Publishing Working Group F2F, 2nd day — Minutes
Date: 2017-11-07
See also the Agenda and the IRC Log
Attendees
Present: George Kerscher, Mateus Teixeira, Tzviya Siegman, Rachel Comerford, Lillian Sullam, Brady Duga, Evan Yamanishi, Jun Gamo, Avneesh Singh, Toshiaki Koike, Charles LaPierre, Garth Conboy, Marisa DeMeglio, Liisa McCloy-Kelley, Daniel Weck, Dave Cramer, Tim Cole, David Wood, Ivan Herman, Ric Wright, Benjamin Young, Luc Audrain, Takeshi Kanai, Leonard Rosenthol, Cristina Mussinelli, Laurent Le Meur, Bill McCoy, Rick Johnson, Baldur Bjarnason, Karen Myers, Hadrien Gardeur, Florian Rivoal
Regrets:
Guests: Dave Browning, David Singer, Dan Sanicola, Lars Wallin, Jasmine Mulliken, Ken Brooks, Samuel Petit, Paul Belfanti
Chair: Tzviya Siegman, Garth Conboy
Scribe(s): Romain Deltour, Benjamin Young, Luc Audrain, Paul Belfanti, Daniel Weck, Evan Yamanishi
Content:
- 1. Warm-up
- 2. Media Overlays
- 3. Security, privacy, integrity (with leonardr)
- 4. Manifest revisit
- 5. Pagination, page transitions
- 6. Locators
- 7. Wrap of the meeting
Tzviya Siegman: quick introduction, some new faces today
1. Warm-up
Tzviya Siegman: yesterday we went through a lot of stuff
… discussion on the lifecycle of a publication, and packaging
… we basically agreed we had 4 stages: discover, identify, select, obtain
… that’s were we are with WP
… we also talked about i18n
… discussion about UA and where we are with browsers
… the point is to have a FPWD
… we did close one issue (smile)
Ivan Herman: we had some discussions about the manifest / waybill
2. Media Overlays
Marisa DeMeglio: let’s talk about synchronized audio ebooks
… EPUB 3 introduced media overlays, to sync narrated audio with the text of the publication
… done with the SMIL language, got historical precedent with the DAISY format
… SMIL is a very complicated language, we just use a small subset
… the SMIL file sits in the publication, referenced in the manifest
… [quick demo with Readium]
Marisa DeMeglio: we heard the audio, and saw the text highlighted as audio proceeded
Daniel Weck: https://github.com/w3c/publ-wg/wiki/Requirements-and-design-options-for-synchronized-multimedia
Marisa DeMeglio: requirements: audio playback is synchronized, navigate in the audio the same way you navigate in the text
… escape complex structures (e.g. out of a table), some customization (eg. don’t follow footnotes)
Leonard Rosenthol: these all sound like UA requirements
Marisa DeMeglio: yes, except it has to be defined in the spec
Tzviya Siegman: one of the thing this group has to figure out is what to do with media sync, whether to create a TF, a Note, etc
Leonard Rosenthol: OK, was trying to understand what was the dividing line between UA and content spec
Marisa DeMeglio: good question, as daniel said it’s mostly metadata
Leonard Rosenthol: identifying things semantically is a different thing than things like trying to escape structures
Daniel Weck: as a content creator, I want to be able to identify categories of content (page numbers, aside) that would automatically be skipped during playback
… as a user, I want to select / opt-in this behavior
Marisa DeMeglio: more user requirements: playing the audio faster, time-based navigation (fast-forward)
… for WP, we looked at a few different candidates
… TTML and Web VTT intend to embed text captions in videos, not really fit, we want the inverse
… Web Animations have no declarative syntax
… SMIL, which nobody loves
… I think we can do better
… XML processing in the browser is not optimal
… Web Annotations look more promising
David Wood: Web Annotations++
Marisa DeMeglio: in a way you can see MO as an annotation for a publication
Tim Cole: [scribe didn’t hear]
Ivan Herman: how do we specify what we need?
… we also have to see how we can provide some initial implementation, polyfill, etc
… if I look at the list, probably the Web Animation is in a different category. Not declarative syntax but it has some implementations
… SVG and others reformulate what they do based off Web Animations
Ric Wright: what are the requirements in terms of backward compatibility?
… SMIL and MO are used, we have to support them forever in RS
… we can do something cool with new tech, but then I have two different ways of doing the same thing
Garth Conboy: our charter is very specific (facetiously) on this point
… roundtripping to EPUB 3 is intended for EPUB 4
Tim Cole: Re Web Annotations - a subset of the WA data model focused on locating content within WPub is being developed with extensions
Tim Cole: We will want to track closely relevant to media overlays
Garth Conboy: it depends a lot on the approach taken, but providing backward compatibility is a SHOULD for EPUB 4
Ivan Herman: I think the problem raised by Ric is that the SMIL subset, in terms of expressing what we need, is something that will live on for a while
… it’s an unfortunate fact that that syntax will not live on for a long time
… for publications done on the Web, it’s unrealistic to keep that
Liisa McCloy-Kelley: we talked about the idea of using the packaging structure for audio books, how does that relate to what we’re using here?
… are we thinking it enables synchronization?
