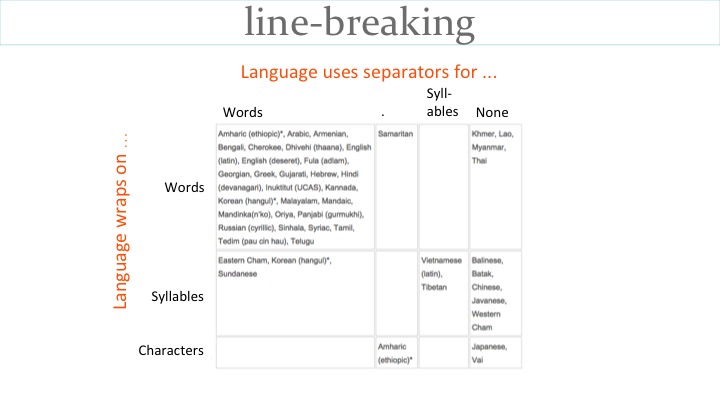
Hindi wraps whole words to the next line, by default, in the same way as this English text. (We won't talk here about hyphenation or justification techniques.)
Arabic text does the same, but the words wrap to the right, rather than to the left. However, one peculiarity of right-to-left scripts is that the words in embedded Latin script text appear to be rearranged if the line break appears between them. In fact, nothing changes in the memory store – this is all just smoke and mirrors. Although scripts like Arabic allow text to be read bidirectionally on a line (numbers and Latin text are read left-to-right), they require text to always be read downwards, from line to line.

There are no word or syllable separators in Khmer or Thai, and yet text needs to be wrapped word by word to the next line. This requires the use of dictionary lookup.
In some cases, users get frustrated because the algorithms used to detect word boundaries don't match their expectations, especially when dealing with compound words.

