1. Introduction
2. Transforming Text
2.1. Case Transforms: the text-transform property
2.2. Word Boundaries
In a number of languages and writing system, such as Japanese or Thai, words are not deliminated by spaces (or any other character) as is the case in English (See Approaches to line breaking for a discussion the approach various languages take to word separation and line breaking).
However, even if text without spaces is the dominant style in such languages, there are cases where making word boundaries (or phrase boundaries) visible through the use of spaces is desired. This is a purely stylistic effect, with no implication on the semantics of the text.
In Japan for instance, this is commonly done in books for people learning the language—
The mechanism described in this specification builds upon the existing use
of the wbr element
or of U+200B ZERO WIDTH SPACE
(See [UNICODE])
in the document markup as a word (or phrase) delimiter.
Should we have a shorthand for the following two properties?
2.2.1. Detecting Word Boundaries: the word-boundary-detection property
| Name: | word-boundary-detection |
|---|---|
| Value: | normal | manual | auto(<lang>) |
| Initial: | normal |
| Applies to: | inline boxes |
| Inherited: | yes |
| Percentages: | N/A |
| Computed value: | as specified (However, see special provision for unsupported <lang>) |
| Canonical order: | per grammar |
| Animation type: | discrete |
This property allows the author to decide whether and how the User Agent must analyse the content to determine where word boundaries are, and to insert virtual word boundaries accordingly.
A virtual word boundary is similar to the presence of the ZERO WIDTH SPACE (U+200B) character: it introduces a soft wrap opportunity and is affected by the word-boundary-expansion property. Its presence has no effect on text shaping, nor on word-spacing. However, inserting virtual word boundaries must have no effect on the underlying content, and must not affect the content of a plain text copy & paste operation.
- manual
-
Linguistic analysis is not used
in any language or writing system
to determine line wrapping opportunities not indicated by the markup or characters of the element.
The User Agent must not insert virtual word boundaries.
Typographic character units with class SA in [UAX14] must be treated as if they had class AL (i.e. assuming word-break: normal and a value of line-break other than anywhere, there is no soft wrap opportunity between pairs of such characters).
Authors using this value for Southeast Asian languages are expected to manually indicate word boundaries, for instance usingwbror U+200B. Otherwise, there will be no soft wrap opportunity and the text may overflow. - normal
-
The User Agent must not insert virtual word boundaries,
except within runs of characters belonging to Southeast Asian languages,
where content analysis must be performed
to determine where to insert virtual word boundaries.
As with manual, typographic character units with class SA in [UAX14] must be treated as if they had class AL; however, the User Agent must additionally analyse the content of a run of such characters and insert virtual word boundaries where appropriate. Within the constraints set by this specification, the specific algorithm used is UA-dependent.
As various languages can be written in scripts which use the characters with class SA, if the content language is known, the User Agent should use this information to tailor its analysis.
In order to avoid unexpected overflow, if the User Agent is unable to perform this analysis for any subset of the characters with class SA—
for example due to lacking a dictionary for certain languages— there must be a soft wrap opportunity between pairs of typographic letter units in that subset. Note: This soft wrap opportunity is not a virtual word boundary, and is ignored by word-boundary-expansion.
Note: This provision is not triggered merely when the UA fails to find a word boundary in a particular text run; the text run may well be a single unbreakable word. It applies for example when a text run is composed of Khmer characters (U+1780 to U+17FF) if the User Agent does not know how to determine word boundaries in Khmer.
- auto(<lang>)
-
This value directs the User Agent to perform language-specific content analysis
to determine where to insert virtual word boundaries.
<lang> must be a valid CSS <ident> or <string>. It represents an IETF BCP 47 language range (see [BCP47]). If the UA does not support word-boundary detection for all languages represented by the specified range, that specified value is invalid (and will cause the declaration to be ingored).
Note: Wildcards in the language subtag would imply support for detecting word boundaries in an undefined and effectively unlimited set of languages. As this this is not possible, wildcards in the language subtag always result in the declaration being treated as invalid.
Note: Whether a word boundary detection system designed for one language is suitable for some or all dialects of that language is somewhat subjective, and this specifications leaves it at the discretion of the User Agent. Even if a detection system is not able to cope with all nuances of a particular dialect, it may be reasonable to claim support if the detection correctly recognizes word boundaries most of the time. However, the User Agent would do a disservice to authors and users if it claimed support for languages where it fails to detect most word boundaries or has a high error rate.
If the element’s content language, as represented in BCP 47 syntax [BCP47], does not match the language range described by the computed value’s <lang> in an extended filtering operation per [RFC4647] Matching of Language Tags (section 3.3.2) with both the content language and <lang> then the used value is normal, and this property has no effect on this element. Otherwise, the User Agent must insert a virtual word boundary at each detected word boundary within the text run children of this element. Within the constraints set by this specification, the specific algorithm used is UA-dependent.
Note: This is the same matching logic as the one used for the :lang() selector.
However, if the User Agent supports a generic word-boundary detection system that is suitable for Chinese in general, it is expected to accept the broad auto(zh) characterization, as well as any more specific ones, such as auto(zh-yue), auto(zh-Hant-HK), auto(zh-Hans-SG), or auto(zh-hak).
For example, Japanese text normally allows line breaking between letters of a word
(see word-break: normal).
The following code disables that in h1 elements,
and only allows line breaking at autodetected word boundaries instead,
without requiring the author to manually indicate word boundaries in the markup.
However, if word boundary detection is not supported for Japanese,
this change is not applied,
as word-break: keep-all could remove all line breaking opportunities from the element,
and risk causing overflow.
@supports ( word-boundary-detection: auto(ja)) {
h1 : lang ( ja) {
word-boundary-detection: auto(ja);
word-break: keep-all;
}
}
User Agents may activate language-specific content analysis in response to user preferences. User Agents with this behavior must do this by setting the declared value of word-boundary-detection to ''word-boundary-detection/auto(<lang>)'' in the User Origin. User Agents that do not support the User Origin may use the User Agent Origin instead.
wbr or U+200B
to exhaustively indicate word boundaries.
