Abstract
RDF - the Resource Description Framework - is a metadata
language developed by the W3C. Metadata is simply a term for
"data about data". Metadata is used in all walks of life - from
information in Web pages such as: title, author, and last
modified dates; to information about books from online shopping
facilities: prices, publisher, availablility. RDF is a common
framework enabling people to express this data in an
interoperable way. By choosing to use this common framework,
you get the added benefit that you can use some of the many
tools around (RDF parsers and processors) to maintain the data.
This Primer is designed to provide the reader the basic
fundamentals required to effectively use RDF in their
particular metadata applications.
This is a draft document and may be updated, replaced, or
obsoleted by other documents at any time. It is inappropriate
to use it as reference material or to cite as other than "work
in progress".
Table of contents
@@ toc goes here @@
Introduction
RDF - the Resource Description Framework - is a metadata
language developed by the W3C. Metadata is simply a term for
"data about data". Metadata is used in all walks of life -
from information in Web pages such as: title, author, and
last modified dates; to information about books from online
shopping facilities: prices, publisher, availablility. RDF is
a common framework enabling people to express this data in an
interoperable way. By choosing to use this common framework,
you get the added benefit that you can use some of the many
tools around (RDF parsers and processors) to maintain the
data.
@@fm: Â I'd like to replace describing RDF as a
metadata language (since some of the things we describe with
RDF aren't data, and hence statements about them can't be
"data about data") with the idea that it is a language for
describing Web resources, and we'll tell you what things
"resources" are later on. However, I haven't got
a real good way to say that yet.@@.
There is a dedicated community working on RDF, and it is
very easy to get help on projects, to ascertain how RDF may
or may not be able to help in your application. This primer
is not intended as a substitute for reading the
specifications, or getting to grips with the work currently
being done, but it is intended as a valuable resource for
enabling you to find out:-
- What does RDF look like?
- How can I write/access/process RDF?
- How does RDF affect me?
The key principles behind RDF are in fact very simple, and
it is relatively easy to port current information models so
that they use RDF. It is also just as easy to build new
information systems from scratch using RDF.
RDF itself is related to many different academic and
business environments and domains. Among the groups finding
utility in RDF are librarians, logicians, database
maintainers, knowledge representation communities, and
news/information syndicators.
Enough procastrination; what does RDF "look" like? The
following a small chunk of RDF in XML format (don't worry if
you don't know what XML is for the time being):-
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
 xmlns="http://www.w3.org/2000/10/swap/pim/contact#">
<Person
rdf:about="http://www.w3.org/People/EM/contact#me">
<mailbox rdf:resource="mailto:em@w3.org"/>
<fullName>Eric Miller</fullName>
<personalTitle>Semantic Web Activity
Lead</personalTitle> </Person>
</rdf:RDF>
This example is just a representation of some simple data
which roughly translates as "there is someone called Eric
Miller, with the email address em@w3.org, and who is the
Semantic Web Activity Lead". Note that there seem to be Web
addresses in there - the utility of which we shall explain
later on - and some rather obvious things including some
"properties" like "mailbox" and "fullName", and the values
"em@w3.org", and "Eric Miller".
The advantage of having this information in a machine
processable format is that we can link bits of data across
the Web. The twist in the plot is that instead of the simple
"hyperlinks" that one would find in HTML (the links in the
documents), we can link any "thing" to any other "thing". So,
instead of talking about Web pages, and sites, we can talk
about cars, business, personnel, news events... in fact,
anything.
As we continue through the primer, we shall be addressing
typical ways of modelling things in RDF, implementing
systems, the relationship between RDF and the "Semantic Web",
and discussing further resources and implementation for you
to chase up.
Making Statements About Resources
RDF is intended to provide a simple way to state
properties of (facts about) Web resources, e.g., Web
pages. For example, imagine that we want to
record the fact that someone named John Smith created a
particular Web page. A straightforward way to state this fact
in English would be in the form of a simple statement,
e.g.:
“The creator of
http://www.foobar.org/index.html is John
Smith“
We’ve underlined parts of this
statement to illustrate that, in order to describe the
properties of something, we need ways to name, or identify, a
number of things:
- We need a way to identify the thing we want to describe
(the Web page, in this case)
- We need a way to identify a specific property (the
creator) of the thing that we want to describe
- We need a way to identify the thing we want to assign
as the value of this property (who the creator is), for the
thing we want to describe
In this statement, we've used the Web page's URL (Uniform
Resource Locator) to identify it. Â In addition,
we’ve used the word
“creator†to identify the
property we want to talk about, and the two words
“John Smith†to identify the
thing (a person) we want to say is the value ofÂ
this property.
