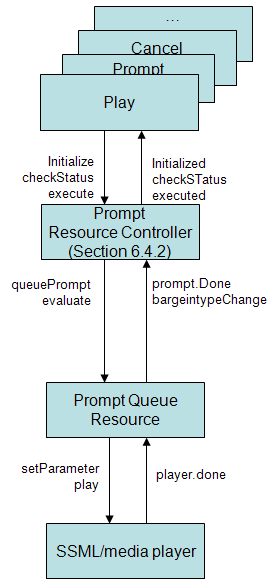
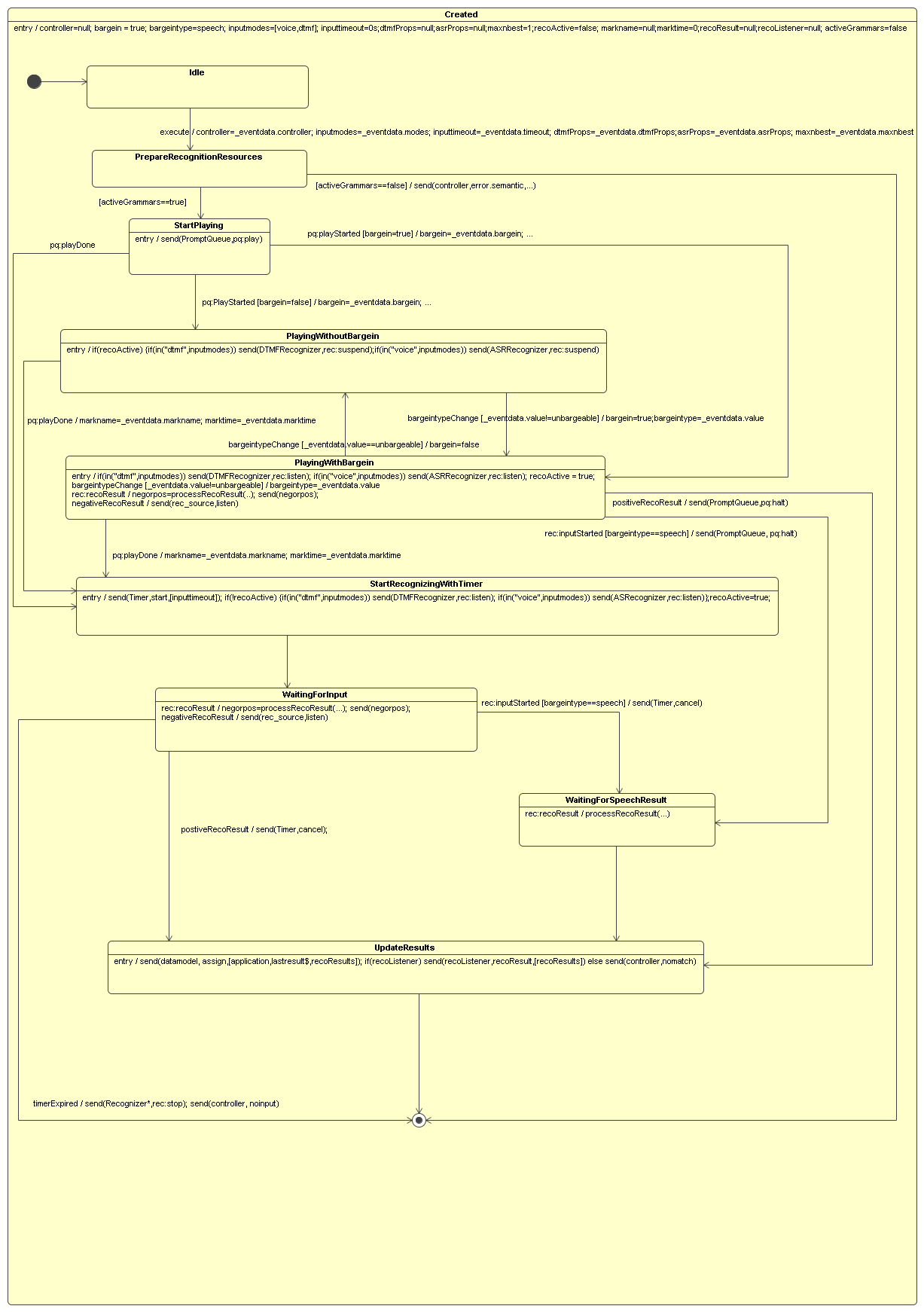
The PlayandRecognize RC coordinates media input with Recognizer
resources and media output with the PromptQueue Resource.
