My first post here so hope it is in the right place.
I have have built a basic HTML website for a friend (car dealer). I am looking to add a database to this which would hold details of cars in stock and display them on the website. I have done this in the past using Ruby on Rails at uni (I’m a student). I’m looking for help or tutorials on how to incorporate this feature into the current site.
Other option is to use the ruby site I created in the past but I have not a clue on how to host this. I have spent many hours searching but can not find a solution.
Any help will be much appreciated. Sorry if this is such a novice question as I am still learning!
The post in semanticweb.com (see email post below) is titled “Organisational not semantic problem?” It received more than 1000 views within a short time. I think this was due to recognition that real progress has always involved reorganisation and that people are always looking for something new.
With this in mind it seems a good time to suggest W3C introduce a more adventurous operating system division. W3C’s established work with governments and big business is not affected (cf. main frame computing remains a mainstay despite the widespread introduction of personal computing).
The suggested operating system provides a public webpage that transforms an uploaded nameset created by its owner into a web-based process with an interface like this:
The animated sliding panels remove complications and contraints of window/sheet navigation providing a machine rather than paper-like experience.
After all, that great scientist Vannevar Bush offered this advice: “He [Man] has built a civilization so complex that he needs to mechanize his records more fully if he is to push his experiment to its logical conclusion.”
For commentary on more of Bush’s recommendations relevant today please visit Memex 2000. You can also access more detailed information on namesets, models and so on from the sidebar menu.
Finally I believe that a new division would be more agile in responding to the Baroness’ dynamic themes:
– open data has huge power but needs to move from technologists to mainstream – the uk cannot rest on its digital laurels. we must equip the private, public and not for profit sector with the skills to handle technology better – the ODI and others need to go on a charm offensive to make the case for more and better data
I took your advice and followed the links you gave me. This led on to try and get a wider understanding of your work on the semantic web, in particular on Sir Tim Berners Lee’s visions expressed in his videos. First about “Raw data now!” that Sir Tim got his TED audience to chant in 2009. To me raw data means unadulterated plain text captured directly at source.
I find it easy to keep raw data from the markup needed to display it as unique links (a set up where both parties need only reassign their skills rather than learn new). Practitioners can readily list names of objects and their properties using words understood by their associates in a particular context (part of building, for example), meanings being inherent in storage location names (e.g. “Products” means specify; “Regulations” means comply). But I acknowledge the involvement of ordinary people must be difficult for scientists and technologists so used to working in areas where others fear to tread.
The phrase “When I get the information I can start” pretty much sums up how the general public at work sees WWW – a repository-cum-postal service. W3C needs to demonstrate what’s on WWW can be the work, like online banking, if “Web for all” is to take up its full potential. When “information” got tacked onto “technology” as “IT”, and more so when everyday and specialist semantics come under this new hybrid competency, while it has to take the lead because of the diversity of practices, technology should be careful not to run a closed shop. To illustrate this I posted a scenario on the W3C forum.
Really this forum is an embarrassment. Many of the few comments posted have nothing to do with “ideas for new work or a new Community Group or Business Group” and should have been politely redirected to Stack Overflow. There seems to be no moderator, administrator nor indeed anyone interested from W3C after the first posts in 2011 (ten years after initial publication of Sir Tim’s Dream). There is no banner on W3C main page with BBC style “World Have Your Say” or anything really to show the forum exists. It all seems so different from the publicity.
I also find the following difficult to understand:
“The overall vision of the Data Activity is that people and organizations should be able to share data as far as possible using their existing tools and working practices.”
Being British myself I recognise reluctance to rock the boat but then I remember we managed to make significant progress with the opposite attitude for the Agricultural and Industrial Revolutions. Also I think we were quite prominent in changing banking from tail-coated floor walker at Coutts & Co to hole-in-the-wall and that conservative taste for mahogany counter service at grocers quite quickly gave way to expansion of American-style self-service more because of a brave gamble on reversing customer sentiment than any new technology like bar coding. Re-organisation and technological advance went hand in hand.
With this in mind I posted a question on semanticweb Q&A whether the problem [lack of progress] was an organisational not semantic one. I left the idea that a truly universal semantic web can only be the product of practitioner/ technologist joint venture.
