The activity of this group is to apply Web standards to trusted read and write operations.
w3c-cg/rwwGroup's public email, repo and wiki activity over time
Note: Community Groups are proposed and run by the community. Although W3C hosts these
conversations, the groups do not necessarily represent the views of the W3C Membership or staff.
Q2 was a relatively quiet, yet has seen quite a bit of progress. Some work is being done on the EU INSPIRE directive and ESWC took place in Slovenia with some interesting demos. One that caught the eye was QueryVOWL, a visual query language, for linked data.
For those that enjoy such things, there was some interesting work and discussion on deterministic naming of blank nodes. Also a neat new framework called Linked Data Reactor, which can be used for developing component based applications. The web annotation group has also published an Editor’s draft.
Much of the work that has been done in this group has come together in a new spec, SoLiD (Social Linked Data). As an early adopter of this technology I have been extraordinarily impressed, and would encourage trying it out. There has also been a proposed charter for the next version of the Linked Data Platform.
Communications and Outreach
A few of this group met with the Social Web Working Group in Paris. Over two days we got to demo read write technologies in action, and also to see the work from members of the indieweb community and those working with the Activity Streams specification.
Community Group
Relatively quiet this quarter on the mailing list with about 40 posts. I get the impression that more focus has shifted to implementations and applications, where I think there is starting to be an uptick in progress. Some ontologies have been worked on, one for SoLiD apps, and another for micrblogging.
Applications
The first release of a contacts manager on the SoLiD platform came out this month. Which allows you to set up and store your own personal address book, in your own storage. An interesting feature of this app is that it includes logic for managing workspaces and preferences. Import and export is currently targeted to vcard, but more will be added, or simply fork the app and and your own!
Lots of work has been done on the linkeddata github area. General improvements and some preliminary work on a keychain app. One feature that I have found useful was the implementation of HTTP PATCH sending notifications to containers when something has changed. This helped me create a quick demo for webid.im to show how it’s possible to cycle through a set of images and have them propagate through the network as things change.
Last but not Least…
The Triple Pattern fragments client was released and is able to query multiple APIs for data at the same time. This is a 100% client side app and supports federated SPARQL queries. Another great open source app, you can read the specification or dive into the source code here.
2015 is to shaping up be the year that standards for reading and writing, and the web in general, start to be put together into, next generation, systems and applications. Quite a comprehensive review post, contains much of what is being looked forward to.
The Spatial Data on the Web working group was announced and the EU funded Aligned project also kicked off.
Congratulations to the Linked Data Platform working group, who achieved REC status this quarter, after several years of hard work. Having spent most of the last three month testing various implementations, I’m happy to say it has greatly exceeded my already high expectations.
Communications and Outreach
A number of read write web standards and apps were demoed at the W3C Social Web Working group F2F, hosted by MIT. This seems to have gone quite well and resulted in the coining of a new term “SoLiD” — Social Linked Data! Apps based on the Linked Data Platform have been considered as part of the work of this group.
Community Group
A relatively quiet quarter in the community group, tho still around 60 posts on our mailing list. There is much interest on the next round of work that will be done with the LDP working group. Some work has been done on login and signup web components for WebID, websockets and a relaunch of WebIDRealm.
Applications
Lots of activity on the apps front. Personally I’ve been working using GOLD, but for also announced was the release of Virtuoso 7.2 for those that like a feature rich enterprise solution.
Making use of the experimental pub sub work with websockets, I’ve started to work on a chat application. A profile reader and editor allows you to create and change your profile. I’ve continued to work on a decentralized virtual wallet and props goes out to timbl who in his vanishingly small amounts of spare time has been working on a scheduler app.
Last but not Least…
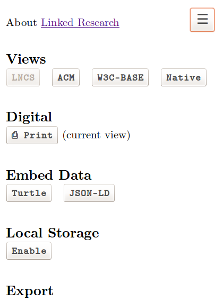
For those of you that like the web, like documentation, like specs and like academic papers, all four have been wrapped into one neat package with the announcement of linked open research. It’s a great way to document work and create templates for upstream delivery. Hover over the menu in the top right and see many more options. I’m looking forward to using this to try to bridge the gap between the worlds of documentation, the web, and research.
The web ponders moving further towards SSL, with the W3C TAG publishing a draft finding on how this could be more easily achieved. There was a great review by the EFF on progress, as well as some interesting suggestions by timbl.
Linked data continues it’s inexorable march towards the mainstream with steady progress throughout the quarter and whole year. Some good reviews are available here, here, and here. With a look forward to what we may see in 2015. A cool ontology viewer called VOWL also caught the eye.
