This PRISM Introduction provides an overview of the PRISM Specification Package.
Status of this document
This section describes the status of this document at the
time of its publication. Other documents may supersede this document. A
list of current W3C publications can be found in the W3C technical reports index at https://www.w3.org/TR/.
By publishing this document, W3C acknowledges that the Submitting Members
have made a formal Submission request to W3C for discussion.
Publication of this document by W3C indicates no endorsement of its
content by W3C, nor that W3C has, is, or will be allocating any
resources to the issues addressed by it. This document is not the
product of a chartered W3C group, but is published as potential input
to the W3C Process.
A W3C Team Comment has been published in conjunction
with this Member Submission.
Publication of acknowledged Member Submissions at the W3C site is one
of the benefits of W3C
Membership. Please consult the requirements associated with
Member Submissions of section
3.3 of the W3C Patent Policy. Please consult the complete
list of acknowledged W3C Member
Submissions.
The following terms and phrases are used throughout this document in
the sense listed below. Readers will most likely not fully understand
these definitions without also reading through the remainder of the
PRISM documentation package.
Authority File
One of the forms of a controlled vocabulary, in which a list of
uniquely identified entities, such as companies, authors, countries,
employees, or customers, is maintained over time.
Content
Content, as it is used in the PRISM Specification, is a
non-normative term assumed to be a resource or a collection of
resources.
Content Provider
A publisher, business, portal site, person or entity making content available in any medium.
Controlled Vocabulary
A list of uniquely identified terms with known meaning. The list
itself has a defined maintenance procedure and restricted update access.
For example, an employee database is one type of controlled vocabulary.
The list of terms (staff names) is uniquely identified (employee
number) and is maintained by a known procedure and staff (the HR
department). There are two major types of controlled vocabularies -
authority files and taxonomies.
Metadata
Information about a resource. In this specification, metadata is expressed as one or more properties.
Property
A field with a defined meaning used to describe a resource. A
property plus the value of that property for a specific resource is a
statement about that resource. [W3C-RDF]
Resource
Text, graphics, sound, video or anything else that can be
identified with a URI or other identification scheme. The PRISM
Specification uses this term because it is not used in casual writing,
so it can be used unambiguously in the PRISM Specification.
Statement
An assertion about a resource. Typically, statements assert that
relations such as "part of" exist between resources, or that a resource
has a particular value of a property, such as a "format" of
"text/html.".
Taxonomy
One of the forms of a controlled vocabulary, in which the
uniquely identified concepts are arranged in a hierarchy that represents
the relations between more specific and more general concepts.
This document is entirely non-normative. It provides an introduction
and tutorial overview of the PRISM Specification. Despite being
non-normative, there are occasional statements using the key words MUST,
SHOULD, MAY, etc. Those statements will be repeated in other, normative
documents.
This document is divided into four general sections. The first
section, About PRISM 3.0 provides a general overview and establishes
some of the context for the PRISM 3.0 Specification. The second section
provides an overview of the PRISM Specification. The third section
provides an accounting of the documentation structure for PRISM 3.0.
The fourth section provides an overview of the PRISM .Specification with
examples. The fifth, sixth and seventh sections document the
recommended PRISM namespaces, listings of domain-specific metadata
vocabularies, controlled vocabularies and a bibliography.
The PRISM Documentation Package has been reorganized and some
specifications renamed to more accurately reflect the nature of each
specification module. The PRISM documentation package includes the
following specifications and documents:
This is the set of documents that outline the prism metadata fields
and values by PRISM metadata category. PRISM has modularized its
metadata specification by namepace so users may pick those modules that
meet their unique business requirements without having to implement the
entire PRISM specification.
Describes the metadata elements contained in the PRISM Metadata
for Images Namespace and other related image namespaces, includes
normative material.
The PRISM Recipe Metadata Specification [PRISMRMS]
Describes the metadata elements contained in the PRISM Recipe
Metadata Namespace (prm:). Includes normative material.
The PRISM Rights Summary Metadata Specification [PRISMRSMS]
Describes the metadata elements contained in the PRISM Rights
Summary Metadata Namespace (prsm:). Includes normative material.
The PRISM Usage Rights Metadata Specification [PRISMURMS]
Describes the metadata elements contained in the PRISM Usage
Rights Namespace; includes normative material. This namespace will
supersede elements in both the prism: and prl: namespaces in version 3.0
of the specification.
Some elements from PUR are referenced from the newer, more
comprehensive PRISM Rights Summary Metadata Specification [PRISMRSMS].
This module documents the PRISM Markup Elements and Attributes for
use with the PRISM Aggregator Message (PAM) and other aggregator
messages. This set of documents includes:
Describes the XML elements and attributes used to encode the
PRISM Aggregator Message from both the pam: and pim: namespaces;
includes normative material.
The PRISM PAM Markup for Web Content Specification [PRISMPAMWMS]
Describes the XML elements and attributes used to encode the
PRISM Aggregator Message for Web Content. This Specification draws
from both the pam: and pim: namespaces and includes normative material.
PAMW is used to automate the harvesting of Web Content so that it may
be sent to aggregators or stored in a publishers PAM-based content
management system.
These modules are new with PRISM 3.0. All controlled
vocabularies and their terms are documented in this publication
set.
Document
Description
The PRISM Controlled Vocabulary Markup Specification [PRISMCVMS]
Describes the metadata fields in the PRISM Controlled Vocabulary
Namespace that can be used to describe a controlled
vocabulary. Actual PRISM controlled vocabularies are now
placed in the PRISM Controlled Vocabularies Specification [PRISMCVS]
The PRISM Controlled Vocabularies Specification [PRISMCVS]
The PRISM Controlled Vocabularies are now documented in this document.
• The Guide to the PRISM Aggregator Message [PAMGUIDE] documents the PRISM Aggregator Message (PAM), an XML-based application of PRISM.
• The Guide to the PRISM Aggregator Message for Web Content [PAMWGUIDE] documents the PRISM Aggregator Message (PAM), an XML-based application of PRISM.
• The Guide to the PSV Aggregator/Distributor Message Package [PAMPGUIDE]
documents how to use the PRISM metadata fields and pamP XML messaging
tags to deliver content to content aggregators/distributors. The
Guide documents the pamP XML message structure and provides the pamP XSD
and document samples.
• The Guide to PRISM Contract Management [CONTRACTSGUIDE]
documents an XML-based PRISM contract management model. The Guide
is accompanied by an XSD that can be used as the basis for developing a
contract management system that interfaces with the PRISM Rights
Summary to populate ODRL policy statements.
• The Guide to PRISM Metadata for Images [IMAGEGUIDE]
documents an XML-based PRISM Profile 1 application for the expression
of the structure and use of PRISM Metadata for Images and can be used as
the basis for developing an image management system based on PRISM
Metadata for Images and for implementing PMI in XML.
• The Guide to PRISM Recipe Metadata and XML Encoding [RECIPEGUIDE]
documents the XML-based recipe model for developing a recipe database,
for tagging a wide variety of recipes in XML and for tagging recipes
within a PAM Message.
• The Guide to PRISM Usage Rights [RIGHTSGUIDE]
documents an XML-based PRISM application for the expression of PRISM
Usage Rights. The Guide is accompanied by an XSD that can be used
as the basis for developing a digital rights management system based on
PRISM Usage Rights.
