The mission of the W3C Credible Web Community Group is to help shift the Web toward more trustworthy content without increasing censorship or social division. We want users to be able to tell when content is reliable, accurate, and shared in good faith, and to help them steer away from deceptive content. At the same time, we affirm the need for users to find the content they want and to interact freely in the communities they choose. To balance any conflict between these goals, we are committed to providing technologies which keep end-users in control of their Web experience.
The group's primary strategy involves data sharing on the Web, in the style of schema.org, using existing W3C data standards like JSON-LD. We believe significant progress toward our goals can be reached by properly specifying "credibility indicators", a vocabulary/schema for data about content and the surrounding ecosystem, which can help a person and/or machine decide whether a content item should be trusted.
w3c/credweb/Group's public email, repo and wiki activity over time
Note: Community Groups are proposed and run by the community. Although W3C hosts these
conversations, the groups do not necessarily represent the views of the W3C Membership or staff.
This group is going to change, at least temporarily, from one building credibility indicators, to one that tests efforts to improve the information ecosystem, based in part on the credibility indicators documented previously by this group.
Building a “test suite” for anti-misinformation efforts will help all those efforts, we hope, improve.
We need a fresh start and some new expertise to make this happen. We hope that you will re-engage with this group, and invite others who can help make this group even stronger.
Below is an edited version of a note that I wrote recently to the group email. I’ll expand on that and have the next steps below:
In the years since I first met Sandro and then joined this group, I’ve seen what happened in this email thread happen a number of times. I’ve also seen it happen in CredCo threads, MisinfoCon discussions, and other groups.
What happens is essentially this: Someone proposes a new thing, let’s call it a MacGuffin. The person who proposes this MacGuffin explains it in great detail, yet is a bit hand-wavy on some of the aspects, especially those about how it will be supported, or how it would get adoption. That doesn’t bother me at all. If we didn’t have people dreaming up new things we wouldn’t have anything new. But the reality is that these are just ideas, not actual initiatives.
Then in Act II there is some discussion about the MacGuffin, talking about the pros and the cons, etc.
Then there is a pause. This pause comes because the group is made up of people who all have full-time jobs. People who have jobs can’t just drop everything and put in the work needed to launch a new MacGuffin. In some cases they can to some degree, which is what Sandro has done with TrustLamp. He would be the first to tell you, I think, how hard that is.
After the pause comes Act III, in which some people who are in the group realize that much of the MacGuffin is a lot like what they are already doing, and so they promote their own thing. Or sometimes they provide a link to something else that exists that is similar.
After that, the play is over, everyone goes home. And then after a while it happens again.
My suggestion (and the reason that I ran for the chair) is that we reverse the order of this play. Rather than: 1. Idea, 2. Evaluation, 3. Look at related existing initiatives. We do this: 1. Look at existing initiatives, 2. Evaluation, 3. (with luck) Propose new ideas that fill an existing and yet un-served need.
To evaluate the current initiatives effectively, I would propose that first we come up with some guidelines. To do that, we start with the documents we have and that we have all agreed to. Then we turn those into the start of a framework for evaluation. Once we agree to that framework, we publish it.
That will give this group the relatively quick win of publishing something that can be used by anyone as they are looking at existing initiatives, or are thinking about starting something new. It essentially puts this group in the middle of many conversations happening about misinformation. It will help everyone to clarify what can actually help, whom it helps, how much it helps, and how much downside there may be.
Once we have that document, we can then decide if we want to meet regularly and evaluate initiatives based on that document, or create a new group to do that, or examine the whole landscape and figure out if there’s something that would be appropriate for this W3C group to try to do next.
I say all this not to say that the original idea doesn’t have merit, or that any idea discussed here (including my own trust.txt) is great or sucks. I’m just saying it would help the world, and each of us individually, if we could evaluate ideas based on a common vocabulary.
