
There is an architecture in which a few existing or Web protocols are gathered together with some glue to make a world wide system in which applications (desktop or Web Application) can work on top of a layer of commodity read-write storage. Crucial design issues are that principals (users) and groups are identifies by URIs, and so are global in scope, and that elements of storage are access controlled using those global identifiers. The result is that storage becomes a commodity, independent of the application running on it.
Current Web Applications typically are based on a web site. The web site stores the state of the system, and javascript programs within web pages. Users typically have an identity on the site, and the site manages access to information about them and about others with some flexibility, typically based on different types of information, and different groups of people.
The applications are made much more usable by the fact that much of the functionality of the web side runs in client-side javascript: inside the browser*. To write a new application, therefore, one needs to write javascript, write a server, and allow the two to communicate. There various patterns for communication between web page and its back end. However, the javascript of the web site is is the only thing which accesses the user's data stored on that site. Indeed, for security purposes, scripts from other sites are deliberately prevented from accessing it.
A well-documented frustration with Social Network Sites (SNS's) is, in 2009, the fact that each site stores the user's data in a silo.
The user is not in control of his or her data.
There are often APIs, but each SNS typically has different types of data and therefore different APIs.
Because the functionality of an application (such as looking at photos) is on a given web site, when the user wants to use that application to access photos on another site, the first site must get access to the second site on the user's behalf. This is a more complex form of authentication, and is subject to "confused deputy" attacks.
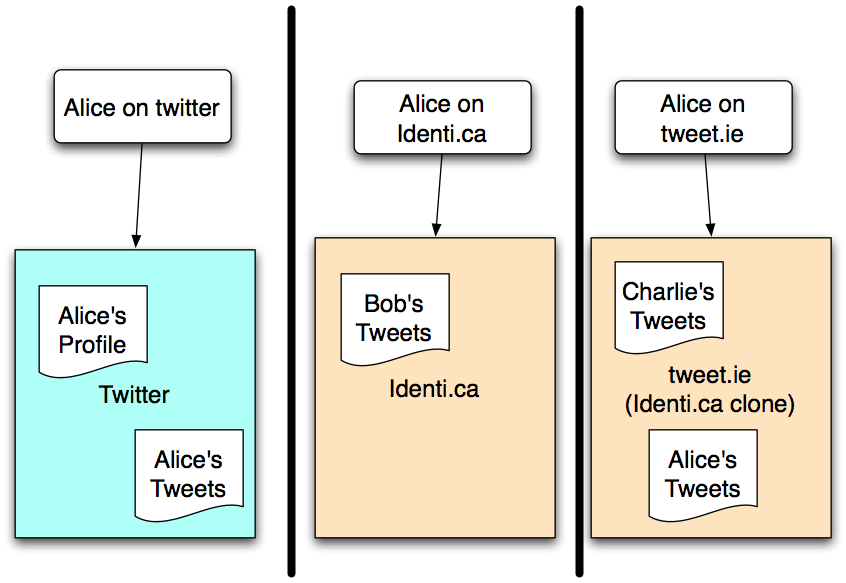
The typical web 2.0 architecture is that the information, typically user-generated content, is stored and used within the site. There is a significant loss of functionality from the fact that the data is not easily reusable outside the site, and that when access to the data is controlled, it is controlled in terms of the user-names on that site.
Systems such as OAuth tackle this issue by allowing users to make individual connections from one social networking site to another, specifically allowing an application one site to access specific data, such as a list of friends. This is however a clumsy in some ways, and it does require that the application web site which gets the data be completely trusted.
Imagine then that users everywhere have bought or been given some of this storage. Imagine that as students at MIT have for years had access to Athena services, including disk space and now web space, so some and maybe all of this web space is controlled under this WebID and group system. This socially-aware storage then becomes a commodity.
This then allows a market in independently written applications. Free apps can be freely distributed to the extent they are trusted. Various ways exist of charging for apps, but the market is decentralized as anyone can write and sell one.
The application is locally resident on the user's machine: installed on the phone, the desktop, perhaps managed by the user's web browser. When an App runs, it runs in the user-controlled environment. It can access the user's remote data by using the user's credentials. This of course allows as bad app to do bad things. However, because the data is stored in a storage the user controls, the risk of information misuse by those that run unscrupulous web sites is reduced.
