1. Introduction
1.1 Terminology
A character is a Unicode codepoint, together with some properties. For example, the Latin letter “a” has the hexadecimal Unicode codepoint 0061 and has the properties of being alphabetic, being lower-case (“A” is upper case), not being a numeral, and not being punctuation.
A glyph is a visual representation of (one or more) characters, used on screen or in print. There can be multiple glyph styles corresponding to a character. For example, these are all glyphs for the Latin letter “a”:
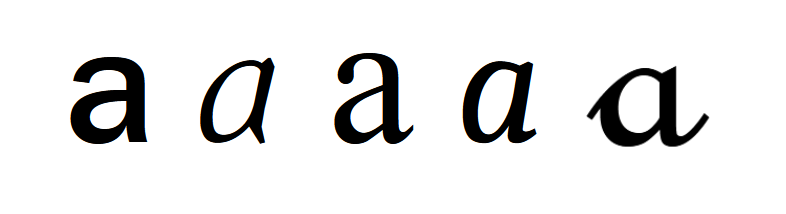
A font is a computer file which allows (sequences of) characters to be rendered as (sequences of) glyphs. In addition to the glyph shapes themselves (usually stored as scalable vector outlines) it also contains alignment and positioning information, describes when one glyph should be substituted for another, and so on.
Although languages such as English often have a 1:1 relationship between characters and glyphs, this is not the case in general. As a simple example, in Arabic, a single character will be rendered with different glyphs depending on whether it is at the start, middle, or end of a word; and also depending on the characters preceeding and following it. For example, here are different glyphs for the Arabic letter “Noon” (Unicode codepoint 0646), considering only the glyphs used at the start of a word [Arabic Language Requirements]:

These contextual changes to the shape of a glyph are referred to as shaping.
1.2 Installed fonts, Web fonts
Computers, phones, and tablets come with a selection of fonts installed. On some systems the user can choose to install additional fonts. In the early days of the Web, installed fonts were all that could be used to render Web pages.
Webfonts are fonts which are referenced from a stylesheet, automatically downloaded on demand by the browser, used to render a Web page, but are not installed on a system.
1.3 Uneven success
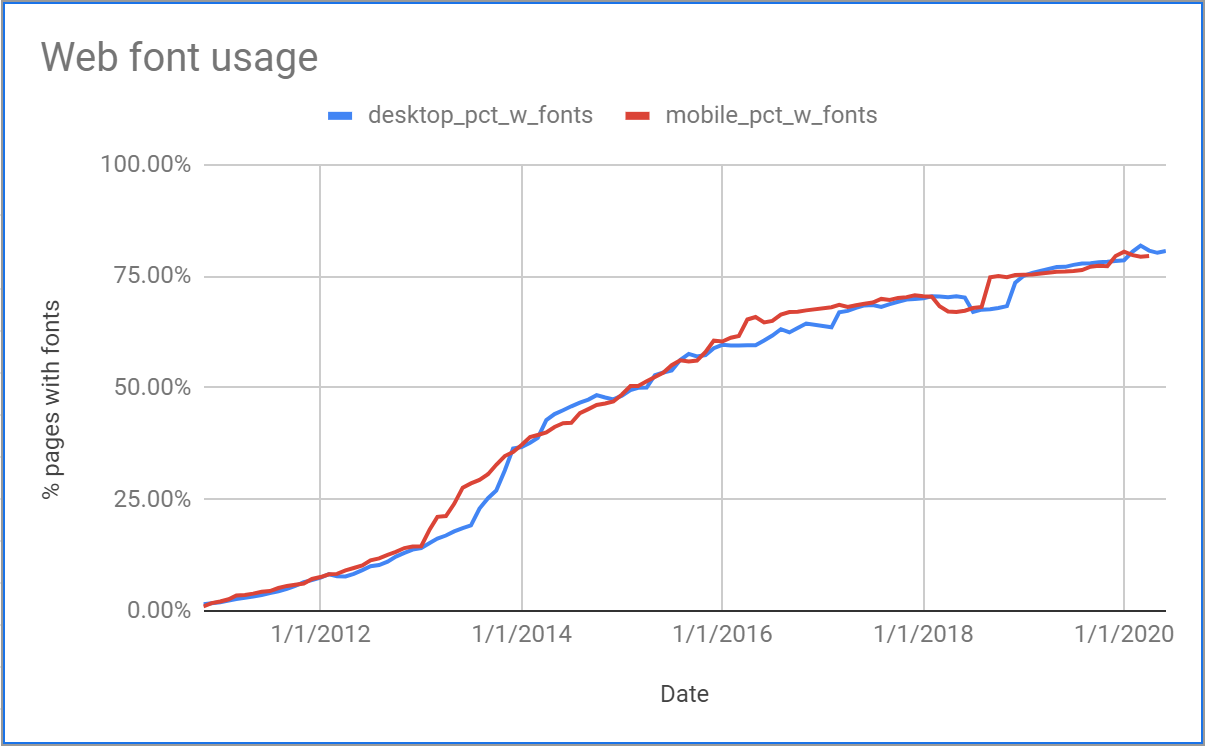
The success of Webfonts is widespread (globally, 80% of the top 10 million websites use Webfonts) but unevenly distributed. In certain areas of the world, usage is zero. This study evaluates solutions which would allow WebFonts to be used where slow networks, very large fonts, or complex subsetting requirements currently preclude their use.
2. Webfont deployment - successes, problems, solutions
This section examines the historical deployment of Webfonts from their inception in 1997 to date. The reasons for the success in deployment are described. Then, problems which prevented further deployment are examined. Lastly, potential solutions are briefly introduced. The detailed evaluation of these solutions comprises the majorty of this report.