That was the note that I sent to all the current members of the group after a round of emails, and I was indeed elected chair, along with the incomparable Aviv Ovadya. Here’s what I am now proposing that this group does, more specifically:
Members
I’m first going to propose that we expand the membership. I will be reaching out to some journalists that I know, and I’d encourage all of the current members to reach out to at least one other person as well. We have a lot of technical firepower in this group now when it comes to technical standards, but we don’t have journalists, even though this group’s goals are inextricably bound up with journalism. We are talking about systems of credibility for people, but we don’t have deep expertise in user interface, psychology, or any other discipline related to distribution and consumption of credible information online. If we want to fix a problem that big, we need a lot more tools in the toolbox.
It’s been so long since we had regular meetings, that as soon as we’ve grown the group to the size and with the profile that meets the above goal, we should send out a new doodle poll to find a time to meet that works as well as it can work. My suggestion is that we shoot for a monthly cadence at the start.
Process for a new working document
There are several ways we could do this, but I think perhaps for the sake of expediency, the best might be this: I will create a first working draft of the document. It will be rough, have giant holes, and probably will bear no qualities that will be in the final draft. But at least we’ll have a document.
I’ll send it out to the members of the group at least two weeks before the first meeting. The agenda for the first meeting will be to get a sense from the group that the document is indeed the direction that the Credibility Group wants to move in. We’ll also come up with a target for when we’ll be ready to publish a public draft, and then the final document. My hope is that the final document will come about six months after the first meeting.
At that first meeting, my hope is that we’ll get at least a couple of volunteers who will be willing to take a stab at either writing the bits to fill in the holes, or even running small sub-committees to hash through the thorny issues and present potential language to the larger group.
Long-range goals
The document I’m talking about here is somewhat different from most W3C documents. It won’t be a standard in the sense that it will be a reference document. It will be, I hope, a document that can be used to evaluate just about anything that hopes to work on the web to fight misinformation in general. So, in that way, it’s a bit like a tool that a W3C group might come up with. For instance, W3C has a long history of building and advocating for tests to drive interoperability, like this suite of tests for CSS, and these for internationalization. But instead of testing code, this test will be one to check misinformation efforts.
Indeed, some of the questions we have will be similar, I’m guessing. For example, if there’s a proposed effort to to find credibility signals on a page, will it work in other languages? Will it be available to people with visual or other disabilities? Will it work in all browsers/platforms/devices?
While the test that we create may not be able to be run as software, I would think we’d want it to be as close to software as possible. For instance, if some new effort claims that it works internationally, the person making that claim should have some evidence to make that claim verifiable by anyone.
What will this document look like?
This will be up to the group, but as one of the co-chairs, a guiding principle for me be the idea that this testing document be as universal as possible. That is, I don’t want any document to get too far away from its implementation. Perhaps the document that we create isn’t a document at all, but instead is a Google Form that is filled out answering questions about misinformation-fighting efforts, and the resulting data is available for all.
I envision us creating what educators would call a rubric, a guide that will allow us to grade efforts that are built to improve the information infrastructure of the open web.
My goal is that we create something that builds a new body of information that will be really useful in this fast-changing world. What exactly will happen with it is unknown, but I do know that when I talk to people in the world of misinformation I find that the conversation often turns to trying to remember which effort does what exactly. If we can provide a quick common basis for analysis and familiar and easily searchable repository, it will help us that are inside of the efforts first. From there, it should make all of us just a bit stronger and better informed.
Last month, we decided to try writing a spec for some credibility signals. What observations can be made (perhaps by machine) which are likely to indicate whether you can trust something online? In the past, we’ve listed well over a hundred, but that turned out to be not very useful. With so many signals, we weren’t able to say much about each one, and it wasn’t clear to readers where to focus their attention. (See https://credweb.org/signals for some drafts.)
This time, we decided to focus on a small handful, so we could say something useful about each one and only include ones we actually expect to be useful. Personally, I was able to think of about 15 where I have some real confidence.
Today, based on discussion at five of our weekly meetings, we’ve released a draft with five signals, three of which are variations on a theme. This is intended as a starting point, and we’re very interested in feedback. What signals do you think are most promising? Are you involved in building products or services that could produce or use this kind of information? Is the format and style of this document useful? The draft includes some ways to contact us, but perhaps the best way is to join the group and introduce yourself.
