This
section
describes
the
status
of
this
document
at
the
time
of
its
publication.
Other
documents
may
supersede
this
document.
A
list
of
current
W3C
publications
and
the
latest
revision
of
this
technical
report
can
be
found
in
the
W3C
technical
reports
index
at
http://www.w3.org/TR/.
This
is
the
9
December
2003
Last
Call
Working
10
May
2004
Editor's
Draft
of
"Architecture
of
the
World
Wide
Web,
First
Edition."
The
Last
Call
review
period
ends
5
March
2004,
at
23:59
ET.
Please
send
Last
Call
review
comments
on
this
document
before
This
draft
takes
into
account
a
few
additional
TAG
resolutions
that
date
to
were
omitted
from
the
7
May
draft;
see
the
deleted text:
public
W3C
TAG
mailing
list
public-webarch-comments@w3.org
(
archive
).
Last
Call
Working
Draft
status
is
described
in
<a href="http://www.w3.org/2003/06/Process-20030618/tr.html#last-call" shape="rect">
section
7.4.2
</a>
of
the
W3C
Process
Document.
)
.
This
document
has
been
developed
by
W3C's
Technical
Architecture
Group
(TAG)
(
charter
).
deleted text:
The
TAG
decided
unanimously
to
advance
to
Last
Call
at
their
4
Dec
2003
teleconference
(
<a href="http://www.w3.org/2003/12/04-tag-summary#lcdecision" shape="rect">
minutes
</a>
).
A
complete
list
of
changes
to
this
document
since
the
first
public
Working
Draft
is
available
on
the
Web.
The
TAG
charter
describes
a
process
for
issue
resolution
by
the
TAG.
In
accordance
with
those
provisions,
the
TAG
maintains
a
running
issues
list
.
The
First
Edition
of
"Architecture
of
the
World
Wide
Web"
does
not
address
every
issue
that
the
TAG
has
accepted
since
it
began
work
in
January
2002.
The
TAG
has
selected
a
subset
of
issues
that
the
First
Edition
does
address
to
the
satisfaction
of
the
TAG;
those
issues
are
identified
in
the
TAG's
issues
list.
The
TAG
intends
to
address
the
remaining
(and
future)
issues
after
publication
of
the
First
Edition
as
a
Recommendation.
This
document
uses
the
concepts
and
terms
regarding
URIs
as
defined
in
draft-fielding-uri-rfc2396bis-03,
preferring
them
to
those
defined
in
RFC
2396.
The
IETF
Internet
Draft
draft-fielding-uri-rfc2396bis-03
draft-fieldi
ng-uri-rfc2396bis-03
is
expected
to
obsolete
RFC
2396
,
which
is
the
current
URI
standard.
The
TAG
is
tracking
the
evolution
of
draft-fielding-uri-rfc2396bis-03.
Publication
as
a
Working
Draft
does
not
imply
endorsement
by
the
W3C
Membership.
This
is
a
draft
document
and
may
be
updated,
replaced
or
obsoleted
by
other
documents
at
any
time.
It
is
inappropriate
to
cite
this
document
as
other
than
"work
in
progress."
The
latest
information
regarding
patent
disclosures
related
to
this
document
is
available
on
the
Web.
The
World
Wide
Web
(
WWW
</acronym>,
,
or
simply
Web)
Web
)
is
an
information
space
in
which
the
items
of
interest,
referred
to
as
resources
,
are
identified
by
global
identifiers
called
Uniform
Resource
Identifiers
(
URIs
URI
).
A
travel
scenario
is
used
throughout
this
document
to
illustrate
typical
behavior
of
Web
agents
—
people
or
software
(on
behalf
of
a
person,
entity,
or
process)
acting
on
this
information
space.
Software
agents
include
servers,
proxies,
spiders,
browsers,
and
multimedia
players.
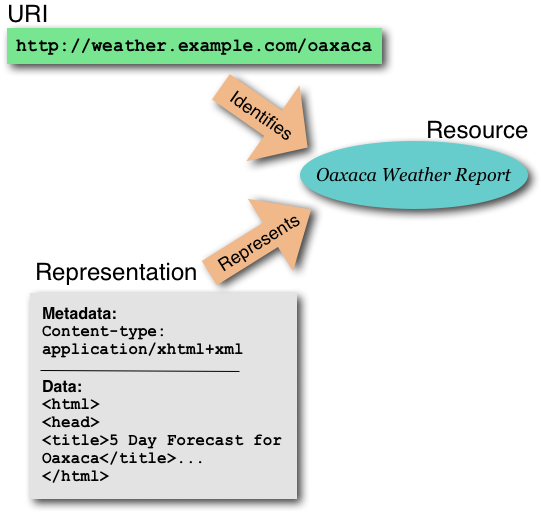
Story
While
planning
a
trip
to
Mexico,
Nadia
reads
"Oaxaca
weather
information:
'http://weather.example.com/oaxaca'"
in
a
glossy
travel
magazine.
Nadia
has
enough
experience
with
the
Web
to
recognize
that
"http://weather.example.com/oaxaca"
is
a
URI.
Given
the
context
in
which
the
URI
appears,
she
expects
that
it
allows
her
to
access
weather
information.
When
Nadia
enters
the
URI
into
her
browser:
-
The
browser
performs
an
information
retrieval
action
in
accordance
with
its
configured
behavior
for
resources
identified
via
the
"http"
URI
scheme.
-
The
authority
responsible
for
"weather.example.com"
provides
information
in
a
response
to
the
retrieval
request.
-
The
browser
displays
the
retrieved
information,
which
includes
hypertext
links
to
other
information.
Nadia
can
follow
these
hypertext
links
to
retrieve
additional
information.
This
scenario
illustrates
the
three
architectural
bases
of
the
Web
that
are
discussed
in
this
document:
-
Identification
.
Each
resource
is
identified
by
a
URI.
In
this
travel
scenario,
the
resource
is
about
a
periodically-updated
report
on
the
weather
in
Oaxaca
Oaxaca,
and
the
URI
is
"http://weather.example.com/oaxaca".
-
Interaction
.
Protocols
define
the
syntax
and
semantics
of
messages
exchanged
by
agents
over
a
network.
Web
agents
communicate
information
about
the
state
of
a
resource
through
the
exchange
of
representations
.
In
the
travel
scenario,
Nadia
(by
clicking
on
a
hypertext
link
)
tells
her
browser
to
request
a
representation
of
the
resource
identified
by
the
URI
in
the
hypertext
link.
The
browser
sends
an
HTTP
GET
request
to
the
server
at
"weather.example.com".
The
server
responds
with
a
representation
that
includes
XHTML
data
and
the
Internet
Media
Type
"application/xml+xhtml".
media
type
"application/xhtml+xml".
-
Formats
.
Representations
are
built
from
a
non-exclusive
set
of
data
formats,
used
separately
or
in
combination
(including
XHTML,
CSS,
PNG,
XLink,
RDF/XML,
SVG,
and
SMIL
animation).
In
this
scenario,
the
representation
data
format
is
XHTML.
While
interpreting
the
XHTML
representation
data,
the
browser
retrieves
and
displays
weather
maps
identified
by
URIs
within
the
XHTML.
The
following
illustration
shows
the
relationship
between
identifier,
resource,
and
representation.
This
document
describes
the
properties
we
desire
of
the
Web
and
the
design
choices
that
have
been
made
to
achieve
them.
This
document
promotes
re-use
of
existing
standards
when
suitable,
and
gives
guidance
on
how
to
innovate
in
a
manner
consistent
with
the
Web
architecture.
The
terms
MUST,
MUST
NOT,
SHOULD,
SHOULD
NOT,
and
MAY
are
used
in
the
principles,
constraints,
and
good
practice
notes,
principles,
etc.
notes
in
accordance
with
RFC
2119
[
RFC2119
].
However,
this
document
does
not
include
conformance
provisions
for
deleted text:
at
least
these
reasons:
-
Conforming
software
is
expected
to
be
so
diverse
that
it
would
not
be
useful
to
be
able
to
refer
to
the
class
of
conforming
software
agents.
-
Some
of
the
good
practice
notes
concern
people;
specifications
generally
define
conformance
for
software,
not
people.
-
The
addition
of
a
conformance
section
is
not
likely
to
increase
the
utility
of
the
document.
This
document
is
intended
to
inform
discussions
about
issues
of
Web
architecture.
The
intended
audience
for
this
document
includes:
-
Participants
in
W3C
Activities;
i.e.,
developers
designers
of
Web
technologies
and
specifications
in
W3C
-
Other
groups
and
individuals
developing
designing
technologies
to
be
integrated
into
the
Web
-
Implementers
of
W3C
specifications
-
Web
content
authors
and
publishers
Readers
will
benefit
from
familiarity
with
the
Requests
for
Comments
(
RFC
)
series
from
the
IETF
,
some
of
which
define
pieces
of
the
architecture
discussed
in
this
document.
Note:
This
document
does
not
distinguish
in
any
formal
way
the
terms
"language"
and
"format."
Context
determines
which
term
is
used.
The
phrase
"specification
designer"
encompasses
language,
format,
and
protocol
designers.
This
document
presents
the
general
architecture
of
the
Web.
Other
groups
inside
and
outside
W3C
also
address
specialized
aspects
of
Web
architecture,
including
accessibility,
internationalization,
device
independence,
and
Web
Services.
The
section
on
Architectural
Specifications
includes
references.
This
document
strikes
a
balance
between
brevity
and
precision
while
including
illustrative
examples.
TAG
findings
are
informational
documents
that
complement
the
current
document
by
providing
more
detail
about
selected
topics.
This
document
includes
some
important
material
excerpts
from
the
findings.
Since
the
findings
evolve
independently,
this
document
also
includes
references
to
approved
TAG
findings.
For
other
TAG
issues
covered
by
this
document
but
without
an
approved
finding,
references
are
to
entries
in
the
TAG
issues
list
.
Many
of
the
examples
in
this
document
involve
human
activity
suppose
the
familiar
Web
interaction
model
where
a
person
follows
a
link
via
a
user
agent,
the
user
agent
retrieves
and
presents
data,
the
user
follows
another
link,
etc.
This
document
does
not
discuss
in
any
detail
other
interaction
models
such
as
voice
browsing.
For
instance,
when
a
graphical
user
agent
running
on
a
laptop
computer
or
hand-held
device
encounters
an
error,
the
user
agent
can
report
errors
directly
to
the
user
through
visual
and
audio
cues,
and
present
the
user
with
options
for
resolving
the
errors.
On
the
other
hand,
when
someone
is
browsing
the
Web
through
voice
input
and
audio-only
output,
stopping
the
dialog
to
wait
for
user
input
may
reduce
usability
since
it
is
so
easy
to
"lose
one's
place"
when
browsing
with
only
audio-output.
This
document
does
not
discuss
how
the
principles,
constraints,
and
good
practices
identified
here
apply
in
all
interaction
contexts.
The
important
points
of
this
document
are
categorized
as
follows:
-
<a name="cat-constraint" id="cat-constraint" shape="rect">
Constraint
Principle
-
An
architectural
constraint
principle
is
a
restriction
in
behavior
or
interaction
within
the
system.
Constraints
may
be
imposed
for
technical,
policy,
or
other
reasons.
</dd>
<dt>
<a name="cat-design" id="cat-design" shape="rect">
Design
Choice
</a>
</dt>
<dd>
In
the
design
of
the
Web,
some
design
choices,
like
the
names
fundamental
rule
that
applies
to
a
large
number
of
the
<p>
situations
and
<li>
variables.
Architectural
principles
include
"separation
of
concerns",
"generic
interface",
"self-descriptive
syntax,"
"visible
semantics,"
"network
effect"
(Metcalfe's
Law),
and
Amdahl's
Law:
"The
speed
of
a
system
is
limited
by
its
slowest
component."
-
Constraint
-
In
the
design
of
the
Web,
some
design
choices,
like
the
names
of
the
p
and
li
elements
in
HTML,
or
the
choice
of
the
colon
(:)
character
in
URIs,
are
somewhat
arbitrary;
if
deleted text:
<par>,
<elt>,
or
*
paragraph
had
been
chosen
instead,
instead
of
p
or
asterisk
(*)
instead
of
colon,
the
large-scale
result
would,
most
likely,
have
been
the
same.
Other
design
choices
are
more
fundamental;
these
are
the
focus
of
this
document.
Design
choices
can
lead
to
constraints,
i.e.,
restrictions
in
behavior
or
interaction
within
the
system.
Constraints
may
be
imposed
for
technical,
policy,
or
other
reasons
to
achieve
certain
properties
of
the
system,
such
as
accessibility
and
global
scope,
and
non-functional
properties,
such
as
relative
ease
of
evolution,
re-usability
of
components,
efficiency,
and
dynamic
extensibility.
-
Good
practice
-
Good
practice
—
by
software
developers,
content
authors,
site
managers,
users,
and
specification
writers
designers
—
increases
the
value
of
the
Web.
deleted text:
<dt>
<a name="cat-principle" id="cat-principle" shape="rect">
Principle
</a>
</dt>
<dd>
An
architectural
principle
is
a
fundamental
rule
that
applies
to
a
large
number
of
situations
and
variables.
Architectural
principles
include
"separation
of
concerns",
"generic
interface",
"self-descriptive
syntax,"
"visible
semantics,"
"network
effect"
(Metcalfe's
Law),
and
Amdahl's
Law:
"The
speed
of
a
system
is
determined
by
its
slowest
component."
</dd>
<dt>
<a name="cat-property" id="cat-property" shape="rect">
Property
</a>
</dt>
<dd>
Architectural
properties
include
both
the
functional
properties
achieved
by
the
system,
such
as
accessibility
and
global
scope,
and
non-functional
properties,
such
as
relative
ease
of
evolution,
re-usability
of
components,
efficiency,
and
dynamic
extensibility.
</dd>
This
categorization
is
derived
from
Roy
Fielding's
work
on
"Representational
State
Transfer"
[
REST
].
deleted text:
Authors
of
protocol
specifications
in
particular
should
invest
time
in
understanding
the
REST
model
and
consider
the
role
to
which
of
its
principles
could
guide
their
design:
statelessness,
clear
assignment
of
roles
to
parties,
uniform
address
space,
and
a
limited,
uniform
set
of
verbs.
A
number
of
general
architecture
principles
apply
to
deleted text:
across
all
three
bases
of
Web
architecture.
1.2.1.
<a id="orthogonal-specs" name="orthogonal-specs" shape="rect">
Orthogonal
Independent
Specifications
Identification,
interaction,
and
representation
are
orthogonal
independent
(or,
"independent",
"orthogonal",
or
"loosely
coupled")
concepts:
an
identifier
can
be
assigned
-
one
identifies
a
resource
with
a
URI.
One
may
publish
and
use
a
URI
without
knowing
what
building
any
representations
are
available,
agents
can
interact
with
of
the
resource
or
determining
whether
any
deleted text:
identifier,
and
representations
can
are
available.
-
a
generic
URI
syntax
allows
agents
to
function
in
many
cases
without
knowing
specifics
of
URI
schemes.
-
in
many
cases
one
may
change
the
representation
of
a
resource
without
regard
disrupting
references
to
the
identifiers
or
interactions
that
may
dereference
them.
</p>
resource.
Orthogonality
in
Independence
of
specifications
facilitates
a
flexible
design
that
can
evolve
over
time.
The
fact,
for
For
example,
that
the
one
may
refer
to
an
image
can
be
identified
using
with
a
URI
without
needing
any
information
worrying
about
the
representation
format
chosen
to
represent
the
image.
This
independence
has
allowed
the
introduction
of
deleted text:
that
image
allowed
formats
such
as
PNG
and
SVG
without
disrupting
references
to
deleted text:
evolve
independent
of
the
specifications
that
define
image
elements.
resources.
Orthogonal
Independent
abstractions
deserve
orthogonal
benefit
from
independent
specifications.
Specifications
should
clearly
indicate
those
features
that
simultaneously
access
information
from
otherwise
orthogonal
independent
abstractions.
For
example
a
specification
should
draw
attention
to
a
feature
that
requires
information
from
both
the
header
and
the
body
of
a
message.
Although
the
HTTP,
HTML,
and
URI
specifications
are
orthogonal
independent
for
the
most
part,
they
are
not
completely
orthogonal.
independent.
Experience
demonstrates
that
where
they
are
not
orthogonal,
not,
problems
have
arisen:
-
The
HTML
specification
includes
a
protocol
extension
of
sorts:
it
specifies
how
a
user
agent
sends
HTML
form
data
to
a
server
(as
a
URI
query
string).
The
design
works
reasonably
well,
although
there
are
limitations
related
to
internationalization
(see
the
TAG
finding
"
URIs,
Addressability,
and
the
use
of
HTTP
GET
and
POST
"
)
and
the
query
string
design
impinges
on
the
server
design.
Developers
Software
developers
(for
example,
of
[
CGI
]
applications)
might
have
an
easier
time
finding
the
specification
if
it
were
published
separately
and
then
cited
from
the
HTTP,
URI,
and
HTML
specifications.
-
The
HTML
specification
allows
content
providers
to
instruct
HTTP
servers
to
build
response
headers
from
META
element
instances.
This
is
an
abstraction
violation;
the
software
developer
community
deserves
to
be
would
benefit
from
being
able
to
find
all
HTTP
headers
from
the
HTTP
specification
(including
any
associated
extension
registries
and
specification
updates
per
IETF
process).
Perhaps
as
a
result,
this
feature
of
the
HTML
specification
is
not
widely
deployed.
Furthermore,
this
design
has
led
to
confusion
in
user
agent
development.
The
HTML
specification
states
that
META
in
conjunction
with
http-equiv
is
intended
for
HTTP
servers,
but
many
HTML
user
agents
interpret
http-equiv='refresh'
as
a
client-side
instruction.
-
Some
content
authors
use
the
META
/
http-equiv
approach
to
declare
the
character
encoding
scheme
of
an
HTML
document.
By
design,
this
is
a
hint
that
an
HTTP
server
should
emit
a
corresponding
"Content-Type"
header
field.
In
practice,
the
use
of
the
hint
in
servers
is
not
widely
deployed.
Furthermore,
many
user
agents
use
this
information
to
override
the
"Content-Type"
header
sent
by
the
server.
This
works
against
the
principle
of
authoritative
representation
metadata
.
The
information
in
the
Web
and
the
technologies
used
to
represent
that
information
change
over
time.
Some
examples
of
successful
technologies
designed
to
allow
change
while
minimizing
disruption
include:
-
the
fact
that
URI
schemes
are
independently
specified,
specified;
-
the
use
of
an
open
set
of
Internet
media
types
in
mail
and
HTTP
to
specify
document
interpretation,
interpretation;
-
the
separation
of
the
generic
XML
grammar
and
the
open
set
of
XML
namespaces
for
element
and
attribute
names,
names;
-
Extensibility
extensibility
models
in
Cascading
Style
Sheets
(CSS),
XSLT
1.0,
and
SOAP
SOAP;
-
user
agent
plug-ins
plug-ins.
The
following
applies
to
languages,
in
particular
Below
we
discuss
the
specifications
property
of
"extensibility,"
exhibited
by
URIs
and
some
data
formats,
of
and
message
formats,
deleted text:
and
URIs.
<strong>
Note:
</strong>
This
document
does
not
distinguish
in
any
formal
way
the
terms
"format"
and
"language."
Context
has
determined
which
term
is
used.
promotes
technology
evolution
and
interoperability.
Language
subset
:
one
language
is
a
subset
(or,
"profile")
of
a
second
language
if
any
document
in
the
first
language
is
also
a
valid
document
in
the
second
language
and
has
the
same
interpretation
in
the
second
language.
Language
extension
:
one
language
is
an
extension
of
a
second
language
if
the
second
is
a
language
subset
of
the
first
(thus,
the
extension
is
a
superset).
Clearly,
creating
an
deleted text:
extension
language
extension
is
better
for
interoperability
than
creating
an
incompatible
language.
Ideally,
many
instances
of
a
superset
language
can
be
safely
and
usefully
processed
as
though
they
were
in
the
subset
language.
language
subset.
Languages
that
exhibit
this
property
are
said
to
be
"extensible."
Language
designers
can
facilitate
extensibility
by
defining
how
implementations
must
handle
unknown
extensions
--
for
example,
that
they
be
ignored
(in
some
way)
or
should
be
considered
errors.
For
example,
from
early
on
in
the
Web,
HTML
agents
followed
the
convention
of
ignoring
unknown
elements.
