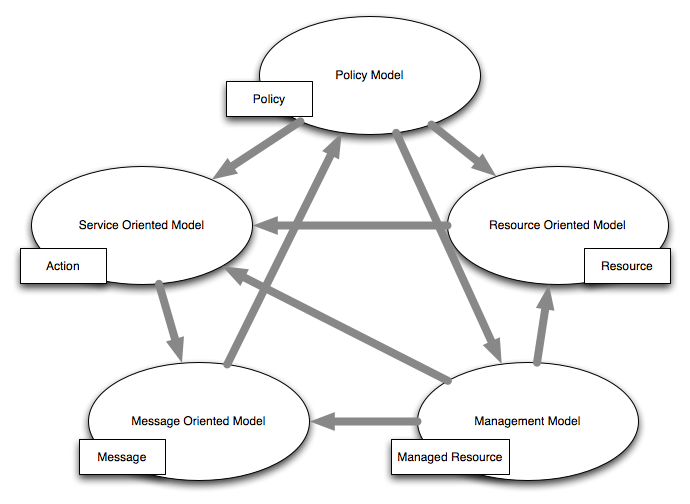
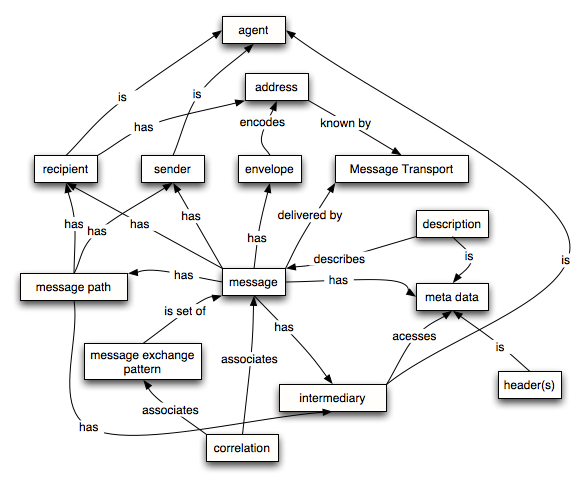
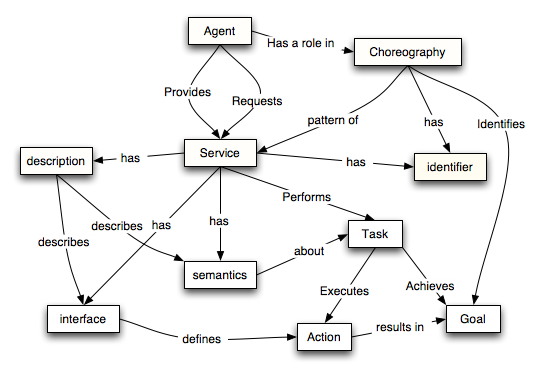
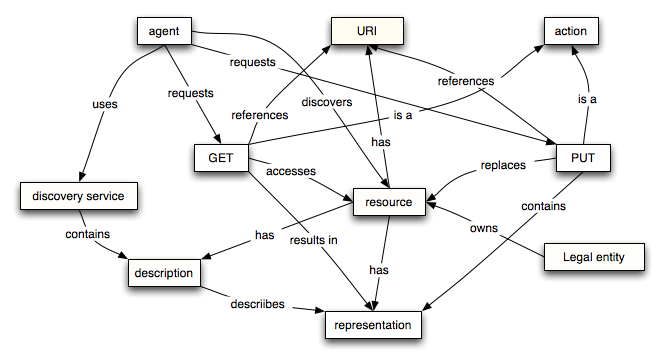
1 Introduction
| Editorial note | |
| dbooth editing this section. The previous "Contract with the Reader" has been
merged into this section. |
1.1 Purpose of the Web Service Architecture
Web services provide a standard means of interoperating between different software
applications, running on a variety of platforms and/or frameworks. This document (WSA) is
intended to provide a common definition of a Web service, and define its place within a
larger Web services framework to guide the community.
The WSA provides a model and a context for understanding Web services and the
relationships between the various specifications and technologies that comprise the WSA.
The WSA promotes interoperability through the definition of compatible protocols. The
architecture does not attempt to specify how Web services are implemented, and imposes no
restriction on how services might be combined. The WSA describes both the minimal
characteristics that are common to all Web services, and a number of characteristics that
are needed by many, but not all, Web services.
The WSA integrates different conceptions of Web services under a common "reference
architecture". There isn't always a simple one to one correspondence between the
architecture of the Web and the architecture of existing SOAP-based Web services, but
there is a substantial overlap.
We offer a framework for the future evolution of Web services standards that will promote
a healthy mix of interoperability and innovation. That framework must accommodate the edge
cases of pure SOAP-RPC at one side and HTTP manipulation of business document resources at
the other side, but focus on the area in the middle where the different architectural
styles are both taken into consideration.
1.2 Intended Audience
This document is intended for a large and diverse audience. Expected readers include
users and creators of individual Web services, Web service specification authors, and others.
1.3 Document Organization
This document provides introductory overview material followed by normative material.
The body of the architecture is presented as a set of core concepts and key relationships
between them. A core concept is usually a noun, but does not have to be, and the
relationships between conncepts are usually predicates, i.e., verbs. Both noun-style and
verb-style concepts are present in the architecture, the latter playing a prominent role
in the relationships between concepts.
A primary goal of the concepts
section is to provide a basis for measuring conformance to the
architecture. For example, the resource concept states
that resources have identifiers (in fact they have URIs). Using this assertion as a basis,
we can measure conformance to the architecture of a particular resource by looking for its
identifier. If, in a given instance of this architecture, a resource has no identifier,
then it is not a valid instance of the architecture.
While the concepts and relationships
represent an enumeration of the architecture, the stakeholders'
viewpoints approaches from a different perspective: how the architecture meets
the goals and requirements. In this section we elucidate the more global properties of the
architecture and demonstrate how the concepts actually
achieve important objectives.
A primary goal of the Stakeholder's Perspectives
section is to relate the actual architecture with the requirements of the architecture,
especially as outlined in the Web services requirements [WSA Reqs] document.
For example, in the 3.14 Web service manageability section we show how the
management of Web services is modeled within the architecture. The aim here is to
demonstrate that Web services are manageable and which key concepts and features of the
architecture achieve that goal. In this case, manageability is realized by showing a link
between the concept of a physically deployed
resource and the abstract concept it realizes (such as a Web service).
Management of such deployed resources then leads to management of Web services
themselves.
The key stakeholder's viewpoints supported in this document reflect the major goals of
the architecture itself: interopability, extensibility, security, Web integration,
implementation and manageability.
Where appropriate, the WSA also identifies candidate technologies that have been
determined to meet the functionality requirements defined within the architecture.
1.4 Notational Conventions
The key words "MUST", "MUST NOT", "REQUIRED",
"SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT",
"RECOMMENDED", "MAY", and "OPTIONAL" in this document are to
be interpreted as described in [RFC 2119].
1.5 What is a Web service?
There are many things that might be called "Web services" in the world at large. However, for the purpose of this Working Group and this architecture, and without prejudice toward other definitions, we will use the following definition:
[Definition: A Web service is a software system designed to support interoperable machine-to-machine interaction over a network. It has an interface described in a machine-processable format (specifically WSDL). Other systems interact with the Web service in a manner prescribed by its description using SOAP-messages, typically conveyed using HTTP with an XML serialization in conjunction with other Web-related standards.]
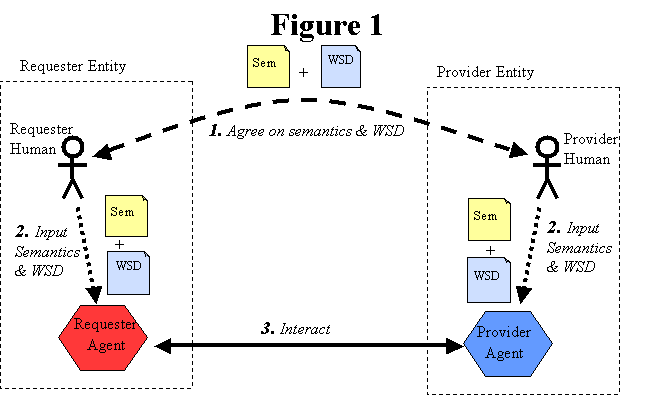
1.5.1 Agents and Services
A Web service is viewed as an abstract notion that must be implemented by
a concrete agent. (See Figure 1.) The agent is the concrete entity (a piece
of software) that sends and receives messages, while the service is the abstract set of
functionality that is provided. To illustrate this distinction, you might implement a
particular Web service using one agent one day (perhaps written in one programming
language), and a different agent the next day (perhaps written in a different
programming language). Although the agent may have changed, the Web service remains the same.
