This is a W3C Working Draft produced by the Evaluation and Repair Tools Working
Group (ERT WG). The purpose of this document is to explain how and why to
use Evaluation and Report Language (EARL) 1.0. The ERT Working Group
encourages feedback about this document as well as implementation of the
language in authoring tools, testing tools, search engines, and other
relevant tools.
Evaluation and Report Language (EARL) is a general-purpose language for
expressing test results. This specification describes how to use EARL to
describe test results and defines a basic vocabulary for this purpose.
This section describes the status of this document at the time of its
publication. Other documents may supersede this document. The latest status
of this document series is maintained at the W3C.
While the need to express conformance in metadata was recognized in 1999
and an EARL schema has existed since 2001, this is the first time it is being
published as a W3C Working Draft. For a detailed history, refer to [EARL-Background]. In short, in 1999, Daniel
Dardailler proposed a PICS scheme and Dan Brickley and Charles McCathieNevile
developed "RDF Conformance Language." In 2000, the ERT WG began developing
what would become EARL 0.95. Since then, several developers have implemented
EARL [EARL-imps].
Throughout this draft, questions and to dos are prefixed with "Editor's
note:" and contained in square brackets e.g., [Editor's note:...]. After
these are cleaned up and reviewer's comments are handled, EARL 1.0 is likely
to be published as a W3C Note.
This draft document may be updated, replaced, or obsoleted by other
documents at any time. It is inappropriate to use W3C Working Drafts as
reference material or to cite them as other than "work in progress." A list
of current W3C Recommendations and other technical documents can be found at
http://www.w3.org/TR/.
Send comments about this document to the Evaluation and Repair Tools Working
Group. The archives for this
list are publicly available.
Patent disclosures relevant to this specification may be found on the ERT
Working Group's patent disclosure page
in conformance with W3C policy.
This document has been produced as part of the W3C Web Accessibility Initiative (WAI). The ERT
WG is part of the WAI
Technical Activity. The goals of the ERT WG are discussed in the Working Group
charter.
Evaluation and Report Language (EARL) is a language to express test
results. Test results include bug reports, test suite evaluations, and
conformance claims. The test subject might be a Web site, an authoring tool,
a user agent or some other entity. Thus, EARL is flexible. It enables any
person, entity, or organization to state test results for any thing
tested against any set of criteria.
Stating test results in EARL creates a variety of opportunities. The data
can be--
- exchanged between tools;
- used to create reports;
- combined to compare how different test subjects fared on the same
test.
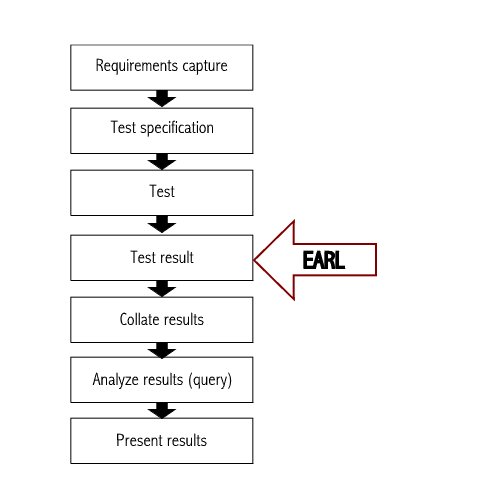
The following figure illustrates a generalized end-to-end test process and
where EARL fits into that process. Requirements for what needs to be tested
are collected then documented in a test specification. The tests are run
based on the test specification and the results may be stored in EARL. If
several tests are run, they are collated, analyzed, and presented in some
sort of report.
The following roles are common in software development.
- product manager - responsible for delivering the product
- product designer - designs the product and documents this in a design
specification
- tester - takes the product through a series of tests to find bugs
- developer - creates something to satisfy the design specification
In small organizations, all of these roles might be performed by a single
person. In large organizations, there might be multiple people in each role
who need to coordinate.
Product developers may accumulate evaluations from a variety of testers.