• The PAM to PSV_Guide [PAMPSVGUIDE] documents mappings from PAM XML to PSV XML.
In 2010, Idealliance developed a series of specifications
collectively known as the PRISM Source Vocabulary. The use case
for PSV is to encode semantically rich content for transformation and
delivery to any platform. This Specification is made up of a modular
documentation package that builds on PRISM 3.0 and HTML5. Over
time new modules may be added to the documentation package. The
documentation package for PSV, PRISM Source Vocabulary Specification
Version 1.0 consists of:
The PRISM Source Vocabulary Specification defines semantically
rich for source metadata and content markup that can be transformed and
served to a wide variety of output devices including eReaders, mobile
tablet devices, smart phones and print.
While PRISM is primarily a metadata specification, it also includes
some XML schemas that define encoding of specific kinds of content for
publication and interchange. The PRISM schemas include:
• Contracts_xsd.zip contains a schema that can be used to encode publication contracts.
• Crafts_xsd.zip contains a schema that can be used to encode crafts.
• Image_xsd.zip contains a schema that can be used to encode images.
• PAM_xsd.zip contains a schema that can be used to encode a PRISM aggregator message.
• pamW_xsd.zip contains a schema that can be used to encode a PRISM aggregator message for Web content.
• pamP_xsd.zip contains a schema that can be used to encode a PRISM aggregator/distributor message package.
• PSV_xsd.zip contains a schema that can be used to encode content in PRISM Source Vocabulary.
• Recipe_xsd.zip contains a schema that can be used to encode recipes.
• Rights_xsd.zip contains a schema that can be used to encode usage rights.
PRISM has defined 38 controlled vocabularies using PRISM controlled
vocabulary markup. See The PRISM Controlled Vocabulary Markup
Specification [PRISMCVMS]. All CVs are available in CVs.zip.
The PRISM (Publishing Requirements for Industry Standard Metadata)
Specification defines a set of metadata vocabularies to facilitate
management, aggregating, packaging, styling and delivery of content
across publishing channels and platforms. PRISM provides a
framework for the interchange and preservation of content and metadata, a
collection of elements to describe that content, and a set of
controlled vocabularies listing the values for those elements. PRISM
metadata can be expressed in XML, RDF/XML, or XMP.
The Publishing Requirements for Industry Standard Metadata (PRISM)
specification defines a set of XML metadata vocabularies for
syndicating, aggregating, post-processing and multi-purposing magazine,
news, newsletter, marketing collateral, catalog, mainstream journal
content, online content and feeds. PRISM provides a framework for the
interchange and preservation of content and metadata, a collection of
elements to describe that content, and a set of controlled vocabularies
listing the values for those elements.
Metadata is an exceedingly broad category of information covering
everything from an article's country of origin to the fonts used in its
layout. PRISM's scope is driven by the needs of publishers to receive,
track, and deliver multi-part content. The focus is on additional uses
for the content, so metadata concerning the content's appearance is
outside PRISM's scope. The Working Group focused on metadata for:
• General-purpose description of a resources on a delivery platform basis
• Specification of a resource’s relationships to other resources
• Definition of intellectual property rights and usage based on rights
• Expressing inline metadata (that is, markup within the resource itself)
Like the Information and Content Exchange protocol [ICE],
PRISM is designed be straightforward to use over the Internet, support a
wide variety of applications, not constrain data formats of the
resources being described, conform to a specific XML syntax, and be
constrained to practical and implementable mechanisms.
The PRISM group’s emphasis on implementable mechanisms is key to
many of the choices made in this specification. For example, the
elements provided for describing intellectual property rights are not
intended to be a complete, general-purpose rights language that will let
unknown parties do business with complete confidence and settle their
accounts with micro-transactions. Instead, it provides elements needed
for the most common cases encountered when one publisher of information
wants to reuse material from another. Its focus is on reducing the cost
of compliance with existing contracts that have been negotiated between a
publisher and their business partners.
Because there are already so many standards, the emphasis of the
PRISM group was to recommend a coherent set of existing standards. New
elements were only to be defined as needed to extend that set of
standards to meet the specific needs of the magazine publishing
scenarios. This section discusses the standards PRISM is built upon, how
it relates to some other well-known standards, and how subsequent
standards can build upon this specification.
PRISM metadata documents are an application of XML [W3C-XML].
Basic concepts in PRISM are represented using the element/attribute
markup model of XML. The PRISM Specification makes use of additional XML
concepts, such as namespaces[W3C-XML-NS].
The Resource Description Framework [W3C-RDF]
defines a model and XML syntax to represent and transport metadata.
PRISM profile two compliance uses a simplified profile of RDF for its
metadata framework. Thus, PRISM profile #2 compliant applications will
generate metadata that can be processed by RDF processing applications.
However, the converse is not necessarily true. The behavior of
applications processing input that does not conform to this
specification is not defined.
A digital object identifier (or DOI) is a permanent identifier given
to a document, which is not related to its current location. A typical
use of a DOI is to give a scientific paper or article a unique
identifying number that can be used by anyone to locate details of the
paper, and possibly an electronic copy. In this way it functions as a
permanent link. Unlike the URL system used on the Internet for web
pages, the DOI does not change over time, even if the article is
relocated (provided the DOI resolution system is updated when the change
of location is made). The International DOI Foundation (IDF), a
non-profit organization created in 1998, is the governance body of the
DOI System, which safeguards all intellectual property rights relating
to the DOI System. The DOI® Handbook [DOI-HB] (Version 4.4.1, released 5 October 2006) is the primary source of information about the DOI® System.
It discusses the components and operation of the system, and provides a
central point of reference for technical information. The Handbook is
updated regularly.
The Dublin Core Metadata Initiative [DCMI]
established a set of metadata to describe electronic resources in a
manner similar to a library card catalog. The Dublin Core includes 15
general elements designed to characterize resources. PRISM uses the
Dublin Core and its relation types as the foundation for its metadata.
PRISM also recommends practices for using the Dublin Core vocabulary. In
addition, Dublin Core has developed an additional metadata set called
Dublin Core Terms. PRISM uses elements from this metadata set as deemed
appropriate by the Working Group.
NewsML [IPTC-NEWSML]
is a specification from the International Press Telecommunications
Council (IPTC) aimed at the transmission of news stories and the
automation of newswire services. PRISM focuses on describing content and
how it may be reused. While there is some overlap between the two
standards, PRISM and NewsML are largely complementary. PRISM’s
controlled vocabularies have been specified in such a way that they can
be used in NewsML. PRISM Profile #1 compliance permits the incorporation
of PRISM elements into NewsML, should the IPTC elect to do so. The
PRISM Working Group and the IPTC are working together to investigate a
common format and metadata vocabulary to satisfy the needs of the
members of both organizations.
NITF [IPTC-NITF]
is another IPTC specification. NITF provides a DTD designed to mark up
news feeds. PRISM is a set of metadata vocabularies designed to describe
magazine, newsletter and journal based resources and their
relationships to other resources. While there is some overlap between
NITF and PRISM, they are designed for different types of content. PRISM
is more applicable to magazine, newsletter and journal based
content.
