Distributed and syndicated content: what's wrong with this picture?
Author(s) and publish date
- By:
-
-
Hadley Beeman
-
- Published:
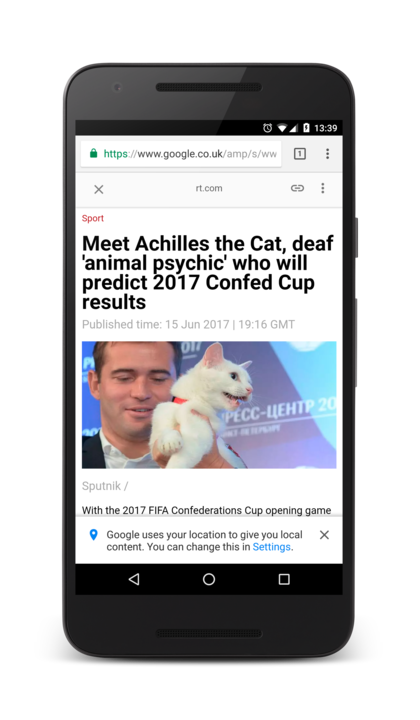
You know those AMP URLs you get from Google search results and which often pop up on Twitter?
Instead of https://www.rt.com/sport/… you’ll get https://www.google.co.uk/amp/ s/www.rt.com/document/…
What you’re seeing is Google’s AMP project hosting content for Russia Today. This lets Google load the page during the search results, so that when you click on the link on the search page, the text appears immediately. (This is solving a big problem, by the way. That shorter loading time can make the web a far more enjoyable experience.)
Facebook’s Instant Articles and Apple News operate similarly but without the benefit of being on the web or using real URLs — a much worse starting point.
The web relies heavily on the “origin policy”, which amongst other things, helps browsers manage permissions (e.g., access to your location, camera, microphone, etc.), attribute bad actions (phishing attacks), and assist you with things like passwords and filling out forms. This core aspect of web architecture ties permissions and security settings to a particular origin, like rt.com. Distributing or syndicating content removes that context by hosting one site’s content within a different site, which can confuse users and stop browsers from keeping the web safe.
In the W3C Technical Architecture Group we have been thinking about this issue. While we understand the value these approaches provide, they also pose serious issues. Fundamentally, we think that it's crucial to the web ecosystem for you to understand where content comes from and for the browser to protect you from harm. We are seriously concerned about publication strategies that undermine them.
We have published this finding to explain our thoughts in more detail.
I understand that the AMP url is confusing and unintuitive, but what exactly makes it unsafe?
Michael, by obscuring the true origin of the page, users who rely on certain browser features (forms & credit card info being prepopulated, conditional execution of scripts, trusting the server with their data) can be easily deceived in various ways.
See, for example:
https://80x24.net/post/the-problem-with-amp/
http://www.bgr.in/news/google-amps-flaw-reportedly-exploited-by-hackers-targeting-journalists/
During a recent AMP conference, web packaging AMP content was mentioned as part of a solution to the URL issue.
https://www.google.ca/amp/s/amphtml.wordpress.com/2018/01/09/improving-urls-for-amp-pages/amp/