1.5.2 Requester and Provider
The purpose of a Web service is to provide some functionality on behalf of its owner --
a person or organization, such as a business or an individual. The provider
entity is the person or organization that provides an appropriate agent to implement a
particular service. (See Figure 1: Basic Architectural Roles.)
A requester entity is a person or organization that wishes to make use of a provider
entity's Web service. It will use a requester agent to exchange messages
with the provider entity's provider agent. In order for this message
exchange to be successful, the requester entity and the provider entity must first agree
on both the semantics and the mechanics of the message exchange.
1.5.3 Service Description
The mechanics of the message exchange are documented in a Web service
description (WSD). (See Figure 1.) The WSD is a machine-processable
specification of the Web service's interface. It defines the message formats, datatypes,
transport protocols, and transport serialization formats that should be used between the
requester agent and the provider agent. It also specifies one or more network locations
("endpoints") at which a provider agent can be invoked, and may provide some
information about the message exchange pattern that is expected.
1.5.4 Semantics
The semantics ("Sem" in Figure 1) of the message exchange
represents the "contract" between the requester entity and the provider entity
regarding the purpose and consequences of the interaction. It also includes any
additional details on the mechanics of the message exchange that are not specified in
the service description. Although this contract represents the overall
agreement between the requester entity and the provider entity on how and why their
respective agents will interact, it is not necessarily written or explicitly negotiated.
It may be explicit or implicit, oral or written, machine processable or human oriented.
While the service description represents a contract governing the mechanics
of interacting with a particular service, the semantics represents a
contract governing the meaning and purpose of that interaction.
1.5.5 The Role of Humans
Although one of the main purposes of Web services is to automate processes that might
otherwise be performed manually, humans still play a role in their architecture and use,
notably in two ways:
Humans need to agree on the semantics and the service description. Since a human
(or organization) ultimately is the legal owner of any Web service, people must
either implicitly or explicitly agree on the semantics and the service description
that will govern the interaction.
Often this agreement will be accomplished by the provider entitity publicizing and
offering both the semantics and the service description as take-it-or-leave-it
"contracts" that the requester entity must accept unmodified as conditions
of use. However, nothing in this architecture prevents them from reaching agreement
by other means. For example, in some situations, the service description (excepting
the network address of the service) may be defined by an industry organization, and
shared by many requester and provider entities. In other situations, it may
originate from the requester entity (even if it is written from provider entity's
perspective).
Humans create the requester and provider agents (either directly or indirectly).
Ultimately, humans must ensure that these agents implement the terms of the
agreed-upon service description and semantics. There are many ways this can be
achieved, and this architecture does not specify or care what means are used. For
example:
an agent could be hard coded to implement a particular, fixed service
description and semantics;
an agent could be coded in a more general way, and the desired service
description and/or semantics could be input dynamically; or
an agent could be created first, and the service description and/or semantics
could be produced from the agent code.
Regardless of the approach used, from an information perspective both the semantics
and the service description must be somehow be input to, or embodied in, both the
requester agent and the provider agent before the two agents can interact.
Figure 1: Basic Architectural Roles.
| Editorial note | |
| dbooth: Not sure how we should label the figures. Also, Figure 1 may need to be resized. |
1.6 Architectural Style
1.6.1 Interoperability Architecture
The Web services architecture is an interoperability architecture it
identifies those global elements of the global Web services network that are required in
order to ensure interoperability between Web services. It is not intended to be an
architecture for individual Web services; the structure and implementation of these is
inherently private and is left to the discretion of the developers of these. However, in
order to ensure interoperability, certain concepts, relationships and constraints are
important; and this architecture identifies those.
The major goals of the architecture are outlined in the Web Services Architecture
Requirements document [WSA Reqs]. These goals are to promote
interoperability between Web services,
integration with the World Wide Web,
reliability of Web services,
security of Web services,
scalability and extensibility of Web services, and
manageability of Web services.
The role of this architecture is to provide a global perspective on the networked
service architecture. Other specifications, such as [SOAP 1.2 Part 1] and
[WSDL 1.2 Part 1] give detailed recommendations for specific requirements. This
architecture is intended to show how these, and other related, technologies fit together
to deliver the benefits of Web services.
Some non-goals of the architecture include:
to prescribe a specific programming model or programming technology
to constrain the internal architecture and implementation of specific Web services
to demonstrate how Web services are constructed
to be specific about how messages or other descriptions are formatted
to determine specific technologies for messaging, discovery, choreography etc.
1.6.2 Service Oriented Architecture
The Web architecture and the Web Services Architecture (WSA) are instances of a Service
Oriented Architecture (SOA). To understand how they relate to each other and to closely
related technologies such as CORBA, it may be useful to look up yet another level and
note that SOA is in turn a type of distributed system. A distributed system, consists of
discrete software agents that must work together to implement some intended
functionality. Furthermore, the agents in a distibuted system do not operate in the same
processing environment, so they must communicate by hardware/software protocol stacks
that are intrinsically less reliable than direct code invocation and shared memory. This
has important architectural implications because distributed systems require that
developers (of infrastructure and applications) consider the unpredictable latency of
remote access, and take into account issues of concurrency and the possibility of
partial failure. [Samuel C. Kendall, Jim Waldo, Ann Wollrath and Geoff Wyant, "A Note On Distributed Computing"].
An SOA is a specific type of distributed system in which the agents are
"services". For the purposes of this document, a service is a software agent
that performs some well-defined operation (i.e., "provides a service") and can
be invoked outside of the context of a larger application. That is, while a service
might be implemented by exposing a feature of a larger application (e.g., the purchase
order processing capability of an enterprise resource planning system might be exposed
as a discrete service), the users of that server need be concerned only with the
interface description of the service. Furthermore, most definitions of SOA stress that
"services" have a network-addressable interface and communicate via standard
protocols and data formats.
Figure 2, Generic Service Oriented Architecture Diagram 
The description of a service in a SOA is essentially a description of the messages that
are exchanged. This architecture adds the constraint of stateless connections, that is
where the all the data for a given request must be in the request.
| Editorial note | |
| Put in a good word about the Semantic web and semantics in general here |
In essence, the key components of a Service Oriented Architecture are the messages that
are exchanged, agents that act as service requesters and service providers, and shared
transport mechanisms that allow the flow of messages. In addition, in public SOAs, we
include the public descriptions of these components: descriptions of the messages,
descriptions of the services and so on. These descriptions may be machine processable,
in which case they become potential messages themselves: for use in service discovery
systems and in service management systems.
1.6.3 SOA and REST archictures
The World Wide Web is a SOA that operates as a networked information system that
imposes some additional constraints: Agents identify objects in the system, called
"resources," with Uniform Resource Identifiers (URIs). Agents represent,
describe, and communicate resource state via "representations" of the resource
in a variety of widely-understood data formats (e.g. XML, HTML, CSS, JPEG, PNG). Agents
exchange representations via protocols that use URIs to identify and directly or
indirectly address the agents and resources. [Web Arch]
An even more constrained architectural style for reliable Web applications known as
"Representation State Transfer" or REST has been proposed by Roy Fielding and
has inspired both the TAG's Architecture document and many who see it as a model for how
to build Web services [Fielding]. The REST Web is the subset of the WWW in
which agents are constrained to, amongst other things, expose and use services via
uniform interface semantics, manipulate resources only by the exchange of
"representations", and thus use "hypermedia as the engine of application state."
The scope of "Web services" as that term is used by this Working Group is
somewhat different. It encompasses not only the Web and REST Web services whose purpose
is to create, retrieve, update, and delete information resources but extends the scope
to consider services that perform an arbitrarily complex set of operations on resources
that may not be "on the Web." Although the distrinctions here are murky and
controversial, a "Web service" invocation may lead to services being performed
by people, physical objects being moved around (e.g. books delivered).
We can identify two major classes of "Web services":
REST-compliant or
"direct resource manipulation" services in which in which the primary purpose
of the service is to manipulate XML representations of Web resources using the a
minimal, uniform set of operations operations,
"distributed object" or
"Web-mediated operation" services in which the primary purpose of the service
is to perform an arbitrarily complex set of operations on resources that may not be
"on the Web", and the XML messages contain the data needed to invoke those
operations.
