2. Making Statements About Resources
RDF is intended to provide a simple way to state properties of (assertions about) resources, e.g., Web pages. For example, imagine that we want to assert that someone named "John Smith" created a particular Web page. A straightforward way to state this in English would be in the form of a simple statement, e.g.:
http://www.example.org/index.html has a creator whose value is John Smith
We've underlined parts of this statement to illustrate the following points. Specifically, the need to:
- identify the resource we want to describe (the Web page, in this case)
- identify a specific property (the creator) of the thing that we want to describe
- identify the value of this property (who the creator is)
In this statement, we've identified the Web page by using a URL (Uniform Resource Locator). In addition, we've used the word "creator" to indicate the property we're associating with it and the string "John Smith" to indicate the value (a person) of this property.
Additional properties of this Web page may be defined by writing statements of the same general form. For example, to specify the date the page was created, and the language in which the page is written, we could write the additional statements:
http://www.example.org/index.html has a
creation-date whose value is August 16,
1999
http://www.example.org/index.html has a
language whose value is English
RDF is based on the idea that the resources we want to describe have assocaited properties which have corresponding values. These properties and values in turn may be viewed as resources, which additionally may be further described in the same way. In essence, also having associated properties and corresponding values. The combination or a resource, a property and a value correspond to a 'statement'.
RDF defines terminology for each part of a statement. The part that identifies the resource (the Web page in this example) is called the subject. The part that identifies the property associated with this resource (e.g. creator, creation-date, or language in these examples) is called the predicate, and the part that identifies the value of that property is called the object.
Deconstructing the the above example
http://www.example.org/index.html has a creator whose value is John Smith
we can define
- the subject which is the URL http://www.example.org/index.html
- the predicate is the word "creator"
- the object is the words "John Smith"
While English, however, is useful for communicating between (English-speaking) humans, RDF is focused on machine-processable statements. To make these kinds of statements suitable for processing by machines, we need two things:
- a system of machine-processable identifiers that allows us to identify a subject, predicate, or object in a statement without any possibility of confusion with a similar-looking identifier that might be used by someone else on the Web.
- a machine-processable format for representing these statements and exchanging them between machines.
Fortunately, the existing Web architecture provides both of these necessary mechanisms. The Web's Uniform Resource Identifier (URI) provides us with a way to uniquely identify anything we want to talk about in an RDF statement, and the Extensible Markup Language (XML) provides us with a format for representing and exchanging RDF statements. The next two sections briefly describe these mechanisms.
2.1 Uniform Resource Identifiers (URIs)
If we want to discuss something, we must first identify it. How else will we know what we are referring to? In everyday communication, we use references such as "Bob", "The Moon", "373 Whitaker Ave.", "California", "VIN 2745534", "today's weather", or individuals with specific "Social Security Number", "employee number", etc. to identify particular resources. In some cases, these identifiers (such as Social Security Numbers) are assigned by a recognized authority. In other cases, these identifiers are generated by private organizations or individuals. Some identifiers have a specific national or international scope (e.g postal addresses) while others may only be unique within a very limited scope (e.g. employee number). Nevertheless, these identifiers serve to identify the things we want to talk about.
The Web provides its own form of identifier called the Uniform Resource Identifier (URI). The URLs we've already discussed in the previous examples are a particular kind of URI. All URIs share the property that different persons or organizations can independently create them, and use them to identify things. However, URIs are not limited to identifying things that have network locations, or use other computer access mechanisms. In fact, we can create a URI to refer to anything we want to talk about, including
- network-accessible things, such as an electronic document, an image, a service (e.g., "today's weather report for Los Angeles"), or a collection of other resources.
- things that are not network-accessible, such as human beings, corporations, and bound books in a library.
- abstract concepts that don't physically exist, like the concept of a "creator".
URIs essentially constitute an infinite stock of names that can be used to identify resources. A number of different URI schemes (URI forms) have been already been developed, and are being used, for various purposes. Examples include:
- http: (Hypertext Transfer Protocol, primarily for Web pages)
- mailto: (email addresses), e.g., mailto:em@w3.org
- ftp: (File Transfer Protocol)
- urn: (Uniform Resource Names, intended to be persistent location-independent resource identifiers), e.g., urn:isbn:0-520-02356-0 (for a book)
URIs are defined in RFC 2396 [URI]. Some additional discussion of URIs can be found in Naming and Addressing: URIs, URLs, ... [NAMEADDRESS]. A list of existing URI schemes can be found in Addressing Schemes [ADDRESS-SCHEMES], and it is a good idea to consider adapting one of the existing schemes for any specialized identification purposes you may have, rather than trying to invent a new one.
No one person or organization controls who makes URIs or how they can be used. While some URI schemes, such as URL's http:, depend on centralized systems such as DNS, other schemes, such as freenet:, are completely decentralized. This means that, as with any other kind of name, you don't need special authority or permission to create a URI for something. Also, you can create URIs for things you don't own, just as in ordinary language you can use whatever name you like for things you don't own. The URI is the foundation of the Web.
