Workshop Minutes
Agenda: https://www.w3.org/Data/events/data-ws-2019/schedule.html
Minutes for Monday 4 March 2019
This is for collaborative minute taking. Help us to create good quality minutes.
Twitter feed: https://twitter.com/hashtag/W3CGraphWorkshop
Live audio/video via Zoom. Recordings will be available for 90 days.
- Recording of day 1 (content starts at 4h, 15m)
- Recording of day 2 (content starts at 15m, 45s)
- Recording of day 3 (content starts at 40m)
- Minutes for Monday 4 March 2019
- Keynote by Brad Bebee, Amazon Neptune
- Panel Discussions
- Vectors and Venues
- Coexistence or Competition
- Lightning presentations
- Querying RDF: SPARQL 1.2/2.0 and imperative query languages, Adrian Gschwend
- Mobile Money in Africa, Alex Miłowski, Orange Silicon Valley
- Need for VIEWs in graph systems, Barry Zane, Cambridge Semantics
- Vehicle graph data, Daniel Alvarez, BMW Research, New Technologies, Innovations
- The Sentient Web: IoT + graphs + AI/ML, Dave Raggett, W3C/ERCIM, Create-IoT & Boost 4.0
- Cypher and Gremlin Interoperation, Dmitry Novikov, Neueda Technologies (summary)
- SPARQL and Gremlin Interoperation, Harsh Thakkar, Smart Data Analytics Lab, University of Bonn, (summary)
- Neo4J for Enterprise RDF Data Management, Ghislain Atemezing, MONDECA
- Cyber-Physical Graphs vs RDF graphs, Gilles Privat, Orange Labs, Grenoble, France
- JSON-LD 1.1 Update, Gregg Kellogg – Spec Ops
- An Executable Semantics as a Tool and Artifact of Language Standardization, Filip Murlak, University of Warsaw, Jan Posiadała, Nodes and Edges and Paweł Susicki, Nodes and Edges (summary)
- NGSI-LD: JSON-LD based representation and Open APIs for Property Graphs, José Manuel Cantera, FIWARE Foundation (summary)
- Implications of Solid, Kjetil Kjernsmo, Inrupt Inc.
- Cypher for Apache Spark, Max Kießling, neo4j
- Information Architecture, Natasa Varytimou, Refinitiv
- Graph Data on the Web extend the pivot, don’t reinvent the wheel, Olivier Corby et al., Inria – Wimmics team
- SQL extensions for Property Graphs (PGs), Oskar van Rest, Jan Michels – Oracle (summary)
- Do we need 3-valued logic to deal with NULLS? Leonid Libkin
- Path Queries in Stardog, Pavel Klinov, VP R&D, Stardog Union, and Evren Sirin, Chief Scientist, Stardog Union
- Compiled GraphQL as a Database Query Language, Predrag Gruevski, Kensho
- A Product View on Graph Data: PoolParty Semantic Suite , Robert David CTO, Semantic Web Company
- Bridges between GraphQL and RDF, Ruben Taelman, IDLab, Ghent University — imec
- Schema validation and evolution for PGs, Russ Harmer, CNRS. Eugenia Oshurko, ENSL, and Angela Bonifati, Peter Furniss, Alastair Green and Hannes Voigt, Neo4J,
- Standardized local property graph models across browsers, Theodoros Michalareas, wappier.com
- Graph the Language Graphs! Thomas Frisendal
- Property Graphs need a Schema Juan Sequeda, Capsenta, on behalf of the Property Graph Schema Working Group
- Minutes for Wednesday 5 March 2019
- Summaries of Tuesday sessions
- Extending, Incubating, Initiating
Monday, 4 March
Keynote by Brad Bebee, Amazon Neptune
http://www.w3.org/Data/events/data-ws-2019/assets/slides/BradBebee.pdf
"It's just a graph"
How customers want to use graphs.
In the past: Resource description, metadata management applications. Machine processable, understandable way to process information. Knowledge rep, NLP, RDF, SW Scientific American article, OWL standard.
Worked on big data for a while, and distributed query
BigData rebranded as Blazegraph. Adopted by Wikidata.
A number of us went to Amazon, and in 2018 released Neptune.
When to use a graph database? If your app needs to process a lot of connected data (data from different sources, relationships, different schemas, information produced at different rates). Lots and lots of different graph use cases. Cancer genomics problem, security issues, etc.
Use of graphs not just for reimagining old applications. But for new functionality.
Can I use a relational DB to process this connected data? Yes, you can. But there are drawbacks: SQL joins, which are complex to develop, kinds of workshops that relational DBs are optimised for are very different than those required for connected data/ SQL joins.
Graphs has the flexibility to let you integrate data ‘like crazy’.
Two camps: property graphs and RDF/SPARQL
Neptune supports both of these. Which one to use? The one that makes more sense to you. Developers coming from relational or document-oriented DBs find that transitioning to a property graph model is more natural to them.
How big is the graph market?
Q - what benefits do other communities see in working together (coming from an RDF community)
A - lot of standards that could help property graph applications; interoperability for property graph apps, move fluently from property graphs to linked data
Q - we are using Neptune and have worked with clients using neo4j. Within the Neptune stack, do people need to make a commitment to property graphs?
A - we don’t provide data interoperability between graph models; we want to. It is much easier to show property graphs from an RDF view than the other way around.
Q - is it important and useful for RDF to evolve so that it makes it easier to model property graphs within RDF? Two approaches to the same problem.
A - from RDF perspective, lots of things we can make better. Lots of features in SPARQL 1.1. that people want to add (e.g. analytics). It’s hard to say in terms of interoperability. RDF-led initiative? Or opportunity to something together?
Q - extending RDF or SPARQL or something in the property graph world to make statements in an analytical way. E.g. find all the connected components of a graph.
Panel Discussions
Vectors and Venues
Moderator: Dave Raggett. Panelists: Jan Michels, Keith Hare, Alan Bird
Alan Bird described the structure and processes for developing standards within W3C. Keith Hare described the structure and processes for developing standards within ISO/IEC JTC1, with an emphasis on ISO/IEC JTC1 SC32 WG3 (Database Languages), the committee that has developed the SQL standard and is working on a property graph standard. Jan Michels described the structure and processes within ANSI INCITS DM32.2, the US national body that corresponds with SC32 WG3.
[Lots missed]
Alan Bird: Today should be day 0.5 of putting together a standard for data querying, where graphs (or relational data, or documents / time-series) are just an incidental implementation detail.
Andy Seaborne: In Apache everything is pushed down to the contributors. But in Apache they are individuals -- people driven by doing. Difficult to see how some of the engagements can be set up, but worthwhile.
James ___: I expected an outcome would be something like R2RML. I want info in any relational DB with semantic consistency across the DBs of different types.
List of Graph “Things”
RDF World
- RDF
- OWL
- RDF Schema
- SPARQL
- SHACL
- ShEX
- RDB2RDF Direct Mapping
- RDB2RDF R2RML
- JSON-LD
- RDF* and SPARQL*
- Notation3
PG World
- Cypher
- openCypher
- Oracle PGQL
- G-CORE
- Apache Tinkerpop
- Tigergraph GQL
- SQL/PGQL
- YARS-PG
Others
- GraphQL, either resolver-based (vanilla) or compiled ahead of time (GraphQL compiler, Postgraphile, etc.)
- Athanassios Hatzis Data Modelling Topologies of a Graph Database
RDF → PG:
- MITRE A Field Guide ETL from RDF to Property Graph
- Java-based procedure to ingest RDF into Cypher (cf. Work of Jesús B. and extensions like Mondeca implementation, mapping rules here)
PG → RDF and RDF -> PG
- Joshua’s A Graph is a Graph is a Graph: Equivalence, Transformation, and Composition of Graph Data Models (slide 52)
Coexistence or Competition
Panelists: Olaf Hartig, Alastair Green, Peter Eisentraut
Background:
- Alastair Green: Neo4j query language research group
- Peter Eisentraut: Postgres dev
- Olaf Hartig: Associate Professor, Linköping University
Olaf’s presentation
- Slides at http://olafhartig.de/slides/W3CWorkshop2019Panel.pdf
- Coexistence between RDF and property graphs is unavoidable. Both have merits and a user base.
- Also SQL, GraphQL, etc.
- Coexistence and competition do not exclude each other
- Well-defined approaches: first conceptual development, before implementation
- Reuse and extend as much as possible
- reuse existing tooling
- leverage existing intuition among users
- RDF* and SPARQL*: Proposal to extend RDF with nested triples (edge properties), and triple patterns nested with each other. Direct mappings between RDF* and RDF. Direct mappings between RDF* and Property Graphs.
- Property Graph Schemas with GraphQL SDL (ongoing work by Olaf Hartig)
- Questions: Integration of SHACL and GraphQL? : There is GraphQL work done for ShACL using it as a schema notation by the editor (Holger Knublauch) of that spec https://www.topquadrant.com/technology/graphql/ and other posts.
Peter Eisentraut’s presentation
- PostgreSQL is not yet a graph database
- Why so few database languages (as compared to programming languages)?
- Prog. languages are often associated with certain ecosystems
- Answer: they are harder to do (e.g. optimisers are tricky)
- Gap between having a DBMS and having a query language
- Standardisation of database languages should be focused in at most 2 initiatives
Alastair Green’s presentation
- Interoperation and cooperation
- interoperation = technical issues
- cooperation = social, interpersonal issues
- Three large software vendors found it hard to agree on reconciling XML and SQL
- Adoption requires standardisation
- Gremlin should not be in the same space as RDF and others PG de facto standard
- Property Graph query languages generally pretty similar, all use pattern-matching (openCypher, PGQL, G-CORE)
- Gremlin is a very different take
- Standards creation takes time
- PG world seems to lag the RDF world (in terms of house in order)
- In principle, GQL / property graph queries can do everything SQL can do
- But shouldn't try to supplant SQL! That will lead to paralysis, entrenchment, endless war.
- Data communities have very deep roots, not likely to switch.
- Extreme positions: PG / SQL / RDF can handle everything
- Cooperate to define exchange standards
- Cooperate to define reasonable interoperation standards
- Gremlin can go to SPARQL and SPARQL can go to Gremlin,
- Cypher can go to Gremlin,
- GraphQL can go to all of these
- Abstract idea of a graph program representing the user's request
- cross boundaries between approaches easily, since everyone agrees on abstraction of edges and vertices, and properties on them
Q&A:
- Q: Standards seem to be query-only.
- A: Not the case.
- Q: …
- Q: (from TigerGraph) Do users want a declarative or an imperative query language?
- A: (PE) They want one, but should not want that.
- A: (AG) common declarative property graph query language is a fundamental step forward, and should have priority
- Q: What about dynamic aspects? Evolution of data. Complex Event Processing
- A: DR: will have session about that tomorrow.
Lightning presentations
Querying RDF: SPARQL 1.2/2.0 and imperative query languages, Adrian Gschwend
- In 2.0 : more graph query stuff, page rank, might break 1.x compatibility
- Tinkerpop / Gremlin like graph traversals
- https://github.com/comunica/comunica
Mobile Money in Africa, Alex Miłowski, Orange Silicon Valley
- Scale out over time / derived properties
Need for VIEWs in graph systems, Barry Zane, Cambridge Semantics
- Views can make complex relationships look simple
- Composability indeed matters
- Q: materialized views? A: both, materialised and dynamic views
- Views are natural hinge for access control
- Q: virtual subgraphs, edges, nodes? A: all of them
Vehicle graph data, Daniel Alvarez, BMW Research, New Technologies, Innovations
https://ssn2018.github.io/submissions/SSN2018_paper_4_submitted.pdf
The Sentient Web: IoT + graphs + AI/ML, Dave Raggett, W3C/ERCIM, Create-IoT & Boost 4.0
- Ecosystems with awareness of the world
- Sentient Web as successor to Semantic Web
- Relies less on logic and deduction
- Aims to deal with messier real world
- Building upon extensive work in Cognitive Psychology
- Open up to other communities and allow different new ways of deriving knowledge (abduction, induction, …)
Cypher and Gremlin Interoperation, Dmitry Novikov, Neueda Technologies (summary)
- Cypher for Gremlin
- SPARQL-Gremlin
- Q: Optimisation? A: We have a set of optimisation rules.
SPARQL and Gremlin Interoperation, Harsh Thakkar, Smart Data Analytics Lab, University of Bonn
This talk described a tool for transforming SPARQL queries to Gremlin for interoperation with a wide range of graph databases including Gremlin, Neo4J, Amazon Web Services, Janus Graph, DataStax, OrientDB and many more. The approach was designed to enable SPARQL queries to be run against TINKERPOP enabled databases.Neo4J for Enterprise RDF Data Management, Ghislain Atemezing, MONDECA
- Target Neo4J + Tinkerpop
- RDF ingestion benchmark with Neo4J
- PO bench challenge with Neo4J
- Applications in PROD: Knowledge Browser (KBr)
- Live public uses:
- ASIP Sane (French agency for Digital Health https://bioloinc.fr/bioloinc/KB/ )
- French ministry of finance vocabularies browser at https://terminologie.finances.gouv.fr/
- Q: how do you query? A: transform RDF into PG, then Cypher
- Q: how was the work of Jesus B. being updated? A: We extended the mapping and would love to send back to the community
Cyber-Physical Graphs vs RDF graphs, Gilles Privat, Orange Labs, Grenoble, France
- Older formalism / model
- Semantics not always reducible to RDF-style semantics
- Finite State Mealy Machine
- Physical network
- Q: Constraints on the whole of the graph? A: RDF-style semantics can added as overlay. The edges represent physical connection, not just relationships as in RDF.
JSON-LD 1.1 Update, Gregg Kellogg – Spec Ops
- Ongoing since RDF1.1, very popular
- Version announcement mechanism
- @id maps: index based on object id, also supports @type and @graph maps
- Graph containers (@graph maps): we can quote some piece of work that is represented in another graph, and indicate that someone said…
- Nested properties
- Scoped contexts
- Lists of lists
An Executable Semantics as a Tool and Artifact of Language Standardization, Filip Murlak, University of Warsaw, Jan Posiadała, Nodes and Edges and Paweł Susicki, Nodes and Edges (summary)
- Three in one: specification that is (1) readable, (2) formal and (3) executable
- Proof of concept: Cypher.PL
- In Prolog, itself a standard
- Q: why in theorem prover? A: would not be 1500 lines of code
NGSI-LD: JSON-LD based representation and Open APIs for Property Graphs, José Manuel Cantera, FIWARE Foundation (summary)
- Example: combined data exchange using property graphs
- Nesting properties into properties, relationships into relationships, by using blank node reification
Implications of Solid, Kjetil Kjernsmo, Inrupt Inc.
- Making people want to share data
- ACID! (as in database transactions)
- Ok not to be ACID, but users should be notified
- PubSub becomes relevant for graph traversal
- Caching is needed for performance
- Cardinality estimation matters, revival of VOID
- Improving paging queries
Cypher for Apache Spark, Max Kießling, neo4j
- Similar to Spark SQL
- Read-only part of Cypher
- Extra: graph catalog, multiple graph queries, ..
