This group gathers people interested in the history of the World Wide Web: how it was invented, what was out there that made it possible, and what happened in its early years. Our main goal is to collect and preserve valuable information (software, documents, testimonials) before it is lost.
This group will not produce specifications.
Group's public email, repo and wiki activity over time
Note: Community Groups are proposed and run by the community. Although W3C hosts these
conversations, the groups do not necessarily represent the views of the W3C Membership or staff.
Chairs, when logged in, may publish draft and final reports. Please see report requirements.
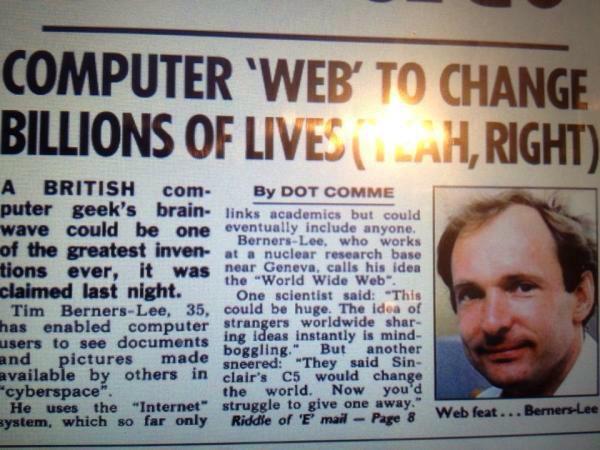
Curious to find a common thread between Xanadu and the Semantic Web, I discovered a treasure trove of videos with Tim Berners Lee, Doug Engelbart, Ted Nelson and others talking about hypertext and all things interconnectivity in the very early days of the Web.
[Some Notes from TimBL’s talk at Bush Symposium at MIT, 1995]
Television vs. A Sea of Shared Knowledge
“I had (and still have) a dream that the Web could be less of a television channel and more of an interactive sea of shared knowledge” [~ 7 min]
“And interactive way of helping people work together” [~ 9 min]
“The team management problem” [~ 10 min]
Neurons, People, Data Objects
Neurons and documents and people can all have these random associations [~ 14 min]
The moment web objects will start talking to each other we will need to bring some rules [~ 17 min]
The rules (between people, particles and web objects) [~ 18 min]
Associations and Links as $, Readership, Confusion
(a slide 🙂 of this section is available here: https://www.w3.org/Talks/9510_Bush/A1.html)
Some people say: Hypertext is very confusing, we’ll get lost in cyberspace [~19]
But soon, the “click here” seized the public imagination:
“A little bit of semantics” [23.06 min]
Fractals and Information Plumbing
Structure. Tree. Building [~ 30 min]
The problem with modern architecture – it’s not fractal.
If we can find a design for protocols that is fractal, we can scale. Structures working at both higher and lower level. [~ 30 min]
Information plumbing (this person is gonna talk to these and these people, so that a human being feels comfortable when they have interactions at a widely diverse scales)[~ 32 min]
Human interaction maybe has fractal properties [~ 33 min]
No one person knows everything in the system [~ 33.40 min]
Confidentiality – can two agents communicate without other agents being aware of this [~ 34 min]
A machine that is the sum of ourselves and our data [~ 36 min]
Semantics [From the Questions and Answers Part]
Labelling things. Setting up filters. All sorts of metadata. That will make the Web a whole lot nicer place.[~ 42 min]
Browsing with different types of personas (anonymously, or in this and this role) [~ 42 min]
Protocols for reasonable behaviour [~43]
Question about Topology [~43]
Type links [~44 min]
You can make structure. You can make relationships.
Documents being representative of thing, people, other documents.
Stating relationships between objects is where things become really interesting.
#semantics
People abandoned semantics because they felt they cannot solve the AI problem. But in fact to put some semantics on the Web would enable so many things.When you invent link types you can represent the whole thing as a bunch of linked objects.[~45 – 47 min]
P.S. The panel discussion after the event is also worth watching. There notes from it available here: http://cs.brown.edu/memex/Bush_Symposium_Panels.html#Day%202%20Panel
Yesterday via the “Restoring the first website” CERN Website, I discovered Accessing the line mode browser with 1960s tech, an interview of computer hobbyist Suhayl Khan, who shows us in a 15-minute video how to access the line-mode browser using 1960s tech.
Today is the twentieth anniversary of the publication of a document by CERN that made the web available to all on a royalty-free basis. To mark this occasion we’re kicking off a project to restore the first website, and preserve the digital assets associated with the birth of the web: http://first-website.web.cern.ch
I was talking with Robert Cailliau this morning about our project to restore the first website. He mentioned an interesting anecdote that could possibly lead us to an earlier version of the first website, but it’s a long shot.
In 1997 Tim Berners-Lee’s NeXT machine was shipped out to Santa Clara in California for the sixth World Wide Web Conference.
When the NeXT was returned by mail (via Stanford, I believe), the machine’s optical read-write drive was missing. This drive contained a 1990 version of the first website.
The NeXT had a removable drive module that looked like this.
It’s a long shot, but does anyone have any ideas on how we might trace such a thing? Would the NeXT’s serial number lead us to a matching drive number range? Is anyone using this thing as a paperweight?
I work in the communications group at CERN where I am in charge of CERN’s public-facing websites. We’ve set up a project to restore and preserve the first URL, which is sadly no longer active: http://info.cern.ch/hypertext/WWW/TheProject.html
We are in the process of selling the project to internal stakeholders and starting to build a team – and quite a few of us are really excited about this. We are also working with our design partners Mark Boulton Design to see how we can provide a better experience for visitors to http://info.cern.ch/
I got in touch with my colleague, Anita Hollier, the CERN archivist, for help. She told me about the presence of this group, and I’m now turning to you for your help, input, guidance and ideas.
But it could also be so much more than this. For instance:
CERN has two of the early WWW team’s NeXT machines. We really think the ones and zeros on those computers should be preserved, and, if possible, shared.
We should document the NeXT browsing (and editing) experience. There is a lot of TBL’s original vision for the web in there that is as new and exciting now as it was circa 1990. These machines will not be usable forever.
I’d love to see the line-mode browser experience somehow preserved – a browser-based emulator?
There are IP addresses and machine names in the original WWW documentation mentioned that we could (p)reserve, and protocols such as telnet and FTP put back in place on certain servers.
The original code packages that were available for download could be restored.
The next step is that we are going to outline our intentions via a blog, which will be available at http://info.cern.ch towards the end of April.
Anyone here want to get involved? If you have ideas, suggestions, offers of help, then please get in touch.
We’ve already mentioned Paul Otlet and The Mundaneum museum here. Google Cultural Institute has just published a site dedicated to them, showing how they designed the very first search engine in 1935 by inventing the Universal Decimal Classification system and storing 16 million fact cards in the Mundaneum in Brussels, which people could “query” by post.
Representatives from both Google and the Mundaneum museum are on this group, so congratulations to both!