URIs provide a general identification mechanism, capable of identifying anything. RDF leverages URIs for identifying the subjects, predicates, and objects in statements. To be more precise, RDF uses URI references [URI] to define its subjects, predicates, and objects. A URI reference (or URIref) is a URI, together with an optional fragment identifier at the end. For example, the URI reference http://www.example.org/index.html#section2 consists of the URI http://www.example.org/index.html and (separated by the "#" character) the fragment identifier Section2. RDF defines a resource as anything that is identifiable by a URI reference, and hence using URIrefs allows RDF to describe practically anything, and to state relationships between such things as well.
In order to make writing URIrefs easier, URIrefs may be either absolute or relative. An absolute URIref refers to a resource independently of the context in which the URIref appears, e.g., the URIref http://www.example.org/index.html. A relative URIref is a shorthand form of an absolute URIref, where some prefix of the URIref is missing, and information from the context in which the URIref appears is required to fill in the missing information. For example, the relative URIref otherpage.html, when appearing in a resource http://www.example.org/index.html, would be filled out to the absolute URIref http://www.example.org/otherpage.html. A URIref that does not contain a URI is considered a reference to the current document (the document in which it appears). So, an empty URIref within a document is considered equivalent to the URIref of the document itself. A URIref consisting of just a fragment identifier is considered equivalent to the URIref of the document in which it appears, with the fragment identifier appended to it. For example, within http://www.example.org/index.html, if #section2 appeared as a URIref, it would be considered equivalent to the absolute URIref http://www.example.org/index.html#section2.
Both RDF and web browsers use URIrefs to identify things. However, RDF and browsers interpret URIrefs in slightly different ways. This is because RDF uses URIrefs only to identify things, while browsers also use URIrefs to retrieve things. Often there is no effective difference, but in some cases the difference can be significant. One obvious difference is when a URIref is used in a browser, there is the expectation that it identifies a resource that can actually be retrieved: that something is actually "at" the location identified by the URI. However, in RDF a URIref may be used to identify something, like a person, that has no physical existence on the web, and hence can't be retrieved. People sometimes use RDF together with a convention that, when a URIref is used to identify an RDF resource, a page containing descriptive information about that resource will be placed on the web "at" that URI, so that the URIref can be used in a browser to retrieve that information. This can be a useful convention in some circumstances (although it creates a difficulty in distinguishing the identity of the original resource from the identity of the web page describing it). However, this convention is not an explicit part of the definition of RDF, and RDF itself does not assume that a URIref identifies something that can be retrieved.
Another difference is in the way URIrefs with fragment identifiers are handled. Fragment identifiers are often seen in URLs that identify HTML documents, where they serve to identify a specific place within the document identified by the URL. In normal HTML usage, where URI references are used to retrieve the indicated resources, the two URIrefs:
http://www.example.org/index.html
http://www.example.org/index.html#Section2
In later sections, we'll see how RDF uses URIrefs for identifying the subjects, predicates, and objects in statements. But before we do that, we need to briefly introduce, in the next section, the basis of how RDF statements can be physically represented and exchanged.
2.2 Documents: Extensible Markup Language (XML)
The Extensible Markup Language [XML] was designed to allow anyone to design their own document format and then write a document in that format. Like HTML documents (Web pages), XML documents contain text. This text consists primarily of plain text content, and markup in the form of tags. This markup allows a processing program to interpret the various pieces of content (elements). In HTML, the set of permissible tags, and their interpretation, is defined by the HTML specification. However, XML allows users to define their own markup languages (tags and the structures in which they can appear) adapted to their own specific requirements. For example, the following is a simple passage marked up using an XML-based markup language:
<sentence><person href="http://example.com/#me">I</person> just got a new pet <animal>dog</animal>.</sentence>
Elements delimited by tags (<sentence>, <person>, etc.) are introduced to reflect a particular structure associated with the passage. These tags allow a program written with an understanding of these particular elements to properly interpret the passage.
This particular markup language uses the words "sentence," "person," and "animal" as tag names in an attempt to convey some of the meaning of the elements; and they would convey meaning to an English-speaking person reading it, or to a program specifically written to interpret this vocabulary. However, there is no built-in meaning here. For example, to non-English speakers, or to a program not written to understand this markup, the element <person> may mean absolutely nothing. Take the following passage, for example:
<dfgre><reghh bjhb="http://example.com/#me">I</reghh> just got a new pet <yudis>dog</yudis>.</dfgre>
To a machine, this passage has exactly the same structure as the previous example. However, it is no longer clear to an English-speaker what is being said, because the tags are no longer English words. Moreover, others may have used the same words as tags in their own markup languages, but with completely different intended meanings. For example, "sentence" in another markup language might refer to the amount of time that a convicted criminal must serve in a penal institution. So additional mechanisms must be provided to help keep XML vocabulary straight.
