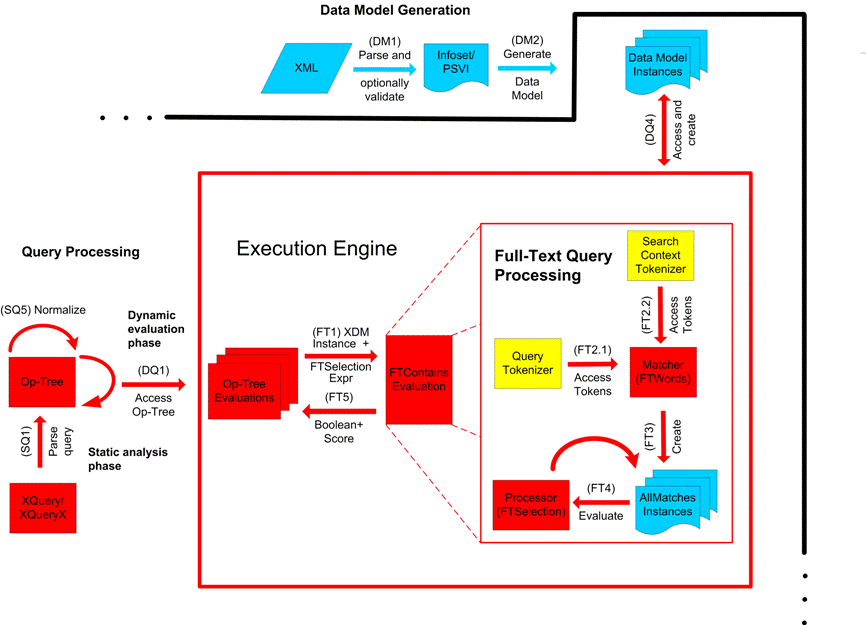
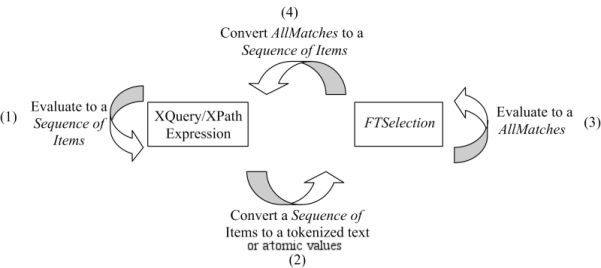
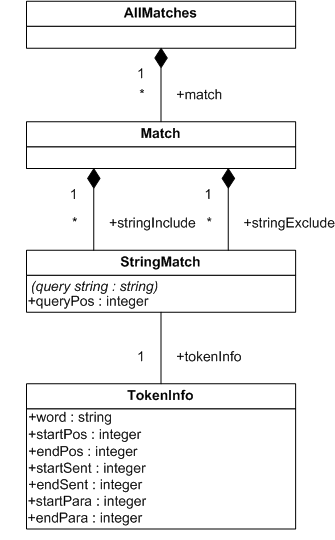
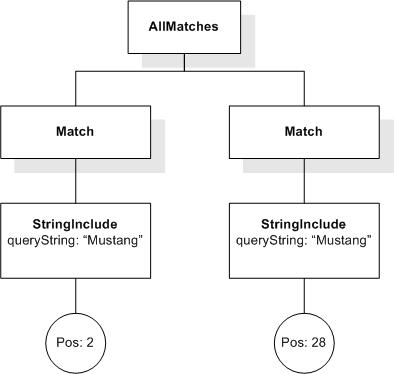
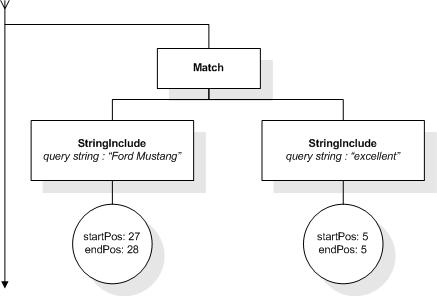
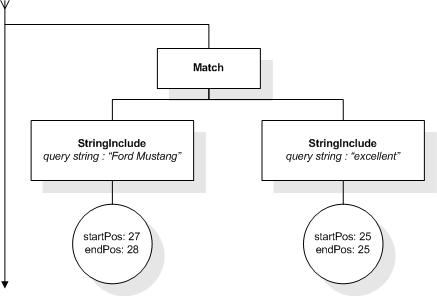
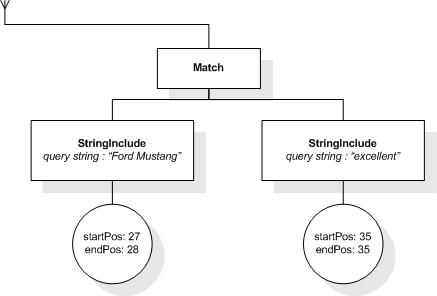
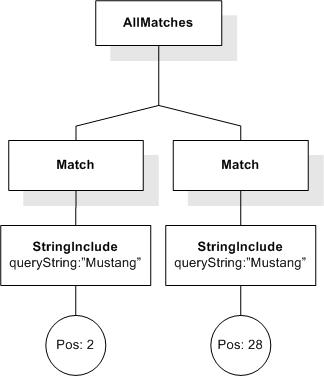
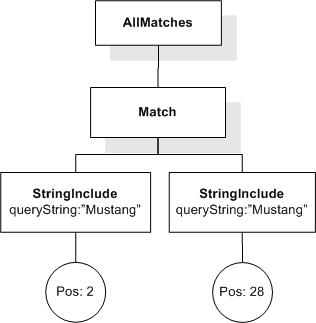
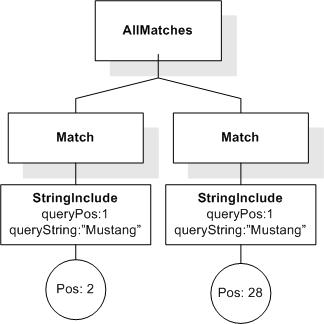
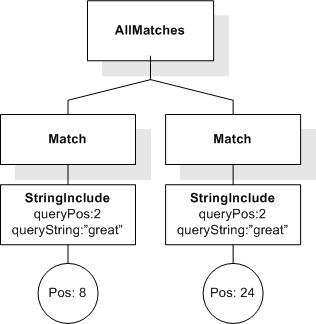
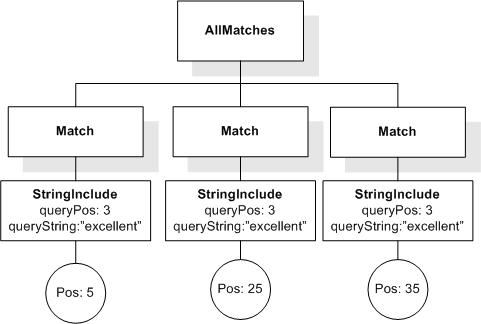
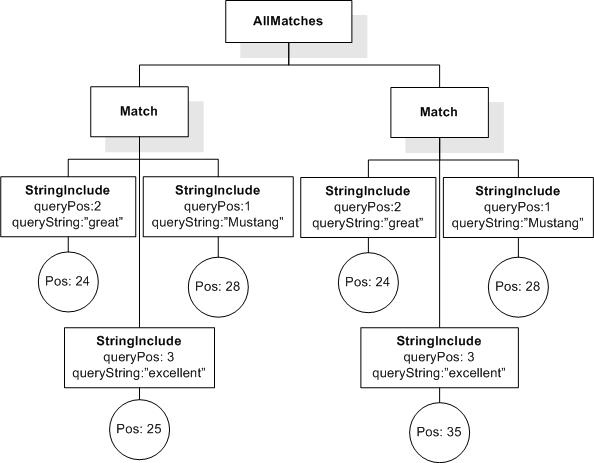
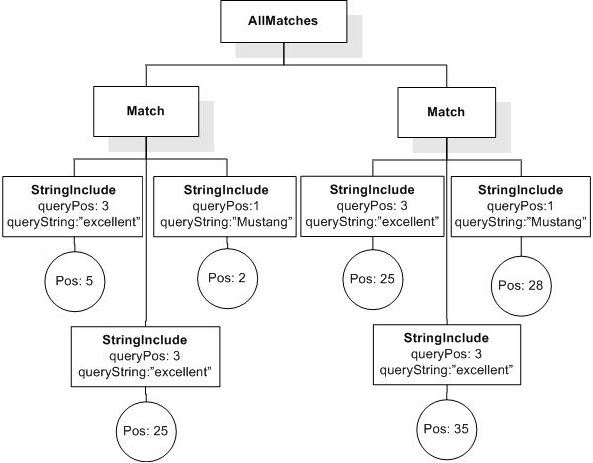
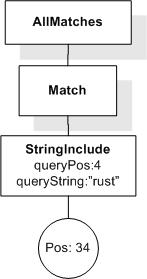
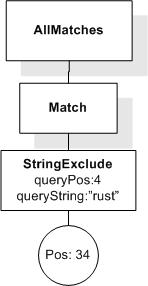
This section describes FTSelections which contain the full-text operators in the FTContainsExpr, and the match options in FTMatchOptions which modify the matching semantics of the full-text selection expressions.
The "weight" value is the result of evaluating ExprSingle and can be any numeric value.
The syntax and semantics of the individual full-text selection operators follow.
This XML document fragment is the source document for examples in this section.
Tokenization is implementation-defined. A sample tokenization is used for the examples in this section. The results may be different for other tokenizations.
Unless stated otherwise, the results assume a case-insensitive match.
3.1 Full-Text Operators
[Definition: Full-text operators perform operations on tokens, phrases, and expressions. Some require that the relative positions of tokens in the document be known (e.g., proximity operators).]
3.1.1 FTWords
FTWords specifies the tokens and phrases that are being searched as the left-hand side argument of FTContainsExpr.