Marisa DeMeglio: there’s a gap there from EPUB 3 on what we do with books with more audio, or audio-only
… the user has some high-level structure with TOC, but not the full text
Ric Wright: we see that form the publishing point of view, then add audio, then we have comics. all of these have different requirements
Tzviya Siegman: we’re not just talking about accessible audio, but audio books for everybody
… trade audio books could replace the specialized publications
Laurent Le Meur: refining what Ric said: if we keep the same kind of model as SMIL, our work will be lower than if we move to something entirely different like Web Annotations
… the solution will impact the development
… to answer to Lisa, if you want audio books in EPUB 4, the problem is much simpler than if we want synchronization
… there’s a strict parallel to a ToC pointing to text and a ToC pointing to audio
… we need to have a solution for audio books, it’s not necessarily this one
Charles LaPierre: Marisa showed sentence-level highlighting, you can have word-level, character-level, to be considered
David Singer: this question was asked in a whole bunch of forums: how do I keep my page synchronized with some multimedia running inside the page
… we have to put together a lot of tools
… you may have all the pieces you need, but it takes a while to gather them
Bill McCoy: I think more generally we call it Media Overlays not audio overlays, we can imagine e.g. VR overlays
David Singer: syncing media with the page is a struggle in DVB, ATSC, 3GPP, MPEG and other places. we should see if we can find a common solution there; there are a lot of pieces that, when put together, help, but they are all over our specs (e.g. VTT, TTML, JS, DOM, HTML and so on)
Bill McCoy: that’s an example where keeping it flexible may enable more use cases
Luc Audrain: it w/b very useful for dyslexic people to be able to highlight syllables in words
Marisa DeMeglio: people have mentioned a lot of the issues we ran into
… there are a lot of similarities between sync video+text, audio+text, etc
… we’ll have to put some parameters on what type of content we want to tackle
… if we piggy back on a spec like Web Annotations, we require UA to implement it
… we also looked at using our own syntax, JSON structure
… w/b easy for implementers, lighter weight, easier to work with in a browser context
… we can have a Note about a custom syntax
Daniel Weck: there’s a link in the slides about a very early prototype
… I invite you to have a look at the wiki page, including high level reqs and use cases
… we have an opportunity to move away from SMIL and use a more webby format
… but also support use cases not supported in EPUB 3 MO
… MO were a regression from the DAISY world, which support a wider range of text/audio combination
… it’s a great opportunity to come up with a lightweight webby declarative synchronized multimedia format
… there was a proposal from a decade ago called SMIL timesheets
… might not be a good time now to look into the details of what we do in Readium 2
Leonard Rosenthol: in the slides, the advantages are compared to SMIL, do you have a more detailed analysis with the other specs (Web VTT, etc)
Marisa DeMeglio: I don’t have a precise answer. if we make our own thing, it can be tailored but we own it
… if we use an existing standard, we may be able to leverage support
Avneesh Singh: https://www.w3.org/WAI/PF/media-a11y-reqs/
Avneesh Singh: the Media Accessibility Requirements have been described already at W3C
… not a new thing
… we should find out how to shape out
Benjamin Young: [describes how to translate the prototype to Web Annotations]
Ivan Herman: one thing is that this kind of requirements are not exclusively for publications
… in my view, the current web world is missing something
Benjamin Young: if you change
texttotargetandaudiotobodyin the readium-2 media-overlays JSON, you have web annotations
Leonard Rosenthol: bigbluehat - yup!
Ivan Herman: my instinct says that whatever we do here, other communities should benefit from it
… I realize it means more work, more synchronization
Benjamin Young: they can be structured more richly, however, and enable more features and better findability (consequently)
Ivan Herman: the other thing, at the moment we know the browsers don’t do much in this area, eventually we want them to do something
… we need to spec in parallel with an implementation, ending up being taken up, at least with a polyfill
… putting more energy into this makes a lot of sense
… publishing community is not only a taker but also a giver, we can push forward things we need
… I realize it has a price, but I wouldn’t want to stop that
Marisa DeMeglio: I have more technical details, but this might be premature
… I agree with what ivan said, it would be great to do this outside our little world
tzivya: we’ll try to get some broader interest
… what are the next steps?
Ivan Herman: I don’t know how far the implementations are
… there are 2 possible ways, not necessarily exclusive
… setup some meeting with key people
… and go through the way that the Web platform likes to work, using the WICG
… coming with a spec, implementation, and trying to get feedback
… I think due diligence is required
Daniel Weck: I was going to ask about the possibility of creating a new CG
Ivan Herman: the WICG is one big CG, but actually setting up a separate CG might be a very good idea
Tzviya Siegman: somebody will have to chair it :)
Daniel Weck: I expect there will be a gap in velocity. Some of us already suggested a successor to SMIL
… in Readium 2 we already have our own internal BFF
… what we have right now is a wiki page with UC and Req, have a gap analysis
… we want to reuse the web platform bits as much as possible
… the OWP is like a toolkit, it gives us all the tools we need to implement MO
… the gap analysis is that what we need is a declarative format to map different media types and replace SMIL
… we have the technologies, but lacking a declarative format
Ivan Herman: I think the next step is to setup a CG and start from there
Daniel Weck: there’s a caveat to the statement that it’s not specific to Web Publications
… I agree that it would be good to have something for the regular need
… but there are also hooks needed in publication metadata
… e.g. to define durations, or to identify that some chapters have MO and others don’t
Marisa DeMeglio: talking about synchronized audio book as a sort of animation: that’s the default rendering we used so far, but it may depend on the user’s preference
Daniel Weck: the metadata and discovery part will need to be defined in Web Publication
Tim Cole: couple different approaches can be used
… web annotation approach tends to leave the document intact
Luc Audrain: +1
Tim Cole: otherwise you need to have control on the original document
… it has impact on content producers
Benjamin Young: the Web Anno model doesn’t assume that these things come from the same origin
… that’s a very common use case
… something to keep in mind
Marisa DeMeglio: that’s something we had in mind in EPUB 3, to have a extra layer
Daniel Weck: EPUB 3 is single-origin by nature
… in Readium 2 we allow MO to be externalized
Luc Audrain: as publishers MO have a very big impact due to the hooks in the text
George Kerscher: I want to make sure I understand the next steps
… I’m hearing WICG, CG, and possible integration with other existing WG
… I’d like to know how to figure this out, are we gonna explore all these path?
Ivan Herman: my proposal is to setup a CG right away
… once it’s setup, have the specifications / documentation that you have published in a readable format for outsiders
… even implementations
… once those are there you can stat the procedure within the WICG to see whether this is something that could eventually raise interest in the Web platform
… in parallel, we can already contact key people
… if I understand well, you have already listed what other WG can be interested
… with this list, Garth, Tzviya, and I can setup a call with the staff contact or the chairs
… but having a CG and good documentation on what you have being published gives you much more weight
Daniel Weck: we need to present a compelling case for creating something new
George Kerscher: the CG could end up extending some other specs?
