This document describes the basic requirements for Indic script layout and text support on the Web and in Digital Publications. These requirements provide information for Web technologies such as CSS, HTML, and SVG about how to support users of Indic scripts. The current document focuses on Devanagari, but there are plans to widen the scope to encompass additional Indian scripts as time goes on.
Status of This Document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at https://www.w3.org/TR/.
This document describes the basic requirements for Indic script layout and text support on the Web and in eBooks. These requirements provide information for Web technologies such as CSS, HTML and SVG about how to support users of Indic scripts. The current document focuses on Devanagari, but there are plans to widen the scope to encompass additional Indian scripts as time goes on.
If you wish to make comments regarding this document, please raise them as github issues. Only send comments by email if you are unable to raise issues on github (see links below). All comments are welcome.
To make it easier to track comments, please raise separate issues or emails for each comment, and point to the section you are commenting on using a URL for the dated version of the document.
Publication as a Working Draft does not imply endorsement by the W3C Membership. This is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to cite this document as other than work in progress.
This document was produced by a group operating under the
5 February 2004 W3C Patent
Policy. The group does not expect this document to become a W3C Recommendation.
W3C maintains a public list of any patent
disclosures made in connection with the deliverables of the group; that page also includes instructions for disclosing a patent. An individual who has actual knowledge of a patent which the individual believes contains
Essential
Claim(s) must disclose the information in accordance with
section
6 of the W3C Patent Policy.
This document describes the basic requirements for Indian Languages layout for display purpose. It discusses some of the major layout requirements in first letter pseudo-element, vertical arrangements of characters, letter spacing, text segmentation, line breaking and collation rules in Indic languages.
The current document focuses on Devanagari, but there are plans to widen the scope to encompass additional Indian scripts as time goes on.
The minimal requirements presented in this document for Indian languages text layout will also be used in E-publishing and CSS standards. This documents covers major issues of e-content in Indian languages in order to create a standard format of text layout to address storage, rendering problems, vertical writing, letter spacing, collation, line breaking etc.
It also describes a set of ABNF-based rules for valid segmentation of Indic orthographic syllables in order to get the proper display in browsers. Text segmentation[UAX29] and line breaking [UAX14] algorithms are considered in detail. Standards for CSS and digital publications will benefit from this document.
1.2 Indian language complexities
India has large linguistic diversity with 22 constitutionally recognized languages and 12 scripts.This document is currently focused largely on the Devanagari script. The expectation is that over time its scope will widen to cover additional major scripts from the list below.
The mapping between languages and scripts is complex. Multiple languages may have common scripts, while a language can be written in multiple scripts. Each language and script is unique in nature and cannot be easily replicated, even if they share common characteristics. The orthographic changes may also occur in some languages and adoption of new orthography is a gradual process, thus posing additional challenges.
Serial No.
Language
Script
1
Hindi
Devanagari
2
Sanskrit
Devanagari
3
Marathi
Devanagari
4
Konkani
Devanagari
5
Nepali
Devanagari
6
Maithili
Devanagari
7
Sindhi
Devanagari, Perso-Arabic
8
Bodo
Devanagari
9
Dogri
Devanagari
10
Bengali
Bengali
11
Assamese
Bengali
12
Manipuri
Bengali, Meetei (Mayak)
13
Gujarati
Gujarati
14
Kannada
Kannada
15
Malayalam
Malayalam
16
Odia
Odia
17
Punjabi
Gurmukhi
18
Tamil
Tamil
19
Telugu
Telugu
20
Urdu
Perso-Arabic
21
Santhali
Ol-Chiki, Devanagari
22
Kashmiri
Devanagari, Perso-Arabic
The scripts of South Asia share so many common features that a side-by-side comparison of a few will often reveal structural similarities, even in modern letter forms. They are all abugidas in which most symbols stand for a consonant plus an inherent vowel (usually the sound /ə/).The North Indian branch of scripts was, like Brahmi itself, mainly used to write Indo-European languages such as Pali and Sanskrit, and eventually the Hindi, Bengali, and Gujarati languages, though it was also the source for scripts for non-Indo-European languages such as Tibetan, Mongolian, and Lepcha, as well as many South-East Asian scripts. The South Indian scripts are also derived from Brahmi and, therefore, share many similarities in structural characteristics. For more details visit [South-Asian-Scripts].