Machine-comprehensible exchange of this information allows the developer or
manager to more easily collect and compare this data. Having the data in a
machine-understandable form supports the following possible work-flow:
- Tester tests software using an evaluation tool.
- Tool stores data in EARL.
- Developer imports tests results into development tool.
- Developer makes repairs.
- Tool stores data in EARL.
- Manager keeps track of tester and developer data and is able to track
the progress of tests and repairs.
A variety of user scenarios are covered in more detail in the "User
Scenarios" chapter.
EARL statements contain the following information:
- The context information
- This may include information about: Who or what ran the test, the
date the test was run, information about the hardware and software used
to run the test(s).
- The test subject
- This may include: Web pages, tools (e.g. accessibility checkers,
validators), and user agents
- The result
- Did the test subject pass or fail the test? How certain can we
be?
- Test criteria
- What are we evaluating the test subject against? This could be a
specification, a set of guidelines, a test from a test suite, or some
other test case.
Prose examples that demonstrate the above structure:
- context: Mary Thompson asserts that on 17th December
2000
test subject: the page at http://example.org/
test result: passed
test criteria: checkpoint 1.1 of the Web Content
Accessibility Guidelines 1.0.
- The W3C's validator (context) asserts that the page at
http://example.org/ (test subject) fails (test result) a test for XHTML
compliance (test criteria).
- Bobby Smith (context) asserts that his browser, CoolBrowser v 1.0
revision date 2001-05-17 (test subject) passed (test result) the CSS 1.0
test suite (test criteria).
This section attempts to describe RDF and EARL in non-technical terms. For
a more technical RDF Primer, refer to [RDF-PRIMER].
Resource Description Framework (RDF) [RDF] is a
general-purpose language for describing information. RDF uses the World Wide
Web as a venue for publishing and exchanging information. The purpose of RDF
is to make machine-readable information
machine-understandable. EARL is an RDF vocabulary used to make
statements about how a resource performed against a test.
RDF uses "triples" to describe information. A triple is a statement that
contains a subject, a predicate (a verb), and an object. The simplest
statement in EARL is:
an Assertor ---asserts---> an Assertion
Referring to the prose examples from above:
Bobby Smith (assertor) ---asserts--->
CoolBrowser v 1.0 revision date 2001-05-17
passed the CSS 1.0 test suite(assertion).
The following diagram illustrates a basic EARL statement. The assertor and
assertion resources are "typed." When making information
machine-understandable, the rules and relationships between pieces of
information are declared.
[Editor's note: To understand this does one need to understand the class
structure of RDF? Should we describe here or defer to the RDF primer or
??]
(SVG version of abbreviated basic
assertion).
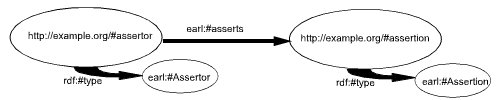
"rdf:" and "earl:" are abbreviations for the namespaces that uniquely
identifies where the data originates or where that type of data is
defined.
[Editor's note: Intro to namespaces needed?]
For more information on RDF, please refer to the following references:
- RDF Primer [RDF-PRIMER]
- Resource Description Framework (RDF) Model and Syntax Specification [RDF]
- Why RDF model is different from the XML model [RDF-XML-DIFFS]
This section outlines some typical examples of how EARL could be used and
by whom.
(single user, multiple tools, single site)
Scenario: A consultant uses a variety of evaluation tools to test a site
against the Web Content Accessibility Guidelines 1.0 [WCAG10] and generate an accessibility report. Where
more than one tool performs the same test, the consultant wants to compare
the results of the test between tools.
Checking for accessibility is similar to using a spell-checker on a
document. There are some spellings that the spell-checker knows are wrong but
there are many others that may not seem right, but it requires the human to
say for sure. For example "teh" is likely a typo for "the" while people's
names are likely to be identified as misspellings.
Accessibility is similar in that the tools can only perform some of the
checks and rely on a human to perform the final check. In matters of syntax,
a machine can be confident in results, but beyond syntax the human needs to
make an assertion. For example, determining if an image has a text equivalent
is a matter of syntax (i.e. rule matching) while determining if the text
equivalent is appropriate is only something a human can do - to determine if
the meaning of the image is properly conveyed in text.
