W3C and Big Data
The term big data, or to give it marketing spin, Big Data, means different things to different people. For operators of wind turbine arrays it might mean handling the 2GB of data created by each turbine every hour describing its power generation and the sensor readings that are then used to predict and prevent component failure. For an agronomist, it might be the result of running natural language processing on thousands of academic journal articles and combining that with images of different vine varieties, and their own research, to derive new insights for wine makers. These are not random examples, rather, they are two of the seven pilots being undertaken in the Big Data Europe project, co-funded by the EU’s Horizon 2020 program.
What’s that got to do with W3C? Why are we even in the project?
Two of the Vs of big data, velocity and volume, are being tackled effectively by improved computing infrastructures – tools like Apache Flink and Hadoop HDFS respectively. The Big Data Europe project uses Docker and Docker Swarm to make it easy to instantiate any number of such components in a customized work flow. Apart from the relative triviality of a Web-based UI, this has nothing to do with W3C technologies. Where we do come in though is in tacking the V that creates most problems: variety.
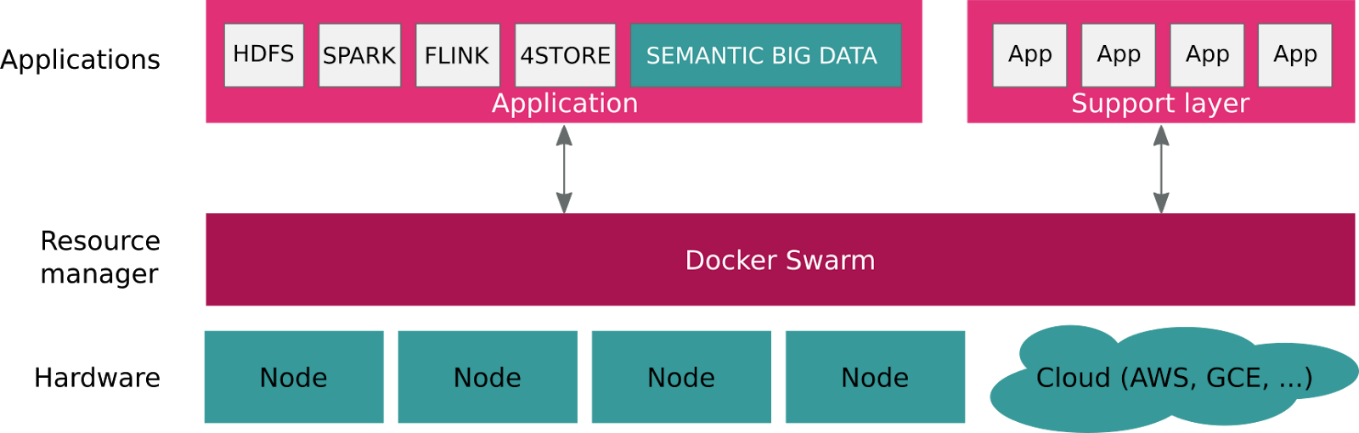
Mixing data from different sources, and doing so at scale, can be hard. It requires a layer within the architecture that adds meaning and interoperability to the data; in other words, it needs a semantic layer. The use of URI references as identifiers and RDF-encoded ontologies to create a semantification application is a key component of the Big Data Europe Platform, realized by the SANSA stack, a processing data flow engine under development at the University of Bonn that provides data distribution, and fault tolerance for distributed computations over large-scale RDF datasets.
The project will be presenting its work on Dockerization and semantification at the forthcoming Apache Big Data Europe event in Seville, 14-16 November for which registration is open.
I am not able to build connection between W3C and Bid Data. As you truly said that Big Data means varies person to person. Help me to understand connection of W3C and Bid Data?