B Property Summary
B.1 Explanation of Trait Mapping Values
- Rendering
Maps directly into a rendering trait of the same name.
- Disappears
There is no trait mapping.
- Shorthand
A shorthand that is mapped into one or more properties.
There are no traits associated with a shorthand property.
The traits are associated with the individual
properties.
- Refine
Disappears in refinement. During refinement it sets
up one or more other traits.
- Formatting
Maps directly into a formatting trait of the same name.
- Specification
Sub-class of formatting. It is the same
as a formatting trait, but is specified on formatting
objects that are referenced.
- See prose
Used to calculate a formatting trait, which does not have the
same name as the property. Other properties may also influence the
trait value. See the property description for
details.
- Font selection
Property that participates in font selection.
- Value change
Maps to a trait of the same name, but the value is not just
copied.
- Reference
An association between two names. Establishes a
reference within the formatting object tree.
- Action
Behavior trait.
- Magic
Handled by the formatter in an
implementation-defined way.
There are no specific traits for this property.
B.2 Property Table: Part I
| Name | Values | Initial Value | Inherited | Percentages |
|---|
| 7.6.1 absolute-position | auto | absolute | fixed | inherit | auto | no | N/A |
| 7.24.1 active-state | link | visited | active | hover | focus | no, a value is required | no | N/A |
| 7.15.1 alignment-adjust | auto | baseline
| before-edge
| text-before-edge | middle | central
| after-edge
| text-after-edge | ideographic | alphabetic | hanging | mathematical
| <percentage> | <length>
| inherit | auto | no | see prose |
| 7.15.2 alignment-baseline | auto | baseline | before-edge
| text-before-edge | middle | central | after-edge
| text-after-edge | ideographic | alphabetic | hanging | mathematical
| inherit | auto | no | N/A |
| 7.16.1 allowed-height-scale | [ any | <percentage> ]* | inherit | any | yes | intrinsic height |
| 7.16.2 allowed-width-scale | [ any | <percentage> ]* | inherit | any | yes | intrinsic width |
| 7.24.2 auto-restore | true | false | false | yes | N/A |
| 7.7.1 azimuth | <angle> | [[ left-side | far-left | left
| center-left | center | center-right | right | far-right | right-side
] || behind ] | leftwards | rightwards | inherit | center | yes | N/A |
| 7.34.1 background | [<background-color> ||
<background-image>
|| <background-repeat> || <background-attachment> || <background-position>
]] | inherit | not defined for shorthand properties | no | allowed on 'background-position' |
| 7.8.1 background-attachment | scroll | fixed | inherit | scroll | no | N/A |
| 7.8.2 background-color | <color> | transparent | inherit | transparent | no | N/A |
| 7.8.3 background-image | <uri-specification> | none | inherit | none | no | N/A |
| 7.34.2 background-position | [ [<percentage> | <length> ]{1,2} |
[ [top | center | bottom] || [left | center | right] ] ] | inherit | 0% 0% | no | refer to the size of the box itself |
| 7.8.4 background-position-horizontal | <percentage> | <length> |
left | center | right | inherit | 0% | no | refer to the size of the padding-rectangle |
| 7.8.5 background-position-vertical | <percentage> | <length> |
top | center | bottom | inherit | 0% | no | refer to the size of the padding-rectangle |
| 7.8.6 background-repeat | repeat | repeat-x | repeat-y | no-repeat | inherit | repeat | no | N/A |
| 7.15.4 baseline-shift | baseline | sub | super | <percentage> | <length>
| inherit | baseline | no | refers to the "line-height" of the parent area |
| 7.30.1 blank-or-not-blank | blank | not-blank | any | inherit | any | no | N/A |
| 7.16.3 block-progression-dimension | auto | <length> | <percentage> | <length-range>
| inherit | auto | no | see prose |
| 7.34.3 border | [ <border-width> || <border-style>
|| [ <color> | transparent ] ] | inherit | see individual properties | no | N/A |
| 7.8.7 border-after-color | <color> | transparent | inherit | the value of the 'color' property | no | N/A |
| 7.31.1 border-after-precedence | force | <integer> | inherit | fo:table: 6, fo:table-cell: 5, fo:table-column: 4,
fo:table-row: 3, fo:table-body: 2, fo:table-header: 1, fo:table-footer: 0
| no | N/A |
| 7.8.8 border-after-style | <border-style> | inherit | none | no | N/A |
| 7.8.9 border-after-width | <border-width> | <length-conditional> | inherit | medium | no | N/A |
| 7.8.10 border-before-color | <color> | transparent | inherit | the value of the 'color' property | no | N/A |
| 7.31.2 border-before-precedence | force | <integer> | inherit | fo:table: 6, fo:table-cell: 5, fo:table-column: 4,
fo:table-row: 3, fo:table-body: 2, fo:table-header: 1, fo:table-footer: 0
| no | N/A |
| 7.8.11 border-before-style | <border-style> | inherit | none | no | N/A |
| 7.8.12 border-before-width | <border-width> | <length-conditional> | inherit | medium | no | N/A |
| 7.34.4 border-bottom | [ <border-width> || <border-style>
|| [ <color> | transparent ] ] | inherit | see individual properties | no | N/A |
| 7.8.13 border-bottom-color | <color> | transparent | inherit | the value of the 'color' property | no | N/A |
| 7.8.14 border-bottom-style | <border-style> | inherit | none | no | N/A |
| 7.8.15 border-bottom-width | <border-width> | inherit | medium | no | N/A |
| 7.31.3 border-collapse | collapse | collapse-with-precedence | separate | inherit | collapse | yes | N/A |
| 7.34.5 border-color | [ <color> | transparent ]{1,4} | inherit | see individual properties | no | N/A |
| 7.8.16 border-end-color | <color> | transparent | inherit | the value of the 'color' property | no | N/A |
| 7.31.4 border-end-precedence | force | <integer> | inherit | fo:table: 6, fo:table-cell: 5, fo:table-column: 4,
fo:table-row: 3, fo:table-body: 2, fo:table-header: 1, fo:table-footer: 0
| no | N/A |
| 7.8.17 border-end-style | <border-style> | inherit | none | no | N/A |
| 7.8.18 border-end-width | <border-width> | <length-conditional> | inherit | medium | no | N/A |
| 7.34.6 border-left | [ <border-width> || <border-style>
|| [ <color> | transparent ] ] | inherit | see individual properties | no | N/A |
| 7.8.19 border-left-color | <color> | transparent | inherit | the value of the 'color' property | no | N/A |
| 7.8.20 border-left-style | <border-style> | inherit | none | no | N/A |
| 7.8.21 border-left-width | <border-width> | inherit | medium | no | N/A |
| 7.34.7 border-right | [ <border-width> || <border-style>
|| [ <color> | transparent ] ] | inherit | see individual properties | no | N/A |
| 7.8.22 border-right-color | <color> | transparent | inherit | the value of the 'color' property | no | N/A |
| 7.8.23 border-right-style | <border-style> | inherit | none | no | N/A |
| 7.8.24 border-right-width | <border-width> | inherit | medium | no | N/A |
| 7.31.5 border-separation | <length-bp-ip-direction> | inherit | .block-progression-direction="0pt" .inline-progression-direction="0pt" | yes | N/A |
| 7.34.8 border-spacing | <length> <length>? | inherit | 0pt | yes | N/A |
| 7.8.25 border-start-color | <color> | transparent | inherit | the value of the 'color' property | no | N/A |
| 7.31.6 border-start-precedence | force | <integer> | inherit | fo:table: 6, fo:table-cell: 5, fo:table-column: 4,
fo:table-row: 3, fo:table-body: 2, fo:table-header: 1, fo:table-footer: 0
| no | N/A |
| 7.8.26 border-start-style | <border-style> | inherit | none | no | N/A |
| 7.8.27 border-start-width | <border-width> | <length-conditional> | inherit | medium | no | N/A |
| 7.34.9 border-style | <border-style>{1,4} | inherit | see individual properties | no | N/A |
| 7.34.10 border-top | [ <border-width> || <border-style>
|| [ <color> | transparent ] ] | inherit | see individual properties | no | N/A |
| 7.8.28 border-top-color | <color> | transparent | inherit | the value of the 'color' property | no | N/A |
| 7.8.29 border-top-style | <border-style> | inherit | none | no | N/A |
| 7.8.30 border-top-width | <border-width> | inherit | medium | no | N/A |
| 7.34.11 border-width | <border-width>{1,4} | inherit | see individual properties | no | N/A |
| 7.6.2 bottom | <length> | <percentage> | auto | inherit | auto | no | refer to height of containing block |
| 7.21.1 break-after | auto | column | page | even-page | odd-page | inherit | auto | no | N/A |
| 7.21.2 break-before | auto | column | page | even-page | odd-page | inherit | auto | no | N/A |
| 7.31.7 caption-side | before | after | start | end | top | bottom | left | right | inherit | before | yes | N/A |
| 7.24.3 case-name | <name> | none, a value is required | no, a value is required | N/A |
| 7.24.4 case-title | <string> | none, a value is required | no, a value is required | N/A |
| 7.33.1 change-bar-class | <name> | none, value required | no | N/A |
| 7.33.2 change-bar-color | <color> | the value of the color property | yes | N/A |
| 7.33.3 change-bar-offset | <length> | 6pt | yes | N/A |
| 7.33.4 change-bar-placement | start | end | left | right | inside | outside | alternate | start | yes | N/A |
| 7.33.5 change-bar-style | <border-style> | none | yes | N/A |
| 7.33.6 change-bar-width | <border-width> | medium | yes | N/A |
| 7.18.1 character | <character> | N/A, value is required | no, a value is required | N/A |
| 7.20.1 clear | start | end | left | right | inside | outside | both | none | inherit | none | no | N/A |
| 7.22.1 clip | <shape> | auto | inherit | auto | no | N/A |
| 7.19.1 color | <color> | inherit | depends on user agent | yes | N/A |
| 7.19.2 color-profile-name | <name> | inherit | N/A, value is required | no | N/A |
| 7.30.2 column-count | <number> | inherit | 1 | no | N/A |
| 7.30.3 column-gap | <length> | <percentage> | inherit | 12.0pt | no | refer to width of the region being divided into columns. |
| 7.31.8 column-number | <number> | see prose | no | N/A |
| 7.31.9 column-width | <length> | <percentage> | see prose | no | refer to width of table |