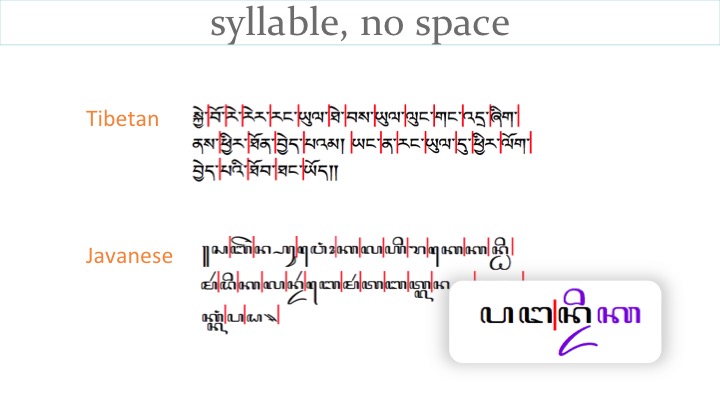
Tibetan has punctuation to mark syllable boundaries, but no punctuation to identify word boundaries (which can be composed of multiple syllables). Since Tibetan wraps syllables at the end of a line, rather than words, this is generally not too problematic.
Javanese, however, also wraps syllables to the next line, but has no clear indicators of syllable (or word) boundaries. To further complicate matters, the final character in one word may be in a stack with the first character of the next word. These stacks cannot be broken. Therefore Javanese wraps orthographic, rather than phonetic, syllables as a unit, and those units may split words. The example on the slide is panga|ndika, where the two words are pangan and dika.
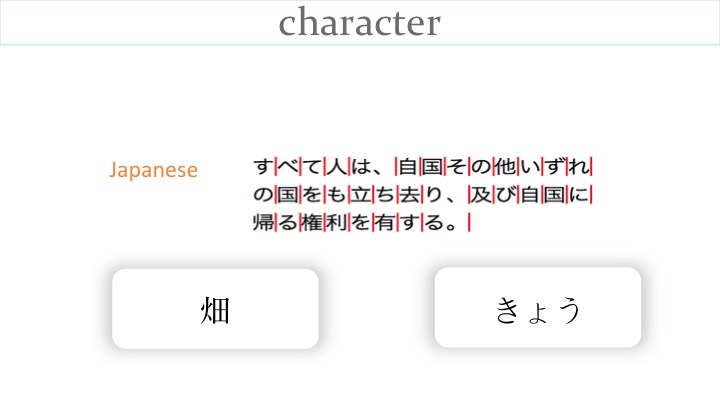
Japanese typically wraps characters at the end of a line, even if the characters are only part of a phonetic syllable. (On the other hand, a single character may represent several syllables.)
Actually, in some circumstances, Japanese will wrap word phrases (bunsetsu) to the next line (eg. in titles, or for accessibility purposes), but this is hard to do given that there are no spaces or other marks between words.
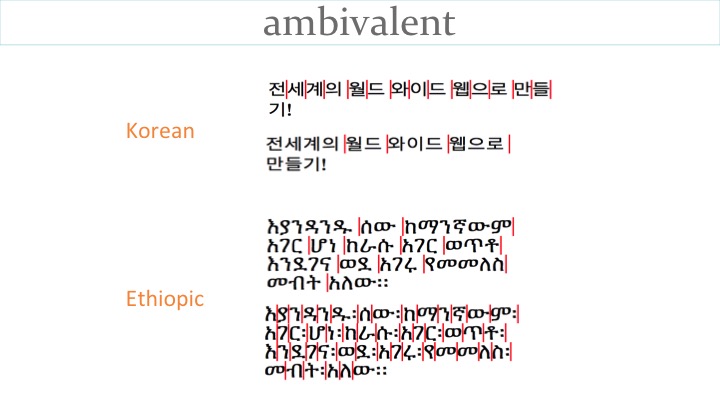
Some scripts can wrap in different ways, according to user preference. For example, Korean (which separates words with spaces), can either wrap syllables/characters or can wrap whole words to the next line.
For languages using the Ethiopic script, the space is becoming more common as a word separator. In the past a special punctuation mark was used between words. When spaces are used, Ethiopic text is usually wrapped word by word. When the punctuation mark is used, then character-based wrapping is more common.
Most writing systems have special rules, such as characters that must not start a line, and others that must not end a line. The slide shows how a comma in Japanese can either pull the previous character with it to the next line, or be left sticking into the margin – according to user preference.
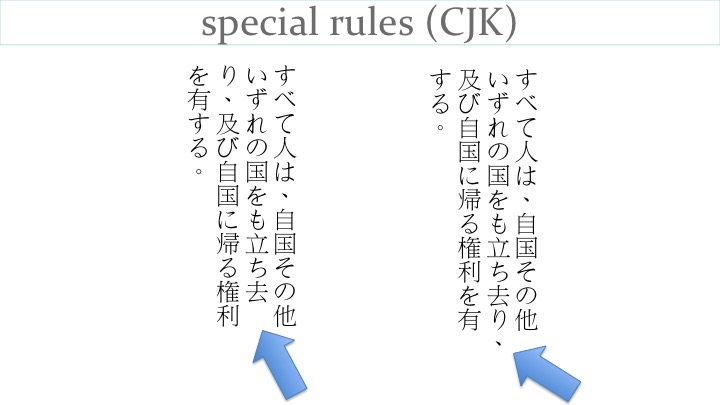
Some rules are more complicated, and difficult to support on non-fixed layouts. For example, the punctuation used to indicate the end of a sentence in Tibetan may be rendered using different code points if it appears on a new line with only one syllable before it. This transformation only occurs when the window or text area is exactly the right width to produce that situation.

With Javanese, a syllable that starts a new line and that begins with a taling character will produce another 'ghost' taling at the end of the previous line (a little like hyphenation). This phenomenon, again, only occurs when the text width is exactly right.


The examples above are only a very cursory review of the ways line-breaking can differ in various writing systems. There is much more detail involved, but here we can only give a flavour of the diversity involved.
Furthermore there are many other typographic features than need to be explored.
Let's now look at how the W3C has been organising itself recently to gather information about local typographic requirements, and how those are supported, or not, by browsers and ebook readers.
Several years ago, work was completed on a document called Requirements for Japanese Text Layout (or jlreq for short). Jlreq started a quest to document how writing systems work. It was a requirements document, which spec developers and implementers could refer to in order to understand what they needed to do. It contained no technology-specific information, so that it could remain evergreen.
Since then other requirements documents have been worked on, including klreq (Korean hangul), clreq (Chinese, Simplified & Traditional), alreq (Arabic & Persian), elreq (Ethiopic script), and ilreq/IIP (indic scripts). We also have an initial draft for tlreq (Tibetan), but we need experts to review and work on that.

