| Name | Last modified | Size | Description | |
|---|---|---|---|---|
| Parent Directory | - | |||
| 01-primermodel12.html | 2001-12-07 14:38 | 32K | ||
| Makefile | 2001-12-07 14:38 | 2.0K | ||
| PrimerIntroduction.html | 2001-12-14 14:32 | 3.9K | ||
| ex1.gif | 2001-12-07 14:38 | 12K | ||
| ex1.rdf | 2001-12-07 14:38 | 396 | ||
| ex1.svg | 2001-12-07 14:38 | 1.2K | ||
| ex2.gif | 2001-12-07 14:38 | 17K | ||
| fig0intro.png | 2002-11-26 13:48 | 54K | ||
| fig1-full.png | 2002-03-19 16:37 | 4.2K | ||
| fig1-full.svg | 2002-03-19 16:27 | 1.0K | ||
| fig1.jpg | 2002-01-30 01:06 | 12K | ||
| fig1.png | 2002-03-15 20:05 | 3.9K | ||
| fig1.rdf | 2002-03-15 19:05 | 306 | ||
| fig1dec16.png | 2002-12-19 02:52 | 54K | ||
| fig1new.png | 2002-11-26 13:49 | 37K | ||
| fig2-full.png | 2002-03-19 16:37 | 7.6K | ||
| fig2-full.svg | 2002-03-19 16:31 | 2.3K | ||
| fig2.jpg | 2002-01-30 01:07 | 16K | ||
| fig2.png | 2002-03-15 20:05 | 6.5K | ||
| fig2.rdf | 2002-03-15 19:05 | 463 | ||
| fig2dec16.png | 2002-12-19 02:53 | 37K | ||
| fig2new.png | 2002-11-26 13:50 | 45K | ||
| fig3-full.png | 2002-03-19 16:37 | 7.3K | ||
| fig3-full.svg | 2002-03-19 16:27 | 2.3K | ||
| fig3.jpg | 2002-01-30 01:07 | 15K | ||
| fig3.png | 2002-03-15 20:05 | 5.5K | ||
| fig3.rdf | 2002-03-15 19:05 | 512 | ||
| fig3dec16.png | 2002-12-19 02:54 | 45K | ||
| fig3new.png | 2002-11-26 13:52 | 42K | ||
| fig4-full.png | 2002-03-19 16:37 | 9.6K | ||
| fig4-full.svg | 2002-03-19 16:27 | 3.6K | ||
| fig4.jpg | 2002-01-30 01:08 | 23K | ||
| fig4.png | 2002-03-15 20:05 | 8.7K | ||
| fig4.rdf | 2002-03-15 19:11 | 612 | ||
| fig4dec16.png | 2002-12-19 02:57 | 42K | ||
| fig4new.png | 2002-11-26 13:53 | 50K | ||
| fig5-full.png | 2002-03-19 16:37 | 8.9K | ||
| fig5-full.svg | 2002-03-19 16:27 | 3.4K | ||