An FTWords is an FTWordsValue followed by the optional modifier FTAnyallOption. The right-hand side of FTWordsValue is an XQuery expression which must evaluate to a sequence of string values or nodes of type "xs:string". The result is then atomized into a sequence of strings which is tokenized into a sequence of tokens and phrases. If the atomized sequence is not a subtype of "xs:string*", an error is raised: [err:XPTY0004]XP.
If the "any" option is specified, a match occurs, if and only if at least one token or phrase in the sequence has a match in the searched text.
If the "all" option is specified, a match occurs, if and only if all of the tokens and phrases in the sequence are matched in the searched text.
If the "phrase" option is specified, all words and phrases are used to create a sequence of ordered words representing a new phrase. A match occurs, if and only if the resulting phrase is matched in the searched text.
If the "any word" option is specified, a match occurs, if and only if at least one token in the sequence of tokens and phrases is matched in the searched text.
If the "all word" option is specified, a match occurs, if and only if all tokens in the sequence of tokens and phrases are matched in the searched text.
If no option is specified, "any" is the default.
If the result is a single string, "any", "all", and "phrase" are equivalent.
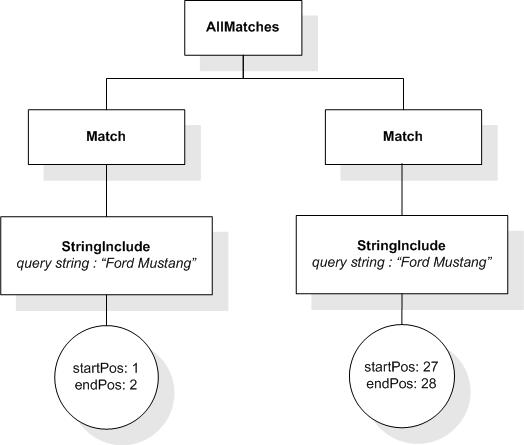
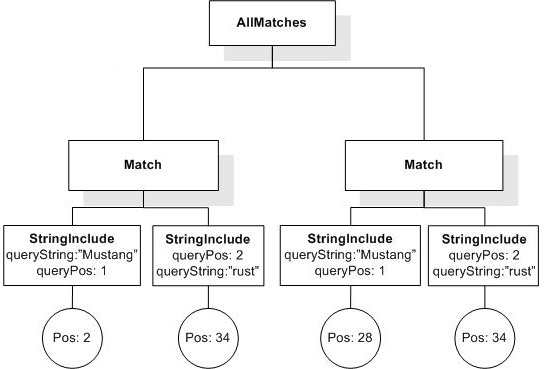
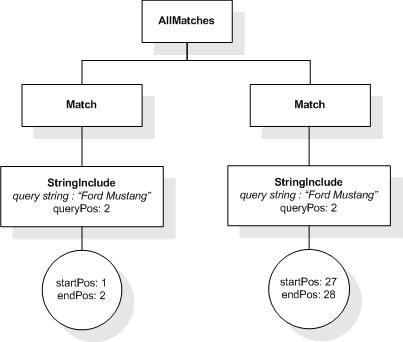
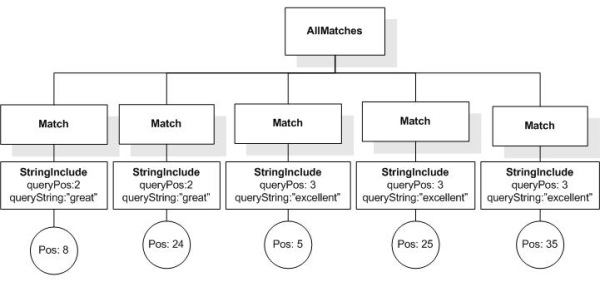
/book[@number="1" and ./title ftcontains "Expert"]
returns the book element whose number is 1, because its title element contains the token "Expert".