There were some more discussion regarding the HTTP PATCH verb and how it applies to data, with specs and implementations reaching readiness. A comprehensive wishlist covering much of the future of LDP and RWW was posted by Sandro, as well as a new authentication system, called SPOT (Simple Page-Owner Token).
Communications and Outreach
Henry Story delivered an outstanding presentation at Scala eXchange conference in London, where he outlined the current state of play of the read write web and decentralized social web. An overview of the project is available on github, as well as source code.
Some conversations took place in the identity credentials group and open badges which aims to allow writing of achievements, via badges, on servers, in images and data structures, and using digital signatures.
Community Group
The LDP Patch specification is now reaching readiness and I believe the integration into GOLD is going to happen as we speak. GOLD has also now integrated JSON LD.
Community group has added a slack instance, which allows slightly more realtime chat, an API and many other features.
A stub wiki page has been added on the concept of “nanotations“, linking to Kingley’s blog explanation, feel free to add your own examples!
Applications
Some initial work has started on intelligent personal assistants. Juergen has written a sioc bot which is able to take real time conversations and convert them to linked data. Leveraging adapters in hubot the code is available on git and was up and running in just a couple of days.
I’ve also been working on a linked data robot that allows simple transfer of credit (aka marking) from one URI to another. The hope is to build out a linked data based transfer and reputation system. A slightly related side project I’ve started is virtual wallet, which will allow holding of web currencies and transfer between WebIDs, much more standards work to be done here…
Last but not Least…
An interesting system called webhose has been launched. “The Webhose.io API – Easily integrate data from hundreds of thousands of global online sources: message boards & forums, blogs, comments, reviews, news and more”. Seems like a neat bridge to pull into your apps news from many web2.0 data sources!
A massive amount of work has come together under the EU funded, LOD2 banner, which has now been renamed to Linked Data Stack. Far too much to pack into one blog post, but an excellent overview is available under Open Access, called, “Linked Open Data — Creating Knowledge Out of Interlinked Data“. Congrats to everyone involved!
“Linked Data Platform Best Practices and Guidelines” has been published as a note, and looks like a great guide for how to get the most out of reading and writing data on the web. Additionally, the “Data Shapes” WG has got under way which aims to provide for web data what XML Schema provided for XML.
Communications and Outreach
Our members continue to work closely with the Linked Data Platform Working Group. There has been continued work on Access Control, Linked Data PATCH and more implementations.
Personally, I have spent the last month reviewing and working with the bitmark project. Which hopes to bring together the best ideas from REST, Linked Data and crypto currencies in order to bring reputation and transferable ratings to the web, in a way that can also federate existing walled gardens. Still only two months old, an impressive amount of work has been done with much more in the pipeline. An update on this work is available here.
Community Group
A relatively quiet quarter in the community group, but still averaging about one post a day. Interop tests have got under way between CIMBA and Virtuoso. Results are documented here, hopefully many more to follow!
The Web Credentials Community Group has got under way and is another effort to standardize identity, access control, personae etc. Hopefully work will align to produce interoperable solutions.
Applications
A free software linked data file manager, named WARP, has been released, with demo available here. Additionally a very fast Linked Data Platform application has been written in the Go language (GOLD) and is available on Github or via a docker image.
Last but not Least…
A great post how the popular CMS system Drupal, is “Deepening its Semantic Web Ties“, including comments from Community Group member, Stéphane Corlosquet. Drupal powers over 5 million web properties, so is a great vehicle for proliferation of content management, using read and write web standards.
WWW 2014 kicked off in Korea with some interesting material presented. Two that caught my eye were, “Trust in Social Computing” and “The Mobile Semantic Web“. The first one may be particularly related to our merger with the Trust CG last year. Feel free to browse the slides and much more that are available online.
The RWW CG has had some interesting discussions with a slight uptick in mail list activity, from about 1 post per day last quarter, to 2 posts per day this quarter. I’ll try and summarize some of the more interesting topics below.
Communications and Outreach
Work has continued with the The Linked Data Platform Working Group who are getting close to publishing their final spec. Of particular interest is some work that is starting related to Access Control, with the outline of a charter for an Access Control Working Group.
The Web Payments Community Group have done some work on tying credentials to identity and allowing reading and writing to those documents. A blog post describing the pros and cons with a full demo is available here.
Community Group
A collection of very interesting work was announced by Thomas Bergwinkl, codenamed, LDApp. It is a full LD stack in javascript, including, Universal Access Control, an extension to RDF Interfaces, JSON LD support, and much more!
Apart from this, lots of libraries received work, including, ldp4j (java), GOLD (go) and node-rdf (node-js).
Applications
Decentralized identity and authentication was showcased, using a single access controlled image, which enabled you to login with a huge variety of web 1.0/2.0/3.0 methods. See the demo here.
