Publishing Working Group F2F, 1st day — Minutes
Date: 2017-11-06
See also the Agenda and the IRC Log
Attendees
Present: Ivan Herman, Mateus Teixeira, Luc Audrain, Garth Conboy, Leonard Rosenthol, Tzviya Siegman, Dave Cramer, Charles LaPierre, Ben Schroeter, Brady Duga, Chris Maden, Ric Wright, Rachel Comerford, Takeshi Kanai, Laurent Le Meur, George Kerscher, Matt Garrish, Romain Deltour, Reinaldo Ferraz, Benjamin Young, Tim Cole, Cristina Mussinelli, JunGamo, Evan Yamanishi, Marisa DeMeglio, Avneesh Singh, Liisa McCloy-Kelley, Toshiaki Koike, Tess O’Connor, David Wood, Bill McCoy, Lillian Sullam, Hadrien Gardeur, Daniel Weck, Baldur Bjarnason, Dave Cramer, Paul Belfanti
Regrets: Chris Maden
Guests: Dave Browning, Tess O’Connor, Dan Sanicola, Jeff Jaffe, Richard Ishida, Addison Phillips, Fuqiao Xue, Kenneth Rohde Christiansen, Jasmine Mulliken
Chair: Tzviya Siegman, Garth Conboy
Scribe(s): Ric Wright, Brady Duga, Lillian Sullam, Rachel Comerford, Mateus Teixeira, Leonard Rosenthol, Cristina Mussinelli
Content:
Ric Wright: Introductions first
Garth Conboy: Dinner: https://docs.google.com/document/d/1X2BgP5mP1xuwQvT-IK1xNTnsw73wrJB_fdtxbHEOp34/edit
Garth Conboy: Dinner plan is in your email, across the freeway, an easy walk (see link above)
… Room holds 22, please sign up. Everyone needs to kick in $30 Give money to Garth, but be sure to get a receipt!
Tzviya Siegman: welcome everyone. We are going to go over protocols, general plans, etc.
… for tomorrow note that we are swapping the morning and afternoon agendas
Garth Conboy: Dinner location: https://www.fattoriaemare.com/
Garth Conboy: MOVED PUBLISHING WG DINNER TO 7:00p — to make room for folks attend most of the Benetech reception 6:00p to 7:00p at the Hyatt 3SIXTY bar.
1. Work Mode
Tzviya Siegman: https://www.w3.org/publishing/groups/publ-wg/WorkMode/
Tzviya Siegman: same old procedures. Everybody should know the drill. But make sure you are signed up to watch all the repositories on github
… patent policy is the same as always (W3C)
Ivan Herman: We need to be very careful to keep github issues focused so don’t mix issues. If in doubt, open a new issue
… Note that if we get to recommendation point, then if we keep all the issues/repos in good shape we will be better off
… Query: Are there still workflow problems we need to look at
Tim Cole: Bear in mind that we work/interact with other groups, so we need to keep those interactions visible
Ivan Herman: we have a good set of labels for the issues, but if you feel that others are needed, please let Ivan know
George Kerscher: note that more people will be joining the WG, so if we have a guide to help the on-boarding process
Ivan Herman: there is such a “newbie” guide. If anyone sees that anything is wrong or missing there, please generate a PR to correct that
2. FPWD update
Ivan Herman: Just to remind everyone, the first working draft is extremely important. So it is critical that the first draft be clear and precise
Tzviya Siegman: FPWD https://w3c.github.io/wpub/
Ivan Herman: This is especially important as this group is new and there is some concern in other WGs that we may try to “re-invent web”
… this doesn’t mean that we have to solve all the technical issues in the first public draft.
… we need to publish that first public draft by the end of 2017
… the FPWD is also important because it may have patents, implicit or explicit
… we need both the WP and PWP documents, though the latter is likely to be much shorter
… also need a first draft of the EPUB-Aria-2 spec by March
… also we need a FPWD of EPUB4 by end of Q1 2018 (yikes!)
George Kerscher: what are the expectations for the samples that will be in FPWD?
Tzviya Siegman: This is TBD, depending on what the actual content of the FPWD is
Luc Audrain: Perhaps we need to create some of those examples
Ivan Herman: That is a goal but not a requirement for FPWD
Tim Cole: We also are on the hook for a draft on locators. What is the expectation for that?
Ivan Herman: in the charter we wave our hands so it is OK to, for example, to have a separate Locator document
Leonard Rosenthol: Are we going to discuss Locators tomorrow?
Ivan Herman: yes
Tzviya Siegman: Do we think we are on track?
Leonard Rosenthol: yes
Tzviya Siegman: Most of the people in the WG are from the publishing industry. We need to ensure that we garner support from other members/WGs of the W3C
Ivan Herman: This is one of the reasons we need to get the FPWD out, so we can beat the bushes to get that support and input
… Also, we need to reach out to the browser community and try to get participation or at least input from the big 4 browsers
… They have said they are waiting to see the FPWD
David Wood: Has there been preliminary discussions with the browser-folks?
Ivan Herman: We first need indicate what our direction is, i.e. the FPWD THEN it will be time to engage in that conversation
David Wood: I believe that engagement takes a long time so we need to get started
Leonard Rosenthol: +1 on waiting till the FPWD is published
Ivan Herman: The browsers have indicated they are waiting for the FPWD
David Wood: In our experience it took years to get that dialog going and see any fruit (i.e. implementation in the browser)
Luc Audrain: It is important to start testing our proposals against the browsers. This can start the dialog
Ivan Herman: That is correct, this is part of starting the dialog. We have seen this in the CSS WG
Tim Cole: Note that we need to ensure that that the specs are written in such a way that they are testable
Ivan Herman: this is very true, we are still looking for a testing champion
Tzviya Siegman: Yes, this is very important. We need someone to step up
Mateus Teixeira: willing to help but cannot lead the effort
Takeshi Kanai: I would be able to help out but cannot take the lead
Ivan Herman: We really need some one to step up to do this.
… there are some extensive tests in the W3C for testing, but it isn’t clear that this will be sufficient
Tim Cole: One of the aspects we need to pay attention to is to verify that the features we spec are implementable (as opposed to testable)
Benjamin Young: We are not ready to write tests because we don’t have the spec, but we need people who will keep track whether the spec is both implementable and testable
… You don’t need to be a developer for this
Romain Deltour: Do we have any concrete requirements for what the tests will be like? API? Declarative? JS?