Authors who prepare their content in this manner should not rely on the initial value, and should explicitely specify word-boundary-detection: manual on the relevant parts of the content, in order to override a potential ''word-boundary-detection: auto(<lang>)'' in the User Origin or User Agent Origin.
Virtual word boundary insertion happens before CSS Text Module Level 3 §white-space-phase-1 and before § 2.2.2 Makig Word Boundaries Visible: the word-boundary-expansion property. Later operations (including CSS Text Module Level 3 §white-space-rules, line breaking, and intrinsic sizing) must take the presence of the virtual word boundary into account. Selectors are not affected.
Inline box boundaries and out-of-flow elements must be ignored when determining word boundaries.
If a word boundary is found at the same position as one or more inline box boundaries, the virtual word boundary must be inserted in the outermost element that participates in this inline box boundary.
|” indicates
reasonable positions for a User Agent to insert virtual word boundaries:
กรุงเทพ|คือ|สวยงามIf that sentence had contained some inline markup, the following example shows the correct position to insert the virtual word boundaries:
กรุงเทพ|คือ|< em > สวยงาม</ em > The following example shows incorrect positions:
กรุงเทพ|คือ< em > |สวยงาม</ em > The following shows the correct positions in a more contrieved situation:
กรุงเทพ|< b >< u > คือ</ u > |< em > สวยงาม</ em ></ b > The User Agent may tailor its word boundary detection algorithm depending on whether line-break is loose/normal/strict.
The User Agent must not insert a virtual word boundary:
- at the beginning or end of any box (including inline boxes) whose parent box has a used value of manual.
-
immediately adjacent to a word-separator character,
or an other space separator,
or a ZERO WIDTH SPACE (U+200B) character.
Note: This implies that for languages such as English where words are separated by spaces or other separating characters, auto() has no effect.
- between characters that compose a single typographic character unit.
- between a typographic letter unit and a subsequent typographic character unit from the [UAX14] CL, CP, IS, or EX line break classes,
- between a typographic letter unit and a preceeding typographic character unit from the [UAX14] OP line break class,
- between a typographic letter unit and an adjacent typographic character unit from the [UAX14] GL, WJ, or ZWJ line break classes.
The User Agent should not insert a virtual word boundary:
- between a typographic letter unit and a subsequent typographic character unit from the [UAX14] PO, NS line break classes,
- between a typographic letter unit and a preceeding typographic character unit from the [UAX14] PR line break class,
2.2.2. Makig Word Boundaries Visible: the word-boundary-expansion property
| Name: | word-boundary-expansion |
|---|---|
| Value: | none | space | ideographic-space |
| Initial: | none |
| Applies to: | inline boxes |
| Inherited: | yes |
| Percentages: | N/A |
| Computed value: | as specified |
| Canonical order: | per grammar |
| Animation type: | discrete |
This name is quite long, we may want to find a better one. We should also consider how we may want to add values to this property, so that the name is compatible with them. For example, it has been suggested that we may want to use this to turn visible “spaces” such as the ETHIOPIC WORD SPACE (U+1361) into an ordinary SPACE (U+0020).
This property allows transforming certain word-separating characters into other word-separating characters, to accomodate variant typesetting styles.
- none
- This property has no effect.
- space
- Instances of U+200B ZERO WIDTH SPACE within the text run children of this element are replaced by U+0020 SPACE.
- ideographic-space
- Instances of U+200B ZERO WIDTH SPACE within the text run children of this element are replaced by U+3000 IDEOGRAPHIC SPACE.
The User Agent must not replace instances of U+200B immediately preceding or following a forced line break (ignoring any intervening inline box boundaries, and associated margin/border/padding).
Instances of wbr are considered equivalent to U+200B,
and are also replaced,
as are virtual word boundaries inserted by word-boundary-detection.
Unlike text-transform, this substitution happens before CSS Text Module Level 3 §white-space-phase-1 so that later operations that depend on the characters in the content (including CSS Text Module Level 3 §white-space-rules, line breaking, and intrinsic sizing) use that character instead of the original U+200B.
Like text-transform, this property transforms text for styling purposes. It has no effect on the underlying content, and must not affect the content of a plain text copy & paste operation.
-
This property needs to take effect before CSS Text Module Level 3 §white-space-rules, but text-transform happens after that. This is needed so that the spaces inserted by this property behave as normal spaces for text layout purposes, and can collapse with other collapsible spaces or participate in Trimming and Positioning.
-
The uses cases for this property and text-transform, and the author’s decision to apply either or both, are independent, making it desirable for these two properties to cascade separately.
Unlike books for adults, Japanese books for young children often feature spaces between sentence segments, to facilitate reading.
Absent any particular styling, the following sentence would be rendered as depicted below.
< p > むかしむかし、< wbr > あるところに、< wbr > おじいさんと< wbr > おばあさんが< wbr > すんでいました。
むかしむかし、あるところに、おじいさんとおばあさんがすんでいました。
Phrase-based spacing can be achieved with the following css:
p {
word-boundary-expansion : ideographic-space;
}
むかしむかし、 あるところに、 おじいさんと おばあさんが すんでいました。
Another common variant additionally restricts the allowable line breaks to these phrase boundaries. Using the same markup, this is easily achieved with the following css:
p {
word-break : keep-all;
word-boundary-expansion : ideographic-space;
}
むかしむかし、
In addition to making the source code more readable,
using wbr rather than U+200B in the markup
also allow authors to classify the delimiters into different groups.
In the following example, wbr elements are either
unmarked when they delimit a word,
or marked with class p when they also delimit a phrase.
< p > らいしゅう< wbr > の< wbr > じゅぎょう< wbr > に< wbr class = p
> たいこ< wbr > と< wbr > ばち< wbr > を< wbr class = p
> もって< wbr > きて< wbr > ください。
Using this, it is possible not only to enable the rather common phrase-based spacing, but also word-by-word spacing that is likely to be preferred by people with dyslexia to reduce ambiguities, or other variants such as a combination of phrase-based spacing and of word-based wrapping.
