Deutsch English Español Italiano Nederlands Português Pусский Українська
Utiliser la touche d'accès n pour naviguer au sein de la page. Sauter au début du contenu.
Ce document est une traduction. En cas de divergences ou d'erreurs, la dernière version originale en anglais fait autorité. Comme indiqué ci-dessous, les droits d'auteur reviennent au W3C.
Traducteur: French Translation Team, Trusted Translations, Inc.
http://www.w3.org/International/tutorials/svg-tiny-bidi/
Public visé : Auteurs de contenu SVG mettant en œuvre des pages SVG Tiny de scripts de droite à gauche comme l'arabe ou l'hébreu, ou devant traiter des textes de scripts incorporés de droite à gauche. Ce matériel est utilisable que vous créiez des documents par éditeur ou par langages de script.
Les scripts de droite à gauche comprennent l'arabe, l'hébreu, le thaana et le n'ko, et sont utilisés par un grand nombre de personnes à travers le monde. Si vous utilisez des textes bidirectionnels pour la première fois, il peut sembler complexe et déroutant de les afficher correctement de prime abord, mais vous n'avez pas besoin de le croire. Si cela vous est difficile ou si vous êtes débutant, ce didacticiel devrait vous aider à adopter la meilleure approche au marquage possible de votre contenu. Il vous expliquera aussi suffisamment la manière dont l'algorithme bidirectionnel fonctionne pour que vous compreniez mieux les causes premières de la plupart des problèmes. Nous aborderons également quelques idées fausses en termes de façons de traiter avec le marquage du contenu bidirectionnel.
En suivant ce didacticiel, vous devriez pouvoir :
Remarquez que la spécification SVG Tiny 1.2 a été publiée en tant que Recommendation le 22 décembre 2008. Un peu de temps est nécessaire avant que la fonctionnalité décrite dans ce didacticiel soit entièrement déployée.
Cette section couvre :
Ajoutez direction="rtl" au tag svg pour régler le sens de base du document à chaque fois que le sens général du document est de droite à gauche. Le sens de base établit le contexte directionnel général du texte à l'intérieur de l'élément où il est déclaré.
Vous n'avez pas besoin de définir explicitement le sens de base des documents qui sont de droite à gauche de manière prédominante, puisque ceci est une valeur par défaut.
Ceci étant fait, vous n'aurez peut-être pas besoin de marquage directionnel supplémentaire dans votre contenu. La valeur de propriété direction réglée sur l'élément svg est héritée par les éléments relatifs au texte dans tout le document. La plupart de réorganisation nécessaire à l'affichage du texte est prise en charge automatiquement par l'algorithme bidirectionnel Unicode ('algorithme bidi'). Ceci peut être illustré par l'exemple ci-dessous.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="fa">
<title>...</title>
<desc>...</desc>
<text x="200" y="200"
font-size="10">داستان SVG Tiny 1.2 طولا ني است.</text>
</svg>
Ceci affichera le texte dans l'ordre (correct) suivant, si la mise en œuvre prend en charge la manipulation de texte bidi :
![]()
Sans la propriété sens, le texte aurait eu cet apparence :
![]()
Bien sûr, dans certaines situations vous devrez appliquer plus de marquage, et nous décrirons celles-ci ci-dessous. Aussi, l'ajout de direction="rtl" à l'élément svg entraînera la création d'effets automatiques sur les propriétés text-align et text-anchor que nous décrirons aussi peu après.
Alors que vous déclarez la directivité du document du tag svg, n'oubliez pas de déclarer la langue du document à l'aide de l'attribut xml:lang (voir Tags de langue en HTML et XML).
Cependant, ne faites pas l'erreur d'assumer que les déclarations de langue indiquent la directivité, ou vice versa !
Même si un sous-tag de script est utilisé dans la valeur d'attribut de langue, ceci n'a aucune implication en ce qui concerne la directivité du texte de l'agent utilisateur. Vous devez toujours déclarer le sens en utilisant l'attribut dir.
La mise en ordre visuelle du texte hébreu était commune chez les agents utilisateur (très) anciens HTML qui ne prenaient pas en charge l'algorithme bidirectionnel Unicode. Le texte était stocké dans le code source dans le même ordre que vous vous imagineriez le voir affiché. (Ce n'était pas aussi commun pour le texte de script arabe, car cela bouleverse la façon dons les caractères arabes sont joints.)
Grâce à la mise en ordre logique, le texte est stocké en mémoire dans l'ordre dans lequel il serait normalement frappé (et ordinairement prononcé). L'algorithme bidirectionnel Unicode est alors appliqué par le navigateur pour rendre l'affichage visuel correct. De nos jours presque tous les textes du Web sont réalisés en ordre logique.
Vous devriez toujours taper votre contenu droite-gauche en ordre logique, et vous baser sur l'algorithme bidirectionnel et le marquage pour le faire s'afficher correctement. Sinon, il ne sera pas possible de rechercher votre texte, de réutiliser le texte, de réviser facilement votre contenu, etc.
Dans l'image ci-dessous, la phrase "פעילות הבינאום, W3C" (en haut en bleu) apparaît de la même manière que lorsqu'elle est affichée dans un paragraphe droite-gauche. Les flèches numérotées indiquent le sens de lecture. Vous lisez les séquences dans l'ordre des numéros.
Ordre de stockage logique et visuel contrasté.

