1 Introduction
A large and growing set of specifications describe processes operating on XML documents. Many applications depend on the use of more than one of the many inter-related XML family of specifications. How implementations of these specifications interact affects interoperability. XProc: An XML Pipeline Language is designed for describing operations to be performed on XML documents.
"An XML Pipeline specifies a sequence of operations to be performed on a collection of XML input documents. Pipelines take zero or more XML documents as their input and produce zero or more XML documents as their output. A pipeline consists of steps. Like pipelines, steps take zero or more XML documents as their inputs and produce zero or more XML documents as their outputs. The inputs of a step come from the web, from the pipeline document, from the inputs to the pipeline itself, or from the outputs of other steps in the pipeline. The outputs from a step are consumed by other steps, are outputs of the pipeline as a whole, or are discarded. There are three kinds of steps: atomic steps, compound steps, and multi-container steps. Atomic steps carry out single operations and have no substructure as far as the pipeline is concerned. Compound steps and multi-container steps control the execution of other steps, which they include in the form of one or more subpipelines." -- XProc: An XML Pipeline Language
This specification contains requirements for an anticipated XProc V.next. This specification is concerned with the conceptual model of XML process interactions, the language for the description of these interactions, and the inputs and outputs of the overall process. This specification is not generally concerned with the implementations of actual XML processes participating in these interactions.
1.1 XProc V.next Goals [Goals]
| Editorial note | |
| The editors intend to enumerate the Working Group's goals for XProc V.next to guide our efforts, and these may ultimately inform 3 Design Principles. | |
Improving ease of use (syntactic improvements)
Improving ease of use (increasing the scope: non XML content, for example)
Addressing known shortcomings in the language
Improve relationship with streaming and parallel processing
1.2 Editorial Process [Editorial]
The following is a strawman list; it has no standing with the Working Group and is likely to be replaced and/or expanded daily until further notice.
Iterate until ready to declare success. (<p:iterate-until value="success" />)
Review 2 Terminology.
Review 3 Design Principles.
Review 4 Requirements.
Review 5 Use cases
Gather and review A Normative References
Gather and review C Unsatisfied V1 CR Issues
Audit existing D Unsatisfied V1 Requirements and Use Cases
Gather and review E FYI: Categorized Steps
Gather and review input from stakeholders.
Discuss.
Update existing definitions, design principles, requirements and use cases.
Enumerate new definitions, design principles, requirements and use cases.
Review.
Approve.
Publish.
2 Terminology
Note:
The Working Group should review the definitions included here to determine whether changes are warranted in light of the publication of XProc: An XML Pipeline Language. Additional term definitions may be warranted and will be added as needed.
- [Definition: XML Information Set or "Infoset"]
An XML Information Set or "Infoset" is the name we give to any implementation of a data model for XML which supports the vocabulary as defined by the XML Information Set recommendation [xml-infoset-rec].
- [Definition: XML Pipeline]
An XML Pipeline is a conceptualization of a flow of a configuration of steps and their parameters. The XML Pipeline defines a process in terms of order, dependencies, or iteration of steps over XML information sets.
"[A pipeline is a set of connected steps, with outputs of one step flowing into inputs of another.]" -- XProc: An XML Pipeline Language
- [Definition: XML Pipeline Specification Document]
A pipeline specification document is an XML document that described an XML pipeline.
This definition does not seem to be helpful any longer. XProc 1.0 refers to an XML pipeline, or simply a pipeline.
- [Definition: Step]
A step is a specification of how a component is used in a pipeline that includes inputs, outputs, and parameters.
"[A step is the basic computational unit of a pipeline.] A typical step has zero or more inputs, from which it receives XML documents to process, zero or more outputs, to which it sends XML document results, and can have options and/or parameters. There are three kinds of steps: atomic, compound, and multi-container. A pipeline is itself a step and must satisfy the constraints on steps. Connections between steps occur where the input of one step is connected to the output of another."-- XProc: An XML Pipeline Language
- [Definition: Component]
A component is an particular XML technology (e.g. XInclude, XML Schema Validity Assessment, XSLT, XQuery, etc.).
- [Definition: Input Document]
An XML infoset that is an input to a XML Pipeline or Step.
Relates to F.1.1 What Flows?
- [Definition: Output Document]
The result of processing by an XML Pipeline or Step.
"[The output ports declared on a step are its declared outputs.] When a step is used in a pipeline, it is connected to other steps through its inputs and outputs." -- XProc: An XML Pipeline Language
- [Definition: Parameter]
A parameter is input to a Step or an XML Pipeline in addition to the Input and Output Document(s) that it may access. Parameters are most often simple, scalar values such as integers, booleans, and URIs, and they are most often named, but neither of these conditions is mandatory. That is, we do not (at this time) constrain the range of values a parameter may hold, nor do we (at this time) forbid a Step from accepting anonymous parameters.
"Some steps accept parameters. Parameters are name/value pairs, like variables and options. Unlike variables and options, which have names known in advance to the pipeline, parameters are not declared and their names may be unknown to the pipeline author. Pipelines can dynamically construct sets of parameters. Steps can read dynamically constructed sets on parameter input ports. [...] A parameter input port is a distinguished kind of input port which accepts (only) dynamically constructed parameter name/value pairs".-- XProc: An XML Pipeline Language
Relates to F.4.4 Parameter Rules and C.2 Issue 004: attribute value templates
- [Definition: XML Pipeline Environment]
The technology or platform environment in which the XML Pipeline is used (e.g. command-line, web servers, editors, browsers, embedded applications, etc.).
"[The environment is a context-dependent collection of information available within subpipelines.] Most of the information in the environment is static and can be computed for each subpipeline before evaluation of the pipeline as a whole begins. The in-scope bindings have to be calculated as the pipeline is being evaluated." -- XProc: An XML Pipeline Language
Relates to proposed steps: F.5.2.2 pos:env and F.5.3.5 pxf:info
- [Definition: Streaming]
The ability to parse an XML document and pass infoitems between components without building a full document information set.
This editor has not discovered corresponding language in XProc: An XML Pipeline Language. Relates to Usability: F.4.13 Streaming and Parallel Processing. -- MM
3 Design Principles
Note:
The Working Group should review the design principles included here to determine whether changes are warranted in light of the publication of XProc: An XML Pipeline Language. Additional design principles may be warranted and will be added as needed.
Please note that section numbering has been added to facilitate hypertextual references to the individual design principles.
