Hi! I am Florian Rivoal, member of the Advisory Board, and co-editor of the W3C Process document.
I’d like to tell you about a couple of things happening in this year’s ongoing revision of the W3C Process.
The goal is both to keep you informed, and to solicit feedback.
What is the Process
The W3C Process Document describes the organizational structure of the W3C and processes,
responsibilities and functions that enable W3C to accomplish its mission.
- Revised in the Process Community Group
- Open to anyone, includes the AB
- Final decision by AC Review, CG has no authority
[Slide 2]
First, a brief reminder, to help put things in context.
The W3C Process is one of our key governing documents.
It describes the organizational structure of the W3C,
as well as processes, responsibilities and functions that enable W3C to accomplish its mission.
In particular, it describes the lifecycle of the various documents we publish.
Revisions of the Process are developed in the Process Community Group,
which is open to anyone, and includes the W3C’s Advisory Board.
This Process Community Group does not make any final decisions though:
when it thinks it is ready for an update,
it submits its work to the Advisory Committee,
for review and ratification.
Selected Topics from the Process 2021 Cycle
[Slide 3]
There are always a number of open issues against the Process
making progress in parallel,
but in today’s presentation,
I would like to draw attention to two topics:
Registries, and Tooling.
Registries
[Slide 4]
Let’s start with Registries.
What is a Registry
A registry documents a data set
consisting of one or more associated registry tables,
each table representing an updatable collection of logically independent,
consistently-structured registry entries.
[Slide 5]
A registry documents a data set
consisting of one or more associated registry tables,
each table representing an updatable collection of logically independent,
consistently-structured registry entries.
What is it for?
- collision avoidance
- duplication avoidance
- ease of submission
- centralization of information / ease of discovery
- consensus
[Slide 6]
Maintaining a registry document collects all that information in one place.
This makes it easy to discover and to reference,
and help avoid collisions or duplication between entries.
It also ensures that the community who maintains this document
works under a common agreement about how this information is organized
and under what rules entries can be added or changed.
The Problem
W3C has no standard way to maintain registries
People have been using various ad-hoc and inconsistent work-arounds
[Slide 7]
The problem that we are facing is that so far,
there has been no official way at W3C to maintain such registries.
Over time, since there is a need,
people have worked around it in various ways,
and I would like to walk you through a few examples.
Registry in a wiki
(This particular example is a deprecated registry)
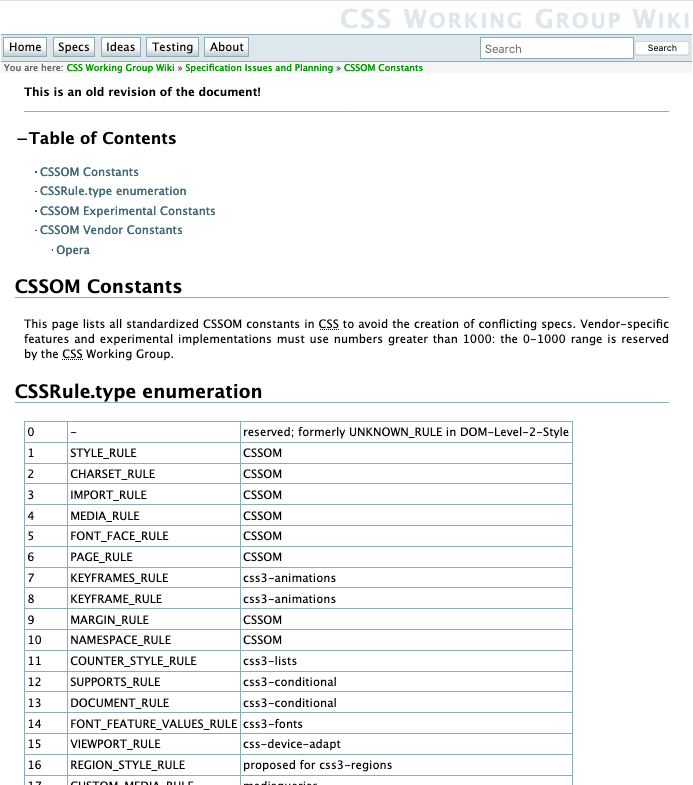
[Slide 8]
Sometimes, Working Groups have used a wiki.
This is certainly easy to update,
but maybe even too easy,
as there’s nothing guarding against edits that don’t respect the policy that the group wants to follow.
