3.1 What are Internationalization and Localization?
Users from different countries or cultural backgrounds require software and
services that are adapted to correctly process information using their
native languages, writing systems, measurement systems, calendars, and
other linguistic rules and cultural conventions.
[Definition: International Preferences]The specification of the particular
set of cultural conventions that software or Web services must employ to
correctly process information exchanged with a user.
[Definition: Internationalization]The process of designing, creating, and
maintaining software that can serve the needs of users with differing
language, cultural, or geographic requirements and expectations.
There are many kinds of international preferences that a Web service may
need to offer, to be considered usable and acceptable by users around the
world. Some of these preferences might include:
Natural language for text processing: parsing, spell checking, and grammar checking are examples of this
User interface language, which may include items like images, colors, sounds, formats, and navigational elements
Presentation (human-oriented formatting) of dates, times, numbers, lists, and other values
Collation and sorting
Alternate calendars, which may include holidays, work rules, weekday/weekend distinctions, the number and organization of months, the numbering of years, and so forth
Tax or regulatory regime
Currency
... and many more
Because there are a large number of preferences, software systems (operating environments and programming languages) often use an identifier based on language and location as a
shorthand indicator for collections of preferences that typify categories of
users.
HTML for example uses the lang attribute to indicate the language of segments of content. XML
uses the xml:lang attribute for the same purpose.
Java, POSIX, .NET and other software development
methodologies use a similar-looking (but not identical) construct known as a
locale. In this document, we will use the term locale as the name for this
shorthand indicator for a user's particular set of international preferences.
[Definition: Locale] Shorthand identifier representing the particular
specification of international preferences that a (certain category of) user
requires.
Generally, systems that are internationalized can support a wide variety of
languages and behaviors to meet the international preferences of many
kinds of users. When a particular set of content and preferences is operationally
available (often called "enabled"), then the system is referred to as
localized.
[Definition: Localization] The tailoring of a system to the
individual cultural
expectations for a specific target market or group of individuals. The target
group is often indicated by the locale identifier.
Localized systems often need to perform matching between end user preferences represented by the locale and localized resources. This process is called language (or locale) negotiation.
[Definition: Language Negotiation] The process of matching a user's preferences to available localized resources. The system searches for matching content or logic "falling-back" from more-specific to more-general following a deterministic pattern.
However, it is important to note that many of the international preferences
do not correlate strongly with locale identifiers based solely on language and
location.
For example, a system might define a locale of "en-US" (English, United States). This locale encompasses
several time zones, so the user's preferred time zone cannot be deduced
by the locale identifier alone. Many cultures have more than one way of
collating text, and so the appropriate sort ordering cannot always be
inferred from the locale. For example, Japanese applications may use different
orderings known as radical-stroke and stroke-radical.
Germany and other parts of the world may use different sort orderings known as
dictionary versus phonebook.
Distinguishing these situations requires forethought in the design of the
service
and the setting of reasonable default values.
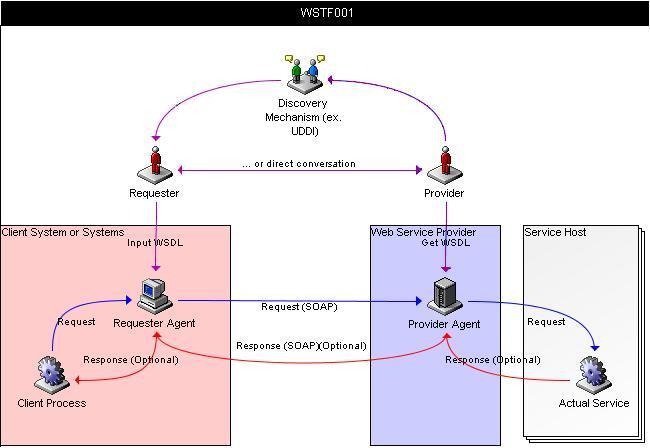
Each user or system in a Web services interaction may have its own
default locale settings. The interplay between the requester, provider,
service host, intermediaries, and other entities may have complex implications.
3.1.1 Relationship of Locale to Natural Language
There is not yet an Internet standard for locale identifiers. However, there is one for natural language identifiers, RFC3066. Since these language identifiers can imply a locale and in the absence of a standard for locale interchange, language identifiers are often used by software as the source for locale identification. Language and locale are distinct properties and should not be used interchangeably, but there is a relationship between these parameters in the area of resource selection and localization.
The danger of using one for the other lies in the distinction between them. A language preference controls only the language of the textual content, while locale objects are used to control culturally affected (software) behavior within the system. For example, making the assumption that the language parameter ja (Japanese) means the data should be presented in the locale-determined format for Japan could be a mistake if the requester actually lives and works in Australia.