The design principles described in this document are requirements whose compliance with is an overall goal for the specification. It is not necessarily the case that a specific feature meets the requirement. Instead, it should be viewed that the whole set of specifications related to this requirements document meet that overall goal specified in the design principle.
3.1 Technology Neutral [principal-technology-neutral]
Applications should be free to implement XML processing using appropriate technologies such as SAX, DOM, or other infoset representations.
3.2 Platform Neutral [principal-platform-neutral]
Application computing platforms should not be limited to any particular class of platforms such as clients, servers, distributed computing infrastructures, etc. In addition, the resulting specifications should not be swayed by the specifics of use in those platform.
3.3 Small and Simple [principal-small-simple]
The language should be as small and simple as practical. It should be "small" in the sense that simple processing should be able to stated in a compact way and "simple" in the sense the specification of more complex processing steps do not require arduous specification steps in the XML Pipeline Specification Document.
3.4 Infoset Processing [principal-infoset-processing]
At a minimum, an XML document is represented and manipulated as an XML Information Set. The use of supersets, augmented information sets, or data models that can be represented or conceptualized as information sets should be allowed, and in some instances, encouraged (e.g. for the XPath 2.0 Data Model).
Relates to F.4.11 XPath
3.5 Straightforward Core Implementation [principal-core-plus]
It should be relatively easy to implement a conforming implementation of the language but it should also be possible to build a sophisticated implementation that implements its own optimizations and integrates with other technologies.
3.6 Address Practical Interoperability [principal-interoperability]
An XML Pipeline must be able to be exchanged between different software systems with a minimum expectation of the same result for the pipeline given that the XML Pipeline Environment is the same. A reasonable resolution to platform differences for binding or serialization of resulting infosets should be expected to be address by this specification or by re-use of existing specifications.
3.7 Validation of XML Pipeline Documents by a Schema [principal-validation]
The XML Pipeline Specification Document should be able to be validated by both W3C XML Schema and RelaxNG.
Probably should add Schematron. [Schematron]
3.8 Reuse and Support for Existing Specifications [principal-existing-specs]
XML Pipelines need to support existing XML specifications and reuse common design patterns from within them. In addition, there must be support for the use of future specifications as much as possible.
3.9 Arbitrary Components [principal-arbitrary-components]
The specification should allow use of any component technology that can consume or produce XML Information Sets.
3.10 Control of Inputs and Outputs [principal-io-control]
An XML Pipeline must allow control over specifying both the inputs and outputs of any process within the pipeline. This applies to the inputs and outputs of both the XML Pipeline and its containing steps. It should also allow for the case where there might be multiple inputs and outputs.
3.11 Control of Flow and Errors [principal-flow-error-control]
An XML Pipeline must allow control of the explicit and implicit handling of the flow of documents between steps. When errors occur, these must be able to be handled explicitly to allow alternate courses of action within the XML Pipeline.
4 Requirements
Note:
In this section, Editor's Notes appended to each sub-section provide commentary on the status of each requirement. In particular, the editors have made note of whether a requirement has been demonstrably "Satisfied" or whether it remains "Unsatisfied". In the case of requirements that remain Unsatisfied, the editors intend to record potential solutions, in the form of proposals for new steps or changes to existing steps. In the case of demonstrably Satisfied requirements, the editors intend to provide examples, or links to examples, especially those in XProc: An XML Pipeline Language.
4.1 Standard Names in Step Inventory [req-standard-names]
XProc must have standard names for atomic steps that correspond with, but not limited to, the following specifications [xml-core-wg]:
XML Base [XMLBase]
XInclude [XInclude]
XSLT [XSLT-1.0], [XSLT-2.0]
XSL FO [Serialization]
XQuery [XQuery-1.0]
XPath and Functions [XPath1.0], [XPath-2.0][XPath-Functions]
XML Schema [XMLSchema1][XMLSchema2]
RELAX NG. [RELAX-NG]
Schematron [Schematron]
HTTP Request and Authentication [RFC-2616] [RFC-2616]
| Editorial note: Satisfied | 20120407 |
| This requirement is satisfied. | |
4.2 Allow Defining New Components and Steps [req-new-components-steps]
An XML Pipeline must allow applications to define and share new steps that use new or existing components. [xml-core-wg]
| Editorial note: Satisfied | 20120407 |
| The ability to define additional step types is Implementation-defined. | |
4.3 Minimal Component Support for Interoperability [req-minimal-components]
There must be a minimal inventory of components defined by the specification that are required to be supported to facilitate interoperability of XML Pipelines.
XProc identifies its Standard Step Library and subdivides it into Required Steps and Optional Steps.
| Editorial note: Satisfied | 20120407 |
| Minimal Component Support has been defined. | |
4.4 Allow Pipeline Composition [req-allow-composition]
Mechanisms for XML Pipeline composition for re-use or re-purposing must be provided within the XML Pipeline Specification Document.
| Editorial note: Satisfied | 20120407 |
| See Example 1. A simple, linear XInclude/Validate pipeline | |
4.5 Iteration of Documents and Elements [req-iteration]
XML Pipelines should allow iteration of a specific set of steps over a collection of documents and or elements within a document.
| Editorial note: Satisfied | 20120407 |
| This requirement is satisfied. Both p:for-each and p:viewport process a sequence of documents. Relates to F.5.11 Iteration | |
4.6 Conditional Processing of Inputs [req-conditional-processing]
To allow run-time selection of steps, XML Pipelines should provide mechanisms for conditional processing of documents or elements within documents based on expression evaluation. [xml-core-wg]
| Editorial note: Satisfied | 20120407 |
| This requirement is satisfied. See Figure 2, “A validate and transform pipeline”. | |
4.7 Error Handling and Fall-back [req-error-handling-fallback]
XML Pipelines must provide mechanisms for addressing error handling and fall-back behaviors. [xml-core-wg]
| Editorial note: Satisfied | 20120407 |
| This requirement is at least partially satisfied by XProc: All steps have an implicit output port for reporting errors; error handling and fallback are manageable through use of p:try. and p:catch. Relates to F.3.5 Fall-back Mechanism | |
4.8 Support for the XPath 2.0 Data Model [req-xdm]
Relates to F.4.11 XPath
XML Pipelines must support the XPath 2.0 Data Model to allow support for XPath 2.0, XSLT 2.0, and XQuery as steps.