In breaking news: we have just launched a Mongolian layout task force, which will work on a mongolian layout requirements document, for which we already have a first draft.

Update: We have recently added task forces looking at African and European languages. We are looking to build participation in those groups.
Writing the lreq docs is hard, and we were finding that the crucial step of matching the requirements to reality was really only taking place via adhoc means, if at all. We wanted a quicker way to start the analysis and resolution of gaps.
Phase 2 saw us develop a gap-analysis framework, which we are rolling out to the existing task forces. It helps figure out what we should be working on, helps focus on documenting key issues, and should provide an increased sense of momentum for participants. Gap analyses are not focused on solutions – only on clarifying barriers to use. However, it provides important information for prioritising work on solutions.

For example, despite good documentation of the requirements, there are still important features for Japanese that are not supported in browsers, or sometimes in the standards. These include upright orientations for character in vertical text, positioning of ruby annotations below base text, form orientation for vertically set text, and markup that allows sensible fallbacks for ruby annotations.
There is a close correspondence between the structure of the language matrix and the gap-analysis documents, so that you can link between them.
Gap-analysis documents describe gaps, give them a priority, and point to specifications, tests, etc.

We are currently rolling out phase 3 of the language enablement work. The goal is to significantly lower the barriers to participation, and to significantly increase participation in the work – especially from regions that have been under-represented in the past.
The sealreq (Southeast Asian) task force was the trail blazer here. We started the group without editors, but just focused on discussion on GitHub issue lists. I am currently trying to capture the information that is coming out of that forum, and we have gap analysis documents in progress for Khmer, Lao, and Javanese.

The discussion is supported by a notification system that sends an maximum of one email a day, containing links to issues that have changed either in the task force repository, or in issue lists for CSS, HTML, or other W3C working groups.

There is also a page that tracks issues related to requests for information, spec issues, and browser bugs. The list can be filtered, and the slide shows just those outstanding questions about how Mongolian works.
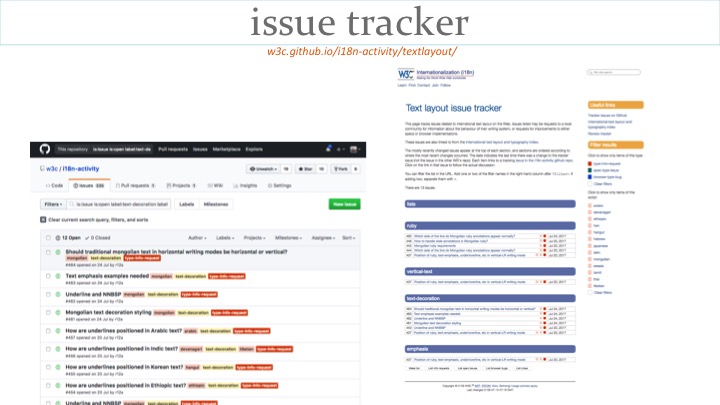
In more breaking news: we have just reconstituted the jlreq task force, and are recruiting participants. The aims will be to work on Japanese gap analysis, jlreq errata and improvements, and to produce new, informative documents to supplement jlreq. There will also be issue list discussions, of course.

People need a way to find the information which we are developing about writing systems and language support. The text layout index performs that role. It is organised by the same feature classification as the matrix and gap-analysis documents, and points to requirements, trackers, specs, tests, etc.

We also have a type sample repository, where people can upload pictures of typographic features in the wild.