To prevent confusion, it is necessary to uniquely identify markup elements. This is done in XML using XML Namespaces [XML-NS]. A namespace is just a way of identifying a part of the Web (space) which acts as a qualifier for a specific set of names. A namespace is created for an XML markup language by creating a URI for it. By qualifying tag names with the URIs of their namespaces, anyone can create their own tags and properly distinguish them from tags with identical spellings created by others. A useful practice is to create a Web page to describe the markup language (and the intended meaning of the tags) and use the URL of that Web page as the URI for its namespace. The following example illustrates the use of an XML namespace.
<my:sentence xmlns:my="http://example.org/xml/documents/"> <my:person my:href="http://example.com/#me">I</my:person> just got a new pet <my:animal>dog</my:animal>. </my:sentence>
In this example, xmlns:my="http://example.org/xml/documents/" declares a namespace for use in this piece of XML. It maps the prefix my to the namespace URI http://example.org/xml/documents/. The XML content can then use qualified names (or QNames) like my:person as tags. A QName contains a prefix that identifies a namespace, followed by a colon, and then a local name for an XML tag (element) or attribute. By using namespace URIs to distinguish specific collections of names, and qualifying tags with the URIs of the namespaces they come from, as in this example, we don't have to worry about tag names conflicting. Two tags having the same spelling are considered the same only if they also have the same namespace URIs.
RDF defines a specific XML markup language, referred to as RDF/XML, for use in representing RDF information, and for exchanging it between machines. An example of RDF/XML was given in Section 1, and the language is described in more detail in Section 3.
2.3 The RDF Model
Based on the fundamentals of URI references for identifying resources and XML as a machine-processable syntax for structuing data, we can describe how RDF leverages these technologies to make statements about resources. In the introduction, we said that RDF was based on the idea of expressing simple statements about resources, where those statements are built using subjects, predicates, and objects. Thus, the original English statement:
http://www.example.org/index.html has a creator whose value is John Smith
would be represented in RDF as:
- a subject http://www.example.org/index.html
- a predicate http://purl.org/dc/elements/1.1/creator
- and an object http://www.example.org/staffid/85740
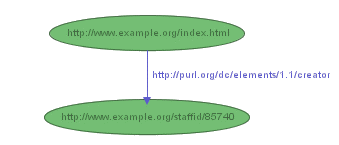
Note how we have introduced URIrefs to identify not only the subject of the original statement, but also the predicate and object, instead of using the words "creator" and "John Smith", respectively. RDF models statements as nodes and arcs in a graph. In this notation, a statement is represented by:
- a node for the subject, labeled with its URIref
- a node for the object, labeled with its URIref
- an arc for the predicate, labeled with its URIref, directed from the subject node to the object node.
So the RDF statement above would be represented by the graph shown in Figure 1:
Collections of statements are represented by corresponding collections of nodes and arcs. So if we wanted to also represent the additional statements
http://www.example.org/index.html has a
creation-date whose value is August 16,
1999
http://www.example.org/index.html has a
language whose value is English
we could, by introducing suitable URIrefs to name the properties "creation-date" and "language", use the graph shown in Figure 2:
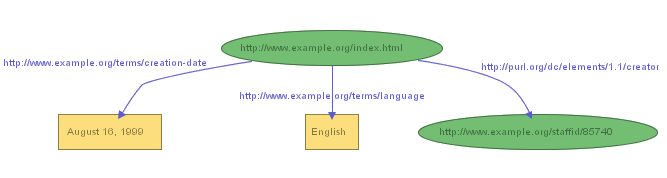
Figure 2 illustrates that RDF permits the objects of statements (but not the subjects or predicates) to be constant values (called literals) represented by character strings, as well as URIrefs, in order to represent certain kinds of property values. In drawing RDF graphs, nodes that represent resources identified by URIrefs are shown as ellipses, while nodes that represent literals are shown as boxes (labeled by the literal itself). RDF graphs are technically "directed labeled graphs", since the arcs have labels point in a specific direction, from subject to object).
An alternative, but equal way of writing down statements called N-Triples, can also be used. In the N-Triples notation, each statement in the graph is written as a simple triple of subject, predicate, and object node labels (either URIref or literals), in that order. The N-Triples representing the three statements shown in Figure 2 would be written:
<http://www.example.org/index.html> <http://purl.org/dc/elements/1.1/creator> <http://www.example.org/staffid/85740> . <http://www.example.org/index.html> <http://www.example.org/terms/creation-date> "August 16, 1999" . <http://www.example.org/index.html> <http://www.example.org/terms/language> "English" .
Each triple corresponds to a single arc in the graph, complete with the arc's beginning and ending nodes (the subject and object of the statement). Unlike the drawn graph (but like the original statements), the N-Triples notation requires that a node be separately identified for each statement it appears in. So, for example, http://www.example.org/index.html appears three times (once in each triple) in the N-Triples representation of the graph, but only once in the drawn graph. However, the triples represent exactly the same information as the graph.
