RDF Primer
W3C Editor's Draft 12 March 2002
- This version:
- rdf-primer-20020312
- Latest version:
- rdf-primer
- Previous version:
- rdf-primer-20020308
- Editors:
- Frank Manola, The MITRE Corporation,
fmanola@mitre.org
- Eric Miller, W3C, em@w3.org
Copyright
©2001,2002
W3C
®
(
MIT
,
INRIA
,
Keio
),
All Rights Reserved. W3C
liability
,
trademark
,
document use
and
software licensing
rules
apply
.
Abstract
The Resource Description Framework (RDF) is a general-purpose
language for representing information in the World Wide Web. It is
particularly intended for representing metadata about Web resources,
such as the title, author, and modification date of a Web page, the
copyright and syndication information about a Web document, the availability
schedule for some shared resource, or the description of a Web user's
preferences for information delivery. RDF provides a common framework
for expressing this information in such a way that it can be exchanged
between applications without loss of meaning. Since it is a common framework,
application designers can leverage the availability of common RDF parsers
and processing tools. Exchanging information between different applications
means that the information may be made available to applications
other than those for which it was originally created. This Primer is
designed to provide the reader the basic fundamentals required to effectively
use RDF in their particular applications.
This is a draft document, is undergoing active editorial
work, and may be updated, replaced, or obsoleted by other documents
at any time. It is inappropriate to use it as reference material or to
cite it as other than "work in progress".
Table of contents
1. Introduction
2. Making Statements About Resources
2.1 Identifiers: Uniform
Resource Identifier (URI)
2.2 Documents: Extensible Markup Language (XML)
2.3 The RDF Model
2.4 Structured Property Values
3. An XML Syntax for RDF
4. Defining RDF Vocabularies: RDF Schema
4.1 Core Classes
4.2 Core Properties
4.3 Constraints
5. RDF In The Field: Some
RDF Application
5.1 Dublin Core Metadata
Initiative
5.2 PRISM
5.3 Intelligent Routing
5.4 RSS: RDF Site Summary 1.0
6. Other Parts of RDF
7. References
8. Acknowledgements
1. Introduction
The Resource Description Framework (RDF) is a
general-purpose language for representing information in the World
Wide Web. It is particularly intended for representing metadata about
Web resources, such as the title, author, and modification date of
a Web page, the copyright and syndication information about a Web document,
the availability schedule for some shared resource, or the description
of a Web user's preferences for information delivery. However, by
generalizing the concept of a "Web resource", RDF can be used to represent
information about anything that can be identified on the Web, such
as information about items available from online shopping facilities
(e.g., information about prices, publishers, and availability of books
or recordings).
RDF provides a common framework for expressing
this information in such a way that it can be exchanged between
applications without loss of meaning. Since it is a common framework,
application designers can leverage the availability of common RDF
parsers and processing tools. Exchanging information between different
applications means that the information may be made available to applications
other than those for which it was originally created.
To make this discussion somewhat more concrete
as soon as possible, the following is a small chunk of RDF in its
XML serialization format.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns="http://www.w3.org/2000/10/swap/pim/contact#">
<Person rdf:about="http://www.w3.org/People/EM/contact#me">
<mailbox rdf:resource="mailto:em@w3.org"/>
<fullName>Eric Miller</fullName>
<personalTitle>Semantic Web Activity Lead</personalTitle>
</Person>
</rdf:RDF>
This example roughly translates as a collection
of statements "there is someone called Eric Miller, with the email
address em@w3.org, and who is the Semantic Web Activity Lead". Note
that the example contains what seem to be Web addresses, as well
as some "properties" like "mailbox" and "fullName", and the values
"em@w3.org", and "Eric Miller".
Like HTML, this form of information is machine
processable, and links pieces of data acorss the Web. However,
unlike conventional hypertext, RDF links can also be to any identifiable
things, including things that may or may not be Web-based data. The
result is that in addition to describing Web pages, we can also convey
information about cars, businesses, people, news events, etc. Further,
RDF links themselves can be labeled, to indicate the kind of
relationship that exists between the linked items.
The complete specification of RDF consists of a
number of documents:
This Primer is intended to augment the other parts
of the RDF specification, to help information system designers and
application developers understand the features of RDF, and how to
use them. In particular, the Primer is intended to answer such questions
as:
- What information can RDF represent?
- What does RDF look like?
- How is RDF information created, accessed, and
processed?
- How can existing information be combined with
RDF?
The Primer is a non-normative document, which means
that it does not provide a definitive (from the W3C's point of view) specification
of RDF. The examples and other explanatory material in this document are
provided to help you understand RDF, but they may not always provide definitive
or fully-complete answers. In such cases, you should refer to the relevant
normative parts of the RDF specification. To help you do this, we provide
links pointing to the relevant parts of the normative specifications.
2. Making Statements About Resources
RDF is intended to provide a simple way to state
properties of (facts about) Web resources, e.g., Web pages.
For example, imagine that we want to record the fact that someone
named John Smith created a particular Web page. A straightforward
way to state this fact in English would be in the form of a simple
statement, e.g.:
The creator
of
http://www.example.org/index.html
is
John Smith
We've underlined parts of this statement to illustrate
that, in order to describe the properties of something, we
need ways to name, or identify, a number of things:
- We need a way to identify the thing we want
to describe (the Web page, in this case)
- We need a way to identify a specific property
(the creator) of the thing that we want to describe
- We need a way to identify the thing we want
to assign as the value of this property (who the creator is),
for the thing we want to describe
In this statement, we've used the Web page's URL
(Uniform Resource Locator) to identify it. In addition, we've used
the word "creator" to identify the property we want to talk
about, and the two words "John Smith" to identify the thing (a person)
we want to say is the value of this property.
We could state other properties of this Web page
by writing additional English statements of the same general
form, using the URL to identify the page, and words (or other expressions)
to identify the properties and their values. For example, to specify
the date the page was created, and the language in which the page
is written, we could write the additional statements, e.g.:
The creation-date of
http://www.example.org/index.html
is August 16, 1999
The language of
http://www.example.org/index.html
is English
(note the use of "August 16, 1999" to identify
a date).
RDF is based on the idea that the things
we want to describe have properties which have values, and that
resources can be described by making statements, similar
to those above, that specify those properties and values. RDF uses
a particular terminology for talking about the various parts of statements.
Specifically, the part that identifies the thing the statement is
about (the Web page in this example) is called the subject .
The part that identifies the property or characteristic of the subject
that the statement specifies (creator, creation-date, or language
in this case) is called the predicate, and the part that
identifies the value of that property is called the object
. So, taking the English statement
The creator of
http://www.example.org/index.html
is John Smith
the RDF terms for the various parts of the statement
are:
However, while English is good for communicating
between (English-speaking) humans, RDF is about making
machine-processable statements. To make these kinds of
statements suitable for processing by machines, we need two things:
- a system of machine-processable identifiers
that allows us to identify a subject, object, or predicate in
a statement without any possibility of confusion with a similar-looking
identifier that might be used by someone else on the Web.