La 2ème ligne indique l'ordre des caractères en mémoire en ordre d'encodage logique (en assumant que le premier caractère en mémoire se trouve sur la gauche, le suivant sur la droite, etc.).
La 3ème ligne indique l'ordre des caractères en mémoire en ordre d'encodage visuel (avec les mêmes suppositions sur l'ordre en mémoire).
Cette section couvre :
Après avoir établi le sens de base au niveau de l'élément svg, vous ne devriez pas utiliser la propriété direction des autres éléments à moins que vous ne souhaitiez changer le sens de base de cet élément.
Une utilisation inutile de la propriété direction a un impact sur la largeur de bande et crée potentiellement un travail additionnel inutile de maintenance de page.
Le sens de base établit par la propriété direction affecte, cependant, la façon dont le texte de langue et de ponctuation mélangé est mis en ordre dans un élément text ou textArea (ceci sera décrit en détail un peu plus loin). De temps en temps vous pourrez peut-être changer le sens de base d'un de ces éléments, s'il se trouve dans une langue différente du reste de la page.
Pour ce faire, utilisez simplement la propriété direction de cet élément, ou d'un élément de groupage qui entoure le contenu approprié.
Dans cet exemple, nous utilisons un élément de groupage autour de plusieurs éléments de text ayant besoin d'un sens de base droite-gauche pour avoir une apparence correcte. L'utilisation d'un élément de groupage diminue la quantité de travail à effectuer pour accomplir le résultat escompté. Le sens réglé est hérité des éléments texte joints.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="he">
<title>...</title>
<desc>...</desc>
<text x="200" y="20"
font-size="10">כתובת לפניות באנגליה:</text>
<g direction="ltr">
<text x="100" y="40"
font-size="10">3, Tennyson House</text>
<text x="100" y="50"
font-size="10">17 Clairbourne Road,</text>
<text x="100" y="60"
font-size="10">Harpenden AL5 4SD</text>
</g>
</svg>
Sans le marquage de sens de l'élément g, cela affichera le texte d'une manière comme celle qui suit :
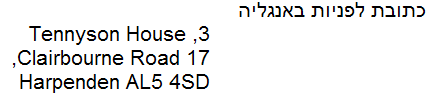
Avec la propriété direction réglée, le texte aura l'apparence prévue.

Vous aurez remarqué que l'alignement du texte en fonction de la coordonnée x est différent pour les deux exemples ci-dessus. Nous aborderons ce sujet ci-après.
La propriété text-align est utilisée avec l'élément textArea, et ses valeurs sont start, middle et end. Il est important de se rappeler que la première et la dernière de ces valeurs est en rapport avec le texte de manière logique plutôt que physique.
start indique l'endroit où vous commenceriez d'habitude à lire une ligne selon le sens de base courant. Lorsque le sens de base est gauche-droite, cela veut dire vers la gauche de l'élément textArea. Si, d'une manière opposée, le sens de base est droite-gauche, cela signifie le côté droit de l'élément textArea.
Pour end, adoptez la procédure inverse.
Ceci se fait de manière intuitive si vous avez utilisé le CSS avec l'HTML, puisque la propriété direction de CSS aligne automatiquement à droite le texte dans un élément bloc.
Dans cet exemple en Urdu, le sens droite-gauche réglé sur l'élément svg est hérité de l'élément textArea.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
dir="rtl" xml:lang="ur">
<title>...</title>
<desc>...</desc>
<textArea x="20" y="20" width="200">
فعالیت بینالمللیسازی، W3Cنا
عالمگیر ویب کو حقیقی طور پر عالمگیر بنانا
</textArea>
</svg>
Affiché, le texte devrait être aligné sur la droite dans la zone textArea, comme indiqué ci-dessous, puisque la valeur par défaut de text-align est start, ce qui pour un sens de base droite-gauche veut dire 'aligné à droite'.

