Workshop Report
This is a summary and recommendations for the W3C Workshop held in Berlin on 4-6 March 2019. The main recommendation is to launch a W3C Business Group to coordinate technical work on Graph Data and liaisons with external organizations. Our thanks to Neo4J for hosting the workshop, and to our gold sponsors: ontotext and Oracle, and to our silver sponsors: ArangoDB. We also acknowledge support from the LDBC and the Boost 4.0 project on big data for factories.
Table of Contents
Recommendations
The main recommendation is to launch a W3C Business Group on Graph Data and the Digital Transformation of Industry:
- This would bring together stakeholders to consider the use cases and high level requirements for standardisation, and to coordinate work across a number of technical standardization groups including incubation in Community Groups and moving work along the standardization track in Working Groups.
- The W3C Business Group would further coordinate with external organisations, in particular, for work on Property Graphs, where W3C has an opportunity to provide an interchange framework based upon RDF across different Property Graph implementations. For this, it will be important to coordinate with work on clarifying the core data model across Property Graph implementations and the variations between them.
- Work on defining the core data model for Property Graphs is expected to take place externally to W3C, starting with the openCipher implementers meeting co-located with the W3C workshop and following directly after it. It was felt that initial discussions on the data model could take place under the aegis of the Linked Data Benchmark Council (LDBC), but with a view to it being continued at ISO/IEC JTC/1 WG3, i.e. the group responsible for SQL. LDBC has a formal liaison with WG3, which has all kinds of advantages in terms of document exchange etc. So LDBC is also making efforts to a) widen its membership, b) strengthen its administrative and financial position, and c) regularize its IP policies, so that work on GQL can flow into the ISO process. A liaison between LDBC and W3C would likewise benefit coordination between work on RDF and work on Property Graphs.
- The W3C Business Group would also liaise with initiatives around the World on the Digital Transformation of Industry, where graphs are playing an important role in enabling integration across diverse sources of information and enterprise wide data governance.
The Workshop further recommended that technical work should be considered for:
- Continuing work on Easier RDF: Incubating ideas for a higher level framework for graph data and rules that builds on top of RDF, and which is aimed at appealing to the middle 33% of developers.
- A look at what’s needed to simplify the handling of property graphs in RDF and the implications for the RDF core, serialisation formats and query languages.
- The potential for extending SPARQL based upon industry experience.
- What’s needed to support the use of RDF as an interchange framework across different Property Graph databases.
- The potential for context sensitive mappings for data across vocabularies defined by different communities.
- And more speculatively, to encourage exploration of opportunities to combine graphs with AI/ML, including ideas for integrating computational statistics.
Introduction
This was a two day workshop spread over three days, that brought together people from the SQL, Property Graph and Semantic Web/Linked Data communities for discussion on the future of standards in relation to graph data, and its ever growing importance in relation to the Internet of Things, smart enterprises, smart cities, etc., open markets of services, and synergies with Artificial Intelligence and Machine Learning.
Traditional formats for data include tabular databases (SQL/RDBMS), comma separated values (CSV), PDF documents and spreadsheets. Recent years have seen rapid growth of interest in graph data based upon nodes connected by edges. This often offers superior performance compared to SQL with its expensive JOIN operations. Graph data is easier to work with for integrating diverse sources of information, and where the data model is loose or subject to frequent change.
The workshop started with a keynote presentation by Brad Bebee from the Amazon Neptune team. We then had a panel session on venues and vectors: How do de jure and de facto standards venues operate and cooperate? How can informal communities and open source projects contribute alongside official specifications like International Standards and Recommendations. This was followed by a panel session on coexistence or competition. This explored the landscape and asked the question of how many standards are needed and how they should relate to each other. The first day then featured a session of lightning talks which was very popular, with lots of ideas, and followed by the social dinner sponsored by our host.
The second day included twelve sessions split across three rooms: Graph data Interchange, Easier RDF, SQL and GQL, Graph query interoperation, Composition, patterns and tractability, Triumphs and tribulations, Specifying a standard, Queries and computation, Rules and reasoning, Graph models and schema, Temporal, spatial and streaming, and Outreach and education. The session summaries are provided at the end of this report.
The third day started with reports from the previous day’s sessions, and was followed by a session summarising discussions and drawing up recommendations for next steps.