This
choice
left
room
for
innovation
(i.e.,
non-standard
elements)
and
encouraged
the
deployment
of
HTML.
However,
interoperability
problems
arose
as
well.
In
this
type
of
environment,
there
is
an
inevitable
tension
between
interoperability
in
the
short
term
and
the
desire
for
extensibility.
Experience
shows
that
designs
that
strike
the
right
balance
between
allowing
change
and
preserving
interoperability
are
more
likely
to
thrive
and
are
less
likely
to
disrupt
the
Web
community.
<a href="#orthogonal-specs" shape="rect">
Orthogonal
Independent
specifications
help
reduce
the
risk
of
disruption.
For
further
discussion,
see
the
section
on
versioning
and
extensibility
.
See
also
TAG
issue
xmlProfiles-29
.
Errors
occur
in
networked
information
systems.
The
manner
in
which
they
are
dealt
with
depends
on
application
context.
A
user
agent
acts
on
behalf
of
the
user
and
therefore
is
expected
to
help
the
user
understand
the
nature
of
errors,
and
possibly
overcome
them.
User
agents
that
correct
errors
without
the
consent
of
the
user
are
not
acting
on
the
user's
behalf.
Principle:
Error
recovery
Silent
Agent
recovery
from
error
without
user
consent
is
harmful.
Consent
does
not
necessarily
imply
that
the
receiving
agent
must
interrupt
the
user
and
require
selection
of
one
option
or
another.
The
user
may
indicate
through
pre-selected
configuration
options,
modes,
or
selectable
user
interface
toggles,
with
appropriate
reporting
to
the
user
when
the
agent
detects
an
error.
To
promote
interoperability,
specifications
specification
designers
should
set
expectations
about
behavior
in
the
face
of
known
error
conditions.
Experience
has
led
to
the
following
observations
about
error-handling
approaches.
-
Protocol
designers
should
provide
enough
information
about
the
error
condition
so
that
deleted text:
a
an
agent
can
address
the
error
condition.
For
instance,
an
HTTP
404
message
("resource
not
found")
is
useful
because
it
allows
user
agents
to
present
relevant
information
to
users,
enabling
them
to
contact
the
author
representation
provider
in
case
of
the
representation
that
included
the
(broken)
link.
</li>
<li>
Experience
with
problems.
-
Experience
with
the
cost
of
building
a
user
agent
to
handle
the
diverse
forms
of
ill-formed
HTML
content
convinced
the
authors
designers
of
the
XML
specification
to
require
that
agents
fail
deleted text:
deterministically
upon
encountering
ill-formed
content.
Because
users
are
unlikely
to
tolerate
such
failures,
this
design
choice
has
pressured
all
parties
into
respecting
XML's
constraints,
to
the
benefit
of
all.
-
An
agent
that
encounters
unrecognized
content
may
handle
it
in
a
number
of
ways,
including
as
an
error;
see
also
the
section
on
extensibility
and
versioning
.
-
Error
behavior
that
is
appropriate
for
a
person
may
not
be
appropriate
for
software.
People
are
capable
of
exercising
judgement
in
ways
that
software
applications
generally
cannot.
An
informal
error
response
may
suffice
for
a
person
but
not
for
a
processor.
See
the
TAG
issues
contentTypeOverride-24
and
errorHandling-20
.
The
Web
follows
Internet
tradition
in
that
its
important
interfaces
are
defined
in
terms
of
protocols,
by
specifying
the
syntax,
semantics,
and
sequence
of
the
messages
interchanged.
The
technology
shared
among
Web
agents
lasts
longer
than
the
agents
themselves.
It
is
common
for
programmers
working
with
the
Web
to
write
code
that
generates
and
parses
these
messages
directly.
It
is
less
common,
but
not
unusual,
for
end
users
to
have
direct
exposure
to
these
messages.
This
leads
It
is
often
desirable
to
the
well-known
"view
source"
effect,
whereby
provide
users
with
access
to
format
and
protocol
details:
allowing
them
to
"
view
source
,"
whereby
they
may
gain
expertise
in
the
workings
of
the
deleted text:
systems
by
direct
exposure
to
the
underlying
protocols.
system.
Parties
who
wish
to
communicate
effectively
must
agree
(to
a
reasonable
extent)
upon
a
shared
set
of
identifiers
and
on
their
meanings.
The
ability
to
use
common
identifiers
across
communities
motivates
global
identifiers
in
Web
architecture.
Thus,
Uniform
Resource
Identifiers
([
URI
],
currently
being
revised)
which
are
global
identifiers
in
the
context
of
the
Web,
are
central
to
Web
architecture.
Constraint:
Identify
with
URIs
The
identification
mechanism
for
the
Web
is
the
URI.
A
URI
must
be
assigned
to
a
resource
in
order
for
agents
to
be
able
to
refer
to
the
resource.
It
follows
that
a
resource
should
be
assigned
a
URI
if
a
third
party
might
reasonably
want
to
link
to
it,
make
or
refute
assertions
about
it,
retrieve
or
cache
a
representation
of
it,
include
all
or
part
of
it
by
reference
into
another
representation,
annotate
it,
or
perform
other
operations
on
it.
</p>
<p>
When
a
<a href="#def-representation" shape="rect">
representation
</a>
uses
a
URI
(instead
Formats
that
allow
content
authors
to
use
URIs
instead
of
deleted text:
a
local
identifier)
as
an
identifier,
then
it
gains
great
power
from
the
vastness
of
the
choice
of
resources
to
which
it
can
refer.
The
phrase
identifiers
foster
the
"network
effect"
describes
the
fact
that
effect":
the
usefulness
value
of
the
technology
is
dependent
on
these
formats
grows
with
the
size
of
the
deployed
Web.
Resources
exist
before
URIs;
a
resource
may
be
identified
by
zero
URIs.
However,
there
are
many
benefits
to
assigning
a
URI
to
a
resource,
including
linking,
bookmarking,
caching,
and
indexing
by
search
engines.
Designers
Software
developers
should
expect
that
it
will
prove
useful
to
be
able
to
share
a
URI
across
applications,
even
if
that
utility
is
not
initially
evident.
The
scope
of
a
URI
is
global;
the
resource
identified
by
a
URI
does
not
depend
on
the
context
in
which
the
URI
appears
(see
also
the
section
about
URIs
in
other
roles
).
Of
course,
what
an
agent
does
with
a
URI
may
vary.
The
TAG
finding
"
URIs,
Addressability,
and
the
use
of
HTTP
GET
and
POST
"
discusses
additional
benefits
and
considerations
of
URI
addressability.
Principle:
URI
assignment
A
resource
owner
SHOULD
One
should
assign
a
URI
to
each
resource
anything
that
others
will
expect
to
refer
to.
This
principle
dates
back
at
least
as
far
as
Douglas
Engelbart's
seminal
work
on
open
hypertext
systems;
see
section
Every
Object
Addressable
in
[
Eng90
].
The
most
straightforward
way
of
establishing
that
two
parties
are
referring
to
the
same
resource
is
to
compare,
character-by-character,
the
URIs
they
are
using.
Two
URIs
that
are
identical
(character
for
character)
refer
to
the
same
resource.
However,
Web
architecture
allows
resource
owners
people
to
assign
more
than
one
URI
to
a
resource.
Constraint:
<a name="design-mult-URI" id="design-mult-URI" shape="rect">
URI
uniqueness
multiplicity
Web
architecture
does
not
constrain
a
deleted text:
Web
resource
to
be
identified
by
a
single
URI.
Thus,
Consequently,
two
URIs
that
are
not
identical
(character
for
character)
can
still
refer
to
the
same
resource
(i.e.,
they
do
not
necessarily
refer
to
different
resources.
The
most
straightforward
way
resources).
To
reduce
the
risk
of
establishing
a
false
negative
comparison
(i.e.,
an
incorrect
conclusion
that
two
parties
are
referring
URIs
do
not
refer
to
the
same
Web
resource
resource)
or
a
false
positive
comparison
(i.e.,
an
incorrect
conclusion
that
two
URIs
do
refer
to
the
same
resource),
certain
specifications
license
applications
to
apply
tests
in
addition
to
character-by-character
comparison.
For
example,
for
"http"
URIs,
the
authority
component
(the
part
after
"//"
and
before
the
next
"/")
is
defined
to
compare,
as
character
strings,
be
case-insensitive.
Thus,
the
URIs
they
are
using.
"http"
URI
equivalence
is
discussed
specification
licenses
applications
to
conclude
that
authority
components
in
section
6
of
[
two
"http"
URIs
are
equivalent
when
those
strings
are
character-by-character
equivalent
or
differ
only
by
case.
By
following
the
"http"
URI
specification,
agents
are
licensed
to
conclude
that
"http://Weather.Example.Com/Oaxaca"
and
"http://weather.example.com/Oaxaca"
identify
the
same
resource.
Agents
that
reach
conclusions
based
on
comparisons
that
are
not
licensed
by
relevant
specifications
take
responsibility
for
any
problems
that
result.
Agents
should
not
assume,
for
example,
that
"http://weather.example.com/Oaxaca"
and
"http://weather.example.com/OAXACA"
identify
the
same
resource,
since
none
of
the
specifications
involved
states
that
the
path
component
of
an
"http"
URI
is
case-insensitive.
Section
6
[
URI
]
provides
more
information
about
comparing
URIs
and
reducing
the
risk
of
false
negatives
and
positives.
See
the
section
below
on
approaches
other
than
string
comparison
that
allow
different
parties
to
assert
that
two
URIs
identify
the
same
resource
.
<div class="boxedtext">
<p>
<span class="practicelab">
Good
practice:
2.1.1.
URI
aliases
Aliases
</span>
</p>
<p class="practice">
Resource
owners
should
not
create
arbitrarily
different
There
are
many
benefits
to
ensuring
that
software
can
determine,
by
following
specifications,
that
two
URIs
for
refer
to
the
same
resource.
deleted text:
</p>
</div>
<p>
URI
producers
should
be
conservative
about
the
number
of
different
URIs
they
produce
for
the
same
resource.
resource,
especially
when
software
cannot
determine
the
equivalence
of
those
URIs.
For
example,
the
parties
responsible
for
weather.example.com
should
not
use
both
"http://weather.example.com/Oaxaca"
and
"http://weather.example.com/oaxaca"
to
refer
to
the
same
resource;
agents
software
will
not
detect
the
equivalence
relationship
by
following
specifications.
On
Good
practice:
Avoiding
URI
aliases
A
URI
owner
should
not
create
arbitrarily
different
URIs
for
the
other
hand,
there
may
same
resource.
There
may,
of
course,
be
good
reasons
for
creating
similar-looking
URIs.
For
instance,
one
might
reasonably
create
URIs
that
begin
with
"http://www.example.com/tempo"
and
"http://www.example.com/tiempo"
to
provide
access
to
resources
by
users
who
speak
Italian
and
Spanish.
Likewise,
URI
consumers
should
ensure
URI
consistency.
For
instance,
when
transcribing
a
URI,
agents
should
not
gratuitously
escape
characters.
The
term
"character"
refers
to
URI
characters
as
defined
in
section
2
of
[
URI
].
Good
practice:
Consistent
URI
usage
If
a
URI
has
been
assigned
to
a
resource,
agents
SHOULD
refer
to
the
resource
using
the
same
URI,
character
for
character.
Applications
may
apply
rules
beyond
basic
string
comparison
that
are
licensed
by
specifications
When
a
URI
alias
does
become
common
currency,
the
URI
owner
should
use
protocol
techniques
such
as
server-side
redirects
to
reduce
connect
the
risk
of
false
negatives
and
positives.
For
example,
for
"http"
URIs,
the
authority
component
is
case-insensitive.
Agents
that
reach
conclusions
based
on
comparisons
that
are
not
licensed
by
relevant
specifications
take
responsibility
for
any
problems
that
result.
Agents
should
not
assume,
for
example,
that
"http://weather.example.com/Oaxaca"
and
"http://weather.example.com/oaxaca"
identify
the
same
resource,
since
none
of
the
specifications
involved
states
that
two
resources.
The
community
benefits
when
the
deleted text:
path
part
of
an
"http"
URI
is
case-insensitive.
</p>
<p>
See
section
6
[
<a href="#URI" shape="rect">
URI
</a>
]
for
more
information
about
comparing
URIs
and
reducing
owner
supports
both
the
risk
of
false
negatives
"unofficial"
URI
and
deleted text:
positives.
See
the
section
on
future
directions
for
approaches
other
than
string
comparison
that
may
allow
different
parties
to
<a href="#future-comparison" shape="rect">
assert
that
two
URIs
identify
the
same
resource
</a>.
alias.
2.2.
<a name="uri-ownership" id="uri-ownership" shape="rect">
URI
Ownership
Overloading
The
requirement
for
URIs
to
be
<a href="#URI-ambiguity" shape="rect">
unambiguous
</a>
demands
that
At
times,
different
agents
do
not
assign
intentionally
or
unintentionally
use
the
same
URI
to
identify
different
resources.
<a href="#URI-scheme" shape="rect">
URI
scheme
overloading
specifications
assure
this
using
a
variety
of
techniques,
including:
</p>
<ul>
<li>
Hierarchical
delegation
of
authority.
This
approach,
exemplified
by
refers
to
the
"http"
and
"mailto"
schemes,
allows
use,
in
the
assignment
context
of
a
part
Web
protocols
and
formats,
of
one
URI
deleted text:
space
to
refer
to
more
than
one
party,
reassignment
of
resource.
Just
as
promoting
a
piece
of
that
space
to
another,
and
so
forth.
</li>
<li>
Random
numbers.
The
generation
of
shared
vocabulary
has
tangible
value,
overloading
often
imposes
a
fairly
large
random
number,
used
cost
in
the
"uuid"
scheme,
reduces
the
risk
of
ambiguity
to
a
calculated
small
risk.
</li>
<li>
Checksums.
The
generation
of
communication.
Suppose
that
one
organization
uses
a
URI
deleted text:
as
a
checksum
based
on
a
data
object
has
similar
properties
their
site
to
refer
to
the
random
number
approach.
This
is
the
approach
taken
by
the
"md5"
scheme.
</li>
<li>
Combination
of
approaches.
The
"mid"
movie
"The
Sting",
and
"cid"
schemes
combine
some
of
the
above
approaches.
</li>
</ul>
<p>
The
approach
taken
for
another
organization
uses
the
"http"
same
URI
scheme
follows
the
pattern
whereby
to
refer
to
a
resource
that
talks
about
"The
Sting."
Inconsistent
use
of
the
Internet
community
delegates
authority,
via
URI
creates
confusion
about
what
the
deleted text:
IANA
URI
scheme
registry
[
<a href="#IANASchemes" shape="rect">
IANASchemes
</a>
]
and
identifies.
In
many
contexts,
inconsistent
use
may
not
lead
to
error
or
cause
harm.
However,
in
some
contexts
such
as
the
DNS,
over
a
set
Semantic
Web,
software
relies
on
consistent
use
of
URIs
with
a
common
prefix
to
URIs.
If
one
particular
owner.
One
consequence
of
this
approach
is
wanted
to
talk
about
the
Web's
heavy
reliance
on
creation
date
of
the
central
DNS
registry.
</p>
<p>
Whatever
resource
identified
by
the
techniques
used,
except
URI,
for
instance,
it
would
not
be
clear
whether
this
meant
"when
the
checksum
case,
movie
created"
or
"when
the
agent
has
a
unique
relationship
with
resource
about
the
URI,
called
<a name="def-uri-ownership" id="def-uri-ownership">
movie
was
created."
<dfn>
Good
practice:
Avoiding
URI
ownership
</dfn>
Overloading
</a>.
The
phrase
"authority
responsible
for
a
URI"
is
synonymous
with
"URI
owner"
in
this
document.
Avoid
URI
overloading.
The
social
implications
of
URI
ownership
are
not
discussed
here.
However,
the
success
or
failure
of
these
different
approaches
depends
on
the
extent
to
which
there
is
consensus
in
the
Internet
community
section
below
on
abiding
by
the
defining
specifications.
The
concept
of
URI
ownership
is
especially
visible
in
the
case
of
the
HTTP
protocol,
which
enables
examines
approaches
for
establishing
the
deleted text:
URI
owner
to
serve
<a href="#authoritative-metadata" shape="rect">
authoritative
representations
</a>
source
of
information
about
what
resource
a
deleted text:
resource.
In
this
case,
the
HTTP
origin
server
(defined
in
[
<a href="#RFC2616" shape="rect">
RFC2616
</a>
])
is
the
agent
acting
on
behalf
of
the
URI
owner.
</p>
</div>
<div class="section">
<h3>
2.3.
<a name="URI-ambiguity" id="URI-ambiguity" shape="rect">
URI
Ambiguity
</a>
</h3>
<p>
Just
as
a
shared
vocabulary
has
tangible
value,
the
ambiguous
use
of
terms
imposes
a
cost
in
communication.
<a name="def-uri-ambiguity" id="def-uri-ambiguity">
<dfn>
URI
ambiguity
</dfn>
</a>
refers
to
the
use
of
the
same
URI
to
refer
to
more
than
one
distinct
resource.
</p>
<div class="boxedtext">
<p>
<span class="practicelab">
Good
practice:
<a name="pr-uri-ambiguity" id="pr-uri-ambiguity" shape="rect">
URI
ambiguity
</a>
</span>
</p>
<p class="practice">
Avoid
URI
ambiguity.
</p>
</div>
<p>
URI
ambiguity
should
not
be
confused
with
ambiguity
in
natural
language.
The
English
statement
"'http://www.example.com/moby'
identifies
'Moby
Dick'"
is
ambiguous
because
one
could
understand
the
phrase
"Moby
Dick"
to
refer
to
distinct
resources:
a
particular
printing
of
this
work,
or
the
work
itself
in
an
abstract
sense,
or
the
fictional
white
whale,
or
a
particular
copy
of
the
book
on
the
shelves
of
a
library
(via
the
Web
interface
of
the
library's
online
catalog),
or
the
record
in
the
library's
electronic
catalog
which
contains
the
metadata
about
the
work,
or
the
<a href="http://ibiblio.org/gutenberg/etext01/moby10b.txt" shape="rect">
Gutenberg
project's
online
version
</a>.
identifies.
In
Web
architecture,
URIs
identify
resources.
Outside
the
bounds
context
of
Web
architecture
specifications,
URIs
can
be
useful
for
other
purposes,
for
example,
as
database
keys.
For
instance,
the
organizers
of
a
conference
might
use
"mailto:nadia@example.com"
to
refer
to
Nadia.
While
this
usage
is
not
licensed
by
Web
architecture
specifications,
in
the
context
of
the
conference,
all
parties
may
agree
to
that
local
policy
and
understand
one
another.
Certain
properties
of
URIs,
such
as
their
potential
for
global
uniqueness,
make
them
appealing
as
general-purpose
identifiers.
In
the
Web
architecture,
"mailto:nadia@example.com"
identifies
an
Internet
mailbox;
that
is
what
is
licensed
by
the
"mailto"
URI
scheme
specification.
The
fact
that
the
URI
serves
other
purposes
in
non-Web
contexts
does
not
lead
to
URI
ambiguity.
overloading.
URI
ambiguity
overloading
arises
when
a
URI
is
used
to
identify
two
different
<em>
resources
within
the
context
of
Web
</em>
resources.
protocols
and
formats.
2.4.
<a name="URI-scheme" id="URI-scheme" shape="rect">
2.3.
URI
Schemes
Ownership
In
The
requirement
that
URIs
not
be
overloaded
(explained
below)
demands
that
different
agents
do
not
assign
the
same
URI
"http://weather.example.com/",
to
different
resources.
URI
scheme
specifications
assure
this
using
a
variety
of
techniques,
including:
-
Hierarchical
delegation
of
authority.
This
approach,
exemplified
by
the
"http"
that
appears
before
and
"mailto"
schemes,
allows
the
colon
(":")
names
assignment
of
a
part
of
URI
scheme.
Each
URI
scheme
has
space
to
one
party,
reassignment
of
a
normative
specification
that
explains
how
identifiers
are
assigned
within
that
scheme.
The
URI
syntax
is
thus
a
federated
and
extensible
naming
mechanism
wherein
each
scheme's
specification
may
further
restrict
the
syntax
and
semantics
piece
of
deleted text:
identifiers
within
that
scheme.
