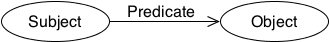RDF 1.1 Concepts and Abstract Syntax
W3C Working Draft 15 January 2013
- This version:
- http://www.w3.org/TR/2013/WD-rdf11-concepts-20130115/
- Latest published version:
- http://www.w3.org/TR/rdf11-concepts/
- Latest editor's draft:
- https://dvcs.w3.org/hg/rdf/raw-file/default/rdf-concepts/index.html
- Previous version:
- http://www.w3.org/TR/2012/WD-rdf11-concepts-20120605/
- Latest recommendation:
- http://www.w3.org/TR/rdf-concepts/
- Editors:
- Richard Cyganiak, DERI, NUI Galway
- David Wood, 3 Round Stones
- Previous editors:
- Graham Klyne, Nine by Nine
- Jeremy J. Carroll, Hewlett Packard Labs
- Brian McBride, Hewlett Packard Labs (RDF 2004 Series Editor)
Copyright © 2004-2013 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply.
Abstract
The Resource Description Framework (RDF) is a framework for
representing information in the Web.
RDF 1.1 Concepts and Abstract Syntax defines an abstract syntax
(a data model) which serves to link all RDF-based languages and
specifications. The abstract syntax has two key data structures:
RDF graphs are sets of subject-predicate-object triples,
where the elements may be IRIs, blank nodes, or datatyped literals. They
are used to express descriptions of resources. RDF datasets are used
to organize collections of RDF graphs, and comprise a default graph
and zero or more named graphs.
This document also introduces key concepts and terminology, and discusses
datatyping and the handling of fragment identifiers in IRIs within
RDF graphs.
1 Introduction
This section is non-normative.
This is a work-in-progress Working Draft. Various open
issues are flagged throughout the text with boxes like this.
Feedback on these issues is particularly welcome.
The Resource Description Framework (RDF) is a framework
for representing information in the Web.
This document defines an abstract syntax (a data model)
which serves to link all RDF-based languages and specifications,
including:
1.1 Graph-based Data Model
The core structure of the abstract syntax is a set of
triples, each consisting of a subject,
a predicate and an object. A set of such triples is called
an RDF graph. An RDF graph can be visualized as a node and
directed-arc diagram, in which each triple is represented as a
node-arc-node link.
There can be three kinds of nodes in an
RDF graph: IRIs, literals,
and blank nodes.
1.2 Resources and Statements
Any IRI or literal denotes
some thing in the universe of discourse. These things are called
resources. Anything can be a resource,
including physical things, documents, abstract concepts, numbers
and strings; the term is synonymous with “entity”.
The resource denoted by an IRI is called its referent, and the
resource denoted by a literal is called its
literal value. Literals have
datatypes that define the range of possible
values, such as strings, numbers, and dates. A special kind of literals,
language-tagged strings, denote plain-text strings in a
natural language.
The assertion of an RDF triple says that some relationship,
indicated by the predicate, holds between the
resources denoted by
the subject and object. This statement corresponding
to an RDF triple is known as an RDF statement.
The predicate itself is an IRI and denotes a property,
that is, a resource that can be thought of as a binary relation.
(Relations that involve more than two entities can only be
indirectly
expressed in RDF [SWBP-N-ARYRELATIONS].)
Unlike IRIs and literals,
blank nodes do not denote specific
resources.
Statements involving
blank nodes say that something with the given
relationships exists, without explicitly naming it.
1.3 The Referent of an IRI
The resource denoted by an IRI
is also called its referent.
What exactly is denoted by any given IRI is not defined by this
specification.
Guidelines for determining the referent of an IRI are
provided in other documents, like
Architecture of the
World Wide Web, Volume One [WEBARCH] and
Cool URIs for the
Semantic Web [COOLURIS].
A very brief, informal and partial account follows:
- IRIs have global scope: An IRI is assumed to denote
the same resource regardless of where the IRI occurs.
- By social convention, the
IRI owner
[WEBARCH] gets to say what an IRI denotes.
They do this when “minting” a new IRI.