A chrome extension to webizen was released. YouID for android and IOS was also put live and a boilerplate for creating RWW apps was also built, this quarter. Additionally, I have done some more work on creating test currency for the RWW.
Last but not Least…
Best wishes to Tim Berners-Lee, the person who started the whole Read Write Web idea, in his marriage to Rosemary Leith. Congratulations!
This month The Web celebrated its 25th birthday. Celebrating on web25 Tim Berners-Lee poses 3 important questions. 1. How do we connect the nearly two-thirds of the planet who can’t yet access the Web? 2. Who has the right to collect and use our personal data, for what purpose and under what rules? 3. How do we create a high-performance open architecture that will run on any device, rather than fall back into proprietary alternatives? Join the discussion at the web we want campaign and perhaps we can help make the web more interactive and more read/write.
Two important technologies became W3C RECs this month, the long awaited JSON LD and RDF 1.1. Well done to everyone involved on reaching these milestones.
This community group reaches 2.5 years old. Congrats to our co-chair Andrei Sambra who has moved over to work with Tim, Joe and team at MIT. Some work on identity, applications and libraries has moved forward this quarter, more below!
Communications and Outreach
In Paris this month there was a well attended workshop on Web Payments. The group hopes to take a set of specs to REC status including some on identity credentials and access controlled, reading and writing, of user profiles.
Andrei had a productive talk with Frank Karlitschek the creator of the popular personal data store, OwnCloud. Hopefully, it is possible to mutually benefit by reusing some of the ideas created in this group.
Community Group
There’s been some updated software for our W3C CG blogging platform, so anyone that wishes to make a post related to read and write web standards ping Andrei or myself, or just dive in!
There’s been some useful contributions to rdflib.js and a new library which proposes the ‘pointed graph’ idea. I’ve also taken feedback on the User Header discussions we have had and put them in a wiki page. Additionally, the WebID specs now have a permanent home.
There have also been discussions on deeplinking / bookmarkability for single page apps. I’ve also been working on an ontology for crypto currencies which I am hoping to integrate into the RWW via a tipping robot next quarter.
Applications
Great work from the guys over at MIT with a new decentralized blogging platform, Cimba. Cimba is also a 100% client side app, it can run on a host, on github, or even on your local file system. Feel free to sign up and start some channels, or just take a look at the screencast.
In addition to Cimba, Webizen has been launched to help you search for connections more easily. Search for friends on the decentralized social web, or add your own public URI.
Last but not least…
For those of you that enjoy SPARQL, Linked Data Fragments, presents new ways to query linked data via a web client. This tool is designed to provide a ‘fragment’ of a whole data set with high reliability, so happy SPARQLing!
TPAC 2013 got under way in Shenzhen, China, this month. The RWW group didn’t have a session this year, as not too many from the group were able to travel, however, hopefully we’ll have a room in next year’s event.
Congratulations to our co-chair, Andrei Sambra, who successfully defended his PhD thesis on “Data ownership and Interop. in Decentralized Social SemWeb”. There was also some interesting discussion this month on advanced used of ACLs.
Communications and Outreach
Henry Story and Andrei Sambra, among others, were at a well attended 4 day workshop in Paris, hosted by Mozilla, entitled “Weave the web we want”.
Some of you may be interested by the interview I gave to the lod2 group. I tried to talk about the advantages of read and write linked data as well as pointers to this, and other, community groups.
There was some interesting discussions on ACLs this month, with advanced features explored such as regular expressions and cross origin resource sharing. With also the idea of generic ACLs explored.
Applications
YouID, featured last month, is now available in both the IOS and Android app stores. Congrats on bringing the goodness of linked data identity to the two biggest mobile platforms.
Last but not least…
Gmail.js – JavaScript API for Gmail seemed to be an interesting read and write technology that could augment the popular Gmail web service. It may a valuable future exercise to try and combine a webmail server and client side javascript to make create new kinds of social experience.
The Open Web Platform got a boost this month as Mozilla announced they are expanding their app store. The aim is to make HTML5 apps (based on HTML + JavaScript) first class citizens of the web. In their progress report they have demonstrated support for Android, Windows, Mac OS X, and Linux devices, in addition to regular browsers.
ISWC kicked off in Sydney Australia, which marked a meeting of the top minds in Linked Data. One interesting paper that was noted as relevant to the Read Web, talks about the “Secure Manipulation of Linked Data“.
The Read Write Web Group has begun to incubate some specs on the broad topic of reading and writng, as well as access control. More on this below.
Communications and Outreach
I was kindly invited to spend two days at the lod2 plenary. Many thanks to Jindřich Mynarz for organizing a fantastic event. I met with Sören Auer and many of the team working on lod2. There is a a lot of impressive work coming out of this project. You can check out the individual components or download the whole lod2 stack.
