1 Introduction
1.1 Goals and Scope
The goal of this document is to facilitate use of the Web by all people, regardless of their language, script, writing system, and
cultural conventions, in accordance with the W3C goal of universal access. One basic
prerequisite to achieve this goal is to be able to transmit and process the characters used around the world in a well-defined and well-understood
way.
The main target audience of this document is W3C specification developers. This document defines conformance requirements for other W3C
specifications. This document and parts of it can also be referenced from other W3C specifications.
Other audiences of this document include software developers, content developers, and authors of specifications outside the W3C.
Software developers and content developers implement and use W3C specifications. This document defines some conformance requirements for software
developers and content developers that implement and use W3C specifications. It also helps software developers and content developers to understand
the character-related provisions in other W3C specifications.
The character model described in this document provides authors of specifications, software developers, and content developers with a
common reference for consistent, interoperable text manipulation on the World Wide Web. Working together, these three groups can build a more
international Web.
Topics addressed include character encoding identification, early uniform normalization, string identity matching, string indexing, and
URI conventions. Some introductory material on characters and character encoding is also provided.
Topics not addressed or barely touched include collation (sorting), fuzzy matching and language tagging. Some of these topics may be
addressed in a future version of this specification.
At the core of the model is the Universal Character Set (UCS), defined jointly by the Unicode Standard [Unicode]
and ISO/IEC 10646 [ISO/IEC 10646]. In this document, Unicode is used as a synonym for the
Universal Character Set. The model will allow Web documents authored in the world's scripts (and on different platforms) to be exchanged, read, and
searched by Web users around the world.
All W3C specifications must conform to this document (see section 2 Conformance). Authors of other
specifications (for example, IETF specifications) are strongly encouraged to take guidance from it.
1.2 Background
This section provides some historical background on the topics addressed in this document.
Starting with Internationalization of the Hypertext Markup Language [RFC 2070], the Web community
has recognized the need for a character model for the World Wide Web. The first step towards building this model was the adoption of Unicode as the
document character set for HTML.
The choice of Unicode was motivated by the fact that Unicode:
-
is the only universal character repertoire available,
-
provides a way of referencing characters independent of the encoding of the text,
-
is being updated/completed carefully,
-
is widely accepted and implemented by industry.
W3C adopted Unicode as the document character set for HTML in [HTML 4.0]. The same approach was later used for
specifications such as XML 1.0 [XML 1.0] and CSS2 [CSS2]. W3C specifications and applications now use
Unicode as the common reference character set.
The IETF has adopted some policies on the use of character sets on the Internet (see [RFC 2277]).
When data transfer on the Web remained mostly unidirectional (from server to browser), and where the main purpose was to render
documents, the use of Unicode without specifying additional details was sufficient. However, the Web has grown:
-
Data transfers among servers, proxies, and clients, in all directions, have increased.
-
Non-ASCII characters [ISO/IEC 646] are being used in more and more places.
-
Data transfers between different protocol/format elements (such as element/attribute names, URI components, and textual content)
have increased.
-
More and more APIs are defined, not just protocols and formats.
In short, the Web may be seen as a single, very large application (see [Nicol]), rather than as a collection of
small independent applications.
While these developments strengthen the requirement that Unicode be the basis of a character model for the Web, they also create the
need for additional specifications on the application of Unicode to the Web. Some aspects of Unicode that require additional specification for the
Web include:
-
Choice of Unicode encoding forms (UTF-8, UTF-16, UTF-32).
-
Counting characters, measuring string length in the presence of variable-length character encodings and combining
characters.
-
Duplicate encodings of characters (e.g. precomposed vs decomposed).
-
Use of control codes for various purposes (e.g. bidirectionality control, symmetric swapping, etc.).
It should be noted that such aspects also exist in legacy encodings (where legacy
encoding is taken to mean any character encoding not based on Unicode), and in many cases have been inherited by Unicode in one way or another
from such legacy encodings.
The remainder of this document presents additional specifications and requirements to ensure an interoperable character model for the
Web, taking into account earlier work (from W3C, ISO and IETF).
For information about the requirements that informed the development of important parts of this specification, see Requirements
for String Identity Matching and String Indexing [CharReq].
1.3 Terminology and Notation
For the purpose of this specification, the producer of text data is the sender
of the data in the case of protocols, and the tool that produces the data in the case of formats. The recipient of text
data is the software module that receives the data.
NOTE: A software module may be both a recipient and a producer.
Unicode code points are denoted as U+hhhh, where "hhhh" is a sequence of at least four, and at most six hexadecimal
digits.
2 Conformance
The key words "MUST", "MUST NOT", "REQUIRED",
"SHALL", "SHALL NOT", SHOULD", "SHOULD
NOT", "RECOMMENDED", "MAY" and "OPTIONAL" in this
document are to be interpreted as described in RFC 2119 [RFC 2119].
NOTE: RFC 2119 makes it clear that requirements that use SHOULD are not
optional and must be complied with unless there are specific reasons not to: "This word, or the adjective "RECOMMENDED", mean
that there may exist valid reasons in particular circumstances to ignore a particular item, but the full implications must be understood and
carefully weighed before choosing a different course."
This specification places conformance criteria on specifications, on software and on Web content. To aid the reader, all conformance
criteria are preceded by '[X]' where 'X' is one of 'S' for
specifications, 'I' for software implementations, and 'C' for Web content. These markers
indicate the relevance of the conformance criteria and allow the reader to quickly locate relevant conformance criteria by searching through this
document. [S] [I] [C] In order to conform to this document, specifications MUST NOT violate any
conformance criteria preceded by [S], software MUST NOT violate any conformance criteria preceded by [I], and content
MUST NOT violate any conformance criteria preceded by [C].
[S] All new W3C specifications MUST:
-
conform to the conformance criteria applicable to specifications,
-
specify that implementations MUST conform to the conformance criteria applicable to software,
and
-
specify that content created according to that specification MUST conform to the conformance criteria
applicable to content.
[S] If an existing W3C specification does not conform to the conformance
criteria for new W3C documents, then the next version of that specification SHOULD be modified so that it becomes
conformant.
[I] Where this specification contains a procedural description, it
MUST be understood as a way to specify the desired external behavior. Implementations MAY
use other means of achieving the same results, as long as observable behavior is not affected.
3 Characters
3.1 Perceptions of Characters
3.1.1 Introduction
The glossary entry in [Unicode 3.0] gives:
"Character. (1) The smallest component of written language that has semantic values; refers to the abstract
meaning and/or shape ..."
The word 'character' is used in many contexts, with different meanings. Human cultures have radically
differing writing systems, leading to radically differing concepts of a character. Such wide variation in end user experience can, and often does,
result in misunderstanding. This variation is sometimes mistakenly seen as the consequence of imperfect technology. Instead, it derives from the
great flexibility and creativity of the human mind and the long tradition of writing as an important part of the human cultural heritage. The
alphabetic approach used by scripts such as Latin, Cyrillic and Greek is only one of several possibilities.
EXAMPLE: A character in Japanese hiragana and katakana scripts corresponds to a syllable (usually
a combination of consonant plus vowel).
EXAMPLE: Korean Hangul combines symbols for individual sounds of the language into square blocks,
each of which represents a syllable. Depending on the user and the application, either the individual symbols or the syllabic clusters can be
considered to be characters.
EXAMPLE: In Indic scripts each consonant letter carries an inherent vowel that is eliminated or
replaced using semi-regular or irregular ways to combine consonants and vowels into clusters. Depending on the user and the application, either
individual consonants or vowels, or the consonant or consonant-vowel clusters can be perceived as characters.
EXAMPLE: In Arabic and Hebrew vowel sounds are typically not written at all. When they are written
they are indicated by the use of combining marks placed above and below the consonantal letters.
The developers of W3C specifications, and the developers of software based on those specifications, are likely to be more familiar
with usages of the term 'character' they have experienced and less familiar with the wide variety of usages in an
international context. Furthermore, within a computing context, characters are often confused with related concepts, resulting in incomplete or
inappropriate specifications and software.
This section examines some of these contexts, meanings and confusions.
3.1.2 Units of aural rendering
In some scripts, characters have a close relationship to phonemes (a phoneme is a minimally distinct
sound in the context of a particular spoken language), while in others they are closely related to meanings. Even when characters (loosely)
correspond to phonemes, this relationship may not be simple, and there is rarely a one-to-one correspondence between character and phoneme.
EXAMPLE: In the English sentence, "They were too close to the door to close
it." the same character 's' is used to represent both /s/ and /z/ phonemes.
EXAMPLE: In the English language the phoneme /k/ of "cool" is like the
phoneme /k/ of "keel".
EXAMPLE: In many scripts a single character may represent a sequence of phonemes, such as the
syllabic characters of Japanese hiragana.
EXAMPLE: In many writing systems a sequence of characters may represent a single phoneme, for
example 'wr' and 'ng' in "writing".
[S] [I]
[C] Specifications, software and content MUST NOT assume that there is a
one-to-one correspondence between characters and the sounds of a language.
3.1.3 Units of visual rendering
Visual rendering introduces the notion of a glyph. Glyphs are defined by ISO/IEC
9541-1 [ISO/IEC 9541-1] as "a recognizable abstract graphic symbol which is independent of a specific
design". There is not a one-to-one correspondence between characters and glyphs:
-
A single character can be represented by multiple glyphs (each glyph is then part of the representation of that character). These
glyphs may be physically separated from one another.
-
A single glyph may represent a sequence of characters (this is the case with ligatures, among others).
-
A character may be rendered with very different glyphs depending on the context.
-
A single glyph may represent different characters (e.g. capital Latin A, capital Greek A and capital Cyrillic A).
Each glyph can be represented by a number of different glyph images; a set of glyph images makes up a font. Glyphs can be construed as the basic units of organization of the visual rendering of text, just as characters are the
basic unit of organization of encoded text.
[S] [I]
[C] Specifications, software and content MUST NOT assume a one-to-one mapping
between characters and units of displayed text.
See the appendix B Examples of Characters, Keystrokes and Glyphs for examples of the
complexities of character to glyph mapping.
Some scripts, in particular Arabic and Hebrew, are written from right to left. Text including characters from these scripts can run in
both directions and is therefore called bidirectional text. The Unicode Standard [Unicode] requires that characters be stored
and interchanged in logical order, i.e. roughly corresponding to the order in which text is typed in via the keyboard
(for a more detailed definition see [Unicode 3.0], Section 2.2). Logical ordering is important to ensure interoperability of
data, and also benefits accessibility, searching, and collation. [S]
[I] [C] Protocols, data formats and APIs MUST store, interchange or process text data in logical order.
In the presence of bidirectional text, two possible selection modes must be considered. The first is logical
selection mode, which selects all the characters logically located between the end-points of the user's mouse gesture. Here the user
selects from between the first and second letters of the second word to the middle of the number. Logical selection looks like this:
It is a consequence of the bidirectionality of the text that a single, continuous logical selection in memory results in a
discontinuous selection appearing on the screen. This discontinuity, as well as the somewhat unintuitive behavior of the cursor, makes some
users prefer a visual selection mode, which selects all the characters visually located between the end-points
of the user's mouse gesture. With the same mouse gesture as before, we now obtain:
In visual selection mode, as seen in the example above, a single visual selection range may result in two logical ranges,
which have to be accommodated by protocols, APIs and implementations.