Unicode is the Universal character encoding standard, used for representing text for information processing. Unicode encodes all of the individual characters used for all the written languages of the world. The standards provide information about the character and their use.
Common Locale Data Repository is the largest standard repository of locale data in the world. It is managed by the Unicode Consortium. It provides locale data in an XML format for use in computer applications. It facilitates locale-related information sharing among applications regardless of their domains. Its goal is to provide basic linguistic information for diverse “locales” in an open, interoperable form.
This data is usable for localizing applications.
Some examples of the information that CLDR gathers for languages and territories are:
Date formats
Time Zones
Number formats
Currency and its formats
Measurement Systems
Collation (Sort order) Specification: Sorting, Searching and Matching
Translations of names for language, territory, script, time zones, currencies
Unicode normalization [UAX15] is a form of text normalization that transforms equivalent sequences of characters into the same representation. Unicode normalization is important in Unicode text processing applications, because it affects the semantics of comparing, searching, and sorting Unicode sequences
When a unique representation is required , a normalized form of Unicode text can be used to eliminate unwanted distinctions. The key part of normalization is to provide a unique canonical order for visually non distinct sequences of combining characters.
1.3.2.1 Canonical & Compatible Equivalence
Unicode contains numerous characters to maintain compatibility with existing standards, some of which are functionally equivalent to other characters or sequences of characters. Because of this, Unicode defines some code point sequences as equivalent. Unicode provides two notions of equivalence: canonical and compatible.
Canonical equivalence is a form of equivalence that preserves visually and functionally equivalent characters.
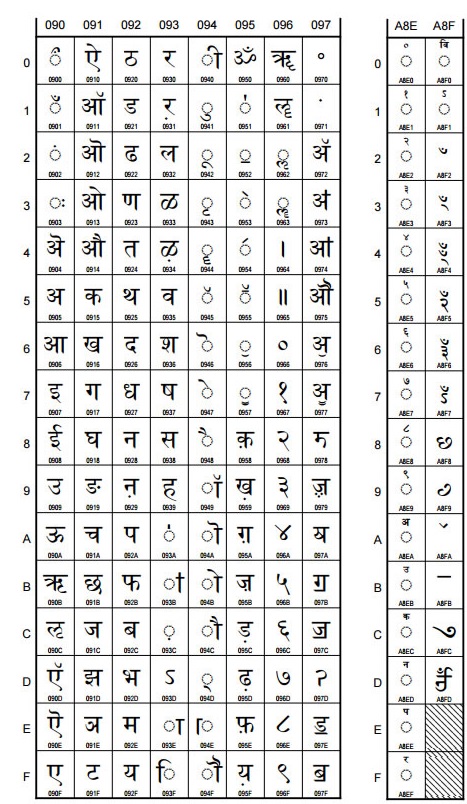
The following Unicode Character Code chart is per The Unicode Standard, Version 9.0 :
Fig. 3Unicode Devanagari and Devanagari extended Code Chart
Note
The Unicode code charts for other Indic scripts are available at [Code-Charts]
1.3.4 Character Set for Hindi
This section provides the basic alphabetic system of Devanagari Script as used for Hindi Consonants, Vowels, Modifiers, Matras, Halant, Nukta etc.
1.3.4.1 Consonant set
क
क़
ख
ख़
ग
ग़
घ
ङ
च
छ
ज
ज़
झ
ञ
ट
ठ
ड
ड़
ढ
ढ़
ण
त
थ
द
ध
न
प
फ
फ़
ब
भ
म
य
र
ल
व
श
ष
स
ह
1.3.4.2 Vowel set
अ
आ
इ
ई
उ
ऊ
ऋ
ए
ऍ
ऐ
ओ
ऑ
औ
1.3.4.3 Modifiers
ं – Anuswara
Anuswara, an archinasal, is denoted by a dot above the letter after which it is to be pronounced. This falls under Nasal category.
ँ – Chandrabindu
Candrabindu is pure nasalization as air comes from the nose. It is denoted by a breve with a dot superposed above the letter after which it is to be pronounced. This falls under Nasal category.
ः – Visarga
Visarga (sending forth), is denoted by two dots placed one above the other.