Ivan Herman: with an implementation created on top of other APIs that the Web already has, that gives a very stable basis
Avneesh Singh: what’s the time to engage with external groups?
Ivan Herman: the email was sent, we’ll see when we get answers
… I don’t know how much time it takes, but once you have a document ready to be presented to the outside world we can setup a meeting
Tzviya Siegman: break time, see slightly changed agenda:
Romain Deltour: https://docs.google.com/document/d/12J3Y3bb5fdPh1r2XH9YloINkNSxBJArocKY108sYCZ0/edit#
Marisa DeMeglio: synchronized audio book slides: https://docs.google.com/presentation/d/e/2PACX-1vQVMWPFcdnF_tSKIW_ODM5-MUmXlQ87GE96fXi-N6gWogyNwdsOI6Tx6SSZelJNvvjNhp-CHhYRPiSK/pub?start=false&loop=false&delayms=3000
3. Security, privacy, integrity (with leonardr)
Ivan Herman: Slides of Leonard’s presentation
Leonard Rosenthol: there are series of points I’d like to make, and then I’d like to lead some discussion
… there are several related issues that I have some text ready for the FPWD
… mainly want to get us on the same page
… and discuss some problematic issues
… I only want to talk about Web Publications–not the packaging
… “Web Publications and their UAs must not compromise the basic security model of the Web.”
… I’d like to look at a few specific things around that
… and see if we can’t come to consensus around some solutions
… first, Secure Contexts (WP)
… this is the difference between HTTP and HTTPS
… Service Workers are a big one for us
… they require a secure context
… whether or not we require their use, even leaving open the option means we should require a secure context
… there are other things as well
… device features, geolocation, microphones, cameras, and notifications
… among others
Ivan Herman: what you mean by recommendations on that slide would imply that all Web Publications must be served over HTTPS
Leonard Rosenthol: Almost. All primary resources would need to be
… secondary resources could be loaded as mixed content
… the rules for what can be (image, fonts, etc), and what can’t be (javascript) are defined for us
Ivan Herman: is it even better to say–beyond this–even those secondary resources SHOULD be loaded over HTTPS
Leonard Rosenthol: I would welcome a SHOULD on that
David Wood: that’s consistent with the current trend on the Web
Ivan Herman: correct
Leonard Rosenthol: right. I want to be sure that publishers and those that will focus on WPs will also continue that trend
… next, Restricting JS (WP) - #90
… groups such as Google and AMP have done this to some extent
… they specifically call out things that shouldn’t happen
… which also work to increase performance
… we could also go farther and turn off scripting
… but that’s likely too far–though some publishers might
… some amount of restriction should be considered
… thoughts?
Ivan Herman: my initial reaction is that we should avoid saying MUST NOT, but perhaps SHOULD NOT to caution publishers away from over using scripting
Tzviya Siegman: I agree with ivan. If we start restricting scripting, we’ll be hit with questions from publishers about how to enable interactivity
… we’ll have to have answers for that, and right now that’s scripting…in JavaScript.
… if we restrict JS, we restrict publishing
Rachel Comerford: +1 - a javascript restriction would be death for educational publishing
Ric Wright: Readium ran into this and had to enable scripting
Romain Deltour: [said good things that the scribe missed…]
Liisa McCloy-Kelley: we also have some examples of things we provide with JavaScript especially in children’s books
… popup callout boxes and things
Mateus Teixeira: +1 - specs that strictly constrain js would not be viable in publishing; we’d be forced to find non-standard workarounds
Liisa McCloy-Kelley: one big thing we often hit is localStorage
Romain Deltour: I don’t think we can restrict anything for Web Publications, even a SHOULD is too strong. For Packaged WP, we need to align with whatever is said in the packaging spec
Liisa McCloy-Kelley: not having that has limited what we can create
Luc Audrain: +1
Romain Deltour: the only area where we could restrict something is in the specific profiles, like EPUB 4
Leonard Rosenthol: the secure context would provide localStorage capabilities
Baldur Bjarnason: How can we get a secure context for a packaged web publication without TLA-based signing?
Matt Garrish: what about UA requirements?
Leonard Rosenthol: that’s perhaps UA specific
Leonard Rosenthol: (in response to Baldur Bjarnason) so. when it loads content outside of the Web–as in from a file–a custom reading system could load it into a secure context
Benjamin Young: said interesting things about Browser Extensions use of CSP and secure contexts
Leonard Rosenthol: next, Restricting Content (WP) - #91
… No Plugins, No Embed/Object, Restricted CSS, Restricted SVG and MathML
… it would also be a way to keep things out…like Flash for example
Tzviya Siegman: we do often, as publishers, make publications of publishers
Leonard Rosenthol: perhaps (for example) it uses something like an iframe…but we do want to avoid embed and object as they are “old school” things
Ivan Herman: I’m not quite sure what we could completely restrict here
… because how do we test and enforce these?
Leonard Rosenthol: perhaps we restrict the language to prevent use of certain elements
… but some UAs do and some don’t support plugins and things–and there’s no way we can restrict that support
Ivan Herman: exactly, there’s no way we can restrict all that
Tzviya Siegman: we can recommend no supporting them in a best practices document
Matt Garrish: EPUB did this a bit. saying essentially don’t rely on these things as they may not exist
… and I agree they can go into a best practices document
… I’m not even sure we need to be specific about recursiveness as UA’s will handle that because they have to
Leonard Rosenthol: there seems to be a consensus to not restrict anything on the Web, and I’m OK with that as well
… next, Privacy
… it would be great to say “Web Publications and their UAs must not compromise the basic privacy model of the Web.”
… in trying to find out what the privacy model for the Web is, it proved quite hard actually
… I did find one.