- Maps to SQL, so can be transferred to anything supporting that
- https://github.com/opencypher/cypher-for-apache-spark
Information Architecture, Natasa Varytimou, Refinitiv
- ECP metadata registry and Bold Framework for Graph distribution
- Build on SHACL models, using JSON-LD
- Using GraphQL to query datasets
- Data is bitemporal, so information in terms of quads ( Named Graphs)
- For now views implemented with small SHACL files combined in a model with Sparql Predefined Constructs
- Rules and function in SHACL are not in the core W3C recommendation
Graph Data on the Web extend the pivot, don’t reinvent the wheel, Olivier Corby et al., Inria – Wimmics team
- RDF and PG are not in opposition
- Requirements (they are) for RDF2.0
- Ideas on how to make graph data interoperable
- Nested triples, triple with URI identifier, entailment using named graphs
- Secure and trusted RDF graphs
- RDF graph style sheets (a la CSS)
- Transformation language for RDF
SQL extensions for Property Graphs (PGs), Oskar van Rest, Jan Michels – Oracle (summary)
- PGs in SQL database
- Involved: ISO (JTC 1 / SC32 / WG3) / ANSI (INCITS / DM32 / .. )
- SQL extension to query PGs in SQL database
- Can define a derived property graph (based on SQL tables) which operates as a view
Do we need 3-valued logic to deal with NULLS? Leonid Libkin
- 3VL: SQL nightmare, followed by everyone
- We don’t need it: does not change expressive power (KR 2018 best paper award)
- Don’t do it!
Path Queries in Stardog, Pavel Klinov, VP R&D, Stardog Union, and Evren Sirin, Chief Scientist, Stardog Union
- Goal: add graph traversals to SPARQL
- Similar to property graphs, but with intermediate nodes
- Can use SPARQL for end and begin nodes (to specify conditions)
- Implemented in Stardog Studio, demo tomorrow
- Q: like path queries in G-CORE and … ? A: yes, is why we are here
- Q: in Cypher this led to complex properties. List comprehensions. Projections. You expect that also? A: Yes, if you use this nested in full query language.
Compiled GraphQL as a Database Query Language, Predrag Gruevski, Kensho
- Integrate data from graph / relational / time-series databases.
- Product engineer gives declarative specification of query.
- Infrastructure engineer implements and optimises it.
- Compile GraphQL to single database query
- Full GraphQL query is available at once, let’s use it -- no need to execute one step at a time
- Because the high number of roundtrips caused by GraphQL resolvers killed performance
- Q: what can you not say in GraphQL, which you are missing? A: GraphQL does not natively support features like “order by” or aggregations. We can define custom directives for this, but nothing exists in the language itself.
- Q: what type of mappings can you do (compared to R2RML)? A: fixed mapping based on source schema
- Links:
- https://blog.kensho.com/compiled-graphql-as-a-database-query-language-72e106844282
- https://github.com/kensho-technologies/graphql-compiler
- https://github.com/kensho-technologies/game-of-graphql
A Product View on Graph Data: PoolParty Semantic Suite , Robert David CTO, Semantic Web Company
- PoolParty semantic suite
- Future work:
- SHACL/ShEx do not cover all use cases for constraint checking
- RDF data as basis for ML
- Explainable AI
Bridges between GraphQL and RDF, Ruben Taelman, IDLab, Ghent University — imec
- GraphQL can be lifted to apply to RDF
- GraphQL-LD, HyperGraphQL, TopBraid, Stardog
- Federation is hard in GraphQL, but easy in RDF/SPARQL
- Need for a standard?
Schema validation and evolution for PGs, Russ Harmer, CNRS. Eugenia Oshurko, ENSL, and Angela Bonifati, Peter Furniss, Alastair Green and Hannes Voigt, Neo4J,
- Data graph and schema graph (with formal relation)
- Validate if update will keep instance within schema (or rather, adapt either update or the schema so that this is true)
- Schema updates propagate to the data
- Data updates propagate to the schema
Standardized local property graph models across browsers, Theodoros Michalareas, wappier.com
- Strengthen graph data application development model for decentralized applications
- Use cases for PGs in the browser
- Interest graph (Brave)
- Privacy graph (Chrome)
Graph the Language Graphs! Thomas Frisendal
- ELWG - Existing Languages Working Group
- Graph of: implementation status of features in 5 languages
- GCORE, GSQL, Cypher, PGQL, SQL
- Open positions: please help collect the metadata
Property Graphs need a Schema Juan Sequeda, Capsenta, on behalf of the Property Graph Schema Working Group
- PGs need schemas
- WG consisting of industry and academia
- Produced preliminary versions:
- Academic survey on schema languages (history of, lessons learned)
- Industry survey on the same
- Use case and requirements document
Tuesday, 5 March
This day was split across three rooms, with twelve sessions in all.
Graph Data Interchange
Moderators: George Anadiotis, Dominik Tomaszuk
Minutes - Graph Data Interchange
Moderators: George Anadiotis, Dominik Tomaszuk
George Anadiotis. https://my.pcloud.com/publink/show?code=XZOjYq7ZuHjtvPmooepzOtl8J3Br5yM7lcXX
Working in data since 92. With graph db since 2005
Graph data interchange = minimum viable product for standardisation
Key decision points: Formats → Protocol → Semantics
Graph Data Interchange Syntax
What would that format be? JSON based or not?
Based on a twitter poll, 80% prefer JSON-LD. https://twitter.com/aaranged/status/1090237302217924608
Graph Data Interchange Protocol: Graphson, JSON Graph (used by netflix), Json Graph Format JGF, mostly used by a company ADS, GraphML used for visualization tools
Graph Data Interchange Semantics: JSON-LD/ Schema.org
Connecting vocabularies (i.e. schema.org) to the serialization/syntax of the graph data
Q/Comment: There was a lot of discussion between XML vs JSON. Both syntax can represent the same data.
Does Neo4j has a serialization format?
Not really. There is a format to serialize between the server and visualization front end but that is not general purpose.
Bolt is a data record serialization but not a graph serialization. There will be a graph serialization format for Bolt in the future.
There is already data in existing format so focus is on importing that one (CSV).
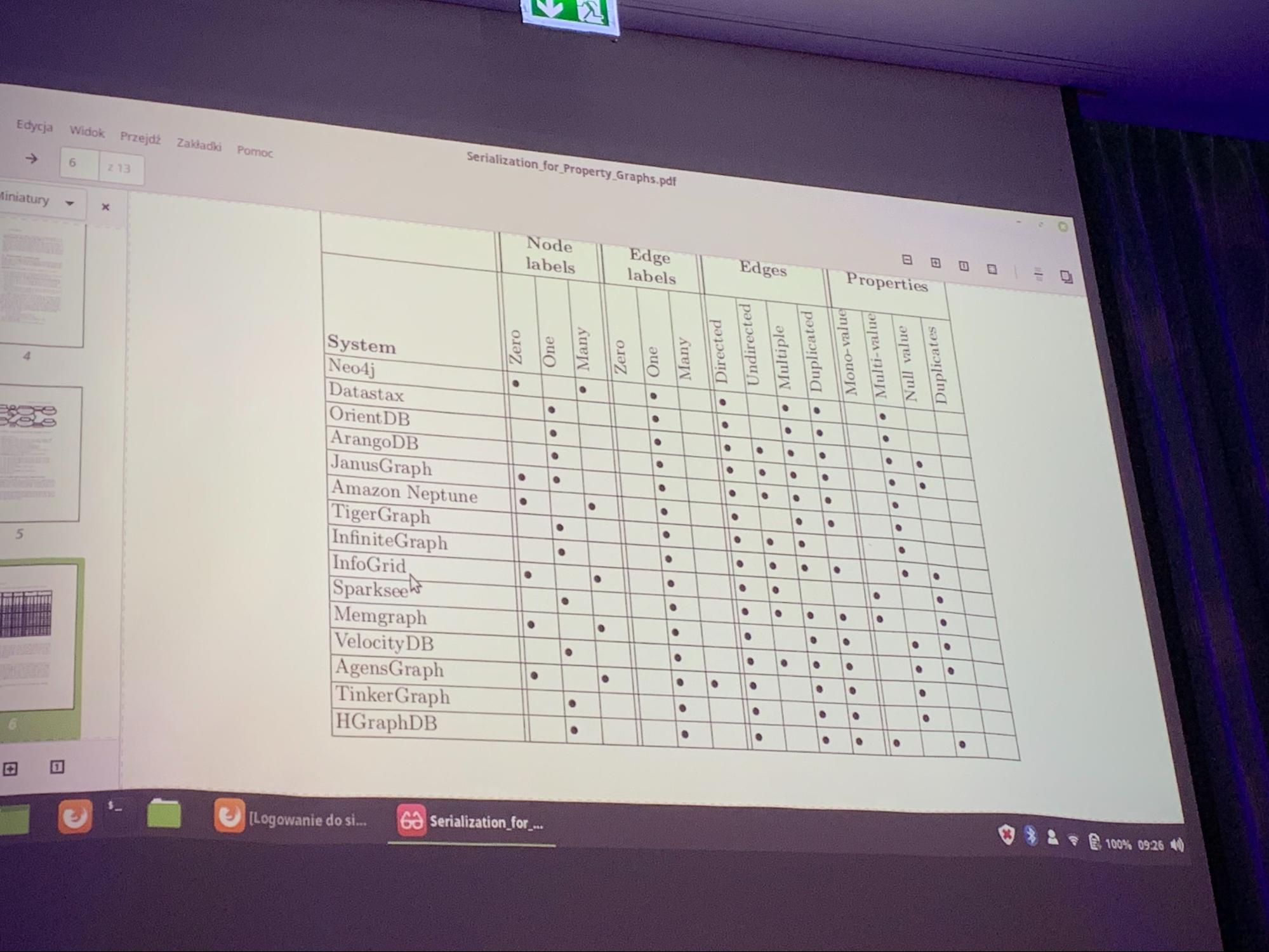
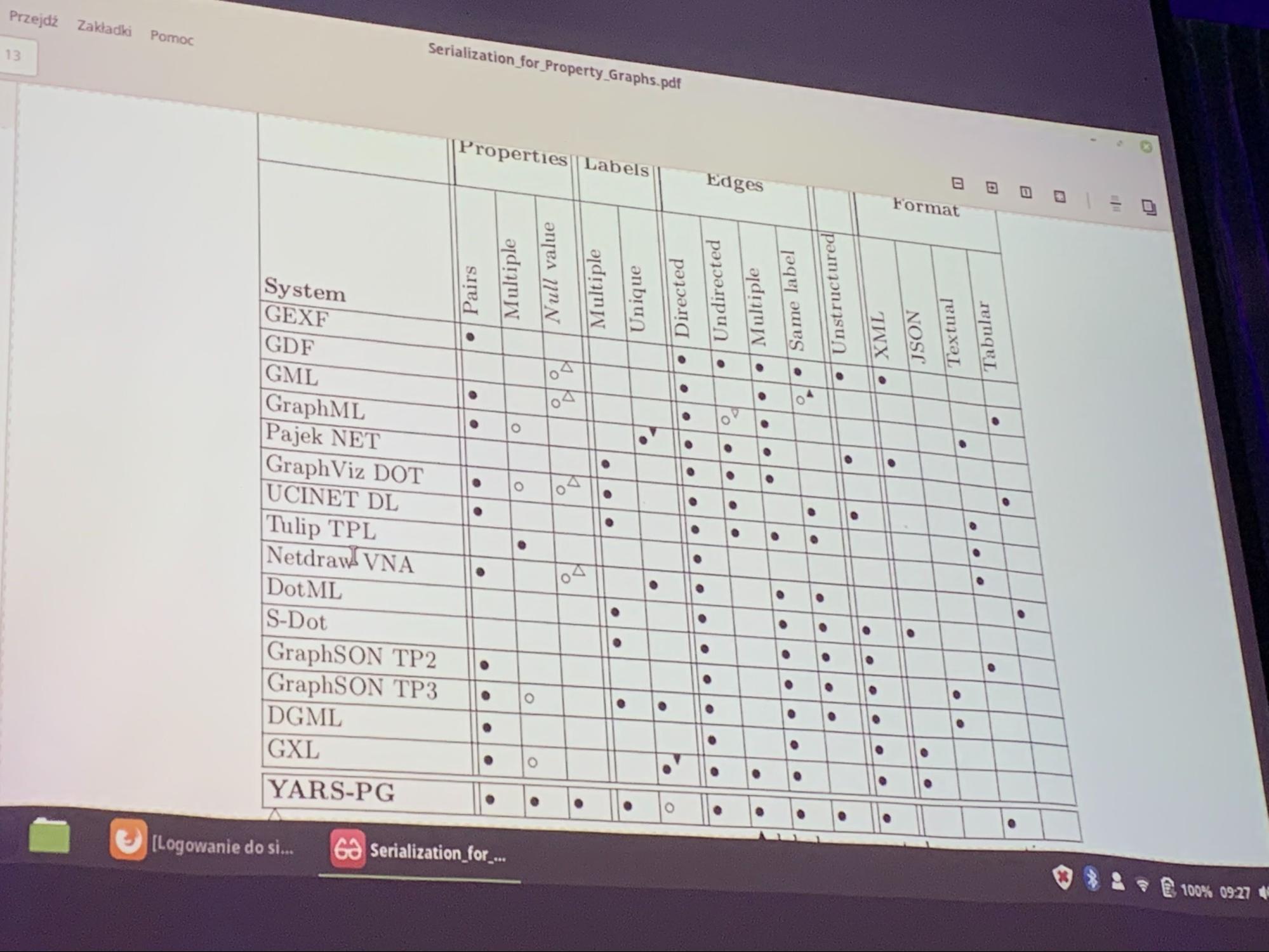
YARS-PG (more at poster session)
We should enable different communities to work with the tools that work best for them.
A bit of history: RDF and XML started at the same time and many people saw RDF that it was not very good XML. The communities moved on from using RDF/XML
AxelP: Why not start from the RDF syntaxes such as Turtle and JSON-LD. Or N3.
Barry: Nothing against JSON representation, but it sounds that there is not a widely adopted method of representing graphs. But with Turtle there is.
In cambridge semantics, we don’t see data in RDF/XML but we do see ontologies.
GreggK: Just to be clear, JSON-LD is a w3c recommendation to represent RDF Graphs. It’s important to be syntax independent and it seems that RDF* is syntax dependent.
MonikaS: what does the developer community like? It seems that the dev prefer JSON.
JSON community is bigger than Turtle.
AxelP: there is an advantage of using Turtle. Additionally, Turtle is also a basis of SPARQL.
Be careful by allowing to do different things with the syntax. In XML you can add values in tags or attributes and that gets complicated.
Olaf Hartig: RDF* and SPARQL*
Slides: http://olafhartig.de/slides/W3CWorkshop2019RDFStarAndSPARQLStar.pdf
It’s not just about serialization. We need to understand how to exchange data between different systems (RDF vs PG)
RDF at a triple level does not support metadata about statements.