La propriété text-anchor est utilisée avec l'élément text, et ses valeurs sont aussi start, middle et end. Encore une fois, la première et la dernière de ces valeurs est en rapport avec le texte de manière logique plutôt que physique.
Si vous n'avez pas encore indiqué de sens de base, ou si vous avez indiqué direction="ltr", et si text-anchor est réglé sur start, le texte s'étendra sur la droite de la coordonnée x. Si vous avez réglé direction="rtl", le texte s'étendra vers la gauche de la coordonnée x. Par défaut text-anchor est réglé sur start.
Pour end, adoptez la procédure opposée.
Dans cet exemple en anglais/arabe, nous employons deux éléments de texte, les deux comportant la même coordonnée x, les deux utilisant la valeur par défaut pour text-anchor.
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
xml:lang="en">
<title>...</title>
<desc>...</desc>
<text x="200" y="10"
font-size="10">Internationalization activity, W3C</text>
<text direction="rtl" x="200" y="20"
font-size="10">نشاط التدويل، W3C</text>
</svg>
Bien que la coordonnée x des deux éléments texte est la même, cela affichera le texte d'une manière comme celle qui suit :

Gardez à l'esprit que le sens dans lequel le texte s'étend à l'écart du point x (voir exemple précédent) dépend du sens de base, c.-à-d. la valeur de la propriété direction, et non du fait que vous traitiez de texte en latin ou arabe (ou hébreu). Ceci est important.
Cela signifie que, par exemple, une liste de termes comprenant à la fois des mots latin et moyen-orientaux ne désaligne pas de manière imprévue les éléments.
L'exemple suivant comprend des lignes alternantes en script hébreu et latin :
<svg xmlns="http://www.w3.org/2000/svg"
width="100%" height="100%" viewBox="0 0 400 400"
direction="rtl" xml:lang="he">
<title>...</title>
<desc>...</desc>
<text x="200" y="20"
font-size="10">פעילות הבינאום, W3C</text>
<text x="200" y="30" xml:lang="en"
font-size="7">(Internationalization Activity, W3C)</text>
<text x="200" y="50"
font-size="10">ליצור מהרשת רשת כלל עולמית באמת</text>
<text x="200" y="60" xml:lang="en"
font-size="7">(Making the World Wide Web worldwide)</text>
</svg>
Tous les éléments de la liste d'adresse apparaîtront toujours sur la droite. Nous n'avons pas besoin d'effectuer quoi que ce soit de spécial aux lignes en latin uniquement pour qu'elles s'alignent avec le reste :

Ce dont vous devez vous rappeler, toutefois, est que si vous, pour quelque raison que ce soit, appliquez direction="ltr" pour l'un des éléments text, vous devrez également spécifier text-anchor="end"
Cette section couvre :
Dans les sections précédentes, nous avons mentionné qu'il n'est pas suffisant occasionnellement d'ajouter uniquement des informations de sens au tag svg. Dans cette section, nous étudierons pourquoi et quand plus de contrôle est requis, et plus spécifiquement nous étudierons la façon de marquer les éléments tspan pour le sens (pour lequel nous devons introduire la propriété unicode-bidi).
Le résultat de mise en œuvre de l'algorithme bidirectionnel dépend du sens de base général de la phrase, du paragraphe, du bloc ou de la plage dans lequel il est mis en œuvre. Le sens de base établit un contexte directionnel auquel l'algorithme bidi réfère à des points divers pour décider de la manière de manipuler le texte.
Le sens de base est soit réglé explicitement par l'élément parent le plus proche qui utilise la propriété direction, ou, en l'absence d'un tel parent, il sera hérité de la directivité par défaut du tag svg, qui est de sens gauche-droite.
Remarquez que pour les éléments bloc un sens de base droite-gauche ne peut être réglé qu'en utilisant la propriété direction.
Nous savons déjà qu'une séquence de caractères en latin est rendue (c.-à-d. affichée) l'une après l'autre de gauche à droite (nous pouvons voir cela sur cette page). D'autre part, l'algorithme bidi rendra une séquence de caractères RTL frappés fortement (droite-gauche) les uns après les autres de droite à gauche.
Ceci est indépendant du sens de base courant et fonctionne puisque chaque caractère en Unicode a une propriété directionnelle associée. La plupart des lettres sont frappées fortement LTR (gauche à droite). Les lettres des scripts droite-gauche sont frappées fortement RTL (droite à gauche).
Frappe directionnelle.