2.1 @font-face
Initially introduced in 1997 [WebFonts] and later integrated into CSS2 [CSS2] and SVG1 [SVG1], the CSS @font-face allows for the automatic fetching of a font, on demand as the stylesheet is used to render a document, without user intervention. The font is used immediately, without being installed onto the system.
This technology was a necessary but not sufficient requirement for deployment. At the time, no consensus could be found on a single interoperable WebFont format, nor on a way to automatically convey licensing and other IPR information. Thus, early implementations each used their own format:
- Embedded OpenType™(MS Internet Explorer 3)
- Portable Font Resources (Netscape Navigator 4/Bitstream)
- SVG Fonts (pre-smartphone SVG implementations)
Due to lack of interoperability, plus other technical drawbacks of the initial font formats used, when in 2002 CSS 2.1 [CSS21 FPWD] was developed as the “core, interoperable subset” of CSS2, @font-face was dropped from the specification [CSS21].
It was only added back to CSS with CSS3 WebFonts [CSS3 WebFonts], which was merged into the First Public Working Draft of CSS Fonts 3 in 2011 [CSS Fonts 3 FPWD ] CSS Fonts 3
2.2 Common font format
The first attempts to use fonts on the web reflected the plethora of font formats in use on computers at the time. In 2002 the [CSS3 WebFonts] specification
noted an “initial” list
of eight different font formats
representing formats likely to be used by implementations on various platforms
- TrueDoc™ Portable Font Resource (Bitstream)
- Embedded OpenType™(Microsoft)
- PostScript™ Type 1 (Adobe)
- TrueType™ (Apple)
- OpenType™, including TrueType Open (Microsoft>
- TrueType™ with GX extensions (Apple)
- Speedo™ (Bitstream)
- Intellifont (Compugraphic)
(and this was without mentioning the many bitmapped formats still in common use at the time; or the SVG font format which came later).
Over time TrueType™ [ TrueType ], and OpenType™ [OpenType], which uses TrueType™ outlines and can also include Type 1 outlines (as CFF) and SVG outlines, and was then expanded to include chromatic fonts and the GX-like variable fonts, became the dominant formats in use. OpenType™ was eventually standardized by ISO as Open Font Format [OFF], the name change caused by the trademark on the name OpenType™.
OpenType™ has a tabular structure, each table holding a particular type of information. For example the cmap tabe holds character map information, the hhea and OS/2 tables hold glyph metrics, kerning information is stored in the GPOS or kern tables, while the actual glyph outlines are in the glyf, CFF, CFF2 or SVG tables.

