
WriteWebOfData
This page discusses the idea of realizing a write-enabled Web Of Data. There are several related pages on this Wiki (such as EditingData), however, this page aims to gather a high-level overview on the available proposals and ongoing work. Please add as you see fit.
Realizing a write-enabled Web of Data
Overview
TimBL has drafted an overview of the entire eco-system, here redrawn and a bit polished by Michael:
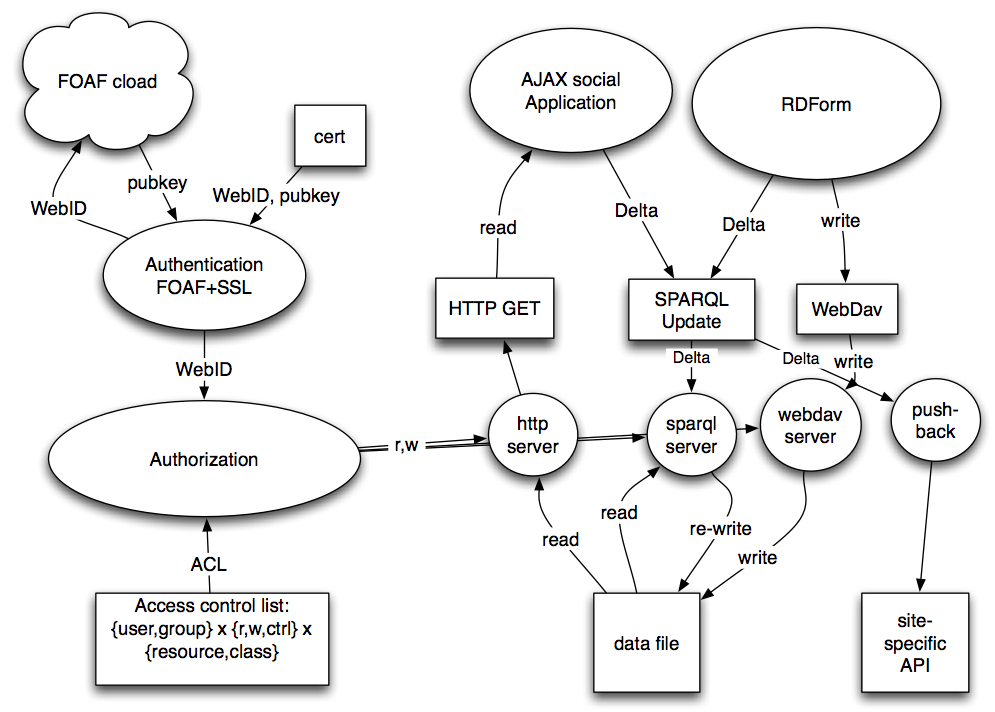{kind=link}

Components
There are several components already available for realizing a write-enabled WoD, including:
- Entity (person) identifiers, WebID
- An authentication scheme and protocol, FOAF+SSL
- An authorization (access control) scheme and protocol, WAC
- Update protocols (see also the editing data page):
- A standard way to update RDF data, a DML, SPARQL Update
- An HTTP extension that can be used to update RDF data, WebDAV
- Write-wrappers around Web 2.0 sites, pushback
- Decorating HTML forms to enable updates, RDForms
Discussion
Open Issues
Michael: One thing that is undefined in the current setup is the relation between FOAF+SSL/WAC and the update mechanism. Who evaluates the ACL? How does a SPARQL endpoint or a WebDAV server now about the WAC rights?
Nathan: TimBL pointed to this in the Socially Aware Cloud Storage Design Issue, in a recent implementation of ACL one took the approach of storing ACLs in access control files (ACF), exposing them via the Link header for each resource under WAC, ACL is (and has to be) evaluated on the http application side, through http server mod(s) or via a custom system which evaluates the ACF as part of the identification/authorisation process, access to an ACF is not given unless the identified user has Control permissions over the ACF, at which point it can be modified and updated client side using HTTP verbs like GET and PUT. This approach remains true for WebDav.
Nathan: SPARQL endpoints comes under two issues, one is for accessing remote resources which are under WAC, for this to work SPARQL has to be on the client side or running with a machine identified foaf+ssl, in both cases the aforementioned approach remains the same; the other issue is when web mounted SPARQL endpoints themselves need to be under wac, in which case the approach is again the same - as already implemented in Openlink Virtuoso (see foaf+ssl https protected sparql endpoints)
Michael: This problem gets even worse when trying to implement this in the current eco-system. Imagine, for example, a pushback (i.e. a write-wrapper) around Google's Data API coming with its own set of authentication mechanisms and built-in access control. How can one make the Google API 'speak' FOAF+SSL/WAC? There are several options, non of them looking very promising:
- transparent auth/access control (that is, by-passing FOAF+SSL/WAC entirely), where the origin system mechanism is directly relayed to the user;
- local or distributed repository with user credentials
- cookie-based solution
What are we missing?
- Transactions? How are we handling concurrence edits?
- How do we integrate/play together with established (Web 2.0) standards such as OpenID, OAuth, etc.