- a machine-processable format for representing
these statements and exchanging them between machines.
Fortunately, the existing Web architecture provides
us with both of the necessary mechanisms. The Web's Uniform
Resource Identifier (URI) provides us with a way to uniquely identify
anything we want to talk about in an RDF statement, and the Extensible
Markup Language (XML) provides us with a format for representing
and exchanging RDF statements. The next two sections briefly describe
these mechanisms.
2.1 Identifiers: Uniform Resource Identifier (URI)
If we want to discuss something, we must first
identify it. How else will you know what one is referring to? In
everyday communication, identity is assigned in many ways: "Bob",
"The Moon", "373 Whitaker Ave.", "California", "VIN 2745534", "todays
weather", etc., and ambiguities are generally resolved due to a
shared semantic context between the sender and the receiver. To
identify "things" on the Web, we also use identifiers.
As we've seen, the Web already provides one form
of identifier, the Uniform Resource Locator (URL). We
used a URL in our original example to identify the Web page that
John Smith created. A URL is a string that identifies a Web resource
by representing its primary access mechanism (essentially, its network
"location"). However, we would like to be able to record information
about many things in addition to Web pages. In particular, we'd like
to record information about lots of things that don't have URLs. For
example, I don't have a URL, and yet my employer needs to
record all sorts of things about me in order to pay my salary, keep
track of the work that I've been doing, and so on. My doctor needs
to record other sorts of things about me in order to keep track of
my medical history:� tests that have been performed (and the results,
who performed them, and when), shots I've received, etc.
We've recorded information about lots of things
that don't have URLs in files (both manual and automated) for many
years, and the way we identify those things is by assigning
them identifiers : values that we uniquely
associate with the individual things. The identifiers we use to
identify various kinds of things go by names like "Social Security
Number", "Part Number", "license number", "employee number", "user-id",
etc. In some cases, these identifiers (such as Social Security Numbers)
are assigned by an official authority of some kind. In other cases,
these identifiers are generated by a private organization or individual.
In some cases, these identifiers have a national or international
scope within which they are unique (a Social Security Number
has national scope), while in other cases they may only be unique
within a very limited scope (my employee number is only unique among
the numbers assigned by my specific employer). Nevertheless, these
identifiers serve, if used properly, to identify the things we want
to talk about.
The Web provides its own form of identifier for
these purposes, called the
Uniform Resource Identifier
(URI). URIs are similar to URLs, in that different persons or
organizations can independently create them, and use them to identify
things. However, unlike URLs, URIs are not limited to identifying
things that have network locations, or use other computer access
mechanisms. In fact, we can create a URI to refer to anything we
want to talk about, including
- network-accessible things, such as an electronic
document, an image, a service (e.g., "today's weather
report for Los Angeles"), or a collection of other resources.
- things that are not network-accessible, such
as human beings, corporations, and bound books in a library.
- abstract concepts that don't physically exist,
like the concept of a "creator".
URIs essentially constitute an infinite stock of
names that can be used to identify things. No one person or
organization controls who makes URIs or how they can be used. While
some URI schemes (such as URL's http:) depend on centralized
systems (such as DNS), other schemes (such as freenet:
) are completely decentralized. This means that (as with any other kind of name), you don't need special authority
or permission to create a URI for something, and you can create
URIs for things you don't own (just as you can use whatever name
you like for things you don't own in ordinary language). The URI is the
foundation of the Web. While nearly every other part of the Web can
be replaced, the URI cannot: it holds the Web together.
Since the URI is such a general identification
mechanism, capable of identifying anything, it should not be surprising
that RDF uses URIs as its mechanism for identifying the subjects,
objects, and predicates in statements. In fact, RDF defines a
resource as anything that is identifiable by a URI, and
hence using URIs allows RDF to describe practically anything, and
to state relationships between such things as well. We'll see how
this works just a bit further on. But before we do that, we need
to introduce a way for RDF statements to be physically represented
and exchanged.
@@May want a better seque to the next section.@@
@@Also need to resolve where the fragment identifiers text goes. It logically
goes here with the URI discussion, but the explanatory text uses N-triples,
which are not introduced until later. NB: That explanatory text also needs
to be reformulated to use absolute URIs.@@
2.2 Documents: Extensible Markup Language (XML)
XML
was designed to allow anyone to design their own document
format and then write a document in that format. Like HTML documents
(Web pages), XML documents contain text. This text consists primarily
of plain text content, andmarkup in the form of tags.
This markup allows a processing program to interpret the various
pieces of content (elements). In HTML, the set of permissable tags,
and their interpretation, is defined by the HTML specification.
However, XML allows users to define their own markup languages (tags
and the structures in which they can appear) adapted to their own
specific requirements. For example, the following is a simple passage
marked up using an XML-based markup language:
<sentence><person href="http://example.com/#me">I</person>
just got a new pet <animal>dog</animal>.</sentence>
Elements delimited by tags ("sentence", "person",
etc.) are introduced to reflect a particular structure associated
with the passage. These tags allow a program written with an
understanding of these particular elements to properly interpret the
passage.
This particular markup language uses the words
"sentence," "person," and "animal" to attempt to convey meaning.
And they would to an English-speaking person reading it, or to a
program specifically written to interpret this vocabulary. However,
there is no built-in meaning here. For example, to non-English speakers,
or to a program not written to understand this markup, the element
"person" may mean absolutely nothing. Take the following for example.
<dfgre><reghh bjhb="http://example.com/#me">I</reghh>
just got a new pet <yudis>dog</yudis>.</dfgre>
To a machine, this is the exact same structure
as the previous example. However, it is no longer clear what is
being said. Moreover, others may have used the same words in their
own markup languages, but with completely different intended meanings.
For example, "sentence" in another markup language might refer to
the amount of time that a convicted criminal must serve in a penal
institution. So additional mechanisms must be provided to help keep
XML vocabulary straight.
To prevent confusion, it is necessary to uniquely
identify markup elements. This is done in
XML using XML Namespaces
. A namespace is just a way of identifying a part of the
Web (space) which acts as a qualifier for a specific set of
names. A "namespace" is created for an XML markup language by
creating a URI for it. By qualifying tag names with the URIs of their
namespaces, anyone can create their own tags and properly distinguish
them from tags created by others. A useful practice is to create
a Web page to describe the markup language (and the intended meaning
of the tags) and use the URL of that Web page as the URI for its namespace.
<my:sentence my:xmlns="http://example.org/xml/documents/">
<my:person my:href="http://example.com/#me">I</my:person>
just got a new pet <my:animal>dog</my:animal>.
</my:sentence>
Since everyone's tags have their own URIs, we don't
have to worry about tag names conflicting. The elements mean the
same if they have the same URIs.