| 7.16.4 content-height | auto | scale-to-fit | scale-down-to-fit | scale-up-to-fit |
<length> | <percentage> | inherit | auto | no | intrinsic height |
| 7.33.7 content-type | <string> | auto | auto | no | N/A |
| 7.16.5 content-width | auto | scale-to-fit | scale-down-to-fit | scale-up-to-fit |
<length> | <percentage> | inherit | auto | no | intrinsic width |
| 7.10.1 country | none | <country> | inherit | none | yes | N/A |
| 7.34.12 cue | <cue-before> || <cue-after> | inherit | not defined for shorthand properties | no | N/A |
| 7.7.2 cue-after | <uri-specification> | none | inherit | none | no | N/A |
| 7.7.3 cue-before | <uri-specification> | none | inherit | none | no | N/A |
| 7.24.5 destination-placement-offset | <length> | 0pt | no | N/A |
| 7.32.1 direction | ltr | rtl | inherit | ltr | yes | N/A |
| 7.15.5 display-align | auto | before | center | after
| inherit | auto | yes | N/A |
| 7.15.8 dominant-baseline | auto | use-script | no-change | reset-size
| ideographic | alphabetic | hanging | mathematical
| central | middle | text-after-edge | text-before-edge
| inherit | auto | no (see prose) | N/A |
| 7.7.4 elevation | <angle> | below | level | above | higher
| lower | inherit | level | yes | N/A |
| 7.31.10 empty-cells | show | hide | inherit | show | yes | N/A |
| 7.11.1 end-indent | <length> | <percentage> | inherit | 0pt | yes | refer to inline-progression-dimension
of containing reference-area |
| 7.31.11 ends-row | true | false | false | no | N/A |
| 7.30.5 extent | <length> | <percentage> | inherit | 0.0pt | no | refer to the corresponding block-progression-dimension
or inline-progression-dimension of the
page-viewport-area. |
| 7.24.6 external-destination | empty string | <uri-specification> | empty string | no | N/A |
| 7.20.2 float | before | start | end | left | right | inside | outside | none | inherit | none | no | N/A |
| 7.30.6 flow-map-name | <name> | none, a value is required | no | N/A |
| 7.30.7 flow-map-reference | <name> | see prose | no | N/A |
| 7.30.8 flow-name | <name> | an empty name | no, a value is required | N/A |
| 7.30.9 flow-name-reference | <name> | none, a value is required | no | N/A |
| 7.34.13 font | [ [ <font-style> || <font-variant>
|| <font-weight> ]? <font-size> [ / <line-height>]? <font-family>
] | caption | icon | menu | message-box | small-caption | status-bar
| inherit | see individual properties | yes | N/A |
| 7.9.1 font-family | [[ <family-name> | <generic-family>
],]* [<family-name> | <generic-family>] | inherit | depends on user agent | yes | N/A |
| 7.9.2 font-selection-strategy | auto | character-by-character | inherit | auto | yes | N/A |
| 7.9.3 font-size | <absolute-size> | <relative-size> | <length>
| <percentage> | inherit | medium | yes, the computed value is inherited | refer to parent element's font size |
| 7.9.4 font-size-adjust | <number> | none | inherit | none | yes | N/A |
| 7.9.5 font-stretch | normal | wider | narrower | ultra-condensed
| extra-condensed | condensed | semi-condensed | semi-expanded |
expanded | extra-expanded | ultra-expanded | inherit | normal | yes | N/A |
| 7.9.6 font-style | normal | italic | oblique | backslant | inherit | normal | yes | N/A |
| 7.9.7 font-variant | normal | small-caps | inherit | normal | yes | N/A |
| 7.9.8 font-weight | normal | bold | bolder | lighter | 100 | 200
| 300 | 400 | 500 | 600 | 700 | 800 | 900 | inherit | normal | yes | N/A |
| 7.30.10 force-page-count | auto | even | odd | end-on-even | end-on-odd | no-force
| inherit | auto | no | N/A |
| 7.29.1 format | <string> | 1 | no | N/A |
| 7.32.2 glyph-orientation-horizontal | <angle> | inherit | 0deg | yes | N/A |
| 7.32.3 glyph-orientation-vertical | auto | <angle> | inherit | auto | yes | N/A |
| 7.29.2 grouping-separator | <character> | no separator | no | N/A |
| 7.29.3 grouping-size | <number> | no grouping | no | N/A |
| 7.16.6 height | <length> | <percentage> | auto | inherit | auto | no | see prose |
| 7.10.2 hyphenate | false | true | inherit | false | yes | N/A |
| 7.10.3 hyphenation-character | <character> | inherit | The Unicode hyphen character U+2010 | yes | N/A |
| 7.17.1 hyphenation-keep | auto | column | page | inherit | auto | yes | N/A |
| 7.17.2 hyphenation-ladder-count | no-limit | <number> | inherit | no-limit | yes | N/A |
| 7.10.4 hyphenation-push-character-count | <number> | inherit | 2 | yes | N/A |
| 7.10.5 hyphenation-remain-character-count | <number> | inherit | 2 | yes | N/A |
| 7.33.8 id | <id> | see prose | no, see prose | N/A |
| 7.25.1 index-class | <string> | empty string | no | N/A |
| 7.25.2 index-key | <string> | none | no | N/A |
| 7.24.7 indicate-destination | true | false | false | no | N/A |
| 7.30.11 initial-page-number | auto | auto-odd | auto-even | <number> | inherit | auto | no | N/A |
| 7.16.7 inline-progression-dimension | auto | <length> | <percentage> | <length-range>
| inherit | auto | no | see prose |
| 7.24.8 internal-destination | empty string | <idref> | empty string | no | N/A |
| 7.33.9 intrinsic-scale-value | <percentage> | inherit | 100% | yes | user defined |
| 7.20.3 intrusion-displace | auto | none | line | indent | block | inherit | auto | yes | N/A |
| 7.21.3 keep-together | <keep> | inherit | .within-line=auto, .within-column=auto, .within-page=auto | yes | N/A |
| 7.21.4 keep-with-next | <keep> | inherit | .within-line=auto, .within-column=auto, .within-page=auto | no | N/A |
| 7.21.5 keep-with-previous | <keep> | inherit | .within-line=auto, .within-column=auto, .within-page=auto | no | N/A |
| 7.10.6 language | none | <language> | inherit | none | yes | N/A |
| 7.17.3 last-line-end-indent | <length> | <percentage> | inherit | 0pt | yes | refer to inline-progression-dimension of closest ancestor block-area that is not a line-area |
| 7.23.1 leader-alignment | none | reference-area | page | inherit | none | yes | N/A |
| 7.23.4 leader-length | <length-range> | <percentage> | inherit | leader-length.minimum=0pt, .optimum=12.0pt, .maximum=100% | yes | refer to the inline-progression-dimension of content-rectangle of parent area |
| 7.23.2 leader-pattern | space | rule | dots | use-content | inherit | space | yes | N/A |
| 7.23.3 leader-pattern-width | use-font-metrics | <length> | <percentage> | inherit | use-font-metrics | yes | refer to the inline-progression-dimension of content-rectangle of parent area |
| 7.6.3 left | <length> | <percentage> | auto | inherit | auto | no | refer to width of containing block |
| 7.18.2 letter-spacing | normal | <length> | <space> | inherit | normal | yes | N/A |
| 7.29.4 letter-value | auto | alphabetic | traditional | auto | no | N/A |
| 7.17.7 linefeed-treatment | ignore | preserve | treat-as-space | treat-as-zero-width-space | inherit | treat-as-space | yes | N/A |
| 7.17.4 line-height | normal | <length> | <number> | <percentage> | <space>
| inherit | normal | yes | refer to the font size of the element itself |
| 7.17.5 line-height-shift-adjustment | consider-shifts | disregard-shifts | inherit | consider-shifts | yes | N/A |
| 7.17.6 line-stacking-strategy | line-height | font-height | max-height | inherit | max-height | yes | N/A |
| 7.34.14 margin | <margin-width>{1,4} | inherit | not defined for shorthand properties | no | refer to width of containing block |
| 7.11.2 margin-bottom | <margin-width> | inherit | 0pt | no | refer to width of containing block |
| 7.11.3 margin-left | <margin-width> | inherit | 0pt | no | refer to width of containing block |
| 7.11.4 margin-right | <margin-width> | inherit | 0pt | no | refer to width of containing block |
| 7.11.5 margin-top | <margin-width> | inherit | 0pt | no | refer to width of containing block |
| 7.26.1 marker-class-name | <name> | an empty name | no, a value is required | N/A |
| 7.30.12 master-name | <name> | an empty name | no, a value is required | N/A |
| 7.30.13 master-reference | <name> | an empty name | no, a value is required | N/A |
| 7.16.8 max-height | <length> | <percentage> | none | inherit | none | no | refer to height of containing block |
| 7.30.14 maximum-repeats | <number> | no-limit | inherit | no-limit | no | N/A |
| 7.16.9 max-width | <length> | <percentage> | none | inherit | none | no | refer to width of containing block |
| 7.30.15 media-usage | auto | paginate | bounded-in-one-dimension | unbounded | auto | no | NA |
| 7.25.6 merge-pages-across-index-key-references | merge | leave-separate | merge | yes | N/A |
| 7.25.4 merge-ranges-across-index-key-references | merge | leave-separate | merge | yes | N/A |
| 7.25.5 merge-sequential-page-numbers | merge | leave-separate | merge | yes | N/A |
| 7.16.10 min-height | <length> | <percentage> | inherit | 0pt | no | refer to height of containing block |
| 7.16.11 min-width | <length> | <percentage> | inherit | depends on UA | no | refer to width of containing block |
| 7.31.12 number-columns-repeated | <number> | 1 | no | N/A |
| 7.31.13 number-columns-spanned | <number> | 1 | no | N/A |
| 7.31.14 number-rows-spanned | <number> | 1 | no | N/A |
| 7.30.16 odd-or-even | odd | even | any | inherit | any | no | N/A |
| 7.21.6 orphans | <integer> | inherit | 2 | yes | N/A |
| 7.22.2 overflow | visible | hidden | scroll | error-if-overflow | repeat | auto | inherit | auto | no | N/A |
| 7.34.15 padding | <padding-width>{1,4} | inherit | not defined for shorthand properties | no | refer to width of containing block |
| 7.8.31 padding-after | <padding-width> | <length-conditional> | inherit | 0pt | no | refer to width of containing block |
| 7.8.32 padding-before | <padding-width> | <length-conditional> | inherit | 0pt | no | refer to width of containing block |
| 7.8.33 padding-bottom | <padding-width> | inherit | 0pt | no | refer to width of containing block |
| 7.8.34 padding-end | <padding-width> | <length-conditional> | inherit | 0pt | no | refer to width of containing block |
| 7.8.35 padding-left | <padding-width> | inherit | 0pt | no | refer to width of containing block |