Community Perspectives
ISO and SQL
ISO is responsible for standards for the SQL query and update language for traditional databases with data arranged as a set of tables. Work in ISO (ISO/IEC / JTC 1 / SC32 / WG3) and ANSI (INCITS / DM32) is underway on extending SQL for access to Property Graphs, and aimed at the large numbers of industry developers familiar with SQL and RDBMS. The first version of SQL/PGQ will address data with vertices and edges, where both may have labels and properties. An API will be defined including set operators, capable of returning tables, and possibly scalars or Booleans. In more detail, read-only graph queries, with support for multiple named graphs, over existing relational tables, with directed edge support, and the ability to find and return shortest and cheapest paths.
Property Graphs
Property Graphs are a class of graph data in which both vertices and edges may be annotated with sets of property/values pairs. With a rapid expansion of the number of vendors offering graph data solutions, there are increasing challenges for interoperability. This is driving interest in work on a common standard for graph query languages that complements SQL, the traversal API of Apache Tinkerpop’s Gremlin as well as SPARQL and SHACL for RDF. This work is expected to merge the best of existing languages such as PGQL, G-CORE and Cypher.
RDF, Semantic Web and Linked Data
RDF emerged from efforts to combine Semantic Networks with the Web. RDF takes a reductionist approach focusing on graphs with labeled directed binary relationships (triples). RDF has been widely adopted for Linked Data and the Semantic Web. A notable feature of RDF compared to other graph data formalisms is the use of URIs as globally unique identifiers for graph nodes and edge labels. This makes it easier to combine data from different sources as you can be sure of the meaning based upon the use of global identifiers from shared vocabularies. In addition, you may be able to dereference the identifiers to obtain further information. For HTTP based identifiers, a common pattern is to support the use of HTTP content negotiation to declare preferences amongst RDF serialisation formats, e.g. Turtle, N3, JSON-LD, RDF/XML, and HTML with RDFa. RDF also has a solid foundation in formal logic.
There has been extensive work on defining RDF vocabularies, along with the use of RDF/S and OWL for describing data models (ontologies). The Semantic Web has been described as “an extension of the current web in which information is given well-defined meaning, better enabling computers and people to work in cooperation”. Developers can define meaning operationally in terms of the application of rules to data, or to exploit automated reasoners based upon Description Logics and ontologies. There is a mature suite of standards for RDF, e.g. RDF core, OWL (web ontology language), SPARQL (RDF query and update language), Turtle and JSON-LD as serialisation formats, and SHACL as a graph constraint language.
Whilst RDF can be used to express Property Graphs, several approaches are possible, and none have been standardized. Some approaches can be achieved using existing RDF 1.1 features, such as reification or conventions for n-ary relations,, and some would require a modest extension to RDF 1.1, such as the RDF* and SPARQL* extension previously proposed by Olaf Hartig. The rise in popularity of Property Graphs has stimulated interest in standardizing an approach for representing Property Graphs in RDF, along with corresponding extensions to the SPARQL query language (if needed).
- RDF’s focus on semantics along with its generality also makes it attractive as a basis for an interchange framework across different Property Graph solutions.
- New work is needed to standardise extensions to RDF standards, e.g. proposals for extending Turtle and SPARQL, or for standardizing property/class names for existing usage patterns, such as for n-ary relations.
- Work is already underway on an updated version of JSON-LD, and there are separate discussions on whether to put N3 onto the W3C standards track.
- Additional work is needed on standards for use in mapping data between RDF vocabularies defined by different communities: with context dependent mappings, this is loosely speaking analogous to translating between different human languages.
- Easier RDF is an initiative to make RDF more attractive and easier to use for a much broader range of developers. This is expected to lead to new higher level representations for data and rule languages that are formally based on top of RDF, as well as work on educational and outreach materials, tools and demos. This has the potential to fill the gap for rule languages for Property Graphs.
- The Web of Things seeks to overcome the fragmentation of the IoT through the use of RDF identifiers for things as digital twins for sensors, actuators and information services. Things are exposed to applications as local objects with properties, actions and events, independently of physical location, and the protocols and technologies needed to access IoT devices. W3C expects to release an associated W3C Recommendation on the use of JSON-LD for thing descriptions in mid-2019.
