1 Preface
The names in a namespace form a collection:
-
Sometimes it is a collection of element names (DocBook and
XHTML, for example),
-
sometimes it is a collection of attribute names (XLink, for
example),
-
sometimes it is a collection of functions (XQuery 1.0 and XPath
2.0 Data Model),
-
sometimes it is a collection of properties (FOAF),
-
sometimes it is a collection of concepts (WordNet), and many
other uses are likely to arise.
There's no requirement that the names in a namespace only
identify items of a single type; elements and attributes can both
come from the same namespace as could functions and concepts or any
other homogeneous or heterogeneous collection you can imagine. The
names in a namespace can, in theory at least, be defined to
identify any thing or any number of things.
Given the wide variety of things that can be identified, it
follows that an equally wide variety of ancillary resources may be
relevant to a namespace. A namespace may have documentation
(specifications, reference material, tutorials, etc., perhaps in
several formats and several languages), schemas (in any of several
forms), stylesheets, software libraries, applications, or any other
kind of related resource. The names in a namespace likewise may
have a range of information associated with them.
A user encountering a namespace might want to find any or all of
these related resources. In the absence of any other information, a
logical place to look for these resources, or information about
them, is at the location of the namespace URI itself. The details
of exactly what this means may be subtlely different in different
cases, but the general point is clear, as [WebArch Vol 1] says: It is Good
Practice for the owner of a namespace to make available at the
namespace URI “material intended for people to read and material
optimized for software agents in order to meet the needs of those
who will use the namespace”.
The question remains, how can we best provide both human and
machine readable information at the namespace URI such that we can
achieve the good practice identified by web architecture? One early
attempt was [RDDL 1.0] . RDDL 1.0 is an
XLink-based vocabulary for connecting a namespace document to
related resources and identifying their nature and purpose.
Several attempts were made to simplify RDDL. The TAG's original
plan for addressing namespaceDocument-8
was to help define a simpler, standard RDDL format. However, this
space has matured somewhat since the TAG's original discussions and
RDDL 1.0 is now widely deployed. In addition, some of the proposed
alternative formats are also deployed, and it seems likely that
over time new variations may arise based on other evolving web
standards.
This finding therefore attempts to address the problem by
considering it in a more general fashion. We:
-
Define a conceptual model for identifying related resources that
is simple enough to garner community consensus as a reasonable
abstraction for the problem.
-
Show how RDDL 1.0 is one possible concrete syntax for this
model.
-
Show how other concrete syntaxes could be defined and identified
in a way that would preserve the model.
We'll define this model using RDF. RDF allows us to describing
the model formally and allows us to integrate the semantics of
terms in a namespace into the semantic web. It is important to note
that the use of RDF for modelling the abstraction does not
place any onus on implementors to use RDF technologies to locate
ancillary resources nor does it require that authors writing
namespace documents understand semantic web technologies or
RDF.
Directing humans or machines to related resources is by no means
the only kind of information about a namespace that a namespace
document might provide. For humans, ordinary language, and for
machines, [GRDDL] and [RDFa] , may be used to provide additional relevant
information, for example the type and intended use of the things
identified by individual names in the namespace. The RDF model
defined here does not constrain whether or how such additional
information may be provided.
2 The Model
There may exist any number of ancillary resources that are
related to a namespace. Borrowing on the terminology defined by
[RDDL 1.0] , we say that each of these other
resources has a nature and serves a
purpose.
In RDDL 1.0, the nature of a resource is specified using a URI,
which identifies “what kind of thing” the resource is. For example,
the URI http://www.w3.org/TR/html4/ is used to specify
that a related resource is an HTML4 document, while
http://www.isi.edu/in-notes/iana/assignments/media-types/text/css
specifies that it's a CSS stylesheet and
http://www.w3.org/2001/XMLSchema specifies that it's a
W3C XML Schema document. The URIs used in RDDL 1.0 to specify
natures varied widely, as these examples show (being URIs for
respectively a W3C specification, an unresolvable node in IANA's
web space and a namespace document).
In RDDL 1.0 the purpose of
served by an ancillary resource is also
specified using a URI, which identifies “what the ancillary
resource is for” with respect to the resource to which it is
related. For example, its purpose might be “validation” or
“normative reference” or “specification” or “transformation”. The
URIs used for purposes in RDDL 1.0 are all of the form
http://www.rddl.org/purposes# plus the name of the
purpose.
In order to model this set of relationships in RDF, there are
two aspects which we must consider with care. The first is the
range of “nature” labels. The second is the fact that we're
describing a relationship between four terms: namespace, purpose,
nature, and ancillary resource.
