

Library Linked Data Incubator Group: Datasets, Value Vocabularies, and Metadata Element Sets
W3C Incubator Group Report 25 October 2011
- This Version:
- http://www.w3.org/2005/Incubator/lld/XGR-lld-vocabdataset-20111025/
- Latest Published Version:
- http://www.w3.org/2005/Incubator/lld/XGR-lld-vocabdataset/
- Authors
- Antoine Isaac, Europeana and Vrije Universiteit Amsterdam, Netherlands
- William Waites, University of Edinburgh (School of Informatics), UK
- Jeff Young, OCLC Online Computer Library Center, Inc., US
- Marcia Zeng, Kent State University, US (W3C Invited Expert)
See also translations.
Copyright © 2011 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply.
Abstract
The mission of the W3C Library Linked Data Incubator Group, chartered from May 2010 through August 2011, has been "to help increase global interoperability of library data on the Web, by bringing together people involved in Semantic Web activities — focusing on Linked Data — in the library community and beyond, building on existing initiatives, and identifying collaboration tracks for the future." In Linked Data, data is expressed using standards such as the Resource Description Framework (RDF), which specifies relationships between things, and Uniform Resource Identifiers (URIs, or "Web addresses").
This report on datasets, value vocabularies and metadata elements sets is a complement to the main report of the group. Based on the data gathered in the use cases and with additions from the expert group, this document provides a summary of the current state of Linked Data building blocks, in particular those most related to library Linked Data efforts.
Status of This Document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of Final Incubator Group Reports is available. See also the W3C technical reports index at http://www.w3.org/TR/.
Publication of this document by W3C as part of the W3C Incubator Activity indicates no endorsement of its content by W3C, nor that W3C has, is, or will be allocating any resources to the issues addressed by it. Participation in Incubator Groups and publication of Incubator Group Reports at the W3C site are benefits of W3C Membership.
Incubator Groups have as a goal to produce work that can be implemented on a Royalty Free basis, as defined in the W3C Patent Policy. Participants in this Incubator Group have agreed to offer licenses according to the licensing requirements of the W3C Patent Policy for portions of this Incubator Group Report that are subsequently incorporated in a W3C Recommendation.
Table of Contents
1 Introduction: Scope and Definitions
This document, a deliverable from the W3C Library Linked Data Incubator Group, is an attempt to identify a set of useful resources for creating or consuming Linked Data in the library domain. It is intended both for novices seeking an overview of the library Linked Data domain, and for experts in search of a quick look-up or refresher. The final report of the Incubator Group suggests that the success of Linked Data in any domain depends on the ability of its practitioners to identify, re-use, or connect to already available datasets and data models. Library Linked Data is not an exception. Such an identification effort is crucial given the complexity and variety of library data resources, many of them already available as Linked Data at the time of writing this report. We hope that this document will help those who undertake such tasks.
This document also aims to provide the Linked Data community with an opportunity to understand the specific viewpoint, resources, and terminology used by the library community for their data, while helping Library and Information Science professionals to get a grasp of the Linked Data concepts corresponding to their own traditions. In previous library terminology explanation efforts, we have identified the following types of resources of interest, which are not mutually exclusive (as becomes evident later in the document):
- Datasets: In this report we focus on datasets as collections of structured metadata — descriptions of things, such as books in a library. The equivalent of a dataset in the library world is a collection of library records. Library records consist of statements about things, where each statement consists of an element ("attribute" or "relationship") of the entity, and a "value" for that element. The elements that are used are usually selected from a set of standard elements, such as MARC21 or Dublin Core (DC). The values for the elements are either taken from value vocabularies such as the
Library of Congress Subject Headings (LCSH), or are free text values. Similar concepts to "dataset" include "collection" or "metadata record set". Note that in the Linked Data context, datasets do not necessarily consist of clearly identifiable "records". They are merely a consistent set of triples that can be queried or downloaded from a specific point, without making a strict distinction between metadata and data. We expect this view to impact the way the library community conceives of its own data, as it creates or re-uses Resource Description Framework (RDF) vocabularies with domain and range settings and documentation that conforms to best practices. In addition, as more application cases emerge in which "traditional" descriptive metadata is being used together with other types of data, library data will probably take on a very different form.
Examples:
- a record from a dataset for a given book could have a subject element drawn from Dublin Core, and a value for subject drawn from LCSH.
- the same dataset may contain records for authors as first-class entities that are linked from their book, and described with elements like "name" from Friend of a Friend (FOAF).
- a dataset may be self-describing in that it contains information about itself as a distinct entity, for example by including date modified and maintainer/curator elements drawn from Dublin Core.