Also, this does not look official at all.
Registry in a (set of) custom-built pages

[Slide 9]
There are also examples of the W3C Staff creating a set of dedicated custom pages for a particular registry.
In this example,
there is one page with the content of registry itself,
one with the policy about how it is maintained,
and one with a form to submit new values.
This is quite functional,
but due to its ad-hoc nature,
it is unclear how you go about setting up another one of these,
not only from a technical standpoint, but also from a process standpoint.
Registry in a (perpetual?) CR

[Slide 10]
But Working Groups publish technical documents all the time,
so some have attempted to treat registries like any other specification,
by putting them on the Recommendation track.
However, when you do that,
it’s not clear how to go beyond the Candidate Recommendation stage.
That would require demonstrating implementation experience,
but registries are not specifications with normative requirements on implementations.
They merely document a set of entries.
Registry in a (perpetual?) Working Draft
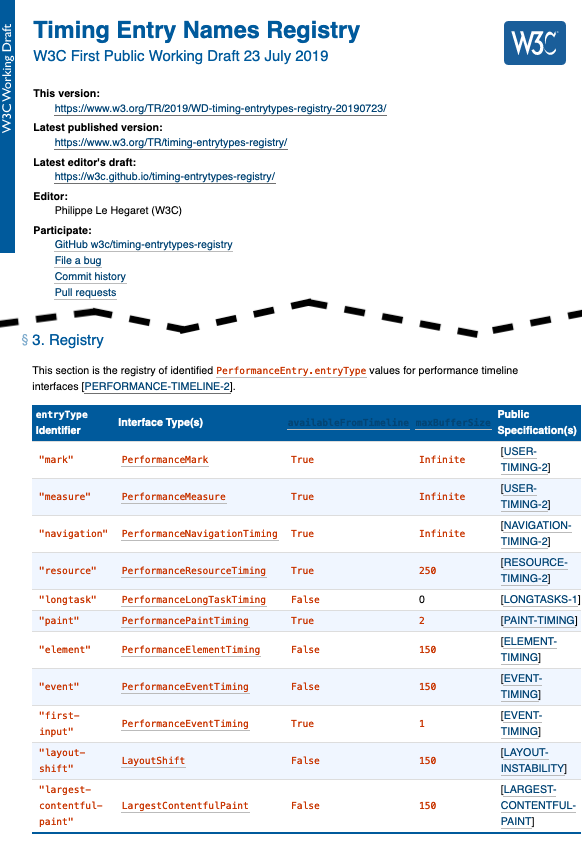
[Slide 11]
Other groups don’t even try to reach Candidate Recommendation,
and keep their registry in a Working Draft.
But a Working Draft, in its status section,
claims that it has no official standing,
and that it is a work in progress intending to eventually become a Recommendation.
Registry in a Working Group Note

[Slide 12]
This has lead some other groups to maintain their registry as a Working Group Note.
This is no more official, but at least it doesn’t claim to be on its way to Recommendation.
At the same time, neither the Note nor the Working Draft
offer any guarantee of stability or maturity to users of the registry.
Registry Proposal
Makes registries ‘first class’ deliverables of the W3C, on /TR,
referenced by W3C URLs,
with a process for defining, publishing, and maintaining one in the Process document.
[Slide 13]
So we want to fix that,
and make registries first class deliverables of the W3C,
officially defined in the W3C Process,
published with a W3C URL on /TR like everything else,
but with rules that are tailored to their specificities.
Let me walk you through what that would entail.
Anatomy
- One or more Registry Tables
- Registry Definitions, which define for each table:
- the purpose & scope
- the fields
(name, type, constraints…)
- what kind of changes to are allowed
(addition, deletion, modification, deprecation…)
- the process & criteria to register or modify entries
- the custodian (not necessarily the Working Group)
- Must not contain normative requirements on implementations
[Slide 14]
First, what is a Registry made of?
First and foremost, a Registry is made of one or more Tables:
a collection of logically independent,
consistently-structured entries.
But we also need information about those tables,
which we call the Registry Definition.
What are the tables for?
I talked about "consistently structured entries".
What is that structure?
How many fields?
What are they called?
What kind of data does each field hold?
Are there any uniqueness guarantees,
or other constrains on how this is structured?
We not only need to define what the table is,
but also how it can change.