Ivan Herman: It is up to us to decide what the testing environment and the tests themselves are like
… The key is that when we get to point of a recommendation, that we have a concrete plan to test the specification
David Wood: In the absence of tests which we don’t have yet we do need to layout a skeletal plan for what those tests might be.
Benjamin Young: +1 to dwood’s thinking here
Tzviya Siegman: Are there existing resources in the W3C to help us in this process?
Ivan Herman: not really. there is a test harness but there are no dedicated resources
… and it is clear that the web-platform tests will not be sufficient
Tzviya Siegman: https://github.com/w3c/web-platform-tests
Laurent Le Meur: EDRLab has no experience in testing a specification. But as EDRLab will implement the spec in Readium, we’ll fully test our implementation of the spec, which is already a good asset.
David Wood: Specifically, I suggested that GitHub issues should be created against spec sections. Further, GitHub tags for the various types of tests (DOM, API, manual, etc) should be added to the issues in order to assist the eventual test coordinator.
Tess O’Connor: I have some experience.
Tzviya Siegman: ac krk
Ric Wright: I am happy to help but can’t commit to leading it. I do have some TIME available, but can’t afford to work for free (my management objects)
3. Lifecycle and Manifests 1
Matt Garrish: https://github.com/w3c/wpub/wiki/Options-for-Processing-a-Manifest
Benjamin Young: We are calling these Bill of Lading
Benjamin Young: well…it’s clearer anyhow :)
Garth Conboy: Or even Waybill
Benjamin Young: garth++ much shorter
Matt Garrish: Questions - if we go with Web App manifest, how does the work withthin what we want in WP
… App itself is self contained
… not true with publications
… web app manifest and WP are different use cases
… web app is installation, WP has pagination, etc, etc
… Can we extend web app manifest for our needs? [WAM here out]
… Use WAM as is, or extend WAM, or make our own thing?
Garth Conboy: This link? https://github.com/w3c/wpub/wiki/Options-for-Processing-a-Manifest
Leonard Rosenthol: @hadrien - IIF? Image operability?
Benjamin Young: +1 Matt!
… WAM doesn’t really manifest anything
Hadrien Gardeur: @leonardr yes
Benjamin Young: points to a URL, and has some stuff about icons.
… We need something bigger, with, say, a Manifest (or Bill of Lading, etc)
Luc Audrain: Waybill : http://www.businessdictionary.com/definition/waybill.html
Benjamin Young: We need a lot more in our manifest
Leonard Rosenthol: One thing we are divided on is whether a pub can also be an app
David Wood: +1 to bigbluehat’s comments. We might also need support for authentication components in the WAM on a per-resource basis.
Leonard Rosenthol: Can the user experience be bundled with the publication itself
Benjamin Young: You can use a WAM to point at a single web page
… They are starting to hook in service workers
Garth Conboy: Seems like a bad direction to allow bundling of publications
Luc Audrain: +1
Garth Conboy: Content can last a long time, but Reading software will stop working
Tzviya Siegman: +1 to garth
Ivan Herman: WAM is registered as an official media type
… browser will have built in behavior for that media type, even if we don’t want it to
… So if a built in behavior conflicts with what we want to do, that can bite us
… We can not tell the browser to not do certain things
Benjamin Young: Web App Manifest (WAM) https://w3c.github.io/manifest/
Ivan Herman: We have a divergence, what do we do?
… . 1) diverge entirely
… 2) ask them to accept we diverge and get them to split the spec
… We could share some data structures, but actual processing diverges.
… Need the WAM people here to help us decide if 2 is a reasonable path forward
Bill McCoy: Bikeshedding on names
… Waybill isn’t publication specific
… find something that expresses structure
Benjamin Young: Table of contents is good!
… Other topic: what happens when a browser sees a Waybill by itself?
Ivan Herman: What does it mean then that there is a claim that several browsers support WAM?
Benjamin Young: The manifest is irrelevant to the browser until the user says “download”
… The presence of download UI is triggered by the reference, not the media type
… WAM and Waybill are very different models
… not sure WAM is ready to have us cram all our stuff in their spec
Tim Cole: typically the trigger is the rel type in the link, e.g.,
Benjamin Young: WAM may be a bad foundation
Romain Deltour: +1 bigbluehat
Hadrien Gardeur: @timCole and the fact that the rel is the trigger is IMO a bug, not a feature of the WAM spec
Ivan Herman: Welcome Kenneth from WAM
Benjamin Young: Summarizing for Kenneth
Luc Audrain: FWIW : https://www.w3.org/TR/appmanifest/
Kenneth Rohde Christiansen,: We try to keep WAM as simple as possible, to avoid adding things we later regret
… using other tech (eg service workers) to provide functionality (like file lists)
Benjamin Young: We want something between appcache and service workers
Garth Conboy: Things in our manifest: metadata, default reading order, list of other resources (not primary), and a fourth one? Which he forgets
Benjamin Young: The Lifecycle section of our spec https://w3c.github.io/wpub/#wp-lifecycle
Ivan Herman: Our view of WAM is, you install something that is an app by itself
… publishing is much more declarative view
… the app part is outside the manifest
Leonard Rosenthol: We disagree
Ivan Herman: Ok, then “not necessarily” included
… our manifest is data, full stop
Kenneth Rohde Christiansen,: WAM has metadata about the app
… like should there be a status bar, etc
… in WAM, pushing as much as possible to service workers
Laurent Le Meur: WP manifest could be a subclass of WAM. But personally, don’t see it that way
… We may have multiple pubs in one app
… many people will want to choose what app to read the pub in (eg a11y case)
… we don’t want to rely on the web, like service workers, since we may not always have the web case (eg reading an book)
Kenneth Rohde Christiansen,: Don’t see a problem using WAM for that
… currently, the manifest points to service worker, but you could point at something else
Benjamin Young: You can do that today, did it for my demo
… Made a service worker that had an html doc that pointed at the actual resources. Then could have a WAM that points at that doc
… doable now, but question is, what is the Bill of Lading? Where does it live? Do we need a service worker?