We could state other properties of this Web page by
writing additional English statements of the same general
form, using the URL to identify the page, and words (or other
expressions) to identify the properties and their
values. For example, to specify the date the
page was created, and the language in which the page is
written, we could write the additional statements, e.g.:
“The creation-date of
http://www.foobar.org/index.html is August 16, 1999"
“The language of
http://www.foobar.org/index.html is English
“
(note the use of "August 16, 1999" to
identify a date).
RDF is based on the idea that the things
we want to describe have properties which have values, and
that resources can be described by making statements,
similar to those above, that specify those properties and
values. RDF uses a particular terminology for
talking about the various parts of statements.Â
Specifically, the part that identifies the thing the
statement is about (the Web page in this example) is called
the subject . The part that identifies
the property or characteristic of the subject that the
statement specifies (creator, creation-date, or language in
this case) is called the predicate, and the part that
identifies the value of that property is called the
object. So, taking the English statement
“The creator of
http://www.foobar.org/index.html is John
Smith“
the RDF terms for the various parts of the statement
are:
However, while English is good for communicating between
(English-speaking) humans, RDF is about making
machine-processable statements. Â To make
these kinds of statements suitable for processing by
machines, we need two things:
- a system of machine-processable
identifiers that allows us to identify a
subject, object, or predicate in a statement without any
possibility of confusion with a similar-looking identifier
that might be used by someone else on the Web.
- a machine-processable format for representing these
statements and exchanging them between machines.
Fortunately, the existing Web architecture provides us with
both of the necessary mechanisms. The Web's Uniform Resource
Identifier (URI) provides us with a way to uniquely identify
anything we want to talk about in an RDF statement, and the
Extensible Markup Language (XML) provides us with a format
for representing and exchanging RDF statements. The next two
sections briefly describe these mechanisms.
   Â
Â
Identifiers: Uniform Resource Identifier
(URI)
If we want to discuss something, we must first identify
it. How else will you know what one is referring to? In
everyday communication, identity is assigned in many ways:
"Bob", "The Moon", "373 Whitaker Ave.", "California", "VIN
2745534", "todays weather", etc., and ambiguities are
generally resolved due to a shared semantic context between
the sender and the receiver. To identify "things" on the Web,
we also use identifiers.
As we’ve seen, the Web already provides
one form of identifier, the Uniform Resource Locator
(URL). We used a URL in our original example to identify the
Web page that John Smith created. Â A URL is a
string that identifies a Web resource by representing its
primary access mechanism (essentially, its network
“locationâ€).Â
However, we would like to be able to record information about
many things in addition to Web pages. In
particular, we’d like to record
information about lots of things that
don’t have URLs. For example,
I don’t have a URL, and yet my employer
needs to record all sorts of things about me in order to pay
my salary, keep track of the work that
I’ve been doing, and so on.Â
My doctor needs to record other sorts of things about me in
order to keep track of my medical history:Â tests
that have been performed (and the results, who performed
them, and when), shots I’ve received,
etc.
We’ve recorded information about lots
of things that don’t have URLs in files
(both manual and automated) for many years, and the way we
identify those things is by assigning them identifiers
: values that we uniquely associate with the individual
things. The identifiers we use to identify
various kinds of things go by names like
“Social Security Numberâ€,
“Part Numberâ€,
“license numberâ€,
“employee numberâ€,
“user-idâ€, etc.Â
In some cases, these identifiers (such as Social Security
Numbers) are assigned by an official authority of some
kind. In other cases, these identifiers are
generated by a private organization or
individual. In some cases, these identifiers
have a national or international scope within which they are
unique (a Social Security Number has national scope), while
in other cases they may only be unique within a very limited
scope (my employee number is only unique among the numbers
assigned by my specific employer). Nevertheless,
these identifiers serve, if used properly, to identify the
things we want to talk about.
The Web provides its own form of identifier for these
purposes , called the Uniform
Resource Identifier (URI). URIs are similar
to URLs, in that different persons or organizations can
independently create them, and use them to identify
things. However, unlike URLs, URIs are not
limited to identifying things that have network locations, or
use other computer access mechanisms. In fact,
we can create a URI to refer to anything we want to talk
about, including
- network-accessible things, such as an electronic
document, an image, a service (e.g., "today's weather
report for Los Angeles"), or a collection of other
resources.