In other words, "direct" services are implemented by Web servers
that manipulate data directly, and "mediated" services are external code
resources that are invoked via messages to Web servers.
| Editorial note | |
| Lots of open terminology issues here, such as what we call these two types of
services, and whether the "Web service" is the interface to the external
code or the external code itself. |
Both classes of "Web services" use URIs to identify resources and use Web
protocols and XML data formats for messaging. Where they fundamentally differ is that
"distributed object" (editors' note: or "mediated services") use
application specific vocabularies as the engine of application state, rather than
hypermedia. Also, they achieve some of their benefits in a somewhat different way. The
emphasis on messages, rather than on the actions that are caused by messages, means that
SOAs have good "visibility": trusted third parties may inspect the flow of
messages and have a good assurance as to the services being invoked and the roles of the
various parties. This, in turn, means that intermediaries, such as firewalls, are in a
better situation for performing their functions. A firewall can look at the message
traffic, and at the structure of the message, and make predictable and reasonable
decisions about security.
In REST-compliant SOAs, the visibility comes from the uniform interface semantics,
essentially those of the HTTP protocol: an intermediary can inspect the URI of the
resource being manipulated, the TCP/IP address of the requester, and the interface
operation requested (e.g. GET, PUT, DELETE) and determine whether the requested
operation should be performed. The TCP/IP and HTTP protocols have a widely supported set
of conventions (e.g. known ports) to support intermediaries, and firewalls, proxies,
caches, etc. are almost universal today. In non-REST [Ed. note: or "distributed
object" or "mediated" ] but XML-based services, the visibility comes from
the fact that XML is the universal meta-format for the data. Intermediaries can be
programmed or configured to use the specifics of the SOAP XML format, standardized SOAP
headers (e.g. for encryption, digital signature exchange, access control, etc.), or even
generic XPath expressions to make routing, filtering, and cacheing decisions. XML-aware
firewall and other "edge appliance" products are just coming to market as of
this writing.
1.7 Web Service Technologies
Web service architecture involves many layered and interrelated technologies. There are
many ways to visualize these technologies, just as there are many ways to build and use
Web services. Figure 3 provides one illustration of some of these technology families.
Figure 3: Stack Diagram.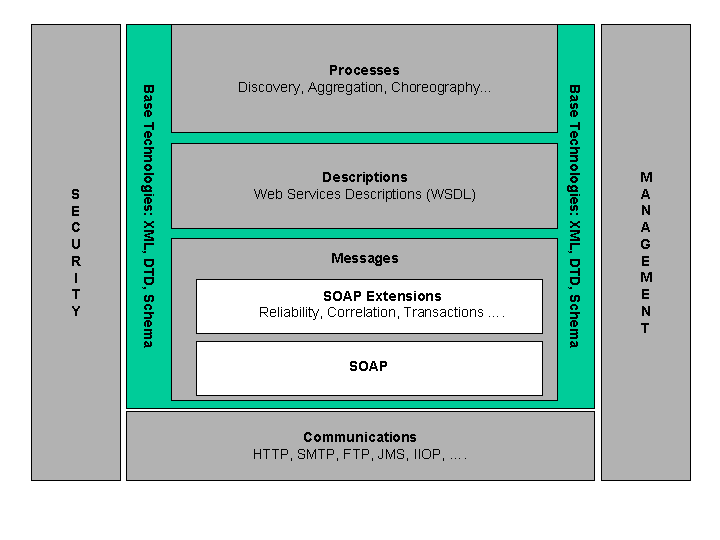
Marketing documents from Web services vendors often contain a three-part diagram to show
how the different Web services "standards" relate to one another: WSDL describes
the format SOAP messages, and UDDI serves as a discovery service for the WSDL
descriptions. The problem with such diagrams is that they don't convey the multiple
dimensions of the Web services standards "space" and can't easily be extended to
handle new standards, e.g. for security, management, choreography, and so on. In order to
show the big picture of the Web services architecture as we envision it, the picture needs
to be somewhat more complex.
First and foremost, XML is the "backplane" of the WSA. One can imagine Web
services that don't depend on the SOAP envelope framework or processing model, or that
don't employ WSDL to describe the interaction between a service and its consumers, but XML
is much more fundamental. It provides the extensibility and vendor, platform, and language
neutrality that is the key to loosely-coupled, standards-based interoperability that are
the essence of the Web services value proposition. Furthermore, XML helps blur the
distinction between "payload" data and "protocol" data, allowing
easier mapping and bridging across different communications protocols, which is necessary
in many enterprise IT infrastructures that are built on industrial-strength but
proprietary components. Thus, the "base technology" of the WSA consists of some
key XML specifications, including XML 1.x, XML Schema Description Language and the
XML Base specification. Note that we do not rely on all XML technologies; for
example, we do not rely on XML DTDs, in the architecture.
This leads to the next key concept in the WSA: services are invoked and provide results
via messages that must be exchanged over some communications medium. The WSA encompasses a
wide, almost infinite variety of communications mechanisms: HTTP (the dominant protocol of
"the Web"), other Internet protocols such as SMTP and FTP, generic interface
APIs such as JMS, earlier distributed object protocols such as IIOP, and so on. In
principle, Web services invocation and result messages could be passed around by
"sneakernet", RFC 1149-compliant carrier pigeons, or mechanisms that have not
yet been invented. WSA says almost nothing about this communication layer other than it
exists -- it does not specificy that it be at any particular level of the OSI reference
architecture protocol stack, and allows Web services messages to be "tunnelled"
over protocols designed for another purpose.
WSA does have quite a bit to say about the messages themselves, if not about the
mechanism by which they are communicated. SOAP is the key messaging technology in the WSA:
while very simple information transfer services can be implemented without SOAP, secure,
reliable, multi-part, multi-party and/or multi-network applications are much easier to
build if there is a standard way of packaging the messaging information in a protocol
neutral way. This also allows the messaging infrastructure (which may be specialized
hardware, SOAP intermediaries, or code libraries called by the ultimate recipient of a
SOAP message) to provide authentication, encryption, access control, transaction
processing, routing, delivery confirmation, etc. services. SOAP's envelope (and
attachment) structure and header / processing model have proven to be a very robust and
powerful framework within which to do this.
Interoperability across heterogenous systems requires a mechanism to allow the precise
structure and data types of the messages to be commonly understood by Web services
producers and consumers. WSDL is an obvious choice today as the means by which the precise
description of Web services messages can be exchanged.
| Editorial note | |
| Obviously we have open issues with respect to whether description mechanisms such
as shared code "qualify" here. |
In the future, more sophisticated description languages that handle more of the
*semantic* content of the messages are likely to become technologically viable, and such
languages (perhaps based on RDF and OWL) will fit well in the WSA framework.
Beyond the description of individual messages such as WSDL provides, the WSA envisions a
variety process descriptions: the process of discovering service descriptions that meet
specified criteria, the process of describing multi-part and stateful sequences of
messages, the aggregation of processes into higher-level processes, and so on. This area
is much much clearly defined than other parts of the WSA, but there is much work going on
and the WSA incorporates them at an abstract level.
In addition to specific messaging and description technologies, the architecture also
provides for security and management. These are complex areas that touch on many of the
different levels and technologies deployed in the service of Web services.
3 Stakeholder's perspectives
In this section we examine how the architecture meets the Web services requirements.
We present this as a series of stakeholders' viewpoints; the objective being that, for
example, security represents a major stakeholder's viewpoint of the architecture itself.
| Editorial note | |
| When developing a particular stakeholder's viewpoint, one should make sure that the
concepts discussed are properly documented in the architecture. |
3.1 Web integration
Goal AG003 of the Web Services Architecture Requirements [WSA Reqs]
identifies Web services must be consistent with the current and evolving nature of the
World Wide Web.
This goal can be divided into two sub-goals relating to the architectural principles of
the Web [Web Arch] and, more pragmatically, relating the architecture to the
various technologies in use.
Critical Success Factor AC011 notes that
the architecture should be consistent with the architectural principles and design goals
of the Web. For our purposes we use the Architecture of the World Wide Web [Web Arch] as our reference for the architecture of the Web. It defines the
architecture of the Web to be founded on a few basic concepts: agents that are programs
that represent people, identification of resources using URIs representations of resources
as data objects and interaction via standard protocols — most notably of course
HTTP.
3.2 Information and service
Unlike the World Wide Web in general, it is of the essence that Web services, like
service oriented architectures in general, are essentially about the provision of action.
I.e., whereas the World Wide Web is a networked information system, the Web service World
Wide Web is a networked service system: information is exchanged between Web service agents for the purpose of requesting and provisioning
service, not simply information.
This is a key specialization of the World Wide Web in general; and it drives a number of
the specific features of this architecture. However, it is also the case that requests for
action and the various possible responses are also information and have representations.