David Wood: WAMs are a good idea
… We have a need for an app specific purpose, not something that is general purpose
… A little scared by: caching. Have very special needs for that in WP
… we also have reading order
… To get something into WAM, have a publishing section of WAM, or have a special profile of WAM
… either way, we are in a bad place, because we won’t know if a browser that supports WAM supports our specific WAM
… Browser understands WAM, grabs our data, then can’t do anything with it
… Better to have a Waybill specific to us, so we know the browser supports it
Kenneth Rohde Christiansen,: You can specify it so we know what the WAM is [but I missed the details because bigbluehat was messing around]
Tim Cole: One possibility, you can link differently
David Wood: Relying on the browsers to implement whether it supports a specific route or not
Tim Cole: Already has to do that
David Wood: If you have a content type that is unsupported, the default behavior will be different
… browser will know if it supports a type or not
… Different than the link following behavior
Ivan Herman: Is there an expected behavior is a browser has a WAM link?
Kenneth Rohde Christiansen,: If you are adding to home screen then it is defined
Benjamin Young: what Kenneth just described is what we attempted in the HTML First demo https://dauwhe.github.io/html-first/MobyDickNav/index.html
Kenneth Rohde Christiansen,: Likes the link, because browsers could do something different
… like show a book icon
… could have two links, one for the Book, the other for a web app to install a book reader
David Wood: My concern is that the default behaviour of a browser for a WAM might not be appropriate for a WebPub manifest (waybill). Thus, we need a mechanism to differentiate how a browser will react (including in the face of differentiated browser actions/bugs).
Tzviya Siegman: Pubs have lots of metadata
Ivan Herman: Want to make clear what the info is. Some overlaps with WAM, but we have a lot more
… There should also be a property to say, if you want more metadata or “here”
Kenneth Rohde Christiansen,: The only fear I have is if you extend it, it would need prefixes
… To avoid conflict
… Also good to decide if our metadata makes sense in general for WAM to pull it back
Ivan Herman: Say we use the link mechanism, the content of what we refer can be the same as what a WAM refers to?
… content, structure, etc?
Kenneth Rohde Christiansen,: With a WAM, most things are optional
… you would just add some more stuff to it
Ivan Herman: Current WAM, data that is stored is one section, installation is separate section
… can we split this into two specs?
… Since we may not care about installation
Kenneth Rohde Christiansen,: You could also make a new spec
… And say it is a WAM, then say what is different
… just point to the section you care about
… splitting might be confusing
Romain Deltour: We are talking about pubs, and browser behavior, and how it fits with what we want
… thinking about WAM, looking at what is progressive on top of WAM
… has several pubs installed as WAMs
… works great
… now we need to install in another app
… There are some details, like must install in a top level browsing context
… but in general we are not in conflict and we need progressive enhancement
Kenneth Rohde Christiansen,: Browsing contexts are there for security reasons
… . but maybe could relax for pubs
Benjamin Young: Has a demo
… shows relationship between WAM and Bill of Lading and the experience of what happens when you use them
… Bill of Lading is additive to WAM, much larger in scope in various needs (like offlining and sandbox)
Liisa McCloy-Kelley: +1
Tzviya Siegman: Next steps?
… we have a way of working with WAM
… but Marcos said “show us demos!”
Benjamin Young: What we build is orthogonal to WAM
Kenneth Rohde Christiansen,: But we should coordinate
… and we can decide to move some things to WAM
Tim Cole: Tend to agree but concerned the only commonality is there is a list of things
… is that enough to make this reusable?
… Are using most of WAM and adding? Or is it just the manifest we are using? Is it too much of a headache to use WAM?
David Wood: bigbluehat, In your conception, would each publisher define their own service worker?
Ivan Herman: Still wondering about next steps
… We have kept away from putting into specific serialization
Benjamin Young: dwood: I’d hope there’s a browser/reading-system one, but it could potentially be overridden by a publication-specific one (perhaps)
Ivan Herman: wanted to clarify what information we really need for a WP
David Wood: bigbluehat That makes sense to me. Thanks.
Ivan Herman: what would be the next step? Define what have and put it into JSON, then prefix wpub, then look at WAM
… if there is an existing term, then use WAM
… And WAM WG looks at our list and decides to incorporate it
… Then what we have, is it the same media type as WAM?
Kenneth Rohde Christiansen: Depends. If you want both app vs pub installs then different media types, if you don’t care then use the same.
Benjamin Young: That is the distinction. WAM is additive, but our doc is mandatory
… lifecycle needs to be done first
David Wood: +1 to Hadrien, a rel shouldn’t be a different media types. That would be mixing approaches.
Benjamin Young: do I need to visit the about page 3 times before we get the WP reading experience
… If it is something you don’t care about then can reuse WAM type
Kenneth Rohde Christiansen: Not everyone looks at web apps the same way. MS is crawling the web, looking for apps
Benjamin Young: If we need a different UI the first time you enter a WP on the web you get the WP experience, then we need something other than just WAM model
… If not, then WAM is fine
… Basically, is Bill of Lading required or optional?
Kenneth Rohde Christiansen: Could be when you click on the book icon, you just get a new UI. Or it could be you download the book and add it to your library, etc
… nice that it is up to the UA
David Wood: It is “nice” for it to be up to the UA only if the UA is well-behaved.
Benjamin Young: Do you ever check to see if the WAM has changed?
Kenneth Rohde Christiansen: Up to the UA, Chrome checks on occasion
… but not defined
Takeshi Kanai: Concerned about post processing
… when I install thousands of titles, how do I find a specific title?
… For instance, how do we sort by name, etc?
Leonard Rosenthol: Seems like it is up to UA
Kenneth Rohde Christiansen: Seems like this is out of scope for the manifest
Tzviya Siegman: Wrapping up - what now?
Ivan Herman: Don’t want to plan on JSON format for FPWD
… but once we have a draft, how do we work together?