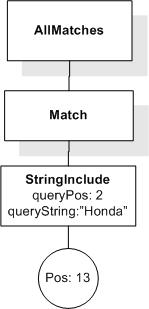
/book[@number="1" and ./title ftcontains "Expert Reviews"]
returns the book element whose number is 1, because its title element contains the phrase "Expert Reviews".
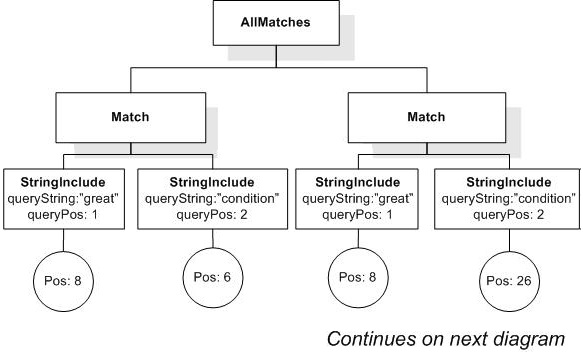
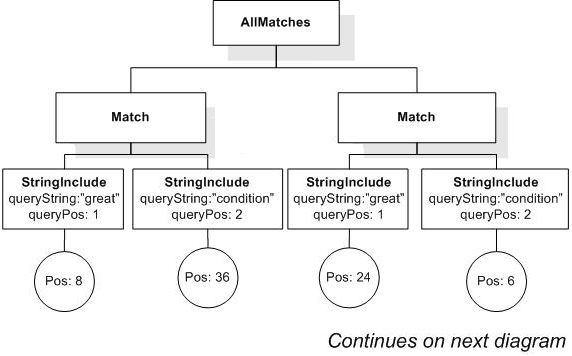
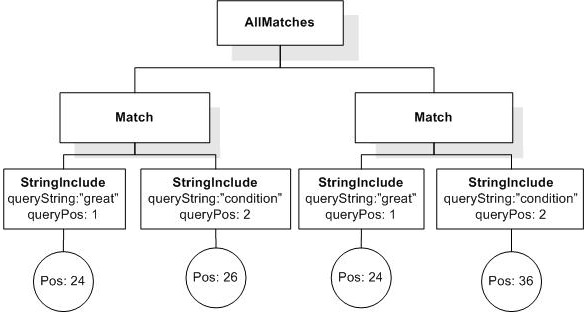
/book[@number="1" and ./title ftcontains {"Expert",
"Reviews"} all]
returns the book element whose number is 1, because its title element contains two tokens "Expert" and "Reviews".
/book[@number="1"]//p ftcontains "Web Site Usability"
returns false, because the p element doesn't contain the phrase "Web Site Usability" although it contains all of the tokens in the phrase.
for $book in /book[.//author ftcontains "Marigold"]
let score $score := $book/title ftcontains "Web Site Usability"
where $score > 0.8
order by $score descending
return $book/@number
returns book numbers of book elements by "Marigold" with a title about "Web Site Usability" sorting them in descending score order.
3.1.2 FTOr
FTOr finds matches that satisfy at least one of the selection criteria.
A match must satisfy at least one of the FTSelection criteria.
/book[.//author ftcontains "Millicent" ||
"Voltaire"]
returns the book element written by "Millicent".
3.1.3 FTAnd
FTAnd finds matches that satisfy both of the selection criteria.
A match must satisfy all of the FTSelection criteria which are specified by one or more FTMildNot expressions.
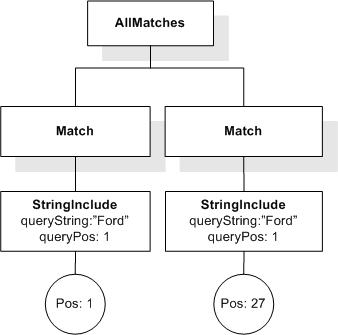
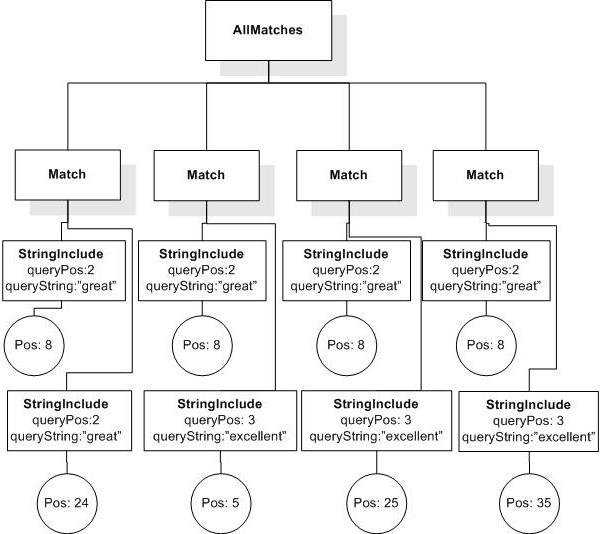
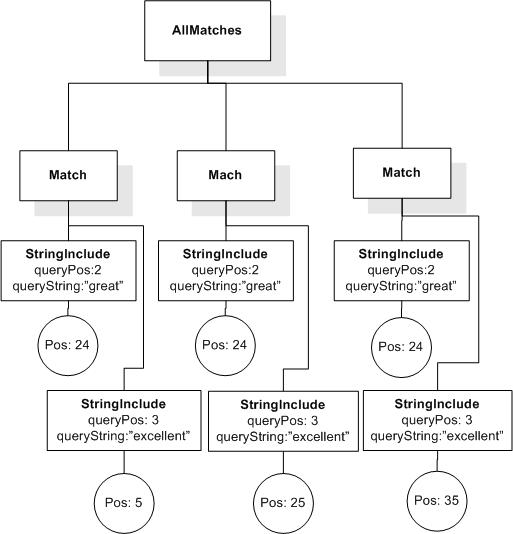
/book[@number="1"]/title ftcontains ("usability" && "testing")
returns true, since the book title contains "usability" and "testing".
