- Gregorian
-
In the operator mapping tables, the term Gregorian refers
to the types xs:gYearMonth, xs:gYear,
xs:gMonthDay, xs:gDay, and
xs:gMonth.
- NaN
-
NaN is the string used to represent the double value NaN
(not-a-number); the default value is the string "NaN"
- SequenceType matching
-
SequenceType matching compares the dynamic type of a value
with an expected sequence type.
- Static Base URI
-
Static Base URI. This is an absolute URI, used to resolve
relative URI references.
- URI
-
Within this specification, the term URI refers to a
Universal Resource Identifier as defined in [RFC3986] and extended in [RFC3987] with the new name IRI.
- XDM instance
-
The term XDM instance is used, synonymously with the term
value, to denote an
unconstrained sequence
of items.
- XPath 1.0 Processor
-
An XPath 1.0 Processor processes a query according to the
XPath 1.0 specification.
- XPath 1.0 compatibility mode
-
XPath 1.0 compatibility mode. This
value is true if rules for backward compatibility with
XPath Version 1.0 are in effect; otherwise it is
false.
- XPath 2.0 Processor
-
An XPath 2.0 Processor processes a query according to the
XPath 2.0 specification.
- XPath 3.0 Processor
-
An XPath 3.0 Processor processes a query according to the
XPath 3.0 specification.
- argument
expression
-
An argument to a function call is either an argument
expression or an ArgumentPlaceholder ("?").
- argument
value
-
Argument
expressions are evaluated with respect to DC,
producing argument values.
- arity
-
The number of Arguments in an
ArgumentList is its arity.
- array
-
An array is a function that associates a set
of positions, represented as positive integer keys, with
values.
- arrow operator
-
An arrow operator applies a function to the value
of a primary expression, using the value as the
first argument to the function.
- associated value
-
The value associated with a given key is called the
associated value of the key.
- atomic
value
-
An atomic value is a value in the value space of an
atomic type, as defined in [XML
Schema 1.0] or [XML Schema 1.1].
- atomization
-
Atomization of a sequence is defined as the result of
invoking the fn:data function, as defined in
Section 2.4
fn:data FO31.
- available documents
-
Available documents. This is a mapping of strings to
document nodes. Each string represents the absolute URI of a
resource. The document node is the root of a tree that represents
that resource using the data model. The document node is returned by
the fn:doc function when applied to that URI.
- available item collections
-
Available collections. This is a mapping of strings to
sequences of items. Each string represents the
absolute URI of a resource. The sequence of items
represents the result of the fn:collection function
when that URI is supplied as the argument.
- available text resources
-
Available text resources. This is a mapping of strings to
text resources. Each string represents the absolute URI of a
resource. The resource is returned by the
fn:unparsed-text function when applied to that
URI.
- available uri collections
-
Available URI collections. This is a mapping
of strings to sequences of URIs. The string represents the absolute
URI of a resource which can be interpreted as an aggregation of a
number of individual resources each of which has its own URI. The
sequence of URIs represents the result of the
fn:uri-collection function when that URI is supplied
as the argument.
- axis step
-
An axis step returns a sequence of nodes that are
reachable from the context node via a specified axis. Such a step
has two parts: an axis, which defines the "direction of
movement" for the step, and a node test, which selects nodes based on their
kind, name, and/or type annotation.
- built-in function
-
The built-in functions are the functions
defined in [XQuery and XPath
Functions and Operators 3.1] in the
http://www.w3.org/2005/xpath-functions,
http://www.w3.org/2001/XMLSchema,
http://www.w3.org/2005/xpath-functions/math,
http://www.w3.org/2005/xpath-functions/map, and
http://www.w3.org/2005/xpath-functions/array
namespaces.
- collation
-
A collation is a specification of the manner in which
strings and URIs are compared and, by extension, ordered. For a
more complete definition of collation, see Section
5.3 Comparison of strings FO31.
- comma operator
-
One way to construct a sequence is by using the comma
operator, which evaluates each of its operands and concatenates
the resulting sequences, in order, into a single result
sequence.
- constructor function
-
The constructor function for a given type is used to
convert instances of other simple types into the given
type. The semantics of the constructor function call
T($arg) are defined to be equivalent to the expression
(($arg) cast as T?).
- context
item
-
The context item is the item currently being processed.
- context item static type
-
Context item static type. This component defines the
static type of
the context item within the scope of a given expression.
- context
node
-
When the context item is a node, it can also be referred to as
the context node.
- context position
-
The context position is the position of the context item
within the sequence of items currently being processed.
