This document contains examples in another language or script.
Accesskey n skips to in-page navigation. Skip to the content start
This talk was presented at the Pan African Workshop on Localization, in Casablanca, June 2005.
After this presentation you should have a better understanding of:
Please send any comments to ishida@w3.org.
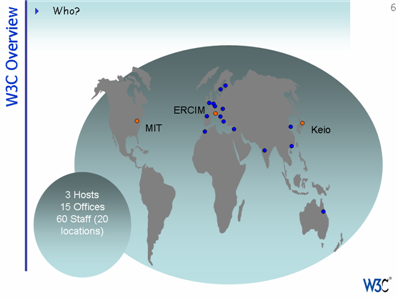
Note that, in order to assist organizations in developing countries in Africa and elswhere to join the W3C, the Consortium has just recently announced a new fee structure. See the W3C web site for details.

A long list exists, but we are interested in knowing what additional topics people would like us to address. See the list.

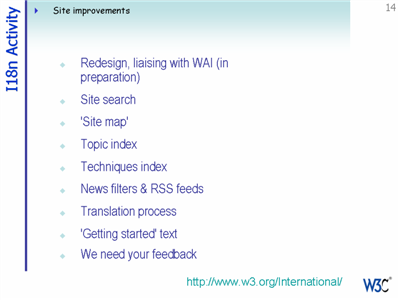
We are in the process of making several improvements to the Internationalization subsite.
We need your feedback.
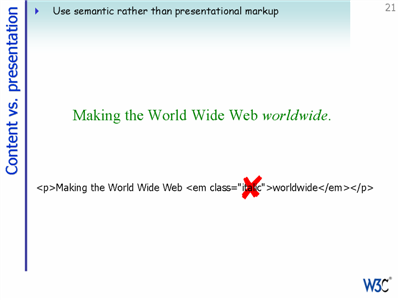
The X/HTML should contain no presentational information - this should be in a CSS stylesheet.

The default browser styling should be able to display the content in a readable fashion, even without the CSS.
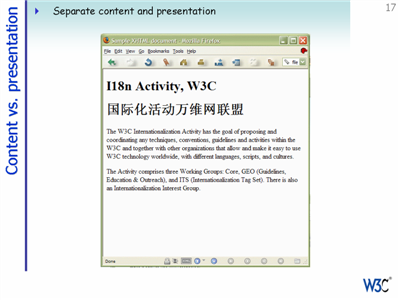
Using <i> tags is putting presentational information in the markup, and should be avoided.

If you need to qualify the type of emphasis, use something like <em class="important">, etc. In other words, keep the markup to expressing the meaning, not the presentation.

Do the same for application of styles relating to document conventions, eg. call out references to document titles as, eg., <span class="doctitle"> rather than in terms of the styling.

Appropriate styling approaches can vary for different scripts. All the following are reasons that it is good to avoid presentational markup when text is to be localized.

Declaring the shape of the quotes in CSS, rather than hard-coding in the text, can make localization faster and less error-prone. A single change in the CSS can be applied to all text in your document.
Note that for this to work, the appropriate selectors need to be supported on all user agents.

Universal accessibility has always been a key objective of the World Wide Web Consortium. The slide shows the phrase 'Making the World Wide Web world wide' in 15 different scripts. Only ten years ago having so many scripts on the same page would have been very difficult.