[S] Specifications of protocols and APIs that involve selection of ranges
SHOULD provide for discontiguous selections, at least to the extent necessary to support implementation of visual
selection on screen on top of those protocols and APIs.
3.1.4 Units of input
In keyboard input, it is not always the case that keystrokes and input characters correspond one-to-one. A limited number of
keys can fit on a keyboard. Some keyboards will generate multiple characters from a single keypress. In other cases ('dead
keys') a key will generate no characters, but affect the results of subsequent keypresses. Many writing systems have far too many characters
to fit on a keyboard and must rely on more complex input methods, which transform keystroke sequences into character
sequences. Other languages may make it necessary to input some characters with special modifier keys. See B Examples
of Characters, Keystrokes and Glyphs for examples of non-trivial input.
[S] [I] Specifications and software
MUST NOT assume that a single keystroke results in a single character, nor that a single character can be input with a
single keystroke (even with modifiers), nor that keyboards are the same all over the world.
3.1.5 Units of collation
String comparison as used in sorting and searching is based on units which do not in general have a one-to-one relationship to encoded
characters. Such string comparison can aggregate a character sequence into a single collation unit with its own
position in the sorting order, can separate a single character into multiple collation units, and can distinguish various aspects of a character
(case, presence of diacritics, etc.) to be sorted separately (multi-level sorting).
In addition, a certain amount of pre-processing may also be required, and in some languages (such as Japanese and Arabic) sort order
may be governed by higher order factors such as phonetics or word roots. Collation methods may also vary by application.
EXAMPLE: In traditional Spanish sorting, the character sequences 'ch' and 'll' are treated as
atomic collation units. Although Spanish sorting, and to some extent Spanish everyday use, treat 'ch' as a single unit,
current digital encodings treat it as two characters, and keyboards do the same (the user types 'c', then 'h').
EXAMPLE: In some languages, the letter 'æ' is sorted as two consecutive
collation units: 'a' and 'e'.
EXAMPLE: The sorting of text written in a bicameral script (i.e. a script which has distinct upper
and lower case letters) is usually required to ignore case differences in a first pass; case is then used to break ties in a later pass.
EXAMPLE: Treatment of accented letters in sorting is dependent on the script or language in
question. The letter 'ö' is treated as a modified 'o' in French, but as a letter completely
independent from 'o' (and sorting after 'z') in Swedish. In German certain applications treat
the letter 'ö' as if it were the sequence 'oe'.
EXAMPLE: In Thai the sequence
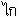 (U+0E44 U+0E01) must be sorted as if it were written
(U+0E44 U+0E01) must be sorted as if it were written
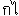 (U+0E01
U+0E44). Reordering is typically done during an initial pre-processing stage.
(U+0E01
U+0E44). Reordering is typically done during an initial pre-processing stage.
EXAMPLE: German dictionaries typically sort 'ä', 'ö' and 'ü' together with 'a', 'o' and 'u' respectively. On the other hand, German telephone books typically sort 'ä', 'ö' and 'ü' as if they were spelled 'ae', 'oe'
and 'ue'. Here the application is affecting the collation algorithm used.
[S] [I] Software that sorts or
searches text for users SHOULD do so on the basis of appropriate collation units and ordering rules for the relevant
language and/or application.
[S] [I] Where searching or sorting
is done dynamically, particularly in a multilingual environment, the 'relevant language' SHOULD be determined to be that
of the current user, and may thus differ from user to user. [S]
[I] Software that allows users to sort or search text SHOULD allow the user to
select alternative rules for collation units and ordering.
[S] [I] Specifications and
implementations of sorting and searching algorithms SHOULD accommodate all characters in the Unicode set.
A default collation order for all Unicode characters can be obtained from ISO/IEC 14651 [ISO/IEC 14651] or
from Unicode Technical Report #10, the Unicode Collation Algorithm [UTR #10]. This default collation order can be used in
conjunction with rules tailored for a particular locale to ensure a predictable ordering and comparison of strings, whatever characters they
include.
3.1.6 Units of storage
Computer storage and communication rely on units of physical storage and information interchange, such as bits and bytes (8-bit units,
also called octets). A frequent error in specifications and implementations is the equating of characters with units of physical storage. The mapping
between characters and such units of storage is actually quite complex, and is discussed in the next section, 3.2 Digital
Encoding of Characters.
[S] [I]
[C] Specifications, software and content MUST NOT assume a one-to-one
relationship between characters and units of physical storage.
3.1.7 Summary
The term character is used differently in a variety of contexts and often leads to confusion when used
outside of these contexts. In the context of the digital representations of text, a character can be defined informally as a small logical unit of
text. Text is then defined as sequences of characters. While such an informal definition is sufficient to create or
capture a common understanding in many cases, it is also sufficiently open to create misunderstandings as soon as details start to matter. In order
to write effective specifications, protocol implementations, and software for end users, it is very important to understand that these
misunderstandings can occur.
This section, 3.1 Perceptions of Characters, has discussed terms for units that do not
necessarily overlap with the term 'character', such as phoneme, glyph, and collation unit. The next section,
3.2 Digital Encoding of Characters, lists terms that should be used rather than 'character' to precisely define units of encoding (code point, code unit, and byte).
[S] When specifications use the term 'character'
the specifications MUST define which meaning they intend. [S] Specifications SHOULD avoid the use of the term 'character' if a more specific term is available.
3.2 Digital Encoding of Characters
To be of any use in computers, in computer communications and in particular on the World Wide Web, characters must be encoded. In fact,
much of the information processed by computers over the last few decades has been encoded text, exceptions being images, audio, video and numeric
data. To achieve text encoding, a large variety of character encodings have been devised. Character encodings can loosely be explained as mappings
between the character sequences that users manipulate and the sequences of bits that computers manipulate.
Given the complexity of text encoding and the large variety of mechanisms for character encoding invented throughout the computer age, a
more formal description of the encoding process is useful. The process of defining a text encoding can be described as follows (see Unicode Technical
Report #17: Character Encoding Model [UTR #17] for a more detailed description):
-
A set of characters to be encoded is identified. The characters are pragmatically chosen to express text and to efficiently allow
various text processes in one or more target languages. They may not correspond precisely to what users perceive as letters and other characters. The
set of characters is called a repertoire.
-
Each character in the repertoire is then associated with a (mathematical, abstract) non-negative integer, the code point (also known as a character number or code position).
The result, a mapping from the repertoire to the set of non-negative integers, is called a coded character set
(CCS).
-
To enable use in computers, a suitable base datatype is identified (such as a byte, a 16-bit unit of storage or other) and a
character encoding form (CEF) is used, which encodes the abstract integers of a CCS into sequences of the code units of the base datatype. The character encoding
form can be extremely simple (for instance, one which encodes the integers of the CCS into the natural
representation of integers of the chosen datatype of the computing platform) or arbitrarily complex (a variable number of code units, where the value
of each unit is a non-trivial function of the encoded integer).
-
To enable transmission or storage using byte-oriented devices, a serialization scheme or
character encoding scheme (CES) is next used. A CES is a mapping
of the code units of a CEF into well-defined sequences of bytes, taking into account the necessary
specification of byte-order for multi-byte base datatypes and including in some cases switching schemes between the code units of multiple
CESes (an example is ISO 2022). A CES,
together with the CCSes it is used with, is called a character encoding,
and is identified by a unique identifier, such as an IANA charset identifier. Given a
sequence of bytes representing text and a character encoding identified by a charset identifier, one can in principle
unambiguously recover the sequence of characters of the text.
NOTE: The term 'character encoding' is somewhat ambiguous, as it is
sometimes used to describe the actual process of encoding characters and sometimes to denote a particular way to perform that process (as in "this file is in the X character encoding"). Context normally allows the distinction of those uses, once one is aware of the
ambiguity.
NOTE: Given a sequence of characters, a given 'character encoding' may not
always produce the same sequence of bytes. In particular for encodings based on ISO 2022, there may be choices available during the encoding
process.
In very simple cases, the whole encoding process can be collapsed to a single step, a trivial one-to-one mapping from characters to
bytes; this is the case, for instance, for US-ASCII [ISO/IEC 646] and ISO-8859-1.
Text is said to be in a Unicode encoding form if it is encoded in UTF-8, UTF-16
or UTF-32.
3.3 Transcoding
Transcoding is the process of converting text from one character encoding to another. Transcoders work only at the level of character encoding and do not parse the text; consequently,
they do not deal with character escapes such as numeric character references (see 3.7
Character Escaping) and do not adjust embedded character encoding information (for instance in an XML declaration or in an HTML
meta element).
NOTE: Transcoding may involve one-to-one, many-to-one, one-to-many or many-to-many mappings. In
addition, the storage order of characters varies between encodings: some, such as the Unicode encoding forms, prescribe logical ordering, while
others use visual ordering; among encodings that have separate diacritics, some prescribe that they be placed before the base character, some after.
Because of these differences in sequencing characters, transcoding may involve reordering: thus XYZ may map to yxz.
EXAMPLE: This first example shows the nearly trivial transcoding of the Russian word "Русский",
meaning "Russian" (language), from the UTF-16 encoding of Unicode to the ISO 8859-5 encoding:
EXAMPLE: This second example shows a much more complex case, where the Arabic word "السلام", meaning
"peace", is transcoded from the visually-ordered, contextualized encoding IBM CP864 to the UTF-16 encoding of Unicode:
Notice that the order of the characters has been reversed, that the single LAM-ALEF in CP864 has been converted to a LAM ALEF sequence
in UTF-16 and that the contextual variants (initial, median or final) in the source encoding have been converted to generic characters in the target
encoding.
A normalizing transcoder is a transcoder that converts from a
legacy encoding to a Unicode encoding form and ensures
that the result is in Unicode Normalization Form C (see 4.2.1 Unicode-normalized text). For most legacy
encodings, it is possible to construct a normalizing transcoder (by using any transcoder followed by a normalizer); it is not possible to do so if
the encoding's repertoire contains characters not represented in Unicode.
3.4 Strings
Various specifications use the notion of a 'string', sometimes without defining precisely what is meant and
sometimes defining it differently from other specifications. The reason for this variability is that there are in fact multiple reasonable
definitions for a string, depending on one's intended use of the notion; the term 'string' is used for all these different
notions because these are actually just different views of the same reality: a piece of text stored inside a computer. This section provides specific
definitions for different notions of 'string' which may be reused elsewhere.
Byte string: A string viewed as a sequence of bytes representing characters in a
particular character encoding. This corresponds to a CES. As a definition for a string, this definition is most often
useless, except when the textual nature is unimportant and the string is considered only as a piece of opaque data with a length in bytes.
[S] Specifications in general SHOULD NOT define a string as a
'byte string'.
