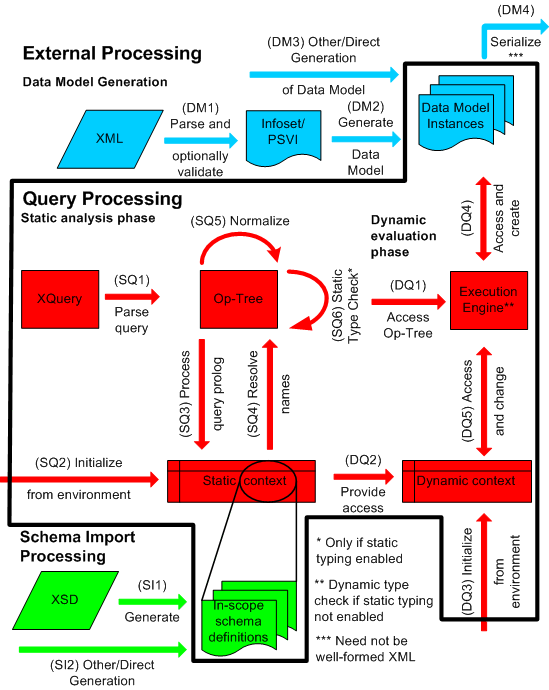
1 Introduction
This document defines the formal semantics of XQuery 1.0 and XPath 2.0. The present document is part of a set of documents that together define the XQuery 1.0 and XPath 2.0 languages:
-
[XQuery 1.0: A Query Language for XML] introduces the XQuery 1.0 language, defines its capabilities from a user-centric view, and defines the language syntax.
-
[XML Path Language (XPath) 2.0] introduces the XPath 2.0 language, defines its capabilities from a user-centric view, and defines the language syntax.
-
[Functions and Operators] lists the functions and operators defined for the [XPath/XQuery] language and specifies the required types of their parameters and return value.
-
[Data Model] formally specifies the data model used by [XPath/XQuery] to represent the content of XML documents. The [XPath/XQuery] language is formally defined by operations on this data model.
-
[Data Model Serialization] specifies how [XPath/XQuery] data model values are serialized into XML.
The scope and goals for the [XPath/XQuery] language are discussed in the charter of the W3C [XSL/XML Query] Working Group and in the [XPath/XQuery] requirements [XML Query 1.0 Requirements].
This document defines the semantics of [XPath/XQuery] by giving a precise formal meaning to each of the expressions of the [XPath/XQuery] specification in terms of the [XPath/XQuery] data model. This document assumes that the reader is already familiar with the [XPath/XQuery] language. This document defines the formal semantics for XPath 2.0 only when the XPath 1.0 backward compatibility rules are not in effect.
Two important design aspects of [XPath/XQuery] are that it is functional and that it is typed. These two aspects play an important role in the [XPath/XQuery] Formal Semantics.
[XPath/XQuery] is a functional language. [XPath/XQuery] is built from expressions, rather than statements. Every construct in the language (except for the XQuery query prolog) is an expression and expressions can be composed arbitrarily. The result of one expression can be used as the input to any other expression, as long as the type of the result of the former expression is compatible with the input type of the latter expression with which it is composed. Another characteristic of a functional
language is that variables are always passed by value, and a variable's value cannot be modified through side effects.
[XPath/XQuery] is a typed language. Types can be imported from one or more XML Schemas that describe the input documents and the output document, and the [XPath/XQuery] language can then perform operations based on these types. In addition, [XPath/XQuery] supports static type analysis. Static type analysis infers the output type of an expression based on the type of its input expressions. In addition to infering the type an an expression for the user, static typing allows early detection
of type errors, and can be used as the basis for certain classes of optimization. The [XPath/XQuery] type system captures most of the features of [Schema Part 1], including global and local element and attribute declarations, complex and simple type definitions, named and anonymous types, derivation by restriction, extension, list and union, substitution groups, and wildcard types. It does not model uniqueness constraints and facet constraints on simple types.
This document is organized as follows. [2 Preliminaries] introduces the notations used to define the [XPath/XQuery] Formal Semantics. These include the formal notations for values in the [XPath/XQuery] data model and for types in XML Schema. The next three sections: [3 Basics], [4 Expressions], and [5 Modules and Prologs] have the same structure as the
corresponding sections in the [XQuery 1.0: A Query Language for XML] and [XML Path Language (XPath) 2.0] documents. This allows the reader to quickly find the formal definition of a particular language construct. [3 Basics] defines the semantics for basic [XPath/XQuery] concepts, and [4 Expressions] defines the dynamic and static semantics of each [XPath/XQuery] expression. [5 Modules and Prologs] defines the semantics of the [XPath/XQuery] prolog. [7 Additional Semantics of Functions] defines the static semantics of several functions in [Functions and Operators] and gives the dynamic and static semantics of several supporting functions used in this document. The remaining sections, [8 Auxiliary Judgments] and [C Importing Schemas], contain material that supports the formal semantics of [XPath/XQuery]. [8 Auxiliary Judgments] defines formal judgments that relate data model values to types, that relate types to types, and that support the formal definition of validation. These judgments are used in the definition of expressions in [4 Expressions]. Lastly, [C
Importing Schemas], specifies how XML Schema documents are imported into the [XPath/XQuery] type system and relates XML Schema types to the [XPath/XQuery] type system.
1.1 Normative and Informative Sections
Certain aspects of language processing are described in this specification as implementation-defined or implementation-dependent.
-
[Definition: Implementation-defined indicates an aspect that may differ between implementations, but must be specified by the implementor for each particular implementation.]
-
[Definition: Implementation-dependent indicates an aspect that may differ between implementations, is not specified by this or any W3C specification, and is not required to be specified by the implementor for any particular implementation.]
A language aspect described in this specification as implementation-defined or implementation dependent may be further constrained by the specifications of a host language in which XPath is embedded.
This document contains the normative static semantics of [XPath/XQuery]. The static semantics rules in [3 Basics], [4 Expressions], [5 Modules and Prologs], and [7 Additional Semantics of Functions] are normative. [3.1.1 Static Context] is normative, because it defines the static context used in the static typing
rules. [8 Auxiliary Judgments] is normative, because it contains all the judgments necessary for defining SequenceType Matching.
The dynamic semantics of [XPath/XQuery] are normatively defined in [XQuery 1.0: A Query Language for XML] and [XML Path Language (XPath) 2.0]. In this document, the dynamic semantic rules in [3 Basics], [4 Expressions], and [5 Modules and Prologs], the examples and material labeled as "Note" are provided for explanatory purposes and are not
normative.
The mapping rules from XML Schema to the XQuery type system provided in [C Importing Schemas], and the formal semantics of XML Schema validation in [E Auxiliary Judgments for Validation] are informative and do not handle every feature of XML Schema.
2 Preliminaries
This section provides the background necessary to understand the Formal Semantics, introduces the notations that are used, and explains its relationship to other documents.
2.1 Introduction to the Formal Semantics
Why a Formal Semantics? The goal of the formal semantics is to complement the [XPath/XQuery] specification ([XQuery 1.0: A Query Language for XML] and [XML Path Language (XPath) 2.0]), by defining the meaning of [XPath/XQuery] expressions with mathematical rigor.
A rigorous formal semantics clarifies the intended meaning of the English specification, ensures that no corner cases are left out, and provides a reference for implementation.
Why use formal notations? Rigor is achieved by the use of formal notations to represent [XPath/XQuery] objects such as expressions, XML values, and XML Schema types, and by the systematic definition of the relationships between those objects to reflect the meaning of the language. In particular, the dynamic semantics relates [XPath/XQuery] expressions to the XML value to which they evaluate, and the static semantics relates [XPath/XQuery] expressions to the XML Schema type that is inferred for
that expression.
The Formal Semantics uses several kinds of formal notations to define the relationships between [XPath/XQuery] expressions, XML values, and XML Schema types. This section introduces the notations for judgments, inference rules, and mapping rules as well as the notation for environments, which implement the dynamic and static contexts. The reader already familiar with these notations can skip this section and continue with [2.3 XML Values].
2.1.1 Notations from grammar productions
Grammar productions are used to describe "objects" (values, types, [XPath/XQuery] expressions, etc.) manipulated by the Formal Semantics. The Formal Semantics makes use of several kinds of grammar productions: productions from the [XPath/XQuery] grammar itself, productions for a subset of the [XPath/XQuery] language called the XQuery core which is used throughout this document, and other productions used for formal specification only such as for the XQuery type system.
XQuery grammar productions describe the XQuery language and expressions. XQuery productions are identified by a number, which corresponds to their number in the [XQuery 1.0: A Query Language for XML] document, and are marked with "(XQuery)". For instance, the following production describes FLWOR expressions in XQuery.
[For/FLWR] Expressions
For the purpose of this document, the differences between the XQuery 1.0 and the XPath 2.0 grammars are mostly irrelevant. By default, this document uses XQuery 1.0 grammar productions. Whenever the grammar for XPath 2.0 differs from the one for XQuery 1.0, the corresponding XPath 2.0 productions are also given. XPath productions are identified by a number, which corresponds to their number in [XML Path Language (XPath) 2.0], and are marked with "(XPath)". For instance, the
following production describes for expressions in XPath.
[For/FLWR] Expressions
XQuery Core grammar productions describe the XQuery Core. The Core grammar is given in [A Normalized core grammar]. Core productions are identified by a number, which corresponds to their number in [A Normalized core grammar], and are marked with "(Core)". For instance, the following production describes the simpler form of the "FLWOR" expression in the XQuery Core.
Core FLWOR Expressions
The Formal Semantics manipulates "objects" (values, types, expressions, etc.) for which there is no existing grammar production in the [XQuery 1.0: A Query Language for XML] document. In these cases, specific grammar productions are introduced. Notably, additional productions are used to describe values in the [Data Model], and to describe the [XPath/XQuery] type system. Formal Semantics productions are identified by a number, and are marked by
"(Formal)". For instance, the following production describes global type definitions in the [XPath/XQuery] type system.
Type Definitions
Note that grammar productions that are specific to the Formal Semantics (i.e., marked with "(Formal)") are not part of [XPath/XQuery]. They are not accessible to the user and are only used in the course of defining the languages' semantics.
Grammar non-terminals are used extensively in this document to represent objects in inference rules (see the next section). As a convenience, non-terminals used in inference rules link to the appropriate grammar production.
2.1.2 Notations for judgments
The basic building block of the formal specification is called a judgment. A judgment expresses whether a property holds or not.
For example:
Notation
The judgment
Painting is beautiful
holds if the object Painting is beautiful.
Notation
Here are three judgments that are used extensively in this document.
The judgment
holds if the expression Expr yields (or evaluates to) the value Value.
The judgment
holds when the expression Expr has the type Type.
Most other judgments used in this document are short english sentences intended to reflect their meaning, and written in bold fonts. For instance, the judgment
holds when the expression Expr raises the error Error.
A judgment can contain symbols and patterns.
Symbols are purely syntactic and are used to write the judgment itself. In general, symbols in a judgment are chosen to reflect its meaning. For example, 'is beautiful', '=>' and ':' are symbols, the second and third of which should be read "yields", and "has type" respectively.
Patterns are written with italicized words. The name of a pattern is significant: each pattern name corresponds to an "object" (a value, a type, an expression, etc.) that can be substituted legally for the pattern. By convention, all patterns in the Formal Semantics correspond to grammar non-terminals, and are used to represent entities that can be constructed through application of the corresponding grammar production. For example, Expr represents any [XPath/XQuery] expression, and Value represents any value in the [XPath/XQuery] data model.
When applying the judgment, each pattern must be instantiated to an appropriate sort of "object" (value, type, expression, etc). For example, '3 => 3' and '$x+0 => 3' are both instances of the judgment 'Expr => Value'. Note that in the first judgment, '3' corresponds to both the expression '3' (on the left-hand side of the => symbol) and to the the value '3' (on the right-hand side of the =>
symbol).
Patterns may appear with subscripts (e.g. Expr1, Expr2) to distinguish different instances of the same sort of pattern. Each distinct pattern must be instantiated to a single "object" (value, type, expression, etc.). If the same pattern occurs twice in a judgment description then it should be instantiated with the same "object". For example, '3 => 3' is an instance of the judgment 'Expr1 => Expr1' but '$x+0 => 3' is not since the two expressions '$x+0' and '3' cannot be both instance of the pattern Expr1. The judgment'$x+0 => 3' is an instance of the judgment 'Expr1 => Expr2'.
Patterns may have a name that is not exactly the name of a grammar production but is based on it. For instance, a BaseTypeName is a pattern that stands for a type name, as would TypeName, or TypeName2. This usage is limited, and only occurs to improve the readability of some of the inference rules.
In some cases, inference rules may need to use the fact that a certain judgment does not hold. We may write not(Judgment) the judgment which holds iff Judgment does not hold.
In some cases, an "object" may take a value within a finite set of pre-determined values. We may write those set of possible value using the in judgment. For instance, the judgment
which holds, if the object Color has either the value blue or the value green.
2.1.3 Notations for inference rules
Inference rules are used to specify whether a judgment holds or not. Inference rules express the logical relation between judgments and describe how complex judgments can be concluded from simpler premise judgments.
A logical inference rule is written as a collection of premises and a conclusion, written respectively above and below a dividing line:
| premise1 ... premisen |
|
| conclusion |
All premises and the conclusion are judgments. The interpretation of an inference rule is: if all the premise judgments above the line hold, then the conclusion judgment below the line must also hold.
Here is a simple example of inference rule, which uses the example judgment 'Expr => Value' from above:
| $x => 0 3 => 3 |
|
| $x + 3 => 3 |
This inference rule expresses the following property of the judgment 'Expr => Value': if the variable expression '$x' yields the value '0', and the literal expression '3' yields the value '3', then the expression '$x + 3' yields the value '3'.
An inference rule may have no premises above the line, which means that the expression below the line always holds:
This inference rule expresses the following property of the judgment 'Expr => Value': evaluating the literal expression '3' always yields the value '3'.
The two above rules are expressed in terms of specific variables and values, but usually rules are more abstract. That is, the judgments they relate contain patterns. Here is a rule that says that for any variable Variable that yields the integer value Integer, adding '0' yields the same integer value:
| Variable => Integer |
|
| Variable + 0 => Integer |
As in a judgment, each pattern in a particular inference rule must be instantiated to the same "object" within the entire rule. This means that one can talk about "the value of Variable" instead of the more precise "what Variable is instantiated to in (this particular instantiation of) the inference rule".
2.1.4 Notations for environments
Logical inference rules use environments to record information computed during static type analysis or dynamic evaluation so that this information can be used by other logical inference rules. For example, the type signature of a user-defined function in a [expression/query] prolog can be recorded in an environment and used by subsequent rules. Similarly, the value assigned to a variable within a "let" expression can be captured in an environment and accessed later on during evaluation when that
variable is accessed.
An environment is a dictionary that maps a symbol (e.g., a function name or a variable name) to an "object" (e.g., a function body, a type, a value). One can access information in an environment or update the environment.
If "env" is an environment, then "env(symbol)" denotes the "object" to which symbol is mapped. The notation is intentionally similar to function application, because an environment can be considered a function from the argument symbol to the "object" to which the symbol is mapped.
This document uses environment groups that group related environments. If "group" is an environment group with the environment component "env", then that environment is denoted "group.env" and the value that symbol is mapped to is denoted "group.env(symbol)".
The two main environment groups used in the Formal Semantics are: a dynamic environment group (dynEnv), which models to the [XPath/XQuery]'s dynamic context, and a static environment group (statEnv), which models the [XPath/XQuery]'s static context. Both are defined in [3.1 Expression Context].
For example, dynEnv.varValue denotes the dynamic environment that maps variables to values and dynEnv.varValue(Variable) denotes the value of the variable Variable in the dynamic context.
Environment groups are used in a judgment to capture some of the context in which the judgment is computed, and most judgments are computed assuming that some environment is given. This assumption is denoted by prefixing the judgment with "env |-". The "|-" symbol is called a "turnstile" and is used in almost all inference rules.
For instance, the judgment
is read as: Assuming the dynamic environment group dynEnv, the expression Expr yields the value Value.
Environment groups can be updated, using the following notation:
-
"group + env(symbol => object) " denotes the new environment group that is identical to group except that the env environment has been updated to map symbol to object. The notation symbol => object indicates that symbol is mapped to object in the new environment.
-
The following shorthand is also allowed: "group + env( symbol1 => object1 ; ... ; symboln => objectn ) " in which each symbol is mapped to a corresponding object in the new environment.
This notation is equivalent to nested updates, as in " (group + env( symbol1 => object1) + ... ) + env(symboln => objectn)".
Updating an environment creates a copy of the original environment and overrides any previous binding that might exist for the same name and the same group in that environment. Updating the environment is used to capture the scope of a symbol (e.g., for variables, namespace prefixes, etc). For instance, in the following expression
let $x := 1 return
let $x := $x + 2 return
$x - 3
each let expression changes the dynamic context by binding a new variable to a new value. Each different context is represented by a different environment. The original environment, in which the expression 1 is evaluated, does not contain any binding for variable $x. This environment is updated a first time with a binding of variable $x to the value 1, and this environment is used for the evaluation of the expression $x + 2. Then it is
updated a second time with a binding of variable $x to the value 3, and this environment is used for the evaluation of the expression$x - 3.
Also, note that there are no operations to remove entries from environments. This is never necessary as updating an environment effectively creates a new extended copy of the original environment, leaving the original environment accessible wherever it is in scope along with the updated copy.
2.1.5 Putting it together
Putting the above notations together, here is an example of an inference rule that occurs later in this document:
This rule is read as follows: if two expressions Expr1 and Expr2 are known to have the static types types Type1 and Type2 (the two premises above the line), then it is the case that the expression below the line "Expr1 ,
Expr2" must have the static type "Type1, Type2", which is the sequence of types Type1 and Type2. The above inference rule does not modify the (static) environment.
The following rule defines the static semantics of a "let" expression. The binding of the new variable is captured by an update to the varType component of the original static environment.
This rule is read as follows: First, because the variable is a QName, it is first expanded into an expanded QName. Second, the type Type1 for the "let" input expression Expr1 is computed. Then the "let" variable with expanded name, expanded-QName with type Type1 is added into the
varType component of the static environment group statEnv. Finally, the type Type2 of Expr2 is computed in that new environment.
Each inference rule describes a fragment of the semantics for a given expression. Here is how those rules are combined. Consider the following expression.
let $x := 1 return ($x,$x)
We have just seen the static typing rule for the let clause and sequence construction. To handle this expression completely, we need inference rules for integer literals and variable access. Those two rules are as follows.
With this set of rules, we can compute the type of the expression above in a bottom-up fashion, i.e., starting with the sub-expressions. The resulting type inference proceeds as follows.
statEnv0 = ()
statEnv0 |- 1 : xs:integer
statEnv1 = ($x -> 1)
statEnv1 |- $x : xs:integer
statEnv1 |- $x : xs:integer
statEnv1 |- ($x,$x) : xs:integer,xs:integer
statEnv0 |- let $x := 1 return ($x,$x) : xs:integer,xs:integer
This example illustrates how each rule is applied to individual sub-expressions, and how the environment is used to maintain the relevant context information.
2.2 URIs, Namespaces, and Prefixes
The Formal Semantics does not formally specify the adjustment of relative URIs according to a base URI. All URIs used in this document are assumed to be absolute URIs.
The Formal Semantics uses the following namespace prefixes.
-
fn: for functions and operators from the [Functions and Operators] document.
-
xs: for XML Schema components and built-in types.
-
xdt: for [XPath/XQuery] built-in types.
All these prefixes are assumed to be bound to the appropriate URIs.
In addition, the Formal Semantics uses the following special prefixes for specification purposes.
These prefixes are always italicized to emphasize that the corresponding functions, variables, and types are abstract: they are not and cannot be made accessible in [XPath/XQuery]. None of these special prefixes are given a URI.
2.3 XML Values
The [XPath/XQuery] language is defined over values of the [XPath/XQuery] data model. The [XPath/XQuery] data model is defined normatively in [Data Model]. We define the formal notation that is used in this document to describe and manipulate values in inference rules. Formal values are used for specification purposes only and are not exposed to the [XPath/XQuery] user.
This section gives the grammar for formal values, along with a summary of the corresponding data model properties. In the context of this document, all constraints on values that are specified in [Data Model] are assumed to hold.
2.3.1 Formal values
A value is a sequence of zero or more items. An item is either an atomic value or a node.
An atomic value is a value in the value space of an atomic type, labeled with the name of that atomic type. An atomic type is either a primitive or derived atomic type according to XML Schema [Schema Part 2], xdt:untypedAtomic, or xdt:anyAtomicType.
A node is either an element, an attribute, a document, a text, a comment, or a processing-instruction node.
Element nodes have a type annotationXQ and contain a complex value or a simple value. Attribute nodes have a type annotationXQ and contain a simple value. Text nodes always contain one string value of type xdt:untypedAtomic, therefore the corresponding type annotation is omitted in
the formal notation of a text node. Document nodes do not have a type annotation and contain a sequence of element, text, comment, or processing-instruction nodes.
A simple value is a sequence of atomic values.
A complex value is a sequence of attribute nodes followed by a sequence of element, text, comment, or processing-instruction nodes.
A type annotationXQ can be either the QName of a declared type or an anonymous type. An anonymous type corresponds to an XML Schema type for which the schema writer did not provide a name. Anonymous type names are not visible to the user, but are generated during schema validation and used to annotate nodes in the data model. By convention, anonymous type names are written using the fs: Formal
Semantics prefix: fs:anon0, fs:anon1, etc.