… DNT - Do Not Track, P3P - Platform for Privacy Preferences, and POWDER were listed on this privacy document
Tzviya Siegman: https://www.w3.org/Privacy/
Leonard Rosenthol: there is also a Privacy Considerations for Web Protocols…but its an unofficial draft
Romain Deltour: https://www.w3.org/standards/webdesign/privacy
Ivan Herman: there is a privacy check list
… and we will have to look at those
Tzviya Siegman: security and privacy checklist https://www.w3.org/TR/security-privacy-questionnaire/
Ivan Herman: the big question is are there new privacy things we need to introduce
… in this case it’s different than security.
Brady Duga: the privacy situation on the web amounts to a Privacy Policy linked to someplace on a site..maybe
… that the global understanding of it anyway
… there’s not much we have to add to that
… however, we will hit this most with Packaged Web Publications
… if someone distributes that PWP and it includes tracking of some kind
… that person may also be tracked by privacy policies that I agreed to
… or that by distributing it the PWP is now outside of that policy
Ivan Herman: is there any precedence for this in EPUB3?
Brady Duga: disable JS?
Romain Deltour: we could allow that publishers add metadata about their privacy policies for each publication
Ivan Herman: so they would need to link to or express their privacy statements in their manifests?
Tzviya Siegman: if we’re putting this information in the publication, we actually fall under laws (wrt to GDPR and things)
Ivan Herman: (I think doing what rdeltour sounds good for me)
Tzviya Siegman: so there are things like this that will dictate some of this
Liisa McCloy-Kelley: this is a tricky thing. and not something most publishers want to get into
… readers want to be along when they’re reading–and not be watched
… there is some trust in publishers that if they do any sort of tracking–even links back to their site–that any tracking must comply with legal requirements–especially with to children
Matt Garrish: I don’t think we should go beyond what’s being defined by legal requirements now
Daniel Weck: is there anything specific to publishing around analytics and usage patterns? this is common on the Web, but is there something specific to the publishing?
Tzviya Siegman: there’s nothing specific, but there are expectations that you’re spending far more time with a single publishing–a novel for instance–and consequently revealing very specific information
Leonard Rosenthol: when people are off the web they have a very different experience–they expect far less (or more likely no) tracking
… at most they may expect to be asked to have data collected about them
Tzviya Siegman: there are expectations changing…especially in education
Leonard Rosenthol: I wanted to go back to Brady’s comment about prior art in terms of tracking
… in acrobat and PDF we stared this sort of effort
… to warn people about documents “phoning home”
Ric Wright: It rings every time leonardr is mentioned
Leonard Rosenthol: the expectation is that they are offline
Daniel Weck: things like cookies get called out when they are being used (per law) so perhaps something like that
Ivan Herman: I think what we can do is list various metadata items that could be added to the core set of information
… in a similar vein we should make some explicit examples that show best practices
Leonard Rosenthol: if we do that, then we have to pick a specific grammar–and there are a lot of those
… but we’d then also need to go farther to say what happens when those are expressed
Ivan Herman: so if we express those in the publication then those should be provided to the reader
Romain Deltour: if I go to a web site, there are typically privacy policy links–perhaps we do something very lightweight
… we don’t need an ontology
Leonard Rosenthol: but there are ontologies for these that we could use
Luc Audrain: the main difference between the Web and publications is reading experience
… blogs and things do show some reading time things, but otherwise most of the Web does not provide reading time/scope information
… publications always do
Benjamin Young: should incognito mode–or more accurately “forgetful browsing” be the default for publications?
… things like reading state could be persisted similar to bookmarks (perhaps via annotations), but stay outside of the wider more exposed space of non-incognito-mode browsing
David Wood: the web is not a private place, and the choices we make here could have similarly wide reaching ramifications
… if we miss an opportunity to say things about privacy, then we miss an opportunity and shame on us.
Bill McCoy: I have a completely different perspective
… on the Web could mean it’s being accessed through a browser
… or it could mean it’s being accessed through an app that uses the Web
… or it could be just a bunch of Web pieces HTML, etc. and read through a reader
… we need to clarify what we mean so we don’t fall into a trap
… when it’s truly on the Web, then it is exactly in the same space
… when it’s offline, then it should come with those privacy expectations.
… but if it’s in a browser, it’s on the Web
… and completely in that state and subject to that privacy situation
Ivan Herman: as was mentioned the packaged web publication does introduce other issues
… what I’m interested in right now, does Web Publication (not packaged) introduce any new privacy situations
… we can’t solve the privacy situation of the Web
… it’s too huge…but we need to be aware of our state within it
Leonard Rosenthol: I still have one more thing to cover: Integrity
… there are number of integrity related issues with packaged publications
… but it’s not clear to me that there are issues for Web Publications beyond what you get on the Web
Ivan Herman: it’s the same kind of issue as before. obviously not enforcing things.
… like with the privacy thing, perhaps we add some slots where I can put some information about signatures
… or signatures of the manifest itself
… or some kind of crypto information that nobody has changed the information since I published it
… do we want to provide a space for that information?
Leonard Rosenthol: I’d thought about that and found the Sub-resource Integrity spec
Dave Cramer: https://developer.mozilla.org/en-US/docs/Web/Security/Subresource_Integrity
Leonard Rosenthol: i don’t think there’s more we need to provide beyond that
… as I understand it you can add cryptographic hashes or file information that the UA can match with the resource it requests to be sure they match
Ivan Herman: I would love to see if this can be done with the “waybill” of the publication
… does that need some additional information?
David Wood: I noticed that we have 4 success criteria in our charter
… “ Each specification should contain a section detailing any known security or privacy implications for implementers, Web authors, and end users. “
… shouldn’t we be specific about what happens with reading time, etc?
Ivan Herman: that section could be almost empty by saying “look at these issues in these other specifications”
… we are not to add anything that is specified elsewhere
David Wood: the reason that level of reading privacy since the early Web until now
… is because we have a complete scripting language that goes beyond the simple, originally conceived document transport Web
… doing that for publications introduces a user expectation violation
… users currently have a much higher level of privacy expectations with a publication
… I’m not asking that we necessarily have a technical solution, but a social statement
… and yes tzviya I will write it
Lars Wallin: there perhaps could be a whitelist of domains or origins, that set an expectation of what this publication will be doing
… and the user should be told about these expectations
… this way you make your intentions explicit
… the user can then make the determination
… if you then add the publication to your reading system, the publication may spy on you, but we should also keep in mind that more likely the reading system will be spying as well
… and that restricting the publication will not be restricted from its watching of your reading habits, or eye tracking, etc.