Why is it valuable to separate the Apps from the data?
This note describes a way of re-architecting social web applications so the application is run by the user, and trusted by the user, and works by accessing data on many sites on the user's behalf.
A key benefit is that anyone creative can make an app and sell it (like the 2009 iPhone app market but open), as new apps can create and control access to data resources in the existing storage cloud. This separates the market for storage from the market for applications, which one can expect to be stimulative to both markets. Just as the internet provides connectivity as a commodity independent of applications, and that allows network applications to be sold without each one having to build a new network stack or install a new network for the user.
This design connects up together a number of existing protocols.
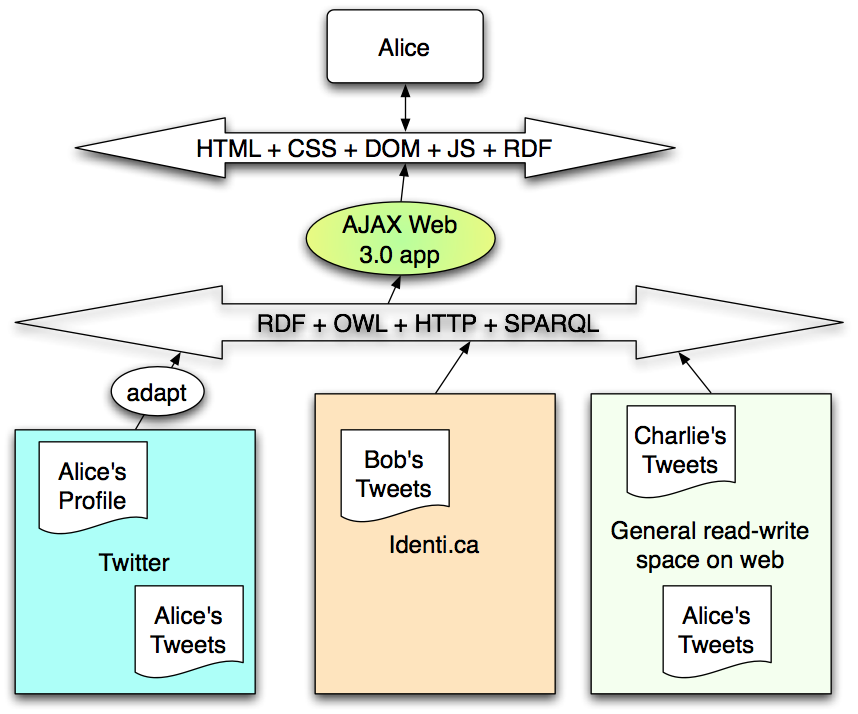
A requirement then is that the system should be able to produce the same functionality as the old silos of site-anchored web applications.
Of course the SNS business model in part rests on the ability of the SNS company, rather than the user, to control the data. The SNS site sells ads, because it forces the user to use its web site to access her data. It can also sell her data, index it, generate profiles of her, and so on. However, there are other business models, and other ways of getting people to come to your site than hoarding their data.
The Linked Data article gave simple rules for putting data on the web so that it is linked. Then, "Read-Write Linked Data" follows on from that to discuss allowing applications to write as well as read data. This note adds decentralized access control of reading and of writing to linked data.
This can be called "socially-aware" storage, because the access control within the storage layer is just powerful enough to implement the social requirements of the social network applications. (In the current model proves insufficiently powerful to do this, then it could be enhanced by adding more inference to the ACL system, and more expressivity to the ACL -- or rather policy language -- used to express the social constraints). The overall goal is one in which storage with the necessary functionality is a ubiquitous commodity, and application growth becomes dramatic as the provision of storage is decoupled from the design and deployment of applications.
In summary, for a simple initial design,
@prefix acl: <http://www.w3.org/ns/auth/acl>.
A design issue is how much inference the ACL system is expected to do. For example, is it enough to in the file returned for a class, to just return information that the class is a superset of some other classes, allowing the ACL system to in turn look those classes up.