</p>
<p>
Examples
of
URIs
from
various
schemes
include:
</p>
<ul>
<li>
mailto:joe@example.org
</li>
<li>
ftp://example.org/aDirectory/aFile
</li>
<li>
news:comp.infosystems.www
</li>
<li>
tel:+1-816-555-1212
</li>
<li>
ldap://ldap.example.org/c=GB?objectClass?one
space
to
another,
and
so
forth.
-
urn:oasis:names:tc:entity:xmlns:xml:catalog
</li>
</ul>
<p>
While
the
Web
architecture
allows
the
definition
Large
numbers.
The
generation
of
deleted text:
new
schemes,
introducing
a
new
scheme
is
costly.
Many
aspects
fairly
large
random
number
or
a
checksum
reduces
the
risk
of
URI
processing
are
scheme-dependent,
and
overloading
to
a
significant
amount
calculated
small
risk.
A
draft
"uuid"
scheme
adopted
this
approach;
one
could
also
imagine
a
scheme
based
on
md5
checksums.
-
Combination
of
deployed
software
already
processes
URIs
approaches.
The
"mid"
and
"cid"
schemes
combine
some
of
well-known
schemes.
Introducing
a
new
the
above
approaches.
The
approach
taken
for
the
"http"
URI
scheme
requires
follows
the
development
and
deployment
not
only
of
client
software
to
handle
pattern
whereby
the
scheme,
but
also
of
ancillary
agents
such
as
gateways,
proxies,
and
caches.
See
Internet
community
delegates
authority,
via
the
IANA
URI
scheme
registry
[
<a href="#RFC2718" shape="rect">
RFC2718
IANASchemes
]
deleted text:
for
other
considerations
and
costs
related
the
DNS,
over
a
set
of
URIs
with
a
common
prefix
to
URI
scheme
design.
one
particular
owner.
One
consequence
of
this
approach
is
the
Web's
heavy
reliance
on
the
central
DNS
registry.
Because
of
these
costs,
if
Except
when
a
URI
scheme
exists
that
meets
the
needs
is
constructed
from
a
checksum,
all
of
an
application,
designers
should
use
it
rather
than
invent
one.
</p>
<div class="boxedtext">
<p>
the
techniques
seek
to
establish
a
unique
relationship
between
a
social
entity
and
a
URI.
This
relationship
is
called
<span class="practicelab">
Good
practice:
<a name="pr-new-scheme-expensive" id="pr-new-scheme-expensive" shape="rect">
New
URI
schemes
</a>
</span>
ownership
</p>
<p class="practice">
Authors
of
specifications
SHOULD
NOT
introduce
a
new
URI
scheme
when
an
existing
scheme
provides
.
In
this
document,
the
desired
properties
of
identifiers
phrase
"authority
responsible
for
domain
X"
indicates
that
the
same
entity
owns
those
URIs
where
the
authority
component
is
domain
X.
This
document
does
not
address
how
the
benefits
and
their
relation
responsibilities
of
URI
ownership
may
be
delegated
to
resources.
other
parties
(e.g.,
to
individuals
managing
an
HTTP
server).
deleted text:
</div>
Consider
our
<a href="#scenario" shape="rect">
travel
scenario
</a>:
should
the
authority
providing
information
about
the
weather
in
Oaxaca
register
a
new
A
URI
scheme
"weather"
for
the
identification
owner
may
provide
representations
of
deleted text:
resources
related
to
the
weather?
They
might
then
publish
URIs
such
as
"weather://travel.example.com/oaxaca".
resource
identified
by
the
URI
upon
request.
When
a
software
agent
dereferences
such
a
URI,
if
what
really
happens
is
that
the
HTTP
GET
protocol
is
invoked
used
to
retrieve
a
representation
of
the
resource,
then
an
"http"
URI
would
have
sufficed.
</p>
<p>
If
provide
representations,
the
motivation
behind
registering
a
new
scheme
HTTP
origin
server
(defined
in
[
RFC2616
])
is
to
allow
a
the
software
agent
to
launch
a
particular
application
when
retrieving
a
representation,
such
dispatching
can
be
accomplished
at
lower
expense
via
Internet
Media
Types.
When
designing
a
new
data
format,
the
appropriate
mechanism
to
promote
its
deployment
acting
on
behalf
of
the
URI
owner.
The
URI
owner
has
a
privileged
position
in
the
Web
is
architecture
as
the
Internet
Media
Type.
</p>
<p>
Note
entity
that
even
if
an
agent
cannot
process
representation
data
in
an
unknown
format,
it
can
at
least
retrieve
it.
The
data
may
contain
enough
information
to
allow
a
user
or
user
agent
assigns
authoritative
metadata
to
make
some
use
such
representations;
see
the
section
on
authoritative
metadata
for
more
information.
There
are
also
social
expectations
for
responsible
representation
management
by
URI
owners.
Additional
social
implications
of
deleted text:
it.
When
an
agent
does
not
handle
a
new
URI
scheme,
it
cannot
retrieve
a
representation.
ownership
are
not
discussed
here.
However,
the
success
or
failure
of
these
different
approaches
depends
on
the
extent
to
which
there
is
consensus
in
the
Internet
community
on
abiding
by
the
defining
specifications.
<h4>
2.4.1.
<a name="URI-registration" id="URI-registration" shape="rect">
The
Internet
Assigned
Numbers
Authority
(
<acronym>
IANA
</acronym>
)
maintains
a
registry
[
<a href="#IANASchemes" shape="rect">
IANASchemes
</a>
]
of
mappings
between
In
the
URI
scheme
names
and
scheme
specifications.
For
instance,
"http://weather.example.com/",
the
IANA
registry
indicates
"http"
that
appears
before
the
"http"
scheme
is
defined
in
[
<a href="#RFC2616" shape="rect">
RFC2616
</a>
].
The
process
for
registering
colon
(":")
names
a
new
URI
scheme.
Each
URI
scheme
is
defined
in
[
<a href="#RFC2717" shape="rect">
RFC2717
</a>
].
</p>
<p>
has
a
normative
specification
that
explains
how
identifiers
are
assigned
within
that
scheme.
The
deleted text:
use
of
unregistered
URI
schemes
syntax
is
discouraged
for
thus
a
number
federated
and
extensible
naming
mechanism
wherein
each
scheme's
specification
may
further
restrict
the
syntax
and
semantics
of
reasons:
identifiers
within
that
scheme.
Examples
of
URIs
from
various
schemes
include:
-
There
is
no
generally
accepted
way
to
locate
the
scheme
specification.
mailto:joe@example.org
-
Someone
else
may
be
using
the
scheme
for
other
purposes.
ftp://example.org/aDirectory/aFile
-
One
should
not
expect
that
general-purpose
software
will
do
anything
useful
with
URIs
of
this
scheme;
the
network
effect
is
lost.
news:comp.infosystems.www
-
tel:+1-816-555-1212
-
ldap://ldap.example.org/c=GB?objectClass?one
-
urn:oasis:names:tc:entity:xmlns:xml:catalog
<strong>
Note:
</strong>
Some
URI
scheme
specifications
(such
as
the
"ftp"
URI
scheme
specification)
use
While
the
term
"designate"
where
Web
architecture
allows
the
current
document
uses
"identify."
</p>
<p>
TAG
issue
<a href="http://www.w3.org/2001/tag/issues.html#siteData-36" shape="rect">
siteData-36
</a>
is
about
expropriation
definition
of
naming
authority.
</p>
</div>
</div>
<div class="section">
<h3>
2.5.
<a name="uri-opacity" id="uri-opacity" shape="rect">
URI
Opacity
</a>
</h3>
<p>
It
new
schemes,
introducing
a
new
scheme
is
tempting
to
guess
the
nature
costly.
Many
aspects
of
URI
processing
are
scheme-dependent,
and
a
resource
by
inspection
significant
amount
of
deployed
software
already
processes
URIs
of
well-known
schemes.
Introducing
a
new
URI
that
identifies
it.
However,
scheme
requires
the
Web
is
designed
so
that
agents
communicate
resource
state
through
<a href="#def-representation" shape="rect">
representations
</a>,
development
and
deployment
not
identifiers.
In
general,
one
cannot
determine
only
of
client
software
to
handle
the
Internet
Media
Type
scheme,
but
also
of
representations
ancillary
agents
such
as
gateways,
proxies,
and
caches.
See
[
RFC2718
]
for
other
considerations
and
costs
related
to
URI
scheme
design.
Because
of
a
resource
by
inspecting
these
costs,
if
a
URI
for
scheme
exists
that
resource.
For
example,
the
".html"
at
meets
the
end
needs
of
"http://example.com/page.html"
an
application,
designers
should
use
it
rather
than
invent
one.
Good
practice:
New
URI
schemes
A
specification
SHOULD
NOT
introduce
a
new
URI
scheme
when
an
existing
scheme
provides
deleted text:
no
guarantee
that
representations
of
the
identified
resource
will
be
served
with
the
Internet
Media
Type
"text/html".
The
HTTP
protocol
does
not
constrain
the
Internet
Media
Type
based
on
the
path
component
of
the
URI;
the
server
is
free
to
return
a
representation
in
PNG
or
any
other
data
format
for
that
URI.
</p>
<p>
Resource
state
may
evolve
over
time.
Requiring
resource
owners
to
change
URIs
to
reflect
resource
state
would
lead
to
a
significant
number
desired
properties
of
broken
links.
For
robustness,
Web
architecture
promotes
independence
between
an
identifier
identifiers
and
the
identified
resource.
</p>
<div class="boxedtext">
<p>
<span class="practicelab">
Good
practice:
<a name="pr-uri-opacity" id="pr-uri-opacity" shape="rect">
URI
opacity
</a>
</span>
</p>
<p class="practice">
Agents
making
use
of
URIs
MUST
NOT
attempt
their
relation
to
infer
properties
of
the
referenced
resource
except
as
licensed
by
relevant
specifications.
resources.
The
example
URI
used
in
the
Consider
our
travel
scenario
</a>
("http://weather.example.com/oaxaca")
suggests
that
the
identified
resource
has
something
to
do
with
:
should
the
weather
in
Oaxaca.
A
site
reporting
agent
providing
information
about
the
weather
in
Oaxaca
could
just
as
easily
be
identified
by
the
register
a
new
URI
"http://vjc.example.com/315".
And
scheme
"weather"
for
the
URI
"http://weather.example.com/vancouver"
identification
of
resources
related
to
the
weather?
They
might
identify
then
publish
URIs
such
as
"weather://travel.example.com/oaxaca".
When
a
software
agent
dereferences
such
a
URI,
if
what
really
happens
is
that
HTTP
GET
is
invoked
to
retrieve
a
representation
of
the
resource
"my
photo
album."
resource,
then
an
"http"
URI
would
have
sufficed.
On
the
other
hand,
the
URI
"mailto:joe@example.com"
indicates
that
If
the
URI
refers
to
motivation
behind
registering
a
mailbox.
The
"mailto"
URI
new
scheme
specification
authorizes
agents
is
to
infer
that
URIs
of
this
form
identify
allow
a
software
agent
to
launch
a
particular
application
when
retrieving
a
representation,
such
dispatching
can
be
accomplished
at
lower
expense
via
Internet
mailboxes.
media
types.
When
designing
a
new
data
format,
the
appropriate
mechanism
to
promote
its
deployment
on
the
Web
is
the
Internet
media
type.
In
some
cases,
relevant
technical
specifications
license
URI
assignment
authorities
to
publish
assignment
policies.
For
more
Note
that
even
if
an
agent
cannot
process
representation
data
in
an
unknown
format,
it
can
at
least
retrieve
it.
The
data
may
contain
enough
information
about
to
allow
a
user
or
user
agent
to
make
some
use
of
it.
When
an
agent
does
not
handle
a
new
URI
opacity,
see
TAG
issue
<a href="http://www.w3.org/2001/tag/ilist#metadataInURI-31" shape="rect">
metaDataInURI-31
</a>.
scheme,
it
cannot
retrieve
a
representation.
deleted text:
</div>
<h3>
2.6.
<a name="fragid" id="fragid" shape="rect">
Fragment
Identifiers
2.4.1.
URI
Scheme
Registration
</h3>
<div class="boxedtext">
<p>
<span class="storylab">
Story
</span>
</p>
<div class="story">
When
navigating
within
the
XHTML
data
that
Nadia
receives
as
The
Internet
Assigned
Numbers
Authority
(
IANA
)
maintains
a
representation
registry
[
IANASchemes
]
of
mappings
between
URI
scheme
names
and
scheme
specifications.
For
instance,
the
resource
identified
by
"http://weather.example.com/oaxaca",
Nadia
finds
IANA
registry
indicates
that
the
URI
"http://weather.example.com/oaxaca#tom"
refers
to
information
about
tomorrow's
weather
"http"
scheme
is
defined
in
Oaxaca.
This
[
RFC2616
].
The
process
for
registering
a
new
URI
includes
the
fragment
identifier
"tom"
(the
string
after
the
"#").
scheme
is
defined
in
[
RFC2717
].
deleted text:
</div>
</div>
The
<a name="def-fragid" id="def-fragid">
<dfn>
fragment
identifier
</dfn>
</a>
use
of
a
unregistered
URI
allows
indirect
identification
of
schemes
is
discouraged
for
a
<a name="def-secondary-resource" id="def-secondary-resource">
<dfn>
secondary
resource
</dfn>
</a>
by
reference
number
of
reasons:
-
There
is
no
generally
accepted
way
to
a
primary
resource
and
additional
information.
The
secondary
resource
locate
the
scheme
specification.
-
Someone
else
may
be
some
portion
or
subset
of
the
primary
resource,
some
view
on
representations
of
using
the
primary
resource,
or
some
scheme
for
other
resource.
The
interpretation
purposes.
-
One
should
not
expect
that
general-purpose
software
will
do
anything
useful
with
URIs
of
fragment
identifiers
this
scheme
beyond
URI
comparison;
the
network
effect
is
discussed
in
lost.
Note:
Some
URI
scheme
specifications
(such
as
the
section
on
<a href="#media-type-fragid" shape="rect">
media
types
and
fragment
identifier
semantics
</a>.
"ftp"
URI
scheme
specification)
use
the
term
"designate"
where
the
current
document
uses
"identify."
deleted text:
See
TAG
issues
<a href="http://www.w3.org/2001/tag/issues.html#abstractComponentRefs-37" shape="rect">
abstractComponentRefs-37
issue
siteData-36
and
<a href="http://www.w3.org/2001/tag/issues.html#DerivedResources-43" shape="rect">
DerivedResources-43
</a>.
is
about
expropriation
of
naming
authority.
2.7.
<a name="identifiers-future" id="identifiers-future" shape="rect">
Future
Directions
for
Identifiers
2.5.
URI
Opacity
There
remain
open
questions
regarding
identifiers
on
It
is
tempting
to
guess
the
Web.
The
following
sections
identify
nature
of
a
few
areas
resource
by
inspection
of
future
work
in
a
URI
that
identifies
it.
However,
the
Web
community.
</p>
<div class="section">
<h4>
2.7.1.
<a id="i18n-id" name="i18n-id" shape="rect">
Internationalized
Identifiers
</a>
</h4>
<p>
The
integration
is
designed
so
that
agents
communicate
resource
state
through
representations
,
not
identifiers.
In
general,
one
cannot
determine
the
Internet
media
type
of
internationalized
identifiers
(i.e.,
composed
representations
of
characters
beyond
those
allowed
a
resource
by
[
<a href="#URI" shape="rect">
inspecting
a
URI
</a>
])
into
for
that
resource.
For
example,
the
Web
architecture
is
an
important
and
open
issue.
See
TAG
issue
<a href="http://www.w3.org/2001/tag/ilist#IRIEverywhere-27" shape="rect">
IRIEverywhere-27
</a>
for
discussion
about
work
going
on
in
this
area.
</p>
</div>
<div class="section">
<h4>
2.7.2.
<a name="future-comparison" id="future-comparison" shape="rect">
Assertion
".html"
at
the
end
of
"http://example.com/page.html"
provides
no
guarantee
that
Two
URIs
Identify
representations
of
the
Same
Resource
</a>
</h4>
<p>
Emerging
Semantic
Web
technologies,
including
identified
resource
will
be
served
with
the
"Web
Ontology
Language
(OWL)"
[
<a href="#OWL10" shape="rect">
OWL10
</a>
],
define
RDF
[
<a href="#RDF10" shape="rect">
RDF10
</a>
]
properties
such
as
<code>
sameAs
</code>
Internet
media
type
"text/html".
The
HTTP
protocol
does
not
constrain
the
Internet
media
type
based
on
the
path
component
of
the
URI;
the
URI
owner
is
free
to
assert
that
two
URIs
identify
configure
the
same
resource
or
<code>
functionalProperty
</code>
server
to
imply
it.
return
a
representation
using
PNG
or
any
other
data
format.
deleted text:
</div>
</div>
</div>
<div class="section">
<h2>
3.
<a name="interaction" id="interaction" shape="rect">
Interaction
</a>
</h2>
Communication
between
agents
Resource
state
may
evolve
over
time.
Requiring
a
network
about
resources
involves
URIs,
messages,
URI
owner
to
publish
a
new
URI
for
each
change
in
resource
state
would
lead
to
a
significant
number
of
broken
links.
For
robustness,
Web
architecture
promotes
independence
between
an
identifier
and
data.
the
identified
resource.
<span class="storylab">
Story
Good
practice:
URI
opacity
<div class="story">
<p>
Nadia
follows
a
hypertext
link
labeled
"satellite
image"
expecting
Agents
making
use
of
URIs
MUST
NOT
attempt
to
retrieve
a
satellite
photo
infer
properties
of
the
Oaxaca
region.
referenced
resource
except
as
licensed
by
relevant
specifications.
The
link
to
example
URI
used
in
the
satellite
image
is
an
XHTML
link
encoded
as
<code>
<a href="http://example.com/satimage/oaxaca">satellite image</a>
</code>.
Nadia's
browser
analyzes
the
URI
and
determines
that
its
<a href="#URI-scheme" shape="rect">
scheme
travel
scenario
is
"http".
The
browser
configuration
determines
how
it
locates
("http://weather.example.com/oaxaca")
suggests
that
the
identified
information,
which
might
be
via
a
cache
of
prior
retrieval
actions,
by
contacting
an
intermediary
(such
as
a
proxy
server),
or
by
direct
access
resource
has
something
to
do
with
the
server
identified
by
the
URI.
In
this
example,
the
browser
opens
a
network
connection
to
port
80
on
weather
in
Oaxaca.
A
site
reporting
the
server
at
"example.com"
and
sends
a
"GET"
message
weather
in
Oaxaca
could
just
as
specified
easily
be
identified
by
the
HTTP
protocol,
requesting
a
representation
of
URI
"http://vjc.example.com/315".
And
the
URI
"http://weather.example.com/vancouver"
might
identify
the
resource
identified
by
"/satimage/oaxaca".
"my
photo
album."
The
server
sends
a
response
message
to
On
the
browser,
once
again
according
to
other
hand,
the
HTTP
protocol.
The
message
consists
of
several
headers
and
URI
"mailto:joe@example.com"
indicates
that
the
URI
refers
to
a
JPEG
image.
mailbox.
The
browser
reads
the
headers,
learns
from
the
"Content-Type"
field
"mailto"
URI
scheme
specification
authorizes
agents
to
infer
that
the
Internet
Media
Type
URIs
of
this
form
identify
Internet
mailboxes.
In
some
cases,
relevant
technical
specifications
license
URI
assignment
authorities
to
publish
assignment
policies.
For
more
information
about
URI
opacity,
see
TAG
issue
metaDataInURI-31
.
Story
When
navigating
within
the
XHTML
data
that
Nadia
receives
as
a
representation
deleted text:
is
"image/jpeg",
reads
the
sequence
of
octets
the
resource
identified
by
"http://weather.example.com/oaxaca",
Nadia
finds
that
deleted text:
comprises
the
representation
data,
and
renders
URI
"http://weather.example.com/oaxaca#tom"
refers
to
information
about
tomorrow's
weather
in
Oaxaca.
This
URI
includes
the
image.
fragment
identifier
"tom"
(the
string
after
the
"#").
This
section
describes
the
architectural
principles
and
constraints
regarding
interactions
between
agents,
including
such
topics
as
network
protocols
and
interaction
styles,
along
with
interactions
between
the
Web
as
The
fragment
identifier
component
of
a
system
and
the
people
that
make
use
URI
allows
indirect
identification
of
deleted text:
it.
The
fact
that
the
Web
is
a
highly
distributed
system
affects
architectural
constraints
and
assumptions
about
interactions.