Kubrik influencedBy Welles → X
X significance 0.8
Solutions to this are:
- RDF Reification. Query becomes very verbose
- Named graphs: but then you can't use the named graphs to make statements about the graph
- Singleton Properties: databases are not optimized for this.
Proposal: Nested Triples [http://olafhartig.de/files/Hartig_ISWC2017_RDFStarPosterPaper.pdf]
<<Kubrik influencedBy Welles>> significance 0.8
Two Perspectives:
1. Syntactic sugar on top of standard RDF/SPARQL
2. A logical model in its own right, with the possibility of a dedicated physical schema
Use SPARQL* to 1) query data in RDF reification 2) Query Property Graphs by translation to Gremlin/Cypher
Contributions 1) mapping between RDF* and RDF and 2) definition of RDF* as its own data model and SPARQL* as a formal extension of SPARQL
Additionally defined mappings for RDF* to PG and PG to RDF*, 3) full support in the Blazegraph triple store
Axel: what is the real advantage of RDF*/SPARQL* over singleton property reification
Olaf: RDF*/SPARQL* abstract over the concrete reification used to store the data
Axel:… IIUC, you mean, there could be roundtripable mappings to different reifications underneath, or to graph stores supporting PGs directly?
Olaf: yes.
Barry: This is also in Cambridge Semantics “this plugs a big hole in RDF”
Brad: The tinkerpop community would say that Graphson3 would be the de facto syntax.
Olaf: Right! Our RDFstarPGConnectionTools contain a converter from RDF* (Turtle* files) to a Tinkerpop Graph object.
Barry: RDF* is not just syntax sugar, at ingest time it is very valuable.
JSON-LD for Property Graphs Jose Manuel Cantera
Use case is in Smart Cities
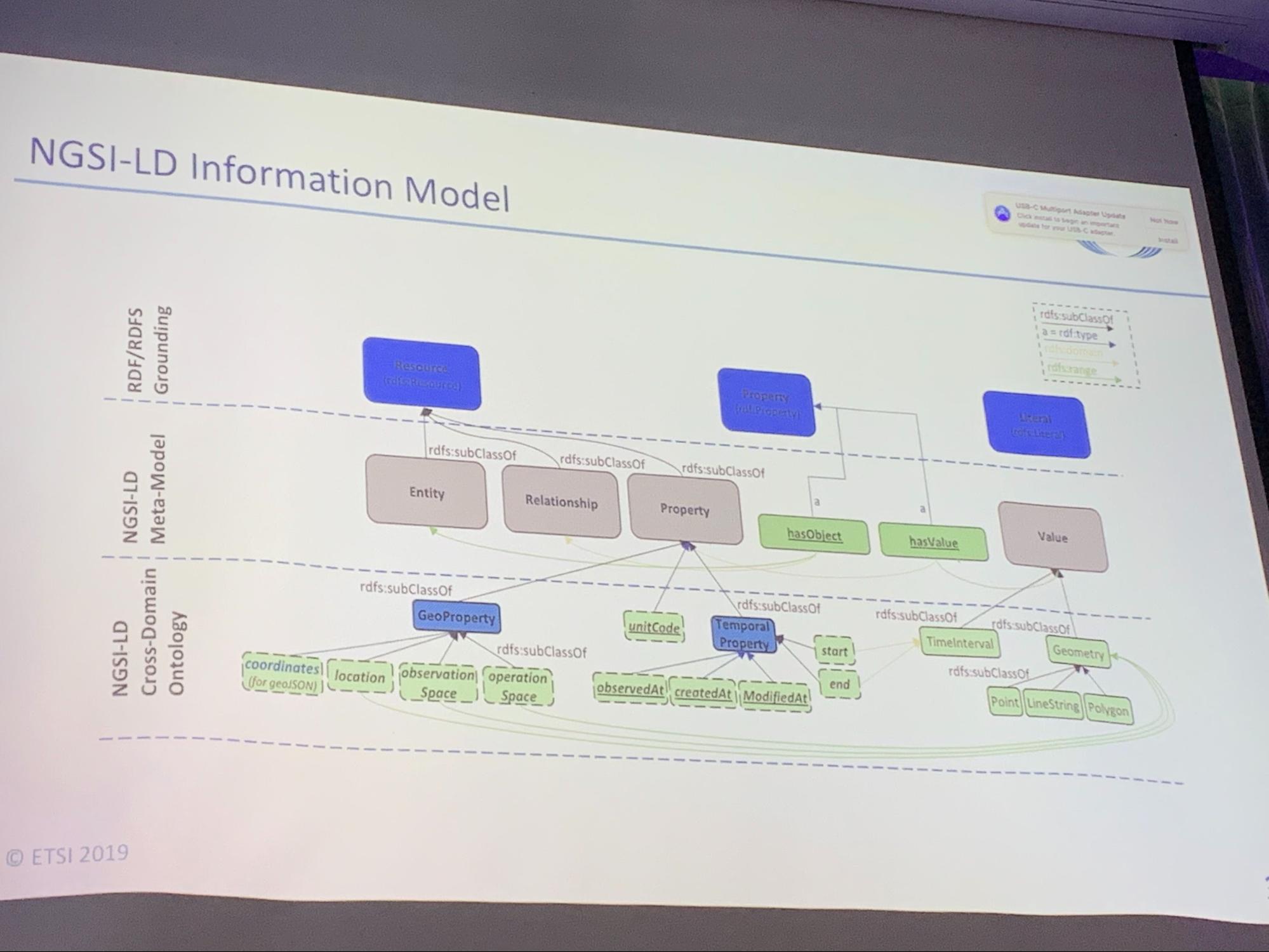


Gregg Kellogg


JSON-LD introduced the notion that blank nodes can be the identifier of the named graph.
Toward interoperable use of RDF and property graphs - Hirokazu Chiba
Mapping RDF graphs to property graphs.


G2GML currently supports RDF → PG
Barry: Is this a general mapping tool?
Hirokazu: It’s similar to SPARQL CONSTRUCT
Discussion
Hands raised (on Zoom) that we should spend time on JSON-LD for PG and on a mapping language.
Should we see how JSON-LD can support PG? Everybody raised their hand
Do we need a mapping language that does RDF<->PG? ~50% raised hand for yes. ~50% raised hand for “I don’t know/care.
Brad Bebee: Apache Tinkerpop community under-represented here. GraphSON is a de facto standard, it should be taken into account.
Should RDF*/SPARQL* be sent as a W3C member submission? Everybody raised their hand
AxelP: and it should include a mapping to JSON-LD
Easier RDF and Next Steps
Moderator: David Booth - Slides
Collaborative minutes, please join in!
David Booth: Yosemite Project
Guiding slides for discussion:
Difficulties in using RDF?
Background in ground up effort in getting healthcare data to be interoperable. (yosemite project). Allow different syntax but information content the same due to shared semantic mapping through RDF.
Claim that RDF is to hard to use. Can be used successfully but by highly skilled teams.
https://github.com/w3c/EasierRDF has a collection of issues that where collected earlier.
Summary:
- Lack of standard n-ary relations
- Moribundity of tools
- Lack of SPARQL-friendly lists
- Blank nodes
- Lack of beginner-friendly tutorials
- RDF is too low level
Lack of standard way to represent n-ary relations - just patterns. https://www.w3.org/TR/swbp-n-aryRelations/
Example with “has_ceo” between company and employee, with a start date. One common pattern to represent this in RDF involves a blank node.
Question: please expand on why you want to tag n-ary relations?
Answer: So that tools can know that it is an n-ary relation.
Question: The example is more like a qualified relationship. Another example is for a sensor: where it is located, what it measures, what its accuracy is, when it was last calibrated, etc.
Answer: Yes, it is a restricted kind of n-ary relation. It was chosen so that later I can easily illustrate how property graphs can be represented in RDF.
Some meta discussion on what we are doing in this session - we should avoid spending too much time on the low level details.
David takes us through a list of challenges (see slides), e.g. issues with blank nodes, lack of tutorials, the sense that RDF is too low level (assembly language vs high level language)
Question about how to determine what the middle 33% actually think, other than that they aren’t using RDF in a meaningful way other that sprinkling RDF into web pages for better search results.
Adrian: our experience is that beginners needs lots of tutorial stuff including JavaScript libraries and tools.
Maybe we don’t have good visualisation tools because we don’t have a standard way to represent n-ary terms etc.
Ivan: Maybe graphs are the problem: many people “think in trees”
David: I don’t quite agree with that, but they don't think in RDF graphs or property graphs. They think in higher level graphs. We need to work up to a higher level RDF that capture more directly the graphs that people visualize.
DanBri: agree with Ivan that property graphs are roughly similar in difficulty to RDF. Adds that unfriendly reactions on mailing lists put beginners off
Maybe IRIs are the problem instead of blank nodes. IRIs are a pain for new users whereas blank nodes are much easier for them.
Richard Cyganiak:
- RDF is good for hard data problems, for simple stuff just use JSON! :-)
- We might think how can we solve hard problems?
- Enterprise data are behind the firewall, so not concerned by web use cases of RDF
Dave Raggett: we need a sustainable model for a strong community around developing tutorials, javascript demos etc. and perhaps the Mozilla Developer Network (MDN) provides a good precedent.
I also agree that enterprise support is a key for RDF, and that we need to step up to defining the mapping to property graphs and a role for an interchange framework across heterogeneous data silos using different database technologies and standards
David: RDF is at the assembly language level and we need to define a high level framework that is better suited to average developers.
Adrian walked out
Quick overview of 5 ways of representing n-ary relations in RDF, with their pros and cons.
Ivan: these are mostly hacks, the question is whether we need to revisit the RDF core. Can we have local IRIs? That would make it so much easier to get started. (Jerven’s thought: can we also have more formal automatic skolemization of bnodes as a default?)
Richard: if we open RDF core, then RDF* is a promising thing to look at.
Discusses the challenge of sustainable funding for educational materials. Maybe we can approach companies?
Property graphs are successful because they differentiate links and properties, and use the closed world model. If we had reification with a standard “hash” name, just a W3C note then reification is nice and enough for property graph capabilities. Also then just needs syntax sugar in SPARQL and the serializations.
IRIs can be hidden (JSON-LD @context) as they are only relevant when it comes to external links. We need a higher level framework and representation that is easy to use
David: we still aren’t clear what the higher level RDF syntax should look like
DanBri: I want to pick up on packaging. Docker goes a long way to seamless packaging, making it easy to install applications without having to deal with the dependencies. If only there was an easy way to add the data.
A higher level framework should simplify handling of identifiers, JSON-LD is a good example.
Dave: we should incubate a high level framework and tooling above RDF, including visual editors for graph data and rules, look at sustainable models for tutorials etc., and ensuring that RDF can act as an interoperability framework for integration across different property graph and SQL data stores etc.
David does a straw poll:
- How many favor representing property graphs in existing RDF 1.1? ~12 hands up
- How many favor extending RDF to represent property graphs, perhaps along the lines of RDF*? ~16 hands up
Andy: we should ask the users for what they find hard in practice and we need to engage with enterprise users in particular.
Need for work on richer mapping standards across heterogeneous silos.
Lift the turtle syntax to make it easier to express property graphs and then make it easier to SPARQL (Robert Buchmann?)
We haven’t talked about semantics. This proved a painful area for RDF1.1.
Lack of courses on RDF. This is the tutorials space.
David: Some vendors offer courses.
If I had a bunch of money to improve RDF uptake I would hire a designer. More designers! Nicer layouts for the tools.
Need to start writing standards for nicer Turtle and Sparql (Richard Cyganiak) we know the issues.
Ivan: RDF has lots of work on inference that virtually nobody uses - we need to work out why?
Perhaps this is because this isn’t what people actually need?
We should work on RDF*, SPARQL* etc. this would address much of what people are looking for.
Need for work on SPARQL 1.2
We’re in competition with Property Graphs and need to make RDF better fitted to succeed[a].
We differ in respect to whether we need the semantics in the Semantic Web. Some people are comfortable with defining inference in terms of the application of rules rather than relying on a logic prover. Standard vocabularies (ontologies) make it easier to re-use shared semantics.
Inference is very important but needs to be easier to specify selectively what inference to use and where to use it.
[a]the only place where PGs outcompete RDF is marketing
https://twitter.com/jindrichmynarz/status/775633426149965824
SQL and GQL
Moderator: Keith Hare
Summary:
The SQL and GQL session had four parts:
- Keith Hare, Convenor of the ISO/IEC SQL Standards committee, presented a quick history of the SQL Database Language standards, and talked about how the new SQL part, SQL/PGQ -- Property Graph Queries, and the potential new Graph Query Language (GQL) standard fit together with the existing SQL standard.
- Victor Lee, TigerGraph, talked about how TigerGraph achieves high performance using defined graph schemas. TigerGraph also supports Accumulators to gather summary data during graph traversals.
- Oskar van Rest, Oracle, described the SQL/PGQ syntax to create property graph “views” on top of existing tables. He also provided an introduction to the Oracle PGQL property graph language.
- Stefan Plantikow, Neo4j, provided an overview of the capabilities currently planned for the proposed GQL standard.One key goal is composability – the ability to return the result of a graph query as a graph that can be referenced in other graph queries.
Minute takers: Alex Miłowski, Predrag Gruevski
SQL Standardization
(a summarization of the slides - see presentation for reference)
Keith Hare
“The SQL Standard has been the borg!” - 30 years of history of expanding SQL
SQL technical reports describe parts of the standard:
- Descriptive text that doesn’t belong in the standard
- Free
Next:
- Streaming SQL
- Property graphs!
- Streaming property graph
What’s a property graph?
- Vertices and edges, each with properties
- Pattern matching: declarative “find me all graphs shaped like this” querying, returns a table as a result
SQL/PGQ = the intersection of SQL and GQL
- SQL/PGQ is the SQL property graph extensions designation, and represents the intersection of SQL and GQL
- In terms of standards, SQL/PGQ is going to be another part of the SQL standard, with dependencies on SQL/Schemata and SQL/Foundation (the part most of us consider as the “core” SQL standard)
- GQL is expected to be fully done first, so read-only embedded GQL (“Read GQL”) in SQL expected to be available first
- Possibly pull some functionality from GQL into the SQL/Foundation or SQL/Framework
SQL/PGQ and GQL work -
- ANSI INCITS DM32.2 (Databases) Property Graph Ad Hoc
- Most technical discussion has been here
- ANSI INCITS DM32.2 (Databases)
- Approves US inputs into :
- ISO/IEC JTC1 SC32 WG3 - Database Languages
- International committee
- By the time something gets here, many people will have seen it three times (so it’s either good or there are delusions)
GQL project potential structure
- Incorporate by reference the relevant parts of SQL/Foundation and SQL/Framework, to avoid reinventing the wheel
- “Read GQL” contains pattern matching, and possibly might become part of SQL
- GQL will also contain graph operations that are not necessary in SQL
Various inputs to SQL/PGQ to GQL
- OpenCypher and Neo4j Cypher
- Oracle PGQL
- LDBC G-Core
- GXPATH
- Diagram here
Tiger Graph (Victor Lee)
“Property Graph Language for High Performance”
Origins of GSQL: attempting to design a property graph database of the future
- Designed for large-scale OLTP/OLAP - “billions-to-trillions” scale graphs
- Native graph - storage engine knows it’s representing a graph
- Easy parallelism for performance
- ACID-compliant
- Schema-based
- SQL-like
- Procedural and conventional control flow (for, while, if/else)
- Hybrid transactional model
Why schema-based?