(Note that the information returned by looking up the user's webID is not trusted for access control purposes. Links are only followed out from the ACL. The server operator can also provide the server with other trusted information to include in the search for a reason to give the requester the access. Eventually, something else will be found which points to it)
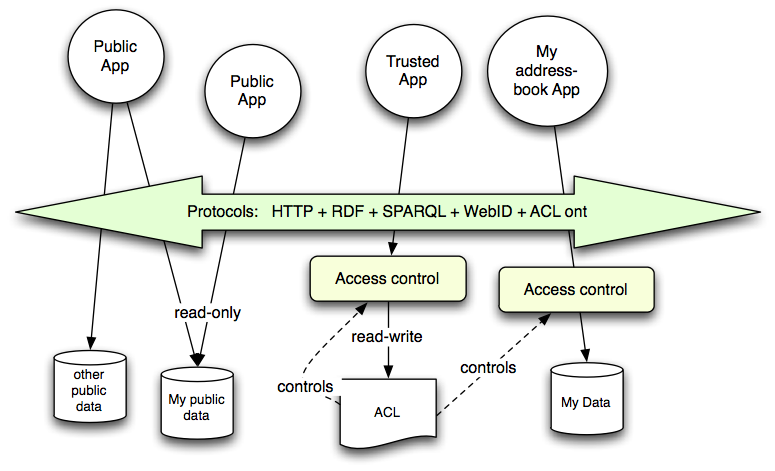
The effect of this design is then a user can run a program to set aside storage for particular purposes, and control who has what sort of access to it. The storage can br provided by any organization, but the interface, the control over its access, and the set of applications which can run on it, will be the same. The functionality is very similar to that of the filesystem on multiuser unix machine, but webized, so it becomes a decentralized global system.
Another article in this series describes the processing of Webizing a technology. This involves taking the system-wide identifiers and replacing them in the design with URIs. This sometimes makes an interesting decentralized system. In this case, the web storage proposed is quite like the result of webizing the unix file system. A unix file system controls access to files using the short string user names (or numbers) and short string group names (or numbers). These identifiers are system-wide: although there are certain conventions, in general user names and numbers on one system are not related to those on another system. The HTTP protocol allows us already to webize the files: now let us see what happens if we webize the access control lists.
Many interesting and powerful systems have of course already been built in this space. The AFS system using Kerberos principals is one. Systems such as OpenId have also been built for single log-on with URIs as user identifiers.
This new global computing environment answers some simple old questions, and opens a lot more, some old, some new. Here I simply flag some of them at a high level. Some of them may become the subject of future articles.
As in a unix-like file system, in a global access-controlled storage space, an application must be able to find a place (generate a URI) at which to store data of various sorts -- secret data, data shared with certain others, public data. This is the same problem that has been tacked by operating system designers over that 40 years. One method for this is that a user's secret data contain a template for any given application to construct such URIs. Experience suggests that it is valuable:
In a centralized SNS, when a semantic link is made, all related parties are easily informed. When A notes that a picture P taken by B depicts person C, then B and C can be immediately notified. Because there can be site-wide indexes, it is easy to ask "Which pictures did I take", "Which picture am I in", and "Which pictures did I annotate" just a easily as "Who took/is in/annotated this picture?". The links can all run back wards as well as forwards. (There is a certain analogy with some pre-web hypertext systems)
In a decentralized system, this is not immediately the case. On the web, there are two typical solutions. One is that a central third party crawls the whole web and forms an Index, just as search engines do of text. (There is, for example, a reverse index of FOAF built by QDOS.com site). A second method is that whenever a reader traverses a link, there is an indication of the source of the link sent t the destination. This happens with HTTP via the "Referer" field. In this way an incomplete but useful set of back-links can be built up on the destination side. A third method, that proposed here, if that when the links is made, the destination site is notified in real time.