Kenneth Rohde Christiansen: Github, meetings
Ivan Herman: Love github, great for specific issues. But this is a bit higher level
Kenneth Rohde Christiansen: We can have meetings. Not on regular basis, but when we need to
Toshiaki Koike: toshiaki-koike has joined #pwg
Tzviya Siegman: https://w3c.github.io/wpub/#wp-lifecycle
3.1. Flow chart for WPUB, Lifecycle
Ivan Herman: See flow chart image
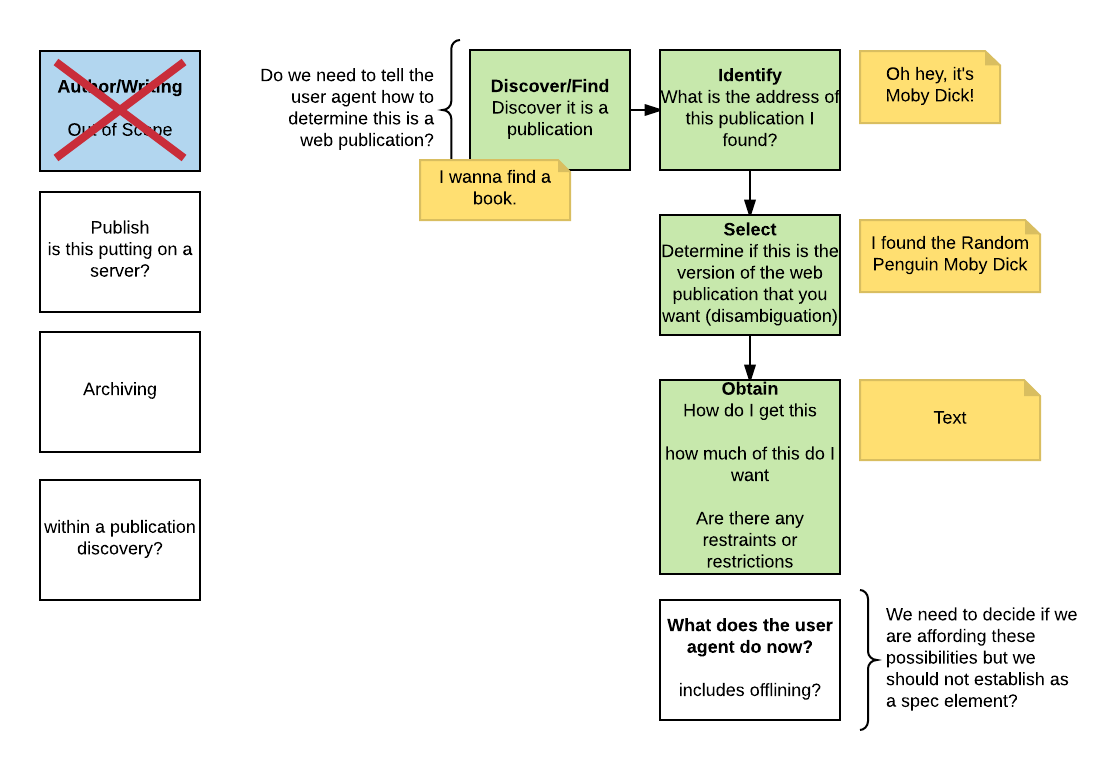{kind=link}
Matt Garrish: differences between web application and how it is launched and instillation
… good basis for moving forward
Benjamin Young: would like to see flow charts for web publication
Rachel Comerford: +1 bigbluehat - I was curious about the same thing
Benjamin Young: something that says this is the web publication on the web, the moment the user sees it, the moment the publication goes offline
… WAM is totally additive, we need to define when a collection of web pages becomes a publication
Leonard Rosenthol: I hear where you’re going Ben and I don’t disagree
… I just want to make sure we don’t jump too far into the user experience
… what is the tipping point from regular web experience to pub experience
Benjamin Young: for annotation we had to imagine user experiences
… some of the life cycle stuff has to need to know what the experience is
… what are those moments and how do we enable those
Matt Garrish: we launched into adapting the web app, pulled back too detailed, now we’re looking at going forward without getting into the technical details
… let’s run through the use cases to get more details
Rachel Comerford: I 100% support what you’re saying
… identifying the key points in the process helps know what the consumer/publisher want
Liisa McCloy-Kelley: are we always thinking about it as predefined
… we could see where someone wants something defined by the publisher, but also when someone would want to define it themselves
Leonard Rosenthol: keep the packaging stuff separate, as long as everything lives in one location, all you’re doing is building a manifest
… you could bundle up anything in a manifest that exists on the web
Tzviya Siegman: we need to define the life cycle events
… ben made a good point that we haven’t defined these moments yet
Rachel Comerford: offers to project
Leonard Rosenthol: whether we think that every web publication should have those things defined…
Tzviya Siegman: keep in mind we’re going to have to describe the things that Rachel is projecting
… we have a few events that we can define, so let’s think about these life cycle events are
… publish is an event
Benjamin Young: it doesn’t really matter if you put it on the web if the user can’t get it
… offlining means that the user can keep it
Tzviya Siegman: print publishing has dates, I don’t want to get there
Liisa McCloy-Kelley: you’re put something out in the universe
Leonard Rosenthol: there is something before you publish and that is you author
Matt Garrish: discovery how does the user agent even know how to find the publication
Ivan Herman: I can’t care about the thing with authoring or publishing
… I don’t a care about the workflow that lead to the point of finding the publication
Benjamin Young: matt do you mean that you are discovering it’s a publication
Ivan Herman: that’s our starting point and what the browser does and what events lead to that situation are irrelevant
Ivan Herman: discovery is done what happens next with the browser
Tzviya Siegman: I think we’re trying to put ourselves in mind of the user agent
… how do we make it a functional piece of the web
Leonard Rosenthol: we should tell the user agent how define one of these things
Benjamin Young: we can’t tell the browsers of the past what to do with it
… what are we adding to the browsers of the future
… what does the browser do?
Ivan Herman: the question of whether it needs an active user to display as a book is not up to us to decide
… it’s up to the browser, as the user of the browser I can set a preference, but not up to us in the working group to define this
Kenneth Rohde Christiansen: WAM made an analysis document
Ivan Herman: the web app manifest doesn’t impose on the browser to do this and this steps
… the same holds here…
Kenneth Rohde Christiansen: browser may show ambient batching, microsoft, google, I think it is nice there is innovation
Benjamin Young: we’ve discovered we have a publication…browser decides options…
Tim Cole: discovery, be able to identify what you found, select, obtain
… if your manifest supports all of those things
… that is what the record is about…those 4 things…we can talk about after obtain
Benjamin Young: that is a good start, there is more beyond that, there needs to be a reading order
Tim Cole: enough information for those 4 things
Benjamin Young: I’d prefer to decouple from the manifest
Tim Cole: I’m talking about what the record has to do, the web page has to have enough information to know that’s the 1984 I’m talking about
Ivan Herman: can we document what those actions are?
Leonard Rosenthol: Discover, Identify, Select, Obtain
Tim Cole: Here’s the publication: https://www.ifla.org/publications/functional-requirements-for-bibliographic-records
Benjamin Young: rachel can you take tim’s 4 words and put to right of discover
Ivan Herman: so discover, identify, select, obtain, what do these things mean?