6.10.2.2.1 Definition
The PlayandRecognize RC coordinates media input with recognition
resources and media output with the PromptQueue Resource on behalf
of a form item.
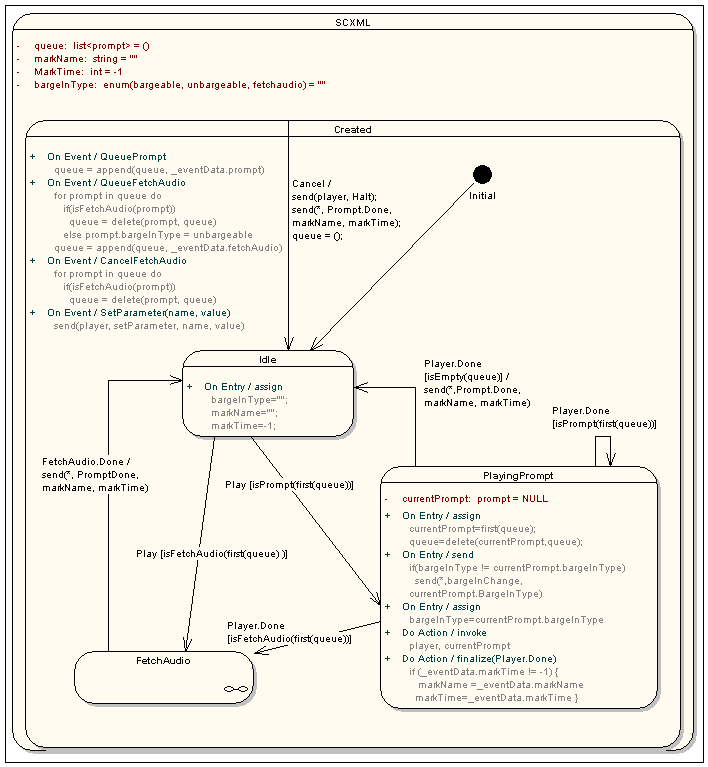
This RC activates prompt queue playback, activates recognition