The N-triples syntax requires that URI references be
written out in full, in angle brackets, which, as the example
above illustrates, can result in very long lines. For
convenience, we will use a shorthand way of writing triples in
the rest of this Primer, and also in other RDF
specifications. In this shorthand, we can substitute a QName
without angle brackets as an abbreviation of a full URI
reference. We will also make extensive use in these examples
of several "well-known" QName prefixes (which we will use
without explicitly specifying them each time), defined as
follows:
prefix rdf:, namespace URI:
http://www.w3.org/1999/02/22-rdf-syntax-ns#
prefix rdfs:, namespace URI:
http://www.w3.org/2000/01/rdf-schema#
prefix
dc:, namespace URI:
http://purl.org/dc/elements/1.1/
prefix
daml:, namespace URI:
http://www.daml.org/2001/03/daml+oil#
prefix
ex:, namespace URI: http://www.example.org/
(or http://www.example.com/)
prefix
xsd:, namespace URI:
http://www.w3.org/2001/XMLSchema#
We will also use variations on the "example" prefix
ex: as needed in the examples, where this will not
cause confusion, for example,
prefix exterms:, namespace URI:
http://www.example.org/terms/ (for terms used by
our example organization),
prefix exstaff:, namespace URI:
http://www.example.org/staffid/ (for our example
organization's staff identifiers),
prefix ex2:, namespace URI:
http://www.domain2.example.org/ (for a second
example organization), and so on.
Using our new shorthand, we can write the previous set of triples as:
ex:index.html dc:creator exstaff:85740 . ex:index.html exterms:creation-date "August 16, 1999" . ex:index.html exterms:language "English" .
The examples we've just given of RDF statements begin to illustrate some of the advantages of using URIrefs as RDF's basic way of identifying things. For instance, instead of identifying the creator of the Web page in our first example by the literal "John Smith", we've assigned him a URIref, in this case (using a URIref based on his employee number) http://www.example.org/staffid/85740 . An advantage of using a URIref in this case is that we can be more precise in our identification. That is, the creator of the page isn't the literal "John Smith", or any one of the thousands of people named John Smith, but the particular John Smith associated with that URIref (whoever created the URIref defines the association). Moreover, since we have a URIref for the creator of the page, it is a full-fledged resource, and we can record additional information about him, such as his name, and age, as in the graph shown in Figure 3:
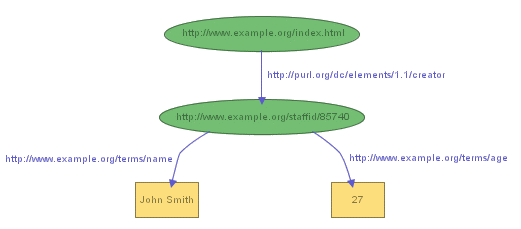
These examples also illustrate that RDF uses URIrefs as predicates in RDF statements. That is, rather than using literls such as "creator" or "name" to identify properties, RDF uses URIrefs. Using URIrefs to identify properties is important for a number of reasons. First, it allows us to distinguish the properties we use from properties someone else may use that would otherwise be identified by the same literal. For instance, in our example, example.org uses "name" to mean someone's full name written out as a literal (e.g., "John Smith"), but someone else may intend "name" to mean something different (e.g., the name of a variable in a piece of program text). A program encountering "name" as a property identifier on the Web wouldn't necessarily be able to distinguish these uses. However, if example.org writes http://www.example.org/terms/name for its "name" property, and the other person writes http://www.domain2.example.org/genealogy/terms/name for hers, we can keep straight the fact that there are distinct properties involved (even if a program cannot automatically determine the distinct meanings). Another reason why it is important to use URIrefs to identify properties is that it allows us to treat RDF properties as resources themselves. Since properties are resources, we can record descriptive information about them (e.g., the English description of what example.org means by "name"), simply by adding additional RDF statements with the property's URIref as the subject.
Using URIrefs as subjects, predicates, and objects in RDF statements allows us to begin to develop and use a shared vocabulary on the Web, reflecting (and creating) a shared understanding of the concepts we talk about. For example, in the triple
ex:index.html dc:creator exstaff:85740 .
the predicate dc:creator, when fully expanded as a URIref, is an unambiguous reference to the "creator" attribute in the Dublin Core Element Set, a widely-used collection of attributes (properties) for describing information of all kinds. The writer of this triple is effectively saying that the relationship between the Web page (identified by http://www.example.org/index.html ) and the creator of the page (a distinct person, identified by http://www.example.org/staffid/85740 ) is exactly the concept defined by http://purl.org/dc/elements/1.1/creator . Moreover, anyone else, or any program, that understands http://purl.org/dc/elements/1.1/creator will know exactly what is meant by this relationship.
Of course, RDF's use of URIrefs doesn't solve all our problems because, for example, people can still use different URIrefs to refer to the same thing. However, the fact that these different URIrefs are used in the commonly-accessible "Web space" creates the opportunity both to identify equivalences among these different references, and to migrate toward the use of common references.