A Working Group of the IDEAlliance nextPub Initiative has developed
the new PRISM Source Vocabulary Specification that defines XML elements
and attributes in the psv: namespace to encode semantically rich source
content. Metadata fields and values used in this specification are
drawn from the IDEAlliance PRISM 3.0 Metadata and Controlled Vocabulary
Specifications. Content encoding is based on HTML5.
The Information and Content Exchange protocol manages and automates
syndication relationships, data transfer, and results analysis. PRISM
complements ICE by providing an industry-standard vocabulary to automate
content reuse and syndication processes. To quote from the ICE
specification [ICE]:
Reusing and redistributing information and content from one Web site
to another is an ad hoc and expensive process. The expense derives from
two different types of problem:
• Before successfully sharing
and reusing information, both ends need a common vocabulary.
• Before successfully
transferring any data and managing the relationship, both ends need a
common protocol and management model.
Successful content syndication requires solving both halves of this puzzle.
Thus, there is a natural synergy between ICE and PRISM. ICE provides
the protocol for syndication processes and PRISM provides a description
of the resource being syndicated, which can be used to personalize the
delivery of content to tightly-focused target markets.
RSS (RDF Site Summary) 1.0 [RSS] is a lightweight format for
syndication and descriptive metadata. Like PRISM, RSS is an XML
application, conforms to the W3C's RDF Specification and is extensible
via XML-namespaces and/or RDF based modularization. The RSS-WG is
currently developing and standardizing new modules.
The primary application of RSS is as a very lightweight syndication
protocol for distributing headlines and links. It is easy to implement,
but does not offer the syndication management and delivery confirmation
features of ICE.
XMP [XMP]
is an open, extensible framework developed by Adobe Systems to enable
capturing and carrying metadata within a digital asset throughout the
publishing workflow. XMP is based on the same standards upon which PRISM
is based, i.e. XML and RDF. As such, XMP is one viable option for
implementing PRISM metadata across assets with different media formats.
However, the XMP subset of RDF is significantly different from the PRISM
RDF subset. Therefore, PRISM Profile #3 has been added to enable
PRISM/XMP compliant implementations.
Wherever possible the metadata fields defined for advertising are
based on the Ghent Work Group (GWG) ad ticket V1.2 metadata fields,
which in turn are based on fields defined for the industry by
AdsML. It is important to note that the PRISM advertising metadata
specifications have been driven by North American publishers to meet
their specific needs. If unique fields are required for this
market, these fields will be brought to GWG for inclusion on the next
major revision of their Ad Ticket specification, V2.0. Mapping
from this specification to GWG is included in the documentation for each
field.
Ad-ID has participated in the development of the PRISM Advertising
Metadata Specification and a mapping for fields in this specification to
fields included in the Ad-ID specification is included in the
documentation for each field.
It is important to note that Ad-ID describes the advertisement to be
placed but not about the actual placement. So it makes sense that
no mappings are available that describe the ad placement.
PRISM defines XML metadata fields and controlled vocabularies in
domain-specific specifications. The metadata fields are grouped by
function and modularized by namespaces. As use of PRISM metadata
evolves, new metadata sets in new namespaces will be added.
Candidate metadata specifications for the next version of PRISM include
metadata for advertising, metadata for short-form video, metadata for
projects from crafts, quilting, knitting to home repair, metadata for
marketing and product description and metadata to describe the
demographic audience for both content and advertising.
In addition to defining metadata vocabularies, the PRISM Working
Group may define a specific use case and develop an XML tag set to code
both content and metadata fields may be developed. Currently PRISM
has developed the PRISM Aggregator Message tag set, a tag set to define
a controlled vocabulary, a usage rights tag set and a tag set for
recipes. The nextPub initiative has also defined the PRISM Source
Vocabulary (PSV) tag set based on PRISM. Other applications of
PRISM, requiring the development of an XML tag set may be defined in the
future.
Extensible Markup Language (XML) [W3C-XML]
is a W3C data encoding language. XML can be used to describe metadata
as elements with attributes and element content. When using XML by
itself, relationships between metadata elements can only be expressed
through the order, frequency and hierarchy of the elements and their
attributes. Well-formed PRISM XML provides the simplest model for
encoding PRISM metadata.
PRISM Profile 1 simply requires the use of well-formed XML. If a
schema is added, as in the case of the PRISM Aggregator Message, the
model becomes constrained in ways well-formed XML is not. The XML
expression of PRISM along with best practice recommendations are
documented in Section 4 of this document.
The Resource Description Framework (RDF) is a W3C language [W3C-RDF]
for representing information about resources in the World Wide Web but
can be used to represent information about any resource that can be
identified with a URI, or Uniform Resource Identifier. It is
particularly useful for representing metadata about resources, such as
the title, author modification date of a digital asset and copyright and
licensing information for a resource. RDF describes resources in terms
of simple properties and property values.
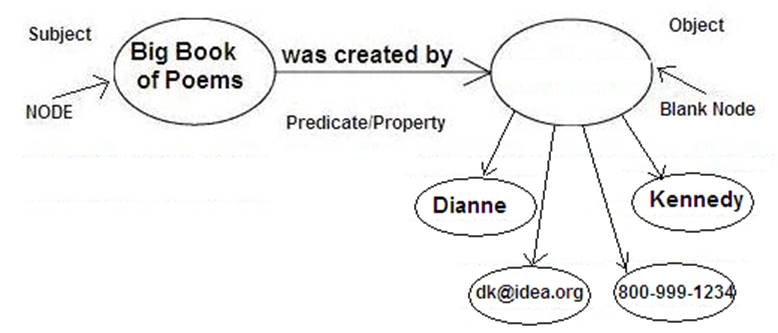
The underlying structure of any expression in RDF is a triple
consisting of a Subject, a Predicate and an Object. A set of such
triples is called an RDF graph. Figure 2.1 shows a node and directed-arc
diagram of a single triple.
Figure 2.1 RDF Graph
The Predicate specifies a characteristic or property of the Subject.
The Object provides the value for the property. For example: The “Big
Book of Poems” was authored/created by “D. Kennedy”. Here the Subject is
the Big Book of Poems. The Predicate or Property we are describing is
“was created by” and the value of the property, or Object, is “D.
Kennedy”. See Figure 2.2.
Figure2.2 Sample RDF Graph
Subject nodes and predicates must be URIs. An object node may be a
URI reference, a literal, or blank (having no separate form of object
identification itself).
When expressing RDF in XML, we express the nodes, properties and
property values with XML elements and attributes. When using XML to
represent RDF triples, there is far greater flexibility in tagging than
we are used to when we define XML elements and attributes with an XML
DTD. RDF is designed to represent information in a minimally
constraining, flexible way. The impact of combining XML with RDF is that
several XML representation models can exist for the same RDF Graph. In
other words, the content model and attributes can vary in a way that is
not easy to define using an XML DTD. This is a bit foreign to those from
a strict XML world where elements have one fixed content model and
attribute definition. And it makes writing documentation for XML/RDF
elements and attributes quite challenging.
Consider the following options that RDF offers when expressed as XML:
A URI reference, a literal, or a hierarchy of elements can be used
to indicate what a node represents or is used to give the node a value.