resources, manages bargein behavior and handles results from
recognition resources.
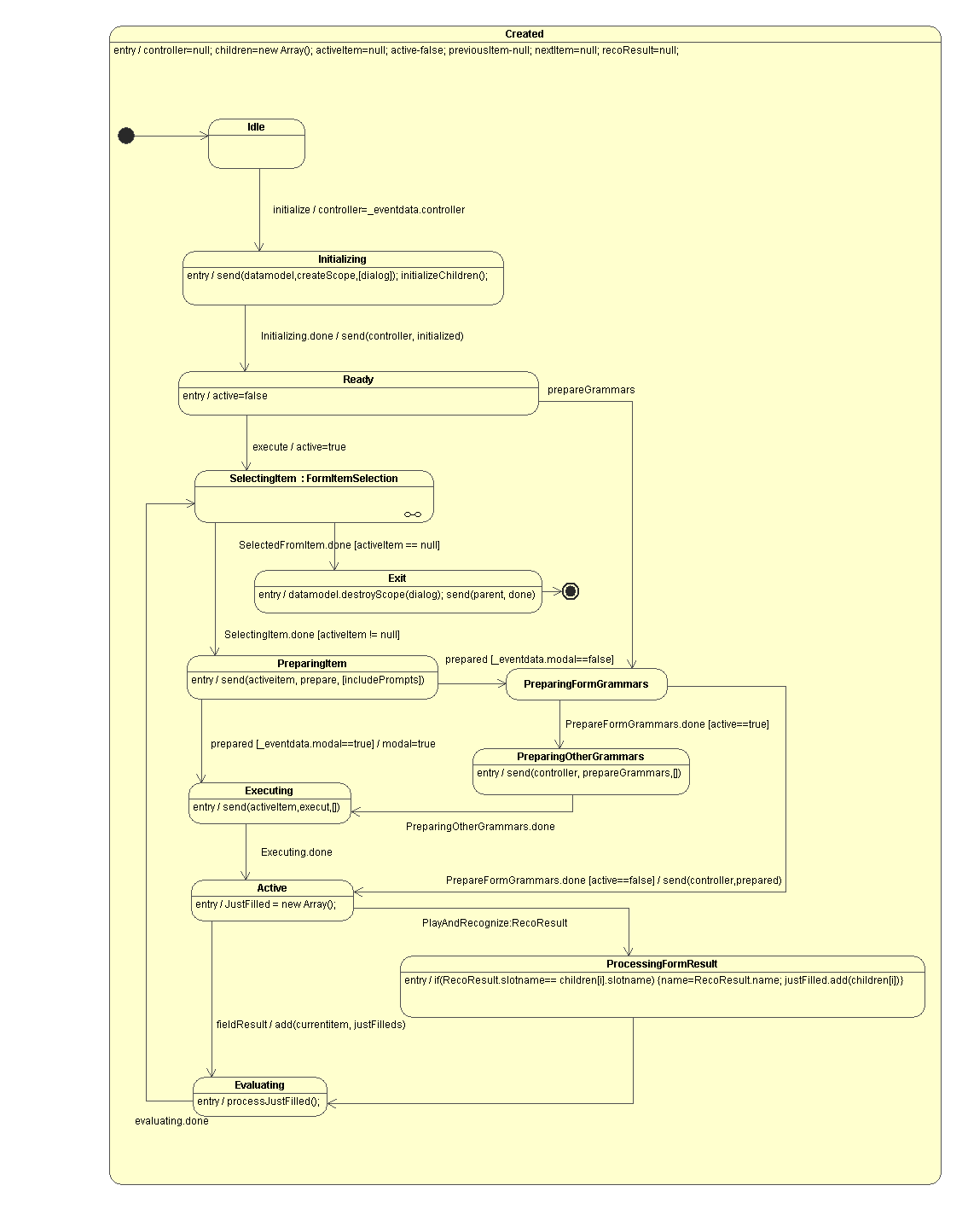
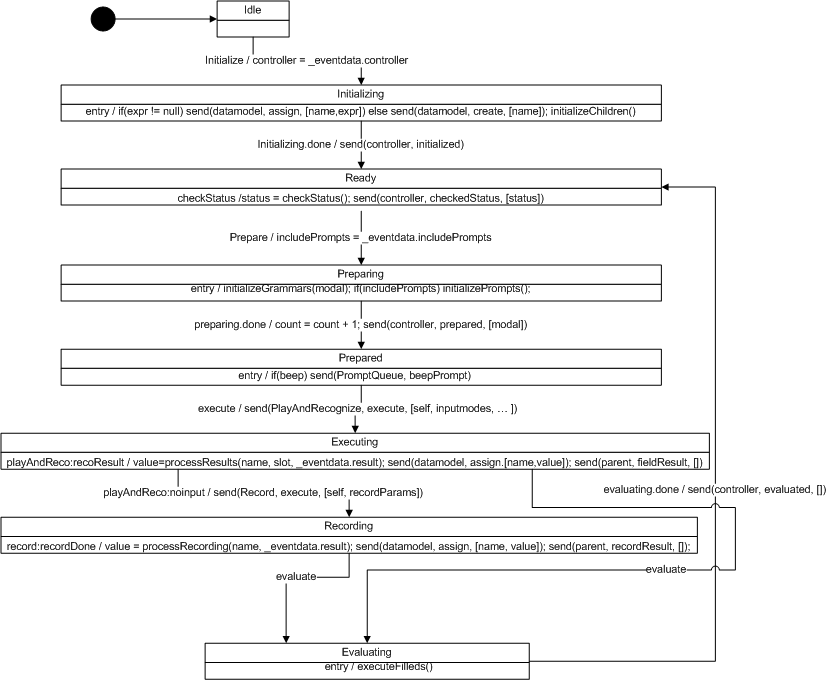
The RC is defined in terms of a data model and a state
model.