… it should enforce the manifest of the publication
… but the reading system will also need its own privacy policy
David Wood: I agree the whitelist is a great idea
… I believe the reading system MUST show it to the user
… and not add domains to that list
… can we enforce it? no
… should we say it? yes
Lars Wallin: by having a whitelist section, we’ve taken it as far as the publication
Benjamin Young: browser extensions do something similar to what Lars mentioned about whitelist
Luc Audrain: the existing reading systems do spy on users and don’t necessarily tell them
… something should certainly be stated
… to explicit that
Matt Garrish: there are certainly issues around browsing history
… also wanting to be able to erase that history, etc.
… and I think we should explore those parallels
Daniel Weck: publication wide integrity does not seem possible. we can reference that existing spec, but we’d need to go farther
… in relationship to the content itself, not just its dependencies
Brady Duga: these reading systems will likely be built on browsers. How will they restrict these things?
Leonard Rosenthol: there are things being discussed like sub-origins that will help
Brady Duga: if we release our spec before those, then what?
Tzviya Siegman: it will happen auto-magically
Paul Belfanti: it’s not like every kind of tracking is ill intentioned.
… it can be part of the use of the publication, and education is a key example where communicating the use of the publication to the educator could be valuable
Brady Duga: we’ve been using the word spying a lot. but it’s not necessarily done to spy. it might be done for the experience of the text
Tzviya Siegman: so. we have a lot of questions and a few actions
Ivan Herman: we did mention that there should be a link to a privacy policy or something
Leonard Rosenthol: I feel we should hold off on that piece
Ivan Herman: because
Leonard Rosenthol: I don’t think we can agree on the method quickly enough for FPWD
Ivan Herman: in the first public draft i can be totally vague and point to our intentions
David Wood: if I understand what you
… are saying, then the link to the privacy policy simply points to where they can find the info
… and does seem sufficient for FPWD
Brady Duga: we should keep in mind that there might be several privacy policies governing the various resources
4. Manifest revisit
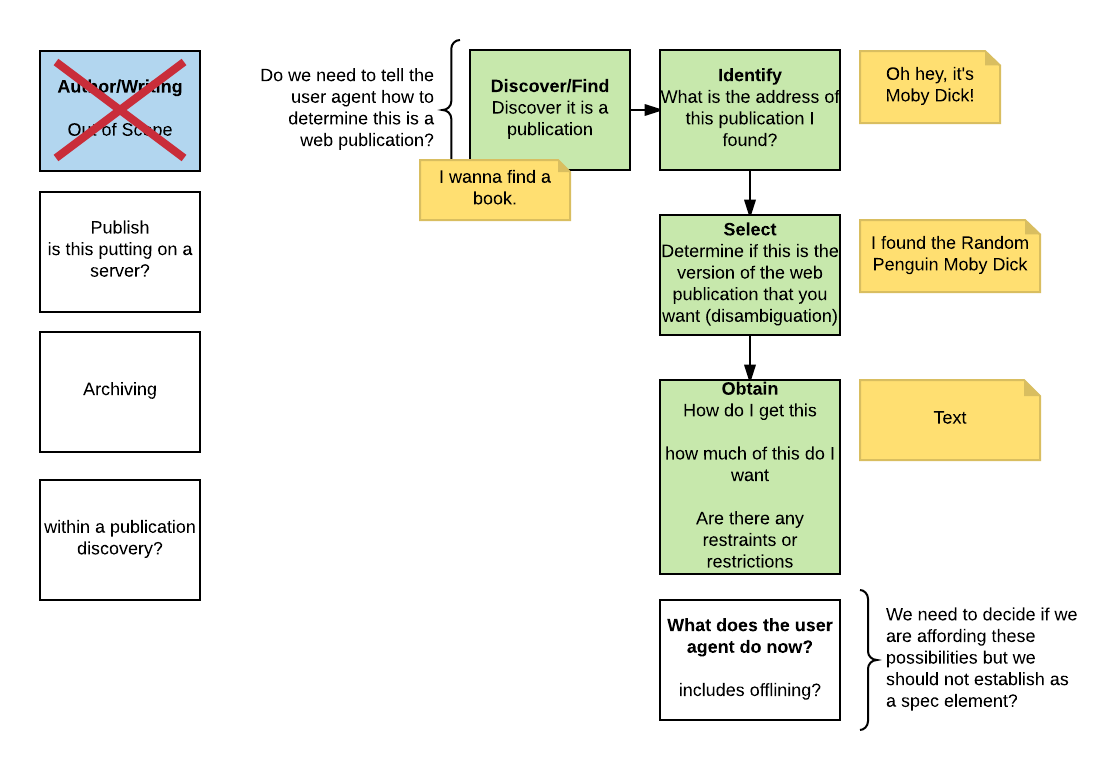
Luc Audrain: Rachel’s figure
{kind=link}
Tzviya Siegman: four categories
… Discover, Identify, Select, Obtain
Garth Conboy: problem with identity
Tzviya Siegman: parent/child and vice-versa
… we made a decision
Tim Cole: question on granularity in obtain
Ivan Herman: consensus : a resource may contain a reference to its parents.
… if a resource belongs to a WP, I may not know about the Publication
… if the publisher want that back link, ok, but is is not an obligation
Benjamin Young: it belongs to the discovery thing
… how do you find a thing if it is not in the thing itself?
Tzviya Siegman: we don’t need to revisit all
… Discovery: I am a WP
laudrain>..: Identity: what is the address of this thing I found
Tzviya Siegman: Select: right version?