In the early days there was ASCII, which allowed for a maximum of 128 character assignments, and was based on English support.
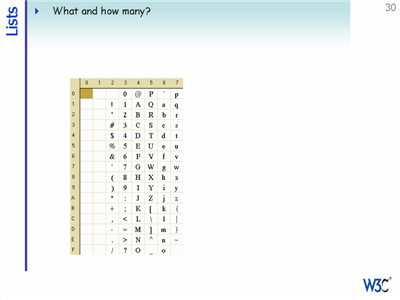
With multiple code pages you could support other regions, such as Western European languages, Greek, Russian, etc. But handling multiple code pages causes problems for multilingual text and for expansion into new regions.
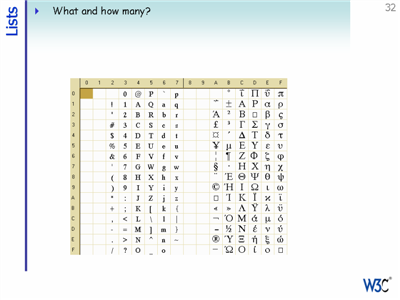
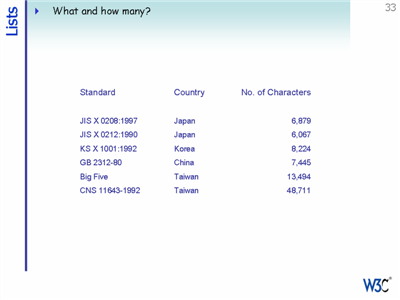
Meanwhile, in the Far East computers had to deal with 'alphabets' of thousands of characters. The solution was to use 'double-byte' character sets - ie. two bytes per character. These character sets still restricted multilingual text and expansion into other areas, just as code pages did.
Originating in the early 1980's, Unicode provides an architecture that allows for the support of pretty much all of the world's languages and scripts currently in use.
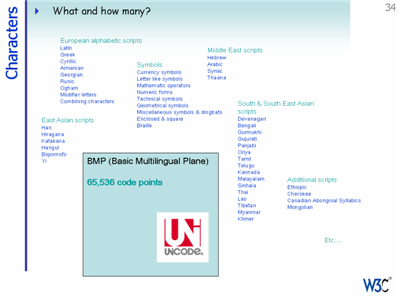
It provides for around a million possible code points. This removes the need for code page switching and makes it easy to extent your product to support characters required for new areas. Its use is now very widespread.

The visual representation of a character is called a 'glyph'. The letter 'a' may have different glyph shapes in different circumstances (eg. standard vs. italic text), but it is still the same character. The different glyph shapes are described by the font that is used to display the character.

In a script such as Arabic, where letters are shaped in different ways according to the joining context, Unicode uses the same character for each of the different shapes displayed, and relies on the font and rendering software to produce the appropriate glyph shapes. This significantly simplifies input and many computer-based operations on characters.

On the wall outside the place we are meeting is an inscription that uses a magreb form of arabic script. For example, the letter qaf is represented with one dot below, rather two dots above. In Unicode this is purely a presentational difference. The same character is used but the font provides a different glyph.


In the following slides we will show just a couple of examples of considerations that have to be taken into account to build international Web technologies.
When the characters in Unicode are mapped to numbers for use in the computer (ie. a character encoding), one character may be represented by one to four bytes.

This means that as you step through text, character by character, or point to a specific location in text, you must know where one character starts and another ends. This is one of the things we have had to ensure is taken into account in specifications of W3C technologies to ensure international support.

Another aspect that has to be considered at a low, architectural level by specifications and implementations of Web technologies is the need to normalise equivalent text where graphemes can be expressed using more than one combination of characters.

Since Unicode is not the only character set that can be used on the Web, it is also important to declare the character encoding of any document or text on the Web. For advice on how to do this for XHTML, see the GEO tutorial.

Until recently Web addresses had to use English letters. Standards recently published by the IETF, with contributions from the W3C, have changed that. Using native script for Web addresses makes them easier to create, memorize, transcribe, interpret, guess, find and relate to (branding).

The domain name and the path are handled separately for native script Web addresses. The client converts each to a form that can pass through the protocols used to retrieve resources.
There is currently some concern about 'phishing' that has slowed the implementation of this technology. The fear is that a domain name such as www.pаypаl.com could, say, use a Russian 'а' and therefore point to a different place than the user suspects. This is not a new problem - previous phishing attempts have replaced the 'l' with a digit '1', for example. Discussion is taking place in a number of organizations about how to make this type of deception much more difficult.

In this section we will mention just a couple of topics that the W3C is or has been working on with regards to internationalization of markup.
It is important to declare the language of text in documents on the Web, and will become more important as technology develops in the future. There are two types of language declaration:

The primary language metadata of a document describes the intended audience of a document in terms of the language or langauges they speak.

There are a number of places where you can declare language for an XTHML document. For more information about this see the GEO tutorial.