ऽ – Avagraha
For extra length with long vowels as seen in the Sanskrit text
1.3.4.4 Matras
ा
ि
ी
ु
ू
ृ
े
ॅ
ै
ो
ॉ
ौ
1.3.4.5 Halant(्)
Halant is used in most writing systems to signify the lack of inherent vowel. It is also called virama by Unicode.
2. Indic orthographic syllable boundaries (ABNF Valid segmentation-Proposed solution for layout issues in Indian languages)
2.1 Need for ABNF valid segmentation
ABNF Valid Segmentation based Indic orthographic syllable definition is provided here for correct and standardized representation of Indian languages layout. This will address various issues mentioned in the following sections.
This definition will be useful in order to get the uniform display of Indic layout in the browsers, applications, Digital publishing etc.
2.2 ABNF based definition of Indic orthographic syllable
Augmented Backus–Naur Form (ABNF) is a meta-language based on Backus–Naur Form (BNF), but consisting of its own syntax and derivation rules. The motive principle for ABNF is to describe a formal system of a language to be used as a bidirectional communications protocol.
V[m] |{CH}C[v][m]|CH
The linguistic definition of Indic orthographic syllable has been mapped to ABNF (Augmented Backus–Naur Form) for the purpose of text segmentation, line breaking , drop letter, letter spacing in horizontal text and vertical text representation. The definition has been elaborated , taking Hindi as an example.
The definition is a combination of 3 rules :
Rule 1 : V[m]
Rule 2 : {CH}C[v][m]
Rule 3 : CH (This rule is applicable only at the end of the word)
V(upper case) is independent vowel
m is modifier (Anusvara/Visarga/Chandrabindu)
C is a consonant with inherent vowel which may or may not include a single nukta
v (lower case) is any dependent vowel or vowel sign (mātrā)
H is halant / virama
| is a rule separator
[ ] - The enclosed items is optional under this bracket
{} - The enclosed item/items occurs zero or repeated multiple times
2.3 Various example use cases of ABNF based Indic orthographic syllable definition for Indian languages
Rule 1 : V[m]
V (Vowel) is a syllable
V+ Modifier is a syllable
Hindi
अ, ई, उ
अं, उँ, आः
Kannada
ಅ, ಇ
ಅಂ , ಅಃ
Tamil
அ, ஆ, இ
NA
Telugu
అ, ఇ,
అం , ఆః
Malayalam
അ, ഇ, ഉ
അം, അഃ
Bengali
অ , ই , ঋ
উঃ , এঁ, আঁ
Nepali
अ, आ, इ, उ
अँ, अं, उः
Manipuri
অ, ই, উ
ওঁ, অং (হোয়)
Kashmiri
अ
अं ॲ अँ
Maithili
अ, ई, उ
अं, उँ, आः
Dogri
अ, ई, उ
अं
Odia
ଅ, ଈ, ଉ
ଅଂ, ଉଁ, ଆଃ
Punjabi
ਅ, ਆ, ਇ
ਇੰ, ਉਂ
Sanskrit
अ, ई, उ
अं, उँ, आः