When we say 'developer support' here, we mostly mean developers of specifications and implementers of applications.
A key activity of the W3C Internationalization Working Group is to review specifications. Here is a snapshot of our 'review radar', which shows what specifications we are reviewing, are about to review, or have reviewed. We're always happy to receive comments from the public about specs, and always looking for people to join the group to help.
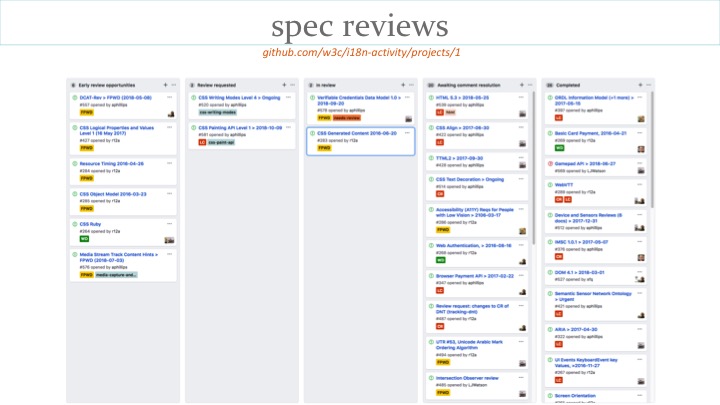
The larger part of the work is not the review itself, but the ensuing discussions with the spec authors. We have a page that tracks ongoing discussions. The example on the slide is about a spec that truncates strings after 64 bytes. Let's take a slightly closer look at this issue.
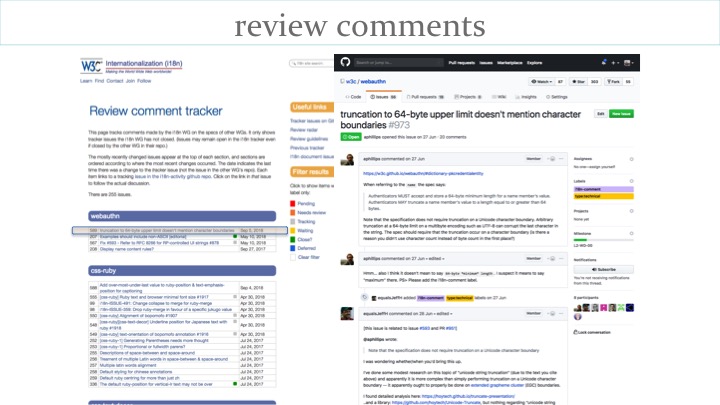
The table on the slide shows that truncating strings after 38 bytes can split characters in Unicode encoded text, leading to unpredictable results.
We try to distill potential issues into advice to developers. For example, when truncating or counting characters in text, developers need to think carefully about what they are doing. For example, the following recommendations arise from consideration of the table.
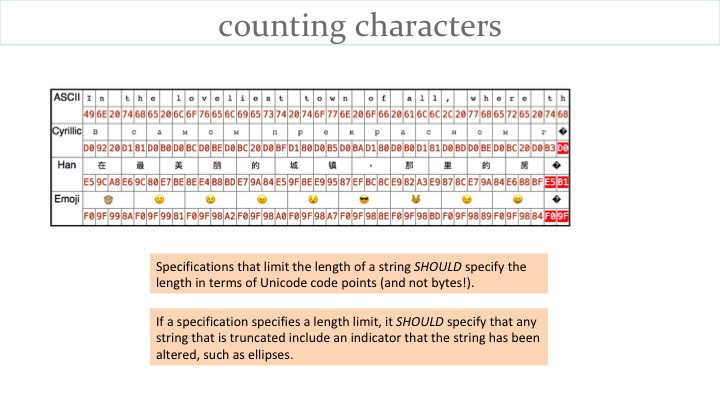
However, the recommendations above are possibly still not sufficient. Just the two emojis shown on the slide take up 17 + 25 bytes = 42, because each is made up of several characters.
The first, representing a female juggler, is:
The second, representing a family, is:
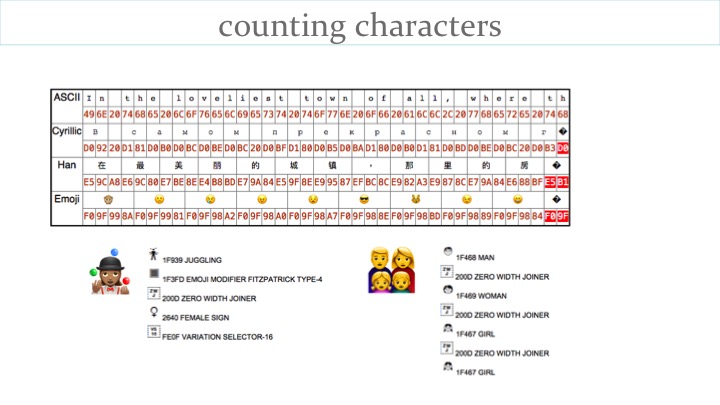

