The purpose of the CV 2.0 - Global Resume group is to move the current textual data and partly chaotic graphical resumes to a well-structured and accessible CV 2.0 that supports applicants as well as recruiters.
The group will publish and update:
specifications on the creation and usage of a CV 2.0,
guidance on the implementation of new systems using the CV 2.0 and integration into existing professional networks or resume filtering software,
Group's public email, repo and wiki activity over time
Note: Community Groups are proposed and run by the community. Although W3C hosts these
conversations, the groups do not necessarily represent the views of the W3C Membership or staff.
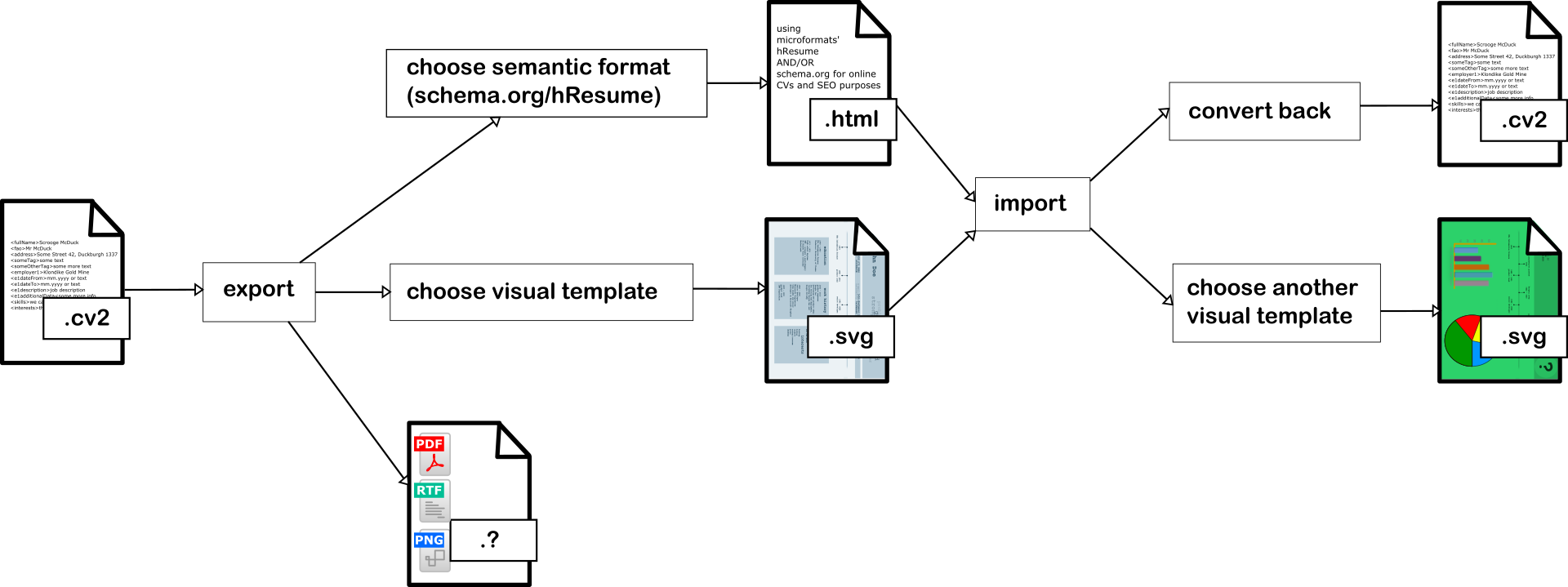
As described in the e-mail to the public list, I propose the following general workflow and file extension for a CV 2.0.
Workflow
Proposal: textual file format that can be exported into semantic HTML, SVG, and other file formats as well as a specification on how to convert it back
If the proposal is accepted, these are the follow-up tasks:
define tags – main part of our specification
write code for transformation that can be reused by developers who want to implement our specification
design example templates in SVG
write use cases
Filename Extension
Similar to .html, .css, .svg, and other formats, I also propose that we use a file extension called .cv2 that enables us to distinguish our specified resume tags from other text formats. Like HTML, CSS, and other source code, it is obviously a text file that is then parsed by software that understands this format.