Lorsque du texte avec directivité différente est mélangé inline, l'algorithme bidi rend chaque séquence de caractères avec la même directivité en tant que session directionnelle séparée.
Ainsi, dans l'exemple suivant, il y a trois sessions directionnelles :
Sessions directionnelles.

Une autre façon d'observer cela est que les changements de sens marquent les limites des sessions directionnelles. Remarquez que vous n'avez pas besoin de marquage ou de stylisation pour que cela ce produise.
Il est particulièrement important de comprendre que l'ordre dans lequel les sessions directionnelles sont affichées sur la page dépend du sens de base prédominant.
Les mots de l'image ci-dessous représentent des sessions directionnelles distinctes. La ligne supérieure se trouve dans un contexte pour lequel le sens de base est LTR ; la ligne inférieure : RTL. Les caractères des deux lignes de l'image sont stockés en mémoire dans exactement le même ordre, mais la mise en ordre visuelle des sessions directionnelles, lorsqu'affichée, est inversée.
L'effet du sens de base d'affichage des sessions directionnelles.

Les espaces et ponctuations ne sont pas frappés fortement comme LTR ou RTL en Unicode, car ils peuvent être utilisés dans chaque type de script. Ils sont donc classés comme neutres.
à ce stade, les choses deviennent intéressantes. Lorsque l'algorithme bidi trouve des caractères à propriétés directionnelles neutres (comme des espaces et une ponctuation), il recherche la manière de les manipuler en regardant les caractères alentours.
Un caractère neutre entre deux caractères fortement frappés au même type directionnel assumera également cette directivité. Ainsi un caractère neutre entre deux caractères fortement frappés RTL sera traité comme un caractère RTL lui-même, et aura l'effet d'étendre la session directionnelle. C'est pourquoi, les trois mots en arabe de cette phrase LTR (séparés uniquement par des espaces, ayant une directivité neutre) sont lus de droite à gauche comme pour une session unique directionnelle. (Le premier mot en arabe que vous lisez est مفتاح puis معايير puis الويب.)
Les caractères neutres font partie de la session directionnelle.

Remarquez que vous n'avez toujours pas besoin de marquage ou de stylisation pour cela. Et qu'il n'y a que trois sessions directionnelles ici.
Le côté particulièrement intéressant réside dans l'espace ou la ponctualtion se trouvant entre deux caractères fortement frappés à directivité différente, c.à.d. à la limite entre les sessions directionnelles. Dans ce cas, le caractère neutre, ou les caractères seront traités comme s'ils avaient la directivité du sens de base.
Même s'il y a plusieurs caractères neutres entre les deux caractères différents frappés fortement, ils seront tous traités de la même manière.
Caractères neutres.