Formal values are defined by the following grammar.
Values
Notation
In that grammar, "String" indicates the value space of xs:string, "Decimal" indicates the value space of xs:decimal, etc.
Element (resp. attributes) without type annotations, are assumed to have the type annotation xs:anyType (resp. xs:anySimpleType). Atomic values without type annotations, are assumed to have a type annotation which is the base type for the corresponding value. For instance, "Hello, World!" is equivalent to "Hello, World!" of type xs:string.
Untyped elements (e.g., from well-formed documents) have the type annotationXQ xdt:untyped, untyped attributes have the type annotationXQ xdt:untypedAtomic, and untyped atomic values have the type annotationXQ xdt:untypedAtomic.
An element has an optional "nilled" marker. This marker can only be present if the element has been validated against an element type in the schema which is "nillable", and the element has no content and an attribute xsi:nil set to "true".
An element also has a sequence of namespace bindings, which are the set of in-scope namespaces for that element. Each namespace binding is a prefix, URI pair. Elements without namespace bindings are assumed to have an empty set of in-scope namespaces.
Note:
In [XPath], the in-scope namespaces of an element node are represented by a collection of namespace nodes arranged on a namespace axis, which is optional and deprecated in [XML Path Language (XPath) 2.0]. XQuery does not support the namespace axis and does not represent namespace bindings in the form of nodes.
In examples, we omit the namespace bindings when they are empty. For example, the following two values are the same (note that the xs and xdt prefixes are built-in):
element weight of type xs:integer { text { "42" } } {}
element weight of type xs:integer { text { "42" } }
The same rule about constructing sequences apply to the values described by that grammar. Notably sequences are automatically flattened. For example, the sequence (10, (1, 2), (), (3, 4)) is equivalent to the sequence (10, 1, 2, 3, 4).
When the context is clear, we may omit the type annotationXQ on literal values. For instance:
"Hello World!" instead of "Hello World!" of type xs:string
10 instead of 10 of type xs:integer
2.3.2 Examples of values
A well-formed document
<fact>The cat weighs <weight units="lbs">12</weight> pounds.</fact>
In the absence of a Schema, this document is represented as
element fact of type xdt:untyped {
text { "The cat weighs " },
element weight of type xdt:untyped {
attribute units of type xdt:untypedAtomic {
"lbs" of type xdt:untypedAtomic
}
text { "12" }
},
text { " pounds." }
}
A document before and after validation.
<weight xsi:type="xs:integer">42</weight>
The formal model for values can represent values before and after validation. Before validation, this element is represented as:
element weight of type xdt:untyped {
attribute xsi:type of type xdt:untypedAtomic {
"xs:integer" of type xdt:untypedAtomic
},
text { "42" }
}
After validation, this element is represented as:
element weight of type xs:integer {
attribute xsi:type of type xs:QName {
"xs:integer" of type xs:QName
},
42 of type xs:integer
}
An element with a list type
Before validation, this element is represented as:
element sizes of type xdt:untyped {
text { "1 2 3" }
}
Assume the following Schema.
<xs:element name="sizes" type="sizesType"/>
<xs:simpleType name="sizesType">
<xs:list itemType="sizeType"/>
</xs:simpleType>
<xs:simpleType name="sizeType">
<xs:restriction base="xs:integer"/>
</xs:simpleType>
After validation against this Schema, the element is represented as:
element sizes of type sizesType {
1 of type sizeType,
2 of type sizeType,
3 of type sizeType
}
An element with an anonymous type
Before validation, this element is represented as:
element sizes of type xdt:untyped {
text { "1 2 3" }
}
Assume the following Schema.
<xs:element name="sizes">
<xs:simpleType>
<xs:list itemType="xs:integer"/>
</xs:simpleType>
</xs:element>
After validation, this element is represented as:
element sizes of type fs:anon1 {
1 of type xs:integer,
2 of type xs:integer,
3 of type xs:integer
}
where fs:anon1 stands for the internal anonymous name generated by the system for the sizes element.
An nillable element with xsi:type set to true:
Before validation, this element is represented as:
element sizes of type xdt:untyped {
attribute xsi:nil of type xdt:untypedAtomic { "true" as xdt:untypedAtomic }
}
Assume the following Schema.
<xs:element name="sizes" type="sizesType" nillable="true"/>
After validation against this Schema, the element is represented as:
element sizes nilled of type sizesType {
attribute xsi:nil of type xs:boolean { true as xs:boolean }
}
An element with a union type
<sizes>1 two 3 four</sizes>
Before validation, this element is represented as:
element sizes of type xdt:untyped {
text { "1 two 3 four" }
}
Assume the following Schema:
<xs:element name="sizes" type="sizesType"/>
<xs:simpleType name="sizesType">
<xs:list itemType="sizeType"/>
</xs:simpleType>
<xs:simpleType name="sizeType">
<xs:union memberType="xs:integer xs:string"/>
</xs:simpleType>
After validation against this Schema, the element is represented as:
element sizes of type sizesType {
1 of type xs:integer,
"two" of type xs:string,
3 of type xs:integer,
"four" of type xs:string
}
2.4 The [XPath/XQuery] Type System
The [XPath/XQuery] type system is used in the specification of the dynamic and of the static semantics of [XPath/XQuery]. This section introduces formal notations for describing types.
2.4.1 XML Schema and the [XPath/XQuery] Type System
The [XPath/XQuery] type system is based on [Schema Part 1] and [Schema Part 2]. [Schema Part 1] and [Schema Part 2] specify normatively the type information available in [XPath/XQuery]. We define the formal notation that is used in this document to describe and manipulate types in inference rules. Formal types are used for specification purposes only and are not exposed to the [XPath/XQuery]
user.
Representation of content models. For the purpose of static typing, the [XPath/XQuery] type system only describes minOccurs, maxOccurs, and minLength, maxLength on list types for the occurrences that correspond to the DTD operators +, *, and ?. Choices are represented using the DTD operator |. All groups are represented using the interleaving operator (&).
Representation of anonymous types. To clarify the semantics, the [XPath/XQuery] type system makes all anonymous types explicit.
Representation of XML Schema simple type facets and identity constraints. For simplicity, XML Schema simple type facets and identity constraints are not formally represented in the [XPath/XQuery] type system. However, an [XPath/XQuery] implementation supporting XML Schema import and validation must must take simple type facets and identity constraints into account.
The mapping from XML Schema into the [XPath/XQuery] type system is given in [C Importing Schemas]. The rest of this section is organized as follows. [2.4.2 Item types] describes types items, [2.4.3 Content models] describes content models, and [2.4.4 Top level definitions] describe top-level type declarations.
2.4.2 Item types
An item type is either an atomic type, an element type, an attribute type, a document node type, a text node type, a comment node type, or a processing instruction type. We distinguish between document nodes, attribute nodes, and nodes that can occur in element content (elements, comments, processing instructions, and text nodes), as we need to refer to element content types later in the formal semantics.
Item Types
An element or attribute type has an optional name and an optional type reference. A name alone corresponds to a reference to a global element or attribute declaration. A name with a type reference corresponds to a local element or attribute declaration. The word "element" or "attribute" alone refers to the wildcard types for any element or any attribute. In addition, an element type has an optional nillable flag that indicates whether the element can be nilled or not.
A document type has an optional content type. If no content type is given, then the type is treated as being the wildcard type for documents, i.e., a sequence of text and element nodes. For consistency with element nodes, PIs and comments are not indicated in that wildcard type, but may occur in instances.
Note
Generic node types (e.g., node()) such as used in the SequenceType production, are interpreted in the type system as union types (e.g., element | attribute | text | comment | processing-instruction) and therefore do not appear here. The semantics of sequence types is described in [3.5.4 SequenceType Matching].
Examples
The following is a text node type
The following is a type for all elements
The following is a type for all elements of type string
element of type xs:string
The following is a type for a nillable element of type string and with name size
element size nillable of type xs:string
The following is a reference to a global attribute declaration
The following is a type for elements with anonymous type fs:anon1:
element sizes of type fs:anon1
2.4.3 Content models
Following XML Schema, types in [XPath/XQuery] are composed from item types by optional, one or more, zero or more, all group, sequence, choice, empty sequence (written empty), or empty choice (written none).
The type empty matches the empty sequence. The type none matches no values. none is the identity for choice, that is (Type | none) = Type)). The type none is the static type for [7.2.9 The fn:error function].
Types
The [XPath/XQuery] type system includes three binary operators on types: ",", "|" and "&", corresponding respectively to sequence, choice and all groups in Schema. The [XPath/XQuery] type system includes three unary operators on types: "*", "+", and "?", corresponding respectively to zero or more instances of the type, one or more instances of the type, or an optional instance of the type.
The "&" operator builds the "interleaved product" of two types. The type Type1 & Type2 matches any sequence that is an interleaving of a sequence that matches Type1 and a sequence that matches Type2. The
interleaved product captures the semantics of all groups in XML Schema, but it more general has it applies to arbitrary types. All groups in XML Schema are restricted to apply only on global or local element declarations with minOccurs 0 or 1, and maxOccurs 1.
The "&" operator builds the "interleaved product" of two types. The type Type1 & Type2 matches any sequence that is an interleaving of two sequences of items, the first one matching Type1 and the second matching Type2. Where the interleaving of two sequences of items Value1 and Value2 is any sequence Value0 such that there is an ordered partition of Value0 into the two sub-sequences Value1 and Value2.
For example, consider the types Type1 = xs:integer,xs:integer,xs:integer and Type2 = xs:string,xs:string. Value1 = (1,2,3) matches the type Type1 and
Value2 = ("a","b") matches the type Type2. Any of the following Value0 are interleavings of Value1 and Value2, and therefore match the type (Type1 & Type2):
Value0 = (1,2,3,"a","b")
Value0 = (1,2,"a",3,"b")
Value0 = (1,2,"a","b",3)
Value0 = (1,"a",2,3,"b")
Value0 = (1,"a",2,"b",3)
Value0 = (1,"a","b",2,3)
Value0 = ("a",1,2,3,"b")
Value0 = ("a",1,2,"b",3)
Value0 = ("a",1,"b",2,3)
Value0 = ("a","b",1,2,3)
Types precedence order. To improve readability when writing types, we assume the following precedence order between operators on types.
| # |
Operator |
Associativity |
| 1 |
| (choice) |
left-to-right |
| 2 |
& (interleaving) |
right-to-left |
| 3 |
, (sequence) |
left-to-right |
| 4 |
*, +, ? (occurrence) |
left-to-right |
Parenthesis can be used to enforce precedence. For instance
xs:string | xs:integer, xs:float*
is equivalent to
xs:string | (xs:integer, (xs:float*))
and a different precedence can be obtained by writing
((xs:string | xs:integer), xs:float)*
Examples
A sequence of elements
The "," operator builds the "sequence" of two types. For example,
element title of type xs:string, element year of type xs:integer
is a sequence of an element title of type string followed by an element year of type integer.
The union of two element types
The "|" operator builds the "union" of two types. For example,
element editor of type xs:string | element bib:author
means either an element editor of type string, or a reference to the global element bib:author.
An all group of two elements
The "&" operator builds the "interleaved product" of two types. For example,
(element a & element b) =
element a, element b
| element b, element a
which specifies that the a and b elements can occur in any order.
An empty type
The following type matches the empty sequence.
A sequence of zero or more elements
The following type matches zero or more elements each of which can be a surgeon or a plumber.
(element surgeon | element plumber)*
2.4.4 Top level definitions
Top level definitions correspond to global element declarations, global attribute declarations and type definitions in XML Schema.
Type Definitions
A type definition has a name (possibly anonymous) and a type derivation. In the case of a complex type, or a simple type derived by list or union, derivation indicates if the type is derived by extension or restriction from its base type, gives its content model, and an optional flag indicating if it has mixed content. In the case of an atomic type, it just indicates from which type it is derived. When the type derivation is omitted, the type derives by restriction from xs:anyType, as
in:
define type Bib { element book* } =
define type Bib restricts xs:anyType { element book* }
Empty content can be indicated with the explicit empty sequence, or omitted, as in:
define type Bib { } =
define type Bib { empty }
Global element and attribute declarations always have a name and a reference to a (possibly anonymous) type. A global element declaration also may declare a substitution group for the element and whether the element is nillable.
Examples
A type declaration with one element name of type xs:string follows by one or more elements street of type xs:string.
define type Address {
element name of type xs:string,
element street of type xs:string*
}
A type declaration with complex content derived by extension
define type USAddress extends Address {
element zip name of type xs:integer
}
A type declaration with mixed content
define type Section mixed {
(element h1 of type xs:string |
element p of type xs:string |
element div of type Section)*
}
A type declaration with simple content derived by restriction
define type SKU restricts xs:string
An element declaration
define element address of type Address
An element declaration with a substitution group
define element usaddress substitutes for address of type USAddress
An element declaration which is nillable
define element zip nillable of type xs:integer
2.4.5 Example of a complete Schema
Here is a schema describing purchase orders from [XML Schema Part 0].
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:annotation>
<xsd:documentation xml:lang="en">
Purchase order schema for Example.com.
Copyright 2000 Example.com. All rights reserved.
</xsd:documentation>
</xsd:annotation>
<xsd:element name="purchaseOrder" type="PurchaseOrderType"/>
<xsd:element name="comment" type="xsd:string"/>
<xsd:complexType name="PurchaseOrderType">
<xsd:sequence>
<xsd:element name="shipTo" type="USAddress"/>
<xsd:element name="billTo" type="USAddress"/>
<xsd:element ref="comment" minOccurs="0"/>
<xsd:element name="items" type="Items"/>
</xsd:sequence>
<xsd:attribute name="orderDate" type="xsd:date"/>
</xsd:complexType>
<xsd:complexType name="USAddress">
<xsd:sequence>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="street" type="xsd:string"/>
<xsd:element name="city" type="xsd:string"/>
<xsd:element name="state" type="xsd:string"/>
<xsd:element name="zip" type="xsd:decimal"/>
</xsd:sequence>
<xsd:attribute name="country" type="xsd:NMTOKEN" fixed="US"/>
</xsd:complexType>
<xsd:complexType name="Items">
<xsd:sequence>
<xsd:element name="item" minOccurs="0" maxOccurs="unbounded">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="productName" type="xsd:string"/>
<xsd:element name="quantity">
<xsd:simpleType>
<xsd:restriction base="xsd:positiveInteger">
<xsd:maxExclusive value="100"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:element>
<xsd:element name="USPrice" type="xsd:decimal"/>
<xsd:element ref="comment" minOccurs="0"/>
<xsd:element name="shipDate" type="xsd:date" minOccurs="0"/>
</xsd:sequence>
<xsd:attribute name="partNum" type="SKU" use="required"/>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
<!-- Stock Keeping Unit, a code for identifying products -->
<xsd:simpleType name="SKU">
<xsd:restriction base="xsd:string">
<xsd:pattern value="\d{3}-[A-Z]{2}"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:schema>
Here is the mapping of the above schema into the [XPath/XQuery] type system.
declare namespace xsd = "http://www.w3.org/2001/XMLSchema";
define element purchaseOrder of type PurchaseOrderType;
define element comment of type xsd:string;
define type PurchaseOrderType {
attribute orderDate of type xsd:date?,
element shipTo of type USAddress,
element billTo of type USAddress,
element comment?,
element items of type Items
};
define type USAddress {
attribute country of type xsd:NMTOKEN,
element name of type xsd:string,
element street of type xsd:string,
element city of type xsd:string,
element state of type xsd:string,
element zip of type xsd:decimal
};
define type Items {
attribute partNum of type SKU,
element item of type fs:anon1*
};
define type fs:anon1 {
element productName of type xsd:string,
element quantity of type fs:anon2,
element USPrice of type xsd:decimal,
element comment?,
element shipDate of type xsd:date?
};
define type fs:anon2 restricts xsd:positiveInteger;
define type SKU restrict xsd:string;
Note that the two anonymous types in the item element declarations are mapping to types with names fs:anon1 and fs:anon2.
The following additional definitions illustrate how more advanced XML Schema features (a complex type derived by extension, an anonymous simple type derived by restriction, and substitution groups) are represented in the [XPath/XQuery] type system.
<complexType name="NYCAddress">
<complexContent>
<extension base="USAddress">
<sequence>
<element ref="apt"/>
</sequence>
</extension>
</complexContent>
</complexType>
<element name="apt">
<xsd:simpleType>
<xsd:restriction base="xsd:positiveInteger">
<xsd:maxExclusive value="10000"/>
</xsd:restriction>
</xsd:simpleType>
</element>
<element name="usaddress" substitutionGroup="address" type="USAddress"/>
<element name="nycaddress" substitutionGroup="usaddress" type="NYCAddress"/>
The above definitions are mapped into the [XPath/XQuery] type system as follows:
define type NYCAddress extends USAddress {
element apt
}
define element apt of type fs:anon3
define type fs:anon3 restricts xsd:positiveInteger
define element usaddress substitutes for address of type USAddress
define element nycaddress substitutes for usaddress of type NYCAddress
2.5 Functions and operators
The [Functions and Operators] document defines built-in functions available in [XPath/XQuery]. A number of these functions are used to define the [XPath/XQuery] semantics; those functions are listed in [B.1 Functions and Operators used in the Formal Semantics].
Many functions in the [Functions and Operators] document are generic: they perform operations on arbitrary components of the data model, e.g., any kind of node, or any sequence of items. For instance, the fn:unordered returns its input sequence in an implementation-dependent order. The signature of the fn:unordered function takes arbitrary items as input and output:
fn:unordered($sourceSeq as item()*) as item()*
As defined, this signature provides little useful type information. For such functions, better type information can often be obtained by having the output type depend on the type of input parameters. For instance, if the function fn:unordered is applied on a sequence of a elements, the resulting sequence is also a collection of either a elements.
In order to provide better static typing for those functions, specific typing rules are given in [7 Additional Semantics of Functions].
4 Expressions
This section gives the semantics of all the [XPath/XQuery] expressions. The organization of this section parallels the organization of Section 3 ExpressionsXQ.
For each expression, a short description and the relevant grammar productions are given. The semantics of an expression includes the normalization, static analysis, and dynamic evaluation phases. Recall that normalization rules translate [XPath/XQuery] syntax into Core syntax. In the sections that contain normalization rules, the Core grammar productions into which the expression is normalized are also provided. After normalization, sections on static type inference and dynamic evaluation define the
static type and dynamic value for the Core expression.
Core Grammar
The Core grammar productions for expressions are:
Static Type Analysis
It is a static type error for any expression to have the empty type, except for the following expressions and functions:
-
Empty parenthesis (), which denote the empty sequence.
-
The fn:data function and all functions in the fs namespace applied to empty parenthesis().
-
Any function which returns the empty type.
The reason for those exception is that they are typically part of the result of normalizing a larger user-level expression and are used to capture the semantics of the user-level expression when applied to the empty sequence.
The rule below enforces the above constraints. The static typing rule for () is in [4.1.3 Parenthesized Expressions].
| statEnv |- Expr : Type |
not(Expr is empty parenthesis () or fn:data or any fs function applied to empty parenthesis ()) |
not(Type = empty) |
|
|
|
|
|
The rule is written in this way (i.e., in the double negative), because for any expression such that no static type rule applies to the expression, a static type error is raised. That is, the absence of an applicable static rule indicates an error. For example, if an expression is not an empth parenthesis () but has the empty type, the above rule does not apply and therefore a static error is raised.
Example
The above rule can catch common mistakes, such as the misspelling of an element or attribute name or referencing of an element or attribute that does not exist. For instance, the following path expression
raises a static error if the type of variable $x does not include any title children elements.
4.1 Primary Expressions
Primary expressions are the basic primitives of the language.They include literals, variables, function calls, and the parenthesized expressions.
Primary Expressions
Core Grammar
The Core grammar production for primary expressions is:
Primary Expressions
4.1.1 Literals
Introduction
A literal is a direct syntactic representation of an atomic value. [XPath/XQuery] supports two kinds of literals: string literals and numeric literals.
Literals
Core Grammar
The Core grammar productions for literals are:
Literals
Normalization
All literals are Core expressions, therefore no normalization rules are required for literals. Predefined entity references and character references in strings are resolved to characters as part of parsing and therefore they do not occur in the Core grammar.
Static Type Analysis
In the static semantics, the type of an integer literal is simply xs:integer:
Dynamic Evaluation
In the dynamic semantics, an integer literal is evaluated by constructing an atomic value in the data model, which consists of the literal value and its type:
|
dynEnv |- IntegerLiteral => xs:integer (IntegerLiteral) |
|
|
The formal definitions of decimal, double, and string literals are analogous to those for integer.
Static Type Analysis
Dynamic Evaluation
|
dynEnv |- DecimalLiteral => xs:decimal(DecimalLiteral) |
|
|
Static Type Analysis
Dynamic Evaluation
|
dynEnv |- DoubleLiteral => xs:double(DoubleLiteral) |
|
|
Static Type Analysis
Dynamic Evaluation
|
dynEnv |- StringLiteral => xs:string(StringLiteral) |
|
|
Dynamic Errors
Literal expressions never raise a dynamic error. Note that literal overflows are raised during parsing.
4.1.2 Variable References
Introduction
A variable evaluates to the value to which the variable's QName is bound in the dynamic context.
Variable References
Core Grammar
The Core grammar productions for variable references are:
Primary Expressions
Normalization
A variable is a Core expression, therefore no normalization rule is required for a variable.
Static Type Analysis
In the static semantics, the type of a variable is simply its type in the static type environment statEnv.varType:
If the variable is not bound in the static environment, a static error is raised.