RDF defines a specific XML markup language for
use in writing down RDF information, and for exchanging it between
machines. An example of this language was given in
Section 1
, and the language is described in Section 3
.
@@Needs some brief additional explanation of the
namespace mechanism, and how it's used.@@
Now that we've introduced URIs for identifying
things we want to talk about on the Web, and XML as a machine-processable
way of representing RDF statements, we can describe how RDF lets us
use URIs to make statements about resources. In the introduction,
we said that RDF was based on the idea of expressing simple statements
about resources, using subjects, predicates, and objects. In RDF, we
could represent our original English statement:
The creator of
http://www.example.org/index.html
is John Smith
by an RDF statement having:
RDF models statements as nodes and arcs in a graph.
In this notation, a statement is represented by a node for the subject,
a node for the object, and a labeled arc between them for the
predicate. So the RDF statement above would be represented by the
graph
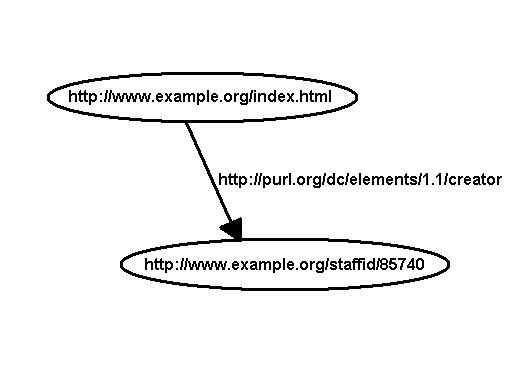
Figure 1: A Simple RDF Statement
Collections of statements are represented by corresponding
collections of nodes and arcs. So if we wanted to also represent
the additional statements
The creation-date of
http://www.example.org/index.html
is August 16, 1999
The language of
http://www.example.org/index.html
is English
we could, introducing suitable URIs to name the
properties "creation-date" and "language", use the following graph:
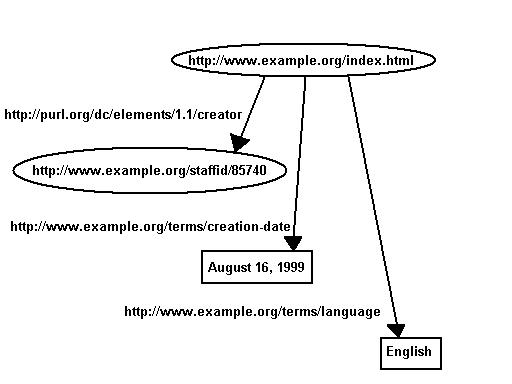
Figure 2: Several Statements About the Same Resource
This graph illustrates that RDF permits the objects
in statements to be simple strings, if necessary to represent
property values, as well as URIs. In drawing RDF graphs, nodes that
represent URIs are shown as ellipses, while nodes that represent strings
are shown as boxes. RDF graphs are technically "labeled directed graphs",
since the arcs have labels, and are "directed" (point in a specific
direction, from subject to object).
Sometimes it is not convenient to draw graphs,
so an alternative way of writing down the statements, called
N-triples
, can also be used. In the N-triples notation, each statement
in the graph is written as a simple triple of subject, predicate, and
object, in that order. The N-triples representing the above three statements
would be written:
<http://www.example.org/index.html>
<http://purl.org/dc/elements/1.1/creator>
<http://www.example.org/staffid/85740> .
<http://www.example.org/index.html>
<http://www.example.org/terms/creation-date>
"August 16, 1999" .
<http://www.example.org/index.html>
<http://www.example.org/terms/language>
"English" .
Each triple corresponds to a single arc in the
graph, complete with the arc's beginning and ending nodes (the subject
and object of the statement). Unlike the drawn graph, the N-triple
notation requires that a node be separately identified for each statement
it appears in. So, for example,
http://www.example.org/index.html
appears three times (once in each triple) in the N-triple
representation of the graph, but only once in the drawn graph.
These examples begin to illustrate some of the
advantages of using URIs as RDF's basic way of identifying things.
For instance, instead of identifying the creator of the Web page in
our first example by the string "John Smith", we've assigned him
a URI, in this case (using a URI based on his employee number)
http://www.example.org/staffid/85740
. An advantage of using a URI in this case is that we can be
more precise in our identification. That is, the creator of the
page isn't the string "John Smith'', or any one of the thousands
of people having "John Smith" as their name, but the particular John
Smith associated with that URI (whoever created the URI defines the
association). Moreover, since we have a URI for the creator of the
page, it is a full-fledged resource, and we can record additional
information about him, such as his name, and age, as in the graph
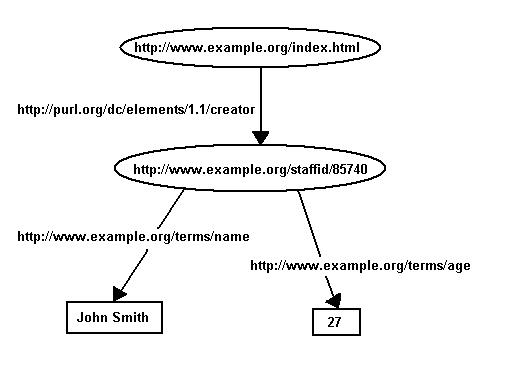
Figure 3: More Information about John Smith
The examples also illustrate that RDF uses URIs
as predicates in RDF statements. That is, rather than using
strings such as "creator" or "name" to identify properties, RDF uses
URIs. Using URIs to identify properties is important for a number of
reasons. First, it allows us to distinguish the properties we use from
properties someone else may use that would otherwise be identified by
the same text string. For instance, in our example, example.org uses
"name" to mean someone's full name written out as a string (e.g., "John
Smith"), but someone else may intend "name" to mean something different
(e.g., the name of a variable in a piece of program text). A program
encountering "name" as a property identifier on the Web wouldn't necessarily
be able to distinguish these uses. However, if example.org writes
http://www.example.org/terms/name
for its "name" property, and the other person writes
http://example.geneology.org/terms/name
for hers, we can keep straight the fact that there are distinct
properties involved (even if a program can't automatically determine
the distinct meanings). Another reason why it is important to use
URIs to identify properties is that it allows us to treat RDF properties
as resources themselves. Since properties are resources, we can record
descriptive information about them (e.g., the English description of
what example.org means by "name"), simply by adding additional RDF
statements with the property's URI as the subject.
Using URIs as subjects, objects, and predicates
in RDF statements allows us to begin to develop and use a shared
vocabulary on the Web, reflecting (and creating) a shared understanding
of the concepts we talk about. For example, in the N-triple
<http://www.example.org/index.html>
<http://purl.org/dc/elements/1.1/creator>
<http://www.example.org/staffid/85740> .
the predicate
http://purl.org/dc/elements/1.1/creator
is an unambiguous reference to the "creator" attribute in the
Dublin Core metadata attribute set, a widely-used collection of
attributes (properties) for describing information of all kinds. The
writer of this triple is effectively saying that the relationship between
the Web page (identified by
http://www.example.org/index.html
) and the creator of the page (a distinct person, identified
by
http://www.example.org/staffid/85740
) is exactly the concept defined by
http://purl.org/dc/elements/1.1/creator
. Moreover, anyone else, or any program, that understands
http://purl.org/dc/elements/1.1/creator
will know exactly what is meant by this relationship.
