
Update on HTML vocabulary: draft report
Hi all!
Exciting news on our end: a first version of a draft report for the community group regarding the HTML vocabulary is available now through the Github. This specifies the HTML vocabulary in a readable format, using the ReSpec standard. Here one can see a preview of the draft report for the W3C community group:

In this document, one can read the specification of classes, properties, shapes and the like to get an understanding of the HTML vocabulary.
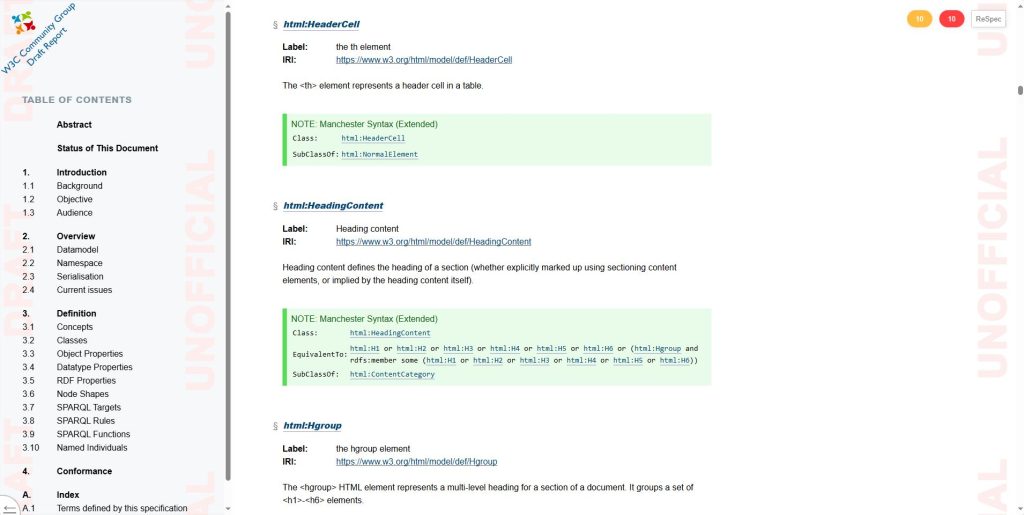
The document was actually generated using OntoReSpec, an open source tool based on semantic web technology. Here comes the twist: OntoReSpec uses the HTML vocabulary to generate the very HTML document we are looking at. The HTML vocabulary proves that it works by generating its own specification.
The HTML vocabulary has changed somewhat since the last time we sent out an update. Not so much a change of course, but more of a finetuning to align as much as possible with the Living Standard of HTML itself.
Consider for example the algorithm to serialize HTML fragments, modeled through the SHACL node shape shp:HTMLFragmentSerializationAlgorithm. This is the engine of the vocabulary that does all the work.
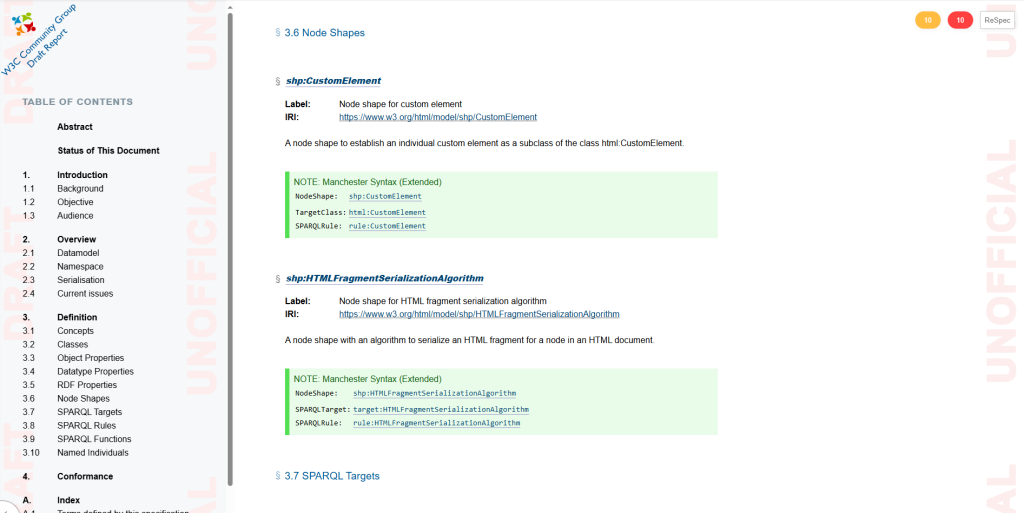
It now calls several SPARQL functions in order to serialize a HTML document from its leaf nodes up and till the root element and the document containing it. We thus could remove four unnecessary node shapes and improve the efficiency and readability of the vocabulary.