In consequence, the total information needed to render a single glyph is scattered throughout many tables in an OpenType™ font. This has consequences for font subsetting, and foils attempts to use simple video-like streaming, as we will see later.
2.3 WOFF 1.0
Developed between 2010 and 2012, WOFF 1.0 [WOFF1] is a Web delivery format for OpenType. It compresses each OpenType™ table separately with gzip, and adds optional metadata which can, for example, include a link to the license for that font. Notably, the user agent is not expected to (indeed, is specifically forbidden from) behaving differently based on the presence, absence, or contents of such metadata. This allayed concerns by browser vendors that they would be required to police font usage; and allayed concerns from font vendors that font data would be forever separated from its licensing metadata.

By using a lightweight compression scheme which already existed in browsers (gzip, used in the PNG image format and also for HTTP compression), implementation burden was lessened. By offering bit-for-bit lossless compression, concerns over substandard “approximate” fonts (which had, for example, affected the PFR format) were also allayed.
By providing an agreed interoperable font format for download, which met the requirements of both type vendors and browser vendors, WOFF 1.0 was responsible for taking global WebFont usage from 0.1% in 2006 to 35% in 2014 [Sheeter BigQuery].
2.4 WOFF 2.0
Developed between 2014 and 2018, WOFF 2.0 [WOFF2], significantly improves over WOFF 1.0 by using a font-specific preprocessing step followed by Brotli compression.
Once WOFF 1.0 had paved the way by demonstrating the utility of WebFonts, it was possible to put in place a more complex, but more space efficient two-part compression scheme. As the volume of font data worldwide was increasing, this was seen as a high priority. As it was demonstrated [WOFF2-ER] that WOFF 2.0 would never give a worse compression result than WOFF 1.0, WOFF 2.0 rapidly became supported by all browsers and has taken over from WOFF 1.0.

Global webfont usage is now over 80%.
2.5 Static subsets and unicode-range
CSS has a feature, unicode-range [UNICODE-RANGE], which states which characters a font doesn't have glyphs for. This prevents a webfont being needlessly downloaded. Combined with static subsetting, this greatly reduces the volume of font data for common, monolingual websites.
For example, a font which supports Latin, Greek, and Cyrillic can be split into three subsets; typically only one will be downloaded. Google Fonts uses this approach extensively [Google script subsets], and it works well for languages which use only a small number of glyphs.
This study assumes that the target to beat is a static subset font, with glyph coverage for only the characters actually used, compressed with the best available method, WOFF 2.0.
2.6 Success: Widespread success for simple fonts
Websites with content languages using the Latin alphabet (such as Vietnamese, most European and African languages), Greek and Cyrillic alphabets, and Thai all make modest demands on fonts. The number of unique characters is limited, typically under a hundred; contextual shaping is rare to non-existent, and thus fonts are easy to subset and compressed font sizes are very small.
2.7 Failure: Large glyph repertoires
Languages such as Chinese, Japanese, and Korean have many thousands of characters. For example, the Zhonghua Zihai (simplified Chinese: 中华字海; traditional Chinese: 中華字海) lists 85,568 Chinese characters. The Hangul Syllables block in Unicode lists 11,172 precomposed Hangul syllable blocks for modern Korean. Font data is thus massive. While there is statistical variation in usage from character to character, it is not in general possible to statically subset fonts into “always used” and never used” subsets; the size of the sometimes used” group predominates.
Static subsetting is unusable, font sizes are in the megabytes, and mobile Web usage is significant.
A 2019 study by the HTTP Archive found that the median number of bytes used for Web Fonts on websites in China was zero. [Web Almanac 2019: Fonts]
Pan-Unicode fonts (fonts which aim to cover a very large number of languages) can be difficult to subset and, if subsetted, the functionality can be reduced. For example, due to size, the Noto family is currently served as a bunch of separate families. It is up to the developer to explicitly pick which ones they might need.