- The IRI owner can establish the intended referent
by means of a specification or other document that explains
what is denoted. For example, the
Organization Ontology
document [VOCAB-ORG] specifies the referents
of various IRIs that start with
http://www.w3.org/ns/org#.
- A good way of communicating the intended referent
is to set up the IRI so that it
dereferences
[WEBARCH] to such a document.
- Such a document can, in fact, be an RDF document
that describes the denoted resource by means of
RDF statements.
Perhaps the most important characterisitic of IRIs
in web architecture is that they can be
dereferenced,
and hence serve as starting points for interactions with a remote server.
This specification, however, is not concerned with such interactions.
It does not define an interaction model. It only treats IRIs as globally
unique identifiers in a graph data model that describes resources.
1.4 RDF Vocabularies and Namespace IRIs
An RDF vocabulary is a collection of IRIs
with clearly established referents
intended for use in RDF graphs. For example,
the IRIs documented in [RDF-SCHEMA] are the RDF Schema vocabulary.
RDF Schema can itself be used to define and document additional
RDF vocabularies. Some such vocabularies are mentioned in the
Primer [RDF-PRIMER].
The IRIs in an RDF vocabulary often share
a common substring known as a namespace IRI.
Some namespace IRIs are associated by convention with a short name
known as a namespace prefix. Some examples:
In some contexts it is common to abbreviate IRIs
that start with namespace IRIs by using the
associated namespace prefix. For example, the IRI
http://www.w3.org/1999/02/22-rdf-syntax-ns#XMLLiteral
would be abbreviated as rdf:XMLLiteral.
Note however that these abbreviations are not valid IRIs,
and must not be used in contexts where IRIs are expected.
Namespace IRIs and namespace prefixes are not a formal part of the
RDF data model. They are merely a syntactic convenience for
abbreviating IRIs.
The term “namespace” on its own does not have a
well-defined meaning in the context of RDF, but is sometimes informally
used to mean “namespace IRI” or “RDF vocabulary”.
1.5 RDF and Change Over Time
The RDF data model is atemporal: It does not deal with time,
and does not have a built-in notion of temporal validity of information.
RDF graphs are static snapshots of
information.
However, RDF graphs can express information
about events and about temporal aspects of other entities,
given appropriate vocabulary terms.
Since RDF graphs are defined as mathematical
sets, adding or removing triples from an
RDF graph yields a different RDF graph.
We informally use the term RDF source to refer to a
persistent yet mutable source or container of
RDF graphs. An RDF source is a resource
that may be said to have a state that can change over time.
A snapshot of the state can be expressed as an RDF graph.
For example, any web document that has an RDF-bearing representation
may be considered an RDF source. Like all resources, RDF sources may
be named with IRIs and therefore described in
other RDF graphs.
Intuitively speaking, changes in the universe of discourse
can be reflected in the following ways:
1.6 Working with Multiple RDF Graphs
As RDF graphs are sets of triples, they can be
merged easily, supporting the use of data from
multiple sources. Nevertheless, it is sometimes desirable to work
with multiple RDF graphs while keeping their contents separate.
RDF datasets support this requirement.
An RDF dataset is a collection of
RDF graphs. All but one of these graphs have
an associated IRI. They are called
named graphs, and the IRI is called the
graph name.
The remaining graph does not have an associated IRI, and is called
the default graph of the RDF dataset.
There are many possible uses for RDF datasets.
One such use is to hold snapshots of multiple
RDF sources. It is common to have the
default graph contain triples
that involve the graph names
of the other graphs in the dataset.
1.7 Equivalence, Entailment and Inconsistency
No Editor's Draft of RDF 1.1 Semantics is
available yet
(ACTION-214),
and its relationship to this document is not yet
entirely clear. Some Semantics-related material may be moved here,
in particular the definition of graph merge and
subgraph, and informative
entailment rules
for the entailments over the RDF data model
(excluding any specific vocabulary). This is
ISSUE-106.
The Working Group intends to publish a Working Group
Note detailing some of its efforts to define a formal semantics for
RDF datasets. It should be referenced here when available. This is
ACTION-209.
