Author: Dan Brickley (danbri@w3.org)
This document provides a brief introduction to the underlying structure of the RDF/XML 1.0 graph serialization syntax. The Intended audience is mainly content and tool developers familiar with XML basics, and with the RDF model, who want a minimalistic understanding of RDF's XML syntax, so they can read and write RDF/XML with more confidence.
Many RDF developers encounter the details of the RDF XML syntax at a relatively late stage. RDF distinguishes carefully between the edge-labeled graph information model and the encoding of this model in XML documents. This allows a lot of work to be done without familiarity with the XML syntax in which RDF is written. Some familiarity with the XML syntax is still valuable, and for developers familiar with XML in general and with the RDF graph model, this knowledge can be acquired fairly easily.
The notion of "striping" is a very useful conceptual tool for understanding RDF/XML: the RDF 1.0 syntax has been informally described as a "striped" graph encoding syntax. Striping is described in more detail below.
Two other tools are also useful when learning RDF/XML: parsers and visualisers. The first such tool was Janne Sareela's SiRPAC; there are now a large number of RDF parsers available, in a variety of programming languages. An RDF parser is a tool that takes an XML encoding ("serialization") of an RDF graph, and returns a textual or programmatic representation of the graph. Playing with an RDF parser such as ARP, the parser used by W3C's RDF Validation Service makes it easy to experiment with RDF/XML files and see the associated node-edge-node triples that constitute the corresponding graph structure.
The other tool that can help an RDF developer get to grips with the syntax is GraphViz, or one of the GraphViz-based RDF visualization tools such as RDFViz. GraphViz is a graph visualisation toolkit. It can take descriptions of (various kinds of) graph and generate reasonably pretty pictures in various image formats. There are now a variety of filters that take the output from an RDF/XML parser and generate .dot input files for GraphViz. This can be incredibly useful when learning the RDF/XML syntax, or debugging RDF content. A GraphViz-based RDF visualizer is now also part of W3C's RDF Validator service.
So, armed with parsers, visualisation tools and the RDF syntax spec, all of which are available from the RDF home page, how can a content-producer get a quick feel for the structure of RDF/XML? The basic concept to understand when looking at the XML syntax is striping. This can give one a handle on the essential organising principle of RDF's XML syntax. It should be noted, however, that this emphasis is slightly contrary to the way the original RDF spec is organised.
To learn how to read and write RDF in XML syntax, you need to feel comfortable with the graph-based information model at the heart of RDF. Objects ('resources') linked together by typed relationships or 'properties'. And you need to be at ease with the way RDF tries to use names in URI syntax wherever possible, to name both resources, their types ('classes') and their attributes and interelationships ('properties'). If you're happy with all that, you'll also need some mental baggage from the XML side of things. RDF graphs are encoded in XML, and this encoding makes use of some features of XML. You need to know about the basic abstract structure of all XML documents: the tree of elements (some decorated with attribute/value pairs), and about the way these are manifested as nested hierachies of opening and closing angle-bracketted "tags" in XML documents. You'll also perhaps have heard of the notion of a well-formed XML document, of 'namespaces', of DTDs, of XML Schemas and various other features. These are all good to know about, but the critical concepts to possess here are the notions of (i) well-formedness, and (ii) XML namespaces, backed up by general comfort with XML's elements/attributes/nesting structure. Having gotten this far, it isn't such a big leap to grasp the basic pattern that underlies the RDF/XML serialization syntax: striping.
An XML syntax for RDF specifies a strategy for encoding the node-edge-node structure that RDF cares about in terms of the (attribute-decorated) element hierarchy that XML cares about. There are a number of ways this can be done. RDF 1.0 adopts a style that we term 'striped'; other conventions have been proposed, but the focus here is on RDF 1.0. The XML syntax needs to map from RDF's URI-named resources, properties and classes ( nodes, edge-types, node types... if you prefer a more visual terminology) into a class of well-formed XML documents. The XML namespace mechanism is used for this. So our main task here is to explain how the node-edge-node structures from RDF become element and attribute structures in XML. To do this, we can focus on the notion of striping and forget some annoying details for now.
disclaimer: not all RDF/XML fits this pattern (but a lot of it does). You could do worse than learn the striping style, and pick up on the variations later. The online validation service is your friend: it checks your syntax, and can generate tabular and graphical views of the graph so you can make sure you're written what you mean to write.