Les numéros des scripts RTL vont de gauche à droite dans le flux droite-gauche, mais sont traités quelque peu différemment des mots par l'algorithme bidi. On dit qu'ils ont une faible directivité. Les deux exemples de l'image illustrent cette différence.
Chiffres
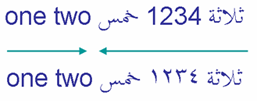
Le premier exemple utilise les chiffres européens '1234', le second exprime le même nombre à l'aide de chiffres arabo-indiens, ١٢٣٤. Dans les deux cas, les chiffres du numéro sont lus de gauche à droite.
Puisque il est frappé faiblement, le numéro est vu comme faisant partie du texte arabe, ainsi les deux mots arabes entourant le numéro sont traités comme partie de la même session directionnelle, bien que la séquence de chiffres exécute LTR à l'écran.
Remarquez aussi que, à côté d'un numéro, certains caractères autrement neutres, comme les symboles de devises, seront traités comme faisant partie du numéro plutôt que d'un neutre.
L'algorithm bidi manipule le texte parfaitement bien dans la plupart des situations et en général aucun marquage spécial ou autre dispositif n'est requis en dehors du réglage du sens général du document. Vous auriez de la chance, néanmoins si cela était aussi facile à chaque fois. Voici notre premier exemple de situation pour laquelle l'algorithme bidirectionnel nécessite un coup de pouce.
La première ligne de cette image indique un point d'exclamation qui fait partie du texte incorporé en arabe et apparaît au mauvais endroit. La deuxième ligne indique le résultat escompté.
Les neutres entre les sessions directionnelles peuvent terminer là où ils ne le devraient pas.
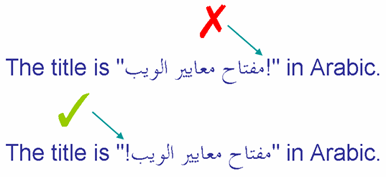
Étant donné notre discussion précédente concernant l'algorithme bidi, nous pouvons facilement comprendre ce qui s'est passé. Puisque le point d'exclamation était frappé entre la dernière lettre de RTL 'ب' (sur la gauche) et la lettre LTR 'i' (du mot 'in'), sa directivité est déterminée par le sens de base du paragraphe (dans ce cas LTR). Remarquez que cela ne fait pas de différence qu'il y ait en fait deux signes de ponctuation et un espace dans cette position ; ils sont tous neutres et ainsi sont tous affectés de la même manière. Puisque le point d'exclamation est considéré comme LTR il se joint à la session directionnelle qui comprend le texte 'in Arabic'.
Alors comment plaçons-nous la ponctuation au bon endroit ?
Une des réponses est de placer la citation arabe dans un élément tspan et d'utiliser la propriété direction pour changer le sens de base du tspan en RTL.
Contrairement aux éléments du conteneur observés précédemment, tspan vous demande de spécifier la propriété unicode-bidi, ainsi que la propriété direction, afin que le changement de sens de base soit efficace. La valeur dont vous avez besoin est embed. (Nous étudierons l'utilisation de bidi-override plus tard.)
<text>The title is "<tspan="rtl" unicode-bidi="embed" xml:lang="ar"> ... !</tspan>" in Arabic.</text>L'environnement d'édition que vous utilisez peut ne pas montrer le point d'exclamation au bon endroit du code source, mais il devrait apparaître de manière correctement quand il est affiché.
Remarquez précisément la manière dont le tag 'étendue' tombe à l'intérieur des guillemets, les guillemets font partie du texte anglais alentours.
Une autre possibilité serait de frapper un caractère RTL invisible fortement après le point d'exclamation. Ainsi, le point d'exclamation serait interprété comme RTL et rejoindrait la session directionnelle arabe.
Il se trouve en fait qu'il y a un caractère de cette sorte : le caractère Unicode U+200F, appelé le MARQUEUR DROITE-GAUCHE (RLM). Il existe un caractère similaire, U+200E, appelé le MARQUEUR GAUCHE-DROITE (LRM). Puisque le caractère est invisible vous pouvez préférer de frapper en fait une référence de caractère numérique (‏).
L'ajout de ce caractère juste après le point d'exclamation produira le résultat escompté.
<text>The title is "... !" in Arabic.</text>S'il y a déjà un marquage autour du guillemet, il est probablement sensé d'utiliser seulement direction, plutôt que le caractère de contrôle. Autrement il peut être plus facile d'utiliser le caractère de contrôle.
La ligne supérieure de l'image suivante indique ce qui arriverait à une liste d'éléments RTL dans une phrase LTR si nous nous basions uniquement sur l'algorithme bidirectionnel (c.-à-d. si nous n'utilisions pas la propriété direction pour établir le sens de base). Dans notre exemple l'ordre de liste est incorrect puisque les deux premiers mots arabes devraient être inversés et la virgule intervenante, qui fait partie du texte anglais, devrait apparaître immédiatement sur la droite du premier mot.
La deuxième ligne de l'image indique le résultat escompté.
Les neutres entre du texte de même sens peuvent être interprétés de manière inappropriée comme faisant partie d'une seule session.