As a result, RDF provides a way to make statements
that applications can more easily process. Now an application can't
actually "understand" such statements, of course, but it can deal
with them in a way that makes it seem like it does. For example, a
user could search the Web for all book reviews and create an average rating
for each book. Then, the user could put that information back on the
Web. Another website could take that information (the list of book rating
averages) and create a "Top Ten Highest Rated Books" page. @@This discussion
of machine-processability could use some further qualification and amplification.@@
RDF statements are similar to a number of other
formats for recording information, such as:
- entries in a simple record or catalog listing
describing the resource in a data processing system.
- rows in a simple relational database.
- simple assertions in formal logic
and information in these formats can be treated as RDF
statements, allowing RDF to be used as a unifying model for integrating
data from many sources.
2.4 Structured Property Values
Things would be very simple if the only types of
information we had to record about things were obviously in the form
of the simple RDF statements we've illustrated so far. However, most
real-world data involves structures that are more complicated than
that, at least on the surface. For instance, in our original example,
we recorded the date the Web page was created as a simple string value.
However, suppose we wanted to record the month, day, and year as separate
pieces of information? Or, in the case of John Smith's personal information,
suppose we wanted to record his address. We might write the whole
address out as a string, as in the N-triple
<http://www.example.org/staffid/85740>
<http://www.example.org/terms/address>
"1501 Grant Avenue, Bedford, Massachusetts 01730" .
However, suppose we wanted to use RDF to record
the various pieces of information about his address as separate street,
city, state, and Zip code values. How do we do this?
We can represent such structured information
in RDF by considering the aggregate thing we want to talk about (like
John Smith's address) as a separate resource, and then making
separate statements about that new resource. So, in the RDF graph,
in order to break up John Smith's address into its component parts, we
create a new node to represent the concept of John Smith's address, and
assign that concept a new URI to identify it, say
http://www.example.org/addressid/85740
. We then write RDF statements (create additional arcs and
nodes) with that node as the subject, to represent the additional
information, producing the graph below:
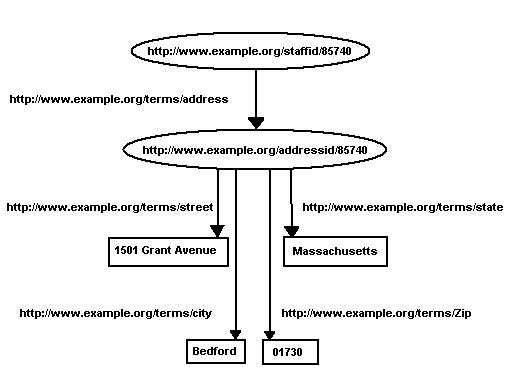
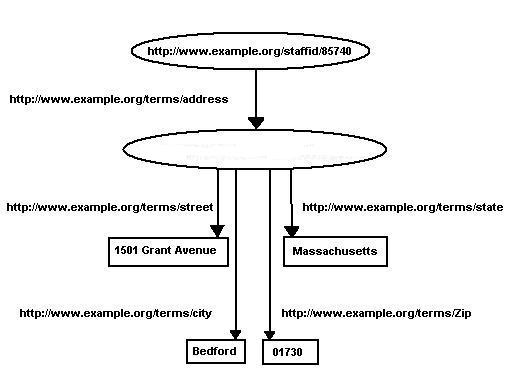
Figure 4: Breaking Up John's Address
or the N-triples:
<http://www.example.org/staffid/85740>
<http://www.example.org/terms/address>
<http://www.example.org/addressid/85740> .
<http://www.example.org/addressid/85740>
<http://www.example.org/terms/street>
"1501 Grant Avenue" .
<http://www.example.org/addressid/85740>
<http://www.example.org/terms/city>
"Bedford" .
<http://www.example.org/addressid/85740>
<http://www.example.org/terms/state>
"Massachusetts" .
<http://www.example.org/addressid/85740>
<http://www.example.org/terms/Zip>
"01730" .
In the drawing of the graph above, the new URI
we assigned to identify "John Smith's address" really serves
no purpose, since we could just as easily have drawn the graph:�
In this drawing, which is a perfectly good
RDF graph, we've used a node without a label to stand for the concept
of "John Smith's address". This unlabeled node, or bNode
(for blank node) functions perfectly well in the drawing without needing
a URI. However, we do need some form of explicit identifier for that
node in order to represent this graph as N-triples. To see this, we can
try to write the N-triples corresponding to what is shown in the drawn
graph. What we would get would be something like:
<http://www.example.org/staffid/85740>
<http://www.example.org/terms/address>
??? .
???
<http://www.example.org/terms/street>
"1501 Grant Avenue" .
???
<http://www.example.org/terms/city>
"Bedford" .
???
<http://www.example.org/terms/state>
"Massachusetts" .
???
<http://www.example.org/terms/Zip>
"01730" .
where ??? stands for something that indicates
the presence of the bNode. Since in a complex graph there might be more
than one such bNode, we also need a way to differentiate between the
various bNodes in the corresponding N-triples representation. To
do this, the N-triples notation uses a concept of node identifiers
(or nodeIDs) to identify bNodes. These are temporary identifiers
distinct from URIs (and having their own syntax in N-triples) that
are used to indicate the presence of bNodes in the N-triples representation.
In this example, we might generate the node identifier _:johnaddress
to refer to the bNode, in which case the resulting triples might be:
<http://www.example.org/staffid/85740>
<http://www.example.org/terms/address>
_:johnaddress .
_:johnaddress
<http://www.example.org/terms/street>
"1501 Grant Avenue" .
_:johnaddress
<http://www.example.org/terms/city>
"Bedford" .
_:johnaddress
<http://www.example.org/terms/state>
"Massachusetts" .
_:johnaddress
<http://www.example.org/terms/Zip>
"01730" .
This is all there is to basic
RDF: nodes-and-arcs diagrams interpreted as statements about concepts
or digital resources represented by URIs . However, the need for standardized
vocabularies for things like "city" and the predicate "creator"
is evident. The basis for such vocabularies in RDF is RDF Schema
, which will be described in Section 4
. Additional discussion of the basic ideas underlying the RDF data
model, and its role in providing a general language for describing Web
information, can be found in [
WEBDATA
].
3. An XML Syntax for RDF
To summarize what we've said already, RDF
models statements in terms of a graph consisting of nodes
and arcs. The nodes describe
resources that can be labelled with URIs, string literals or are blank.
The arcs connect the nodes and are all labelled with URIs.