| 7.8.36 padding-right | <padding-width> | inherit | 0pt | no | refer to width of containing block |
| 7.8.37 padding-start | <padding-width> | <length-conditional> | inherit | 0pt | no | refer to width of containing block |
| 7.8.38 padding-top | <padding-width> | inherit | 0pt | no | refer to width of containing block |
| 7.34.16 page-break-after | auto | always | avoid | left | right | inherit | auto | no | N/A |
| 7.34.17 page-break-before | auto | always | avoid | left | right | inherit | auto | no | N/A |
| 7.34.18 page-break-inside | avoid | auto | inherit | auto | yes | N/A |
| 7.33.10 page-citation-strategy | [ all | normal | non-blank | inherit | all | no | N/A |
| 7.30.17 page-height | auto | indefinite | <length> | inherit | auto | no | N/A |
| 7.25.3 page-number-treatment | link | no-link | no-link | yes | N/A |
| 7.30.18 page-position | only | first | last | rest | any | inherit | any | no | N/A |
| 7.30.19 page-width | auto | indefinite | <length> | inherit | auto | no | N/A |
| 7.34.19 pause | [<time> | <percentage>]{1,2} | inherit | depends on user agent | no | see descriptions of 'pause-before' and 'pause-after' |
| 7.7.5 pause-after | <time> | <percentage> | inherit | depends on user agent | no | see prose |
| 7.7.6 pause-before | <time> | <percentage> | inherit | depends on user agent | no | see prose |
| 7.7.7 pitch | <frequency> | x-low | low | medium | high
| x-high | inherit | medium | yes | N/A |
| 7.7.8 pitch-range | <number> | inherit | 50 | yes | N/A |
| 7.7.9 play-during | <uri-specification> mix? repeat? | auto | none | inherit | auto | no | N/A |
| 7.34.20 position | static | relative | absolute | fixed | inherit | static | no | N/A |
| 7.30.20 precedence | true | false | inherit | false | no | N/A |
| 7.33.11 provisional-distance-between-starts | <length> | <percentage> | inherit | 24.0pt | yes | refer to inline-progression-dimension of closest ancestor block-area that is not a line-area |
| 7.33.12 provisional-label-separation | <length> | <percentage> | inherit | 6.0pt | yes | refer to inline-progression-dimension of closest ancestor block-area that is not a line-area |
| 7.22.3 reference-orientation | 0 | 90 | 180 | 270 | -90 | -180 | -270 | inherit | 0 | no | N/A |
| 7.33.13 ref-id | <idref> | inherit | none, value required | no | N/A |
| 7.25.7 ref-index-key | <string> | none, value required | no | N/A |
| 7.30.21 region-name | xsl-region-body | xsl-region-start | xsl-region-end
| xsl-region-before | xsl-region-after |
<name> | see prose | no, a value is required | N/A |
| 7.30.22 region-name-reference | <name> | none, a value is required | no | N/A |
| 7.15.9 relative-align | before | baseline
| inherit | before | yes | N/A |
| 7.13.1 relative-position | static | relative | inherit | static | no | N/A |
| 7.19.3 rendering-intent | auto | perceptual | relative-colorimetric | saturation | absolute-colorimetric | inherit | auto | no | N/A |
| 7.26.4 retrieve-boundary | page | page-sequence | document | page-sequence | no | N/A |
| 7.26.2 retrieve-boundary-within-table | table | table-fragment | page | table | no | N/A |
| 7.26.3 retrieve-class-name | <name> | an empty name | no, a value is required | N/A |
| 7.26.5 retrieve-position | first-starting-within-page | first-including-carryover |
last-starting-within-page | last-ending-within-page | first-starting-within-page | no | N/A |
| 7.26.6 retrieve-position-within-table | first-starting | first-including-carryover |
last-starting | last-ending | first-starting | no | N/A |
| 7.7.10 richness | <number> | inherit | 50 | yes | N/A |
| 7.6.4 right | <length> | <percentage> | auto | inherit | auto | no | refer to width of containing block |
| 7.5.2 role | <string> | <uri-specification> | none | inherit | none | no | N/A |
| 7.23.5 rule-style | none | dotted | dashed | solid | double | groove
| ridge | inherit | solid | yes | N/A |
| 7.23.6 rule-thickness | <length> | 1.0pt | yes | N/A |
| 7.33.14 scale-option | width | height | inherit | width | yes | N/A |
| 7.16.12 scaling | uniform | non-uniform | inherit | uniform | no | N/A |
| 7.16.13 scaling-method | auto | integer-pixels | resample-any-method | inherit | auto | no | N/A |
| 7.33.15 score-spaces | true | false | inherit | true | yes | N/A |
| 7.10.7 script | none | auto | <script> | inherit | auto | yes | N/A |
| 7.24.9 show-destination | replace | new | replace | no | N/A |
| 7.34.21 size | <length>{1,2} | auto | landscape | portrait
| inherit | auto | N/A [XSL:no, is optional] | N/A |
| 7.5.1 source-document | <uri-specification> [<uri-specification>]* | none | inherit | none | no | N/A |
| 7.11.6 space-after | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | no | N/A (Differs from margin-bottom in CSS) |
| 7.11.7 space-before | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | no | N/A (Differs from margin-top in CSS) |
| 7.12.1 space-end | <space> | <percentage> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | no | refer to inline-progression-dimension of closest ancestor block-area that is not a line-area |
| 7.12.2 space-start | <space> | <percentage> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | no | refer to inline-progression-dimension of closest ancestor block-area that is not a line-area |
| 7.22.4 span | none | all | inherit | none | no | N/A |
| 7.7.11 speak | normal | none | spell-out | inherit | normal | yes | N/A |
| 7.7.12 speak-header | once | always | inherit | once | yes | N/A |
| 7.7.13 speak-numeral | digits | continuous | inherit | continuous | yes | N/A |
| 7.7.14 speak-punctuation | code | none | inherit | none | yes | N/A |
| 7.7.15 speech-rate | <number> | x-slow | slow | medium | fast
| x-fast | faster | slower | inherit | medium | yes | N/A |
| 7.33.16 src | <uri-specification> | inherit | none, value required | no | N/A |
| 7.11.8 start-indent | <length> | <percentage> | inherit | 0pt | yes | refer to inline-progression-dimension
of containing reference-area |
| 7.24.10 starting-state | show | hide | show | no | N/A |
| 7.31.15 starts-row | true | false | false | no | N/A |
| 7.7.16 stress | <number> | inherit | 50 | yes | N/A |
| 7.18.3 suppress-at-line-break | auto | suppress | retain | inherit | auto | no | N/A |
| 7.24.11 switch-to | xsl-preceding | xsl-following | xsl-any | <name>[ <name>]* | xsl-any | no | N/A |
| 7.31.16 table-layout | auto | fixed | inherit | auto | no | N/A |
| 7.31.17 table-omit-footer-at-break | true | false | false | no | N/A |
| 7.31.18 table-omit-header-at-break | true | false | false | no | N/A |
| 7.24.12 target-presentation-context | use-target-processing-context | <uri-specification> | use-target-processing-context | no | N/A |
| 7.24.13 target-processing-context | document-root | <uri-specification> | document-root | no | N/A |
| 7.24.14 target-stylesheet | use-normal-stylesheet | <uri-specification> | use-normal-stylesheet | no | N/A |
| 7.17.8 text-align | start | center | end | justify | inside | outside
| left | right | <string> | inherit | start | yes | N/A |
| 7.17.9 text-align-last | relative | start | center | end | justify | inside
| outside | left | right | inherit | relative | yes | N/A |
| 7.32.4 text-altitude | use-font-metrics | <length> | <percentage> | inherit | use-font-metrics | no | refer to font's em-height |
| 7.18.4 text-decoration | none | [ [ underline | no-underline] || [ overline | no-overline ]
|| [ line-through | no-line-through ] || [ blink | no-blink ] ]
| inherit | none | no, but see prose | N/A |
| 7.32.5 text-depth | use-font-metrics | <length> | <percentage> | inherit | use-font-metrics | no | refer to font's em-height |
| 7.17.10 text-indent | <length> | <percentage> | inherit | 0pt | yes | refer to width of containing block |
| 7.18.5 text-shadow | none | [<color> || <length> <length> <length>?
,]* [<color> || <length> <length> <length>?] | inherit | none | no, see prose | N/A |
| 7.18.6 text-transform | capitalize | uppercase | lowercase | none | inherit | none | yes | N/A |
| 7.6.5 top | <length> | <percentage> | auto | inherit | auto | no | refer to height of containing block |
| 7.18.7 treat-as-word-space | auto | true | false | inherit | auto | no | N/A |
| 7.32.6 unicode-bidi | normal | embed | bidi-override | inherit | normal | no | N/A |
| 7.34.22 vertical-align | baseline | middle | sub | super | text-top |
text-bottom | <percentage> | <length> | top | bottom | inherit | baseline | no | refer to the 'line-height' of the element itself |
| 7.33.17 visibility | visible | hidden | collapse | inherit | visible | yes | N/A |
| 7.7.17 voice-family | [[<specific-voice> | <generic-voice>
],]* [<specific-voice> | <generic-voice> ] | inherit | depends on user agent | yes | N/A |
| 7.7.18 volume | <number> | <percentage> | silent | x-soft
| soft | medium | loud | x-loud | inherit | medium | yes | refer to inherited value |
| 7.34.23 white-space | normal | pre | nowrap | inherit | normal | yes | N/A |
| 7.17.11 white-space-collapse | false | true | inherit | true | yes | N/A |
| 7.17.12 white-space-treatment | ignore | preserve | ignore-if-before-linefeed |
ignore-if-after-linefeed | ignore-if-surrounding-linefeed | inherit | ignore-if-surrounding-linefeed | yes | N/A |
| 7.21.7 widows | <integer> | inherit | 2 | yes | N/A |
| 7.16.14 width | <length> | <percentage> | auto | inherit | auto | no | refer to width of containing block |
| 7.18.8 word-spacing | normal | <length> | <space> | inherit | normal | yes | N/A |
| 7.17.13 wrap-option | no-wrap | wrap | inherit | wrap | yes | N/A |
| 7.32.7 writing-mode | lr-tb |
rl-tb |
tb-rl |
tb-lr |
bt-lr |
bt-rl |
lr-bt |
rl-bt |
lr-alternating-rl-bt |
lr-alternating-rl-tb |
lr-inverting-rl-bt |
lr-inverting-rl-tb |
tb-lr-in-lr-pairs |
lr |
rl |
tb |
inherit | lr-tb | yes (see prose) | N/A |
| 7.34.24 xml:lang | <language-country> | inherit | not defined for shorthand properties | yes | N/A |
| 7.33.18 z-index | auto | <integer> | inherit | auto | no | N/A |
B.3 Property Table: Part II
The Trait Mapping Values are explained in B.1 Explanation of Trait Mapping Values.