An RDF triple encodes a statement—a
simple logical expression, or claim about the world.
An RDF graph is the conjunction (logical AND) of
its triples, and the conjunction of two RDF graphs is their merge.
This treatment of RDF graphs as logical expressions is
normatively defined in the
RDF Semantics
specification [RDF-MT], using a model-theoretic semantics.
It yields various relationships between RDF graphs:
- Entailment
- An RDF graph A entails another RDF graph B
if every possible arrangement of the world
that makes A true also makes B true. When A
entails B, if the truth of A is presumed or demonstrated
then the truth of B is established.
- Equivalence
- Two RDF graphs A and B
are equivalent if they make the same claim about the world.
A is equivalent to B if and only if
A entails B and
B entails A.
- Inconsistency
- An RDF graph is inconsistent if it contains
an internal contradiction. There is no possible arrangement
of the world that would make the expression true.
An entailment regime [RDF-MT] is a specification that
defines precise conditions that make these relationships hold.
RDF itself recognizes only some basic cases of entailment, equivalence
and inconsistency. Other specifications, such as
RDF Schema [RDF-SCHEMA]
and OWL 2
[OWL2-OVERVIEW], add more powerful entailment regimes,
as do some domain-specific vocabularies.
Some entailment regimes are defined with respect to a
datatype map.
This specification does not constrain how implementations
use the logical relationships defined by
entailment regimes.
Implementations may or may not detect
inconsistencies, and may make all,
some or no entailed information
available to users.
3 RDF Graphs
An RDF graph is a set of
RDF triples.
3.1 Triples
An RDF triple consists of three components:
An RDF triple is conventionally written in the order subject,
predicate, object.
The set of nodes of an RDF graph
is the set of subjects and objects of triples in the graph.
It is possible for a predicate IRI to also occur as a node in
the same graph.
IRIs, literals and
blank nodes are collectively known as
RDF terms.
IRIs, literals
and blank nodes are distinct and distinguishable.
For example, http://example.org/ as a string literal
is not equal to http://example.org/ as an IRI,
nor to a blank node with the blank node identifier
http://example.org/.
3.2 IRIs
An IRI
(Internationalized Resource Identifier) within an RDF graph
is a Unicode string [UNICODE] that conforms to the syntax
defined in RFC 3987 [RFC3987].
IRIs in the RDF abstract syntax must be absolute, and may
contain a fragment identifier.
IRI equality:
Two IRIs are equal if and only if they are equivalent
under Simple String Comparison according to
section 5.1
of [RFC3987]. Further normalization must not be performed when
comparing IRIs for equality.
URIs and IRIs:
IRIs are a generalization of
URIs [RFC3986] that permits a much wider range of Unicode characters.
Every absolute URI and URL is an IRI, but not every IRI is an URI.
When IRIs are used in operations that are only
defined for URIs, they must first be converted according to
the mapping defined in
section 3.1
of [RFC3987]. A notable example is retrieval over the HTTP
protocol. The mapping involves UTF-8 encoding of non-ASCII
characters, %-encoding of octets not allowed in URIs, and
Punycode-encoding of domain names.
Relative IRIs:
Some concrete RDF syntaxes permit
relative IRIs as a convenient shorthand
that allows authoring of documents independently from their final
publishing location. Relative IRIs must be
resolved
against a base IRI to make them absolute.
Therefore, the RDF graph serialized in such syntaxes is well-defined only
if a base IRI
can be established [RFC3986].
IRI normalization:
Interoperability problems can be avoided by minting
only IRIs that are normalized according to
Section 5
of [RFC3987]. Non-normalized forms that are best avoided
include:
- Uppercase characters in scheme names and domain names
- Percent-encoding of characters where it is not
required by IRI syntax
- Explicitly stated HTTP default port
(
http://example.com:80/);
http://example.com/ is preferrable
- Completely empty path in HTTP IRIs
(
http://example.com);
http://example.com/ is preferrable
- “
/./” or “/../” in the path
component of an IRI
- Lowercase hexadecimal letters within percent-encoding
triplets (“
%3F” is preferable over
“%3f”)
- Punycode-encoding of Internationalized Domain Names
in IRIs
- IRIs that are not in Unicode Normalization
Form C [NFC]
3.3 Literals
Literals are used to denote values such as strings, numbers and dates
by means of a lexical representation.