Marathi
अ, ई, ऐ
अं, उँ, आः
Assamese
অ , ই , ঈ
অঁ , অং, আঁ , ইঃ
Santhali
अ, ई, उ
अं, उँ, आः
Gujarati
અ, ઇ, ઈ
અં, અઃ
Rule 2 : {CH}C[v][m]
Consonant is a syllable
Zero or more Consonant + Virama sequences followed by consonant is a syllable
Zero or more Consonant (Nukta)* +Virama followed by consonant is a syllable
Zero or more consonant+ (Nukta)*+ virāma sequences followed by a consonant (+Nukta)* followed by a vowel sign is a syllable
zero or more consonant+ (Nukta)*+ virāma sequences followed by a consonant (+Nukta)* followed by modifier is a syllable
zero or more consonant+ (Nukta)*+ virāma sequences followed by a consonant (+Nukta)* followed by a vowel sign and modifier is a syllable
Hindi
र, क, ज, ल, म
प्प, क्ख,च्त, ज्ज्व, त्क्ल, त्स्न
र्त, र्त्स, र्त्स्न, र्त्स्न्य, फ़्क
र्ता, र्त्स्न्या, फ़्जी, क्या
तः,स्तं, स्त्रँ, स्तः, फ़्ज़ँ
र्त्स्न्या: त्स्न्युं, त्स्न्युँ, फ़्ज़ें,हि
Kannada
ರ, ಕ, ಜ, ಲ, ಮ
ಪ್ಪ , ಕ್ಖ,ಚ್ತ , ಜ್ಜ್ವ , ತ್ಕ್ಲ
NA
ರ್ತಾ , ರ್ತ್ಸ್ನ್ಯಾ
ತಃ, ಸ್ತಂ
ರ್ತ್ಸ್ನ್ಯಾಃ , ತ್ಸ್ನ್ಯುಂ
Tamil
க, ச, ங
க்ஷ
NA
மு , ஶ்ரீ , சீ
NA
NA
Telugu
ర, క, జ
ప్ప, క్ఖ, చ్త,జ్జ్వ
ర్త, ర్త్స, ర్త్స్న , ర్త్స్న్య
ర్తా, ర్త్స్న్యా
తః, స్తం
క్కిం , ఖ్ఖిం , గ్గిం
Malayalam
ര, ക, ജ, ല, മ
പ്പ, ജ്ജ്വ, ത്സ, ക്ത
NA
ക്ഷി, ത്തി, ത്സാ, ജ്ഞി
നഃ, മഃ
ക്ലി , ത്തിം
Bengali
ক, ঙ, ঘ, ছ
ক্ক, ষ্ট, ষ্ণ, থ্র
NA
ণ্যে, ন্ত্রে , গ্নে , গ্নী
NA
স্যাঁ, ট্যাঁ, খ্রীঃ, ষ্টাং
Nepali
क छ ड भ
क्क क्ख ज्ज्व
र्क र्त्स र्त्स्य
र्पे
तः स्त्रं
त्स्न्युँ
Manipuri
ক, ল, ম, প
ন্দ, ক্ত
র্ক, পৃ, র্জ্জ
র্তি, (পার্তি)
ক্তং (খজিক্তং)
দাঃ, ন্দ্রাং, প্ত্রেং
Kashmiri
र, क, ज
त्य, थ्व, च्य
NA
न्यॊ, र्ता प्रा, क्या
स्तं
NA
Maithili
र, क, ज
क्ख , न्ह, न्ध
र्त, र्त्स , फ़्क, गर्म
र्ता, र्त्स्न्या, फ़्जी, क्या
तः,स्तं, स्त्रँ, स्तः
त्स्न्युं , त्स्न्युँ, फ़्ज़ें
Dogri
क, ज,स ,ल
ग्ग, द्ध , क्क
स्स , द्ध
फ्ही , म्मी , ड़ि
जं , सं
यें , च्चैं , रें
Odia
କ, ଜ, ମ, ର, ଳ
କ୍କ, ଚ୍ଚ, ଟ୍ଟ, ଜ୍ଜ, ନ୍ନ
କ୍ର, ଘ୍ନ, ଜ୍ଜ୍ୱ , ର୍ଣ୍ଣ, ର୍ତ୍ସ
ର୍ତ୍ତା, ଜ୍ଞା, ଜ୍ଞୀ
ତଃ, ସ୍ତଂ, ସ୍ତଃ
ହିଂ
Punjabi
ਕ, ਙ, ਧ
ਕੱਕ, ਸ੍ਵ
NA
ਕੱਕਾ, ਸ੍ਵੇ
ਕੱਕੰ
ਕੱਕਾੰ
Sanskrit
ग,ड,प,र,ण
ल्म, त्य, ल्प
NA
क्षे, र्था, यो
तं ,न्तः, मः
षाः, ताः, स्यां
Marathi
ल, ष, ळ
स्व, क्ष्ण
ग्न्य,त्स्य
व्या, त्स्ना
कं, स्पं
त्क्रां,त्र्यां
Assamese
ক , খ, ঘ
ন্ত্ৰ , ৰ্খ, ৰ্জ , ৰ্ট
NA
ৰ্কে , ন্হা, ছ্ছা , ম্প্ৰ্দা
ৰ্নিং , ৰ্ণাং , ট্ৰাং , ৰ্কিং
NA
Santhali
र, क, ज, ल, म
NA
NA
र्ता, ड़ि
तः, कं , मः
ताः, रें
Gujarati
ર, ક , લ, મ
ક્ક, દ્ય, સ્ત્ર
ર્ક, ર્જ્જ, ર્પ્ક્ક
ર્તા,ર્ત્સ્ન્યા, ક્યા
તઃ, સ્તઃ
ર્ત્સ્ન્યાઃ, હિં
* Nukta within a bracket is optional.Consonant may or may not include Nukta.