The key representational requirement of this architecture is that messages exchanged
between Web service agents is encoded in XML. This is consistent with the general
principles of the World Wide Web [Web Arch].
3.3 Web service agents
This architecture also uses the concept of an agent to
identify the computational resource actually involved with Web services. The key
properties of agents required to model Web services are that:
It is a computational activity
It has an owner
It engages in message exchanges with other Web service agents, those messages
counting as equivalent messages between the agents' owners.
It uses standard protocols to:
describe the form and semantics of messages
describe the legal sequences of messages
The distinction between a service requester and service provider is one of the
agent's roles; i.e., it is not intrinsic to the concept of agent that it is bound to
be solely a provider or requester of services. Of course, in many cases, particular
agents will be bound to particular functions that will fix the role of the agent to be
a service provider or requester.
However, it is clear that there is a strong correspondence between a Web service agent
and a Web agent. Both are computational resources that represent people; our definition
requires sufficient detail to be able to account for the greater degree of indirection
expected between Web service agents and Web agents.
3.4 Web Service Discovery
Before a requester agent and a provider agent can interact, the corresponding enties that
own them must first agree on the service description and semantics that will govern the
interaction, as depicted in Figure 1. There are many ways this can be achieved. Some
require discovery, others don't.
3.4.1 Scenarios Not Requiring Discovery
If the requester and provider entities are already known to each other, then one common
way for them to agree on the service description and semantics is for a requester human
and a provider human to communicate directly. For example, the provider human might send
the proposed service description and semantics directly to the requester human. Or the
parties might develop them collaboratively. In these situations, there is no need for discovery.
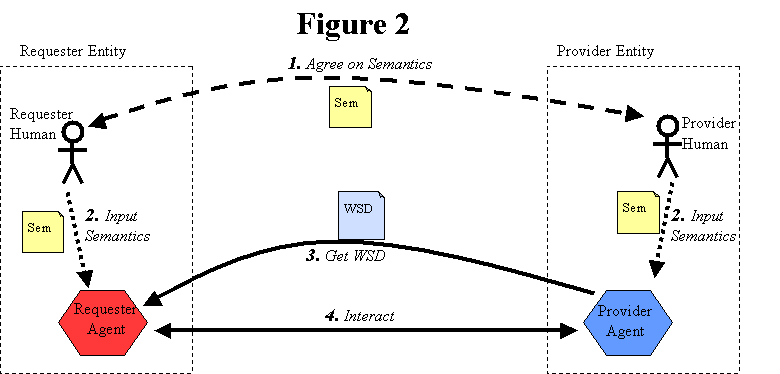
If the provider entity is furnishing the service description unilaterally, then a
variation on this approach is for the requester entity to retrieve the service
description dynamically from the provider agent, at the start of their interaction, as
depicted in Figure 4: Parties Known, Dynamically Getting WSD. This allows the requester
agent to be assured of using the latest version that the provider agent supports, again
without requiring discovery.
[Figure 5: Parties Known, Dynamically Getting WSD]
| Editorial note | |
| dbooth: The label at the top of this diagram needs to be fixed. It should be
"Figure 5" instead of "Figure 2". |
3.4.2 Scenarios Requiring Discovery
On the other hand, if the requester entity does not already know what provider agent it
wishes to engage, then it may need to "discover" a suitable candidate.
Discovery is "the act of locating a machine-processable description of a Web
service that may have been previously unknown and that meets certain functional
criteria." [WS Glossary] Two common ways to approach this are human
discovery, and autonomous selection.
3.4.2.1 Human Discovery
With human discovery, a requester human uses some kind of discovery tool or agent to
help locate a suitable service description, i.e., a description representing a service
that meets the desired functional criteria, as shown in Figure 6: Human Discovery.
[Figure 6: Human Discovery]
| Editorial note | |
| dbooth: The label at the top of this diagram needs to be fixed. It should be
"Figure 6" instead of "Figure 3". |
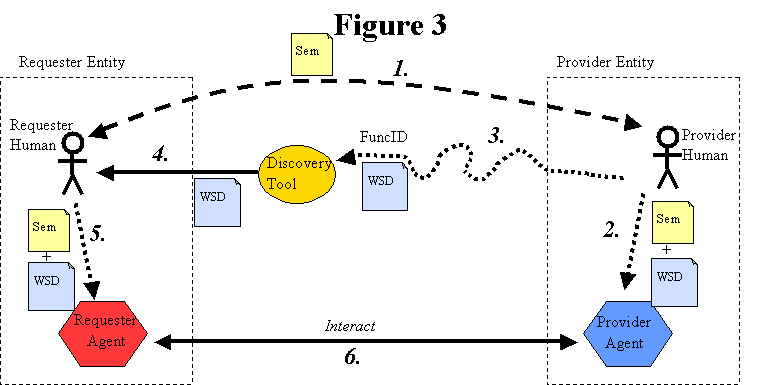
There are several points to note about this situation.
Regardless of how the service description is obtained, somehow the requester and
provider entities must agree on the semantics of the planned interaction. There
are several ways this can be done, and the WSA does not specify or care what way
is used. For example, the provider entity may publish both the service description
and semantics on a take-it-or-leave-it basis, which the requester must accept
unmodified as a condition of engaging the provider agent. Or the parties could
negotiate the desired semantics. Or the semantics might be defined by an industry
standards body that both parties have chosen to follow.
Somehow the discovery agent must obtain both the service description (or at least
a reference to it), and sufficient information (labeled "FuncID" in
Figure 6) to describe or identify the semantics of the service that the provider
entity offers. The FuncID is necessary to allow the requester human to find a
service having the desired semantics. In practice, the FuncID might be as
simple as a few words or a URI, or it may be more complex, such as a TModel (in
UDDI) or a collection of RDF, DAML-S or OWL statements.
The WSA also does not specify or care how the discovery agent obtains the service
description and FuncID. For example, if the discovery agent is implemented as
a search engine (such as Google), then it might crawl the Web, collecting service
descriptions wherever it finds them, with the provider entity having no knowledge
of it. Or, if the discovery agent is implemented as a registry (such as UDDI),
then the provider entity could publish the service description and FuncID
directly to the discovery agent.
| Editorial note | |
| dbooth: Need to add mention of the trust decision here -- the fact that making use of a previously unknown service involves a significant decision to trust that service. |
| Editorial note | |
| dbooth to finish explaining the diagram in this section |
3.4.2.2 Autonomous Selection
With autonomous selection, the requester agent uses a selection agent to select a
service from among several known services, as shown in Figure 7: Autonomous Selection.
There are five important roles involved in Autonomous Selection:
Requester Human, Provider Human, Requester Agent and Provider Agent, as described before; and
Selection Agent, which is a software application or component that may be operated by the Requester Entity, the Provider Entity or a third party entity.
The following artifacts or documents
are relevant in Autonomous Selection:
The WSD, as previously described.
The Semantics, as previously described.
A FuncID, which represents any information that is sufficient to allow the Requester Agent to unambiguously identify the Semantics. The FuncID could be represented by the entire Semantics. In practice, the FuncID is expected to be represented by a URI, a TModel, an RDF description, or some other information that is sufficient to unambiguously identify the Semantics.
[Figure 7: Autonomous Selection]
| Editorial note | |
| dbooth: The label at the top of this diagram needs to be fixed. It should be
"Figure 7" instead of "Figure 5". |
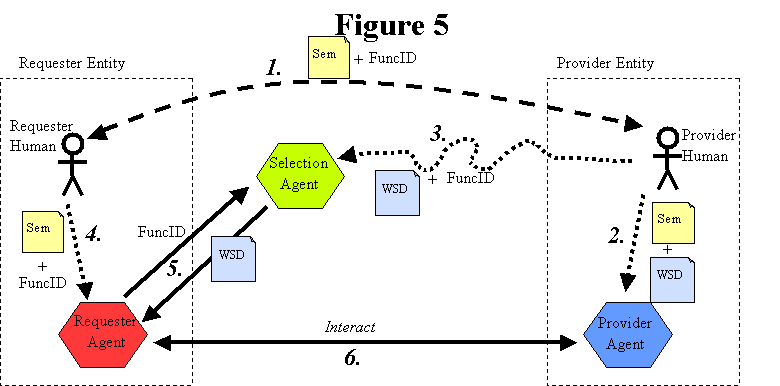
In general, Autonomous Selection involves the following steps. Although the ordering of these steps may vary somewhat, all are important.