The result of all this is that RDF provides a way to make statements that applications can more easily process. Now an application can't actually "understand" such statements, of course, but it can deal with them in a way that makes it seem like it does. For example, a user could search the Web for all book reviews and create an average rating for each book. Then, the user could put that information back on the Web. Another web site could take that list of book rating averages and create a "Top Ten Highest Rated Books" page. Here, the availability and use of a shared vocabulary about ratings, and a shared group of URIrefs identifying the books they apply to, allows individuals to build a mutually-understood and increasingly-powerful (as additional contributions are made) "information base" about books on the Web. The same principle applies to the vast amounts of information that people create about thousands of subjects every day on the Web.
RDF statements are similar to a number of other formats for recording information, such as:
- entries in a simple record or catalog listing describing the resource in a data processing system.
- rows in a simple relational database.
- simple assertions in formal logic
and information in these formats can be treated as RDF statements, allowing RDF to be used as a unifying model for integrating data from many sources. This relationship is further explored in Section 8.
2.4 Structured Property Values and Blank Nodes
For describing many kinds of information, additional structured descriptions is often required. In the previous example of describing person with the name "John Smith", we may want to associate a work address. One way we might write this is decalring the whole address out as a literal.
exstaff:85740 exterms:address "1501 Grant Avenue, Bedford, Massachusetts 01730" .
However, suppose we wanted to record John's address as a structure consisting of separate street, city, state, and Zip code values? How do we do this in RDF? In the exact same way as we've done in the previous examples. We can represent such structured information in RDF by considering the aggregate thing we want to talk about (like John Smith's address) as a separate resource, and then making separate statements about that new resource. So, in the RDF graph, in order to break up John Smith's address into its component parts, we create a new node to represent the concept of John Smith's address, and assign that concept a new URIref to identify it, say http://www.example.org/addressid/85740 (which we will abbreviate as exaddressid:85740). We then write RDF statements (create additional arcs and nodes) with that node as the subject, to represent the additional information, producing the graph shown in Figure 4:
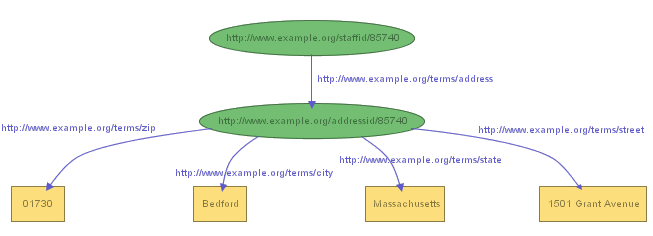
or the triples:
exstaff:85740 exterms:address exaddressid:85740 . exaddressid:85740 exterms:street "1501 Grant Avenue" . exaddressid:85740 exterms:city "Bedford" . exaddressid:85740 exterms:state "Massachusetts" . exaddressid:85740 exterms:Zip "01730" .
Using this approach allows us to represent structured information in RDF. This approach, however, involves generating "intermediate" URIrefs to represent aggregate concepts such as John's address, concepts that may never need to be referred to directly from outside a particular graph, and thus don't, strictly speaking, require "universal" identifiers. In addition, in the drawing of the graph representing the collection of statements shown in Figure 4, we don't really need the URIref we assigned to identify "John Smith's address", since we could just as easily have drawn the graph as in Figure 5:
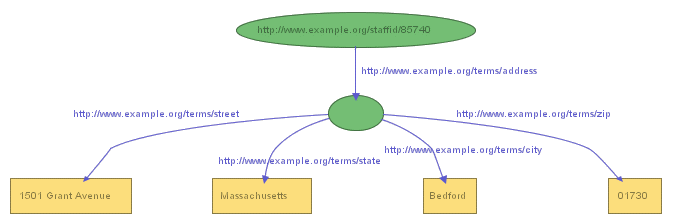
In Figure 5, which is a perfectly good RDF graph, we've used a node without a label to stand for the concept of "John Smith's address". This unlabeled node, or blank node, functions perfectly well in the drawing without needing a URIref, since the node itself provides the necessary connectivity between the various other parts of the graph. However, we do need some form of explicit identifier for that node if we are going to represent this graph as triples. To see this, we can try to write the triples corresponding to what is shown in the drawn graph. What we would get would be something like:
exstaff:85740 exterms:address ??? . ??? exterms:street "1501 Grant Avenue" . ??? exterms:city "Bedford" . ??? exterms:state "Massachusetts" . ??? exterms:Zip "01730"
where ??? stands for something that indicates the presence of the blank node. Since a complex graph might contain more than one blank node, we also need a way to differentiate between the various blank nodes in the triples representation of the graph. To do this, the triples notation uses a node identifier, having the form _:name, to indicate the presence of a blank node. For instance, in this example we might generate the node identifier _:johnaddress to refer to the blank node, in which case the resulting triples might be:
exstaff:85740 exterms:address _:johnaddress . _:johnaddress exterms:street "1501 Grant Avenue" . _:johnaddress exterms:city "Bedford" . _:johnaddress exterms:state "Massachusetts" . _:johnaddress exterms:Zip "01730" .