Rule 3 : CH
This rule is applicable only for those Indian languages where pure consonant appears at the end of the word.
Examples of Rule3 - Consonant + virama at the end of the word
Hindi
NA
Tamil
வணக்கம் , தமிழ் , எண்ணம், செயல்
Kannada
ಬ್ಯಾಂಕ್
Telugu
క్ , జ్ , ఞ్
Malayalam
വാക്ക്, ചാക്ക് , നിനക്ക്
Bengali
ত্ (হঠাৎ) , This rule would not be applicable if ৎ is declared as pure consonant.
Nepali
छन्, हुन्, गर्दैनन्, गर्छस्
Manipuri
খ্বাঙজেৎ
Kashmiri
NA
Maithili
NA
Dogri
राह् , ओह्
Odia
NA
Punjabi
NA
Sanskrit
तेजस्, मरुत् , माम्
Assamese
ত্ (হঠাৎ) , This rule would not be applicable if ৎ is declared as pure consonant.
Santhali
NA
Gujarati
આત્મસાત્
3. Requirements for Indic Layout
3.1 Text segmentation
A string of Unicode-encoded text often needs to be broken up into text elements programmatically. Common examples of text elements include what users think of as characters, words, lines (more precisely, where line breaks are allowed), and sentences. The precise determination of text elements may vary according to orthographic conventions for a given script or language. The goal of matching user perceptions cannot always be met exactly because the text alone does not always contain enough information to unambiguously decide boundaries. For example, the period (U+002E FULL STOP) is used ambiguously, sometimes for end-of-sentence purposes, sometimes for abbreviations, and sometimes for numbers. In most cases, however, programmatic text boundaries can match user perceptions quite closely, although sometimes the best that can be done is not to surprise the user. Word boundaries are used in a number of different contexts. The most familiar ones are selection (double-click mouse selection, or “move to next word” control-arrow keys), and “Whole Word Search” for search and replace. They are also used in database queries, to determine whether elements are within a certain number of words of one another . Grapheme cluster boundaries are important for collation, regular expressions, UI interactions (such as mouse selection, arrow key movement, backspacing), segmentation for vertical text, identification of boundaries for Initial-letter styling, and counting “character” positions within text. [UAX29]
Solution for word boundaries: User-percieved characters boundaries should be based on tailored Grapheme Cluster Boundaries to conform Indic orthographic syllable definition
In case of Devanagari phrase separator called Danda or purna viram (U+0964 DEVANAGARI DANDA ।) and double danda or deergh viram(U+0965 DEVANAGARI DOUBLE DANDA ॥ : used to mark end of the verse as in Sanskrit text, shlokas etc.),In some of the browsers ending word is selected with purnaviram on double-click while in some browsers Danda is selected as a separate. It is recommended that line should not begin with Danda and double danda. So the properties of Danda should be same as the properties of FullStop or other punctuation marks so that new line should not begin with Danda and double danda.
For others characters, the text segmentation should be done as Indic orthographic syllable.
Indic script behavior in initial letter styling is based on syllables, rather than individual letter forms.
The above Figure shows an example of a drop intial in Hindi. In the first word of the paragraph, स्कूल ('skūl'), the sequence of characters is stored in memory is as follows:
There are two syllables in this word: SA+VIRAMA+KA+UU and LA. Note, however, that there are three Unicode grapheme clusters here: SA+VIRAMA, KA+UU and LA.
Styling is done on the basis of the whole orthographic syllable, not the first character, nor even the first grapheme.
A syllable includes a base consonant and any combination of the following characters in the text stream:
sequences of consonants preceded by virama (i.e. conjuncts).
vowel signs
visarga, anusvara or candrabindu.