Agree on Semantics. Again, the requester human and the provider human must somehow agree on the Semantics of the service. In addition, the parties need to agree on what FuncID will be used to identify the Semantics or functionality of the service, so that it can be referenced later.
Input Semantics and WSD to Provider Agent. The Provider Human somehow creates the WSD, and inputs the WSD and the Semantics into the Provider Agent.
Selection Agent gets WSD and FuncID. The Selection Agent somehow obtains the WSD and FuncID from the Provider Human.
Input Semantics to Requester Agent. The Requester Human inputs the desired Semantics and FuncID to the Requester Agent.
Select WSD. The Requester Agent uses the FuncID to query the Selection Agent for an acceptable WSD document that corresponds to the desired Semantics.
Interact. The Requester Agent and the Provider Agent interact using whatever means they have agreed upon.
There are two key differences between Autonomous Selection and the previously described "Human Discovery":
In theory, there is no need for these two characteristics to be bundled together. (I.e., one could operate a requester agent that would autonomously find and engage previously unknown services.) But in practice autonomous service selection is often limited to previously known (and trusted) services, because engaging a service almost always involves some degree of risk -- for example, the risk of transmitting funds or sensitive information to another party.
For this reason, Autonomous Selection is most applicable when the decision to engage the service involves little risk, such as a PDA looking for the nearest printer service in an office. For services involving greater risk (such as those involving the purchase of goods or transmission of credit card numbers), it is less likely that the requester entity would be willing to delegate this trust decision to an autonomous agent to engage a previously unknown service.
| Editorial note | |
| dbooth to finish this section |
3.4.2.3 Triangle Diagram
This section describes the correspondence between the "Triangle Diagram" previously included in our architecture document and the more detailed way that discovery is now described in this document.
[Figure 8: Triangle Diagram]
| Editorial note | |
| dbooth: The label at the top of this diagram needs to be fixed. It should be
"Figure 8" instead of "Figure T". |
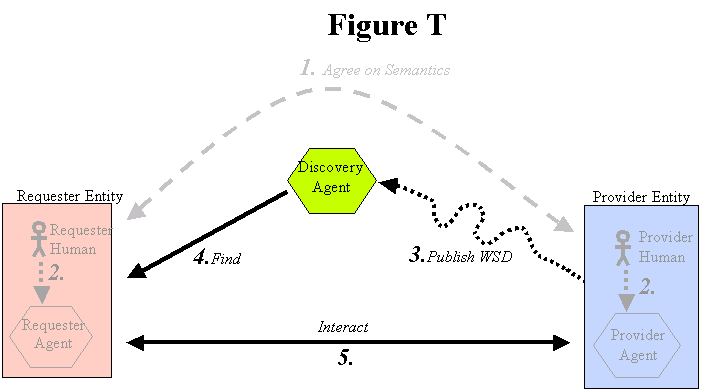
| Editorial note | |
| dbooth to finish this section |
3.5 Web service semantics
For computer programs to successfully interact with each other a number of conditions
must be established:
There must be a physical connection between them, such that data from one process
may reach another
There must be agreement on the form of the data — such as
whether the data is lines of text, XML structures, etc.
The two (or more) programs must share agreement as to the intended meaning of the
data. For example, whether the data is intended to represent an HTML page to be rendered,
or whether the data represents the current status of a bank account; the expectations and
the processing involved in processing the data is different — even if the form of
the data is identical.
As we shall see below, more is required, but for now this list is sufficient.
The architecture addresses the first two of these requirements in the Message oriented Model. That model focuses on how
Web service agents (requesters and providers) may interact with each other using a message
oriented communication model. The form of the messages is XML, and hence any Web service
agent is expected to be able to process XML data.
The intention, or semantics, of the communications between Web service agents
is partially addressed in the Service
Oriented Model and the Resource Oriented
Model.
The Service Oriented Model builds on the
basics of message communication by adding the concept of action and service. Essentially,
the service model allows us to interpret messages as requests for actions and as responses
to those requests. Within the architecture, and in particular using technologies such as
WSDL, a Web service can be described in a machine readable document as to the forms of
expected messages, the datatypes of elements of messages and — using a choreography
description language — the expected flows of messages between Web service agents.
The Resource Oriented Model extends this
further by adding the concepts of Resource, together
with a minimal set of standard actions on resources. The Resource Oriented Model mimics that of the World
Wide Web itself which regards HTML pages as representations of resources (Web pages in Web sites) that may be accessed using the
standard actions (GET, PUT,
etc.) of the HTTP protocol.
However powerful the Resource Oriented Model model is, it
is not sufficient, in general, to capture the semantics of all Web service
interactions. That is because the interactions between Web service agents is considerably
richer than simple resource management. There is currently a gap in the architecture
relating (sic) to the generalized issues of the semantics of interapplication
communication. However, we can postulate certain features that we might expect to see in a
more complete accounting of the semantics of Web services:
It should be possible to identify the real-world entities referenced by elements
of messages. For example, when using a credit card to arrange for the purchase of
goods or services, the element of the message that contains the credit card
information is fundamentally a reference to a real-world entity: the account of the
card holder.
We expect that the Semantic Web technologies will be a sound starting point for
addressing this requirement.
It should be possible to identify the expected effects of any actions undertaken
by Web service requesters and providers. That this cannot be captured by datatyping
can be illustrated with the example of a Web service for withdrawing money from an
account as compared to depositing money (more accurately, transferring from an account
to another account, or vice versa). The datatypes of messages associated with two such
services may be identical, but with dramatically different effects — instead of
being paid for goods and services, the risk is that one's account is drained
instead.
We expect that a richer model of services, together with technologies for identifying
the effects of actions, is required. Such a model is likely to incorporate concepts
such as contracts (both legally binding and technical contracts) as well as ontologies
of action.
Finally, a Web service program may "understand" what a particular
message means in terms of the expected results of the message, but, unless there is
also an understanding of the relationships of the owners of the Web service requester
and provider agents, the Web service provider (say) may not be able to accurately
determine whether the requested actions are warranted.
For example, a Web service provider may receive a valid request to transfer money
from one account to another. The request being valid in the sense that the datatypes
of the message are correct, and that the semantic markers associated with the message
lead the provider to correctly interpret the message as a transfer request. However,
the transaction may still not be valid, or fully comprehensible, unless the Web
service provider can properly identfy the relationship of the requester to the
requested action. Currently, such concerns are often treated simply as security
considerations — which they are — in an ad hoc fashion. However, when one
considers issues such as delegated authority, proxy requests, and so on, it becomes
clear that a simple authentication model cannot accurately capture the
requirements.
As with semantics as a whole, there is a gap in the architecture relating to this
level of semantic descriptions. However, we expect that a model that formalizes
concepts such as institutions, roles (in business terms), "regulations" and
regulation formation will be required. With such a model we should be able to capture
not only simple notions of authority, but more subtle distinctions such as the
authority to delegate an action, authority by virtue of such delegation, authority to
authorize and so on.
This architecture encourages precision of semantic description by ensuring that the
various aspects of the semantics of the information exchanged between agents can be
properly identified — as opposed to being fully described. Where
appropriate, and possible, it also identifies a number of description languages which can
be used to describe different semantic aspects of this exchanged information.
An important technology for realizing the description of the semantics of Web services is
the Semantic Web. "The Semantic Web is
an extension of the current web in which information is given well-defined meaning, better
enabling computers and people to work in cooperation." -- Tim Berners-Lee, James
Hendler, Ora Lassila, The Semantic Web, Scientific American, May 2001.
| Editorial note: fgm | |
| More justice needs to be made to the technologies coming out of the Semantic Web
effort. |
In summary, Web services can be considered to be a specialization of World Wide Web in
general; a specialization that reflects the intended purpose of the exchanged information
to be about services. Similarly, this architecture can be viewed as an elaboration of the
general WWW architecture; albeit with a significant number of additional concepts.
3.6 Web services security
| Editorial note: fgm | |
| This is a working draft of a proposed section on Security for the stakeholder's section.
|
Goal AG004 of the WSA requirements
states that "The WSA must provide a secure environment for online processes". This is
further analyzed into two critical success factors: security (AC006) and privacy
(AC020). [WSA Reqs]
Security, and privacy, issues are often extremely detailed and often quite implementation
specific. For example, there are many famous cases of security being compromised through
the incorrect implementation of fixed-length buffers (so-called buffer overruns permit an
intruder to corrupt a target's address space and sometimes to gain unauthorized
access). This architecture is necessarily at a level of abstraction where such
considerations are moot; since implementation itself is out of scope for the
architecture.
In the context of security, the prime concerns in the development of the WSA are the
identification threats to security and what architectural features are necessary to
respond to those threats.