- Value vocabularies: A value vocabulary defines resources (such as instances of topics, art styles, or authors) that are used as values for elements in metadata records. Typically a value vocabulary does not define bibliographic resources such as books but rather concepts related to bibliographic resources (persons, languages, countries, etc.). They are "building blocks" with which metadata records can be populated. Many libraries mandate specific vocabularies for selecting values for a particular metadata element. A value vocabulary thus represents a controlled list of allowed values for an element. Examples include: thesauri, code lists, term lists, classification schemes, subject heading lists, taxonomies, authority files, digital gazetteers, concept schemes, and other types of knowledge organization systems. To be useful for linking of data, value vocabularies should have Hypertext Transfer Protocol (HTTP) Uniform Resource Identifiers (URIs) assigned for each value; these URIs would then appear in a metadata record instead of or in addition to the literal value.
Examples:
- Metadata element sets or element sets: A metadata element set defines classes and attributes used to describe entities of interest. In Linked Data terminology, such element sets are generally made concrete through RDF Schemas or OWL Web Ontology Language ontologies, the term "RDF vocabulary" often being used as an umbrella for these. Usually a metadata element set does not describe bibliographic entities, rather it provides elements to be used by others to describe such entities.
Examples:
- Dublin Core defines elements such as Creator and Date (but DC does not define bibliographic records that use those elements).
- Functional Requirements for Bibliographic Records (FRBR) defines entities such as Work and Manifestation, and elements that link and describe them. RDA: Resource Description and Access (RDA) defines elements for cataloging, based on the FRBR model.
- MARC21 defines elements (fields) to describe bibliographic records and authorities.
- FOAF defines elements to describe people that could be used for describing authors.
This report is intended as an entry point for practitioners to find, understand, and explore some examples of metadata element sets, value vocabularies, and datasets. It is primarily based on the cases the Incubator Group has gathered. We do not aim here to provide a complete list of the various resources related to the (library) Linked Data "cloud". We hope this report will prove to be an inspirational complement to more complete listing tools such as Semantic Web search engines (like Sindice or Falcons), other surveys such as the Linked Open Vocabularies survey, or registries such as the Open Metadata Registry, Schemapedia or the Data Hub. We of course encourage our readers to also use these, just as we did ourselves for the Data Hub registry.
2 Library Linked Data at the Data Hub
The Data Hub is a registry for data. It is a site where people can share information about data "packages" of all types and collaboratively describe them. Although the Data Hub registry is not itself a Linked Data service, there is a Linked Data version of the information it contains. Much of the data described in the Data Hub is in Linked Data form.
The Data Hub organizes data packages as groups that are curated by a community. It is used to maintain information about membership in the wider LOD Cloud as well as the subset that pertains to library Linked Data — which includes both library datasets and value vocabularies as defined above. The curators of these groups have arrived at a set of conventions for using the tagging facilities in the Data Hub to describe packages that are to be included. This documentation, listed below, includes information about size of data, example resources and access methods (e.g., SPARQL Protocol and RDF Query Language (SPARQL) endpoints) and, crucially, links to other data packages. See:
Adding a new package to the Data Hub aids its visibility: this is a frequently consulted list of packages. Following the conventions of the LOD Cloud and Library Linked Data groups ensures that its relationships to other packages are documented and that it will be counted as part of the growing Linked Data corpus. Datasets listed here will appear in diagrams and visualizations that are produced as part of the study of Linked Data. Having data documented consistently means that we can build tools to gain a greater understanding of their nature and how they fit together. While interesting in itself, this process is important because this kind of understanding makes it easier to determine whether a particular data package is suitable or appropriate for a given task, thus making the data easier to use.
To illustrate an example of the results of this process, consider the diagram below:
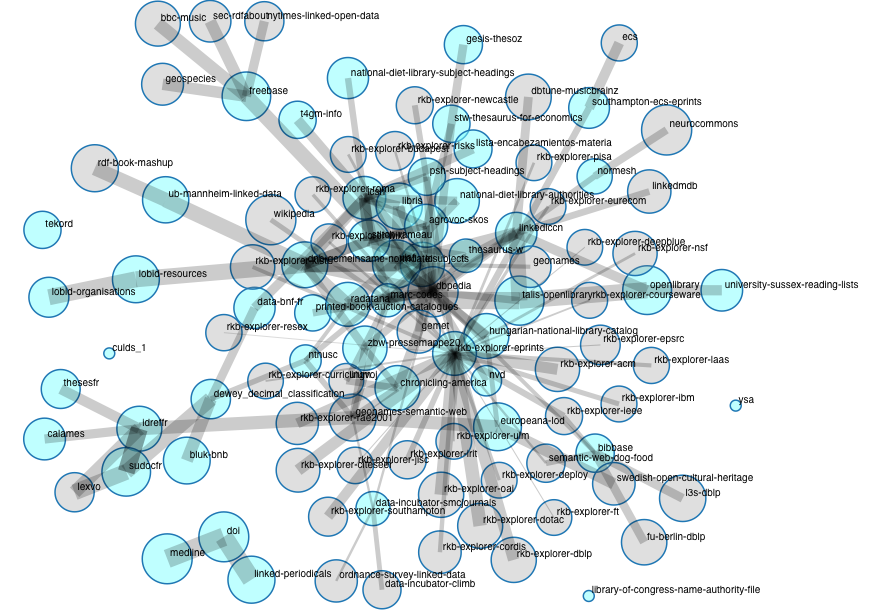
For an updated snapshot, see: http://semantic.ckan.net/group/?group=http://ckan.net/group/lld
The brightly colored circles represent the packages that are part of the Data Hub Library Linked Data group. They grey circles represent packages that are connected to but are not members of this group (they typically are members of the Data Hub Linked Open Data Cloud group). The size of the circles and the thickness of the lines are related to the size of the data and the number of outward links (scaled logarithmically) respectively.