Static subsets where each subset appears to have a distinct font family name are also more difficult to use when creating truly multilingual websites. For example, a discussion forum may have users posting in a variety of languages. A global mapping application will need to render text in a wide array of scripts, depending on what part of the world is being viewed. In both cases, the range of supported languages is wide, and may change as the content is updated.
2.8 Failure: Difficulty with subsetting
Static subsetting can run into difficulties when there are complex inter-relationships between different OpenType™ tables, or when characters are shared between multiple scripts but behave differently in each script.
To take a simple example, both Latin and Cyrillic scripts use the period (.) at the end of a sentence. Because Latin-only or Cyrillic-only content is common, splitting a font that covers both Latin and Cyrillic into two smaller static subsets makes sense. However, if content uses Cyrillic text and also uses the period from the Latin subset, then kerning rules between the Cyrllic characters and the period no longer work, whereas they did in the original font which contained the complete kerning information.

Some background for a more complex example: India has large linguistic diversity, with 22 constitutionally recognized languages and 12 distinct scripts [IndicLR]. In some scripts, there are complex glyph shaping needs [Indic-Intro]. For example a Matra (dependent vowel) can be placed above, below, or be split, part before and part after a consonant.

There are also some shared characters between the scripts. If a font supports two or more of these scripts, which is common, and the content developer wants to present it as a single font family and use unicode range to deliver per-script subsets, the shared characters need to be duplicated in each subset. Not only does this mean that the total size of all subsets is greater than the original font, but also the shared characters will be rendered from only one of the subsets based on the priority of the unicode range declarations. As a result syllable clustering and glyph shaping doesn't work correctly; the text doesn't just look less beautiful, it becomes unreadable.
2.9 Solution: Progressive Font Enrichment
Instead of downloading a static subset (or, where static subsetting canont work, downloading an entire font), this proposed solution uses a continuous process of dynamic subsetting. A small subsetted font is downloaded, which can display the content currently being browsed. As the user moves on to other content, (or as content is added - for example on user forums or with commenting systems) additional data for that font is automatically downloaded and the font becomes progressively enriched over time. In contrast to fine-grained static subsetting, the CSS remains simple because the stylesheet sees only a single font, not a plethora of related fonts.
This helps with single-language fonts for languages such as Chinese, and simplifies robust deployment of pan-Unicode fonts. It avoids kerning and shaping breakage for complex scripts.
While this approach has been deployed experimentally by several font foundries (Adobe TypeKit, Monotype, Google Fonts), it is desirable for interoperability that a standardized solution for Progressive Font Enrichment (PFE) exists.
To ensure that the correct solution is standardized, which works with a variety of network conditions and content languages, the W3C WebFonts Working group was chartered to explore the area and to run simulation experiments on the proposed solution space before undertaking standards-track work.
3. Initial trials
Adobe has already deployed a proprietary form of progressive font enrichment. Performance data from that solution was compared with an early prototype of the Patch Subset method (described below). In this initial trial, these were both compared to a theoretical optimal method (a static subset containing exactly the glyphs needed for a given page sequence).
These simulations used exclusively CJK fonts, primarily the Source Han Sans/Serif or Noto Sans/Serif CJK collections. All of the CFF fonts were de-subroutnized before being used in the simulation. This produced the lowest overall transfer sizes.
Both Adobe's solution and Patch Subset deliver close to optimal results on number of bytes transferred, with Patch Subset transferring an additional 19%, and Adobe's solution an additional 45%, versus the theoretical optimal transfer bytes.
The test was repeated, but this time using fonts provided by Monotype. The results were similar, except that Patch Subset transferred an additional 65% versus the theoretical optimal transfer bytes.
It became clear from both trials that network bandwidth, although important, was not the limiting factor for performance. Rather, the network latency (overall round-trip time for a single request) was the important variable. This is because a font is delivered in response to several requests over time, rather than in one big request and response. This finding informed the study design.
4. Study Design
4.1 Success criteria
The following success criteria were taken into account. A good Progressive Font Enrichment solution will:
- Retain all layout rules found in the source font, which are needed for the codepoints present on a particular page.
- Load font data fairly, that is for each page view the amount of font data loaded is related to the number of new codepoints on that page.