- context
size
-
The context size is the number of items in the sequence
of items currently being processed.
- current
dateTime
-
Current dateTime. This information represents an
implementation-dependent point
in time during the processing of an
expression, and includes an explicit timezone. It can be
retrieved by the fn:current-dateTime function. If
invoked multiple times during the execution of an expression, this function always returns the same
result.
- data
model
-
XPath 3.1 operates on the abstract, logical structure of an XML
document, rather than its surface syntax. This logical structure,
known as the data model, is defined in [XQuery and XPath Data Model (XDM)
3.1].
- decimal-separator
-
decimal-separator is the character used to separate the
integer part of the number from the fractional part, both in the
picture string and in the formatted number; the default value is
the period character (.)
- default URI collection
-
Default URI collection. This is the sequence
of URIs that would result from calling the
fn:uri-collection function with no arguments.
- default calendar
-
Default calendar. This is the calendar used when
formatting dates in human-readable output (for example, by the
functions fn:format-date and
fn:format-dateTime) if no other calendar is requested.
The value is a string.
- default collation
-
Default collation. This identifies one of the collations
in statically known collations as the
collation to be used by functions and operators for comparing and
ordering values of type xs:string and
xs:anyURI (and types derived from them) when no
explicit collation is specified.
- default collection
-
Default collection. This is the sequence of
items that would result from calling the
fn:collection function with no arguments.
- default element/type namespace
-
Default element/type namespace. This is a namespace URI
or absentDM31.
The namespace URI, if present, is used for any unprefixed QName
appearing in a position where an element or type name is
expected.
- default
function namespace
-
Default function namespace. This is a namespace URI or
absentDM31.
The namespace URI, if present, is used for any unprefixed QName
appearing in a position where a function name is expected.
- default language
-
Default language. This is the natural language used when
creating human-readable output (for example, by the functions
fn:format-date and fn:format-integer) if
no other language is requested. The value is a language code as
defined by the type xs:language.
- default place
-
Default place. This is a geographical location used to
identify the place where events happened (or will happen) when
formatting dates and times using functions such as
fn:format-date and fn:format-dateTime, if
no other place is specified. It is used when translating timezone
offsets to civil timezone names, and when using calendars where the
translation from ISO dates/times to a local representation is
dependent on geographical location. Possible representations of
this information are an ISO country code or an Olson timezone name,
but implementations are free to use other representations from
which the above information can be derived.
- delimiting terminal symbol
-
The delimiting terminal symbols are: "!", "!=", StringLiteral, "#", "$", "(",
")", "*", "+", (comma), "-", (dot), "..", "/", "//", (colon), "::",
":=", "<", "<<", "<=", "=", "=>", ">", ">=",
">>", "?", "@", BracedURILiteral, "[", "]",
"{", "|", "||", "}"
- digit
-
digit is a character used in the picture string to
represent an optional digit; the default value is the number sign
character (#)
- document order
-
Informally, document order is the order in which nodes
appear in the XML serialization of a document.
- dynamic context
-
The dynamic context of an expression is defined as
information that is available at the time the expression is
evaluated.
- dynamic error
-
A dynamic error is an error that must be detected during
the dynamic evaluation phase and may be detected during the static
analysis phase. Numeric overflow is an example of a dynamic error .
- dynamic evaluation phase
-
The dynamic evaluation phase is the phase during which
the value of an expression is computed.
- dynamic function call
-
A dynamic function call consists of a base expression
that returns the function and a parenthesized list of zero or more
arguments (argument expressions or
ArgumentPlaceholders).
- dynamic
type
-
A dynamic type is associated with each value as it is
computed. The dynamic type of a value may be more specific than the
static type of
the expression that computed it (for example, the static type of an
expression might be xs:integer*, denoting a sequence
of zero or more integers, but at evaluation time its value may have
the dynamic type xs:integer, denoting exactly one
integer.)
- effective boolean
value
-
The effective boolean value of a value is defined as the
result of applying the fn:boolean function to the
value, as defined in [TITLE OF XP31 SPEC, TITLE OF func-boolean
SECTION]XP31.
- empty sequence
-
A sequence containing zero items is called an empty
sequence.
- entry
-
Each key / value pair in a map is called an entry.
- environment variables
-
Environment variables. This is a mapping from names to
values. Both the names and the values are strings. The names are
compared using an implementation-defined collation,
and are unique under this collation. The set of environment
variables is implementation-defined and
may be empty.