This graphic is generated automatically, on the basis of an algorithm, and represents the state of the Data Hub Library Linked Data group at the time this report is published. It has already changed significantly since the beginning of our work, and will surely look different in the near future. For instance, at the time of this writing the Library of Congress Name Authority File has only recently been published and appears to be unconnected on the periphery, but this is likely to change in the coming months.
The graphic demonstrates the difficulty of rendering a complex and evolving web of links, given the Linked Open Data cloud's current explosive growth. However, it is immediately apparent that there are some densely connected clusters of packages in library Linked Data, and that many are actually connected through data sets that are not from libraries, with DBpedia and GeoNames figuring prominently. It is also clear that linking to other data outside of the central points is quite common: it is not only the hubs that are useful.
3 Published Datasets
The present section lists all datasets (mostly bibliographic) that are available on the Library Linked Data group from the Data Hub at the time of the publication of the report. For more information, the reader is invited to follow the links for individual packages.
- BibBase
- BibBase.org facilitates the dissemination of
scientific publications over the Internet.
- British National Bibliography
(BNB)
- British National Bibliography (BNB) published as
Linked Data, linked to external sources including VIAF, LCSH, Lexvo,
GeoNames, MARC country, and language, Dewey.info, RDF Book
Mashup....
- Calames
- Calames is the French academic
union catalog of archives and manuscripts, maintained by ABES.
- Chronicling America
- Chronicling America provides access to information
about historic newspapers and select digitized newspaper pages. It contains
140,000 newspapers and 3.2 million pages.
- Cambridge University Library dataset
#1
- This data marks the first major output of the
COMET project, a JISC-funded collaboration between
Cambridge University Library and CARET.
- data.bnf.fr - Bibliothèque
nationale de France
- data.bnf.fr gathers data from the different
databases of the Bibliothèque nationale de France, so as to create
Web pages about works and authors, together with a RDF view on the
extracted data.
- Scottish
Mountaineering Council Journals Issues 1-36
- Digital
archive of 'Scottish Mountaineering Club Journal Issues 1 to 36,
1890-1901', which was created by Alan Dawson, University of Strathclyde, with funding from the Scottish Mountaineering Trust.
- CrossRef DOI Resolver
- Digital Object Idenfiers (DOI) are a persistent
identifier strategy used by around 3,000 publishers to identify
their documents, mostly scholarly publications.
- Europeana Linked Open Data
- The data.europeana.eu pilot is part of Europeana's
effort of making its metadata available as Linked Open Data
on the Web. It currently serves metadata on 3.5 million items.
- Freebase
- Freebase is an open database of the
world's information. It is built by the community and for the
community — free for anyone to query, contribute to, built
applications on top, or integrate into their websites.
- Hungarian
National Library (NSZL) catalog
- OPAC and Digital Library and the corresponding
authority data as Linked Open Data.
- Linked Periodicals
Database
- The Linked Periodicals Database is a dataset from
the Data Incubator which aggregates journal metadata provided by
CrossRef, Highwire Press, and the National Library of Medicine.
- lobid. Index of libraries
and related organisations
- lobid-organisations provides URIs for
library organizations, based on the existing and
well-established International Standard Identifier for Libraries and
Related Organizations (ISIL).
- lobid. Bibliographic
Resources
- lobid-resources is a service which offers access
to metadata about bibliographic resources (books, articles, pdfs
etc.). Currently there are more than 7 million records.
- medline
- RDF representation of the Medline catalog.
Information about 19 million articles linked to http://dx.doi.org/
with article identifiers and http://crossref.org/ with journal
identifiers.
- NTNU special collections
- The digitized historical manuscripts held in the
special collections of the Norwegian University of Science and
Technology (NTNU).
- The Open Library
- One Web page for every book ever published.
Currently gathers over 20 million records from a variety of large catalogs as well as single contributions.
- English
Language Books listed in Printed Book Auction Catalogs
from 17th Century Holland
- The books are those listed in the English-language
section of Dutch printed book auction catalogs of collections of
scholars and clergy.
- ePrints3 Institutional
Archive Collection (RKBExplorer)
- Linked Data version of a number of ePrints3
archives.
- ECS Southampton
EPrints
- This is live data produced by the EPrints server, which is
distinct from the service
provided by RKB Explorer.
- Sudoc bibliographic data
- Sudoc is the French academic union
catalog, maintained by ABES. It contains 10 million bibliographic
records.
