| Name |
Short description |
Level |
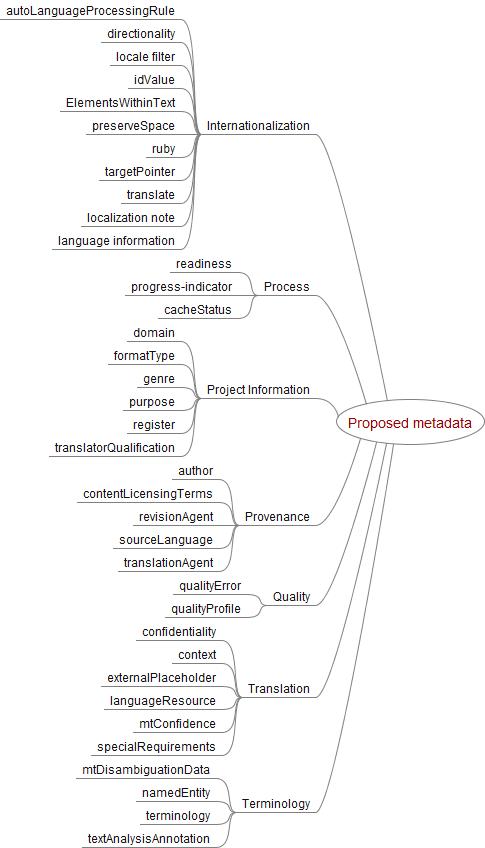
| Internationalization |
| autoLanguageProcessingRule |
This data category captures
information that it is acceptable to create target language
content purely based on automated language processing (such as
automated transliteration, or machine translation). |
span |
| directionality |
Improve handling of ITS directionality
rules |
element, span |
| locale
filter |
provides instruction that content
should be excluded from translated version (not just
untranslated, but deleted) in all cases or for specified locales
|
element, span |
| idValue |
mechanism to associate ITS
translateRule with unique IDs |
element |
| ElementsWithinText |
Provide a way to identify elements
nested within other elements |
element |
| preserveSpace |
identifies whether white space should
be preserved in the translation process |
document, span |
| ruby |
Improve ITS ruby model |
span |
| targetPointer |
identifies relationship between source
and target in a file at the element level, e.g., specifies that
the translation for a <source> element goes in a
<target> element |
document, element, span |
| translate |
specifies whether the content of the
element to which the attribute is applied should be translated
or not |
document, span |
| localization
note |
used to communicate notes to
localizers about a particular item of content |
document, span |
| language
information |
used to express the language of a
given piece of content |
document, span |
| Process |
| readiness |
provides positive guidance regarding
steps to be undertaken in a CMS/localization process |
document, span |
| progress-indicator |
reports the proportion of a document
that has completed by a process |
document |
| cacheStatus |
indicates need to (re)translate
dynamic web content for real time MT |
document, span |
| Project Information |
| domain |
information about the domain (subject
field) of the content |
document, span |
| formatType |
provides information about the format
or service for which the content is produced (e.g., subtitles,
spoken text) |
document, span |
| genre |
information about the genre (text
type) of the content |
document, span |
| purpose |
information about the purpose of the
text |
document, span |
| register |
information about stylistic/register
requirements (e.g., formality level) |
document, span |
| translatorQualification |
information about the qualifications
required for the translator |
document, span |
| Provenance |
| author |
provides information about the author
of content (= dc:author) |
|
| contentLicensingTerms |
Licensing terms for content (e.g., can
it be used in databases or for TM?) |
document, span |
| revisionAgent |
provides information concerning how a
text was revised (e.g., human postediting) |
document, span |
| sourceLanguage |
provides information concerning what
language the original text was in |
document, span |
| translationAgent |
provides information concerning how a
text was translated (e.g., MT, HT) |
document, span |
| Quality |
| qualityError |
describes an authoring or translation
error |
span |
| qualityProfile |
describes the profile/results of a
language-oriented quality assurance task |
document, element, span |
| Translation |
| confidentiality |
States whether text is confidential
(and thus cannot be exposed to public translation services) |
document, element, span |
| context |
Provides information about where the
text occurs (e.g., in a button, a header, body text) |
element, span |
| externalPlaceholder |
Provides instructions for translators
on how to deal with external resources |
element |
| languageResource |
states what translation-oriented
languages resource(s) is/are to be used |
document, span |
| mtConfidence |
Information provided by an MT engine
concerning its confidence in the result |
span |
| specialRequirements |
information about any special
localization requirements (e.g., string length, character
limitations) |
span |
| Terminology |
| mtDisambiguation |
Information required to assist MT to
distinguish between ambiguous cases |
span |
| namedEntity |
Values for types of named entities, |
span |
| terminology |
marking of information about terms
used in the content |
span |
| textAnalysisAnnotation |
embed information generated by text
analysis services |
span |