Curiously, there have historically been many waves of excitement about streamds of real-time notification, or "push". In the end after many waves we are left with a situation in which RSS and tom feeds are generally pulled, not pushed. General notification systems require some sort of publish/subscribe (pub/sub) system. Examples of pub/sub protocols are jabber and pubsubhubbub. These are protocols added to the generally pull-oriented web of information. In the case of an application built on a substrate of read-write data, a notification can be made by writing into a bit of data which a given agent is sensitive to. If I want to say that I want to be your friend, for example, I could write that as a simple one-line statement into a "friend requests" file which you allow me write access to. In fact, I only need append access, and not even read or general write access to that list. A generalization of that is the "dropbox" system used in shared file systems, in which you make available at a well known address (typically, a well-known URI, but better, it is linked from your profile) the URI of a general drop-box file for incoming requests of any kind. Protecting a drop-box against spam may become an important part of the design. There is a value in having a drop-box open for any form of input, as it allows new applications to be created and implemented with full notification. There is security in allowing only predefined forms of notification. A pub/sub system is very constraining in that the receiver has to explicitly sign up for a given well defined source of notifications. In a spam-world this may be safe but unexciting to new application developers.
There are several models for the security of the system. What its it prevens attacks such as, for example, the disclosure of confidential data, or the filling up of one's data resources with spam? there are several security models, and as the socially aware cloud wil be used in many diffent types of scenario, many different models will be used.
One mode is that only trustd users have acces to files, and they only use trusted software to manipulate them. This is is similar to the model for much desktop software. Another model is that a resource such as a drop-box is opened for apped by the general public, but there are only very specific manipulations which can be done. There is some form of RDF message schema used, maybe in connection with a workflow system. When this happens, there is a strong relationship between a conventional API defiition and the set of operations which are allowed in the linked data. A difference is that when constraints are specified on a linked data operation, the semantics of the operation are already defined by the semantics ofthe linked data, wheras that information is not normally available in a conventional API specification. The Paper Trail ideas may apply here.
There are probably many other models, and we can expect them to be elaborated with time.
A separate issue, not mentioned here, is the question of access to the data on a user's behalf by a third site. This (which is the design target for example of OAuth) can be easily fitted into the scheme naively, but perhaps to be effective it needs a stronger concept of acceptable uses for information. It is enough to add the identity of a third party web site to the ACL, or it necessary to add defined classes of use?
The tracking of provenance of information and its modification history is a very important feature. Access Control at the resource (data file or graph) level requires data to be segmented thoughtfully into different resources. When there write access by many agents, different bits of data in the same file may have very different provanance. Many data stores do track this. RDF "Triple stores" are often in reality Quad stores (Subject, Predicate, Object, Provenance). Discusion of provenance is beyond the scope of this article.
This is an exciting infrastructure for deparating the provision of commodity data storage from a world of social applications which use it. It has already (2010) been prototyped on the client side in both a set of panes for the tabulator generic data browser and in a widget set
* The client doesn't have to run in Javascript in a web browser. That is a good initial case to explore, but it could also be a desktop app, phone app, etc. There are interesting questions about where these different siuations merge and overlap.
Richard MacManus, Read-Write Web, a blog
RDFAC: James Hollenbach, Joe Presbrey, Tim Berners-Lee, 2009, Using RDF Metadata To Enable Access Control on the Social Semantic Web ISWC 2009
Berners-Lee, T., Hollenbach, J., Lu, K., Presbrey, J., Pru d'ommeaux, E. and schraefel, m. c. , Tabulator Redux: Writing Into the Semantic Web, unpublished, 2007. [eprints]
Berners-Lee et. al., Tabulator: Exploring and Analyzing linked data on the Semantic Web, Procedings of the The 3rd International Semantic Web User Interaction Workshop (SWUI06) Athens, Georgia, 6 Nov 2006.
ESW Wiki, A Web ID A wiki source page for the WebID system which combined RDF IDs for people with browser-side certificates.
The Open ID Foundation, 2007-12-05, OpedID Authentication 2.0-Final
James Hollenbach, 2010-05, "A Widget Library for Creating Policy-Aware Semantic Web Applications", Thesis in Master of Engineering at MIT
Web Access Control Documentation on the W3C wiki.
On the frustrations of lack of portability:
Vidoes: DataPortability, 2008-01-15, Connect, Control, Share,
Remix.
djayers, 2008-03-28, Get your Dat
Out.
The dataportability.org group are not currently, AFAICT, using
linked data standards.
Diaspora Project, 2010, Video: Decentralize the web with Diaspora contains a rant about the current (2010) situation. The project plans to implement a secure distributed sytem involving personal servers.