</p>
<p>
<strong>
Note:
</strong>
The
Web
Architecture
does
not
require
secondary
resource
by
reference
to
a
formal
definition
primary
resource
and
additional
identifying
information.
The
secondary
resource
may
be
some
portion
or
subset
of
the
commonly
used
phrase
"on
primary
resource,
some
view
on
representations
of
the
Web."
Informally,
a
primary
resource,
or
some
other
resource
defined
or
described
by
those
representations.
The
interpretation
of
fragment
identifiers
is
"on
discussed
in
the
Web"
when
it
has
a
URI
section
on
media
types
and
an
agent
can
use
the
URI
to
retrieve
a
representation
of
it
using
network
protocols
(given
appropriate
access
privileges,
network
connectivity,
etc.).
fragment
identifier
semantics
.
See
deleted text:
the
related
TAG
issue
<a href="http://www.w3.org/2001/tag/ilist.html#httpRange-14" shape="rect">
httpRange-14
issues
abstractComponentRefs-37
and
DerivedResources-43
.
3.1.
<a name="dereference-uri" id="dereference-uri" shape="rect">
Using
a
URI
to
Access
a
Resource
2.7.
Future
Directions
for
Identifiers
Agents
may
use
There
remain
open
questions
regarding
identifiers
on
the
Web.
The
following
sections
identify
a
URI
to
access
few
areas
of
future
work
in
the
referenced
resource;
this
is
called
<a name="uri-dereference" id="uri-dereference">
<dfn>
dereferencing
Web
community.
The
integration
of
internationalized
identifiers
(i.e.,
composed
of
characters
beyond
those
allowed
by
[
URI
])
into
the
Web
architecture
is
an
important
and
open
issue.
See
TAG
issue
IRIEverywhere-27
for
discussion
about
work
going
on
in
this
area.
Emerging
Semantic
Web
technologies,
including
the
"Web
Ontology
Language
(OWL)"
[
OWL10
],
define
RDF
[
RDF10
]
properties
such
as
sameAs
to
assert
that
two
URIs
identify
the
same
resource
or
functionalProperty
to
imply
it.
One
consequence
of
this
direction
is
that
URIs
syntactically
different
can
be
used
to
identify
the
same
resource.
This
means
that
multiple
parties
may
create
representations
of
the
(same)
resource,
all
available
for
retrieval
using
multiple
URIs.
A
URI
owner's
rights
(e.g.,
to
provide
authoritative
representation
metadata)
extend
only
to
the
representations
served
for
requests
given
that
URI.
Note
also
that
to
URIs
that
are
sameAs
one
another
does
not
mean
they
are
interchangeable.
For
instance,
suppose
that
two
different
organizations
own
the
URIs
"http://weather.example.org/stations/oaxaca#ws17a"
and
"http://weather.example.com/rdfdump?region=oaxaca&station=ws17a".
The
URIs
might
both
identify
the
same
resource,
a
certain
collection
of
weather-measuring
equipment
shared
by
the
two
organizations.
Although
the
URIs
might
be
declared
"owl:sameAs"
each
other,
the
two
URI
owners
might
provide
very
different
content
when
the
URIs
are
dereferenced.
Communication
between
agents
over
a
network
about
resources
involves
URIs,
messages,
and
data.
Story
Nadia
follows
a
hypertext
link
labeled
"satellite
image"
expecting
to
retrieve
a
satellite
photo
of
the
Oaxaca
region.
The
link
to
the
satellite
image
is
an
XHTML
link
encoded
as
<a href="http://example.com/satimage/oaxaca">satellite image</a>
.
Nadia's
browser
analyzes
the
URI
and
determines
that
its
scheme
is
"http".
The
browser
configuration
determines
how
it
locates
the
identified
information,
which
might
be
via
a
cache
of
prior
retrieval
actions,
by
contacting
an
intermediary
(such
as
a
proxy
server),
or
by
direct
access
to
the
server
identified
by
a
portion
of
the
URI.
In
this
example,
the
browser
opens
a
network
connection
to
port
80
on
the
server
at
"example.com"
and
sends
a
"GET"
message
as
specified
by
the
HTTP
protocol,
requesting
a
representation
of
the
resource
identified
by
"/satimage/oaxaca".
The
server
sends
a
response
message
to
the
browser,
once
again
according
to
the
HTTP
protocol.
The
message
consists
of
several
headers
and
a
JPEG
image.
The
browser
reads
the
headers,
learns
from
the
"Content-Type"
field
that
the
Internet
media
type
of
the
representation
is
"image/jpeg",
reads
the
sequence
of
octets
that
make
up
the
representation
data,
and
renders
the
image.
This
section
describes
the
architectural
principles
and
constraints
regarding
interactions
between
agents,
including
such
topics
as
network
protocols
and
interaction
styles,
along
with
interactions
between
the
Web
as
a
system
and
the
people
that
make
use
of
it.
The
fact
that
the
Web
is
a
highly
distributed
system
affects
architectural
constraints
and
assumptions
about
interactions.
See
the
related
TAG
issue
httpRange-14
.
Agents
may
use
a
URI
to
access
the
referenced
resource;
this
is
called
dereferencing
the
URI
.
Access
may
take
many
forms,
including
retrieving
a
representation
of
resource
the
state
of
the
resource
(for
instance,
by
using
HTTP
GET
or
HEAD),
adding
or
modifying
a
representation
of
the
state
of
the
resource
(for
instance,
by
using
HTTP
POST
or
PUT),
PUT,
which
in
some
cases
may
change
the
actual
state
of
the
resource
if
the
submitted
representations
are
interpreted
as
instructions
to
that
end),
and
deleting
some
or
all
representations
of
the
state
of
the
resource
(for
instance,
by
using
HTTP
DELETE).
DELETE,
which
in
some
cases
may
result
in
the
deletion
of
the
resource
itself).
There
may
be
more
than
one
way
to
access
a
resource
for
a
given
URI;
application
context
determines
which
access
mechanism
an
agent
uses.
For
instance,
a
browser
might
use
HTTP
GET
to
retrieve
a
representation
of
a
resource,
whereas
a
link
checker
might
use
HTTP
HEAD
on
the
same
URI
simply
to
establish
whether
a
representation
is
available.
Some
URI
schemes
set
expectations
about
available
access
mechanisms,
others
(such
as
the
URN
scheme
[
RFC
2141
])
do
not.
Section
1.2.2
of
[
URI
]
discusses
the
separation
of
identification
and
interaction
in
more
detail.
For
more
information
about
relationships
between
multiple
access
mechanisms
and
URI
addressability,
see
the
TAG
finding
"
URIs,
Addressability,
and
the
use
of
HTTP
GET
and
POST
"
.
Although
many
URI
schemes
are
named
after
protocols,
this
does
not
imply
that
use
of
such
a
URI
will
necessarily
result
in
access
to
the
resource
via
the
named
protocol.
Even
when
an
agent
uses
a
URI
to
retrieve
a
representation,
that
access
might
be
through
gateways,
proxies,
caches,
and
name
resolution
services
that
are
independent
of
the
protocol
associated
with
the
scheme
name.
Dereferencing
a
URI
generally
involves
a
succession
of
steps
as
described
in
multiple
independent
specifications
and
implemented
by
the
agent.
The
following
example
illustrates
the
series
of
specifications
that
are
involved
when
a
user
instructs
a
user
agent
to
follow
a
hypertext
link
that
is
part
of
an
SVG
document.
In
this
example,
the
URI
is
"http://weather.example.com/oaxaca"
and
the
application
context
calls
for
the
user
agent
to
retrieve
and
render
a
representation
of
the
identified
resource.
-
Since
the
URI
is
part
of
a
hypertext
link
in
an
SVG
document,
the
first
relevant
specification
is
the
SVG
1.1
Recommendation
[
SVG11
].
Section
17.1
of
this
specification
imports
the
link
semantics
defined
in
XLink
1.0
[
XLink10
]:
"The
remote
resource
(the
destination
for
the
link)
is
defined
by
a
URI
specified
by
the
XLink
href
attribute
on
the
'a'
element."
The
SVG
specification
goes
on
to
state
that
interpretation
of
an
a
element
involves
retrieving
a
representation
of
a
resource,
identified
by
the
href
attribute
in
the
XLink
namespace:
"By
activating
these
links
(by
clicking
with
the
mouse,
through
keyboard
input,
voice
commands,
etc.),
users
may
visit
these
resources."
-
The
XLink
1.0
[
XLink10
]
specification,
which
defines
the
href
attribute
in
section
5.4,
states
that
"The
value
of
the
href
attribute
must
be
a
URI
reference
as
defined
in
[IETF
RFC
2396],
or
must
result
in
a
URI
reference
after
the
escaping
procedure
described
below
is
applied."
-
The
URI
specification
[
URI
]
states
that
"Each
URI
begins
with
a
scheme
name
that
refers
to
a
specification
for
assigning
identifiers
within
that
scheme."
The
URI
scheme
name
in
this
example
is
"http".
-
[
IANASchemes
]
states
that
the
"http"
scheme
is
defined
by
the
HTTP/1.1
specification
(RFC
2616
[
RFC2616
],
section
3.2.2).
-
In
this
SVG
context,
the
agent
constructs
an
HTTP
GET
request
(per
section
9.3
of
[
RFC2616
])
to
retrieve
the
representation.
-
Section
6
of
[
RFC2616
]
defines
how
the
server
constructs
a
corresponding
response
message,
including
the
'Content-Type'
field.
-
Section
1.4
of
[
RFC2616
]
states
"HTTP
communication
usually
takes
place
over
TCP/IP
connections."
This
example
does
not
address
that
step
in
the
process,
or
other
steps
such
as
Domain
Name
System
(
DNS
)
resolution.
-
The
agent
interprets
the
returned
representation
according
to
the
data
format
specification
that
corresponds
to
the
representation's
Internet
Media
Type
(the
value
of
the
HTTP
'Content-Type')
in
the
relevant
IANA
registry
[
MEDIATYPEREG
].
The
Web's
protocols
(including
HTTP,
FTP,
SOAP,
NNTP,
and
SMTP)
are
based
on
the
exchange
of
messages.
A
message
may
include
representation
data
as
well
as
metadata
about
the
resource
(such
as
the
"Alternates"
and
"Vary"
HTTP
headers),
the
representation,
and
the
message
itself
(such
as
the
"Transfer-encoding"
HTTP
header).
A
message
may
even
include
metadata
about
the
message
metadata
(for
message-integrity
checks,
for
instance).
Two
important
classes
of
message
are
those
that
request
a
representation
of
a
resource,
and
those
that
return
the
result
of
such
a
request.
Such
a
response
message
(for
example,
a
response
to
an
HTTP
GET)
includes
a
representation
of
the
deleted text:
state
of
the
resource.
A
representation
is
an
octet
sequence
that
consists
logically
of
two
parts:
-
Representation
data
,
deleted text:
electronic
data
about
resource
state,
expressed
in
one
or
more
formats
used
separately
or
in
combination,
and
-
Representation
metadata
.
One
important
piece
of
metadata
is
the
Internet
Media
Type
media
type
,
discussed
below.
Agents
use
representations
to
modify
as
well
as
retrieve
resource
state.
Note
that
even
though
the
response
to
an
HTTP
POST
request
may
contain
the
above
types
of
data,
the
response
to
an
HTTP
POST
request
is
not
necessarily
a
representation
of
the
deleted text:
state
of
the
resource
identified
in
the
POST
request.
The
Internet
Media
Type
media
type
[
RFC2046
])
of
a
representation
determines
which
data
format
specification(s)
provide
the
authoritative
interpretation
of
the
representation
data
(including
fragment
identifier
syntax
and
semantics
,
if
any).
The
IANA
registry
[
MEDIATYPEREG
]
maps
media
types
to
data
formats
.
See
the
TAG
finding
"
Internet
Media
Type
media
type
registration,
consistency
of
use
"
for
more
information
about
media
type
registration.
Story
In
one
of
his
XHTML
pages,
Dirk
links
to
an
image
that
Nadia
has
published
on
the
Web.
He
creates
a
hypertext
link
with
<a
href="http://www.example.com/images/nadia#hat">Nadia's
hat</a>
.
Nadia
serves
an
SVG
representation
of
the
image
(with
Internet
Media
Type
media
type
"image/svg+xml"),
so
the
authoritative
interpretation
of
the
fragment
identifier
"hat"
depends
on
the
SVG
specification.
Per
[
URI
],
in
order
to
know
the
authoritative
interpretation
of
given
a
deleted text:
fragment
identifier,
one
must
dereference
the
URI
containing
"U#F",
and
a
representation
retrieved
by
dereferencing
URI
"U"
(which
is
authoritative),
the
fragment
identifier.
The
Internet
Media
Type
of
(
secondary
)
resource
identified
by
"U#F"
is
determined
by
interpreting
"F"
according
to
the
retrieved
representation
specifies
specification
associated
with
the
authoritative
interpretation
Internet
media
type
of
the
fragment
identifier.
the
representation
data.
Thus,
in
the
case
of
Dirk
and
Nadia,
the
authoritative
interpretation
depends
on
of
the
fragment
identifier
is
given
by
the
SVG
specification,
not
the
XHTML
specification
(i.e.,
the
context
where
the
URI
appears).
Given
The
semantics
of
a
URI
"U#F",
fragment
identifier
are
defined
by
the
set
of
representations
that
might
result
from
a
retrieval
action
on
the
primary
resource.
The
fragment's
format
and
resolution
is
therefore
dependent
on
the
media
type
[
RFC2046
]
of
a
representation
potentially
retrieved
by
dereferencing
URI
"U",
representation,
even
though
such
a
retrieval
is
only
performed
if
the
(
<a href="#def-secondary-resource" shape="rect">
secondary
</a>
)
resource
identified
by
"U#F"
URI
is
determined
by
interpreting
"F"
according
to
dereferenced.
If
no
such
representation
exists,
then
the
specification
associated
with
semantics
of
the
Internet
Media
Type
fragment
are
considered
unknown
and,
effectively,
unconstrained.
Fragment
identifier
semantics
are
independent
of
the
representation.
URI
scheme
and
thus
cannot
be
redefined
by
URI
scheme
specifications.
Interpretation
of
the
fragment
identifier
during
a
retrieval
action
is
performed
solely
by
the
agent;
the
fragment
identifier
is
not
passed
to
other
systems
during
the
process
of
retrieval.
This
means
that
some
intermediaries
in
the
Web
architecture
(such
as
proxies)
have
no
interaction
with
fragment
identifiers
and
that
redirection
(in
HTTP
[
RFC2616
],
for
example)
does
not
account
for
them.
deleted text:
</p>
<p>
Note
also
that
one
can
use
since
dereferencing
a
URI
(e.g.,
using
HTTP)
does
not
involve
sending
a
fragment
identifier
to
a
server
or
other
agent,
certain
access
methods
(e.g.,
HTTP
PUT,
POST,
and
DELETE)
cannot
be
used
to
interact
with
secondary
resources.
As
with
any
URI,
use
of
a
fragment
identifier
even
if
one
component
does
not
have
imply
that
a
retrieval
action
will
take
place.
A
URI
with
a
deleted text:
representation
available
for
interpreting
the
fragment
identifier
(one
can
may
be
used
to
refer
to
the
secondary
resource
without
any
implication
that
the
primary
resource
is
accessible
or
will
ever
be
accessed.
One
may
compare
two
such
URIs,
for
example).
URIs
with
fragment
identifiers
without
a
retrieval
action.
Parties
that
draw
conclusions
about
the
interpretation
of
a
fragment
identifier
without
retrieving
a
representation
do
so
at
their
own
risk;
such
interpretations
are
not
authoritative.
Story
Dirk
informs
Nadia
that
he
would
also
like
her
to
make
her
images
available
in
formats
other
than
SVG.
For
the
same
resource,
Nadia
makes
available
a
PNG
image
as
well.
Dirk's
user
agent
and
Nadia's
server
negotiate
so
that
the
user
agent
retrieves
a
suitable
representation.
Which
specification
specifies
the
authoritative
interpretation
of
the
"hat"
fragment
identifier,
the
PNG
specification
or
the
SVG
specification?
For
a
given
resource,
an
agent
may
have
the
choice
between
representation
data
in
more
than
one
data
format
(through
HTTP
content
negotiation,
for
example).
Since
different
Individual
data
formats
may
define
different
their
own
restrictions
on,
or
structure
within,
the
fragment
identifier
semantics,
it
is
important
to
note
syntax
for
specifying
different
types
of
subsets,
views,
or
external
references
that
are
identifiable
as
secondary
resources
by
design,
that
media
type.
If
the
primary
resource
has
multiple
representations,
as
is
often
the
case
for
resources
whose
representation
is
selected
based
on
attributes
of
the
secondary
resource
retrieval
request
("content
negotiation"),
then
whatever
is
identified
by
a
URI
with
a
the
fragment
identifier
is
expected
to
should
be
the
same
consistent
across
all
representations.
Thus,
if
a
fragment
has
defined
semantics
in
any
one
representation,
of
those
representations:
each
representation
should
either
define
the
fragment
is
identified
for
all
such
that
it
corresponds
to
the
same
secondary
resource,
regardless
of
them,
even
though
a
particular
data
format
may
not
how
it
is
represented,
or
the
fragment
should
be
able
to
represent
it.
left
undefined
by
the
representation
(i.e.,
not
found).
Suppose,
for
example,
that
the
authority
responsible
for
owner
of
"http://weather.example.com/oaxaca/map#zicatela"
provides
representations
of
the
resource
identified
by
http://weather.example.com/oaxaca/map
using
three
image
formats:
SVG,
PNG,
and
JPEG/JFIF.
The
SVG
specification
defines
semantics
for
fragment
identifiers
while
the
other
specifications
do
not.
It
is
not
considered
an
error
that
only
one
of
the
data
formats
specifies
semantics
for
the
fragment
identifier.
Because
the
Web
is
a
distributed
system
in
which
formats
and
agents
are
deployed
in
a
non-uniform
manner,
the
architecture
allows
this
sort
of
discrepancy.
This
design
allows
content
authors
to
take
advantage
of
new
data
formats
while
still
ensuring
reasonable
backward-compatibility
for
users
whose
agents
do
not
yet
implement
them.
deleted text:
<p>
On
the
other
hand,
it
is
considered
an
error
if
the
semantics
of
the
fragment
identifiers
used
in
two
representations
of
a
secondary
resource
are
inconsistent.
</p>
Good
practice:
Fragment
identifier
consistency
A
resource
The
owner
who
creates
of
a
URI
with
a
fragment
identifier
deleted text:
and
who
uses
content
negotiation
to
serve
multiple
representations
of
the
identified
resource
SHOULD
NOT
serve
representations
with
inconsistent
fragment
identifier
semantics.
Inconsistent
fragment
identifier
semantics
are
URI
overloading
is
one
potential
source
possible
consequence
of
<a href="#URI-ambiguity" shape="rect">
URI
ambiguity
</a>.
inconsistent
fragment
identifier
semantics.
See
related
TAG
issues
httpRange-14
and
RDFinXHTML-35
.
Successful
communication
between
two
parties
using
a
piece
of
information
relies
on
shared
understanding
of
the
meaning
of
the
information.
Arbitrary
numbers
of
independent
parties
can
identify
and
communicate
about
a
deleted text:
Web
resource.
To
give
these
parties
the
confidence
that
they
are
all
talking
about
the
same
thing
when
they
refer
to
"the
resource
identified
by
the
following
URI
..."
the
design
choice
for
the
Web
is,
in
general,
that
the
<a href="#uri-ownership" shape="rect">
owner
metadata
provided
by
a
message
sender
is
authoritative.
When
a
message
is
a
response
to
a
request
for
a
representation
of
a
resource
</a>
assigns
identified
by
a
given
URI,
the
authoritative
interpretation
of
representations
of
representation
metadata
provided
by
the
resource.
owner
of
that
URI
is
authoritative
for
that
representation
data.
In
our
travel
scenario
,
the
authority
responsible
owner
of
"http://weather.example.com/oaxaca"
provides
the
authoritative
metadata
for
deleted text:
"weather.example.com"
has
license
to
create
representations
of
this
resource.
Which
retrieved
for
that
URI.