らいしゅう
p wbr.p {
word-boundary-expansion : ideographic-space;
}
らいしゅう
p wbr {
word-boundary-expansion : ideographic-space;
}
らいしゅう
p {
word-break : keep-all;
}
p wbr.p {
word-boundary-expansion : ideographic-space;
}
らいしゅう
p {
word-break : keep-all;
}
p wbr {
word-boundary-expansion : ideographic-space;
}
らいしゅう
3. White Space Processing
Add final level 3 tab-size and processing details
3.1. White Space Collapsing: the text-space-collapse property
This section is still under discussion and may change in future drafts.
| Name: | text-space-collapse |
|---|---|
| Value: | collapse | discard | preserve | preserve-breaks | preserve-spaces |
| Initial: | collapse |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | per grammar |
| Animation type: | discrete |
This property declares whether and how white space inside the element is collapsed. Values have the following meanings, which must be interpreted according to the white space processing rules:
- collapse
- This value directs user agents to collapse sequences of white space into a single character (or in some cases, no character).
- preserve
- This value prevents user agents from collapsing sequences of white space. Segment breaks are preserved as forced line breaks.
- preserve-breaks
- This value collapses white space as for collapse, but preserves segment breaks as forced line breaks.
- preserve-spaces
- This value prevents user agents
from collapsing sequences of white space,
and converts tabs and segment breaks to spaces.
(This value is intended to match the behavior
of
xml:space="preserve"in SVG.) - discard
-
This value directs user agents to “discard”
all white space in the element.
Does this preserve line break opportunities or no? Do we need a "hide" value?
The following style rules implement MathML’s white space processing:
@namespace m "http://www.w3.org/1998/Math/MathML";
m|* {
text-space-collapse: discard;
}
m|mi, m|mn, m|mo, m|ms, m|mtext {
text-space-trim: trim-inner;
}
3.2. White Space Trimming: the text-space-trim property
| Name: | text-space-trim |
|---|---|
| Value: | none | trim-inner || discard-before || discard-after |
| Initial: | none |
| Applies to: | all elements |
| Inherited: | no |
| Percentages: | n/a |
| Computed value: | specified keyword(s) |
| Canonical order: | per grammar |
| Animation type: | discrete |
This property allows authors to specify trimming behavior at the beginning and end of a box. Values have the following meanings, which must be interpreted according to the white space processing rules:
- trim-inner
- For block containers this value directs UAs to discard all whitespace at the beginning of the element up to and including the last segment break before the first non-white-space character in the element as well as to discard all white space at the end of the element starting with the first segment break after the last non-white-space character in the element. For other elements this value directs UAs to discard all whitespace at the beginning and end of the element.
- discard-before
- This value directs the UA to collapse all collapsible whitespace immediately before the start of the element.
- discard-after
- This value directs the UA to collapse all collapsible whitespace immediately after the end of the element.
The following style rules render DT elements as a comma-separated list:
dt { display: inline; }
dt + dt:before { content: ", "; text-space-trim: discard-before; }
4. Line Breaking and Word Boundaries
5. Text Wrapping
Text wrapping is controlled by the text-wrap, wrap-before, wrap-after, wrap-inside, and overflow-wrap properties:
Add final level 3 overflow-wrap
5.1. Text Wrap Settings: the text-wrap property
| Name: | text-wrap |
|---|---|
| Value: | wrap | nowrap | balance | stable | pretty |
| Initial: | wrap |
| Applies to: | inline boxes and block containers |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | per grammar |
| Animation type: | discrete |
This property specifies the mode for text wrapping. Possible values:
- wrap
-
Inline-level content may break across lines
at allowed soft wrap opportunities,
as determined by the line-breaking rules in effect
in order to minimize inline-axis overflow.
The exact algorithm is UA-defined. The algorithm may consider multiple lines when making break decisions. The UA may bias for speed over best layout. The UA must not attempt to even out all lines (including the last) as for balance. This value selects the UA’s preferred (or most Web-compatible) wrapping algorithm.
- nowrap
- Inline-level content does not break across lines; content that does not fit within the block container overflows it.
- balance
-
Same as wrap for inline boxes.
For block containers that
establish an inline formatting context,
line breaks are chosen to balance
the remaining (empty) space in each line box,
if better balance than wrap is possible.
This must not change the number of line boxes
the block would contain
if text-wrap were set to wrap.
The remaining space to consider is that which remains after placing floats and inline content, but before any adjustments due to text justification. Line boxes are balanced when the standard deviation from the average inline-size of the remaining space in each line box is reduced over the block (including lines that end in a forced break).
The exact algorithm is UA-defined.
UAs may treat this value as wrap if there are more than ten lines to balance.
- stable
- When applied to a block container that establishes an inline formatting context, specifies that content on subsequent lines should not be considered when making break decisions so that when editing text any content before the cursor remains stable; otherwise equivalent to wrap,
- pretty
- When applied to a block container that establishes an inline formatting context, specifies the UA should bias for better layout over speed, and is expected to consider multiple lines, when making break decisions. Otherwise equivalent to wrap,
Regardless of the text-wrap value, lines always break at forced breaks: for all values, line-breaking behavior defined for the BK, CR, LF, CM, NL, and SG line breaking classes in [UAX14] must be honored. Additionally, if wrapping is allowed (i.e. text-wrap is not none), line breaking behavior defined for the WJ, ZW, and GL line-breaking classes in [UAX14] must be honored.
UAs that allow breaks at punctuation other than spaces should prioritize breakpoints. For example, if breaks after slashes have a lower priority than spaces, the sequence “check /etc” will never break between the ‘/’ and the ‘e’. The UA may use the width of the containing block, the text’s language, and other factors in assigning priorities. As long as care is taken to avoid such awkward breaks, allowing breaks at appropriate punctuation other than spaces is recommended, as it results in more even-looking margins, particularly in narrow measures.
Note: The wrap value is will typically map to Web browsers’ speedy legacy line breaking, which has so far used first-fit/greedy algorithms that can often give sub-optimal results. UAs can experiment with better line breaking algorithms with this default value, but as optimal results often take more time, pretty is offered as an opt-in to take more time for better results. The pretty value is intended for body text, where the last line is expected to be a bit shorter than the average line; the balance value is intended for titles and captions, where equal-length lines of text tend to be preferred; and the stable is intended for sections that are, or are likely become toggled as, editable.