The language parameter may be available in several places. In HTTP, there is an Accept-Language header field which can be used (see the HTTP Accept-Language section for more information). MIME has a Content-Language header which contains a language identifier (see the MIME Tags section for more information). In XML, there is an attribute which can be defined for elements called xml:lang. xml:lang marks all the contents and attribute values of the corresponding element as belonging to the language identified. What that means for processing those contents varies from application to application.
Here are some examples:
<p xml:lang="en">The quick brown fox jumps over the lazy dog.</p>
<p xml:lang="en-GB">What colour is it?</p>
<p xml:lang="en-US">What color is it?</p>
<sp who="Faust" desc='leise' xml:lang="de">
<l>Habe nun, ach! Philosophie,</l>
<l>Juristerei, und Medizin</l>
<l>und leider auch Theologie</l>
<l>durchaus studiert mit heißem Bemüh'n.</l>
</sp>
For more detailed information on the behavior of xml:lang, see the XML specification.
3.1.2 I-025: Specifying and Exchanging International Preferences in Web Services
Web service and provider implementations, like Web based applications, face the problem of language and locale negotiation.
Most Web based application environments have established proprietary standards for performing language and locale negotiation and provide greater or lesser support for managing this form of personalization and content management.
Web services, in contrast, must allow disparate systems to interoperate in a consistent, non-proprietary manner. This design allows systems to invoke each other without regard to the internal architecture of any part of the system. It is helpful to think of a Web service as an remote procedure call ("RPC"), even though many Web services do not use the SOAP-RPC pattern. Unlike Web applications that can store user preferences in a session-like object hidden from the requester, Web service interoperability requires a shared model, if processing is to produce consistency between expectations and result.
Some of the problems inherent in dealing with locale negotiation and identifiers in Web services include:
Web Service Description Scenario A: A method is implemented in the Java programming language which takes a java.util.Locale argument. A Web service description is generated from this method via reflection of the Java class so that the method can be deployed as a Web service. The implementation of the Java java.util.Locale class is exposed in the Web service description and requests must be submitted with field values appropriate for Java, which may be difficult or impossible for non-Java clients to provide.
Description Scenario B: The same method is implemented taking a single string argument instead. The programmer creating the method writes logic to translate the string into the appropriate internal locale object. This logic may be substantial and must be repeated or shared for each locale-affected method. There is no way to associate the string argument with locale functionality in the provider, locale or language identifiers available in the transport, or to describe the parameter fully and consistently in directories. A system invoking the service might not be able to create a string in the expected format. The provider may not be able to validate the information appropriately.
Description Scenario C: A existing or "legacy" function or method which obtains its locale information from the runtime environment is deployed as a Web service. Existing locale negotiation mechanisms, such as Accept-Language in many application servers, rely on the container (formerly an Application server, but in this case the service provider) to populate this information. The service provider cannot know that this information is needed. The Web service description doesn't have a mechanism for describing this environment setting and the results from the service are limited to the runtime default locale of the provider or service host.
Scenario A, Different Locale Identifiers:: Sender sends a request to a provider and wants a specific
locale and uses its identifier for that. The provider is running on a different platform
and doesn't produce the same result as the sender expects.
Scenario A1, Different Locale Semantics: Sender sends a request to a provider, expecting a result in a specific
locale-affected format. The provider has a locale with the same ID, but the specific
operation is different from the sender's implementation and the
results don't match. These differences are generally subtle, but may vary widely depending on the specifics of the implementation. For example: collation or formatting dates as a string often display subtle variation from one platform to another.
Scenario A2, Fallback Produces Different Results: Sender requests a specific locale. Provider's fallback
produces wildly different results. For example, zh-Hant, the RFC3066 language tag for Chinese written in the Traditional Han script might fall back to zh which represents
generic Chinese and, on many systems, implies the use of the Simplified Han script.