The tagging of the graph in XML differs depending upon our model for
providing Node property values:
<dc:description>Browse our catalog of desktop and
notebook computers to find one just right for you.</dc:description>
Example 2.1 Literal provides Node value for the dc:description property
RDF allows property values to be represented by a literal or by a
URI. Each representation has different characteristics, so it is
important to know about those characteristics in order to make the right
design choice. The advantage of URIs over literals is their lack of
ambiguity. Literals however are often simpler and more convenient. But
either option is valid and is documented in the PRISM Specification.
To complicate matters even further, there are different types of
literals in RDF. These must be coded differently in XML and an RDF
processor will handle them differently. To start with, literals may be
plain or typed:
A plain literal is a string combined with an
optional language tag (xml:lang). This may be used for plain text in a
natural language. As recommended in the RDF formal semantics [RDF-SEMANTICS],
these plain literals are self-denoting. This means that we do not have
to specify a plain literal to an RDF processor; it simply assumes it is
dealing with this literal type.
A typed literal is a string combined with a
datatype URI. It denotes the member of the identified datatype's value
space obtained by applying the lexical-to-value mapping to the literal
string.
Datatypes are used by RDF in the representation of values such as
integers, floating point numbers and dates. There is no built-in concept
of numbers or dates or other common values in RDF. Rather, RDF defers
to datatypes that are defined separately, and identified with URI
references. The predefined XML Schema datatypes [XML-SCHEMA2] are widely used for this purpose.
Some literals contain XML markup. XML literals is a
string combined with a rdf:parseType=”literal” attribute that indicates
a fragment of XML is embedded. This signals the RDF processor to handle
the literal as an XML fragment.
A third kind of node is known as a blank node. This
is a node that does not have properties specified with a URI or a
literal, but is made up of other elements that themselves have
properties. See Figure 1.3.
Figure 2.3 RDF Graph with a Blank Node
A blank node must have the rdf:parseType="Resource" attribute on the
containing property element to turn the property element into a
property-and-node element, which can itself have both property elements
and property attributes.
Example 2.4 Blank Node with rdf:parseType=”Resource” attribute
While a blank node can occur anywhere within PRISM metadata fields,
some elements from the PRISM subset of Dublin Core are more likely to be
modeled as blank nodes than others. These elements are listed in Table
2.1.
Name
Identifier
Comment
Description
dc:description
The description may be modeled as being made up of a number of
other elements from other namespaces. For example, one might model
dc:description using dc:abstract and dc:educationLevel.
Rights
dc:rights
Dublin Core Rights may be modeled as being made up of a number
of other elements from other name spaces. For example, one might model
dc:rights using elements from the prism: namespace.
Table 2.1 Possible Blank Nodes from prism: Namespace
There is often a need to describe groups of things
as a property value. If the “Big Poetry Book” was created by several
authors, how could we indicate that? RDF provides several predefined
(built-in) types and properties that can be used to describe a group of
property values. XMP [XMP]
uses these mechanisms when multiple field values are to be entered. If
there are multiple values for a metadata field for the resource PRISM
recommends listing the multiple values inside a single PRISM element
using the RDF “Bag,” “Alt” or “Seq” containers to be compatible with
XMP.
First, RDF provides a container vocabulary consisting of three predefined types (together with some associated predefined properties). A container is a resource that contains a group of values. Containers include:
A Bag (a resource having type rdf:Bag) represents a group of
property values where there is no significance to the order of the
members. A Bag might be used to describe a group of authors in which the
order of entry or processing does not matter.
A SequenceorSeq
(a resource having type rdf:Seq) represents a group of property values
where the order of the members is significant. For example, a Sequence
might be used to describe a group that must be maintained in
alphabetical order.
An AlternativeorAlt(a resource having type rdf:Alt) represents a group of property values that are alternatives (typically for a single value of a property). For example, an Alt might be used to describe alternative names for an author.
The members of the container can be described by defining a container membership property for each member. These container membership properties may have names of the form rdf:_n, where n
is a decimal integer greater than zero, with no leading zeros, e.g.,
rdf:_1, rdf:_2, rdf:_3, and so on, and are used specifically for
describing the members of containers. Or the container membership
properties may have names of the form rdf:li (list item) for the
convenience of not having to explicitly number each membership property.
Grouped Property Values are not used in any examples within this
document. Note, however, that these RDF structures may be used with
metadata fields defined for the dc: namespace. See Example 2.5.
XML/RDF content and attribute models are defined with keywords in
Table 2.2 for use in documenting the XML/RDF Elements and Attributes
within PRISM.
Representation
Definition
URI Resource
This specifies that the property element (that is, the element
specifying a particular property of the subject) is EMPTY and that the
value is specified using a URI Resource attribute value.
Authority Reference
This specifies that the property value is specified using a kind
of URI Reference where the attribute, “rdf:resource,” has a value that
is a URI referring to a term in a controlled vocabulary.
Resource Reference
This specifies the requirement of the attribute, “rdf:resource,”
whose value is a URI reference to a resource. The set of Authority
References is a subset of the set of Resource References.
Plain Literal
This specifies that a plain literal will be used to provide the property value within an element.
Enumerated Literal
This specifies that a plain literal with specifically enumerated
values will be used to provide the property value within an element.
Note that RDF does not support the concept of an enumerated literal, but
XSD, RNG, and DTD attribute specifications do.
XML Literal
This specifies that an XML literal content model will be used to
specify the property value within an element. In this case, the
rdf:parseType must be specified as “Literal.”
Typed Literal
This specifies that a typed literal is being use to specify the
property value within an element. The attribute rdf:datatype must be
specified to indicate the datatype of the element content.
Resource Node
This specifies that the property element contains other property
element nodes. The attribute rdf:parseType must be specified to be
“Resource”.
Table 2.2 Keywords for XML/RDF Element and Attribute Definitions
The Extensible Metadata Platform [XMP],
developed by Adobe Systems and fostered by the open industry XMP-Open
initiative of IDEAlliance provides for a unique implementation of XML
and RDF. The profile of RDF specified within the XMP Specification
differs in some ways from the RDF profile recommended by PRISM. But
because XMP provides for an implementation for embedding RDF/XML
metadata into a wide variety of multimedia objects, PRISM adopted XMP as
a third compliance profile in 2007. XMP provides the unique ability to
facilitate PRISM implementation in the multimedia environment. XMP
fields are documented as PRISM Profile three in Section 4 of this
document.
An XMP schema is a set of properties. Each schema is identified by means of a namespace (which
follows the usage of XMLnamespaces) to avoid conflict between
properties in different schemas that have the same name but different
meanings. XMP properties follow the form of prefix:name. For PRISM XMP, the PRISM namespaces can be duplicated directly when constructing XMP schemas; for example, prism:number.
When more than one metadata field is allowed, it is represented in
XMP by an array, or a group of property values. XMP array are expressed
using RDF containers. XMP supports rdf:Bag, rdf:Alt and rdf:Seq. The
container structure should be expressed when developing an XMP schema.
HTML5 [HTML5] is gaining
credibility as a delivery platform for publications, not only on the Web
but as an alternative to the publication apps that we see today on
tablets and smart phones. In addition, EPUB3 is using HTML5 as the
base content format for EPUB3 [EPUB3].
The IDEAlliance nextPub initiative, while basing its PRISM Source
Vocabulary metadata on PRISM 3.0, is implementing an HTML5-compliant
head and body for content encoding.