We’ve spoken to two social projects this month, lorea, and gnu.io (previously the status.net code base). Both are interested in federating linked profiles for reading and writing. The Linked Data Platform has also updated their Use Case and Requirements document.
Community Group
Claus Stadler, from the team at Uni Leipzig has joined our group and demoed some impressive work on javascript based visualizations of Linked Data. More on this soon!
Work has continued towards creating a draft spec that describes what we’ve learnt so far in this ans other Community Group. Also there has been some interest in an official Spec for Access Control on the Web.
Applications
An EU funded consortium have announced a linked data based social network, digital me, which is now ready for the first sign up.
Some great work from OpenLink as they have released a new version of YouID, an identity provider that allows you to take control of your existing social profile on the web. I put together I simple “Hello World” app, which shows how to read and write linked data via HTTP PUT, PATCH and SPARQL Update.
As the read write community group enters it’s third year, there has been activity on infrastructure, apps (both server and client side) and some work on identity which will be an important component of Web 3.0. To wit, the W3C has formed a brand new community group, Federated Identities for the Open Web Community Group, we hope this will enable federated identity to claim it’s rightful place as a first class citizen of the web.
The widely awaited JSON LD spec nears completion, with a feature freeze and call for implementations.
The community group welcomes new members, has begun towards writing up a Read Write Web Spec documenting some of the work we’ve been doing over the years, and now has a new apps areas with it’s first app. There’s also upgrades to server software and a new identity provider, hosted by MIT.
Communications and Outreach
I was fortunate enough to meet up with one of the core Drupal developers, Stéphane Corlosquet, and others at the Drupal 2013 conference. We had a productive chat about him continuing his great work to get linked data into the core of Drupal, which powers 2% of web sites.
I also met up with the team at the unhosted project, for their annual unconfernece, who are working projects that separate apps from commodity storage. We talked about how we could work together to make a larger, and higher quality app eco system.
Community Group
The first work (mainly brainstorming) has begun to put together the ideas we’ve been talking about into a coherent document. It will be something like a spec meets primer, and will hopefully show the techniques that can leverage the arch of WWW to read and write to resources with a given identity, that can be verified, and access controlled.
The Community Group welcomes Sean Tilley, the community manager, from the Diaspora Project. Diaspora are hoping to make their system more federated and able to benefit from standards that join networks together, hopefully we can work together to achieve that!
Applications
The RWW now has an application area on github, located here. The first app to date is a linked data calendar, ld-cal, which uses rdflib.js to write your calendar events to commodity storage of your choosing — something I’m already using on a daily basis!
Data.fm has had a major upgrade with lots of the new features form rww.io important into the code base. Notable also is a new identity provider hosted by MIT which can issue you client side certificates tied to your google identity, or a new webID.
Last but not least…
For those that like mapping, you may enjoy the linked data annotation application, maphub. There are 100s of maps both current and historic, that allow you to write to a point or rectangle and add annotations. The data if fully exportable and linkable using web standards.
This month marks the two year anniversary of the RWW Community Group. A big thank you to everyone that has participated so far, some great progress, but still lots more to be done, in order to realize the full potential of the web as a decentralized read / write space.
In linked data the RDFa Working Group published three RDFa Recommendations. (HTML+RDFa 1.1, RDFa Core 1.1 and XHTML+RDFa 1.1) RDFa lets authors put machine-readable data in HTML documents. Using RDFa, authors may turn their existing human-visible text and links into machine-readable data without repeating content.
Andrei Sambra has released a personal cloud computing solution rww.io. More protocols have been discussed on our mailing list, including access control, authentication and the Linked Data Platform.
Communications and Outreach
The social web business group met this month in San Francisco, with positive follow on discussions about the possibility of forming a social web Working Group in conjunction with the OpenSocial Foundation. This may be helpful in creating a truly decentralized social app eco system for the Web itself. Looking forward to further discussions!
Community Group
The community group announced the release of rww.io a great solution for personal clouds using read and write standards for identity, authentication and access control. Already there have been a few patches submitted, in addition to make it compliant with the upcoming Linked Data Platform standard (LDP).
There has been discussion on access control, in particular, a rel type of “meta” or “acl” to link to a file that contains meta data for who can read, write, control or append to various documents. There has also been an example of Delegated Protected Resource Access Authorization
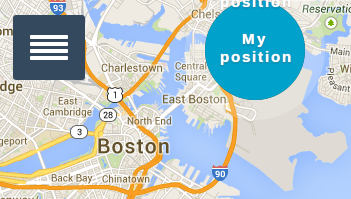
More great work from Andrei with a geo location app for the rww.io platform, called FindMyLoc. The app allows you to share your location with your friends using our own commodity storage, and in a privacy aware way.