- error
value
-
In addition to its identifying QName, a dynamic error may also
carry a descriptive string and one or more additional values called
error values.
- expanded QName
-
An expanded QName is a triple: its components are a
prefix, a local name, and a namespace URI. In the case of a name in
no namespace, the namespace URI and prefix are both absent. In the
case of a name in the default namespace, the prefix is absent.
- exponent-separator
-
exponent-separator is the character used to separate the
mantissa from the exponent in scientific notation both in the
picture string and in the formatted number; the default value is
the character (e).
- expression context
-
The expression context for a given expression consists of
all the information that can affect the result of the
expression.
- filter expression
-
An expression followed by a predicate (that is,
E1[E2]) is referred to as a filter expression:
its effect is to return those items from the value of
E1 that satisfy the predicate in E2.
- fixed position
-
In a partial function application, a fixed position is an
argument/parameter position for which the ArgumentList
has an argument expression (as opposed to an
ArgumentPlaceholder).
- focus
-
The first three components of the dynamic context (context item,
context position, and context size) are called the focus of
the expression.
- function coercion
-
Function coercion wraps a functionDM31
in a new function with signature the same as the expected type.
This effectively delays the checking of the argument and return
types until the function is invoked.
- function conversion rules
-
The function conversion rules are used to convert an
argument value to its expected type; that is, to the declared type
of the function parameter.
- generalized atomic type
-
A generalized atomic type is a type which is either (a)
an atomic type or (b) a pure union type
- grouping-separator
-
grouping-separator is the character typically used as a
thousands separator, both in the picture string and in the
formatted number; the default value is the comma character (,)
- ignorable whitespace
-
Ignorable whitespace consists of any whitespace characters that may
occur between terminals,
unless these characters occur in the context of a production marked
with a ws:explicit
annotation, in which case they can occur only where explicitly
specified (see A.2.4.2
Explicit Whitespace Handling).
- implementation dependent
-
Implementation-dependent indicates an aspect that may
differ between implementations, is not specified by this or any W3C
specification, and is not required to be specified by the
implementor for any particular implementation.
- implementation defined
-
Implementation-defined indicates an aspect that may
differ between implementations, but must be specified by the
implementor for each particular implementation.
- implicit
timezone
-
Implicit timezone. This is the timezone to be used when a
date, time, or dateTime value that does not have a timezone is used
in a comparison or arithmetic operation. The implicit timezone is
an implementation-defined value of
type xs:dayTimeDuration. See Section
3.2.7.3 Timezones XS1-2 or Section 3.3.7
dateTime XS11-2 for the range of
valid values of a timezone.
- in-scope
attribute declarations
-
In-scope attribute declarations. Each attribute
declaration is identified either by an expanded QName (for a top-level
attribute declaration) or by an implementation-dependent
attribute identifier (for a local attribute declaration).
- in-scope element
declarations
-
In-scope element declarations. Each element declaration
is identified either by an expanded QName (for a top-level element
declaration) or by an implementation-dependent element
identifier (for a local element declaration).
- in-scope namespaces
-
The in-scope namespaces property of an element node is a
set of namespace bindings, each of which associates a namespace
prefix with a URI.
- in-scope schema
definitions
-
In-scope schema definitions. This is a generic term for
all the element declarations, attribute declarations, and schema
type definitions that are in scope during static analysis of an
expression.
- in-scope schema
type
-
In-scope schema types. Each schema type definition is
identified either by an expanded QName (for a named type)
or by an implementation-dependent type
identifier (for an anonymous type). The in-scope schema
types include the predefined schema types described in 2.5.1 Predefined Schema
Types.
- in-scope variables
-
In-scope variables. This is a mapping from expanded QName to
type. It defines the set of variables that are available for
reference within an expression. The expanded QName is the name of the
variable, and the type is the static type of the variable.
- infinity
-
infinity is the string used to represent the double value
infinity (INF); the default value is the string
"Infinity"
- inline
function expression
-
An inline function expression creates an anonymous
functionDM31
defined directly in the inline function expression itself.
- item
-
An item is either an atomic value, a node, or a functionDM31.
- kind test
-
An alternative form of a node test called a kind test can
select nodes based on their kind, name, and type
annotation.
- lexical QName
-
A lexical QName is a name that conforms to the syntax of
the QName production
- literal
-
A literal is a direct syntactic representation of an
atomic value.
- map
-
A map is a function that associates a set of keys
with values, resulting in a collection of key / value
pairs.
- may
-
MAY means that an item is truly optional.
- member
-
The values of an array are called its members.