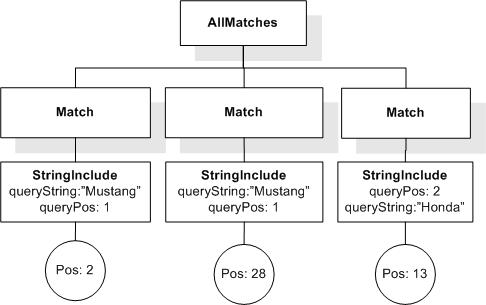
/book/author ftcontains "Millicent" && "Montana"
returns false, because "Millicent" and "Montana" are not contained by the same author element in any book element.
3.1.4 FTMildNot
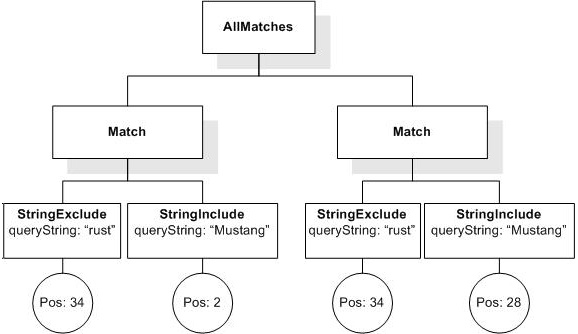
FTMildNot is a milder form of && ! (and not). 'a not in b' matches an expression that contains "a", but not when it is a part of "b". For example, a search for "Mexico" not in "New Mexico" returns, among others, a document which is all about "Mexico" but mentions at the end that "New Mexico was named after Mexico", which would not be returned by an "and not" search.
A match to FTMildNot must contain at least one token occurrence that satisfies the first condition and does not satisfy the second condition. If it contains a token occurrence that satisfies both the first and the second condition, the occurrence is not considered as a result.
/book ftcontains "usability" not in "usability
testing"
returns true, because "usability" appears in the title and the p elements and the occurrence within the phrase "Usability Testing" in the title element is not considered.
The right-hand side of a FTMildNot may not contain an FTSelection that evaluates to an AllMatches that contains a StringExclude. Such FTSelections are FTUnaryNot and FTTimes with at most, from-to, and exactly occurrences ranges.
3.1.5 FTUnaryNot
FTUnaryNot finds matches that do not satisfy the selection criteria.
/book[. ftcontains ! "usability"]
returns the empty sequence, because all book elements contain "usability".
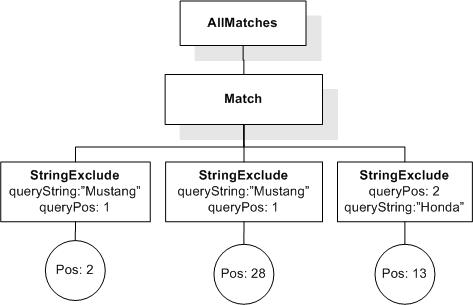
/book ftcontains "information" &&
"retrieval" && ! "information retrieval"
returns true, because book elements contain "information" and "retrieval" but not "information retrieval".
/book[. ftcontains "web site usability" &&
!"usability testing"]
return book elements containing "web site usability" but not "usability testing".
3.1.6 FTOrder
FTOrder controls the order of tokens and phrases to be the same as the order in which they are written in the query.
The default is unordered. Unordered is in effect when ordered is not specified in the query. Unordered cannot be written explicitly in the query.
FTOrder finds matches which must satisfy the nested selection condition and the match must contain the tokens in the order specified in the query.
/book/title ftcontains ("web site" && "usability")
ordered
returns true, because titles of book elements contain "web site" and "usability" in the order in which they are written in the query, i.e., "web site" must precede "usability".
/book[@number="1"]/title ftcontains ("Montana" &&
"Millicent") ordered
returns false, because although "Montana" and "Millicent" appear in the title element, they do not appear in the order they are written in the query.
3.1.7 FTScope
FTScope finds tokens and phrases contained in the same or a different scope.
Possible scopes are sentences and paragraphs.
By default, there are no restrictions on the scope of the matches.
If two tokens appear in the same sentence and in different sentences, then both same sentence and different sentence return true. The same is true for same paragraph and different paragraph.
/book ftcontains "usability"
&& "Marigold" same sentence
returns false, because the tokens "usability" and "Marigold" are not contained within the same sentence.
/book ftcontains "usability"
&& "Marigold" different sentence
returns true, because the tokens "usability" and "Marigold" are contained within different sentences.
/book[. ftcontains "usability" && "testing"
same paragraph]
returns a book element, because it contains "usability" and "testing" in the same paragraph.
/book[. ftcontains "site" && "errors"
same sentence]
returns a book element, because "site" and "errors" appear in the same sentence.
Some subtle relationships between FTScope and FTDistance will be discussed in Section 4.
3.1.8 FTDistance
FTDistance finds matches by specifying the distance between tokens and phrases in FTUnits (tokens, sentences, and paragraphs). The number of intervening FTUnits is specified in the integer value of FTRange.
FTRange specifies a range of integer values, providing a minimum and maximum value. Each UnionExpr in an FTRange must evaluate (after atomization) to a singleton sequence with an atomic value of type "xs:integer". Otherwise, an error is raised [err:XPTY0004]XP.
Let the value of the first (or only) UnionExpr be M. If "from" is specified, let the value of the second UnionExpr be N. FTDistance may cross element boundaries when computing distance.
The following rule applies to FTDistance:
If "exactly" is specified, then the range is the closed interval [M, M]. If "at least" is specified, then the range is the half-closed interval [M, unbounded). If "at most" is specified, then the range is the closed interval [0, M]. If "from-to" is specified, then the range is the closed interval [M, N].
Here are some examples of FTRanges:
-
'exactly 0' specifies the range [0, 0].
-
'at least 1' specifies the range [1,unbounded].
-
'at most 1' specifies the range [0, 1].
-
'from 5 to 10' specifies the range [5, 10].
The distances computed by FTDistance are not affected by the presence or absence of element boundaries in the text. Stop words are counted in those computations whether they are ignored or not.
/book ftcontains ("information" &&
"retrieval") not in ("information" && "retrieval"
distance at least 11 words)
returns false, because "information" and "retrieval" are more than at least 11 tokens apart.
