17–18 April 2018, WU Vienna, Vienna, Austria, Europe
![[graphic: WU campus, a group of four people, a network, a hand on a chin]](workshop-banner.jpg)
On 17 and 18 April 2018, some forty people took part in a W3C workshop on data privacy controls and vocabularies. The initial idea was that linked data annotations can help tackle the issue of privacy in modern data environments. This would allow the creation of a new generation of privacy enhancing technologies. Of course, the advent of the enactment of the GDPR was also prominent in the discussions.
Support for the workshop came from the European research project SPECIAL. The WU Vienna (Vienna University of Economics and Business) provided the meeting facilities.
Stefan Decker (Fraunhofer FIT/RWTH Aachen) and Vassilios Peristeras (Hellenic University) chaired the program committee. They also led the discussions at the workshop.
The agenda, developed on the basis of position statements submitted by the participants before the workshop, consisted of sessions on four themes, ‘relevant vocabularies and initiatives’, ‘industry perspective’, ‘research topics’ and ‘the governmental side & initiatives’. The workshop ended with a discussion on next steps and more in particular on priorities.
The next steps with the highest priority were to develop a taxonomy of privacy terms (which include in particular terms from the GDPR) and a taxonomy of personal data. Classification of purposes (i.e., purposes for data collection), of disclosures and of methods of data anonymisation were other possible next steps.
Such taxonomies can help with automatic processing of privacy data: software to help users keep track of which company they gave what data to and how to update or retract it; and software for companies to keep track of the data they collected and verify that the data conforms to their own policies and to applicable laws. A taxonomy of anonymisation methods in addition helps buyers and sellers of personal data to know exactly what they buy/sell and what it can be used for.
(See also the minutes of day 1.)
At the start of the first session, Sabrina Kirrane, Rigo
Wenning and the two co-chairs, Stefan Decker and Vassilios
Peristeras, introduce the goals of the workshop:  a plan for
achieving interoperability of machine-readable notations for
personal data, for the operations on them, and for the rules
governing them, all in the form of Linked Data (i.e., RDF).
a plan for
achieving interoperability of machine-readable notations for
personal data, for the operations on them, and for the rules
governing them, all in the form of Linked Data (i.e., RDF).
The session consists of short talks by seven panellists, followed by a panel discussion.
Joss Langford [position statement] [slides] presents the work of the COEL Technical Committee of OASIS and the COELITION organisation. They aim to create a taxonomy of everyday human behavior, based on a few thousand identifiable, observable actions and a hierarchical classification. They currently have some 5000 such actions identified and found that a person typically does about a 100 of them in a day. Smart sensors in the IoT, e.g., might detect and communicate such actions.
Jaroslav Pullman [position statement] [slides] works in a research project called ‘Industrial Data Space’, which aims at establishing a ‘network of trust’ for exchange of sensitive data among business partners. The model is that of ‘connectors’, pieces of software that connect where data is stored to where it is processed and they are trying to use ODRL as the metadata formalism for connectors to express what may be done with each piece of data.
Michael Lux [position
statement] works on a different part of the same
project and tries to use ODRL in automatic enforcement of data
usage policies in the IoT.  He found the need for some
additions to ODRL, but also found that some aspects, in
particular the generation of a unique ID for each asset, are
unnecessary/burdensome if the assets are implied by the context
(such as when the policy is embedded in the data it talks
about).
He found the need for some
additions to ODRL, but also found that some aspects, in
particular the generation of a unique ID for each asset, are
unnecessary/burdensome if the assets are implied by the context
(such as when the policy is embedded in the data it talks
about).
Mark Lizar [position statement] presents the idea of ‘consent receipts’. A working group of the Kantara Initiative developed a format to formally describe the purpose of data collection, the identity of the data controller, and more. Mark is working on making such receipts, and the policies they refer to, easier to understand.