5.2. Inline breaks between boxes: the wrap-before/wrap-after properties
| Name: | wrap-before, wrap-after |
|---|---|
| Value: | auto | avoid | avoid-line | avoid-flex | line | flex |
| Initial: | auto |
| Applies to: | inline-level boxes and flex items |
| Inherited: | no |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | per grammar |
| Animation type: | discrete |
These properties specify modifications to break opportunities in line breaking (and flex line breaking [CSS3-FLEXBOX]). Possible values:
- auto
- Lines may break at allowed break points before and after the box, as determined by the line-breaking rules in effect.
- avoid
- Line breaking is suppressed immediately before/after the box: the UA may only break there if there are no other valid break points in the line. If the text breaks, line-breaking restrictions are honored as for auto.
- avoid-line
- Same as avoid, but only for line breaks.
- avoid-flex
- Same as avoid, but only for flex line breaks.
- line
- Force a line break immediately before/after the box if the box is an inline-level box.
- flex
- Force a flex line break immediately before/after the box if the box is a flex item in a multi-line flex container.
Forced line breaks on inline-level boxes propagate upward through any parent inline boxes the same way forced breaks on block-level boxes propagate upward through any parent block boxes in the same fragmentation context. [CSS3-BREAK]
5.3. Line breaks within boxes: the wrap-inside property
| Name: | wrap-inside |
|---|---|
| Value: | auto | avoid |
| Initial: | auto |
| Applies to: | inline boxes |
| Inherited: | no |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | per grammar |
| Animation type: | discrete |
- auto
- Lines may break at allowed break points within the box, as determined by the line-breaking rules in effect.
- avoid
-
Line breaking is suppressed within the box:
the UA may only break within the box
if there are no other valid break points in the line.
If the text breaks,
line-breaking restrictions are honored as for auto.
If boxes with avoid are nested and the UA must break within these boxes, a break in an outer box must be used before a break within an inner box may be used.
5.3.1. Example of using 'wrap-inside: avoid' in presenting a footer
The priority of breakpoints can be set to reflect the intended grouping of text.
Given the rules
footer { wrap-inside: avoid; }
venue { wrap-inside: avoid; }
date { wrap-inside: avoid; }
place { wrap-inside: avoid; }
and the following markup:
<footer> <venue>27th Internationalization and Unicode Conference</venue> • <date>April 7, 2005</date> • <place>Berlin, Germany</place> </footer>
In a narrow window the footer could be broken as
27th Internationalization and Unicode Conference • April 7, 2005 • Berlin, Germany
or in a narrower window as
27th Internationalization and Unicode Conference • April 7, 2005 • Berlin, Germany
but not as
27th Internationalization and Unicode Conference • April 7, 2005 • Berlin, Germany
6. Last Line Minimum Length
- At least as long as the text-indent.
- At least X characters.
- Percentage-based.
Suggestion for value space is ''match-indent | <length> | <percentage>'' (with Xch given as an example to make that use case clear). Alternately <integer> could actually count the characters.
It’s unclear how this would interact with text balancing (above); one earlier proposal had them be the same property (with 100% meaning full balancing).
People have requested word-based limits, but since this is really dependent on the length of the word, character-based is better.
7. Shorthand for White Space and Wrapping: the white-space property
| Name: | white-space |
|---|---|
| Value: | normal | pre | nowrap | pre-wrap | pre-line |
| Initial: | auto |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | see individual properties |
| Animation type: | discrete |
| Canonical order: | per grammar |
This property is a shorthand for text-space-collapse, text-wrap, and text-space-trim.
Note: This shorthand combines both inheritable and non-inheritable properties. If this is a problem, please inform the CSSWG.
The following table gives the mapping of the values of the shorthand to its longhands.
| white-space | text-space-collapse | text-wrap | text-space-trim |
|---|---|---|---|
| normal | collapse | wrap | none |
| pre | preserve | nowrap | none |
| nowrap | collapse | nowrap | none |
| pre-wrap | preserve | wrap | none |
| pre-line | preserve-breaks | wrap | none |
8. Breaking Within Words
8.1. Hyphens: the hyphenate-character property
| Name: | hyphenate-character |
|---|---|
| Value: | auto | <string> |
| Initial: | auto |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | per grammar |
| Animation type: | discrete |
This property specifies the string that is shown between parts of hyphenated words. Values have the following meanings:
- auto
- Specifies that the user agent should find an appropriate string based on the content language’s typographic conventions, possibly from the same source as the hyphenation dictionary.
- <string>
- Specifies the string that appears at the end of the line before a hyphenation break. The UA may truncate the used value to a limited number of typographic character units. (It must not truncate only part of a typographic character unit.)
article { hyphenate-character: "᐀" /* CANADIAN SYLLABICS HYPHEN (U+1400) */ }
Note: Both hyphens triggered by automatic hyphenation and hyphens triggered by soft hyphens are rendered according to hyphenate-character.
8.2. Hyphenation Size Limit: the hyphenate-limit-zone property
| Name: | hyphenate-limit-zone |
|---|---|
| Value: | <length-percentage> |
| Initial: | 0 |
| Applies to: | block containers |
| Inherited: | yes |
| Percentages: | refers to length of the line box |
| Computed value: | computed <length-percentage> value |
| Canonical order: | per grammar |
| Animation type: | by computed value type |
Is hyphenate-limit-zone a good name? Comments/suggestions?
This property specifies the maximum amount of unfilled space (before justification) that may be left in the line box before hyphenation is triggered to pull part of a word from the next line back up into the current line.
8.3. Hyphenation Character Limits: the hyphenate-limit-chars property
| Name: | hyphenate-limit-chars |
|---|---|
| Value: | [ auto | <integer> ]{1,3} |
| Initial: | auto |
| Applies to: | all elements |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | three values, each either the auto keyword or an integer |
| Canonical order: | per grammar |
| Animation type: | by computed value type |
This property specifies the minimum number of characters in a hyphenated word. If the word does not meet the required minimum number of characters in the word / before the hyphen / after the hyphen, then the word must not be hyphenated. Nonspacing combining marks (Unicode class) and intra-word punctuation (Unicode classes P*) do not count towards the minimum.