3.2 Line breaking
When inline-level content is laid out into lines, it is broken across line boxes. Such a break is called a line break. In most writing systems, in the absence of hyphenation a line break occurs only at word boundaries. Many writing systems use spaces or punctuation to explicitly separate words, and line break opportunities can be identified by these characters. Line breaking, also known as word wrapping, is the process of breaking a section of text into lines such that it will fit in the available width of a page, window or other display area.
3.2.1 Hyphenation
There are different cases of hyphenation, some of the cases are given below :
Case 1 : Hyphens are commonly used in Copulative compounds words in Hindi language. Hindi has both prefixes and suffixes which are joined to words with a hyphen.
नर-नारी, लाभ-हानि, माता-पिता, ऊंच-नीच
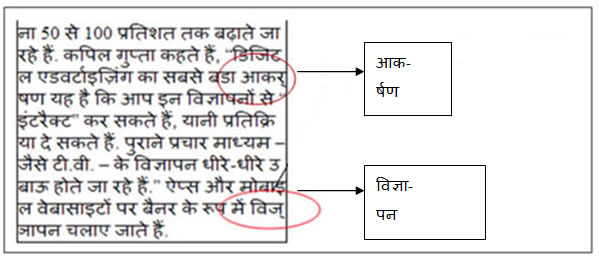
Case 2:Single word can breaks at the end of the line follow Indic orthographic syllable using hyphen.Following example shows correct representation of word आकर्षण and विज्ञापन using hyphen :
3.2.2 Guiding principles of Line breaking for Indian languages
In Indic writing system , it is preferred that line breaks at word boundaries ,if required following principles may be adhered :
Rule 1: New line cannot begin with following symbols/Punctuation marks. Also these should be retain with the associated text
Rule 2: The definition of Indic orthographic syllable may be used to break the line and a hyphen should be at the breaking point so that word can be read intuitively However the language specific morpho-phonemic rules and industry practices (from media, publishing and grammar books) could be used for hyphenation. U+ 00AD (soft hyphen) is used in some languages such as Tamil and Malayalam.
Rule 3: The hyphenated words can be broken at the hyphen e.g.:
नर-नारी should be treated as:
नर- on the first line and नारी on the next line
Rule 4: Expression with mathematical symbol should be treated as single unit so that at the end of the line expression should not breaks at operator level
Rule 5: Breaking should not be allowed at numerical values such as currency values, year etc. e.g.
“100.00” or “10,000”, nor in “12:59”
3.3 Initial letter styling
Drop initial is a typographic effect emphasizing the initial letter(s) of a block element with a presentation similar to a 'floated' element.
3.3.1 Selecting initial letters
Initial letters in Indic scripts must be selected on the basis of orthographic syllables, rather than individual letter forms (see an example at the end of section 3, Text segmentation). The orthographic syllable may be a single Consonant/Vowel or the combinations of Unicode code points. A detailed definition of Indic syllables can be found in section 2, Indic Syllable boundaries.In Indian languages the size of the Initial Letter is determined by the number of the lines between top line of the syllable and lowest bit in the orthographic Indic syllable cluster where subjoined consonant and other diacritics appears.
3.3.2 Typical drop initial usage in Indic scripts
Most of the Indic drop initial letters in magazines and newspapers use 2 to 4 line drops. Some examples are shown below.
Fig. 4Examples of Indic Initial letters
The Sunken and raised Initial letter are not preffered in Indian languages.In examples of this kind, reference points on the drop cap must align precisely with reference points in the text. In Indic scripts the top reference point is the hanging base line for those scripts that have one, and the bottom alignment point is the text after-edge.
Initial letter wrap property is not applicable for Indian languages.No contour-filling is required in Indian languages.
Alignment of the top line of the non-highlighted characters is at the top of the thicker top line of the initial letter is commonly used in India.In some examples top lines of the initial letter and the following letters don't touch. This is due to variable technology/formats used by the publishers. It is preferred that both the top lines of Initial letter and neighbouring text should touch.Here are some additional examples of initial highlighted letter and drop letter based on the Indic syllable definition.
The remainder of this section describes the detailed rules for placement and alignment of hindi characters with initial letter styling relative to the adjacent text.