Dynamic Evaluation
In the dynamic semantics, a locally declared variable is evaluated by "looking up" its value in dynEnv.varValue:
In the dynamic semantics, an imported variable is evaluated in the dynamic context of the module in which it is declared:
Dynamic Errors
If the variable is not bound in the dynamic environment, a dynamic error is raised; the default rules in [3.3 Error Handling] cover this error.
4.1.3 Parenthesized Expressions
Core Grammar
The Core grammar production for parenthesized expressions is:
Empty parenthesis () always have the empty type. Remember that it is a static error for most expressions other than () to have the empty type (see [4 Expressions] for the complete rule.)
Static Type Analysis
Dynamic Evaluation
Empty parenthesis () evaluate to the empty sequence.
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to parenthesized expressions.
4.1.4 Context Item Expression
Introduction
A context item expression evaluates to the context item, which may be either a node or an atomic value.
Normalization
A context item expression is normalized to the built-in variable $fs:dot. Because it can only be bound through the external context or a path expression, there is no need for a specific typing rule to enforce that its value is a singleton item.
4.1.5 Function Calls
Introduction
A function call consists of a QName followed by a parenthesized list of zero or more expressions. In [XPath/XQuery], the actual argument to a function is called an argument and the formal argument of a function is called a parameter. We use the same terminology here.
Function Calls
Because [XPath/XQuery] implicitly converts the values of function arguments, a normalization step is required.
Notation
Normalization of function calls uses an auxiliary mapping []FunctionArgument(SequenceType) used to insert conversions of function arguments that depend only on the expected SequenceType of the corresponding parameters. It is defined as follows:
where
-
[Expr]AtomizeAtomic(SequenceType) denotes
which specifies that if the function expects atomic parameters, then fn:data is called to obtain them.
-
[Expr]Convert(SequenceType) denotes
where PrototypicalValue is a built-in atomic value used to encode the corresponding atomic type. A value is used here since [XPath/XQuery] expressions cannot operate directly on types. Which value is chosen does not have any impact on the actual semantics, only its actual atomic type matters.
Note
The fs:convert-simple-operand function takes a PrototypicalValue, which is a value of the target type, to ensure that conversion to base types is possible even though types are not first class objects in [XPath/XQuery].
Core Grammar
The Core grammar production for function calls is:
Function Calls
Normalization
Each argument expression in a function call is normalized to its corresponding Core expression by applying []FunctionArgument(SequenceType) for each argument with the expected SequenceType for the argument inserted.
Note that this normalization rule depends on the static environment containing function signatures and is the only normalization rule that depends on statEnv. Furthermore notice that the normalization is only well-defined when it is guaranteed that overloading is restricted to atomic types with the same quantifier. This is presently the case.
Static Type Analysis
To typecheck a Core function call we first check in Section [7 Additional Semantics of Functions] if there is a specialized typing rule for the function, and, if so, use it. Otherwise, the function signatures matching the function name and arity are retrieved from the static environment. The type of each argument to the function must be a subtype of a type that is promotable to the corresponding function parameter type of the function; if the inferred type is
a union of atomic types then this check is performed separately for each possibility.
The first rule bootstraps type checking of a function call: It expands the function's QName and then applies the function call rule for the expanded function call:
For a function call in which the static type of one of the expressions passed as argument is a union of atomic types, the function call is type checked once separately for each atomic type in that union. The static type of the entire function call expression is then the union of the types computed in each case, as follows:
Note
Notice that this semantics makes sense since the type declared for a function parameter, which uses the sequence types syntax, cannot itself be a union.
Finally, the following auxilliary rule type checks a function call in which none of the actual arguments has a type that is a union of atomic types. The rule looks up the function in the static environment and checks that some signature for the function satisfies the following constraint: the type of each actual argument is a subtype of some type that can be promoted to the type of the correponding function parameter. In this case, the function call is well typed and the result type is the
return type specified in the function's signature.
The function body itself is not analyzed for each invocation: static typing of the function definition itself guarantees that the function body always returns a value of the declared return type.
Notice that the static typing rule checks the function signature in order to determine whether a function exists rather than just the function arity: this is consistent because it will reject function calls with the wrong arity in addition to function calls with the right arity but incompatible parameter types.
Dynamic Evaluation
Based on a function's name and parameter types, the function body is retrieved from the dynamic environment.
If the function is a locally-declared, user-defined function then it is evaluated as follows. First, the rule evaluates each actual function argument expression. Next, a match is searched for among the function's possible declaration signatures, retrieved from statEnv.funcType. If the function is not present in the environment, or there is no matching declaration signature, a type error is raised. Otherwise, the function
body and formal variables are obtained from dynEnv.funcDefn for the matching declaration signature. The rule then extends dynEnv.varValue by binding each formal variable to its corresponding value (converted by the normalization as required for the expected type), and evaluates the body of the function in the new environment. The resulting value is
the value of the function call.
Note that the function body is evaluated in the default (top-level) environment extended with just the parameter bindings. Note also that input values and output values are matched against the types declared for the function. If static analysis was performed, all these checks are guaranteed to be true and may be omitted.
The rule for evaluating an imported function is similar to that for evaluating a locally declared function, except that the function call is evaluated in the dynamic context of the module in which it is declared.
| dynEnv |- Expr1 => Value1 |
| ... |
| dynEnv |- Exprn => Valuen |
| statEnv |- QName of func expands to expanded-QName |
| statEnv.funcType(expanded-QName) = { FunctionDecl1, ..., FunctionDeclm } |
| FunctionDecli = declare function expanded-QName(Type1, ..., Typen) as Type |
dynEnv.funcDefn(expanded-QName(Type1, ..., Typen)) = #IMPORTED(URI) |
| URI =>module_statEnv statEnv1 |
| URI =>module_dynEnv dynEnv1 |
| statEnv.funcType1(expanded-QName) = { FunctionDecl1', ..., FunctionDeclm' } |
| FunctionDecli' = declare function expanded-QName(Type1', ..., Typen') as Type' |
| dynEnv1.funcDefn(expanded-QName(Type1, ..., Typen)) = (Expr, Variable1, ... , Variablen) |
| statEnv |- Value1 against Type1 promotes to Value1' |
| ... |
| statEnv |- Valuen against Typen promotes to Valuen' |
| dynEnvDefault + varValue( Variable1 => Value1'; ...; Variablen => Valuen') |- Expr => Value' |
|
|
|
|
|
If the function is a built-in or external function then the rule is somewhat simpler:
Calls to built-in or external functions use the following auxiliary judgment to evaluate the built-in or external function:
Dynamic Errors
If the evaluation of any actual argument raises an error, the function call can raise an error. This rule applies to both user-defined and built-in functions. Note that if more than one expression may raise an error, the function call may raise any one of the errors.
If, for all possible function signatures, the evaluation of some actual argument yields a value that cannot be promoted to the corresponding formal type of the parameter, the function call raises a type error. This rule applies to both user-defined and built-in functions.
If the evaluation of the function call to a user-defined function yields a value that cannot be promoted to the corresponding return type of the function, the function call raises a type error.
If the evaluation of the function call to a built-in or external function yields a value that cannot be promoted to the corresponding return type of the function, the built-in or external function call raises a type error.
Built-in function calls use the following auxiliary judgment to evaluate the built-in function call. If the built-in function raises an error, the function call raises an error.
| "The built-in function F (from data model, type constructor, or functions and operators) applied to the given parameter raises an error" |
|
|
|
4.2 Path Expressions
Introduction
Path expressions are used to locate nodes within a tree. There are two kinds of path expressions, absolute path expressions and relative path expressions. An absolute path expression is a rooted relative path expression. A relative path expression is composed of a sequence of steps.
Path Expressions
Core Grammar
PathExpr and RelativePathExpr are fully normalized, therefore they have no corresponding productions in the Core. The grammar for path expressions in the Core starts with the StepExpr production.
Normalization
Absolute path expressions are path expressions starting with the / or // symbols, indicating that the expression must be applied on the root node in the current context. The root node in the current context is the greatest ancestor of the context node. The following two rules normalize absolute path expressions to relative ones. They use the fn:root function, which returns the greatest ancestor of its argument node. The treat expressions guarantee that the value
bound to the context variable $fs:dot is a document node.
| |
| [/]Expr |
| == |
(fn:root(self::node()) treat as document-node()) |
| |
| [/ RelativePathExpr]Expr |
| == |
[((fn:root(self::node())) treat as document-node()) / RelativePathExpr]Expr |
| |
| ["//" RelativePathExpr]Expr |
| == |
[((fn:root(self::node())) treat as document-node) / descendant-or-self::node() / RelativePathExpr]Expr |
| |
| [ StepExpr // RelativePathExpr ]Expr |
| == |
| [StepExpr / descendant-or-self::node() / RelativePathExpr]Expr |
A composite relative path expression (using /) is normalized into a for expression by concatenating the sequences obtained by mapping each node of the left-hand side in document order to the sequence it generates on the right-hand side. The call to the fs:distinct-doc-order function ensures that the result is in document order without duplicates. The dynamic context is defined by binding the
$fs:dot, $fs:sequence, $fs:position and $fs:last variables.
Note that sorting by document order enforces the restriction that input and output sequences contains only nodes, and that the last step in a path expression may actualy return atomic values.
| |
| [StepExpr / RelativePathExpr]Expr |
| == |
|
|
4.2.1 Steps
Note that for this section uses some auxiliary judgments which are defined in [8.2 Judgments for step expressions and filtering].
Introduction
Steps
Core Grammar
The Core grammar productions for XPath steps are:
Steps
Note
Step expressions can be followed by predicates. Normalization of predicates uses the following auxiliary mapping rule: []Predicates, which is specified in [4.2.2 Predicates]. Normalization for step expressions also uses the following auxiliary mapping rule: []Axis, which is specified in [4.2.1.1 Axes].
Normalization
Normalization of predicates need to distinguish between forward steps, reverse steps, and primary expressions.
As explained in the [XPath/XQuery] document, applying a step in XPath changes the focus (or context). The change of focus is made explicit by the normalization rule below, which binds the variable $fs:dot to the node currently being processed, and the variable $fs:position to the position (i.e., the position within the input sequence) of that node.
There are two sets of normalization rules for Predicates. The first set of rules apply when the predicate is a numeric literal or the expression last(). The second set of rules apply to all predicate expressions other than numeric literals and the expression last(). In the first case, the normalization rules provides a more precise static type than if the general rules were applied.
When the predicate expression is a numeric literal or the fn:last function, the following normalization rules apply.
| |
| [ForwardStep PredicateList "[" Numeric "]"]Expr |
| == |
|
|
| |
[ForwardStep PredicateList "[" fn:last() "]"]Expr |
| == |
|
|
When predicates are applied on a reverse step, the position variable is bound in reverse document order.
| |
| [ReverseStep PredicateList "[" Numeric "]"]Expr |
| == |
|
|
When the step is a reverse axis, then the last item in the context sequence is the first in document order.
| |
[ReverseStep PredicateList "[" fn:last() "]"]Expr |
| == |
|
|
The normalization rules above all use the function fn:subsequence to select a particular item. The static typing rules for this function are defined in [7.2.13 The fn:subsequence function].
When predicates are applied on a forward step, the input sequence is first sorted in document order and duplicates are removed. The context is changed by binding the $fs:dot variable to each node in document order.
| |
| [ForwardStep PredicateList "[" Expr "]"]Expr |
| == |
|
|
When predicates are applied on a reverse step, the input sequence is first sorted in document order and duplicates are removed. The context is changed by binding the $fs:dot variable to each node in document order.
| |
| [ReverseStep PredicateList "[" Expr "]"]Expr |
| == |
|
|
Finally, a stand-alone forward or reverse step is normalized by the auxiliary normalization rule for Axis.
Static Type Analysis
The static semantics of an Axis NodeTest pair is obtained by retrieving the type of the context node, and applying the two filters (the Axis, and then the NodeTest with a PrincipalNodeKind) on the result.
Note
Note that the second judgment in the inference rule requires that the context item be a node, guaranteeing that a type error is raised when the context item is an atomic value.
Dynamic Evaluation
The dynamic semantics of an Axis NodeTest pair is obtained by retrieving the context node, and applying the two filters (Axis, then NodeTest) on the result. The application of each filter is expressed through the filter judgment as follows.
Note
Note that the second judgment in the inference rule guarantees that the context item is bound to a node.
Dynamic Errors
If the context item is not a node, the evaluation of an axis node test expression raises a dynamic error.
4.2.1.1 Axes
Introduction
The XQuery grammar for forward and reverse axis is as follows.
Axes
| [72 (XQuery)] |
ForwardAxis |
::= |
("child" "::")
| ("descendant" "::")
| ("attribute" "::")
| ("self" "::")
| ("descendant-or-self" "::")
| ("following-sibling" "::")
| ("following" "::") |
| [75 (XQuery)] |
ReverseAxis |
::= |
("parent" "::")
| ("ancestor" "::")
| ("preceding-sibling" "::")
| ("preceding" "::")
| ("ancestor-or-self" "::") |
In the case of XPath, forward axis also contain the namespace:: axis.
Axes
| [30 (XPath)] |
ForwardAxis |
::= |
("child" "::")
| ("descendant" "::")
| ("attribute" "::")
| ("self" "::")
| ("descendant-or-self" "::")
| ("following-sibling" "::")
| ("following" "::")
| ("namespace" "::") |
Core Grammar
The Core grammar productions for XPath axis are:
Axes
| [56 (Core)] |
ForwardAxis |
::= |
("child" "::")
| ("descendant" "::")
| ("attribute" "::")
| ("self" "::")
| ("descendant-or-self" "::")
| ("following-sibling" "::")
| ("following" "::")
| ("namespace" "::") |
| [58 (Core)] |
ReverseAxis |
::= |
("parent" "::")
| ("ancestor" "::")
| ("preceding-sibling" "::")
| ("preceding" "::")
| ("ancestor-or-self" "::") |
Notation
Normalization of axis uses the following auxiliary mapping rule: []Axis.
Normalization
Normalization for all axis is specified as follows.
The semantics of the following(-sibling) and preceding(-sibling) axes are expressed by mapping them to Core expressions, all other axes are part of the Core and therefore are left unchanged through normalization.
| |
[following-sibling:: NodeTest]Axis |
| == |
| [let $e := . in $e/parent::node()/child:: NodeTest [.>>$e]]Expr |
| |
[following:: NodeTest]Axis |
| == |
[ancestor-or-self::node()/following-sibling::node()/descendant-or-self::NodeTest]Expr |
All other forward axes are part of the Core [XPath/XQuery] and handled by the normalization rules below:
| |
[child:: NodeTest]Axis |
| == |
child:: NodeTest |
| |
[attribute:: NodeTest]Axis |
| == |
attribute:: NodeTest |
| |
[self:: NodeTest]Axis |
| == |
self:: NodeTest |
| |
[descendant:: NodeTest]Axis |
| == |
descendant:: NodeTest |
| |
[descendant-or-self:: NodeTest]Axis |
| == |
descendant-or-self:: NodeTest |
| |
[namespace:: NodeTest]Axis |
| == |
namespace:: NodeTest |
Reverse axes:
| |
[preceding-sibling:: NodeTest]Axis |
| == |
| [let $e := . in $e/parent::node()/child:: NodeTest [.<<$e]]Expr |
| |
[preceding:: NodeTest]Axis |
| == |
[ancestor-or-self::node()/preceding-sibling::node()/descendant-or-self::NodeTest]Expr |
All other reverse axes are part of the core:
| |
[parent:: NodeTest]Axis |
| == |
parent:: NodeTest |
| |
[ancestor:: NodeTest]Axis |
| == |
ancestor:: NodeTest |
| |
[ancestor-or-self:: NodeTest]Axis |
| == |
ancestor-or-self:: NodeTest |
4.2.1.2 Node Tests
Introduction
A node test is a condition applied on the nodes selected by an axis step. Node tests are described by the following grammar productions.
Node Tests
Core Grammar
The Core grammar productions for node tests are:
Node Tests
Notation
For convenience, we will use the grammar non-terminals Prefix, and LocalPart, both of which are NCNames, in some of the inference rules. They are defined by the following grammar productions.
Prefix and LocalPart
| [18 (Formal)] |
Prefix |
::= |
NCName |
| [19 (Formal)] |
LocalPart |
::= |
NCName |
4.2.2 Predicates
Introduction
A predicate consists of an expression, called a predicate expression, enclosed in square brackets.
Notation
Normalization of predicates uses the following auxiliary mapping rule: []Predicates.
Normalization
Predicates in path expressions are normalized with a special mapping rule:
| |
| [Expr]Predicates |
| == |
| typeswitch (Expr) |
case $v as fs:numeric return op:numeric-equal($v, $fs:position) |
default $v return fn:boolean($v) |
|
Note that the semantics of predicates whose parameter is a numeric value also works for other numeric than integer values, in which case the op:numeric-equal returns false when compared to a position. For example the expression //a[3.4] is allowed and always returns the empty sequence)
4.2.3 Unabbreviated Syntax
The corresponding Section in the [XPath/XQuery] document just contains examples.
4.2.4 Abbreviated Syntax
Abbreviated Syntax
Normalization
Here are normalization rules for the abbreviated syntax.
| |
| [ @ NameTest ]Expr |
| == |
| attribute :: NameTest |
| |
| [ NodeTest ]Expr |
| == |
| [child :: NodeTest]Axis |
4.3 Sequence Expressions
Introduction
[XPath/XQuery] supports operators to construct and combine sequences. A sequence is an ordered collection of zero or more items. An item is either an atomic value or a node.
4.3.2 Filter Expressions
Introduction
Filter Expression
Core Grammar
There are no Core grammar productions for filter expressions as they are normalized to other Core expressions.
Normalization
When predicates are applied on a primary expression, the input sequence is processed in sequence order and the context is bound as in the case of forward axes. In that case, the sequence can contain both nodes and atomic values.
| |
| [PrimaryExpr PredicateList "[" Numeric "]"]Expr |
| == |
let $fs:sequence := [PrimaryExpr PredicateList]Expr return |
fn:subsequence($fs:sequence,Numeric,1) |
|
When predicates are applied on a primary expression, the input sequence is processed in sequence order and the context variable is bound to each item in the input sequence, which may contain both nodes and atomic values.
| |
| [PrimaryExpr PredicateList "[" Expr "]"]Expr |
| == |
|
|
Static Type Analysis
There are no additional static type rules for filter expressions.
Dynamic Evaluation
There are no additional dynamic evaluation rules for filter expressions.
Dynamic Errors
There are no additional error semantics rules for filter expressions.
4.4 Arithmetic Expressions
[XPath/XQuery] provides arithmetic operators for addition, subtraction, multiplication, division, and modulus, in their usual binary and unary forms.
Arithmetic Expressions
Core Grammar
The Core grammar production for arithmetic expressions is:
Notation
The mapping functions []ArithOp and UnaryArithOp are defined by the following tables:
| ArithOp |
[ArithOp]ArithOp |
| "+" |
fs:plus |
| "-" |
fs:minus |
| "*" |
fs:times |
| "div" |
fs:div |
| "mod" |
fs:mod |
| UnaryArithOp |
[UnaryArithOp]UnaryArithOp |
| "+" |
fs:unary-plus |
| "-" |
fs:unary-minus |
Core Grammar
There are no Core grammar productions for arithmetic expressions as they are normalized to other Core expressions.
Normalization
The normalization rules for all the arithmetic operators except idiv first atomize each argument by applying fn:data and then apply the internal function fs:convert-operand to each argument. If the first argument to this function has type xdt:untypedAtomic, then the first argument is cast to a double, otherwise it is returned unchanged. The overloaded internal function
corresponding to the arithmetic operator is then applied to the two converted arguments. The table above maps the operators to the corresponding internal function. The mapping from the overloaded internal functions to the corresponding monomorphic function is given in [B.2 Mapping of Overloaded Internal Functions].
| |
| [Expr1 ArithOp Expr2]Expr |
| == |
|
|
The normalization rules for the idiv operator are similar, but instead of casting arguments with type xdt:untypedAtomic to xs:double, they are cast to xs:integer.
| |
[Expr1 idiv Expr2]Expr |
| == |
|
|
The unary operators are mapped similarly.
Static Type Analysis
The static semantics for function calls is given in [4.1.5 Function Calls].
Dynamic Evaluation
The dynamic semantics for function calls is given in [4.1.5 Function Calls].
Dynamic Errors
The error semantics for function calls is given in [4.1.5 Function Calls].
4.5 Comparison Expressions
Introduction
Comparison expressions allow two values to be compared. [XPath/XQuery] provides four kinds of comparison expressions, called value comparisons, general comparisons, node comparisons, and order comparisons.
Comparison Expressions
4.5.1 Value Comparisons
Notation
The mapping function []ValueOp is defined by the following table:
| ValueOp |
[ValueOp]ValueOp |
"eq" |
fs:eq |
"ne" |
fs:ne |
"lt" |
fs:lt |
"le" |
fs:le |
"gt" |
fs:gt |
"ge" |
fs:ge |
Core Grammar
There are no Core grammar productions for value comparisons as they are normalized to other Core expressions.
Normalization
The normalization rules for the value comparison operators first atomize each argument by applying fn:data and then apply the internal function fs:convert-operand defined in [7.1.3 The fs:convert-operand function]. If the first argument to this function has type xdt:untypedAtomic, then the first argument is cast to a string, otherwise it is
returned unchanged. The overloaded internal function corresponding to the value comparison operator is then applied to the two converted arguments. The table above maps the value operators to the corresponding internal function. The mapping from the overloaded internal functions to the corresponding monomorphic function is given in [B.2 Mapping of Overloaded Internal Functions].
| |
| [Expr1 ValueOp Expr2]Expr |
| == |
|
|
Static Type Analysis
The static semantics for function calls is given in [4.1.5 Function Calls]. The comparison functions all have return type xs:boolean, as specified in [Functions and Operators].