| fig5.jpg | 2002-01-30 01:09 | 21K | ||
| fig5.png | 2002-03-15 20:05 | 8.1K | ||
| fig5.rdf | 2002-03-15 19:08 | 550 | ||
| fig5dec16.png | 2002-12-19 02:58 | 50K | ||
| fig5may19.png | 2003-07-01 01:02 | 50K | ||
| fig5new.png | 2002-11-26 13:54 | 47K | ||
| fig6-full.png | 2002-03-19 16:37 | 9.0K | ||
| fig6-full.svg | 2002-03-19 16:27 | 2.8K | ||
| fig6.png | 2002-03-15 20:05 | 8.1K | ||
| fig6.rdf | 2002-03-15 19:15 | 561 | ||
| fig6dec16.png | 2002-12-19 02:59 | 47K | ||
| fig6dt.png | 2002-10-24 00:50 | 34K | ||
| fig6may19.png | 2003-07-01 01:01 | 48K | ||
| fig6new.jpg | 2002-04-19 00:47 | 11K | ||
| fig7-full.png | 2002-03-19 16:37 | 11K | ||
| fig7-full.svg | 2002-03-19 16:27 | 2.8K | ||
| fig7.png | 2002-03-15 20:05 | 9.2K | ||
| fig7dec16.png | 2002-12-19 03:00 | 34K | ||
| fig7dt.png | 2002-10-24 00:51 | 35K | ||
| fig7dtnew.png | 2002-11-01 01:35 | 35K | ||
| fig8-full.png | 2002-03-19 16:37 | 13K | ||
| fig8-full.svg | 2002-03-19 16:27 | 3.4K | ||
| fig8.png | 2002-03-15 20:05 | 16K | ||
| fig8.rdf | 2002-03-15 19:34 | 946 | ||
| fig8dec16.png | 2002-12-19 03:01 | 35K | ||
| fig8dt.png | 2002-10-24 00:52 | 35K | ||
| fig8dtnew.png | 2002-11-01 01:36 | 35K | ||
| fig8jul23.png | 2003-07-25 00:17 | 36K | ||
| fig9dec16.png | 2002-12-19 03:02 | 35K | ||
| fig9dt.png | 2002-10-24 00:53 | 35K | ||
| fig9dtnew.png | 2002-11-01 01:37 | 35K | ||
| fig9jul23.png | 2003-07-25 00:15 | 37K | ||
| fig10.jpg | 2002-04-19 00:48 | 26K | ||
| fig10bag.png | 2002-10-28 00:24 | 61K | ||
| fig10dec16.png | 2002-12-19 03:03 | 35K | ||
| fig10jul23.png | 2003-07-25 00:16 | 36K | ||
| fig10new.png | 2002-11-26 13:56 | 35K | ||
| fig11.jpg | 2002-04-19 00:51 | 20K | ||
| fig11alt.png | 2002-10-28 00:25 | 51K | ||
| fig11dec16.png | 2002-12-19 03:04 | 35K | ||
| fig12list.png | 2002-11-01 01:38 | 73K | ||