PAM is the PRISM Aggregator Message documented in the PRISM PAM Guide [PAMGUIDE].
The use case for PAM is to encode magazine articles in XML to deliver
content to aggregators. PAM is an XML tag set built on the foundation of
PRISM metadata and controlled vocabularies. PAM is an application
of PRISM, but PAM and PRISM are not synonymous. PAM is an XML tag
set that uses PRISM metadata for a very specific purpose while PRISM
remains the core specification for metadata and controlled vocabularies.
See Figure 1.4.
PAM is the PRISM Aggregator Message. The use case for PAM was
originally to encode magazine articles in XML to deliver content to
aggregators. While some publishers currently use PAM XML as a
content source, that was not the original intent. Now a new use case, to
encode semantically rich content for transformation and delivery to any
platform has led to the development of a new XML tag set, the PRISM
Source Vocabulary, or PSV. PSV, like PAM is also built on the
foundation of PRISM metadata and controlled vocabularies, But
PSV and PAM are not the same. Each has a very specific use
case and each is a different XML tag set. See Figure 1.4.
Figure 2.4 Relationship between PRISM, PAM and PSV
Redundancy is a necessary consequence of re-using existing work. For
example, when sending PRISM data in an ICE payload, there will be
duplication of PRISM timestamp information and ICE header data.
Therefore, in some cases, the same information will be specified in more
than one place. This is normally a situation to be avoided. On the
other hand, PRISM descriptions need to be able to stand alone, so there
is no way to optimize PRISM’s content for a particular protocol. The
working group decided that redundancy should neither be encouraged nor
avoided.
PRISM does not specify or impose a standard interchange format for
metadata or content. There are many ways to exchange the
descriptions and the content they describe. Developers of such
interchange protocols should consider the following factors:
• Easily separable content: A tool that provides
metadata will need to get at this information quickly. If metadata is
mixed with content, these tools will have to always scan through the
content. On the other hand, it is significantly easier to keep the
metadata associated with the content if it is mixed in (as a header, for
example).
• Reference vs. Inline content: Referencing content is
visually clean, but presents a challenge with access (security, stale
links, etc). Inline requires larger data streams and longer updates in
the face of changes.
• Encoding. Depending on the choice of format, encoding
of the content may be necessary. Extra computation or space will be
needed.
The PRISM Specification deliberately does not address security
issues. The working group decided that the metadata descriptions could
be secured by whatever security provisions might be applied to the
resource(s) being described. PRISM implementations can achieve necessary
security using a variety of methods, including:
Encryption at the transport level, e.g., via SSL, PGP, or S/MIME.
Sending digitally signed content as items within the PRISM
interchange format, with verification performed at the application level
(above PRISM).
The PRISM Specification does not address the issue of rights
enforcement mechanisms. The working group decided that the most
important usage scenarios at this time involved parties with an existing
contractual relationship. This implied that the most important
functionality required from PRISM’s usage rights elements was to reduce
the costs associated with clearing rights, not to enable secure commerce
between unknown parties. Therefore the PRISM Specification provides
mechanisms to describe the most common rights and permissions associated
with content, but does not specify the means to enforce compliance with
those descriptions. Essentially, the goal is to make it less expensive
for honest parties to remain honest, and to let the courts serve their
current enforcement role.
PRISM compliance has been defined to include three forms or "profiles." These profiles are defined in a separate document, PRISM Compliance [PRISMCOMP].
Every effort has been made to edit other sections of the PRISM
documentation package in order to reflect this important change, but it
is possible that language may still exist, in either normative or
non-normative sections, that is in conflict with the new definitions of
compliance. Should the reader encounter any such ambiguity, he or she
may assume that PRISM Compliance is authoritative.
PRISM is described in a set of formal, modularized documents that,
taken together, represent “the PRISM Specification”. Together these
documents comprise the PRISM Documentation Package.
Documents in the PRISM Documentation Package may contain both
normative and non-normative material; normative material describes
element names, attributes, formats, and the contents of elements that is
required in order for content or systems to comply with the PRISM
Specification. Non-normative material explains, expands on, or clarifies
the normative material, but it does not represent requirements for
compliance. Normative material in the PRISM Documentation Package is
explicitly identified as such; any material not identified as normative
can be assumed to be non-normative.
This section provides a non-normative overview of the PRISM
Specification and the types of problems that it addresses. It introduces
the core concepts and many of the elements present in the PRISM
Specification by starting with a basic document with Dublin Core
metadata, then uses PRISM metadata elements to create richer
descriptions of the article.
Although the PRISM Specification contains a large number of elements
and controlled vocabulary terms, most of them are optional. A
PRISM-compliant description can be very simple, or quite elaborate. It
is not necessary to put forth a large amount of effort to apply metadata
to every resource, although it is possible to apply very rich metadata
to resources whose potential for reuse justifies such an investment.
Similarly, PRISM implementations need not support every feature in the
specification. Simple implementations will probably begin with the
elements listed in Section 5, PRISM Namespaces and Elements and only add
more capability as needed.
Note that PRISM provides three forms of compliance, PRISM Profile
#3, PRISM Profile #2 and PRISM Profile #1. The primary difference is
that profile two requires RDF-based structure as shown in virtually all
the examples in this document. Profile #1 does not require the use of
RDF. Profile #3 was added to provide the ability to embed PRISM metadata
fields in resources using XMP.
One of the most common uses of PRISM is to encode both the metadata
of an article and the text of an article in XML using the PRISM
Aggregator Message. Metadata may be specified both within the
header and inline with the text. Note that in addition to encoding
the metadata for the article, PAM also provides XML tagging for the
article content, including associated media.
Wanderlust, a major travel publication, has a business relationship
with travelmongo.com, a travel portal. After Wanderlust goes to press,
they syndicate all of their articles and sidebars to content partners
like travelmongo.com. Like many other publications, Wanderlust does not
have the right to resell all of their images, because some of them have
been obtained from stock photo agencies.
When Wanderlust creates syndication offers, an automated script
searches through the metadata for the issue’s content to ensure that
anything that cannot be syndicated is removed from the syndication offer
with alternatives substituted when possible. Since Wanderlust tags its
content with rights information in a standard way, this process happens
automatically using off-the-shelf software.
Because Wanderlust includes standard descriptive information about
people, products, places and rights when it syndicates its content,
travelmongo.com can populate its content management system with all the
appropriate data so that the articles can be properly classified and
indexed. This reduces the cost to travelmongo.com of subscribing to
third party content and makes content from Wanderlust even more
valuable.
The elements in Dublin Core form the basis for PRISM’s metadata
vocabulary. The simple PRISM metadata document shown in Figure 4.1 uses
some Dublin Core and PRISM elements to describe an article. Note
that this is not using the PAM XML tag set to tag article content, but
is using an XML metadata container to hold PRISM metadata fields
expressed as XML.
Example 4.1: Basic PRISM Description Profile 1, XML
PRISM descriptions are XML documents [W3C-XML],
thus they begin with the standard XML declaration: <?xml
version=”1.0”?>. A character encoding may be given if needed. As
indicated by the two attributes beginning with “xmlns:,” PRISM documents
use the XML Namespace mechanism [W3C-XML-NS].