- The Sentient Web names the combination of the IoT, graph data, rules and algorithms, and Artificial Intelligence and Machine Learning (see below).
The proposed Business Group on Graph Data and the Digital Transformation of Industry will help to coordinate activities across different W3C groups as well as with external organisations across the Worlds.
Artificial Intelligence and Machine Learning
The IoT and online services has enabled the collection of vast amounts of data, and this is driving interest in data hungry Artificial Intelligence and Machine Learning techniques. Much of the focus of the AI/ML community is on deep learning using artificial neural networks. Whilst this has provided some extraordinary successes, the limitations are becoming clearer. Neural network classifiers are unsuited to providing clear explanations for their decisions, moreover, they rely on the data they were trained on continuing to be representative of the data they are applied to. Small changes can have big effects, as witness examples where often imperceptible changes to an image fools state of the art classifiers. The lack of transparency also exacerbates problems due to biases in the training data. This makes it risky, and potentially even unethical, to use deep learning in its current form for many applications. Symbolic approaches by contrast offer greater transparency in explaining how decisions were reached, and there is an increasing recognition of the potential for new approaches that combine symbolic representations, computational statistics and continuous learning. There are opportunities for interdisciplinary solutions inspired by decades of work in Cognitive Psychology.
This is particularly relevant in respect to real world data that is often uncertain, incomplete, and inconsistent, including errors due to bad data. For this, we need to make use of rational forms of reasoning exploiting prior knowledge and past experience, i.e. reasoning based upon what you were taught and what you have learned from experience. This includes many forms of reasoning: deductive, inductive, abductive, causal, counterfactual, temporal, spatial, social, emotional, and even reasoning about reasoning itself, dramatically broadening what can be done with graph data. W3C, as a global forum for Web technologies, is a natural place to encourage discussion and incubation of these ideas, and as they mature, work on new standards.
Session Reports
These are the reports from the twelve sessions held on Tuesday 5th March 2019.
Graph Data Interchange
Moderators: George Anadiotis and Dominik Tomaszuk
The Graph Data Interchange session featured six presentations:
- George Anadiotis -- Introduction?
- Dominik Tomaszuk -- functional requirements for PG serializations
- Olaf Hartig -- RDF* and SPARQL*
- Jose Manuel Cantera -- JSON-LD for Property Graphs
- Gregg Kellogg -- JSON-LD anonymous named graph
- Hirokazu Chiba -- Toward interoperable use of RDF and property graphs
In the first presentation, George Anadiotis wondered what format should be the basic format for graph serialization. He proposed different formats i.e. Graphson, JSON Graph (used by netflix), Json Graph Format JGF, GraphML (used for visualization tools).
In the second presentation, Dominik Tomaszuk showed two tables with PG serializations that support / not support features like: key-value pairs, multiple values, null value, directed edges, structured data etc. He the most important PG serializations e.g. GDF, GraphML, GraphSON, GML, GDF etc.
The next talk concerned RDF* and SPARQL*. Olaf Hartig presented his proposal for an RDF extension called RDF*, which allows statements to be made about other statements. He showed pros of RDF* and how nested triples works. He also proposed SPARQL*, a query languages for RDF*. The proposal can be seen in two different perspectives:
- Syntactic sugar on top of standard RDF/SPARQL,
- A logical model in its own right, with the possibility of a dedicated physical schema.
Jose Manuel Cantera showed the use case of the smart city. His proposal used JSON-LD.
Gregg Kellogg focused on anonymous named graph in JSON-LD that can be useful for property graphs. JSON-LD 1.1 introduced the notion that blank nodes can be the identifier of the named graph.
The last presentation was about mapping RDF graphs to property graphs. This proposal is called Graph to Graph Mapping Language (G2GML). Using this framework, accumulated graph data described in the RDF model can be converted to the property graph model and can be loaded to several graph database engines.
The last part of the section was discussion. Two the most important conclusions are:
- We should spend time on JSON-LD for PG and on a mapping language.
- RDF*/SPARQL* should be sent as a W3C member submission.
Easier RDF and Next Steps
Moderator: David Booth
This session discussed how we might make the RDF ecosystem easier to use -- specifically, how to make it easy enough for adoption by developer in the middle 33% of ability. There were about 35 participants -- mostly experienced RDF users, with some RDF newcomers and some people from other graph backgrounds.