| fig12new.png | 2002-11-26 13:55 | 48K | ||
| fig13dec16.png | 2002-12-19 03:05 | 48K | ||
| fig14dec16.png | 2002-12-19 03:06 | 61K | ||
| fig14july12.png | 2003-07-17 19:26 | 75K | ||
| fig14may19.png | 2003-07-01 00:59 | 63K | ||
| fig15dec16.png | 2003-07-01 01:13 | 51K | ||
| fig15july12.png | 2003-07-15 12:57 | 60K | ||
| fig16bjuly12.png | 2003-07-17 19:24 | 70K | ||
| fig16bmay19.png | 2003-07-01 00:58 | 57K | ||
| fig16dec16.png | 2002-12-19 03:08 | 73K | ||
| fig17dec16.png | 2003-07-01 01:03 | 66K | ||
| fig17new.png | 2002-11-26 13:58 | 60K | ||
| fig18dec16.gif | 2002-12-19 03:10 | 22K | ||
| fig19Adec16.gif | 2002-12-19 03:11 | 12K | ||
| fig19Bdec16.gif | 2002-12-19 03:12 | 14K | ||
| figure1.jpg | 2002-03-13 01:27 | 19K | ||
| figure2.jpg | 2002-03-13 01:29 | 23K | ||
| figure3.jpg | 2002-03-13 01:30 | 22K | ||
| figure4.jpg | 2002-03-13 01:32 | 26K | ||
| figure5.jpg | 2002-03-13 01:33 | 24K | ||
| figure6.jpg | 2002-03-13 01:38 | 25K | ||
| figure7.jpg | 2002-03-13 01:39 | 25K | ||
| figure8.jpg | 2002-03-13 01:41 | 27K | ||
| image001.gif | 2001-11-19 21:41 | 1.4K | ||
| image002.gif | 2001-11-19 21:41 | 2.6K | ||
| image003.gif | 2001-11-19 21:41 | 4.0K | ||
| image004.gif | 2001-11-19 21:41 | 1.8K | ||
| image005.gif | 2001-11-19 21:41 | 2.6K | ||
| meerkat-rss.crop.gif | 2003-07-17 13:00 | 44K | ||
| meerkat-rss.small.gif | 2002-11-01 01:40 | 12K | ||
| meetingnotes-20010927.html | 2001-10-12 13:12 | 10K | ||
| metadata.rdf | 2002-11-11 21:06 | 865 | ||
| metadata.xml | 2002-03-20 15:29 | 841 | ||
| newsisfree-rss.crop.gif | 2003-07-17 12:59 | 104K | ||
| newsisfree-rss.small.gif | 2002-11-01 01:41 | 14K | ||
| nfig5.png | 2002-04-23 18:00 | 4.0K | ||
| nfig5.rdf | 2002-04-23 18:00 | 298 | ||
| nfig5.svg | 2002-04-23 18:00 | 1.0K | ||