The range of labels used to identify the nature of a resource is
very broad, ranging from terms defined in an RDF ontology to media
types to the URI of specification documents to XML namespaces to
the URI of a web site. To say that the nature of a resource is any
one of these things suggests that the notion of “nature” has an
exceptionally broad range. If a URI identifies a nature, is it
coherent to say that it also identifies a HTML document, a media
type or a namespace?
We can address this problem by observing that we don't really
need to model what a nature is, we simply need to model the fact
that we use a nature-related URI as a key to distinguish between
different resources that could satisfy the same purpose.
With respect to the number of terms in the relationship, recall
that RDF deals naturally with triples; addressing relationships
with four or more parts is less straightforward. It's also worth noting that RDDL 1.0 doesn't set up
links directly from a namespace to its ancilliary resources, but
rather from individual resource description anchors within a
namespace document.
We deal with both of these issues in our model by introducing a
new, anonymous resource. The namespace is
related to this This anonymous
resource by its purpose; serves a purpose with respect to the anonymous resource namespace; it has a nature key and a target
resource. We can show this graphically as follows:
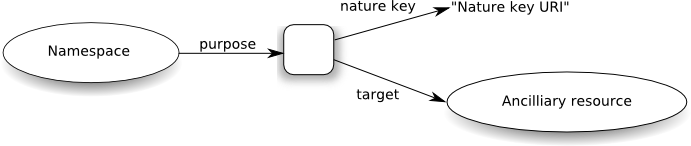
The model treats the collection of
anonymous resources as indexed by the purposes
they serve. The label purpose in the above
diagram will be replaced by specific purposes in any actual
instance of the model. For example, here's a diagram of the
model for some DocBook-related resources:
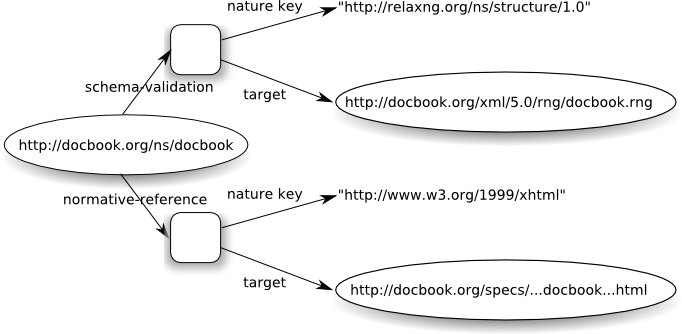
This model indicates that for the purpose of validation there is
a resource whose nature key is the one for Relax NG, and for the
purpose of normative documentation, there is a resource whose
nature key is the one for XHTML documents.
If an application can obtain this model from the document that
it gets from the namespace URI, then it can find the relevant
related resources. (It may also, of course, find the relevant
related resources more directly if it has a native understanding of
the format of the document.)
For example, a Relax NG validator could find all the resources
that serve the purpose “validation” and identify the one (or one of
the ones) with the nature “Relax NG” and proceed with a validation
task. Similarly, a human being could find the resource with the
purpose “normative reference” to locate the specification in a
convenient format. The value of the nature
information is that it enables software (or people) to identify the
resources they are looking for without having to dereference many
URIs looking for the right media type/namespace/...
Here's an expanded example of the DocBook model above, expressed
in RDF using [N3] , with two
. :
# RDDL Model for DocBook
@prefix purpose: <http://www.rddl.org/purposes#> .
@prefix nature: <http://www.rddl.org/natures#> .
<http://docbook.org/ns/docbook>
purpose:validation [a nature:Object;
nature:key "http://relaxng.org/ns/structure/1.0";
nature:target <http://docbook.org/xml/5.0b1/rng/docbook.rng> ];
purpose:validation [a nature:Object;
nature:key "http://www.w3.org/2000/10/XMLSchema";
nature:target <http://docbook.org/xml/5.0b1/rng/docbook.xsd> ];
purpose:reference [a nature:Object;
nature:key "http://www.w3.org/1999/xhtml";
nature:target <http://docbook.org/tdg5/en/html/> ];
purpose:normative-reference [a nature:Object;
nature:key "http://www.w3.org/1999/xhtml";
nature:target <http://docbook.org/specs/wd-docbook-docbook-5.0b1.html> ] .
Although it is often the case the purpose and nature are closely
coupled, it is not always possible to determine one given the
other, as this expanded example shows. On the one hand we have two
XHTML documents, one for the purpose of normative, and the
non-normative, reference. On the other hand the purpose of schema
validation is be satisfied by two resources, one a Relax NG
document and the other a W3C XML Schema document.