| Name | Values | Initial Value | Trait mapping | Core |
|---|
| 7.6.1 absolute-position | auto | absolute | fixed | inherit | auto | See prose. | Complete |
| 7.24.1 active-state | link | visited | active | hover | focus | no, a value is required | Action | Extended. Fallback: N/A use fallback for fo:multi-properties |
| 7.15.1 alignment-adjust | auto | baseline
| before-edge
| text-before-edge | middle | central
| after-edge
| text-after-edge | ideographic | alphabetic | hanging | mathematical
| <percentage> | <length>
| inherit | auto | Formatting | Basic |
| 7.15.2 alignment-baseline | auto | baseline | before-edge
| text-before-edge | middle | central | after-edge
| text-after-edge | ideographic | alphabetic | hanging | mathematical
| inherit | auto | Formatting | Basic |
| 7.16.1 allowed-height-scale | [ any | <percentage> ]* | inherit | any | Formatting | Extended. Fallback: Initial value |
| 7.16.2 allowed-width-scale | [ any | <percentage> ]* | inherit | any | Formatting | Extended. Fallback: Initial value |
| 7.24.2 auto-restore | true | false | false | Action | Extended. Fallback: N/A use fallback for fo:multi-switch |
| 7.7.1 azimuth | <angle> | [[ left-side | far-left | left
| center-left | center | center-right | right | far-right | right-side
] || behind ] | leftwards | rightwards | inherit | center | Rendering | Basic |
| 7.34.1 background | [<background-color> ||
<background-image>
|| <background-repeat> || <background-attachment> || <background-position>
]] | inherit | not defined for shorthand properties | Shorthand | Complete |
| 7.8.1 background-attachment | scroll | fixed | inherit | scroll | Rendering | Extended. Fallback: Initial value |
| 7.8.2 background-color | <color> | transparent | inherit | transparent | Rendering | Basic |
| 7.8.3 background-image | <uri-specification> | none | inherit | none | Rendering | Extended. Fallback: Initial value |
| 7.34.2 background-position | [ [<percentage> | <length> ]{1,2} |
[ [top | center | bottom] || [left | center | right] ] ] | inherit | 0% 0% | Shorthand | Complete |
| 7.8.4 background-position-horizontal | <percentage> | <length> |
left | center | right | inherit | 0% | Value change | Extended. Fallback: Initial value |
| 7.8.5 background-position-vertical | <percentage> | <length> |
top | center | bottom | inherit | 0% | Value change | Extended. Fallback: Initial value |
| 7.8.6 background-repeat | repeat | repeat-x | repeat-y | no-repeat | inherit | repeat | Rendering | Extended. Fallback: no-repeat |
| 7.15.4 baseline-shift | baseline | sub | super | <percentage> | <length>
| inherit | baseline | Formatting | Basic |
| 7.30.1 blank-or-not-blank | blank | not-blank | any | inherit | any | Specification | Extended. Fallback: N/A use fallback for fo:repeatable-page-master-alternatives |
| 7.16.3 block-progression-dimension | auto | <length> | <percentage> | <length-range>
| inherit | auto | Formatting | Basic |
| 7.34.3 border | [ <border-width> || <border-style>
|| [ <color> | transparent ] ] | inherit | see individual properties | Shorthand | Complete |
| 7.8.7 border-after-color | <color> | transparent | inherit | the value of the 'color' property | Rendering | Basic |
| 7.31.1 border-after-precedence | force | <integer> | inherit | fo:table: 6, fo:table-cell: 5, fo:table-column: 4,
fo:table-row: 3, fo:table-body: 2, fo:table-header: 1, fo:table-footer: 0
| Formatting | Basic |
| 7.8.8 border-after-style | <border-style> | inherit | none | Rendering | Basic |
| 7.8.9 border-after-width | <border-width> | <length-conditional> | inherit | medium | Formatting and Rendering | Basic |
| 7.8.10 border-before-color | <color> | transparent | inherit | the value of the 'color' property | Rendering | Basic |
| 7.31.2 border-before-precedence | force | <integer> | inherit | fo:table: 6, fo:table-cell: 5, fo:table-column: 4,
fo:table-row: 3, fo:table-body: 2, fo:table-header: 1, fo:table-footer: 0
| Formatting | Basic |
| 7.8.11 border-before-style | <border-style> | inherit | none | Rendering | Basic |
| 7.8.12 border-before-width | <border-width> | <length-conditional> | inherit | medium | Formatting and Rendering | Basic |
| 7.34.4 border-bottom | [ <border-width> || <border-style>
|| [ <color> | transparent ] ] | inherit | see individual properties | Shorthand | Complete |
| 7.8.13 border-bottom-color | <color> | transparent | inherit | the value of the 'color' property | Disappears | Basic |
| 7.8.14 border-bottom-style | <border-style> | inherit | none | Disappears | Basic |
| 7.8.15 border-bottom-width | <border-width> | inherit | medium | Disappears | Basic |
| 7.31.3 border-collapse | collapse | collapse-with-precedence | separate | inherit | collapse | Formatting | Extended. Fallback: Initial value |
| 7.34.5 border-color | [ <color> | transparent ]{1,4} | inherit | see individual properties | Shorthand | Complete |
| 7.8.16 border-end-color | <color> | transparent | inherit | the value of the 'color' property | Rendering | Basic |
| 7.31.4 border-end-precedence | force | <integer> | inherit | fo:table: 6, fo:table-cell: 5, fo:table-column: 4,
fo:table-row: 3, fo:table-body: 2, fo:table-header: 1, fo:table-footer: 0
| Formatting | Basic |
| 7.8.17 border-end-style | <border-style> | inherit | none | Rendering | Basic |
| 7.8.18 border-end-width | <border-width> | <length-conditional> | inherit | medium | Formatting and Rendering | Basic |
| 7.34.6 border-left | [ <border-width> || <border-style>
|| [ <color> | transparent ] ] | inherit | see individual properties | Shorthand | Complete |
| 7.8.19 border-left-color | <color> | transparent | inherit | the value of the 'color' property | Disappears | Basic |
| 7.8.20 border-left-style | <border-style> | inherit | none | Disappears | Basic |
| 7.8.21 border-left-width | <border-width> | inherit | medium | Disappears | Basic |
| 7.34.7 border-right | [ <border-width> || <border-style>
|| [ <color> | transparent ] ] | inherit | see individual properties | Shorthand | Complete |
| 7.8.22 border-right-color | <color> | transparent | inherit | the value of the 'color' property | Disappears | Basic |
| 7.8.23 border-right-style | <border-style> | inherit | none | Disappears | Basic |
| 7.8.24 border-right-width | <border-width> | inherit | medium | Disappears | Basic |
| 7.31.5 border-separation | <length-bp-ip-direction> | inherit | .block-progression-direction="0pt" .inline-progression-direction="0pt" | Formatting | Extended. Fallback: Initial value |
| 7.34.8 border-spacing | <length> <length>? | inherit | 0pt | Shorthand | Complete |
| 7.8.25 border-start-color | <color> | transparent | inherit | the value of the 'color' property | Rendering | Basic |
| 7.31.6 border-start-precedence | force | <integer> | inherit | fo:table: 6, fo:table-cell: 5, fo:table-column: 4,
fo:table-row: 3, fo:table-body: 2, fo:table-header: 1, fo:table-footer: 0
| Formatting | Basic |
| 7.8.26 border-start-style | <border-style> | inherit | none | Rendering | Basic |
| 7.8.27 border-start-width | <border-width> | <length-conditional> | inherit | medium | Formatting and Rendering | Basic |
| 7.34.9 border-style | <border-style>{1,4} | inherit | see individual properties | Shorthand | Complete |
| 7.34.10 border-top | [ <border-width> || <border-style>
|| [ <color> | transparent ] ] | inherit | see individual properties | Shorthand | Complete |
| 7.8.28 border-top-color | <color> | transparent | inherit | the value of the 'color' property | Disappears | Basic |
| 7.8.29 border-top-style | <border-style> | inherit | none | Disappears | Basic |
| 7.8.30 border-top-width | <border-width> | inherit | medium | Disappears | Basic |
| 7.34.11 border-width | <border-width>{1,4} | inherit | see individual properties | Shorthand | Complete |
| 7.6.2 bottom | <length> | <percentage> | auto | inherit | auto | Formatting | Extended. Fallback: N/A due to fallback for absolute-position, relative-position |
| 7.21.1 break-after | auto | column | page | even-page | odd-page | inherit | auto | Formatting | Basic |
| 7.21.2 break-before | auto | column | page | even-page | odd-page | inherit | auto | Formatting | Basic |
| 7.31.7 caption-side | before | after | start | end | top | bottom | left | right | inherit | before | Formatting | Complete |
| 7.24.3 case-name | <name> | none, a value is required | Action | Extended. Fallback: N/A use fallback for fo:multi-switch |
| 7.24.4 case-title | <string> | none, a value is required | Action | Extended. Fallback: N/A use fallback for fo:multi-switch |
| 7.33.1 change-bar-class | <name> | none, value required | Reference | Extended. Fallback: N/A use fallback for fo:change-bar-begin, fo:change-bar-end |
| 7.33.2 change-bar-color | <color> | the value of the color property | Rendering | Extended. Fallback: N/A use fallback for fo:change-bar-begin, fo:change-bar-end |
| 7.33.3 change-bar-offset | <length> | 6pt | Formatting | Extended. Fallback: N/A use fallback for fo:change-bar-begin, fo:change-bar-end |
| 7.33.4 change-bar-placement | start | end | left | right | inside | outside | alternate | start | Formatting | Extended. Fallback: N/A use fallback for fo:change-bar-begin, fo:change-bar-end |
| 7.33.5 change-bar-style | <border-style> | none | Rendering | Extended. Fallback: N/A use fallback for fo:change-bar-begin, fo:change-bar-end |
| 7.33.6 change-bar-width | <border-width> | medium | Rendering | Extended. Fallback: N/A use fallback for fo:change-bar-begin, fo:change-bar-end |
| 7.18.1 character | <character> | N/A, value is required | Formatting | Basic |
| 7.20.1 clear | start | end | left | right | inside | outside | both | none | inherit | none | Formatting | Extended. Fallback: N/A use fallback for fo:float |
| 7.22.1 clip | <shape> | auto | inherit | auto | Rendering | Extended. Fallback: Initial value |
| 7.19.1 color | <color> | inherit | depends on user agent | Rendering | Basic |
| 7.19.2 color-profile-name | <name> | inherit | N/A, value is required | Formatting | Extended. Fallback: N/A use fallback for fo:color-profile |
| 7.30.2 column-count | <number> | inherit | 1 | Specification | Extended. Fallback: Initial value |
| 7.30.3 column-gap | <length> | <percentage> | inherit | 12.0pt | Specification | Extended. Fallback: N/A due to fallback for column-count |
| 7.31.8 column-number | <number> | see prose | Value change | Basic |
| 7.31.9 column-width | <length> | <percentage> | see prose | Specification | Basic |
| 7.16.4 content-height | auto | scale-to-fit | scale-down-to-fit | scale-up-to-fit |
<length> | <percentage> | inherit | auto | Formatting | Extended. Fallback: Initial value |