Last week we talked about ClaimReview, with a presentation from Chris Guess (group member and lead technologist at Duke Reporters Lab). See notes and a video is available on request. ClaimReview continues to see wide adoption as a way for fact checkers to make their results available to platforms and other applications, and various improvements are in the works. There’s now a high-level website about it, at claimreviewproject.com
This past long weekend a few of us attended WikiCredCon, a credibility-focused instance of the North American Wiki Conference.
I was fascinated to see more behind the scenes of the Wikipedia world and was surprised how much difficult work is necessary to keep Wikipedia running. Perhaps most daunting from a credibility perspective is how hard it is to combat the sock puppets / bots. Many parallel tracks, so each of us could only see a small slice of the conference. Most sessions had extensive note-taking and even video recording, thanks to sponsors. Not all the video is online yet, and currently session notes are at the “etherpad” links from the session detail pages; I imagine those might move soon.
This week, group member Brendan Quinn (Managing Director of IPTC – the global standards body of the news media) will present and lead a discussion about their current work with credibility data interoperability. See you there!
Last week, we talked about AM!TT, an approach to extending currently deployed infrastructure for coordinating efforts to resist information security attacks to also help with misinformation attacks. Most of us aren’t experts in that technology, so we didn’t get into the details during the hour, but it was a good start. Folks are encouraged to followup with the presenter (Sara-Jayne Terp), or the misinfosec group. Lots of notes, details, links, and slides in the meeting record.
Today, (the 50th anniversary of the internet) we talked about “credibility scores”, numbers people sometimes assign to content or content providers to indicate their “credibility” (or something vaguely like credibility, depending on the system). I can’t do justice to all the points of view presented (please read the meeting record for that), but I’ll highlight a few that struck me:
There’s a difference between scoring the process and scoring the content produced. For a restaurant, there’s a kind of process review done by the health department, which gives one score, which is different from the reviews of how the food actually tastes.
There’s another distinction between scoring done by professionals and experts (eg Michelin restaurant reviews) vs crowd sourcing (eg Yelp). They are each vulnerable to different kinds of manipulation.
Some folks are quite skeptical that any kind of scoring could ever be net helpful. Others see great potential in systematizing scoring, aiming for something like “Mean Time Between Failure” numbers used in engineering some systems (eg airplanes) to be extremely reliable.
There is clearly a danger here, as the scoring systems would be a major target for attack, and their vulnerabilities could make the overall media system even more vulnerable to misinformation attacks. Even if they are highly secure, they might not be trusted anyway.
Aviv agreed to start drafting a document to focus discussion going forward.
Next Week, we’ll have a presentation and discussion on ClaimReview. This is the technology which enables fact checkers to get search engines (at least Google and Bing) to recognize fact checks and handle them specially. It is a clear success story of how standard data interchange can help against misinformation, but much remains to be done. I expect we’ll hear more about plans and ideas for the future.
As usual, people are welcome to join the group, or just joint for a meeting of special interest to them.
Last week’s meeting was about the Journalism Trust Initiative (JTI), the European effort to standardize quality process for journalism. Thanks so much to JTI lead Olaf Steenfadt for joining us, along with Scott Yates. We have recorded video of the presentation and some of the discussion. As usual, this is available on request to group members, but remains group confidential.
Some things discussed that particularly resonated for me:
I appreciated the point that as with most industry self-regulation efforts, it’s about providing consumer safety. Many industries face this problem of some members of the industry not living up to the standards most of the industry considers appropriate.
The word “trust” in JTI is both problematic and redundant, although it’s too difficult to change now. This is more about defining what is legitimate, real, high-quality journalism. All journalism is supposed to be trustworthy.
I still get confused on how a whitelist (like this) is anything other than the complement of a blacklist (which this is explicitly not). I’m still looking for a distinction that feels right to me.
There’s no answer yet on how this data might be interchanged, or how this all might be verified and used in practice
Even though we’re past the comment period, and JTI is about to be finalized in the standards process, work will continue, and there should be ongoing revisions in due course.
Tomorrow’s meeting is about a plan to categorize misinformation attacks and allow data about them to be shared, potentially in real time. It’s an extension to MITRE ATT&CK™ (“A knowledge base for describing behavior of cyber adversaries across their intrusion lifecycle”) and is intended to be compatible with Cyber Threat Intelligence data exchange technologies STIX and TAXII.