Note:
At this point, there is no consensus in the working group that minimal conforming implementations are required to support the XPath 2.0 Data Model.
| Editorial note: Satisfied | 20120407 |
| This requirement is satisfied, with the caveats noted in 2.6 XPaths in XProc. There have been suggestions that support for the XPath 2.0 Data Model should be required. | |
4.9 Allow Optimizations [req-allow-optimization]
An XML Pipeline should not inhibit a sophisticated implementation from performing parallel operations, lazy or greedy processing, and other optimizations. [xml-core-wg]
| Editorial note: Partially Satisfied | 20120407 |
| This requirement is partially satisfied, with the caveats noted in H Sequential steps, parallelism, and side-effects. That is, XProc does not inhibit sophisticated implementations; pipelines which take advantage of implementation features may be less interoperable. See Editors' Notes under 4.10 Streaming XML Pipelines | |
4.10 Streaming XML Pipelines [req-streaming-pipes]
An XML Pipeline should allow for the existence of streaming pipelines in certain instances as an optional optimization. [xml-core-wg]
| Editorial note: Unsatisfied | 20120407 |
| This requirement neither explicitly satisfied nor unsatisfied by anything in the language or an existence proof, except as noted 7.1.23 p:split-sequence. | |
| Editorial note | |
| We observe that streaming, parallel processing and clustering are optimizations that may impose requirements on various aspects of processor implementation and pipeline design. Notably, any step, atomic or otherwise, that buffers its input or output can be an impediment to streaming. Documentation about the streamability of each atomic step may be warranted. Pipeline design can also affect the ability to process a stream, or to process parallel streams. The editors note the absence of streaming XProc processors or exemplars of parallel pipelines from which to interpolate requirements. The editors therefore request that the WG engage in a targeted discussion of the design principles and requirements incumbent upon XProc in support of Streaming, Parallel Processing and Clustering. See Usability: F.4.13 Streaming and Parallel Processing . See also Use Cases: 5.29 Large-Document Subtree Iteration and 5.30 Adding Navigation to an Arbitrarily Large Document. | |
5 Use cases
This section contains a set of use cases that supported our requirements and informed our design. While there was a want to address all the use cases listed in this document, in the end, the first version may not have solved all the following use cases. Those unsolved use cases may be migrated into XProc V.next.
Note:
In this section, Editor's Notes appended to each sub-section provide commentary on the status of each Use Case. In particular, the editors have made note of whether a Use Case has been demonstrably "Satisfied" or whether it remains "Unsatisfied". A "TBD" anotation indicates that the status has yet to be ascertained. Some use cases may be only partially satisfied.
In the case of requirements that remain Unsatisfied, the editors intend to record potential solutions, in the form of proposals for new steps or changes to existing steps. In the case of demonstrably Satisfied requirements, the editors intend to provide illustrative examples, or links to examples, especially those in the XProc: An XML Pipeline Language.
Note that these determinations of status are subject to change, especially in the early stages of the development of this document. -- MM
5.1 Apply a Sequence of Operations [use-case-apply-sequence]
Apply a sequence of operations such XInclude, validation, and transformation to a document, aborting if the result or an intermediate stage is not valid.
(source: [xml-core-wg])
| Editorial note: Satisfied | 20120407 |
| This use case is satisfied by Example 1. A simple, linear XInclude/Validate pipeline in the Introduction | |
5.2 XInclude Processing [use-case-xinclude]
Retrieve a document containing XInclude instructions.
Locate documents to be included.
Perform XInclude inclusion.
Return a single XML document.
| Editorial note: Satisfied | 20120407 |
| This use case is satisfied by Example 1. A simple, linear XInclude/Validate pipeline in the Introduction | |
5.3 Parse/Validate/Transform [use-case-parse-validate-transform]
Parse the XML.
Perform XInclude.
Validate with Relax NG, possibly aborting if not valid.
Validate with W3C XML Schema, possibly aborting if not valid.
Transform.
| Editorial note: Satisfied | 20120407 |
| This use case is almost satisfied by Examples 1-3 in the Introduction. The example does not include Relax NG validation, but it could have, and Schematron as well. | |
5.4 Document Aggregation [use-case-document-aggregation]
Locate a collection of documents to aggregate.
Perform aggregation under a new document element.
Return a single XML document.
| Editorial note: Satisfied | 20120407 |
| This use case is satisfied, as exemplified in p:for-each | |
5.5 Single-file Command-line Document Processing [use-case-simple-command-line]
Read a DocBook document.
Validate the document.
Process it with XSLT.
Validate the resulting XHTML.
Save the HTML file using HTML serialization.
| Editorial note: Satisfied | 20120407 |
| Although the processing scenario described above is exemplified in p:for-each, the command-line requirement is considered to be implementation defined. ["How outside values are specified for pipeline parameters on the pipeline initially invoked by the processor is implementation-defined. In other words, the command line options, APIs, or other mechanisms available to specify such parameter values are outside the scope of [XProc 1.0]."] | |
5.6 Multiple-file Command-line Document Generation [use-case-multiple-command-line]
Read a list of source documents.
For each document in the list:
Read the document.
Perform a series of XSLT transformations.
Serialize each result.
Alternatively, aggregate the resulting documents and serialize a single result.
| Editorial note: Satisfied | 20120407 |
| Although the processing scenario described above is exemplified in p:for-each, the command-line requirement is considered to be implementation defined. ["How outside values are specified for pipeline parameters on the pipeline initially invoked by the processor is implementation-defined. In other words, the command line options, APIs, or other mechanisms available to specify such parameter values are outside the scope of [XProc 1.0]."] | |
5.7 Extracting MathML [use-case-extract-mathml]
Extract MathML fragments from an XHTML document and render them as images. Employ an SVG renderer for SVG glyphs embedded in the MathML.
(source: [xml-core-wg])
| Editorial note: TBD | 20120407 |
| This use case is [not] satisfied. Describe a step that performs these steps. | |
We could refactor this use case, using p:viewport to extract MathML. We could model the rendering steps, but the existence of implementations is beyond the scope of XProc itself. That is, steps 2 is a black box to us; we simply don't care whether it works, so long as we can model it.
Extract MathML fragments from an XHTML document
Transform each MathML element into one or more substitutes:
Apply a computation (e.g. compute the kernel of a matrix).
Render extracted fragments as JPEG images.
Employ an SVG renderer for SVG glyphs embedded in the MathML.
Render using TeX
Render using eqn/troff
Replace MathML fragments with computed and/or rendered equivalents.
Please provide an example of a step that responds to this use case.
5.8 Style an XML Document in a Browser [use-case-style-browser]
Style an XML document in a browser with one of several different stylesheets without having multiple copies of the document containing different xml-stylesheet directives.