In a triples representation of a graph, each distinct blank node in the graph is given a different node identifier. Unlike URIrefs and literals, node identifiers are not considered to be actual parts of the RDF graph (this can be seen by looking at the drawn graph in Figure 5 and noting that there is no node identifier used to label the blank node). Node identifiers only have significance within the triple representation of the graph, and only for the purpose of distinguishing one blank node from another (so that two collections of triples that differ only by re-naming their node identifiers are considered to represent identical RDF graphs). Node identifiers also have significance only within the triples representing a single graph (so that two different graphs with the same number of blank nodes might use the same node identifiers to distinguish them, and it would be unwise to assume that blank nodes from different graphs having the same node identifiers referred to the same resource). If it is expected that a node in a graph will need to be referenced from outside the graph, a URIref should be assigned to identify it.
At the beginning of this section, we noted that we can represent aggregate structures, like John Smith's address, by considering the aggregate thing we want to talk about as a separate resource, and then making separate statements about that new resource. This example illustrates an important aspect of RDF: RDF directly represents only binary relationships, e.g. the relationship between "John Smith" and the literal representing his address. When we try to deal with the relationship between John and the collection of separate components of this address, we are dealing with an n-ary (n-way) relationship (in this case, n=5) between John and the street, city, state, and zip components. In order to represent such structures directly in RDF (e.g., considering the address as a collection of street, city, state, and zip sub-components), we need to break this n-way relationship up into a collection of separate binary relationships. Blank nodes give us one way to do this. Each time we have an n-ary relationship, we can choose one of the participants as the subject of the relationship (John in this case), and create a blank node to represent the rest of the relationship (John's address in this case). We can then represent the remaining participants in the relationship (such as the city in our example) as separate properties of the new resource represented by the blank node.
Blank nodes also give us a way to more accurately model statements about resources that may not have URIs, but that are described in terms of relationships with other resources that do have URIs. For example, when making statements about a person, say Jane Smith, it may seem natural to use that person's email address as her URI, e.g., mailto:jane@example.org. However, this approach can cause a number of problems. One obvious problem is that Jane Smith's email address may change when she changes jobs, and so it may be hard to combine information about Jane recorded at different times. Another problem is that we may want to record information about Jane's mailbox (e.g., the server it is on) as well as about Jane herself (e.g., her current address), and using a URIref for Jane based on her email address makes it difficult to know which thing we're talking about. The same problem exists when a company's Web page URL, say http://www.example.com/, is used as the URI of the company itself. Once again, we may need to record information about the Web page (e.g., who created it and when) as well as about the company, and using http://www.example.com/ as an identifier for both makes it difficult to know which thing we're talking about.
The fundamental problem is that using Jane's email address as a stand-in for Jane is an inaccurate model: Jane's email address identifies a mailbox, and Jane and her mailbox are not the same thing. When Jane herself doesn't have a URI, a blank node gives us a more accurate way of modeling this situation. We can represent Jane by a blank node, and give the blank node an exterms:emailaddress property having the URIref mailto:jane@example.org as its value. We can also assign the blank node an rdf:type property with a value of exterms:Person (we will discuss types in more detail in the following sections), a exterms:name property with a value of "Jane Smith", and any other descriptive information we might want to provide, as shown in the following triples:
_:jane exterms:emailaddress mailto:jane@example.org . _:jane rdf:type exterms:Person . _:jane exterms:name "Jane Smith" . _:jane exterms:empID "23748" _:jane exterms:age "26" .
This says, accurately, that "there is a resource of type Person, whose email address is mailto:jane@example.org, whose name is Jane Smith, etc." That is, the existence of a blank node effectively says "there is a resource". Statements with that blank node as subject then provide information about the characteristics of that resource.
In practice, using blank nodes instead of URIrefs in these cases doesn't change the way we actually handle this kind of information very much. For example, if we know independently that an email address uniquely identifies someone at example.org (particularly if the address is unlikely to be reused), we can still use that fact to associate information about that person from multiple sources, even though the email address is not the person's URI. For example, if we were to find another piece of RDF on the web that described a book, and gives the author's contact information as the email address mailto:jane@example.org, we might reasonably conclude that the author's name is Jane Smith. The point is that saying something like "the author of the book is mailto:jane@example.org" is actually a shorthand for "the author of the book is someone whose email address is mailto:jane@example.org". Using a blank node to represent this "someone" simply makes what is actually happening more explicit. (Incidentally, some RDF-based schema languages allow specifying that certain properties are unique identifiers. This is discussed further in Section 5.5.)
2.5 Typed Literals
In the last section, we described how to handle situations in which we needed to take property values represented by literals, and break them up into structured values that identify the individual parts of those property values. Using this approach, instead of, say, recording the date a Web page was created as a single exterms:creation-date property, with a single literal as its value, we could represent the value as a structure consisting of the month, day, and year as separate pieces of information. However, so far, we've followed the practice of representing any constant values that serve as objects in RDF statements by literals, even when we probably intend for the value of the property to be a number (e.g., the value of a year or age property) or some other kind of more specialized value.