Can rows be added?
Removed?
Modified?
Deprecated?
How is one supposed to go about asking for any of these changes?
Depending on what the registry is for,
Additions could be on a first-come-first served basis.
Or maybe there are conditions to be fulfilled and there is a verification step.
Or maybe there needs to be a consensus of some group.
Also, the Working Group who sets the registry up
is not necessarily the body who will have to do this verification step,
or to be in consensus,
or whatever the rule is,
and then to then update the registry entries when appropriate.
So we also have to define who that Custodian is.
All of that information is referred to as the Registry Definition.
It’s also important to note what isn’t in a Registry:
neither the Registry Tables nor the Registry Definitions
can contain normative requirements on implementations.
The process for defining such things is different,
and they belong in a regular specification.
Registry Process
(base case)
-
Put the Definitions in a section of a REC track document
-
Put the Tables in the REC track document as well
-
Take the Definitions to REC normally
(consensus, wide review, WD→CR→PR→REC, AC Review…)
-
Tables can be updated with no more process than required by the Definitions
(no Director or AC Review, no Transition Call, can be fully automated if desired…)
[Slide 15]
Now, what do we propose we do with these Registry Tables and Definitions?
Let’s first look at the simple case.
A Working Group would write their Registry Definitions and Registry Tables
in dedicated sections of a Recommendation Track document.
The Working Group would then move that document through the various stages of the Recommendation Track,
deciding through consensus,
soliciting wide review on the Registry Definitions,
addressing feedback,
publishing a Candidate Recommendation,
gathering implementation experience on any other section of the document
that would define implementation requirements,
eventually requesting a Proposed Recommendation and getting a formal Advisory Committee Review,
before publishing a Recommendation.
But here’s the important difference:
all this Process applies just to the Registry Definitions.
For the content of Registry Tables themselves,
the W3C Process imposes nothing.
No Director approval, no AC Review, no wide review, not even consensus.
If you need any rule, you need to state them in the Registry Definitions.
And as long as you follow those rules,
you can update the Registry Tables
with no other constraint.
Even if they are in a finalized W3C Recommendation,
if the Definitions say that anyone in the world can register a value by typing it in a form and pressing submit,
then that’s all it takes.
The rest is mechanical, and can be fully automated.
That is not to say that the rules have to be lax,
just that they can be.
For a given registry,
if the appropriate thing to do is to require new entries to be approved by the United Nations,
you can write that down too.
Definitions themselves will be subject to wide review and to AC Approval,
but once approved,
they, and only they, govern what can happen to the entries of a Table.
-
In line with current practices

-
Stable rules approved by the AC
let us grant official standing
-
Full flexibility for updates / additions within those rules
[Slide 16]
As can be seen through the table of contents of this example,
in addition to the Registry Tables,
writing down Registry Definitions
that include detailed requirements and procedures for updates
is actually in line with the current practices of Working Groups who publish registries in the absence of a formal Process.
Elevating this practice to a formal process lets us grant stability and official standing to the Registry Definitions,
while keeping updates to Registry Tables as flexible as needed.
Automation
Allows automated submission/publication if desired
Could be Pull-Request based, or anything convenient
[Slide 17]
Since the Process itself does not put any constraint on Registry Table updates
other than following the Registry Definitions,
to the extent that these definitions do not require some form of human assessment of proposed updates,
the entire process, from submission to publication of the updated document can be automated.
So we could build a form like the one we saw in the earlier example,
and have that drive automated updates to the document holding the Registry Table.
And if that particular approach isn’t to our taste,
and we would prefer Registry Definitions that allow or require
a submission process based on Pull Requests for example,
that’s fine too.
Publication
Can be in the same REC as the referencing specification…
…or in a standalone REC containing only the Registry Definitions and Tables.
Tables can be inline in the REC as HTML content…
…or in an attached machine-readable file…
…or both.
[Slide 18]
I would like to draw attention to a couple of subtleties and implications of publishing Registries that way.
First, I said that Registry Definitions and Tables are written into a Recommendation Track document,
but this proposal does not constrain what else can go in that document.
It is possible to have a Registry be one of many sections in a Recommendation,
with the other sections being an ordinary specification obeying the usual rules.
The Registry process will allow flexible updates to the registry tables,
while everything else follows the Recommendation Track rules we are used to.