This graph is more precisely called a directed edge-labelled graph;
each edge is an arc with a direction (an arrow) connecting two nodes.
These edges can also be described as triples of subject node
, at the blunt end of the arrow/arc, property
arc and an object node at the sharp end of the arrow/arc.
The property arc is interpreted as an attribute, relationship or predicate
of the resource, with a value given by the object node content.
RDF also defines an XML syntax for writing
down and exchanging RDF graphs. This syntax is defined in the
RDF/XML Syntax Specification
. In order to encode the graph in XML, the nodes and arcs are
turned into XML elements, attributes, element content and attribute
values. The URI labels for properties and object nodes are written
in XML using
XML Namespaces
(
[XML-NS]
) which gives a namespace URI for a short prefix along with
namespace-qualified elements and attributes names called local names.
The (namespace URI, local name) pair are chosen such that concatenating
them forms the original node URI. The URIs labelling subject nodes
are stored in XML attribute values. The nodes labelled by string literals
(which are always object nodes) become element text content or attribute
values.
This transformation turns paths in the graph
of the form Node, Arc, Node, Arc, Node, Arc, ... into sequences of
nested elements (elements inside elements). This results in a
striping when the elements are written
down; alternating between
node elements
and
property elements
. The Node at the start of the sequence is always a subject
node and turns into a containing element called an rdf:Description
that is written at the top level of RDF/XML, after the XML
document element (in this case rdf:RDF). So the chains
of stripes start at the top of an RDF/XML document and always begin
with nodes.
For example, the figure below shows a graph
saying "there exists a document (identified by its URL) with a title,
'RDF/XML Syntax Specification (Revised)' and that document has
an editor, the editor has a name 'Dave Beckett' and a home page 'http://purl.org/net/dajobe/'
".
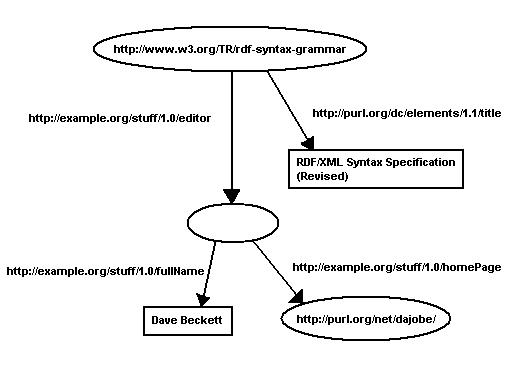
Figure 6: Graph
for RDF/XML Example
If we take the path through the graph shown
below:
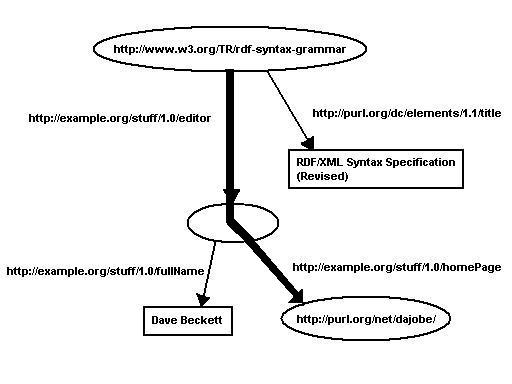
Figure 7: One
Path Through the Graph
this corresponds to the node/arc stripes:
- Node:
http://www.w3.org/TR/rdf-syntax-grammar
- Arc:
http://example.org/stuff/1.0/editor
- Node:
[a bNode]
- Arc:
http://example.org/stuff/1.0/homepage
- Node:
http://purl.org/net/dajobe/
In RDF/XML this sequence of 5 nodes and arcs
correponds to 5 XML elements (using some namespace abbreviations)):
<rdf:Description>
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description>
</rdf:Description>
</ex:homePage>
</rdf:Description>
</ex:editor>
</rdf:Description>
Which consists of some nodes with known URIs
that can be filled in and others that remain blank:
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description rdf:about="http://purl.org/net/dajobe/">
</rdf:Description>
</ex:homePage>
</rdf:Description>
</ex:editor>
</rdf:Description>
There are several abbreviations that can
be used to make very common uses more easy to write down. For example,
it is typical for the same resource to be described with multiple
properties and values at the same time, so multiple child elements
can be put inside rdf:Description ,
all of which are properties of that node.
Similarly, when the property value is a string
it can be encoded more simply as an XML attribute and value, as an
attribute of the node element. This is known as a
property attribute
.
Another very common use is when a node is
an instance of a class with rdf:type relationship, usually
called a typed node. This shorthand is done by replacing the
rdf:Description element name with the namespaced-element
corresponding to the URI of the value of the type relationship.
The above forms the basis of the RDF/XML
syntax. although there are some other abbreviated forms, such as for
generating RDF list properties and for skipping having to write down
a blank element node. This latter abbreviation breaks the striping,
but is useful for, among other things, encoding properties with multiple
values.
The full example above, filled out and completed,
and using some of these additional abbreviations, gives:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
<ex:editor rdf:parseType="Resource">
<ex:fullName>Dave Beckett</ex:fullName>
<ex:homePage rdf:resource="http://purl.org/net/dajobe/" />
</ex:editor>
</rdf:Description>
</rdf:RDF>
For a longer introduction to the RDF/XML
striped syntax with a historical
perspective, see RDF:
Understanding the Striped RDF/XML Syntax
(
[STRIPEDRDF]
).
Two kinds of tools are useful when learning
RDF/XML: parsers and visualisers. The first such tool was Janne Sareela's
SiRPAC; there are now a large number of RDF parsers available, in
a variety of programming languages. An RDF parser is a tool that takes
an XML encoding ("serialization") of an RDF graph, and returns a textual
or programmatic representation of the graph. Playing with an RDF parser
such as ARP, the parser used by W3C's
RDF Validation Service
makes it easy to experiment with RDF/XML files and see the
associated node-edge-node triples that constitute the corresponding
graph structure.
Another tool that can help an RDF developer
get to grips with the syntax is GraphViz, or one of the GraphViz-based
RDF visualization tools such as RDFViz. GraphViz is a graph visualisation
toolkit. It can take descriptions of (various kinds of) graph and
generate reasonably pretty pictures in various image formats. There
are now a variety of filters that take the output from an RDF/XML parser
and generate .dot input files for GraphViz. This can be incredibly useful
when learning the RDF/XML syntax, or debugging RDF content. A GraphViz-based
RDF visualizer is now also part of W3C's RDF Validator service.
@@Discussion of these examples may need amplification@@
@@The discussion of tools is a bit brief. Could alternatively have
a separate section on tools that includes this material, plus a brief
discussion of other tools and tool types@@
4. Defining RDF Vocabularies: RDF Schema
RDF defines a simple data model for describing
the properties of resources, and interrelationships among resources,
in terms of named properties and values. However, the RDF data model
itself provides no mechanisms for declaring specific types
or classes of resources, or for declaring
which properties might apply to which classes of resources. However,
RDF user communities require the ability to say certain things about
certain kinds of resources. For describing bibliographic resources, for
example, descriptive attributes including "author", "title", and "subject"
are common. For digital certification, attributes such as "checksum"
and "authorization" are often required. The declaration of these properties
(attributes) are defined for RDF in an RDF schema . A schema
defines not only the properties of a resource (e.g., title, author,
subject, size, color, etc.) but may also define the kinds of resources
being described (books, Web pages, people, companies, etc.).