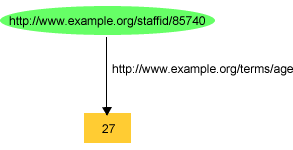
For example, earlier in Figure 3, we illustrated an RDF graph recording information about John Smith. In that graph, we recorded the value of John Smith's exterms:age property as the literal "27", as shown in Figure 6:
In this case, our hypothetical organization example.org probably intends for "27" to be interpreted as a number, rather than as the literal consisting of the character "2" followed by the character "7". However, an application reading that literal "27" would only know how to do that if the application was explicitly given the information that the literal "27" was intended to represent a number, and knew which number the literal "27" was supposed to represent. The common practice in programming languages or database systems is to provide this kind of information by associating a datatype with the literal, in this case, a datatype like decimal or integer. An application that understands the datatype then knows, for example, whether the literal "10" is intended to represent the number ten, the number two, or the literal consisting of the character "1" followed by the character "0", depending on whether the specified datatype is integer, binary, or string. In RDF, typed literals are used to provide this kind of information.
Using a typed literal, we could describe John Smith's age as being the integer number 27 using the N-triple:
<http://www.example.org/staffid/85740> <http://www.example.org/terms/age> <http://www.w3.org/2001/XMLSchema#integer"27"> .
or, using our QName simplification for writing long URIs:
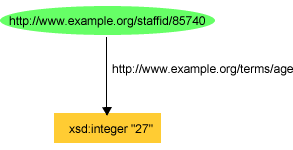
exstaff:85740 exterms:age xsd:integer"27" .
or as shown in Figure 7:
@@Above Ntriples and abbreviated syntax for typed literals is temporary until the official syntax for these is determined.@@
Similarly, in the graph shown in Figure 2 describing information about a Web page, we recorded the value of the page's exterms:creation-date property as the character string literal "August 16, 1999". However, using a typed literal, we could describe the creation date of the Web page as being the date August 16, 1999, using the triple:
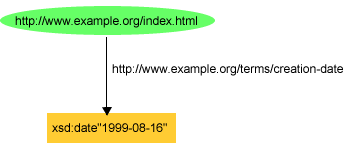
ex:index.html exterms:creation-date xsd:date"1999-08-16" .
or as shown in Figure 8:
As these examples illustrate, an RDF typed literal is formed by explicitly pairing a URIref identifying a particular datatype (in these examples, the datatypes integer and date from XML Schema Part 2: Datatypes [XML-SCHEMA2]) with a literal that the datatype uses to represent the intended value. In each case, this results in a single node in the RDF graph with the pair as its label.
We've used XML Schema datatypes in the two examples we've just presented, and will be using XML Schema datatypes in most of our other examples as well (for one thing, XML Schema data types have URIrefs we can use to refer to them, specified in [XML-SCHEMA2]). However, unlike typical programming languages and database systems (and unlike the XML Schema language), RDF does not build in any particular collection of datatypes (not even XML Schema datatypes). Instead, RDF typed literals simply provide a way to explicitly indicate, for a given literal, what datatype should be used to interpret it. As far as RDF is concerned, you can write any pair of URIref and literal you want as a typed literal. This gives RDF the flexibility to directly represent information coming from different sources without the need to perform type conversions between these sources and a native set of RDF datatypes. (Type conversions would still be required when moving information between systems with different datatype systems, but RDF would impose no extra conversions into and out of a native set of RDF types.)
However, this flexibility comes at a price. For one thing, RDF has no way of knowing whether or not a URIref in a typed literal actually identifies a datatype. Moreover, even when a URIref does identify a datatype, RDF cannot check the validity of pairing that datatype with a particular literal. For example, you could write the triple:
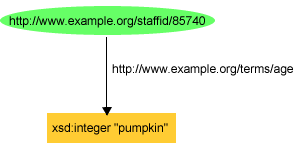
exstaff:85740 exterms:age xsd:integer"pumpkin" .
or the graph shown in Figure 9:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
and RDF would not see anything wrong with this. However, proper use of typed literals clearly requires that, given a pair of datatype URIref and literal, the literal should be a legal representation of one of the datatype's legal values.
RDF datatype concepts borrow a conceptual framework from XML Schema datatypes [XML-SCHEMA2] to more precisely describe these datatype requirements. RDF's use of this framework is defined in RDF Concepts and Abstract Data Model [RDF-CONCEPTS]. The framework involves distinguishing between what might be written in RDF (or program) text as a literal to represent a value, (usually a literal of some kind), and the actual value that literal is intended to represent or denote. For example, the literal "10" may be written to refer to the value ten in a decimal representation, to the value two in a binary representation, or to the literal consisting of a "1" followed by a "0". Which value the literal denotes is determined by the datatype associated with the literal "10". In the case of numbers, the terms numeral and number are commonly used to distinguish between the figures that are written down (the numeral) and the value that is meant (the number). We use this distinction when we talk about the "Roman numerals" like "IV" that we sometimes see chiseled on buildings. We don't call these "Roman numbers" because the Romans were using the same numbers (the number four in this case) that we do; it's the way they wrote them down that was different.
