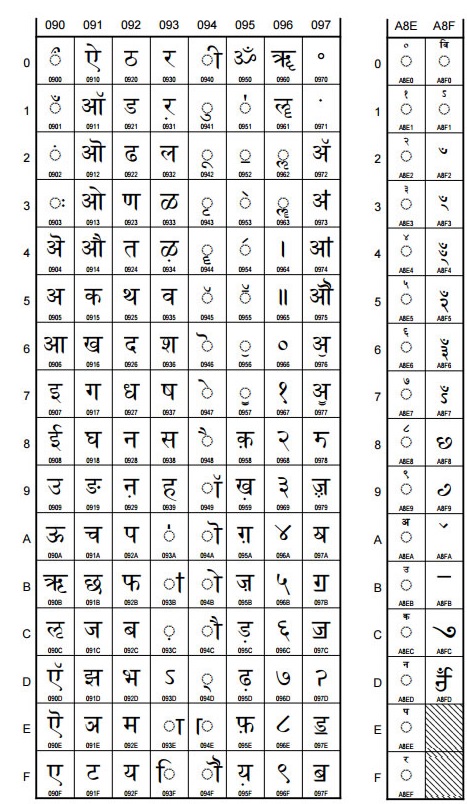
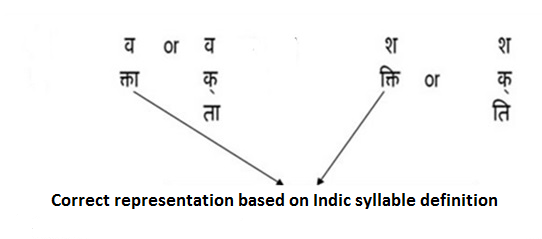
|
Consonant is a syllable |
Zero or more Consonant(Nukta *) + Virama sequences followed by consonant (+Nukta*)is a syllable |
Zero or more consonant+ (Nukta*)+ virāma sequences followed by a consonant (+Nukta*) followed by a vowel sign is a syllable |
zero or more consonant+ (Nukta*)+ virāma sequences followed by a consonant (+Nukta*) followed by modifier is a syllable |
zero or more consonant+ (Nukta*)+ virāma sequences followed by a consonant (+Nukta*) followed by a vowel sign and modifier is a syllable |
Hindi |
र, क, ज, ल, म |
प्प, क्ख,च्त, ज्ज्व, त्क्ल, त्स्न , र्त्स्न्य, फ़्क |
र्ता, र्त्स्न्या, फ़्जी, क्या, स्थि |
तः,स्तं, स्त्रँ, स्तः, फ़्ज़ँ |
र्त्स्न्या: त्स्न्युं, त्स्न्युँ, फ़्ज़ें,हि |
Kannada |
ರ, ಕ, ಜ, ಲ, ಮ |
ಪ್ಪ, ಕ್ಖ,ಚ್ತ, ಜ್ಜ್ವ, ತ್ಕ್ಲ, ರ್ತ, ರ್ತ್ಸ, ರ್ತ್ಸ್ನ |
ರ್ತಾ, ರ್ತ್ಸ್ನ್ಯಾ , ಖ್ವಾ |
ತಃ, ಸ್ತಂ |
ರ್ತ್ಸ್ನ್ಯಾಃ , ತ್ಸ್ನ್ಯುಂ |
Tamil |
க, ச, ங |
க்ஷ |
ஶ்ரீ , ஸ்ரீ , ரா |
NA |
NA |
Telugu |
ర, క, జ, ల |
ప్ప, క్ఖ, చ్త,జ్జ్వ , ర్త్స్న , ర్త్స్న్య |
ర్తా, ర్త్స్న్యా , ఖ్ఖి |
తః, స్తం |
క్కిం , ఖ్ఖిం , గ్గిం |
Malayalam |
ര, ക, ജ, ല, മ |
പ്പ, ജ്ജ്വ, ത്സ, ക്ത |
ക്ഷി, ത്തി, ത്സാ, ജ്ഞി , മ്മീ |
നഃ, മഃ |
ക്ലി , ത്തിം |
Bengali |
ক, ঙ, ঘ, ছ |
ক্ক, ষ্ট, ষ্ণ, থ্র |
ণ্যে, ন্ত্রে , গ্নে , গ্নী , ন্ত্রী |
NA |
স্যাঁ, ট্যাঁ, খ্রীঃ, ষ্টাং |
Nepali |
क छ ड भ |
क्क क्ख ज्ज्व |
र्पे , स्ति |
तः स्त्रं |
त्स्न्युँ |
Manipuri language of Bengali script |
ক, ল, ম, প |
ন্দ, ক্ত , পৃ, র্জ্জ |
র্তি, (পার্তি) , ঙ্থ্রৈ |
ক্তং (খজিক্তং) |