| 7.33.7 content-type | <string> | auto | auto | Formatting | Extended. Fallback: Initial value |
| 7.16.5 content-width | auto | scale-to-fit | scale-down-to-fit | scale-up-to-fit |
<length> | <percentage> | inherit | auto | Formatting | Extended. Fallback: Initial value |
| 7.10.1 country | none | <country> | inherit | none | Formatting | Extended. Fallback: Initial value |
| 7.34.12 cue | <cue-before> || <cue-after> | inherit | not defined for shorthand properties | Shorthand | Complete |
| 7.7.2 cue-after | <uri-specification> | none | inherit | none | Rendering | Basic |
| 7.7.3 cue-before | <uri-specification> | none | inherit | none | Rendering | Basic |
| 7.24.5 destination-placement-offset | <length> | 0pt | Action | Extended. Fallback: N/A use fallback for fo:basic-link |
| 7.32.1 direction | ltr | rtl | inherit | ltr | See prose. | Basic |
| 7.15.5 display-align | auto | before | center | after
| inherit | auto | Formatting | Extended. Fallback: Initial value |
| 7.15.8 dominant-baseline | auto | use-script | no-change | reset-size
| ideographic | alphabetic | hanging | mathematical
| central | middle | text-after-edge | text-before-edge
| inherit | auto | Formatting | Basic |
| 7.7.4 elevation | <angle> | below | level | above | higher
| lower | inherit | level | Rendering | Basic |
| 7.31.10 empty-cells | show | hide | inherit | show | Formatting | Extended. Fallback: Initial value |
| 7.11.1 end-indent | <length> | <percentage> | inherit | 0pt | Formatting | Basic |
| 7.31.11 ends-row | true | false | false | Formatting | Extended. Fallback: Initial value |
| 7.30.5 extent | <length> | <percentage> | inherit | 0.0pt | Specification | Extended. Fallback: N/A use fallback for fo:region-before, fo:region-after, fo:region-start, and fo:region-end |
| 7.24.6 external-destination | empty string | <uri-specification> | empty string | Action | Extended. Fallback: N/A use fallback for fo:basic-link |
| 7.20.2 float | before | start | end | left | right | inside | outside | none | inherit | none | Formatting | Extended. Fallback: N/A use fallback for fo:float |
| 7.30.6 flow-map-name | <name> | none, a value is required | Specification | Extended. Fallback: N/A use fallback for fo:flow-map |
| 7.30.7 flow-map-reference | <name> | see prose | Specification | Extended. Fallback: N/A use fallback for fo:flow-map |
| 7.30.8 flow-name | <name> | an empty name | Reference | Basic |
| 7.30.9 flow-name-reference | <name> | none, a value is required | Specification | Extended. Fallback: N/A use fallback for fo:flow-map |
| 7.34.13 font | [ [ <font-style> || <font-variant>
|| <font-weight> ]? <font-size> [ / <line-height>]? <font-family>
] | caption | icon | menu | message-box | small-caption | status-bar
| inherit | see individual properties | Shorthand | Complete |
| 7.9.1 font-family | [[ <family-name> | <generic-family>
],]* [<family-name> | <generic-family>] | inherit | depends on user agent | Font selection | Basic |
| 7.9.2 font-selection-strategy | auto | character-by-character | inherit | auto | Font selection | Complete |
| 7.9.3 font-size | <absolute-size> | <relative-size> | <length>
| <percentage> | inherit | medium | Formatting and Rendering | Basic |
| 7.9.4 font-size-adjust | <number> | none | inherit | none | Font selection | Extended. Fallback: Initial value |
| 7.9.5 font-stretch | normal | wider | narrower | ultra-condensed
| extra-condensed | condensed | semi-condensed | semi-expanded |
expanded | extra-expanded | ultra-expanded | inherit | normal | Font selection | Extended. Fallback: Initial value |
| 7.9.6 font-style | normal | italic | oblique | backslant | inherit | normal | Font selection | Basic |
| 7.9.7 font-variant | normal | small-caps | inherit | normal | Font selection | Basic |
| 7.9.8 font-weight | normal | bold | bolder | lighter | 100 | 200
| 300 | 400 | 500 | 600 | 700 | 800 | 900 | inherit | normal | Font selection | Basic |
| 7.30.10 force-page-count | auto | even | odd | end-on-even | end-on-odd | no-force
| inherit | auto | Specification | Extended. Fallback: no-force |
| 7.29.1 format | <string> | 1 | Formatting | Basic |
| 7.32.2 glyph-orientation-horizontal | <angle> | inherit | 0deg | Formatting | Extended. Fallback: Initial value |
| 7.32.3 glyph-orientation-vertical | auto | <angle> | inherit | auto | Formatting | Extended. Fallback: Initial value |
| 7.29.2 grouping-separator | <character> | no separator | Formatting | Extended. Fallback: no separator |
| 7.29.3 grouping-size | <number> | no grouping | Formatting | Extended. Fallback: no grouping |
| 7.16.6 height | <length> | <percentage> | auto | inherit | auto | Disappears | Basic |
| 7.10.2 hyphenate | false | true | inherit | false | Formatting | Extended. Fallback: Initial value |
| 7.10.3 hyphenation-character | <character> | inherit | The Unicode hyphen character U+2010 | Formatting | Extended. Fallback: N/A due to fallback for hyphenate |
| 7.17.1 hyphenation-keep | auto | column | page | inherit | auto | Formatting | Extended. Fallback: N/A due to fallback for hyphenate |
| 7.17.2 hyphenation-ladder-count | no-limit | <number> | inherit | no-limit | Formatting | Extended. Fallback: N/A due to fallback for hyphenate |
| 7.10.4 hyphenation-push-character-count | <number> | inherit | 2 | Formatting | Extended. Fallback: N/A due to fallback for hyphenate |
| 7.10.5 hyphenation-remain-character-count | <number> | inherit | 2 | Formatting | Extended. Fallback: N/A due to fallback for hyphenate |
| 7.33.8 id | <id> | see prose | Reference | Basic |
| 7.25.1 index-class | <string> | empty string | Reference | Extended. Fallback: N/A use fallback for fo:index-page-citation-list |
| 7.25.2 index-key | <string> | none | Reference | Extended. Fallback: N/A use fallback for fo:index-page-citation-list |
| 7.24.7 indicate-destination | true | false | false | Action | Extended. Fallback: N/A use fallback for fo:basic-link |
| 7.30.11 initial-page-number | auto | auto-odd | auto-even | <number> | inherit | auto | Formatting | Basic |
| 7.16.7 inline-progression-dimension | auto | <length> | <percentage> | <length-range>
| inherit | auto | Formatting | Basic |
| 7.24.8 internal-destination | empty string | <idref> | empty string | Action | Extended. Fallback: N/A use fallback for fo:basic-link |
| 7.33.9 intrinsic-scale-value | <percentage> | inherit | 100% | Refine | Extended. Fallback: N/A use fallback for fo:scaling-value-citation |
| 7.20.3 intrusion-displace | auto | none | line | indent | block | inherit | auto | Formatting | Extended. Fallback: none |
| 7.21.3 keep-together | <keep> | inherit | .within-line=auto, .within-column=auto, .within-page=auto | Formatting | Extended. Fallback: Initial value |
| 7.21.4 keep-with-next | <keep> | inherit | .within-line=auto, .within-column=auto, .within-page=auto | Formatting | Basic |
| 7.21.5 keep-with-previous | <keep> | inherit | .within-line=auto, .within-column=auto, .within-page=auto | Formatting | Basic |
| 7.10.6 language | none | <language> | inherit | none | Value change | Extended. Fallback: Initial value |
| 7.17.3 last-line-end-indent | <length> | <percentage> | inherit | 0pt | Formatting | Extended. Fallback: Initial value |
| 7.23.1 leader-alignment | none | reference-area | page | inherit | none | Formatting | Extended. Fallback: Initial value |
| 7.23.4 leader-length | <length-range> | <percentage> | inherit | leader-length.minimum=0pt, .optimum=12.0pt, .maximum=100% | Formatting | Basic |
| 7.23.2 leader-pattern | space | rule | dots | use-content | inherit | space | Formatting | Basic |
| 7.23.3 leader-pattern-width | use-font-metrics | <length> | <percentage> | inherit | use-font-metrics | Formatting | Extended. Fallback: Initial value |
| 7.6.3 left | <length> | <percentage> | auto | inherit | auto | Formatting | Extended. Fallback: N/A due to fallback for absolute-position, relative-position |
| 7.18.2 letter-spacing | normal | <length> | <space> | inherit | normal | Disappears | Extended. Fallback: Initial value |
| 7.29.4 letter-value | auto | alphabetic | traditional | auto | Formatting | Basic |
| 7.17.7 linefeed-treatment | ignore | preserve | treat-as-space | treat-as-zero-width-space | inherit | treat-as-space | Formatting | Extended. Fallback: Initial value |
| 7.17.4 line-height | normal | <length> | <number> | <percentage> | <space>
| inherit | normal | Formatting | Basic |
| 7.17.5 line-height-shift-adjustment | consider-shifts | disregard-shifts | inherit | consider-shifts | Formatting | Extended. Fallback: Initial value |
| 7.17.6 line-stacking-strategy | line-height | font-height | max-height | inherit | max-height | Formatting | Basic |
| 7.34.14 margin | <margin-width>{1,4} | inherit | not defined for shorthand properties | Shorthand | Complete |
| 7.11.2 margin-bottom | <margin-width> | inherit | 0pt | Disappears | Basic |
| 7.11.3 margin-left | <margin-width> | inherit | 0pt | Disappears | Basic |
| 7.11.4 margin-right | <margin-width> | inherit | 0pt | Disappears | Basic |
| 7.11.5 margin-top | <margin-width> | inherit | 0pt | Disappears | Basic |
| 7.26.1 marker-class-name | <name> | an empty name | Formatting | Extended. Fallback: N/A use fallback for fo:marker |
| 7.30.12 master-name | <name> | an empty name | Specification | Basic |
| 7.30.13 master-reference | <name> | an empty name | Specification | Basic |
| 7.16.8 max-height | <length> | <percentage> | none | inherit | none | Shorthand | Complete |
| 7.30.14 maximum-repeats | <number> | no-limit | inherit | no-limit | Specification | Extended. Fallback: N/A use fallback for fo:repeatable-page-master-reference and fo:repeatable-page-master-alternatives |
| 7.16.9 max-width | <length> | <percentage> | none | inherit | none | Shorthand | Complete |
| 7.30.15 media-usage | auto | paginate | bounded-in-one-dimension | unbounded | auto | Formatting | Extended. Fallback: Initial value |
| 7.25.6 merge-pages-across-index-key-references | merge | leave-separate | merge | Specification | Extended. Fallback: N/A use fallback for fo:index-page-citation-list |
| 7.25.4 merge-ranges-across-index-key-references | merge | leave-separate | merge | Specification | Extended. Fallback: N/A use fallback for fo:index-page-citation-list |
| 7.25.5 merge-sequential-page-numbers | merge | leave-separate | merge | Specification | Extended. Fallback: N/A use fallback for fo:index-page-citation-list |
| 7.16.10 min-height | <length> | <percentage> | inherit | 0pt | Shorthand | Complete |
| 7.16.11 min-width | <length> | <percentage> | inherit | depends on UA | Shorthand | Complete |