Tim Cole: info in metadata to tell that
Benjamin Young: Select to disambiguate
Tzviya Siegman: Obtain : get it
… opening the book, what happens?
Leonard Rosenthol: depends from where we come
Benjamin Young: how i have this publication?
… to keep it
Leonard Rosenthol: where you starts is very significant
Ivan Herman: if i have an URL, what do I get?
Lars Wallin: a WP as Internet of books, use google and Internet engine to index books
… you identify and select a book, the manifest will tell the context of the WP
Benjamin Young: what is the user get from that affordance?
Tim Cole: resources listed in the manifest, default reading order
Tzviya Siegman: https://w3c.github.io/wpub/#wp-enhancements
Ivan Herman: we are degrading what we have done, repeating details
… Issues have been closed, but some stay open
Leonard Rosenthol: the pb lay in we do need what the UA will do
Liisa McCloy-Kelley: example as a sample book, with a chapter for free for discovery
… at some point the user want the book, whatever rule, the uer obtain the book
… they end up with the object they want ti read
Daniel Weck: a possible way to discover is OPDS
… obtain: loading in my context, reading experience with state and context
Matt Garrish: what is key is to have the information in the manifest
… we don’t know all the scenarios
Tzviya Siegman: +1000 to matt
Ivan Herman: there is nothing about these scenarios in EPUB3
… it’s a way of implementation
… Do we try to setup an imaginary system with all the scenarios?
Lars Wallin: in the manifest, could be possible to extent to info on individual content document
Daniel Weck: distributable objects
Daniel Weck: (clarification: DO = humour)
Tzviya Siegman: to wrapup, read the draft, report holes, open issues, before 2 weeks
Ivan Herman: do we want to put something about the discussion yesterday on WAM?
Matt Garrish: a summary
Leonard Rosenthol: draft something
5. Pagination, page transitions
Tzviya Siegman: https://w3c.github.io/wpub/#Layout
Florian Rivoal: Layouts on the web is interesting discussion due to nature of HTML documents
… Rules: don’t break anything, change as little as possible
… Each chapter is created as a separate document
Dave Cramer: some discussion of differences of publications re how they exist in the world, scrolling, etc.
… Books don’t typically do that
… Much implementation experience to indicate that paginated experience is desired by users
… More issues come up with paginated docs on the web - real issues that need to be addressed
… counters flowing from document to document, seems like a big challenge. Is this a problem for the PWG to solve? Thought that in Lisbon it was decided that that would be addressed by a different group
Florian Rivoal: issue of collections
… counters that link to a collection, need to define a sensible model for that
Paul Belfanti: Leonard - thanks to Florian for the excellent work so far
Florian Rivoal: good work on static and flowing model
Florian Rivoal: while the web is typically flowed, while others are paginated. On web model the presentation isn’t controlled by the author, but by the reader
… hopefully browsers will increasingly support pagination. Allow authors to choose their preference
… second part is that unless we want to reinvent most of web, we can’t change what the web calls a document
… CSS, etc. is based on what the web calls a document. must render documents 1 by 1
… We can try and guide the rendering a bit more than is currently done
… for pagination, you don’t want a lot of interaction(?), you just want to turn the page
… what if documents are different sizes? want to start on the next page, etc. Need to make a distinction between a portable document vs a regular web page
Brady Duga: collections-based CSS - may need to load entire book before counter can calculate and display the content
Florian Rivoal: do we want 1000 page books, with indexes, etc. on the web?
… in Vivliostyle - pages within the browsers, with TOC, indexes. User agent running in javascript with other user agents
Benjamin Young: http://vivliostyle.com/en/ on the web
Dave Cramer: counters are not the most important thing, but are a handy example of how to communicate information across documents. Google will solve the problem :)
Florian Rivoal: What is the expectation that each document/chapter is a separate file? why not one large file for each book?
… maybe it’s simpler to have one file
Dave Cramer: Obligatory link: Moby-Dick as one HTML file http://www.clickhole.com/blogpost/time-i-spent-commercial-whaling-ship-totally-chang-768
Paul Belfanti: Ivan may work for some books (Moby Dick) vs calculus book or HTML5 spec
Liisa McCloy-Kelley: some reading systems have limitations to the # of images or bytes that are allowed in file
… also used to indicate page breaks when presentation can’t be controlled in a different way
Florian Rivoal: if we are primarily thinking about browsers, must push to have features better supported
… shouldn’t develop CSS to address limitations on how certain browsers deal with presentation
Tim: List of HTML files may be incomplete
Florian Rivoal: as long as we have top level documents, CSS should be able to render
… will go back to describe when need to work on collections and when not
Daniel Weck: list of HTML resources in not currently a requirement in manifests; what else do we need to include?
Florian Rivoal: from CSS perspective, only thing that exists is a document
… Need to come to CSS and state: we have this collections of documents, indicate what CSS needs to recognize or ignore
… SVG can be an image within CSS; no concept of SVG within CSS, just as not HTML
Dave Cramer: https://html.spec.whatwg.org/#read-media
Florian Rivoal: CSS point of view: we don’t care why there is a document; concept of collections is probably limited
… Do we have to be concerned with how many sections, elements?
Florian Rivoal: CSS is comfortable ignoring certain sections
Lars Wallin: people will read documents on a different number of devices; I’m viewing a page on my phone, but someone next to me is viewing on another device, the pages won’t match. We need to use other reference points on the web.Ex: heading levels or some other device
… if you have fixed page layouts, fine
Garth Conboy: circumstances where you have externally enforced structure (for accessibility, e.g.)
Tzviya Siegman: page markers were defined in EPUB3 spec
Liisa McCloy-Kelley: we went away from page numbers, but have since come back
Florian Rivoal: we want the page numbering mechanism to be possible; page can flex in different devices/views, but can be applied where appropriate
… I’m having trouble seeing how this plays into the work we do in this WG
Florian Rivoal: to tell CSS what to do with this collection of documents
Ivan Herman: that’s true, but it’s not a problem, may be something that someone else will do, but we may need to provide use cases for development of features.