So, this is what we mean about striping.
Consider a graph of nodes, each with a type (ie. category or 'class'), and each having a bunch of named properties (relationships) connecting it to other nodes, which might be simply string-y values, or further nodes that are themselves at the sharp and/or blunt ends of various other edges in the graph. We need to create XML elements (possibly with associated attributes) that stand for these nodes and arcs. RDF's convention for doing this is called striped because, as you look at the XML element nesting structure, elements alternately represent nodes and edges.
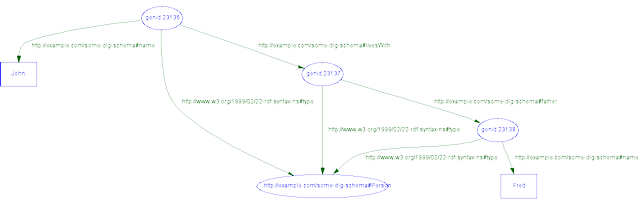
Here we're saying, loosly, that "there exists a Person with a name, 'John', and that person 'livesWith' a Person that has a father that is a Person with a name 'Fred' ". That's all our example piece of RDF/XML tells us.
The RDF node-and-edge view of this is shown graphically below. To undestand striping, we need compare the abstract graph structure of RDF to the details of the XML nesting structure, ie. the way some elements are 'inside' (rather than alongside) others.
note: this RDF/XML example is numbered, to show the
levels of XML nesting inside the rdf:RDF wrapper element.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/rdf-syntax-ns#"
xmlns="http://example.com/some-dlg-schema#">
1:<Person>
2: <name> John </name>
2: <livesWith>
3: <Person>
4: <father>
5: <Person>
6: <name> Fred </name>
5: </Person>
4: </father>
3: </Person>
2: </livesWith>
1:</Person>
</rdf:RDF>
This RDF/XML encodes the graph depicted in the following diagram. Note that the blank nodes indicate resources that were mentioned but not explicitly named with URIs in the XML serialization.
Represented as triples, the graph is as follows:
The RDF graph is a collection of triples that represent statements about the named properties of resources. The 'subject' denotes the resource described; the 'predicate' denotes a property of that resource, and the 'object' indicates a value of that property for the specified resource. Predicates correspond to edges in the graph, and to the even-numbered stripes in the XML document hierarchy shown here.
| Number | Subject | Predicate | Object |
| 1 | genid:23334 | http://example.com/some-dlg-schema#name | John |
| 2 | genid:23336 | http://example.com/some-dlg-schema#name | Fred |
| 3 | genid:23336 | http://www.w3.org/1999/02/22-rdf-syntax-ns#type | http://example.com/some-dlg-schema#Person |
| 4 | genid:23335 | http://example.com/some-dlg-schema#father | genid:23336 |
| 5 | genid:23335 | http://www.w3.org/1999/02/22-rdf-syntax-ns#type | http://example.com/some-dlg-schema#Person |
| 6 | genid:23334 | http://example.com/some-dlg-schema#livesWith | genid:23335 |
| 7 | genid:23334 | http://www.w3.org/1999/02/22-rdf-syntax-ns#type | http://example.com/some-dlg-schema#Person |
The same data, presented in the RDF Core WG's "ntriples" graph dump syntax is written as:
_:j23337 <http://example.com/some-dlg-schema#name> " John " . _:j23339 <http://example.com/some-dlg-schema#name> " Fred " . _:j23339 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://example.com/some-dlg-schema#Person> . _:j23338 <http://example.com/some-dlg-schema#father> _:j23339 . _:j23338 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://example.com/some-dlg-schema#Person> . _:j23337 <http://example.com/some-dlg-schema#livesWith> _:j23338 . _:j23337 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://example.com/some-dlg-schema#Person> .
Here is an informal walk-through of the XML document's structure. The
first level of XML elements, our first occurance of Person,
stands for a node (some specific instance of the type of thing we're calling
'Person'). And then the striping starts. The next level in, we
see two XML elements: one is 'name', the other
'livesWith'. These stand not for nodes in the graph, but edges.