A literal in an RDF graph consists of two or three
elements:
- a lexical form, being a Unicode [UNICODE] string,
which should be in Normal Form C [NFC],
- a datatype IRI, being an IRI that determines
how the lexical form maps to a literal value.
A literal is a language-tagged string if and only if its
datatype IRI is
http://www.w3.org/1999/02/22-rdf-syntax-ns#langString,
and only in this case the third element is present:
- a non-empty language tag as defined by [BCP47].
The language tag must be well-formed according to
section 2.2.9
of [BCP47], and must be normalized to lowercase.
Concrete syntaxes may support simple
literals, consisting of only a lexical form
without any datatype IRI or language tag. Simple literals only
exist in concrete syntaxes, and are treated as
syntactic sugar for abstract syntax
literals with the datatype IRI
http://www.w3.org/2001/XMLSchema#string.
Literal equality:
Two literals are equal if and only if the two
lexical forms, the two
datatype IRIs, and the two
language tags (if any)
compare equal, character by character.
3.4 Blank Nodes
Various proposals have been made for revising
this section, ranging from editorial re-wordings to major re-writes
that introduce notions of a “scope” for blank node identifiers
and define the concept of a “fresh” blank node. This is
ISSUE-107.
The blank nodes in an RDF graph
are drawn from an infinite set. This set is disjoint from the set
of all IRIs and the set of all
literals.
Otherwise, this set of blank nodes is arbitrary.
Given two blank nodes, it is
possible to determine whether or not they are the same.
Besides that, RDF makes no reference to any internal structure
of blank nodes.
Blank node identifiers
are local identifiers that are used in some
concrete RDF syntaxes
or RDF store implementations.
They are always locally scoped to the file or RDF store,
and are not persistent or portable identifiers
for blank nodes. Blank node identifiers are not
part of the RDF abstract syntax, but are entirely dependent
on the concrete syntax or implementation. The syntactic restrictions
on blank node identifiers, if any, therefore also depend on
the concrete RDF syntax or implementation.
3.5 Replacing Blank Nodes with IRIs
Blank nodes do not have identifiers in the RDF abstract syntax. The
blank node identifiers introduced
by some concrete syntaxes have only
local scope and are purely an artifact of the serialization.
In situations where stronger identification is needed, systems may
systematically replace some or all of the blank nodes in an RDF graph
with IRIs. Systems wishing to do this should
mint a new, globally
unique IRI (a Skolem IRI) for each blank node so replaced.
This transformation does not appreciably change the meaning of an
RDF graph, provided that the Skolem IRIs do not occur anywhere else.
It does however permit the possibility of other graphs
subsequently using the Skolem IRIs, which is not possible
for blank nodes.
Systems may wish to mint Skolem IRIs in such a way that they can
recognize the IRIs as having been introduced solely to replace a blank
node. This allows the system to map IRIs back to the source blank node
if needed.
Systems that want Skolem IRIs to be recognizable outside of the system
boundaries should use a well-known IRI [WELL-KNOWN] with the registered
name genid. This is an IRI that uses the HTTP or HTTPS scheme,
or another scheme that has been specified to use well-known IRIs; and whose
path component starts with /.well-known/genid/.
For example, the authority responsible for the domain
example.com could mint the following recognizable Skolem IRI:
http://example.com/.well-known/genid/d26a2d0e98334696f4ad70a677abc1f6
RFC 5785 [WELL-KNOWN] only specifies well-known URIs,
not IRIs. For the purpose of this document, a well-known IRI is any
IRI that results in a well-known URI after IRI-to-URI mapping [RFC3987].
3.6 Graph Isomorphism
Two
RDF graphs G and G' are
isomorphic if there
is a bijection M between the sets of nodes of the two graphs,
such that:
- M maps blank nodes to blank nodes.
- M(lit)=lit for all RDF literals lit which
are nodes of G.