| 7.31.12 number-columns-repeated | <number> | 1 | Specification | Basic |
| 7.31.13 number-columns-spanned | <number> | 1 | Formatting | Basic |
| 7.31.14 number-rows-spanned | <number> | 1 | Formatting | Basic |
| 7.30.16 odd-or-even | odd | even | any | inherit | any | Specification | Extended. Fallback: N/A use fallback for fo:repeatable-page-master-alternatives |
| 7.21.6 orphans | <integer> | inherit | 2 | Formatting | Basic |
| 7.22.2 overflow | visible | hidden | scroll | error-if-overflow | repeat | auto | inherit | auto | Formatting | Basic |
| 7.34.15 padding | <padding-width>{1,4} | inherit | not defined for shorthand properties | Shorthand | Complete |
| 7.8.31 padding-after | <padding-width> | <length-conditional> | inherit | 0pt | Formatting and Rendering | Basic |
| 7.8.32 padding-before | <padding-width> | <length-conditional> | inherit | 0pt | Formatting and Rendering | Basic |
| 7.8.33 padding-bottom | <padding-width> | inherit | 0pt | Disappears | Basic |
| 7.8.34 padding-end | <padding-width> | <length-conditional> | inherit | 0pt | Formatting and Rendering | Basic |
| 7.8.35 padding-left | <padding-width> | inherit | 0pt | Disappears | Basic |
| 7.8.36 padding-right | <padding-width> | inherit | 0pt | Disappears | Basic |
| 7.8.37 padding-start | <padding-width> | <length-conditional> | inherit | 0pt | Formatting and Rendering | Basic |
| 7.8.38 padding-top | <padding-width> | inherit | 0pt | Disappears | Basic |
| 7.34.16 page-break-after | auto | always | avoid | left | right | inherit | auto | Shorthand | Complete |
| 7.34.17 page-break-before | auto | always | avoid | left | right | inherit | auto | Shorthand | Complete |
| 7.34.18 page-break-inside | avoid | auto | inherit | auto | Shorthand | Complete |
| 7.33.10 page-citation-strategy | [ all | normal | non-blank | inherit | all | Specification | Extended. Fallback: N/A use fallback for fo:page-number-citation-last |
| 7.30.17 page-height | auto | indefinite | <length> | inherit | auto | Specification | Basic |
| 7.25.3 page-number-treatment | link | no-link | no-link | Action | Extended. Fallback: N/A use fallback for fo:index-page-citation-list |
| 7.30.18 page-position | only | first | last | rest | any | inherit | any | Specification | Extended. Fallback: N/A use fallback for fo:repeatable-page-master-alternatives |
| 7.30.19 page-width | auto | indefinite | <length> | inherit | auto | Specification | Basic |
| 7.34.19 pause | [<time> | <percentage>]{1,2} | inherit | depends on user agent | Shorthand | Complete |
| 7.7.5 pause-after | <time> | <percentage> | inherit | depends on user agent | Rendering | Basic |
| 7.7.6 pause-before | <time> | <percentage> | inherit | depends on user agent | Rendering | Basic |
| 7.7.7 pitch | <frequency> | x-low | low | medium | high
| x-high | inherit | medium | Rendering | Basic |
| 7.7.8 pitch-range | <number> | inherit | 50 | Rendering | Basic |
| 7.7.9 play-during | <uri-specification> mix? repeat? | auto | none | inherit | auto | Rendering | Basic |
| 7.34.20 position | static | relative | absolute | fixed | inherit | static | Shorthand | Complete |
| 7.30.20 precedence | true | false | inherit | false | Specification | Extended. Fallback: N/A use fallback for fo:region-before and fo:region-after |
| 7.33.11 provisional-distance-between-starts | <length> | <percentage> | inherit | 24.0pt | Specification | Basic |
| 7.33.12 provisional-label-separation | <length> | <percentage> | inherit | 6.0pt | Specification | Basic |
| 7.22.3 reference-orientation | 0 | 90 | 180 | 270 | -90 | -180 | -270 | inherit | 0 | See prose. | Extended. Fallback: Initial value |
| 7.33.13 ref-id | <idref> | inherit | none, value required | Reference | Extended. Fallback: N/A use fallback for fo:page-number-citation |
| 7.25.7 ref-index-key | <string> | none, value required | Reference | Extended. Fallback: N/A use fallback for fo:index-page-citation-list |
| 7.30.21 region-name | xsl-region-body | xsl-region-start | xsl-region-end
| xsl-region-before | xsl-region-after |
<name> | see prose | Specification | Basic |
| 7.30.22 region-name-reference | <name> | none, a value is required | Specification | Extended. Fallback: N/A use fallback for fo:flow-map |
| 7.15.9 relative-align | before | baseline
| inherit | before | Formatting | Extended. Fallback: Initial value |
| 7.13.1 relative-position | static | relative | inherit | static | See prose. | Extended. Fallback: Initial value |
| 7.19.3 rendering-intent | auto | perceptual | relative-colorimetric | saturation | absolute-colorimetric | inherit | auto | Formatting | Extended. Fallback: N/A use fallback for fo:color-profile |
| 7.26.4 retrieve-boundary | page | page-sequence | document | page-sequence | Formatting | Extended. Fallback: N/A use fallback for fo:retrieve-marker |
| 7.26.2 retrieve-boundary-within-table | table | table-fragment | page | table | Formatting | Extended. Fallback: N/A use fallback for fo:retrieve-table-marker |
| 7.26.3 retrieve-class-name | <name> | an empty name | Formatting | Extended. Fallback: N/A use fallback for fo:retrieve-marker |
| 7.26.5 retrieve-position | first-starting-within-page | first-including-carryover |
last-starting-within-page | last-ending-within-page | first-starting-within-page | Formatting | Extended. Fallback: N/A use fallback for fo:retrieve-marker |
| 7.26.6 retrieve-position-within-table | first-starting | first-including-carryover |
last-starting | last-ending | first-starting | Formatting | Extended. Fallback: N/A use fallback for fo:retrieve-table-marker |
| 7.7.10 richness | <number> | inherit | 50 | Rendering | Basic |
| 7.6.4 right | <length> | <percentage> | auto | inherit | auto | Formatting | Extended. Fallback: N/A due to fallback for absolute-position, relative-position |
| 7.5.2 role | <string> | <uri-specification> | none | inherit | none | Rendering | Basic |
| 7.23.5 rule-style | none | dotted | dashed | solid | double | groove
| ridge | inherit | solid | Rendering | Basic |
| 7.23.6 rule-thickness | <length> | 1.0pt | Rendering | Basic |
| 7.33.14 scale-option | width | height | inherit | width | Refine | Extended. Fallback: N/A use fallback for fo:scaling-value-citation |
| 7.16.12 scaling | uniform | non-uniform | inherit | uniform | Formatting | Extended. Fallback: Initial value |
| 7.16.13 scaling-method | auto | integer-pixels | resample-any-method | inherit | auto | Formatting | Extended. Fallback: Initial value |
| 7.33.15 score-spaces | true | false | inherit | true | Formatting | Extended. Fallback: Initial value |
| 7.10.7 script | none | auto | <script> | inherit | auto | Formatting | Extended. Fallback: none |
| 7.24.9 show-destination | replace | new | replace | Action | Extended. Fallback: N/A use fallback for fo:basic-link |
| 7.34.21 size | <length>{1,2} | auto | landscape | portrait
| inherit | auto | Shorthand | Complete |
| 7.5.1 source-document | <uri-specification> [<uri-specification>]* | none | inherit | none | Rendering | Basic |
| 7.11.6 space-after | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | Formatting | Basic |
| 7.11.7 space-before | <space> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | Formatting | Basic |
| 7.12.1 space-end | <space> | <percentage> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | Formatting | Basic |
| 7.12.2 space-start | <space> | <percentage> | inherit | space.minimum=0pt, .optimum=0pt, .maximum=0pt,
.conditionality=discard, .precedence=0 | Formatting | Basic |
| 7.22.4 span | none | all | inherit | none | Formatting | Extended. Fallback: Initial value |
| 7.7.11 speak | normal | none | spell-out | inherit | normal | Rendering | Basic |
| 7.7.12 speak-header | once | always | inherit | once | Rendering | Basic |
| 7.7.13 speak-numeral | digits | continuous | inherit | continuous | Rendering | Basic |
| 7.7.14 speak-punctuation | code | none | inherit | none | Rendering | Basic |
| 7.7.15 speech-rate | <number> | x-slow | slow | medium | fast
| x-fast | faster | slower | inherit | medium | Rendering | Basic |
| 7.33.16 src | <uri-specification> | inherit | none, value required | Reference | Basic |
| 7.11.8 start-indent | <length> | <percentage> | inherit | 0pt | Formatting | Basic |
| 7.24.10 starting-state | show | hide | show | Action | Extended. Fallback: N/A use fallback for fo:multi-switch |
| 7.31.15 starts-row | true | false | false | Formatting | Extended. Fallback: Initial value |
| 7.7.16 stress | <number> | inherit | 50 | Rendering | Basic |
| 7.18.3 suppress-at-line-break | auto | suppress | retain | inherit | auto | Formatting | Extended. Fallback: Initial value |
| 7.24.11 switch-to | xsl-preceding | xsl-following | xsl-any | <name>[ <name>]* | xsl-any | Action | Extended. Fallback: N/A use fallback for fo:multi-switch |
| 7.31.16 table-layout | auto | fixed | inherit | auto | Formatting | Extended. Fallback: fixed |
| 7.31.17 table-omit-footer-at-break | true | false | false | Formatting | Extended. Fallback: Initial value |
| 7.31.18 table-omit-header-at-break | true | false | false | Formatting | Extended. Fallback: Initial value |
| 7.24.12 target-presentation-context | use-target-processing-context | <uri-specification> | use-target-processing-context | Action | Extended. Fallback: N/A use fallback for fo:basic-link |
| 7.24.13 target-processing-context | document-root | <uri-specification> | document-root | Action | Extended. Fallback: N/A use fallback for fo:basic-link |
| 7.24.14 target-stylesheet | use-normal-stylesheet | <uri-specification> | use-normal-stylesheet | Action | Extended. Fallback: N/A use fallback for fo:basic-link |
| 7.17.8 text-align | start | center | end | justify | inside | outside
| left | right | <string> | inherit | start | Value change | Basic |
| 7.17.9 text-align-last | relative | start | center | end | justify | inside
| outside | left | right | inherit | relative | Value change | Extended. Fallback: Initial value |
| 7.32.4 text-altitude | use-font-metrics | <length> | <percentage> | inherit | use-font-metrics | Formatting | Extended. Fallback: Initial value |
| 7.18.4 text-decoration | none | [ [ underline | no-underline] || [ overline | no-overline ]
|| [ line-through | no-line-through ] || [ blink | no-blink ] ]
| inherit | none | See prose. | Extended. Fallback: Initial value |
| 7.32.5 text-depth | use-font-metrics | <length> | <percentage> | inherit | use-font-metrics | Formatting | Extended. Fallback: Initial value |
| 7.17.10 text-indent | <length> | <percentage> | inherit | 0pt | Formatting | Basic |
| 7.18.5 text-shadow | none | [<color> || <length> <length> <length>?