Code unit string: A string viewed as a sequence of code units representing characters in a particular character encoding. This corresponds to a CEF.
This definition is useful in APIs that expose a physical representation of string data. Example: For the DOM [DOM Level 1],
UTF-16 was chosen based on widespread implementation practice.
Character string: A string viewed as a sequence of characters, each represented
by a code point in Unicode [Unicode]. This is usually what programmers consider to be a
string, although it may not match exactly what most users perceive as characters. This is the highest layer of abstraction that ensures
interoperability with very low implementation effort. [S] The 'character string' definition of a string is generally the most useful and SHOULD be used by most
specifications, following the examples of Production [2] of XML 1.0 [XML 1.0], the SGML declaration of HTML 4.0
[HTML 4.01], and the character model of RFC 2070 [RFC 2070].
EXAMPLE: Consider the string
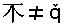 comprising the characters U+233B4 (a Chinese character meaning 'stump of tree'), U+2260 NOT EQUAL
TO, U+0071 LATIN SMALL LETTER Q and U+030C COMBINING CARON, encoded in UTF-16 in
big-endian byte order. The rows of the following table show the string viewed as a character string, code unit string and byte string,
respectively:
comprising the characters U+233B4 (a Chinese character meaning 'stump of tree'), U+2260 NOT EQUAL
TO, U+0071 LATIN SMALL LETTER Q and U+030C COMBINING CARON, encoded in UTF-16 in
big-endian byte order. The rows of the following table show the string viewed as a character string, code unit string and byte string,
respectively:
NOTE: It is also possible to view a string as a sequence of graphemes. In
this case the string is divided into text units that correspond to the user's perception of where character boundaries occur in a visually rendered
text. However, there is no standard rule for the segmentation of text in this way, and the segmentation will vary from language to language and even
from user to user. Examples of possible approaches can be found in sections 5.12 and 5.15 of the Unicode Standard, Version 3 [Unicode 3.0].
3.5 Reference Processing Model
Many Internet protocols and data formats, most notably the very important Web formats HTML, CSS and XML, are based on
text. In those formats, everything is text but the relevant specifications impose a structure on the text, giving meaning to certain constructs so as
to obtain functionality in addition to that provided by plain text (text where no markup or programming language
applies). HTML and XML are markup languages, defining documents entirely composed of text but with conventions allowing
the separation of this text into markup and character data. Citing from the XML 1.0
specification [XML 1.0], section 2.4:
"Text consists of intermingled character data and markup. [...] All text that is not markup constitutes the
character data of the document."
For the purposes of this section, the important aspect is that everything is text, that is, a sequence of characters.
[S] [C] Textual
entities defined by protocol or format specifications MUST be in a
single character encoding. An entity is a whole protocol message or a whole document, or a part of it
that is treated separately for purposes of external storage and retrieval. Examples include external entities in XML and MIME entities. Note that
this does not imply that character set switching schemes such as ISO 2022 cannot be used, since such schemes perform character set switching within a
single character encoding.
Since its early days, the Web has seen the development of a Reference Processing
Model, first described for HTML in RFC 2070 [RFC 2070]. This model was later embraced by XML and CSS. It is applicable
to any data format or protocol that is text-based as described above. The essence of the Reference Processing Model is the use of Unicode as a common
reference. Use of the Reference Processing Model by a specification does not, however, require that implementations actually use Unicode. The
requirement is only that the implementations behave as if the processing took place as described by the Model.
[S] All specifications that involve processing of text
MUST specify the processing of text according to the Reference Processing
Model, namely:
-
Specifications MUST define text in terms of Unicode characters, not bytes or
glyphs.
-
Specifications SHOULD not arbitrarily exclude characters from the full range of Unicode
code points from U+0000 to U+10FFFF inclusive; code points above U+10FFFF MUST NOT be
allowed.
-
Specifications MAY allow use of any character encoding which can be transcoded to Unicode for its
text entities.
-
Specifications MAY choose to disallow or deprecate some character encodings and to make others
mandatory. Independent of the actual character encoding, the specified behavior MUST be the same as if the
processing happened as follows:
-
The character encoding of any text entity received by the application implementing the specification MUST be determined and the text entity MUST be interpreted as a sequence of Unicode characters -
this MUST be equivalent to transcoding the entity to some
Unicode encoding form, adjusting any character encoding label if necessary, and receiving it in that
Unicode encoding form.
-
All processing MUST take place on this sequence of Unicode characters.
-
If text is output by the application, the sequence of Unicode characters MUST be encoded using an
character encoding chosen among those allowed by the specification.
-
If a specification is such that multiple text entities are involved (such as an XML document referring to external parsed
entities), it MAY choose to allow these entities to be in different character encodings. In all cases, the
Reference Processing Model MUST be applied to all entities.
NOTE: All specifications which define applications of the XML 1.0 specification [XML
1.0] automatically inherit this Reference Processing Model. XML is entirely defined in terms of Unicode characters and mandates the UTF-8 and
UTF-16 character encodings while allowing any other character encoding for parsed entities.
NOTE: When specifications choose to allow character encodings other than Unicode encoding forms,
implementers should be aware that the correspondence between the characters of a legacy encoding and Unicode
characters may in practice depend on the software used for transcoding. See the Japanese XML Profile
[XML Japanese Profile] for examples of such inconsistencies.
3.6 Choice and Identification of Character Encodings
Because encoded text cannot be interpreted and processed without knowing the encoding, it is vitally important that the
character encoding (see 3.2 Digital Encoding of Characters) is known at all times and places where text is
exchanged or processed. In what follows we use 'character encoding' to mean either CEF or
CES depending on the context. When text transmitted as a byte stream is involved, for instance in a protocol,
specification of a CES is required to ensure proper interpretation; in contexts such as an API, where the environment (typically the processor
architecture) specifies the byte order of multibyte quantities, specification of a CEF suffices. [S] Specifications MUST either specify a unique character encoding, or provide
character encoding identification mechanisms such that the encoding of text can be reliably identified.
[S] When designing a new protocol, format or API, specifications SHOULD mandate a
unique character encoding. [S] When basing a protocol, format, or API on a
protocol, format, or API that already has rules for character encoding, specifications SHOULD use rather than change
these rules.
EXAMPLE: An XML-based format should use the existing XML rules for choosing and determining the
character encoding of external entities, rather than invent new ones.
3.6.1 Mandating a unique character encoding
Mandating a unique character encoding is simple, efficient, and robust. There is no need for specifying, producing, transmitting, and
interpreting encoding tags. At the receiver, the character encoding will always be understood. There is also no ambiguity as to which character
encoding to use if data is transferred non-electronically and later has to be converted back to a digital representation. Even when there is a need
for compatibility with existing data, systems, protocols and applications, multiple character encodings can often be dealt with at the boundaries or
outside a protocol, format, or API. The DOM [DOM Level 1] is an example of where
this was done. The advantages of choosing a unique character encoding become more important the smaller the pieces of text used are and the closer to
actual processing the specification is.
[S] When a unique character encoding is mandated, the character encoding
MUST be UTF-8, UTF-16 or UTF-32. [S] If a unique
character encoding is mandated and compatibility with US-ASCII is desired, UTF-8 (see [RFC 2279]) is RECOMMENDED. In other situations, such as for APIs, UTF-16 or UTF-32 may be more appropriate. Possible reasons for
choosing one of these include efficiency of internal processing and interoperability with other processes.
NOTE: The IETF Charset Policy [RFC 2277] specifies that on the Internet "Protocols MUST be able to use the UTF-8 charset".
NOTE: The XML 1.0 specification [XML 1.0] requires all conforming XML processors
to accept both UTF-16 and UTF-8.
3.6.2 Character encoding identification
The MIME Internet specification [MIME] provides a good example of a mechanism for character encoding
identification. The MIME charset parameter definition is intended to supply sufficient information to uniquely decode
the sequence of bytes of the received data into a sequence of characters. The values are drawn from the IANA charset registry [IANA].
NOTE: Unfortunately, some charset identifiers do not represent a single, unique character encoding.
Instead, these identifiers denote a number of small variations. Even though small, the differences may be crucial and may vary over time. For these
identifiers, recovery of the character sequence from a byte sequence is ambiguous. For example, the character encoded as 0x5C in Shift_JIS is
ambiguous. The character sometimes represents a YEN SIGN and sometimes represents a REVERSE
SOLIDUS. See the [XML Japanese Profile] for more detail on this example and for additional examples of
such ambiguous charset identifiers.
NOTE: The term charset derives from 'character
set', an expression with a long and tortured history (see [Connolly] for a discussion).
[S] Specifications SHOULD avoid using the
terms 'character set' and 'charset' to refer to a character encoding, except when the latter is
used to refer to the MIME charset parameter or its IANA-registered values. The term 'character
encoding', or in specific cases the terms 'character encoding form' or 'character encoding
scheme', are RECOMMENDED.
NOTE: In XML, the XML declaration or the text declaration contains the encoding
pseudo-attribute which identifies the character encoding using the IANA charset.
The IANA charset registry is the official list of names and aliases for character encodings on the Internet.
[S] If the unique encoding approach is not taken, specifications
SHOULD mandate the use of the IANA charset registry names, and in particular the names identified in the registry as
'MIME preferred names', to designate character encodings in protocols, data formats and APIs.
[S] [I] [C] Character encodings
that are not in the IANA registry SHOULD NOT be used, except by private agreement.
[S] [I] [C] If an unregistered
character encoding is used, the convention of using 'x-' at the beginning of the name MUST be
followed. [I] [C] Content and software that
label text data MUST use one of the names mandated by the appropriate specification (e.g. the XML specification when
editing XML text) and SHOULD use the MIME preferred name of a character encoding to label data in that character
encoding. [I] [C] An IANA-registered
charset name MUST NOT be used to label text data in a character encoding other than the one
identified in the IANA registration of that name.
[S] If the unique encoding approach is not chosen, specifications
MUST designate at least one of the UTF-8 and UTF-16 encoding forms of Unicode as admissible character encodings and
SHOULD choose at least one of UTF-8 or UTF-16 as mandated encoding forms (encoding forms that MUST be supported by implementations of the specification). [S] Specifications MAY define either UTF-8 or UTF-16 as a default encoding form (or
both if they define suitable means of distinguishing them), but they MUST NOT use any other character encoding as a
default. [S] Specifications MUST NOT propose the use
of heuristics to determine the encoding of data.
Examples of heuristics include the use of statistical analysis of byte (pattern) frequencies or character (pattern) frequencies.
Heuristics are bad because they will not work consistently across different implementations. Well-defined instructions of how to unambiguously
determine a character encoding, such as those given in XML 1.0 [XML 1.0],
Appendix F, are not considered heuristics.
[I] Receiving software MUST determine
the encoding of data from available information according to appropriate specifications. [I] When an IANA-registered charset name is recognized, receiving software
MUST interpret the received data according to the encoding associated with the name in the IANA registry.
[I] When no charset is provided receiving software MUST adhere
to the default character encoding(s) specified in the specification.