Beyond tomorrow, for now I’ve scheduled four more meetings, continuing our Tuesday pattern (29 Oct, 5 Nov, 12 Nov, 19 Nov). I have IPTC penciled in for the 12th, and we have several other pending topics:
What data protocols and formats should NewsQA, JTI, etc be using for exchanging data?
How can we help manage these overlapping signals schemas?
Is there a good objective framework for measuring credibility? (We asked the question in last years report. I recently had an idea I really like on this.)
Should we update and re-issue the report? Are there people who want to help?
What about credibility tools inside web browsers?
Claim Review, data about fact checking
NewsQA part 2, looking at specific signals
If you’d like to present or help organize on any of these topics, please let me know. We could also run them as an open discussion, without a presenter.
In retrospect, I should have described NewsQA before yesterday’s meeting, to frame the discussion and help people decide whether to attend. With that in mind, I want to say a few things about next week’s topic, JTI. Both projects use online data sharing and have real potential to combat disinformation, in very different ways.
First, here’s what I should have said about NewsQA:
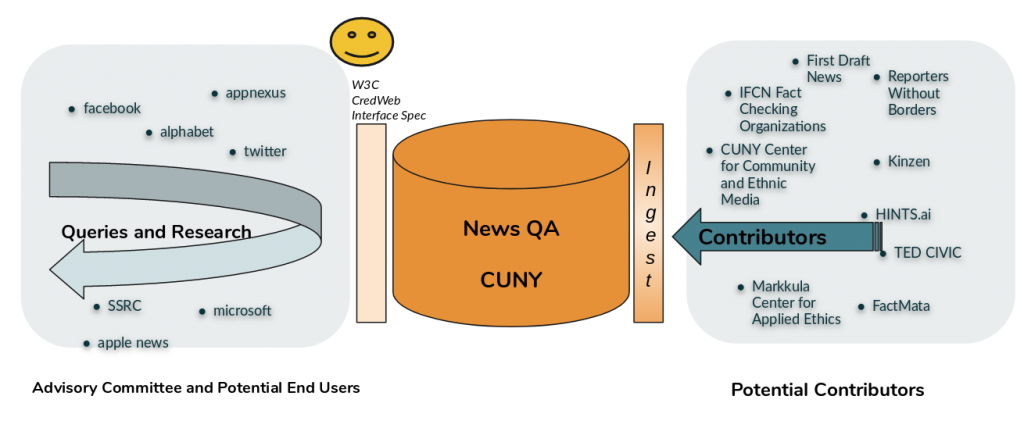
The NewsQA project, run by Jeff Jarvis’s group at CUNY, is building a service that will aggregate signals of credibility, to be available at no cost in 1Q20. Access will likely have restrictions related to intent.
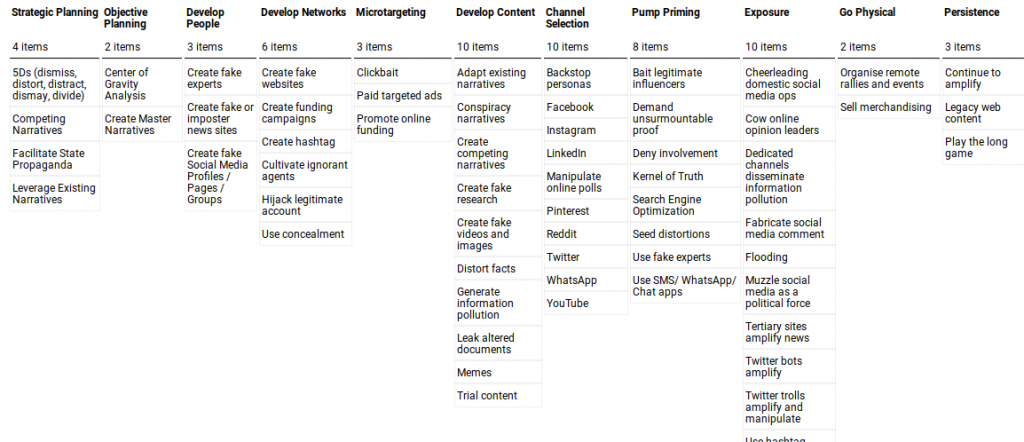
They’re currently working with about 100 credibility signals about domains, provided by various commercial and public data providers. They have data for about 12,000 domains serving news content, mostly in the US.