| nfig10.png | 2002-04-23 18:00 | 18K | ||
| nfig10.rdf | 2002-04-23 18:00 | 681 | ||
| nfig10.svg | 2002-04-23 18:00 | 4.4K | ||
| nfig11.png | 2002-04-23 18:00 | 11K | ||
| nfig11.rdf | 2002-04-23 18:00 | 480 | ||
| nfig11.svg | 2002-04-23 18:00 | 3.2K | ||
| primer.txt | 2001-12-07 14:38 | 8.3K | ||
| rdf-primer-2003LCrevised13july.html | 2003-07-15 12:52 | 375K | ||
| rdf-primer-2003LCrevised14July.html | 2003-07-17 12:57 | 376K | ||
| rdf-primer-2003LCrevised15July.html | 2003-07-18 01:39 | 379K | ||
| rdf-primer-2003LCrevised17July.html | 2003-07-23 00:43 | 382K | ||
| rdf-primer-2003LCrevised21July.html | 2003-08-15 21:12 | 398K | ||
| rdf-primer-2003LCrevised30June.html | 2003-07-01 00:56 | 369K | ||
| rdf-primer-20010921.html | 2001-09-27 14:21 | 9.8K | ||
| rdf-primer-20010927.html | 2001-09-27 14:21 | 20K | ||
| rdf-primer-20011101.html | 2001-12-17 21:57 | 83K | ||
| rdf-primer-20011221.html | 2002-01-03 14:22 | 50K | ||
| rdf-primer-20020127.html | 2002-01-27 22:37 | 67K | ||
| rdf-primer-20020308.html | 2002-03-09 13:12 | 82K | ||
| rdf-primer-20020312.html | 2002-03-13 02:09 | 179K | ||
| rdf-primer-20020314.html | 2002-03-15 01:50 | 84K | ||
| rdf-primer-20020315.html | 2002-03-21 14:30 | 89K | ||
| rdf-primer-20020418fm.html | 2002-04-23 18:06 | 137K | ||
| rdf-primer-20020424.html | 2002-04-26 17:47 | 150K | ||
| rdf-primer-20020725.html | 2002-07-26 00:28 | 200K | ||
| rdf-primer-20020823.html | 2002-08-23 13:35 | 270K | ||
| rdf-primer-20021023.html | 2002-10-23 18:19 | 267K | ||
| rdf-primer-20021024.html | 2002-10-24 00:48 | 290K | ||
| rdf-primer-20021027 | 2002-10-28 00:32 | 297K | ||
| rdf-primer-20021027.html | 2002-10-28 00:22 | 297K | ||
| rdf-primer-20021031.html | 2002-11-01 01:46 | 312K | ||
| rdf-primer-20021107.html | 2002-11-07 23:08 | 290K | ||