The following graphics show some Chinese language tags and the resulting locale object in various systems. Note the differences in interpretation:
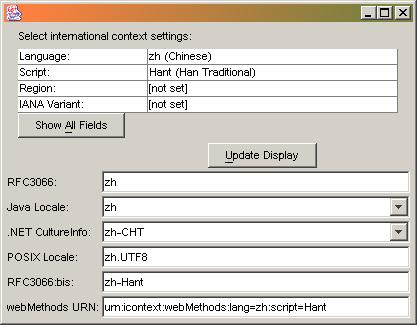
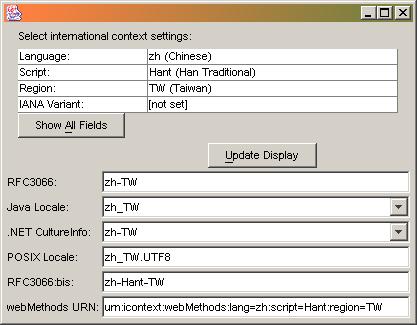
Here are two additional examples, one for Serbian and another for Azerbaijani:
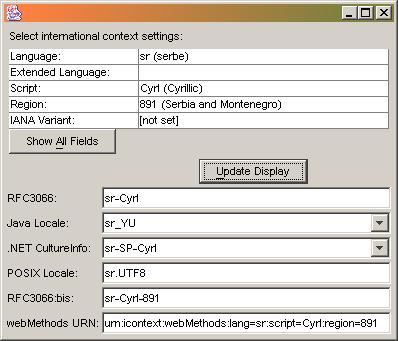
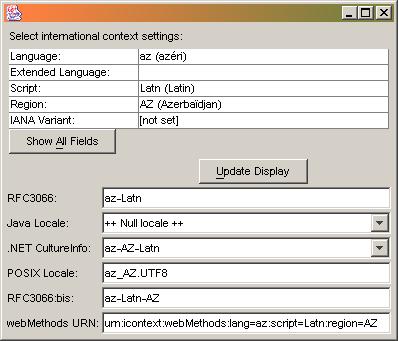
Scenario B: Sender sends a request to a provider, expecting results in in a specific
locale-affected format. The sender uses its own locale identifiers. The provider and/or service is on an incompatible
platform and cannot interpret the request. For example, converting Microsoft Windows's LCID identifier to Java's java.util.Locale.
Scenario C: Sender wants a specific format or set of processing rules for
a specific item or set of items. The provider is running on a different platform, so the semantics differ. For example, the sender expects the Java SHORT date format, but the provider is written in the C# language.
Scenario D: Sender wants a specific format and sends a picture string or
other very specific identifier. The provider and sender must agree on picture
string semantics. For example, they must agree on what the picture string symbols stand for. Even in the presence of such an agreement, the underlying data in the different locale models may not match, such as the particular abbreviation for a month name.
Scenario E: Sender wants a specific locale and the provider doesn't
support it. This isn't fatal to or detected by the receiving process, which returns data in
an unexpected format or with unexpected results. For example, the date May 6, 2004 might be returned in a locale-formatted string as 06/05/2004 and be interpreted by a U.S. English end user as June 5, 2004.
Scenario F: Scenario E, except that it is detected by or fatal to the service. It may be
difficult to interpret why the service failed. For example, the date returned in Scenario E might have been 13/05/2004, which is clearly in the wrong format for a U.S. user, but the receiving service may not be able to correct for the problem
Scenario G: Sender requests results that contain human readable text. The provider returns all languages available.
3.1.3 Locales in Web Service Descriptions
Web service descriptions should consider how to communicate language or
locale choices in a consistent manner. In the sections that
follow, specific patterns are recommended as good canonical references.
However experience shows that a specific implementation may require additional
contextual information not conveyed with a simple language tag. Generally
this type of additional information should be encoded into the message body (that is, as part of the application's design, not as part of the Web services infrastructure). This expresses specific implementation decisions as part of
the service's signature: you might require additional or different data in future versions. Some of the examples below show this type of information exchanged in headers and some of the complications that may arise from this.
In the examples below, adoption of a generic method for exchanging
"international contextual information" would allow implementations to
better model the natural language and locale processing choices offered
by the services.
Implementers should consider adding a language tag to any
operation fault elements to show what language to expect fault messages
to be generated in.
In all cases, descriptive text should be tagged with its actual content language
using the xml:lang attribute (where permitted). Consideration should be given to
providing documentation within services in alternate languages when the service
is expected to be utilized by users such as those in other countries or who speak
other languages.
3.1.4 Locales in SOAP
Some applications of Web services require a locale in order to meet end user expectations. An example of this is any process that returns human readable text messages (many more examples exist and some are given below).
Software developers generally get their messages from language resources using an API provided by the programming environment. This functionality
is implemented in many ways, but the pattern for writing the logic is always similar:
the language and locale preferences are not included in the parameter list of the
service itself because the processing environment (JVM, OS, .NET framework, etc.)
maintains this information as metadata about the process or user.
A SOAP Processor implementation might provide accessible natural language or locale preference information, received either in the transport (such as HTTP
Accept-Language) or in SOAP headers defined for a particular binding of a service.