[I] Receiving software MAY recognize as many
character encodings and as many charset names and aliases for them as appropriate. A field-upgradeable mechanism may be appropriate for this
purpose. Certain character encodings are more or less associated with certain languages (e.g. Shift_JIS with Japanese); trying to support a given
language or set of customers may mean that certain character encodings have to be supported. The character encodings that need to be supported may
change over time. This document does not give any advice on which character encoding may be appropriate or necessary for the support of any given
language.
[I] Software MUST completely implement the
mechanisms for character encoding identification and SHOULD implement them in such a way that they are easy to use (for
instance in HTTP servers).
[C] Content MUST make use of available
facilities for character encoding identification by always indicating character encoding; where the facilities offered for character encoding
identification include defaults (e.g. in XML 1.0 [XML 1.0]), relying on such defaults is sufficient to satisfy this
identification requirement.
Because of the layered Web architecture (e.g. formats used over protocols), there may be multiple and at times conflicting information
about character encoding. [S] Specifications MUST define
conflict-resolution mechanisms (e.g. priorities) for cases where there is multiple or conflicting information about character encoding.
[I] [C] Software and content MUST carefully follow conflict-resolution mechanisms where there is multiple or conflicting information about character
encoding.
3.6.3 Private use code points
The Unicode Standard designates certain ranges of code points for private use: the Private Use Area
(U+E000-F8FF) and planes 15 and 16 (U+F0000-FFFFD and U+100000-10FFFD). These code points are guaranteed to never be allocated to standard
characters, and are available for use by private agreement between a producer and a
recipient. However, their use on the Web is strongly discouraged, since private agreements do not
scale on the Web. Code points from different private agreements may collide. Also a private agreement, and therefore the meaning of the code points,
can quickly become lost.
[S] Specifications MUST NOT define any
assignments of private use code points. [S] Conformance to a specification
MUST NOT require the use of private use area characters. [S] Specifications MUST NOT require the use of mechanisms for agreement on the use of
private use code points. [S] [I]
Specifications and implementations SHOULD NOT disallow the use of private use code points by private arrangement.
As an example, XML does not disallow the use of private use code points.
[S] Specifications MAY define
markup to allow the transmission of symbols not in Unicode or to identify specific variants of Unicode
characters.
EXAMPLE: MathML (see [MathML2]
section 3.2.9) defines an element mglyph for
mathematical symbols not in Unicode.
EXAMPLE: SVG (see [SVG]
section 10.14) defines an element altglyph which
allows the identification of specific display variants of Unicode characters.
3.7 Character Escaping
Markup languages or programming languages often designate certain characters as syntax-significant, giving them specific functions within the language (e.g. '<' and '&' serve as markup delimiters in HTML and XML). As a consequence, these syntax-significant characters cannot be used to
represent themselves in text in the same way as all other characters do, creating the need for a mechanism to "escape"
their syntax-significance. There is also a need, often satisfied by the same or similar mechanisms, to express characters not directly representable
in the character encoding chosen for a particular document or program (an instance of the markup or programming language).
Formally, a character escape is a syntactic device defined in a markup or programming
language that allows one or more of:
-
expressing syntax-significant characters while disregarding their significance in the syntax of the language, or
-
expressing characters not representable in the character encoding chosen for an instance of the language, or
-
expressing characters in general, without use of the corresponding character codes.
Escaping a character means expressing it using such a construct, appropriate to the format or protocol in which the character appears;
expanding a character escape (or unescaping) means replacing it with the character that
it represents.
EXAMPLE: HTML and XML define 'Numeric Character References' which allow
both the escaping of syntax-significance and the expression of arbitrary characters. Expressed as < or < the character '<' will not be parsed as a markup delimiter.
EXAMPLE: The programming language Java uses '"' to delimit strings. To
express '"' within a string, one may escape it as '\"'.
EXAMPLE: XML defines 'CDATA sections' which allow escaping the
syntax-significance of all characters between the CDATA section delimiters. CDATA sections do not allow the expression of unrepresentable characters
and in fact prevent their expression using numeric character references.
The following guidelines apply to the way specifications define character escapes. In addition, character escapes have an impact on
character normalization, to be addressed in 4.2.2 Include-normalized text.
-
[S] Specifications MUST NOT invent a new
escaping mechanism if an appropriate one already exists.
-
[S] The number of different ways to escape a character
SHOULD be minimized (ideally to one). [A well-known counter-example is that for historical reasons, both HTML
and XML have redundant decimal (&#ddddd;) and hexadecimal (&#xhhhh;) character escapes.]
-
[S] Escape syntax SHOULD either require
explicit end delimiters or mandate a fixed number of characters in each character escape. Escape syntaxes where the end is determined by any
character outside the set of characters admissible in the character escape itself SHOULD be avoided. These
character escapes are not clear visually, and can cause an editor to insert spurious line-breaks when word-wrapping on spaces. Forms like SPREAD's
&UABCD; [SPREAD] or XML's &#xhhhh;, where the character escape is explicitly terminated by a semicolon, are much
better.
-
[S] Whenever specifications define character escapes that allow the
representation of characters using a number, the number MUST represent the Unicode code point of the character and
SHOULD be in hexadecimal notation.
-
[S] Escaped characters SHOULD be acceptable
wherever their unescaped forms are; this does not preclude that syntax-significant characters, when
escaped, lose their significance in the syntax. In particular, if a character is acceptable in identifiers and comments, then its escaped form should
also be acceptable.
The following guidelines apply to content developers, as well as to software that generates content:
-
[I] [C] Escapes
SHOULD be avoided when the characters to be expressed are representable in the character encoding of the document.
-
[I] [C] Since character set
standards usually list character numbers as hexadecimal, content SHOULD use the hexadecimal form of character escapes
when there is one.
-
[I] [C] The character encoding of
a document SHOULD be chosen so that it maximizes the opportunity to directly represent characters and minimizes the need
to represent characters by markup means such as character escapes.
NOTE: Due to Unicode's large repertoire and wide base of support, a character encoding based on
Unicode is a good choice to encode a document.
4 Early Uniform Normalization
This chapter discusses text normalization for the Web. 4.1 Motivation discusses the need
for normalization, and in particular early uniform normalization. 4.2 Definitions for W3C Text
Normalization defines the various types of normalization and 4.3 Examples gives supporting
examples. 4.4 Responsibility for Normalization assigns reponsibilities to various components and
situations. The requirements for early uniform normalization are discussed in Requirements for String Identity Matching
[CharReq], section 3.
4.1 Motivation
4.1.1 Why do we need character normalization?
Text in computers can be encoded in one of many character encodings. In addition, some character encodings allow multiple
representations for the 'same' string, and Web languages have escape mechanisms that introduce even more equivalent
representations. For instance, in ISO 8859-1 the letter 'ç' can only be represented as the single character E7 'ç', in a Unicode encoding it can be represented as the single character U+00E7 'ç' or the
sequence U+0063 'c' U+0327 '¸', and in HTML it could be additionally represented as
ç or ç or ç.
There are a number of fundamental operations that are sensitive to these multiple representations: string matching, indexing,
searching, sorting, regular expression matching, selection, etc. In particular, the proper functioning of the Web (and of much other software)
depends to a large extent on string matching. Examples of string matching abound: parsing element and attribute names in Web documents, matching CSS
selectors to the nodes in a document, matching font names in a style sheet to the names known to the operating system, matching URI pieces to the
resources in a server, matching strings embedded in an ECMAScript program to strings typed in by a Web form user, matching the parts of an XPath
expression (element names, attribute names and values, content, etc.) to what is found in an instance, etc.
String matching is usually taken for granted and performed by comparing two strings byte for byte, but the existence on the Web of
multiple character representations means that it is actually non-trivial. Binary comparison does not work if the strings are not in the same
character encoding (e.g. an EBCDIC style sheet being directly applied to an ASCII document, or a font specification in a Shift_JIS style sheet
directly used on a system that maintains font names in UTF-16) or if they are in the same character encoding but show variations allowed for the
'same' string by the use of combining characters or by the constructs of the Web language.
Incorrect string matching can have far reaching consequences, including the creation of security holes. Consider a contract, encoded
in XML, for buying goods: each item sold is described in a Stück element; unfortunately, "Stück" is subject
to different representations in the character encoding of the contract. Suppose that the contract is viewed and signed by means of a user agent that
looks for Stück elements, extracts them (matching on the element name), presents them to the user and adds up their prices. If different
instances of the Stück element happen to be represented differently in a particular contract, then the buyer and seller may see (and
sign) different contracts if their respective user agents perform string identity matching differently, which is fairly likely in the absence of a
well-defined specification for string matching. The absence of a well-defined specification would also mean that there would be no way to resolve the
ensuing contractual dispute.
Solving the string matching problem involves normalization, which in a nutshell means bringing the two strings to be compared to a
common, canonical encoding prior to performing binary matching. (For additional steps involved in string matching see 6 String Identity Matching.)
4.1.2 The choice of early uniform normalization
There are options in the exact way normalization can be used to achieve correct behavior of normalization-sensitive operations such as
string matching. These options lie along two axes:
The first axis is a choice of when normalization occurs: early (when strings are created) or late (when strings are
compared). The former amounts to establishing a canonical encoding for all data that is transmitted or stored, so that it doesn't need any
normalization later, before being used. The latter is the equivalent of mandating 'smart' compare functions, which will
take care of any encoding differences.
This document specifies early normalization. The reasons for that choice are manifold:
-
Almost all legacy data as well as data created by current software is normalized (if using NFC).
-
The number of Web components that generate or transform text is considerably smaller than the number of components that receive
text and need to perform matching or other processes requiring normalized text.
-
Current receiving components (browsers, XML parsers, etc.) implicitly assume early normalization by not performing or verifying
normalization themselves. This is a vast legacy.
-
Web components that generate and process text are in a much better position to do normalization than other components; in
particular, they may be aware that they deal with a restricted repertoire only, which simplifies the process of normalization.
-
Not all components of the Web that implement functions such as string matching can reasonably be expected to do normalization.
This, in particular, applies to very small components and components in the lower layers of the architecture.
-
Forward-compatibility issues can be dealt with more easily: less software needs to be updated, namely only the software that
generates newly introduced characters.
-
It improves matching in cases where the character encoding is partly undefined, such as URIs [RFC 2396] in
which non-ASCII bytes have no defined meaning.
-
It is a prerequisite for comparison of encrypted strings (see [CharReq],
section 2.7).
The second axis is a choice of canonical encoding. This choice needs only be made if early normalization is chosen. With late
normalization, the canonical encoding would be an internal matter of the smart compare function, which doesn't need any wide agreement or
standardization.
By choosing a single canonical encoding, it is ensured that normalization is uniform throughout the web. Hence the two axes lead us to
the name 'early uniform normalization'.
4.1.3 The choice of Normalization Form C
The Unicode Consortium provides four standard normalization forms (see Unicode Normalization Forms [UTR
#15]). These forms differ in 1) whether they normalize towards decomposed characters (NFD, NFKD) or precomposed characters (NFC, NFKC) and 2)
whether they normalize away compatibility distinctions (NFKD, NFKC) or not (NFD, NFC).