(source: [xml-core-wg])
| Editorial note: Satisfied | 20120407 |
| This use case is satisfied, as exemplified in p:for-each | |
5.9 Run a Custom Program [use-case-run-program]
Run a program of your own, with some parameters, on an XML file and display the result in a browser.
(source: [xml-core-wg])
| Editorial note: Satisfied | 20120412 |
| This use case is satisfied, as exemplified in the following example. | |
<?xml version="1.0" encoding="UTF-8"?>
<p:declare-step
xmlns:c="http://www.w3.org/ns/xproc-step"
xmlns:p="http://www.w3.org/ns/xproc"
xmlns:cx="http://xmlcalabash.com/ns/extensions"
version="1.0" exclude-inline-prefixes="cx c p">
<p:input port="source">
<p:inline>
<test/>
</p:inline>
</p:input>
<p:output port="result"/>
<p:exec command="/bin/cat" result-is-xml="true"/>
</p:declare-step> will generate
<c:result xmlns:c="http://www.w3.org/ns/xproc-step">
<test/>
</c:result>5.10 XInclude and Sign [use-case-xinclude-dsig]
Process an XML document through XInclude.
Transform the result with XSLT using a fixed transformation.
Digitally sign the result with XML Signatures.
| Editorial note: XInclude Satisfied | |
| This use case is satisfied. | |
| Editorial note: XML Signatures Unsatisfied | |
This use case is not satisfied. The editors note that this Use Case cannot be
satisfied unless/until a new sign step is created. Accordingly, a
sign step has been included in the list of proposed new steps. The chair
has noted that design and implementation of a sign step could prove
difficult and that another group is likely better equipped to produce a solution.
Discuss. | |
5.11 Make Absolute URLs [use-case-make-absolute-urls]
Process an XML document through XInclude.
Remove any xml:base attributes anywhere in the resulting document.
Schema validate the document with a fixed schema.
For all elements or attributes whose type is xs:anyURI, resolve the value against the base URI to create an absolute URI. Replace the value in the document with the resulting absolute URI.
This example assumes preservation of infoset ([base URI]) and PSVI ([type definition]) properties from step to step. Also, there is no way to reorder these steps as the schema doesn't accept xml:base attributes but the expansion requires xs:anyURI typed values.
| Editorial note: Satisfied | 20120407 |
| This use case is satisfied, as exemplified in 7.2.10 p:xsl-formatter | |
5.12 A Simple Transformation Service [use-case-simple-transform-service]
Alex to refactor these use cases:
Extract XML document (XForms instance) from an HTTP request body
Execute XSLT transformation on that document.
Call a persistence service with resulting document
Return the XML document from persistence service (new XForms instance) as the HTTP response body.
| Editorial note: TBD | |
| This use case is [not] satisfied, as exemplified in TBD. Alex to write example and description of persistence. | |
5.13 Service Request/Response Handling on a Handheld [use-case-handheld-service]
Allow an application on a handheld device to construct a pipeline, send the pipeline and some data to the server, allow the server to process the pipeline and send the result back.
(source: [xml-core-wg])
| Editorial note: TBD | 20120419 |
| This use case is UNSATISFIED and deemed not worth the effort to prove. The Use Case is underspecified and we estimate that it would cost up to 1/2 day to create example of working pipeline in mobile browser, as suggested by VT. | |
5.14 Interact with Web Service (Tide Information) [use-case-web-service]
Parse the incoming XML request.
Construct a URL to a REST-style web service at the NOAA (see website).
Parse the resulting invalid HTML document with by translating and fixing the HTML to make it XHTML (e.g. use TagSoup or tidy).
Extract the tide information from a plain-text table of data from document by applying a regular expression and creating markup from the matches.
Use XQuery to select the high and low tides.
Formulate an XML response from that tide information.
| Editorial note: TBD | |
| This use case is [not] satisfied, as exemplified in TBD. Alex to write a pipeline to demonstrate. | |
5.15 Parse and/or Serialize RSS descriptions [use-case-rss-descriptions]
Parse descriptions:
Iterate over the RSS description elements and do the following:
Gather the text children of the 'description' element.
Parse the contents with a simulated document element in the XHTML namespace.
Send the resulting children as the children of the 'description element.
Apply rest of pipeline steps.
Serialize descriptions
Iterate over the RSS description elements and do the following:
Serialize the children elements.
Generate a new child as a text children containing the contents (escaped text).
Apply rest of pipeline steps.
| Editorial note: Alex MilowskiSatisfied | |
| This use case is satisfied, as exemplified in the following example: | |
Part 1: Parsing the descriptions:
<?xml version="1.0" encoding="UTF-8"?> <p:declare-step
xmlns:p="http://www.w3.org/ns/xproc" xmlns:c="http://www.w3.org/ns/xproc-step"
version="1.0" type="e:get-rss" xmlns:e="http://example.org/steps"> <p:output
port="result"/> <p:http-request> <p:input port="source"> <p:inline> <c:request
method="GET" href="http://rss.cnn.com/rss/cnn_topstories.rss"/> </p:inline>
</p:input> </p:http-request> <p:viewport match="description">
<p:unescape-markup/> </p:viewport> </p:declare-step>Part 2: Escaping the description markup:
<?xml version="1.0" encoding="UTF-8"?> <p:declare-step
xmlns:p="http://www.w3.org/ns/xproc" xmlns:c="http://www.w3.org/ns/xproc-step"
version="1.0" xmlns:e="http://example.org/steps"> <p:output port="result"/>
<p:import href="use-case-5-15.xpl"/> <e:get-rss/> <p:viewport
match="description"> <p:escape-markup/> </p:viewport> </p:declare-step>5.16 XQuery and XSLT 2.0 Collections [use-case-collections]
In XQuery and XSLT 2.0 there is the idea of an input and output collection and a pipeline must be able to consume or produce collections of documents both as inputs or outputs of steps as well as whole pipelines.
For example, for input collections:
Accept a collection of documents.
Apply a single XSLT 2.0 transformation that processes the collection and produces another collection.
Serialize the collection to files or URIs.
For example, for output collections:
Accept a single document as input.
Apply an XQuery that produces a sequence of documents (a collection).