For example, a .NET SOAP Processor might set the service's thread default
CultureInfo using a language tag. A J2EE implementation might populate
the javax.servlet.ServletRequest class's Locale property with a java.util.Locale constructed from
the ISO639 and ISO3166 fields embedded in a language tag. And so forth.
3.1.5 Faults, Errors, and Human Readable Text
Fault message "text" elements must be labelled with an appropriate language
identifier, as defined in XML 1.0. That is, an xml:lang tag containing an RFC3066
(or its successor) language identifier. If the transport provides the user's
language preference (such as HTTP Accept-Language), then that language or set
of languages should be preferred, followed by the SOAP Processor machine's
local language preference.
Ideally there should always be a "message of last resort" included in the fault.
In many cases this message may be in English, but consideration should be given
to the likely users of the system, including the administrators trying to puzzle
out the error. Numeric (or ASCII-only alpha-numeric) error codes should be
considered for inclusion in all fault messages. This may provide valuable
reference when the text of the message itself is in a language not understood
by the recipient.
When designing specifications intended for interoperability between vendors
or implementations, consideration should be given to enumerating the possible
faults in advance so that reference numbers can be universally and consistently
referenced by disparate implementations.
3.2 Locale Independent vs. Locale Dependent Data
When designing data structures for applications in general and for
Web services
in particular, it is important to design data structures in a
locale-independent way
wherever possible. Keeping the data itself from the representation for
the user leads
to a clearer application structure, drastically reduces the number of
formats for
interchange, avoids the need for additional information to distinguish
different
formats, and allows 'late localization' or 'just in time localization'.
An interesting, informative paper describing late localization is available here: [JITXL]
The use of XML Schema in Web services helps promote
locale-independent data
because most of the XML Schema datatypes [XMLS-2] have
been designed
to be locale-independent.
3.2.1 Textual vs. Binary Representations
In many traditional applications, the distinction between
locale-independent and
locale-dependent datatypes is also a distinction between binary
and
textual representations.
As an example, a floating-point number is
represented in some
binary format internal to an application. It is converted to a textual
format when displayed to the user, and
appropriate localization is applied to the formatting. For example, it would use a comma rather
than a decimal
point for many European locales.
Because XML is an
inherently textual format, the XML Schema Datatypes also are textual.
Nevertheless,
most of them were carefully designed to be locale-independent, and are
intended to
be used in a locale-independent manner.
As an example, the XML Schema Datatype
date
uses the format YYYY-MM-DD from [ISO8601]. This format is similar
(and in some
cases even identical) to some actual formats used in some locales. The format is unambiguous and can be
understood by a human reading the XML file. Although it is the appropriate format in some locales and not in others, it can be understood to be a locale-independent format. By contrast, if XML Schema had chosen a format
that is not
used in any locale, such as just numbering days since a well-defined
day, it would
have made the format much more difficult for humans to work with,
without any
benefits.
3.2.2 Locale-Dependent XML Schema Datatypes
While most datatypes in XML Schema are locale-independent, there are
a few that
are locale-dependent, and therefore should be avoided. These are
all the
datatypes that start with 'g', namely gYearMonth,
gYear,
gMonthDay, gDay, and gMonth, and the
duration datatype.
The semantics of these datatypes are
bound to the Gregorian calendar.
As an example, a field of type gMonth with a value set to 5 refers to
the month of May in the Gregorian calendar. This concept cannot be converted to
calendars that
do not have their months aligned with the months of the Gregorian
calendar, such as the Islamic, Hebrew, or Ethiopic calendars.
As another example, a gMonthDay field with value of 09-12 refers to September 12th in the Gregorian calendar. This date may coincide with the first or the second day of the month Meskerem in the Ethiopian calendar depending on the year.
On the other hand, the semantics of the other date- and time-related
XML Schema datatypes are not bound to the Gregorian calendar, although they
rely on the Gregorian calendar for their lexical form. For example, the
date 2004-09-12 can not only be converted to
September 12, 2004 (using the Gregorian calendar), but also
to the first day in the month Meskerem in the year 1997 in the Ethiopic calendar (the Ethiopic New Year).
3.2.3 Examples
Example: Some locale-independent XML Schema datatypes
TYPE : EXAMPLE
---------------- ---------------------------
date : 2003-05-31
time : 13:20:00
dateTime : 2003-05-31T13:20:00+09:00
double : 1267.43233E12
integer : 2678967543233
Example: Locale-dependent XML Schema datatypes
TYPE : EXAMPLE
---------------- ---------------------------
duration : P1Y2M3D
gYearMonth : 2003-05
gYear : 2003
gMonthDay : 05-25
gDay : 25
gMonth : 05