Tim Cole: Select means there is enough in there to determine it’s what I want
… title is not enough
… would also need publisher
Benjamin Young: when you get it how much do you want
David Wood: you might not get the whole thing beyond the subset
Tim Cole: Chapter 6 is the relevant Chapter (User Tasks)
Tzviya Siegman: can I interupt? we only have kenneth for part of the day
… let’s use Kenneth’s time wisely
… we need to come back to this
… parallel road to WAM…let’s go back to next best step
… we can figure this out in a timely way
Kenneth Rohde Christiansen: it sounds good, WAP, do everything on github
… we don’t want to create a different working group for manifest
Ivan Herman: I still need to understand how the work we do connect to the subgroup
Leonard Rosenthol: until we know everything we need and the life cycle we can’t go back to the web app
Kenneth Rohde Christiansen: give us a list of what you have, and we can see if it makes sense and if have what you need
… we can have a more thorough review of what you need
Benjamin Young: once we’ve determined what we want and where we want it, we can figure out where WAM fits in the life cycle
Ivan Herman: yes, but what do we end up with at the end
… do we have to different manifest that try to synchronize
Kenneth Rohde Christiansen: you have a specific manifest that refers to WAM
… we have an example with web payments
Ivan Herman: that would be interesting to see
Kenneth Rohde Christiansen: payment method manifest
… it’s very very simple
Tzviya Siegman: https://w3c.github.io/payment-method-manifest/
Ivan Herman: what’s your timeline?
Kenneth Rohde Christiansen: living timeline
… google might have additions…more work discussing android, ios
Ivan Herman: for us where it becomes a problem, when we have a normative dependency, by the time we can to our standard…
… there is a need to have a recommendation where there is a “version 1”
… if you look at the planning there are recommendations very two years
Kenneth Rohde Christiansen: I don’t see any problem with that… living standard
David Wood: how to manage the interaction…argument against putting in a publication sub to WAM
Kenneth Rohde Christiansen: we’ll if it’s an extension and you’re extensions have a prefix I don’t see a problem
Leonard Rosenthol: as long as the WAM doesn’t have more ids…
Kenneth Rohde Christiansen: one user agent can say if there is no service worker we can’t put in our microsoft store, but how to handle that and if that’s a problem is invoation in the browser space
… we don’t say anything is mandatory, it’s more for the user agents
… up to the user agent
Tzviya Siegman: so how do we continue, next steps
Ivan Herman: come up with our view of manifests, clear manifest…these are our terms…once we have a clear idea we can synchronize
… whenever is a term in the WAM we would use, we use that, clear naming scheme
Kenneth Rohde Christiansen: I think it’s still good to create an issue on the manifest…other people might see it and think it’s interesting
Ivan Herman: flow chart is important let’s matt start to write things
… we have to talk about packaging…
Tzviya Siegman: half of the pagination people are not here
Benjamin Young: what comes after the four stages of discovery, identify, select, obtain?
David Wood: is keeping different from archiving?
Ivan Herman: yes, but we’re not looking at that now
… what is the difference between identify and discovery?
Benjamin Young: your browser affords the user that you’re within a publication; now the UA needs to identify what the publication is
Tim Cole: so, in some context I discover that I am within a “web publication,” then I identify the things that make it up, then I select certain items that are important to it (what are technical requirements, for example?)
Ivan Herman: that’s fine, but that’s not identification
Tim Cole: right, that’s selection
Liisa McCloy-Kelley: a practical example: looking at a website with an instruction manual that has several options (search, nav, etc.), but it’s not done as a “publication”
… you’re trying to find this manual and you somehow link deeply into a page within it
… “identifying” is finding that you’re part of a bigger object
… “select” is trying to figure out whether that piece is a part of something larger and selecting your context and range of information
… “obtain” is “how do I get this”?
Tim Cole: right, including any constraints that go with it
David Wood: so, you get linked off to some place inside a web pub, and then your UA knows that you have discovered the web pub. is that always true?
Liisa McCloy-Kelley: that goes back to how we define this “thing” so that the UA knows it is a web pub; the user doesn’t care, they’re just looking for information
David Wood: the linkage won’t happen unless we make it happen
Liisa McCloy-Kelley: i can make the choice to have the full thing so I can reference it in the future
Benjamin Young: now that I have it, what can I do with it? that might be the next step after “obtain”
… is this making any sense (@ivan)?
Ivan Herman: I’m not skeptical, just trying to connect our diagram with the record that we have (i.e., in the FPWD)
… “discover” is within a publication; “select” means I need to find out what pub I’m part of; “obtain” is “can I get the publication?”; still don’t see the role of “identify”
… we have to be careful so each part of the workflow has the same “weight”, that each has a specific role
Benjamin Young: identify, select, obtain are all in the “manifest” – this is the identifier, this is the metadata, these are the components of the publication
Ivan Herman: I understand what Rachel added — “find my parent” under “identify” — but then “select” becomes unclear to me
Benjamin Young: I think we have an understanding that each step is additive to the one before it, it becomes “larger”; we’re giving us the steps needed to understand the publication
Tim Cole: the important thing is to recognize that there are certain steps that need to happen
Rachel Comerford: on the education level, i think of “select” as a way to choose a specific version of a single publication
… the element of “selection” is deciding where I’m going with that publication–what version I need
Ivan Herman: so it’s the same publication with the same identifier, but different ways of reading it?
Benjamin Young: there’s nothing in “identify” and “select” that we haven’t already identified in the metadata conversations
Ivan Herman: except that, it may happen that i get on a page, but in fact that page may belong to three or four different web pubs, so it’s shared by several publications, meaning it can link out to several manifests; it become sup to the user to choose which one they want to use
Liisa McCloy-Kelley: yes, but we then need to be clear that individual asset within a package can/cannot have multiple parents
Ivan Herman: this is not reflected in our current info items
Benjamin Young: even if not possible, “select” needs to give the UA/human enough info so that they can make an intelligent decision about it being something they want
Ivan Herman: i want a better word
Liisa McCloy-Kelley: choose!
Benjamin Young: “obtaining” is the hard part, and beyond that is even harder–what does the UA do then? does it tell me how far along I am in a web pub? are there interface changes in my browser?