It is also possible to make a document that contains nothing but Registry Tables and their Definitions.
Different situations may call for one or the other, and the Process allows either.
Secondly, having the Registry Tables be in a Recommendation is more flexible than people may realize at first.
It can mean that they are written as HTML tables as part of the Overview.html file of the document. And that is indeed what we saw in all the examples I showed earlier.
But publications on TR are not restricted to being a single HTML file.
Quite a few existing document are multi-chapter packages, with one HTML file per chapter,
so the Tables and the Definitions could be in separate files.
More over, attachments being embedded into linked to from the HTML document are also possible.
By far the most common ones are image files,
but there’s no real restriction.
And so, Registry Tables can be inline in the HTML document,
or they could be machine readable files riding alongside with it,
or they can be both.
Being part of the Recommendation only means that they are packaged, published, versioned, archived, together.
Open Questions
-
For registry-only documents: usual REC Track or simplified Registry Track?
Do we need both CR and PR?
-
Should we allow Definitions and Tables to be published separately?
(i.e. not just separate files, but completely separate /TR publications)
[Slide 19]
We are still early in the cycle, so nothing I’ve presented so far has been formally approved,
but so far there doesn’t seem to be any disagreement about that.
We do have some open questions,
and are hoping that this presentation will help gather feedback.
First, in the case of documents that only contain a registry,
making them go through the Recommendation Track can work,
but it might be overkill.
Should we define a simplified Registry Track?
If we do so, does that track need both a Candidate Registry and a Proposed Registry,
or can they be combined?
Another question is whether it is desirable to allow Registry Tables to be published separately from Registry Definitions,
not merely as separate files within the same Recommendation,
but as completely separate /TR publications.
Must be Together?
- Pros:
- Easy to keep everything in sync
- All information is available without duplication nor external reference
- One thing to reference
- Data-only attachment possible anyway
- Cons:
- Rules for updating Definitions and Tables are different
- Most readers of the Tables have no interest in maintenance rules
[Slide 20]
Keeping Definitions and Tables together has the advantage that it is easy to keep everything synchronized.
All information necessary to readers is available
without needing duplication nor external references.
If another document
needs to make a reference to the Registry,
there is no ambiguity on how to do so,
as the Registry is just one thing.
And it’s worth noting that even then, since a single TR publication can be made of multiple files,
we still have flexibility on how to best present the information.
At the same time, the rules for updating Definitions and Tables are different,
and having both in the same document could be confusing
or complicate automation.
And most people looking up a registry are only interested in the Tables,
and have no interest in maintenance rules.
May be Separate?
- Pros:
- IETF+IANA do it, why not us?
- Tables document can be shorter
- Can set up a different back-end (proxy?) for Tables, to ease automation, with no risk to Definitions
- Only allows separation, does not mandate it
- Cons:
- Partial duplication of Definitions needed for readability
- Mutual cross-links needed between Tables and Definitions
- Need to manage potential incompatibilities between updates
[Slide 21]
If we look at allowing separate publication,
it is worth noting that this is how the IETF and IANA do it,
and they are prominent maintainers of many registries.
First off, this lets us make the Tables documents shorter,
by moving all the material that is of interest to fewer people to some other place.
Handling them as separate publications could also make it easier
to set up different back-ends,
with the Tables publication being powered by a different system,
making automated updates easier to set up.
It’s also worth noting that
those who favor this approach only want to allow separate publication,
not require it.
Downsides have been identified though,
leading to some pushback.
First, the parts of the Definitions that define what the various fields of the Tables are
are needed to make sense of the Tables.
This either means that readers of the Tables document will need to look up the Definitions document,
or that the Tables document will need to include some duplicate information.
What if it gets out of sync,
or contradicts the actual Definitions?
What process governs changes to such parts of the Tables documents which aren’t themselves Table Entries?
Separate publication also introduces a need for mutual cross-links between the Tables document and the Definitions document,
and potentially for synchronized updates in case of incompatible changes to the Definitions
or changes to their status.
Feedback and uses cases on whether allowing separate publication is a good or bad idea would be very much appreciated.
Separate track?
(For standalone registries only)
Use REC Track as-is
- Pros:
- Well known
- Cons:
- Unnecessarily invokes Patent Policy
- Requires separate CR and PR
Define simplified Registry Track
- Pros:
- Avoids invoking Patent Policy
- Can merge CR with PR
- Cons:
- One more thing to define/know
[Slide 22]
Now onto a different open question.