If three values are specified, the first value is the required minimum for the total characters in a word, the second value is the minimum for characters before the hyphenation point, and the third value is the minimum for characters after the hyphenation point. If the third value is missing, it is the same as the second. If the second value is missing, then it is auto. The auto value means that the UA chooses a value that adapts to the current layout.
Note: Unless the UA is able to calculate a better value, it is suggested that auto means 2 for before and after, and 5 for the word total.
p { hyphenate-limit-chars: auto 3; }
8.4. Hyphenation Line Limits: the hyphenate-limit-lines and hyphenate-limit-last properties
| Name: | hyphenate-limit-lines |
|---|---|
| Value: | no-limit | <integer> |
| Initial: | no-limit |
| Applies to: | block containers |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword or integer |
| Canonical order: | per grammar |
| Animation type: | by computed value type |
This property indicates the maximum number of successive hyphenated lines in an element. The no-limit value means that there is no limit.
In some cases, user agents may not be able to honor the specified value. (See overflow-wrap.) It is not defined whether hyphenation introduced by such emergency breaking influences nearby hyphenation points.
| Name: | hyphenate-limit-last |
|---|---|
| Value: | none | always | column | page | spread |
| Initial: | none |
| Applies to: | block containers |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | per grammar |
| Animation type: | discrete |
This property indicates hyphenation behavior at the end of elements, column, pages, and spreads. A spread is a set of two pages that are visible to the reader at the same time. Values have the following meanings:
- none
- No restrictions imposed.
- always
- The last full line of the element, or the last line before any column, page, or spread break inside the element should not be hyphenated.
- column
- The last line before any column, page, or spread break inside the element should not be hyphenated.
- page
- The last line before page or spread break inside the element should not be hyphenated.
- spread
- The last line before any spread break inside the element should not be hyphenated.
A paragraph may be formatted like this when hyphenate-limit-last: none is set:
This is just a simple example to show Antarc- tica.
With 'hyphenate-limit-last: always' one would get:
This is just a simple example to show Antarctica.
9. Alignment and Justification
9.1. Text Alignment: the text-align shorthand
Add this value to text-align
- <string>
- The string must be a single character; otherwise the declaration is invalid and must be ignored. When applied to a table cell, specifies the alignment character around which the cell’s contents will align. See below for further details and how this value combines with keywords.
9.2. Character-based Alignment in a Table Column
When multiple cells in a column have an alignment character specified, the alignment character of each such cell in the column is centered along a single column-parallel axis and the rest of the text in the column shifted accordingly. (Note that the strings do not have to be the same for each cell, although they usually are.)
Is this intended to say that it’s the centers of the alignment characters that should be aligned? It’s not clear that’s what it says, but that (or a different behavior) needs to be specified, to describe what happens when different occurrences of the alignment character are in different fonts. (Further, is that the intended behavior? Probably the most significant use case to consider is bold vs. non-bold text, which only varies slightly in width.) [feedback] [minutes face-to-face 2016-02-02 10:00 AM]
The following style sheet:
TD { text-align: "." center }
will cause the column of dollar figures in the following HTML table:
<TABLE> <COL width="40"> <TR> <TH>Long distance calls <TR> <TD> $1.30 <TR> <TD> $2.50 <TR> <TD> $10.80 <TR> <TD> $111.01 <TR> <TD> $85. <TR> <TD> N/A <TR> <TD> $.05 <TR> <TD> $.06 </TABLE>
to align along the decimal point. The table might be rendered as follows:
+---------------------+ | Long distance calls | +---------------------+ | $1.30 | | $2.50 | | $10.80 | | $111.01 | | $85. | | N/A | | $.05 | | $.06 | +---------------------+
A keyword value may be specified in conjunction with the <string> value; if it is not given, it defaults to right. This value is used:
- when character-based alignment is applied to boxes that are not table cells.
- when the text wraps to multiple lines (at unforced break points).
- when a character-aligned cell spans more than one column. In this case the keyword alignment value is used to determine which column’s axis to align with: the leftmost column for left, the rightmost column for right and center, the startmost column for start, the endmost column for end.
- when the column is wide enough that the character alignment alone does not determine the positions of its character-aligned contents. In this case the keyword alignment of the first cell in the column with a specified alignment character is used to slide the position of the character-aligned contents to match the keyword alignment insofar as possible without changing the width of the column. For center, the UA may center the aligned contents using its extremes, center the alignment axis itself (insofar as possible), or optically center the aligned contents some other way (such as by taking a weighted average of the extent of the cells' contents to either side of the axis).
Note: Right alignment is used by default for character-based alignment because numbering systems are almost all left-to-right even in right-to-left writing systems, and the primary use case of character-based alignment is for numerical alignment.
If the alignment character appears more than once in the text, the first instance is used for alignment. If the alignment character does not appear in a cell at all, the string is aligned as if the alignment character had been inserted at the end of its contents.
This needs to specify what text is searched for the alignment character. Is it only in-flow text whose containing block is the cell? Or is text within any in-flow descendants in the block formatting context established by the cell considered? If so, is it considered only as long as its text-align property is consistent with the cell’s? (Consistent in the alignment character, or fully consistent?)
This behavior of aligning as though he alignment character had been inserted at the end of the contents of the cell, combined with center-of-character alignment, will produce gaps on the end-side of lines that are alone on a line with <string> text-alignment, when none of the lines of the column has the alignment character, or, more importantly, when some of the lines do have the alignment character, but the column is not laid out at its max-content width. This is probably undesirable.
When the alignment character is inserted at the end of the contents, which font is used? (In particular, if the alignment character might be within a descendant block, is it the font of the block or the font of the table cell? Or if the insertion is at a forced break within an inline, does it use the font of the inline or the font of the block or cell?)
Character-based alignment occurs before table cell width computation so that auto width computations can leave enough space for alignment. Whether column-spanning cells participate in the alignment prior to or after width computation is undefined. If width constraints on the cell contents prevent full alignment throughout the column, the resulting alignment is undefined.