- M(uri)=uri for all IRIs uri
which are nodes of G.
- The triple ( s, p, o ) is in G if and
only if the triple ( M(s), p, M(o) ) is in
G'
See also: IRI equality, literal equality.
With this definition, M shows how each blank node
in G can be replaced with
a new blank node to give G'. Graph isomorphism
is needed to support the RDF Test Cases [RDF-TESTCASES] specification.
4 RDF Datasets
An RDF Dataset is a collection of
RDF graphs, and comprises:
- Exactly one default graph, being an RDF graph.
The default graph does not have a name and may be empty.
- Zero or more named graphs.
Each named graph is a pair consisting of an IRI
(the graph name), and an RDF graph.
Graph names are unique within an RDF dataset.
Blank nodes may be shared between graphs
in an RDF dataset.
Despite the use of the word “name”
in “named graph”, the graph name does not formally
denote the graph. It is merely syntactically paired with
the graph. RDF does not place any formal restrictions on what
resource the graph name may denote, nor on the relationship between
that resource and the graph.
Some RDF dataset
implementations do not track empty named graphs.
Applications can avoid interoperability issues by not
ascribing importance to the presence or absence of empty named graphs.
Should RDF Concepts define any operations on RDF datasets,
such as merge, union, isomorphism, equality, equivalence? Is anything
needed to support the TriG test cases, SPARQL, etc.? This is
ISSUE-111.
5 Datatypes
Datatypes are used with RDF literals
to represent values such as strings, numbers and dates.
The datatype abstraction used in RDF is compatible with XML Schema
[XMLSCHEMA11-2]. Any datatype definition that conforms
to this abstraction may be used in RDF, even if not defined
in terms of XML Schema. RDF re-uses many of the XML Schema
built-in datatypes,
and provides two additional built-in datatypes,
rdf:HTML and rdf:XMLLiteral.
The list of datatypes supported by an implementation is determined
by its datatype map.
A datatype consists of a lexical space,
a value space and a lexical-to-value mapping, and
is denoted by one or more IRIs.
The lexical space of a datatype is a set of Unicode [UNICODE] strings.
The lexical-to-value mapping of a datatype is a set of
pairs whose first element belongs to the lexical space,
and the second element belongs to the value space
of the datatype. Each member of the lexical space is paired with exactly
one value, and is a lexical representation
of that value. The mapping can be seen as a function
from the lexical space to the value space.
Language-tagged
strings have the datatype IRI
http://www.w3.org/1999/02/22-rdf-syntax-ns#langString.
No datatype is formally defined for this IRI because the definition
of datatypes does not accommodate
language tags in the lexical space.
The value space associated with this datatype IRI is the set
of all pairs of strings and language tags.
For example, the XML Schema datatype xsd:boolean,
where each member of the value space has two lexical
representations, is defined as follows:
- Lexical space:
- {“
true”, “false”, “1”, “0”}
- Value space:
- {true, false}
- Lexical-to-value mapping
- {
<“
true”, true>,
<“false”, false>,
<“1”, true>,
<“0”, false>,
}
The literals that can be defined using this
datatype are:
| Literal |
Value |
<“true”, xsd:boolean> |
true |
<“false”, xsd:boolean> |
false |
<“1”, xsd:boolean> |
true |
<“0”, xsd:boolean> |
false |
5.1 The XML Schema Built-in Datatypes
IRIs of the form
http://www.w3.org/2001/XMLSchema#xxx,
where xxx
is the name of a datatype, denote the built-in datatypes defined in
XML Schema 1.1 Part 2:
Datatypes [XMLSCHEMA11-2]. The XML Schema built-in types
listed in the following table are the
RDF-compatible XSD types. Their use is recommended.
The other built-in XML Schema datatypes are unsuitable
for various reasons, and should not be used.
5.2 The rdf:HTML Datatype
RDF provides for HTML content as a possible literal value.
This allows markup in literal values. Such content is indicated
in an RDF graph using a literal whose datatype
is a special built-in datatype rdf:HTML.
This datatype is defined as follows:
- An IRI denoting this datatype
- is
http://www.w3.org/1999/02/22-rdf-syntax-ns#HTML.