- minus-sign
-
minus-sign is the single character used to mark negative
numbers; the default value is the hyphen-minus character
(#x2D).
- must
-
MUST means that the item is an absolute requirement of
the specification.
- must not
-
MUST NOT means that the item is an absolute prohibition
of the specification.
- name test
-
A node test that consists only of an EQName or a Wildcard is
called a name test.
- named
function
-
A named function is a function defined in the static
context for the expression. To uniquely
identify a particular named function, both its name as an expanded
QName and its arity are required.
- named function reference
-
A named function reference denotes a named function.
- named functions
-
Named functions. This is a mapping from (expanded QName,
arity) to functionDM31.
- namespace-sensitive
-
The namespace-sensitive types are xs:QName,
xs:NOTATION, types derived by restriction from
xs:QName or xs:NOTATION, list types that
have a namespace-sensitive item type, and union types with a
namespace-sensitive type in their transitive membership.
- node
-
A node is an instance of one of the node kinds
defined in Section 6 Nodes
DM31.
- node test
-
A node test is a condition on the name, kind (element,
attribute, text, document, comment, or processing instruction),
and/or type
annotation of a node. A node test determines which nodes
contained by an axis are selected by a step.
- non-delimiting terminal symbol
-
The non-delimiting terminal symbols are: IntegerLiteral, URIQualifiedName, NCName, DecimalLiteral, DoubleLiteral, QName, "ancestor", "ancestor-or-self",
"and", "array", "as", "attribute", "cast", "castable", "child",
"comment", "descendant", "descendant-or-self", "div",
"document-node", "element", "else", "empty-sequence", "eq",
"every", "except", "following", "following-sibling", "for",
"function", "ge", "gt", "idiv", "if", "in", "instance",
"intersect", "is", "item", "le", "let", "lt", "map", "mod",
"namespace", "namespace-node", "ne", "node", "of", "or", "parent",
"preceding", "preceding-sibling", "processing-instruction",
"return", "satisfies", "schema-attribute", "schema-element",
"self", "some", "text", "then", "to", "treat", "union"
- numeric
-
When referring to a type, the term numeric denotes the
types xs:integer, xs:decimal,
xs:float, and xs:double which are
all member types of the built-in union type
xs:numeric .
- numeric predicate
-
A predicate whose predicate expression returns a numeric type is
called a numeric predicate.
- operator function
-
For each operator and valid combination of operand types, the
operator mapping tables specify a result type and an operator
function that implements the semantics of the operator for the
given types.
- partial function
application
-
A static or dynamic function call is a
partial function application if one or more arguments is an
ArgumentPlaceholder.
- path expression
-
A path expression can be used to locate nodes within
trees. A path expression consists of a series of one or more
steps, separated by
"/" or "//", and optionally beginning
with "/" or "//".
- pattern-separator
-
pattern-separator is a character used to separate
positive and negative sub-pictures in a picture string; the default
value is the semi-colon character (;)
- per-mille
-
per-mille is the character used both in the picture
string and in the formatted number to indicate that the number is
written as a per-thousand fraction; the default value is the
Unicode per-mille character (#x2030)
- percent
-
percent is the character used both in the picture string
and in the formatted number to indicate that the number is written
as a per-hundred fraction; the default value is the percent
character (%)
- primary expression
-
Primary expressions are the basic primitives of the
language. They include literals, variable references, context item
expressions, and function calls. A primary expression may also be
created by enclosing any expression in parentheses, which is
sometimes helpful in controlling the precedence of operators.
- principal node kind
-
Every axis has a principal node kind. If an axis can
contain elements, then the principal node kind is element;
otherwise, it is the kind of nodes that the axis can contain.
- pure union type
-
A pure union type is an XML Schema union type that
satisfies the following constraints: (1) {variety} is
union, (2) the {facets} property is
empty, (3) no type in the transitive membership of the union type
has {variety} list, and (4) no type in
the transitive membership of the union type is a type with
{variety} union having a non-empty
{facets} property
- resolve
-
To resolve a relative URI $rel against a
base URI $base is to expand it to an absolute URI, as
if by calling the function fn:resolve-uri($rel,
$base).
- reverse document order
-
The node ordering that is the reverse of document order is
called reverse document order.
- same key
-
Two atomic values K1 and K2 have the
same key value if the the following two conditions are both
true: (1) the relation fn:deep-equal(K1, K2, $UCC)
holds, where $UCC is the Unicode codepoint collation;
and (2) has-timezone(K1) eq has-timezone(K2), where
the function has-timezone(V) returns true
if and only if the timezone component of V is present
and V is an instance of xs:dateTime,
xs:date, xs:time, xs:gYear,
xs:gYearMonth, xs:gMonth,
xs:gMonthDay, or xs:gDay.