Markus Sabadello [position statement] [slides] talks about decentralised identifiers, and in particular about a URI scheme called ‘did’, which tries to implement the concept of ‘self-sovereign identity’: Anybody can make as many identities as he wants and there is no centralised registry. Combined with a system of public & private keys (PKI) and Verifiable Claims, they can nevertheless be used for verification. In the subsequent discussion somebody remarks that such identities can also be fragile: nobody keeps a backup of your private keys or other data for you. And it is probably not much harder to make http-based URIs, which can use already existing technology as resolvers.
Sabrina Kirrane [position statement] [slides] presents the work done in the SPECIAL project to analyse the GDPR and create vocabularies for it, often building on more general vocabularies developed in W3C or elsewhere (OWL Time, ODRL, PROV, FOAF, P3P, etc.). Fully automating compliance checking is still far away, though, especially because legal texts have many interpretations. You can try to represent them, but it is difficult to choose between them.
Ensar Hadziselimovic is also interested in applying ODRL. With his colleagues, he is developing an ODRL profile to model the GDPR and its workflow. A related project is to use the model in an automated reasoner to answer what-if questions.
In the panel discussion, the question of identities and identifiers comes up again and also the question what ‘deleting data’ means exactly. Is anonymisation, de-identifying, a form of deletion? That also leads to the issue of modelling time and knowing when something has been deleted.
Michael Markevich [position statement] explains how browser maker Opera tries to protect users' privacy on the different online services it offers, and how people in different countries use the available configuration options.
Martin Kurze and Matthias Schunter [position statement and position statement] explain the state of the DNT specification in the Tracking Protection Working Group. DNT can be used to consent or not to one policy per Internet domain. That may not be fine-grained enough.
Georg Philip Krog [position statement] [slides] works for a company that tries to model and automate the management of consent, so that companies can rent an online (‘cloud’) service to manage their users' policies.
Freddy de Meersmann [position statement] [slides] explains how Proximus, the Belgian telecom operator, works with Eurostat and the Belgian government on projects such as population statistics and emergency services. The challenge is to eventually track population movement across borders, i.e., to provide precise yet anonymous data aggregated from several phone operators.
Victor Mireles [position statement] [slides] represents the Lynx project, which aims to help companies be compliant with European laws by providing online services that semi-automatically determine which laws, regulations and standards apply. Common vocabularies and common legal identifiers are important and can also help with automatic translation of the results.
In the discussion, people note that there are often multiple ways to refer to legal articles, i.e., there are multiple identifiers. Also, all modelling introduces bias, because it is not complete and depends on the knowledge of the human who annotates the texts to model. Another problem is how to express time, i.e., rules that applied in the past but do not any longer.
Monica Palmirani [position statement] works on the PrOnto (Privacy Ontology) project, which uses XML (such as LegalRuleML) and LOD to annotate legal text and describe processes. The current work is primarily based on an analysis of UK law.
David Watts [position statement] [slides] talks about the privacy landscape in Australia and compares it to the GDPR. Like the EU, Australia tries to balance privacy and security, such as terrorist threats. It is necessary to identify concepts correctly and standardise them, also to allow computer scientists and lawyers to understand each other. The existing implementations of consent management typically try to manipulate, rather than inform the user. Which doesn't mean consent is useless, but it must be supported both by technology and law.
Peter Bruhn Andersen [position statement] works for the Danish government, in a country that is already very much digitised. There are thousands of databases in use at various government services, but there is little cooperation between them. Linked Data may help, to describe what's in the databases, but also to describe access control.
Darren Bell [position statement] [slides] works for the UK Data Archive, which is charged with the long-term archiving of social data, such as surveys and census data. Traditionally, each dataset is an independent file, manually anonimised before each use. That doesn't scale. There is, e.g., a lot of new data coming in from devices, such as smart electricity meters.. Formalised descriptions, de-identification methods and provenance data can automate the processes, help with risk management, and help to comply with the GDPR.
Eva Schlehahn & Harald Zwingelberg [position statement] [slides] give a brief overview of the transparency requirements of the GDPR. Several articles of the GDPR require forms of transparency, from access to the collected data itself, via the processes used to collect and transform the data, to the usage of the data and its impact.