দাঃ, ন্দ্রাং, প্ত্রেং |
Kashmiri language of Devanagari script |
र, क, ज, ल |
त्य, थ्व, च्य |
न्यॊ, र्ता प्रा, क्या , प्रॉ |
स्तं |
NA |
Maithili |
र, क, ज |
क्ख , न्ह, न्ध , फ़्क |
र्ता, र्त्स्न्या, फ़्जी, क्या |
तः,स्तं, स्त्रँ, स्तः |
त्स्न्युं , त्स्न्युँ, फ़्ज़ें |
Dogri |
क, ज,स ,ल |
ग्ग, द्ध , क्क |
फ्ही , म्मी , ड़ि , क्का |
जं , सं |
यें , च्चैं , रें |
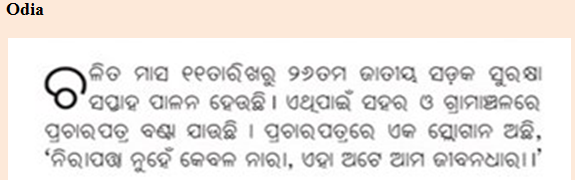
Odia |
କ, ଜ, ମ, ର, ଳ |
କ୍କ, ଚ୍ଚ, ଟ୍ଟ, ଜ୍ଜ, ନ୍ନ , ଜ୍ଜ୍ୱ , ର୍ଣ୍ଣ, , ର୍ତ୍ସ |
ର୍ତ୍ତା, ଜ୍ଞା, ଜ୍ଞୀ , ସ୍ଥି |
ତଃ, ସ୍ତଂ, ସ୍ତଃ |
ହିଂ |
Punjabi |
ਕ, ਜ, ਧ,ਵ |
ਪ੍ਰ, ਕ੍ਰ , ਸ੍ਵ |
ਨ੍ਹਾ,ਕੌ,ਹੋ |
ਧੰ, ਯੱ, ਨੰ |
ਮਾਂ, ਪੁੱ, ਚਿੱ |
Sanskrit (Excluding Vedic Extensions) |
ग,ड,प,र,ण |
ल्म, त्य, ल्प |
क्षे, र्था, यो , प्तो |
तं ,न्तः, मः , प॑ , र॒ |
षाः, ताः, स्यां , दी॑ , हि॒ |
Marathi |
ल, ष, ळ |
स्व, क्ष्ण |
व्या, त्स्ना |
कं, स्पं |
त्क्रां,त्र्यां |
Assamese |
ক , খ, ঘ |
ন্ত্ৰ , ৰ্খ, ৰ্জ , ৰ্ট |
ৰ্কে , ন্হা, ছ্ছা , ম্প্ৰ্দা |
ৰ্নিং , ৰ্ণাং , ট্ৰাং , ৰ্কিং |
NA |
Santhali language of Devanagari script |
र, क, ज, ल, म |
NA |
र्ता, ड़ि |
तः, कं , मः |
ताः, रें |
Gujarati |
ર, ક , લ, મ |
ક્ક, દ્ય, સ્ત્ર , ર્જ્જ, ર્પ્ક્ક |
ર્તા,ર્ત્સ્ન્યા, ક્યા |
તઃ, સ્તઃ |
ર્ત્સ્ન્યાઃ, હિં |
Konkani |
ळ |
य, स्प, ल्म, स्थ , ल्ल्य |
ज्यु, त्मे, स्त्री, स्तू, भ्रू |
स्कं, स्थं, न्हं, द्वं |
व्हां, म्हों, ल्लें, र्दें |
Bodo |
ब, फ, ख , ज |
प्ता , ज्ज , ब्ला |
ब्ला , यो , न्दो , न्थि |
सं , रं , गं , न्थं |
खां , दुं |
Sindhi language of Devanagari script |
क, घ , ज , ग |
क्ट , ग्घ , फ्ख , स्त्र , च्ग़ , न्ज |
बि , लू , यि , क्षी |
धं , धृं , षं |
हिं , सौं , श्रिं |