Serialize the collection to files or URIs.
| Editorial note: Satisfied | 20120425 |
| This use case is satisfied, as exemplified the sample pipeline. | |
<p:pipeline name="main" version="1.0"
xmlns:cx="http://xmlcalabash.com/ns/extensions"
xmlns:p="http://www.w3.org/ns/xproc">
<p:declare-step type="cx:collection-manager">
<p:input port="source" sequence="true"/>
<p:output port="result" sequence="true" primary="false"/>
<p:option name="href" required="true"/>
</p:declare-step>
<cx:collection-manager name="cxmgr" href="http://example.org/collection">
<p:input port="source">
<p:inline><doc1/></p:inline>
<p:inline><doc2/></p:inline>
<p:inline><doc3/></p:inline>
</p:input>
</cx:collection-manager>
<p:xslt>
<p:input port="source">
<p:pipe step="cxmgr" port="result"/>
</p:input>
<p:input port="stylesheet">
<p:inline>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0">
<xsl:output method="xml" encoding="utf-8" indent="no" omit-xml-declaration="yes"/>
<xsl:param name="collection" select="'http://example.org/collection'"/>
<xsl:template match="/">
<collection uri="{$collection}">
<xsl:value-of select="count(collection($collection))"/>
</collection>
</xsl:template>
</xsl:stylesheet>
</p:inline>
</p:input>
</p:xslt>
</p:pipeline>
5.17 An AJAX Server [use-case-ajax-server]
Receive XML request with word to complete.
Call a sub-pipeline that retrieves list of completions for that word.
Format resulting document with XSLT.
Serialize response to XML.
| Editorial note: REFACTOR | |
| This use case to be refactored into 5.12 A Simple Transformation Service | |
5.18 Dynamic XQuery [use-case-dynamic-xquery]
Dynamically create an XQuery query using XSLT, based on input XML document.
Execute the XQuery against a database.
Construct an XHTML result page using XSLT from the result of the query.
Serialize response to HTML.
| Editorial note: TBD | |
| This use case is [not] satisfied, as exemplified in TBD. Norm to write a pipeline to demonstrate. | |
This pipeline accepts a "uri" document on the source port, uses that URI to construct a (brain-dead simple) query against a database, runs that query, and styles the result.
<p:declare-step name="main" version="1.0"
xmlns:c="http://www.w3.org/ns/xproc-step"
xmlns:ml="http://xmlcalabash.com/ns/extensions/marklogic"
xmlns:p="http://www.w3.org/ns/xproc">
<p:input port="source">
<p:inline>
<uri>/2003/08/20/fungus</uri>
</p:inline>
</p:input>
<p:output port="result"/>
<p:input port="parameters" kind="parameter"/>
<p:declare-step type="ml:adhoc-query">
<p:input port="source"/>
<p:input port="parameters" kind="parameter"/>
<p:output port="result" sequence="true"/>
<p:option name="host"/>
<p:option name="port"/>
<p:option name="user"/>
<p:option name="password"/>
<p:option name="content-base"/>
<p:option name="wrapper"/>
</p:declare-step>
<p:template>
<p:input port="template">
<p:inline>
<c:xquery>
doc("/production{string(/uri)}.xml")
</c:xquery>
</p:inline>
</p:input>
<p:input port="source">
<p:pipe step="main" port="source"/>
</p:input>
</p:template>
<ml:adhoc-query host="localhost" port="8404" user="admin" password="password"/>
<p:xslt>
<p:input port="stylesheet">
<p:document href="essay.xsl"/>
</p:input>
</p:xslt>
</p:declare-step>
5.19 Read/Write Non-XML File [use-case-rw-non-xml]
Relates to F.1.1 What Flows? and 5.19 Read/Write Non-XML File and 5.26 Non-XML Document Production
Read a CSV [CSV] file and convert it to XML.
Process the document with XSLT.
Convert the result to a CSV format using text serialization.
| Editorial note: UNSATISFIED | 20120407 |
| This use case is UNSATISFIED. Relates to XProc Architecture: F.1.1 What Flows?. An example, possibly relying on a shell command for conversion to/from CSV format could be constructed, but that would miss the point; XProc could/should have native ability to convert to/from trivial data formats such as CSV and JSON. Presumably there are algorithmic transforms. Vojtech to provide reference to XML Prague paper. | |
The specific use case described in 5.19 (converting a CSV file to XML) can be solved by using XSLT 2.0 to tokenize the CSV data and turn it into XML. The example below uses the stylesheet developed by Andrew Welsh (http://andrewjwelch.com/code/xslt/csv/csv-to-xml_v2.html):
<p:declare-step >
<p:output port="result"/>
<p:option name="pathToCSV" required="true"/>
<p:xslt template-name="main">
<p:input port="source">
<p:empty/>
</p:input>
<p:input port="stylesheet">
<p:document href="http://andrewjwelch.com/code/xslt/csv/csv-to-xml_v2.xslt"/>
</p:input>
<!-- note that relative paths are resolved against the stylesheet's base URI -->
<p:with-param name="pathToCSV" select="$pathToCSV"/>
</p:xslt>
</p:declare-step>In this solution, the stylesheet loads the CSV file. I think it should be straightforward to modify the pipeline/stylesheet so that the pipeline itself loads the CSV file (using p:data or p:http-request) and passes the c:data-wrapped representation to the stylesheet.
5.20 Update/Insert Document in Database [use-case-update-insert-db]
Receive an XML document to save.
Check the database to see if the document exists.
If the document exists, update the document.
If the document does not exists, add the document.
| Editorial note: TBD | 20120419 |
| This use case is TBD.. There is no specific language in XProc: An XML Pipeline Language to suggest communication with a database engine. Certainly, there are no references to SQL or other database languages. Examples available from Norm, Vojtech. Requirement for new atomic steps for database access? This is an open issue. | |
Need an example showing a step accessing a DB.
5.21 Content-Dependent Transformations [use-case-content-depend]
Receive an XML document to format.
If the document is XHTML, apply a theme via XSLT and serialize as HTML.
If the document is XSL-FO, apply an XSL FO processor to produce PDF.