The first is an edge labeled 'name' connecting our person to the node whose
content is the string 'John'. The second is an edge labeled
'livesWith' that points from our first Person node
to a second Person node.
So now we're into the third level of XML nesting, and the striping pattern
means that this odd-numbered level of nesting is describing a node. Any XML
sub-elements below it in the XML tree are, accordingly, representations of
that Person's properties, ie. edges in the graph. We have one
such edge, 'father', whose XML element contains the third
'Person' element (standing for a node of type
Person). That element has just one sub-element,
'name', which provides a label for an edge connecting the third
person to a node whose content is the string 'Fred'.
So to recap we've seen: a node (of type Person), with edge ('name': John), and edge ('livesWith') pointing at a node (of type Person) having an edge ('father') pointing at a node (of type Person) with an edge ('name': John).
The XML elements at the 1st, 3rd, and 5th levels of nesting all stand for individual nodes, in our scenario they happen to all be of the same type, Person. The XML elements at the 2nd, 4th, and 6th levels of nesting represent labeled edges in the graph, ie. RDF properties.
We alternate between node-describing and edge-describing XML elements, starting always with the description of a node. For node-describing elements the XML element name maps onto the type, or class of the resource represented by the node. For edge-describing elements, the XML element name supplies a label for the RDF property that connects the associated resources.
This is RDF striping. Understanding this basic representational convention is all you need to understand most RDF/XML examples you'll encounter.
You can't tell, without starting at the top and counting on your fingers, whether an XML element in the RDF serialisation represents an edge, or a node. But often you can cheat! Look again at the example, and notice that edge even-numbered layer of XML, the red 'edge label' stripes, has a name beginning with a lower case letter. Many RDF vocabularies (including the core RDF specs themselves) adopt this convention. We name properties with a lower case, and classes of thing with an upper case name (eg. 'Person').
I haven't mentioned the rdf:Description element. The RDF 1.0 Model and Syntax spec gives this a lot of attention when presenting the RDF syntax. Basically it can occur on any of the node-describing XML elements (ie. odd-numbered) in the striped syntax. It is redundant, and a bit confusing since apart from the option of putting rdf:Description on the node-describing elements, we can always map from the name of these nodes to an RDF type that is a class for the thing the node describes. In our example, 'Person'. So the existence of rdf:Description in the syntax complicates things. Whenever you see it, pretend you saw a node called 'Resource' instead; that way, you can read it as 'there exists a Resource...'.
We've said nothing about namespaces here yet. RDF uses the XML namespace mechanism to associate all these classes and properties with Web identifiers (URIs). We've said nothing here about the use of XML attributes. Here's a short version. When you see an attribute on a node-level element, eg on the 'Person' elements in the example above, it always stands for an RDF property, whose value is always written a simple literal string.. Except for some some special cases, of course, otherwise things would be too simple. One special case is important: the rdf:about attribute. When you see rdf:about, this is RDF's way of telling you that we know a URI name for the thing concerned. These are not treated as properties, but are in a sense 'built in' to RDF at a deep level. Also rdf:ID, and xmlns:*, xml:lang, xml:base and probably some others. See the syntax spec for details. But the basic idea is: when you see attributes on a node-level XML element (the ones whose names often begin with capital letters), the attribute represents an edge pointing to a literal value.
Another important case: representing edges that point to nodes that are described elsewhere (within the same document but not within this part of the element tree; or elsewhere in the Web). For this, RDF has the rdf:resource attribute. This always appears at the edge-level of the XML document, ie. on elements that stand for edges rather than for nodes. Apart from that, it functions similarly to the rdf:about, in that it uses URIs to point off to a node instead of describing it inline.
There are many other corner cases in the spec. RDF's rdf:parseType attribute, for example, complicates the simplistic striping model described here. But for many common cases, the notion of 'striped syntax' will provide some useful mental scaffolding that'll help you read the XML not just "as XML", but as an XML description of the abstract RDF graph. If in doubt, experiment with the free online parsing and visualisation service at W3C.
Add better images, hyperlinks, another example.
$Id: Overview.html,v 1.30 2002/08/02 15:43:23 danbri Exp $