This should have a formal definition of how character alignment affects the min-content and max-content intrinsic widths (of table columns and all content that can be inside table columns). Max-content intrinsic widths need to be split into three numbers (assuming that it’s the centers of the alignment character that are aligned): one for widths without alignment characters, one for widths on the inline-start side of the center of the alignment character, one for widths on the inline-end side of the center of the alignment character. This operates based on all segments of text between forced breaks for max-content widths. For min-content widths, segments of text between forced breaks that contain optional breaks within them should clearly contribute only to the without-alignment-character width. However, it’s less clear whether all min-content widths should work this way, or whether segments between forced breaks that do not have optional breaks (and perhaps only those that actually contain the alignment character) should contribute to start-side-of-alignment-character and end-side-of-alignment-character min-content widths instead; this choice is a tradeoff between the meaning of min-content sizing of a table meaning the narrowest reasonable size versus honoring alignment characters in more cases. Another option might be to use whether line-breaking of optional breaks is allowed as a control for which behavior to use.
Formally defining the intrinsic width contributions of column-spanning cells with <string> values of text-align is a complicated (although straightforward) extension of the decisions made for intrinsic width contributions of non-column-spanning cells; this should also be formally defined. Contributions end up being made to the split intrinsic widths of the startmost or endmost column (whichever is used for alignment), and to the without-alignment-character intrinsic widths of the other spanned columns.
9.3. Aligning a block of text within its container: the text-group-align property
| Name: | text-group-align |
|---|---|
| Value: | none | start | end | left | right | center |
| Initial: | none |
| Applies to: | block containers |
| Inherited: | no |
| Percentages: | N/A |
| Computed value: | specified keyword |
| Canonical order: | per grammar |
| Animation type: | discrete |
This property aligns the contents of the line boxes as a group while maintaining their text alignment.
Group alignment is performed by finding the line box with the shortest remaining space and adding that amount of space as padding to one or both sides of the line box, reducing the amount of space available for its contents; text alignment is then applied to its contents within the remaining space. All descendant in-flow line boxes within the same block formatting context are considered both when searching for the shortest remaining space and when adding the padding; the contents of descendants that establish independent formatting contexts are skipped.
A variant of this property is inherited, and applies on each block container individually, only affecting the line boxes that are direct children of that block. This is less useful, but probably easier to implement.
Somehow also moving the floats that originate in the same block container by the same amount would make things line up more nicely, which would be especially valuable in CJK layout. Exactly how that works, and how it interacts with intruding floats from ancestor elements is left as an exercise for the reader.
Values have the following meanings:
- none
- Text alignment happens normally: group alignment is not performed.
- start
- Inline-level content is group-aligned to the inline start side, by padding the inline end side of each line box.
- end
- Inline-level content is group-aligned to the inline end side, by padding the inline start side of each line box.
- left
- Inline-level content is group-aligned to the line-left side, by padding the line-right side of each line box.
- right
- Inline-level content is group-aligned to the line-right side, by padding the line-left side of each line box.
- center
- Inline-level content is group-aligned to the center, by padding both sides of each line box, half the spacing to each side.
10. Spacing
Add final level 3 word-spacing, letter-spacing
10.1. Line Start/End Padding: the line-padding property
| Name: | line-padding |
|---|---|
| Value: | <length> |
| Initial: | 0 |
| Applies to: | inline boxes |
| Inherited: | yes |
| Percentages: | N/A |
| Computed value: | absolute length |
| Canonical order: | per grammar |
| Animation type: | by computed value type |
Whereas letter-spacing adjusts spacing between typographic letter units and does not apply at the start or end of a line, this property adjusts spacing only at the start/end of a line. The extra spacing is applied only by the innermost inline box at the start/end of the line box, and is inserted between that inline box’s content edge and the adjacent inline-level content (text run or atomic inline). This extra space is not a justification opportunity.
p { line-padding: 0.5em; line-height: 1; text-align: center }
span { background: black; color: white; }
em { background: green; color: white; }
<p><span>Here is <em>some text</em></span>
Line-padding will be inserted such that an extra 0.5em of inline background will be visible on each side of each line. If it renders such that there is a break between “some” and “text”, the the additional padding will be: on the first line, black on the left and green on the right, and on the second line, green on both sides.
Here is some
text
10.2. Character Class Spacing: the text-spacing property
| Name: | text-spacing |
|---|---|
| Value: | normal | none | [ trim-start | space-start | space-first ] || [ trim-end | space-end | allow-end ] || [ trim-adjacent | space-adjacent ] || no-compress || ideograph-alpha || ideograph-numeric || punctuation |
| Initial: | normal |
| Applies to: | block containers |
| Inherited: | yes |
| Percentages: | N/A |
| Computed value: | specified keyword(s) |
| Canonical order: | per grammar |
| Animation type: | discrete |
This property controls spacing between adjacent characters on the same line within the same inline formatting context using a set of character-class-based rules. Such spacing can either be created between or trimmed from the affected glyphs. Values are defined as follows:
- normal
- Specifies the baseline behavior, equivalent to space-start allow-end trim-adjacent.
- none
- Turns off all text-spacing features. All fullwidth characters are set with full-width glyphs.
- ideograph-alpha
-
Creates 1/4em extra spacing between runs of ideographs and non-ideographic letters.
Note: A commonly used algorithm for determining this behavior is specified in [JLREQ].
- ideograph-numeric
-
Creates 1/4em extra spacing between runs of ideographs and non-ideographic numerals glyphs.
Note: A commonly used algorithm for determining this behavior is specified in [JLREQ].
- punctuation
-
Creates extra non-breaking spacing around punctuation as required by language-specific typographic conventions.
In this level, if the element’s content language is French, narrow no-break space (U+202F) and no-break space (U+00A0) is inserted where required by French typographic guidelines. Otherwise this value has no effect. However future specifications may add automatic spacing behavior for other languages.
Integrate rules for correcting incorrect spaces? Issue 318
- space-start
- Set fullwidth opening punctuation with full-width glyphs (spaced) at the start of each line.