[Editor's note: it might be helpful to describe when EARL is generated,
where it is stored, how it is used (for each scenario).]
Questions that the consultant should be able to derive from EARL
statements:
- Have all of the tests been completed? If not, which tests are not
complete?
- Are there conflicts between results?
- Are the results inconclusive because test X relies on test Y?
- Can I derive a result from the results that I have?
The consultant should be able to use the EARL data to programmatically
derive a report for the client.
[Editor's note: generate a graph of combined results of tool A and tool
B.]
Scenario: A developer maintaining a company's Web site fixes bugs reported
by a team of testers. Where a tester has identified a bug, the developer
should be able to answer the following questions from the EARL generated by
the test team's tools:
- Where is the problem?
- Is the problem true?
- Has it already been fixed?
- Which tester generated this bug report?
- What tools did the tester use to identify the bug?
The developer may combine the testers' data with data from the project
history or with other developers and answer the following questions:
- Is there a history of this problem or something similar?
- Have any test results been invalidated by changes?
- What should the tester retest?
Scenario: A W3C Working Group is trying to meet their exit criteria for
Candidate Recommendation by developing a test suite to show at least two
independent implementations. As a User Agent is tested, the results are
stored in EARL. Periodically, the working group will ask the following
questions to see how much more implementation work is needed:
[Editor's note: a graph of data might be helpful. Perhaps a chart of
results? Based on or similar to the CSS
test suite data (currently on IE6, add other User Agents))]
(many sets of tests, one Use Agent)
Scenario: A user agent developer wants to determine conformance that can
be claimed for her user agent product. Using the data generated by the
working group as they tested her product against their test suite, she can
find out:
- Which tests does my User Agent fail/passes?
- What percentage of tests are passed for each group (e.g. css1 vs css2
vs css3)?
- Which are the most severe failures?
- How does my tool compare to a competitor?
[Editor's note: provide a graph of data or a chart of results?]
Scenario: A student, who is deaf, is using an online education tool and
needs to take an assessment. The system constructs the assessment from a set
of existing assessment pieces for the current lesson. The student has a
learning profile that is matched against what tests need to pass. Matching
the student's profile (not EARL) against the accessibility profile of the
data (EARL), the education tool is able to assemble an assessment that does
not use sound and presents all information visually.
[Editor's note: To provide an example of this scenario, is there something
to point to within IMS work?]
Scenario: A Web site development unit that includes database developers,
Web page developers and quality assurance testers synthesizes design from the
public relations office and content from the operations units. Multiple tests
conducted by the development unit, public relations office, and the
operations units need to share results to report successful development or
specific points of test failure and track status of work on repair of
failures. The manager needs to track answers to the following questions:
- Where are the problems?
- Who is working on them?
- What are the status of repairs?
- What are the changes over time?
[Editor's note: a possible example of this scenario is to demonstrate the
ability tot from EARL reports between time x derive a management chart of
some sort from EARL reports between time x and time y.]
[Editor's note: Do we need a brief intro of RDF class/property model or is
this covered earlier or ??]
An assertion is a statement about the results of performing a test.
An assertion can have the following properties:
- assertedBy
- subject
- testCase
- result
- mode
Here is an example assertion block:
<earl:Assertion rdf:about="http://example.org/#assertion-1">
<earl:subject rdf:resource="http://example.org/#someID02495"/>
<earl:result rdf:resource="pass"/>
<earl:mode rdf:resource="&earl;manual"/>
<earl:testcase rdf:resource="http://example.org/#tc-1"/>
<earl:assertedBy rdf:resource="http://example.org/#assertor123" />
</earl:Assertion>
An assertor states the results of a test (i.e. an assertor asserts and
assertion). An assertor may be a person or a machine.
An assertor can have the following properties:
- contactInfo
- email
- name
- platform
- Person
- The Assertor is a human being.
- Tool
- The Assertor is a tool, such as: a black box testing tool of some
sort or an evaluation and repair tool.