Otherwise, serialize the document as XML.
| Editorial note: TBD | |
| This use case is [not] satisfied, as exemplified in TBD. Vojtech to write pipeline to demonstrate. | |
This one is a little tricky as XProc does not support specifying serialization options on output ports dynamically. Because of that, it is not possible to write a pipeline with a single "result" output port that uses different serialization options that depend on the (dynamic) data content type. One solution is to have multiple output ports ("result-html", "result-xml", ...) with different serialization options, but that's probably silly and too inconvenient to work with (plus it does not work with non-XML data). Another solution is not to have any output ports at all and use p:store instead. The drawback of this is that p:store writes the data to an external location and therefore breaks the pipeline flow, but you can have multiple p:store steps with different serialization options, or you can even set the serialization options on p:store dynamically. Because the p:xsl-formatter renders the XSL-FO document to an external location, I went for the p:store solution:
<p:declare-step
xmlns:html="http://www.w3.org/1999/xhtml"
xmlns:fo="http://www.w3.org/1999/XSL/Format">
<p:input port="source"/>
<p:option name="output" required="true"/>
<p:choose>
<p:when test="/html:html">
<!-- apply a theme using XSLT and serialize as HTML -->
<p:xslt>
<p:input port="stylesheet">
<p:document href="style.xsl"/>
</p:input>
<p:input port="parameters">
<p:empty/>
</p:input>
</p:xslt>
<p:store method="html">
<p:with-option name="href" select="$output"/>
</p:store>
</p:when>
<p:when test="/fo:root">
<!-- apply an XSL-FO processor-->
<p:xsl-formatter>
<p:with-option name="href" select="$output"/>
<p:input port="parameters">
<p:empty/>
</p:input>
</p:xsl-formatter>
</p:when>
<p:otherwise>
<!-- serialize as XML -->
<p:store>
<p:with-option name="href" select="$output"/>
</p:store>
</p:otherwise>
</p:choose>
</p:declare-step>
5.22 Configuration-Dependent Transformations [use-case-config-depend]
Mobile example:
Receive an XML document to format.
If the configuration is "desktop browser", apply desktop XSLT and serialize as HTML.
If the configuration is "mobile browser", apply mobile XSLT and serialize as XHTML.
News feed example:
Receive an XML document in Atom format.
If the configuration is "RSS 1.0", apply "Atom to RSS 1.0" XSLT.
If the configuration is "RSS 2.0", apply "Atom to RSS 2.0" XSLT.
Serialize the document as XML.
| Editorial note: TBD | |
| This use case is [not] satisfied, as exemplified in TBD. Vojtech to write pipeline to demonstrate. | |
The newsfeed example (the mobile example is just a combination of the newsfeed example and 5.21):
<p:pipeline >
<p:option name="configuration" required="true"/>
<p:choose>
<p:when test="$configuration='RSS 1.0'">
<p:xslt>
<p:input port="stylesheet">
<p:document href="atom-to-rss-10.xsl"/>
</p:input>
</p:xslt>
</p:when>
<p:when test="$configuration='RSS 2.0'">
<p:xslt>
<p:input port="stylesheet">
<p:document href="atom-to-rss-20.xsl"/>
</p:input>
</p:xslt>
</p:when>
</p:choose>
</p:pipeline>
5.23 Response to XML-RPC Request [use-case-xml-rpc]
Receive an XML-RPC request.
Validate the XML-RPC request with a RelaxNG schema.
Dispatch to different sub-pipelines depending on the content of /methodCall/methodName.
Format the sub-pipeline response to XML-RPC format via XSLT.
Validate the XML-RPC response with an W3C XML Schema.
Return the XML-RPC response.
| Editorial note: TBD | |
| This use case is [not] satisfied, as exemplified in TBD. Duplicates 5.12 A Simple Transformation Service and 5.17 An AJAX Server. Some conditional sub-pipeline. Vojtech to write pipeline to demonstrate. | |
This pipeline takes an XML-RPC request document and invokes a method (an XProc pipeline) based on the value of /methodCall/methodName. Because there is no standard p:eval step for dynamic evaluation of XProc pipelines, we have to use p:choose which lists all possible pipelines statically.
The pipeline below is rather simplistic in the sense that it does not try to interpret XMLRPC's "int", "string", "struct", etc. elements. The input data is passed in the original XMLRPC format to the invoked pipelines, and likewise, the pipelines are expected to represent their results in XMLRPC format.
<p:pipeline xmlns:p="http://www.w3.org/ns/xproc"
version="1.0"
xmlns:ex="http://www.example.org">
<!-- Defines various 'method' pipelines in the "http://www.example.org" namespace.
Pipeline interface contract:
- a single (primary) input port
- a single (primary output port)
- expect a single <params> input document
- produce a single <params> or <fault> output document
-->
<p:import href="method-library.xpl"/>
<p:pipeline type="ex:invoke-method">
<p:variable name="method" select="/methodCall/methodName"/>
<p:identity>
<p:input port="source" select="/methodCall/params"/>
</p:identity>
<p:try>
<p:group>
<!-- Note: the p:choose could be replaced with a single call
to p:eval if we had such a step -->
<p:choose>
<p:when test="$method = 'method1'">
<ex:method1/>
</p:when>
<p:when test="$method = 'method2'">
<ex:method2/>
</p:when>
<p:otherwise>
<p:template name="error-message">
<p:input port="template">
<p:inline>
<message>Unsupported method: {$method}</message>
</p:inline>
</p:input>
<p:with-param name="method" select="$method"/>
</p:template>
<p:error code="ex:error">
<p:input port="source">
<p:pipe step="error-message" port="result"/>
</p:input>
</p:error>
</p:otherwise>
</p:choose>
</p:group>
<p:catch name="catch">
<p:template>
<p:input port="source">
<p:pipe step="catch" port="error"/>
</p:input>
<p:input port="template">
<p:inline>
<fault>
<value>
<struct>
<member>
<name>faultCode</name>
<value><int>-1</int></value>
</member>
<member>
<name>faultString</name>
<value><string>{string(/*)}</string></value>
</member>
</struct>
</value>
</fault>
</p:inline>
</p:input>
</p:template>
</p:catch>
</p:try>
<p:wrap-sequence wrapper="methodResponse"/>
</p:pipeline>
<p:validate-with-relax-ng>
<p:input port="schema">
<p:data href="xmlrpc.rnc" content-type="text/plain"/>
</p:input>
</p:validate-with-relax-ng>
<ex:invoke-method/>
<p:validate-with-xml-schema>
<p:input port="schema">
<p:document href="xmlrpc-response.xsd"/>
</p:input>
</p:validate-with-xml-schema>
</p:pipeline>
5.24 Database Import/Ingestion [use-case-import-ingestion]
Import example:
Read a list of source documents.
For each document in the list:
Validate the document.
Call a sub-pipeline to insert content into a relational or XML database.
Ingestion example:
Receive a directory name.
Produce a list of files in the directory as an XML document.
For each element representing a file:
Create an iTQL query using XSLT.
Query the repository to check if the file has been uploaded.
Upload if necessary.
Inspect the file to check the metadata type.
Transform the document with XSLT.
Make a SOAP call to ingest the document.
| Editorial note: TBD | |
| This use case is [not] satisfied, as exemplified in TBD. A db Access Requirement emerges from combining 5.20 Update/Insert Document in Database with 5.24 Database Import/Ingestion. Someone to write up a proposal. MM to create related topics. | |
5.25 Metadata Retrieval [use-case-metadata]
Relates to F.1.1 What Flows?