Dynamic Evaluation
The dynamic semantics for function calls is given in [4.1.5 Function Calls].
Dynamic Errors
The error semantics rules for function calls is given in [4.1.5 Function Calls].
4.5.2 General Comparisons
Introduction
General comparisons are defined by adding existential semantics to value comparisons. The operands of a general comparison may be sequences of any length. The result of a general comparison is always true or false.
Notation
For convenience, GeneralOp denotes the operators "=", "!=", "<", "<=", ">", or ">=".
The function []GeneralOp is defined by the following table:
| GeneralOp |
[GeneralOp]GeneralOp |
"=" |
fs:eq |
"!=" |
fs:ne |
"<" |
fs:lt |
"<=" |
fs:le |
">" |
fs:gt |
">=" |
fs:ge |
Core Grammar
There are no Core grammar productions for general comparisons as they are normalized to existentially quantified Core expressions.
Normalization
The normalization rule for a general comparison expression first atomizes each argument by applying fn:data and then applies the existentially quantified some expression to each sequence. The internal function fs:convert-operand is applied to each pair of atomic values. If the first argument to this function has type xdt:untypedAtomic, then the first argument is cast to type of the
second argument. If the second argument has type xdt:untypedAtomic, the first argument is cast to a string. The overloaded internal function corresponding to the general comparison operator is then applied to the two converted values.
| |
| [Expr1 GeneralOp Expr2]Expr |
| == |
|
|
4.6 Logical Expressions
Introduction
A logical expression is either an and-expression or an or-expression. The value of a logical expression is always one of the boolean values: true or false.
Logical Expressions
Core Grammar
The Core grammar productions for logical expressions are:
Core Logical Expressions
Normalization
The normalization rules for "and" and "or" first get the effective boolean value of each argument, then apply the appropriate Core operator.
| |
[Expr1 and Expr2]Expr |
| == |
fn:boolean([Expr1]Expr) and fn:boolean([Expr2]Expr) |
| |
[Expr1 or Expr2]Expr |
| == |
fn:boolean([Expr1]Expr) or fn:boolean([Expr2]Expr) |
Static Type Analysis
The logical expressions require that each subexpression have type xs:boolean. The result type is also xs:boolean.
Dynamic Evaluation
The dynamic semantics of logical expressions is non-deterministic. This non-determinism permits implementations to use short-circuit evaluation strategies when evaluating logical expressions. In the expression, Expr1 and Expr2, if either expression raises an error or evaluates to false, the entire expression may raise an error or evaluate to false. In the expression, Expr1 or Expr2, if either expression raises an error or evaluates to true, the entire expression may raise an error or evaluate to true.
Dynamic Errors
4.7 Constructors
[XPath/XQuery] supports two forms of constructors: a direct constructor, which supports literal XML syntax for elements, attributes, and text nodes, and a computed constructor, which can be used to construct element and attribute nodes, possibly with computed names, and also document and text nodes. All direct constructors are normalized into computed constructors, i.e., there are no direct-constructor expressions in the Core.
4.7.1 Direct Element Constructors
Introduction
The static and dynamic semantics of the direct forms of element and attribute constructors are specified on the equivalent computed element and attribute constructors.
Constructors
Notation
The auxiliary mapping rules []ElementContent, and []ElementContent-unit are defined in this section and are used for the normalization of the content of direct element constructors.
Core Grammar
The Core grammar productions for constructors are:
Constructors
There are no Core grammar productions for direct XML element or attribute constructors as they are normalized to computed constructors.
Normalization
We start with the rules for normalizing a direct element constructors' content. Literal XML character data (CDATA) is assumed to be processed directly at parsing level so it does not require any formal treatment. We distinguish between direct element constructors that contain only one element-content unit and those that contain more than one element-content unit. An element-content unit is a contiguous sequence of literal characters (character references, escaped braces, and predefined entity
references), one enclosed expression, one direct element constructor, one XML comment, or one XML processing instruction. Here are three direct element constructors that each contain one element-content unit:
<date>{ xs:date("2003-03-18") }</date>
<name>Dizzy Gillespe</name>
<comment><!-- Just a comment --></comment>
The first contains one enclosed expression, the second contains one contiguous sequence of characters, and the third contains one XML comment.
After boundary-space is stripped, the next example contains six element-content units:
<address>
<!-- Dizzy's address -->
{ 123 }-0A <street>Roosevelt Ave.</street> Flushing, NY { 11368 }
</address>
It contains one XML comment, followed by one enclosed expression that contains the integer 123, one contiguous sequence of characters ("-0A "), one direct XML element constructor, one contiguous sequence of characters (" Flushing, NY"), and one enclosed expression that contains the integer 11368. Evaluation of that constructor will result in the following element.
<address><!-- Dizzy's address -->123-0A <street>Roosevelt Ave.</street> Flushing, NY 11368</address>
Adjacent element-content units are convenient because they permit arbitrary interleaving of text and atomic data. During evaluation, atomic values are converted to text nodes containing the string representations of the atomic values, and then adjacent text nodes are concatenated together. In the example above, the integer 123 is converted to a string and concatenated with "-0A" and the result is a single text node containing "123-0A".
In general, we do not want to convert all atomic values to text nodes, especially when performing static-type analysis, because we lose useful type information. For example, if we normalize the first example above as follows, we lose the important information that the user constructed a date value, not just a text node containing an arbitrary string:
<date>{ xs:date("2003-03-18") }</date>
(normalization that loses type information) ==
element date { text { "2003-03-18" } }
To preserve useful type information, we distinguish between direct element constructors that contain one element-content unit and those that contain more than one (because multiple element-content units commonly denote concatenatation of atomic data and text). Below are two examples of normalization for element constructors.
<date>{ xs:date("2003-03-18") }</date>
==
element date { xs:date("2003-03-18") }
<address>
<!-- Dizzy's address -->
{ 123 }-0A <street>Roosevelt Ave.</street> Flushing, NY { 11368 }
</address>
==
element address {
fs:item-sequence-to-node-sequence(
comment { " Dizzy's address "},
123,
text { "-0A "},
element street {"Roosevelt Ave."},
text { " Flushing, NY " },
11368
)
}
Given the distinction between direct element constructors that we made above, we give two normalization rules for a direct element constructor's content. If the direct element constructor contains exactly one element-content unit, we simply normalize that unit by applying the normalization rule for the element content:
If the direct element constructor contains more than one element-content unit, we normalize each unit individually and construct a sequence of the normalized results interleaved with empty text nodes. The empty text nodes guarantee that the results of evaluating consecutive element-content units can be distinguished. Then we apply the function fs:item-sequence-to-node-sequence. Section
3.7.1 Direct Element ConstructorsXQ specifies the rules for converting a sequence of atomic values and nodes into a sequence of nodes before element construction. The Formal Semantics function fs:item-sequence-to-node-sequence implements these conversion rules.
We need to distinguish between multiple element-content units, because the rule for converting sequences of atomic values into strings apply to sequences within distinct enclosed expressions. The empty text nodes are eliminated during evaluation of fs:item-sequence-to-node-sequence when consecutive text nodes are coalesced into a single text node. The text node guarantees that a whitespace character will not be inserted between atomic values
computed by distinct enclosed expressions. For example, here is an expression, its normalization, and the resulting XML value:
<example>{ 1 }{ 2 }</example>
==
element example { fs:item-sequence-to-node-sequence ((1, text {""}, 2)) }
==>
<example>12</example>
In the absence of the empty text node, the expression would evaluate to the following incorrect value:
<example>{ 1 }{ 2 }</example>
(incorrect normalization) ==
element example { fs:item-sequence-to-node-sequence ((1, 2)) }
(incorrect value) ==>
<example>1 2</example>
Now that we have explained the normalization rules for direct element content, we give the rules for the two forms of direct XML element constructors. Note that the direct attribute constructors are normalized twice: the []NamespaceAttrs normalizes the namespace-declaration attributes and []Attribute normalizes all other attributes that are not namespace-declaration attributes.
Next, we give the normalization rules for each element-content unit. The normalization rule for a contiguous sequence of characters assumes:
-
that the significant whitespace characters in element constructors have been preserved, as described in [4.7.1.4 Whitespace in Element Content];
-
that character references have been resolved to individual characters and predefined entity references have been resolved to sequences of characters, and
-
that the rule is applied to the longest contiguous sequence of characters.
The following normalization rule takes the longest consecutive sequence of individual characters that include literal characters, escaped curly braces, character references, and predefined entity references and normalizes the character sequence as a text node containing the string of characters.
| |
| [(Char | "{{" | "}}" | CharRef | PredefinedEntityRef)+]ElementContent |
| == |
text { fn:codepoints-to-string((Char | "{{" | "}}" | CharRef | PredefinedEntityRef)+) } |
XML processing instructions and comments in element content are normalized by applying the standard normalization rules for expressions, which appear in [4.7.2 Other Direct Constructors].
An enclosed expression in element content is normalized by normalizing each individual expression in its expression sequence and then constructing a sequence of the normalized values:
Static Type Analysis
There are no additional static type rules for direct XML element or attribute constructors.
Dynamic Evaluation
There are no additional dynamic evaluation rules for direct XML element or attribute constructors.
Dynamic Errors
There are no additional error semantics rules for direct XML element or attribute constructors.
4.7.1.1 Attributes
Like literal XML element constructors, literal XML attribute constructors are normalized to computed attribute constructors.
Notation
The auxiliary mapping rules []Attribute, []AttributeContent, and []AttributeContent-unit, are defined in this section
and are used for the normalization of the content of direct attribute constructors.
Normalization
Direct attributes may contain namespace-declaration attributes. The normalization rules for attributes ignore namespace-declaration attributes -- they are handled by the normalization rules in [4.7.1.2 Namespace Declaration Attributes].
An AttributeList is normalized by the following rule, which maps each of the individual attribute-value expressions in the attribute list and constructs a sequence of the normalized values.
Namespace-declaration attributes, i.e., those attributes whose prefix is xmlns are ignored by mapping them to the empty sequence.
All attributes that are not namespace-declaration attributes are mapped to computed attribute constructors.
As with literal XML elements, we need to distinguish between direct attribute constructors that contain one attribute-content unit and those that contain multiple attribute-content units, because the rule for converting sequences of atomic values into strings are applied to sequences within distinct enclosed expressions. If the direct attribute constructor contains exactly one attribute-content unit, we simply normalize that unit by applying the normalization rule for the
attribute content:
If the direct attribute constructor contains more than one attribute-content unit, we normalize each unit individually and construct a sequence of the normalized results interleaved with empty text nodes. The empty text nodes guarantee that the results of evaluating consecutive attribute-content units can be distinguished. Then we apply the function fs:item-sequence-to-untypedAtomic, which applies the appropriate
conversion rules to the normalized attribute content:
Literal characters, escaped curly braces, character references, and predefined entity references in attribute content are treated as in element content. In addition, the normalization rule for characters in attributes assumes:
-
that an escaped single or double quote is converted to an individual single or double quote.
The following normalization rules take the longest consecutive sequence of individual characters that include literal characters, escaped curly braces, escaped quotes, character references, predefined entity references, and escaped single and double quotes and normalizes the character sequence as a string.
| |
| [( Char | CharRef | EscapeQuot | EscapeApos | PredefinedEntityRef ) +]AttributeContent |
| == |
fn:codepoints-to-string(( Char | CharRef | EscapeQuot | EscapeApos | PredefinedEntityRef )+) |
We normalize an enclosed expression in attribute content by normalizing each individual expression in its expression sequence and then construct a sequence of the normalized values:
4.7.1.2 Namespace Declaration Attributes
Notation
The auxiliary mapping rules []NamespaceAttr, and []NamespaceAttrs are defined in this section and are used for the normalization of namespace declaration attributes.
Normalization
Direct attributes may contain namespace-declaration attributes. The normalization rules for namespace-declaration attributes ignore all non-namespace attributes -- they are handled by the normalization rules in [4.7.1.1 Attributes].
An AttributeList containing namespace-declaration attributes is normalized by the following rule, which maps each of the individual namespace-declaration attributes in the attribute list and constructs a sequence of the normalized namespace attribute values.
Attributes whose prefix is not xmlns are ignored by mapping them to the empty sequence.
Namespace-declaration attributes are normalized to local namespace declarations (CompElemNamespace).
4.7.1.4 Whitespace in Element Content
Section 3.7.1.4 Boundary WhitespaceXQ describes how whitespace in element and attribute constructors is processed depending on the value of the xmlspace declaration in the query prolog. the Formal Semantics assumes that the rules for handling whitespace are applied prior to normalization rules, for example, during parsing of a query. Therefore, there are no formal rules for handling whitespace.
4.7.2 Other Direct Constructors
Other Constructors
Normalization
A literal XML processing instruction is normalized into a computed processing-instruction constructor; its character content is converted to a string as in attribute content.
| |
| [<? NCName Char* ?>"]Expr |
| == |
| [processing-instruction NCName { Char* }]Expr |
A literal XML comment is normalized into a computed comment constructor; its character content is converted to a string as in attribute content.
| |
| [<!-- Char* -->]Expr |
| == |
| [comment { Char* }]Expr |
Static Type Analysis
There are no additional static type rules for direct processing-instruction or comment constructors.
Dynamic Evaluation
There are no additional dynamic evaluation rules for direct processing-instruction or comment constructors.
Dynamic Errors
There are no additional error semantics rules for direct processing-instruction constructors.
4.7.3 Computed Constructors
Computed Constructors
4.7.3.1 Computed Element Constructors
Notation
Local namespace declarations may occur explicitly in a computed element constructor or may be the result of normalizing namespace-declaration attributes contained in direct element constructors. For local element declarations that occur explicitly in a query, the immediately enclosing expression of the local namespace declaration (CompElemNamespace) must be a computed element constructor; otherwise, as specified in [XPath/XQuery], a static error is raised.
Core Grammar
The Core grammar productions for computed element constructors are:
Computed Element Constructors
Normalization
If the content expression is missing, the computed element constructor is normalized as if its content expression was the empty sequence.
| |
| [element QName { }]Expr |
| == |
| [element QName { () }]Expr |
Computed element constructors using the fs:item-sequence-to-node-sequence function over their content expression.
When the name of the element is also computed, the normalization rule applies atomization to the name expression.
Static Type Analysis
The normalization rules of direct element and attribute constructors leave us with only the computed forms of constructors. The static semantic for constructors is defined on all the computed forms. The computed element constructor itself has two forms: one in which the element name is a literal QName, and the other in which the element name is a computed expression.
A computed element constructor creates a new element with either the type annotationXQ xdt:untyped (in strip construction mode), or with the type annotationXQ xs:anyType (in preserve construction mode). The content expression must return a sequence of nodes with attribute nodes
at the beginning.
|
|
|
statEnv |- element QName { Expr } : element QName of type xs:anyType |
In case the element name is computed as well, the name expression must be of type xs:QName, xs:string, or xdt:untypedAtomic.
|
|
|
statEnv |- element { Expr1 } { Expr2 } : element of type xs:anyType |
Dynamic Evaluation
The following rules take a computed element constructor expression and construct an element node. The dynamic semantics for computed element constructors is the most complex of all expressions in XQuery. Here is how to read the rule below.
First, the element's content expression is partitioned into the local namespace declarations and all other expressions, and the local namespace declarations are evaluated, yielding a sequence of namespace bindings. The static environment is extended to include the new namespace bindings, which are all active. In Section 3.7.1.2 Namespace Declaration AttributesXQ, it is implementation-defined
whether undeclaration of namespace prefixes (by setting the namespace prefix to the zero-length string) in an element constructor is supported. In the dynamic semantics below, we assume all local namespace declarations declare a binding of a prefix to a URI.
Second, the function fs:item-sequence-to-node-sequence is applied to the element's content expression (excluding local namespace declarations); this function call is evaluated in the new static and dynamic environment. Recall from [4.7.1 Direct Element Constructors] that during normalization, we do not convert the content of direct element constructors that contain one element-content unit. This
guarantees that useful type information is preserved for static analysis. Since the conversion function fs:item-sequence-to-node-sequence was not applied to all element constructors during normalization, we have to apply it at evaluation time. (Obviously, it is possible to elide the application of fs:item-sequence-to-node-sequence injected during normalization and the application injected during
evaluation.) The resulting value Value0 must match zero-or-more attributes followed by zero-or-more element, text, processing-instruction or comment nodes.
Third, The namespace bindings are concatenated with the list of active namespaces in the namespace environment statEnv.namespace and the namespaces corresponding to the element's name and all attributes names. The resulting sequence is the sequence of namespace bindings for the element.
| Expr = CompElemNamespace1, ..., CompElemNamespacen, (Expr0) |
| CompElemNamespace1 = namespace NCName1 { URI1 } |
| ... |
| CompElemNamespacen = namespace NCNamen { URIn } |
| statEnv1 = statEnv + namespace(NCName1 => (active, URI1)) |
| ... |
| statEnvn = statEnvn-1 + namespace(NCNamen => (active, URIn)) |
statEnvn; dynEnv |- fs:item-sequence-to-node-sequence(Expr0) => Value0 |
| statEnv |- Value0 matches (attribute*, (element | text | processing-instruction | comment)*) |
NamespaceBindings = CompElemNamespace1, ..., CompElemNamespacen, fs:active_ns(statEnv.namespace), fs:get_static_ns_from_items(statEnv, Value0) |
|
|
|
| statEnv; dynEnv |- element QName { Expr } => Value0 |
The dynamic evaluation of an element constructor with a computed name is similar. There is one additional rule that checks that the value of the element's name expression matches xs:QName.
dynEnv |- Expr1 => Value0 statEnv |- Value0 matches xs:QName |
| Expr2 = CompElemNamespace1, ..., CompElemNamespacen, (Expr3) |
| CompElemNamespace1 = namespace NCName1 { URI1 } |
| ... |
| CompElemNamespacen = namespace NCNamen { URIn } |
| statEnv1 = statEnv + namespace(NCName => (active, URI1)) |
| ... |
| statEnvn = statEnvn-1 + namespace(NCName => (active, URIn)) |
statEnvn, dynEnv |- fs:item-sequence-to-node-sequence(Expr3) => Value1 |
| statEnvn |- Value1 matches (attribute*, (element | text | processing-instruction | comment)*) |
NamespaceBindings = CompElemNamespace1, ..., CompElemNamespacen, fs:active_ns(statEnv.namespace), fs:get_static_ns_from_items(statEnv, Value1) |
|
|
|
| statEnv; dynEnv |- element { Expr1 } { Expr2 } => Value1 |
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to element constructors. In addition, a computed element constructor with a computed name raises a type error if the name value is not a xs:QName.
Both forms of computed element constructors raise a type error if the element's content is not a sequence of attributes followed by a sequence of element, text, comment, and processing-instruction nodes, or a sequence of atomic values.
4.7.3.2 Computed Attribute Constructors
Core Grammar
The Core grammar production for computed attribute constructors is:
Computed Attribute Constructors
Normalization
Computed attribute constructors are normalized by mapping their name and content expression in a similar way as computed element constructors. The normalization rule uses the fs:item-sequence-to-untypedAtomic function.
| |
| [attribute QName { }]Expr |
| == |
| [attribute QName { () }]Expr |
Static Type Analysis
The normalization rules for direct attribute constructors leave us with only the computed form of the attribute constructors. Like in a computed element constructor, a computed attribute constructor has two forms: one in which the attribute name is a literal QName, and the other in which the attribute name is a computed expression.
In the case of attribute constructors, the type annotationXQ is always xdt:untypedAtomic.
Dynamic Evaluation
The following rules take a computed attribute constructor expression and construct an attribute node. The rules are similar to those rules for element constructors. First, the attribute's name is expanded into a qualified name. Second, the function fs:item-sequence-to-untypedAtomic is applied to the content expression and this function call is evaluated in the dynamic environment. Recall from [4.7.3.2 Computed Attribute Constructors] that during normalization, we do not convert the content of direct attribute constructors that contain one attribute-content unit. This guarantees that useful type information is preserved for static analysis. Since the conversion function fs:item-sequence-to-untypedAtomic was not applied to all attribute constructors during normalization, we have to apply it
at evaluation time. (As before, it is possible to elide the application of fs:item-sequence-to-untypedAtomic injected during normalization and the application injected during evaluation.)
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to attribute constructors. In addition, an attribute constructor with a computed name raises a type error if the name value is not a xs:QName. the xmlns namespace.
A dynamic error is raised if the namespace URI of the attribute's QName, whether known statically or dynamically, is in the xmlns namespace.
4.7.3.3 Document Node Constructors
Core Grammar
The Core grammar production for a computed document constructor is:
Core computed document construtor
Normalization
A document node constructor contains an expression, which must evaluate to a sequence of element, text, comment, or processing-instruction nodes. Section 3.7.3.3 Document Node ConstructorsXQ specifies the rules for converting a sequence of atomic values and nodes into a sequence of nodes before document construction. The built-in function [7.1.7 The
fs:item-sequence-to-node-sequence function] implements this conversion.
Static Type Analysis
The static semantics checks that the type of the argument expression is a sequence of element, text, processing-instruction, and comment nodes. The type of the entire expression is the most general document type, because the document constructor erases all type annotationXQ on its content nodes.