- Minimize the user perceptible delay caused by font loading.
- Have good network performance, that is it minimizes:
- The worst case network delay caused by font loading for clients when viewing a sequence of pages.
- The total number of bytes transferred (both requests and responses) caused by font loading for clients when viewing a sequence of pages.
- the total number of network requests caused by font loading for clients when viewing a sequence of pages.
4.2 Server type: intelligent vs. simple
Two entirely different types of font enrichment have been studied. They differ in the demands made of the server which serves the fonts (both approaches require client support). One requires an active server extension. The other requires only a standard Web server, so could be deployed anywhere. They make differing tradeoffs and have correspondingly different advantages and disadvantages.
4.2.1 Patch Subset
In one approach, Patch Subset, the entire font is dynamically subsetted on the server. The client and the server communicate closely to generate the optimal set of enrichment glyphs and other font information with each transaction.
The first response is a standalone OpenType font, (served over HTTP/2, and with Brotli Content Transfer Encoding) containing only the data (glyphs and metrics) required to render the specific codepoints requested. This means that every OpenType table has been dynamically subsetted on the server, to produce this response.
For subsequent responses, a Brotli binary patch is used to update the font stored on the client. (Generating these patches, and applying them, are both features of the standard Brotli library). The patches make use of the Brotli compression dictionary created to serve the initial font, and thus the cost of any duplicated data is greatly reduced. This approach tends more closely towards the theoretical peak efficiency in terms of bytes transfered and minimal network latency, but requires an intelligent server which can subset all OpenType tables, without breaking layout, retain the compression dictionary, and woff-compress the font on the fly. This approach also allows parameters to be tuned to maximize efficiency based on the current network conditions.
4.2.2 Range Request
In the second approach, Range Request, a streaming approach similar to video streaming is used. Again, an OpenType font is served (over HTTP/2, and with Brotli Content Transfer Encoding). As previously mentioned, information required for a given glyph is scattered throughout the font. Thus, the client stops the transfer as soon as the table directory is seen. Individual tables, as needed, are then loaded with HTTP/2 byterange requests. Individual glyph outlines are also requested with HTTP/2 byterange requests. Therefore, in this method, only the glyph outlines are subsetted, thus ensuring that all the other tables are preserved. Ths means that the download size for the processed font is the same as the original font, for all tables which do not contain glyph outlines.
In addition, the font must be pre-processed to move glyph outlines to the end of the file, and to ensure that the outlines are independent [Font Optimizer]. Thus:
- Composite glyphs are flattened into the resulting outlines
- The CFF table, if present, is desubroutinized, charstrings (glyph outlines) moved to the end of the table
- The glyf or CFF table (whichever one is present) is moved to the end of the font (the SVG table, if present is not moved and thus, any glyphs there are always downloaded)
Optionally, the preprocessor can sort the font file, to keep glyphs that are commonly used close together. This allows groups of glyph outlines to be served with a single HTTP range request. The font will still work with the Range Request if this is not done, but performance will be less. In this study, glyph sorting was done using a simulated annealing algorithm [Font Optimizer].
This preprocessing need only happen once, so can be done by an authoring tool or a utility. (An experimental proof-of-concept utility to do this preprocessing is available [Streamable Fonts]).
The resulting preprocessed font is larger, but byterange streaming can be used to download portions of the glyph outline data. First a static subset of the entire font (but with zero glyph outlines) is downloaded. The client then requests glyph outliness as needed using standard HTTP byre range requests, which are supported on all common servers. The efficiency loss from this approach depends on the balance of glyph outline data to other font data. Efficiency is improved if glyphs are re-ordered in terms of statistical occurrence.
This approach allows easier deployment, because any standard server can be used. There is no risk of accidentally breaking font rendering due to mis-subsetting complex tables. There is however no tuning for differing network conditions. Also, compared to WOFF2 which compresses redundant or duplicate data, there is no compression of redundant data between requests in this model.