Discussion centered around four themes, in roughly descending order of emphasis:
- Existing technical issues with RDF 1.1. Discussion almost amounted to a shopping list of desired improvements, with many opinions. There was widespread support for fixing these issues, but uncertainty about whether they could be done as small improvements (RDF 1.2) or would require significant changes (RDF 2.0). Also pointed out: it was also pointed out that it is hard for us "experts" to know what the middle 33% needs.
- RDF suffers from lack of easy entry point. RDF newcomers struggle for lack of tutorials, packaging and marketing, and materials are widely scattered. There is no central starting point website for RDF. There was broad agreement that such a site would be very beneficial to create, but no conclusion about how to fund and operate it, to ensure that it will sustain in the long run.
- A higher-level form of RDF could make RDF easier. RDF is currently like using assembly language. But what should a higher level RDF look like? This was discussed, with no consensus. Property graphs add some convenience, and could be viewed as a higher level form of RDF (with some limitations). A couple of strong opinions favored an (existing) approach based on JavaScript libraries.
- Ways to represent labeled property graphs in RDF. There are several ways this can be done, either using existing RDF 1.1 standards, or by extending RDF. A quick straw poll indicated:
- 12 participants favored using the existing RDF 1.1 standard; and
- 16 participants favored extending RDF, perhaps along the lines of RDF*/SPARQL* proposed by Olaf Harting and Bryan Thomson.
SQL and GQL
Moderator: Keith Hare
The SQL and GQL session had four parts:
Keith Hare, Convenor of the ISO/IEC SQL Standards committee, presented a quick history of the SQL Database Language standards, and talked about how the new SQL part, SQL/PGQ -- Property Graph Queries, and the potential new Graph Query Language (GQL) standard fit together with the existing SQL standard.
Victor Lee, TigerGraph, talked about how TigerGraph achieves high performance using defined graph schemas. TigerGraph also supports Accumulators to gather summary data during graph traversals.
Oskar van Rest, Oracle, described the SQL/PGQ syntax to create property graph “views” on top of existing tables. He also provided an introduction to the Oracle PGQL property graph language.
Stefan Plantikow, Neo4j, provided an overview of the capabilities currently planned for the proposed GQL standard.One key goal is composability – the ability to return the result of a graph query as a graph that can be referenced in other graph queries.
Graph Query Interoperation
Moderators: Olaf Hartig, Hannes Voigt
Summary:
The aim of this session was to discuss challenges and opportunities for interoperability at the level of queries and query languages. As a basis for the session, we invited some initial statements by people who have worked on approaches to re-purpose query languages over forms of graph data for which they were not originally intended. Thereafter, we invited a few more general statements and these led into the discussion.
In the initial statement, Predrag Gruevski (Kensho Technologies) described how Kensho is using GraphQL for database federation where the GraphQL query language is used both as the language for the users of the federation and as an intermediate language within the federation. Hence, the queries operate over a virtual graph view of the underlying data and, within the federation, local query snippets are compiled to the native query language of the system containing the base data.
In the second statement, Ruben Taelman (Ghent University) also advocated for using the GraphQL query language--in this case, for querying RDF data. Ruben listed existing approaches to this end (GraphQL-LD, Stardog, HyperGraphQL, TopBraid) and mentioned that these approaches are highly incompatible with each other. As a consequence, Ruben proposed to work on standardization of GraphQL-based querying of RDF data.
The third and the fourth statement focused on the Gremlin language as a compilation target; on the one hand, from SPARQL queries (as presented by Harsh Thakker from the University of Bonn), and on the other hand from Cypher queries (as presented by Dmitry Novikov from Neueda Technologies). Both presenters mentioned ideas to mix Gremlin expressions into their respective source query languages.
In his statement, Andy Seaborne (Apache Foundation) reminded us of the need to understand communication problems between the involved groups, and of the fact that there are more points to query interoperability than just query rewriting. For instance, the format of how query results flow from implementation to implementation needs to be agreed on.
Thereafter, Victor Lee (TigerGraph) gave his perspective with a focus on requests from TigerGraph users. There are requests to move RDF data back and forth from and to a property graph, which calls for a more standard approach to do that. TigerGraph considers whether they can run SPARQL queries, Cypher queries, or Gremlin traversals next to TigerGraph’s native GSQL queries.