- Open Library data mirror in
the Talis Platform
- Modeled using the JSON data dumps from the Open
Library.
Provides a SPARQL endpoint and OpenSearch interface (with RSS 1.0
output).
- theses.fr
- theses.fr is the french
dissertations search engine, maintained by ABES.
- Linked Data Service
der Universitätsbibliothek Mannheim
- Publishes RDF for a number of bibliographic
resources: Bibliograhic data of the Südwestdeutscher
Bibliotheksverbund, Bibliographic data of the Hessisches Bibliotheksinformationssystem, and others.
- University of
Sussex Reading Lists
- Linked Data version of the resources available through the university's reading-list search engine.
- 20th Century Press
Archives
- More than 30 million documents, mostly press clippings about individual persons, companies and other corporate bodies, products and a wide variety of economics-related topics.
4 Value vocabularies
4.1 Published value vocabularies
This section describes value vocabularies that have been made available as Linked Data or are mentioned as being relevant by one of the Incubator Group's use cases.
Every entry features a brief introduction to the vocabulary, as well as links to their locations. Cases collected by the Incubator Group that refer to the value vocabulary are also listed under each entry.
4.1.1 Classification systems
Dewey Summaries is a suitable data set containing the top classes of Dewey Decimal Classification (DDC) 22. It provides access to the top three levels of the DDC in eleven languages along with access to Abridged Edition 14 (assignable numbers and captions) in three languages.
The Universal Decimal Classification (UDC) is a multilingual classification scheme for all fields of knowledge. The UDC Summary represents a selection of around 2,000 classes extracted from the UDC scheme. [1]
4.1.2 Subject headings/subject authority files
LCSH is a comprehensive list of subject headings published in print and as Linked Data. Subject authority headings can be accessed through the Library of Congress Authoritiesand Vocabularies service.
RAMEAU is a subject heading vocabulary used by the French National Library (BnF). It has been developed starting from the subject heading repository of the Quebec University, being derived itself from the Library of Congress Subject Headings (LCSH). RAMEAU has been published as Linked Data by the TELplus project.
A controlled vocabulary system managed by the German National Library (DNB) in cooperation with various library networks. The inclusion of keywords in the SWD is defined by "Rules for the Keyword Catalogue" (RSWK). [2]
The National Diet Library List of Subject Headings (NDLSH) is a list of subject headings applied to the catalog of the National Diet Library (Japan), including mainly the topical headings and some proper name headings. [3]
4.1.3 Name authority data
VIAF is a joint project of multiple national libraries in the world which virtually combine the name authority files of participating institutions into a single name authority service. As of the date of this report, there are 21 authority files of personal, corporate, and conference names from 18 organizations participating in VIAF. [4]
ULAN is a structured vocabulary containing more than 225,000 names as well as biographical and bibliographic information about artists and architects, including a wealth of variant names, pseudonyms, and language variants.
Although ULAN is not yet published as Linked Data per se, it is included in the VIAF as the Getty Research Institute's contribution.
LC/NAF provides authoritative data for names of persons, organizations, events, places, and titles, with over 8 million descriptions created over multiple decades, according to different cataloging policies. LC Names is officially called the Name Authority Component (NACO) Authority File and is a cooperative effort in which participants follow a common set of standards and guidelines.
The GeoNames geographical database contains over 10 million geographical names and consists of 7.5 million unique features whereof 2.8 million populated places and 5.5 million alternate names. [5]
4.1.4 Thesauri
This thesaurus provides vocabulary on any economic subject. It also covers technical terms used in law, sociology, or politics, and geographic names. [6]
AGROVOC is a multilingual structured and controlled vocabulary published by the Food and Agriculture Organization of the United Nations (FAO). It is designed to cover the terminology of all subject fields in agriculture, forestry, fisheries, food, and related domains (e.g., environment). [7]
Eurovoc is a multilingual, multidisciplinary thesaurus covering the activities of the European Union, the European Parliament in particular. It contains terms in 24 languages (as of the date of this report). [8]
The Library of Congress' Thesaurus for Graphic Materials includes more than 7,000 subject terms to index topic shown or reflected in pictures, and 650 genre/format terms to index types of photographs, prints, design drawings, ephemera, and other categories. [9]
4.1.5 Other controlled vocabularies
A general, cross-domain list of Dublin Core Metadata Initiative (DCMI) approved terms that may be used as values for the resource type element to identify the genre of a resource.
The MARC (MAchine-Readable Cataloging) Relators provide a list of properties for describing the relationship between a name and a bibliographic resource.
PRONOM is the online registry of technical information about the file formats, software products, and other technical components required to support long-term access to electronic records and other digital objects of cultural, historical, or business value. [10]
Creative Commons provides an infrastructure that consists of a set of copyright licenses and tools to create a balance inside the traditional “all rights reserved” setting that copyright law creates. [11]
Preservation vocabularies from LoC
Two main vocabularies are provided. Preservation Events is a concept scheme for the preservation events, i.e., actions performed on digital objects within a preservation repository.