4.3 Cost function
The impact of network delay was modelled as a cost function. This is not straightforward to model as there are two boundding factors:
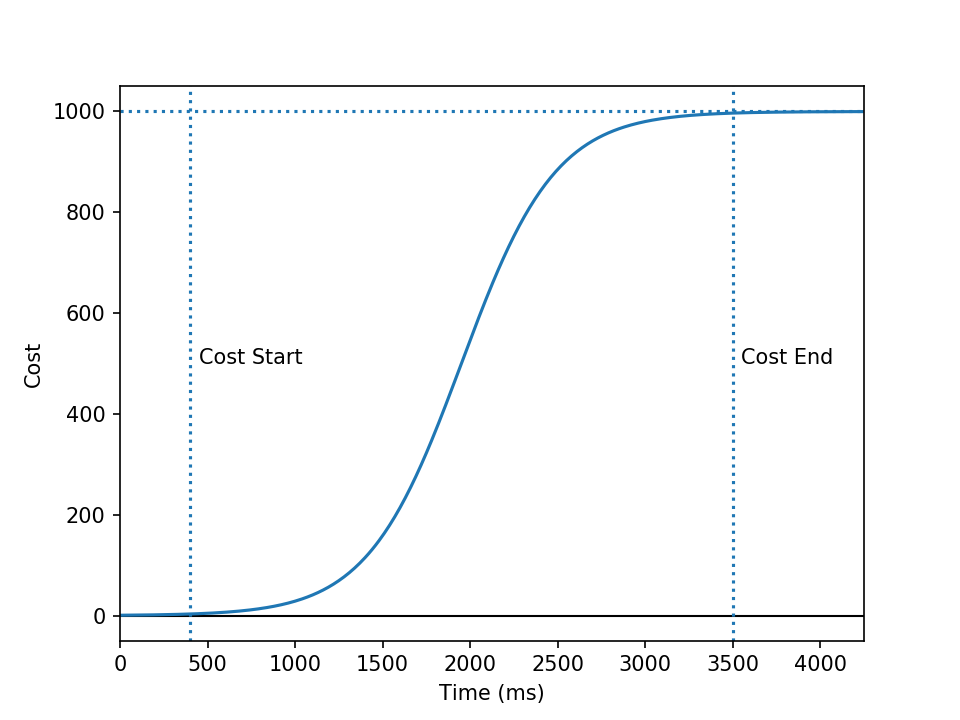
- Too slow
- Beyond a certain point, the user may give up and go to a different page. Or, beyond a certain maximum time Tm the browser may substitute a system font so that page rendering can occur. Delays beyond that point do not further impact the user experience. In this study, Tm was set to 3.5 seconds.
- Too fast
- Not that anything can really be too fast, but the inherent delays in HTML page and CSS stylesheet loading, and image loading, mean that further shortening the load time Tz for a font that already loads rapidly will not improve the user experience because it is no longer the limiting factor. Tz was set to 400 milliseconds.
Denoting the maximum cost as M, the cost at time t can be represented by a sigmoid function, chosen to give a cost rising from 0 after Tz, approaching 1000 at Tm, and centered within that range.
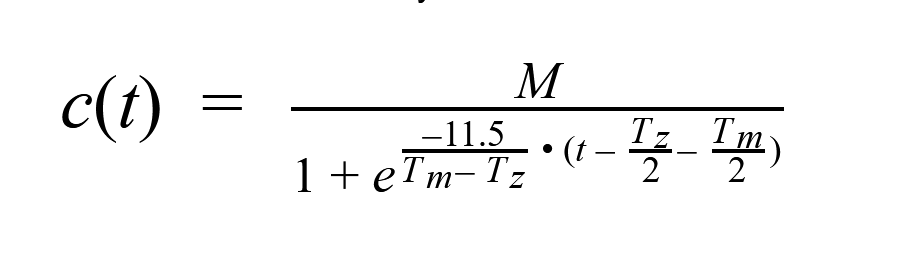
4.4 Network type - slow 2G to fast broadband
The type of network has a large impact on perceived performance (time from network request to first rendered text). Not only bandwidth but also latency, which can be substantial (ten seconds!) on slower mobile networks, must be considered.
In this study each network type is represented by a network model. A network model is defined as the estimated round trip time, the upstream bandwidth, and the downstream bandwidth.