/book ftcontains "web" && "site" &&
"usability" distance at most 2 words
returns true, because "web", "site", and "usability" have at most 2 intervening tokens between them.
/book[. ftcontains "web site"
&& "usability" distance at most 1 words]/title
returns the book title. A similar query for the p element would return false because "web site" and "usability" have two intervening tokens between them.
3.1.9 FTWindow
FTWindow finds matches within a number of FTUnits (tokens, paragraphs, and phrases). The number of FTUnits is specified as an integer.
FTWindow may cross element boundaries. The size of the window is not affected by the presence or absence of element boundaries. Stop words are included in those computations whether they are ignored or not.
UnionExpr must evaluate to an atom of type "xs:integer".
A match of an FTSelection is considered a match within a window, if there exists a window of the given number of consecutive units (tokens, sentences, or paragraphs) in the document within which the match lies.
/book/title ftcontains "web" && "site"
&& "usability" window 5 words
returns true, because "web", "site", and "usability" are within a window of 5 tokens in the title element.
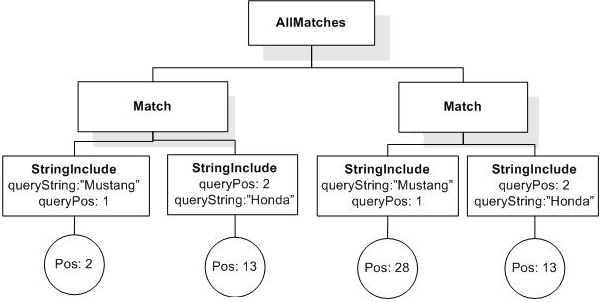
/book ftcontains ("web" && "site" ordered)
&& ("usability" || "testing") window 10 words
returns true, because "web" and "site" in the order they are written in the query and either "usability" or "testing" are within a window of at most 10 tokens.
/book//title ftcontains "web site" &&
"usability" window 3 words
returns true, because the title element contains "Web Site Usability". A similar query on the p element would not return true, because its occurrences of "web site" and "usability" are not within a window of 3.
/book[@number="1" and . ftcontains "efficient"
&& ! "and" window 3 words]
returns the empty sequence, because in the selected book element, there is no occurrence of "efficient" within a window of 3 tokens which would not also contain an occurrence of "and".
3.1.10 FTTimes
FTTimes finds matches in which an FTSelection occurs a specified number of times.
FTTimes limits the number of different occurrences of FTSelection, within the specified range.
In the document fragment "very very big":
-
The FTSelection "very big" has 1 occurrence consisting of the second "very" and "big".
-
The FTSelection "very && big" has 2 occurrences; one consisting of the first "very" and "big", and the other containing the second "very" and "big".
-
The FTSelection "very || big" has 3 occurrences.
-
The FTSelection ! "small" has 1 occurrence.
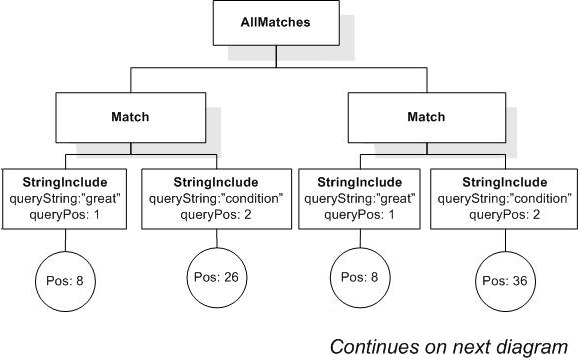
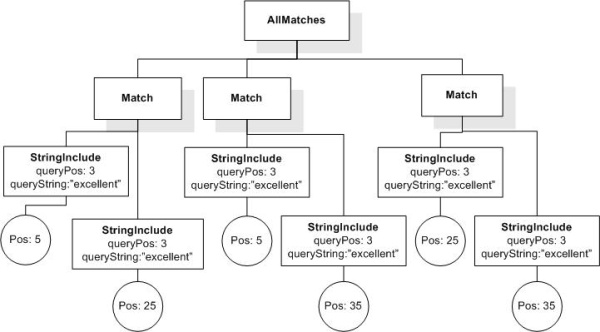
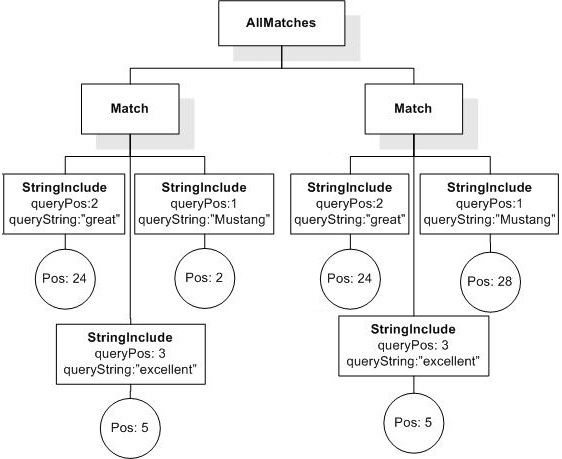
/book[. ftcontains "usability" occurs at least 2 times]/@number
returns book numbers because book elements contain 2 or more occurrences of "usability".
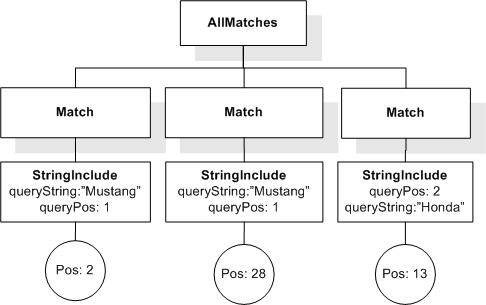
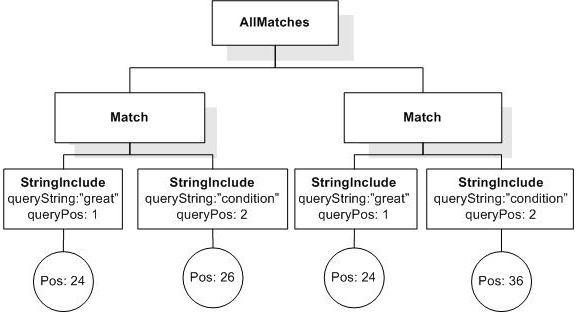
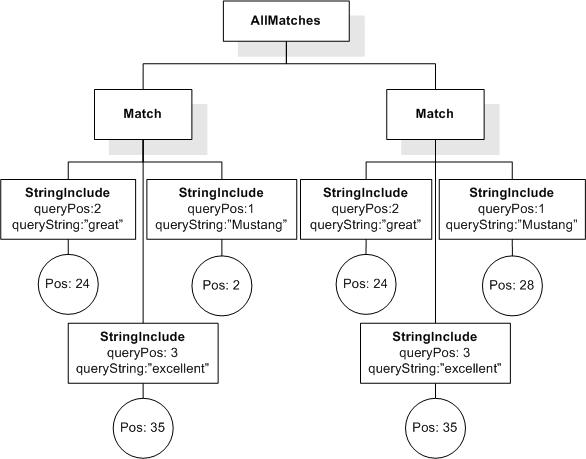
/book[@number="1" and title ftcontains "usability" ||
"testing" occurs at most 3 times]
returns the empty sequence, because there are 4 occurrences of "usability" || "testing" in the designated title.