- trim-start
- Set fullwidth opening punctuation with half-width glyphs (flush) at the start of each line.
- space-first
-
Behaves as space-start on the first line the block container
and each line after a forced line break but as trim-start on all other lines.
This value exists for UA compat requirements, and is not recommended for general authoring use.
This value exists to improve formatting of existing Japanese ePUB content, for which trim-start would have been appropriate typographically, except that they are typeset to expect the first line to be set as space-first.Specifically, due to the lack of reliable hanging-punctuation support across ePUB readers, such content uses U+3000 ideographic space in place of text-indent, but omits it when the paragraph begins with punctuation that is desired to hang in the indent in order to create the hanging punctuation effect. Using trim-start on the first line would thus trim away the effective indent in such content and thus obscure that line’s distinction as the first line of a new paragraph.
Note that this ePUB typesetting practice is not recommended for CSS in general (i.e. where not dictated by compat): authors should use hanging-punctuation and text-indent to control paragraph formatting rather than tweaking the text content of the document. This preserves the text’s true semantics in the document source and allows the style sheet designer to freely switch among the various spacing/indentation styles without needing to alter the content. See § 10.2.3 Japanese Paragraph-start Conventions in CSS for examples.
UAs are encouraged to use this value as part of their UA default style sheet for Japanese ePUB content: to preserve the paragraph distinctions in such content while applying trim-start behavior to wrapped lines (which creates better optical alignment along the start edge and helps emphasize paragraph breaks denoted by indentation).
Whether this value should also be part of the UA defaults for Web content is currently under discussion.
- allow-end
- Set fullwidth closing punctuation with half-width glyphs (flush) at the end of each line if it does not otherwise fit prior to justification; otherwise set the punctuation with full-width glyphs.
- space-end
- Set fullwidth closing punctuation with full-width glyphs (spaced) at the end of each line.
- trim-end
- Set fullwidth closing punctuation with half-width glyphs (flush) at the end of each line.
- space-adjacent
- Set fullwidth opening punctuation with full-width glyphs (spaced) when not at the start of the line. Set fullwidth closing punctuation with full-width glyphs (spaced) when not at the end of the line.
- trim-adjacent
- Collapse spacing between punctuation glyphs as described below.
- no-compress
-
Justification may not compress text-spacing.
(If this value is not specified, the justification process may reduce autospacing
except when the spacing is at the start or end of the line.)
Note: An example of compression rules is given for Japanese in 3.8 Line Adjustment in [JLREQ].
This property is additive with the word-spacing and letter-spacing properties. That is, the amount of spacing contributed by the letter-spacing setting (if any) is added to the spacing created by text-spacing. The same applies to word-spacing.
At element boundaries, the amount of extra spacing introduced between characters is determined by and rendered within the innermost element that contains the boundary. If the extra spacing is applied to a particular glyph, then the spacing is determined by the innermost element containing that glyph.
Note: Values other than normal, none, trim-start, trim-end, and space-end are at-risk and may be dropped from this level of CSS. They are defined here currently to help work out a complete design of this feature.
Support for this property is optional. It is strongly recommended for UAs that wish to support CJK typography.
It was requested to add a value for doubling the space after periods.
10.2.1. Fullwidth Punctuation Collapsing
Typically, fullwidth characters have glyphs with the same advance width as a standard Han character (e.g. 水 U+6C34). However, many fullwidth punctuation glyphs only take up part of the fullwidth design space. Thus such punctuation are not always set fullwidth. Several values of text-spacing allow the author to control when such characters are set half-width (typically half the width of an ideograph) and when they are set full-width.
In order to set the text as specified, the UA will need to either
- trim (kern) the blank half of the glyphs, if they are given full-width and must be set half-width, or
- add space to the glyphs, if they are given half-width and must be set full-width.
The UA may use the OpenType halt and vhal features
if implemented by a font
in order to perform the requisite trimming of a particular glyph.
The UA must not use the hwid feature
or otherwise substitute halfwidth forms
as switching to halfwidth glyphs can change the glyph shape
which is not acceptable here.
Some fonts use proportional glyphs for fullwidth punctuation characters. If there is no support in the font for distinguishing fullwidth vs halfwidth glyph shapes (e.g. through font features), then for such proportional glyphs, the given advance width is considered simultaneously full-width and half-width: the UA must not add or remove space to these glyphs.
Note: The advance width of a standard Han character
can be determined either from font metrics
such as the OpenType ideo and idtp baselines for the opposite writing mode,
or by taking the advance width of a Han character such as 水 U+6C34.
(The opposite writing mode must be used because some fonts are compressed
so that the characters are not square.)
More information on OpenType metrics can be found in the OpenType spec.
Note that if 水 U+6C34, 卜 U+535C, and 一 U+4E00 do not all have the same advance width,
the font has proportional ideographs
and the fullwidth advance width cannot be reliably determined by measuring glyphs.
Unless text-spacing is set to space-adjacent or none (or the font has proportional fullwidth punctuation glyphs), the UA must collapse the space typically associated with such full width glyphs when placed adjacently on a line as follows:
- Set fullwidth opening punctuation half-width if the previous character is a fullwidth opening punctuation, fullwidth middle dot punctuation, or ideographic space (U+3000), or if the previous character is a fullwidth closing punctuation of an equivalent or larger font-size. Else set it full-width.
- Set fullwidth closing punctuation half-width if the next character is a fullwidth closing punctuation, fullwidth middle dot punctuation, or ideographic space (U+3000), or if the next character is a fullwidth opening punctuation of a larger font-size. Else set it full-width.
| Combination | Sample Pair | Looks Like |
|---|---|---|
| Opening—Opening | 〔+( | 〔( |
| Middle Dot—Opening | ・+( | ・( |
| Closing—Opening | 〕+( | 〕( |
| Ideographic Space—Opening | +( | ( |
| Closing—Closing | )+〕 | )〕 |
| Closing—Middle Dot | )+・ | )・ |
| Closing—Ideographic Space | )+ | ) |
10.2.2. Text Spacing Character Classes
In the context of this property the following definitions apply:
Classes and Unicode code points need to be reviewed.