The result is the loss of one of the family members from the second emoji !
So let's add a couple more recommendations:
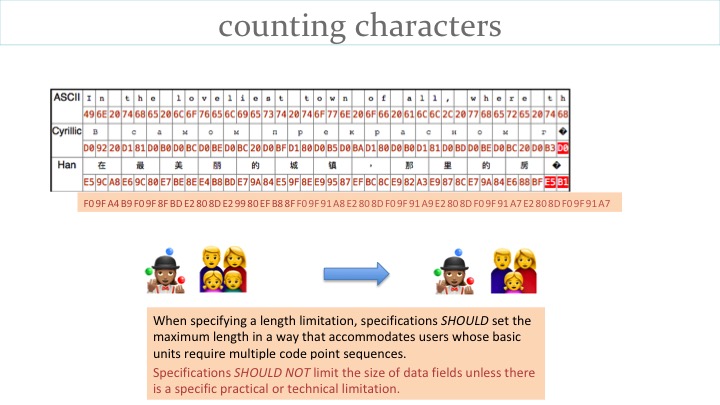
We capture this kind of advice in our 'specdev' document.

From the specdev document we generate a self-review checklist, which is organised along task-based lines.

We are also running some special, in-depth research projects. One centres on how to associate internationalisation-relevant metadata with plain strings. With the rise of JSON and other frameworks, these strings are becoming more and more common.
Let's look at some difficulties related to text direction that we may encounter when dealing with strings.
The first slide shows some bidirectional (Arabic) text being typed into a form field, and because a RTL base direction isn't set it ends up badly mangled.
By adding dir="auto" to the input element we invoke heuristics that examine the first strongly directional character in the input string, and use that to guess the necessary base direction. In this case that fixes the problem, and the user sees the Arabic text as intended.
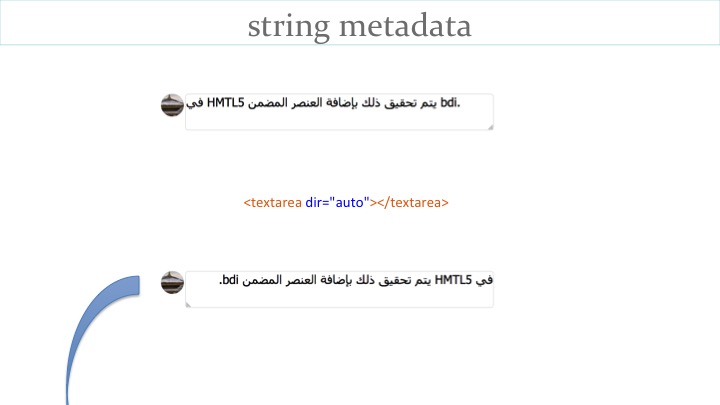
However, when that string is then displayed as part of an HTML page (for example in a social media stream), the same problem arises unless the dir attribute is also set to auto there. An alternative is to use the bdi element.
It is important, therefore, when designing forms and using the results to recognise that people may type in text in right-to-left scripts, and to prepare to handle that.
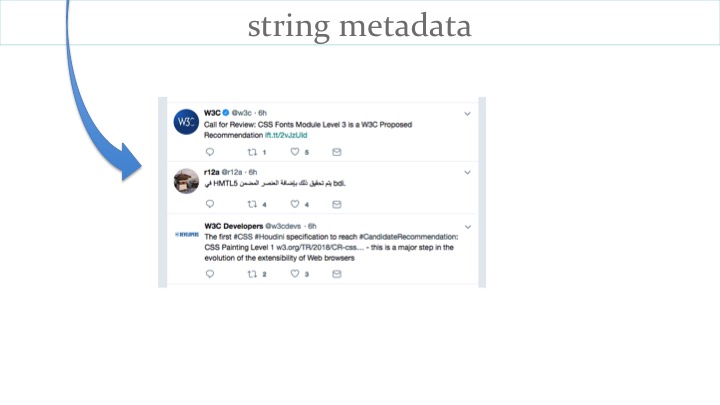
Unfortunately, however, this still may not solve the problem. If the string input by the user starts with a hashtag such as #bidi the first strong directional character is LTR, and as a consequence the display will remain incorrect despite all our previous efforts.
This is a difficult problem to solve, and requires the ability to set the input direction explicitly and pass that information around with the string. We're still not 100% sure what is the best way to do that.
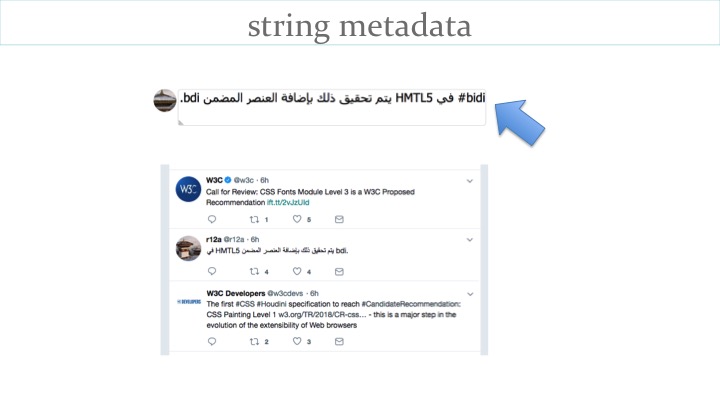
Let's look at another problem related to string handling. This one relates to the language of the text in the string.
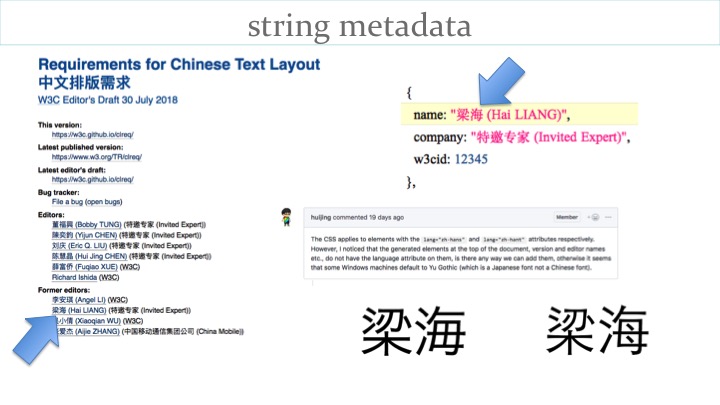
The list of editors for the Chinese layout requirements document is derived from a list of JavaScript strings in the document. In some browsers, the Han characters used to represent the name of one of the Chinese authors was displayed using a Japanese font. His name contained one of the characters that has a systematic difference in shape between Chinese and Japanese, and so it looked wrong.
The problem arose because there was nothing associated with the string to say "This text is in Chinese, so it needs to be displayed with a Chinese font!". Again, the challenge is to figure out how to pass this kind of metadata around with the string.
For a detailed discussion of problems related to language and directional data in strings, and how to address them, see the document Requirements for Language and Direction Metadata in Data Formats.
We are also investigating other topics in detail and producing explanations and recommendations. For example, we expect to very soon publish the document Character Model for the World Wide Web: String Matching.