The data model is composed of the following parameters:
- controller: the RC controlling this RC
- bargein: Boolean indicates whether bargein is active or not.
Default: true.
- bargeintype: indicates the type of bargein, if active. Default:
speech.
- inputmodes: active recognition input modes. Default: voice and
dtmf.
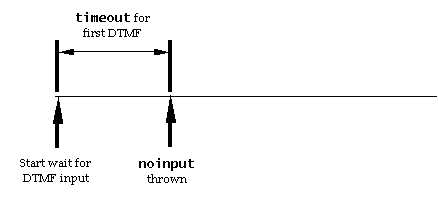
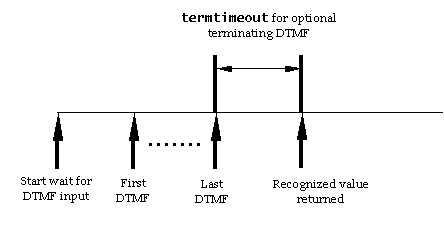
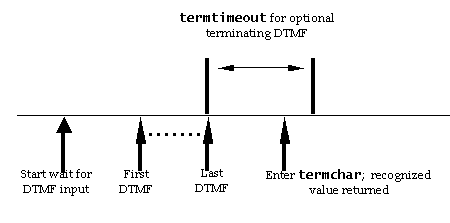
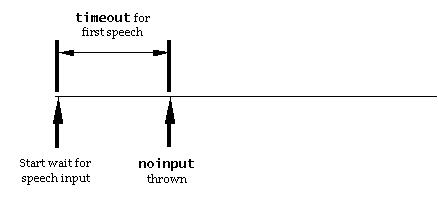
- inputtimeout: timeout to wait for input. Default: 0s. (Required
since the prompt queue may be empty).
- dtmfProps: DTMF properties
- asrProps: Speech recognition properties
- maxnbest: maximum number of nbest results. Default: 1.
- recoActive: boolean indicating whether recognition is active.
Default: false.
- markname: string indicating current markname. Default:
null
- marktime: time designator indicating current marktime. Default:
0s.
- recoResult:
- recoListener:
- activeGrammars: Boolean indicating whether grammars are active.
Default: false.
The RC model consists of the following states: idle, prepare
recognition resources, start playing, playing prompts with bargein,
playing prompts without bargein, recognizing with a timer, waiting
for input, waiting for speech result and update results. The
complexity of this model is partially a consequence of supporting
the relationship between hotword bargein and recognition result
processing.
While in the idle state, the RC may receive an 'execute' event,
whose event data is used to update the data model. The event
information includes: controller, inputmodes, inputtimeout,
dtmfProps, asrProps and maxnbest. The RC transition to the prepare
recognition resources state.
In the prepare recognition resources, the RC sends 'prepare'
events to the ASR and DTMF recognition resource. Both events
specify this RC as the controller parameter, while the properties
parameter differs. In this state, the RC can received 'prepared' or
'notPrepared' events from either recognition resources. If neither
resource returns a 'prepared' event, then activeGrammars is false
(i.e. no active DTMF or speech grammar) and the RC sends an
'error.semantic' event to the controller and exits. If at least one
resource returns a 'prepared' event, then the RC moves into the
start playing state.