,]* [<color> || <length> <length> <length>?] | inherit | none | Rendering | Extended. Fallback: Initial value |
| 7.18.6 text-transform | capitalize | uppercase | lowercase | none | inherit | none | Refine | Extended. Fallback: Initial value |
| 7.6.5 top | <length> | <percentage> | auto | inherit | auto | Formatting | Extended. Fallback: N/A due to fallback for absolute-position, relative-position |
| 7.18.7 treat-as-word-space | auto | true | false | inherit | auto | Formatting | Extended. Fallback: Initial value |
| 7.32.6 unicode-bidi | normal | embed | bidi-override | inherit | normal | Formatting | Extended. Fallback: See prose |
| 7.34.22 vertical-align | baseline | middle | sub | super | text-top |
text-bottom | <percentage> | <length> | top | bottom | inherit | baseline | Shorthand | Complete |
| 7.33.17 visibility | visible | hidden | collapse | inherit | visible | Magic | Extended. Fallback: Initial value |
| 7.7.17 voice-family | [[<specific-voice> | <generic-voice>
],]* [<specific-voice> | <generic-voice> ] | inherit | depends on user agent | Rendering | Basic |
| 7.7.18 volume | <number> | <percentage> | silent | x-soft
| soft | medium | loud | x-loud | inherit | medium | Rendering | Basic |
| 7.34.23 white-space | normal | pre | nowrap | inherit | normal | Shorthand | Complete |
| 7.17.11 white-space-collapse | false | true | inherit | true | Formatting | Extended. Fallback: Initial value |
| 7.17.12 white-space-treatment | ignore | preserve | ignore-if-before-linefeed |
ignore-if-after-linefeed | ignore-if-surrounding-linefeed | inherit | ignore-if-surrounding-linefeed | Formatting | Extended. Fallback: Initial value |
| 7.21.7 widows | <integer> | inherit | 2 | Formatting | Basic |
| 7.16.14 width | <length> | <percentage> | auto | inherit | auto | Disappears | Basic |
| 7.18.8 word-spacing | normal | <length> | <space> | inherit | normal | Disappears | Extended. Fallback: Initial value |
| 7.17.13 wrap-option | no-wrap | wrap | inherit | wrap | Formatting | Basic |
| 7.32.7 writing-mode | lr-tb |
rl-tb |
tb-rl |
tb-lr |
bt-lr |
bt-rl |
lr-bt |
rl-bt |
lr-alternating-rl-bt |
lr-alternating-rl-tb |
lr-inverting-rl-bt |
lr-inverting-rl-tb |
tb-lr-in-lr-pairs |
lr |
rl |
tb |
inherit | lr-tb | See prose. | Basic |
| 7.34.24 xml:lang | <language-country> | inherit | not defined for shorthand properties | Shorthand | Complete |
| 7.33.18 z-index | auto | <integer> | inherit | auto | Value change | Extended. Fallback: N/A due to fallback for fo:block-container |
B.4 Properties and the FOs they apply to
For each property the formatting objects it applies to is
listed. It should be noted, however, that for some formatting objects
there are qualifications on applicability or values permitted.
Property absolute-position applies to:
fo:block-container.
Property active-state applies to:
fo:multi-property-set.
Property alignment-adjust applies to:
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:basic-link.
Property alignment-baseline applies to:
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:basic-link.
Property allowed-height-scale applies to:
fo:external-graphic, and
fo:instream-foreign-object.
Property allowed-width-scale applies to:
fo:external-graphic, and
fo:instream-foreign-object.
Property auto-restore applies to:
fo:multi-switch.
Property azimuth applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property background-attachment applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property background-color applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property background-image applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property background-position-horizontal applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property background-position-vertical applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property background-repeat applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property baseline-shift applies to:
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:basic-link.
Property blank-or-not-blank applies to:
fo:conditional-page-master-reference.
Property block-progression-dimension applies to:
fo:block-container,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:table,
fo:table-caption,
fo:table-row, and
fo:table-cell.
Property border-after-color applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-after-precedence applies to:
fo:table,
fo:table-column,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row, and
fo:table-cell.
Property border-after-style applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-after-width applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-before-color applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-before-precedence applies to:
fo:table,
fo:table-column,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row, and
fo:table-cell.
Property border-before-style applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-before-width applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-bottom-color applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-bottom-style applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-bottom-width applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-collapse applies to:
fo:table.
Property border-end-color applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-end-precedence applies to:
fo:table,
fo:table-column,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row, and
fo:table-cell.
Property border-end-style applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-end-width applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-left-color applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-left-style applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-left-width applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-right-color applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-right-style applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-right-width applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-separation applies to:
fo:table.
Property border-start-color applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-start-precedence applies to:
fo:table,
fo:table-column,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row, and
fo:table-cell.
Property border-start-style applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-start-width applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-top-color applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-top-style applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property border-top-width applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-column,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property bottom applies to:
fo:block-container.
Property bottom applies to:
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property break-after applies to:
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:table-row,
fo:list-block, and
fo:list-item.
Property break-before applies to:
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:table-row,
fo:list-block, and
fo:list-item.
Property caption-side applies to:
fo:table-and-caption.
Property case-name applies to:
fo:multi-case.
Property case-title applies to:
fo:multi-case.
Property change-bar-class applies to:
fo:change-bar-begin, and
fo:change-bar-end.
Property change-bar-color applies to:
fo:change-bar-begin.
Property change-bar-offset applies to:
fo:change-bar-begin.
Property change-bar-placement applies to:
fo:change-bar-begin.
Property change-bar-style applies to:
fo:change-bar-begin.
Property change-bar-width applies to:
fo:change-bar-begin.
Property character applies to:
fo:character.
Property clear applies to:
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:list-block, and
fo:float.
Property clip applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:block-container,
fo:external-graphic,
fo:instream-foreign-object, and
fo:inline-container.
Property color applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:inline,
fo:leader, and
fo:bookmark-title.
Property color-profile-name applies to:
fo:color-profile.
Property column-count applies to:
fo:region-body.
Property column-gap applies to:
fo:region-body.
Property column-number applies to:
fo:table-column, and
fo:table-cell.
Property column-width applies to:
fo:table-column.
Property content-height applies to:
fo:external-graphic, and
fo:instream-foreign-object.
Property content-type applies to:
fo:external-graphic, and
fo:instream-foreign-object.
Property content-width applies to:
fo:external-graphic, and
fo:instream-foreign-object.
Property country applies to:
fo:block, and
fo:character.
Property cue-after applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property cue-before applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property destination-placement-offset applies to:
fo:basic-link.
Property direction applies to:
fo:bidi-override.
Property display-align applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:block-container,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline-container, and
fo:table-cell.
Property dominant-baseline applies to:
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:basic-link.
Property elevation applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property empty-cells applies to:
fo:table-cell.
Property end-indent applies to:
fo:simple-page-master,
fo:region-body,
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:list-block, and
fo:list-item.
Property ends-row applies to:
fo:table-cell.
Property extent applies to:
fo:region-before,
fo:region-after,
fo:region-start, and
fo:region-end.
Property external-destination applies to:
fo:basic-link, and
fo:bookmark.
Property float applies to:
fo:float.
Property flow-map-name applies to:
fo:flow-map.
Property flow-map-reference applies to:
fo:page-sequence.
Property flow-name applies to:
fo:flow, and
fo:static-content.
Property flow-name-reference applies to:
fo:flow-name-specifier.
Property font-family applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property font-selection-strategy applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property font-size applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property font-size-adjust applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property font-stretch applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property font-style applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property font-variant applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property font-weight applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property force-page-count applies to:
fo:page-sequence.
Property format applies to:
fo:page-sequence, and
fo:scaling-value-citation.
Property glyph-orientation-horizontal applies to:
fo:character.
Property glyph-orientation-vertical applies to:
fo:character.
Property grouping-separator applies to:
fo:page-sequence, and
fo:scaling-value-citation.
Property grouping-size applies to:
fo:page-sequence, and
fo:scaling-value-citation.
Property height applies to:
fo:block-container,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:table,
fo:table-caption,
fo:table-row, and
fo:table-cell.
Property hyphenate applies to:
fo:block, and
fo:character.
Property hyphenation-character applies to:
fo:block, and
fo:character.
Property hyphenation-keep applies to:
fo:block.
Property hyphenation-ladder-count applies to:
fo:block.
Property hyphenation-push-character-count applies to:
fo:block, and
fo:character.
Property hyphenation-remain-character-count applies to:
fo:block, and
fo:character.
Property id applies to:
fo:root,
fo:page-sequence,
fo:page-sequence-wrapper,
fo:flow,
fo:static-content,
fo:block,
fo:block-container,
fo:bidi-override,
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:list-item-body,
fo:list-item-label,
fo:basic-link,
fo:multi-switch,
fo:multi-case,
fo:multi-toggle,
fo:multi-property-set,
fo:index-range-begin,
fo:float,
fo:footnote,
fo:footnote-body, and
fo:wrapper.
Property index-class applies to:
fo:root,
fo:page-sequence,
fo:page-sequence-wrapper,
fo:flow,
fo:static-content,
fo:block,
fo:block-container,
fo:bidi-override,
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:list-item-body,
fo:list-item-label,
fo:basic-link,
fo:multi-switch,
fo:multi-case,
fo:multi-toggle,
fo:multi-property-set,
fo:index-range-begin,
fo:float,
fo:footnote,
fo:footnote-body, and
fo:wrapper.
Property index-key applies to:
fo:root,
fo:page-sequence,
fo:page-sequence-wrapper,
fo:flow,
fo:static-content,
fo:block,
fo:block-container,
fo:bidi-override,
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:list-item-body,
fo:list-item-label,
fo:basic-link,
fo:multi-switch,
fo:multi-case,
fo:multi-toggle,
fo:multi-property-set,
fo:index-range-begin,
fo:float,
fo:footnote,
fo:footnote-body, and
fo:wrapper.
Property indicate-destination applies to:
fo:basic-link.
Property initial-page-number applies to:
fo:page-sequence.
Property inline-progression-dimension applies to:
fo:block-container,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:table,
fo:table-caption, and
fo:table-cell.
Property internal-destination applies to:
fo:basic-link, and
fo:bookmark.
Property intrinsic-scale-value applies to:
fo:scaling-value-citation.
Property intrusion-displace applies to:
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:list-block, and
fo:list-item.
Property keep-together applies to:
fo:block,
fo:block-container,
fo:inline,
fo:inline-container,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-row,
fo:list-block,
fo:list-item,
fo:list-item-body,
fo:list-item-label, and
fo:basic-link.
Property keep-with-next applies to:
fo:block,
fo:block-container,
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-row,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property keep-with-previous applies to:
fo:block,
fo:block-container,
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-row,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property language applies to:
fo:block, and
fo:character.
Property last-line-end-indent applies to:
fo:block.
Property leader-alignment applies to:
fo:leader.