Sometimes specific markup is required to support behaviour in a particular script. For example, bidirectional text in Arabic cannot be achieved solely by reliance on the bidirectional algorithm specified by the Unicode standard. Additional markup is needed.
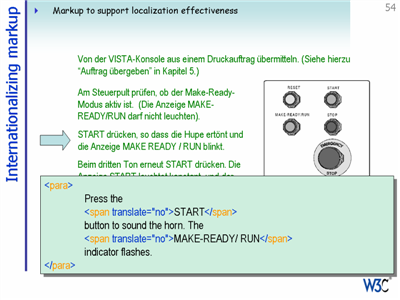
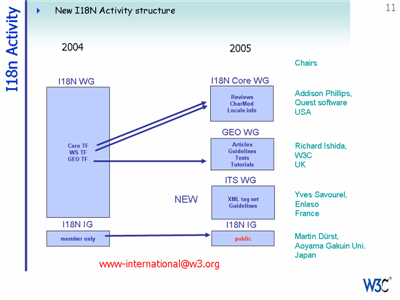
The International Tag Set (ITS) Working Group at the W3C is currently looking at the requirements for markup needed to support international document formats, with a view to producing a set of tags that people can include in new schemas.
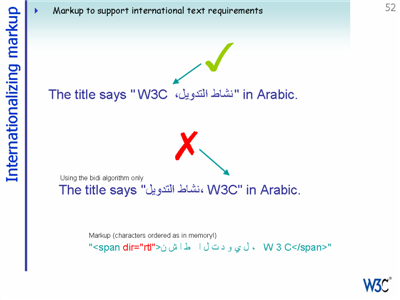
The ITS Working Group is also looking at requirements for tags that would improve the efficiency of localization For example, some way on indicating whether or not specific ranges of text should be translated can improve the efficiency of translation.
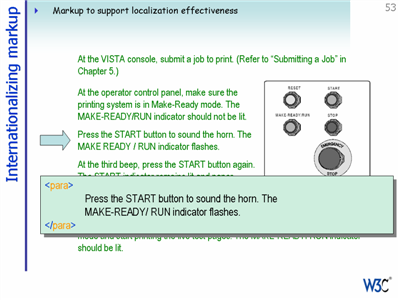
Some requirements for better internationalized schemas cannot be addressed by the provision of elements and attributes. In some cases it is merely a question of best practise. For example, translatable text in attribute values cannot be annotated for language, directionality, abbreviation, styling, etc. It would be much better for schema developers to simply avoid creating such attributes, and use embedded elements instead.

Next we will look at some examples of the type of work the W3C Internationalization Activity does in addressing the needs of stylesheets.
One of the issues we are currently discussing is how to reflow text across line breaks. This is particularly problematic for East Asian and South-east Asian scripts, but we need to also be made aware if there are any special behaviours required by African scripts.

The CSS3 specification will not only attempt to deal with reflowed text appropriately, but will allow for script specific preferences in how text wrapping occurs. For example, you will be able to specify whether embedded Latin text in Chinese wraps on a word by word basis, or character by character.

You will also be able to specify whether you prefer small kana characters in Japanese to begin a new line or not.

Where sentence final punctuation would otherwise appear at the beginning of a new line, you will be able to specify whether it pulls down the last character on the previous line or sticks out of the margin.

CSS3 will also allow for different approaches to text justification, supporting the needs of various scripts.

Amongst other preferences, you will be able to specify that Arabic justification be done using kashidas to lengthen the word, and you will have some control about how that is applied.

Another area where work is still ongoing is that of text direction - particularly where horizontal and vertical text are mixed. For example, how should it be possible to embed Latin or Arabic text in vertical Chinese, Japanese, Korean or Mongolian.

Other CSS3 properties allow you to trim large spaces associated with punctuation during justification or ...
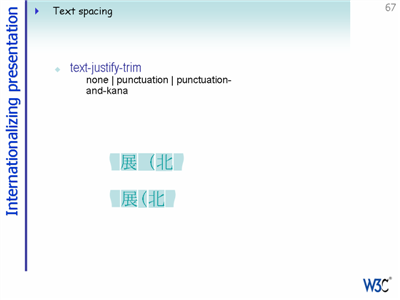
You will also be able to introduce small amounts of space between ideographic text and embedded Latin or numeric text through styling rather than by adding space characters (since this is presentational in nature).

You will also be able to implement typical Japanese typographic conventions such as warichu (reduced size double-layered text) and kumimoji (up to 5 characters in a single glyph space).

You will be able to implement Japanese conventions for emphasis such as dots or accents associated with characters.

And, in conjunction with the work on markup already in place for XHTML 1.1, you will be able to apply styling preferences to text annotations ('ruby').