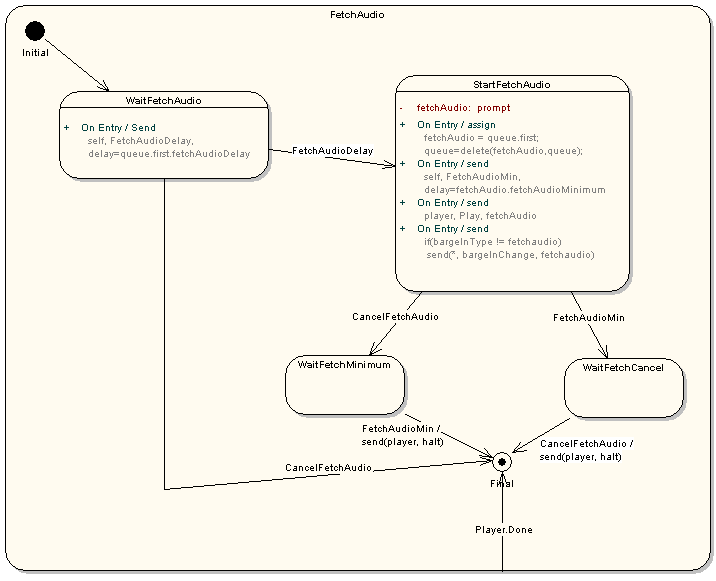
The start playing state begins by sending the PromptQueue
resource a 'play' event. The PromptQueue responds with a 'playDone'
event if there are no prompt in the prompt queue; as a result, this
RC moves into the start recognizing with timer state. If there is
at least one prompts in the queue, the PromptQueue sends this RC a
'playStarted' event whose data contains the bargein and bargeintype
values for the first prompt, and the input timeout value for the
last prompt in the queue. The data model is updated with this
information.
| Editorial note
|
|
| Open issue: PromptQueue
Resource doesn't currently have playStarted event. If we don't add
playStarted event, then is there a better way to get the bargein,
bargeintype, and timeout information from the prompts in the
PromptQueue? |
Interaction with the recognizer during prompt playback is
determined by the data model's bargein value. If bargein is true,
then this RC transitions to the playing with bargein state. If
bargein is false, the RC transitions to the playing without bargein
state.
| Editorial note
|
|
| Open Issue: The event
"bargeinChange" as a one way notification could pose a problem, as
it takes finite time for recognizer to suspend or resume. This
might work better if PromptQueue Resource waited for an event
"bargeinChangeAck" (or similar) from PlayandRecognize RC before
starting the next play. PlayandRecognize RC will send the event
"bargeinChangeAck" after it completed suspend or resume action on
the recognizer. |
In the playing without bargein state, recognition is suspended
if it has been previously activated (recoActive parameter of the
data model tracks this). Suspending recognition is conditional on
the value of 'inputmodes' data parameter; if 'dtmf' is in
inputmodes, then DTMF recognition is suspended; if 'voice' is in
inputmodes, the ASR recognition is suspended. In this state, the
PromptQueue can report to this RC changes in bargein and
bargeintype as prompts are played: a 'bargeintypeChange' event with
the values 'hotword' or 'speech' cause the data model parameter
'bargein' to the set to 'true' and the 'bargeintype' parameter to
be updated with event data value. If the PromptQueue resource sends
a 'playDone' event, then the data model markname and marktime
parameters are updated and the RC transitions to the start
recognizing with timer state.
In the playing with bargein state, recognition is activated if
it has not been previously activated (determined by recoActive
parameter in the data model). Activating recognition is conditional
on the value of 'inputmodes' data parameter; if 'dtmf' is in
inputmodes, then DTMF recognition is activated; if 'voice' is in
inputmodes, then ASR recognition is activated. In this state, the
PromptQueue can report changes in bargein and bargeintype as
prompts are played: a 'bargeintypeChange' event where the event
data value is not 'unbargeable' causes the data model 'bargeintype'
parameter to be updated with the event data ('hotword' or
'speech'); while a 'bargeintypeChange' where the event data value
is 'unbargeable' causes the data model 'bargein' parameter to set
to false and the RC transitions to the playing without bargein
state. If the PromptQueue resources sends a 'playDone' event, then
the data model markname and marktime parameters are updated and the
RC transitions to the start recognizing with timer state.
Recognition handling in this state depends upon the bargeintype
data parameter. If the bargeintype is 'speech' and a recognizer
sends a 'inputStarted' event, then the RC transition to the waiting
for speech result state. If the bargeintype is 'hotword', then
recognition results are processed within this state. In particular,
if a recognition resource sends a 'recoResults' event, then its
event data is processed to determine if the recognition result is
positive or negative.
| Editorial note
|
|
| Further details on
recognition processing to be added in later versions. recoResults
data parameter is updated with the recognition results (truncated
to maxnbest). A speech result is positive iff there is at least one
result whose confidence level is equal to or greater than the
recognition confidence level; otherwise the result is negative.