3.6.1 Threats to security and privacy
Security issues tend to revolve around access and use of resources; the primary task
being to ensure that it is not possible for intruders to access resources for which they
do not have the appropriate rights. We can summarize the principal security threats as:
Inappropriate access on behalf on unauthorized entities. It should be possible
to reliably determine the identity of entities such as agents, service providers,
resources and so on.
Corruption of communication and resources. It should be possible to ensure the
data integrity of communications and transactions.
Information leaking. It should be possible to ensure that information is accessible
only to intended parties. This certainly includes the content of messages; but may
also include the mere fact that a communication between particular parties has taken
place.
Inappropriate access to resources. It should be possible to ensure that resources
and actions are not possible for entities not properly authorized. Again, this often
extends to the right to even see that a given resource exists: unauthorized persons
may not even be permitted to know the existence of certain resources or certain
actions.
Denial of service. It should not be possible for parties to prevent legitimate
parties to access resources and perform actions that they have the right to.
Note that certain theoretical limitations will prevent us from ever guaranteeing that
these risks do not become realities. However, it is certainly a viable goal to
significantly reduce the risk of security breaches.
There are other security-related threats that this architecture is not designed to
combat:
Non-repudiation. The risk associated with this is that a party may subsequently
deny its involvement with a transaction. Non-repudiation is important; however,
this architecture regards this threat as primarily an application-level threat.
Mis-information. A malicious party may attempt to corrupt a Web service by
deliberately feeding it incorrect information. For example, by communicating invalid
credit card information, a fraudulent Web service requester may attempt to gain
service that it would not normally have the right to. This is similar to the buffer
overrun style of security breach; however, generally this security breach involves
sending well-formed but false information.
Copy and replay. Given a copy of a Web service agent, it may be possible to execute
it in an environment that could give a malicious party information not ordinarily
available. For example, given a copy of a Web service requester agent that acts on
behalf of a customer, a malicious Web service provider may simulate a series of
transactions with the captured agent in order to determine the maximum price the end
user is expected to pay for goods and services.
Privacy issues tend to revolve around the use of personal information, in particular
the abuse of personal information; again, this can often be expressed in terms of the
wrong people having access to the wrong information. We can summarize the threats to
privacy as:
Information use. An end user may have the right to know how, when, and to what
extent their personal or sensitive information will be used by the Web services
processing nodes. Protected usage includes the sharing of personal or sensitive
information obtained by a processing node with any third party. These rights are
often founded on legislation that varies on a global basis.
Confidentiality. Similar to above security threat: third party access access to
sensitive information represents a threat to the privacy of the end user.
Also central is that these practices should be exposed by the processing nodes prior to
a service invocation, allowing a service requestor to factor a processing node's privacy
practices in the decision to use a particular Web service or to follow a particular
message route. Hence, the publishing and accessibility of a Web service processor's
privacy practices will aid an end user to retain control over his personal
information. This is contingent on the compliance to the published privacy by the Web
service processor and is outside of the scope of technology solutions.
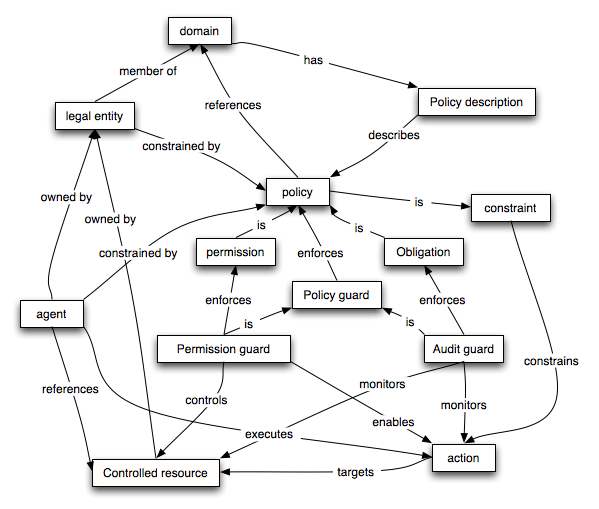
3.6.2 Policies
The approach adopted in the WSA to address both security and privacy concerns revolves
around the concept of policy. A policy is a document,
preferably machine-processable, that expresses some constraint on the behavior of the
overall system; generally on the behavior of agents. Closely connected to the concept of
policy is the concept of policy guard. A policy
guard is some mechanism that is used to enforce policy. Hence security is expressed in
terms of the policies that the owners of
resources wish to enforce, together with mechanisms
put in place to enforce those policies. Similarly, privacy is expressed in terms of the
policies that the owners of data -- typically the users of Web services -- have,
together with mechanisms necessary to ensure that the owners' rights are respected.
While many policies relate to actions, and to resources, it is not always the
case. Many security and privacy-related constraints are concerned with maintaining
certain kinds of state. For example, a Web service provider may have a constraint that
any P3P tags associated with a use of one of its Web services are appropriately
propagated to third parties. Such a constraint cannot easily expressed in terms of the
allowed actions that the Web service provider may perform; it is really an obligation to
ensure that the publicly observable condition (the proper use of P3P tags) is always
maintained (presumably maintained in private also). Similarly, a Web service provider
may (will) link the possible actions that a Web service requester may perform to the Web
service requester maintaining a particular level of secure access (e.g., administrative
tasks may only be performed if the request is using secure communications).
Policies can be logically broken down into two main types: permissive policies and
obligatory policies. A permissive policy concerns those actions and accesses that
entities are permitted to perform and an obligation policy concerns those actions and
states that entities are required to perform. These are closely related, and dependent:
it is not consistent to be obliged to perform some action that one does not have
permission to perform. A given policy document is likely to contain a mix of obligation
and permission policy statements.
The two kinds of policies have different enforcement mechanisms: a permission guard is
a mechanism that can be used to verify that a requested action or access is permitted;
an audit guard can only verify after the fact that an obligation has not been met. The
precise form of these guards is likely to vary, both with the resources being controlled
and with the implementation technologies deployed. The architecture is principally
concerned with the existence of guards and their role in the architecture. In a well
engineered system it may be possible to construct guards that are not directly visible
to either the requester nor the provider of Web services.
A permission guard acts as a guard enabling or disabling action to a resource or
action. In the context of SOAP, for example, one important role of SOAP intermediaries
is that of permission guards: the intermediary may not, in fact, forward a message if
some security policy is violated.
An audit guard acts as a monitor; watching resources and agents, validating that
obligations that have been established are respected and/or discharged. Due to the
nature of obligations it is often not possible to prevent obligations; instead the focus
is on observing that obligations are respected. If an audit guard detects a policy
violation, then it normally cannot prevent the violation; instead some form of
retribution or remediation must be enacted. The precise forms of this are, of course,
beyond the scope of this architecture.
3.6.2.1 Policies and security
The threats enumerated above can be countered by a combination of suitable mechanisms
and policy documents that govern the enforcement mechanisms. For example, the
unauthorized access threat may be countered by a mechanism that validates the identity
of potential agents who wish access the controlled resource. That mechanism is, in
turn, controlled by the policy document which expresses what evidence must be offered
by which agents before the access is permitted.
Not all guards are active processes. For example, confidentiality of information is
encouraged (we hesitate to claim guaranteed) by encryption of messages. As noted
above, it is potentially necessary to encrypt not only the content of SOAP messages
(say) but also the identities of the sender and receiver agents. The guard here is the
encryption itself; although this may be further backed up by other active guards that
apply policy.
3.6.2.2 Policies and privacy
Privacy policies are typically much more of the obligatory form than access control
policies. A policy that requires a Web service provider to properly propagate P3P
tags, for example, represents an obligation on the provider. It is not possible to
prevent a rogue Web service provider from leaking private information; it should be
possible, however, to monitor the public actions of the Web service to ensure that the
tags are propagated.
3.6.3 Policies beyond security
Policies have application beyond security and privacy. For example, many Quality of
Service requirements can be expressed in terms of policies (especially obligation-style
policies). Furthermore, many application-level policies may also apply. Thus the
fundamental concepts of policies and guards may also benefit Web services applications
as well as helping to ensure their security.
It should be noted that the focus of the Architecture is those elements that are needed
to ensure that policies are adhered to. Currently, the architecture does not address the
issues associated with enacting policies; except in so far that enactment can be modeled
in terms of Web services that are themselves subject to policies.
The issues involved with enacting policies include determining how policies are
established, in particular who has the right to establish a policy and who does a policy
relate to. This can be modeled in terms of meta-policies; however, issues of legal
responsibility, relationships between agents and between owners. These are beyond the
scope of the Architecture.