… part of the deliverables in an indirect sense; not something this group needs to wrtie specs for
Florian Rivoal: need to guide CSS WG on how to apply re to collections
5.1. transitions
Samuel Petit: read document re transitions; will be a need to…
Paul Belfanti: [sorry - not hearing clearly enough to take notes here]
Samuel Petit: Markets everywhere, Japan, US, Europe..
… very interested in the proposition, great for a complicated document
… in an industry where we are engaged…?
Dave Cramer: https://extensiblewebmanifesto.org
Florian Rivoal: don’t know how many are familiar with he extensible web manifesto
… What we should do: start with low-level javascript APIs
… The look back and see what people are doing to implement
Florian Rivoal: coming from the POV that what we want to achieve is something that works reasonably well in browsers as they exist today
… currently moving from one object to another does not work well in existing browsers
Florian Rivoal: agree that web industry at large is based on HTML - need to make HTML work for comic books. Other options will not work on the web, so are not viable solution
… we need to fix HTML, not find a way not to use it
Hadrien Gardeur: not just an issue with comics, also with audiobooks
… EPUB has not talked the issue of comics, reading systems need to go around HTML, not something that makes it better
Paul Belfanti: .. instead of using a web view, uses a specific viewer
Hadrien Gardeur: for viewing images, etc
… When we think of comics, etc. we mix up things that would normally be handled by the client.
… vs being reliant on HTML to handle
Takeshi Kanai: will CSS transition work - some CSS animations work, from object to object. How will transition be designed? Object to object, or other?
Florian Rivoal: no set answer; CSS has ways of handling transitions, animations, etc.
… and navigation; many proposals, none have caught up. Pick your favorite and advocate for it
… need a standard format for images, transitions, but not what this group is chartered for
6. Locators
Tzviya Siegman: https://github.com/w3c/publ-loc
Leonard Rosenthol: https://w3c.github.io/wpub/#enh-locators
Tim Cole: Media Fragment URLs (identifiers)
… Web Annotations model (reference existing spec.)
… CFI Canonical Fragment Identifiers
… Web Annotation selectors and states
… mechanism to express which range of document was highlighted
Tzviya Siegman: https://w3c.github.io/publ-loc/
Tim Cole: “publ-loc” selector for fragment of resource, + 2 new members for positioning
… position or range between two positions
Leonard Rosenthol: was is the intent? (as this is already defined elsewhere)
Tim Cole: selector part of Web Annotation is subset
… therefore identify / document it separately
Ivan Herman: simplifies reading / learning about the selectors part of annotations
… there is a technical gap, so we reference the selectors in a non-normative way (informative sections about existing specs.) => “delta” document
Leonard Rosenthol: is the intent to go back to the annotation WG
… WG is closed, does not actually exist
… if in future the WG re-opens, then yes will go back to them
Tim Cole: there are other groups beside the PWG that will need this spec.
… (identify + reference a part out of the whole)
Benjamin Young: https://github.com/w3c/publ-wg/pull/6
Benjamin Young: https://github.com/w3c/publ-loc/pull/6
Tim Cole: CFI in the fragment identifier part requires obtaining an additional resource (level of indirection)
Brady Duga: EPUB itself is the resource, therefore not so different from the contract of the hash / fragment part of URL
Leonard Rosenthol: within WP (not Packaged) each resource has its own URL
Ivan Herman: we cannot use CFI for various technical reasons
… that being said, we need to reproduce functionality, biggest problem was figuring out whether requirements of CFI are still relevant in this WPUB context
Benjamin Young: is side bias still relevant, for example
… annotation for chapter 5 within the publication, cannot just reference the HTML as it may pertain to more than a single publication
Tim Cole: scope issue, to be discussion continued
… annotation model with JSON multiple properties (instead of single URL frag)
Tim Cole: text position selector, differs from CFI side bias
… how useful has side bias proved to be?
Leonard Rosenthol: isn’t that similar to refine by in annotations?
Ivan Herman: real problem was we were trying to reproduce feature in CFI, but is it useful?
tzvia: let’ walk through the main issues
6.1. Need for fragment id-s?
Tim Cole: we have to think about the user agents. do they prefer fragment id’s or are JSON objects enough?
Ivan Herman: if we keep the fragment id’s, a) it’s incredibly ugly and unreadable
… 2) I think there’s a size limit put on it
… but the biggest problem is that fragment id’s become valid if they are registered with a specific media type
… what media type would we register that against? HTML? SVG?
… to do that, we would have to get those groups to accept it, and I do not see them accepting it
… unless there is a strong use-case, we should drop it
Benjamin Young: the use case is linking to a specific item inside a resource
… which is the only reason it’s staying around in Apache Annotator
… some people want to link to specific highlights within a document
… with a PWP, all bets are off
Leonard Rosenthol: is this a conversation to have with the web app working group?
… this has a lot to do with the Web at large, not specifically with WP
… I think we should strongly consider taking this as a general web problem
George Kerscher: video and audio are needed as well
Benjamin Young: the web annotation spec allows for that
Tim Cole: can I suggest that we summarize and move this to an issue to resolve later?
6.2. Positions
Tzviya Siegman: https://github.com/w3c/publ-loc/issues/9
Tim Cole: this issue is missing good use-cases
Brady Duga: the obvious use-case would be bookmarks. I want to specify “this page,” but nothing specific on this page
… the bookmark tends to align to the top, and when you reflow it, you may need to move it
Benjamin Young: here’s an example of an annotation selecting a time range in a video using media fragments https://www.w3.org/TR/annotation-model/#example-17
Ivan Herman: you can select the first character of that word (that the bookmark references)
Daniel Weck: we use CFI extensively. But to be clear, it is not used in authoring tools/interchange
Ivan Herman: if you want to reproduce the way you use it, is that selector enough?