Precisely
which
representation(s)
Nadia
receives
depends
on
a
number
of
factors,
including:
-
Whether
the
authority
responsible
for
"weather.example.com"
responds
to
requests
at
all;
-
Whether
the
authority
responsible
for
"weather.example.com"
makes
available
one
or
more
representations
for
the
resource
identified
by
"http://weather.example.com/oaxaca";
-
Whether
Nadia
has
access
privileges
to
such
representations
(see
the
section
on
linking
and
access
control
);
-
If
the
authority
responsible
for
"weather.example.com"
has
provided
more
than
one
representation
(in
different
formats
such
as
HTML,
PNG,
or
RDF,
or
RDF;
in
different
languages
such
as
English
and
Spanish),
Spanish;
or
transformed
dynamically
according
to
the
hardware
or
software
capabilities
of
the
recipient),
the
resulting
representation
may
depend
on
negotiation
between
the
user
agent
and
server
that
occurs
as
part
of
the
HTTP
transaction.
-
When
Nadia
made
the
request.
Since
the
weather
in
Oaxaca
changes,
Nadia
should
expect
that
representations
will
change
over
time.
Note
that
the
choice
and
expressive
power
of
a
format
can
affect
how
precisely
a
representation
provider
communicates
resource
state.
The
use
of
natural
language
to
communicate
resource
state
may
lead
to
ambiguity
about
what
the
associated
resource
is.
This
ambiguity
can
in
turn
lead
to
URI
overloading
.
See
TAG
issues
contentTypeOverride-24
and
rdfURIMeaning-39
.
Inconsistencies
between
the
data
format
of
representation
data
and
assigned
representation
metadata
do
occur.
Examples
that
have
been
observed
in
practice
include:
-
The
actual
character
encoding
of
a
representation
(e.g.,
"iso-8859-1",
specified
by
the
encoding
attribute
in
an
XML
declaration)
is
inconsistent
with
the
charset
parameter
in
the
representation
metadata.
metadata
(e.g.,
"utf-8",
specified
by
the
'Content-Type'
field
in
an
HTTP
header).
-
The
namespace
of
the
root
element
of
XML
representation
data
(e.g.,
as
specified
by
the
"xmlns"
attribute)
is
inconsistent
with
the
value
of
the
'Content-Type'
field
in
an
HTTP
headers.
header.
User
agents
Agents
should
detect
such
inconsistencies
but
should
not
resolve
them
without
deleted text:
involving
the
user.
consent
of
the
user;
see
the
section
on
error
handling
for
more
information.
Principle:
Authoritative
deleted text:
server
metadata
User
agents
Agents
MUST
NOT
deleted text:
silently
ignore
authoritative
server
metadata.
metadata
without
the
consent
of
the
user.
Thus,
for
example,
if
the
parties
responsible
for
"weather.example.com"
mistakenly
label
the
satellite
photo
of
Oaxaca
as
"image/gif"
instead
of
"image/jpeg",
and
if
Nadia's
browser
detects
a
problem,
Nadia's
browser
must
not
deleted text:
silently
ignore
the
problem
and
render
(e.g.,
by
simply
rendering
the
JPEG
image.
image)
without
Nadia's
consent.
Nadia's
browser
can
notify
Nadia
of
the
problem
or
notify
Nadia
and
take
corrective
action.
Of
course,
user
agent
designers
developers
should
not
ignore
usability
issues
when
handling
this
type
of
error;
notification
may
be
discreet,
and
handling
may
be
tuned
to
meet
the
user's
preferences.
See
the
TAG
finding
"
Client
handling
of
MIME
headers
"
for
more
in-depth
discussion
and
examples.
</p>
<p>
Furthermore,
server
managers
can
help
reduce
the
risk
of
error
through
careful
assignment
of
representation
metadata
(especially
that
which
applies
across
representations).
The
section
on
<a href="#xml-media-types" shape="rect">
media
types
for
XML
</a>
presents
an
example
of
reducing
the
risk
of
error
by
providing
no
metadata
about
character
encoding
when
serving
XML.
</p>
</div>
</div>
<div class="section">
<h3>
3.5.
<a name="safe-interaction" id="safe-interaction" shape="rect">
Safe
Interactions
</a>
</h3>
<div class="boxedtext">
<p>
<span class="storylab">
Story
</span>
</p>
<div class="story">
<p>
Nadia
decides
to
book
a
vacation
to
Oaxaca
at
"booking.example.com."
She
enters
data
into
a
series
of
online
forms
and
is
ultimately
asked
for
credit
card
information
to
purchase
the
airline
tickets.
She
provides
this
information
in
another
form.
When
she
presses
the
"Purchase"
button,
her
browser
opens
another
network
connection
to
the
server
at
"booking.example.com"
and
sends
a
message
composed
of
form
data
using
the
POST
method.
Note
that
this
is
not
a
<a href="#safe-interaction" shape="rect">
safe
interaction
</a>
;
Nadia
wishes
to
change
the
state
of
the
system
by
exchanging
money
for
airline
tickets.
</p>
<p>
The
server
reads
the
POST
request,
discussion
and
after
performing
the
booking
transaction
returns
a
message
to
Nadia's
browser
that
contains
a
examples.
Furthermore,
representation
of
providers
can
help
reduce
the
results
risk
of
error
through
careful
assignment
of
deleted text:
Nadia's
request.
The
representation
data
is
in
XHTML
so
metadata
(especially
that
it
can
be
saved
or
printed
out
which
applies
across
representations).
The
section
on
media
types
for
Nadia's
records.
Note
that
neither
the
data
transmitted
with
the
POST
nor
the
data
received
in
XML
presents
an
example
of
reducing
the
response
necessarily
correspond
to
any
resource
named
risk
of
error
by
a
URI.
providing
no
metadata
about
character
encoding
when
serving
XML.
Nadia's
retrieval
of
weather
information
(an
example
of
a
read-only
query
or
lookup)
qualifies
as
a
"safe"
interaction;
a
safe
interaction
is
one
where
the
agent
does
not
incur
any
obligation
beyond
the
interaction.
An
agent
may
incur
an
obligation
through
other
means
(such
as
by
signing
a
contract).
If
an
agent
does
not
have
an
obligation
before
a
safe
interaction,
it
does
not
have
that
obligation
afterwards.
Other
Web
interactions
resemble
orders
more
than
queries.
These
unsafe
interactions
may
cause
a
change
to
the
state
of
a
resource
and
the
user
may
be
held
responsible
user
may
be
held
responsible
for
the
consequences
of
these
interactions.
Unsafe
interactions
include
subscribing
to
a
newsletter,
posting
to
a
list,
or
modifying
a
database.
Note:
In
this
context,
the
word
"unsafe"
does
not
mean
"dangerous";
the
term
"safe"
is
used
in
section
9.1.1
of
[
RFC2616
]
and
"unsafe"
is
the
natural
opposite.
Story
Nadia
decides
to
book
a
vacation
to
Oaxaca
at
"booking.example.com."
She
enters
data
into
a
series
of
online
forms
and
is
ultimately
asked
for
credit
card
information
to
purchase
the
airline
tickets.
She
provides
this
information
in
another
form.
When
she
presses
the
"Purchase"
button,
her
browser
opens
another
network
connection
to
the
server
at
"booking.example.com"
and
sends
a
message
composed
of
form
data
using
the
POST
method.
This
is
an
unsafe
interaction
;
Nadia
wishes
to
change
the
state
of
the
system
by
exchanging
money
for
airline
tickets.
The
server
reads
the
consequences
of
these
interactions.
Unsafe
interactions
include
subscribing
to
POST
request,
and
after
performing
the
booking
transaction
returns
a
newsletter,
posting
message
to
Nadia's
browser
that
contains
a
list,
representation
of
the
results
of
Nadia's
request.
The
representation
data
is
in
XHTML
so
that
it
can
be
saved
or
modifying
a
database.
printed
out
for
Nadia's
records.
Safe
interactions
are
important
because
these
are
interactions
where
users
can
browse
with
confidence
and
where
agents
(including
search
engines
and
browsers
that
pre-cache
data
for
the
user)
can
follow
links
safely.
Users
(or
agents
acting
on
their
behalf)
do
not
commit
themselves
to
anything
by
querying
a
resource
or
following
a
link.
Principle:
Safe
retrieval
Agents
do
not
incur
obligations
by
retrieving
a
representation.
For
instance,
it
is
incorrect
to
publish
a
link
that,
when
followed,
subscribes
a
user
to
a
mailing
list.
Remember
that
search
engines
may
follow
such
links.
For
more
information
about
safe
and
unsafe
operations
using
HTTP
GET
and
POST,
and
handling
security
concerns
around
the
use
of
HTTP
GET,
see
the
TAG
finding
"
URIs,
Addressability,
and
the
use
of
HTTP
GET
and
POST
"
.
Story
Nadia
pays
for
her
airline
tickets
online
(through
a
POST
interaction
as
described
above).
She
receives
a
Web
page
with
confirmation
information
and
wishes
to
bookmark
it
so
that
she
can
refer
to
it
when
she
calculates
her
expenses.
Although
Nadia
can
print
out
the
results,
or
save
them
to
a
file,
she
cannot
would
also
like
to
bookmark
the
results.
In
fact,
them.
Note
that
neither
the
data
transmitted
with
the
POST
request,
which
expresses
nor
the
data
received
in
the
response
necessarily
correspond
to
any
resource
identified
by
a
URI.
Although
HTTP
includes
mechanisms
to
allow
representation
providers
to
assign
a
URI
to
POST
results,
the
mechanism
is
not
widely
deployed.
Thus,
in
practice,
Nadia
cannot
bookmark
her
commitment
to
pay,
nor
pay
(expressed
via
the
POST
request)
or
the
airline
company's
deleted text:
response,
which
expresses
its
acknowledgment
and
its
own
commitment,
can
be
referenced
by
URIs.
commitment
(expressed
via
the
response
to
the
POST).
It
is
a
breakdown
of
the
Web
architecture
if
agents
cannot
use
URIs
to
reconstruct
a
"paper
trail"
of
transactions,
transaction
results,
i.e.,
to
refer
to
receipts
and
other
evidence
of
accepting
an
obligation.
Indeed,
each
electronic
mail
message
includes
a
unique
message
identifier,
one
reason
why
email
is
so
useful
for
managing
accountability
(since,
for
example,
email
can
be
copied
to
public
archives).
On
the
other
hand,
HTTP
servers
and
deployed
user
agents
do
not
generally
keep
records
of
POST
transactions,
making
it
difficult
for
all
parties
to
reconstruct
a
series
of
transactions.
There
are
mechanisms
in
HTTP,
not
widely
deployed,
to
remedy
this
situation.
HTTP
servers
can
assign
a
URI
to
the
results
of
a
POST
transaction
using
the
"Content-Location"
header
(described
in
section
14.14
of
[
RFC2616
]),
and
allow
authorized
parties
to
retrieve
a
record
of
the
transaction
thereafter
via
this
URI
(the
value
of
URI
persistence
is
apparent
in
this
case).
User
agents
can
provide
an
interface
for
managing
transactions
where
the
user
agent
has
incurred
an
obligation
on
behalf
of
the
user.
Story
Since
Nadia
finds
the
Oaxaca
weather
site
useful,
she
emails
a
review
to
her
friend
Dirk
recommending
that
he
check
out
'http://weather.example.com/oaxaca'.
Dirk
clicks
on
the
link
in
the
email
he
receives
and
is
surprised
to
see
his
browser
display
frustrated
by
a
"404
page
about
auto
insurance.
not
found".
Dirk
confirms
tries
again
the
URI
next
day
and
receives
a
representation
with
Nadia,
"news"
that
is
two-weeks
old.
He
tries
one
more
time
the
next
day
only
to
receive
a
representation
that
claims
that
the
weather
in
Oaxaca
is
sunny,
even
though
his
friends
in
Oaxaca
tell
him
by
phone
that
it
in
fact
it
is
raining
(and
he
trusts
them
more
than
he
trusts
the
Web
site
in
question).
Dirk
and
they
both
Nadia
conclude
that
the
resource
is
unreliable.
URI
owners
are
unpredictable.
Although
the
managers
of
Oaxaca
have
URI
owner
has
chosen
the
Web
as
a
communication
medium,
they
have
lost
two
customers
due
to
ineffective
resource
management.
The
usefulness
of
a
resource
URI
depends
on
good
management
by
its
owner.
As
is
the
case
with
many
human
interactions,
confident
interactions
with
a
resource
depend
on
stability
and
predictability.
The
value
of
a
URI
increases
with
the
predictability
of
interactions
using
that
URI.
Avoiding
unnecessary
URI
aliases
is
one
aspect
of
proper
resource
management.
Good
practice:
Consistent
representation
Publishers
of
a
A
URI
owner
SHOULD
provide
representations
of
the
identified
resource
consistently
and
predictably.
This
section
discusses
important
aspects
of
representation
management.
The
authority
responsible
for
a
resource
A
URI
owner
may
supply
zero
or
more
representations
of
a
resource.
The
authority
the
resource
identified
by
that
URI.
That
agent
is
also
responsible
for
accepting
or
rejecting
requests
to
modify
a
resource,
the
resource
identified
by
that
URI,
for
example,
by
configuring
a
server
to
accept
or
reject
HTTP
PUT
data
based
on
Internet
Media
Type,
media
type,
validity
constraints,
or
other
constraints.
Good
practice:
Available
representation
Publishers
of
a
A
URI
owner
SHOULD
provide
representations
of
the
identified
resource.
For
example,
the
owner
of
an
XML
Namespace
should
provide
namespace
representations
;
below
we
discuss
useful
characteristics
of
a
namespace
representation.
There
are
strong
social
expectations
that
once
a
URI
identifies
a
particular
resource,
it
should
continue
indefinitely
to
refer
to
that
resource;
this
is
called
URI
persistence
.
URI
persistence
is
a
matter
of
policy
and
commitment
on
the
part
of
authorities
servicing
URIs.
The
choice
of
a
particular
URI
scheme
provides
no
guarantee
that
those
URIs
will
be
persistent
or
that
they
will
not
be
persistent.
Since
representations
are
used
to
communicate
resource
state,
persistence
is
directly
affected
by
how
well
representations
are
served.
Service
breakdowns
include:
-
Inconsistent
representations
served.
Note
the
difference
between
a
resource
URI
owner
changing
representations
predictably
in
light
of
the
nature
of
the
resource
(the
changing
weather
of
Oaxaca)
and
the
URI
owner
changing
representations
arbitrarily.
-
Improper
use
of
content
negotiation,
such
as
serving
two
images
as
equivalent
through
HTTP
content
negotiation,
where
one
image
represents
a
square
and
the
other
a
circle.
HTTP
[
RFC2616
]
has
been
designed
to
help
manage
URIs.
For
example,
HTTP
redirection
(using
the
3xx
response
codes)
permits
servers
to
tell
an
agent
that
further
action
needs
to
be
taken
by
the
agent
in
order
to
fulfill
the
request
(for
example,
the
resource
has
been
assigned
a
new
URI).
In
addition,
content
negotiation
also
promotes
consistency,
as
a
site
manager
is
not
required
to
define
new
URIs
when
adding
support
for
a
new
format
specification.
Protocols
that
do
not
support
content
negotiation
(such
as
FTP)
require
a
new
identifier
when
a
new
data
format
is
introduced.
For
more
discussion
about
URI
persistence,
see
[
Cool
].
It
is
reasonable
to
limit
access
to
a
resource
(for
commercial
or
security
reasons,
for
example),
but
it
is
unreasonable
to
prohibit
others
from
merely
identifying
the
resource.
As
an
analogy:
The
owners
of
a
building
might
have
a
policy
that
the
public
may
only
enter
the
building
via
the
main
front
door,
and
only
during
business
hours.
People
who
work
in
the
building
and
who
make
deliveries
to
it
might
use
other
doors
as
appropriate.
Such
a
policy
would
be
enforced
by
a
combination
of
security
personnel
and
mechanical
devices
such
as
locks
and
pass-cards.
One
would
not
enforce
this
policy
by
hiding
some
of
the
building
entrances,
nor
by
requesting
legislation
requiring
the
use
of
the
front
door
and
forbidding
anyone
to
reveal
the
fact
that
there
are
other
doors
to
the
building.
Story
Nadia
and
Dirk
both
subscribe
to
the
"weather.example.com"
newsletter.
Nadia
wishes
to
point
out
an
article
of
particular
interest
to
Dirk,
using
a
URI.
The
authority
responsible
for
"weather.example.com"
can
offer
newsletter
subscribers
such
as
Nadia
and
Dirk
the
benefits
of
URIs
(such
as
bookmarking
and
linking)
and
still
limit
access
to
the
newsletter
to
authorized
parties.
The
Web
provides
several
mechanisms
to
control
access
to
resources;
these
mechanisms
do
not
rely
on
hiding
or
suppressing
URIs
for
those
resources.
For
more
information,
see
the
TAG
finding
"
'Deep
Linking'
in
the
World
Wide
Web
"
.
There
remain
open
questions
regarding
Web
interactions.
The
TAG
expects
future
versions
of
this
document
to
address
in
more
detail
the
relationship
between
the
architecture
described
herein,
Web
Services
,
the
Semantic
Web
,
peer-to-peer
systems
(including
Freenet
,
MLdonkey
,
and
NNTP
[
RFC977
]),
instant
messaging
systems
(including
[
XMPP
]),
and
voice-over-ip
voice-over-IP
(including
RTSP
[
RFC2326
]).
]).
A
data
format
(including
XHTML,
CSS,
PNG,
XLink,
RDF/XML,
and
SMIL
animation)
specifies
the
interpretation
of
representation
data
.
The
first
data
format
used
on
the
Web
was
HTML.
Since
then,
data
formats
have
grown
in
number.
The
Web
architecture
does
not
constrain
which
data
formats
content
providers
can
use.
This
flexibility
is
important
because
there
is
constant
evolution
in
applications,
resulting
in
new
data
formats
and
refinements
of
existing
formats.
Although
the
Web
architecture
allows
for
the
deployment
of
new
data
formats,
the
creation
and
deployment
of
new
formats
(and
agents
able
to
handle
them)
is
expensive.
Thus,
before
inventing
a
new
data
format,
designers
should
carefully
consider
re-using
one
that
is
already
available.
For
a
data
format
to
be
usefully
interoperable
between
two
parties,
the
parties
must
agree
(to
a
reasonable
extent)
about
its
syntax
and
semantics.
Shared
understanding
of
a
data
format
promotes
interoperability
but
does
not
imply
constraints
on
usage;
for
instance,
a
data
sender
cannot
count
on
being
able
to
constrain
the
behavior
of
a
data
receiver.
Below
we
describe
some
characteristics
of
a
data
format
that
facilitate
integration
into
the
Web
architecture.
This
document
does
not
address
generally
beneficial
characteristics
of
a
specification
such
as
readability,
simplicity,
attention
to
programmer
goals,
attention
to
user
needs,
accessibility,
nor
internationalization.
The
section
on
architectural
specifications
includes
references
to
additional
format
specification
guidelines.
deleted text:
</div>
</div>
<h2>
4.
<a id="formats" name="formats" shape="rect">
A
Binary
data
format
(including
XHTML,
CSS,
PNG,
XLink,
RDF/XML,
and
SMIL
animation)
specifies
the
interpretation
formats
are
those
in
which
portions
of
<a href="#representation-data" shape="rect">
representation
the
data
</a>.
are
encoded
for
direct
use
by
computer
processors,
for
example
thirty-two
bit
little-endian
two's-complement
and
sixty-four
bit
IEEE
double-precision
floating-point.
The
first
portions
of
data
so
represented
include
numeric
values,
pointers,
and
compressed
data
of
all
sorts.
A
textual
data
format
used
on
is
one
in
which
the
deleted text:
Web
was
HTML.
Since
then,
data
is
specified
as
a
sequence
of
characters.
HTML,
Internet
e-mail,
and
all
XML-based
formats
have
grown
in
number.
are
textual.
Increasingly,
internationalized
textual
data
formats
refer
to
the
Unicode
repertoire
[
UNICODE
]
for
character
definitions.
In
principle,
all
data
can
be
represented
using
textual
formats.
The
Web
architecture
does
not
constrain
which
trade-offs
between
binary
and
textual
data
formats
content
providers
are
complex
and
application-dependent.
Binary
formats
can
use.
This
flexibility
is
important
because
there
is
constant
evolution
in
applications,
resulting
in
new
be
substantially
more
compact,
particularly
for
complex
pointer-rich
data
structures.
Also,
they
can
be
consumed
more
rapidly
by
agents
in
those
cases
where
they
can
be
loaded
into
memory
and
used
with
little
or
no
conversion.
Textual
formats
are
usually
more
portable
and
interoperable.
Textual
formats
also
have
the
considerable
advantage
that
they
can
be
directly
read
and
understood
by
human
beings.