For use on the Web, it is important not to lose the so-called compatibility distinctions, which may be important (see [UXML] Chapter 4 for a discussion). The NFKD and NFKC normalization
forms are therefore excluded. Among the remaining two forms, NFC has the advantage that almost all legacy data (if transcoded trivially, one-to-one)
as well as data created by current software is already in this form; NFC also has a slight compactness advantage and a better match to user
expectations with respect to the character vs. grapheme issue. This document therefore chooses NFC as the
base for Web-related text normalization.
NOTE: Roughly speaking, NFC is defined such that each combining
character sequence (a base character followed by one or more combining characters) is replaced, as far as possible, by a canonically equivalent
precomposed character. Text in a Unicode encoding form is said to be in NFC if it doesn't contain any
combining sequence that could be replaced and if any remaining combining sequence is in canonical order.
For a list of programming resources related to normalization, see D Resources for
Normalization.
4.2 Definitions for W3C Text Normalization
For use on the Web, this document defines Web-related text normalization forms by starting with Unicode Normalization Form C (NFC), and additionally addressing the issues of legacy encodings, character
escapes, includes, and character and markup boundaries. Examples illustrating these definitions can be found in 4.3 Examples.
4.2.1 Unicode-normalized text
Text is, for the purposes of this specification, Unicode-normalized if it is in a
Unicode encoding form and is in Unicode Normalization Form C, according to a version of
Unicode Standard Annex #15: Unicode Normalization Forms [UTR #15] at least as recent as the oldest version of the Unicode
Standard that contains all the characters actually present in the text, but no earlier than version 3.2 [Unicode
3.2].
4.2.2 Include-normalized text
Markup languages, style languages and programming languages often offer facilities for including a piece of text
inside another. An include is an instance of a syntactic device specified in a language to include an
entity at the position of the include, replacing the include itself. Examples of includes are entity references in XML,
@import rules in CSS and the #include preprocessor statement in C/C++. Character escapes are a special case of
includes where the included entity is predetermined by the language.
Text is include-normalized if:
-
the text is Unicode-normalized and does not contain any
character escapes or includes whose expansion would cause the text to become
no longer Unicode-normalized; or
-
the text is in a legacy encoding and, if it were transcoded to a
Unicode encoding form by a normalizing transcoder,
the resulting text would satisfy clause 1 above.
NOTE: A consequence of this definition is that legacy text (i.e. text in a legacy encoding) is always
include-normalized unless i) a normalizing transcoder cannot exist for that encoding (e.g. because the repertoire contains characters not in Unicode)
or ii) the text contains character escapes or includes which, once expanded, result in un-normalized text.
NOTE: The specification of include-normalization relies on the syntax for character escapes and
includes defined by the (computer) language in use. For plain text (no character escapes or includes) in a Unicode encoding form,
include-normalization and Unicode-normalization are equivalent.
4.2.3 Fully-normalized text
Formal languages define constructs, which are identifiable pieces, occurring in
instances of the language, such as comments, identifiers, element tags, processing instructions, runs of character
data, etc. During the normal processing of include-normalized text, these various constructs may be
moved, removed (e.g. removing comments) or merged (e.g. merging all the character data within an element as
done by the string() function of XPath), creating opportunities for text to become denormalized. The software performing those
operations then has to re-normalize the result, which is a burden. One way to avoid such denormalization is to make sure that the various important
constructs never begin with a character such that appending that character to a normalized string can cause the string to become denormalized. A
composing character is a character that is one or both of the following:
-
the second character in the canonical decomposition mapping of some primary composite (as defined in
D3 of [UTR #15]), or
-
of non-zero canonical combining class (as defined in [Unicode]).
Please consult Appendix C Composing Characters for a discussion of composing characters,
which are not exactly the same as Unicode combining characters.
Text is fully-normalized if:
-
the text is in a Unicode encoding form, is include-normalized and none of the constructs comprising the text begin with a composing character or a character escape representing a composing character;
or
-
the text is in a legacy encoding and, if it were transcoded to a
Unicode encoding form by a normalizing transcoder,
the resulting text would satisfy clause 1 above.
NOTE: Full-normalization is specified against the context of a (computer) language (or the absence
thereof), which specifies the form of character escapes and includes and the separation into constructs. For
plain text (no includes, no constructs, no character escapes) in a Unicode encoding form, full-normalization and Unicode-normalization are
equivalent.
Identification of the constructs that should be prohibited from beginning with a composing
character (the relevant constructs) is language-dependent. As specified in 4.4 Responsibility for Normalization, it is the responsibility of the specification for a language to
specify exactly what constitutes a relevant construct. This may be done by specifying important boundaries, taking into account which operations
would benefit the most from being protected against denormalization. The relevant constructs are then defined as the spans of text between the
boundaries. At a minimum, for those languages which have these notions, the important boundaries are entity (include) boundaries as well as the
boundaries between most markup and character data. Many languages will
benefit from defining more boundaries and therefore finer-grained full-normalization constructs.
NOTE: In general, it will be advisable not to include character escapes designed to express
arbitrary characters among the relevant constructs; the reason is that including them would prevent the expression of combining sequences using
character escapes (e.g. 'q̌' for q-caron), which is especially important in legacy encodings that lack the
desired combining marks.
NOTE: Full-normalization is closed under concatenation: the concatenation of two fully-normalized
strings is also fully-normalized. As a result, a side benefit of including entity boundaries in the set of boundaries important for
full-normalization is that the state of normalization of a document that includes entities can be assessed without expanding the
includes, if the included entities are known to be fully-normalized. If all the entities are known to be
include-normalized and not to start with a composing character, then it can be concluded that
including the entities would not denormalize the document.
4.3 Examples
In some of the following examples, '¸' is used to depict the character U+0327 COMBINING
CEDILLA, for the purposes of illustration. Had a real U+0327 been used instead of this spacing (non-combining) variant, some browsers might
combine it with a preceding 'c', resulting in a display indistinguishable from a U+00E7 'ç' and
a loss of understandability of the examples. In addition, if the sequence c + combining cedilla were present, this document would not be
include-normalized and would therefore not conform to itself.
It is also assumed that the example strings are relevant constructs for the purposes of full-normalization.
4.3.1 General examples
The string suçon (U+0073 U+0075 U+00E7 U+006F U+006E) encoded in a Unicode encoding form, is Unicode-normalized,
include-normalized and fully-normalized. The same string encoded in a legacy encoding for which there exists a
normalizing transcoder would be both include-normalized and fully-normalized but not Unicode-normalized (since not in a Unicode encoding form).
In an XML or HTML context, the string suçon is also include-normalized, fully-normalized and, if encoded in a
Unicode encoding form, Unicode-normalized. Expanding ç yields suçon as above, which contains no replaceable combining
sequence.
The string suc¸on (U+0073 U+0075 U+0063 U+0327 U+006F U+006E), where U+0327 is the COMBINING
CEDILLA, encoded in a Unicode encoding form, is not Unicode-normalized (since the combining sequence 'c¸' (U+0063
U+0327) should appear instead as the precomposed 'ç' (U+00E7)). As a consequence this string is neither include-normalized
(since in a Unicode encoding form but not Unicode-normalized) nor fully-normalized (since not include-normalized). Note however that the string
sub¸on (U+0073 U+0075 U+0062 U+0327 U+006F U+006E) in a Unicode encoding form is Unicode-normalized since there is no
precomposed form of 'b' plus cedilla. It is also include-normalized and fully-normalized.
In plain text the string suçon is Unicode-normalized, since plain text doesn't recognize that ̧
represents a character in XML or HTML and considers it just a sequence of non-replaceable characters.
In an XML or HTML context, however, expanding ̧ yields the string suc¸on (U+0073 U+0075 U+0063 U+0327
U+006F U+006E) which is not Unicode-normalized ('c¸' is replaceable by 'ç'). As a consequence
the string is neither include-normalized nor fully-normalized. As another example, if the entity reference &word-end; refers to an
entity containing ¸on (U+0327 U+006F U+006E), then the string suc&word-end; is not include-normalized for the same
reasons.
In an XML or HTML context, expanding ̧ in the string sub̧on yields the string sub¸on
which is Unicode-normalized since there is no precomposed character for 'b cedilla' in NFC. This string is
therefore also include-normalized. Similarly, the string sub&word-end; (with &word-end; as above) is
include-normalized, for the same reasons.
In an XML or HTML context, the strings ¸on (U+0327 U+006F U+006E) and ̧on are not
fully-normalized, as they begin with a composing character (after expansion of the character escape for the second). However, both are
Unicode-normalized (if expressed in a Unicode encoding form) and include-normalized.
The following table consolidates the above examples. Normalized forms are indicated using 'Y', a hyphen
means 'not normalized'.
4.3.2 Examples of XML in a Unicode encoding form
Here is another summary table, with more examples but limited to XML in a Unicode encoding form. The following list describes what the
entities contain and special character usage. Normalized forms are indicated using 'Y'. There is no precomposed 'b with cedilla' in NFC.
-
"ç" LATIN SMALL LETTER C WITH CEDILLA
-
"¸la;" CEDILLA (combining)
-
"&c;" LATIN SMALL LETTER C
-
"&b;" LATIN SMALL LETTER B
-
"¸" CEDILLA (combining)
-
"/" (immediately before 'on' in last example) COMBINING
LONG SOLIDUS OVERLAY
NOTE: From the last example in the table above, it follows that it is impossible to produce a
normalized XML or HTML document containing the character U+0338 COMBINING LONG SOLIDUS OVERLAY immediately following an
element tag, comment, CDATA section or processing instruction, since the U+0338 '/' combines with the '>' (yielding U+226F NOT GREATER-THAN). It is noteworthy that U+0338 COMBINING
LONG SOLIDUS OVERLAY also combines with '<', yielding U+226E NOT LESS-THAN.
Consequently, U+0338 COMBINING LONG SOLIDUS OVERLAY should remain excluded from the initial character of XML
identifiers.
4.3.3 Examples of restrictions on the use of combining characters
Include-normalization and full-normalization create restrictions on the use of combining characters. The following examples discuss
various such potential restrictions and how they can be addressed.
Full-normalization prevents the markup of an isolated combining mark, for example for styling it differently from its base character
(Benoi<span style='color: blue'>^</span>t, where '^' represents a combining circumflex). However,
the equivalent effect can be achieved by assigning a class to the accents in an SVG font or using equivalent technology. View an
example using SVG (SVG-enabled browsers only).
Full-normalization prevents the use of entities for expressing composing characters. This limitation can be circumvented by using
character escapes or by using entities representing complete combining character sequences. With appropriate entity definitions, instead of
A´, write Á (or better, use 'Á' directly).
4.4 Responsibility for Normalization
This section defines the W3C Text Normalization Model, based on early uniform normalization.