Now we look at resources to help content authors.
Let's begin with some clickbait: 8 things content authors should always do.
Follow the links for more information.

We have a set of articles, many with translations, that describe how to use the internationalised features of HTML & CSS (and some other Web technologies). Topics include:
Anyone who is interested in translating one of these articles to French (or any other language) should contact me.
This slide shows an example of an article. This one is about how to style your Chinese, Japanese, or Mongolian page so that the text is vertical. It contains step by step guides, information about what is and isn't supported in major browsers with descriptions of workarounds, and test files you can try on your browser.

See also our techniques index for authoring HTML & CSS. This expands to reveal task-based advice such as do's and dont's, and pointers to explanatory information.

We also have a test suite, which not only presents you with tests in a framework, but allows you to record the results and send to us. We then display the test results for major browsers.
There is also an Internationalization Checker. You run this on your page and it:



We have been unable to do more than lift the cover on the world of Web internationalisation and allow you to peek in at a few of the issues involved. However, we have tried to introduce you to a number of resources which can help you learn more, and will guide you in internationalising your content and implementations. Please use the various resources pointed to in this presentation.

Also, consider helping to develop the information!
The W3C isn't a Genie in a lamp that solves all your problems. It brings people together and facilitates work, but this is your Web, not the W3C's.
To produce change we need people like you to step up and provide guidance and work through issues.
Get involved and help us ensure that the Web meets local needs around the world.

For more information, contact Richard Ishida at ishida@w3.org.

Content created Sept 2018. Last update 2019-12-18 14:19 GMT.
Copyright © 2018 W3C® (MIT, ERCIM, Keio, Beihang), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Your interactions with this site are in accordance with our public and Member privacy statements.
Photos © Richard Ishida.