3 Namespace
Document Formats
This section describes two formats deployed explicitly to
address the question of namespace documents and a third format
which can be seen as simultaneously providing a unified view of
these two formats and also providing a model to make other new
formats available.
3.1 RDDL 1.0
A RDDL 1.0 document encodes the nature and purpose of the
related resource in a rddl:resource element. That
element uses XLink:
<rddl:resource xlink:title="Relax NG for validation"
xlink:arcrole="http://www.w3.org/2005/12/assoc#relaxng-validation"
xlink:role="http://relaxng.org/ns/structure/1.0"
xlink:href="http://docbook.org/xml/5.0b1/rng/docbook.rng">
A <a href="http://docbook.org/xml/5.0b1/rng/docbook.rng">schema</a>
for Relax NG validation.
</rddl:resource>
Extacting the model is a simple matter of reading the
xlink:href , xlink:role , and
xlink:arcrole attributes of each
rddl:resource .
3.2 RDDL 2.0
One of the RDDL 2.0 proposals encodes the nature and purpose of
the related resource directly on the HTML a
element:
A
<a rddl:nature="http://relaxng.org/ns/structure/1.0"
rddl:purpose="http://www.w3.org/2005/12/assoc#relaxng-validation"
href="http://docbook.org/xml/5.0b1/rng/docbook.rng">schema</a>
for
Relax
NG
validation.
Extacting the model is a simple matter of reading the
rddl:nature , rddl:purpose , and
href attributes of each HTML a .
3.3 Using GRDDL
A third approach is to use [GRDDL] . GRDDL
provides a mechanism for gleaning resource descriptions from XML.
Employing GRDDL allows an author to associate a transformation with
a document. The result of applying that transformation is an RDF
model (the resource description).
Given that our RDDL model can be expressed in RDF, such a
gleaned resource description can be seen as a RDDL model. Consider
the following example:
The URI http://www.w3.org/2000/10/swap/pim/usps is
the namespace name for an RDF vocabulary that describes United
States postal addressing terms. Its namespace document is
an XHTML document that uses GRDDL to identify an XSLT
transformation into RDF.
If this transformation is applied, the resulting resource
description includes the following model fragment:
<http://www.w3.org/2000/10/swap/pim/usps>
purpose:normative-reference [nature:target <http://pe.usps.gov/cpim/ftp/pubs/Pub28/pub28.pdf>],
[nature:target
<http://pe.usps.gov/cpim/ftp/pubs/Pub63/Pub63.pdf>]
.
In other words, this RDDL model:
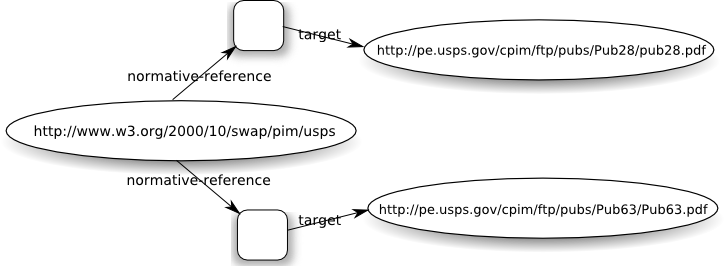
(The lack of nature keys in this example is not a bug, it simply
reflects a lack of information in the HTML original.)
It's important to note that XSLT processing is not required to
take advantage of GRDDL. For well-known transformation URIs, an
application can be written to extract the data directly from the
source markup without actually running an XSLT transformation. XSLT
is only required when an application wants to support arbitrary
GRDDL transformations.
In fact, a pair of well-known GRDDL transformation URIs for RDDL
1.0 and RDDL 2.0 will allow us to unify both RDDL variants and the
GRDDL case.
4 Namespace URIs
and Namespace Documents
In its finding on how responses to requests for resources which
are not information resources should be constructed [HTTPRANGE] , the TAG recommended that
documents descriptive of non-information resources should not be
simply returned normally in response to requests for URIs which
identify those resources. Since a namespace document is precisely
such a descriptive document, and namespaces are not information
resources, what should be done? How should namespace documents, as
opposed to namespaces themselves, be identified and retrieved. retrieved?
Broadly speaking there are two distinct patterns of namespace
naming, one virtually universal for namespaces identifying names in
XML document vocabularies, and one at least dominant for namespaces
identifying constituents of Semantic Web ontologies. Different
solutions to the namespace document identification/retrieval
problem are appropriate in these two cases.