This
can
simplify
the
tasks
of
creating
and
refinements
maintaining
software,
and
allow
the
direct
intervention
of
existing
formats.
Although
humans
in
the
Web
architecture
allows
for
processing
chain
without
recourse
to
tools
more
complex
than
the
deployment
of
new
data
formats,
ubiquitous
text
editor.
Finally,
it
simplifies
the
creation
and
deployment
necessary
human
task
of
new
formats
(and
agents
able
to
handle
them)
is
expensive.
Thus,
before
inventing
a
learning
about
new
data
format,
designers
should
carefully
consider
re-using
one
that
formats;
this
is
already
available.
called
the
"view
source"
effect
.
For
a
data
format
It
is
important
to
be
usefully
interoperable
between
two
parties,
the
parties
must
have
a
shared
understanding
of
its
syntax
emphasize
that
intuition
as
to
such
matters
as
data
size
and
semantics.
This
processing
speed
is
deleted text:
<em>
not
deleted text:
</em>
to
imply
that
a
sender
of
reliable
guide
in
data
can
count
on
constraining
its
treatment
by
format
design;
quantitative
studies
are
essential
to
a
receiver;
simply
that
making
good
use
correct
understanding
of
the
trade-offs.
Therefore,
designers
of
a
data
format
requires
knowledge
of
its
designers'
intentions.
Below
we
describe
some
characteristics
specification
should
make
a
considered
choice
between
binary
and
textual
format
design.
Note:
Text
(i.e.,
a
sequence
of
characters
from
a
repertoire)
is
distinct
from
serving
data
format
make
it
easier
to
integrate
into
the
Web
architecture.
This
document
does
with
a
media
type
beginning
with
"text/".
Although
XML-based
formats
are
textual,
many
XML-based
formats
do
not
address
generally
beneficial
characteristics
consist
primarily
of
a
specification
such
as
readability,
simplicity,
attention
to
programmer
goals,
attention
to
user
needs,
accessibility,
and
internationalization.
The
phrases
in
natural
language.
See
the
section
on
<a href="#archspecs" shape="rect">
architectural
specifications
media
types
for
XML
includes
references
to
additional
format
specification
guidelines.
for
issues
that
arise
when
"text/"
is
used
in
conjunction
with
an
XML-based
format.
See
TAG
issue
binaryXML-30
.
A
textual
data
format
is
one
in
which
the
data
is
specified
as
a
sequence
of
characters.
HTML,
Internet
e-mail,
Extensibility
and
all
<a href="#xml-formats" shape="rect">
XML-based
formats
</a>
versioning
are
textual.
In
modern
textual
data
formats,
strategies
to
help
manage
the
characters
are
usually
taken
from
natural
evolution
of
information
on
the
Unicode
repertoire
Web
and
technologies
used
to
represent
that
information.
For
more
information
about
versioning
strategies
and
agent
behavior
in
the
face
of
unrecognized
extensions,
see
TAG
issue
XMLVersioning-41
and
"Web
Architecture:
Extensible
Languages"
[
<a href="#UNICODE" shape="rect">
UNICODE
EXTLANG
].
Binary
data
formats
are
those
in
There
is
typically
a
(long)
transition
period
during
which
portions
multiple
versions
of
the
data
a
format,
protocol,
or
agent
are
encoded
for
direct
use
by
computer
processors,
for
example
thirty-two
bit
little-endian
two's-complement
and
sixty-four
bit
IEEE
double-precision
floating-point.
The
portions
of
data
so
represented
include
numeric
values,
pointers,
and
compressed
data
of
all
sorts.
simultaneously
in
use.
In
principle,
all
data
can
be
represented
using
textual
formats.
Good
practice:
Version
information
<p>
The
trade-offs
between
binary
and
textual
data
formats
are
complex
and
application-dependent.
Binary
formats
can
be
substantially
more
compact,
particularly
A
format
specification
SHOULD
provide
for
complex
pointer-rich
data
structures.
Also,
they
can
be
consumed
more
rapidly
by
agents
version
information
in
those
cases
where
they
can
be
loaded
into
memory
language
instances.
Story
Textual
formats
are
usually
more
portable
Nadia
and
interoperable.
Textual
formats
also
have
Dirk
are
designing
an
XML
data
format
to
encode
data
about
the
considerable
advantage
film
industry.
They
provide
for
extensibility
by
using
XML
namespaces
and
creating
a
schema
that
allows
the
inclusion,
in
certain
places,
of
elements
from
any
namespace.
When
they
can
be
directly
read
and
understood
by
human
beings.
This
can
simplify
revise
their
format,
Nadia
proposes
a
new
optional
"lang"
attribute
on
the
tasks
"film"
element.
Dirk
feels
that
such
a
change
requires
them
to
assign
a
new
namespace
name,
which
might
require
changes
to
deployed
software.
Nadia
explains
to
Dirk
that
their
choice
of
creating
extensibility
strategy
in
conjunction
with
their
namespace
policy
allows
certain
changes
that
do
not
affect
conformance
of
existing
content
and
deleted text:
maintaining
software,
and
allow
the
direct
intervention
of
humans
in
the
processing
chain
without
recourse
thus
no
change
to
deleted text:
tools
more
complex
than
the
ubiquitous
text
editor.
Finally,
it
simplifies
namespace
identifier
is
required.
They
choose
this
policy
to
help
them
meet
their
goals
of
reducing
the
necessary
human
task
cost
of
learning
about
new
data
formats
(the
"view
source"
effect).
change.
It
is
important
Dirk
and
Nadia
have
chosen
a
particular
namespace
change
policy
that
allows
them
to
emphasize
avoid
changing
the
namespace
name
whenever
they
make
changes
that
intuition
as
to
such
matters
as
data
size
and
processing
speed
are
do
not
affect
conformance
of
deployed
content
and
software.
They
might
have
chosen
a
reliable
guide
in
data
format
design;
quantitative
studies
are
essential
different
policy,
for
example
that
any
new
element
or
attribute
has
to
belong
to
a
correct
understanding
namespace
other
than
the
original
one.
Whatever
the
chosen
policy,
it
should
set
clear
expectations
for
users
of
the
trade-offs.
Therefore,
data
format.
Good
practice:
Namespace
policy
A
format
specification
authors
should
make
a
considered
choice
between
binary
and
textual
format
design.
SHOULD
include
information
about
change
policies
for
XML
namespaces.
<strong>
Note:
</strong>
Text
(i.e.,
a
sequence
As
an
example
of
deleted text:
characters
from
a
repertoire)
is
distinct
from
serving
data
with
a
media
type
beginning
with
"text/".
Although
XML-based
formats
are
textual,
many
such
formats
are
not
primarily
comprised
change
policy
designed
to
reflect
the
variable
stability
of
phrases
in
natural
language.
See
a
namespace,
consider
the
section
on
<a href="#xml-media-types" shape="rect">
media
types
for
XML
W3C
namespace
policy
for
issues
documents
on
the
W3C
Recommendation
track.
The
policy
sets
expectations
that
arise
when
"text/"
is
used
the
Working
Group
responsible
for
the
namespace
may
modify
it
in
any
way
until
a
certain
point
in
deleted text:
conjunction
with
an
XML-based
format.
</p>
<p>
See
TAG
issue
<a href="http://www.w3.org/2001/tag/ilist#binaryXML-30" shape="rect">
binaryXML-30
</a>.
</p>
</div>
<div class="section">
<h3>
4.2.
<a name="ext-version" id="ext-version" shape="rect">
Versioning
and
Extensibility
</a>
</h3>
<p>
Extensibility
and
versioning
are
strategies
to
help
manage
the
natural
evolution
process
("Candidate
Recommendation")
at
which
point
W3C
constrains
the
set
of
information
on
possible
changes
to
the
Web
and
technologies
used
namespace
in
order
to
represent
that
information.
promote
stable
implementations.
For
more
information
on
about
versioning
strategies
and
agent
behavior
in
Note
that
since
namespace
names
are
URIs,
the
face
owner
of
unrecognized
extensions,
see
TAG
issue
<a href="http://www.w3.org/2001/tag/issues.html#XMLVersioning-41" shape="rect">
XMLVersioning-41
</a>
and
"Web
Architecture:
Extensible
Languages"
[
<a href="#EXTLANG" shape="rect">
EXTLANG
</a>
].
a
namespace
URI
has
the
authority
to
decide
the
namespace
change
policy.
4.2.1.
<a name="versioning" id="versioning" shape="rect">
Versioning
4.2.3.
Extensibility
There
is
typically
a
(long)
Designers
can
facilitate
the
transition
period
process
by
making
careful
choices
about
extensibility
during
which
multiple
versions
the
design
of
a
format,
protocol,
language
or
agent
are
simultaneously
in
use.
protocol
specification.
Good
practice:
<a name="pr-version-info" id="pr-version-info" shape="rect">
Version
information
Extensibility
mechanisms
Format
designers
A
specification
SHOULD
provide
for
version
information
in
language
instances.
mechanisms
that
allow
any
party
to
create
extensions
that
do
not
interfere
with
conformance
to
the
original
specification.
deleted text:
</div>
<div class="section">
<h4>
4.2.2.
<a name="versioning-xmlns" id="versioning-xmlns" shape="rect">
Versioning
and
XML
Namespace
Policy
</a>
</h4>
<div class="boxedtext">
<p>
<span class="storylab">
Story
</span>
</p>
<div class="story">
Nadia
and
Dirk
are
designing
an
XML
data
format
to
encode
data
about
Application
needs
determine
the
film
industry.
They
provide
most
appropriate
extension
strategy
for
deleted text:
extensibility
by
using
XML
namespaces
and
creating
a
schema
that
allows
the
inclusion,
in
certain
places,
of
elements
from
any
namespace.
When
they
revise
their
format,
Nadia
proposes
a
new
optional
"lang"
attribute
on
the
"film"
element.
Dirk
feels
that
such
a
change
requires
them
to
assign
a
new
namespace
name,
which
might
require
changes
specification.
For
example,
applications
designed
to
deployed
software.
Nadia
explains
operate
in
closed
environments
may
allow
specification
designers
to
Dirk
define
a
versioning
strategy
that
their
choice
would
be
impractical
at
the
scale
of
the
Web.
As
part
of
defining
an
extensibility
strategy
mechanism,
specification
designers
should
set
expectations
about
agent
behavior
in
conjunction
with
their
namespace
policy
allows
certain
changes
that
do
not
affect
conformance
the
face
of
existing
content
and
software,
and
thus
no
change
to
unrecognized
extensions.
Good
practice:
Unknown
extensions
A
specification
SHOULD
specify
agent
behavior
in
the
namespace
identifier
face
of
unrecognized
extensions.
Two
strategies
have
emerged
as
being
particularly
useful:
-
"Must
ignore":
The
agent
ignores
any
content
it
does
not
recognize.
-
"Must
understand":
The
agent
treats
unrecognized
markup
as
an
error
condition.
A
powerful
design
approach
is
required.
They
chose
this
policy
for
the
language
to
help
them
meet
their
goals
allow
either
form
of
reducing
extension,
but
to
distinguish
explicitly
between
them
in
the
cost
of
change.
syntax.
deleted text:
</div>
</div>
Dirk
Additional
strategies
include
prompting
the
user
for
more
input,
automatically
retrieving
data
from
available
links,
and
Nadia
have
chosen
falling
back
to
default
behavior.
More
complex
strategies
are
also
possible,
including
mixing
strategies.
For
instance,
a
particular
namespace
change
policy
that
allows
them
language
can
include
mechanisms
for
overriding
standard
behavior.
Thus,
a
data
format
can
specify
"must
ignore"
semantics
but
also
allow
people
to
avoid
changing
the
namespace
name
whenever
they
make
changes
create
extensions
that
do
not
affect
conformance
of
deployed
content
and
software.
They
might
have
chosen
override
that
semantics
in
light
of
application
needs
(for
instance,
with
"must
understand"
semantics
for
a
different
policy,
particular
extension).
Extensibility
is
not
free.
Providing
hooks
for
example
that
any
new
element
or
attribute
has
to
belong
extensibility
is
one
of
many
requirements
to
a
namespace
other
than
be
factored
into
the
original
one.
Whatever
costs
of
language
design.
Experience
suggests
that
the
chosen
policy,
it
should
set
clear
expectations
for
users
long
term
benefits
of
extensibility
generally
outweigh
the
format.
costs.
<div class="boxedtext">
<p>
<span class="practicelab">
Good
practice:
<a name="pr-doc-ns-policy" id="pr-doc-ns-policy" shape="rect">
Namespace
policy
4.2.4.
Composition
of
Data
Formats
</span>
</p>
<p class="practice">
Format
designers
SHOULD
document
change
policies
Many
modern
data
format
include
mechanisms
for
XML
namespaces.
composition.
For
example:
</div>
<p>
As
an
example
of
a
change
policy
designed
-
It
is
possible
to
reflect
the
variable
stability
of
a
namespace,
consider
embed
text
comments
in
some
image
formats,
such
as
JPEG/JFIF.
Although
these
comments
are
embedded
in
the
<a href="http://www.w3.org/1999/10/nsuri" shape="rect">
W3C
namespace
policy
</a>
for
documents
containing
data,
they
have
little
or
no
effect
on
the
W3C
Recommendation
track.
The
policy
sets
expectations
that
the
Working
Group
responsible
for
display
of
the
namespace
may
modify
it
in
any
way
until
image.
-
There
are
container
formats
such
as
SOAP
which
fully
expect
to
be
composed
from
multiple
namespaces
but
which
provide
an
overall
semantic
relationship
of
message
envelope
and
payload.
-
RDF
allows
well-defined
mixing
of
vocabularies,
and
allows
text
and
XML
to
be
used
as
a
data
type
values
within
a
statement
having
clearly
defined
semantics.
These
relationships
can
be
mixed
and
nested
arbitrarily.
In
principle,
a
certain
point
in
the
process
("Candidate
Recommendation")
at
SOAP
message
can
contain
an
SVG
image
that
contains
an
RDF
comment
which
point
W3C
constrains
the
set
possible
changes
refers
to
a
vocabulary
of
terms
for
describing
the
namespace
in
order
to
promote
stable
implementations.
image.
Note
however,
that
deleted text:
since
namespace
names
are
URIs,
the
party
(if
any)
responsible
for
general
XML
there
is
no
semantic
model
that
defines
the
interactions
within
XML
documents
with
elements
and/or
attributes
from
a
variety
of
namespaces.
Each
application
must
define
how
namespaces
interact
and
what
effect
the
namespace
URI
of
an
element
has
on
the
authority
to
decide
the
namespace
change
policy.
element's
ancestors,
siblings,
and
descendants.
See
TAG
issues
mixedUIXMLNamespace-33
,
xmlFunctions-34
,
and
RDFinXHTML-35
.
<h4>
4.2.3.
<a name="extensibility" id="extensibility" shape="rect">
Extensibility
Designers
can
facilitate
the
transition
process
by
making
careful
choices
about
extensibility
during
the
design
of
The
Web
is
a
language
or
protocol
specification.
</p>
<div class="boxedtext">
<p>
<span class="practicelab">
Good
practice:
<a name="pr-allow-exts" id="pr-allow-exts" shape="rect">
Extensibility
mechanisms
</a>
</span>
</p>
<p class="practice">
Language
designers
SHOULD
heterogeneous
environment
where
a
wide
variety
of
agents
provide
mechanisms
that
allow
any
party
access
to
create
extensions
that
do
not
interfere
with
conformance
content
to
the
original
specification.
</p>
</div>
<p>
Application
needs
determine
the
most
appropriate
extension
strategy
for
users
with
a
specification.
For
example,
applications
designed
wide
variety
of
capabilities.
It
is
good
practice
for
authors
to
operate
in
closed
environments
create
content
that
can
reach
the
widest
possible
audience,
including
users
with
graphical
desktop
computers,
hand-held
devices
and
mobile
phones,
users
with
disabilities
who
may
allow
specification
require
speech
synthesizers,
and
devices
not
yet
imagined.
Furthermore,
authors
to
define
a
versioning
strategy
cannot
predict
in
some
cases
how
an
agent
will
display
or
process
their
content.
Experience
shows
that
deleted text:
would
be
impractical
at
the
scale
separation
of
content,
presentation,
and
interaction
promotes
the
Web.
As
part
reuse
and
device-independence
of
defining
an
extensibility
mechanism,
a
specification
should
set
expectations
about
agent
behavior
in
content;
his
follows
from
the
face
principle
of
unrecognized
extensions.
independent
specifications
.
For
more
information
about
principles
of
device-independence,
see
[
DIPRINCIPLES
].
Good
practice:
<a name="pr-unknown-extension" id="pr-unknown-extension" shape="rect">
Unknown
extensions
Separation
of
content,
presentation,
interaction
deleted text:
Language
designers
SHOULD
specify
agent
behavior
in
the
face
of
unrecognized
extensions.
</p>
</div>
<p>
Two
strategies
have
emerged
as
being
particularly
useful:
</p>
<ol>
<li>
"Must
ignore":
The
agent
ignores
any
content
it
does
not
recognize.
</li>
<li>
"Must
understand":
The
agent
treats
unrecognized
markup
as
an
error
condition.
</li>
</ol>
<p>
A
powerful
design
approach
is
for
the
language
to
allow
either
form
of
extension,
but
to
distinguish
explicitly
between
them
in
the
syntax.
</p>
<p>
Additional
strategies
include
prompting
the
user
for
more
input,
automatically
retrieving
data
from
available
links,
and
falling
back
to
default
behavior.
More
complex
strategies
are
also
possible,
including
mixing
strategies.
For
instance,
a
language
can
include
mechanisms
for
overriding
standard
behavior.
Thus,
a
data
format
can
specify
"must
ignore"
semantics
but
also
allow
people
to
create
extensions
that
override
that
semantics
in
light
of
application
needs
(for
instance,
with
"must
understand"
semantics
for
a
particular
extension).
specification
SHOULD
allow
authors
to
separate
content
from
both
presentation
and
interaction
concerns.
Extensibility
is
not
free.
Providing
hooks
for
extensibility
Note
that
when
content,
presentation,
and
interaction
are
separated
by
design,
agents
need
to
recombine
them.
There
is
a
recombination
spectrum,
with
"client
does
all"
at
one
of
many
requirements
end
and
"server
does
all"
at
the
other.
There
are
advantages
to
be
factored
into
each:
recombination
on
the
costs
server
allows
the
server
to
send
out
generally
smaller
amounts
of
language
design.
Experience
suggests
data
that
can
be
tailored
to
specific
devices
(such
as
mobile
phones).
However,
such
data
will
not
be
readily
reusable
by
other
clients
and
may
not
allow
client-side
agents
to
perform
useful
tasks
unanticipated
by
the
long
term
benefits
of
extensibility
generally
outweigh
author.
When
a
client
does
the
costs.
</p>
</div>
<div class="section">
<h4>
4.2.4.
<a name="composition" id="composition" shape="rect">
Composition
work
of
Data
Formats
</a>
</h4>
<p>
Many
modern
data
format
specifications
include
mechanisms
for
composition.
For
example:
</p>
<ul>
<li>
It
recombination,
content
is
possible
likely
to
embed
text
comments
in
some
image
formats,
be
more
reusable
by
a
broader
audience
and
more
robust.
However,
such
as
JPEG/JFIF.
Although
these
comments
are
embedded
in
data
may
be
of
greater
size
and
may
require
more
computation
by
the
containing
data,
they
have
little
or
no
effect
on
client.
Of
course,
it
may
not
always
be
desirable
to
reach
the
display
of
widest
possible
audience.
Designers
should
consider
appropriate
technologies
for
limiting
the
image.
</li>
<li>
There
audience.
For
instance
digital
signature
technology,
access
control
,
and
other
technologies
are
appropriate
for
controlling
access
to
content.
Some
data
formats
are
container
designed
to
describe
presentation
(including
SVG
and
XSL
Formatting
Objects).
Data
formats
such
as
SOAP
which
fully
expect
to
be
composed
these
demonstrate
that
one
can
only
separate
content
from
multiple
namespaces
but
which
provide
an
overall
semantic
relationship
of
message
envelope
and
payload.
</li>
<li>
RDF
allows
well-defined
mixing
of
vocabularies,
and
allows
text
and
XML
presentation
(or
interaction)
so
far;
at
some
point
it
becomes
necessary
to
be
used
as
a
talk
about
presentation.
Per
the
principle
of
independent
specifications,
these
data
type
values
within
a
statement
having
clearly
defined
semantics.