- The lexical space
- is the set of Unicode [UNICODE] strings.
- The value space
- is a set of DOM
DocumentFragment
nodes [DOM4]. Two
DocumentFragment
nodes A and B are considered equal if and only if
the DOM method
A.isEqualNode(B)
[DOM4] returns true.
- The lexical-to-value mapping
-
Each member of the lexical space is associated with the result
of applying the following algorithm:
Any language annotation (lang="…") or
XML namespaces (xmlns) desired in the HTML content
must be included explicitly in the HTML literal. Relative URLs
in attributes such as href do not have a well-defined
base URL and are best avoided.
RDF applications may use additional equivalence relations,
such as that which relates an xsd:string with an
rdf:HTML literal corresponding to a single text node
of the same string.
5.3 The rdf:XMLLiteral Datatype
RDF provides for XML content as a possible literal value.
Such content is indicated in an RDF graph using a literal
whose datatype is a special built-in datatype
rdf:XMLLiteral, which is defined as follows:
- An IRI denoting
this datatype
- is
http://www.w3.org/1999/02/22-rdf-syntax-ns#XMLLiteral.
- The lexical space
- is the set of all strings which are well-balanced, self-contained
XML content
[XML10]; and for which embedding between an arbitrary
XML start tag and an end tag yields a document conforming to
XML Namespaces
[XML-NAMES].
- The value space
- is a set of DOM
DocumentFragment
nodes [DOM4]. Two
DocumentFragment
nodes A and B are considered equal
if and only if the DOM method
A.isEqualNode(B)
returns true.
- The lexical-to-value mapping
-
Each member of the lexical space is associated with the result
of applying the following algorithm:
- The canonical mapping
- defines a
canonical lexical form
[XMLSCHEMA11-2] for each member of the value space.
The
rdf:XMLLiteral canonical mapping is the
exclusive
XML canonicalization method (with comments, with empty
InclusiveNamespaces PrefixList) [XML-EXC-C14N].
Any XML namespace declarations (xmlns),
language annotation (xml:lang) or base URI
declarations (xml:base) desired in the
XML content must be included explicitly in the XML literal.
Note that some concrete RDF syntaxes may define mechanisms
for inheriting them from the context
(e.g., @parseType="literal"
in RDF/XML [RDF-SYNTAX-GRAMMAR]).
5.4 Datatype Maps
A datatype map is an implementation-defined set of
<IRI, datatype> pairs such that no
IRI appears twice in the set.
It can be seen as a function from IRIs to datatypes,
where the IRIs denote the datatypes.
If a datatype map contains the IRI
http://www.w3.org/1999/02/22-rdf-syntax-ns#XMLLiteral,
then it must be paired with the datatype
rdf:XMLLiteral.
If a datatype map contains the IRI
http://www.w3.org/1999/02/22-rdf-syntax-ns#HTML,
then it must be paired with the datatype
rdf:HTML.
If a datatype map contains an IRI of the form
http://www.w3.org/2001/XMLSchema#xxx,
then it must be paired with the
RDF-compatible XSD type
named xsd:xxx.
Other specifications
may impose additional constraints on the datatype map,
for example, require support for certain datatypes.
The Web Ontology Language
[OWL2-OVERVIEW] offers facilities for formally defining
custom
datatypes that can be used with RDF. Furthermore, a practice for
identifying
user-defined simple XML Schema datatypes
is suggested in [SWBP-XSCH-DATATYPES]. RDF implementations
are not required to support either of these facilities.
5.5 The Value Corresponding to a Literal
The literal value associated with a literal is:
- If the literal is a language-tagged string,
then the literal value is a pair consisting of its lexical form
and its language tag, in that order.
- If the literal's datatype IRI is not in the
implementation-defined datatype map, then the literal value
is not defined by this specification.
- Let d be the datatype associated with the
datatype IRI in the implementation-defined datatype map.
- If the literal's lexical form is in the
lexical space of d, then the literal value
is the result of applying the lexical-to-value mapping
of d to the lexical form.