4.1
Namespace URIs and Namespace Documents: The XML language case
Many XML languages use namespaces to distinguish the element and
attributes names in that language from all others. For many of
these languages, a namespace document can be retrieved from the
namespace URI today, whether they are official W3C standards (for
example W3C XML Schema (namespace URI http://www.w3.org/2001/XMLSchema
), SVG (namespace URI http://www.w3.org/2000/svg )) or
created by government (State of Minnessota Criminal Justice
Integration http://www.it.ojp.gov/jxdm/3.0.2
), industry groups (Auto parts (PIES) www.aftermarket.org/eCommerce/Pies http://www.aftermarket.org/eCommerce/Pies ) or
individuals (RelaxNG http://relaxng.org/ns/structure/1.0
). We recommend that in all such cases server
configurations should be changed, in line with [HTTPRANGE] , to respond with a 303 redirection
from the namespace URI to a related URI for the namespace document.
For all of the above examples, and for virtually all cases we are
aware of, an appropriate URI for the namespace document (and indeed
one from which it is often already available) can be formed by
simply adding .html to the namespace URI.
Note:
The examples above, and in the next section, were as described
at the time of publication, but may change over time.
4.2
Namespace URIs and Namespace Documents: The Semantic Web case
Many namespaces have been created in the context of Semantic Web
projects to distinguish the names of classes, properties and
individuals defined and/or described by that project from all
others. One common approach is to use a namespace URI ending with a
hash ( # ) to identify the namespace, in which case
the URI without the hash is available to identify the
information resource which describes the namespace, that is, the
namespace document. Some Semantic Web vocabularies, however, use
plain URIs without a # , in which case the same
303-based approach recommended above should be used. Some
namespaces in this category already do this, for as illustrated by
this example t. . Others do
different kinds of redirection. For example, we find RDF and HTML
descriptions of the FOAF namespace http://xmlns.com/foaf/0.1/ at
http://xmlns.com/foaf/0.1/index.rdf
and http://xmlns.com/foaf/0.1/index.html
respectively, to which we are silently redirected via content
negotiation, whereas for the one of the Dublin Core namespaces
http://purl.org/dc/terms/
we find its RDF description at http://dublincore.org/2006/12/18/dcq.rdf
, to which we get a 302 ('Found') redirection.
4.3 GRDDL and
Namespace documents
When both human-readable and RDF-format descriptions of a
namespace are available, with the latter being derived from the
former via GRDDL, it is good practice to make the
GRDDL-derived description available at its own URI. Whether this is
done using a static copy or by applying the GRDDL-specified
transformation on demand is an implementation detail.
5 Identifying
Individual Terms
For many applications of namespaces, it's valuable not only to
be able to point to the namespace as a whole, but also to be able
to point to terms within that namespace. Fragment identifiers are
the obvious mechanism for achieving this. For example,
http://www.w3.org/2005/xpath-functions/#matches is the
URI for the “matches” function, a term in the XQuery 1.0, XPath
2.0, and XSLT 2.0 Functions and Operators Namespace ,
http://www.w3.org/2005/xpath-functions/ .
If it would be valuable to directly address specific terms in a
namespace, namespace owners SHOULD provide
identifiers for them. It follows that if the namespace document is
available in multiple forms (RDDL 1.0, RDF through GRDDL, etc.)
that consistent fragment identifiers MUST be made
available. See 3.2.2.
Fragment identifiers and content negotiation in [WebArch Vol 1] .
6 Nature
Keys
The nature key of a resource specifies the fundamental or
essential characteristics of that resource. We often speak of the
nature of documents in an informal manner: when we say “that's an
XML Schema”, or “that's an HTML document”, or “that's an XML DTD”,
we are identifying the nature of those documents.
The RDDL Model uses a URI to uniquely identify the nature of a
resource. For XML vocabularies, the namespace URI is often suitable
as a key for the nature of a resource encoded in that vocabulary.
For other resources, the URI of the
a media type or normative specification
is appropriate. Here are the nature keys corresponding to the
natures listed in [RDDL 1.0] :
- http://www.rddl.org/natures#term
-
The nature key for a defined term.
-
http://www.isi.edu/in-notes/iana/assignments/media-types/text/css
-
The nature key for CSS.
-
http://www.isi.edu/in-notes/iana/assignments/media-types/application/xml-dtd
-
The nature key for an XML DTD.
- http://www.rddl.org/natures#mailbox
-
The nature key for a mailbox.