In the last of the initial statements, Juan Sequeda (Capsenta) emphasized the need for mappings that are well defined. Given such mappings, we need to study and to understand the limits of these mappings regarding query preservation. Additionally, we also need to understand the tipping points regarding when to migrate data into a different data model.
The initial discussion, following the statements, focused on data model interoperability. It was restated that we should solve data model interoperability first before discussing query language interoperability. Having established a clear understanding of how to map data between different models sets the stage for establishing a clear understanding of how to map operations on this data.
More precisely, for mapping from the Property Graph Model (PGM) to RDF, the point was made that this data model interoperability needs to deal with variations between different implementations of the PGM. However, a standardized PGM can help as being used as an intermediate step for mappings.
There is also variation in what precise mapping is needed for a given application, which gives rise to two views on mappings between data model: Direct mapping vs. customized mapping. A standard should offers both ways. For instance, RDF2RDB does so.
Later, for query language mappings, an abstract query model such as an abstract query algebra can help with mapping queries between models.
Next, the discussion shifted to topics regarding the actual standardization. In particular, the question of what the right venue would be, was asked. If two sides of the bridge come from different standardization venues, how to standardize the bridge? For some people in the discussion, ISO takes too long. On the other hand, where is the Web in property graphs? The point was made that a good standard needs the right timing to ensure a certain level of maturity, while not being too late. Everyone seemed to agree that we should not standardize the same thing twice in two venues.
The session closed with a quick poll in which the majority of the attendees in the session were in favor of first standardizing (1) the property graph model (PGM) and (2) mapping(s) between PGM and RDF, before attempting to begin with standardizing options for query language interoperability.
Composition, Patterns and Tractability
Moderator: Peter Bonz
Petra Selmer showed the following family tree of graph query languages:
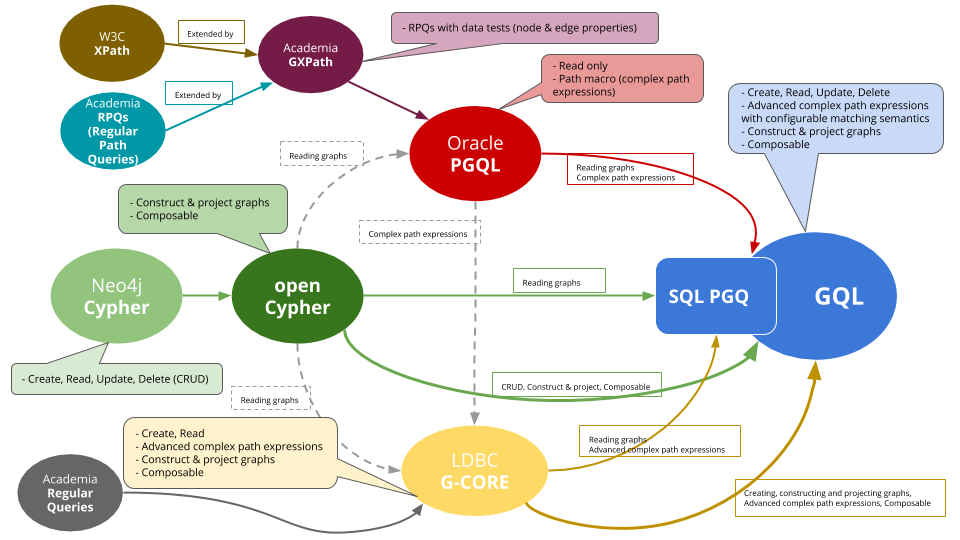
One question is how to compare path queries. The Linked Data BenchMark Council (LDBC) developed its own path-based query language (G-CORE) in order to express queries for benchmarks. By contrast, SPARQL lacks the means to find paths, only to match reachability in terms of property patterns. G-CORE has similarities to SQL including the means to consume data from tables and to output tables as well as graphs. G-CORE offers grouping capabilities suitable for graph transformation.
Triumphs and Tribulations
Moderator: Keith Hare
Keith Hare presented the processes used by ISO/IEC JTC1 SC32 WG3 (Database Languages) for the SQL standards along with the benefits and challenges of those processes.
Peter Eisentraut described the processes used by the Postgres open source database project.
Ivan Herman described the W3C processes.