Preservation Level Role is a concept scheme for the preservation level roles, i.e., values that specify in what context a set of preservation options is applicable.
4.1.6 Additional sources
WordNet is a lexical database of English in which nouns, verbs, adjectives, and adverbs are grouped into sets of cognitive synonyms (called "synsets"). Each synset expresses a distinct concept. Synsets are interlinked by means of conceptual-semantic and lexical relations [12]. Wordnet has been published as Linked Data by the Vrije Universiteit Amsterdam.
Freebase (also in datasets)
Freebase is an open, Creative Commons licensed collection of structured data, and a platform for accessing and manipulating that data via the Freebase API. Freebase imports data from a wide variety of open data sources, such as Wikipedia, MusicBrainz, and others [13]. Note that Freebase is essentially a dataset, but its inclusion of many reference resources allows some parts of it to be used as value vocabularies in certain cases.
DBpedia extracts structured information from Wikipedia. The DBpedia data set features labels and abstracts for over three million things, with a half of them classified in an ontology, and contains millions of links to images, external Web pages, and external links to other RDF datasets [14]. Similarly to Freebase, DBpedia can be seen as a general dataset, but some of the entities it describes — places, persons, "categories" — can be used as reference value vocabularies in some cases.
4.2 Work in progress, or relevant for cases but not officially in progress
This thesaurus is used for the subject indexing of the Aquatic Sciences and Fisheries Abstracts (ASFA), an abstracting and indexing service that covers the world's literature on the science, technology, management, and conservation of marine, brackish water, and freshwater resources and environments, including their socio-economic and legal aspects.
The Fisheries Reference Metadata system stores all the classification systems (for species, countries, water areas, commodities, fishing vessels, fishing gears, etc.) used by FAO to describe fisheries observations such as time-series data on fisheries capture and production and species fact sheets.
The Agricultural Thesaurus and Glossary are online vocabulary tools of agricultural terms in English and Spanish provided by the USDA National Agricultural Library (NAL). The subject scope of agriculture is broadly defined in the NAL Agricultural Thesaurus, and includes terminology in the supporting biological, physical, and social sciences. The definitions of terms in the thesaurus were separately published as the Glossary of Agricultural Terms. [15]
A multilingual controlled vocabulary for fine art, architecture, decorative arts, archival materials, and material culture for the purposes of indexing, cataloging, searching, as being a research tool.
A comprehensive controlled vocabulary produced by the National Library of Medicine (NLM) for biomedical and health-related information and documents. Spanish and French MeSH are available as Semantic Web ontologies at BioPortal. The Norwegian translation of MeSH is published as Linked Data by the Norwegian University of Science and Technology. Another version of MeSH, in Simple Knowledge Organization System (SKOS), is available through OCLC Terminology Services.
A classification system for describing and classifying the subject of images represented in various media such as paintings, drawings, and photographs.
A structured, world-coverage vocabulary of over 1.3 million names, including vernacular and historical names, coordinates, place types, and descriptive notes, focusing on places important for the study of art and architecture.
4.3 Other value vocabularies relevant to the Library Linked Data field, not mentioned in the cases
The New York Times uses approximately 30,000 tags to power its Times Topics Pages. These tags (categorized into 'people', 'organization', 'place', and 'descriptor') as published as Linked Data and are mapped to Freebase, DBpedia, and GeoNames.
The MARC List for Countries identifies current national entities, states of the United States, provinces and territories of Canada and Australia, divisions of the United Kingdom, and internationally recognized dependencies. The entries include references to their equivalent ISO 3166 codes.
The MARC List for Languages provides three-character lowercase alphabetic strings that serve as the identifiers of languages and language groups. It have been cross referenced with ISOs 639-1, 639-2, and 639-5, where appropriate.
The MARC List for Geographic Areas identifies separate countries, first order political divisions of some countries, regions, geographic features, areas in outer space, and celestial bodies. The list contains over 550 different codes. [16]
5 Metadata Element Sets
This section lists metadata element sets mentioned in the cases gathered by the Library Linked Data group in 2010-2011. These include some of the most relevant RDF vocabularies for practitioners who want to re-use available Semantic Web technology for creating or converting data from the library domain.
These RDF vocabularies are represented using the constructs offered by the RDF Schema (RDFS) and OWL Web Ontology Language modeling languages. In addition to the documentation provided by its maintainers, an ontology can also be viewed using generic ontology creation and visualization tools such as Protégé, the Manchester ontology browser, OWL Sight or the Live OWL Documentation Environment (LODE) (see for example the Description of a Project (DOAP) ontology rendered in LODE).
For each element set, we give a pointer to a human-readable website and indicate the corresponding RDF namespace, as well as a common prefix abbreviation used for it, using the XML namespace declaration syntax. We also provide or re-use a short description, focused on the main scope or usage domain for the element set. We have sometimes emphasized important design decisions that characterize the element set, including indications on whether the element set is connected to another one, and its relation to traditional library usages. Finally, cases collected by the Incubator Group are also listed under each entry as relevant usage examples.