The size of HTTP/2 request headers and responses (using HPACK) was based on observing request header sizes for sample requests to a fonts Content Distribution Network (CDN).
The network models for mobile 2G, 3G, 4G, mobile WiFi, and Desktop (on a fast connection) were derived from browser reported connection speeds (from Chrome), across each connection type. For each connection type 5 different speeds were provided, ranging from the slowest observed speeds to the fastest observed for that connection type.
| Slowest | Slow | Median | Fast | Fastest | |
|---|---|---|---|---|---|
| mobile 2G | 10,000 | 4,500 | 2,750 | 1,500 | 125 |
| mobile 3G | 2,750 | 550 | 300 | 175 | 115 |
| mobile 4G | 650 | 225 | 150 | 110 | 70 |
| mobile WiFi | 500 | 170 | 115 | 65 | 35 |
| Desktop | 350 | 150 | 80 | 50 | 20 |
| Slowest | Slow | Median | Fast | Fastest | |
|---|---|---|---|---|---|
| mobile 2G | 4 | 6 | 9 | 19 | 200 |
| mobile 3G | 13 | 50 | 156 | 219 | 750 |
| mobile 4G | 47 | 181 | 238 | 750 | 2,250 |
| mobile WiFi | 100 | 200 | 563 | 1,250 | 3,438 |
| Desktop | 125 | 313 | 938 | 2,188 | 7,500 |
Note: In this study, download bandwidth was considered far more important than upload bandwidth (because requests are small and responses large). Therefore, even though asymmetric networks such as ADSL are common, the bandwidth in both directions was treated as the same.
For the Patch Subset model, a simple HTTP POST was used for the request, consisting of a binary protocol buffer (proto3) which identified the font, the characters needed, and the characters already downloaded. For the Range Request model, HTTP GET byterange requests were used. Reasonable defaults for request and response header size (35 bytes each) were used in the simulation.
For the earlier tests, results were reported for each speed class in each network type. However this was found to be too cluttered for meaningful comparison and so the resuts for each network type were aggregated as a weighted average. Slowest and Fastest were weighted 5%, Slow and Fast weighted 20%, and Median weighted 50%.
4.5 Language type: small & simple, complex shaping, large
To better understand how progressive font enrichment performs for different scripts, the Web page corpus data and the corresponding fonts were divided into three groups based on the characteristics of those languages:
- Simple alphabetic languages: using Latin, Cyrillic, Greek and Thai scripts
- Languages which require glyph shaping: Arabic and Indic
- Languages with large character repertoires: Chinese, Japanese, and Korean
The study evaluated performance for these three linguistic groupings separately. The groupings were selected by grouping together scripts that should have similar behaviour with respect to progressive font enrichment.
4.5.1 Web corpus
To simulate the sort of multiple-page browsing experience which would benefit from PFE, a corpus of Web page views was assembled for each language group. These were analyzed to yeild sequences of character requests which would generate font requests for the characters not previously encountered.
The breakdown of languages within each linguistic category was as follows:
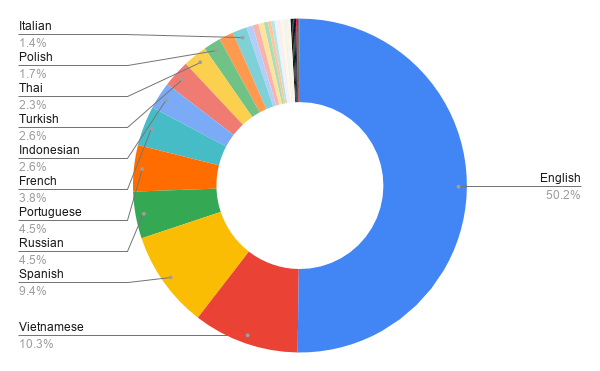
Due to the large number of sequences present in the simple alphabetic group, one out of every 1000 of the sequences in the data set was randomly selected for use in the analysis. After sampling, this data set is composed of approximately 130,000 sequences. English predominates, at 50%.
Note: Using different sampling to increase the number of non-English sequences was considered, but it was decided to retain the observed language distribution of websites.