Unless otherwise specified, the word 'normalization' in this section may refer to 'include-normalization' or 'full-normalization', depending on which is most appropriate for the
specification or implementation under consideration.
An operation is normalization-sensitive if its output(s) are different
depending on the state of normalization of the input(s); if the output(s) are textual, they are deemed different only if they would remain different
were they to be normalized. These operations are any that involve comparison of characters or character counting, as well as some other operations
such as ‘delete first character’ or ‘delete last character’.
EXAMPLE: Consider the string normalisé, where the 'é' may be
a single character (in NFC) or two. The following are three examples of normalization-sensitive operations involving this string. Counting the number
of characters may yield either 9 or 10, depending on the state of normalization. Deleting the last character may yield either normalis
or normalise (no accent). Comparing normalisé to normalisé matches if both are in the same state of
normalization, but doesn't match otherwise.
EXAMPLE: Examples of operations that are not normalization-sensitive are normalization, and
the copying or deletion of an entire document.
A text-processing component is a component that recognizes data as text. This specification
does not specify the boundaries of a text-processing component, which may be as small as one line of code or as large as a complete application. A
text-processing component may receive text, produce text, or both.
Certified text is text which satisfies at least one of the following conditions:
-
it has been confirmed through inspection that the text is in normalized form
-
the source text-processing component is identified and is known to produce only normalized
text.
Suspect text is text which is not certified.
Given the definitions and considerations above, specifications, implementations and content have some responsibilities which are listed
below.
-
[C] Text content SHOULD be in
fully-normalized form and if not SHOULD at least be in
include-normalized form.
-
[S] Specifications of text-based formats and protocols
SHOULD, as part of their syntax definition, require that the text be in normalized form.
-
[S] [I] A
text-processing component that receives suspect text SHOULD NOT perform any normalization-sensitive operations unless it has
first confirmed through inspection that the text is in normalized form, and MUST NOT normalize the
suspect text. Private agreements MAY, however, be created within private
systems which are not subject to these rules, but any externally observable results SHOULD be the same as if the rules
had been obeyed.
-
[I] A text-processing component which
modifies text and performs normalization-sensitive operations SHOULD
behave as if normalization took place after each modification, so that any subsequent normalization-sensitive operations always behave as if they were dealing with normalized text.
EXAMPLE: If the 'z' is deleted from the (normalized) string
cz¸ (where '¸' represents a combining cedilla, U+0327), normalization is necessary to turn the denormalized
result c¸ into the properly normalized ç. If the software that deletes the 'z' later uses the
string in a normalization-sensitive operation, it needs to normalize the string before this
operation to ensure correctness; otherwise, normalization may be deferred until the data is exposed. Analogous cases exist for insertion and
concatenation (e.g. xf:concat(xf:substring('cz¸', 1, 1), xf:substring('cz¸', 3, 1)) in XQuery [XQuery
Operators]).
NOTE: Software that denormalizes a string such as in the deletion example above does not need to
perform a potentially expensive re-normalization of the whole string to ensure that the string is normalized. It is sufficient to go back to the last
non-composing character and re-normalize forward to the next non-composing character; if the string was
normalized before the denormalizing operation, it will now be re-normalized.
-
[S] Specifications of text-based languages and protocols
SHOULD define precisely the construct boundaries necessary to obtain a complete
definition of full-normalization. These definitions SHOULD include at least
the boundaries between markup and character data as well as entity
boundaries (if the language has any include mechanism) and SHOULD include any other boundary that may create
denormalization when instances of the language are processed.
-
[C] Even when authoring in a (formal) language that does not mandate
full-normalization, content developers SHOULD avoid
composing characters at the beginning of constructs that may be
significant, such as at the beginning of an entity that will be included, immediately after a construct that
causes inclusion or immediately after markup.
-
[I] Authoring tool implementations for a (formal) language that does not
mandate full-normalization SHOULD prevent users from creating content with
composing characters at the beginning of constructs that may be
significant, such as at the beginning of an entity that will be included, immediately after a construct that
causes inclusion or immediately after markup, or SHOULD warn users when they do
so.
-
[I] Implementations which transcode text from a
legacy encoding to a Unicode encoding form SHOULD use a normalizing transcoder.
NOTE: Except when an encoding's repertoire contains
characters not represented in Unicode, it is always possible to construct a normalizing transcoder by using any transcoder followed by a
normalizer.
-
[S] Where operations may produce unnormalized output from normalized text
input, specifications of API components (functions/methods) that implement these operations MUST define whether
normalization is the responsibility of the caller or the callee. Specifications MAY state that performing normalization
is optional for some API components; in this case the default SHOULD be that normalization is performed, and an explicit
option SHOULD be used to switch normalization off. Specifications SHOULD NOT make the
implementation of normalization optional.
EXAMPLE: The concatenation operation may either concatenate sequences of codepoints without
normalization at the boundary, or may take normalization into account to avoid producing unnormalized output from normalized input. An API
specification must define whether the operation normalizes at the boundary or leaves that responsibility to the application using the
API.
-
[S] Specifications that define a mechanism (for example an API or a
defining language) for producing a document SHOULD require that the final output of this mechanism be normalized.
EXAMPLE: XSL Transformations [XSLT] and the DOM Load & Save
specification [DOM3 LS] are examples of specifications that define text output and that should specify that this output be in
normalized form.
NOTE: As an optimization, it is perfectly acceptable for a system to define the
producer to be the actual producer (e.g. a small device) together with a remote component (e.g. a
server serving as a kind of proxy) to which normalization is delegated. In such a case, the communications channel between the device and proxy
server is considered to be internal to the system, not part of the Web. Only data normalized by the proxy server is to be exposed to the Web
at large, as shown in the illustration below:
A similar case would be that of a Web repository receiving content from a user and noticing that the content is not properly
normalized. If the user so requests, it would certainly be proper for the repository to normalize the content on behalf of the user, the repository
becoming effectively part of the producer for the duration of that operation.
[S] [I] Specifications and
implementations MUST document any deviation from the above requirements.
[S] Specifications MUST document any security issues related to normalization.
5 Compatibility and Formatting Characters
This specification does not address the suitability of particular characters for use in markup
languages, in particular formatting characters and compatibility equivalents. For detailed recommendations about the use of compatibility and
formatting characters, see Unicode in XML and other Markup Languages [UXML].
[S] Specifications SHOULD exclude compatibility
characters in the syntactic elements (markup, delimiters, identifiers) of the formats they define.
6 String Identity Matching
One important operation that depends on early normalization is string identity matching [CharReq], which is a subset of the more general problem of string matching. There are various degrees of specificity for string
matching, from approximate matching such as regular expressions or phonetic matching, to more specific matches such as case-insensitive or
accent-insensitive matching and finally to identity matching. In the Web environment, where multiple character encodings are used to represent
strings, including some character encodings which allow multiple representations for the same thing, identity is
defined to occur if and only if the compared strings contain no user-identifiable distinctions. This definition is such that strings do not match
when they differ in case or accentuation, but do match when they differ only in non-semantically significant ways such as character encoding, use of
character escapes (of potentially different kinds), or use of precomposed vs. decomposed character
sequences.
To avoid unnecessary conversions and, more importantly, to ensure predictability and correctness, it is necessary for all
components of the Web to use the same identity testing mechanism. Conformance to the rule that follows meets this requirement and supports the above
definition of identity.
[S] [I] String
identity matching MUST be performed as if the following steps were followed:
Step 1 ensures 1) that the identity matching process can produce correct results using the next three steps and 2) that a minimum of
effort is spent on solving the problem.
NOTE: The expansion of character escapes and includes (step 3 above) is dependent on context, i.e. on
which markup or programming language is considered to apply when the string matching operation is performed. Consider a search for the string 'suçon' in an XML document containing suçon but not suçon. If the search is performed in a
plain text editor, the context is plain text (no markup or programming language applies), the ç character
escape is not recognized, hence not expanded and the search fails. If the search is performed in an XML browser, the context is
XML, the character escape (defined by XML) is expanded and the search succeeds.
An intermediate case would be an XML editor that purposefully provides a view of an XML document with entity references left
unexpanded. In that case, a search over that pseudo-XML view will deliberately not expand entities: in that particular context, entity
references are not considered includes and need not be expanded.
[S] [I] Forms of
string matching other than identity matching SHOULD be performed as if the following steps were followed:
Appropriate methods of matching text outside of string identity matching can include such things as case-insensitive matching,
accent-insensitive matching, matching characters against Unicode compatibility forms, expansion of abbreviations, matching of stemmed words, phonetic
matching, etc.
EXAMPLE: A user who specifies a search for the string suçon against a Unicode encoded XML
document would expect to find string identity matches against the strings suçon, suçon and
suçl;on (where the entity ç represents the precomposed character 'ç'). Identity matches
should also be found whether the string was encoded as 73 75 C3 A7 6F 6E (in UTF-8) or 0073 0075 00E7 006F 006E (in
UTF-16), or any other character encoding that can be transcoded into normalized Unicode characters.
It should never be the case that a match would be attempted against strings such as suçon or suc¸on
since these are not fully-normalized and should cause the text to be rejected. If, however, matching is done against such strings they should also
match since they are canonically equivalent.
Forms of matching other than identity, if supported by the application, would have to be used to produce a match against the following
strings: SUÇON (case-insensitive matching), sucon (accent-insensitive matching), suçons (matched stems),
suçant (phonetic matching), etc.
7 String Indexing
There are many situations where a software process needs to access a substring or to point within a string and does so by the use of
indices, i.e. numeric "positions" within a string. Where such indices are exchanged between
components of the Web, there is a need for an agreed-upon definition of string indexing in order to ensure consistent behavior. The requirements for
string indexing are discussed in Requirements for String Identity Matching [CharReq],
section 4. The two main questions that arise are: "What is the unit of
counting?" and "Do we start counting at 0 or 1?".
EXAMPLE: Consider the string
encoded in UTF-16 in big-endian byte order. The rows of the following table show the string viewed as a
character string, code unit string and
byte string, respectively, each of which involves different units for indexing.
Depending on the particular requirements of a process, the unit of counting may correspond to definitions of a string provided in section
3.4 Strings. In particular:
-
[S] [I] The
character string is RECOMMENDED as a basis for string indexing.
(Example: the XML Path Language [XPath]).
-
[S] [I] A
code unit string MAY be used as a basis for string indexing if this results
in a significant improvement in the efficiency of internal operations when compared to the use of character
string. (Example: the use of UTF-16 in [DOM Level 1]).
Counting graphemes will become a good option where user interaction is the primary concern,
once a suitable definition is widely accepted. The use of byte strings for indexing is discouraged.
It is noteworthy that there exist other, non-numeric ways of identifying substrings which have favorable properties. For instance,
substrings based on string matching are quite robust against small edits; substrings based on document structure (in structured formats such as XML)
are even more robust against edits and even against translation of a document from one human language to another.
[S] Specifications that need a way to identify substrings or point within a string SHOULD provide ways other than string indexing to perform this operation.
[I] [C] Users of specifications (software developers, content
developers) SHOULD whenever possible prefer ways other than string indexing to identify substrings or point within a
string.