Ivan Herman: this is true, but we shouldn’t define it
Benjamin Young: right, but we need to acknowledge it
… this happened in the annotations wg also
Ivan Herman: just to repeat, I haven’t seen anything that would not be covered by the data we have in our document, which is a good thing
Benjamin Young: once we get past “obtain”, do we afford only a linear experience, “nonlinear”, etc.? we need to prescribe something to the UA after it obtains the publication
… for example, a PDF affords a “reading” context; you have search, nav, forward-backward progression, etc.
Ivan Herman: right, so the data is defined so that the browser can use it
Benjamin Young: yes, but what sort of thing do we want to be done with that data?
… what is it supposed to afford the user? think about audio books, a11y, etc.
… what does the user get from knowing there are 10 pages instead of just the 1 they discovered?
… need to define what we “hope” the UA will do
Ivan Herman: i’m not sure
George Kerscher: once you get from a chunk of info, you can’t know what its parent is… too unpredictable, but a browser can find the manifest, and the UA can switch state into an intelligent browser that knows it is accessing a publication
Ivan Herman: exactly, but the problem is we can spend days trying to come up with complicated ways of handling wpubs… i think what we have in the document is there for covering what we know at this moment, but we at some point need to become specific; for the time being it’s an abstract set of info; i’m afraid of “that’s useful, but we need to be more tangible”
Benjamin Young: offline becomes a question here too
… if offlining is a requirement, is it human-centric UAs, or more general?
… yes, we’re all talking about a collection of documents and how it’s obtained, but we don’t know what those mean
… personally, i think in a more book-like manner
… but what happens when that web pub involves other resources than itself?
Tim Cole: problem is, can we resolve any of those issues and how comprehensive does it need to be?
David Wood: the issues around linking to/from manifests are there for a reason; the term is “document transclusion” when you have resources used in more than one publication
… there are good reasons not to link from a single item to all the others that include it; it’s fragile, metadata might conflicts, etc.
… unless we want to break the web, i suggest “issue 76” be closed as unresolved because we probably won’t do that
… let’s not spend valuable f2f time on that; would love to fix it, but it’s theoretically unfixable
Benjamin Young: so, what if I have a copy of “1984” and the publisher redacts it? I want that history, but I want access to an original copy that I obtained. Are we saying all of these copies should be replicated with separate URLs?
David Wood: that’s fine, but the individual document doesn’t need to link to many different manifests
Garth Conboy: given that perspective, can you not mandate the “find my parent” part of “identify”?
David Wood: it’s occasionally useful, but we can’t do it
Benjamin Young: if we release many versions of a manifest, what does the publication then reference? is everything kept in sync, is the publisher required to always keep the publication manifestations updated in all their different versions?
David Wood: in some context, publisher might choose to transclude and keep the data updated, but that’s not going to be true in all cases; it should be allowed, but not mandated
Ivan Herman: trying to translate in a practical way–in HTML file, e.g., “part 22 of the manual”, i may link to the manifest that identifies the full publication, but that’s where I stop–it’s not mandated, but it’s allowed
David Wood: not only should it be a “may”, but there should be a caveat that it’s dangerous if the versions aren’t maintained
Brady Duga: this is true any time you place a link in a document
George Kerscher: if this is in the metadata, in the manifest about this resource, and a discover tool can find all the related manifests, that can be done through search, but not listed in every related file
Ivan Herman: we agree
Liisa McCloy-Kelley: so, stepping back to what bigbluehat said—books get updated all the time, so when the book gets offlined, you get a snapshot of the book, just like buying a physical book
… oftentimes the same changes are made across many files (e.g., ad cards)
Laurent Le Meur: right, and what we’re saying is that this is nice, but not a requirement
Ivan Herman: so can we close the issue as unresolved?
Benjamin Young: yes, but which resource SHOULD reference the manifest? all of them “may”? so what if none of them do?
… if a resource is found by itself, what is its manifest? what does it point to?
Garth Conboy: the children don’t know its parent, but the parent knows all its children; that’s where we are at
Ivan Herman: right
Benjamin Young: if we remove the findability of the “total thing”, the only way we can really find the publication is via metadata and URLs within the document–that’s weird
Tzviya Siegman: example, assembling journal articles in a journal, in print we use pages; in digital, we call them “e-locators”; people want a “boundedness” to a publication, a way to find the whole from a part
Ivan Herman: well, we know a manifest MUST have a URL; the server returns what? we haven’t completely decided, but the URL is there… I will get the manifest in one way or another
… once I get that, I can access the publication, search, whatever; the only problem we have now, is what happens when we encounter a smaller part, and where I go back to, what is its parent?
… that’s what we are talking about
Tzviya Siegman: publishers often link to a ToC
Liisa McCloy-Kelley: but that’s bad, it’s clunky and ugly
… the body of the book must still somehow know it’s part of a whole, a user would want to know it’s in a specific book
Benjamin Young: in a web context, if you’re on “page 25”, that’s all you would know. you lose the context of the publication as a whole
Ivan Herman: that’s what we’re saying, we MAY place such metadata links, but we can’t require it because it is an unreasonable burden on authors/publishers
Liisa McCloy-Kelley: that’s fine
David Wood: we can’t in general in a web context link from child to parent due to several technical concerns; it’s better to make it a choice to maintain these links instead of mandating them
Ivan Herman: so, ok to close with these comments?
group: yes
David Wood: we achieved consensus–this is it!
Proposed resolution: close issue 76, with the comment that a link to the WP MAY be part of the resources, but WP does not require it (Ivan Herman)
David Wood: +1
Mateus Teixeira: +1
Luc Audrain: +1
Brady Duga: -1
Tzviya Siegman: https://github.com/w3c/wpub/issues/76
Ivan Herman: https://github.com/w3c/wpub/issues/76
Benjamin Young: that doesn’t solve 76 which is about multiple parents
Proposed resolution: close issue 76, with the comment that a link to the WP(s) MAY be part of the resources, but WP does not require it (Ivan Herman)
Benjamin Young: we still need to consider multiples
Leonard Rosenthol: the user chooses
Garth Conboy: Yes, the “(s)” makes this what we agreed, I think.
Tzviya Siegman: we’re all confused
Ivan Herman: so can we agree on the current proposal with the “(s)” added?
Benjamin Young: fine, but i think it introduces a messy problem: which one of the manifests is THE one that signifies the publication to the UA?
George Kerscher: there’s a discovery state, the browser can choose among many manifests, but not necessarily moving into a “reading” state?