- The freedom of expression of schema-less models comes at very high performance cost in practice.
- Schema-first: Data model is known in advance for performance reasons - read/write values faster - DB knows where everything is stored.
Proposed GQL graph model: schema-first options
- Predefined vertex and edge types
- Sets of property name/type associated with vertex/edge
- Edges can define reverse edge type, but not required (edges can be used in reverse in query syntax)
- Vertices/edges can have properties, but those are not required.
- Each vertex/edge has a “label” which is a set of zero or more properties
- Properties can be typed or can be just string-only tags (key-values or just string keys with no value)
- Vertices have a primary key
- Graph is a user-defined combination of vertex and edge types, including all instances of the named types
- Can have multiple graphs that potentially share data.
- Each graph is a domain for access control.
Proposal for GQL (see slides):
- Basic:
- Multi-hop paths
- Composable
- Features for analytics:
- …
- accumulators
Accumulators:
- Two parts: what datatype (e.g., integer), what computation (e.g., sum)
- Local - per vertex - each vertex does its own processing
- Global - visible to all - every vertex/edge has access
Oskar van Rest - Oracle
Property Graph DDL:
- Create graphs from existing tables or views
- Infer keys/connections from primary/foreign keys
- All columns are exposed as properties
More complex DDL:
- Can specify keys, labels, and properties
- Connections in graph are specified in the edge definition explicitly
Query:
- Using GRAPH_TABLE(... query ...) syntax
- COLUMNS clause exposes values to the outer query
- Example: CHEAPEST clause - graph algorithm in query
PGQL = Property Graph Query Language
- SQL-like syntax
- Used in various Oracle products for several years
Stephan Plantikow - Neo4J
Cypher - MATCH/RETURN structure - conceptually simple for users
From Cypher/PGQL/etc. to GQL:
- Simple pattern matching -> complex patterns (RPQs, shortest/cheapest paths, etc.)
- Tables out -> graphs, tables, scalars,
- Single graph -> multiple graphs
- DML -> DML, graph computations, graph projections
- No schema -> schema & advanced type systems
Alignment w/ basic data types from SQL
Query composition:
- Linear combinations of queries
- The output of one is used as the input graph to another
- Allow nested queries
- Enables abstraction and views
Enable graph construction via query composition
Queries can be defined by name with functional semantics - used in later queries like a function call.
Graph types:
- Types define property bags
- Graph types define which types can be vertices or edges
Type system:
- Base data types from SQL
- Nested data/documents
- Dynamic typing - optional static typing
- Graph types
GQL Scope and Features - document from Neo4J (need link)
Among questions:
Specifying cardinality constraints in a graph schema - how many edges of a type in/out of a node; how many nodes of a type
Composibiity -- if the output from graph query One is a graph, that output can be used as input for graph query two.
Graph Query Interoperation
Moderators: Olaf Hartig, Hannes Voigt
Initial Statements
- Predrag Gruevski
- The missing thing is a mean to express a narrow business question on rich datasets in a heterogeneous system landscape
- Most native query language are “too expressive” and by that to complicated for the business user
- Often relevant data is spread across multiple database with different data model, schemas, and query languages
- Solution being advocated:
- Have a narrow language for the end user, eg. GraphQL
- Use this language to also a intermediate language to do federation, virtual edges (view-like functionality), etc.
- Compile local queries snippets from intermediate language to native query language of the system containing the base data
- Performance is not the primary concern, because it the approach allows functionality that would otherwise not have been feasible at all
- Ruben Taelman
- Nice thing about GraphQL that it is WYSIWYG, i.e. query looks similar to the result
- That is not given for a SPARQL query (and similarly expressive query languages)
- Different approaches exist to map GraphQL to RDF (GraphQL-LD, Stardog, HyperGraphQL, TopBraid)
- All these approaches are highly incompatible
- Different underlying data (model) mapping
- As a result the same GraphQL is mapped to different SPARQL queries by the different approaches
- Extensions over core GraphQL (eg. aggregates, filtering, ordering, named graphs, etc.) are different
- Hence, the call for a standardisation of GraphQL-based querying of RDF data
- Harsh Thakkar
- Declarative Sparql is matched to declarative Gremlin code (using match()-step)
- Allow to using Sparql on a wide range of graph databases systems that offer Gremlin
- Allows also to mix SPARQL with Gremlin, i.e. SPARQL followed by more Gremlin steps
- Calling Gremlin from SPARQL would be interesting, too
- Dmitry Novikov
- Cypher for Gremlin translates Cypher into Gremlin
- Architecture is setup in a way that Cypher is parsed into an intermediate representation
- Gremlin as output is generated from this intermediate representation
- Gremlin as an input can be parsed into the same intermediate representation
- Allows for combine/nest both language fairly freely
- Typical (end)user:
- People who prefer Cypher over Gremlin, but get to use a Gremlin endpoint
- Cypher users that need the imperative nature of Gremlin for e.g. analytics in combination with Cypher
- Andy Seaborne
- Systems have already done implementations. Although we like standardization, we might need to start thinking about interoperability going forwards
- Example: Format of the result because this will flow from implementation to implementation
- Understanding communication problems around the groups
- What are the interoperability points besides the result format?
- Victor Lee
- Requests from (TigerGraph) users
- Frequently move RDF data back and forth from and to a property graph → call for a more standard approach to do that
- Can we run SPARQL, Gremlin, Cypher, etc. next to GSQL
- Juan Sequeda
- We need mappings, i.e. we need well-defined mappings
- We need query preservation, i.e. study and understand limits of mappings regarding query preservation
- We need to understand the tipping points, i.e. we need to understand for when to migrate into a different data model world
Discussion
- We should solve data model interoperability first before discussing query language interoperability
- For mapping from Property Graph Model (PGM) to RDF
- Needs to deal with variations between different implementations of the PGM
- A canonical PGM can help as be used as a intermediate step for mapping
- Two views on mapping data model
- Direct mapping vs. customized mapping
- For instance, R2RMDB offers both in one standard
- For query language mapping an abstract query model (e.g. abstract query algebra) can help with mapping query between model
- Regarding standardization
- What is the right venue?
- ISO takes to long for some commenters
- On the other hand, where is the Web in property graphs?
- To make a good standard needs the right timing
- To ensure a certain level of maturity
- While not being to late
- Do not standardize the same thing twice in two venues!
- Quick pool: Majority favored
- Standardize the property graph model (PGM)
- Standardize mapping(s) between PGM and RDF
Composition, Patterns and Tractability
Moderator: Peter Boncz
- Petra Selmer shares “family tree of (property) graph query languages”: link
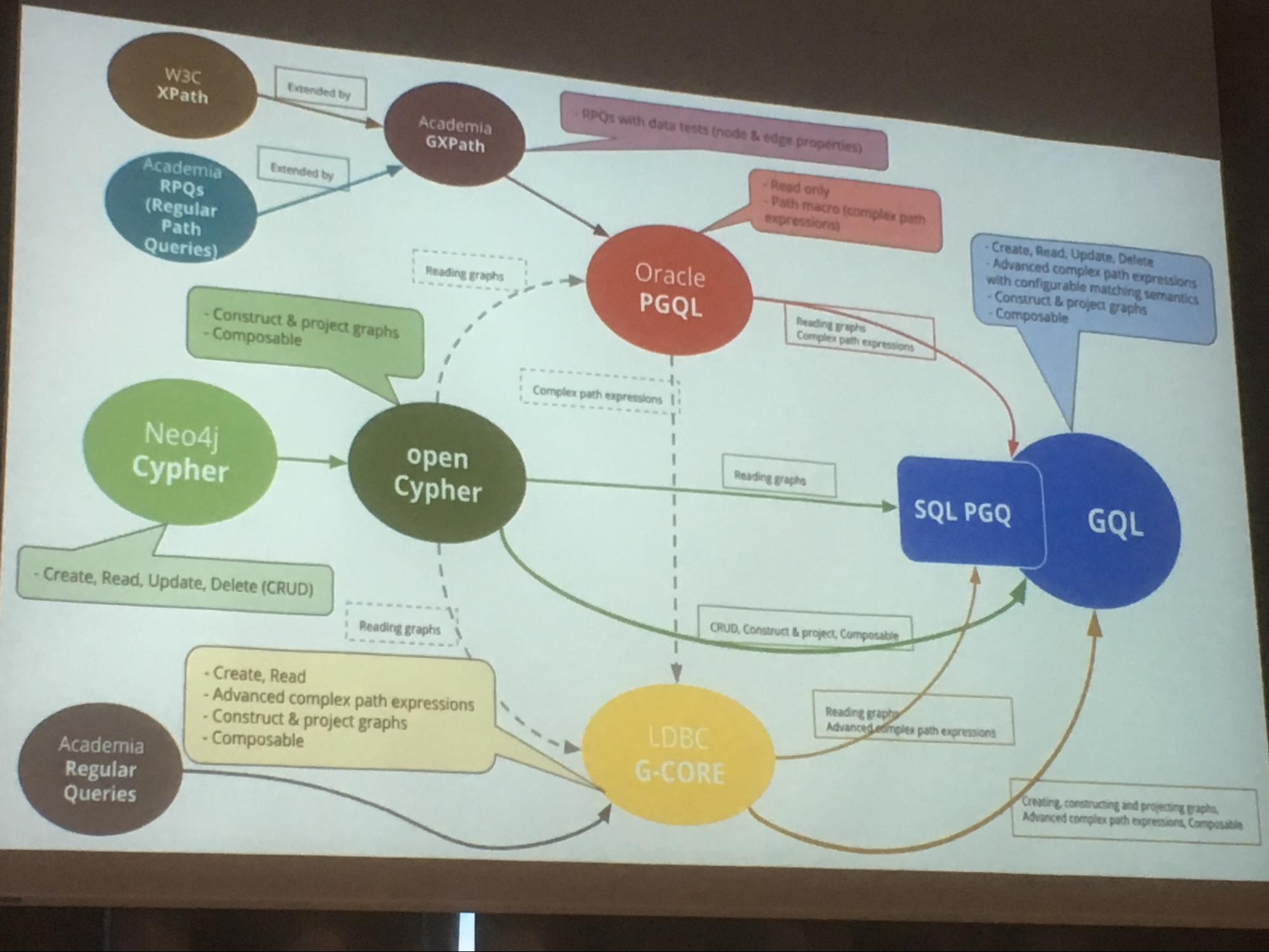
- Leonid Libkin asks Are there use cases for comparing paths?
This has been academically studied in the recent years.
- Petra Selmer: no customers are explicitly asking for this, but then again customers didn’t know to ask for RPQs either a few years ago, but with more exposure to graphs they start to ask for such functionality, so it is possible that there will be desires for comparing paths as levels of sophistication raises further.
- Peter Boncz - G-CORE originated from LDBC not having a single standardized query language for expressing queries for benchmarks. A task force was started to investigate languages, analyzing the capabilities required of a language and how existing languages measure against this capabilities, ultimately making recommendations for what should be considered in future evolutions of graph query languages. G-CORE defines such a core set of features for languages that were felt important:
- Ensure the language is composable over graphs
- Languages at the time queried graphs, output tables
No graphs as output means no queries over (results of) queries: No subqueries and no views - this is a severe limitation that needs to be improved! - Queries in G-CORE always return a graph.
- Queries are structured as a CONSTRUCT of a new graph based on a MATCH of patterns in a source graph
- Paths should be central to the query processing
In G-CORE paths are an explicit first class member of the model, in order to be able to return paths as part of the graphs being returned by a query.
This leads to what the authors call the Path Property Graph Data Model
- Allows labels and properties on paths
- Question: can you have an edge to or from paths? i.e. is there “(RDF-style) reification of paths”?
- Alastair Green: Can there be two paths with identical composition?
Answer: yes, G-CORE supports paths with different identity with the same vertices and edges - Tractability was central to G-CORE
- Enumerating (all) paths can be intractable
- Matching paths without cycles (simple paths) can be intractable
- Arbitrary conditions on paths (e.g. certain comparisons between paths) can be intractable
- optional pattern matching can lead to intractability
- The assumption in the design of G-CORE is that the set of users will involve people who are not graph complexity experts, so the language should lead (or possibly even force) users towards safe and tractable queries.
- Comment from Alastair Green: There was a study trying to do similar designs, and it was found that users learned by experience which kind of queries lead to intractable behaviour
- G-CORE allows data integration by querying from multiple graphs.
Example: querying a graph of companies (company_graph) and a social graph (social_graph) combining this with the same social graph creating a new graph that augments the social graph with employment edges to companies:
CONSTRUCT (c)<-[:worksAt]-(n)
MATCH (c:Company) ON company_graph,
(n:Person) ON social_graph
WHERE c.name = n.employer
UNION social_graph
- G-CORE could also transform data. Example turning a property into a vertex:
CONSTRUCT social_graph, // another way to express a union
(n)-[:worksAt]->(x:Company {n=n.employer})
MATCH (n:Person) ON social_graph
In order to get only one Company vertex per distinct employer name, grouping is used:
CONSTRUCT social_graph
(n)-[y:worksAt]->(x GROUP e :Company {name=e})
MATCH (n:Person {employer=e}) ON social_graph
- G-CORE allows binding property values as well as elements (as seen above), as a means for handling multiple valued properties. In the query above, if n.employer is a multivalued property, the variable e will hold each individual value, unrolling the multiple values into distinct bindings.
- Comment from Leonid: With duplicate elimination on a “tabular” level (of bindings) before the creation of the Company nodes, it would be possible to express the same thing through composing multiple queries.
- Path pattern matching is either reachability queries or SHORTEST path queries, under homomorphic pattern matching semantics.
- G-CORE supports defining named path patterns, e.g.
PATH wKnows = (x)-[e:knows]->(y)
WHERE NOT 'Google' IN y.employer
COST 1 / (1 + e.nr_messages)
- This allows defining a function for computing the cost of a path, which is then used for finding the shortest paths matching the pattern, where the shortest is the one with the lowest cost.
- The cost function must produce a positive number
in order to ensure that Dijkstra-style algorithms can be used for the evaluation
- G-CORE can also return a table (in order to get data “out of the graph”), by using a SQL-like SELECT clause.
- Related, G-CORE can also consume data from tables using a FROM clause specifying a table for input.
- By that G-CORE could be composed with SQL to create a union language that is closed over both tables and graphs.
- Paolo Guagliardo asks: How far along is the implementation of this?
- Peter had a masters student last year working on this.
- There is a Chilean group taking this further.
- There is a demo submitted to VLDB.