The RDF Schema specification does not specify
a specific vocabulary of descriptive elements such as "author". Instead,
it specifies the mechanisms needed to define such elements, to
define the classes of resources they may be used with, and to restrict
possible combinations of classes and relationships. In other words,
the RDF Schema mechanism provides a basic type system for use
in RDF models. The RDF Schema type system is similar to the type systems
of object-oriented programming languages such as Java. For example,
the type system allows resources to be defined as instances of one or
more classes. In addition, it allows classes to be organized in a hierarchical
fashion; for example a class
Dog might be defined as a subclass of
Mammal which is a subclass of
Animal , meaning that any resource which is of
rdf:type
Dog is also considered to be of
rdf:type
Animal . However, RDF differs from many programming
language type systems in that instead of defining a class in terms
of the properties its instances may have, an RDF schema defines
properties in terms of the classes of resource to which they apply.
This is done using domain and range constraints on the properties. For
example, we could define the author
property to have a domain of
Book and a range of
Literal , whereas a classical object-oriented
system might typically define a class
Book with an attribute called
author of type
Literal . One benefit of the RDF property-based
approach is that it is very easy for anyone to say anything they want
about existing resources, which is one of the architectural principles
of the Web [
BERNERS-LEE98
].
4.1. Core Classes
This RDF type system is specified in terms
of the basic RDF data model, as a set of pre-defined RDF resources and
properties. As a result, the resources that make up the type system
become part of the RDF model of any description that uses them. The
following resources are the core classes that are defined as
part of the RDF Schema vocabulary. Every RDF model that draws upon the
RDF Schema namespace (implicitly) includes these.
rdfs:Class
:
This corresponds to the generic concept of
a Type or Category, similar to the notion of
a Class in object-oriented programming languages such as Java. When
a schema defines a new class, the resource representing that class
must have an
rdf:type property
(one of the core properties defined below) whose value is the
resource
rdfs:Class. RDF classes can be defined
to represent almost anything, such as Web pages, people, document
types, databases or abstract concepts.
rdfs:
Resource :
All things being described by RDF expressions
are called resources, and are considered to be instances of
the class
rdfs :Resource.
rdf:
Property:
rdf:Property
represents the subset of RDF resources that are properties.
4.2. Core Properties
Every RDF model which uses the schema mechanism
also (implicitly) includes the following core properties.
These are instances of the
rdf:Property class,
and provide a mechanism for expressing relationships between
classes and their instances or superclasses
.
rdf:
type:
This property indicates that a resource is
a member of a class, and thus has all the characteristics that are
to be expected of a member of that class. When a resource has an
rdf
:type property whose value is some specific
class, we say that the resource is an instance of the specified
class. The value of an
rdf:type property
for some resource is another resource which must be an instance of
rdfs:Class
. The resource known as
rdfs:Class is itself
a resource whose
rdf:type
isrdfs:Class. Individual classes
(for example, 'Dog') will always have an
rdf:type property
whose value is
rdfs:Class (or some subclass of
rdfs:Class, as described below). A resource
may be an instance of more than one class.
rdfs:
subClassOf:
This property specifies a subset/superset
relation between classes. The
rdfs:subClassOf
property is transitive. If class A is a subclass of some broader
class B, and B is a subclass of C, then A is also implicitly a
subclass of C. Consequently, resources that are instances of class
A will also be instances of C, since A is a sub-set of both
B and C. Only instances of
rdfs :Class can have
the rdfs:subClassOf
property and the property value is always of
rdf:type
rdfs:Class . A class may be a subclass
of more than one class.
The following example expresses a simple
class hierarchy. We first define a class
MotorVehicle. We then define three subclasses
of
MotorVehicle, namely
PassengerVehicle,
Truck and
Van . We then define a class
Minivan which is a subclass of both
Van and
PassengerVehicle .
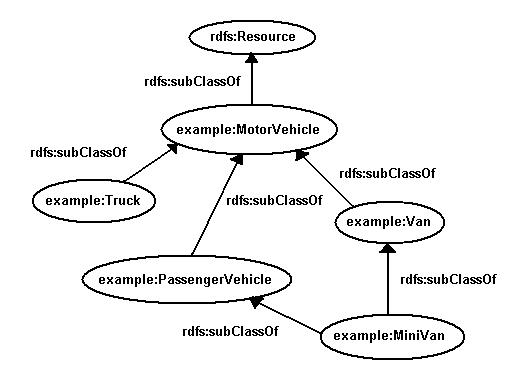
Figure 8: A Simple Class
Hierarchy
Some corresponding RDF/XML serialization
syntax is shown below:
<rdf:RDF xml:lang="en"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">
<!-- Note: this RDF schema would typically be used in RDF instance data
by referencing it with an XML namespace declaration, for example
xmlns:xyz="http://www.w3.org/2000/03/example/vehicles#". This allows
us to use abbreviations such as xyz:MotorVehicle to refer
unambiguously to the RDF class 'MotorVehicle'. -->
<rdf:Description ID="MotorVehicle">
<rdf:type resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="http://www.w3.org/2000/01/rdf-schema#Resource"/>
</rdf:Description>
<rdf:Description ID="PassengerVehicle">
<rdf:type resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description ID="Truck">
<rdf:type resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description ID="Van">
<rdf:type resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description ID="MiniVan">
<rdf:type resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#Van"/>
<rdfs:subClassOf rdf:resource="#PassengerVehicle"/>
</rdf:Description>
</rdf:RDF>
rdfs:
subPropertyOf:
The property
rdfs:subPropertyOf
is an instance of
rdf:Property that is used to specify that
one property is a specialization of another. A property may be a specialization
of zero, one or more properties. If some property P2 is a
subPropertyOf another more general property
P1, and if a resource A has a P2 property with a value B, this implies
that the resource A also has a P1 property with value B.
As an example, if the property
biologicalFather is a
subproperty of the broader property
biologicalParent, and if Fred is the
biologicalFather of John, then it is implied
that Fred is also the
biologicalParent of John.
<rdf:RDF xml:lang="en"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">
<rdf:Description ID="biologicalParent">
<rdf:type resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
</rdf:Description>
<rdf:Description ID="biologicalFather">
<rdf:type resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:subPropertyOf rdf:resource="#biologicalParent"/>
</rdf:Description>
</rdf:RDF>
4.3. Constraints
RDF Schema also provides a mechanism for
specifying simple constraints on the use of properties and classes
in RDF data. The basic constraints are those that describe limitations
on the types of values that are valid for some property, or on the
classes to which it makes sense to assign such properties. Specifically:
-
A range constraint specifies that the value
of a property should be a resource of a designated class. For
example, a range constraint applyied to the
author property might specify that the value
of an
author property must be a resource of class
Person.