Experience shows that more general, flexible and robust specifications result when individual characters are understood and processed as
substrings, identified by a position before and a position after the substring. Understanding indices as boundary positions between the
counting units also makes it easier to relate the indices resulting from the different string definitions.
[S] Specifications SHOULD understand and process single characters as substrings,
and treat indices as boundary positions between counting units, regardless of the choice of counting units.
[S] Specifications of APIs SHOULD NOT specify
single character or single encoding-unit arguments.
EXAMPLE: uppercase('ß') cannot return the proper result (the two-character string 'SS') if the return type of the uppercase function is defined to be a single character.
The issue of index origin, i.e. whether we count from 0 or 1, actually arises only after a decision has been made on whether it is the
units themselves that are counted or the positions between the units. [S] When the
positions between the units are counted for string indexing, starting with an index of 0 for the position at the start of the string is the
RECOMMENDED solution, with the last index then being equal to the number of counting units in the string.
8 Character Encoding in URI References
According to the definition in RFC 2396 [RFC 2396], URI references are restricted to a subset of US-ASCII, with an
escaping mechanism to encode arbitrary byte values, using the %HH convention. However, the %HH convention by itself is of limited use because there
is no definitive mapping from characters to bytes. Also, non-ASCII characters cannot be used directly. Internationalized Resource Identifiers
(IRIs) [I-D IRI] solves both problems with an uniform approach that conforms to the
Reference Processing Model.
[S] W3C specifications that define protocol or format elements (e.g. HTTP
headers, XML attributes, etc.) which are to be interpreted as URI references (or specific subsets of URI references, such as absolute URI references,
URIs, etc.) SHOULD use Internationalized Resource Identifiers (IRIs) [I-D IRI] (or
an appropriate subset thereof). [S] W3C specifications MUST define when the conversion from IRI references to URI references (or subsets thereof) takes place, in accordance with
Internationalized Resource Identifiers (IRIs) [I-D IRI].
[S] W3C specifications that define new syntax for URIs, such as a new URI
scheme or a new kind of fragment identifier, MUST specify that characters outside the US-ASCII repertoire are encoded
using UTF-8 and %HH-escaping, in accordance with Guidelines for new URL Schemes [RFC 2718], Section 2.2.5.
[S] Such specifications SHOULD also define the normalization requirements for the
syntax they introduce.
9 Referencing the Unicode Standard and ISO/IEC 10646
Specifications often need to make references to the Unicode Standard or International Standard ISO/IEC 10646. Such references must be made
with care, especially when normative. The questions to be considered are:
-
Which standard should be referenced?
-
How to reference a particular version?
-
When to use versioned vs. unversioned references?
ISO/IEC 10646 is developed and published jointly by ISO (the International Organization for
Standardization) and IEC (the International Electrotechnical Commission). The Unicode Standard is developed and
published by the Unicode Consortium, an organization of major computer corporations, software producers,
database vendors, national governments, research institutions, international agencies, various user groups, and interested individuals. The Unicode
Standard is comparable in standing to W3C Recommendations.
ISO/IEC 10646 and the Unicode Standard define exactly the same CCS (same
repertoire, same code points) and encoding forms. They are actively maintained
in synchrony by liaisons and overlapping membership between the respective technical committees. In addition to the jointly defined CCS and encoding
forms, the Unicode Standard adds normative and informative lists of character properties, normative character equivalence and normalization
specifications, a normative algorithm for bidirectional text and a large amount of useful implementation information. In short, the Unicode Standard
adds semantics to the characters that ISO/IEC 10646 merely enumerates. Conformance to the Unicode Standard implies conformance to ISO/IEC 10646, see
[Unicode 3.0] Appendix C.
[S] Since specifications in general need both a definition for their characters
and the semantics associated with these characters, specifications SHOULD include a reference to the Unicode Standard,
whether or not they include a reference to ISO/IEC 10646. By providing a reference to the Unicode Standard implementers can benefit from the
wealth of information provided in the standard and on the Unicode Consortium Web site.
The fact that both ISO/IEC 10646 and the Unicode Standard are evolving (in synchrony) raises the issue of versioning: should a
specification refer to a specific version of the standard, or should it make a generic reference, so that the normative reference is to the version
current at the time of reading the specification? In general the answer is both. [S] A generic reference to the Unicode Standard MUST be made if it is desired that
characters allocated after a specification is published are usable with that specification. A specific reference to the Unicode Standard
MAY be included to ensure that functionality depending on a particular version is available and will not change over
time. An example would be the set of characters acceptable as Name characters in XML 1.0 [XML 1.0], which is an
enumerated list that parsers must implement to validate names.
A generic reference can be formulated in two ways:
-
By explicitly including a generic entry in the bibliography section of a specification and simply referring to that entry in
the body of the specification. Such a generic entry contains text such as "... as it may from time to time be revised or
amended".
-
By including a specific entry in the bibliography and adding text such as "... as it may from time to
time be revised or amended" at the point of reference in the body of the specification.
It is an editorial matter, best left to each specification, which of these two formulations is used. Examples of the first formulation can
be found in the bibliography of this specification (see the entries for [ISO/IEC 10646] and [Unicode]). Examples of the latter, as well as a discussion of the versioning issue with respect to MIME charset parameters for UCS encodings, can be found in [RFC 2279] and [RFC
2781].
[S] All generic references to the Unicode Standard [Unicode] MUST refer to Unicode 3.0 [Unicode 3.0] or later.
[S] Generic references to ISO/IEC 10646 [ISO/IEC 10646]
MUST be written such that they make allowance for the future publication of additional parts of the standard.
When referring to Part 1, they MUST refer to ISO/IEC 10646-1:2000 [ISO/IEC 10646-1:2000] or
later, including any amendments.
A References
A.1 Normative References
- IANA
- Internet Assigned Numbers Authority, Official Names for Character
Sets. (See http://www.iana.org/assignments/character-sets.)
- ISO/IEC 10646
- ISO/IEC 10646-1:2000, Information
technology -- Universal Multiple-Octet Coded Character Set (UCS) -- Part 1: Architecture and Basic Multilingual Plane and ISO/IEC
10646-2:2001, Information technology -- Universal
Multiple-Octet Coded Character Set (UCS) -- Part 2: Supplementary Planes, as, from time to time, amended, replaced by a new edition or
expanded by the addition of new parts. (See http://www.iso.ch for the latest version.)
- ISO/IEC 10646-1:2000
- ISO/IEC 10646-1:2000, Information
technology -- Universal Multiple-Octet Coded Character Set (UCS) -- Part 1: Architecture and Basic Multilingual Plane. (See
http://www.iso.ch/iso/en/CatalogueDetailPage.CatalogueDetail?CSNUMBER=29819.)
- ISO/IEC 10646-2:2001
- ISO/IEC 10646-2:2001, Information
technology -- Universal Multiple-Octet Coded Character Set (UCS) -- Part 2: Supplementary Planes. (See
http://www.iso.ch/iso/en/CatalogueDetailPage.CatalogueDetail?CSNUMBER=33208.)
- ISO/IEC 646
- ISO/IEC 646:1991, Information technology -- ISO 7-bit coded character set for information interchange. This standard
defines an International Reference Version (IRV) which corresponds exactly to what is widely known as ASCII or US-ASCII. ISO/IEC 646 was based on the
earlier standard ECMA-6. ECMA has maintained its standard up to date with respect to ISO/IEC 646 and makes an electronic copy available at
http://www.ecma.ch/ecma1/STAND/ECMA-006.HTM
- MIME
- Multipurpose Internet Mail Extensions (MIME). Part One: Format of Internet
Message Bodies, N. Freed, N. Borenstein, RFC 2045, November 1996, http://www.ietf.org/rfc/rfc2045.txt. Part Two: Media Types, N. Freed, N. Borenstein, RFC
2046, November 1996. Part Three: Message Header Extensions for Non-ASCII Text, K. Moore, RFC 2047, November 1996. Part Four:
Registration Procedures, N. Freed, J. Klensin, J. Postel, RFC 2048, November 1996. Part Five: Conformance Criteria and Examples,
N. Freed, N. Borenstein, RFC 2049, November 1996.
- RFC 2119
- S. Bradner, Key words for use in RFCs to Indicate Requirement Levels,
IETF RFC 2119. (See http://www.ietf.org/rfc/rfc2119.txt.)
- RFC 2396
- T. Berners-Lee, R. Fielding, L. Masinter, Uniform Resource Identifiers (URI):
Generic Syntax, IETF RFC 2396, August 1998. (See http://www.ietf.org/rfc/rfc2396.txt.)
- RFC 2732
- R. Hinden, B. Carpenter, L. Masinter, Format for Literal IPv6 Addresses in
URL's, IETF RFC 2732, 1999. (See http://www.ietf.org/rfc/rfc2732.txt.)
- Unicode
- The Unicode Consortium, The Unicode Standard, Version 3, ISBN 0-201-61633-5, as updated from time to time by the
publication of new versions. (See http://www.unicode.org/unicode/standard/versions
for the latest version and additional information on versions of the standard and of the Unicode Character Database).
- Unicode 3.0
- The Unicode Consortium, The Unicode Standard, Version 3.0, ISBN 0-201-61633-5. (See
http://www.unicode.org/unicode/standard/versions/Unicode3.0.html.)
- Unicode 3.1
- The Unicode Consortium, The Unicode Standard, Version 3.1.0 is defined by The Unicode Standard, Version 3.0
(Reading, MA, Addison-Wesley, 2000. ISBN 0-201-61633-5), as amended by the Unicode Standard Annex #27: Unicode 3.1 (see
http://www.unicode.org/reports/tr27).
- Unicode 3.2
- The Unicode Consortium, The Unicode Standard, Version 3.2.0 is defined by The Unicode Standard, Version 3.0
(Reading, MA, Addison-Wesley, 2000. ISBN 0-201-61633-5), as amended by the Unicode Standard Annex #27: Unicode 3.1 (see
http://www.unicode.org/reports/tr27) and by the Unicode Standard Annex #28: Unicode
3.2 (see http://www.unicode.org/reports/tr28).
- UTR #15
- Mark Davis, Martin Dürst, Unicode Normalization Forms,
Unicode Standard Annex #15. (See http://www.unicode.org/unicode/reports/tr15 for the
latest version).
A.2 Other References
- CharReq
- Martin J. Dürst, Requirements for String Identity Matching and String
Indexing, W3C Working Draft. (See http://www.w3.org/TR/WD-charreq.)
- Connolly
- D. Connolly, Character Set Considered Harmful, W3C
Note. (See http://www.w3.org/MarkUp/html-spec/charset-harmful.)
- CSS2
- Bert Bos, Håkon Wium Lie, Chris Lilley, Ian Jacobs, Eds., Cascading Style Sheets,
level 2 (CSS2 Specification), W3C Recommendation. (See http://www.w3.org/TR/REC-CSS2.)