Dynamic Evaluation
The dynamic semantics checks that the argument expression evaluates to a value that is a sequence of element, text, processing-instruction, or comment nodes. The entire expression evaluates to a new document node value. If the construction mode is set to strip, the type annotationXQ for all the nodes in content of a document node are erased.
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to document node constructors. In addition, if the argument expression evaluates to a value that is not a sequence of element, text, processing-instruction, or comment nodes, a type error is raised.
4.7.3.4 Text Node Constructors
Core Grammar
The Core grammar production for a computed text constructor is:
Normalization
A text node constructor contains an expression, which must evaluate to an xs:string value. Section 3.7.3.4 Text Node ConstructorsXQ specifies the rules for converting a sequence of atomic values into a string prior to construction of a text node. Each node is replaced by its string value. For each adjacent sequence of one or more atomic values returned by an enclosed expression, a untyped atomic value is
constructed, containing the canonical lexical representation of all the atomic values, with a single blank character inserted between adjacent values. As formal specification of these conversion rules is not instructive, [7.1.8 The fs:item-sequence-to-untypedAtomic function] implements this conversion.
Static Type Analysis
The static semantics checks that the argument expression has type xs:string or empty. The type of the entire expression is an optional text node type, as the text node constructor returns the empty sequence if its argument is the empty sequence.
Dynamic Evaluation
If the argument expression returns the empty sequence, the text node constructor returns the empty sequence.
If the argument expression returns a value of type xs:string, the text node constructor returns a text node with that string as content.
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to text node constructors. In addition, if the argument expression evaluates to a value that is not a string or the empty sequence, a type error is raised.
4.7.3.5 Computed Processing Instruction Constructors
| [114 (XQuery)] |
CompPIConstructor |
::= |
(("processing-instruction" NCName "{") | ("processing-instruction" "{" Expr "}" "{")) Expr? "}" |
Core Grammar
The Core grammar production for computed processing-instruction constructors is:
Normalization
Computed processing-instruction constructors are normalized by mapping their name and content expression in the same way that computed element and attribute constructors are normalized.
| |
| [processing-instruction NCName { }]Expr |
| == |
| [processing-instruction NCName { () }]Expr |
Static Type Analysis
The static typing rules for processing-instruction constructors are straightforward.
Dynamic Evaluation
The dynamic evaluation rules for computed processing instructions are straightforward.
|
|
|
| dynEnv |- processing-instruction NCName { Expr } => processing-instruction NCName { Value } |
|
|
|
| dynEnv |- processing-instruction { Expr1 } { Expr2 } => processing-instruction NCName1 { Value2 } |
|
|
|
| dynEnv |- processing-instruction { Expr1 } { Expr2 } => processing-instruction NCName1 { Value2 } |
|
|
|
| dynEnv |- processing-instruction { Expr1 } { Expr2 } => processing-instruction NCName1 { Value2 } |
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to computed processing-instruction constructors. The normalization rules guarantee that a dynamic error is raised if the target expression is not a string or a QName.
4.7.3.6 Computed Comment Constructors
Core Grammar
The Core grammar production for computed comment constructors is:
Normalization
Computed comment constructors are normalized by mapping their content expression.
Static Type Analysis
The static typing rule for computed comment constructors is straightforward.
Dynamic Evaluation
The dynamic evaluation rule for computed comment constructors is straightforward.
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to computed comment constructors.
4.8 [For/FLWR] Expressions
Introduction
[XPath/XQuery] provides [For/FLWR] expressions for iteration, for binding variables to intermediate results, and filtering bound variables according to a predicate.
A FLWORExpr in XQuery 1.0 consists of a sequence of ForClauses and LetClauses, followed by an optional WhereClause, followed by the , as described by the following grammar productions. Each variable binding is preceded by an optional type declaration which specify the type expected for the variable.
The dynamic semantics of the ordering mode in FLWOR expressions is not specified formally. The dynamic semantics is not specified formally as it would require the introduction of tuples, which are not supported in the [XPath/XQuery] data model.
[For/FLWR] Expressions
Core Grammar
The Core grammar productions for FLWOR expressions are:
For Expressions
4.8.1 FLWOR expressions
Notation
Individual [For/FLWR] clauses are normalized by means of the auxiliary normalization rules:
Where FLWORClause can be any either a ForClause, a LetClause, a WhereClause, or an OrderByClause. The OrderByClause is discussed in [4.8.4 Order By and Return Clauses].
Normalized FLWOR expressions restrict a For and Let clause to bind only one variable. Otherwise, the Core FLWOR expression is the same as the XQuery FLWOR expression.
Notation
The auxiliary rule []FLWOR(Expr) normalizes a For, Let, or Where clause in a FLWORExpr expression. Note that the rule takes the remainder of the FLWOR expression (other For, Let, or Where clauses and the Return clause) as a parameter in Expr.
Normalization
The [For/FLWR] expressions include the FLWORExpr of XQuery and the ForExpr of XPath. The normalization rule for ForExpr is simple: It simply unrolls a ForExpr that binds multiple variables into nested ForExprs, each of which bind one variable.
Full FLWORExpr expressions are normalized to nested core expressions using two sets of normalization rules. Note that some of the rules also accept ungrammatical FLWORExprs such as "where Expr1 return Expr2". This does not matter, as normalization is always applied on parsed [XPath/XQuery] expressions, and ungrammatical FLWORExprs would be rejected by the parser beforehand.
The first set of rules is applied on a full [For/FLWR] expression, splitting it at the clause level, then applying further normalization on each separate clause.
| |
| [ (ForClause | LetClause | WhereClause | OrderByClause) FLWORExpr ]Expr |
| == |
| [(ForClause | LetClause | WhereClause | OrderByClause)]FLWOR([FLWORExpr]Expr) |
| |
| [ (ForClause | LetClause | WhereClause | OrderByClause) return Expr ]Expr |
| == |
| [(ForClause | LetClause | WhereClause | OrderByClause)]FLWOR([Expr]Expr) |
Then each [For/FLWR] clause is normalized separately. A ForClause may bind more than one variable, whereas a For expression in the [XPath/XQuery] Core binds and iterates over only one variable. Therefore, a ForClause is normalized to nested for expressions:
| |
[
| for VarRef1 TypeDeclaration1? PositionalVar1? in Expr1, |
| ···, |
| VarRefn TypeDeclarationn? PositionalVarn? in Exprn |
] FLWOR(Expr) |
| == |
| for VarRef1 TypeDeclaration1? PositionalVar1? in [Expr1]Expr return |
| ··· |
| for VarRefn TypeDeclarationn? PositionalVarn? in [ Exprn ]Expr return Expr |
|
Note that the additional Expr parameter of the auxiliary normalization rule is used as the final return expression.
Likewise, a LetClause clause is normalized to nested let expressions, each of which binds one variable:
| |
[
| let VarRef1 TypeDeclaration1? := Expr1, |
| ···, |
| VarRefn TypeDeclarationn? := Exprn |
]FLWOR(Expr) |
| == |
| let VarRef1 TypeDeclaration1? := [Expr1 ]Expr return |
| ··· |
| let VarRefn TypeDeclarationn? := [Exprn]Expr return Expr |
|
A WhereClause is normalized to an IfExpr, with the else-branch returning the empty sequence:
| |
| [ where Expr1]FLWOR(Expr) |
| == |
| if ( [Expr1]Expr ) then Expr else () |
Example
The following simple example illustrates, how a FLWORExpr is normalized. The for expression in the example below is used to iterate over two collections, binding variables $i and $j to items in these collections. It uses a let clause to binds the local variable $k to the sum of both numbers, and a where clause to select only those numbers that have a sum equal to or greater than the integer 5.
for $i as xs:integer in (1, 2),
$j in (3, 4)
let $k := $i + $j
where $k >= 5
return
<tuple>
<i> { $i } </i>
<j> { $j } </j>
</tuple>
By the first set of rules, this is normalized to (except for the operators and element constructor which are not treated here):
for $i as xs:integer in (1, 2) return
for $j in (3, 4) return
let $k := $i + $j return
if ($k >= 5) then
<tuple>
<i> { $i } </i>
<j> { $j } </j>
</tuple>
else
()
For each binding of $i to an item in the sequence (1 , 2) the inner for expression iterates over the sequence (3 , 4) to produce tuples ordered by the ordering of the outer sequence and then by the ordering of the inner sequence. This core expression eventually results in the following document fragment:
(<tuple>
<i>1</i>
<j>4</j>
</tuple>,
<tuple>
<i>2</i>
<j>3</j>
</tuple>,
<tuple>
<i>2</i>
<j>4</j>
</tuple>)
4.8.2 For expression
Static Type Analysis
A single for expression is typed as follows: First Type1 of the iteration expression Expr1 is inferred. Then the prime type of Type1, prime(Type1), is computed. This is a union over all item types in
Type1 (See [8.4 Judgments for FLWOR and other expressions on sequences]). With the variable component of the static environment statEnv extended with VarRef1 as type prime(Type1),
the type Type2 of Expr2 is inferred. Because the for expression iterates over the result of Expr1, the final type of the iteration is Type2 multiplied with the possible number of items in Type1 (one,
?, *, or +). This number is determined by the auxiliary type-function quantifier(Type1).
When a positional variable Variablepos is present, the static environment is also extended with the positional variable typed as an xs:integer.
When a type declaration is present, the static semantics also checks that the type of the input expression is a subtype of the declared type and extends the static environment by typing VarRef1 with type Type0. This semantics is specified by the following typing rule.
The last rule contains a For expression that contains a type declaration and a positional variable. When the positional variable is present, the static environment is also extended with the positional variable typed as an integer.
Example
For example, if $example is bound to the sequence 10.0, 1.0E1, 10 of type xs:decimal, xs:float, xs:integer, then the query
for $s in $example
return $s * 2
is typed as follows:
(1) prime(xs:decimal, xs:float, xs:integer) =
xs:decimal | xs:float | xs:integer
(2) quantifier(xs:decimal, xs:float, xs:integer) = +
(3) $s : xs:decimal | xs:float | xs:integer
(4) $s * 2 :
xs:decimal | xs:float | xs:integer
(5) result-type :
( xs:decimal | xs:float | xs:integer ) +
This result-type is not the most specific type possible. It does not take into account the order of elements in the input type, and it ignores the individual and overall number of elements in the input type. The most specific type possible is: element out {element one {}}, element out {element two {}}, element out {element three {}}. However, inferring such a specific type for arbitrary input types and arbitrary return clauses requires significantly more complex type inference rules. In
addition, if put into the context of an element, the specific type violates the "unique particle attribution" restriction of XML schema, which requires that an element must have a unique content model within a particular context.
Dynamic Evaluation
The evaluation of a for expression distinguishes two cases: If the iteration expression Expr1 evaluates to the empty sequence, then the entire expression evaluates to the empty sequence:
Otherwise, the iteration expression Expr1, is evaluated to produce the sequence Item1, ..., Itemn. For each item Itemi in this sequence, the body of the for expression Expr2 is evaluated in the
environment dynEnv extended with VarRef1 bound to Itemi. This produces values Valuei, ..., Valuen which are concatenated to produce the result sequence.
The following rule is the same as the rule above, but includes the optional positional variable VarRefpos. If present, VarRefpos is bound to the position of the item in the input sequence, i.e., the value i.
When a type declaration is present, the dynamic semantics also checks that each item in the result of evaluating Expr1 matches the declared type. This semantics is specified by the following dynamic rule.
The last rule covers a For expresstion that contains a type declaration and a positional variable.
Note that this definition allows non-deterministic evaluation of the resulting sequence, since the judgments above the inference rule can be evaluated in any order.
Dynamic Errors
If evaluation of the first expression raises an error, the entire expression raises an error. This rule applies to all forms of a For expression, i.e., those with or without a type declaration or positional variable.
If any evaluation of the body of the for expression raises an error, then the entire expression raises an error. This rule applies to for expressions with or without the type declaration.
When a type declaration is present, a type error is raised if any item in the result of evaluating Expr1 does not match the declared type.
Example
Note that if the expression in the return clause results in a sequence, sequences are never nested in the [XPath/XQuery] data model. For instance, in the following for expression:
for $i in (1,2)
return (<i> {$i} </i>, <negi> {-$i} </negi>)
each iteration in the for results in a sequence of two elements, which are then concatenated and flattened in the resulting sequence:
(<i>1</i>,
<negi>-1</negi>,
<i>2</i>,
<negi>-2</negi>)
4.8.3 Let Expression
Static Type Analysis
A let expression extends the type environment statEnv with Variable1 of type Type1 inferred from Expr1, and infers the type of Expr2 in the extended environment to produce the result type Type2.
When a type declaration is present, the static semantics also checks that the type of the input expression is a subtype of the declared type and extends the static environment by typing Variable1 with type Type0. This semantics is specified by the following static rule.
Dynamic Evaluation
A let expression extends the dynamic environment dynEnv with Variable bound to Value1 returned by Expr1, and evaluates Expr2 in the extended environment to produce Value2.
When a type declaration is present, the dynamic semantics also checks that the result of evaluating Expr1 matches the declared type. This semantics is specified as the following dynamic rule.
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to let expressions. In addition, in the case that a type declaration is present, a type error is raised if the result of evaluating Expr1 does not match the declared type.
Example
Note the use of the environment discipline to define the scope of each variable. For instance, in the following nested let expression:
let $k := 5 return
let $k := $k + 1 return
$k+1
the outermost let expression binds variable $k to the integer 5 in the environment, then the expression $k+1 is computed, yielding value 6, to which the second variable $k is bound. The expression then results in the final integer 7.
4.8.4 Order By and Return Clauses
Introduction
The dynamic semantics of the OrderByClause is not specified formally. The dynamic semantics is not specified formally as it would require the introduction of tuples, which are not supported in the [XPath/XQuery] data model. The dynamic semantics of the order-by clause can be found in Section 3.8.3 Order By and Return ClausesXQ.
Because an OrderByClause does not effect the type of a FLWORExpr expression, the static semantics of a FLWORExpr expression with an OrderByClause is equivalent to the static semantics of an equivalent FLWORExpr in which the OrderByClause is omitted but a gt comparison is applied.
Notation
To define normalization of OrderBy, the following auxiliary mapping rule is used.
which specify that OrderSpecList is mapped to Expr.
Normalization
An OrderByClause is normalized to a Let clause, nested For expressions, and atomization, which guarantees that the OrderSpecList is well typed. Note that if evaluated dynamically, the normalization of OrderByClause given here does not express the required sorting semantics, but this normalization does provide the correct static type. Notably, the normalization rule uses the gt operation, which implies that the ordering criteria is typed using the same static
typing rules, taking into account existential quantification, atomization and type promotion.
Each OrderSpec is normalized the auxiliary atomization normalization rule.
| |
| [Expr OrderModifier, OrderSpecList]OrderSpecList |
| == |
| let $fs:new0 := |
| for $fs:new1 in Expr |
| for $fs:new2 in Expr return |
| [$fs:new1 gt $fs:new2]Expr |
| [OrderSpecList]OrderSpecList |
|
4.9 Ordered and Unordered Expressions
Introduction
The purpose of ordered and unordered expressions is to set the ordering mode in the static context to ordered or unordered for a certain region in a query. The specified ordering mode applies to the expression nested inside the curly braces.
Core Grammar
The Core grammar productions for ordered/unordered expressions are:
Normalization
OrderedExpr (resp. UnorderedExpr) expressions are normalized to OrderedExpr (resp. UnorderedExpr) expressions in the [XPath/XQuery] core.
| |
| [ordered { Expr }]Expr |
| == |
| ordered { [Expr]Expr } |
| |
| [unordered { Expr }]Expr |
| == |
| unordered { [Expr]Expr } |
Dynamic Evaluation
OrderedExpr and UnorderedExpr expressions only have an effect on the static context. The effect on the evaluation of its subexpression(s) is captured using the fs:apply-ordering-mode function, which introduced during normalization of axis steps, union, intersect, and except expressions, and FLWOR expressions that have no order by clause.
Static Type Analysis
OrderedExpr and UnorderedExpr expressions set the ordering mode in the static context to ordered or unordered.
4.10 Conditional Expressions
Introduction
A conditional expression supports conditional evaluation of one of two expressions.
Conditional Expression
Core Grammar
The Core grammar production for the conditional expression is:
Core Conditional Expression
Normalization
| |
| [if (Expr1) then Expr2 else Expr3]Expr |
| == |
if (fn:boolean([ Expr1 ]Expr)) then [Expr2]Expr else [Expr3]Expr |
|
Static Type Analysis
Dynamic Evaluation
If the conditional's boolean expression Expr1 evaluates to true, Expr2 is evaluated and its value is produced. If the conditional's boolean expression evaluates to false, Expr3 is evaluated and its value is produced. Note that the existence of two separate evaluation rules ensures that only one branch of the conditional is evaluated.
Dynamic Errors
If the conditional's boolean expression raises an error, then the conditional expression raises an error.
If the conditional's boolean expression Expr1 evaluates to true, and Expr2 raises an error, then the conditional expression raises an error. Conversely, if the conditional's boolean expression evaluates to false, and Expr3 raises an error, then the conditional raises an error.
4.11 Quantified Expressions
Introduction
[XPath/XQuery] defines two quantification expressions:
Quantified Expression
Core Grammar
The Core grammar production for quantified expressions is:
Normalization
The quantified expressions are normalized into nested Core quantified expressions, each of which binds one variable.
Static Type Analysis
The static semantics of the quantified expressions uses the prime operator on types, which is explained in [8.4 Judgments for FLWOR and other expressions on sequences]. These rules are similar to those for For expressions in [4.8.2 For expression].
The next rule is for SomeExpr with the optional type declaration.
|
|
|
statEnv |- some VarRef1 as SequenceType in Expr1 satisfies Expr2 : xs:boolean |
The next rule is for EveryExpr without the optional type declaration.
The next rule is for EveryExpr with the optional type declaration.
|
|
|
statEnv |- every VarRef1 as SequenceType in Expr1 satisfies Expr2 : xs:boolean |
Dynamic Evaluation
The existentially quantified "some" expression yields true if any evaluation of the satisfies expression yields true. The existentially quantified "some" expression yields false if every evaluation of the satisfies expression is false. A quantified expression may raise an error if any evaluation of the satisfies expression raises an error. The dynamic semantics of quantified expressions is non-deterministic. This non-determinism permits implementations to use short-circuit evaluation strategies when
evaluating quantified expressions.
The next rule is for SomeExpr with the optional type declaration, in which some evaluation of the satisfies expression yields true.
|
|
|
| dynEnv |- some VarRef1 as SequenceType in Expr1 satisfies Expr2 => true |
The next rule is for SomeExpr without the optional type declaration, in which all evaluations of the satisfies expression yields false.
The next rule is for SomeExpr with the optional type declaration, in which all evaluations of the satisfies expression yields false.
|
|
|
| dynEnv |- some VarRef1 as SequenceType in Expr1 satisfies Expr2 => false |
The universally quantified "every" expression yields false if any evaluation of the satisfies expression yields false. The universally quantified "every" expression yields true if every evaluation of the satisfies expression is true.
The next rule is for EveryExpr with the optional type declaration, in which some evaluation of the satisfies expression yields false.
|
|
|
| dynEnv |- every VarRef1 as SequenceType in Expr1 satisfies Expr2 => false |
The next rule is for EveryExpr in which all evaluations of the satisfies expression yields true.
The next rule is for EveryExpr with the optional type declaration in which all evaluations of the satisfies expression yields true.
|
|
|
| dynEnv |- every VarRef1 as SequenceType in Expr1 satisfies Expr2 => true |
Dynamic Errors
An existentially quantified expression raises an error if:
-
evaluation of the first expression raises an error,
-
any evaluation of the satisfies expression raises an error.
An existentially quantified expression raises a type error if evaluation of the first expression yields a value, and some item in this value does not match the declared type of the variable.
4.12 Expressions on SequenceTypes
Introduction
Expressions on SequenceTypes are expressions whose semantics depends on the type of some of the sub-expressions to which they are applied. The syntax of SequenceType expressions is described in [3.5.3 SequenceType Syntax].
4.12.1 Instance Of
SequenceType expressions
Introduction
The SequenceType expression "Expr instance of SequenceType" is true if and only if the result of evaluating expression Expr is an instance of the type referred to by SequenceType.
Normalization
An InstanceofExpr expression is normalized into a TypeswitchExpr expression. Note that the following normalization rule uses a variable $fs:new, which is a newly created variable which must not conflict with any variables already in scope. This variable is necessary to comply with the syntax of typeswitch expressions in the core [XPath/XQuery], but is never used.
| |
| [Expr instance of SequenceType]Expr |
| == |
| typeswitch ([ Expr ]Expr) |
case $fs:new as SequenceType return fn:true() |
default $fs:new return fn:false() |
|
4.12.2 Typeswitch
SequenceType expressions
Introduction
The typeswitch expression chooses one of several expressions to evaluate based on the dynamic type of an input value.
Each branch of a typeswitch expression may have an optional VarRef, which is bound to the value of the input expression. This variable is optional in [XPath/XQuery] but mandatory in the [XPath/XQuery] Core. One of the reasons for having this variable is that it is assigned a specific type for the corresponding branch.
Core Grammar
The Core grammar productions for typeswitch are:
Notation
To define normalization of case clauses to the [XPath/XQuery] core, the following auxiliary mapping rule is used.
| |
| [CaseClause]Case |
| == |
| CaseClause |
specifies that CaseClause is mapped to CaseClause, in the [XPath/XQuery] type system.