- things that are not network-accessible, such as human
beings, corporations, and bound books in a library.
- abstract concepts that don't physically exist, like
"creator".
URIs essentially constitute an infinite stock of names
that can be used to identify things. Â No one
person or organization controls who makes URIs or how they
can be used. While some URI schemes (such as URL's
http:) depend on centralized systems (such as DNS),
other schemes (such as freenet:) are completely
decentralized. This means that (as with
any other kind of name), you don’t
need special authority or permission to create a URI for
something, and you can create URIs for things you
don’t own (just as you can use whatever
name you like for things you don’t own in
ordinary language). Â The URI is the foundation of
the Web. While nearly every other part of the Web can be
replaced, the URI cannot: it holds the Web together.
Since the URI is such a general identification mechanism,
capable of identifying anything, it should not be surprising
that RDF uses URIs as its mechanism for identifying the
subjects, objects, and predicates in statements.Â
In fact, RDF defines a resource as anything that is
identifiable by a URI, and hence using URIs allows RDF to
describe practically anything, and to state relationships
between such things as well. Â We'll see how this
works just a bit further on. Â But before we do
that, we need to introduce a way for RDF statements to be
physically represented and exchanged.
@@better segue needed@@
Documents: Extensible Markup Language (XML)
XML was designed to allow anyone to
design their own document format and then write a document in
that format. These document formats can include markup to
enhance the meaning of the document's content. This markup is
"machine-readable," that is, programs can read and understand
the corresponding structure.
The following is a simple passage marked up using an
XML-based markup language:
<sentence><person
href="http://example.com/#me">I</person> just got
a new pet
<animal>dog</animal>.</sentence>
Elements ("sentence", "person", etc.) are introduced to
reflect a particular structure associated with the passage.
As you might have guessed already, there is a problem here.
I've used the words "sentence," "person," and "animal" in my
markup language to convey meaning. But these are pretty
common words so we should be ok, right? Wrong. To a
non-English speakers, the element "person" may mean absoluely
nothing to him/her. Take the following for example.
<dfgre><reghh
bjhb="http://example.com/#me">I</reghh> just got a
new pet <yudis>dog</yudis>.</dfgre>
To a machine, its the exact same structure. All of the
sudden, its no longer clear what it is ones trying to say.
Also, what if others have used these same words in their own
markup languages but indeed have completely different
meanings? Perhaps "sentence" in another markup language
refers to the amount of time that a convicted criminal must
serve in a penal institution. How is my computer to keep
these straight?
To prevent confusion, one must uniquely
identify my markup elements. And what better way to
identify them than with a Uniform Resource Identifier. To do
this in XML, we use XML
Namespaces . This way, anyone can create their own tags
and mix them with tags made by others. A namespace is just a
way of identifying a part of the Web (space) from which we
derive the meaning of these names. I create a "namespace" for
my markup language by creating a URI for it. I'll probably
create a Web page to describe my markup language and use the
URL of my Web page as the URI for my namespace, as in: @@
reference The Professor and the Madman? @@
<my:sentence
my:xmlns="http://example.org/xml/documents/">
  <my:person
my:href="http://example.com/#me">I</my:person>
just got a new pet
<my:animal>dog</my:animal>.
</my:sentence>
Since everyone's tags have their own URIs, we don't have
to worry about tag names conflicting. The elements mean the
same if they have the same URI's.
@@fm: Â I've left this XML material in for the
moment, but I still have qualms about it, at least as it is,
since the specific connection with RDF is not really made
directly. Â Either something more needs to be said
to explicitly connect XML with RDF, or we could introduce XML
(and the whole issue of physically representing RDF
statements) after the model section, when we start to talk
about representing the graphs, and the striping approach.
 At the same time, the Intro presented an example
of RDF in XML, so perhaps we could build on that in this
section. Â But I still think I'd rather describe
the model first, then how to do it in XML.@@
The RDF Model
Now that we've introduced URIs for identifying things we
want to talk about on the Web, @@and XML as a
machine-processable way of representing RDF statements,@@ we
can describe how RDF lets us use URIs to make statements about
resources. Â In the introduction, we said that RDF
was based on the idea of expressing simple statements about
resources, using subjects, predicates, and objects.