For illustration purposes, we include a tag cloud rendition of the element sets presented in this section, adapting a site created by Paul Walk:

Note that this tag cloud is a context-specific snapshot of the usage of metadata element sets. In particular, the size of each tag is directly related to the number of individual cases that use it, as gathered by the Library Linked Data Incubator Group. Beyond this analysis based on the Incubator Group cases, Library Linked Data community members should consider helping maintain precise and up-to-date listings of datasets and value vocabularies, such as the Data Hub Library Linked Data group, so that the usage of element sets can be measured. A refined, domain-specific version of the usage statistics for the Linked Open Data Cloud would help the community to develop a clearer idea about which elements sets are widely used and which are less common.
Rendering links between metadata element sets would also be valuable for practitioners willing to re-use data across vocabularies, or to make their data better usable by a wide community. The Upper Mapping and Binding Exchange Layer (UMBEL) constellation has been the first to illustrate connections between classes from popular Linked Data vocabularies. The Linked Open Vocabulary effort generalizes and automatizes the gathering of such information. For a wide range of metadata element sets, e.g., Dublin Core, Linked Open Vocabulary offers a detailed view of the relationships with other element sets, based on the available machine-readable definitions (ontologies).
5.1 Metadata element sets published as RDF vocabularies
This sub-section lists the relevant ontologies (OWL or RDFS) available at the time of writing this report. To help readers orient themselves in our selection, we first introduce metadata element sets that originate from the Libraries, Archives, Museums, and Information communities. We then present relevant element sets, which are rooted in other communities. This categorization is often arbitrary, as many vocabularies already result from cross-community work. We believe, however, that this shows the great potential for the Linked Data approach, where easily sharing, re-using or extending a diversity of element sets independently from their origin is the rule.
Originating from the Libraries, Archives, Museums, and Information communities
The original properties of the Dublin Core Metadata Element Set — fifteen generic property elements for describing information resources — are identified using the namespace http://purl.org/dc/elements/1.1/. Declared as RDF properties in 2000 — before the finalization of RDFS in 2004 — these properties lack defined ranges (rdfs:range), allowing them to be used both with literal values or fully-fledged RDF resources.
A second namespace in the larger set of DCMI Metadata Terms — http://purl.org/dc/terms/ — includes fifteen properties in parallel to the "unrestricted" /elements/1.1/ properties, with added rdfs:range restrictions, plus several dozen additional properties. Interoperability of the "restricted" /terms/ properties with the "unrestricted" /element/1.1/ properties is preserved with sub-property relationships (rdfs:subPropertyOf).
- xmlns:dc="http://purl.org/dc/elements/1.1/"
- xmlns:dcterms="http://purl.org/dc/terms/"
- Usage examples: Enhanced Publications, Publishing 20th Century Press Archives, Data BNF, VIAF, Browsing And Searching In Repositories With Different Thesauri, Pode, Archipel, SEO, LOCAH, Digital Text Repository, Europeana, Migrating Library Legacy Data, Library Address Data, NLL Digitized Map Archive, Collecting material related to courses at The Open University
The Open Archives Initiative Object Reuse and Exchange model define elements to describe aggregations of Web resources, which together form complex digital objects, such as a journal article and its different digital variations and accompanying material. It also proposes a "resource map" mechanism for indicating and describing provenance of metadata on these aggregations, as well as "proxies" to describe any given resource from the perspective of a specific aggregation, when resources are included in different aggregations.
SKOS provides a model for expressing the basic structure and content of concept schemes such as thesauri, classification schemes, subject heading lists, taxonomies, folksonomies, and other similar types of controlled vocabulary [17]. SKOS deliberately avoids providing rdfs:domains with some of its properties (especially labelling and note properties), enabling one to re-use them for any kind of resource.
- xmlns:skos="http://www.w3.org/2004/02/skos/core#"
- Usage examples: Publishing 20th Century Press Archives, Data BNF, LOCAH, Browsing And Searching In Repositories With Different Thesauri, Component Vocabularies, Pode, Subject Search, Europeana, VIAF, AGROVOC Thesaurus, AGRIS, Vocabulary Merging (SKOS mapping), Migrating Library Legacy Data, NLL Digitized Map Archive, Collecting material related to courses at The Open University
SKOS-XL is a SKOS extension that provides support for describing lexical entities attached to concepts. It "reifies" the labels of skos:Concepts, treating them as fully-fledged RDF resources. This allows them to be annotated further, or support linking them using, say, a "isTranslationOf" property.
The MARC Relators vocabulary provides a list of properties for describing the relationship between a name and a bibliographic resource.
The CIDOC object-oriented Conceptual Reference Model (CRM) is developed by the International Council of Museums (ICOM) to represent and make interoperable description of objects from the cultural sector. It makes intensive use of events to link objects, persons, places, and more conceptual notions together.