While the processes have some bureaucratic differences, they have many similarities. Perhaps the biggest similarity is that the end result is determined by the people who show up to do the work.
Specifying a Standard
Moderator: Leonid Libkin
The session addressed the question: How should the new GQL Standard be specified? The SQL standard is written entirely in natural language, but this is known to be prone to ambiguities and thus multiple discrepancies between implementations and numerous points of confusion by programmers. Are there better alternatives?
The most commonly considered alternatives are a denotational semantics description of the language, and a reference implementation (or at least a test suite). In the case of SQL the natural language standard came first; attempts at formal semantics followed much later. With Cypher on the other hand the picture is different. There is a natural language description (but no standard); the formal semantics was developed soon thereafter. The session concentrated on the proposal that for GQL, a natural language specification and a formal (executable) semantics should be developed in parallel.
The formal semantics should not be the only specification of the language, but an additional artifact that helps reduce or eliminate ambiguity. It can be used for verifying compliance of implementations with the standard, and for proving optimization rules, for example.
It should be developed in parallel with the development of the standard, not as an afterthought. It should inform the development of the language (much like the semantics of Cypher led to changes in the language), and help discover corner cases and ambiguities.
While there was a very strong general agreement that this is the right way to proceed, there are some important issues to consider, a sample of which is below:
- If several different artifact's contribute to the standard, it is important to maintain each of them up to date, and in sync with the others.
- Should the formal semantics be a normative part of the standard? If so we need experts in the standardization committee. Alternatives exists: for example, it can be published as a separate technical report.
- Formalizations are developed by and large by academics. How do they participate in the work of standardization committees? (perhaps via industrial committee members?) How do they receive credit from their institutions for this work? And how are copyright issues handled, since ISO claims copyright on its drafts?
- How do we ensure continuity if it is collaboration between different communities that leads to a successful standard?
In conclusion, there was general consensus that a formal specification should be devised in the context of the new GQL standard (the vast majority of people in the room agree with this and no one is directly against it). It remains to be seen who will be responsible for developing and maintaining this formal specification, whether it will be an integral part of the standard, or how it will otherwise influence the standardization process.
Queries and Computation
Moderator: Victor Lee
This session focused on the computational resources needed for efficient queries and the role of graph schema where available for optimisation. Some graph databases are transactional, i.e. rolling back updates upon errors. Graph algorithms offer high performance for specific tasks compared to reasoning with rules. Many statistical analysis techniques can exploit well-known network or graph algorithms to establish connectedness, clustering and comparative metrics. Such algorithms are frequently iterative, and may benefit from focussing on sub-graphs. These needs emphasize the importance of graph schema, transformations/projections, and the ability to marry computation with data operations. Increasing emphasis on graph networks in the machine learning space underlines the significance of this relatively unexplored synthesis between querying and computation.
Rules and Reasoning
Moderators: Harold Boley, Dörthe Arndt
Rule languages offer a high level alternative to low level graph APIs. What can we learn from existing rule languages, including RDF shapes? How can we make rules easier for the middle 33% of developers? This includes ideas for graphical visualisation and editing tools.
How can rules support different forms of reasoning, e.g. deductive, inductive, abductive, causal, counterfactual, temporal and spatial reasoning? This would take us beyond the limits of sound deductive reasoning and into the realm of rational beliefs that are based upon prior knowledge and past experience, and which enable reasoning when data is incomplete, uncertain, inconsistent and includes errors. What can we learn from work in Cognitive Psychology?
How can rules be combined with graph algorithms on the instance and schema (vocabulary/ontological) levels, for instance techniques based upon constraint propagation? How can rules be used with reinforcement learning, simulated annealing and other machine learning techniques (beyond induction and abduction)? This points to the need for ways to combine symbolic reasoning with computational statistics. How can we collect use cases that offer clear business benefits that decision makers can easily understand?
Harold started with some Introductory slides.
- Database views are a special kind of rules (cf. Datalog).
- Rules can describe one-step derivations: iform ==> oform, replacing iform with oform;
or (equivalently), oform <== iform, obtaining oform from iform.
- Reasoning can chain rules for multi-step derivations, forward (adding data), backward (querying data) or forward/backward (bidirectional). Ontologies complement rules and prune conflict space.
