
Why Spatial Is Very Special
Web Semantics1
TL;DR: “machines” use the HTML structure of Web pages to enable the coherent transmission of the document content’s meaning to the user. Maps and locations are not currently reflected in HTML’s structure, nor browser rendering engines, and so a) their meaning is proprietary to Web sites, concocted as they are, from ever-more-opaque code, and b) Web-based assistive technology, aka “machines”, are unable to follow the markup that might convey locations to users, and so the machines need hints, which are typically omitted or badly implemented. Maps and location are important for everyone, but especially important for non-visual users who must rely on textual location descriptions and search. Maps and location semantics may also be important on the Web for future applications such as the metaverse, digital twins, smart cities, the Web of Things, spatial data infrastructure, indoor mapping and autonomous vehicles, to name a few. To sustainably and fairly enable these applications on the Web, maps and location should be integrated in the browser engines, with standardised HTML semantics.
- The usage of the word “semantics” in this document is distinct from that of its usage in the Semantic Web. The latter is not discussed here.
- Understanding semantics – Tink
HTML semantics are for a11y2
Web pages contain a mix of structure (HTML markup) and content (text, images, media, etc). Web pages are structured using HTML elements so that the “machines” that process them (browsers, screen readers, search engine crawlers, etc) understand what the parts are and can render or process them accordingly. Machines process HTML element structure, so that humans can consume and understand the meaning of the HTML contents. The standardised meaning accorded HTML elements (structure) is often described as HTML semantics, which refers to how that markup is specified and how it is intended to be processed. The contents of an HTML page also have meaning (for humans, mostly), and it is the raison d’être of browsers and assistive technology to facilitate the transmission of the images’, graphics’ and text’s meaning to the user, through graphic or other rendering techniques.