They would like wider review and potential standardization around those 100 signals. They also have experimental/research questions around the project for which they’d like community discussion and input.
The presentation included more about this, as well as plans for the future and open questions. You can read the notes of yesterday’s meeting or see the slides for more detail. Here’s the key architecture slide:
Looking forward, I’m thinking:
We should look over the list of 100 signals, try to align them with other signals folks are using, and make sure they’re documented in a way others can use
I’d like to understand the ecosystem around data providers and consumers. What’s motivating each party now, and what do we expect in the future
How secure are these signals against manipulation and misuse?
And then we have all the questions that came up during that meeting, still needing a lot more work before we have answers. (Like, “What is news?”)
The project is led by Reporters Without Borders (RSF), which has a strong reputation in fighting news censorship and bias
Using an open standards process (under CEN), they’ve gathered a community and together written down a general consensus of how news organizations ought to behave. The idea is that if you follow these practices, you’re far more likely to be trustworthy. If you can show the world you’re following them, especially via some kind of certification, you probably ought to be trusted more by individuals and by systems.
There’s a survey (start here) with about 200 questions covering all these rules and practices. Some of the questions are about whether you do a thing journalists are supposed to do, and others are asking you to disclose information that journalists ought to make public.
There are still wide open questions about how the data from those 200 questions might be published, distributed, and certified.
First, I want to apologize for the long silence. In April, I circulated a survey for working in six subgroups, and response was good. As things turned out, however, I didn’t do the necessary follow-up. Worse, I didn’t post anything about any change of plans. I’m sorry if that caused you any difficulty.
Going forward, I’m hoping a few people will volunteer to help me organize these activities. If you’d be up for this, please reply directly to me and let’s figure something out. Also, I’ve left the survey open so you can edit your previous response or fill it out now if you never did: it’s here.
On September 17th, at the next W3C TPAC meeting, we’re scheduled to hold a face-to-face meeting of this group. It’s in Japan, though, and only four group members have registered, along with 13 observers. I’ve decided not to make the trip, so we’ll need a volunteer who is there to set up and run the meeting with remote participation, or I think we should cancel. The meeting is at 10:30am Japan time, which is probably okay for folks in Asia and the Americas, but quite difficult for Europe or Africa. Bottom line: if you’re going to be at TPAC and might be able to run things, please talk to me soon.
From responses to the scheduling survey, it looks like Tuesdays and Thursdays 1pm US/Eastern would be good for nearly everybody. If that’s changed, or you didn’t fill out the survey before and you want your availability taken into account, please do so now. (If doodle won’t let you edit your old entry, because you didn’t log in, just add another entry with your name.)
I’m thinking we’ll start having some subgroup meetings in 2-3 weeks, depending in part on responses to this post.
A quick update on where things are with Credibility at W3C. If you’re interested, please join the group (if you haven’t) then answer this survey on how you’d like to be involved. Newcomers are welcome, not just folks who were involved last year, and please help spread the word.
Things in the works for 2019:
Evolve Credibility Signals into more of an open directory/database of credibility signal definitions, with filtering and data about adoption and research for each signal, when available.
Document best practices for exchanging credibility data. Primarily technical (json-ld, csv), but also legal and commercial aspects.
Revise our draft report on credibility tech, maybe splitting it up into chunks people are more likely to read, and with different section editors.
Have some general meetings, with presentations, to discuss various credibility-tech topics. This might include some of the signal provider companies or credibility tool projects.
Document how credibility issues fit into larger Online Safety issues. I’d like a more specific and concrete handle on “First, Do No Harm”.
Prototype a browser API which would support a market of credibility assessment modules, working together to protect the user in the browser. (See mockup.)
If you’re up for working on any of these topics, please fill in the survey. We’ll use that to help with meeting scheduling and general planning.
And of course, if you think the group should work on something not listed above, please reply on or off-list.
If you have any questions, please contact the group on their public list: public-credibility@w3.org. Learn more about the Credible Web Community Group.