This allows elements and attributes from different namespaces to be
combined. Namespaces are the primary extension mechanism in PRISM.
PRISM Profile #2 descriptions are compliant with the RDF constraints
on the XML syntax. Thus, they begin with the rdf:RDF element. Because
PRISM obeys the RDF constraints on XML structure, implementations are
guaranteed to correctly parse even unknown elements and attributes.
PRISM-compliant applications MUST NOT throw an error if they encounter
unknown elements or attributes. They are free to delete or preserve such
information, although recommended practice is to retain them and pass
them along. Retaining the information is an architectural principle
which helps new functionality be established in the presence of older
versions of software. See Example 4.2.
Example 4.2: Basic PRISM Description Profile 2, RDF/XML
PRISM recommends that the language of the metadata record, which is
potentially different than the language of the resource it describes, be
explicitly specified with the xml:lang attribute.
PRISM REQUIRES that resources have a unique identifier specified
within the dc:identifier field. Other, more precise identifiers
may also be specified. The dc:identifier may be any unique
identifier including a DOI. In the above PRISM Profile #2 compliant
example, the article is identified by a dc:identifier.
PRISM follows the case convention adopted in the RDF specification.
All elements, attributes and attribute values typically begin with an
initial lower case letter, and compound names have the first letter of
subsequent words capitalized (camel case). Element types may begin with
an uppercase letter when they denote Classes in the sense of the RDF
Schema [W3C-RDFS]. Only
one of the elements in any of the PRISM namespaces, pcv:Descriptor, does
so. PRISM uses a simple naming convention. We avoid abbreviations, use
American English spelling, and make the element names into singular
nouns (or a pseudoNounPhrase, because of the case convention).
In PRISM Profile #2, property values that are URI references are
given as the value of an rdf:resource attribute, as shown in the
dc:identifier element of Example 4.1. Prose or non-URI values are given
as element content, as seen in the dc:description element. This allows
automated systems to easily determine when a property value is a URI
reference.
A common question is "Where do I put PRISM metadata?" There are three common places, depending on the application.
A description of a single resource can be provided as a complete,
standalone, XML document that describes another file. Such a use is
shown in Example 4.1 and Example 4.2.
A description can be included in the content. PRISM metadata can be
included as a header in an XML file or within the XMP envelope [http://wXMP].
Example 4.1 shows a sample of a simple PAM XML file which contains an
embedded PRISM description in the head and PRISM metadata inline within
the content. See Example 4.3.
Descriptions of a number of files can be collected together in a 'manifest'. See Example 4.4.
<dcterms:hasPart>See also additional image(s) in Cover
Description file and Table of Contents of same
issue.</dcterms:hasPart>
</head>
<body>
<p prism:class="deck">
<pim:keyword>Political spouses</pim:keyword> have
traditionally wielded their influence in private. But in this race, all
the rules will have to be rewritten . . .</p>
<p prism:class="box">SPOUSE TALK AT TIME.COM<br/><br/>
To read interviews with the running mates and see photos of the
couples on the trail, visit time.com/spouses. Plus,
<pim:person>Elizabeth Edwards</pim:person> and
<pim:person>Ann Romney</pim:person> speak about campaigning
while battling breast cancer and MS</p>
<p prism:class="pullQuote">'If you're not
moving votes or moving voters ... then you're not using your
time very wisely.' --ELIZABETH EDWARDS</p>
<pam:media>
<pam:mediaTitle>Bill Clinton</pam:mediaTitle>
<pam:credit>BROOKS KRAFT--CORBIS FOR TIME</pam:credit>
<pam:caption>This Clinton campaign again offers
"two for one," but the aspiring First Laddie and
strategist in chief, shown with Hillary in New Hampshire, is trying not
to outshine his wife</pam:caption>
<pam:textDescription>PHOTO</pam:textDescription>
</pam:media>
</body>
</pam:article>
</pam:message>
Example 4.3: Embedding a Description inside the Resource it describes Profile #1, XML
Example 4.2 illustrates another important point. Note that the name
given in the dc:creator element is “Abraham Lincoln,” not the name of
the person who actually created the XML file and entered Lincoln’s
famous line into it. There are applications, such as workflow, quality
assurance, and historical analysis, where it would be important to track
the identity of that individual. However, none of those are problems
PRISM attempts to solve. PRISM’s purpose is to describe information for
exchange and reuse between different systems, but not to say anything
about the internal operations of those systems. The PRISM Working Group
decided that workflow was an internal matter. This focus on a particular
problem allows PRISM descriptions to avoid some thorny issues that more
general specifications must address.
Property values in PRISM may be strings, as shown in Example 4.5, or
may be terms from a controlled vocabulary. Controlled vocabularies are
an important extensibility mechanism. They also enable significantly
more sophisticated applications of the metadata. As an example, consider
the two descriptions below. The first provides a basic, human-readable,
value for the dc:creator element, telling us that the Corfu photograph
was taken by John Peterson. The second description appears harder to
read, because it does not give us John Peterson’s name. Instead, it
makes reference to John Peterson’s entry in the employee database for
Wanderlust.
Example 4.5: Use of a String Value vs. Controlled Vocabulary Reference, Profile #2, XML/RDF
That employee database is an example of a controlled vocabulary – it
keeps a list of terms (employee names). It has a defined and controlled
update procedure (only authorized members of the HR department can
update the employee database, and all changes are logged). It uses a
unique identification scheme (employee numbers) to handle the cases
where the terms are not unique (Wanderlust might have more than one
employee with a name like “John Peterson”). It can associate additional
information with each entry (salary, division, job title, etc.)
The unique identifier is one of the keys to the power behind the use
of controlled vocabularies. If we are given metadata like the first
example, we are limited in the types of displays we can generate. We can
list Wanderlust’s photographs, sorted by title or by author name. By
using the employee database, we can generate those, but also lists
organized by department, job title, salary, etc. We also avoid problems
around searching for common names like “John Smith,” dealing with name
changes such as those due to marriage and divorce, and searching for
items that have been described in other languages. Finally, content
items are easier to reuse if they have been coded with widely adopted
controlled vocabularies, which increases their resale value.
Defining additional vocabularies for specialized uses is a way to
extend descriptive power without resorting to prose explanations. This
makes them far more suited to automatic processing.
PRISM specifies controlled vocabularies of values for some elements
such as prism:genre. Others elements will use controlled vocabularies
created and maintained by third parties, such as the International
Standards Organization (ISO). For example, PRISM recommends the use of
ISO 3166 (Codes for Countries) for specifying the value of elements like
prism:location. Other third-party controlled vocabularies, such as the
Getty Thesaurus of Geographic Names [TGN]
may be used. Site-specific controlled vocabularies, such as from
employee or customer databases, may also be used at the risk of limiting
interoperability.
In Example , 4.6 Identifier rdf:resource="http://wanderlust/content/2357845"/>
PRISM provides a small namespace of XML elements so that new
controlled vocabularies can be defined. For example, Wanderlust might
have prepared an exportable version of its employee database that
contained entries like:
Example 4.6: Providing Custom Controlled Vocabularies
These entries use elements from the Prism Controlled Vocabulary
(PCV) namespace for information important to the controlled vocabulary
nature of the entries – the employee name and the employee ID. The PCV
namespace also includes other elements so it can represent basic
hierarchical taxonomies. The PCV namespace is not intended to be a
complete namespace for the development, representation, and maintenance
of taxonomies and other forms of controlled vocabularies. Other
vocabularies, such as XTM or VocML, may be used for such purposes. As
long as URI references can be used to refer to the terms defined in
these other markup languages, there is no problem is using them in PRISM
descriptions.