Web maps model physical space, just like words model conceptual space
In an analogous way that humans use language and text to convey ideas, Web maps describe the physical world with coordinate reference systems (CRS) and math (of course). That is, maps may reflect the real, physical world. The relation between this model and the real world can easily be experienced, right now, by anyone with a smartphone, by viewing your device’s location, rendered on a web map, as a symbol:
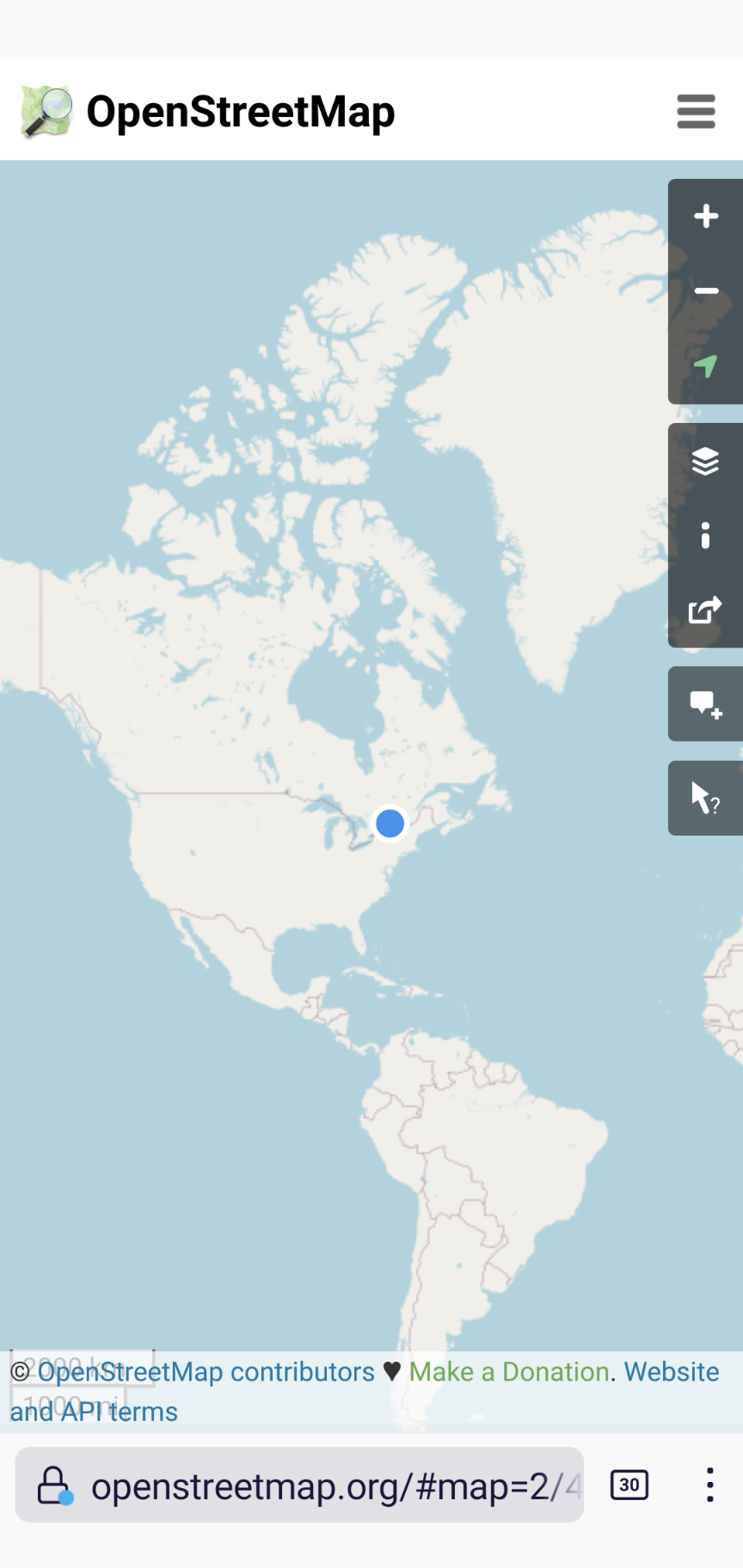
An example of well-known CRS coordinates are provided by the WGS 843 coordinates reported for your device by its Global Positioning System (GPS) sensor. The geospatial standards community has spent decades of effort, and billions of dollars defining and standardising the details of spatial CRS, to enable geographic information to be processed and rendered by machines, for use by humans. These coordinates represent the most fundamental map semantics. The relationship between the multi-billion dollar GPS CRS system and the map on your phone is today provided exclusively by the JavaScript on the page, not by the browser engine. In other words, the browser doesn’t ‘understand’ the map, it leaves that up to each site, with a very few, very large sites dominating and brokering that space.
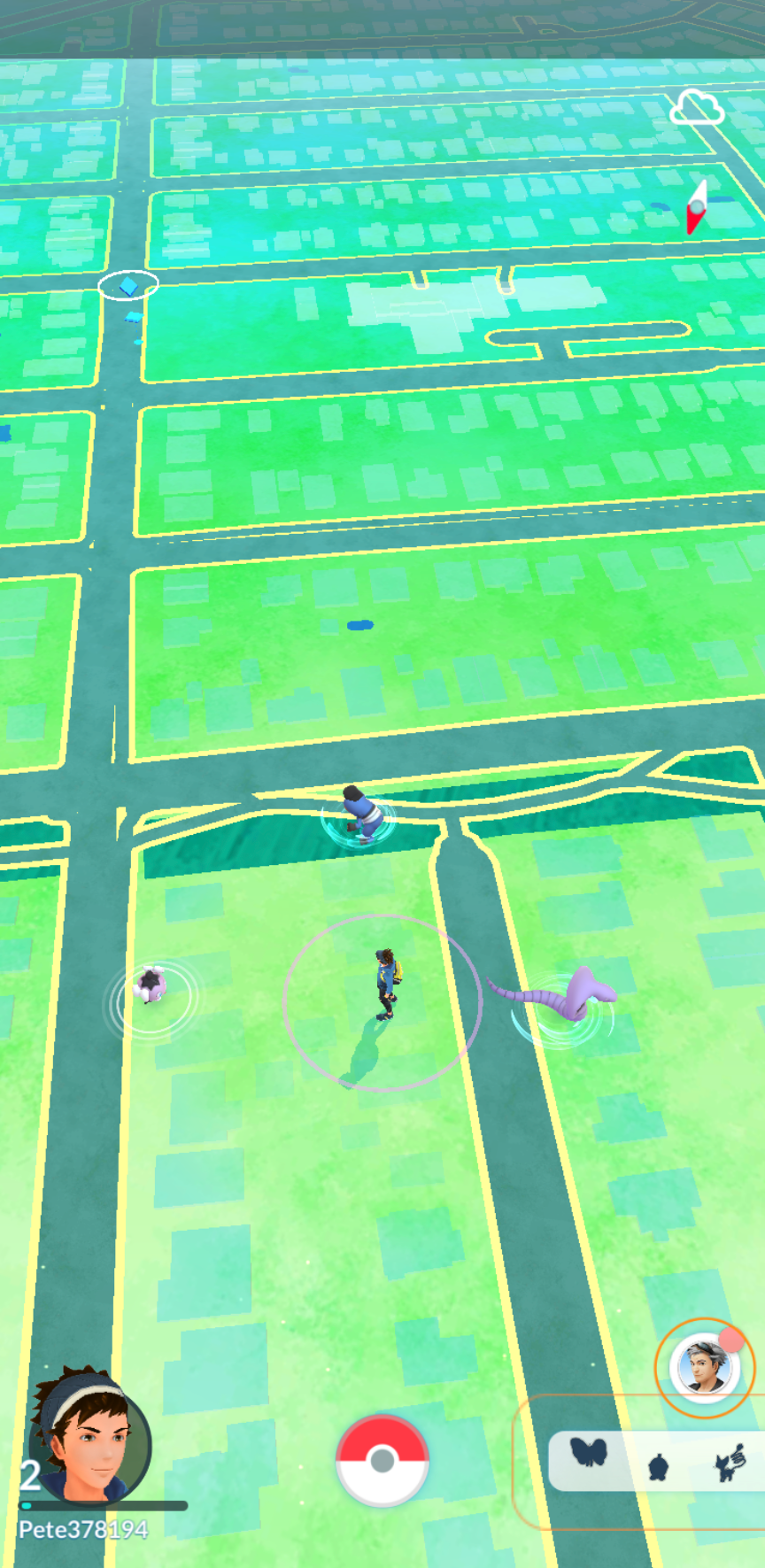
Extended and augmented reality (XR, AR) can also be models of reality, collectively known as the Immersive Web. The (potential) commonality between the Immersive Web and Web maps is that, to some degree, they each represent physical and virtual reality integrated together, sometimes relying on user device sensors to “place” the user into the virtual representation, as shown by both our Web map examples above. The value of placing the user into a virtual representation of reality, be it a 2D map or 3D representation, lies in the accessibility, privacy and performance delivered by HTML semantics, and rendered by browsers for the benefit of the user. Such value can only be realised only if all Web sites have a simple (declarative), open (standard) and fair way to represent physical reality that does not depend for existence on procedural browser extension (JavaScript, WebGL, WASM etc.).