In the case of a document that only contains a Registry
as opposed to a larger specification also containing normative requirements on implementations,
should we still be using the Recommendation Track,
or should we use a simplified Registry Track?
The upside of using the Recommendation Track as-is
is that it is well known,
and we don’t have to come up with, or document, anything new.
However, documents on the Recommendation Track invoke the Patent Policy,
including mandatory exclusion periods and communications to member companies
asking them to review potential clashes with their patent portfolios,
even though this is a logical impossibility,
since Registries cannot contain requirements on implementations.
Similarly, the Recommendation Tack requires a Candidate Recommendation followed a Proposed Recommendation,
but it’s not clear we need both in the case of registries,
as I will explain on the next slide.
We could define a separate Registry track,
based on the Recommendation track,
but with the unnecessary parts removed,
decoupling it from the Patent Policy,
and potentially merging Candidate Registry and Proposed Registry.
Of course, that means we’d have to define how that Registry Track works.
That’s not necessarily a huge undertaking,
as it can be defined to be identical to the Recommendation Track but for a few exceptions,
but that’s still more to write
and to read
than nothing.
Do we need both CR and PR?
- Upsides of having both:
- CR signals “we think we’re done”, which some wait for before reviewing
- Only one AC Review, at PR
(though multiple CRs less likely)
- Upsides of merging:
- No phase dedicated to gathering implementation feedback due to no implementation to wait for
- No artificial delay due to minimum review periods stacking up
[Slide 23]
As I mentioned, we are wondering about the need to have both a Candidate and a Proposed phase.
Candidate Recommendation signals that the Working Group thinks its done,
and some people wait for that before reviewing the document,
counting on the possibilities of further revisions before Proposed Recommendations.
That could still be useful.
Also, the AC Review is triggered by the Proposed phase,
ensuring there’s only one of them.
At the same time, since Registries are less complex than specifications,
fewer CR revisions should be expected,
so AC Reviews at triggered CR may not be that numerous anyway.
Fundamentally though,
the primary purpose of the phase between CR and PR is to gather implementation experience,
and in the case of Registries, there is no implementation to wait for.
So this is somewhat nonsensical,
and would cause unnecessary busy work for the sponsoring Working Group,
as well as potential delays as minimum review periods stack up.
It’s your turn!
- Review the draft Process:
- Ask questions at the AC meeting
- Talk to your favorite AB member
- Participate in the Process CG
[Slide 24]
If you want to dive deeper into this topic,
there are two experimental branches of the Process
I would like to invite you to review.
They are largely identical,
except that one includes a dedicated Registry Track with no Proposed Registry phase,
and only allows Definitions and Tables to be published together,
while the other variant only uses the Recommendation Track,
and allows separate publication of Definitions and Tables as well.
A diff between the two is also available.
If Registries matter to you,
I encourage you to bring any feeback, use case, or question you may have
to the upcoming AC meeting,
to reach out to members of the Advisory Board,
and to participate in the Process Community Group.
Tooling
[Slide 25]
I would like to briefly touch on another topic: Tooling.
[Side 26]
Historically, every group in W3C used largely the same tools to do their work.
- Telephone conferences hosted by Zakim
- IRC and the IRC bots
- Tracker, Bugzilla, or email, for issues and actions
- Email for asynchronous communication
- Wikis for exploring ideas
- CVS for source control
This is far from modern, and a few of these tools have been retired anyway.
[Slide 27]
Nowadays, each group picks their own tools to suit their needs.
In many ways, this is very positive.
This enables more effective work flows
better usability,
and lets us keep up with community norms.
But this is also a source of problems.
When every group does things differently,
it can be challenging to find out how to participate
when joining a new group,
especially when documentation is lacking.
Moreover, the need for accessibility / archival / persistence not always respected.
[Slide 28]
Due to these concerns,
a discussion has started in the Advisory Board and in the Process Community Group.
It seems clear that we will a least need to document best practices and write down guidelines.
But maybe we need to go further,
and actually need to establish some measure of enforceable mandatory rules
to ensure that the output of our work is as long lived as it should be,
and that participating isn’t hampered by accessibility concerns.
Whether we do need rules,
and if so, what such rules should be,
is under discussion.
This is all documented in a wiki page, which I would encourage you to read.