3.8 Modularity
The critical success factor AC002focuses on the modularity of the
architecture; with appropriate granularity. This is reduced to an overall conceptual
integrity with appropriate decomposition and easy comprehension.
Our architecture is laid out using the simple style of concepts and relationships. This modeling technique is simple, and yet
allows us to expose the critical properties of Web services. A major design goal of the
architecture has been the appropriate separation of concerns. In general, this is achieved
by rigorous minimalism associated with each concept: only associating those properties of
a concept that are truly necessary to meet the requirements.
The overall themes in this architecture can be summarized as:
Web services are used and presented by agents interacting on behalf of real-world actors.
Message structures, service
interfaces, conversations are first of all
explicitly identified and potentially described
using using a variety of description languages. This has the effect of documenting the
various aspects involved in two or more interacting Web services.
Minimal assumptions about required components. For example, although Web services may
be documented, it is not required. Similarly, although descriptions may be published,
that is also not required.
3.10 Peer to peer interaction
To support Web services interacting in a peer to peer style, the architecture must
support peer to peer message exchange patterns, must permit Web services to have
persistent identity, must permit descriptions of the capabilities of peers and must
support flexibility in the discovery of peers by each other.
In the message exchange pattern concept we allow for Web
services to communicate with each other using a very general concept of message exchange.
Furthermore, we allow for the fact that a message exchange pattern can itself be
identified -- this permits interacting Web service agents to explicitly reference a
particular message pattern in their interactions.
A Web service wishing to use a peer-to-peer style interaction may use, for example, a
publish-subscribe form of message exchange pattern. This kind of message exchange is just
one of the possible message exchange patterns possible when the pattern is explicitly identifiable.
In the agent concept we note that agents have identifiers. The primary role of an agent identifier is to
permit long running interactions spanning multiple messages. Much like correlation, an
agent's identifier can be used to link messages together. For example, in a publish and
subscribe scenario, a publishing Web service may include references to the Web service
that requested the subscription, separately from and additionaly to, the actual recipient
of the service.
The agent concept also clarifies that a given agent may
adopt the role of a service provider and/or a
service requester. I.e., these are roles of
an agent, not necessarily intrinsic to the agent itself. Such flexibility is a key part of
the peer to peer mode of interaction between Web services.
In the service concept we state that services have a semantics that may
be identified in aservice description and
that may be expressed in a service description language. This identification of
the semantics of a service, and for more advanced agents the description of the service
contract itself, permits agents implementing Web services to determine the capabilities of
other peer agents. This is turn, is a critical success factor in the architecture
supporting peer-to-peer interaction of Web services.
Finally, the fact that services have descriptions means that these descriptions may be
published in discovery agencies and also
retrieved from such agencies. In effect, the availability of explicit descriptions enables
Web services and agents to discover each other automatically as well as having these hard-coded.
3.11 Long running transactions
In CSF AC017 are identified two
requirements that support applications in a similar manner to traditional EDI systems:
reliable messaging and support for long-running stateful choreographed interactions. This
architecture supports transactions by allowing messages to be part of message exchanges
and extended choreographies. It also permits support for message reliability.
3.12 Conversations
Conversations are supported in this architecture at two levels: the single use of a Web
service and the combination of Web services.
A message exchange pattern is defined to be the set of
messages that makes a single use of a service. Typical examples of message exchange
pattern are request-response, publish-subscribe and event notification.
The details of the message exchange pattern may be documented in a service description expressed in a service description language such as WSDL.
In addition, the architecture supports the correlation of messages by permitting messages to have identifiers.
Web services may be combined into larger scale conversations by means of choreographies. A choreography is the documentation of the
combination of Web services, leaving out the details of the actual messages involved in
each service invocation and focusing on the dependencies between the Web services.
Of particular importance, both to individual message exchange patterns and combined
services, is the handling of exceptions.
3.13 Message reliability
Critical Success Factor AC017 of the requirements notes that the architecture must
satisfy the requirements of enterprises wishing to transition from traditional EDI and
more specifically AR017.1 requires
that the architecture must support reliable messaging.
The goal of reliability is to both reduce the the error frequency for interactions and,
where errors occur, to provide a greater amount of information about either successful or
unsuccessful attempts at service.
In the context of Web services, we can address the issues of reliability at three
distinct levels: of reliable and predictable interactions between services, of the
reliable and predictable delivery of infrastructure services and of the reliable and
predictable behavior of individual service providers and requesters. This analysis is
generally separate from concerns of fault tolerance, availability or security, but there
may of course be overlapping issues.
The architecture addresses the requirements for the highest level of reliability
identified here by accomodating the descriptions of the choreographies of the interactions
between Web service requesters, providers. In effect, reliability at this level becomes a
measurable property of the descriptions of choreographies: in effect, assuming that the
infrastracture is reliable, and assuming that the services are reliable, do the
descriptions of the choreographies describe situations which will behave in predictable ways?
The reliability of the individual service providers and requesters is out of scope of
this architecture as we do not comment on the realization of Web services. However,
reliability at this level is often enhanced by service providers adopting deployment
platforms that have strong management capabilities.
The reliability of the infrastracture services refers to the reliability of the messaging
infrastructure and the discovery infrastructure; the former is often referred to as
reliable messaging. In general, this refers to a predictable quality of service related to
the delivery of the messages involved with the Web service.
In more detail, we identify two properties of message sending that are important: the
sender of the message would like to be able to determine whether a given message has been
received by its intended receiver and that the message has been received exactly once.
Knowing if a message has been received correctly allows the sender to take compensating
action in the event the message has not been received. At the very least, the sender may
attempt to resend a message that has not been received.
The general goal of reliable messaging is to define mechanisms that make it possible to
achieve these objectives with a high probability of success in the face of inevitable but
unpredictable network, system and software failures.
The goals of reliable messaging can be made more explicit by considering the issues
related to multiple receptions of a message and message intermediaries. If there is an
intermediary, does the sender want to know whether the message got to the intermediary or
to the intended end recipient? Does the receiver care whether it receives a message more
than once? The following classification of reliable messaging expectations is taken from
[ebXML MSS].
| Duplicate-Elimination | Ack Requested From End Receiver | Ack Requested from Next Receiver | Comment |
|---|
| 1 | Y | Y | Y | Once-And-Only-Once End-To-End, At Least Once to Intermediate |
| 2 | Y | Y | N | Once-and-only-Once End-to-End based on end-to-end retransmission |
| 3 | Y | N | Y | At-Least-Once at the intermediate level, Once-and-only-once end-to-end if all the
intermediaries are reliable, no end-to-end notification |
| 4 | Y | N | N | At-Most-Once end-to-end, no retries at the intermediate level |
| 5 | N | Y | Y | At-Least-Once with duplicates possible both end-to-end and at intermediate level |
| 6 | N | Y | N | At-Least-Once with duplicates possible both end-to-end and at intermediate level |
| 7 | N | N | Y | At-Least-Once to the intermediaries and the end. No end-to-end notification |
| 8 | N | N | N | Best Effort |
The goals of reliable messaging may also be examined with respect to whether one wishes
to confirm only the receipt of a message, or perhaps also to confirm the validity of that
message. Three questions may be asked about message validity:
Was the message received the same as the one sent? This may be determined by such
techniques as byte counts, check sums, digital signatures.
Does the message conform to the formats specified by the agreed upon protocol for the
message? Typically determined by automatic systems using syntax constraints (eg xml
well formed) and structural constraints (validate against one or more xml schemas or
WSDL message definitions).
Does the message conform to the business rules expected by the receiver? For this
purpose additional constraints and validity checks related to the business process are
typically checked by application logic and/or human process managers.
Of these, first and second are considered to be part of reliable messaging, the last is
partly addressed by Web service choreography.
Message reliability is most often achieved via an acknoweldgement infrastructure, which
is a set of rules defining how the parties to a message should communicate with each other
concerning the receipt of that message and its validity. WS-Reliability
and WS-ReliableMessaging
are examples of specifications for an acknowledgement infrastructure that leverage the
SOAP Extensibility Model. In cases where the underlying transport layer already provides
reliable messaging support (e.g. a queue-based infrastructure), the same reliability
Feature can be achieved in SOAP by defining a binding that relies on the underlying
properties of the transport.