Alternative OWL-Description Logic (OWL-DL) versions (OWL 1 and 2) are available at http://erlangen-crm.org (namespace: http://erlangen-crm.org/current/) and http://bloody-byte.net/rdf/cidoc-crm/ (namespace: http://purl.org/NET/cidoc-crm/core#).
Dublin Core Collection Description vocabularies
A Task Group of the DCMI Collection Description Community developed a Dublin Core collections application profile and several vocabularies. Its work was based on the Research Support Libraries Programme (RSLP) Collection Description Schema.
Functional Requirements for Bibliographic Records (FRBR) and related ontologies
FRBR is a conceptual reference model developed by the International Federation of Library Associations and Institutions (IFLA) "to provide a (...) framework for relating the data that are recorded in bibliographic records to the needs of users of those records" (FRBR Final Report, sec. 2.1) and for assessing their actual relevance. See more details here.
The IFLA "FRBR family" consists of three conceptual models each covering an aspect of the data recorded in bibliographic and authority records. The entities, attributes, and relationships defined by each of the models are included in the Open Metadata Registry:
The FRBR Final Report describes an entity-relationship model that has been the source of a number of other ontology implementations:
- FaBiO- the FRBR-aligned Bibliographic Ontology
This is a preliminary registration of classes and properties from the International Standard Bibliographic Description (ISBD) consolidated edition. The ISBD (see more explanations here) is useful and applicable for descriptions of bibliographic resources in any type of catalog.
MADS/RDF is designed for use with controlled values for names (personal, corporate, geographic, etc.), thesauri, taxonomies, subject heading systems, and other controlled value lists. The MADS/RDF ontology is mapped to SKOS.
For its Linked Data services, the German National Library has created a namespace that is devoted to detailed description of authority resources (Gemeinsame NormDatei, GND). This set of classes and properties especially refines the possibilities offered by SKOS and the RDA vocabularies.
Originated from other communities
FOAF is a widely used ontology for describing persons and their relationships to other persons and to Web resources.
- xmlns:foaf="http://xmlns.com/foaf/0.1/"
- Usage examples: Enhanced Publications, Data BNF, Pode, SEO, Digital Text Repository, FAO Authority Description Concept Scheme, VIAF, LOCAH, Library Address Data, Open Library Data, Authority Data Enrichment, International Registry for Authors, AGRIS, Collecting material related to courses at The Open University, Talis Prism 3
VoID is an RDF-based schema for describing linked datasets. With VoID the discovery and usage of linked datasets can be performed both effectively and efficiently. A VoID dataset is a collection of data, published and maintained by a single provider, available as RDF, and accessible, for example, through dereferenceable HTTP URIs or a SPARQL endpoint.
BIBO can be used as a citation ontology or document classification ontology, or a way to describe any kind of bibliographic things in RDF.
- xmlns:bibo="http://purl.org/ontology/bibo/"
- Usage examples: Bibliographic Network, LOCAH, Community Information Service, Regional Catalog, Pode, Migrating Library Legacy Data, Talis Prism 3, FAO Authority Description Concept Scheme, AGRISInternational Registry for Authors, NDNP (National Digital Newspaper Program), Collecting material related to courses at The Open University, Collection-Level Description
The Upper Mapping and Binding Exchange Layer (UMBEL) Reference Concepts dataset is derived from the OpenCyc ontology. It includes thousands of coherently structured and linked concepts, and is broadly applicable to provide orienting nodes to any knowledge domain. The UMBEL vocabulary provides classes and properties to describe this conceptual knowledge. It also intended to function as the basis for constructing domain ontologies [18]. It re-uses external vocabularies whenever possible.
- xmlns:umbel="http://umbel.org/umbel#"
- Usage example: VIAF
The vCard ontology enables representing business card profiles defined by vCard (RFC2426).
The name Lexvo is derived from the Ancient Greek λεξικόν (lexicon) and the Latin vocabularium (vocabulary) [19]. The ontology provides a vocabulary for defining global URIs for languages, words, characters, and other human language-related objects.
- xmlns:lvont="http://lexvo.org/ontology#"
- Usage example: Pode
This is a RDF Schema for EXIF — a standard for images that supports mainly technical metadata, usually embedded in an image file (e.g., JPEG file), where each key of the EXIF specification has been directly mapped to a corresponding property. In order to preserve the groupings of metadata keys that is provided in the original EXIF specification (e.g., pixel composition and geo location), other efforts have been reported, such an EXIF OWL ontology [20].
The Open Provenance Model is a generic model to express and share provenance information. It consists of a lightweight Open Provenance Model Vocabulary which enables basic representation of provenance data, and a more expressive Open Provenance Model OWL Specification geared towards inference.
"The Music Ontology Specification provides main concepts and properties for describing music (i.e., artists, albums, and tracks) on the Semantic Web". It applies the FRBR distinctions to the music domain.
- xmlns:mo="http://purl.org/ontology/mo/"
- Usage example: Talis Prism 3
CC REL enables describing copyright licenses in RDF.