When everyone is responsible (for map accessibility), no one is responsible
A key argument against extending or even relying on JavaScript to deliver map and location semantics to the user (even if a non-DOM standard library did exist) is that providing accessibility for maps and location content for the Web then becomes the responsibility of individual Web sites and library developers. When everyone is responsible for creating accessible content, when that content is or must be created with JavaScript, canvas, or WebGL, or WASM, inaccessible content is often the result. Other essential characteristics of the Web besides accessibility are also lost or harmed when JavaScript is used as a substitute for HTML semantics, including: performance, generality, internationalisation, and crawl- and search-ability. In short, while JavaScript (and its sidekick JSON) is a fantastic language to progressively enhance the Web experience, it should not be looked to as a focus for Web standardisation of mapping.

What is “special” about spatial?
At our recent Maps for HTML community meeting in September 2022, we had the beginnings of a really interesting, and I believe important discussion, about the intimate relationship between accessibility, map semantics, and rendering. Boaz Sender, from Bocoup, showed us an example of a prototype browser intervention that they have been researching, using a dynamic Leaflet-powered, OpenStreetMap-backed map of Denver, Colorado. The “intervention” part was where the whole map, and especially the set of features highlighted on the map was rendered on request, not graphically, but in an alternate “view” representing the map as a simple text list. This seems to be a prototype implementation of a really important idea, and one that has come up before in our community, and it is an idea that is gaining traction in the mobile app world (yes, the Web Platform community should pay attention – mobile apps surpass the Web by far in location-based usage).
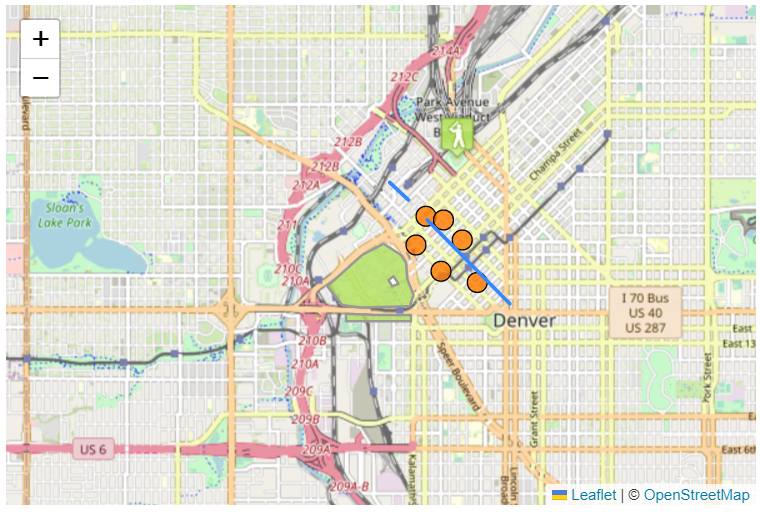
Ed Parsons raised what I consider to be a profound question about the Denver map example: What is it about the map, besides being visually obvious to someone familiar with United States geography, that tells us that it’s a map of Denver? Even the text list representation of the map might not indicate that these are features from Denver, and the map itself even might not be labelled as such, despite the importance of such labelling. Still, there is something significant about the meaning of that map that is instantly obvious to users of its visual rendering that is clearly missing from the current Web.
Globally shared coordinate semantics, defined by a Web standard
What’s missing is the ability to represent Denver in a way that isn’t ephemeral, nor accessible only to sighted users. What’s missing is the ability to represent and render the coordinate space of the Earth and things on Earth in a standard way that is shared by everyone. What’s missing is maps and locations in HTML, implemented and supported by Web browser engines, for everyone!

In my next post, I’ll explore what we’re doing in the Maps for HTML Community Group to change the status quo. See you then, I hope!
Pingback: Why Spatial Is Very Special – GeoNe.ws