DTMF results are always positive. The recoListener data parameter
is defined as the listener associated with the best result if the
result is positive. |
If positive, the RC sends the PromptQueue a 'halt' event, and
transitions to the update results state. If negative, the RC sends
a 'listen' event to the recognition resource which sent the
'recoResults' event.
In the start recognizing with timer state, an input timer is
activated for the value of the inputtimeout data parameter and, if
the recognition is not already active (determined by the recoActive
data parameter). Recognition activation is conditional on the value
of 'inputmodes' data parameter; if 'dtmf' is in inputmodes, then
DTMF recognition is activated; if 'voice' is in inputmodes, the ASR
recognition is activated. The RC then transitions into the waiting
for input state.
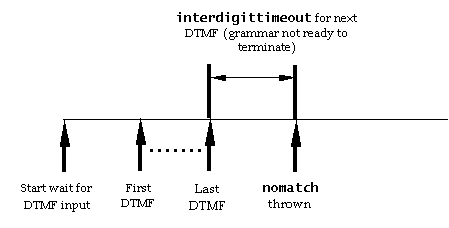
In the waiting for input state, the RC waits for user input. If
it receives a 'timerExpired' event, then the RC sends a 'stop'
event to all recognition resources, sends a 'noinput' event to its
controller and exits. Recognition handling in this state depends
upon the bargeintype data parameter. If the bargeintype is 'speech'
and a recognizer sends a 'inputStarted' event, then the RC
transition to the waiting for speech result state. If the
bargeintype is 'hotword', then recognition results are processed
within this state. In particular, if a recognition resource sends a
'recoResults' event, then its event data is processed to determine
if the recognition result is positive or negative. If positive, the
RC cancels the timer, and transitions to the update results state.
If negative, the RC sends a 'listen' event to the recognition
resource which sent the 'recoResults' event.
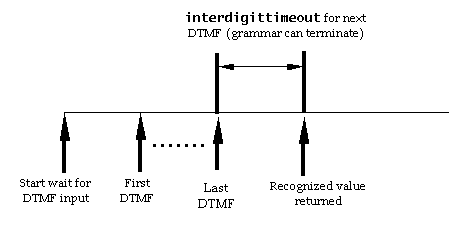
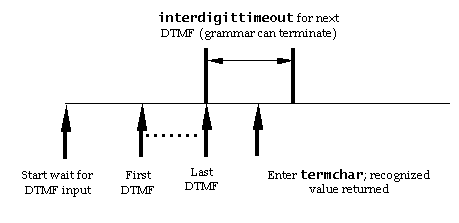
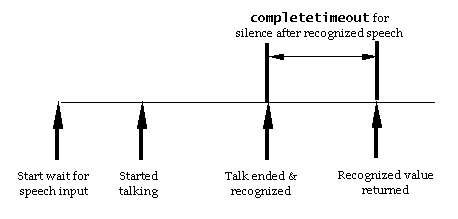
In the waiting for speech result state, the RC waits for a
'recoResult' event whose data is used to update the recoResult data
parameter and to set the recoListener data parameter if the
recognition result is positive. The RC then transitions to the
update results state.
In the update results state, the RC sends 'assign' events to the
data model resource, so that the lastresult object in application
scope is updated with recognition results as well as markname and
marktime information. If the recoListener data parameter is
defined, then the RC sends a 'recoResult' event to the recognition
listener RC; otherwise, it sends 'nomatch' event to its controller.
The RC then exits.
| Editorial note
|
|
|
Open issue: Behavior if one reco resource sends 'inputStarted'
but other sends 'recoResults'? Race conditions between recognizers
returning results? (This problem is inherent to the presence of two
recognizers. For the sake of clear semantics, we could restrict
only one recognizer to respond with 'inputStarted' and
'recoResults'. The other recognizer is always 'stopped'. But a
better choice might be to have only one recognizer that handles
both DTMF and speech, since semantically both recognizers are very
similar.)
|