- Results from the implementation:
- CONSTRUCT queries that produce graphs can be very expensive,
even quite small patterns get translated into multiple queries in the underlying engine. This stems from the grouping feature of CONSTRUCT.
- Source code is available at https://github.com/ldbc/gcore-spark
- Major differences of G-CORE compared to SPARQL:
- SPARQL has no ability to find paths, only to match reachability by a certain property pattern
- The CONSTRUCT clause in SPARQL does not have the grouping feature of G-CORE, making it far less capable for transforming graphs
- Gábor Szárnyas presents LDBC Q25: Weighted interaction paths
- illustrates the need for paths
- cannot be expressed in SPARQL
- Not yet fully investigated if it can be expressed in G-CORE - it is possible that it is not possible
- It is a fairly complicated query in Cypher
- It has also been implemented in SQL, and leads to an extremely complicated query with poor performance
- Max Keißling demonstrates composable queries in Cypher for Apache Spark (“CAPS”)
- Every step of a Cypher query in CAPS produces a table and a graph
Triumphs and Tribulations
Moderator: Keith Hare
Summary:
Keith Hare presented the processes used by ISO/IEC JTC1 SC32 WG3 (Database Languages) for the SQL standards along with the benefits and challenges of those processes.
Peter Eisentraut described the processes used by the Postgres open source database project.
Ivan Herman described the W3C processes.
While the processes have some bureaucratic differences, they have many similarities. Perhaps the biggest similarity is that the end result is determined by the people who show up to do the work.
Minutes:
Keith Hare : presented ISO/IEC JTC1 SC32 WG3, SQL editing process (slides)
Pro:
Detailed specifications
Technical Reports
Standards Documents are built in XML
Process is fairly open
Entry costs depend on national body
Real cost is time to effectively participate
Consistent participation
Collegial participation
Ability to adapt to changing bureaucratic environment
Standards are defined by the people who do the work
Often tied to database implementations
WG3 good at fitting into/around ISO bureaucracy
Con:
spec is complex
Documents cost money (can get round to some degree, tech reports are free)
No external validation testing
Getting new people involved - property graph work is helping
Document format arguments with ISO central secretariat
Work only proceeds where people do the work
4 parts of SQL that won’t be revised - effectively obsolete
Peter Eisentraut - Postgres development (as OpenSource example)
Long-term OS cooperation
Process evolved on realising some things needed
People generally get on
Code-review done but not enough people doing it
Regular release cycle nowadays (longer ago less organised)
Over time, more process structure has helped
Similarities to some of the ISO process
Introductory documentation available
ISO WG3 process is perceived as a difficulty - who is delegate representing ? joining national body may be easy, but if all the real discussion is in US committee ….
Problem with bug reporting into ISO process.
Ivan Herman W3C
Membership by company, not by country
Member company can send as many people to as many groups as they want
But vote by member
Development process fairly similar to ISO
Working groups organise as they like, but weekly 1 hour call + some f-t-f common
Can invite other experts
All material is now on github; any at all can comment via github commenting
WG has to respond to comments
All documents, draft to final are public
Patent policy - member companies have to commit they will not enforce a patent that is required for implementation of a recommendation. Not an issue in recent years.
Groups produce a first public draft, then updated, eventually to candidate recommendation (CR)
Then review - primarily testing - requires every feature to be proven implementable by at least two independent implementations (issue with only 3 continuing browser rendering engines)
W3C does not check the validity as such
Testing phase can be long - 6-12 months
Members voting points:
charter of a working group (requires 5% of members to vote - approx 20 members)
Proposed recommendation - yes/no - potential for director ( T B-L) to overrule
Role of editor : depends on WG, but editor expected to follow WG decisions; Other WGs give editor more authority
Q: is there high signal:noise on open comments : not too much.
Every WG has at least one member of W3C team - so very flat from editor - wg chair - w3c team - w3c Director
All documents have to be checked for security, privacy, internationalization, accessibility concerns. (RDF lacks right-to-left marker for Hebrew etc)
Email discussions archived and accessible. (unlike WG3 - archive exists but not accessible)
Specifying a Standard
Moderator: Leonid Libkin
Leonid Libkin:
- I don’t have the answer (or will not tell mine yet), they should come from you
- Even for standard SQL queries, the different DBMS implementations might not all agree if there is a well-defined result / the query is not well-defined (compilation error)
- Modes of of writing the standards
- Natural language
- Denotational semantics
- Reference implementation
- SQL: only natural language
- Papers on formal semantics of SQL existed
- For Cypher: Neo4J + Edinburgh in SIGMOD’18, read-only core
- Discovered lots of corner cases
- GQL? Ideally parallel development: formal and natural language and executable semantics
- Semantics now come mostly from academics, but they do not get much credit
- Need to address somehow
- Comments?
Jan Posiadala, “Nodes and Edges”
- Cypher.PL (work with U. Of Warsaw)
- Written in Prolog
- ISO standard
BEGIN of notes redacted by Paolo Guagliardo
Initial thoughts for discussion put forward by the moderator (Leonid Libkin):
- Should the new GQL standard follow the lead of SQL? The SQL standard is written entirely in natural language, which is prone to ambiguities (example: differences in the interpretation of SELECT * queries in different DBMSs).
- We should consider corroborating the natural language specification with denotational semantics and a reference implementation (or test suite).
- For SQL, the standard came first; attempts (many of which failed or unsatisfactory) at formal semantics followed. For Cypher: there is a natural language description (but no standard); the formal semantics (see SIGMOD 2018 paper) captures the existing language (Cypher 9) and led to changes to it. For GQL: ideally a natural language specification and a formal (executable) semantics should be developed in parallel.
- Formal semantics are typically developed by academics, who do not get credit (from their own institutions) for participating in standardization efforts.
Contribution by Jan Posiadala: Executable semantics as a tool and artefact to support standardization
- Proof of concept: Cypher.PL, an executable semantics of Cypher 9 written in Prolog.
- It consists of 1500 lines of code, it covers Cypher’s Technology Compatibility Kit (TCK), and reflects the ambiguity due to driving table order.
- Why Prolog? Because it is a fully formalized declarative language that supports multiple matches and has built-in unification.
- This semantics covers grouping (implicit group by), which is not covered in the SIGMOD 2018 paper.
Points raised during the discussion:
- An executable semantics should be usable for verifying compliance of implementations with the standard, and for proving optimization rules/rewritings.
- A formal semantics should not be the only specification of the language, but an additional artefact that helps reduce or eliminate ambiguity.
- HTML5 has algorithmic descriptions (in the form of pseudo-code) of what the API is expected to do. This helps developer implement real algorithms that comply with the prescribed behavior. We should consider including algorithmic descriptions to the new standard.
- The key to a successful standard is to satisfy stakeholders that the standard specifies the behavior they expect. To this end, a formal semantics may not be sufficient on its own, because not everybody understands mathematical descriptions. Industry people should be able to make and propose changes.
- While many different artefacts can successfully contribute to the standard, there is the problem of maintaining each of them up to date, and in sync with the others.
- Should a formal semantics be a normative part of the standard? Who is going to review it for inclusion in the standard? We need experts in the standardization committee.
- Publishing the formal semantics as a separate technical report may be a viable alternative to including it in the standard.
- Copyright issues: ISO claims intellectual property even on drafts.
- A possible way for academic experts to discuss the formal semantics within the standardization committee is to do so via one of the industrial committee members (as a sort of proxy).
- Collaboration between different communities is vital for a successful standard.
- Issue of longevity: how can we ensure that changes to the standard can be made 10-20 years down the road?
Conclusions
There is general consensus that a formal specification should be devised in the context of the new GQL standard (the vast majority of people in the room agree with this and no one is directly against it). It remains to be seen who will be responsible for developing and maintaining this formal specification, whether it will be an integral part of the standard, or how it will otherwise influence the standardization process.
END of notes redacted by Paolo Guagliardo
Queries and Computation
Moderator: Victor Lee
Intro
Victor had slides to help guide the session.
Thinking about queries and the data on which they are running. How to tie into machine learning.
What is a query
- Favor the human or the computer
- To restrict or not restrict inefficient operations
- Influence of schema
- When do you want a schema (dynamic/predefined)
- Digging into query and workload types
Computers are smart, but hardware is dumb.
One line of code can translate into O(n), O(n^2), etc. CPU cycles etc.
Overhead: disk access, OS management, network access
High level queries are just the top of the iceberg
Translation into sequence of ql primitives e.g. loops or subqueries -> IR -> machine language -> hardware
Incurs hidden costs e.g. transactions or memory models. VMs or data layer access
Memory is cheaper but still much more expensive. Latency is a big problem.
Cost of complex algorithms, can it be fast for large N at all?
Amdahl's law hits.
What is a "query"?
Audience responses:
- Does a graph contain similar patterns. Identification of subgraphs.
- Writing back, projection.
- Lots of other examples, will be explored later
Topic 1: Favour human or the computer.
- If driven to an extreme -> we would write assembly.
- Abstraction helps the users.
- When does a hint help.
- Declarative or imperative is not an absolute.
- The boundary between declarative and imperative is context- and user- dependent. In principle, the boundary is the level of abstraction.
- How do functions e.g. REGEX fit into this?
- Segue to standards? What makes a language easy to implement?
- Less is better.
- Need a good test suite
Topic 2: Computational Limits
Some computational tasks are expensive in terms of time or memory.
Some such tasks are built into the language; some are queries that the use writes.
What should we do about excessively expensive operations?
- Prohibit (not support, check at compile time, or check at run time?)
- Warn the user
- No warning
How can you estimate the cost of an operation/query?
Some algorithms give progressive better results the longer you run them, so you can abort them when they reach some limit and possibly still have obtained a good approx. result:
- Iterative improvement or convergence, like PageRank
- Find the best answer/most instances within K hops.
- Pagination as a default. For relational tables, one page of data sometimes can be a good sample of the full data set. Not clear if this works well for graph.
Have parachutes in place
- Anytime Algorithms https://en.wikipedia.org/wiki/Anytime_algorithm
Topic 3: Schema-less vs. schema-first
- Should be named descriptive vs prescriptive schema
- Not all use cases allow to come up with an schema upfront or the schema ends up having a huge number of indirection, which take away the advantages of have a schema up-front (eg. dynamic product catalogs, medical examination data)
- Just In Time schema (e.g. work done for virtuoso and monetdb) find a 90% schema in an RDF database with exceptions left out
- Partially-prescriptive schema
Topic 4: Query and Workload Types
- Transactional: Can RDF be transactional? Yes, not part of the standard, but there are commercial offerings, like ArangoDB.
- Some types:
- Neighborhood traversal from a point source, Shortest Path.
- Reasoning: Available in RDF/Sparql, but not used much due to low performance.
- Given a pattern, find all instances similar to that pattern
- Full graph analytics
- Machine Learning
- Extract graph pattern features, use feature vector for ML out of graph, run ML prediction query in graph.
- Graph embedding and convolution
- In graph ML? May never be the high performance answer.
Rules and Reasoning
Dave: we may want to use mindmaps as a way to sketch the landscape for different kinds of rules and reasoning. This is a convenient way to devise informal taxonomies for concepts.
[Online comment by Harold: An earlier mindmap-like arrangement of rule systems was done in RIFRAF (also see follow-up pages): http://www.w3.org/2005/rules/wg/wiki/Rulesystem_Arrangement_Framework.html]
Moderators: Harold Boley, Dörthe Arndt
Questions to discuss (proposal): https://docs.google.com/presentation/d/1LkyXSE_86JNGoJRJx8HfK0PU6Xv_HUDEOLBnFh_dmgY/edit?usp=sharing
Proposal: Notation3 logic to reason over RDF/LPG graphs https://docs.google.com/presentation/d/1I-gS3lEsmuUlEcy3EK010NVH-0NAT3-TD4yPtTR3nH4/edit?usp=sharing
Harold: Database views are a special kind of rules (cf. Datalog).
Rules can describe one-step derivations: iform ==> oform, replacing iform with oform;
or (equivalently), oform <== iform, obtaining oform from iform.
Reasoning can chain rules for multi-step derivations, forward (adding data), backward (querying data) or forward/backward (bidirectional). Ontologies complement rules and prune conflict space.
Languages for graph rules and reasoning augment languages for graph DBs and relational rules; N3, LIFE, F-logic, RIF, PSOA RuleML are examples.
Ontology languages can be defined by rules, e.g., OWL2RL in RIF and SPIN rules.
Beyond deductive reasoning (from relations to graphs), includes quantitative/probabilistic extensions and qualitative extensions (inductive, abductive, relevance, defeasible and argumentation).
Comment: We have a few billion statements, can interchange rules, but not execute on big data. Usability profiles are important. Shape understanding of PG people.
Harold: Big data rules? See Datalog+/- -- it is scalable.
Evrin: Practicality is important. OWL, RIF, etc. may be too much to use. Worked on reasoning for 15 years. Need semantics people understand. We support a SPARQL-based syntax. Q: What about N3? Evrin: Maybe.
Comment: Want to be able to have wave of rules and use the results of one rule in another. Need to control info based on SPARQL CONSTRUCT, but use the results of another. For derivation rules, we need a standardized way to describe complex rules that is more than a direct derivation from one data to the other
David Booth: I want rules to be: 1. convenient and concise to write and read; and 2. easy to specify where and when I want to apply them. I do not want to apply all rules to all data! For example, I want to apply rules to only a particular named graph, or collection of named graphs. And then I want to use those result in another named graph, for example, and compose results.
Gregg: N3 rules have a difficult mapping to RDF datasets. We should consider basing reasoning on SPARQL query/construct feeding back to the dataset.
Axel Polleres: We had statistical rules, and ontology rules that we computed, and tricky combining them. How to handle them?
Comment: Might want to manipulate graphs having nothing to do with reasoning. If we can associate KG with cyber physical graphs... (missed)
Riccardo Tommasini: I work in two domains. Rules allow me to work at my preferred domain level. Complex event processing. Two domains, both with a concept of rules, and want to mix them. The metadata is timestamps.
Ghislain Atemezing: Rules are important. Our customers want to see rules in action. They want to be able to easily read and write them, and easily understand data that was inferred and how. Q: formal proof and provenance? A: Yes. And sometimes the complexity of the OWL profiles, end users don't want to know that part.
___: Rules control process, and check consistency. Q: validation? A: Yes.
Harold: Rules found inconsistency in Aircraft Characteristics information: an airplane model should not be in both the Light and Medium weight classes (http://ceur-ws.org/Vol-2204/paper9.pdf).
David Raggett: Rules that operate on graph, and rules that operate by miracle and update the data. Also machine learning rules, from reinforcement learning. Different kinds of rules.
Andy Seaborne: Rules have good mind share. If you say "inference" they switch off. They want control and understanding of what the rules are. They're programmers! They start with an idealized expectation of rules. Good potential. Lots of desire for rules to be more used. Better to start low level, e.g., computing a value from the data.
Axel: What would be the starting point? SPARQL-based without datatype inference.
___:
David: A third thing I want: the full power of a programming language.