-
A domain constraint specifies that a property
may be used on resources of a certain class. For example, a domain
constraint applied to the
author property might specify that the
author property could only originate from a
resource that was an instance of class
Book .
Domain and range constraints are specified
using the following predefined RDF properties:
rdfs:
range:
A property that is used to indicate the
class(
es) that the values of a property must be members of. The
value of a range
property is always a Class
. Range constraints are only applied to properties.
A property may have zero, one, or more than one
range property. If there is no range property, the class of the property value
is unconstrained. If there is exactly one range property, the property value
must be an instance of the specified class (which is the value of the range
property). If there is more than one range property, the property value must
be an instance of all of the classes (that are values of
those range properties). For example, if we assert that property xyz:hasMother
has both a rdfs:range of Female and an rdfs:range of Person, this means that
any value of property xyz:hasMother must be both an instance of class
Female and an instance of class Person.
rdfs:
domain:
A property that is used to indicate the
class(
es) on whose members a property can be used.
A property may have zero, one,
or more than one domain property. If there is no domain property, the property
may be used with any resource. If there is exactly one domain property, the
property may only be used on resources that are instances of that class (which
is the value of the domain property). If there is more than one domain property,
the property can only be used on resources that are instances of all
of the classes (that are values of those domain
properties).
We can illustrate the use of these constraint
properties by continuing with our earlier example of
MotorVehicle. In this example, we define
two properties :
registeredTo
and
rearSeatLegRoom. The
registeredTo property is applicable to
any
MotorVehicle and its value is a
Person (defined in the examples below). For the
sake of this example,
rearSeatLegRoom only applies to PassengerVehicle
s. The value is a
Number , which is the number of centimeters of rear
seat legroom. These definitions are shown in the RDF/XML below:
<rdf:RDF xml:lang="en"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">
<rdf:Description ID="registeredTo">
<rdf:type resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:domain rdf:resource="#MotorVehicle"/>
<rdfs:range rdf:resource="#Person"/>
</rdf:Description>
<rdf:Description ID="rearSeatLegRoom">
<rdf:type resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:domain rdf:resource="#PassengerVehicle"/>
<rdfs:range rdf:resource="http://www.w3.org/2000/03/example/classes#Number"/>
</rdf:Description>
</rdf:RDF>
Although RDF Schema provides a mechanism
for describing constraints, it does not say whether or how an application
must process the constraint information. For example, while an RDF
schema can assert that an author
property is used to indicate resources that are members of
the class
Person , it does not say whether or how an application
should act in processing that class information. Different applications
might use these constraints in different ways - e.g., a
validator will look for errors, an interactive editor might
suggest legal values, and a reasoning application might infer the class
and then announce any inconsistencies.
@@This is currently more-or-less copied
from the current RDF Schema draft, and needs rewriting@@
5. Some RDF Applications: RDF in the Field
@@section intro TBD@@
5.1 Dublin Core Metadata Initiative
@@ TBD@@
5.2 PRISM
@@TBD@@
5.3 Intelligent Routing
The world is full of information. Behind
the millions of pages on the Internet's publicly visible part, the
Web, there are many times as many documents flowing in and out of
organizations via emails, cross-company networks and constant
always-on information "feeds".
Every document that passes along the wires
has to be inspected, processed or re-routed. A document simply written
by one human being has to be read by another before anybody
knows its worth or where it should be redirected. This is fine for
a person-to-person email but, for information destined to a broad
circulation, this can be expensive, often reducing the value of
the information by raising its handling cost or simply making it
late.
For example, when an individual subscribes
to a source of news, it's usually on the understanding that everything
in that feed is of interest and so everything will be delivered
without question. For the distributor to sort out the interesting
ones for you manually would be time-consuming, expensive and boring;
so instead we accept dozens of emails and delete most of them every
morning. And of course it is time-consuming, expensive and boring.
Subscription to some less self-critical sources is a step to be taken
very seriously.
When a company subscribes to a news feed,
it may be risking a deluge of unwanted data. If it intends to circulate
the information within the company or to a broad range of clients,
it charges itself with checking every document by eye or investing
in extra software technology. Without such protection, the company's
networks will soon collapse under the load or its clients will consider
themselves willfully "spammed" and withdraw their custom.
The redirection of such feeds is therefore
a matter of utmost commercial sensitivity in a context of huge and
increasing volumes and complexity of data. The technology concerned
is "routing" and, in the most modern cases, relies on RDF.
The need, traditionally, for human inspection
of incoming documents comes from the fact that, on its own, text
has no value. It only has value when you know what it's about, what
authority is its source and who it's intended for. Everything
else is, as we know, just material for spamming. For a software agent
to recognize a document's worth it must have access to an evaluation
that is consistently readable, whatever the format of the document,
and is reliable in its description.
For those two objectives, we need an internationally
standardized language and a globally recognized set of values.
These are RDF, together with RDF Schemas such as defined by Dublin Core
and PRISM. The longed-for independent evaluation takes the form
of an associated RDF document.
Not that every document from every information
source comes with its associated RDF description... yet. It is the
case however that almost every serious source supplies some
value-based annotation in the form of metadata, the significant
content of RDF. For example, news feeds generally come in one of a
selection of annotated formats, mostly based on XML, such as NewsML
or XMLNews. Most standards-oriented companies are adding freely-accessible
metadata to their document formats. Adobe, for example, recently announced
XMP whereby metadata can be inserted into (and more importantly
extracted from) PDF documents. The message from such companies
is that, even if you can't understand or even have no right to read
the contents, you are entitled to know enough to make an evaluation
for your own use or for clients who can use the information. For freely
available information, standards are the key.
Now this basic process (source embeds standard
annotations: annotations are used to divert and sort documents)
is certainly not new. Email (SMTP) and news (NNTP) protocols use
standard keyword-value-pair headers which are fundamental to their
operation: such documents are marked up according to known and publicized
standards. What is new is to normalize all these local formats to
a general You are recommended to use CSS to specify the font and properties
such as its size and color. This will reduce the size of HTML files and
make them easier maintain compared with using elements. one and
thereby be able to appeal to a globally consistent set of values
in making judgments.
For a universal router to do its job,
it needs to cancel out these variations in format. Until the world
adopts one standard, this will be a matter of tact and ingenuity
but the existence of a core standard is important here. When a slew
of formats and value-systems need to be compared it is safer
to have one standard to convert to first and then to compare rather
than do it piecemeal - and that standard must be broader than all
the others. Again, RDF (and RDF Schemas) standards are the natural
choice.