The assertor in the following example is a person and therefore Person (a
subclass of Assertor) is used to describe the assertor.
<earl:Person rdf:about="http://example.org/#assertor123">
<earl:name>Bob B. Bobbington</earl:name>
<earl:email rdf:resource="mailto:bob@example.org"/>
</earl:Person>
The class of things that have been evaluated. It needs to be qualified
with some type of information in order to make it unambiguous. You may use an
unambiguous property, or unambiguous constellation of properties.
- Tool
- A tool. Most likely a piece of software such as an authoring tool, or
evaluation and repair tool.
- UserAgent
- A piece of software used to access information on the World Wide
Web.
- WebContent
- Information on the World Wide Web.
The subject in the following example is Web content and therefore
WebContent (a subclass of TestSubject) is used to describe the test
subject.
<earl:WebContent rdf:about="http://example.org/#someID02495">
<earl:reprOf rdf:resource="http://www.w3.org/" />
<earl:date>2001-05-17T23:07:35Z</earl:date>
</earl:WebContent>
The result of the test.
- validity
- confidence
- message
- cannotTell
- fail
- notApplicable
- notTested
- pass
The following example shows the validity, confidence, and message
properties applied to a result:
<earl:result rdf:parseType="Resource">
<earl:validity rdf:resource="&earl;fail"/>
<earl:confidence rdf:resource="&earl;high"/>
<earl:message>malformed element in line 23</earl:message>
</earl:result>
A TestCase is a resource that another resource is validated against - a
test that can either be passed or failed. This may in fact include many
things - validation classes, code test cases, or more subjective guidelines
such as WCAG 1.0 [WCAG10].
<earl:Testcase rdf:about="http://example.org/#tc-1">
<earl:testId rdf:resource="http://example.org/MyTestCaseThingy-1" />
</earl:Testcase>
For earl:assertedBy(y,x), the assertor (x) asserts the assertion (y).
- Domain: Assertion
- Range: Assertor
The result of the test. Refer to TestResult for possible values.
- Domain: Assertion
- Range: TestResult
That which is being tested.
- Domain: Assertion
- Range: TestSubject
The test that the test subject is put to.
- Domain: Assertion
- Range: TestCase
mode indicates if the test was conducted manually, automatically, or
derived from other test results (heuristic).
- Domain: Assertion
- Range: TestMode
The EARL vocabulary, and to some extent the EARL model, are extensible;
that is, they allow to add new terms or otherwise modify them to fit your own
specific application demands more closely. The level of specificity in EARL
is often not sufficient enough to avoid extending EARL. Thus, EARL was built
to be extended. You may think of it as a core set of structures and terms.
Refer to a document written by Tim Berners-Lee in 1998 called,
"Evolvability." [EVOLVE]
Your application requires a severity property on TestResults to express
that something "passes completely", or "passes with unrelated errors." These
correspond to "pass, severity 100%" and "pass, severity 90%." One way to
accomplish this is to create a new class called "SeverityLevel," a property
called "severity" and a few instances of the SeverityLevel class.
First, declare your new namespace (you will also need to declare the EARL,
RDF, and RDFS namespaces). In an RDF Schema [RDF-Schema] this would look like:
<!DOCTYPE rdf:RDF [[
<!ENTITY my-ext 'http://example.org/ext#'>
]]>
<rdf:RDF ...
xmlns:my-ext="&my-ext;">
Then, define the SeverityLevel Class:
<rdfs:Class rdf:about="my-ext:SeverityLevel"
rdfs:label="SeverityLevel">
<rdfs:subClassOf rdf:resource=&rdfs;Resource"/>
</rdfs:Class>
Next, define a property called "severity" to be used on TestResult:
<rdf:Property rdf:about="&earl;severity"
rdfs:label="severity">
<rdfs:domain rdf:resource="&earl;TestResult"/>
<rdfs:range rdf:resource="&earl;SeverityLevel"/>
</rdf:Property>
To define instances of the class:
<my-ext:SeverityLevel
rdf:about="&my-ext;passCompletely"
rdfs:label="passCompletely">
<rdfs:comment>This means the test passes with
severity of 100%</rdfs:comment>
</my-ext:SeverityLevel>
<my-ext:SeverityLevel
rdf:about="&my-ext;passWithUnrelatedErrors"
rdfs:label="passWithUnrelatedErrors">
<rdfs:comment>This means the test passes with
severity of 90%</rdfs:comment>
</my-ext:SeverityLevel>
Finally, use the new property mixed with other EARL properties.