3.3.3 Alignment of Initial letter of Indic scripts with hanging baseline
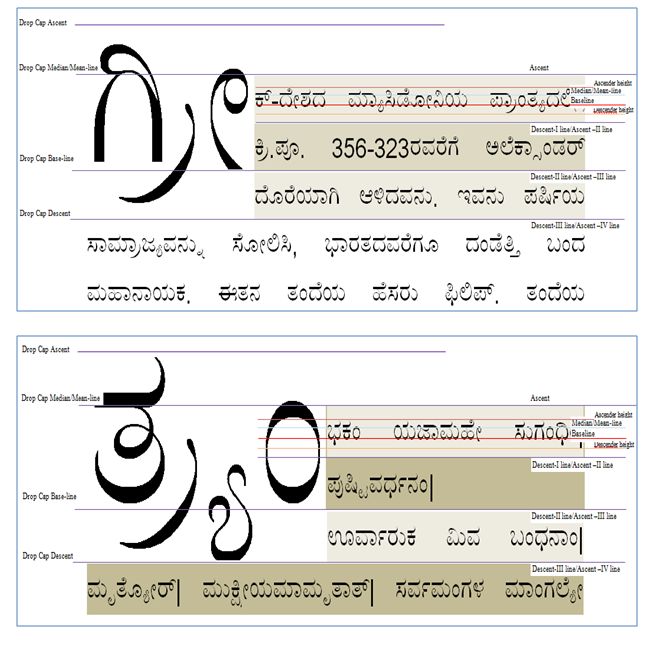
Indian languages which use hanging baseline such as Hindi, Bengali, Gujarati, Marathi, Punjabi etc. The part from the hanging baseline and the ascent of the Initial letter may follow the following mechanism :
Fig. 5Rule of Indic script with hanging baseline
Where n=h/2
In Indic scripts that have hanging baseline, the top alignment point is the hanging baseline, and the bottom alignment point is the text-after-edge and both the Initial letter and first line of text should be same aligned.
3.3.4 Scripts that don't have hanging baseline such as Kannada, Tamil, Telugu, Malayalam , Odia etc
The publishers in India commonly used following rules for such scripts :
The height of the Initial letter is based on the Indic orthographic syllable described in section 2.
Ascent of the first non highlighted line is equal t o the median/mean line of the Initial letter as shown below :
Based on above observations the general rule for South Indian languages Indian languages scripts will be :
¼ height of the total Drop Cap Height projected or ascended above the ascent of the first-line
¾ of the total Drop Cap Height occupied or descended from ascent of first line or X1 to descent of the last line or line XN.
3.3.5 Initial Letter box formatting in Indian languages
The Indian publishers commonly used different height of the boxes and sizes of the characters. But it is proposed that the syllable with in the box is centre-aligned with reference to box parameters as shown in the figure below :
Fig. 6Examples of Indic Initial letters within box
3.4 Letter Spacing
In styling issues like horizontal spacing, the spacing between characters like C E R T I F I C A T E, the space is given between the every character in case of English. But in case of Indian language, the space needs to be introduced after each syllable for correct representation.
For letter spacing in Indian languages it is recommended that spacing should follow Indic orthographic syllable definition.
Here is the some examples of letter spacing that based on definition :
अं त र्रा ष्ट्री य क र ण
स्वा ग त म्
सु स ज्जि त
स म्प्र ति
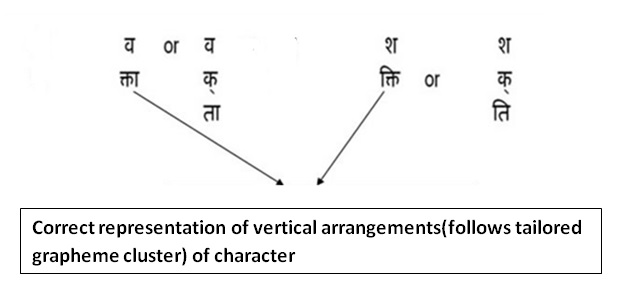
3.5 Vertical arrangements of characters
In vertical arrangement of characters writing each character on a new line may not be suitable in Indian languages. The vertical arrangements of characters are sometimes used in Indian texts. In order to form correct arrangements, it is preferred to follow tailored grapheme cluster approach. Variations of vertical arrangement of the characters in Hindi is represent below :
3.5.1 Variations in vertical arrangements
Fig. 7Variations in vertical arrangements
Given below the example 'स्वागतम्' that follows rule 2 and rule 3 of Indic orthographic syllable definition:
स्वा
CHCv- Rule 2
ग
C - Rule 2
त
C - Rule 2
म्
CH - Rule 3
3.6 Collation
Collation is one of the most important features for Indic languages . It determines the order in which a given culture indexes its characters. This is best seen in a dictionary sorting order where for easy search words are sorted and arranged in a specific order. Within a given script, each allo-script may have a different sort-order. Thus in Hindi the conjunct glyph क्ष is sorted along with क , since the first letter of that conjunct is क and on a similar principle ज्ञ is sorted along with ज . The same is not the case with Marathi and Nepali which admit a different sort order.