Normalization
Normalization of a typeswitch expression guarantees that every branch has an associated VarRef. The following normalization rule adds a newly created variable that does not appear in the rest of the query. Note that $fs:new is a newly generated variable that must not conflict with any variables already in scope and that is not used in any of the sub-expressions.
| |
| [ case SequenceType return Expr ]Case |
| == |
| case $fs:new1 as SequenceType return [ Expr ]Expr |
| |
| [ default return Expr ]Case |
| == |
| default $fs:new1 return [ Expr ]Expr |
| |
[
| typeswitch ( Expr0 ) |
| CaseClause1 |
| ··· |
| CaseClausen |
| default (VarRef)? return Exprn+1 |
]Expr |
| == |
|
|
Notation
The following auxiliary grammar production is used to identify branches of the typeswitch.
CaseRules
The following judgment
is used in the static of typeswitch. It indicates that under the environment statEnv, and with the input type of the typeswitch being Type1, the given case rule yields the type Type.
The following judgment
is used in the dynamic semantics of typeswitch. It indicates that under the environment dynEnv, with the input value of the typeswitch being Value1, the given case rules yields the value Value2.
Static Type Analysis
The static typing rules for the typeswitch expression are simple. Each case clause and the default clause of the typeswitch is typed independently. The type of the entire typeswitch expression is the union of the types of all the clauses.
|
|
|
| statEnv |- |
| (typeswitch (Expr0) |
| case VarRef1 as SequenceType1 return Expr1 |
| ··· |
| case VarRefn as SequenceTypen return Exprn |
| default VarRefn+1 return Exprn+1) |
|
|
: (Type1 | ... | Typen+1) |
|
To type one case clause, the case variable is assigned the type of the case clause CaseType and the body of the clause is typed in the extended environment. Thus, the type of a case clause is independent of the type of the input expression.
To type the default clause, the variable is assigned the type of the input expression and the body of the default clause is typed in the extended environment.
Dynamic Evaluation
The evaluation of a typeswitch proceeds as follows. First, the input expression is evaluated, yielding an input value. The effective case is the first case clause such that the input value matches the SequenceType in the case clause. The return clause of the effective case is evaluated and the value of the return expression is the value of the typeswitch expression.
If the value matches the sequence type, the following rule applies: It extends the environment by binding the variable Variable to Value0 and evaluates the body of the return clause.
If the value does not match the sequence type, the current case is not evaluated, and the remaining case rules are evaluated order by applying the inference rule recursively.
The last rule states that the default branch of a typeswitch expression always evaluates to the value of its return clause.
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to the typeswitch expression. In particular, if evaluation of the input expression or evaluation of any case rule raises an error, then the typeswitch expression raises an error.
4.12.3 Cast
Introduction
The cast expression can be used to convert a value to a specific datatype. It changes both the type and value of the result of an expression, and can only be applied to an atomic value.
Core Grammar
The Core grammar productions for cast expressions are:
Normalization
The normalization of cast applies atomization to its argument. The type declaration asserts that the result is a single atomic value. The second normalization rule applies when the target type is optional.
Static Type Analysis
The static typing rule of cast expression is as follows. The type of a core cast expression is always the target type. Note that a cast expression can fail at run-time if the given value cannot be cast to the target type.
Dynamic Evaluation
The dynamic semantics of cast expressions is defined in Section 17 CastingFO. The semantics of cast expressions depends on the type of the input value and on the target type. For any source and target primitive types, the casting table in Section 17 CastingFO indicates whether the cast from the source type to the
target type is permitted. When a cast is permitted, the detailed dynamic rules for cast in Section 17 CastingFO are applied. These rules are not specified further here.
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to cast expressions.
4.12.4 Castable
Castable expressions check whether a value can be cast to a given type.
Core Grammar
The Core grammar production for castable is:
Normalization
The normalization of castable simply maps its expression argument.
Static Type Analysis
The type of a core castable expression is always a boolean.
Dynamic Evaluation
If casting succeeds, then the castable expression evaluates to true.
If casting raises a dynamic error, 'castable as' evaluates to false.
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to castable expression.
4.12.5 Constructor Functions
Constructor functions provide an alternative syntax for casting.
Normalization
Constructor functions for atomic types are normalized to explicit cast as expressions.
4.12.6 Treat
Introduction
The expression "Expr treat as SequenceType", can be used to change the static type of the result of an expression without changing its value. The treat-as expression raises a dynamic error if the dynamic type of the input value does not match the specified type.
Normalization
Treat as expressions are normalized to typeswitch expressions. Note that the following normalization rule uses a variable $fs:new, which is a newly created variable that does not conflict with any variables already in scope.
| |
| [Expr treat as SequenceType]Expr |
| == |
| typeswitch ([ Expr ]Expr) as $fs:new |
| case SequenceType return $fs:new |
default return fn:error() |
|
4.13 Validate Expressions
Core Grammar
The Core grammar productions for validate are:
A validate expression validates its argument with respect to the in-scope schema definitions, using the schema validation process described in [Schema Part 1]. The argument to a validate expression must be either element or document node. Validation replaces all nodes with new nodes that have their own identity, the type annotationXQ, and default values created during the
validation process.
Normalization
A validate expression with no validation mode is normalized into a validate expression with the validation mode set to strict.
| |
| [validate { Expr }]Expr |
| == |
| validate strict { [Expr]Expr } |
| |
| [validate ValidationMode { Expr }]Expr |
| == |
| validate ValidationMode { [Expr]Expr } |
Static Type Analysis
Static typing of the validate operation is defined by the following rule. Note the use of a subtyping check to ensure that the type of the expression to validate is either an element or a well-formed document node (i.e., with only one root element and no text nodes). The type of the expression to validate may be a union of more than one element type. We apply the with mode judgment to each element type to determine the meaning of that
element type with the given validation mode, which yields a new element type. The result type is the union over all new element types.
4.13.1 Validating an Element Node
Dynamic Evaluation
The normative dynamic semantics of validation is specified in Section 3.13 Validate ExpressionsXQ. The effect of validation of a data model value is equivalent to:
-
serialization of the data model, as described in [Data Model Serialization], followed by
-
validation of the serialized value into a Post-Schema Validated Infoset, as described in [Schema Part 1], followed by
-
construction of a new data model value, as described in [Data Model].
The above steps are expressed formally by the "erasure" and "annotation" judgments. Formally, validation removes existing type annotations from nodes ("erasure"), and it re-validates the corresponding data model instance, possibly adding new type annotations to nodes ("annotation"). Both erasure and annotation are described formally in [E Auxiliary Judgments for Validation]. Indeed, the conjunction of erasure and annotation provides a formal model for a
large part of actual schema validation. The semantics of the validate expression is specified as follows.
In the first premise below, the expression to validate is evaluated. The resulting value must be an element or document node. The second premise constructs a new value in which all existing type annotations have been erased. The third premise determines the element type that corresponds to the element node's name in the given validation mode. The last premise validates erased element node with the type against which it is validated, using the annotate
as judgment, yielding the final validated element.
4.13.2 Validating a Document Node
The rule for validating a document node is similar to that for validating an element node.
Dynamic Evaluation
Dynamic Errors
The default rules for propogating errors, described in [3.3 Error Handling] apply to the validate expression.
4.14 Extension Expressions
Introduction
An extension expression is an expression whose semantics are implementation-defined. An extension expression consists of one or more pragmas, followed by an expression enclosed in curly braces.
Core Grammar
The Core grammar productions for ExtensionExpr are:
Normalization
Extension expressions are normalized as extension expressions in the [XPath/XQuery] core.
| |
| [Pragma+ { Expr }]Expr |
| == |
| Pragma+ { [Expr]Expr } |
If the extension expression does not contain any expression, this is normalized into an extension expression with a call to the fn:error function.
| |
| [Pragma+ { }]Expr |
| == |
Pragma+ { fn:error() } |
Dynamic Evaluation
The QName of a pragma must resolve to a namespace URI and local name, using the statically known namespaces. If at least one of the pragmas is recognized, the dynamic semantics is implementation-defined.
| dynEnv |- Some Pragma are recognized, yielding the implementation-defined value Value. |
|
|
|
| dynEnv |- Pragma+ { Expr } => Value |
If none of the pragmas are recognized the dynamic semantics of an ExtensionExpression are the same as evaluating the given expression.
Static Type Analysis
If at least one of the pragmas is recognized, the static semantics are implementation-defined.
If none of the pragmas are recognized, the static semantics are the same as for the input expression. In both cases, the static typing must be applied on the input expression, possibly raising corresponding static type errors.
5 Modules and Prologs
The organization of this section parallels the organization of Section 4 Modules and PrologsXQ.
Introduction
XQuery supports modules as defined in Section 4 Modules and PrologsXQ. A main moduleXQ contains a PrologXQ followed by a query bodyXQ. A query has exactly one main module. In a main
module, the query bodyXQ can be evaluated, and its value is the result of the query. A library moduleXQ contains a module declaration followed by a PrologXQ.
The Prolog is a sequence of declarations that affect query processing. The Prolog can be used, for example, to declare namespace prefixes, import types from XML Schemas, and declare functions and variables. Namespace declarations and schema imports always precede function and variable declarations, as specified by the following grammar productions.
Query Module
Function declarations are globally scoped, that is, the use of a function name in a function call may precede declaration of the function. Variable declarations are lexically scoped, i.e., variable declarations must precede variable uses.
Core Grammar
The Core grammar productions for the prolog are:
Query Module
Notation
The XQuery Prolog requires that declarations appear in a particular order. In the Formal Semantics, it is simpler to assume the declarations can appear in any order, as it does not change their semantics -- we simply assume that an XQuery parser has enforced the required order.
The Prolog contains a variety of declarations that specify the initial static and dynamic context of the query. The following formal grammar productions represent any Prolog declaration.
Prolog Declarations
The function []PrologDecl takes a prolog declaration and maps it into its equivalent declaration in the Core grammar.
The following auxiliary judgments are applied when statically processing the declarations in the prolog. The effect of the judgment is to process each prolog declaration in order, constructing a new static environment from the static environment constructed from previous prolog declarations.
The judgment:
holds if under the static environment statEnv1, the sequence of prolog declarations PrologDeclList yields the static environment statEnv2 and the normalized sequence of prolog declarations in the Core grammar.
The judgment:
holds if under the static environment statEnv1, the single prolog declaration PrologDecl yields the new static environment statEnv2.
Normalization
Static Context Processing
Prolog declarations are processed in the order they are encountered. The normalization of a prolog declaration PrologDecl depends on the static context processing of all previous prolog declarations. In turn, static context processing of PrologDecl depends on the normalization of the PrologDecl. For example, because variables are lexically scoped, the normalization and static context processing of a variable declaration depends on the normalization and static context
processing of all previous variable declarations. Therefore, the normalization phase and static context processing are interleaved, with normalization preceding static context processing for each prolog declaration.
The following inference rules express this dependency. The first rule specifies that for an empty sequence of prolog declarations, the initial static environment is the default static context.
The next rule interleaves normalization and static context processing. The result of static context processing and normalization is a static context and the normalized prolog declarations.
Static Type Analysis
Static typing of a main module follows context processing and normalization. Context processing and normalization of a main module applies the rules above to the prolog, then using the resulting static environment statEnv, the query body is normalized into a Core expression, and the static typing rules are applied to this Core expression.
|
|
|
| PrologDeclList QueryBody : Type |
Notation
Similary, the judgment:
holds if under the static environment statEnv1, the sequence of prolog declarations PrologDeclList yields the static environment statEnv2 and the normalized sequence of prolog declarations in the Core grammar.
The judgment:
holds if under the dynamic environment dynEnv, the single prolog declaration PrologDecl yields the new dynamic environment dynEnv1.
Dynamic Context Processing
The rules for initializing the dynamic context are as follows. The first rule specifies for an empty sequence of prolog declarations, the initial dynamic environment is the default dynamic context.
The second rule simply computes the dynamic environment by processing the prolog declarations in order.
Dynamic Evaluation
Dynamic evalution of a main module applies the rules for dynamic-context processing to the prolog declarations, then using the resulting dynamic environment dynEnv, the dynamic evaluation rules are applied to the normalized query body.
5.1 Version Declaration
Core Grammar
The core grammar production for version declarations is:
A version declaration specifies the applicable XQuery syntax and semantics for a module. An XQuery implementation must raise a static error when processing a query labeled with a version that the implementation does not support. The Formal Semantics is specified for XQuery 1.0 and does not specify this static error formally.
5.2 Module Declaration
Introduction
We assume that the static-context processing and dynamic-context processing described in [5 Modules and Prologs] are applied to all library modules before the normalization, static context processing, and dynamic context processing of the main module. That is, at the time an "import module" declaration is processed, we assume that the static and dynamic context of the imported module is already available. This assumption does not require or assume separate
compilation of modules. An implementation might process all or some imported modules statically (i.e., before the importing module is identified) or dynamically (i.e., when the importing module is identified and processed).
Notation
We define a new judgment that maps a module's URI to the corresponding module's static environment:
We also define a new judgment that maps a module's URI to the corresponding module's dynamic environment:
Core Grammar
The core grammar production for module declarations is:
Static Context Processing
The effect of a module declaration is to apply the static processing rules defined in [5 Modules and Prologs] to the module's prolog. The resulting static context is then available to any importing module.
The module declaration extends the prolog with a namespace declaration that binds the module's prefix to its URI, then computes the static context for the complete module.
| declare namespace NCName = URILiteral ; PrologDeclList =>stat statEnv |
| module namespace NCName = URILiteral PrologDeclList |
|
|
|
|
|
Note that the rule above and the rules for static processing of an "import module" declaration in [5.11 Module Import] are mutually recursive.
Dynamic Context Processing
The dynamic context processing of a module declaration is similar to that of static processing. The module declaration extends the prolog with a namespace declaration that binds the module's prefix to its URI, then computes the dynamic context for the complete module.
| (declare namespace NCName = URILiteral PrologDeclList) =>dyn dynEnv |
| module namespace NCName = URILiteral PrologDeclList |
|
|
|
|
|
Note that the rule above and the rules for dynamic processing of an "import module" declaration in [5.11 Module Import] are mutually recursive.
5.3 Boundary-space Declaration
| [11 (XQuery)] |
BoundarySpaceDecl |
::= |
"declare" "boundary-space" ("preserve" | "strip") |
The xmlspace declaration is not specified formally as the Formal Semantics is defined on the Core language, which is an abstract, not concrete, syntax and is typically the result of parsing phase described in [3.2.1 Processing model].
5.4 Default Collation Declaration
Core Grammar
The core grammar production for default collation declarations is:
Normalization
The default collation declaration is in the Core grammar, so no normalization rules are necessary.
Static Context Processing
The default collation declaration updates the collations environment of the static context. The collations environment is used by several functions in [Functions and Operators], but is otherwise not used in the Formal Semantics.
Dynamic Context Processing
The default collation declaration does not affect the dynamic context.
5.5 Base URI Declaration
| [20 (XQuery)] |
BaseURIDecl |
::= |
"declare" "base-uri" URILiteral |
Core Grammar
The core grammar production for base uri declarations is:
Normalization
The base URI declaration is already in the Core grammar, so normalization rule is necessary.
Static Context Processing
A base URI declaration specifies the base URI property of the static context, which is used when resolving relative URIs within a module. A static error is raised if more than one base URI declaration is declared in a query prolog.
Dynamic Context Processing
The base URI declaration does not affect the dynamic context.
5.6 Construction Declaration
| [25 (XQuery)] |
ConstructionDecl |
::= |
"declare" "construction" ("preserve" | "strip") |
Core Grammar
The core grammar production for construction declarations is:
| [24 (Core)] |
ConstructionDecl |
::= |
"declare" "construction" ("preserve" | "strip") |
Normalization
The construction declaration is in the Core grammar, so no normalization rule is necessary.
Static Context Processing
The construction declaration modifies the construction mode in the static context.
Dynamic Context Processing
The construction declaration does not have any affect on the dynamic context.
5.7 Ordering Mode Declaration
| [14 (XQuery)] |
OrderingModeDecl |
::= |
"declare" "ordering" ("ordered" | "unordered") |
Core Grammar
The core grammar production for ordering mode declarations is:
5.8 Empty Order Declaration
| [15 (XQuery)] |
EmptyOrderDecl |
::= |
"declare" "default" "order" ("empty" "greatest" | "empty" "least") |
Core Grammar
The core grammar production for empty order declarations is:
| [14 (Core)] |
EmptyOrderDecl |
::= |
"declare" "default" "order" ("empty" "greatest" | "empty" "least") |
5.9 Copy-Namespaces Declaration
Core Grammar
The core grammar productions for copy-namespaces declarations are:
5.10 Schema Import
Schema Imports
| [21 (XQuery)] |
SchemaImport |
::= |
"import" "schema" SchemaPrefix? URILiteral (("at" URILiteral) ("," URILiteral)*)? |
| [22 (XQuery)] |
SchemaPrefix |
::= |
("namespace" NCName "=") | ("default" "element" "namespace") |
The semantics of Schema Import is described in terms of the [XPath/XQuery] type system. The process of converting an XML Schema into a sequence of type declarations is described in Section [C Importing Schemas]. This section describes how the resulting sequence of type declarations is added into the static context when the Prolog is processed.
Core Grammar
The core grammar productions for schema imports are:
Schema Imports
Normalization
Schema import declarations are in the Core grammar, so no normalization rules are necessary.
Notation
Some of the judgments use the following production for LocationHints.
Location Hints
The following auxiliary judgments are used when processing schema imports.
The judgment:
holds if under the static environment statEnv1, the sequence of type definitions Definitions yields the new static environment statEnv2.
The judgment:
holds if under the static environment statEnv1, the single definition Definition yields the new static environment statEnv2.
Static Context Processing
A schema imported into a query is first mapped into the [XPath/XQuery] type system, which yields a sequence of XQuery type definitions. The rules for mapping the imported schema begins in [C.2 Schemas as a whole]. Each type definition in an imported schema is then added to the static environment.
The schema import declaration may also assign an element/type namespace prefix to the URI of the imported schema, or assign the default element namespace to the URI of the imported schema.
An empty sequence of type definitions yields the input environment.
Each type definition is added into the static environment.
Each type, element, or attribute declaration is added respectively to the type, element and attribute declarations components of the static environment.
Note that it is a static error to import two schemas that both define the same name in the same symbol space and in the same scope, that is multiple top-level definitions of the same type, element, or attribute name raises a static error. For instance, a query may not import two schemas that include top-level element declarations for two elements with the same expanded name.
Dynamic Context Processing
The schema import declarations do not affect the dynamic context.
5.11 Module Import
| [23 (XQuery)] |
ModuleImport |
::= |
"import" "module" ("namespace" NCName "=")? URILiteral (("at" URILiteral) ("," URILiteral)*)? |
Core Grammar
The core grammar production for module imports is:
Module Import
Notation
The rules below depend on the following auxilliary functions,
The function fs:local-variables(statEnv, URI) returns all the (expanded-QName, Type) pairs in statEnv.varType such that the URI part of the variable's expanded-QName equals the given URI, that is, the variables that
are declared locally in the module with the given namespace URI.
The function fs:local-functions(statEnv, URI) returns all the function signatures in statEnv.funcType such that the URI part of the function's expanded-QName equals the given URI, that is, the function signatures that are declared locally in the module with the given namespace URI.
Static Context Processing
During static context processing, the effect of an "import module" declaration is to extend the importing module's static context with the global variables (and their types) and the function signatures of the imported module. Module import is not transitive, therefore only the global variables and functions declared explicitly in the imported module are available in the importing module. Also, module import does not import schemas, therefore the importing module must explicitly import any schemas on
which the imported global variables or functions depend.
The first premise below "looks up" the static context of the imported module, as defined in [5.2 Module Declaration], then extends the input static context with the global variables and function signatures declared in the imported static context.
Note that the rule above and the rules for processing a library module in [5.2 Module Declaration] above are mutually recursive.
Dynamic Context Processing
During dynamic context processing, the effect of an "import module" declaration is to extend the importing module's dynamic context with the global variables and the function definitions of the imported module. Each variable and function name is mapped to the special value #IMPORTED(URI) to indicate that the variable or function is defined in the imported module with the given URI.
Notation
The rules below depend on the following auxilliary judgments.
This judgment adds each variable explicitly declared in the imported module to the importing module's dynamic variable environment.
This judgment adds each function explicitly declared in the imported module to the importing module's dynamic function environment.
dynEnv2 = dynEnv1 + funcDefn((expanded-QName1(Type1,1, ..., Type1,n)) =>
#IMPORTED(URI)) |
| dynEnv2 ; URI |- (expanded-QName2(Type2,1, ..., Type2,n)), ···, (expanded-QNamek(Typek,1, ..., Typek,n)) =>import_functions dynEnv3 |
|
|
|
| dynEnv1 ; URI |- (expanded-QName1(Type1,1, ..., Type1,n)), ···, (expanded-QNamek(Typek,1, ..., Typek,n)) =>import_functions dynEnv3 |
|
|
The first premise below "looks up" the dynamic context of the imported module, as defined in [5.2 Module Declaration]. The auxilliary judgments =>import_variables and =>import_functions add each imported global variable and function name to the input dynamic context.
|
|
|
| dynEnv1 |- import module (namespace NCName =)? URILiteral LocationHints? =>dyn dynEnv4 |
|
|
Note that the rule above and the rules for processing a library module in [5.2 Module Declaration] above are mutually recursive.
5.12 Namespace Declaration
| [10 (XQuery)] |
NamespaceDecl |
::= |
"declare" "namespace" NCName "=" URILiteral |
Core Grammar
The core grammar production for namespace declarations is:
Normalization
The namespace declaration is in the Core grammar, so no normalization rules are necessary.