 In RDF, we could represent our original English
statement:
“The creator of
http://www.foobar.org/index.html is John Smith
by an RDF statement having:
RDF models statements as nodes and arcs in a
graph. In this notation, a statement is
represented by a node for the subject, a node for the object,
and a labeled arc between them for the predicate.
 So the RDF statement above would be represented by
the graph:

A Simple RDF Statement
@@figure a placeholder only; Â to be replaced by
one using a URI for the predicate@@
Collections of statements are represented by corresponding
collections of nodes and arcs. So if we wanted to
also represent the additional statementsÂ
“The creation-date of
http://www.foobar.org/index.html is August 16, 1999"
“The language of
http://www.foobar.org/index.html is English
we could, introducing suitable URIs for the predicates
"creation-date" and "language", use the following graph:
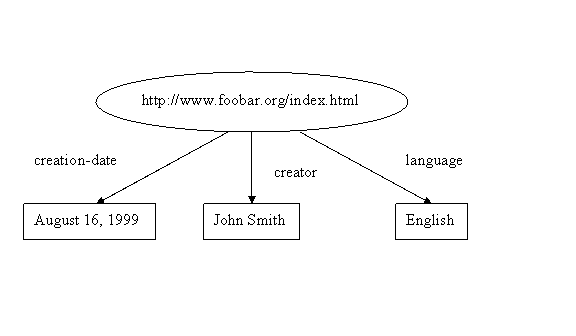
Several Statements About the Same Resource
@@This figure also a placeholder; Â new figure
should have URIs for the additional predicates, and for John
Smith@@
This graph illustrates that RDF permits the objects in
statements to be simple strings, if necessary to represent
property values, as well as URIs. In drawing RDF graphs, nodes
that represent URIs are shown as ellipses, while nodes that
represent strings are shown as boxes  RDF graphs
are technically labeled directed graphs, since the arcs have
labels, and are “directedâ€
(point in a specific direction, from subject to object).
Sometimes it is not convenient to draw graphs, so an
alternative way of writing down the statements, called
Ntriples , can also be used. In the Ntriples
notation, each statement in the graph is written as a simple
triple of subject, predicate, and object, in that
order. The Ntriples representing the above three
statements would be written:Â
<http://www.foobar.org/index.html>Â Â Â Â Â Â Â
<http://purl.org/dc/elements/1.1/creator>Â Â Â
<http://www.foobar.org/staffid/85740> .
<http://www.foobar.org/index.html>Â Â
<http://www.foobar.org/terms/creation-date>Â Â
"August 16, 1999" .
<http://www.foobar.org/index.html>Â Â
<http://www.foobar.org/terms/language>Â Â Â Â Â Â Â Â Â
"English" .
Each triple corresponds to a single arc in the graph,
complete with the arc’s beginning and ending
nodes (the subject and object of the statement).Â
Unlike the drawn graph, the triple notation requires that a
node be separately identified for each statement it appears
in. So, for example,
http://www.foobar.org/index.html appears three times (once
in each triple) in the triple representation of the graph, but
only once in the drawn graph..
These examples begin to illustrate some of the advantages of
using URIs as RDF's basic way of identifying things.