Different scripts admit different sort orders and for all high end NLP applications. Sorting is a crucial feature to ensure that the applications index data as per the cultural perception of that community. In quite a few States, sort order is clearly defined by the statutory bodies of that state and hence it is crucial that such sort order be ascertained and introduced in the document .
The order(left to right) as given below is pertinent to sorting by a computer program and is compliant with CLDR as laid down by Unicode.
़ \u093C
ॐ \u0950
ं \u0902
ँ \u0901>
ः \u0903
अ \u0905
आ \u0906
इ \u0907
ई \u0908
उ \u0909
ऊ \u090A
ऋ \u090B
ऌ \u090C
ऍ \u090D
ए \u090F
ऐ \u0910
ऑ \u0911
ओ \u0913
औ \u0914
क \u0915
ख \u0916
ग \u0917
घ \u0918
ङ \u0919
च \u091A
छ \u091B
ज \u091C
झ \u091D
ञ \u091E
ट \u091F
ठ \u0920
ड \u0921
ढ \u0922
ण \u0923
त \u0924
थ \u0925
द \u0926
ध \u0927
न \u0928
प \u092A
फ \u092B
ब \u092C
भ \u092D
म \u092E
य \u092F
र \u0930
ल \u0932
ळ \u0933
व \u0935
श \u0936
ष \u0937
स \u0938
ह \u0939
ऽ \u093D
ा \u093E
ि \u093F
ी \u0940
ु \u0941
ू \u0942
\U0943
\U0944
\U0945
े \u0947
ै \u0948
ॉ \u0949
ो \u094B
ौ \u094C
् \u094D
Following is the sort order of Consonant 'क'
क
कँ
कं
कः
का
कि
की
कु
कू
कृ
के
कॅ
कै
को
कॉ
कौ
क्
क़
A. Contributors
Serial No.
Name
Organization
1
Swaran Lata
DeitY
2
Dr. Somnath Chandra
DeitY
3
Manoj Kumar Jain
DeitY
4
Gautam Sengupta
University of Hyderabad
5
Girish Nath Jha
JNU
6
Rajeev Sangal
IIT Varanasi
7
Dipti Misra Sharma
IIIT Hyderabad
8
R K Sharma
Thapar University
9
Rajat Mohanty
IIT Bombay
10
Venkatesh Choppella
IIIT Hyderabad
11
Soma Paul
IIIT Hyderabad
12
M D Kulkarni
C-DAC Pune
13
Panchanan Mohanty
University of Hyderabad
14
G. Uma Maheshwar Rao
University of Hyderabad
15
Dr. Bisembli P. Hemananda
University of Mysore
16
Dr. R. Chandrashekar
JNU
17
Dr. Elizabeth Sherly
IIITM-K
18
V K Bhadran
C-DAC
19
Sanjay Kumar Choudhury
C-DAC
20
Dr. Ghanashyam Nepal
University of North Bengal
21
Dr. Sarbajit Singh
Indian Institute of Information Technology, Manipur
22
Dr. Adil Amin Kak
University of Kashmir
23
Dr. Abhijit Dixit
JNU
24
Dr. Panchanan Mohanty
University of Hyderabad
25
Dr.Preeti Dubey
Central University of Jammu
26
Amba Kulkarni
University of Hyderabad
27
Smt. Mridismita Mitra
C-DAC
28
Smt. Pampa Bhattacharyya
C-DAC
B. Revision Log
Various editorial and code tweaks.
Added use cases of ABNF based Indic orthographic syllable definition for various languages and scripts besides Hindi/Devanagari.