- Languages for graph rules and reasoning augment languages for graph DBs and relational rules; N3, LIFE, F-logic, RIF, PSOA RuleML are examples.
- Ontology languages can be defined by rules, e.g., OWL2RL in RIF and SPIN rules.
- Beyond deductive reasoning (from relations to graphs), includes quantitative/probabilistic extensions and qualitative extensions (inductive, abductive, relevance, defeasible and argumentation).
There is general interest in rules. Rules should be easy to write and read. Based on existing syntaxes, perhaps SPARQL or N3. Starting point should be easy rules (no datatype reasoning), then extend. Should we combine rules with full power of a programming language, such as JavaScript? Do we need procedural rules? Should rules over RDF and PGs be over a common abstract layer? Use cases for rules: aligning different vocabularies; data validation; compliance to laws, etc. Advantages of rules: reasoning can be explained (proof trees, provenance); knowledge can be stated more concisely. No rules language for PGs. How to combine statistical reasoning with rules? Future work: make existing rules landscape more understandable; define standard for rules on graphs. Comment: Different applicability of rules languages. Reasoning doesn't work. Q: Where do you see rules living in relation to their data? In the data? As schema? What benefits either way? A: Personal opinion: living in the DB. Comment: Users like rules, because they understand them. Q: RIF does not discussed? A: Mentioned. Worth a postmortem on RIF?
Graph Models and Schema
Moderator: Juan Sequeda
This session started with a presentation by Olaf Hartig on defining property graph schemas using the GraphQL schema definition language. This was followed by a status report from the Property Graph Schema Working Group (PGSWG). A study of general schema language concepts has surveyed a range of languages to see which of them support data models, open vs closed worlds, schema management, reuse and update, support for type hierarchies e.g. for graph nodes, edges and graphs themselves, and the means for expressing data value constraints, as well as cardinality constraints. The trade-offs between simplicity and generality. The PGSWG met immediately after the close of the Graph Data Workshop.
Temporal, Spatial and Streaming
Moderators: Martin Serrano, Ingo Simonis
The session included early discussion at various levels of abstraction and granularity. Previous work has been done on extending SPARQL to GeoSPARQL and JSON to GeoJSON. There was general agreement on requirements for spatio-temporal data processing, in terms of characteristics of data stores and the corresponding filters in query languages. Graphs can change quickly over time, raising the question of how to support this. Should time be an intrinsic feature of RDF? What is needed to make it practical to query the state of an RDF data store at a specific time? How to support fuzziness? Qualitative and quantitative characteristics, e.g. coordinates, cell-indices, relative times and locations, points in time versus intervals, different levels of abstractions.
In respect to streaming, there is a W3C RDF stream processing Community Group, and there is now a complete reference implementation for RSPQL, a proposal for an RDF Stream Processing Query Language. For next steps, it would be desirable to attract newcomers to the RDF stream processing Community Group, to introduce graphs to the Spatial Data on the Web Interest Group, and to continue collaborations between the OGC and W3C.
Education and Outreach
Moderators: Peter Winstanley and James E. (Chip) Masters
About 10 participants in the workshop attended the session on outreach and education. After a brief scene-setting presentation by the moderators the group engaged in a very active discussion to illustrate and establish that there is a definite need for outreach and education. This was evidenced by recognising the challenges of bringing the core cadre of developers into understanding and using routinely property graph/RDF databases. The group recognised that there was a double-whammy in this field of work coming from a low appetite of students in computing science courses for learning about graph databases and the absence of training materials in the catalogues of the principal online tuition and training providers such as Coursera and Udemy. The absence of training materials on these platforms confirms in some students’ minds the importance of training themselves in other areas that are (as they perceive) more important and more relevant to their opportunities for career progression. This lack of training materials is also not satisfied to the expected quality from the graph database community; several examples were presented of dead links, out of date materials, and low visibility of training materials provided by individual commercial organisations that sell graph databases and related services.
The key themes of the solutions proposed by the workshop participants can be summed up as the need to: create sustainable communities to lead this outreach work; monitor and understand consumer behaviour of both students and businesses; provide a small set of high-quality use cases that would be recognised widely and are appropriate to develop training scenarios and solutions architectures; develop cookbooks and other interactive training materials. All of these resources have to be supported by maintaining them for a multi-decade period and refreshing the materials as the technologies develop and standards mature.