Richard Cyganiak: SHACL rules package a SPARQL CONSTRUCT query. It’s a good starting point that already is a W3C Working Group Note. https://www.w3.org/TR/shacl-af/#rules
Ivan Herman: If people come to RDF, they will learn Turtle. From Turtle to SPARQL is relatively easy, because it is based on the same syntax. CONSTRUCT means that they are within the same syntax. Problem w N3: too late. It should have been done years ago, before SPARQL. If we add n3 we force the user to learn another syntax. If we cover 70%-80% of use cases with rules then that would be a good start. Q: Is n3 really hard to learn? A: Yes, n3 is different from SPARQL/Turtle. Yet another obstacle.
Harold: A tiny addition to SPARQL CONSTRUCT could allow results to be chained.
Adrian: I see the temptation in having programming language in rules, but there are limits to what you should do. If your data is so bad that you need to clean it up, then you should use a programming language.
Evrin: Caution against the full power of a programming language. Once you go to procedural semantics, you get problems, like priorities of rules. Simple addition of filters of binds is important to SPARQL. It makes a huge difference in practice.
___: Lots of discussion of RDF and SPARQL. Where do PGs fit in this? Need to think of the PG world also.
Gregg: Might want to define an abstract data model for both RDF and PGs. Perhaps that would be a framework for these rule engines. Not necessarily SPARQL.
Doerthe: Would an extra abstract layer lose people?
Dave Raggett: There is scope for procedural and declarative. I want procedural rules operating on PGs.
Ivan: Has there been dev of rules languages in PGs? Alistair: No. :)
___: In DB communities, there are papers on reasoning over graphs and dependencies on graphs.
Doerthe: Where do you want to use rules?
David Booth: Data alignment. Transform from one data model to another.
___: Check consistency rules for cars.
Adrian: Data pipeline, not have to materialize stuff that is in the schema. The less I have to write the easier it is to maintain.
Evrin: Data alignment, beyond just subclassing. Also encoding business language in your app, like fraud detection. Typically combined with statistical reasoning. Q: How to combine them? A: Relational mapped to RDF, statistical reasoning uses the logical reasoning output.
Riccardo Tommasini: We do the same thing with complex event processing. Correlation of events is also a concept. In most approaches rules rely on a symbolic level that is different from SPARQL. Don't care much how the data looks, but what it means.
___: Data alignment. You can extend these cases as much as you want. You get this with multiple DBs. Also, company based in Seattle, and you know that Seattle is in Washington. Region is transitive.
Peter W: Rules like models of buildings, and whether they comply with regulations. Modeling regulations. Looked at the Scottish legal corpus, putting into LegalRuleML. Building control process.
Doerthe: Base rules on existing languages or new language?
___: Now I am trying to get other people to use our rules. Did anyone try to study how long it takes to solve a problem with a programming language versus rules?
Monika Solanski: We had to make decisions based on certain criteria. Users wanted to do if-then-else all the time, and the benefit was that people in the business could read the rules.
Adrian: We manipulate something very close to triples. We use a DSL on top. It compiles to a more generic rules language. We do code completion also on the DSL.
Dave Raggett: Single format, but visualizable in a convenient rendering. Common underlying model, but not specific to one syntax. Consider a visual rules language.
[Online comment by Harold: One visual data/ontology/rules language: http://wiki.ruleml.org/index.php/Grailog]
___: When you have a set of rules, (missed)
___: Could borrow from programming languages,testing tools to check whether all cases have been covered.
___: Argumentation tools might be helpful.
Doerthe: Most use cases: aligning data. Rule languages must be easy. What take-aways.
___: SHACL rules. Very interested in moving it to core standard. Q: Does it have semantics defined? A: SHACL operates on a graph, and SHACL rules operate on a graph. Q: Rules applied once, or recursively? A: Recursively, and you don't know what will happen. More work was needed to nail down what should happen, and that work could be done as future work.
Andy: Syntax matters. People engage more in the concrete than the theory.
Dave Raggett: What about adding mindmaps?
Harold: Would be nice to add them. This would be a new application.
Harold (shows the one-way return heuristic as a rule example involving CONNECTIONs between Airports: http://wiki.ruleml.org/index.php/Graph-Relational_Data,_Ontologies,_and_Rules#GraRelDOR.2C_AI.2C_and_IT): Rule syntax bridging RDF/Turtle’s and OpenCypher’s data syntaxes (e.g., with a parameterized property: https://dzone.com/articles/rdf-triple-stores-vs-labeled-property-graphs-whats).
Doerthe: Syntax understood?
Gregg: If we extend what we discussed this morning, such as the <<>> reification operator discussed by Olaf.
Harold: The CONNECTION property is a constructor function with two parameters, distanceKm and costUSD, provided as (link-annotation-like) properties of that property. This constructor-function application is used as a property-parameterized property attached to the departure Airport.
[Online comment by Harold: More flexible (especially for rules) than, e.g., use of (reification/bNode-like) ‘symbolic’ property names (e.g., CONNECTIONdistanceKm4100costUSD300 etc., for every distance/cost combination).]
Ivan: If we have a good syntax, trying to reuse syntax both for query and rules makes a lot of sense.
David Booth: I am conflicted about syntax. I like the idea of using familiar SPARQL syntax to write rules, and I've written lots that way. But I also find it overly verbose, and I am drawn also toward N3. Bottom line is that we have to try them out to find out which one is easier.
Doerthe: Why are SPARQL FILTERS different from WHERE clause? A: Unknown. (Andy is not here to answer.)
Richard: Maybe to distinguish functions from prefixed names?
Question from Zoom: Laurent Lefort> Better Rules Better Outcomes is a good example of “legal informatics” use case where users (a mix of legislative drafters and developers) are trying to capture and reuse rules on a large scale see http://www.rules.nz/variables using an approach called Open Fisca. I have similar needs in my organisation and am looking at approaches like the QB-Equations work. My question is has someone defined a URI scheme for rules, especially these kinds of rules defining how variables are derived from other variables?
Similar examples possibly found for GDPR, also Linked Building Data.
Harold: I don't know.
Graph Models and Schemas
Moderator: Juan Sequeda
Olaf’s slides: http://olafhartig.de/slides/W3CWorkshop2019GraphQLSDL4PGs.pdf
- The actual document with the definition is at http://blog.liu.se/olafhartig/documents/graphql-schemas-for-property-graphs/
PGSWG (property graph schema working group)
Links to working documents of PGSWG:
- Academic survey:
- Industrial survey:
- Use cases and requirements:
- PGSWG Industry Survey: Oskar van Rest
- What are existing languages like? For PG, but also RDF, SQL and JSON
- Types of concepts considered: General concepts; type hierarchies; data value constraints, structural constraints
- General concepts: A table with supported concepts in each śwconsidered language
- Open world vs. closed world world
- Schema-first vs. schema-later approach
- Schema-reuse (base definition on older / other definition)
- …
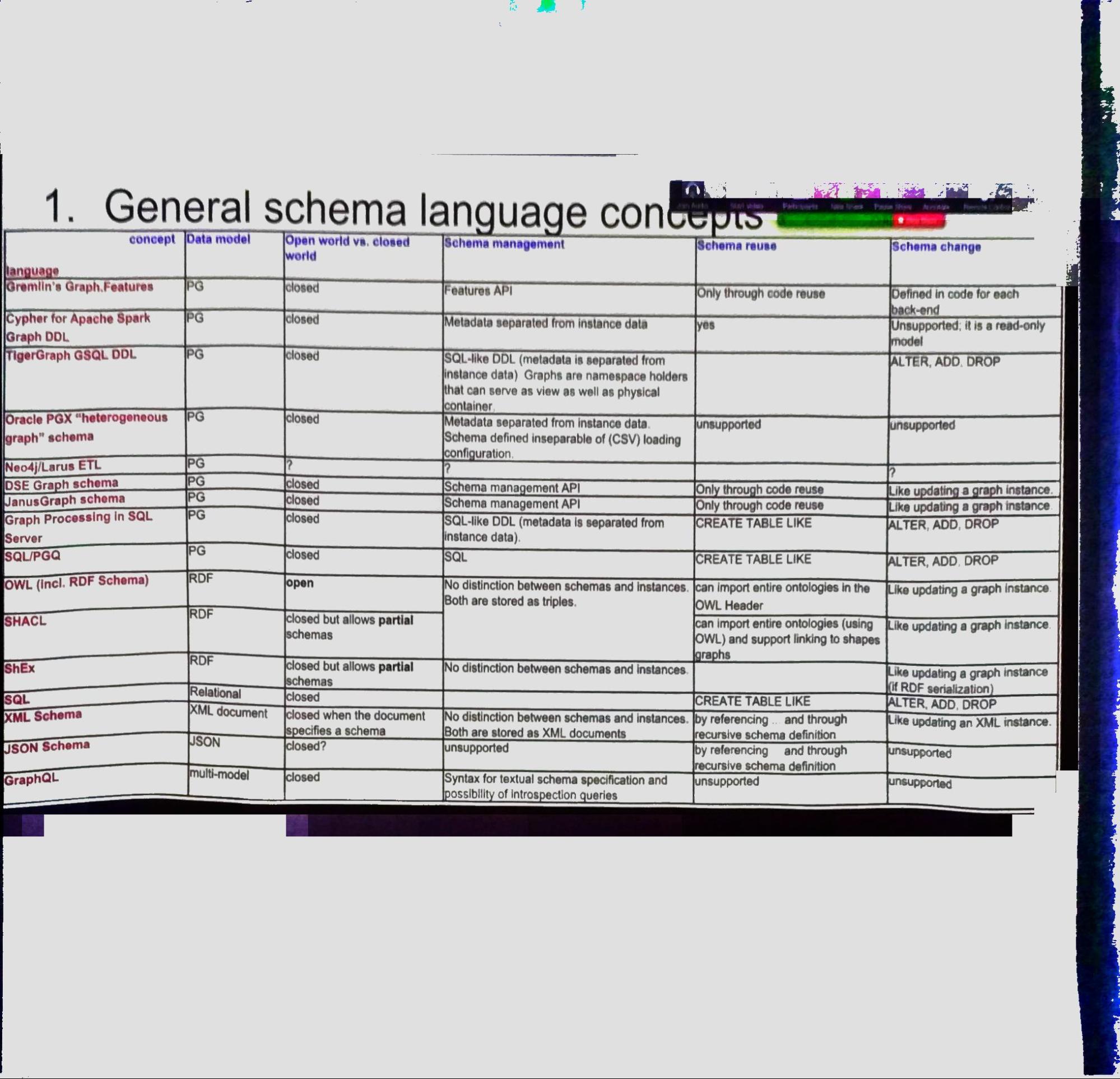
- Type hierarchies, again a table:
- Vertex / Edge / Graph supertyping and subtyping
- ...
- Data value constraints
- Key, type of values, …
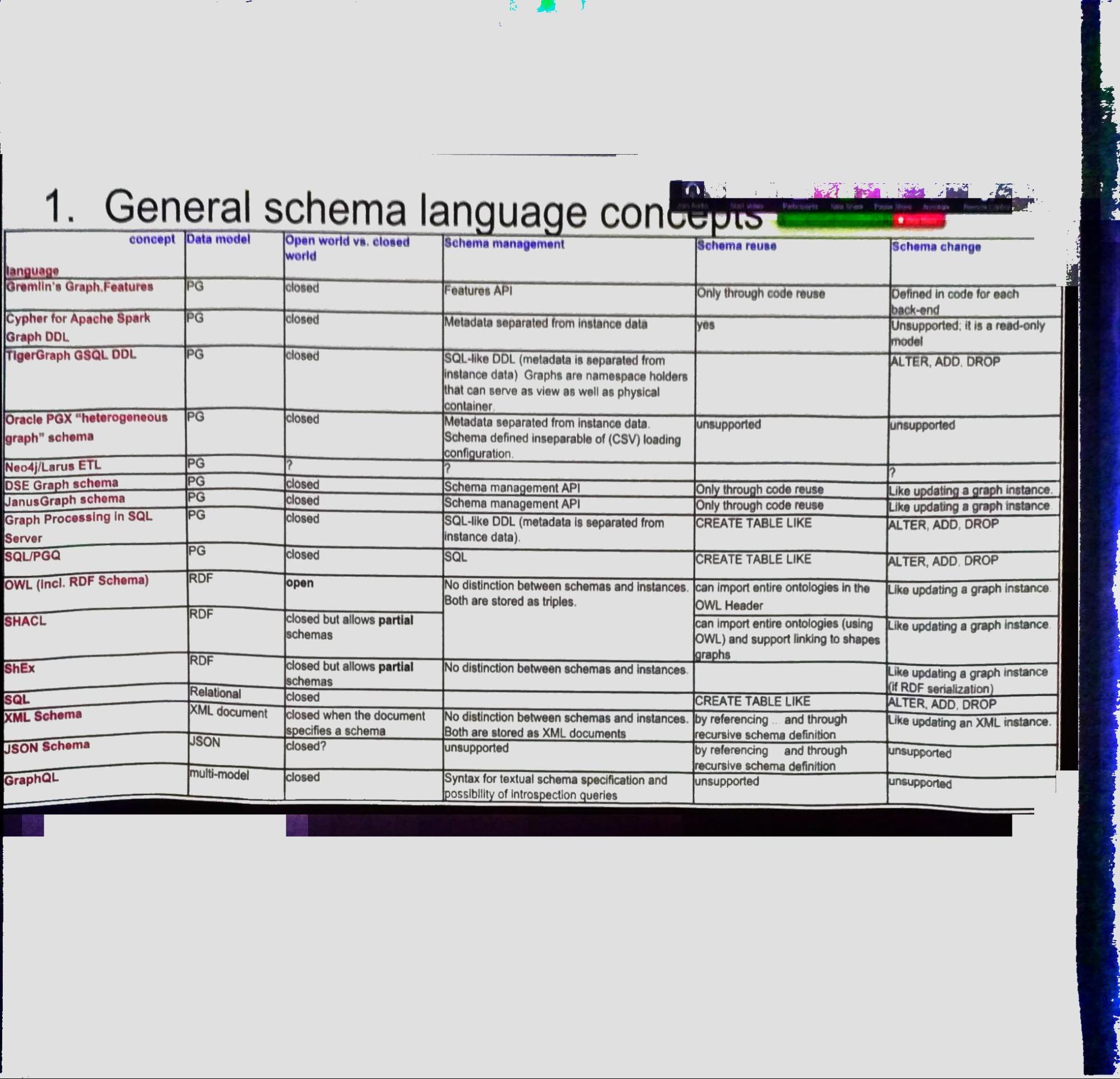
- Structural constraints
- Restrict source and destination of edge
- Cardinality constraint
- …
- First face-to-face meeting this week on Thursday, others are also invited
- (group started in November 2018)
- Question: what is goal?