Much of the specified behaviour in CSS3 derives from input from the Far East. The W3C always wants to hear about requirements from other parts of the world, such as Africa. For example, is there specific behaviour associated with the wordspace character (፡) in Ethiopic that affects justification or line-breaking? If so, we would like to hear from experts in this area.
List style types provide an object lesson in this area. In the CSS 2.0 specification eight non-Latin numbering methods were specified. This was reduced to two in CSS 2.1, since there had not been two or more implementations of the others.

The CSS3 specification includes a very large number of possibilities for numbering lists using non-Latin scripts, including many that are specifically African scripts. If these are to make it to the final version of the specification, however, it would be helpful for potential users to express their interest in seeing this happen. There are regular questions posted on mailing lists about whether these are really worth the effort.

The W3C needs the assistance of users and experts in typography from African countries if we are to ensure that your needs are met in this very important and very internatioanlization-sensitive area of the Web. Not only do we need help to specify the requirements and the specifications, but user agent implementors need to be encouraged to implement the international aspects of the specification. To make the happen, consider doing the following:

Over an above specifying international features of W3C specifications, there are things that content authors must bear in mind to ensure that content is localizable. In this section we will provide just two examples of this. The first discusses issues that arise due to the differing mechanics of languages.
The syntax and content of translations of a single phrase can be widely different in different languages.

One result of this can be that a phrase containing two variables (ie. data supplied at run-time) may need to swap their positions. If you have produced the original text using the wrong type of scripting you may prevent this happening and thereby make it impossible to achieve a good translation.

Sometimes developers provide a single string for a basic sentence pattern and try to swap in alternative words to make a number of similar messages. They do this to save memory. Unfortunately, this tends to only work in translation if the syntax and agreement in the original language and the target are identical - not a likely circumstance. This can produce unsurmountable problems for localization.
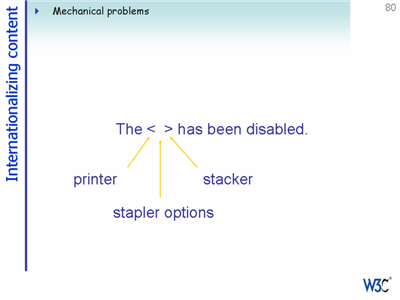
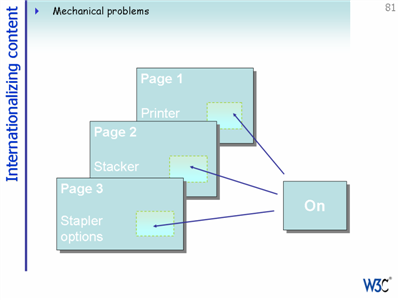
A similar problem arises when a designer uses a single string for a concept such as 'on', intending to copy it to the various parts of the user interface where it is needed. In Spanish, however, 'on' could be translated 'activado', 'encendido' or 'conectado', depending on the subject. Given a single string, it is not possible to provide a sensible translation in all contexts.
For our next set of examples we look at a very different set of problems. Kenneth Keniston said:
"... one Latin American teacher recently complained to me that the US-manufactured and well-translated educational software currently being used in his country's primary schools presupposed 'solitary problem solvers', whereas his culture stressed collective problem-solving."
In this case we are far from mechanical issues.

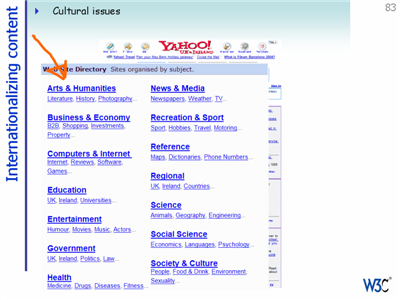
The next few slides show an example of a company that has taken this to heart. If you compare the subtopics on Yahoo's directory in various different localized sites you find that they have adapted the content to suit the audience, not just translated.
The page for the UK and Northern Ireland lists under Arts & Humanities the following: Literature, History, Photography.
Here we list a few examples of the topics that still need work.

Editing and scripting environments are likely to be key to success in getting content authors to ensure that they create internationalized content. We can't rely on content authors and programmers to remember everything they ought to do.
You should always stick with standards as you develop Web content, so that your data is available to everyone. You should always check that you use valid XHTML and CSS.
Don't forget to push for adoption of internationalization features by user agents. Getting it into the standard is only half the battle.
The mobile Web will become increasingly important, especially in places such as Africa, and we should keep our eye on developments in this area.