Call a SOAP service with metadata format as a parameter.
Create an iTQL query with XSLT.
Query a repository for the XML document.
Load a list of XSLT transformations from a configuration.
Iteratively execute the XSLT transformations.
Serialize the result to XML.
| Editorial note: REFACTOR | |
| This use case to be refactored into 5.12 A Simple Transformation Service | |
5.26 Non-XML Document Production [use-case-non-xml-production]
Relates to F.1.1 What Flows? and 5.19 Read/Write Non-XML File and 5.26 Non-XML Document Production
A non-XML document is fed into the process.
That input is converted into a well-formed XML document.
A table of contents is extracted.
Pagination is performed.
Each page is transformed into some output language.
Read a non-XML document.
Transform.
| Editorial note: TBD | |
| This use case is [not] satisfied, as exemplified in TBD. See new steps. | |
5.27 Integrate Computation Components (MathML) [use-case-computations]
Select a MathML content element.
For that element, apply a computation (e.g. compute the kernel of a matrix).
Replace the input MathML with the output of the computation.
| Editorial note: TBD | |
| This use case is [not] satisfied. Alex to write. See instead: refactoring at end of 5.7 Extracting MathML | |
5.28 Document Schema Definition Languages (DSDL) - Part 10: Validation Management [use-case-dsdl-validation]
This document provides a test scenario that will be used to create validation management scripts using a range of existing techniques, including those used for program compilation, etc.
The steps required to validate our sample document are:
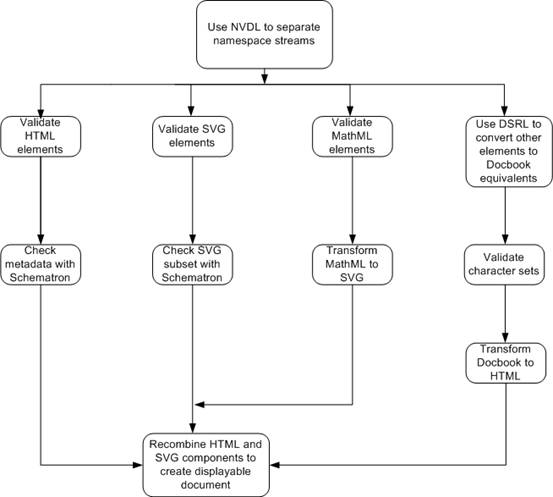
Use ISO 19757-4 Namespace-based Validation Dispatching Language (NVDL) to split out the parts of the document that are encoded using HTML, SVG and MathML from the bulk of the document, whose tags are defined using a user-defined set of markup tags.
Validate the HTML elements and attributes using the HTML 4.0 DTD (W3C XML DTD).
Use a set of Schematron rules stored in check-metadata.xml to ensure that the metadata of the HTML elements defined using Dublin Core semantics conform to the information in the document about the document's title and subtitle, author, encoding type, etc.
Validate the SVG components of the file using the standard W3C schema provided in the SVG 1.2 specification.
Use the Schematron rules defined in SVG-subset.xml to ensure that the SVG file only uses those features of SVG that are valid for the particular SVG viewer available to the system.
Validate the MathML components using the latest version of the MathML schema (defined in RELAX-NG) to ensure that all maths fragments are valid. The schema will make use the datatype definitions in check-maths.xml to validate the contents of specific elements.
Use MathML-SVG.xslt to transform the MathML segments to displayable SVG and replace each MathML fragment with its SVG equivalent.
Use the ISO 19757-8 Document Schema Renaming Language (DSRL) definitions in convert-mynames.xml to convert the tags in the local nameset to the form that can be used to validate the remaining part of the document using docbook.dtd.
Use the IS0 19757-7 Character Repertoire Definition Language (CRDL) rules defined in mycharacter-checks.xml to validate that the correct character sets have been used for text identified as being Greek and Cyrillic.
Convert the Docbook tags to HTML so that they can be displayed in a web browser using the docbook-html.xslt transformation rules.
Each validation script should allow the four streams produced by step 1 to be run in parallel without requiring the other validations to be carried out if there is an error in another stream. This means that steps 2 and 3 should be carried out in parallel to steps 4 and 5, and/or steps 6 and 7 and/or steps 8 and 9. After completion of step 10 the HTML (both streams), and SVG (both streams) should be recombined to produce a single stream that can fed to a web browser. The flow is illustrated in the following diagram:
| Editorial note: TBD | |
| This use case is not satisfied. Proposed new step F.5.7.1 pxp:nvdl relates to this Use Case. Should we allow steps to have varying # of outputs. Norm to write up an explanation of related problems. p:manifold? Henry doubts it's worth the effort. | |
5.29 Large-Document Subtree Iteration [use-case-large-document-transform]
Relates to F.5.11 Iteration
Relates to F.4.11 XPath
Running XSLT on a very large document isn't typically practical. In these cases, it is often the case that a particular element, that may be repeated over-and-over again, needs to be transformed. Conceptually, a pipeline could limit the transformation to a subtree by:
Limiting the transform to a subtree of the document identified by an XPath.
For each subtree, cache the subtree and build a whole document with the identified element as the document element and then run a transform to replace that subtree in the original document.
For any non-matches, the document remains the same and "streams" around the transform.
This allows the transform and the tree building to be limited to a small subtree and the rest of the process to stream. As such, an arbitrarily large document can be processed in a bounded amount of memory.
| Editorial note: Alex MilowskiSatisfied | 30 May 2012 |
| This use case is satisfied, as exemplified in the example below. Merge with 5.30 | |
<?xml version="1.0" encoding="UTF-8"?> <p:declare-step
xmlns:p="http://www.w3.org/ns/xproc" xmlns:c="http://www.w3.org/ns/xproc-step"
version="1.0" xmlns:xhtml="http://www.w3.org/1999/xhtml"> <p:input port="source">
<p:inline> <html xmlns="http://www.w3.org/1999/xhtml"> <head><title>Test
Document</title></head> <body> <div class="main"> <p>I can be arbitrarily
large.</p> </div> </body> </html> </p:inline> </p:input> <p:output
port="result"/> <p:insert position="first-child" match="/xhtml:html/xhtml:body">
<p:input port="insertion" xmlns="http://www.w3.org/1999/xhtml"> <p:inline> <ul
class="navigation"> <li><a href="/about/">About</a></li> <li><a
href="/xml/">Fantastic XML Stuff</a></li> <li><a href="/cats/">Pictures of
Cats</a></li> </ul> </p:inline> </p:input> </p:insert>
</p:declare-step> 5.30 Adding Navigation to an Arbitrarily Large Document [use-case-add-nav]
Relates to F.4.11 XPath
For a particular website, every XHTML document needs to have navigation elements added to the document. The navigation is static text that surrounds the body of the document. This navigation is added by:
Matching the head and body elements using a XPath expression that can be streamed.