[Editor's note: (from SBP's notes from 9 December 2001. are these still
applicable?) How would EARL agents handle this? If they were fully
RDF/SW-ized, then they'd be able to handle it just fine. We could offer EARL
filters as a Web service, but that would introduce a certain amount of
centralization. Deduct and spit out EARL 1.0 could be useful.
In other words, conventionally, if you come across the property "x", and
you don't understand it, then you don't understand it. With rules on the SW,
you can say "well, this is an EARL result property, with a validity of pass,
so it's roughly analogous to pass" - without having to worry about the exact
semantics. It's partial understanding, but it's very difficult for anyone who
is just trying to make EARL work on the basic level. The problem with
powerful languages is that they need a certain level of power in the tools
that grok them, and although that level is not all that great, it's still
great enough to deter some.]
[Editor's note: These used to be in the "user scenarios" section at the
top of the document, but I've moved them back here because that earlier
section was getting too long and I wanted to focus the reader on the most
common scenarios. It's good info, so I didn't want to lose it, but don't
think it is needed for the general understanding and application of EARL.]
[Editor's note: for each user scenario described above, create a sample
piece of EARL.]
Scenario: A tester evaluating a company's Web site uses a variety of
testing tools to discover possible bugs on the site.
"power developer" that uses programming tools to produce site, not a
WYSIWYG editor commonly used by less technical folk. QA folk use different
tools than developers.
queries:
- something that machine says or person?
- group report where need to be fixed (developer vs content creator)
Scenario: test subjects evaluating sites - usability testing. e.g.
together people make an assessment about alt-text.
[Editor's note: Does the schema contain enough info about test
environment? ]
queries:
- Is this page accessible for someone who is deaf? blind? both? (does it
meet the tests that meet the user's needs)
[Editor's note: We still have an outstanding issue with how to group tests
(not yet defined in the schema, although discussed).]
Scenario: Person derives conformance claim from test data. In other words,
they derive EARL statements from EARL statements by asking the following
questions:
- What is the end result?
- If find a faulty test, where did this result come from?
[Editor's note: Traceability of heuristically derived results is not yet
defined in the schema.]
Scenario: test results across semester.
queries
- have 2 students been getting the same grades?
- who passed/failed?
- how does this class's grades compare with another group (previous
year's, other classes of this subject, etc.)
Scenario: Need to meet a new set of requirements. Query existing results,
using a new expression of how to derive a result, to see if there is any new
testing missing
- combining individual tests into suites. [Editor's note: CMN needs to
clarify this point.]
- is there a use case for comparing test suites - the success or use of
test suites.
Scenario: A robot tries to grab contact info from Web pages. It tracks
which pages fail and which tools fail. (ala Nick Gibbons scenario)
EARL is the result of the excellent work of Giorgio Brajnik, Dan Brickley,
Daniel Dardailler, Nick Gibbins, Al Gilman, Nadia Heninger, Ian Hickson,
Leonard Kasday, Nick Kew, Jim Ley, William Loughborough, John Lutts, Charles
McCathieNevile, Libby Miller, Tom Martin, Sean B. Palmer, Dave Pawson, Eric
Prud'hommeaux, Chris Ridpath, Aaron Swartz, and Rob Yonaitis.
Sean B. Palmer produced "EARL Background Material" [EARL-Background] to create a better
understanding of the history and nature of EARL.