Proposal: .cv2 as file extension name
FYI
According to the charter (section Decision Process), we need a group consensus or at least a 2/3 majority vote on this proposal where agreement as well as silence implies consensus.
If no objections arrive by August 31st 2015, this proposal is regarded as accepted. A small reminder: if you agree, please reply to the public mailing list – if all participants agree or disagree before the 31st of August, we can already move forward with our work. Thank you!
The next question we were asked is if we are aware of microformats and how we intend to differ from hResume or whether there is any difference?
Yes, we are aware of microformats. We want to achieve a similar thing as they do which is semantics. This end result is similar but we are striving for a complete approach, a specification and guidelines that cater to a resume and are not only a collection of tags that advanced users can use to add to their resume. While the IndieWeb is great, not many people will find out about it and then even less people will want to take that approach. It is important to bring semantics to the mainstream, which can only happen if enough people have a benefit from it – consumers of the Web just as much as creators. Basically, microformats are great but neither are they widely adopted nor, for most people, simple to use.
We are striving for a clear and uncluttered file format, most likely extending or basing upon schema.org tags, but this is a point of meeting and mailing list discussions. The group can then continue giving clear specifications on how to implement a system that can convert this file into HTML with microformats and to SVG using clear tags so that it could even be converted back to the file or into each other. Let’s say the file extension, for recognition’s sake, is .cv2. We are working on:
defining what the .cv2 looks like and what it can do
defining system specifications and guidelines for
conversion to visual templates in other formats
converstion to meaningful tags for these other formats
If implemented correctly, the system should be able to receive, for example, an .svg and convert it to an .html without losing meaning or data. A recruiter could get hundreds of .cv2, use a corporation-specific system that outputs all the .cv2 files in the recruiter’s preferred style so they have an easier time finding the right match. These are some use cases – we will upload concrete use cases once the group has had their first meetings or mailing list exchanges.
If you have never heard of microformats before and don’t quite get what it’s all about but would still like to ask more questions, share thoughts and ideas – you are welcome to join us!
We are starting a series of questions we were asked about the group via e-mail, social media, or face to face. Question no.1 is about privacy. It was not so much a question as a statement that “the whole thing is bad because it feeds even more data to the NSA”.
Our answer is: no, it does not feed any data to anyone else than the person you are sending it to, just like you would previously send a .doc or .pdf file. We do not plan to establish or even recommend a centralized database of resumes. There are numerous reasons why it would be bad which we might cover in another post. For this post, it is sufficient to say that this group is not a company, not a data collection centre, or anything like it. Our specifications are recommendations and best practice guidelines. We bring together various existing tools and technologies to create a more pleasant application and recruiting experience.
Any software we might produce in the process will be under the MIT license, as stated in the charter. Everything we do is publicly available on this blog, the mailing list, or GitHub. This is a collective process to enhance something that is happening repeatedly – searching for a job.
Welcome to the CV 2.0 – Global Resume Community Group! Join the group and participate in the creation of a global resume specification. We are looking forward to input and contributions from:
recruiters
you can help us with decisions that are best explained from the perspective of someone who looks at resumes daily and knows the issues that come along with it
developers
you can participate by implementing systems that use the specification and by contributing to the specification itself
interaction designers
you can give feedback on existing designs or help with example templates for a CV 2.0
marketers
you can contribute by sharing the idea and getting people on board – the whole CV 2.0 idea only works if people actually use it
researchers
you can improve the specification and systems by conducting studies around the CV 2.0
everyone else who fits in several or none of the above categories
you are welcome to participate with ideas, suggestions, experience, feedback, and concerns regarding a global resume
Communication Within the Group
The main communication is conducted via the public mailing list. You will be automatically subscribed to two mailing lists. One is for public reading – anyone can read and write to it – whereas the internal list is for administrative purposes such as, for example, detailed meeting information. Please read the W3C information on mailing lists. Once the group has more than 15 participants, we will add biweekly teleconferences, i.e. twice a month.
Charter
You can find the goals, scope, and more details about this group in the charter.
About the Creation of This Group
This is a community initiative. This group was originally proposed on 2015-08-01 by Sanja Bonic. The following people supported its creation: Sanja Bonic, Sarven Capadisli, Renoir Boulanger, Jelle Teck, Jaakko Alarto. W3C’s hosting of this group does not imply endorsement of the activities.