Inserting a stub for a transformation for including the style and surrounding navigation of the site.
For each of the stubs, transformations insert the markup using a subtree expansion that allows the rest of the document to stream.
In the end, the pipeline allows arbitrarily large XHTML document to be processed with a near-constant cost.
(source: Alex Milowski)
| Editorial note: Alex MilowskiSatisfied | 30 May 2012 |
| This use case is satisfied, as exemplified in the example above. | |
5.31 Fallback to Choice of XSLT Processor [use-case-fallback-choice]
Relates to F.3.5 Fall-back Mechanism
A step in a pipeline produces multiple output documents. In XSLT 2.0, this is a standard feature of all XSLT 2.0 processors. In XSLT 1.0, this is not standard.
A pipeline author wants to write a pipeline that, at compile-time, the implementation chooses XSLT 2.0 when possible and degrades to XSLT 1.0 when XSLT 2.0 is not supported.
In the case of XSLT 1.0, the step will use XSLT extensions to support the multiple output documents--which again may fail. Fortunately, the XSLT 1.0 transformation can be written to test for this.
(source: Alex Milowski)
| Editorial note: UNSATISFIED | |
| This use case is [not] satisfied, as exemplified in TBD. Try/catch no good. Vojtech & Norm. XSLT 1.0 processor does not handle. | |
The pipeline below does the following:
Checks if XSLT 2.0 is supported.
If XSLT 2.0 is available, it applies an XSLT 2.0 stylesheet to the input XML document. The stylesheet uses xsl:result-document to generate secondary output documents.
If XSLT 2.0 is not available, it applies an XSLT 1.0 stylesheet. The stylesheet uses either the exsl:document or result:write extension (whichever is available) to generate secondary output documents.
The pipeline has two output ports: the "result" output port for the primary result of the XSLT transformation, and "secondary" for the secondary documents.
...the pipeline almost works. The problem is with the XSLT 1.0 transformation, because the secondary documents do not appear on the "secondary" step of the p:xslt step. This is actually a requirement made by the XProc specification: "If XSLT 1.0 is used, an empty sequence of documents must appear on the secondary port." The exact behavior of exsl:document and result:write in the XProc context is implementation-defined; in most cases, the generated documents will be simply written to the specified external location.
<p:pipeline name="main"
xmlns:ex="http://www.example.org" >
<p:output port="secondary" sequence="true">
<p:pipe step="process" port="secondary"/>
</p:output>
<p:declare-step type="ex:is-xslt20-supported">
<p:output port="result"/>
<p:try>
<p:group>
<p:xslt version="2.0">
<p:input port="source"><p:inline><foo/></p:inline></p:input>
<p:input port="stylesheet">
<p:inline>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0">
<xsl:template match="/">
<true><xsl:value-of select="1 to 2"/></true>
</xsl:template>
</xsl:stylesheet>
</p:inline>
</p:input>
<p:input port="parameters"><p:empty/></p:input>
</p:xslt>
</p:group>
<p:catch>
<p:identity>
<p:input port="source">
<p:inline><false/></p:inline>
</p:input>
</p:identity>
</p:catch>
</p:try>
</p:declare-step>
<ex:is-xslt20-supported/>
<p:choose name="process">
<p:when test="/true">
<p:output port="result" primary="true"/>
<p:output port="secondary" sequence="true">
<p:pipe step="xslt" port="secondary"/>
</p:output>
<p:xslt name="xslt" version="2.0">
<p:input port="source"><p:pipe step="main" port="source"/></p:input>
<p:input port="stylesheet">
<p:inline>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0">
<xsl:template name="generate-secondary-content">
<doc>Hello world!</doc>
</xsl:template>
<xsl:template match="/">
<xsl:result-document href="foo.xml">
<xsl:call-template name="generate-secondary-content"/>
</xsl:result-document>
<ignored/>
</xsl:template>
</xsl:stylesheet>
</p:inline>
</p:input>
</p:xslt>
</p:when>
<p:otherwise>
<p:output port="result" primary="true"/>
<p:output port="secondary" sequence="true">
<p:pipe step="xslt" port="secondary"/>
</p:output>
<p:xslt name="xslt" version="1.0">
<p:input port="source"><p:pipe step="main" port="source"/></p:input>
<p:input port="stylesheet">
<p:inline>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:exsl="http://exslt.org/common"
xmlns:redirect="http://xml.apache.org/xalan/redirect"
extension-element-prefixes="exsl redirect" version="1.0">
<xsl:template name="generate-secondary-content">
<doc>Hello world!</doc>
</xsl:template>
<xsl:template match="/">
<exsl:document href="foo.xml">
<xsl:call-template name="generate-secondary-content"/>
<xsl:fallback>
<redirect:write file="foo.xml">
<xsl:call-template name="generate-secondary-content"/>
</redirect:write>
</xsl:fallback>
</exsl:document>
<ignored/>
</xsl:template>
</xsl:stylesheet>
</p:inline>
</p:input>
</p:xslt>
</p:otherwise>
</p:choose>
</p:pipeline>5.32 No Fallback for XQuery Causes Error [use-case-no-fallback-error]
Relates to F.3.5 Fall-back Mechanism
As the final step in a pipeline, XQuery is required to be run. If the XQuery step is not available, the compilation of the pipeline needs to fail. Here the pipeline author has chosen that the pipeline must not run if XQuery is not available.
(source: Alex Milowski)
| Editorial note: Alex MilowskiSATISFIED | |
| This use case is satisfied, as exemplified in the following example. Step available. Fails at run time rather than compile time. | |
<p:declare-step xmlns:p="http://www.w3.org/ns/xproc"
xmlns:c="http://www.w3.org/ns/xproc-step" version="1.0"> <p:output port="result"/>
<p:template> <p:input port="template"> <p:inline> <root> Is XQuery available :
{ $has-xquery } </root> </p:inline> </p:input> <p:input port="source">
<p:empty/> </p:input> <p:with-param name="has-xquery"
select="p:step-available('p:xquery')"/> </p:template> </p:declare-step>