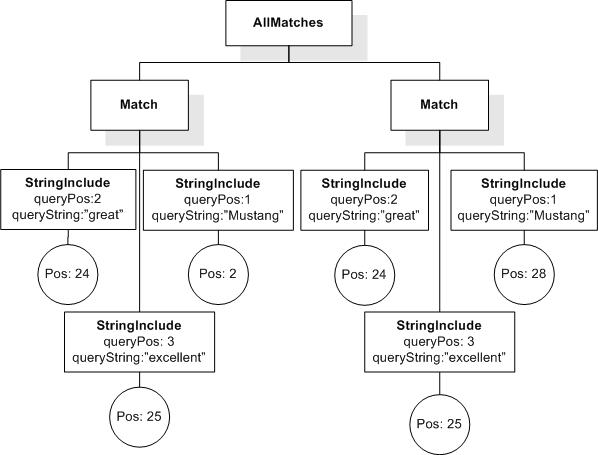
/book ftcontains "usability" occurs at least 2 times
returns true, because the book element contains 3 occurrences of "usability" in its title element although its p element contains only 1 occurrence.
3.1.11 FTContent
| [165] |
FTContent |
::= |
("at" "start") | ("at" "end") | ("entire" "content") |
FTContent finds matches in which the tokens and phrases are the first, last or all of the tokens and phrases in the tokenized form of the items being searched.
The "at" "start" option finds matches in which the tokens or phrases are the first tokens or phrases in the tokenized string value of the element being searched.
The "at" "end" option finds matches in which the tokens or phrases are the last tokens or phrases in the tokenized string value of the element being searched.
The "entire" content" option finds matches in which the tokens or phrases are the entire content of the tokenized string value of the element being searched.
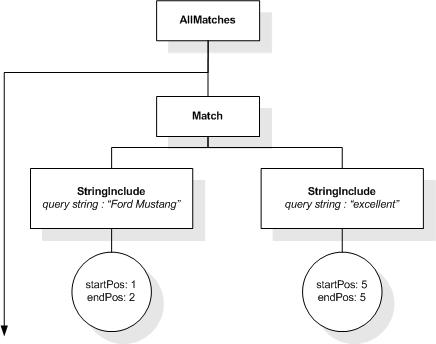
/books//title[. ftcontains "improving the usability
of a web site" at start]
returns each title element starting with the phrase "improving the usability of a web site".
/books//p[. ftcontains "propagat*" && "few
errors" distance at most 2 words at end]
returns each p element ending with the phrase "propagating few errors".
/books//note[. ftcontains "this site has been
approved by the web site users association" entire content]
returns each note element whose entire content is "this site has been approved by the web site users association".
3.2 FTMatchOptions
FTMatchOptions modify the operational semantics of the FTSelection on which they are applied.
FTMatchOptions set environments for the matching options of FTSelection. [Definition: Match options modify the set of tokens and phrases in the query. Some of these options (e.g., stemming) have behaviors which depend on the language of the document, the language of the query, or both.] If a match option isn't specified explicitly in the query, its value is given by
its static context component. Details about these context components, including their default values, are given in Appendix C Static Context Components.
If no match options declarations are present in the prolog and the implementation does not define any overwriting of the static context components for the match options, the query:
/book/title ftcontains "usability"
is equivalent to the query
/book/title ftcontains "usability" case insensitive
diacritics insensitive
without stemming without thesaurus
without stop words language "none" without wildcards
FTMatchOptions are applied in the order in which they are written in the query. More information on their semantics is given in 4.2.3 Match Options Semantics.
We describe each match option in more detail in the following sections.
3.2.1 FTCaseOption
| [155] |
FTCaseOption |
::= |
"lowercase"
| "uppercase"
| ("case" "sensitive")
| ("case" "insensitive") |
FTCaseOption modifies tokens and phrases matching by specifying how upper and lower charcters are considered.
FTCaseOption influences the way FTWords is applied.
There are four possible character case options:
-
The option "uppercase" matches tokens and phrases with uppercase characters, regardless of the case of characters of the tokens and phrases as they are written in the query.
-
The option "lowercase" matches tokens and phrases with lowercase characters, regardless of the case of characters of the tokens and phrases as they are written in the query.
-
The option "case" "insensitive" matches the uppercase and lowercase characters of tokens and phrases. The case of characters as they are written in the query is not considered.
-
The option "case" "sensitive" matches the case of the characters in tokens and phrases as they are written in the query.
The default is "case insensitive".
The following table summarizes the interactions between the case match options and the use of the default collations.
Case Matrix
| Default collation options/Case options |
UCC (Unicode Codepoint Collation) |
CCS (some generic case-sensitive collation) |
CCI (some generic case-insensitive collation) |
| insensitive |
compare as if both lower |
case-insensitive variant of CCS if it exists, else error |
CCI |
| sensitive |
UCC |
CCS |
case-sensitive variant of CCI if it exists, else error |
| uppercase |
uppercase(Expr) + UCC |
uppercase(Expr) + CSS |
CCI |
| lowercase |
lowercase(Expr) + UCC |
lowercase(Expr) + CSS |
CCI |
Note:
In this table, "else error" means "Otherwise, an error is raised: [err:FOCH0002]FO". The phrase "if it exists" is used, because the case-sensitive collation CCS does not always have a case-insensitive variant (and, even if one exists, it may not be possible to determine it algorithmically), and because the case-insensitive collation CCI does not always have a case-sensitive variant (and, even
if one exists, it may not be possible to determine it algorithmically).
/book[@number="1"]/title ftcontains "Usability" lowercase
returns false, because the title element doesn't contain "usability" in lower-case characters.