 For instance, instead of identifying the creator
of the Web page in our first example by the string
“John Smithâ€, we've assigned him
a URI, in this case (using a URI based on his employee number)
http://www.foobar.org/staffid/85740 . An
advantage of using a URI in this case is that we can be more
precise in our identification. That is, the
creator of the page isn’t the string
“John Smithâ€, or any one of the
thousands of people having “John
Smith†as their name, but the particular John Smith
associated with that URI (whoever created the URI defines the
association). Moreover, since we have a URI for
the creator of the page, it is a full-fledged resource, and we
can record additional information about him, such as his name,
and age, as in the graph
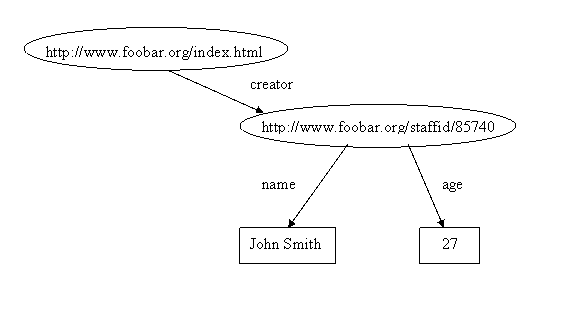
More Information about John Smith
@@also a placeholder; Â predicates need to be
URIs@
The examples also illustrate that RDF uses URIs as
predicates in RDF statements. That is, rather
than using strings such as
“creator†or
“name†to identify properties,
RDF uses URIs. Â Using URIs to identify
properties is important for a number of
reasons. First, it allows us to distinguish the
properties we use from properties someone else may use that
would otherwise be identified by the same text
string. For instance, in our example, foobar.org
uses “name†to mean someone's
full name written out as a string (e.g.,
“John Smithâ€), but someone else
may intend "name" to mean something different (e.g., the name
of a variable in a piece of program text). A
program encountering “name†as a
property identifier on the Web wouldn’t
necessarily be able to distinguish these uses.Â
However, if foobar.org writes
http://www.foobar.org/terms/name for its
“name†property, and the other
person writes
http://geneology.org/terms/name for hers, we can keep
straight the fact that there are distinct properties involved
(even if a program can't automatically determine the distinct
meanings). Another reason why it is important to
use URIs to identify properties is that it allows us to treat
RDF properties as resources themselves. Since
properties are resources, we can record
descriptive information about them (e.g., the English
description of what foobar.org means by
“nameâ€), simply by adding
additional RDF statements with the property's URI as the
subject.
Using URIs as subjects, objects, and predicates in RDF
statements allows us to begin to develop and use a shared
vocabulary on the Web, reflecting (and creating) a shared
understanding of the concepts we talk about. For
example, in the triple
<http://www.foobar.org/index.html>Â Â Â Â Â Â Â
<http://purl.org/dc/elements/1.1/creator>Â Â Â
<http://www.foobar.org/staffid/85740> .
the predicate
http://purl.org/dc/elements/1.1/creator is an unambiguous
reference to the “creatorâ€
attribute in the Dublin Core metadata attribute set, a
widely-used collection of attributes (properties) for
describing information of all kinds. The writer of
this triple is effectively saying that the relationship between
the Web page (identified by
http://www.foobar.org/index.html ) and the creator of the
page (a distinct person, identified by
http://www.foobar.org/staffid/85740 ) is exactly the
concept defined by
http://purl.org/dc/elements/1.1/creator .Â
Moreover, anyone else, or any program, that understands
http://purl.org/dc/elements/1.1/creator will know exactly
what is meant by this relationship.Â
As a result, RDF provides a way to make statements that are
machine-processable. Now the computer can't
actually "understand" what you said, of course, but it can deal
with it in a way that makes it seem like it does. For example,
I could search the Web for all book reviews and create an
average rating for each book. Then, I could put that
information back on the Web. Another website could take that
information (the list of book rating averages) and create a
"Top Ten Highest Rated Books" page. RDF provides a way of
recording knowledge so that applications can more easily
process.
RDF statements are similar to a number of other formats for
recording information, such as:
- entries in a simple record or catalog listing describing
the resource in a data processing system.
- rows in a simple relational database.
- simple assertions in formal logic
and information in these formats can be treated as RDF
statements, allowing RDF to be used as a unifying model for
integrating data from many sources.
Â
More Complex Data Â
Things would be very simple if the only types of information we
had to record about things were obviously in the form of the
simple RDF statements we’ve illustrated so
far. However, most real-world data involves
structures that are more complicated than that, at least on the
surface. For instance, in our original example, we
recorded the date the Web page was created as a simple string
value. However, suppose we wanted to record the
month, day, and year as separate pieces of
information? Or, in the case of John
Smith’s personal information, suppose we
wanted to record his address. We might write the
whole address out as a string, as in the Ntriple
<http://www.foobar.org/staffid/85740>  <http://www.foobar.org/terms/address>  “1501
Grant Avenue, Bedford, Massachusetts 01730†.
However, suppose we wanted to record the various pieces of
information about his address as separate street, city, state,
and Zip code values? How do we do this using
RDF?
In RDF, we can represent such structured information by
considering the aggregate thing we want to talk about (like
John Smith's address) as a separate resource, and then making
separate statements about that new resource. So,
in the RDF graph, in order to break up John
Smith’s address into its component parts, we
create a new node to represent the concept of John
Smith’s address, and assign that concept a
new URI to identify it, say
http://www.foobar.org/addressid/85740 . We
then write RDF statements (create additional arcs and nodes)
with that node as the subject, to represent the additional
information, producing the graph below:
@@Note:Â this figure needs
to be redone, with
<http://www.foobar.org/addressid/85740> in the current
blank address node in the graph

Â
or the Ntriples:
<http://www.foobar.org/staffid/85740>Â Â Â Â Â Â
<http://www.foobar.org/terms/address>Â Â
<http://www.foobar.org/addressid/85740> .