- DOM Level 1
- Vidur Apparao et al., Document Object Model (DOM) Level 1
Specification, W3C Recommendation. (See http://www.w3.org/TR/REC-DOM-Level-1.)
- DOM3 LS
- Ben Chang, Jeroen van Rotterdam, Johnny Stenback, Andy Heninger, Joe Kesselman, Rezaur Rahman Eds.,
Document Object Model (DOM) Level 3 Abstract Schemas and Load and Save
Specification, W3C Working Draft. (See http://www.w3.org/TR/DOM-Level-3-ASLS.)
- HTML 4.0
- Dave Raggett, Arnaud Le Hors, Ian Jacobs, Eds., HTML 4.0
Specification, W3C Recommendation, 18-Dec-1997 (See http://www.w3.org/TR/REC-html40-971218.)
- HTML 4.01
- Dave Raggett, Arnaud Le Hors, Ian Jacobs, Eds., HTML 4.01 Specification, W3C
Recommendation. (See http://www.w3.org/TR/html401.)
- I-D IRI
- Martin Dürst, Michel Suignard, Internationalized
Resource Identifiers (IRIs), Internet-Draft, April 2002. (See http://www.w3.org/International/2002/draft-duerst-iri-00.txt.)
- Info URI-I18N
- Internationalization: URIs and other identifiers. (See
http://www.w3.org/International/O-URL-and-ident.)
- ISO/IEC 14651
- ISO/IEC 14651:2000, Information technology -- International string ordering and comparison -- Method for
comparing character strings and description of the common template tailorable ordering as, from time to time, amended, replaced by a new edition
or expanded by the addition of new parts. (See http://www.iso.ch for the latest version.)
- ISO/IEC 9541-1
- ISO/IEC 9541-1:1991, Information technology --
Font information interchange -- Part 1: Architecture. (See http://www.iso.ch/iso/en/CatalogueDetailPage.CatalogueDetail?CSNUMBER=17277
for the latest version.)
- MathML2
- David Carlisle, Patrick Ion, Robert Miner, Nico Poppelier, Eds., Mathematical Markup
Language (MathML) Version 2.0, W3C Recommendation. (See http://www.w3.org/TR/MathML2.)
- Nicol
- Gavin Nicol, The Multilingual World Wide
Web, Chapter 2: The WWW As A Multilingual Application. (See
http://www.mind-to-mind.com/library/papers/multilingual/multilingual-www.html.)
- RFC 2070
- F. Yergeau, G. Nicol, G. Adams, M. Dürst, Internationalization of the Hypertext
Markup Language, IETF RFC 2070, January 1997. (See http://www.ietf.org/rfc/rfc2070.txt.)
- RFC 2277
- H. Alvestrand, IETF Policy on Character Sets and Languages, IETF RFC
2277, BCP 18, January 1998. (See http://www.ietf.org/rfc/rfc2277.txt.)
- RFC 2279
- F. Yergeau, UTF-8, a transformation format of ISO 10646, IETF RFC
2279, January 1998. (See http://www.ietf.org/rfc/rfc2279.txt.)
- RFC 2718
- L. Masinter, H. Alvestrand, D. Zigmond, R. Petke, Guidelines for new URL
Schemes, IETF RFC 2718, November 1999. (See http://www.ietf.org/rfc/rfc2718.txt.)
- RFC 2781
- P. Hoffman, F. Yergeau, UTF-16, an encoding of ISO 10646, IETF RFC
2781, February 2000. (See http://www.ietf.org/rfc/rfc2781.txt.)
- SPREAD
- SPREAD - Standardization Project for East Asian Documents
Universal Public Entity Set. (See http://www.ascc.net/xml/resource/entities/index.html)
- SVG
- Jon Ferraiolo, Ed., Scalable Vector Graphics (SVG) 1.0 Specification, W3C
Recommendation. (See http://www.w3.org/TR/SVG.)
- UTR #10
- Mark Davis, Ken Whistler, Unicode Collation Algorithm,
Unicode Technical Report #10. (See http://www.unicode.org/unicode/reports/tr10.)
- UTR #17
- Ken Whistler, Mark Davis, Character Encoding Model, Unicode
Technical Report #17. (See http://www.unicode.org/unicode/reports/tr17.)
- UXML
- Martin Dürst and Asmus Freytag, Unicode in XML and other Markup
Languages, Unicode Technical Report #20 and W3C Note. (See http://www.w3.org/TR/unicode-xml.)
- XLink
- Steve DeRose, Eve Maler, David Orchard, Eds, XML Linking Language (XLink) Version
1.0, W3C Recommendation. (See http://www.w3.org/TR/xlink.)
- XML 1.0
- Tim Bray, Jean Paoli, C. M. Sperberg-McQueen, Eve Maler, Eds., Extensible Markup
Language (XML) 1.0, W3C Recommendation. (See http://www.w3.org/TR/REC-xml.)
- XML Schema-2
- Paul V. Biron , Ashok Malhotra , Eds., XML Schema Part 2: Datatypes, W3C
Recommendation. (See http://www.w3.org/TR/xmlschema-2.)
- XML Japanese Profile
- MURATA Makoto Ed., XML Japanese Profile, W3C Note. (See
http://www.w3.org/TR/japanese-xml.)
- XPath
- James Clark, Steve DeRose, Eds, XML Path Language (XPath) Version 1.0, W3C
Recommendation. (See http://www.w3.org/TR/xpath.)
- XQuery Operators
- Ashok Malhotra, Jim Melton, Jonathan Robie, Norman Walsh, Eds, XQuery 1.0 and
XPath 2.0 Functions and Operators, W3C Working Draft. (See http://www.w3.org/TR/xquery-operators.)
- XSLT
- James Clark Ed., XSL Transformations (XSLT), W3C Recommendation. (See
http://www.w3.org/TR/xslt.)
B Examples of Characters, Keystrokes and Glyphs (Non-Normative)
A few examples will help make sense all this complexity of text in computers (which is mostly a reflection of the
complexity of human writing systems). Let us start with a very simple example: a user, equipped with a US-English keyboard, types "Foo", which the computer encodes as 16-bit values (the UTF-16 encoding of Unicode) and displays on the screen.
The only complexity here is the use of a modifier (Shift) to input the capital 'F'.
A slightly more complex example is a user typing 'çé' on a traditional French-Canadian keyboard, which the
computer again encodes in UTF-16 and displays. We assume that this particular computer uses a fully composed form of UTF-16.
A few interesting things are happening here: when the user types the cedilla ('¸'), nothing happens except for
a change of state of the keyboard driver; the cedilla is a dead key. When the driver gets the c keystroke, it provides
a complete 'ç' character to the system, which represents it as a single 16-bit code unit
and displays a 'ç' glyph. The user then presses the dedicated 'é' key, which results in, again, a character represented by two bytes. Most systems will display this as one glyph, but it is
also possible to combine two glyphs (the base letter and the accent) to obtain the same rendering.
On to a Japanese example: our user employs a romaji input method to type " ", which the computer encodes in UTF-16 and displays.
", which the computer encodes in UTF-16 and displays.
The interesting aspect here is input: the user types Latin characters, which are converted on the fly to kana (not shown here), and then
to kanji when the user requests conversion by pressing <space>; the kanji characters are finally sent to the application when the user presses
<return>. The user has to type a total of nine keystrokes before the three characters are produced, which are then encoded and displayed rather
trivially.
An Arabic example will show different phenomena:
Here the first two keystrokes each produce an input character and an encoded character, but the pair is displayed as a single glyph ('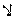 ', a lam-alef ligature). The next keystroke is a
lam-alef, which some Arabic keyboards have; it produces the same two characters which are displayed similarly, but this second lam-alef is placed to
the left of the first one when displayed. The last two keystrokes produce two identical characters which are rendered by two different
glyphs (a medial form followed to its left by a final form). We thus have 5 keystrokes producing 6 characters and 4 glyphs laid out
right-to-left.
', a lam-alef ligature). The next keystroke is a
lam-alef, which some Arabic keyboards have; it produces the same two characters which are displayed similarly, but this second lam-alef is placed to
the left of the first one when displayed. The last two keystrokes produce two identical characters which are rendered by two different
glyphs (a medial form followed to its left by a final form). We thus have 5 keystrokes producing 6 characters and 4 glyphs laid out
right-to-left.
A final example in Tamil, typed with an ISCII keyboard, will illustrate some additional phenomena:
Here input is straightforward, but note that contrary to the preceding accented Latin example, the diacritic ' ' (virama, vowel killer) is entered
after the '
' (virama, vowel killer) is entered
after the ' ' to which it applies. Rendering is
interesting for the last two characters. The last one ('
' to which it applies. Rendering is
interesting for the last two characters. The last one (' ') clearly consists of two glyphs which surround the glyph of the next to last character ('
') clearly consists of two glyphs which surround the glyph of the next to last character (' ').
').
C Composing Characters (Non-Normative)
As specified in 4.2.3 Fully-normalized text, a composing character is any character that is
-
the second character in the canonical decomposition mapping of some primary composite (as defined in
D3 of [UTR #15]), or
-
of non-zero canonical combining class (as defined in [Unicode]).
These two categories are highly but not exactly overlapping. The first category includes a few class-zero characters that do
compose with a previous character in NFC; this is the case for some vowel and length marks in
Brahmi-derived scripts, as well as for the modern non-initial conjoining jamos of the Korean Hangul script. The second category includes some
combining characters that do not compose in NFC, for the simple reason that there is no precomposed character involving them. They must
nevertheless be taken into account as composing characters because their presence may make reordering of combining marks necessary, to maintain
normalization under concatenation or deletion. Therefore, composing characters as defined in 4.2.3 Fully-normalized
text include all characters of non-zero canonical combining class plus the following (as of Unicode 3.2):
NOTE: The characters in the second column of the above table may or may not appear, or may appear as
blank rectangles, depending on the capabilities of your browser and on the fonts installed in your system.
D Resources for Normalization (Non-Normative)
The following are freely available programming resources related to normalization:
E Acknowledgements (Non-Normative)
Special thanks go to Ian Jacobs for ample help with editing. Tim Berners-Lee and James Clark provided important details in the section on
URIs. Asmus Freytag provided significant help in the authoring and editing process. The W3C I18N WG and IG, as well as others, provided many comments
and suggestions.
F Change Log (Non-Normative)
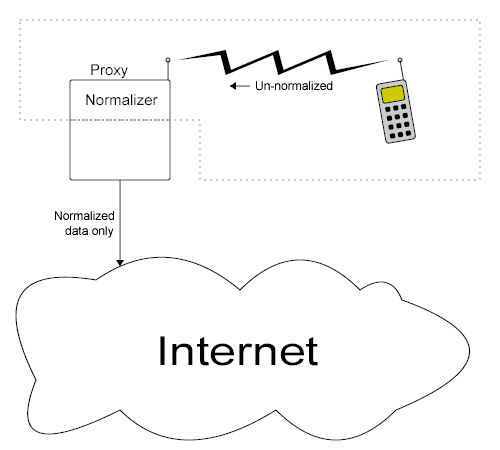
{kind=link}