/book[@number="1"]/title ftcontains "usability"
case insensitive
returns true, because the character case is not considered.
3.2.2 FTDiacriticsOption
| [156] |
FTDiacriticsOption |
::= |
("with" "diacritics")
| ("without" "diacritics")
| ("diacritics" "sensitive")
| ("diacritics" "insensitive") |
FTDiacriticsOption modifies token and phrase matching by specifying how diacritics are considered.
There are four possible diacritics options:
-
The option "with" "diacritics" matches tokens and phrases with diacritics, regardless of whether the diacritics are written in the query.
-
The option "without" "diacritics" matches tokens and phrases without diacritics, regardless of whether the diacritics are written in the query.
-
The option "diacritics" "insensitive" matches tokens and phrases with and without diacritics. Whether diacritics are written in the query or not is not considered.
-
The option "diacritics" "sensitive" matches tokens and phrases only if they contain the diacritics as they are written in the query.
The default is "diacritics insensitive".
The following table summarizes the interactions between the diacritics match options and the use of the default collations.
Diacritics Matrix
| Default collation options/Diacritics options |
UCC (Unicode Codepoint Collation) |
CDS (some generic diacritics-sensitive collation) |
CDI (some generic diacritics-insensitive collation) |
| insensitive |
compare as if with and without |
diacritics-insensitive variant of CDS if it exists, else error |
CDI |
| sensitive |
UCC |
CDS |
diacritics-sensitive variant of CDI if it exists, else error |
| with diacritics |
"resume diacritic insensitive" not in "resume" |
"resume diacritic insensitive" not in "resume" |
CDI |
| without diacritics |
"resume" not in "resume diacritic sensitive" |
"resume" not in "resume diacritic sensitive" |
CDI |
Note:
In this table, "else error" means "Otherwise, an error is raised: [err:FOCH0002]FO". The phrase "if it exists" is used, because the diacritics-sensitive collation CDS does not always have a diacritics-insensitive variant (and, even if one exists, it may not be possible to determine it algorithmically), and because the diacritics-insensitive collation CDI does not always have a
diacritics-sensitive variant (and, even if one exists, it may not be possible to determine it algorithmically).
/book[@number="1"]//editor ftcontains "Vera" with diacritics
returns true, because the editor element contains the token "Vera" with an acute accent.
/book[@number="1"]/editors ftcontains "Véra" without diacritics
returns false, because the editor element does not contain the token "Vera" without an acute accent.
3.2.3 FTStemOption
| [157] |
FTStemOption |
::= |
("with" "stemming") | ("without" "stemming") |
FTStemOption modifies token and phrase matching by specifying whether stemming is applied or not.
FTStemOption influences the way FTWords is applied. It produces a disjunction of the query tokens by expanding the tokens into the list of tokens that share the same stem. By definition, the query tokens are included in that disjunction.
The "with stemming" option specifies that matches may contain tokens that have the same stem as the tokens and phrases written in the query. It is implementation-defined what a stem of a token is.
The "without stemming" option specifies that the tokens and phrases are not stemmed.
It is implementation-defined whether the stemming is based on an algorithm, dictionary, or mixed approach.
The default is "without stemming".
/book[@number="1"]/title ftcontains "improve" with stemming
returns true, because the title of the specified book contains "improving" which has the same stem as "improve".
3.2.4 FTThesaurusOption
FTThesaurusOption modifies token and phrase matching by specifying whether a thesaurus is used or not. If thesauri are used, it locates the thesauri by default or URI reference. It also states the relationship to be applied and how many levels within the thesaurus to be traversed.
FTThesaurusOption influences the way FTWords is applied.
The StringLiteral following the keyword at in FTThesaurusID is of the form of a URI Reference.
Thesauri add related tokens and phrases to the search. Thus, the user may narrow, broaden, or otherwise modify the search using synonyms, hypernyms (more generic terms), etc. The search is performed as though the user has specified all related search tokens and phrases in a disjunction (FTOr).
Note:
A thesaurus may be standards-based or locally-defined. It may be a traditional thesaurus, or a taxonomy, soundex, ontology, or topic map. How the thesaurus is represented is implementation-dependent.
FTThesaurusID specifies the relationship sought between tokens and phrases written in the query and terms in the thesaurus and the number of levels to be queried in hierarchical relationships by including an FTRange "levels". If no levels are specified, the default is to query all levels in hierarchical relationships.
Relationships include, but are not limited to, the relationships and their abbreviations presented in [ISO 2788] and their equivalents in other languages:
-
equivalence relationships (synoymns): PREFERRED TERM (USE), NONPREFERRED USED FOR TERM (UF);
-
hierarchical relationships: BROADER TERM (BT), NARROWER TERM (NT), BROADER TERM GENERIC (BTG), NARROWER TERM GENERIC (NTG), BROADER TERM PARTITIVE (BTP), NARROWER TERM PARTITIVE (NTP), TOP Terms (TT); and
-
associative relationships: RELATED TERM (RT).
The "with thesaurus" option specifies that string matches include tokens that can be found in one of the specified thesauri.
The "without thesaurus" option specifies that no thesaurus will be used.
The "with default thesaurus" option specifies that a system-defined default thesaurus with a system-defined relationship is used. The default thesaurus may be used in combination with other explicitly specified thesauri.
The default is "without thesaurus".
count(.//book/content ftcontains "duties" with
thesaurus at "http://bstore1.example.com/UsabilityThesaurus.xml"
relationship "synonyms")>0
returns true, because it finds a content element containing "tasks" which the thesaurus identified as a synonym for "duties".
doc("http://bstore1.example.com/full-text.xml")
/books/book[count(./content ftcontains "web site components" with
thesaurus at "http://bstore1.example.com/UsabilityThesaurus.xml"
relationship "narrower terms" at most 2 levels)>0]
returns book elements, because it finds a content element containing "web site components", and narrower terms "navigation" and "layout".
doc("http://bstore1.example.com/full-text.xml")
/books/book[count(. ftcontains "Merrygould" with thesaurus at
"http://bstore1.example.com/UsabilitySoundex.xml" relationship
"sounds like")>0]
returns a book element containing "Marigold which sounds which sound like "Merrygould".
3.2.5 FTStopwordOption
FTStopWordOption controls word matching by specifying whether stop words are used or not. It can be used to define a set of tokens that will be replaced with a search on any token if used as search tokens.
FTStopWordOption influences the way FTWords is applied.