- [EARL-Background]
- EARL Background Material -
Sean B. Palmer (2001)
- [EARL-Imps]
- EARL Implementations
- [EVOLVE]
- Evolvability - Tim Berners-Lee
(1998)
- [RDF]
- Resource Description
Framework (RDF) Model and Syntax Specification - Ora Lassila and
Ralph R. Swick. (1999) W3C Recommendation.
- [RDF-PRIMER]
- RDF Primer - Frank Manola and Eric
Miller (2002) W3C Working Draft.
- [RDF-Schema]
- RDF Vocabulary Description Language 1.0:
RDF Schema - Dan Brickley, R.V. Guha. (2002) W3C Working Draft.
- [RDF-XML-DIFFS]
- Why RDF model is different from
the XML model - Tim Berners-Lee (1998)
- [WCAG10]
- Web Content Accessibility Guidelines 1.0 -
Wendy Chisholm, Gregg Vanderheiden, Ian Jacobs. (1999) W3C
Recommendation.
EARL 1.0 Schema available in XML RDF and n3. [Editor's note: need to
publish the schema in rdf and link it.]
<?xml version='1.0' encoding='ISO-8859-1'?>
<!DOCTYPE rdf:RDF [
<!ENTITY earl 'http://www.w3.org/WAI/ER/EARL/nmg-strawman#'>
<!ENTITY rdf 'http://www.w3.org/1999/02/22-rdf-syntax-ns#'>
<!ENTITY rdfs 'http://www.w3.org/TR/1999/PR-rdf-schema-19990303#'>
]>
<rdf:RDF xmlns:earl="&earl;"
xmlns:rdf="&rdf;"
xmlns:rdfs="&rdfs;">
<!-- Classes -->
<rdfs:Class rdf:about="&earl;Assertion" rdfs:label="Assertion">
<rdfs:subClassOf rdf:resource="&rdfs;Resource"/>
</rdfs:Class>
<rdfs:Class rdf:about="&earl;Assertor" rdfs:label="Assertor">
<rdfs:subClassOf rdf:resource="&rdfs;Resource"/>
</rdfs:Class>
<rdfs:Class rdf:about="&earl;ConfidenceLevel" rdfs:label="ConfidenceLevel">
<rdfs:subClassOf rdf:resource="&rdfs;Resource"/>
</rdfs:Class>
<rdfs:Class rdf:about="&earl;Platform" rdfs:label="Platform">
<rdfs:subClassOf rdf:resource="&rdfs;Resource"/>
</rdfs:Class>
<rdfs:Class rdf:about="&earl;TestCase" rdfs:label="TestCase">
<rdfs:subClassOf rdf:resource="&rdfs;Resource"/>
</rdfs:Class>
<rdfs:Class rdf:about="&earl;TestMode" rdfs:label="TestMode">
<rdfs:subClassOf rdf:resource="&rdf;Resource">
</rdfs:Class>
<rdfs:Class rdf:about="&earl;TestResult" rdfs:label="TestResult">
<rdfs:subClassOf rdf:resource="&rdfs;Resource"/>
</rdfs:Class>
<rdfs:Class rdf:about="&earl;TestSubject" rdfs:label="TestSubject">
<rdfs:subClassOf rdf:resource="&rdfs;Resource"/>
</rdfs:Class>
<rdfs:Class rdf:about="&earl;Tool" rdfs:label="Tool">
<rdfs:subClassOf rdf:resource="&earl;TestSubject"/>
</rdfs:Class>
<rdfs:Class rdf:about="&earl;UserAgent" rdfs:label="UserAgent">
<rdfs:subClassOf rdf:resource="&earl;TestSubject"/>
</rdfs:Class>
<rdfs:Class rdf:about="&earl;ValidityLevel" rdfs:label="ValidityLevel">
<rdfs:subClassOf rdf:resource="&rdfs;Resource"/>
</rdfs:Class>
<rdfs:Class rdf:about="&earl;WebContent" rdfs:label="WebContent">
<rdfs:subClassOf rdf:resource="&earl;TestSubject"/>
</rdfs:Class>
<!-- Properties -->
<rdf:Property rdf:about="&earl;assertedBy" rdfs:label="assertedBy">
<rdfs:domain rdf:resource="&earl;Assertion"/>
<rdfs:range rdf:resource="&earl;Assertor"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;confidence" rdfs:label="confidence">
<rdfs:range rdf:resource="&earl;ConfidenceLevel"/>
<rdfs:domain rdf:resource="&earl;TestResult"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;contactInfo" rdfs:label="contactInfo">
<rdfs:range rdf:resource="&rdfs;Resource"/>