- Juan: set of recommendations, maybe syntax and semantics, will be handed over to GCORE initiative
- Alistair Green: want to create an informal community for first reconnaissance, will get formal in June
- Use case and requirements: Juan Sequeda
- List of Personas (i.e. stakeholders) with each a set of requirements
- Architects
- Software developers / engineers / architects
- Data product developers
- Data governance professionals
- Business professionals
- Academics
- History of database schemas: George Fletcher
- Schemas are fundamental for practical data management
- Query optimization; data integration; data quality; data partitioning; …
- Basic core problem: schema validation
- Building on that; schema inference / learning, schema evolution, instance generation for testing/benchmarking, …
- Schemas for property graph data
- Older models we surveyed
- OO database schemas / conceptual models
- Semi-structured / document-oriented databases
- Graph-oriented databases
- Ontologies and vocabularies
- RDF validation
- Tabular (CSV-like) data
- Main insights
- Start small, design a core schema language
- Efficient for users and implementers
- Start from foundations
- Clean mathematical foundations
- Start with change and flexibility in mind
- Support evolution, incomplete information, restrictive/permissive schemas, open and closed-world assumption
- Q: tool called Oxygen exists A: fits in discussionp
GraphQL as a schema definition language (Olaf Hartig)
- GraphQL Schema Definition Language (SDL)
- Defines types and interfaces
- Can we use this (or parts of it) for Property Graphs?
- Node types and Node properties
- Types can define which nodes there can be: what label they have, which properties they have
- Outgoing edges are define with these types
- Mandatory properties (from source, or target),
- multivalued/singlevalued properties
- Injectivity, irreflexivity
- Union types
- Argument on properties (annotated with property)
- Cardinality restrictions
Questions
- Q (Joshua Shinavier): can you apply @uniqueFromTarget to properties as well as edges? How do you specify that an id is uniquely identifying for a given type? I.e. that it is a vertex id and not just another property. Is that what “!” expresses in GraphQL?
- Answers (Olaf):
- No, @uniqueForTarget is only for edges.
- Every property (field) whose value type is ID is a key (i.e., there are no two nodes/objects of the same type that have the same value for such a property/field.
- No, the exclamation mark (!) is used to indicate that a field (i.e., a property or an edge) is mandatory.
- Q (Alistair Green): semantics is different from standard GraphQL semantics? A: yes (because it is defined in the context of Property Graphs and not in the context of GraphQL queries)
- Q: you have inverse relationships? A: no, this is not needed for the purpose of defining Property Graph schemas; however, when extending such a GraphQL SDL-based Property Graph schema into a GraphQL API schema, then we may want to insert the inverse of relationships; I'm still working on a systematic approach to create such a extensions
- Olaf: full formal semantics still needs to defined
Discussion
- ??: For Olaf, warnings about ignored constructs would be useful. Olaf: yes
- Alistair Green shows slide Cypher on Apache Spark schema language
- Most desirable features? (asked to audience)
- Extensibility (like in Olaf’s work)
- Keep this simple, don’t make it XML Schema
- Validate that this is an email address
- Subtypes and subproperties
- Ranges and domains (seen as restrictions)
- Lexical restrictions
- Libkin: other models based on simple formalisms (clean formalization)
- Joshua Shinavier (Zoom): flexibility. There is not one property graph data model, but many. Allow specification of vertex/edge properties, meta-properties, even hyper-edges without excessive complexity of the schema language. See Gremlin’s Graph.Features.
- Core that lends itself to static type checking of queries
- Properties that go to anytype, permissive in that sense
- Some inference should be possible, like in RDFS
- Can indicate that parts of schema are mature (so must be adhered to) and others might be “soft” requirements
- Can indicate if parts of the schema can/are allowed to be changed or not
- Modularity / compositionality
- Question: is this still about bridging? Answer: both sides need to be well-defined, this is now attempted for Property Graphs
- Alistair: goal should not be to create a supermodel, too ambitious
- What do we want to avoid? Lessons from the RDF community?
- Keep it simple
- Comment (Josh): historically, property graphs were somewhat of a reaction to the complexity of RDF. A complex standard will not be accepted by the developer community.
- Be explicit about closed-world and validation
- Which chunk are you validating? Be explicit
- Design your standard in modular fashion
- Make sure you understand who are the implementers
- The ability to have compact human readable syntax
- Alistair: the flexibility causes complexity
- Comment (Josh/Zoom): possible to be simple and flexible at the same time. E.g. we don’t need to distinguish between vertex props, edge props, vertex meta-props, and can even provide a more natural way to specify meta-edges etc. by re-using terms. E.g. see slides 42-50 here.
- Hannes: there can always be a 2.0
- For implementers it’s better to avoid flexibility in the beginning
- Avoid trying to do too much in the beginning
- Remark: there is already an implementation that has a simple core, will be demoed
- Stefan from Neo4J: implementation point of view is missing (does it help the DBMS implementer? Does it help the user?)
From ZOOM
Laurent Lefort:
Agree with Olaf on not having Incoming edges- There is a socio-technical benefit in being rigorous in defining directions in the graph in a multi-party setup.
Josh Shinavier
I agree as well. OK to treat edges as interchangeable with properties in this respect.
Laurent Lefort
Mine (positive) would be modularity and support to multi-party data integration - esp. finding the right balance in managing cyclic dependencies (between sub-parts of the schema supplying atomic definitions when developed by different parties) - that's the main blocker when you scale up - found OWL DL profiles to be a tad too restrictive but not by much. See FIBO, ISO 20022, OGC HMMG.
Laurent Lefort
Mine (Negative) is not having fully addressed the tool interoperability issues associated to the incremental development of the standard stack components (need to track/manage cases when new standards add something handy which has no equivalent in a previously defined standard).
Temporal, Spatial and Streaming
Moderators: Martin Serrano, Ingo Simonis
Summary
- General
- Discussion at various levels of abstraction and granularity → early stages
- History:
- SPARQL → GeoSPARQL
- JSON → GeoJSON
- Agreement: Support for spatio-temporal
- Characteristics in data stores (RDF/PG/…)
- Corresponding filters in Query Languages
- Emphasis on spatio-temporal dynamics → graphs change rapidly
- Time as an intrinsic feature for RDF data stores?
- Comparison of graphs, graph snapshots
- Modeling spatio-temporal
- Support for fuzziness
- Support for quantitative and qualitative characteristics
- Coordinates
- Cell-index reference
- Topological relationships
- Streams
- RDF Stream Processing Community Group
- RSPQL has now a complete reference implementation
- Next steps
- Reactive RDF Stream Processing CP
- Introduce graphs to SDW-IG
- Continue collaboration between OGC and W3C
Christophe: wondering whether GeoSPARQL as a foundation of a data processing platform shouldn’t be revised. GeoSPARQL’s functions are binary, whereas domain experts are used to deal with ternary functions (with error margins/thresholds) as to support some fuzziness (i.e., something with 0.0….6mm^2 overlap is considered touching). Why? Increase uptake by subject matter experts and platforms/standards not inherit limitations
Riccardo Tommasini:
FraPPE: Ontology to represent spatio-temporal data in a streaming environment
RSP-QL: reference model for RDF Stream Processing Query Languages
Use of Named Graph for RDF Stream representation
Vocabulary & Catalog of Linked Streams
Dave: the need to support queries at different levels of abstraction e.g. coordinates, shapes, adjacency graph, and semantic relationships - in respect to both spatial and temporal queries.
Use-Cases:
Smart city: CDC data + social dato to understand how crowd is acting
News stream modeling and processing
Dave: we should consider existing work on temporal reasoning, e.g. the application of event calculus and situation calculus in respect to truth maintenance, i.e. the ability to reconstruct the state of a system at a given time, or during a given time interval.
This is relevant to reasoning about faults, and identifying plausible explanations for the observations, and the likely consequences of particular explanations - this is an example of abductive reasoning. Inductive reasoning is relevant to constructing models that account for a sequence of examples whether these are in time or in space. People are good at spotting repeating patterns. A related use case involves recognising that the current situation is similar to a past one, and using that to make predictions about how to handle the current situation.
Niels: A lot of thinking/research on granularity and time has been done in the BI/Datawarehouse world in the last 20+ years.
Also we are discussing topics on different abstraction levels… I think W3C/OGC should focus on core capabilties/vocabularies and validate whether the different higher level use cases can be satisfied with those.
Daniel: From the IoT perspective (e.g., time-series sensor data), streaming is also essential. Moreover, when several sensors are part of a device (i.e., a Sensor Network), which is moving in time, the spatial component adds complexity too. It would also be feasible to stream Observation entities (i.e., sensor measurements) such as the ones described by the Semantic Sensor Network Ontology. And to attach geospatial and temporal data to the Observations.
Going/Moving Forward Actions:
* Spatial Data on the Web Best Practices Working group is producing good results for spatial moving forward.
* There is a need for further development of GeoSparql addressing a.o. Uncertainties as described earlier as well as serialization.
* RDF Stream Processing Community Group
(re-activate by promoting participation)
* RSPQL has now a complete reference implementation
* Better Coordination with Other Groups i.e. JSON-LD
Outreach and Education
Moderators: Peter Winstanley, James Masters
https://docs.google.com/presentation/d/1PSzSSAAVrBjgYrO8rDtovRv330glCS6xQQPRFeE5YeA/edit?usp=sharing
Attendees: (Apologies if I missed or mispelled anyone’s names)
Adrian Gschwend (adrian.gschwend @ zazuko . com)
David Booth
Richard Cyganiak from TopQuadrant
Robert Buchmann
Natasa
Steve Sarsfield from Cambridge Semantics (steve.sarsfield@cambridgesemantics.com)
Tomas
Peter Winstanley (peter.winstanley@gov.scot)
James Masters (james.masters@credit-suisse.com)
Mo McRoberts
Problem Space:
Successful adoption of standards
Promote sustainable communities
Maintain resources for developers
Evangelist community development and technical writing
Need to create a sustainable community to maintain longer strands of communication over geography
Semantic Web Education and Outreach Interest group is closed - why?
How do we create market conditions for standards?
- We need people demanding standards.
- Need to look at consumer behavior
- What do people think they are going to get from open standards? How do they know the good ones from the bad ones?
MDN - a model for our collaboration? Possibly good for developers, but not for CEOs
People are asking: Should data scientists be licensed? What kind of quality control can be enforced?
Do we need to mimick these efforts?
We are operating in a very western European / American paradigm. The RoW need educational resources through groups like UNESCO for global outreach
Do we need training certification programs? What would they look like / include?
Develop cookbooks for designing and delivering reusable models?
We have numerous small / vendor driven efforts to provide training - how do we converge on a shared resource of training materials?
What about a HackerRank for RDF / graph solutions development?
Recommendations / Suggestions from the audience:
The world of graph is very broad, with many use cases; we aren’t good at identifying what tools are fit to different use-cases.
David: New users coming into the space know what they want to do. Need signposts based on use-case. Need 3-5 common use-cases to direct people into the right technologies.
Richard: Want to reach the different user communities. Developers like RDF less than information architects. That is a pattern that is common. We (in this room) are all in the information architect camp, but we have to hand our work over to developers and that is where it gets complicated. Do we get them to like RDF or get them to “swallow the pill?”
Peter: Do we get them to “swallow the pill” by doing most of the work for them? Give them pre-existing URIs instead of having them invent them?
That is often been the promise, but in reality it falls down. Things have multiple identifiers with different lifecycles and that is just the reality.
Need a “learn python” app for RDF and SPARQL
RDF is really good in the low-level documentation; we suck on the other end of the spectrum.
Adrian: We need to get away from branded training material that we can point people to.
Peter: How are we going to organize that? If we get the market right, things will go. If we get it wrong, we are dead.
Peter: We need a wide partnership of corporate and community resources to build the tutorial and educational materials.
David: Need a central starting point website for all things RDF. Every other commonly used technology has a well maintained website where you get started. RDF doesn’t have that. How do we fund such a thing and sustain it?
?: Terminology is a mess
Richard: The successful examples where there is a single entry point are usually around a product or library, something where you start using it. We need an obvious entry point.
There are parallels with XML in a way; no one goes looking for XML on its own; they do it in the context of an application that needs to interact with it.
Adrian: I do a lot of SPARQL training; I really like the DuCharme Learning Sparql book; also Hendler and Allemang’s book. How would we write a book of practical use-case driven examples?
Adrian: I started documenting our JavaScript library and realise I need to rethink it to be more use-case driven.
Robert: I have the perspective of why students don’t like it.
- Visibility: They think it’s a myth. If there isn’t a tutorial on Coursera it doesn’t exist.
Peter: We absolutely need these resources for students; where can they get a docker image with the tools and data, for example? It wouldn’t take very much to pull stuff together, but who is going to host it? How do we keep it current?
Natasa: Why don’t we give users the ability to describe their use-cases in our portal and have consultants give their advice? Input for design. People are struggling to find RDF consultants.
Hosting isn’t as much a problem as having the people to maintain it. It feels like a coalition of vendors and consultants could collaborate on this.
Robert: Avoid RDF/XML for newbies.
David: OWL community is the biggest offender of RDF/XML propagation. Also: Hosting isn’t the issue, it’s curation.
Chip: Need hackathon problems using RDF
Adrian: We published a lot of Swiss data to use for hackathon; last August our hackathon using RDF / Linked Data went off really well. They were very surprised how far they could get using RDF instead of data in CSV.
Want to show you can rapidly do useful things with RDF in Jupiter Notebooks.
Peter: YasGUI.org is really nice for interfacing with RDF data in development environments.
Steve: Also Zeppelin
Robert: Students are more impressed when they see visual stuff.
We can get mileage out of embracing the correlation between RDF and object-oriented programming models.
Peter: A useful tool is www.visualdataweb.org/relfinder to help capture people’s imagination of what is possible.
Adrian: Also ontopedia.org (or was it ontodia?)
Peter is curating the outcomes and recommendations in a Google PowerPoint document.
Niels: wasn’t able to attend the session, but do you know this site: https://data.labs.pdok.nl/stories/
Preview for Wednesday
Dave Raggett summarised the proposed agenda for Wednesday morning.
Posters and Demos
to be completed
Wednesday, 6 March
Summaries of Tuesday sessions
The chairs will reach out to session moderators for any slides presentations and session summaries, to add these into the minutes.
We listen to summaries from each of the break out sessions on Tuesday.
- Graph Data Interchange
De facto interchange format, role of JSON-LD and need for more work on relation to LPGs, plenty of interest in RDF*/SPARQL*. Apache TinkerPop has a serialization format for graphs. Also consensus around use of RDF* for handling property graphs. JSON-LD is popular; 1.1 effort is ongoing. Discussion around reification.
- Easier RDF
Focus on needs of middle 33% of developers, but how to accurately assess their needs? Can we learn from the experience with microData and the development of RDF/A as a reaction? See summary on slide 54
- SQL and GQL
Views of property graphs, PG queries on top of SQL queries, graph query language that does CRUD.
- Graph Query Interoperation
Reports on graphQL implementations, federation. Reports on projects that map Cypher or SPARQL to Gremlin, intermediate representation with possibility of bidirectional. on interop is important, and we need to put effort into it. Mapping data models, query preservation. To do more on query op we need understanding of how data maps to each other. As long as PG model is not standardized, canonical PG model could help as an intermediate. Nesting of data models. Direct? Customizable? Standard could cover both. Could also take a similar approach for query: use an abstract query model. Discussion around how serialization could look. Quick poll: majority favor PG model and standardized mappings to RDF.