- Otherwise, the literal is
ill-typed, and no literal value can be
associated with the literal. Such a case, while in error, is not
syntactically ill-formed.
What does it mean when a literal is ill-typed or when something is not in the datatype map? What should an implementation do? Should authors avoid generating such graphs? Should consumers reject it? Is an implementation that rejects ill-formed xsd:dates conforming? Why is an ill-typed literal not necessarily an inconsistency? This is ISSUE-109.
6 Fragment Identifiers
This section is non-normative.
This section addresses the use of fragment IRIs
in concrete syntaxes for RDF graphs, but not
for RDF datasets. Going beyond the questions
of pure fragment identifiers, the introduction of RDF datasets raises
additional questions related to content negotiation and the
authoritativeness of representations. For example, is it legitimate
to content-negotiate between an RDF graph representation and an
RDF dataset representation that only contains a default graph?
Are the contents of graphs named <#xxx> an
authoritative representation of whatever is identified by
<#xxx>? This is
ISSUE-105.
RDF uses IRIs, which may include
fragment identifiers, as resource identifiers.
The semantics of fragment identifiers is
defined in
RFC 3986 [RFC3986]: They identify a secondary resource
that is usually a part of, view of, defined in, or described in
the primary resource, and the precise semantics depend on the set
of representations that might result from a retrieval action
on the primary resource.
This section discusses the handling of fragment identifiers
in representations that encode RDF graphs.
In RDF-bearing representations of a primary resource
<foo>,
the secondary resource identified by a fragment bar
is the resource denoted by the
full IRI <foo#bar> in the RDF graph.
Since IRIs in RDF graphs can denote anything, this can be
something external to the representation, or even external
to the web.
In this way, the RDF-bearing representation acts as an intermediary
between the web-accessible primary resource, and some set of possibly
non-web or abstract entities that the RDF graph may describe.
In cases where other specifications constrain the semantics of
fragment identifiers in RDF-bearing representations, the encoded
RDF graph should use fragment identifiers in a way that is consistent
with these constraints. For example, in an HTML+RDFa document [HTML-RDFA],
the fragment chapter1 may identify a document section
via the semantics of HTML's @name or @id
attributes. The IRI <#chapter1> should
then be taken to denote that same section in any RDFa-encoded
triples within the same document.
Similarly, if the @xml:id attribute [XML-ID] is used
in an RDF/XML document, then the corresponding IRI
should be taken to denote an XML element.
Primary resources may have multiple representations that are
made available via
content negotiation
[WEBARCH]. Fragments in RDF-bearing representations
should be used in a way that is consistent with the semantics imposed by any
non-RDF representations. For example, if the fragment
chapter1 identifies a document section in an
HTML representation of the primary resource, then the IRI
<#chapter1>
should be taken to denote that same section in all RDF-bearing
representations of the same primary resource.
7 Acknowledgments
This section is non-normative.
The RDF 1.1 editors acknowledge valuable contributions from
Thomas Baker, Dan Brickley, Gavin Carothers, Jeremy Carroll,
Pierre-Antoine Champin, Dan Connolly,
John Cowan, Martin J. Dürst, Alex Hall, Steve Harris, Pat Hayes,
Ivan Herman, Peter F. Patel-Schneider, Addison Phillips,
Eric Prud'hommeaux, Andy Seaborne, Leif Halvard Silli,
Nathan Rixham, Dominik Tomaszuk and Antoine Zimmermann.
The RDF 2004 editors acknowledge valuable contributions from
Frank Manola, Pat Hayes, Dan Brickley, Jos de Roo, Sergey Melnik,
Dave Beckett, Patrick Stickler, Peter F. Patel-Schneider, Jerome Euzenat,
Massimo Marchiori, Tim Berners-Lee, Dave Reynolds and Dan Connolly.
This specification is a product of extended deliberations by the
members of the RDF Working Group.
It draws upon two earlier specifications,
RDF Model and Syntax, edited by Ora Lassilla and Ralph Swick,
and RDF Schema, edited by Dan Brickley and R. V. Guha, which were produced by
members
of the RDFcore and Schema Working Groups.