La raison de l'échec est que, le caractère étant frappé fortement droite-gauche (RTL) de chaque côté, l'algorithme bidirectionnel voit la virgule neutre* comme faisant partie du texte en arabe. Il interprète les deux premiers mots arabes et la virgule comme une liste en arabe. En fait la virgule fait partie du texte anglais, et devrait marquer la limite des deux sessions directionnelles en arabe.
Dans la section précédente, le caractère neutre a pensé qu'il faisait partie du contexte directionnel établi par le sens de base, mais ce n'était pas le cas ; dans cette session, le caractère neutre pense qu'il fait partie de la session directionnelle, alors qu'il fait réellement partie du contexte directionnel général.
Une simple solution est d'utiliser un autre caractère Unicode invisible, cette fois le MARQUEUR GAUCHE-DROITE, près de la virgule. Ceci place notre ponctuation neutre entre des caractères RTL et LTR fortement frappés et le force à prendre la directivité du sens de base, qui est de la gauche vers la droite, du texte anglais. Ceci coupe les mots arabes en deux sessions directionnelles séparées, qui sont ordonnées LTR selon le sens prédominant du paragraphe.
<texte>The names of these states in Arabic are ..., ... and ... respectively.</texte>Une fois encore, vous pouvez préférer d'utiliser un NCR (‎) dans un but de visibilité.
L'image suivante indique un autre exemple où le marquage n'est pas nécessaire, et un caractère de contrôle Unicode effectue la tâche bien plus simplement. Une fois encore, la ligne supérieure bleue de l'image indique le résultat de se baser uniquement sur l'algorithme bidirectionnel, et la seconde ligne indique le résultat escompté.
Le résultat escompté a été réalisé en plaçant à côté des parenthèses qui étaient supposées faire partie du contexte en hébreu, mais qui semble apparaître entre deux étendues de texte en latin. L'effet du marqueur RLM est de diviser le texte latin en trois sessions directionnelles séparées, ordonnées selon le sens de base RTL.
Autre exemple d'utilisation de RLM ou LRM, cette fois-ci dans un contexte en hébreu.

Vous avez peut-être remarqué que, en plus de changer de position, l'une des parenthèses de l'exemple précédent change en fait de forme également. Ceci était entièrement automatique et s'est produit car les caractères sont ce que l'on appelle des caractères inversés en Unicode.
Les caractères inversés sont ordinairement des paires de caractères comme des parenthèses, des crochets, ou similaires, dont la forme lorsqu'elle est affichée, dépend du fait qu'elle fait partie d'un contexte LTR ou RTL. Vous n'avez pas besoin de changer le caractère pour que la forme change. Les extrémités d'une parenthèse d'ouverture se trouvent toujours en face du sens du flux de texte. Dans l'image ci-dessous, la parenthèse encerclée de rouge fait face sur la droite de la ligne supérieure car elle est traitée comme la parenthèse d'ouverture de texte en latin. Dans la version inférieuere du texte, le même caractère (cerclé en rouge) est traité comme une parenthèse d'ouverture en rapport au texte en hébreu (c-à-d le nom étendu suit l'acronyme en ordre de lecture), ainsi fait face à l'autre côté.
Caractères inversés.

Ceci signifie que, que le contenu stocké soit en script arabe/hébreu ou latin, vous utiliseriez le même caractère PARENTHÈSE GAUCHE au début du texte entre parenthèses. Autrement dit, traitez les caractères inversés comme si tout mot gauche du nom signifiait 'ouverture' et droite signifiait 'fermeture'.
L'algorithme bidi Unicode et les marques LRM/RLM fonctionnent plutôt bien lorsqu'il n'y a qu'un simple niveau de texte mélangé. Si vous vous trouvez dans la situation où il y a deux niveaux imbriqués au moins de texte directionnel, vous aurez besoin d'une solution différente. Cette image montre une phrase en latin qui comporte une citation en hébreu qui, en retour, comporte du texte en hébreu et en latin ('W3C').
L'ordre des deux mots en hébreu est correct, mais le texte 'W3C' devrait apparaître sur le côté gauche du guillement et la virgule devrait apparaître entre le texte en hébreu et 'W3C'.
Parvenir à réaliser l'affichage désiré en utilisant du marquage pour ouvrir un nouveau niveau d'incorporation.