The sample descriptions in Example 4.5 also mix in elements from a
hypothetical Human Resources (hr) namespace. Providing that information
enables useful functions, such as sorting the results by division or by
manager, etc. The hr namespace is only an example, provided to show how
elements from other namespaces may be mixed into PRISM descriptions.
Linking to externally-defined controlled vocabularies is a very
useful capability, as indicated by the range of additional views
described in the earlier example. However, external vocabularies do
require lookups in order to fetch that information, which may make
common operations too slow. PRISM also allows portions of a vocabulary
entry to be provided within a description that uses them, similar to a
caching mechanism. For example, the PRISM description of the Corfu photo
can be made more readable, while still allowing all the power that
comes from controlled vocabularies, by providing some of the information
inline. See Example 4.7.
Example 4.7 Providing Human-Readable Controlled Vocabulary References, Profile #2, XML/RDF
This approach uses the pcv:Descriptor element, which is a subclass
of rdf:Descriptor, indicating that the resource is a taxon in a
controlled vocabulary. Notice it also uses the rdf:about attribute,
instead of the rdf:ID attribute, which means that we are describing the
taxon, not defining it. The actual definitions of those terms are
maintained elsewhere. The XML tag set for defining a controlled
vocabulary is defined in the PRISM Controlled Vocabulary
Specification [PRISMCVS].
The PRISM Specification defines a set of vocabularies for use in
characterizing resources. These vocabularies are defined in PRISM
Controlled Vocabularies Specification [PRISMCVS].
It is often necessary to describe how a number of resources are
related. For example, an image can be part of a magazine article. PRISM
defines a number of elements to express relations between resources, so
describing that this image is part of a magazine article can be coded as
illustrated in Example 4.8.
Many different kinds of information are frequently lumped together
as information about the “type” of a resource. The PRISM Specification
breaks out into a number of different components in order to allow for
more precise searches. Controlled vocabularies are provided for each to
make its use easy to understand and the values immediately accessible.
File formats are indicated through the use of Internet Media Types
(aka MIME types [RFC-2046]) in the dc:format element. An example is
<dc:format>application/pdf</dc:format>.
In the early days of PRISM, it could be assumed the unit was an
article of a magazine, journal or other serial publication. Now,
expanding the scope to cover the broader publishing use cases for
nextPub, the unit of content is not so obvious. This is
particularly true when advertising material or book content is added to
the scope.
In order to refine what we mean by the generic term “article,” the
PRISM Content Type Controlled Vocabulary has been developed. Some
content types that describe the nextPub unit of storage include an
advertisement, article, blog entry, book chapter, front cover, masthead,
and even navigation aids.
See the PRISM Controlled Vocabulary Markup Specification [PRISMCVMS] for complete documentation of the new PRISM Content Type Controlled Vocabulary.
In addition, the PRISM Genre Controlled Vocabulary has been enhanced
to refine the intellectual description of core content units. So
if a unit of stored content is type “article” we can refine the
description by specifying that the genre is a cover story that is an
interview, a profile or even a photo essay.
See the PRISM Controlled Vocabulary Markup Specification [PRISMCVMS] for complete documentation of the PRISM Genre Controlled Vocabulary.
Sometimes PRISM metadata is used to describe a collection of content
that is delivered to a distributor or to a platform for display.
The PRISM Aggregation Type Controlled Vocabulary has been added in PRISM
3.0 to define the aggregation or delivery unit of a resource, and is
used to provide values for prism:aggregationType metadata field.
See the PRISM Controlled Vocabulary Markup Specification [PRISMCVMS] for complete documentation of the PRISM Aggregation Type Controlled Vocabulary.
In today’s environment, a single resource may be delivered across
multiple platforms. The content, the format and even the layout may
differ based on the platform. The PRISM Platform Controlled
Vocabulary begins to address the differences in such platforms as:
broadcast
email
eReader
mobile
other
print
recordableMedia
smartPhone
tablet
web
In earlier versions of PRISM, defining the platform was
sufficient. However, today, even the device type for the tablet or
smart phone platform require further customization. So PRISM 3.0
now includes a new prism:device field (no controlled vocabulary) to
refine the prism:platform.
Table 4.1 shows how metadata from each PRISM controlled vocabulary
may be applied to a single resource. It is the intersection of these
values that provide the precise description of the resource.
Resource #1
Resource #2
Resource #3
dc:format
application/pdf
Text/xml+nextPub
Text/xml+pam
prism:contentType
#article
#bookChapter
#article
prism:genre
#pressRelease
#fiction
#feature
prism:aggregationType
#newsLetter
#book
#magazine
prism:platform
#mobile
#print
#tablet
prism:device
iPhone 2S
Samsung Galaxy 7”
Table 4.1: Grid Showing Complete Model for PRISM Resource Metadata
Licensing content for reuse is a major source of revenue for many
publishers. Conforming to licensing agreements is a major cost – not
only to the licensee of the content but also to the licensor. For these
reasons, PRISM has released a new namespace in PRISM 2.1, PRISM Usage
Rights, for the purpose of describing the rights and permissions granted
to the receiver of content. PRISM assumes that the sender and receiver
of content are engaged in a business relationship. It may be a formal
contract or an informal provision of freely redistributable content. One
of the parties may not know the other. The working group explicitly
rejected imposing any requirements on enforcing trusted commerce between
unknown parties. Instead the PRISM Usage Rights Namespace concentrates
on digital rights description and tracking, which can enable rights
management and lower the associated costs.
Rights elements originally defined within the prism: namespace are
duplicated within the new Usage Rights namespace along with new elements
to provide for more robust usage rights description metadata, often
based on a publisher’s unique distribution channels. Usage rights
elements from the prism: namespace will be deprecated when PRISM 3.0 is
published. In addition, the PRISM Rights Language (PRL) namespace will
also be deprecated. Best practice is to begin the transition from
existing PRISM rights elements to the new elements within the pur:
namespace as soon as possible.
In Example 4.9 no rights information is provided for the Corfu
photograph. Does the lack of explicit restrictions mean the sender gives
the receiver permission to do everything with the image? Or does the
lack of explicitly granted rights imply that they can do nothing?
Neither. Instead, we rely on the assumption of an existing business
relation. In the absence of specific information, parties in a PRISM
transaction assume that the normal rules of their specific business
relation apply.
Example 4.10 Citing a Specific Agreement, Profile #2, XML/RDF
Example 4.10 specifically identifies the terms and conditions for
reusing the image. That can make the process of manually tracking down
rights and permissions a little easier since the contract number is
known. It also lets software be written to enforce the terms of
particular contracts.