- schema
type
-
A schema type is a type that is (or could be) defined
using the facilities of [XML Schema 1.0]
or [XML Schema 1.1] (including the
built-in types).
- sequence
-
A sequence is an ordered collection of zero or more
items.
- sequence type
-
A sequence type is a type that can be expressed using the
SequenceType syntax.
Sequence types are used whenever it is necessary to refer to a type
in an XPath 3.1 expression. The term sequence type suggests
that this syntax is used to describe the type of an XPath 3.1
value, which is always a sequence.
- should
-
SHOULD means that there may exist valid reasons in
particular circumstances to ignore a particular item, but the full
implications must be understood and carefully weighed before
choosing a different course.
- singleton
-
A sequence containing exactly one item is called a
singleton.
- singleton focus
-
A singleton focus is a focus that refers to a single
item; in a singleton focus, context item is set to the item,
context position = 1 and context size = 1.
- stable
-
Document order is stable, which means that the relative
order of two nodes will not change during the processing of a given
expression, even if this order is
implementation-dependent.
- static analysis phase
-
The static analysis phase depends on the expression
itself and on the static context. The static analysis
phase does not depend on input data (other than schemas).
- static context
-
The static context of an expression is the information
that is available during static analysis of the expression, prior
to its evaluation.
- static
error
-
An error that can be detected during the static analysis phase,
and is not a type error, is a static error.
- static function call
-
A static function call consists of an EQName followed by
a parenthesized list of zero or more arguments.
- static
type
-
The static type of an expression is the best inference
that the processor is able to make statically about the type of the
result of the expression.
- static typing feature
-
The Static Typing Feature is an optional feature of XPath
that provides support for static semantics, and requires
implementations to detect and report type errors during the static analysis
phase.
- statically known collections
-
Statically known collections. This is a mapping from
strings to types. The string represents the absolute URI of a
resource that is potentially available using the
fn:collection function. The type is the type of the
sequence of items that would result from calling the
fn:collection function with this URI as its
argument.
- statically
known documents
-
Statically known documents. This is a mapping from
strings to types. The string represents the absolute URI of a
resource that is potentially available using the
fn:doc function. The type is the static type of a call to
fn:doc with the given URI as its literal argument.
- statically known collations
-
Statically known collations. This is an implementation-defined mapping
from URI to collation. It defines the names of the collations that
are available for use in processing expressions.
- statically known decimal
formats
-
Statically known decimal formats. This is a mapping from
QNames to decimal formats, with one default format that has no
visible name, referred to as the unnamed decimal format. Each
format is available for use when formatting numbers using the
fn:format-number function.
- statically known default
collection type
-
Statically known default collection type. This is the
type of the sequence of items that would result from
calling the fn:collection function with no
arguments.
- statically known function
signatures
-
Statically known function signatures. This is a mapping
from (expanded QName, arity) to function
signatureDM31.
- statically known namespaces
-
Statically known namespaces. This is a mapping from
prefix to namespace URI that defines all the namespaces that are
known during static processing of a given expression.
- step
-
A step is a part of a path expression that generates a sequence
of items and then filters the sequence by zero or more predicates. The value of the step consists
of those items that satisfy the predicates, working from left to
right. A step may be either an axis step or a postfix expression.
- string
value
-
The string value of a node is a string and can be
extracted by applying the Section 2.3
fn:string FO31 function to the
node.
- substitution group
-
Substitution groups are defined in Section
2.2.2.2 Element Substitution Group
XS1-1 and Section
2.2.2.2 Element Substitution Group
XS11-1. Informally, the substitution
group headed by a given element (called the head element)
consists of the set of elements that can be substituted for the
head element without affecting the outcome of schema
validation.
- subtype
-
A sequence
type A is a subtype of a sequence type
B if the judgement subtype(A, B) is
true.
- subtype substitution
-
The use of a value whose dynamic type is derived from an expected
type is known as subtype substitution.
- symbol
-
Each rule in the grammar defines one symbol, using the
following format:
- symbol
separators
-
Whitespace and
Comments function as symbol
separators. For the most part, they are not mentioned in the
grammar, and may occur between any two terminal symbols mentioned
in the grammar, except where that is forbidden by the /* ws: explicit */ annotation in the EBNF, or by
the /* xgc: xml-version */
annotation.