An Information Router collects metadata
and stores it (rather like an enormous RDF document describing maybe
millions of resources at once). This metadata store holds the
descriptions in exactly the terms of RDF. They can therefore be
exported or imported as industry-standard RDF without loss or confusion.
World-wide, repositories of metadata may be synchronized and refreshed
by exchanging RDF. While humans are exchanging images, videos and
news items, metadata servers are exchanging compact RDF evaluations
of them (the images, videos and news items, not the humans).
The actual documents described, orders
of magnitude larger than the metadata, can be stored elsewhere or
just left where they are (located by URI, of course). The metadata
is compact and loaded with value. Judgments about distributing material
can be made in a context values (the standard predicate systems
like Dublin Core) and a vast number of alternatives, all without moving
the actual documents around or indeed even looking at them, by computer
or by human eye.
Judgments are made by applying RDF
"queries" which are testing the value of a document to the reader:
whether the subject is interesting, the content is suitable, the
author respected, the source reliable, the document accessible, the
cost reasonable, the language intelligible, the conclusion desirable,
the format tractable, the medium handleable, etc, etc. The actual
form of a query varies from product to product. (In any case, the
consumer would be given a graphical way to express his wishes.)
In one case, a query takes the form
of a modified RDF description which, if you like, asks to be proved
or disproved by a body of metadata. So an RDF Description that
stated that a document exists with the title "Financial history
of Beliz"� can be viewed as a request to find such a document.
The news distributor's server runs,
in addition to the usual server software, one of these Information
Router packages, applies queries on behalf of its clients and
delivers just those documents that survive the evaluation.
If a complex multi-layered query describing
just what it takes to please you is associated with your name as
a subscriber, you can, using software available today, guarantee
that what you get sent is exactly and only what you need. It's
an end to spam, thanks to RDF.
@@ TBD@@
XMP
@@ possible additional section@@
Site Maps / Topic Maps
@@possible additional section@@
6. Other Parts of RDF
@@section intro TBD@@
6.1 Model Theory
RDF is being developed as part of the W3C's
Semantic
Web Activity
. As described in the
Semantic Web Activity Statement
,
The Semantic Web is an extension of the
current Web in which information is given well-defined meaning, better
enabling computers and people to work in cooperation. It is the idea of having
data on the Web defined and linked in a way that it can be used for more
effective discovery, automation, integration, and reuse across various applications.
The Web can reach its full potential if it becomes a place where data can
be shared and processed by automated tools as well as by people.
RDF is a language designed to support the
Semantic Web, in much the same way that HTML is the language that helped initiate
the original Web. In order to serve this purpose, the meaning of RDF statements
must be defined in a very precise manner.
The
RDF Model Theory
document provides this precise definition, through what is technically
called a "model-theoretic semantics". A model-theoretic semantics for
a language assumes that the language refers to a 'world', and describes
the minimal conditions that a world must satisfy in order to assign an
appropriate meaning for every expression in the language. A particular
world is called an interpretation, so that model theory might be
better called 'interpretation theory'. The idea is to provide an abstract,
mathematical account of the properties that any such interpretation must
have, making as few assumptions as possible about its actual nature or
intrinsic structure. The RDF model theory is couched in the language of set
theory simply because that is the normal language of mathematics - for
example, the model theory assumes that names denote things in a set
IR called the 'universe' - but the use of set-theoretic language is
not supposed to imply that the things in the universe are set-theoretic
in nature.
The chief utility of such a semantic theory
is not to suggest any particular processing model, or to provide any
deep analysis of the nature of the things being described by the language
(in our case, the nature of resources), but rather to provide a technical
tool to analyze the semantic properties of proposed operations on the
language; in particular, to provide a way to determine when they preserve
meaning.
The RDF model theory treats RDF as a simple assertional language,
in which each triple makes a distinct assertion, and the meaning of
any triple is not changed by adding other triples. Based on the semantics
defined in the model theory, it is simple to translate an RDF graph into
a logical expression with essentially the same meaning.
@@Revised and/or additional discussion
of the model theory to be added as time permits@@
6.2 Test Cases
The
RDF Test Cases
document supplements the textual RDF specifications with specific
examples of RDF/XML syntax and the corresponding RDF graph triples. To
describe these examples, it introduces the
N
-triples
notation used in earlier sections of the Primer. The test cases
themselves are also published in machine-readable form at Web locations
referenced by the Test Cases document, so developers can use these as the
basis for some automated testing of RDF software.
The Test Cases document also contains
a number of "entailment tests", which indicate entailments (conclusions)
that applications are allowed by the RDF specifications to draw from RDF
data.
The test cases are not a complete
specification of RDF, and are not intended to take precedence over the
normative specification documents. However, they are intended to illustrate
the intent of the RDF Core Working Group with respect to the design of RDF,
and developers may find these test cases helpful should the wording of the
specifications be unclear on any point of detail.
6.3 Reification
@@TBD@@
@@other parts may also be identified;
also TBD@@
7. References
[BERNERS-LEE98]
What the Semantic Web can represent
, Tim Berners-Lee, 1998
http://www.w3.org/DesignIssues/RDFnot.html
[DC] Dublin Core Metadata Initiative
, http://purl.org/dc/
[RDFMT] RDF Model Theory
, W3C Working Draft, 14 February 2002
http://www.w3.org/TR/rdf-mt/
[RDFXML]
RDF/XML Syntax Specification (Revised)
, W3C Working Draft, 18 December 2001
http://www.w3.org/TR/2001/WD-rdf-syntax-grammar-20011218
[RDFTEST]
RDF Test Cases
, W3C Working Draft, 12 September 2001 (contains
N-triples
)
http://www.w3.org/TR/2001/WD-rdf-testcases-20010912/
[RDFSCHEMA]
RDF Schema Specification 1.0
, (editor's working draft), September 2001
http://www.w3.org/2001/sw/RDFCore/Schema/20010913
/
[RDFISSUE] RDF
Issue Tracking
, http://www.w3.org/2000/03/rdf-tracking/
[RFC 2396] RFC
2396 - Uniform Resource Identifiers (URI): Generic Syntax
, August 1998 http://www.isi.edu/in-notes/rfc2396.txt
[WEBDATA] Web Architecture:
Describing and Exchanging Data
, W3C Note, 7 June 1999
http://www.w3.org/1999/04/WebData
[XML] Extensible
Markup Language (XML) 1.0
, W3C Recommendation, 10 February 1988,
http://www.w3.org/TR/1998/REC-xml-19980210.html
[XML-NS]
Namespaces in XML
, W3C Recommendation, 14 January 1999,
http://www.w3.org/TR/1999/REC-xml-names-19990114
@@Formatting of references needs review; e.g.,
cite editors or not?@@
8. Acknowledgments
The following people provided valuable
contributions to this document:
- Dan Brickley
- Graham Klyne
- Sean Palmer
- Aaron Swartz
- Dave Beckett
@@Other editorial notes: Validation has
not been done, and all sorts of cleanup of the HTML is required.@@