FTRefOrList specifies the list of stop words either explicitly as a comma-separated list of string literals, or by a URI following the keyword at. If a URI is used, it must point to a sequence of string atoms or nodes of type "xs:string". In both cases, no tokenization is performed on the strings: they are used as they occur in the sequence.
The "with stop words" option specifies that if a token is within the specified collection of stop words, it is removed from the search and any token may be substituted for it. Stop words retain their position numbers and are counted in FTDistance and FTWindow searches.
Multiple stop word lists may be combined using "union" or "except". If "union" is specified, every string occurring in the lists specified by the left-hand side or the right-hand side is a stop word. If "except" is specified, only strings occurring in the list specified by the left-hand side but not in the list specified by the right-hand side are stop words.
The "with default stop words" option specifies that an implementation-defined collection of stop words is used.
The "without stop words" option specifies that no stop words are used. This is equivalent to specifying an empty list of stop words.
The default is "without stop words".
/book[@number="1"]//p ftcontains "propagation of errors"
with stemming with stop words ("a", "the", "of")
returns true, because the document contains the phrase "propagating few errors".
Note the asymmetry in the stop word semantics: the property of being a stop word is only relevant to query terms, not to document terms. Hence, it is irrelevant for the above-mentioned match whether "few" is a stop word or not, and on the other hand we do not want the query above to match "propagation" followed by 2 stop words, or even a sequence of 3 stop words in the document.
/book[@number="1"]//p ftcontains "propagation of errors"
with stemming without stop words
returns false, because "of" is not in the p element between "propagating" and "errors".
doc("http://bstore1.example.com/full-text.xml")
/books/book[count(.//content ftcontains "planning then
conducting" with stop words at
"http://bstore1.example.com/StopWordList.xml")>0]
uses the stop words list specified at the URL. Assuming that the specified stop word list contains the "then", this query is reduced to a query on the phrase "planning X conducting", allowing any token as a substitute for X. It returns a book element, because its content element contains "planning then conducting". It would have also returned the book if the phrases "planning and conducting" and "planning before conducting" had been in its content.
doc("http://bstore1.example.com/full-text.xml")
/books/book[count(.//content ftcontains "planning then conducting"
with stop words at "http://bstore1.example.com/StopWordList.xml"
except ("the then"))>0]
returns books containing "planning then conducting", but not does not return books containing "planning and conducting", since it is exempting "then" from being a stop word.
3.2.6 FTLanguageOption
FTLanguageOption modifies token matching by specifying the language of search tokens and phrases.
FTLanguageOption influences the way FTWords is applied.
The StringLiteral following the keyword language designates one language. It must either be castable to "xs:language", or be the value "none". Otherwise, an error is raised: [err:XPTY0004]XP.
The "language" option influences tokenization, stemming, and stop words.
If the language "none" option is specified, no language selected.
The set of valid language identifiers is implementation-defined.
By default, there is no language selected.
/book[@number="1"]//editor ftcontains "salon de the"
with default stop words language "fr"
This is an example where the language option is used to select the appropriate stop word list.
3.2.7 FTWildCardOption
FTWildCardOption modifies token and phrase matching by specifying whether wildcards are used or not.
FTWildCardOption influences the way FTWords is applied.
In addition to specifying the "with wildcards"' option, indicators (represented by periods (.)) and qualifiers are appended to or inserted into tokens being searched. Zero or more characters replace each indicator and qualifier.
Indicators are mandatory. When the "with wildcards"' option is present, one or more periods (.) must be appended at the beginning or end of tokens or inserted into tokens. If the period is at the beginning of a token, the wildcard is a prefix wildcard. If the period is at the end of a token, it is a suffix wildcard. If the period is inserted into a token, it is an infix wildcard.
When the "with wildcards" option and one or more periods (.) appended to or inserted into tokens are present, characters are appended or inserted at each of the periods. Any characters may be appended or inserted except newline characters (#xA), return characters (#xD), and tab characters (#x9). The number of characters depends on the qualifier. Qualifiers available are none, question mark, asterisk, plus sign, and two numbers separated by a comma, both enclosed by curly braces.
-
If a period is present, but no qualifiers, one character is appended or inserted.
-
If a period is followed by a question mark (.?), zero or one characters are appended or inserted.
-
If a period is followed by an asterisk (.*), zero or more characters are appended or inserted.
-
If a period is followed by a plus sign (.+), one or more characters are appended or inserted.
-
If a period is followed by two numbers separated by a comma, both enclosed by curly braces (.{n,m}), a specified range of characters is appended or inserted.
The "without wildcards" option finds tokens without recognizing wildcard indicators and qualifiers. Periods, question marks, asterisks, plus signs, and two numbers separated by a comma, both enclosed by curly braces recognized as regular characters.
The default is "without wildcards".
/book[@number="1"]/title ftcontains "improv.*" with
wildcards
returns true, because the title element contains "improving".
/book[@number="1"]/title ftcontains ".?site" with
wildcards
returns true, because the title element contains "site".
/book[@number="1"]/p ftcontains "w.ll" with
wildcards
returns true, because the p element contains "well".
3.3 FTIgnoreOption
FTIgnoreOption specifies a set of element nodes whose content are ignored. [Definition: Ignored nodes are the set of element nodes whose content are ignored.] Ignored nodes are identified by the XQuery expression UnionExpr. Let N1, N2, ..., Nk be the sequence of nodes of the search context. The expression UnionExpr is evaluated in the context of each node Ni being
searched. That is, the search context expression of the ftcontains predicate creates a new focus for the evaluation of the UnionExpr given with FTIgnoreOption, similar to the creation of the dynamic context of a path expression E1/E2 or a filter expression E1[E2] (see Section 2.1.2 Dynamic ContextXQ).
Now, let I1, I2, ..., In be the sequence of items that UnionExpr evaluates to. For each Ni (i=1..k) a copy is made that omits each node Ij (j=1..n) that is not Ni. Those copies form the new search context. If UnionExpr evaluates to an empty sequence no nodes are omitted.
In the following fragment, if .//annotation is ignored, "Web Usability" will be found 2 times: once in the title element and once in the editor element. The 2 occurrences in the 2 annotation elements are ignored. On the other hand, "expert" will not be found, as it appears only in an annotation element.
<book>
<title>Web Usability and Practice</title>
<author>Montana <annotation> this author is an expert in Web Usability</annotation>
Marigold
</author>
<editor>Véra Tudor-Medina on Web <annotation> best editor on Web Usability</annotation>
Usability
</editor>
</book>
By default, no element content is ignored.