Resolution #1: close issue 76, with the comment that a link to the WP(s) MAY be part of the resources, but WP does not require it
Benjamin Young: yes, but there is still that other issue, which we can open later
Brady Duga: the issue is that, given that now there are multiple parents, how to pick the right one? this is a harder issue to solve
Benjamin Young: now that there’s the opportunity to pick the publication, the browser can’t enter the state by default, because a default/parent cannot be identified
Matt Garrish: right, what are the expectations? this is the problem we’ve had since the beginning with multiples
Ivan Herman: we may be in a situation where we may have no idea, upon encountering a resource, what publication it belongs to. we probably won’t have a solution for this
Brady Duga: yes, but that’s not issue 76
Garth Conboy: you might just not be able to do it; that’s all; we accept that
Matt Garrish: it’s not the end of the world, but this introduces a divergence
Brady Duga: issue 76 is not about finding a parent, but about picking among multiples
Garth Conboy: yes, but we seem to be agreeing not to specify it
… that’s the final resolution we seem to come upon
Benjamin Young: but i need to test this stuff!
… how do we do that?
Tim Cole: we don’t need to test if it’s just a “may”
Tzviya Siegman: let’s each state our case
Benjamin Young: i just want to know how we will test it
Ivan Herman: i’m confused… we’re trying to redefine the web
David Wood: if you read issue 76, allow resources to allow to multiple manifests? YES. solve the problem about linking to multiple pubs? NO.
Garth Conboy: yep, ivan is frantically typing the resolution now!
Ivan Herman: comment added, the wp will not define how the choice among multiples
Garth Conboy: time for a 15 minute break since we argued through the scheduled break
4. I18N
Tzviya Siegman: a few folks from the I18n group have come to join us…
Richard Ishida: who’s heard of us? A few… And how many run away? right
… I’m going to do an intro and background about us and why you should care
… no slides, no structure - just ask!
… (shows home page - www.w3c.org/international
Addison Phillips: https://www.w3.org/International
Richard Ishida: everything you need to know is there incl. info, how to participate, current activities, etc.
… three major divisions - requirements, developer support & education/outreach
Fuqiao Xue: https://w3c.github.io/i18n-activity/projects/
Richard Ishida: requirements incl. things needed on various languages
… dev support reviews documents for other groups. there is even a review “radar” on where things are in process
Fuqiao Xue: Review radar: https://github.com/w3c/i18n-activity/projects/1
Richard Ishida: making sure more groups start early (FPWD) rather than at last call. (Note to selves: make sure we do this!)
… also developing a self-review checklist (with github magic incl)
… lots of informative documents, test suites and more for DevSupport
… for education & outreach, explanations about how the web works so that authors can do the right thing
… (walked us through some examples such as vertical text)
… let’s talk more about the requirements
Richard Ishida: https://github.com/w3c/i18n-discuss/wiki/Analysing-support-for-text-layout-on-the-Web
Richard Ishida: showing off the Japanese layout requirements (which are not necessary the same ones used in Word docs)
… emphasis, H&J etc. all included in the doc. And working on the same thing for other scripts
… use these, and don’t think just about English/Roman
… but - we’ve changed our emphasis recently
Fuqiao Xue: https://w3c.github.io/typography/gap-analysis/language-matrix.html
Richard Ishida: working on an attempt to show off what is still missing on the web, for each language
… table shows language/scripts vs. various layout features that might be relevant
… these features come from a document about international typography, https://w3c.github.io/typography/
… and with this document other specs (such as CSS) can refer to it to be the single source for explantation of various features
Leonard Rosenthol: could this document also be used as a referenced for non-web publications (but still digital)?
Richard Ishida: this could be used for non-web scenarios as well by defining the definitions and requirements
George Kerscher: does it also track text to speech?
Richard Ishida: no, it does not
Richard Ishida: there are links in the document to github issues on things that have not yet been solved
… which hopefully people will pick up and help us define them
… also links to spec issues, browser bugs and even type samples
… and anyone can contribute samples
Tzviya Siegman: can I just take photos and submit?
Richard Ishida: yes take pictures of those Hebrew books and upload them!
… the document also describes a new way of approaching the lreq specs. For J, we had a great set of experts who wanted to work on it
… and for Arabic and Hebrew, they are excited to start with and then peter out a bit
… so for J, we didn’t have links to CSS/SVG but they are working on it
… so we think that lreq isn’t the right approach but instead ot find the gaps in a given standard (eg. CSS) and then documenting those
… esp with specific tests
… and once you have pointed out that it doesn’t work, write the section of the lreq that talks about how it should work
… and then working with spec and implementation folks to get it done!
… This is a big message from the I18n committee about how you might want to consider going about your process as well
Ivan Herman: one thing that can be useful for us would be to help fill out the typography table, for language that we speak, so that we can help see where problems are and where we might be able to help
… I spent an afternoon working on Hungarian
Garth Conboy: yes and now Hungarian is greener than English :)
Ivan Herman: please try to help contribute and it will help us in the long run
Tzviya Siegman: list from 2015 https://www.w3.org/TR/dpub-css-priorities/
Tzviya Siegman: back in 2015, the CG produced a document about requirements for CSS (aka missing things) incl H-rules, etc. I bet some of that work would align well here. Perhaps @dauwhe can take a look
Richard Ishida: any other questions?
Brady Duga: this is very helpful and we push back on the UA anyway. one area which we could use guidance on is metadata. format selection, content etc.
Ivan Herman: metadata is important because content is the web, but we ned extra stuff
Richard Ishida: I would need some more info but here you go…
… 1) don’t require plain text for metadata (allow for markup)
… 2) don’t stick it in attribute values, use elements
… 3) make sure that you allow for Hebrew/Arabic issues such as direction
Brady Duga: isn’t that defined by markup?
Richard Ishida: it can be but not always
Richard Ishida: you need additional language info for things like text to speech, semantic search, etc.
Ivan Herman: in web annotations, we identified issues with JSON for doing such things and ask the I18n folks to solve this for JSON.
Richard Ishida: this is an open issue in our group and we are continuing to work on it
… string-meta
Richard Ishida: https://w3c.github.io/string-meta/
Tim Cole: if you have objects, you can add that information. Is there a way to have a default?
Richard Ishida: we don’t know all the details here, but having a default (for each language!) is OK…but make sure you have a way to override.