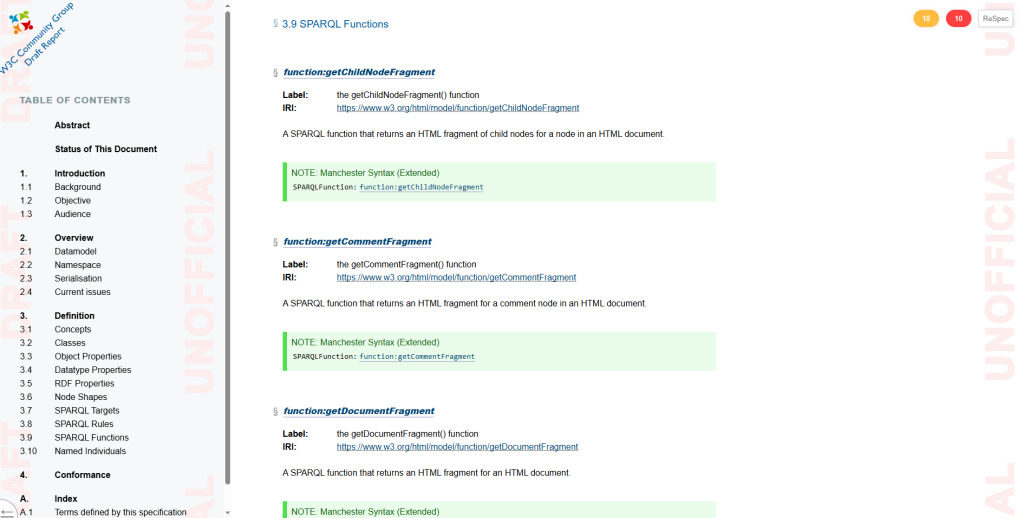
The current version of the HTML vocabulary will now undergo acceptance testing within the Dutch Ministry of Finance; in addition, it has already been proven to work in an OntoReSpec implementation as is mentioned above.
The concepts and methodology behind the HTML vocabulary, basically a form of an abstract syntax tree, are generic and can be applied outside the HTML domain. We came up with an XML vocabulary, with which XML dialects can be modeled. See for instance draft versions of OntoSVG and OntoArchimate. Going even further, we can now also apply this to domains such as English, Python and SPARQL itself. These are for now just inspiring attempts but can be developed more seriously in the future, just like we did with the HTML vocabulary.
Are we done yet with the HTML vocabulary? No. There are still some issues, although minor ones. We still want to finetune the documentation, enriching some definitions, perhaps improving OntoReSpec on the way as well. The ReSpec document contains two oddities at this moment: (1) unnecessary warning of 10 duplicate definitions, caused by classes and properties that are identically written but for an upper case letter. Think of html:abbr (property) versus html:Abbr (class). ReSpec does not like this. I have raised an issue at the Github for ReSpec as I do not know how to handle this in ReSpec. (2) the “Latest editor’s draft:” link in the document refers to a non-existing Github page, of which I do not know its origin. I have added this to another issue at the Github of ReSpec. Finally, and most importantly, we wish to add a rudimentary validation model of the structure of an HTML document.
All in all it looks like we are going to deliver our community group draft report by the end of the year. We can organize a meeting around that time and see what we as a group still want to do with the specification and how and when we can move forward to a formal working group trajectory.
We’ll keep you updated. In the mean time, feel free to read the specification, both the HTML document and the turtle file, and let us know what you think. Are you satisfied with the current state of the HTML vocabulary? Do you have specific wishes to improve the ReSpec documentation? Critical complaints and constructive criticisms are welcome, just as well as charming compliments 🙂
Kind regards,
Flores Bakker
Chair of the HTML vocabulary community group
Enterprise Architect @ Dutch Ministry of Finance
Wouter Beek
Co-founder @ Triply