</li>
</ul>
formats
should
only
address
presentation
issues.
These
relationships
can
be
mixed
See
the
TAG
issues
formattingProperties-19
and
nested
arbitrarily.
In
principle,
a
SOAP
message
can
contain
a
JPEG
image
contentPresentation-26
.
A
defining
characteristic
of
the
Web
is
that
contains
an
RDF
comment
which
refers
it
allows
embedded
references
to
a
vocabulary
other
resources
via
URIs.
The
simplicity
of
terms
creating
links
using
absolute
URIs
(
<a
href="http://www.example.com/foo">
)
and
relative
URI
references
(
<a
href="foo">
and
<a
href="foo#anchor">
)
is
partly
(perhaps
largely)
responsible
for
deleted text:
describing
the
image.
birth
of
the
hypertext
Web
as
we
know
it
today.
Note
however,
that
for
general
XML
there
is
no
semantic
model
that
defines
the
interactions
within
XML
documents
When
one
resource
(representation)
refers
to
another
resource
with
deleted text:
elements
and/or
attributes
from
a
variety
of
namespaces.
Each
application
must
define
how
namespaces
interact
and
what
effect
URI,
this
constitutes
a
link
between
the
namespace
two
resources.
Additional
metadata
may
also
form
part
of
deleted text:
an
element
has
on
the
element's
ancestors,
siblings,
and
descendants.
link
(see
[
XLink10
],
for
example).
See
TAG
issues
<a href="http://www.w3.org/2001/tag/ilist#mixedUIXMLNamespace-33" shape="rect">
mixedUIXMLNamespace-33
</a>,
<a href="http://www.w3.org/2001/tag/ilist#xmlFunctions-34" shape="rect">
xmlFunctions-34
</a>,
Good
practice:
Link
mechanisms
A
specification
SHOULD
provide
mechanisms
for
identifying
links
to
other
resources
and
<a href="http://www.w3.org/2001/tag/ilist#RDFinXHTML-35" shape="rect">
RDFinXHTML-35
</a>.
to
portions
of
representation
data
(via
fragment
identifiers).
</div>
<div class="section">
<h3>
4.3.
<a name="pci" id="pci" shape="rect">
Separation
of
Content,
Presentation,
and
Interaction
Good
practice:
Web
linking
</h3>
A
specification
SHOULD
provide
mechanisms
that
allow
Web-wide
linking,
not
just
internal
document
linking.
The
Web
is
a
heterogeneous
environment
where
Good
practice:
Generic
URIs
A
specification
SHOULD
allow
content
authors
to
use
URIs
without
constraining
them
to
a
wide
variety
limited
set
of
URI
schemes.
What
agents
provide
access
to
content
to
users
do
with
a
wide
variety
of
capabilities.
It
hypertext
link
is
good
practice
for
authors
to
create
content
that
can
reach
the
widest
possible
audience,
including
users
with
graphical
desktop
computers,
hand-held
devices
not
constrained
by
Web
architecture
and
deleted text:
cell
phones,
users
with
disabilities
who
may
require
speech
synthesizers,
and
devices
not
yet
imagined.
Furthermore,
authors
cannot
predict
in
some
cases
how
an
agent
will
display
or
process
their
content.
Experience
shows
depend
on
application
context.
Users
of
hypertext
links
expect
to
be
able
to
navigate
links
among
representations.
Data
formats
that
the
allowing
do
not
allow
content
authors
to
separate
content,
presentation,
and
interaction
concerns
promotes
reuse
and
device-independence
(see
[
<a href="#DIPRINCIPLES" shape="rect">
DIPRINCIPLES
</a>
]);
this
follows
from
create
hypertext
links
lead
to
the
<a href="#orthogonal-specs" shape="rect">
principle
of
orthogonal
creation
of
specifications
</a>.
"terminal
nodes"
on
the
Web.
Good
practice:
<a name="cpi" id="cpi" shape="rect">
Separation
of
content,
presentation,
interaction
Hypertext
links
Language
designers
A
data
format
SHOULD
design
formats
that
allow
authors
to
separate
content
from
presentation
and
interaction
concerns.
incorporate
hypertext
links
if
hypertext
is
the
expected
user
interface
paradigm.
Note
that
when
content,
presentation,
and
interaction
are
separated
by
design,
agents
need
to
recombine
them.
There
is
a
recombination
spectrum,
with
"client
does
all"
at
one
end
and
"server
does
all"
at
the
other.
There
Links
are
advantages
to
each:
recombination
on
the
server
allows
the
server
to
send
out
generally
smaller
amounts
commonly
expressed
using
URI
references
(defined
in
section
4.2
of
data
that
can
be
tailored
to
specific
devices
(such
as
mobile
phones).
However,
such
data
will
not
be
readily
reusable
by
other
clients
and
[
URI
]),
which
may
not
allow
client-side
agents
to
perform
useful
tasks
unanticipated
by
the
author.
When
be
combined
with
a
client
does
the
work
of
recombination,
content
is
likely
base
URI
to
be
more
reusable
by
yield
a
broader
audience
and
more
robust.
However,
such
data
may
be
usable
URI.
Section
5.1
of
greater
size
[
URI
]
explains
different
mechanisms
for
establishing
a
base
URI
for
a
resource
and
may
require
more
computation
by
establishes
a
precedence
among
the
client.
</p>
<p>
Of
course,
it
may
not
always
be
desirable
to
reach
various
mechanisms.
For
instance,
the
widest
possible
audience.
Application
context
base
URI
may
require
a
very
specific
display
(for
be
a
legally-binding
transaction,
URI
for
example).
Also,
digital
signature
technology,
<a href="#id-access" shape="rect">
access
control
</a>,
the
resource,
or
specified
in
a
representation
(see
the
base
elements
provided
by
HTML
and
other
technologies
are
appropriate
for
controlling
access
to
content.
XML,
and
the
HTTP
'Content-Location'
header).
See
also
the
section
on
links
in
XML
.
Some
data
formats
are
designed
Agents
resolve
a
URI
reference
before
using
the
resulting
URI
to
describe
presentation
(including
SVG
and
XSL
Formatting
Objects).
Data
formats
such
as
these
demonstrate
that
one
can
only
separate
interact
with
another
agent.
URI
references
help
in
content
from
presentation
(or
interaction)
so
far;
at
some
point
it
becomes
necessary
management
by
allowing
content
authors
to
design
a
representation
locally,
i.e.,
without
concern
for
which
global
identifier
may
later
be
used
to
refer
to
deleted text:
talk
about
presentation.
Per
the
principle
of
orthogonal
specifications,
these
data
formats
should
<em>
only
</em>
address
presentation
issues.
</p>
<p>
See
the
TAG
issues
<a href="http://www.w3.org/2001/tag/ilist#formattingProperties-19" shape="rect">
formattingProperties-19
</a>
and
<a href="http://www.w3.org/2001/tag/ilist#contentPresentation-26" shape="rect">
contentPresentation-26
</a>.
associated
resource.
4.4.
<a name="hypertext" id="hypertext" shape="rect">
Hypertext
4.5.
XML-Based
Data
Formats
A
defining
characteristic
Many
data
formats
are
XML-based
,
that
is
to
say
they
conform
to
the
syntax
rules
defined
in
the
XML
specification
[XML10]
.
This
section
discusses
issues
that
are
specific
to
such
formats.
Anyone
seeking
guidance
in
this
area
is
urged
to
consult
the
"Guidelines
For
the
Use
of
XML
in
IETF
Protocols"
[IETFXML]
,
which
contains
a
thorough
discussion
of
the
Web
is
considerations
that
govern
whether
or
not
XML
ought
to
be
used,
as
well
as
specific
guidelines
on
how
it
allows
embedded
references
ought
to
other
Web
resources
via
URIs.
The
simplicity
of
creating
links
using
absolute
URIs
(
<code>
<a
href="http://www.example.com/foo">
</code>
)
and
relative
URI
references
(
<code>
<a
href="foo">
</code>
and
<code>
<a
href="foo#anchor">
</code>
)
be
used.
While
it
is
partly
(perhaps
largely)
responsible
for
the
birth
of
directed
at
Internet
applications
with
specific
reference
to
protocols,
the
hypertext
discussion
is
generally
applicable
to
Web
scenarios
as
we
know
it
today.
well.
When
one
resource
(representation)
refers
The
discussion
here
should
be
seen
as
ancillary
to
deleted text:
another
resource
with
a
URI,
this
constitutes
a
<a name="def-link" id="def-link">
<dfn>
link
</dfn>
</a>
between
the
two
resources.
Additional
metadata
may
also
form
part
content
of
the
link
(see
[
<a href="#XLink10" shape="rect">
XLink10
[IETFXML]
.
Refer
also
to
"XML
Accessibility
Guidelines"
[XAG]
deleted text:
],
for
example).
help
designing
XML
formats
that
lower
barriers
to
Web
accessibility
for
people
with
disabilities.
<div class="boxedtext">
<p>
<span class="practicelab">
Good
practice:
<a name="link-mechanism" id="link-mechanism" shape="rect">
Link
mechanisms
XML
defines
textual
data
formats
that
are
naturally
suited
to
describing
data
objects
which
are
hierarchical
and
processed
in
a
chosen
sequence.
It
is
widely,
but
not
universally,
applicable
for
data
formats;
an
audio
or
video
format,
for
example,
is
unlikely
to
be
well
suited
to
expression
in
XML.
Design
constraints
that
would
suggest
the
use
of
XML
include:
<p class="practice">
Language
designers
SHOULD
provide
mechanisms
-
Requirement
for
identifying
links
a
hierarchical
structure.
-
The
data's
usefulness
should
outlive
the
tools
currently
used
to
other
resources
and
process
it
(though
obviously
XML
can
be
used
for
short-term
needs
as
well).
-
Ability
to
portions
support
internationalization
in
a
self-describing
way
that
makes
confusion
over
coding
options
unlikely.
-
Early
detection
of
representation
encoding
errors
with
no
requirement
to
"work
around"
such
errors.
-
A
high
proportion
of
human-readable
textual
content.
-
Potential
composition
of
the
data
(via
fragment
identifiers).
</p>
format
with
other
XML-encoded
formats.
<div class="boxedtext">
<p>
<span class="practicelab">
Good
practice:
<a name="web-linking" id="web-linking" shape="rect">
Web
linking
4.5.2.
Links
in
XML
</span>
</p>
<p class="practice">
Language
designers
SHOULD
provide
Sophisticated
linking
mechanisms
have
been
invented
for
XML
formats.
XPointer
allows
links
to
address
content
that
allow
Web-wide
linking,
does
not
just
internal
document
linking.
</p>
</div>
<div class="boxedtext">
<p>
<span class="practicelab">
Good
practice:
<a name="generic-uri" id="generic-uri" shape="rect">
Generic
URIs
</a>
</span>
</p>
<p class="practice">
Language
designers
SHOULD
allow
authors
to
use
URIs
without
constraining
them
to
a
limited
set
of
URI
schemes.
</p>
</div>
<p>
What
agents
do
with
a
hypertext
link
have
an
explicit,
named
anchor.
XLink
is
not
constrained
by
Web
architecture
and
may
depend
on
application
context.
Users
of
the
an
appropriate
specification
for
representing
links
in
hypertext
XML
applications.
XLink
allows
links
deleted text:
expect
to
be
able
to
navigate
links
among
representations.
Data
formats
that
do
not
allow
authors
have
multiple
ends
and
to
create
hypertext
links
lead
be
expressed
either
inline
or
in
"link
bases"
stored
external
to
the
creation
any
or
all
of
deleted text:
"terminal
nodes"
on
the
Web.
</p>
<div class="boxedtext">
<p>
<span class="practicelab">
Good
practice:
<a name="use-hypertext-links" id="use-hypertext-links" shape="rect">
Hypertext
resources
identified
by
the
links
</a>
</span>
it
contains.
<p class="practice">
Language
designers
SHOULD
incorporate
hypertext
links
into
a
data
format
if
hypertext
is
Designers
of
XML-based
formats
should
consider
using
XLink
and,
for
defining
fragment
identifier
syntax,
using
the
expected
user
interface
paradigm.
XPointer
framework
and
XPointer
element()
Schemes.
See
TAG
issue
xlinkScope-23
.
4.4.1.
<a name="uri-refs" id="uri-refs" shape="rect">
URI
References
4.5.3.
XML
Namespaces
deleted text:
Links
are
commonly
expressed
using
<a name="uriref" id="uriref">
<dfn>
URI
references
</dfn>
Story
</a>
(defined
in
section
4.2
of
[
<a href="#URI" shape="rect">
URI
</a>
]),
which
may
be
combined
with
a
base
URI
to
yield
a
usable
URI.
Section
5.1
of
[
<a href="#URI" shape="rect">
URI
</a>
]
explains
different
mechanisms
for
establishing
a
base
URI
for
a
resource
and
establishes
a
precedence
among
the
various
mechanisms.
For
instance,
the
base
URI
may
be
a
URI
The
authority
responsible
for
the
resource,
or
specified
in
a
representation
(see
the
<code>
base
</code>
elements
provided
"weather.example.com"
realizes
that
it
can
provide
more
interesting
representations
by
HTML
and
XML,
and
the
HTTP
'Content-Location'
header).
See
also
the
section
on
<a href="#xml-links" shape="rect">
links
creating
instances
that
consist
of
elements
defined
in
XML
</a>.
different
XML-based
formats
,
such
as
XHTML,
SVG,
and
MathML.
Agents
resolve
a
URI
reference
before
using
How
can
one
ensure
that
there
are
no
naming
conflicts
when
elements
from
different
XML-based
data
formats
are
mixed?
For
example,
suppose
that
one
designer
defines
the
resulting
URI
para
element
in
an
XML
format
to
interact
with
identify
paragraphs,
and
another
agent.
URI
references
help
designer
defines
the
para
element
in
content
management
by
allowing
authors
a
second
format
to
design
identify
parachutes.
"Namespaces
in
XML"
[
XMLNS
]
provides
a
representation
locally,
i.e.,
without
concern
mechanism
for
which
establishing
globally
unique
names.
Specification
designers
who
declare
namespaces
thus
provide
a
global
identifier
may
later
be
used
context
for
instances
of
the
data
format.
Establishing
this
global
context
allows
those
instances
(and
portions
thereof)
to
refer
be
re-used
and
combined
in
novel
ways
not
yet
imagined.
Failure
to
the
associated
resource.
provide
a
namespace
makes
such
re-use
more
difficult,
perhaps
impractical
in
some
cases.
</div>
</div>
<div class="section">
<h3>
4.5.
<a id="xml-formats" name="xml-formats" shape="rect">
XML-Based
Data
Formats
Good
practice:
Namespace
adoption
</h3>
A
specification
that
establishes
an
XML
vocabulary
SHOULD
place
all
element
names
and
global
attribute
names
in
a
namespace.
Many
data
formats
Attributes
are
<a name="xml-based" id="xml-based">
<dfn>
XML-based
</dfn>
</a>,
always
scoped
by
the
element
on
which
they
appear.
An
attribute
that
is
to
say
they
conform
to
the
syntax
rules
defined
"global,"
that
is,
one
that
might
meaningfully
appear
on
elements
of
any
type,
including
elements
in
other
namespaces,
should
be
explicitly
placed
in
a
namespace.
Local
attributes,
ones
associated
with
only
a
particular
element
type,
need
not
be
included
in
a
namespace
since
their
meaning
will
always
be
clear
from
the
XML
specification
<a href="#XML10" shape="rect">
[XML10]
</a>.
This
section
discusses
issues
that
are
specific
to
such
formats.
Anyone
seeking
guidance
context
provided
by
that
element.
The
xsi:type
attribute,
provided
by
W3C
XML
Schema
for
use
in
this
area
XML
instance
documents,
is
urged
an
example
of
a
global
attribute.
It
can
be
used
by
authors
of
any
vocabulary
to
consult
the
"Guidelines
For
make
an
assertion
in
instance
data
about
the
Use
type
of
XML
in
IETF
Protocols"
<a href="#IETFXML" shape="rect">
[IETFXML]
</a>,
the
element
on
which
contains
a
thorough
discussion
of
it
appears.
The
type
attribute
occurs
in
the
considerations
that
govern
whether
or
not
W3C
XML
ought
to
Schema
namespace
"http://www.w3.org/2001/XMLSchema"
and
must
always
be
used,
as
well
as
specific
guidelines
fully
qualified.
The
frame
attribute
on
how
it
ought
to
be
used.
While
it
an
HTML
table
is
directed
at
Internet
applications
with
specific
reference
to
protocols,
an
example
of
a
local
attribute.
There
is
no
value
in
placing
that
attribute
in
a
namespace
since
the
discussion
attribute
is
generally
applicable
unlikely
to
Web
scenarios
as
well.
be
useful
on
an
element
other
than
an
HTML
table.
The
discussion
here
should
be
seen
as
ancillary
to
Applications
that
rely
on
DTD
processing
must
impose
additional
constraints
on
the
content
use
of
<a href="#IETFXML" shape="rect">
[IETFXML]
</a>.
Refer
also
to
"XML
Accessibility
Guidelines"
<a href="#XAG" shape="rect">
[XAG]
namespaces.
DTDs
perform
validation
based
on
the
lexical
form
of
the
element
and
attribute
names
in
the
document.
This
makes
prefixes
syntactically
significant
in
ways
that
are
not
anticipated
by
[
XMLNS
for
help
designing
].
Story
Nadia
receives
representation
data
from
"weather.example.com"
in
an
unfamiliar
data
format.
She
knows
enough
about
XML
deleted text:
formats
that
lower
barriers
to
Web
accessibility
for
people
with
disabilities.
</p>
<div class="section">
<h4>
4.5.1.
<a name="xml-when" id="xml-when" shape="rect">
When
recognize
which
XML
namespace
the
elements
belong
to.
Since
the
namespace
is
identified
by
the
URI
"http://weather.example.com/2003/format",
she
asks
her
browser
to
Use
an
XML-Based
Format
</a>
retrieve
a
representation
of
the
namespace
via
that
URI;
this
is
called
a
</h4>
.
XML
defines
textual
Nadia
gets
back
some
useful
data
deleted text:
formats
that
are
naturally
suited
allows
her
to
describing
learn
more
about
the
data
objects
which
are
hierarchical
and
processed
in
format.
Nadia's
browser
may
also
be
able
to
perform
some
operations
automatically
(i.e.,
unattended
by
a
chosen
sequence.
It
is
widely,
but
not
universally,
applicable
for
human
overseer)
given
data
format
specifications;
an
audio
or
video
format,
that
has
been
optimized
for
software
agents.
For
example,
is
unlikely
to
be
well
suited
her
browser
might,
on
Nadia's
behalf,
download
additional
agents
to
expression
in
XML.
Design
constraints
that
would
suggest
process
and
render
the
use
of
XML
include:
format.
<ol>
<li>
Requirement
for
There
are
many
reasons
to
provide
information
about
a
hierarchical
structure.
namespace.
A
person
might
want
to:
-
understand
its
purpose,
-
The
data's
usefulness
should
outlive
learn
how
to
use
the
tools
currently
used
markup
vocabulary
in
the
namespace,
-
find
out
who
controls
it,
-
request
authority
to
process
it
(though
obviously
XML
can
access
schemas
or
collateral
material
about
it,
or
-
report
a
bug
or
situation
that
could
be
used
for
short-term
needs
as
well).
considered
an
error
in
some
collateral
material.
A
processor
might
want
to:
-
Ability
to
support
internationalization
in
retrieve
a
self-describing
way
that
makes
confusion
over
coding
options
unlikely.
schema,
for
validation,
-
Early
detection
of
encoding
errors
with
no
requirement
to
"work
around"
such
errors.
retrieve
a
style
sheet,
for
presentation,
or
-
A
high
proportion
of
human-readable
textual
content.
retrieve
ontologies,
for
making
inferences.
<li>
Potential
composition
of
the
In
general,
there
is
no
established
best
practice
for
creating
a
namespace
representation.
Application
expectations
will
influence
what
data
format
with
other
XML-encoded
formats.
</li>
</ol>
</div>
<div class="section">
<h4>
4.5.2.
<a name="xml-links" id="xml-links" shape="rect">
Links
or
formats
are
used
to
create
a
namespace
representation.
Application
expectations
will
also
influence
whether
relevant
information
appears
in
XML
the
namespace
representation
itself
or
is
referenced
from
it.
Good
practice:
Namespace
representations
</h4>
<p>
Sophisticated
linking
mechanisms
have
been
invented
for
XML
formats.