In the discussion people note that collected data must also be portable: a data subject can see what personal data has been collected, but must also be able to extract and reuse it.
(See also the minutes of day 2.)
Ramisa Gachpaz Hamed [position statement] [slides] is studying ‘Privacy Preserving Personalisation’ and in particular how to help a user decide on disclosure of information. This can take the form of a human-readable explanation of an automatic decision, or an interactive decision process enhanced with ‘what-if’ scenarios and recommendations. In the background, it is supported by automatic reasoning and Linked Data. But standardised taxonomies of personal data are rare.
Javier Fernández [position statement] [slides] explains the Policy Log vocabulary developed in the SPECIAL project. It encodes the nature of the event (collection of location data, giving of consent, etc.), the purpose, the data subject, and of course the time. Additional vocabularies are needed for each type of event. More study is necessary to know the level of detail required for checking if an event is compliant with a certain, previously agreed policy. E.g., does the actual data collected figure in the log? And what if the user wants that data deleted?
Yi Yin [position statement] is involved in research around how to make datasets from research available to other researchers. The VRE4EIC project doesn't store datasets itself, but provides researchers with an interface to a catalogue merged from various sources that allows the researcher to connect data sources to data processors (software or online services). The EU, of course, encourages researchers to share data, but the challenge is to know if the data contains personal data and thus if it can be used for a given purpose.
Benjamin Heitmann [position statement] [slides] studies anonymisation techniques and the market for data. Anonymisation alters what the data can be used for and thus it is important for a buyer to know which method was applied. Anonymisation techniques have already been well researched, but there is no standard way yet to describe them.
Dalal Al-Azizy's [position statement] research focuses on deanonymisation attacks, e.g., to establish the risks attached to publication of certain government data (Linked Open Data). There is a lack of tools to help establish such risks, especially to assess what kinds of future data may compromise the anonymity of currently published data.
In the discussion people asked if the requirement to anonymise data in Europe wouldn't lead to buyers looking for data elsewhere. On the other hand, it creates a market for new technology and, if people and companies know their data is protected, they are more willing to share it. We have already seen European companies trying to attract US clients with the argument that their data is safer in the EU.
Another discussion is how to keep data and metadata linked. The latter typically links to the former, but the former not always to the latter.
The final discussion was guided by sticky notes with topics
that participants put on the wall for that purpose during the
two days.  The focus was on opportunities for standardisation. In the first
part of the discussion, the participants tried to group the
topics, in particular along a data processing axis: contacting a
data subject, collecting data, processing data, and finally
disseminating data. Several notes propose developing various
vocabularies or taxonomies.
The focus was on opportunities for standardisation. In the first
part of the discussion, the participants tried to group the
topics, in particular along a data processing axis: contacting a
data subject, collecting data, processing data, and finally
disseminating data. Several notes propose developing various
vocabularies or taxonomies.
The discussions ended with a poll to establish the priority of
the things that could be standardised. In order from highest to
lowest priority, the result is: 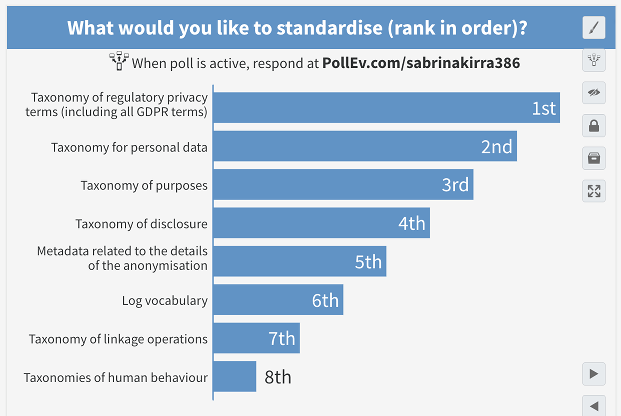
As a next step the Workshop encouraged the creation of a ‘Community Group’ at W3C to work on these vocabularies. As of the Publication of this report, the W3C Data Privacy Vocabularies and Controls CG (DPVCG) is already created. People with an interest in the above topics are encouraged to join.