Sustainable Communities
After recognising that even the W3C “Semantic Web Education and Outreach Interest group” is closed, the workgroup discussed other examples where training that had been a heavy investment by individuals and community groups had fallen by the wayside, with dead links, unavailable sites and similar being commonplace in the graph database/semantic web area. Following this the discussion moved to discuss what might be the models for any renewed efforts. The Mozilla Developer Network (MDN) had been flagged up as a favourite place to go for developers in the web technologies area, and perhaps the recipe behind this thriving site and user base could be a pattern to follow, but the counter-argument to this was that it wasn’t somewhere where the CxO or other, more ‘business oriented’ person would feel at home. There are other examples, such as the “Semantic University” from Cambridge Semantics, but resources such as these are dependent on the owning company continuing to provide support, and there is a barrier to entry for individuals and community groups to contribute their own materials to this platform.
Consumer Behaviour
The meeting was focusing on the standards for graph database query languages, amongst other things. Within the workgroup, after having made people aware of property graph and RDF databases, the next important step related to understanding types of consumer behaviour, and also understanding the diversity of consumer types. This was considered to be an important aspect of determining how we create the right market conditions for standards. We realised that we need people demanding standards. We need to know what people think they are going to get from open standards. More specifically, we need to understand how do they might know the good ones from the bad ones and prepare appropriately. If MDN was a model for our collaboration then it would possibly be good for developers, but probably not for CEOs.
Another aspect of consumer behaviour that we considered was trust in the competence of practitioners. There are already questions in the blogosphere about whether data scientists should be licensed? If so, then what kind of quality control can be enforced? Does the graph database community need to mimic these efforts?
Use Cases
The world of graph models and databases is very broad, with many use cases; we aren’t good at identifying what tools are best fit to different use-cases. Getting a small set of well-defined and realistic use cases would be very helpful to bring about a coherent set of educational and outreach resources aimed at the diverse audiences ‘out there’. New users coming into the space know what they want to do but they might not know how to do it using graph-based technologies. This community would benefit from signposts based on use-case. The workshop recommendation was to prepare 3-5 common use-cases to direct people into the right technologies. These directions would include technical and business perspectives.
Training Materials
The workshop recognised that there is very good documentation of RDF at the fundamental level, but at higher levels it was really very poor. There is not the same sophistication of actual training, as opposed to technical documentation, that one sees in the Python or Javascript worlds, where “apps”, gamification of training (through e.g. HackerRank [https://www.hackerrank.com/] and similar) and the use of notebooks such as Jupyter [https://jupyter.org/] or Zeppelin [https://zeppelin.apache.org/] that allow actionable code to be interspersed with documentation. It is these more sophisticated training environments that allow the learner to read some well-written code and then deconstruct it and reconfigure for their own purposes that results in speedier and deeper learning by doing. This reflects the findings of Brown and Wilson (2018) [ https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1006023 ] who recommend live coding, working on realistic problems, and breaking down the language of a new programming model into small chunks to help the learner grasp the semantics of the new language.
Conclusion
The workshop was convinced that there needs to be more work done in this area. There are real problems with education and outreach that have solutions, but these solutions need support. So whilst we continue to elaborate the problems and the potential solutions (the presentation by David Booth (EasierRDF) and his associated website (https://github.com/w3c/EasierRDF) also cover some of the points discussed in the workshop) the primary recommendation from the session was to get long-lived support from some organisation [perhaps something with solid Government or Charity support] and get a committed community group of companies, groups and individuals to convene a management group to take on the long-term nurturing task. In particular, the workshop arrived at the following recommendations:
- A single portal of entry to a world of training materials is required and this needs to have sustainable sponsorship so that it will remain operational over a multi-decade `timeframe
- Training and informational materials need to be available on an open license (in keeping with UNESCO aims for open educational materials) with long-term support to retain the hosting website. This requires long-term financial support.
- The provision of training materials needs to be collaborative and collegiate with community groups, commercial organisations, and individuals working together. Commercial organisations, vendors and consultants, who have developed proprietary training materials should be encouraged to contribute to curating and publishing open licensed versions that can be further developed within the community portal.
- In order to aid career development in semantic technologies and graph databases, the portal should include resources for career starters to help them identify relevant job opportunities and job postings, also to help them market their expertise in these areas to potential employers.