Static Context Processing
A namespace declaration adds a new (prefix,uri) binding in the namespace component of the static environment. All namespace declarations in the prolog are passive declarations. Namespace declaration attributes of element constructors are active declarations.
Dynamic Context Processing
The namespace declaration does not affect the dynamic context.
5.13 Default Namespace Declaration
| [12 (XQuery)] |
DefaultNamespaceDecl |
::= |
(("declare" "default" "element") | ("declare" "default" "function")) "namespace" URILiteral |
Core Grammar
The core grammar production for default namespace declarations is:
Normalization
The default namespace declarations are in the Core grammar, so no normalization rules are necessary.
Static Context Processing
A default element namespace declaration changes the default element namespace prefix binding in the namespace component of the static environment. If the string literal is the zero-length string, the default element namespace is set to the null namespace.
A default function namespace declaration changes the default function namespace prefix binding in the namespace component of the static environment. If the URI literal is the zero-length string, the default function namespace is set to the null namespace.
Note that multiple declarations of the same namespace prefix in the Prolog result in a static error. However, a declaration of a namespace in the Prolog can override a prefix that has been predeclared in the static context.
Dynamic Context Processing
Default namespace declarations do not affect the dynamic context.
5.14 Variable Declaration
Core Grammar
The core grammar production for variable declarations is:
Normalization
Normalization of a variable declaration normalizes the variable and its corresponding expression, if it is present.
If an external variable declaration does not have a type declaration it is treated as if the type declaration was item()*.
| |
| [ declare variable VarRef as SequenceType external ]PrologDecl |
| == |
| declare variable VarRef as SequenceType external |
Static Context Processing
A variable declaration updates the variable component of the static context by associating the given variable with a static type.
If a variable declaration does not have a type declaration but has an associated expression, then the static type of the variable is the static type of the expression.
If the variable declaration has a type declaration, the static type of the variable is the specified type.
Dynamic Context Processing
To evaluate a variable declaration, its associated expression is evaluated, and the dynamic context is updated with the variable bound to the resulting value.
Dynamic evaluation does not apply to externally defined variables. The evaluation environment must provide the values of external variables in the initial dynamic context (dynEnvDefault).
5.15 Function Declaration
Introduction
User-defined functions specify the name of the function, the names and types of the parameters, and the type of the result. The function body defines how the result of the function is computed from its parameters.
Function declarations
Core Grammar
The core grammar productions for function declarations are:
Function declarations
Notation
The following auxiliary mapping rule is used for the normalization of parameters in function declarations: []Param.
Parameters without a declared typed are given the item* sequence type.
Normalization
The parameter list and body of a user-defined function are all normalized into Core expressions.
| |
| [ declare function QName ( ParamList? ) as SequenceType EnclosedExpr ]PrologDecl |
| == |
| declare function QName ( [ParamList?]Param ) as SequenceType [EnclosedExpr]Expr |
If the return type of the function is not provided, it is given the item* sequence type.
| |
| [declare function QName ( ParamList? ) EnclosedExpr ]PrologDecl |
| == |
| declare function QName( [ParamList?]Param ) as item* [EnclosedExpr]Expr |
Externally defined functions are normalized similarly.
| |
| [ declare function QName ( ParamList? ) as SequenceType external]PrologDecl |
| == |
| declare function QName( [ParamList?]Param ) as SequenceType external |
| |
| [declare function QName ( ParamList? ) external ]PrologDecl |
| == |
| declare function [QName] ( [ParamList?]Param ) as item* external |
Static Context Processing
Because functions are mutually referential, all function signatures must be defined in the static environment before static type analysis is applied to the function bodies. This rule also updates the local functions component of the static context to indicate the function is declared within the given module.
Note that the static context processing is performing type checking of the function, as defined below. Note also that the type checking is done in the new environment in which the function declaration has been added which ensures that recursive calls are type-checked properly.
Static Type Analysis
The static typing rules for function bodies follows normalization and processing of the static context. The typing rules below constructs a new environment in which each variable has the given expected type, then the static type of the function's body is computed under the new environment. The function body's type must be a subtype of the expected return type. If type checking fails, a static error is raised. Otherwise, static typing of the function has no other effect, as function signatures are
already inside the static environment.
|
|
|
| statEnv |- declare function QName (VarRef1 as SequenceType1, ···, VarRefn as SequenceTypen) as SequenceTyper { Expr } :
Typer |
The bodies of external functions are not available and therefore cannot by type checked. To ensure type soundness, the evaluation environment must guarantee that the value returned by the external function matches the expected return type.
|
|
|
| statEnv |- declare function QName ( VarRef1 as SequenceType1 , ···, VarRefn as SequenceTypen ) as SequenceTyper external :
Typer |
Dynamic Context Processing
A function declaration updates the dynamic context. The function name with arity N is associated with the given function body. The number of arguments is required, because XQuery permits overloading of function names as long as each function signature has a different number of arguments.
An external function declaration does not affect the dynamic environment. The evaluation environment must provide the implementation for externally defined functions.
|
|
| dynEnv |- declare function QName ( Variable1 as SequenceType1, ···, Variablen as SequenceTypen ) as SequenceTyper external =>dyn dynEnv |
The dynamic semantics of a function body are applied when the function is called and is described in [4.1.5 Function Calls].
5.16 Option Declaration
Core Grammar
The core grammar production for option declarations is:
8 Auxiliary Judgments
This section defines auxiliary judgments used in defining the formal semantics. Many auxiliary judgments are used in both static and dynamic inference rules. Those auxiliary judgments that are used in only the static or dynamic semantics are labeled as such.
8.1 Judgments for accessing types
Introduction
This section defined several auxiliary judgments to access components of the [XPath/XQuery] type system. The first two judgements (derives from and substitutes for) are used to access the type and element name hierarchies in an XML Schema. The other judgments (name lookup, type lookup,
extended by, adjusts to and expands to) are used to lookup the meaning of element or attribute types from the schema. These judgments are used in many expressions, notably in the specification of type matching (See [8.3 Judgments for type matching]), validation (See [E.1 Judgments
for the validate expression]), and the static semantics of step expressions (See [8.2 Judgments for step expressions and filtering]).
8.1.1 Derives from
Notation
The judgment
holds when the first type name derives from the second type name. This judgment formalizes the definition of the derives-from function in Section 2.5.4 SequenceType MatchingXQ.
Example
For example, assuming the extended XML Schema given in section [2.4.5 Example of a complete Schema], then the following judgments hold.
USAddress derives from xs:anyType
NYCAddress derives from USAddress
NYCAddress derives from xs:anyType
xsd:positiveInteger derives from xsd:integer
xsd:integer derives from xs:anySimpleType
fs:anon3 derives from xsd:positiveInteger
fs:anon3 derives from xsd:integer
fs:anon3 derives from xs:anySimpleType
fs:anon3 derives from xs:anyType
Note
Derivation is a partial order. It is reflexive and transitive by the definition below. It is asymmetric because no cycles are allowed in derivation by restriction or extension.
Semantics
This judgment is specified by the following rules.
Some rules have hypotheses that simply list a type, element, or attribute declaration.
Every type name derives from itself.
Every type name derives from the type it is declared to derive from by restriction or extension.
The above rules all require that the type names be defined in the static context, but [XPath/XQuery] permits references to "unknown" type names, i.e., type names that are not defined in the static context. An unknown type name might be encountered, if a module in which the given type name occurs does not import the schema in which the given type name is defined. In this case, an implementation is allowed (but is not required) to provide an implementation-dependent mechanism for determining whether the
unknown type name is the same as or derived by restriction from the expected type name. The following rule formalizes this implementation dependent mechanism.
The derivation relation is transitive.
8.1.2 Substitutes for
The substitutes judgment is used to know whether an element name is in the substitution group of another element name.
Notation
The judgment
holds when the first element name substitutes for the second element name.
Example
For example, assuming the extended XML Schema given in section [2.4.5 Example of a complete Schema], then the following judgments hold.
usaddress substitutes for address
nyaddress substitutes for usaddress
nyaddress substitutes for address
Note
Substitution is a partial order. It is reflexive and transitive by the definition below. It is asymmetric because no cycles are allowed in substitution groups.
Semantics
The substitutes judgment for element names is specified by the following rules.
Every element name substitutes for itself.
Every element name substitutes for the element it is declared to substitute for.
Substitution is transitive.
8.1.3 Element and attribute name lookup (Dynamic)
The name lookup judgment is used in the definition of the matches judgment, which takes a value and a type and determines whether the value matches, or is an instance of, the given type. Both name lookup and matches are used in the dynamic semantics.
The name lookup judgment takes an element(attribute) name (derived from a node value) and an element(attribute) type and if the element(attribute) name matches the corresponding name in the element(attribute) type, the judgment yields the type's corresponding type reference and for elements, its nillable property.
Notation
The judgment
holds when the given element name matches the given element type and requires that the element be nillable as indicated and have the given type reference.
Example
For example, assuming the extended XML Schema given in section [2.4.5 Example of a complete Schema], then the following judgments hold.
comment name lookup element comment yields of type xsd:string
size name lookup element size nillable of type xs:integer yields nillable of type xsd:string
apt name lookup element apt yields of type fs:anon3
nycaddress name lookup element address yields of type NYCAddress
Note that when the element name is in a substitution group, the name lookup returns the type name corresponding to the original element name (here the type NYCAddress for the element nycaddress, instead of Address for the element address).
Semantics
This judgment is specified by the following rules.
If the element type is a reference to a global element, then name lookup yields the type reference in the element declaration for the given element name. The given element name must be in the substitution group of the global element.
If the given element name matches the element name in the element type, and the element type contains a type reference, then name lookup yields that type reference.
If the element type has no element name but contains a type reference, then name lookup yields the type reference.
If the element type has no element name and no type reference, then name lookup yields xs:anyType.
Notation
The judgment
holds when matching an attribute with the given attribute name against the given attribute type matches the type reference.
Example
For example, assuming the extended XML Schema given in section [2.4.5 Example of a complete Schema], then the following judgments hold.
orderDate name lookup attribute orderDate of type xsd:date yields of type xsd:date?
orderDate name lookup attribute of type xsd:date yields of type xsd:date?
Semantics
This judgment is specified by the following rules.
If the attribute type is a reference to a global attribute, then name lookup yields the type reference in the attribute declaration for the given attribute name.
If the given attribute name matches the attribute name in the attribute type, and the attribute type contains a type reference, then name lookup yields that type reference.
If the attribute type has no attribute name but contains a type reference, then name lookup yields the type reference.
If the attribute type has no attribute name and no type reference, then name lookup yields xs:anySimpleType.
8.1.4 Element and attribute type lookup (Static)
The type lookup judgments are used to obtain the appropriate type reference for an attribute or element.
Notation
The judgment
holds when the element type is optionally nillable and has the given type reference.
Semantics
The element type lookup judgments are specified by the following rules.
A reference to a global element yields the type reference in the global element declaration with the given element name.
In the case of a local element type, type lookup yields the corresponding type reference.
If the element type has no element name but contains a type reference, then type lookup yields that type reference.
If the element type has no element name and no type reference, then lookup yields xs:anyType.
Notation
The judgment
holds when the attribute type has the given type reference.
Semantics
This judgment is specified by the following rules.
A reference to a global attribute yields the type reference in the global attribute declaration with the given attribute name.
If the attribute name is not defined, i.e., it is not declared in the in-scope schema definitions, then the attribute's default type is xdt:untypedAtomic.
In the case of a local attribute type, type lookup yields the corresponding type reference.
If the attribute type has no attribute name but contains a type reference, then type lookup yields the type reference.
If the attribute type has no attribute name and no type reference, then type lookup yields xs:anySimpleType.
8.1.5 Extension
Notation
The judgment
holds when the result of extending Type1 by Type2 is Type. This judgment is used in the definition of type expansion [8.1.9 Type expansion], which expands a type to include the union of all types derived from the given type,
Semantics
This judgment is specified by the following rules.
8.1.6 Mixed content
Notation
The judgment
holds when the result of creating a mixed content from Type1 is Type2.
Semantics
This judgment is specified by the following rule, which interleaves the element content with a sequence of text nodes and adds a union of xdt:anyAtomicType values. The xdt:anyAtomicType sequence is required because it is possible to derive an element containing only atomic values from an element that is mixed.
8.1.7 Type adjustment
In the [XPath/XQuery] type system, a complex-type declaration does not include the implicit attributes and nodes that may be included in the type. Type adjustment takes a complex type and adjusts it to include implicit attributes and nodes. In particular, type adjustment:
-
adds the four (optional) built-in attributes xsi:type, xsi:nil, xsi:schemaLocation, or xsi:noNamespaceSchemaLocation,
-
interleaves the type with a sequence of comments and processing-instructions, and
-
if the complex type is mixed, interleaves the type with a sequence of text nodes and xdt:anyAtomicType.
Notation
The judgment
holds when the second type is the same as the first after the first has been adjusted as described above.
Semantics
This judgment is specified by the following rules.
If the type is flagged as mixed, then mix the type and extend it by the built-in attributes.
Otherwise, just extend the type by the built-in attributes.
8.1.8 Builtin attributes
Schema defines four built-in attributes that can appear on any element in the document without being explicitly declared in the schema. Those four attributes need to be added inside content models when doing matching. The four built-in attributes of Schema are declared as follows.
define attribute xsi:type of type xs:QName
define attribute xsi:nil of type xs:boolean
define attribute xsi:schemaLocation of type fs:anon
define type fs:anon1 { xs:anyURI* }
define attribute xsi:noNamespaceSchemaLocation of type xs:anyURI
For convenience, a type that is an all group of the four built-in XML Schema attributes is defined.
BuiltInAttributes =
attribute xsi:type ?
& attribute xsi:nil ?
& attribute xsi:schemaLocation ?
& attribute xsi:noNamespaceSchemaLocation ?
8.1.9 Type expansion
The expands to judgment is one of the most important static judgments. It is used in the static semantics of the child axis [8.2.2.1 Static semantics of axes], which is used in the definition of many other rules that extract element types from an arbitrary content type.
The judgment takes a type name and computes the union of all types derived from the given type. If the type is nillable, it also makes sure the content model allows the empty sequence. If the type is mixed, it also adjusts the type to include the mixed content model. The judgment depends on the extended with union interpretation of judgment to recursively compute all derived types.
Notation
The judgment
holds when expanding the (nillable) type reference results in the given type.
Semantics
This judgment is specified by the following rules.
If the type is nillable, then its expansion is optional.
The type definition for the type reference is contained in its expansion.
In case the type is xdt:untyped, the type does not need to be adjusted as is required for other XML Schema types. See the corresponding definition in [3.5.1 Predefined Schema Types].
8.1.10 Union interpretation of derived types
Notation
The judgment
holds when the type Type2 is the expansion of the type name TypeName with definition Type1 to include all types derived by extension and restriction from the given type name. This rule is recursive, because each type name itself may have other type names that are derived from it. The recursive rules traverse the entire
derivation tree, identifying every type name derived from the original type name.
Semantics
This judgment is specified by the following rules.
| statEnv.typeDefn(expanded-QNameR,1) = define type TypeNameR,1 restricts TypeName0 Mixed? { TypeR,1? } |
| · · · |
| statEnv.typeDefn(expanded-QNameR,n) = define type TypeNameR,n restricts TypeName0 Mixed? { TypeR,n? } |
| statEnv |- TypeR,1' is TypeR,1 extended with union interpretation of TypeNameR,1 |
| · · · |
| statEnv |- TypeR,n' is TypeR,n extended with union interpretation of TypeNameR,n |
| statEnv.typeDefn(expanded-QNameE,1) = define type TypeNameE,1 extends TypeName0 Mixed? { TypeE,1? } |
| · · · |
| statEnv.typeDefn(expanded-QNameE,m) = define type TypeNameE,m extends TypeName0 Mixed? { TypeE,m? } |
| statEnv |- TypeE,1' is TypeE,1 extended with union interpretation of TypeNameE,1 |
| · · · |
| statEnv |- TypeE,m' is TypeE,m extended with union interpretation of TypeNameE,m |
| Type1 = TypeR,1' | · · · | TypeR,n' | (Type0, TypeE,1' ) | · · · | (Type0,TypeE,m') |
|
|
|
| statEnv |- Type1 is Type0 extended with union interpretation of TypeName0 |
Examples
This expansion does not enforce the XML Schema property of one-determinism in the resulting content models. Implementations may want to implement an equivalent alternative expansion that enforces the one-determinism property. For example, expanding type T1 below yields the following type that is not one-deterministic:
define type T1 { element a }
define type T2 extends T1 { element b }
(element a | element a, element b) is (element a) extended with union interpretation of T1
An implementation might want to infer the equivalent one-deterministic content model:
(element a, (() | element b)) is (element a) extended with union interpretation of T1
8.2 Judgments for step expressions and filtering
Introduction
Step expressions are one of the elementary operations in [XPath/XQuery]. Steps select nodes reachable from the root of an XML tree. Defining the semantics of step expressions requires a detailed analysis of all the possible cases of axis and node tests.
This section introduces auxiliary judgments used to define the semantics of step expressions. The principal judgment ([8.2.1 Principal Node Kind]) captures the notion of principal node kind in XPath. The Axis judgments ([8.2.2 Auxiliary judgments for axes]) define the static and dynamic semantics of all axes, and the Node Test judgments ([8.2.3 Auxiliary judgments for node tests]) define the static and dynamic semantics of all node tests. The filter judgment accesses the value of an attribute and is used in the definition of validation ([E Auxiliary Judgments for Validation]).
8.2.1 Principal Node Kind
Notation
The following auxiliary grammar production describe principal node types (See [XML Path Language (XPath) 2.0]).
PrincipalNodeKind
| [73 (Formal)] |
PrincipalNodeKind |
::= |
"element" | "attribute" | "namespace" |
Notation
The judgment
holds when PrincipalNodeKind is the principal node kind for Axis.
Example
For example, the following judgments hold.
child:: principal element
descendant:: principal element
preceding:: principal element
attribute:: principal attribute
namespace:: principal namespace
Semantics
This judgment is specified by the following rules.
The principal node type for the attribute axis is attribute.
The principal node type for the namespace axis is namespace.
The principal node type for all other axis is element.
Axis != attribute:: Axis != namespace:: |
|
| Axis principal element |
8.2.2 Auxiliary judgments for axes
8.2.2.1 Static semantics of axes
Notation
The following judgment
holds when applying the axis Axis on type Type1 yields the type Type2.
The following two judgments are used in the definition of axis. The judgment
only applies to a type that is a valid element content type and holds when Type1 has the content type Type2. The judgment separates the attribute types from the other node or atomic-valued types of the element content type and yields the non-attribute types.
The judgment
only applies to a type that is a valid element content type and holds when Type1 has attribute types Type2. The judgment yields the attribute types of the element content type.
Example
For example, the following judgments hold.
axis child:: of element of type xs:string : text
axis child:: of element items of type Items : element item of type fs:anon1*
axis child:: of element purchaseOrder :
element shipTo of type USAddress,
element billTo of type USAddress,
element ipo:comment?,
element items of type Items
axis attribute:: of element of type xs:string : empty
attribute partNum of type SKU,
element item of type fs:anon1*
has-node-content
element item of type fs:anon1*
attribute partNum of type SKU,
element item of type fs:anon1*
has-attribute-content
attribute partNum of type SKU
(attribute partNum of type SKU,
element item of type fs:anon1*) |
(attribute orderDate of type xs:date?,
element shipTo of type USAddress,
element billTo of type USAddress,
element comment?,
element items of type Items)
has-node-content
(element item of type fs:anon1*) |
(element shipTo of type USAddress,
element billTo of type USAddress,
element comment?,
element items of type Items)
(attribute partNum of type SKU,
element item of type fs:anon1*) |
(attribute orderDate of type xs:date?,
element shipTo of type USAddress,
element billTo of type USAddress,
element comment?,
element items of type Items)
has-attribute-content
(attribute partNum of type SKU) |
(attribute orderDate of type xs:date?)
8.2.2.1.1 Inference rules for all axis
Semantics
This judgment is specified by the following rules.
The following rules compute the type of the axis expression when applied to each item type in the content model.
The following rules specifies how to compute the type of each axis applied to an item type.
8.2.2.1.2 Inference rules for the self axis
Semantics
Applying the self axis to a node type results in the same node type.
8.2.2.1.3 Inference rules for the child axis
Semantics
In the case of an element type, the static type of the child axis is obtained by type lookup and expansion of the resulting type. Note that the expands to judgment yields the type that corresponds to a given type name. Because the meaning of a type name includes the definitions of all type names derived by extension and restriction from the given type name, expands to yields the
union of all the type definitions of all type names derived from the input type name. Each type in the union contains the complete definition of the type name, i.e., it includes built-in attributes and, if necessary, processing-instruction, comment, and text types.
After type expansion, the judgment has-node-content is applied to each type in the union. The resulting type is the union of all non-attribute types in the expanded type.
If the type is a sequence of attributes, then the content type is empty.
If the type is attributes followed by a simple type, the content type is zero-or-one text. The resulting type is optional since an expression returning the empty sequence results in no text node being constructed.
In the case of an element type with complex content type, the content type is simply the non-attribute part of the complex content type.
In the case of an attribute type, the static type of the child axis is empty.
In the case of a text node type, the static type of the child axis is empty.
In the case of a comment node type, the static type of the child axis is empty.
In the case of a processing-instruction node type, the static type of the child axis is empty.
In case of a document node type, the static type of the child axis is the type of the document node content, interleaved with a sequence of comments and processing-instructions.