Property leader-length applies to:
fo:leader.
Property leader-pattern applies to:
fo:leader.
Property leader-pattern-width applies to:
fo:leader.
Property left applies to:
fo:block-container.
Property left applies to:
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property letter-spacing applies to:
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property letter-value applies to:
fo:page-sequence, and
fo:scaling-value-citation.
Property linefeed-treatment applies to:
fo:block.
Property line-height applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:basic-link.
Property line-height-shift-adjustment applies to:
fo:block.
Property line-stacking-strategy applies to:
fo:block.
Property margin-bottom applies to:
fo:simple-page-master,
fo:region-body,
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:list-block, and
fo:list-item.
Property margin-bottom applies to:
fo:title,
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:basic-link.
Property margin-left applies to:
fo:simple-page-master,
fo:region-body,
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:list-block, and
fo:list-item.
Property margin-left applies to:
fo:title,
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:basic-link.
Property margin-right applies to:
fo:simple-page-master,
fo:region-body,
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:list-block, and
fo:list-item.
Property margin-right applies to:
fo:title,
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:basic-link.
Property margin-top applies to:
fo:simple-page-master,
fo:region-body,
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:list-block, and
fo:list-item.
Property margin-top applies to:
fo:title,
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:basic-link.
Property marker-class-name applies to:
fo:marker.
Property master-name applies to:
fo:page-sequence-master, and
fo:simple-page-master.
Property master-reference applies to:
fo:page-sequence,
fo:single-page-master-reference,
fo:repeatable-page-master-reference, and
fo:conditional-page-master-reference.
Property maximum-repeats applies to:
fo:repeatable-page-master-reference, and
fo:repeatable-page-master-alternatives.
Property media-usage applies to:
fo:root.
Property merge-pages-across-index-key-references applies to:
fo:index-page-citation-list.
Property merge-ranges-across-index-key-references applies to:
fo:index-page-citation-list.
Property merge-sequential-page-numbers applies to:
fo:index-page-citation-list.
Property number-columns-repeated applies to:
fo:table-column.
Property number-columns-spanned applies to:
fo:table-column, and
fo:table-cell.
Property number-rows-spanned applies to:
fo:table-cell.
Property odd-or-even applies to:
fo:conditional-page-master-reference.
Property orphans applies to:
fo:block.
Property overflow applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:block-container,
fo:external-graphic,
fo:instream-foreign-object, and
fo:inline-container.
Property padding-after applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property padding-before applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property padding-bottom applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property padding-end applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property padding-left applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property padding-right applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property padding-start applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property padding-top applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:title,
fo:block,
fo:block-container,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property page-citation-strategy applies to:
fo:page-number-citation-last.
Property page-height applies to:
fo:simple-page-master.
Property page-number-treatment applies to:
fo:index-key-reference.
Property page-position applies to:
fo:conditional-page-master-reference.
Property page-width applies to:
fo:simple-page-master.
Property pause-after applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property pause-before applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property pitch applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property pitch-range applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property play-during applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property precedence applies to:
fo:region-before, and
fo:region-after.
Property provisional-distance-between-starts applies to:
fo:list-block.
Property provisional-label-separation applies to:
fo:list-block.
Property reference-orientation applies to:
fo:page-sequence,
fo:simple-page-master,
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:block-container, and
fo:inline-container.
Property ref-id applies to:
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:index-range-end.
Property ref-index-key applies to:
fo:index-key-reference.
Property region-name applies to:
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start, and
fo:region-end.
Property region-name-reference applies to:
fo:region-name-specifier.
Property relative-align applies to:
fo:table-cell, and
fo:list-item.
Property relative-position applies to:
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property rendering-intent applies to:
fo:color-profile.
Property retrieve-boundary applies to:
fo:retrieve-marker.
Property retrieve-boundary-within-table applies to:
fo:retrieve-table-marker.
Property retrieve-class-name applies to:
fo:retrieve-marker, and
fo:retrieve-table-marker.
Property retrieve-position applies to:
fo:retrieve-marker.
Property retrieve-position-within-table applies to:
fo:retrieve-table-marker.
Property richness applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property right applies to:
fo:block-container.
Property right applies to:
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property role applies to:
fo:root,
fo:title,
fo:block,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:list-item-body,
fo:list-item-label,
fo:basic-link,
fo:multi-switch,
fo:multi-case,
fo:multi-toggle,
fo:multi-properties,
fo:bookmark,
fo:bookmark-title,
fo:footnote,
fo:footnote-body,
fo:change-bar-begin, and
fo:change-bar-end.
Property rule-style applies to:
fo:leader.
Property rule-thickness applies to:
fo:leader.
Property scale-option applies to:
fo:scaling-value-citation.
Property scaling applies to:
fo:external-graphic, and
fo:instream-foreign-object.
Property scaling-method applies to:
fo:external-graphic, and
fo:instream-foreign-object.
Property score-spaces applies to:
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property script applies to:
fo:block, and
fo:character.
Property show-destination applies to:
fo:basic-link.
Property source-document applies to:
fo:root,
fo:title,
fo:block,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:list-item-body,
fo:list-item-label,
fo:basic-link,
fo:multi-switch,
fo:multi-case,
fo:multi-toggle,
fo:multi-properties,
fo:bookmark,
fo:bookmark-title,
fo:footnote,
fo:footnote-body,
fo:change-bar-begin, and
fo:change-bar-end.
Property space-after applies to:
fo:simple-page-master,
fo:region-body,
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:list-block, and
fo:list-item.
Property space-before applies to:
fo:simple-page-master,
fo:region-body,
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:list-block, and
fo:list-item.
Property space-end applies to:
fo:title,
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:basic-link.
Property space-start applies to:
fo:title,
fo:character,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation, and
fo:basic-link.
Property span applies to:
fo:block, and
fo:block-container.
Property speak applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property speak-header applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property speak-numeral applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property speak-punctuation applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property speech-rate applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property src applies to:
fo:color-profile, and
fo:external-graphic.
Property start-indent applies to:
fo:simple-page-master,
fo:region-body,
fo:block,
fo:block-container,
fo:table-and-caption,
fo:table,
fo:list-block, and
fo:list-item.
Property starting-state applies to:
fo:multi-case, and
fo:bookmark.
Property starts-row applies to:
fo:table-cell.
Property stress applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property suppress-at-line-break applies to:
fo:character.
Property switch-to applies to:
fo:multi-toggle.
Property table-layout applies to:
fo:table.
Property table-omit-footer-at-break applies to:
fo:table.
Property table-omit-header-at-break applies to:
fo:table.
Property target-presentation-context applies to:
fo:basic-link.
Property target-processing-context applies to:
fo:basic-link.
Property target-stylesheet applies to:
fo:basic-link.
Property text-align applies to:
fo:block,
fo:external-graphic,
fo:instream-foreign-object, and
fo:table-and-caption.
Property text-align-last applies to:
fo:block.
Property text-altitude applies to:
fo:block,
fo:character,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property text-decoration applies to:
fo:character,
fo:initial-property-set,
fo:inline,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property text-depth applies to:
fo:block,
fo:character,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property text-indent applies to:
fo:block.
Property text-shadow applies to:
fo:character,
fo:initial-property-set,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property text-transform applies to:
fo:character,
fo:initial-property-set,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property top applies to:
fo:block-container.
Property top applies to:
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item, and
fo:basic-link.
Property treat-as-word-space applies to:
fo:character.
Property unicode-bidi applies to:
fo:bidi-override.
Property visibility applies to:
fo:title,
fo:block,
fo:character,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-column,
fo:table-header,
fo:table-footer,
fo:table-body, and
fo:table-row.
Property voice-family applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property volume applies to:
fo:title,
fo:block,
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last,
fo:scaling-value-citation,
fo:table-and-caption,
fo:table,
fo:table-caption,
fo:table-header,
fo:table-footer,
fo:table-body,
fo:table-row,
fo:table-cell,
fo:list-block,
fo:list-item,
fo:basic-link,
fo:change-bar-begin, and
fo:change-bar-end.
Property white-space-collapse applies to:
fo:block.
Property white-space-treatment applies to:
fo:block.
Property widows applies to:
fo:block.
Property width applies to:
fo:block-container,
fo:external-graphic,
fo:instream-foreign-object,
fo:inline,
fo:inline-container,
fo:table,
fo:table-caption, and
fo:table-cell.
Property word-spacing applies to:
fo:bidi-override,
fo:character,
fo:initial-property-set,
fo:leader,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property wrap-option applies to:
fo:block,
fo:inline,
fo:page-number,
fo:page-number-citation,
fo:page-number-citation-last, and
fo:scaling-value-citation.
Property writing-mode applies to:
fo:page-sequence,
fo:simple-page-master,
fo:region-body,
fo:region-before,
fo:region-after,
fo:region-start,
fo:region-end,
fo:block-container,
fo:inline-container, and
fo:table.
Property z-index applies to:
fo:block-container, and
fo:change-bar-begin.















































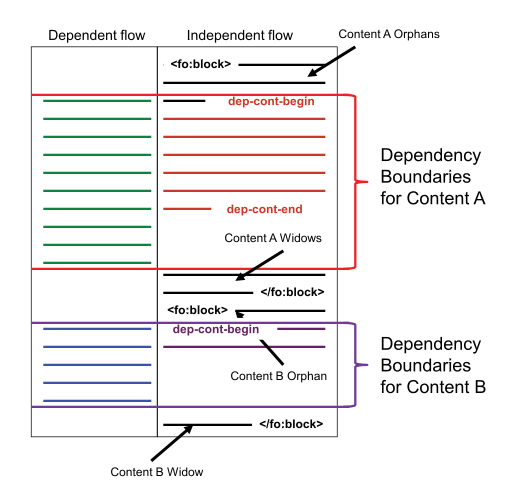
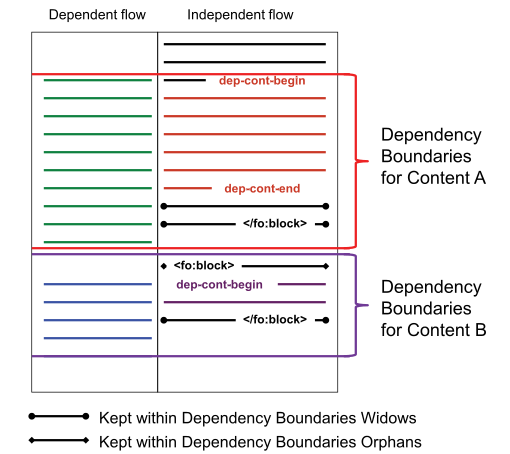



































-aligned ruby when ruby text is shorter than base")
-aligned ruby when ruby text is longer than base")



 than the corresponding base")