Le problème se produit en raison des flux directionnels ordonnés selon le sens de base LTR du paragraphe. à l'intérieur de la citation en hébreu, cependant, la mise en ordre correcte par défaut devrait être RTL.
Pour résoudre ce problème, nous devons ouvrir un nouveau niveau d'incorporation. Pour ce faire, vous devez enrouler la citation d'un élément tspan et lui affecter une directivité de RTL en utilisant les propriétés direction et unicode-bidi.
<texte>The title says "<sens tspan ="rtl" unicode-bidi="embed"> ... </tspan>" in Hebrew.</texte>Il y a aussi des caractères de contrôle Unicode que vous devriez utiliser pour obtenir le même résultat, mais comme ils établissent un sens de base correspondant à une gamme de texte aux limites invisibles, ceci n'est pas recommandé.
En résumé, que vous utilisiez seulement la propriété direction sur des éléments de conteneur comme svg, g, text et textArea, vous devez utiliser à la foisdirectionet unicode-bidi="embed" sur les éléments tspan, comme ils sont inline.
L'autre valeur utile de unicode-bidi est bidi-override. Vous n'aurez pas besoin de l'utiliser très souvent. Elle est décrite dans la section suivante.
Parfois vous ne voulez pas que l'algorithme bidi effectue son travail d'ordonnancement. Dans ces cas-là vous avez besoin de marquage supplémentaire pour entourer le texte que vous souhaitez laisser désordonné.
Dans SVG ceci est réalisé à l'aide de la valeur bidi-override de la propriété unicode-bidi et de la propriété direction. Une fois encore, il y a des caractères de contrôle Unicode que vous devriez utiliser pour obtenir le même résultat, mais comme ils créent des états avec des limites invisibles, ceci n'est pas recommandé.
Exemple de texte pour lequel vous souhaitez remplacer l'algorithme bidirectionnel.
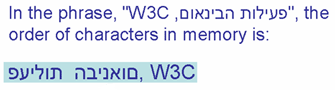
L'exemple de l'image indique le texte en hébreu comme ordonné en mémoire. Vous pouvez utiliser la propriété unicode-bidi pour réaliser cet effet, c.-à-d.
<text x="20" y="80" sens="ltr" unicode-bidi="bidi-override"> ... </text>Unicode offre des code de formatage spéciaux et invisibles pour élaborer sur ou remplacer le résultat de l'algorithme bidirectionnel en texte simple, de la même façon que le marquage SVG décrit dans ce didacticiel.
Il existe un nombre de caractères de contrôle en Unicode qui peuvent être utilisés pour créer le même effet que le marquage pour le texte inline bidirectionnel. Ils sont listés dans la table suivante :
| Caractère | Code | Marquage équivalent |
|---|---|---|
| RLE | U+202B | <tspan direction="rtl" unicode-bidi="embed"> |
| LRE | U+202A | <tspan direction="ltr" unicode-bidi="embed" |
| RLO | U+202E | <tspan direction="rtl" unicode-bidi="bidi-override" |
| LRO | U+202D | <tspan direction="ltr" unicode-bidi="bidi-override" |
| U+202C | </tspan> |
Unicode en langues de marquage déconseille leurs utilisations lorsque le marquage est disponible, et conseille en particulier de ne pas mélanger les codes de contrôle et le marquage.
Pour plus d'informations sur ce sujet consultez contrôles Unicode vs. marquage pour la prise en charge bidi du site W3C Internationalisation.
Il existe, cependant, des situations pour lesquelles les caractères de contrôle Unicode fournissent le seul moyen d'exprimer la directivité. C'est le cas des éléments de texte simple comme title et desc. Ces éléments sont définis pour prendre en charge des caractères uniquement et non des marquages. Il est ainsi impossible d'utiliser les propriétés direction ou unicode-bidi sur une partie du contenu de l'élément.
Le texte d'attribut, également, ne peut pas être marqué pour la directivité, ainsi les caractères de contrôle Unicode doivent être utilisés pour indiquer la directivité.
Veuillez noter que d'autres éléments comme la langue, ne peuvent pas être marqués pour des parties de contenu de texte simple ou des valeurs d'attribut non plus.
Donnez-nous votre avis (en anglais).
Traduit d’un contenu en anglais daté du 2009-01-07. Dernière modification de cette traduction le 2010-12-02 16:59 GMT.
Pour un résumé des changements importants, recherchez tutorial-svg-tiny-bidi dans le blog i18n.
Copyright © 2009-2010 W3C® (MIT, ERCIM, Keio, Beihang), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Your interactions with this site are in accordance with our public and Member privacy statements.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}