<http://www.foobar.org/addressid/85740>
<http://www.foobar.org/terms/street>Â Â Â Â Â
"1501 Grant Avenue" .
<http://www.foobar.org/addressid/85740>
<http://www.foobar.org/terms/city>Â Â Â Â Â Â Â Â
"Bedford" .
<http://www.foobar.org/addressid/85740>
<http://www.foobar.org/terms/state>Â Â Â Â Â Â
"Massachusetts" .
<http://www.foobar.org/addressid/85740>
<http://www.foobar.org/terms/Zip>Â Â Â Â Â Â Â Â Â
"01730" .
In the drawing of the graph above, the new URI we assigned
to identify "John Smith's address" really You are recommended
to use CSS to specify the font and properties such as its size
and color. This will reduce the size of HTML files and make
them easier maintain compared with using
elements. serves no purpose, since we could just as easily have
drawn the graphÂ
In this drawing, which is perfectly good
RDF, we've used a node without a label to stand for the concept
of "John Smith's address". Â This unlabeled node, or
bNode (for blank node) functions perfectly well in the
drawing without needing a URI. However, we do need
some form of explicit identifier for that node in order to
represent this graph in Ntriples. To see this, we
can try to write the Ntriples corresponding to what is shown in
Figure 7. Â What we would get would be
something like:
<http://www.foobar.org/staffid/85740>Â Â Â Â Â Â
<http://www.foobar.org/terms/address>Â Â
??? .
???                                                           Â
<http://www.foobar.org/terms/street>Â Â Â Â Â
"1501 Grant Avenue" .
???                                                           Â
<http://www.foobar.org/terms/city>Â Â Â Â Â Â Â Â
"Bedford" .
???                                                           Â
<http://www.foobar.org/terms/state>Â Â Â Â Â Â
"Massachusetts" .
???                                                           Â
<http://www.foobar.org/terms/Zip>Â Â Â Â Â Â Â Â Â
"01730" .
where ??? stands for something that indicates
the presence of the bNode.  Since in a
complex graph there might be more than one such bNode, we also
need a way to differentiate between the various bNodes in the
corresponding triples representation. To do this,
the triples notation uses a concept of node identifiers (or
nodeIDs) to identify bNodes. These are temporary
identifiers distinct from URIs (and having their own syntax in
Ntriples) that are used to indicate the presence of bNodes in
the Ntriples representation. In this example, we
might generate the node identifier _:johnaddress to refer to
the bNode, in which case the resulting triples might be:
<http://www.foobar.org/staffid/85740>Â Â Â Â Â Â
<http://www.foobar.org/terms/address>Â Â
_:johnaddress .
_:johnaddress                                           Â
<http://www.foobar.org/terms/street>Â Â Â Â Â
"1501 Grant Avenue" .
_:johnaddress                                           Â
<http://www.foobar.org/terms/city>Â Â Â Â Â Â Â Â
"Bedford" .
_:johnaddress                                           Â
<http://www.foobar.org/terms/state>Â Â Â Â Â Â
"Massachusetts" .
_:johnaddress                                           Â
<http://www.foobar.org/terms/Zip>Â Â Â Â Â Â Â Â Â
"01730" .
@@more about bNodes (?)
@@other subjects?
@@following is possible segue to RDF Schema@@
This is all there is to basic RDF - nodes-and-arcs diagrams
interpreted as statements about concepts or digital resources
represented by URIs . However, the need for standardized
vocabularies for things like "organization" and the predicate
"is a" is evident. The basis for such vocabularies in RDF is
RDF Schema.
RDF Schema provides the basic vocabulary to express
relationships between terms: resources being instances of terms
("http://www.w3c.org/organization is an organization"), terms
being subterms of other terms ("a hex-head bolt is a type of
machine bolt") and so on.
It also provides means to restrict the usage of predicates:
"is a parent of" only applies to persons, etc. The terms
instance, subterm, applies to are the kind of terms defined by
the RDF Schema specification.
Using the vocabulary provided by RDF Schema, it is easy to
create your own semantically rich vocabularies