-
http://www.isi.edu/in-notes/iana/assignments/media-types/text/html
-
The nature key for generic HTML.
- http://www.w3.org/TR/html4/
-
The nature key for HTML 4.
- http://www.w3.org/TR/html4/strict
-
The nature key for HTML 4 Strict.
- http://www.w3.org/TR/html4/transitional
-
The nature key for HTML 4 Transitional.
- http://www.w3.org/TR/html4/frameset
-
The nature key for HTML 4 Frameset.
- http://www.w3.org/1999/xhtml
-
The nature key for XHTML 1.0.
-
http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict
-
The nature key for XHTML 1.0 Strict
-
http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional
-
The nature key for XHTML 1.0 Transitional.
- http://www.w3.org/2000/01/rdf-schema#
-
The nature key for an RDF Schema.
- http://www.xml.gr.jp/xmlns/relaxCore
-
The nature key for Relax (not Relax NG) Core.
- http://www.xml.gr.jp/xmlns/relaxNamespace
-
The nature key for Relax (not Relax NG) Namespace.
- http://www.ascc.net/xml/schematron
-
The nature key for Schematron.
- http://www.rddl.org/natures#SOCAT
-
The nature key for an OASIS Open Catalog.
- http://www.w3.org/2000/10/XMLSchema
-
The nature key for a W3C XML Schema.
-
http://www.w3.org/TR/REC-xml.html#dt-chardata
-
The nature key for XML character data.
- http://www.w3.org/TR/REC-xml.html#dt-escape
-
The nature key for escaped XML.
-
http://www.w3.org/TR/REC-xml.html#dt-unparsed
-
The nature key for an XML unparsed entity.
- http://www.ietf.org/rfc/rfc2026.txt
-
The nature key for an IETF RFC.
- http://www.iso.ch/
-
The nature key for an ISO Standard.
7 Purposes
Purpose is a relationship between a namespace, another resource
and the nature of that resource. Broadly, it answers the question
"For this purpose with respect to this namespace, what resource do
I need, and what is the nature of that resource?". For example,
with respect to a particular namespace, the purpose of an W3C XML
Schema might be “validation” (of documents in that namespace). For
the XHTML 1.0 namespace, the purpose of the XHTML Recommendation
might be “normative reference”. Although when expressed as it is
here as the name of an RDF property, the name 'purpose' seems to
read backwards, as it were, it has been retained for compatibility
with RDDL 1.0.
Here are the purposes identified in [RDDL
1.0] :
- http://www.rddl.org/purposes#validation
-
Serves the purpose of SGML or XML DTD validation.
-
http://www.rddl.org/purposes#schema-validation
-
Serves the purpose of W3C XML Schema validation.
- http://www.rddl.org/purposes#module
-
Serves the purpose of a software module.
- http://www.rddl.org/purposes#schema-module
-
Serves the purpose of a schema module.
- http://www.rddl.org/purposes#entities
-
Serves the purpose of an entity or collection of entities.
- http://www.rddl.org/purposes#notations
-
Serves the purpose of a notation or a collection of
notations.
- http://www.rddl.org/purposes#software-module
-
Serves the purpose of a software module.
-
http://www.rddl.org/purposes#software-package
-
Serves the purpose of a software package.
-
http://www.rddl.org/purposes#software-project
-
Serves the purpose of a software project.
- http://www.rddl.org/purposes#JAR
-
Serves the purpose of a Java archive, a package of code and/or
other resources.
- http://www.rddl.org/purposes#reference
-
Serves the purpose of documentation.
-
http://www.rddl.org/purposes#normative-reference
-
Serves the purpose of normative documentation.
-
http://www.rddl.org/purposes#non-normative-reference
-
Serves the purpose of non-normative documentation.
- http://www.rddl.org/purposes#prior-version
-
Serves the purpose of being a prior version.
- http://www.rddl.org/purposes#definition
-
Serves the purpose of a definition (as to a specific term)
- http://www.rddl.org/purposes#icon
-
Serves the purpose of an icon or other relevant image.
- http://www.rddl.org/purposes#alternate
-
Serves the purpose of being an alternate.
-
http://www.rddl.org/purposes#canonicalization
-
Serves the purpose of being canonical.
- http://www.rddl.org/purposes#directory
-
Serves the purpose of being a RDDL directory.
- http://www.rddl.org/purposes#target
-
Serves the purpose of being the target URI (as of a
#directory).
- http://www.rddl.org/purposes#target
-
Serves the purpose of being the target URI (as of a
#directory).