- Composition, Patterns and Tractability
Reminded of query language work -- regular queries, GXPath, restricted REs -- they influenced early work on query. Pattern syntax and Gcore is converging in discussion on how graph query should go. Composability of queries. Gcore is academic exercise in taking this further. In composability, many graph query languages are grah-in-table-out. That means that they are not composable. Need to return a graph to make them composable. Gcore introduced the CONSTRUCT clause to return graph, with multiple types of nodes and edges. Need to include grouping. Paths are also important. Path analytics and discovering them. How do paths and graphs relate? Gcore takes that to the extreme of saying that a path is a part of the data model and can be returned. PG can have a path in it. SPARQL has paths but cannot return a path. Tractability: graph queries can have high complexity, e.g., all possible paths. Other areas: simple paths, or ensure that paths do not have cycles. These also increase complexity. Proposal to exclude everything that is not tractable, and discussion about that. People pointed out that even in SQL, people can write queries that do not finish. Discussion of more advanced path queries, and demo of cypher with Apache Spark, returning query language features. Q: Gcore excludes complex queries? A: Gcore does not allow all paths returned.
- Triumphs and tribulations
Small session. Peter and Ivan described standardization processes. Bureaucratic differences but also similarities. End result is determined by those who show up to do the work. As ISO geek, this helped me understand how other stds processes work. Q: How do people show up in ISO? A: join your national body. Many of them have mirror committees for e.g., SQL standard. Q: Could that work for Tinkerpop, e.g. Gremlin? A: Not in this session, but worth pursuing. (how to involve open source projects in ISO work)
- Specifying a Standard
How to write the new standard? SQL has the standard. Can we follow their lead? Yes, but issues: they used natural language spec (ambiguities). Attempts now to formally define semantics of SQL. Cypher has natural language description, but no standard yet. But formal semantics was written. Should we have parallel development of natural language and formal semantics? Executable semantics? Demo of one in prolog, and another demo. Outcomes of discussion: we should do formal semantics of GQL (unanimous), but not to replace the natural language standard. Issues: many artefacts. Who maintains them? Is formal semantics normative? If not, then what? How to coordinate? Universities will not send someone to attend standards meetings. Q: Was testing discussed? A: Yes. There are test suites for Cypher, but need reference implementation. Q: I have been reading calls for research projects. What would help academics participate in the standards process? A: Stay in the EU. :) But yes, there is a gap. Comment: In Sem Web work we had too many academics, perhaps we can aim for a balance.
- Queries and computation
Overlap with standards sessions. How much work can get done in one CPU cycle? Add, subtract, move one thing, etc. But one line of high level code could be thousands of lines of machine code. Favor human or computer? If you favor human, where does it make sense to consider the workload of the computer? Better imperative or declarative? Conclusion: Lean toward declarative, but mix. Even those terms are ambiguous. Declarative shields the user from what is going on; imperative exposes them. How standards? NL spec? Test suites. No conclusions about what makes it easy, except test suites. Every real system has computational limits. Some things in the language are complex, and sometimes the user query creates complexity. Should we prohibit some things? Nobody said we should prohibit, but assess the complexity and perhaps warn users at compile or runtime. Schemaless or schema first? No such thing as schemaless. Data always conforms to some kind of schema. Nice to have systems support progressive solidification of schema. System could perform better if schema is known, and humans benefit cognitively. Queries and workload types, no standard for ACID in RDF world. That's a requirement for PG commercial systems (transactional consistency). How much is reasoning used? Supported but not a goal. Machine learning: feature vector exported, run outside (graph convolution or embedding), then results brought back in. Not feasible to run ML directly in the graph.
- Rules and reasoning
There is general interest in rules. Rules should be easy to write and read. Based on existing syntaxes, perhaps SPARQL or N3. Starting point should be easy rules (no datatype reasoning), then extend. Should we combine rules with full power of a programming language, such as JavaScript? Do we need procedural rules? Should rules over RDF and PGs be over a common abstract layer? Use cases for rules: aligning different vocabularies; data validation; compliance to laws, etc. Advantages of rules: reasoning can be explained (proof trees, provenance); knowledge can be stated more concisely. No rules language for PGs. How to combine statistical reasoning with rules? Future work: make existing rules landscape more understandable; define standard for rules on graphs. Comment: Different applicability of rules languages. Reasoning doesn't work. Q: Where do you see rules living in relation to their data? In the data? As schema? What benefits either way? A: Personal opinion: living in the DB. Comment: Users like rules, because they understand them. Q: RIF does not discussed? A: Mentioned. Worth a postmortem on RIF?
- Graph models and schema
Presentations from PQ group. Tomorrow we'll continue working on schemas. Academic survey: start small, start from foundation, start with flexibility in mind. How to use graphQL as schema language for PG. Top desired feature? Keep it simple; enable future extensibility; allow permissive vs restrictive, but keep simple; allow OWA and CWA. Historically PGs were a reaction to the complexity of RDF, so keep it simple. XML Schema group did not keep it simple. Summary: Keep it simple!
- Temporal, spatial and streaming
Domain specific session. Historically we have waited for underlying standard before adding spatial, such as SPARQL → GeoSPARQL. But need spatial in the data itself. Lots of cases where things move around, so support for geospatial is important. Temporal dynamics: graphs change. Shouldn't we allow comparison of graphs, yesterday to today? Modeling of spatial-temporal: mathematicians still dominate right now. Need to become more user friendly. Might only need a cell index, or proximity. RDF stream processing group is reactivated. OGC and W3C collaboration for all standards needed. Q: Existing OGC standard sucks. Should be completely redone: not pragmatic and hard to understand. Q: Distinction made between schema and state? A: No, distinguish between self-changing things and graph changes. Both should be supported.
- Outreach and education
11 people discussed. Lots has been done in the past, but withered. Also need to look at who is interested in this, to develop our market. MDM is one example. In data science, people consider regulation. Need to recognize the most of use are from Western countries. Training certificate industry has not picked up on graph DB training. Look at that? Other areas have created cookbooks, for example for gene cloning. Are RDF vendor trainings working? Fragmented. Other efforts have been abandoned. Reached several suggestions: 1. Get a list of common RDF use cases (3-5) to indicate directions available; these give routes from concrete starting points. 2. interactive learning is needed, including gamifying learning. 3. Low level RDF docs are good, but need higher level docs to the same standard. 4. Need to move branded training effort into shared training resources. Also, early learning materials used RDF/XML and that should be jettisoned. 5. Need a central starting website that is well maintained, like react.js, or New4J. Needs funding from vendors/consultants/other. Needs curated materials. 6. Students appreciate Coursera etc courses (ZOOM comment: there are good SW available now e.g. the ones by HPI or INRIA). If they don't see the topic there, they don't think it is important. 7. Career/recruiting resources -- RDF jobs are not very visible in job postings. Q: Graph analysts? A: Yes. Q; Funding? What models available for funding a hub of content? A; Not sure. Need long term sponsorship, possibly from gov bodies. Maybe link with other facilitating the use of tools or consulting services. Comment: Several vendors were present and agreed that we should contribute common materials.
Coffee break and hallway discussion on next steps
Extending, Incubating, Initiating
The final session. Focus on summarising and drawing up recommendations for the workshop report. How much interest is there for participating in incubation and standardisation for different areas? What's the best way to ensure liaison and coordination across different standardisation organisations? What can be done to establish sustainable communities around education and outreach?
Juan Sequeda:
- Propose: RDF* & SPARQL * should be a W3C submission (Olaf Hartig)
- Follow up with a community group looking at consequences
- Follow up with WG to standardize
- WU Vienna and Fraunhofer expressed support for a member submission
- Propose: Define an abstract PG model (Juan Sequeda?) Where? ISO?
- Existing “Schema group” is currently informal. Should this go under W3C somehow? This is the GQL community. Could put this under LDBC. Josh S. will participate… represent TinkerPop
- Propose: Extension of JSON-LD to support PGs (Greg Kellogg)
- Propose: Mapping Relational to PG (may be outside W3C) (Juan Sequeda)
- This work is in flight in ISO.
Alastair:
- Propose: Community Group for CGore
- Already in ISO, why have one in W3C also? To help W3C members not have to navigate ISO. It is so much easier than ISO, apparently. CG’s don’t require membership.
Ricardo:
- Propose: RDF Streaming
- Ref impl has been worked on for RDF and SPARQL re streaming
- Dormant last 1-2 years
- Ricardo volunteers to revive the group.
Ivan Herman: We must be careful to not have too many things going on in parallel that could change the RDF standard.
Thomas Lortsch:
- RDF Metamodeling has issue, e.g. named graphs not formally defined.
David Booth: Consider which of these proposals could be done with the existing RDF 1.1 vs. an RDF 2.0
Alan Bird:
- Proposes: We create a W3C Business Group to go through these issues, as a way to organize our attack.
- (Cost 200 USD as individual, $2000 biz (check tables for your location) ).
- No real commitment to do something w/ CGs. BGs can do this better. BGs set context for all the technical work that needs to take place.
- Charter is written. That dictates type of folks who need to be in it.
- Has W3C member on the team to help through the process.
- BG would help decide what is worth doing
- BG could be a way to keep this week’s community together and moving forward.
- Note: W3C X is an education resource; curated and kept current. Need participation to build content.
General Consensus: PG model needs to come before RDF/PG interop. But PG model should be informed by RDF so the sides of the “bridge” will connect properly when the time comes. Would BG help with this? BG could define task force to liasson between RDF and PG efforts.
Common biz goal is to increase the graph market overall. So BG may be good place to ensure that stays at top of priority list.
Victor:
Sooner we can get PG formal data model, and RDF* and bridge the better for the graph community and businesses using graph.
80% of UCs sooner is best for community (over 100% taking 2 years longer)
Alastair:
Focus in next year to build the piers of the bridge: Formal model on PG side, properties on RDF side (e.g. RDF*).
So next year, can work on the interoperation.
Proposal: on glossary, very light weight, so communities can talk to each other.
OUTCOME:
A W3C BG will be created to coord W3C technical work and liasson w/ ISO folks, etc. on PG/SQL sides.
LDBC will decide by July 2019 on how to coordinate
List of Attendees
The following may include a few people who were unable to turn up in person at late notice.
- Adrian Gschwend, Zazuko
- Alan Bird, W3C
- Alastair Green, Neo4J
- Alex Milowski, Orange
- Andy Seaborne, Apache Foundation
- Atana Kiryakov, Ontotext
- Axel Polleres, WU Vienna
- Barry Zane, Cambridge Semantics
- Brad Bebee, Amazon
- Bryan Thompson, Amazon
- Charalampos Nikolaou, University of Oxford
- Christophe Debruyne, ADAPT Centre
- Dan Brickley, Google
- Danh Le Phuoc, TU Berlin
- Daniel Alvarez, BMW
- Mark Wallace, Semantic Arts
- Dave Raggett, W3C
- David Booth, Consultant
- Dmitry Novikov, openCypher; Neueda Technologies
- Dominik Tomaszuk, University of Bialystok
- Eric Prud'hommeaux, W3C
- Evren Sirin, Stardog
- Filip Murlak, University of Warsaw
- Franck Michel, CNRS
- Friederike Klan, German Aerospace Center (DLR)
- Gabor Szarnyas, Budapest University of Technology and Economics
- Gautam Kishore Shahi, University of Trento
- George Anadiotis, Linked Data Orchestration
- George Fletcher, Eindhoven University of Technology
- Georgios Stamoulis, University of Athens
- Ghislain Atemezing, Mondeca
- Gilles Privat, Orange
- Gregg Kellogg, Consultant
- Gregory Saumier-Finch, Culture Creates
- Hannes Voigt, Neo4J
- Harsh Thakkar, University of Bonn
- Hirokazu Chiba, Database Center for Life Science
- Ian Robinson, Amazon
- Ingo Simonis, OGC
- Ivan Herman, W3C
- James Masters, Credit Suisse
- Jan Hidders, Vrije Universiteit Brussel
- Jan Michels, Oracle
- Jan Posiadała, Nodes and Edges/Cypher.PL
- Jaroslav Pullmann, Fraunhofer Institute for Applied Information Technology
- Jem Rayfield, Ontotext
- Jerven Bolleman, Swiss Institute of Bioinformatics
- Jianan Ma, AITC
- Joel Gustafson, Protocol Labs, MIT
- Jose Manuel Cantera Fonseca, FIWARE Foundation
- Joshua Meekhof, Optum Technology
- Juan Sequeda, Capsenta
- Keith Hare, JCC Consulting
- Kjetil Kjernsmo, Inrupt Inc.
- Leonid Libkin, University of Edinburgh
- Loïc Jeanson, Université de Nantes
- Maria Rosa Gamarra Cespedes, Consultant
- Mark Wallace, Semantic Arts
- Marlène Hildebrand, EPFL
- Martin Serrano, Insight Centre
- Max Kiessling, Neo4J
- Michael Cochez, Fraunhofer Institute for Applied Information Technology
- Michael Schmidt, Amazon
- Mo McRoberts, BBC
- Monika Solanki, Agrimetrics
- Natasa Varytimou, Refinitiv
- Niels Hoffmann, Provincie Noord-Holland
- Olaf Hartig, Linköping University
- Oskar van Rest, Oracle
- Paolo Guagliardo, University of Edinburgh
- Pavel Klinov, Stardog
- Peter Boncz, CWI
- Peter Eisentraut, 2ndQuadrant
- Peter Furniss, Neo4J
- Peter Haase, metaphacts
- Petra Selmer, Neo4J
- Pierre-Antoine Champin, Université de Lyon
- Predrag Gruevski, Kensho Technologies
- Riccardo Tommasini, Politecnico di Milano
- Richard Cyganiak, TopQuadrant
- Robert Buchmann, Babes-Bolyai University of Cluj Napoca
- Robert David, Semantic Web Company
- Romans Kasperovics, SAP
- Ruben Taelman, Ghent University
- Russell Harmer, CNRS
- Shuai Ma, Beihang University
- Sirko Schindler, German Aerospace Center (DLR)
- Stefan Plantikow, Neo4J
- Steven Sarsfield, Cambridge Semantics
- Szymon Klarman, EPISTEMIK.CO
- Theodoros Michalareas, Wappier
- Thomas Bergwinkl, Zazuko
- Thomas Frisendal, Consultant
- Thomas Lörtsch, Consultant
- Tobias Lindaaker, Neo4J
- Victor Lee, TigerGraph
- Victor Marsault, CNRS & Université Paris-Est Marne-la-Vallée
- Wendelin Sprenger, Züblin
- Willem Broekema, Franz Inc.
- Yinglong Xia, Huawei Research America
- Peter Winstanley, Scottish Government
- Lukasz Szeremeta, University of Bialystok
- Harold Boley, University of New Brunswick
- Dörthe Arndt, Ghent University
- Satia Herfet, Neo4J
- Felix Sasaki, Consultant
- Paweł Susicki, CORMAY S.A.