- ideographs
-
Includes all typographic character units [CSS3TEXT] whose base character is listed below:
- All characters in the range of U+3041 to U+30FF, except those that belong to Unicode Punctuation [P*] category.
- CJK Strokes (U+31C0 to U+31EF).
- Katakana Phonetic Extensions (U+31F0 to U+31FF).
- All characters that belongs to Han Unicode Script Property [UAX24].
- non-ideographic letters
-
Includes all typographic character units that
belong to Unicode Letters [L*] and Mark [M*] category,
except when any of the following conditions are met:
- is defined as ideograph.
- is categorized as East Asian Fullwidth (F) by [UAX11].
- is upright in vertical text flow using the text-orientation property or the text-combine-upright property.
- non-ideographic numerals
-
Includes all typographic character units that
belong to the Unicode Decimal Digit Number [Nd] category,
except when any of the following conditions are met:
- is categorized as East Asian Fullwidth (F) by [UAX11].
- is upright in vertical text flow using the text-orientation property or the text-combine-upright property.
- fullwidth opening punctuation
- Includes any opening punctuation character (Unicode category
Ps) that belongs to the CJK Symbols and Punctuation block (U+3000–U+303F) or is categorized as East Asian Fullwidth (F) by [UAX11]. Also includes LEFT SINGLE QUOTATION MARK (U+2018) and LEFT DOUBLE QUOTATION MARK (U+201C). When trimmed, the left (for horizontal text) or top (for vertical text) half is kerned. - fullwidth closing punctuation
- Includes any closing punctuation character (Unicode category
Pe) that belongs to the CJK Symbols and Punctuation block (U+3000–U+303F) or is categorized as East Asian Fullwidth (F) by [UAX11]. Also includes RIGHT SINGLE QUOTATION MARK (U+2019) and RIGHT DOUBLE QUOTATION MARK (U+201D). May also include fullwidth colon punctuation and/or fullwidth dot punctuation (see below). When trimmed, the right (for horizontal text) or bottom (for vertical text) half is kerned. - fullwidth middle dot punctuation
- Includes MIDDLE DOT (U+00B7), HYPHENATION POINT (U+2027), and KATAKANA MIDDLE DOT (U+30FB). May also include fullwidth colon punctuation and/or fullwidth dot punctuation (see below).
- fullwidth colon punctuation
- Includes FULLWIDTH COLON (U+FF1A) and FULLWIDTH SEMICOLON (U+FF1B).
- fullwidth dot punctuation
- Includes IDEOGRAPHIC COMMA (U+3001), IDEOGRAPHIC FULL STOP (U+3002), FULLWIDTH COMMA (U+FF0C), FULLWIDTH FULL STOP (U+FF0E).
Whether fullwidth colon punctuation and fullwidth dot punctuation should be considered fullwidth closing punctuation or fullwidth middle dot punctuation depends on where in the glyph’s box the punctuation is drawn. If the punctuation is centered, then it should be considered middle dot punctuation. If the punctuation is drawn to one side (left in horizontal text, top in vertical text) and the other half is therefore blank then the punctuation should be considered closing punctuation and trimmed accordingly.
The UA must classify fullwidth colon punctuation and fullwidth dot punctuation under either the fullwidth closing punctuation category or the fullwidth middle dot punctuation category as appropriate. The UA may rely on language conventions and the writing mode (horizontal vs. vertical), and/or font information to determine this categorization. The UA may also add additional characters to any category as appropriate.
| colon punctuation | dot punctuation | |
|---|---|---|
| Simplified Chinese (horizontal) | closing | closing |
| Simplified Chinese (vertical) | closing | closing |
| Traditional Chinese | middle dot | middle dot |
| Korean | middle dot | closing |
| Japanese | middle dot | closing |
Note that for Chinese fonts at least, the author observes that the standard convention is often not followed.
10.2.3. Japanese Paragraph-start Conventions in CSS
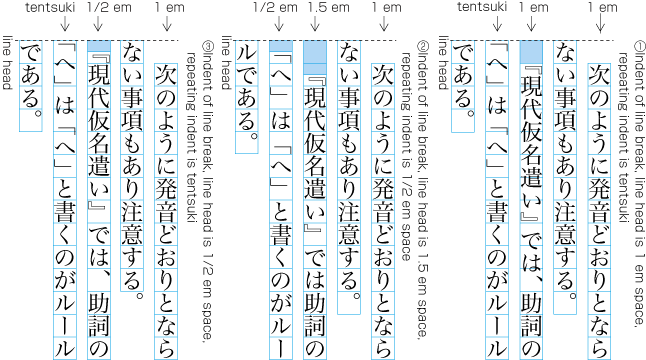
Positioning of opening brackets at line head [JLREQ]
Assuming a UA style sheet of p { margin: 1em 0; },
CSS can achieve the Japanese typesetting styles with the following rules:
-
Brackets flush with indent, flush with other lines (first scheme):
p { /* Flush alignment */ margin: 0; text-indent: 1em; text-spacing: trim-start; } -
Brackets preserve fullwidth spacing on all lines (second scheme):
p { /* Fullwidth alignment */ margin: 0; text-indent: 1em; text-spacing: normal; } -
Brackets hang in indent, flush with other lines (third scheme):
p { /* Hanging alignment */ margin: 0; text-indent: 1em; text-spacing: trim-start; hanging-punctuation: first; }
11. Edge Effects
Note: Add final level 3 content
Acknowledgements
Note: Add final level 3 list, with Randy Edmunds, Florian Rivoal, and Pierre-Anthony Lemieux added.
Changes
Changes since the last Working Draft publication include:
- Adding line-padding.
- Adding text-group-align.
- Adding text-spacing: space-first.
- Allow truncating the hyphenate-character.
- Rename text-wrap: normal to text-wrap: wrap for consistency with flex-wrap.
- Drop preserve-auto and preserve-trim from text-space-collapse.
- Redefine text-wrap: balance in terms of remaining space.
- Note various issues on ''text-wrap: <string>''.
- Miscellaneous minor fixes.