8.2.2.1.4 Inference rules for the attribute axis
Semantics
The static type for the attribute axis is computed in a similar way as the static type for the child axis. As above, the expands to judgment may yield a union type. After type expansion, the judgment has-attribute-content is applied to each type in the union.
When applied to an element type, has-attribute-content yields the type of the element's content that are attributes.
In case of an attribute type, the static type of the attribute axis is empty.
In case of a text node type, the static type of the attribute axis is empty.
In case of a comment node type, the static type of the attribute axis is empty.
In case of a processing-instruction node type, the static type of the attribute axis is empty.
In case of a document node type, the static type of the attribute axis is the empty.
8.2.2.1.5 Inference rules for the parent axis
Semantics
The type for the parent of an element type, a text node type, a PI node type, or a comment node type is either an element, a document, or empty.
|
|
statEnv |- axis parent:: of processing-instruction : (element | document)? |
The type for the parent of an attribute node is an element or empty.
The type for the parent of a document node type is always empty.
8.2.2.1.6 Inference rules for the namespace axis
Semantics
The type for the namespace axis is always empty.
8.2.2.1.7 Inference rules for the descendant axis
Semantics
The types for the descendant axis is obtained as the closure of the type of the child axis. This is expressed by the following inference rule.
Note
Note that the last premise in the above rule terminates the recursion. The rule computes the n-th type Typen such that applying the child axis one more time does not add any new item type to the union. This condition is guaranteed to hold at some point, because the number of item types is bounded by all of the item types defined in the in-scope schema definitions.
8.2.2.1.8 Inference rules for the descendant-or-self axis
Semantics
The type for the descendant-or-self axis is the union of the type for the self axis and for the descendant axis.
8.2.2.1.9 Inference rules for the ancestor axis
Semantics
The type for the ancestor axis is computed similarly as for the descendant axis.
Note that this rule will always result in the type (element | document)* type, but this formulation is prefered for consistency, and in case the static typing for the parent axis gets improved in a future version.
8.2.2.1.10 Inference rules for the ancestor-or-self axis
Semantics
The type for the ancestor-or-self axis is the union of the type for the self axis and for the ancestor axis.
8.2.2.2 Dynamic semantics of axes
Notation
The following judgment
holds when applying the axis Axis on Value1 yields Value2:
Example
For example, the following judgments hold.
axis child:: of element sizes { text { "1 2 3" } } => text { "1 2 3" }
axis attribute:: of
element weight of type xs:integer {
attribute xsi:type of type xs:QName {
"xs:integer" of type xs:QName
},
42 of type xs:integer
}
=> attribute xsi:type of type xs:QName {
"xs:integer" of type xs:QName
}
Semantics
This judgment is specified by the following rules.
The first set of rules are used to process the axis judgment on each individual item in the input sequence.
The following rules specifies how the value filter judgment is applied on each Axis.
The self axis just returns the context node.
The child, parent, attribute and namespace axis are specified as follows.
| Editorial note |
|
The use of the dm: should be removed. This can be removed when adding the notion of store in the dynamic rules. |
The descendant, descendant-or-self, ancestor, and ancestor-or-self axis are implemented through recursive application of the children and parent filters.
In all the other cases, the axis application results in an empty sequence.
8.2.3 Auxiliary judgments for node tests
A node test may be a name test or a kind test. In the static and dynamic semantics, we begin with name tests, followed by kind tests.
8.2.3.1 Static semantics of node tests
Notation
The following judgment
holds when applying the node test NodeTest on the type Type1 in the context of the given principal node kind, yields the type Type2.
Example
For example, assuming the extended XML Schema given in section [2.4.5 Example of a complete Schema], then the following judgments hold.
test shipTo with element of
element shipTo of type USAddress,
element billTo of type USAddress,
element ipo:comment?,
element items of type Items
: element shipTo of type USAddress
Semantics
This judgment is specified by the following rules.
The first set of rules is similar to that for axes, and are used to process the content each individual item type in the input content model.
The following rules specify how the test judgment apply to node tests in the context of a principal node kind. We start with name tests followed by kind tests.
8.2.3.1.1 Name Tests
Name tests on elements and attributes always compute the most specific type possible. For example, if $v is bound to an element with a computed name, the type of $v is element. The static type computed for the expression $v/self::foo is element foo of type xs:anyType, which makes use of foo in the name test to compute a more specific type. Also note that each case of name matching restricts the principal node kind
appropriately.
Similar typing rules apply to the attribute name tests:
Lastly, if none of the above rules holds, then the type of the input expression is empty.
8.2.3.1.2 Kind Tests
All the rules for typing the document, element, and attribute kind tests are similar. First, the document, element, or attribute test is normalized to the equivalent document, element, or attribute type by applying the []sequencetype normalization rule to the kind test.
After normalization of the kind test as an XQuery type, that type is compared to the expression's inferred type. If the latter is a subtype of the former other, then the kind test yields the smaller type.
Document kind test
Semantics
If the type of the expression is a subtype of the document kind test, then we are guaranteed that during evaluation, the expression's value will always match the document kind test, and therefore the type of the entire expression is the type of the input expression.
Conversely, if the type of the document kind test is a subtype of the expression, then during evaluation, the expression's value may or may not match the document kind test, and therefore the type of the entire expression is zero-or-one of the type of the document kind test.
If the types of the expression and document kind test are unrelated, then we apply the kind test rule recursively on the element types, which may yield a non-empty type.
If there is no non-empty type, then the kind test yields the empty type.
Element kind test
Semantics
The rules for the element kind test are similar to those for the document kind test.
If the type of the expression is a subtype of the element kind test, then we are guaranteed that during evaluation, the expression's element value will always match the element kind test, and therefore the type of the entire expression is the type of the input expression.
Conversely, if the type of the element kind test is a subtype of the expression, then during evaluation, the expression's element value may or may not match the element kind test, and therefore the type of the entire expression is zero-or-one of the type of the element kind test.
If the types of the expression and element kind test are unrelated (i.e., neither type is a subtype of the other), then we must compare the structure of the type of the element test with the type of the element expression, as an element type or test may contain wildcards.
In the first case, the element kind test contains an element name and a type name and the input expression's type contains only a type name. If the input expression's content type is a subtype of the element kind test's content type, then the type of the entire expression is zero-or-one of an element with the given name and the input expression's content type.
In the second case, the structure of the input types is reversed: The input expression's type contains an element name and a type name and the element kind test's type contains only a type name. If the element kind test's content type is a subtype of the input expression's content type, then the type of the entire expression is zero-or-one of an element with the given name and the element kind test's content type.
Lastly, if none of the above rules holds, then the type of the input expression is empty.
Attribute kind test
Semantics
The rules for the attribute kind test are isomorphic to those for element kind test.
If the type of the expression is a subtype of the attribute kind test, then we are guaranteed that during evaluation, the expression's attribute value will always match the attribute kind test, and therefore the type of the entire expression is the type of the input expression.
Conversely, if the type of the attribute kind test is a subtype of the expression, then during evaluation, the expression's attribute value may or may not match the attribute kind test, and therefore the type of the entire expression is zero-or-one of the type of the attribute kind test.
If the types of the expression and attribute kind test are unrelated (i.e., neither type is a subtype of the other), then we must compare the structure of the type of the attribute test with the type of the attribute expression, as an attribute type or test may contain wildcards.
In the first case, the attribute kind test contains an attribute name and a type name and the input expression's type contains only a type name. If the input expression's content type is a subtype of the attribute kind test's content type, then the type of the entire expression is zero-or-one of an attribute with the given name and the input expression's content type.
In the second case, the structure of the input types is reversed: The input expression's type contains an attribute name and a type name and the attribute kind test's type contains only a type name. If the attribute kind test's content type is a subtype of the input expression's content type, then the type of the entire expression is zero-or-one of an attribute with the given name and the attribute kind test's content type.
Lastly, if none of the above rules holds, then the type of the input expression is empty.
Processing instruction, comment, and text kind tests.
Semantics
|
statEnv |- test processing-instruction() with PrincipalNodeKind of processing-instruction : processing-instruction |
A processing-instruction node test with a string literal or NCName matches a processing instruction whose target has the given name. Since target matching cannot be checked statically, the static type of the node test is zero-or-one processing instruction.
|
statEnv |- test processing-instruction(StringLiteral | NCName) with PrincipalNodeKind of processing-instruction : processing-instruction ? |
If none of the above rules apply, then the node test returns the empty sequence and the following rule applies:
8.2.3.2 Dynamic semantics of node tests
Notation
The following judgment
holds when applying the node test NodeTest on Value1 in the context of the PrincipalNodeKind yields Value2:
Example
For example, the following judgments hold.
test node() with element of text { "1 2 3" } => text { "1 2 3" }
test size with element of text { "1 2 3" } => ()
test foo:* with element of
(element foo:a of type xs:int { 1 },
element foo:a of type xs:int { 2 },
element bar:b of type xs:int { 3 },
element bar:c of type xs:int { 4 },
element foo:d of type xs:int { 5 })
=> (element foo:a of type xs:int { 1 },
element foo:a of type xs:int { 2 },
(),
(),
element foo:d of type xs:int { 5 })
Note
The last example illustrates how a test judgment operates on a sequence of nodes, applying the test on each node in the sequence individually, while preserving the structure of the sequence.
Semantics
This judgment is specified by the following rules.
The first set of rules are similar to those for axes, and are used to process the test judgment on each individual item in the input sequence.
8.2.3.2.1 Name Tests
The following rules specify how the value filter judgment is applied on a name test in the context of a principal node kind.
Semantics
8.2.3.2.2 Kind Tests
All the rules for evaluating the document, element, and attribute kind tests are similar. First, the document, element, or attribute test is normalized to the equivalent document, element, or attribute type by applying the []sequencetype normalization rule. As explained in [3.5.3 SequenceType Syntax], SequenceTypes are normalized to XQuery
types whenever a dynamic or static rule requires the corresponding type. The reason for this deviation from the processing model is that the result of SequenceType normalization is not part of the [XPath/XQuery] core syntax.
After normalization of the SequenceType to an XQuery type, the document, element, or attribute value is simply matched against the XQuery type. If the value matches the type, then the judgment yields the value, otherwise the judgment yields the empty sequence.
Document kind test
Semantics
Element kind test
Semantics
Attribute kind test
Semantics
Processing instruction, comment, and text kind tests.
Semantics
The node() node test is true for all nodes. Therefore, the following rule does not have any precondition (remember that an empty upper part in the rule indicates that the rule is always true).
If none of the above rules applies then the node test returns the empty sequence, and the following dynamic rule is applied:
8.3 Judgments for type matching
Introduction
XQuery supports type declarations on variable bindings, and several operations on types (typeswitch, instance of, etc). This section describes judgments used for the specification of the semantics of those operations.
-
The "match" judgment specifies formally type matching. It takes as input a value and a type and either succeeds or fails. It is used in matching parameters against function signatures, type declarations, and matching values against cases in "typeswitch". An informal description of type matching is given in Section 2.5.4 SequenceType MatchingXQ.
-
The "subtyping" judgment takes two types and succeeds if all values matching the first type also match the second. It is used to define the static semantics of operations using type matching.
8.3.1 Matches
Notation
The judgment
holds when the given value matches the given type.
Example
For example, assuming the extended XML Schema given in section [2.4.5 Example of a complete Schema], then the following judgments hold.
element comment of type xsd:string { "This is not important" }
matches
element comment of type xsd:string
(element apt of type fs:anon3 { 2510 },
element apt of type fs:anon3 { 2511 })
matches
element apt+
()
matches
element usaddress?
element usaddress of type USAddress {
element name of type xsd:string { "The Archive" },
element street of type xsd:string { "Christopher Street" },
element city of type xsd:string { "New York" },
element state of type xsd:string { "NY" },
element zip of type xsd:decimal { 10210 }
}
matches
element usaddress?
Semantics
We start by giving the inference rules for matching an item value with an item type.
An atomic value matches an atomic type if its type annotationXQ derives from the atomic type. The value itself is ignored -- this is checked as part of validation.
A text node matches text.
A comment node matches comment.
A processing-instruction node matches processing-instruction.
|
|
| statEnv |- processing-instruction QName { String } matches processing-instruction |
A document node matches a document type if the node's content matches the document type's corresponding content type.
The rules for matching an element value with an element type are more complicated. When an element value is not nilled, the element matches an element type if the element name and the element type resolve to some type name, and the element value's type annotationXQ is derived from the resolved type name. Note that there is no need to check structural constraints on the value since since those have been checked during
XML Schema validation and the value is assumed to be consistent with its type annotationXQ.
Note
Type matching uses the name lookup judgment defined in [8.1.3 Element and attribute name lookup (Dynamic)].
In the case the element has been nilled, that is there exists and xsi:nil attribute set to true in the element value, the following rule checks that the type is nillable.
The rule for attributes is similar, but does not require the check for the xsi:nil attribute.
A type can also be a sequence of items, in that case the matching rules also need to check whether the constraints described by the type as a regular expression hold. This is specified by the following rules.
The empty sequence matches the empty sequence type.
If two values match two types, then their sequence matches the corresponding sequence type.
If a value matches a type, then it also matches a choice type where that type is one of the choices.
If two values match two types, then their interleaving matches the corresponding all group.
An optional type matches a value of that type or the empty sequence.
The following rules are used to match a value against a sequence of zero (or one) or more types.
Note
The above definition of type matching, although complete and precise, does not give a simple means to compute type matching. Notably, some of the above rules can be non-deterministic (e.g., the rule for matching of choice or repetition).
The structural component of the [XPath/XQuery] type system can be modeled by regular expressions. Regular expressions can be implemented by means of finite state automata. Computing type matching then is equivalent to check if a given sequence of items is recognized by its corresponding finite state automata. Finite state automata and their relationships to regular expressions have been extensively studied and documented in computer-science literature. The interested reader can consult the
relevant literature, for instance [Languages], or [TATA].
8.3.2 Subtype and Type equality
Introduction
This section defines the semantics of subtyping in [XPath/XQuery]. Subtyping is used during the static type analysis, in typeswitch expressions, treat and assert expressions, and to check the correctness of function applications.
Notation
The judgment
holds if the first type is a subtype of the second.
Semantics
This judgment is true if and only if, for every value Value, if Value matches Type1 holds, then Value matches Type2 also holds.
Note
It is easy to see that the subtype relation <: is a partial order, i.e. it is reflexive:
statEnv |-
Type <: Type
and it is transitive: if,
statEnv |-
Type1 <: Type2
and,
statEnv |-
Type2 <: Type3
then,
statEnv |-
Type1 <: Type3
Finally, two types are equal if each is a subtype of the other, that is:
statEnv |-
Type1 <: Type2
and,
statEnv |-
Type2 <: Type1
then,
statEnv |-
Type1 =
Type2
Note
The above definition although complete and precise, does not give a simple means to compute subtyping. Notably the definition above refers to values which are not available at static type checking time.
The structural component of the [XPath/XQuery] type system can be modeled by regular expressions. Regular expressions can be implemented by means of finite state automata. Computing subtyping between two types can then be done by computing if inclusion holds between their corresponding finite states automata.
Finite state automata and how to compute operations on those automata, such as inclusion, emptiness or intersection have been extensively studied and documented in the literature. The interested reader can consult the relevant literature on tree grammars, for instance [Languages], or [TATA].
8.4 Judgments for FLWOR and other expressions on sequences
Introduction
Some [XPath/XQuery] operations work on sequences of items. For instance, [For/FLWR] expressions iterate over a sequence of items and the fn:unordered function can return all items in a sequence in any order, etc.
Static typing for those operations need to infer a type acceptable for all the items in the sequence. This sometimes require to approximate the type known for each item individually.
Example
Assume the variable $shipTo is bound to the shipTo element
<shipTo country="US">
<name>Alice Smith</name>
<street>123 Maple Street</street>
<city>Mill Valley</city>
<state>CA</state>
<zip>90952</zip>
</shipTo>
and has type
element shipTo of type USAddress
The following query orders all children of the shipTo element by alphabetical order of their content.
for $x in $shipTo/*
order by $x/text()
return $x
resulting in the sequence
(<street>123 Maple Street</street>,
<zip>90952</zip>,
<name>Alice Smith</name>,
<state>CA</state>,
<city>Mill Valley</city>)
This operation iterates over the elements in the input sequence returned by the expression $shipTo/*, whose type is the content of a type USAddress.
(element name of type xsd:string,
element street of type xsd:string,
element city of type xsd:string,
element state of type xsd:string,
element zip of type xsd:decimal)
During static typing, one must give a type to the variable $x which corresponds to the type of each element in the sequence. Since each item as a of a different type, one must find an item type which is valid for all cases in the sequence. This can be done by using a choice for the variable $x, as follows
(element name of type xsd:string |
element street of type xsd:string |
element city of type xsd:string |
element state of type xsd:string |
element zip of type xsd:decimal)
This type indicates that the type of the variable can be of any of the item types in the input sequence.
The static inference also needs to approximate the number of occurrence of items in the sequence. In this example, there is at least one item and more than one, so the closest occurrence indicator is + for one or more items.
The static inference for this example finally results in the following type.
(element name of type xsd:string |
element street of type xsd:string |
element city of type xsd:string |
element state of type xsd:string |
element zip of type xsd:decimal)+
This section defines a prime type, which is a choice of item types. It defines two functions on types that compute the prime type of an arbitrary type, and approximate the occurrence of items in an arbitrary type. Those judgments are used the static semantics of many expressions, including "for", "some", and "every" expressions, many functions, including "fn:unordered" and "fn:distinct" functions.
Notation
A choice of item types is called a prime type, as described by the following grammar production.
Prime Types
Notation
The type function prime(Type) extracts all item types from the type Type, and combines them into a choice.
The function quantifier(Type) approximates the possible number of items in Type with the occurrence indicators supported by the [XPath/XQuery] type system (?, +, *).
For interim results, the auxiliary occurrence indicator 1 denotes exactly one occurrence.
Semantics
The prime function is defined by induction as follows.
Semantics
The quantifier function is defined by induction as follows.
This definition uses the sum (Occurrence1 , Occurrence2), the choice (Occurrence1 | Occurrence2), and the product (Occurrence1 · Occurrence2) of two occurrence indicators Occurrence1, Occurrence2, which are defined by the following tables.
Examples
For example, here are the result of applying prime and quantifier on a few simple types.
prime(element a+) = element a
prime(element a | empty) = element a
prime(element a?,element b?) = element a | element b
prime(element a | element b+, element c*) = element a | element b | element c
quantifier(element a+) = +
quantifier(element a | empty) = ?
quantifier(element a?,element b?) = *
quantifier(element a | element b+, element d*) = +
Note that the last occurrence indicator should be '+', since the regular expression is such that there must be at least one element in the sequence (this element being an 'a' element or a 'b' element).
Note
Note that prime(Type) · quantifier(Type) is always a super type of the original type Type I.e., prime(Type) · quantifier(Type) <: Type always holds. Therefore, it is appropriate to used it as an approximation for the type of an expression. This property is required for the soundness of the static type analysis.
Semantics
Finally, a type Type and an occurrence indicator can be combined back together to yield a new type with the · operation, as follows.
8.5 Judgments for function calls
Introduction
Function calls can perform type promotion between atomic types. This section introduces judgments which describe type promotion for the purpose of the dynamic and static semantics. These promotion rules include promoting xdt:untypedAtomic to any other type.
8.5.1 Type promotion
Notation
The judgment
holds if type Type1 can be promoted to type Type2.
Example
For example, the following judgments hold:
xs:integer can be promoted to xs:integer
xs:decimal can be promoted to xs:float
xs:integer can be promoted to xs:float
xs:float can be promoted to xs:double
xdt:untypedAtomic can be promoted to xs:double
Semantics
This judgment is specified by the following rules.
xs:decimal can be promoted to xs:float:
xs:float can be promoted to xs:double:
xdt:untypedAtomic can be promoted to any type:
A type can be promoted to itself or to any type of which it is a subtype:
Type promotion is transitive:
Finally, type promotion distributes over occurrence and union constructors.
where the "<=" operator for occurrence indicators denotes set inclusion of the subsets of the allowed occurrences.
Notation
The judgment
holds if value Value1 can be promoted to the value Value2 against the type Type2.
Example
For example, the following judgments hold
1 of type xs:integer against xs:integer is promoted to 1 of type xs:integer
1 of type xs:integer against xs:decimal is promoted to 1 of type xs:integer
1 of type xs:integer against xs:float is promoted to 1.0e0 of type xs:float
1.0e0 of type xs:float against xs:double is promoted to 1.0e0 of type xs:double
Note that type promotion changes the value, and only occurs if the input value does not matches the target type.
Semantics
This judgment is specified by the following rules.
If the value matches the target type, then it is promoted to itself
If the value does not match the target type, but matches a type which can be promoted to the target type, then the value is cast to the target type.
8.6 Judgments for validation modes and contexts
8.6.1 Elements in validation mode
Notation
A validation mode may occur explicitly in a validate expression [4.13 Validate Expressions]. The following with mode judgment resolves an element name within a given validation mode to the type that the element name denotes. The judgment is used in the semantics of the validate expression and in sequence type.
The judgment
holds when the possibly optional element name resolves to the given type in the given validation mode.
Semantics
We start with the rules for the global validation context.
If no element name is present, the global validation context resolves to the union of all element types that are globally declared.
If the element name is globally declared in the schema, it resolves to the element type of the corresponding global element declaration, independently of the validation mode.
If an element name is not globally defined and the validation mode is lax, then the element name resolves to the element type with the given element name with any content type.