… we originally had 2 ways of specifying the selector
… and then we added this position selector in
… where we select something that is not a selection, but a character or space in between
… the reason I do not really like it is that when you look at the selectors, those are operations that you can do on top of HTML or the DOM tree
… these positions are not in the DOM
Daniel Weck: that’s not true. you’re going to have to deal with the DOM Range API
… I believe text selectors are about UTF code points, CFI uses something else
… I do not know what is the best option
Benjamin Young: the vast majority of what we ended up with in web-anno was dictated by JavaScript
… it was the best thing we had at the time
Brady Duga: one thing I haven’t seen is sortability. is it sortable?
… (example) I have a manifest with a list of all those annotations. How do I know what order to present them to the user?
Ivan Herman: if you have five in one chapter, there is not something you can do
Benjamin Young: annotation does have an annotation collection system
… you would have a collection relating to the document
Tim Cole: if you always use text position, then you would know
Leonard Rosenthol: theoretically, you could also use CSS
Ivan Herman: we seem to not have an agreement on the fragment id. we hope to get feedback from the FPWD
… (re: #9) what do we do with this issue now?
Tzviya Siegman: we need more input from people who really use CFI (VitalSource)
Benjamin Young: the web-anno spec can support new selectors later. we need to resolve the position item now
Leonard Rosenthol: we can’t compare epub-cfi to what we need today for web publications because they are apples and oranges
Tzviya Siegman: i don’t agree. the reason that we’re looking at CFI is that we’re looking at the world of publishing
… EPUB-CFI exists as a way of locating content, which is why we’re looking at it, not because it’s part of EPUB
Leonard Rosenthol: in the PDF world, we use fragment identifiers
… you can identify to most of the things addressed in the selector model. it’s an equivalent model
… could/should we be able to do the same thing?
Tzviya Siegman: Brady and Daniel: Ben and Tim will split this into issues that you can address
Ivan Herman: we must follow the model of the web-anno document, and provide examples of use-cases
Hadrien Gardeur: nothing stops people from using the right-most part of CFI
… you can continue using CFI internally with WP/PWP, I don’t see the issue really
… but that doesn’t mean that we need to do anything about it at a WG level
Tim Cole: can someone explain side-bias?
Garth Conboy: maybe we can lose side-bias
Daniel Weck: if we do not require canonical, offline identifiers, then we don’t need to use fragment ids
Benjamin Young: CFI is far more brittle in nature
6.3. Embedded Resource Selection
Tzviya Siegman: https://github.com/w3c/publ-loc/issues/24
Tim Cole: (re: #24) you typically use this in a refinement
… this relates to multi-selectors, which allows you to select disjointed parts
… how important is it to talk about this in the context of the greater web publication?
Benjamin Young: I think there’s two situations. In the example of selecting in chapter 5, you’ll need to know what’s next (chapter 6?) if you are selecting across that boundary
Tzviya Siegman: you mentioned discontinuous. that depends on how it’s implemented. I could see someone wanting to use it as a collection tool
… it’s a little bit of a weird use-case, though
Ivan Herman: the original use-case for this was a use-case from Rachel
… it was very clearly a use-case of textbooks using that
David Wood: coming from an editor company, our tooling is used to author or update content. We’ve wrestled with issue with any kind of locator inside the content
… clearly there are advantages to setting it in the content, and advantages to setting it externally
Ken Brooks: when we do this, we have someone go in and update the CFI
Evan Yamanishi: and additional use case we have is annotating poetry
… they’re not necessarily next to each other in the rhyming scheme
Leonard Rosenthol: qq+
Romain Deltour: in our selectors, it depends on what you’re selecting (video, image, etc.). this means that you need to specify which type of resource the selector is selecting
… but could it be used to select an element (for instance) in the shadow DOM
Ivan Herman: the whole concept was that this was part of the web annotation. do we have to define more than that for our use-case?
… the “result” of selection
6.4. Wrap up of Locators
Tzviya Siegman: let’s wrap up. We have a lot of action items. Ivan?
Ivan Herman: the main action item is that this document needs to be reviewed. It’s hardly been reviewed outside of editors
… we need to have a review from people who have experience with EPUB CFI
… are those entries that we’ve added necessary? yes or no?
7. Wrap of the meeting
Tzviya Siegman: many open issues, we must go over the minutes, write summary, we did re-hash a number of topics
… emphasis: not re-inventing the web
… it’s okay to have lots of open issues
… we want people to comment / contribute
… we need input from everybody
… concern: during this meeting we talked about things we talked about 6 months ago
… definitions of web publication, packaged / EPUB4: we’ll come back to that in due time
Ivan Herman: practical level, publish FPWD this year, must have consensus on contents
… task: harmonize spec language styles (contributions from various people_)
… a few Pull Requests to process, but not many. good shape for FPWD overall
Ivan Herman: more worried about PWP document
Daniel Weck: Packaged Web Publications
Ivan Herman: clarify that packaging formats pros/cons various choices (list of potential candidates)
… Matt Garrish already has tons on his plate with WP, we need somebody to take ownership of PWP
… Heather to help with cleanup work, but not the person for PWP draft
Laurent Le Meur: scope for first draft? serialization of “manifest” “waybill”
… first draft without prototype? we want to attract web developers to comment on draft
Ivan Herman: ideal world: yes, prototype would be nice
… consensus with JSON, maybe detail discussion about HTML entry point
… discussions outcome about Web App Manifest etc. will be in draft
… mid-November now, need to be realistic
… as soon as document published, then next draft with prototype
Ivan Herman: the real concern of stakeholders was about this groups re-defining HTML, forking the web etc.
… JSON serialization not a worry
Laurent Le Meur: use case document to be updated / maintained
Ivan Herman: possibly WG note later
… good idea
Matt Garrish: ugly placeholders, to become issues, how to assign?
Ivan Herman: placeholders are okay, we know they have to be taken care of later
… Matt will create issues
Ivan Herman: want PWP editor
Tzviya Siegman: we need participation, there is still confusion, right?
… people confused about “package”, is this a problem / open issue?
Laurent Le Meur: CBOR, zip, different requirements / solutions
David Wood: 3 months and maybe beyond that, significant time for PWP
Daniel Weck: next meeting: next Monday
Daniel Weck: claps