… in most JSON setups thats not possible, but yes it can be done
… you need to specify the details of fallbacks…which is why we want an interchange model
Ivan Herman: yes! we don’t want to invent this, just use it!
Richard Ishida: we are still working on it as there are pros and cons and not agreement
Benjamin Young: we referred to that spec from Annotations
Richard Ishida: because you come from publishing community, you will find things that authors struggle with and therefore “hack around”. So knowing those things will help better understand requirements and commonalities
Tzviya Siegman: sum up - PLEASE help!!
Liisa McCloy-Kelley: where are we going with emojis as language? (images, alt-text, etc)
Richard Ishida: Yes!!
… Chemical symbols are an issue too
… please let us know specific issues around emojis
… I would like to avoid them, but it is getting harder to do
Benjamin Young: if you can get poop in a spec, anything is possible :)
Leonard Rosenthol:
<clap><clap>
5. Packaging
Leonard Rosenthol: https://docs.google.com/document/d/15oig71-ybZDt7G-C0CGmf7KG9k35y0ggu7sXLRadH2k/edit
Ivan Herman: if I take an EPUB and unzip is a web publication who cares
Hadrien Gardeur: sorry Ivan, but this doesn’t make a whole lot of sense
Laurent Le Meur: if you do not use zip as packaging what happens?
Hadrien Gardeur: +1 to what Leonard said
Hadrien Gardeur: that’s my point
Leonard Rosenthol: we want to use a content that doesn’t not have had an absolute url when they were packaged
Ivan Herman: any EPUB4 is something I can put on the web
Laurent Le Meur: this is not the issue
Tzviya Siegman: do we need to support anything that is not on the web?
Brady Duga: is a packaged publication something that was based on Html only?
Brady Duga: will browsers will be able to manage packaged files that are portion of the web?
David Wood: Paraphrased from duga - Does a PWP just use Web technologies or must it be on the Web? If the latter, then there is a lot to do, such as CORS/Fetch.
Benjamin Young: there’s this packaging format the supports both, fwiw…it’s called MIME
Leonard Rosenthol: it depends on how we package, web agent may be indipent from the origin
… packaging from the web or packaging the web, how do you package a data base or a stream?
Ivan Herman: which packaging technology is the best to be used and we need to unpackaged every format we recive
Benjamin Young: one (perhaps the only current) example of browsers consuming packaged, non-Web HTML/JS (etc) https://browserext.github.io/browserext/
Ivan Herman: is a set or requirements on how you put the content in the package, if a publisher create an EPUB4 and follow some guidelines it is fine
Liisa McCloy-Kelley: goal of the group is to make EPUB publication advance as firs class web publications
Tim Cole: depends from use cases
Ivan Herman: today I can create a web site that does not work on the web, you have to follow rules, if you create a publication you also have to follow some rules
Leonard Rosenthol: we do want choices for different publication may have different packages depending on different use cases
Liisa McCloy-Kelley: what happens if something is changed in a publications
5.1. PDF as PWP Profile
Leonard Rosenthol: PDF as PWP Profile (slides)
Leonard Rosenthol: how to move PDF in the future ecosystem: leverage the Open Web Platform - but no commonly accepted portable container
… PDF file Container: series of alternative presentation, a set of resources, using media queries for alternate presentation (for print/Screen/etc)
… different features (CSS/presentation, etc)
… for every resource there is a relative url in pdf, regular resource in PDF or external one, PDF already have locations for all resources
… this is not from Adobe but from PDF association
… the advantage is all their community already know PDF and user find something that already know
Garth Conboy: alternative renditions did not had success in EPUB, what is the PDF container?
Leonard Rosenthol: is not zip, it an serialization of a group of objects
Ivan Herman: what you discuss is very similar to what we are discussing in PWP
Cristina Mussinelli: .. alternative media query is an interesting feature, I would be more happy if PWP if the packaging format can be technically used for PWP?
Leonard Rosenthol: yes
David Wood: I can understand why you propose this, from the Open Web Platform there are at least 3 issues
… would we be happy with binary components and not international?
David Wood: PDF is 7-bit ASCII with binary components
David Wood: - What happens when a default PDF content is not provided because only HTML is created?
David Wood: - What would Richard Ishida say to a 7-bit ASCII wrapper?
David Wood: - Would we be happy with a core binary format instead of OWP?
Leonard Rosenthol: i do not think there is any problem if PDF is a PWP publication
Leonard Rosenthol: media query can be in your normal web content
Cristina Mussinelli: .. our viewer works an any EPUB readers
Leonard Rosenthol: we assume the presentation is in the document
Laurent Le Meur: if the working group define a packaging, what impede you to use it?
Leonard Rosenthol: the backward incompatibility for old PDF content
Luc Audrain: starting from PWD you can produce a classic PDF, do we need to use a pagination tool, that is something we do not need to do with EPUB.
… paginated EPUB did not succeed
Liisa McCloy-Kelley: it is true but there is a request from publisher to have it
5.2. Zip and packaging
Cristina Mussinelli: Tzviya; we must go back to zip and packaging
Ivan Herman: I heard that there are major security issues I’d like to know more
Brady Duga: there are on signing and multiple files
Benjamin Young: zip are hard to create well. zip have restricted metadata
Brady Duga: you can handle with external metadata
Laurent Le Meur: we do not need a streamable content, we can expose it via a extension
Leonard Rosenthol: non easily updatable, for other languages that are not English or latin there are issues
… in Japan there are issues, zip it is not standardized at international level,
David Wood: zip in a web content, there is an other standard used to compress in the web gzip
David Wood: Broad tent publishers don’t typically use multi-part mime because it is “too much trouble” - it works well when people use it, though.
Brady Duga: you may have multiple copies or location of the same content
David Wood: Multi-part mime is widely used in email
Leonard Rosenthol: if our goal is to package content from the web we need it
Garth Conboy: OCF it seems it doesn’t have file restrictions
Ivan Herman: what part of this discussion should go in the working group? we will need to make a choice, which packaging solution is the best or maybe we can invest in a new one.
Leonard Rosenthol: https://tools.ietf.org/html/rfc2557
Laurent Le Meur: CBOR is a binary format, then we need to create a parser for the different platforms?
Cristina Mussinelli: http://cbor.io
6. Resolutions
- Resolution #1: close issue 76, with the comment that a link to the WP(s) MAY be part of the resources, but WP does not require it