- xmlns:cc="http://creativecommons.org/ns#"
- Usage example: SEO
CiTO, one of the SPAR ontologies, is a minimal ontology for describing reference citations in research articles.
Description of a Project (DOAP) is a vocabulary for describing software projects, especially open-source projects.
This small ontology is aimed at representing geo-positioning (latitude, longitude, and altitude) for spatial objects, according to the WGS84 standard.
The SIOC core ontology can be used to describe online communities and their activities (e.g., message boards, wikis, weblogs, etc.).
Schema.org is a set of constructs that allow website designers to include structured metadata in their Web pages, to be consumed by the major search engines Bing, Google, and Yahoo! Schema.org is designed to represent resources from a great diversity of domains. It thus duplicates many elements from other element sets, and fails to capture the richness of library data. However, it can be used to exchange simple information about libraries and the resources they own, as demonstrated in a blog post by Eric Hellman.
- xmlns:schema="http://schema.org/"
- Usage example: SEO
Facebook's Open Graph "protocol" enables the description of resources (movies, books, etc.) that can be of interest to social network members. Its main purpose is to allow websites to include RDFa markup, which is used in combination with the "Like" button to communicate to the Facebook service data about the objects mentioned on web pages.
- xmlns:og="http://ogp.me/ns#"
- Usage example: SEO
The Ontology for Media Resources defines a core set of metadata properties for media resources, along with their mappings to elements from a set of existing metadata formats. It is mainly targeted towards media resources available on the Web, as opposed to resources that are only accessible in local archives or museums.
5.2 Work in progress to make RDF vocabularies available
The General International Standard Archival Description defines the elements that should be included in an archival finding aid.
The Europeana Data Model is a vocabulary aimed at representing metadata for cultural objects and giving access to digital representations of these objects. It is positioned in a data aggregation context, where objects can be complex, and several data providers may entertain different views on them. EDM re-uses, extends or has been inspired by other element sets, notably OAI-ORE, Dublin Core, SKOS, and CIDOC CRM.
EAC-CPF is aimed at representing authoritative information about the context of archival materials, including "the identification and characteristics of the persons, organizations, and families (agents) who have been the creators, users, or subjects of records, as well as the relationships amongst them" [21]. It is a parallel effort to the Encoded Archival Description (EAD) standard for representation of archival finding aids.
A core concept in EAC-CPF is the distinction between agents and identities: a same agent can have different identities, and one identity can correspond to several agents.
MARC (MAchine-Readable Cataloging) has played a crucial role in the creation and exchange of library metadata. An RDF version of the complete MARC21 elements has been published via the Open Metadata Registry as a "basic loss-less way to transition MARC 21 data into RDF." Prior to this, the MarcOnt initiative had created an OWL ontology that includes a small sub-set of MARC elements, related to other ontologies.
- xmlns="http://marc21rdf.info/elements/"
- Usage example: Archipel
PREMIS defines a core set of preservation metadata elements, with a supporting data dictionary, applicable to a broad range of digital preservation activities.
EAD is a standard for encoding archival finding aids using Extensible Markup Language (XML).
Note that the LOCAH element set only handles a part of EAD, and introduces other elements that the LOCAH participants found useful to publish archival collection data as Linked Data. Readers may also be interested in the lightweight Archival vocabulary maintained by Aaron Rubinstein for describing archives and the named entities associated with them.
5.3 Metadata element sets from cases for which no RDF vocabulary is available
Categories for the Description of Works of Art (CDWA) includes 532 categories and subcategories for describing describing and accessing information about works of art, architecture, other material culture, groups and collections of works, and related images. A simpler subset of these elements, CDWA Lite, has been created.
A standard vocabulary for information relating to program information in the professional broadcasting industry.
SPECTRUM is a UK-originated standard for managing museum collections, from descriptive metadata for objects to loan information.
MODS includes a subset of MARC fields and uses language-based tags rather than numeric ones, in some cases regrouping elements from the MARC 21 bibliographic format. MODS is expressed using XML.
The "Guidelines for Electronic Text Encoding and Interchange" is a standard for representing all kinds of literary and linguistic texts for online research and teaching.
5.4 Other metadata element sets (no RDF vocabulary) relevant to the library field, not mentioned in the cases
Visual Resources Association Core Categories (VRA Core) specifies a set of core categories for creating records to describe works of visual culture as well as the images that document them.
- An OWL ontology for VRA Core 3.0 has been created by Mark van Assem for the W3C Semantic Web Best Practices and Deployment Working Group.
PBCore is a metadata standard designed to describe media, both digital and analog. The PBCore XML Schema Definition (XSD) defines the structure and content of PBCore. The element set and related value vocabularies are available at the Open Metadata Registry.
Acknowledgments
Library Linked Data Incubator group members Monica Duke, Ed Summers, and Bernard Vatant provided extensive reviews of this document.
At the time this report is published, the LLD Data Hub group has been maintained by Karen Coyle, Adrian Pohl, Ross Singer, and Lars Svensson, in addition to contributors already acknowledged.