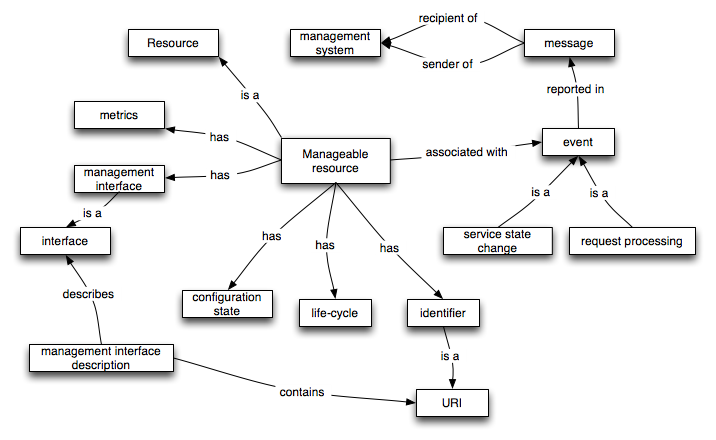
3.14 Web service manageability
Goal AG007 of the requirements [WSA Reqs] identifies that manageability of
Web services is an important goal of this architecture. Since the architecture defines how
to define information, operations and discovery of Web services, it is consistent to use
Web services to provide access to and manageability of Web services also.
Management in this case is defined as a set of capabilities for discovering the
existence, availability, health, and usage, as well the control and configuration of
manageable elements, where these are defined as Web services, descriptions, agents of the
Web services architecture, and roles undertaken in the architecture.
This architecture does not attempt to specify completely how Web services are managed;
that is be the role of a separate specification. The architecture does, however, identify
the key concepts and relationships involved in modeling manageability. These key concepts
include the manageable element, its management capabilities, the manageability interface and the manager.
For example, an executing Web services agent is a
potentially managable element that may require management, as is an actually deployed
Web service and the Web service's service description.
The manager is an agent
that has the responsiblity for managing on behalf of its owner and the owners of the
resources that it is managing. The manager uses the manageability interface to aquire metrics of managed elements and to manage the configuration, the life
cycle, and to monitor the status of those elements. The manager is also a prime recipient of management events.
The key relationship that ensures that the architecture models management appropriately
is the realizes relationship. The entities under
management the manageable elements have a
realizes relationship with other elements of the
architecture. For example, a Web service is provided by
an agent. Both the Web service itself and the agent are
realized in some fashion; as are any descriptions of
the service; as physically deployed resources, and those deployed resources are themselves
potentially manageable.
As with Web services themselves, it may be important for scalability reasons for managers to be able to automatically discover both the manageable
elements it may be responsible for and their manageability interfaces.
| Editorial note | |
| Discovery has a management aspect as well as a service aspect. This needs to be
made clearer. |
Of course, managers that are deployed in order to help the management of Web services are
also potentially subject to management; however, to the extent that such managers are
already modeled as Web services, their management will be handled as any other Web service.
3.15 Web services technologies
There are a number of technologies that are in widespread use in the deployment of Web
services; and other technologies that will arise in the future. In this section we
describe some of those technologies that seem critical and the role they fill in relation
to this architecture. This is a necessarily bottom-up perspective, since, in this section,
we are looking at Web services from the perspective of tools which can be used to design,
build and deploy Web serivces.
The technologies that we consider here, in relation to the Architecture, are XML, SOAP,
WSDL. SOAP provides an extensible framework for the XML data that is interchanged. The
format that SOAP defines has restrictions and places of extensibility. The Web Services
Description Language (WSDL) provides a format for defining the allowable formats for
messages to and from agents. These include SOAP, XML, MIME, and simple HTTP requests.
| Editorial note: fgm | |
| There are almost certainly others we should mention here, such as BPEL,
WS-Security, WS-Policy, WS-Reliability, ... |
3.15.1 XML and Web services
As previously stated, a Web services interaction is two, or more, software agents
exchanging information in the form of messages. The data that is exchanged is usually
XML carried over an underlying transport or transfer protocol, such as HTTP. Similarly,
XML is also the foundation for many of the descriptive technologies — such as
SOAP, WSDL, OWL, and many others. In effect, the use of XML is critical to the overall
picture of Web services.
The reason for the importance of XML is that it solves a key technology requirement
that appears in many places: by offering a standard, flexible and inherently extensible
data format, XML significantly reduces the burden of deploying the many technologies
needed to ensure the success of Web services.
The important aspects of XML, for the purposes of this Architecture, are the core
syntax itself, the concepts of the XML Infoset [XML Infoset], XML-Schema and
XML-Namespaces.
XML Infoset is not a data format per se, but a
formal set of information items and their associated properties that comprise an
abstract description of an XML document [XML 1.0]. The XML Infoset
specification provides for a consistent and rigorous set of definitions for use in other
specifications that need to refer to the information in a well-formed XML document.
Serialization of the XML Infoset definitions of information MAY be expressed using XML
1.0 [XML 1.0]. However, this is not an inherent requirement of the
architecture. The flexibility in choice of serialization format(s) allows for broader
interoperability between agents in the system. In the future, a binary encoding of XML
should be a suitable replacement for the textual serialization — such a binary
encoding may be more efficient and more suitable for machine-to-machine
interactions.
Many of the uses of XML in the architecture relate to the description of machine
processable elements; such as message formats, interface descriptions, choreography
descriptions, policy descriptions and so on. While XML-Schema is not sufficiently
powerful (nor intended to be) to capture all these, it does provide a strong typing
foundation for other kinds of description. Hence, XML-Schema is an integral part of XML
— and Web services, as far as this archicture is concerned.
Similarly, XML-Namespaces is also a critical part of XML technology in relation to the
Architcture. It allows developers to partition all the different types of XML document
that a large-scale Web service installation is likely to need.
3.15.2 SOAP
SOAP Version 1.2 is a simple and lightweight XML-based mechanism for creating
structured data packages that can exchanged between network applications.
SOAP is the standard for XML messaging for a number of reasons.
First, SOAP is relatively simple, defining a thin layer that builds on top of existing
network technologies such as HTTP that are already broadly implemented. Second, SOAP is
flexible and extensible in that rather than trying to solve all of the various issues
developers may face when constructing Web services, it provides an extensible,
composable framework that allows solutions to be incrementally applied as needed.
Thirdly, SOAP is based on XML. Finally, SOAP enjoys broad industry and developer
community support.
[SOAP 1.2 Part 1] defines an XML-based messaging framework: a processing model and an exensibility model. SOAP messages can be carried by a variety of network protocols; such as HTTP, SMTP, FTP, RMI/IIOP, or a
proprietary messaging protocol.
[SOAP 1.2 Part 2] defines three optional components: a set of encoding rules for expressing instances of
application-defined data types, a convention for representing remote procedure calls
(RPC) and responses, and a set of rules for using SOAP with HTTP/1.1.
An extension of the SOAP messaging framework is called a SOAP feature. One special type of SOAP feature is the
Message Exchange Pattern (MEP). A SOAP MEP is a template that establishes a
pattern for the exchange of messages between SOAP nodes. Examples of MEPs include:
request/response, oneway, peer-to-peer conversation, etc. A MEP MAY be supported by one
or more underlying protocol binding instances either directly, or indirectly with
support from software that implements the required processing to support the SOAP
Feature as expressed as a SOAP Module.
3.15.3 WSDL
WSDL is an example of implementation technology for
service descriptions
WSDL 1.2 [WSDL 1.2 Part 1] is an XML document format for describing Web services
as a set of endpoints operating on messages containing either document-oriented or
procedure-oriented (RPC) messages.
WSDL describes Web services starting with the messages that are exchanged between the
service provider and requester. The messages themselves are described abstractly and
then bound to a concrete network protocol and message format.
WSDL is sufficiently extensible to allow description of endpoints and their messages
regardless of what message formats or network protocols are used to communicate.
[WSDL 1.2 Part 3] describes SOAP Version 1.2, HTTP/1.1, and MIME bindings.
Web service definitions can be mapped to any language, object model, or messaging
system. Simple extensions to existing Internet infrastructure can implement web services
for interaction via browsers or directly within an application. The application could be
implemented using COM, JMS, CORBA, COBOL, or any number of proprietary integration
solutions.
Both the sender and receiver of a Web services message must have access to the same
service description. The sender needs the service description to know how to format the
message correctly and the receiver needs the service description to understand how to
receive the message correctly.
As long as both the sender and receiver have the same service description, (e.g. WSDL
file), the implementations behind the Web services can be anything. Web services
typically are implemented using programming languages designed for interaction with the
web, such as Java Servlets or Application Server Pages (ASPs) that call a back-end
program or object. These Web service implementations are also typically represented
using a Web services description language.
Issue (wsdwg_service):
A WSDWG:Service is a collection of *equivalent* endpoints *bound* to the same interface.
Resolution:
None recorded.