I think I can do no better than to sum up using Baroness Martha Lane Fox’s comments in her Power of Open Data blog:
I was part of a panel about finance and politics which I hope the audience enjoyed listening to as much as we enjoyed participating in. I tried to pull out these themes : – open data has huge power but needs to move from technologists to mainstream – the uk cannot rest on its digital laurels. we must equip the private, public and not for profit sector with the skills to handle technology better – the ODI and others need to go on a charm offensive to make the case for more and better data
Artificial intelligence by Michael Wolf | aisa.biz
We want to create a new Community Group named Artificial intelligence. There are a lot of reasons for a AI Group. At the beginning, the group should be divided into different thematic areas. Then the content should be filled dynamically.
Short Group description
Artificial intelligence
Intelligence by machines/software.
Computer science developing machines/software with intelligence.
research, study & design of intelligent systems.
Science, engineering & MMI Man Machine Interface.
Hi everyone,
this is Mr. “no one” and is here to propose two new HTML APIs; one to manage network resources inside JavaScript programs, and another one that allows I/O operations with compressed files. For example.
<resource src="file:///C:/images.zip" dst="http://www.domain.com" id="images" onLoadEnd="download_Or_Upload_Complete_Stopped();" load></resource>
For more details visit bit.ly/1phZv0U; it is an HTML document with examples of the Resource and Archive APIs.
However, to propose it in a formal way there is to open a new group with at least four people. Do you want to help? Do you want to improve it? Do you…; what do you want to do?
“I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers.”
I saw in this dream an opportunity to really improve the building industry and eventually came up with the basics for the scenario described below. It seems to me that W3C works well with Big Data collected by large institutions and businesses whereas most small and medium sized enterprises are concerned with dealing with large amounts of small data in different formats and from different sources. The dream does not really work unless all the data on the web can be analysed and the dream cannot be realised unless those who know what data is needed are intimately involved with its selection and analysis.
So my idea of posting the scenario is see if there is any support for the development of what I suggest or whether there are other suggestions how to enable building industry computers (among others) to analyse data on the web. Personally I feel we owe it to all the Internet Pioneers to use their gifts to automate much more for much more of society.
SCENARIO
John is part of the design team for a large condominium.
He uses his phone to upload the project file to the registry so that he can use its assembler to create a machine in his phone’s display.
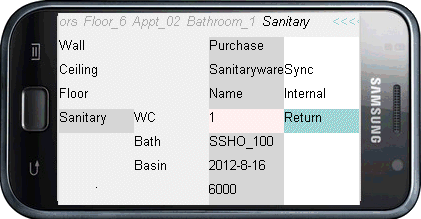
He is in the studio so he can more conveniently display the machine’s output on the big screen on the wall. He wants to double check on his selections for sanitary-ware in a typical bathroom.
He had previously marked up those values returned by the registry’s analyzer that were clearly not appropriate and had run quite a number of reruns on the rest adjusting criteria for price, material, delivery times and sustainability parameters before settling on a combination that seemed to work well enough within the space, budget, quality expected by the developer and his company’s reputation for good design.
REGISTRATION
This scenario relies on data and options being collected from multiple sources. Collection is via market-oriented registration rather than algorithms. Processing is by freely available universal online assemblers and analyzers rather than software applications.
The assembler is a simple application that accepts a ‘json’ specially punctuated plain text file, converts it into hyperlinks that automatically arrange themselves after each selection in accordance with associations set in the file, and returns the amended file at session end. Although made with the same code as a web page the display is more machine than document, just as an eBanking web page is as much part of a banking machine as the screen of an ATM.
Rather than return thousands of web site addresses, the analyzer (being developed) extracts and returns unique options from data links provided by its registrants. The analyzer inherently builds and grades lists of prompts and options used in particular contexts within the industry. The lists are used for registration as well as searching, filtering and flagging returns.
Thanks for looking on this topic. Is there any way without taking a help of developer I can make my website mobile friendly and have sitemap on mobile site as well?
Thanks
This forum is historical. From 2011 to 2015 this Community Forum was used for discussion about potential groups. It was closed because most discussion in practice takes place on the main Community Group blog. Learn more.