XPointer
allows
links
to
address
content
that
does
not
have
an
explicit,
named
anchor.
XLink
is
The
owner
of
an
deleted text:
appropriate
specification
for
representing
links
in
<a href="#hypertext" shape="rect">
hypertext
</a>
XML
applications.
XLink
allows
links
namespace
name
SHOULD
make
available
material
intended
for
people
to
have
multiple
ends
read
and
to
be
expressed
either
inline
or
material
optimized
for
software
agents
in
"link
bases"
stored
external
order
to
any
or
all
meet
the
needs
of
those
who
will
use
the
resources
identified
namespace
vocabulary.
When
a
namespace
representation
is
provided
by
the
links
it
contains.
namespace
URI
owner,
that
material
is
authoritative.
Designers
For
example,
the
following
are
examples
of
formats
used
to
create
namespace
representations:
[
OWL10
],
[
RDDL
],
[
XMLSCHEMA
],
and
[
XHTML11
].
Each
of
XML-based
these
formats
should
consider
using
XLink
and,
meets
different
requirements
described
above
for
defining
fragment
identifier
syntax,
using
satisfying
the
XPointer
framework
needs
of
an
agent
that
wants
more
information
about
the
namespace.
Note,
however,
issues
related
to
fragment
identifiers
and
XPointer
element()
Schemes.
multiple
representations
if
content
negotiation
is
used
with
namespace
representations.
See
TAG
issue
<a href="http://www.w3.org/2001/tag/ilist#xlinkScope-23" shape="rect">
xlinkScope-23
issues
namespaceDocument-8
and
abstractComponentRefs-37
.
deleted text:
<div class="boxedtext">
<p>
<span class="storylab">
Story
</span>
</p>
<div class="story">
The
authority
responsible
Section
3
of
"Namespaces
in
XML"
[
XMLNS
]
provides
a
syntactic
construct
known
as
a
QName
for
"weather.example.com"
realizes
that
it
can
provide
more
interesting
representations
by
creating
instances
that
consist
the
compact
expression
of
elements
defined
qualified
names
in
different
<a href="#xml-based" shape="rect">
XML-based
formats
</a>,
such
XML
documents.
A
qualified
name
is
a
pair
consisting
of
a
URI,
which
names
a
namespace,
and
a
local
name
placed
within
that
namespace.
"Namespaces
in
XML"
provides
for
the
use
of
QNames
as
XHTML,
SVG,
names
for
XML
elements
and
MathML.
attributes.
deleted text:
</div>
</div>
How
do
the
application
designers
ensure
that
there
are
no
naming
conflicts
when
they
combine
elements
from
different
formats
(for
example,
suppose
that
Other
specifications,
starting
with
[
XSLT10
],
have
employed
the
"p"
idea
of
using
QNames
in
contexts
other
than
element
is
defined
and
attribute
names,
for
example
in
two
or
more
attribute
values
and
in
element
content.
However,
general
XML
formats)?
"Namespaces
processors
cannot
reliably
recognize
QNames
as
such
when
they
are
used
in
XML"
[
<a href="#XMLNS" shape="rect">
XMLNS
</a>
]
provides
a
mechanism
for
establishing
a
globally
unique
name
that
can
be
understood
attribute
values
and
in
any
context.
</p>
<p>
Language
specification
designers
that
declare
namespaces
thus
provide
a
global
context
element
content;
for
instances
of
example,
the
data
format.
Establishing
this
global
context
allows
those
instances
(and
portions
thereof)
to
be
re-used
and
combined
in
novel
ways
not
yet
imagined.
Failure
syntax
of
QNames
overlaps
with
that
of
URIs.
Experience
has
also
revealed
other
limitations
to
provide
a
namespace
makes
QNames,
such
re-use
more
difficult,
perhaps
impractical
in
some
cases.
as
losing
namespace
bindings
after
XML
canonicalization.
Good
practice:
<a name="use-namespaces" id="use-namespaces" shape="rect">
Namespace
adoption
QNames
Indistinguishable
from
URIs
Language
designers
who
create
new
XML
vocabularies
A
specification
in
which
QNames
represent
URI/local-name
pairs
SHOULD
place
all
element
names
NOT
allow
both
Qnames
and
global
attribute
names
URIs
in
a
namespace.
</p>
</div>
<p>
Attributes
are
always
scoped
by
the
attribute
values
or
element
on
which
content,
where
they
appear.
An
attribute
that
is
"global,"
that
is,
one
that
might
meaningfully
appear
on
different
elements,
including
elements
in
other
namespaces,
should
be
explicitly
placed
in
a
namespace.
Local
attributes,
ones
associated
with
only
a
particular
element,
need
not
be
included
in
a
namespace
since
their
meaning
will
always
would
be
clear
from
the
context
provided
by
that
element.
indistinguishable.
The
<code>
type
</code>
attribute
from
W3C
XML
Schema
is
an
example
of
a
global
attribute.
It
can
be
used
by
authors
of
any
vocabulary
to
make
an
assertion
about
the
type
of
For
more
information,
see
the
element
on
which
it
appears.
The
<code>
type
</code>
attribute
occurs
TAG
finding
"
Using
QNames
as
Identifiers
in
Content
"
.
Because
QNames
are
compact,
some
specification
designers
have
adopted
the
W3C
XML
Schema
namespace
and
must
always
be
fully
qualified.
The
<code>
frame
</code>
attribute
on
an
HTML
table
is
an
example
same
syntax
as
a
means
of
identifying
resources.
Though
convenient
as
a
local
attribute.
shorthand
notation,
this
usage
has
a
cost.
There
is
no
value
in
placing
that
attribute
in
single,
accepted
way
to
convert
a
namespace
since
QName
into
a
URI
or
vice
versa.
Although
QNames
are
convenient,
they
do
not
replace
the
attribute
is
unlikely
to
be
useful
on
an
element
other
than
an
HTML
table.
</p>
<p>
Applications
that
rely
on
DTD
processing
must
impose
additional
constraints
on
URI
as
the
use
identification
mechanism
of
deleted text:
namespaces.
DTDs
perform
validation
based
on
the
lexical
form
Web.
The
use
of
the
element
and
attribute
names
in
the
document.
This
makes
prefixes
syntactically
significant
in
ways
that
are
not
anticipated
by
[
<a href="#XMLNS" shape="rect">
XMLNS
</a>
].
QNames
to
identify
Web
resources
without
providing
a
mapping
to
URIs
is
inconsistent
with
Web
architecture.
deleted text:
</div>
<div class="section">
<h4>
4.5.4.
<a name="namespace-documents" id="namespace-documents" shape="rect">
Namespace
Documents
</a>
</h4>
<span class="storylab">
Story
Good
practice:
QName
Mapping
<div class="story">
<p>
Nadia
receives
a
representation
data
from
"weather.example.com"
A
specification
in
deleted text:
an
unfamiliar
data
format.
She
knows
enough
about
XML
to
recognize
which
QNames
serve
as
resource
identifiers
MUST
provide
a
mapping
to
URIs.
For
examples
of
QName-to-URI
mappings,
see
[
RDF10
].
See
also
TAG
issues
rdfmsQnameUriMapping-6
,
qnameAsId-18
,
and
abstractComponentRefs-37
.
Consider
the
URI
"http://weather.example.com/2003/format",
she
asks
her
browser
to
retrieve
a
representation
following
fragment
of
XML:
<section
name="foo">
.
Does
the
namespace
via
that
URI.
Nadia
is
requesting
section
element
have
what
the
<a name="def-namespace-document" id="def-namespace-document">
<dfn>
namespace
document
</dfn>
</a>.
</p>
<p>
Nadia
gets
back
some
useful
data
that
allows
her
XML
Recommendation
refers
to
learn
more
about
as
the
data
format.
Nadia's
browser
may
also
be
able
to
perform
some
operations
automatically
(i.e.,
unattended
ID
foo
?
One
cannot
answer
this
question
by
a
human
overseer)
given
data
that
has
been
optimized
for
software
agents.
For
example,
her
browser
might,
on
Nadia's
behalf,
download
additional
agents
to
process
examining
the
element
and
render
its
attributes
alone.
In
XML,
the
format.
</p>
</div>
</div>
<p>
There
are
many
reasons
to
provide
information
about
quality
of
"being
an
ID"
is
associated
with
the
type
of
an
attribute,
not
its
name.
Finding
the
IDs
in
a
namespace.
A
person
might
want
to:
document
requires
additional
processing.
<ul>
<li>
understand
its
purpose,
</li>
-
learn
how
to
use
Processing
the
markup
vocabulary
in
document
with
a
processor
that
recognizes
DTD
attribute
list
declarations
(in
the
namespace,
</li>
<li>
find
out
who
controls
it,
</li>
<li>
request
authority
to
access
schemas
or
collateral
material
about
it,
external
or
</li>
<li>
report
internal
subset)
might
reveal
a
bug
or
situation
declaration
that
could
be
considered
identifies
the
name
attribute
as
an
error
in
some
collateral
material.
</li>
</ul>
<p>
ID.
Note:
This
processing
is
not
necessarily
part
of
validation.
A
non-validating,
DTD-aware
processor
might
want
to:
</p>
<ul>
<li>
retrieve
a
schema,
for
validation,
can
perform
ID
assignment.
-
retrieve
Processing
the
document
with
a
style
sheet,
for
presentation,
or
W3C
XML
schema
might
reveal
an
element
declaration
that
identifies
the
name
attribute
as
an
xs:ID
.
-
deleted text:
retrieve
ontologies,
for
making
inferences.
</li>
</ul>
<p>
In
general,
there
is
no
established
best
practice
for
creating
a
namespace
document.
Application
expectations
will
influence
what
data
format
or
formats
are
used
to
create
a
namespace
document.
Application
expectations
will
also
influence
whether
relevant
information
appears
in
practice,
processing
the
deleted text:
namespace
document
itself
or
is
referenced
from
it.
</p>
<div class="boxedtext">
<p>
<span class="practicelab">
Good
practice:
<a name="namespace-docs" id="namespace-docs" shape="rect">
Namespace
documents
with
another
schema
language,
such
as
RELAX
NG
[
RELAXNG
</span>
</p>
<p class="practice">
Resource
owners
who
publish
an
XML
namespace
name
SHOULD
make
available
material
intended
for
people
to
read
and
material
optimized
for
software
agents
in
order
to
meet
],
might
reveal
the
needs
attributes
declared
to
be
of
those
who
will
use
ID
in
the
namespace
vocabulary.
</p>
</div>
<p>
For
example,
XML
Schema
sense.
Many
modern
specifications
begin
processing
XML
at
the
following
are
examples
of
formats
used
to
create
namespace
documents:
[
<a href="#OWL10" shape="rect">
OWL10
</a>
],
Infoset
[
<a href="#RDDL" shape="rect">
RDDL
INFOSET
],
]
level
and
do
not
specify
normatively
how
an
Infoset
is
constructed.
For
those
specifications,
any
process
that
establishes
the
ID
type
in
the
Infoset
(and
Post
Schema
Validation
Infoset
(
PSVI
)
defined
in
[
XMLSCHEMA
],
and
[
<a href="#XHTML11" shape="rect">
XHTML11
</a>
].
Each
])
may
usefully
identify
the
attributes
of
these
formats
meets
different
requirements
described
above
type
ID.
-
In
practice,
applications
may
have
independent
means
of
specifying
ID-ness
as
provided
for
satisfying
and
specified
in
the
needs
of
an
agent
XPointer
specification.
To
further
complicate
matters,
DTDs
establish
the
ID
type
in
the
Infoset
whereas
W3C
XML
Schema
produces
a
PSVI
but
does
not
modify
the
original
Infoset.
This
leaves
open
the
possibility
that
wants
more
information
about
a
processor
might
only
look
in
the
namespace.
Note,
however,
issues
related
to
<a href="#frag-multiple-reps" shape="rect">
fragment
identifiers
Infoset
and
multiple
representations
</a>
if
content
negotiation
is
used
with
namespace
documents.
consequently
would
fail
to
recognize
schema-assigned
IDs.
The
TAG
expects
to
continue
to
work
with
other
groups
to
help
resolve
open
questions
about
establishing
"ID-ness"
in
XML
formats.
See
TAG
issues
<a href="http://www.w3.org/2001/tag/ilist#namespaceDocument-8" shape="rect">
namespaceDocument-8
</a>
and
<a href="http://www.w3.org/2001/tag/ilist.html#abstractComponentRefs-37" shape="rect">
abstractComponentRefs-37
issue
xmlIDSemantics-32
.
4.5.5.
<a name="xml-qnames" id="xml-qnames" shape="rect">
QNames
in
4.5.7.
Media
Types
for
XML
Section
3
of
"Namespaces
in
XML"
[
<a href="#XMLNS" shape="rect">
XMLNS
</a>
]
provides
a
syntactic
construct
known
as
a
QName
for
the
compact
expression
of
qualified
names
in
XML
documents.
A
qualified
name
is
a
pair
consisting
of
a
URI,
which
names
a
namespace,
and
a
local
name
placed
within
that
namespace.
"Namespaces
in
XML"
provides
for
RFC
3023
defines
the
use
of
QNames
as
names
for
XML
elements
Internet
media
types
"application/xml"
and
attributes.
</p>
<p>
Other
specifications,
starting
with
[
<a href="#XSLT10" shape="rect">
XSLT10
</a>
],
have
employed
the
idea
of
using
QNames
in
contexts
other
than
element
"text/xml",
and
attribute
names,
describes
a
convention
whereby
XML-based
data
formats
use
Internet
media
types
with
a
"+xml"
suffix,
for
example
in
attribute
values
and
in
element
content.
However,
general
XML
processors
cannot
recognize
QNames
"image/svg+xml".
These
Internet
media
types
create
two
problems:
First,
for
data
identified
as
such
when
they
are
used
in
attribute
values
and
in
element
content;
they
"text/*",
Web
intermediaries
are
indistinguishable
from
URIs.
Experience
has
also
revealed
other
limitations
allowed
to
QNames,
such
as
losing
namespace
bindings
after
XML
canonicalization.
"transcode",
i.e.,
convert
one
character
encoding
to
another.
Transcoding
may
make
the
self-description
false
or
may
cause
the
document
to
be
not
well-formed.
Good
practice:
<a name="qname-uri-syntax" id="qname-uri-syntax" shape="rect">
QNames
Indistinguishable
from
URIs
XML
and
"text/*"
Specifications
that
use
QNames
to
represent
URI/local-name
pairs
In
general,
a
representation
provider
SHOULD
NOT
allow
both
forms
in
attribute
values
or
element
content
where
they
would
be
indistinguishable
from
URIs.
assign
Internet
media
types
beginning
with
"text/"
to
XML
representations.
For
more
information,
see
Second,
representations
whose
Internet
media
types
begin
with
"text/"
are
required,
unless
the
TAG
finding
<cite>
"
<a href="http://www.w3.org/2001/tag/doc/qnameids.html" shape="rect">
Using
QNames
as
Identifiers
charset
parameter
is
specified,
to
be
considered
to
be
encoded
in
Content
</a>
"
</cite>.
</p>
<p>
Because
QNames
are
compact,
some
specifications
have
adopted
US-ASCII.
Since
the
deleted text:
same
syntax
deleted text:
as
a
means
of
identifying
Web
resources.
Though
convenient
as
a
shorthand
notation,
this
usage
has
a
cost.
There
XML
is
no
single,
accepted
way
designed
to
convert
a
QName
into
a
URI
or
vice-versa.
Although
QNames
are
convenient,
they
do
not
replace
the
URI
as
make
documents
self-describing,
it
is
good
practice
to
omit
the
identification
mechanism
of
charset
parameter,
and
since
XML
is
very
often
not
encoded
in
US-ASCII,
the
deleted text:
Web.
The
use
of
QNames
to
identify
Web
resources
without
providing
a
mapping
to
URIs
is
inconsistent
with
Web
architecture.
"text/"
Internet
media
types
effectively
precludes
this
good
practice.
Good
practice:
<a name="qname-mapping" id="qname-mapping" shape="rect">
QName
Mapping
XML
and
character
encodings
deleted text:
Language
designers
who
use
QNames
as
identifiers
of
Web
resources
MUST
provide
a
mapping
to
URIs.
</p>
</div>
<p>
For
examples
of
QName-to-URI
mappings,
see
[
<a href="#RDF10" shape="rect">
RDF10
</a>
].
See
also
TAG
issues
<a href="http://www.w3.org/2001/tag/ilist" shape="rect">
rdfmsQnameUriMapping-6
</a>,
<a href="http://www.w3.org/2001/tag/ilist#qnameAsId-18" shape="rect">
qnameAsId-18
</a>,
and
<a href="http://www.w3.org/2001/tag/ilist.html#abstractComponentRefs-37" shape="rect">
abstractComponentRefs-37
</a>.
</p>
</div>
<div class="section">
<h4>
4.5.6.
<a name="xml-id-semantics" id="xml-id-semantics" shape="rect">
XML
ID
Semantics
</a>
</h4>
<p>
Consider
the
following
fragment
of
XML:
<code>
<section
name="foo">
</code>.
Does
the
<code>
section
</code>
element
have
the
ID
"foo"?
One
cannot
answer
this
question
by
examining
the
element
and
its
attributes
alone.
In
XML,
the
quality
of
"being
an
ID"
is
associated
with
the
type
of
the
attribute,
not
its
name.
Finding
the
IDs
in
a
document
requires
additional
processing.
</p>
<ol>
<li>
Processing
the
document
with
a
processor
that
recognizes
DTD
attribute
list
declarations
(in
the
external
or
internal
subset)
might
reveal
a
declaration
that
identifies
the
name
attribute
as
an
ID.
<strong>
Note:
</strong>
This
processing
is
not
necessarily
part
of
validation.
A
non-validating,
DTD-aware
processor
can
perform
ID
assignment.
</li>
<li>
Processing
the
document
with
general,
a
W3C
XML
Schema
might
reveal
an
element
declaration
that
identifies
the
name
attribute
as
an
<code>
xs:ID
</code>.
</li>
<li>
In
practice,
processing
representation
provider
SHOULD
NOT
specify
the
document
with
another
schema
language,
such
as
RELAX
NG
[
<a href="#RELAXNG" shape="rect">
RELAXNG
character
encoding
for
XML
data
in
protocol
headers
since
the
data
is
self-describing.
The
section
on
media
types
and
fragment
identifier
semantics
discusses
the
attributes
interpretation
of
type
ID.
Many
modern
specifications
begin
processing
XML
at
fragment
identifiers.
Designers
of
an
XML-based
data
format
specification
should
define
the
Infoset
semantics
of
fragment
identifiers
in
that
format.
The
XPointer
Framework
[
<a href="#INFOSET" shape="rect">
INFOSET
XPTRFR
]
level
and
do
not
specify
normatively
how
provides
an
Infoset
is
constructed.
For
those
specifications,
any
process
that
establishes
interoperable
starting
point.
When
the
ID
media
type
in
the
Infoset
(and
Post
Schema
Validation
Infoset
(
<acronym>
PSVI
</acronym>
)
assigned
to
representation
data
is
"application/xml",
there
are
no
semantics
defined
for
fragment
identifiers,
and
authors
should
not
make
use
of
fragment
identifiers
in
[
<a href="#XMLSCHEMA" shape="rect">
XMLSCHEMA
</a>
])
may
usefully
identify
such
data.
The
same
is
true
if
the
attributes
of
assigned
media
type
ID.
</li>
</ol>
<p>
To
further
complicate
matters,
DTDs
establish
has
the
ID
type
suffix
"+xml"
(defined
in
"XML
Media
Types"
[
RFC3023
]),
and
the
Infoset
whereas
W3C
data
format
specification
does
not
specify
fragment
identifier
semantics.
In
short,
just
knowing
that
content
is
XML
deleted text:
Schema
produces
a
PSVI
but
does
not
modify
provide
information
about
fragment
identifier
semantics.
Many
people
assume
that
the
original
Infoset.
This
leaves
open
fragment
identifier
#abc
,
when
referring
to
XML
data,
identifies
the
possibility
that
a
processor
might
only
look
element
in
the
Infoset
and
consequently
would
fail
to
recognize
schema-assigned
IDs.
document
with
the
ID
"abc".
However,
there
is
no
normative
support
for
this
assumption.
See
TAG
issue
<a href="http://www.w3.org/2001/tag/issues.html#xmlIDSemantics-32" shape="rect">
xmlIDSemantics-32
fragmentInXML-28
.