Specifically, RDF defines a datatype to have:
- a value space, that defines the collection of legal values that the datatype can represent.
- a lexical space, that defines the collection of legal literals that you can write down to denote members of the value space.
- a datatype mapping, that defines which values (things in the value space) are denoted by which literals (things in the lexical space).
Morever, a useful datatype mapping will satisfy some other conditions:
- Each literal (member of the datatype's lexical space) is associated with exactly one member of the datatype's value space (so that, given a datatype and a literal, there is no ambiguity in which value is meant).
- Each member of the datatype's value space has at least one corresponding literal in the lexical space (so we can represent all the values associated with the data type).
If the datatype mapping satisfies these conditions, an RDF typed literal, since it pairs the URIref of a datatype with a literal, will unambiguously identify a specific member of a datatype mapping and thus a specific member of the value space of the datatype.
For example, using these concepts, the XML Schema datatype xsd:boolean can be described as shown in Table 1. In the datatype mapping for this datatype, each member of the value space (represented here as T and F) has two literal representations defined in the lexical space.
| Value Space | {T, F} |
|---|---|
| Lexical Space | {"0", "1", "true", "false"} |
| Datatype Mapping | {<"true", T>, <"1", T>, <"0", F>, <"false", F>} |
Given the datatype description in Table 1, Table 2 shows the RDF typed literals that can be used for datatype xsd:boolean and how the datatype mapping enables a specific value to be determined for each typed literal.
| Typed Literal | Member of Datatype Mapping Denoted by Typed Literal |
Member of Value Space Denoted by Typed Literal |
|---|---|---|
| <xsd:boolean, "true"> | <"true", T> | T |
| <xsd:boolean, "1"> | <"1", T> | T |
| <xsd:boolean, "false"> | <"false", F> | F |
| <xsd:boolean, "0"> | <"0", F> | F |
With this background, we can see how the interpretation of the triple describing John Smith's age:
exstaff:85740 exterms:age xsd:integer"27" .
works. The triple states that John's age is the member of the value space of the datatype xsd:integer that is represented by the literal "27". Based on the definition of xsd:integer given in [XML-SCHEMA2], it can be determined that John's age is the integer value twenty-seven.
We said earlier that RDF typed literals only provide a
way to explicitly indicate the datatype that should be
used to interpret a given literal, and that RDF doesn't
build The table summary attribute should be used to describe
the table structure. It is very helpful for people using
non-visual browsers. The scope and headers attributes for
table cells are useful for specifying which headers apply
to each table cell, enabling non-visual browsers to provide
a meaningful context for each cell.
For further advice on how to make your pages accessible
see "http://www.w3.org/WAI/GL". You may also want to try
"http://www.cast.org/bobby/" which is a free Web-based
service for checking URLs for accessibility.
HTML and CSS specifications are available from http://www.w3.org/
To learn more about HTML Tidy see http://www.w3.org/People/Raggett/tidy/
Please send bug reports to Dave Raggett care of
This explains why we said earlier that RDF would be unable to see anything wrong with the typed literal in the triple:
exstaff:85740 exterms:age xsd:integer"pumpkin" .
or the graph shown in Figure 9. Even though "pumpkin" is not defined as being in the lexical space of the datatype xsd:integer, for RDF to be able to determine this requires that RDF know whether or not a particular literal is a member of a datatype's lexical space, information RDF doesn't have.
There will continue to be a great deal of RDF in the Web that does not use typed literals, since this is a relatively new facility in RDF. However, as use of RDF develops further, the use of typed literals will develop further as well.
@@Need to add datatype range declarations to the Schema section.@@
@@Need to update all subsequent Figure numbers, and generate SVG versions for the new ones added in this section.@@
@@Need a "Summary" or "Overview" section header here to set the following summary off?@@
This is all there is to basic RDF: nodes-and-arcs diagrams interpreted as statements about concepts or digital resources identified by URIrefs . However, it should be clear that, in addition to the basic techniques for representing RDF statements in diagrams (or triples), we also need a way for people to define the vocabularies they intend to use in those statements, including:
- defining types of things (like ex:Person)
- defining properties (like ex:age and creation-date), and
- defining the types of things (or datatypes) that can serve as the subjects or objects of statements involving those properties (like specifying that the value of an ex:age property should always be an xsd:integer).
The basis for defining such vocabularies in RDF is RDF Schema , which will be described in Section 4 . Additional discussion of the basic ideas underlying the RDF data model, and its role in providing a general language for describing Web information, can be found in [RDF-CONCEPTS] and [WEBDATA].