The prospect of implementing software to enforce the terms of each
contract is not enticing. So, PRISM provides some simple mechanisms to
accommodate common cases without specialized software. One common case
is when a publisher provides a large amount of material, such as the
layouts for an entire magazine issue, to a partner publisher who will
republish parts of it. Much of the content in the issue will be the
property of the sending publisher, and covered under their business
agreement with the receiving publisher. However, the issue will also
contain stock photos and other materials that are not covered by the
agreement. The example below shows how the controlled value #notReusable
indicates to the receiver, travelmongo.com, that this item is not
covered under their agreement with the sender, Wanderlust. This is, in
fact, a benefit to Wanderlust. Travelmongo.com will not ask Wanderlust
staff to search for contract terms on images Wanderlust does not own – a
considerable cost savings. The rightsAgency element is provided so that
the receiver of a contact item has someone to contact should they wish
to obtain the rights to use the non-Wanderlust content.
The description below also shows how the descriptions for multiple
objects can be packaged into a single PRISM file shown in Example 4.11.
PRISM is intended to be a modular specification; it is more likely
that applications will use portions of PRISM than its entirety. The
PRISM elements are separated into a series of functional namespaces,
each covered in a separate normative specification. This section
describes each briefly and provides a reference to the module
specifications. For formal references to the namespaces, see PRISM
Compliance [PRISMCOMP].
The following is an alphabetical list of PRISM metadata
fields. Following the field name is the namespace and the document
in the PRISM documentation package where that element appears.
Note that only metadata fields are included in this list. Elements
developed for a specific use case such as PAM, are not metadata
elements and are not included in this list! PAM markup elements
are documented in The PRISM Aggregator Message Specification [PRISMPAM].
PRISM Inline Markup elements are documented in The PRISM Inline Markup
Specification [PRISMIMS]. And markup elements to define a
controlled vocabulary are documented in The PRISM Controlled Vocabulary
Markup Specification [PRISMCVMS].
PRISM includes a subset of Dublin Core elements for certain basic
metadata. The normative definitions of the Dublin Core elements can be
found in [DCMI]. The specific elements used in PRISM are listed in [PRISMDCMS].The use of some DC elements is encouraged, others are discouraged, and others constrained.
Elements in the PRISM Subset of the Dublin Core include:
PRISM extends its metadata element set beyond those selected from
Dublin Core in order to specifically allow for fuller description of
magazine and journalist content. The “prism:” namespace contains
elements suitable for a wide range of content publication, licensing,
and reuse situations. They are described in [PRISMPRISMNS].
As of the PRISM V2.1 Specification, the PRISM Usage Rights Namespace
is a new addition. This namespace incorporates some elements from the
prism: namespace as well as new rights elements. It is the intent that
both the PRISM Rights Language (prl:) namespace and rights elements from
the PRISM namespace will be deprecated when the next major revision of
PRISM (V3.0) is published.
Elements in the PRISM Rights Language Namespace (pur:) include:
In addition to defining metadata fields to support management,
aggregation, delivery and reuse of publishing content and rich media,
PRISM has also defined a number of values with precise definitions, or
controlled vocabularies, for these metadata fields. URIs for each CV can
be found in the PRISM Controlled Vocabularies Specification [PRISMCVS].
PRISM Article Controlled Vocabularies
Vocabulary Name
Intent
PRISM Aggregation Type
The PRISM Aggregation Type CV provides values for
prism:aggregationType. This vocabulary specifies the unit of
delivery for content, not only to aggregators but to distributors and
devices.
PRISM Compliance Profile
The prism:complianceProfile provides values to identify the compliance of a metadata instance.
PRISM Content Type
The PRISM Content Type CV defines the type of nextPub content
building block and is used with the prism:contentType field. This
element can be refined by PRISM Genre
PRISM Genre
The PRISM Genre CV provides values to identify the intellectual
content of a resource and is used with the prism:genre element.
PRISM Issue Frequency
The PRISM Issue Frequency CV provides values for the prism:issueFrequency metadata field.
PRISM Issue Type
The PRISM Issue Type CV provides values for prism:issueType element.
PRISM Platform
The PRISM Platform CV provides values to identify the delivery
platform of a resource. PRISM Platform is more generic than dc:medium in
that is used to specify the medium of the physical carrier of a
resource in a much more precise way. The controlled vocabulary provides
values for platform= attribute on elements that may vary depending on
the delivery platform.
PRISM Presentation Type
The PRISM Presentation Type CV provides values for dc:type that
specify presentation type for the resource. For nextPub
implementations, this controlled vocabulary provides class= attribute
values for the HTML5 <figure element to express the presentation type
of the figure.
PRISM Role
The PRISM Role CV provides values for the prism:role attribute
for dc:creator and dc:contributor. While the role= attribute is
optional, it provides a mechanism to provide more granular role metadata
for a creator or contributor.
PAM Class
The PAM Class CV provides values for elements in the PAM message
that use the class= attribute to provide more precise description of
elements or groups of elements. While the class attribute can be used
with almost any XHTML element, it is most commonly used with p and div.
PRISM Content Class
The PRISM Content Class CV provides values for elements in the
HTML5 body of an article or other content that use the class= attribute
to provide more precise description. While the class attribute can be
used with almost any HTML5 element, it is most commonly used with <p
and <.
PRISM Inline Class
The PRISM Inline Class controlled vocabulary provides values for
the markup of inline content in the HTML5 body of an article.
These values should be used for the class attribute should be used
exclusively with the <span element.
PSV Figure Class
The Figure Content Class Vocabulary describes classes of PSV
content markup inside a figure. The terms included in this
CV map directly to PAM content elements.
Recipe Controlled Vocabularies
PRM Cooking Equipment
The PRISM Cooking Equipment CV provides values for the prm:cookingEquipment metadata field.
PRM Cooking Method
The PRISM Cooking Method CV provides values for the prm:cookingMethod metadata field.
PRM Course
The PRISM Course CV provides values for the prm:course metadata field.
PRM Cuisine
The PRISM Cuisine CV provides values for the prm:cuisine metadata field.
PRM Dietary Needs
The PRISM Dietary Needs CV provides values for the prm:dietaryNeeds metadata field.
PRM Dish Type
The PRISM Dish Type CV provides values for the prm:dishType metadata field.
PRM Ingredient Exclusion
The PRISM Ingredient Exclusion CV provides values for the prm:dietaryExclusion metadata field.
PRM Meal
The PRISM Meal CV provides values for the prm:meal metadata field.
PRM Recipe Source
The PRISM Recipe Source CV provides values for the prm:recipeSource metadata field.
PRM Skill Level
The PRISM Skill Level CV provides values for the prm:skillLevel metadata field.
PRM Special Occasion
The PRISM Special Occasion CV provides values for the prm:specialOccasion metadata field.
PRM Time
The PRISM Time CV provides values for the prm:otherTime metadata field.
PRISM Image Controlled Vocabularies
PMI Image Color
The PRISM Color CV provides values for the pmi:color metadata field.
PMI Image Orientation
The PRISM Image Orientation CV provides values for the pmi:orientation metadata field.
PMI Season
The PRISM Season CV provides values for the pmi:season metadata field.
PMI Setting
The PRISM Image Setting CV provides values for the pmi:setting metadata field.
PMI Viewpoint
The PRISM Camera Viewpoint CV provides values for the pmi:viewpoint metadata field.
PMI Visual Technique
The PRISM Visual Technique CV provides values for the pmi:visualTechnique metadata field.