<rdfs:domain rdf:resource="&earl;Assertor"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;email" rdfs:label="email">
<rdfs:range rdf:resource="&rdfs;Literal"/>
<rdfs:domain rdf:resource="&earl;Assertor"/>
<rdfs:subPropertyOf rdf:resource="&earl;contactInfo"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;format" rdfs:label="format">
<rdfs:range rdf:resource="&rdfs;Literal"/>
<rdfs:domain rdf:resource="&earl;WebContent"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;message" rdfs:label="message">
<rdfs:range rdf:resource="&rdfs;Literal"/>
<rdfs:domain rdf:resource="&earl;TestResult"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;mode" rdfs:label="mode">
<rdfs:range rdf:resource="&earl;TestMode"/>
<rdfs:domain rdf:resource="&earl;Assertion"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;name" rdfs:label="name">
<rdfs:range rdf:resource="&rdfs;Literal"/>
<rdfs:domain rdf:resource="&earl;Assertor"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;platform" rdfs:label="platform">
<rdfs:range rdf:resource="&rdfs;Resource"/>
<rdfs:domain rdf:resource="&earl;Assertor"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;reprOf" rdfs:label="reprOf">
<rdfs:range rdf:resource="&rdfs;Resource"/>
<rdfs:domain rdf:resource="&earl;WebContent"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;result" rdfs:label="result">
<rdfs:domain rdf:resource="&earl;Assertion"/>
<rdfs:range rdf:resource="&earl;TestResult"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;subject" rdfs:label="subject">
<rdfs:domain rdf:resource="&earl;Assertion"/>
<rdfs:range rdf:resource="&earl;TestSubject"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;testcase" rdfs:label="testcase">
<rdfs:domain rdf:resource="&earl;Assertion"/>
<rdfs:range rdf:resource="&earl;TestCase"/>
</rdf:Property>
<rdf:Property rdf:about="&earl;validity" rdfs:label="validity">
<rdfs:domain rdf:resource="&earl;TestResult"/>
<rdfs:range rdf:resource="&earl;ValidityLevel"/>
</rdf:Property>
<!-- Instances of Classes -->
<earl:TestMode rdf:about="&earl;manual" rdfs:label="manual">
<rdfs:comment>The test was performed by a human.</rdfs:comment>
</earl:TestMode>
<earl:TestMode rdf:about="&earl;heuristic" rdfs:label="heuristic">
<rdfs:comment>The test is derived from other test results.</rdfs:comment>
</earl:TestMode>
<earl:TestMode rdf:about="&earl;automatic" rdfs:label="automatic">
<rdfs:comment>The test was performed by a tool or machine.</rdfs:comment>
</earl:TestMode>
<earl:ValidityLevel rdf:about="&earl;cannotTell" rdfs:label="cannotTell"/>
<earl:ValidityLevel rdf:about="&earl;fail" rdfs:label="fail"/>
<earl:ConfidenceLevel rdf:about="&earl;high" rdfs:label="high"/>
<earl:ConfidenceLevel rdf:about="&earl;low" rdfs:label="low"/>
<earl:ConfidenceLevel rdf:about="&earl;medium" rdfs:label="medium"/>
<earl:ValidityLevel rdf:about="&earl;notApplicable" rdfs:label="notApplicable"/>
<earl:ValidityLevel rdf:about="&earl;notTested" rdfs:label="notTested"/>
<earl:ValidityLevel rdf:about="&earl;pass" rdfs:label="pass"/>
</rdf:RDF>
[Editor's note: need to complete this section.]
- 1.0 uses properties instead of reification
- got rid of some properties and classes
- added some properties and classes
{kind=link}