| rdf-primer-20021108.html | 2002-11-08 20:02 | 290K | ||
| rdf-primer-20021108em.html | 2002-11-11 21:12 | 310K | ||
| rdf-primer-20021124.html | 2002-11-26 13:46 | 297K | ||
| rdf-primer-20021217.html | 2002-12-19 02:50 | 335K | ||
| rdf-primer-20030119.html | 2003-01-20 21:39 | 332K | ||
| rdf-primer-20030905.html | 2003-09-02 23:35 | 399K | ||
| rdf-primer-test1.html | 2002-03-08 12:16 | 74K | ||
| rdf-primer2003LCrevised15July.html | 2003-07-17 19:22 | 379K | ||
| reificationFigJul12.png | 2003-07-23 00:34 | 71K | ||
| reificationFigJul22.png | 2003-07-25 00:19 | 74K | ||
| rss.html | 2002-10-23 15:01 | 7.0K | ||
| section2.html | 2002-10-31 18:06 | 67K | ||
| styleS.css | 2001-12-20 20:09 | 469 | ||
| todo.html | 2002-01-11 15:15 | 2.1K | ||
| vanilla-display.n3 | 2001-12-07 14:38 | 1.6K | ||
| w3c-rss.crop.gif | 2003-07-17 13:01 | 33K | ||
| w3c-rss.small.gif | 2002-11-01 01:42 | 22K | ||
| xmlgraph.jpg | 2002-01-30 01:10 | 20K | ||
| xmlgraph.rdf | 2002-03-08 18:15 | 590 | ||
| xmlstripe2.jpg | 2002-01-30 01:11 | 21K | ||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
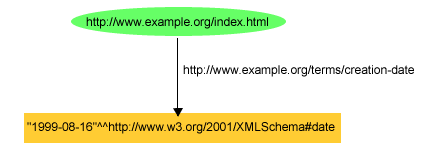{kind=link}
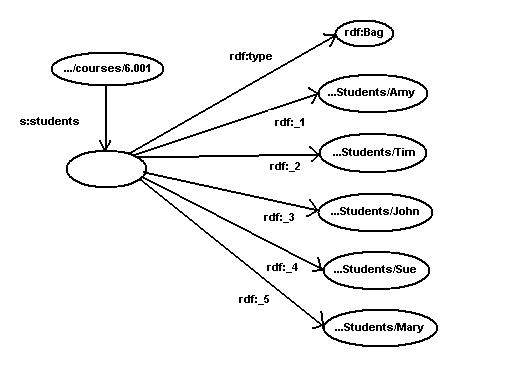{kind=link}
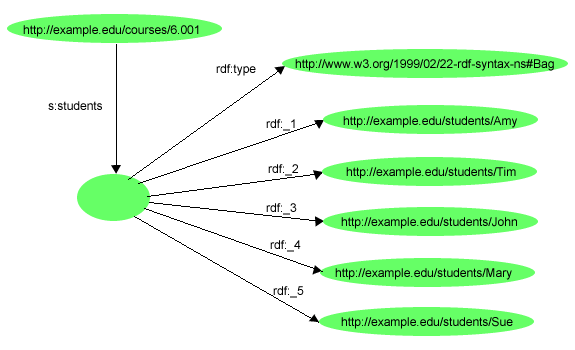{kind=link}
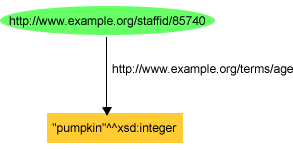{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
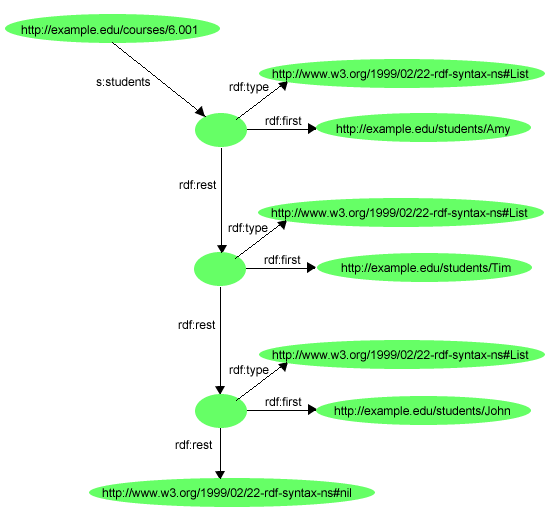{kind=link}
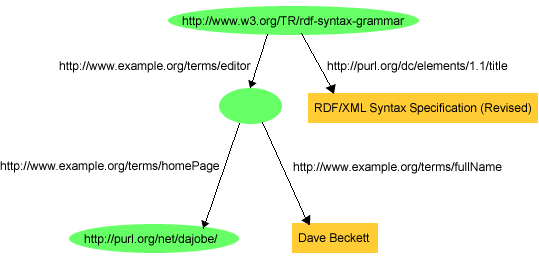{kind=link}
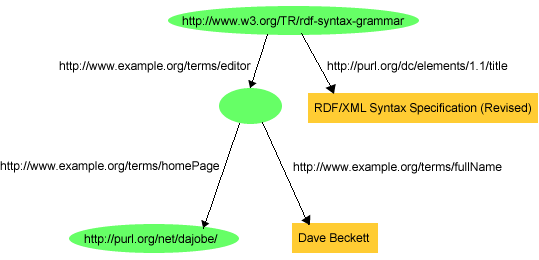{kind=link}
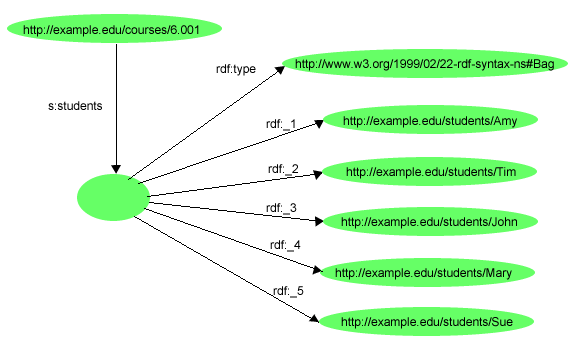{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
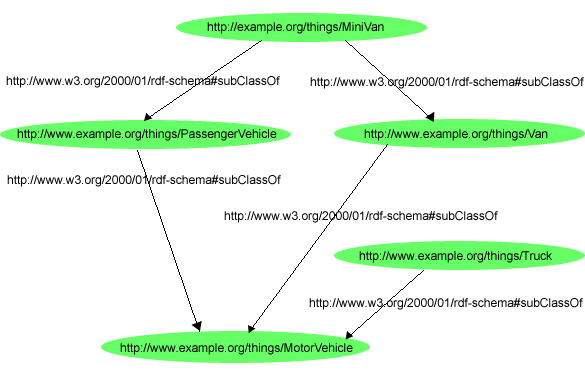{kind=link}
{kind=link}
{kind=link}
{kind=link}
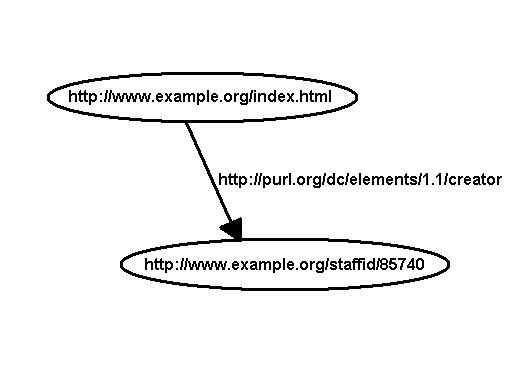{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}