- terminal
-
A terminal is a symbol or string or pattern that can
appear in the right-hand side of a rule, but never appears on the
left-hand side in the main grammar, although it may appear on the
left-hand side of a rule in the grammar for terminals.
- type annotation
-
Each element node and attribute node in an XDM instance has
a type annotation (described in Section 2.7 Schema
Information DM31). The type
annotation of a node is a reference to an XML Schema type.
- type
error
-
A type error may be raised during the static analysis
phase or the dynamic evaluation phase. During the static analysis
phase, a type error
occurs when the static type of an expression does not match
the expected type of the context in which the expression occurs.
During the dynamic evaluation phase, a type error occurs when the dynamic type of a value
does not match the expected type of the context in which the value
occurs.
- type
promotion
-
Under certain circumstances, an atomic value can be promoted
from one type to another. Type promotion is used in
evaluating function calls (see 3.1.5.1 Evaluating Static and Dynamic
Function Calls) and operators that accept numeric or string
operands (see B.2 Operator
Mapping).
- typed
value
-
The typed value of a node is a sequence of atomic values
and can be extracted by applying the Section 2.4
fn:data FO31 function to the
node.
- value
-
In the data
model, a value is always a sequence.
- variable reference
-
A variable reference is an EQName preceded by a
$-sign.
- variable values
-
Variable values. This is a mapping from expanded QName to
value. It contains the same expanded QNames as the in-scope
variables in the static context for the expression. The
expanded
QName is the name of the variable and the value is the dynamic
value of the variable, which includes its dynamic type.
- warning
-
In addition to static errors, dynamic errors, and type errors, an XPath 3.1
implementation may raise warnings, either during the
static
analysis phase or the dynamic evaluation phase. The
circumstances in which warnings are raised, and the ways in which
warnings are handled, are implementation-defined.
- whitespace
-
A whitespace character is any of the characters defined
by [http://www.w3.org/TR/REC-xml/#NT-S].
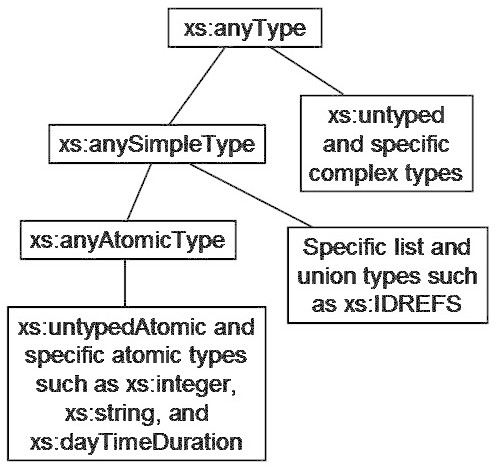
- xs:anyAtomicType
-
xs:anyAtomicType is an atomic type that includes
all atomic values (and no values that are not atomic). Its base
type is xs:anySimpleType from which all simple types,
including atomic, list, and union types, are derived. All primitive
atomic types, such as xs:decimal and
xs:string, have xs:anyAtomicType as their
base type.
- xs:dayTimeDuration
-
xs:dayTimeDuration is derived by restriction from
xs:duration. The lexical representation of
xs:dayTimeDuration is restricted to contain only day,
hour, minute, and second components.
- xs:error
-
xs:error is a simple type with no value space,
available defined in Section 3.16.7.3
xs:error XS11-1. can be used in the
2.5.4 SequenceType
Syntax to raise errors.
- xs:untyped
-
xs:untyped is used as the type annotation of
an element node that has not been validated, or has been validated
in skip mode.
- xs:untypedAtomic
-
xs:untypedAtomic is an atomic type that is used to
denote untyped atomic data, such as text that has not been assigned
a more specific type.
- xs:yearMonthDuration
-
xs:yearMonthDuration is derived by restriction from
xs:duration. The lexical representation of
xs:yearMonthDuration is restricted to contain only
year and month components.
- zero-digit
-
zero-digit is the character used to represent the digit
zero; the default value is the Western digit zero (#x30). This
character must be a digit (category Nd in the Unicode property
database), and it must have the numeric value zero. This property
implicitly defines the ten Unicode characters that are used to
represent the values 0 to 9: Unicode is organized so that each set
of decimal digits forms a contiguous block of characters in
numerical sequence. Within the picture string any of these ten
character can be used (interchangeably) as a place-holder for a
mandatory digit. Within the final result string, these ten
characters are used to represent the digits zero to nine.