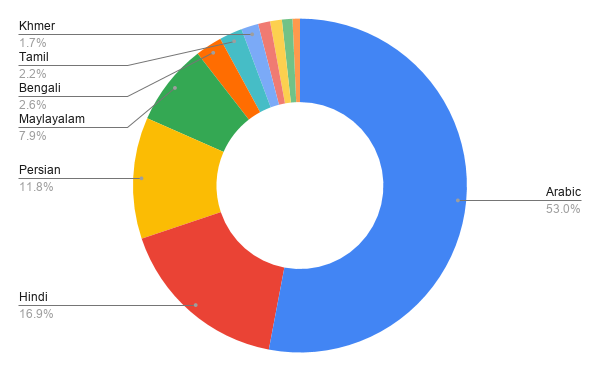
After sampling by a factor of 500, the glyph-shaping data set is composed of approximately 6,500 sequences. Arabic languages, at 53%, predominate in this dataset.
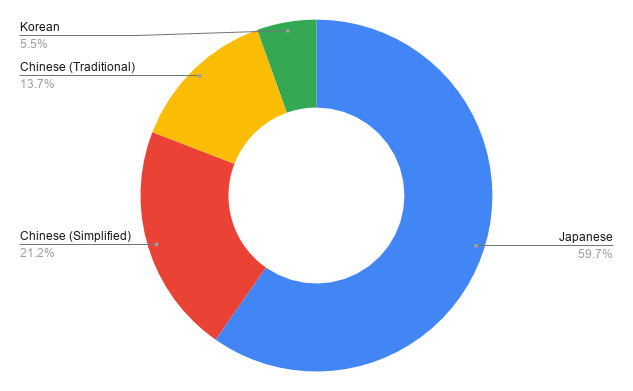
After sampling by a factor of 5000, the CJK datatset contained approximately 6,000 sequences. Japanese predominates at 60%, with Traditional and Simplified Chinese totalling 35%.
4.5.2 Fonts by language type
Fonts vary in size and complexity based on which of these language families they support.
In this study, to enhance replicability, the font corpus consisted entirely of fonts from the open source Google Fonts collection [Google Fonts].
Fonts for alphabetic languages with small glyph repertoires and little to no shaping requirements are the smallest and, to date, the most sucessful in terms of Webfont usage. Many European languages fall into this category. The more recent adoption of glyph alternates, stylistic sets, and variable fonts has not significantly altered Webfont use for this category.
The TrueType or OpenType fonts used for alphabetic languages had a median size of 17,660 bytes, with a spread from 15,784 bytes (5th percentile) to 184,152 bytes (95th percentile). The median size once WOFF2 compressed was 8,360 bytes. [PFE Font Sizes]
Fonts for Indic languages, Arabic, and Farsi fall into a second category. The glyph repertoire is much larger than the character repertoire, because the scripts used have complex, context-dependent shaping requirements. Fonts which fail to support these features do not just provide "less beautiful" text, they provide unreadable text. Fonts in this category tend to use and to be easily broken by poor-quality font subsetting software. When correctly done, a static per-language subset is still fairly small.
The TrueType or OpenType fonts used for glyph shaping languages had a median size of 93,588 bytes, with a spread from 15,784 bytes (5th percentile) to 459,600 bytes (95th percentile). The median size once WOFF2 compressed was 30,332 bytes. [PFE Font Sizes]
Fonts for ideographic languages such as Chinese, Japanese and Korean have extremely large character and glyph repertoires, of the order of tens of thousands of glyphs. On the other hand, besides vertical and horizontal glyph variants, and “full-width” vs. “half-width” glyph variants for a few characters, the shaping requirements are low to none. Thus, the font size is almost entirely determined by the glyph outline data, and subsetting is primarily a case of partitioning the glyph outline data into small groups which are frequently used together.
The TrueType or OpenType fonts used for CJK languages had a median size of 1,834,496 bytes, with a spread from 16,832 bytes (5th percentile) to 5,524,2080 bytes (95th percentile). The median size once WOFF2 compressed was 768,492 bytes. [PFE Font Sizes]
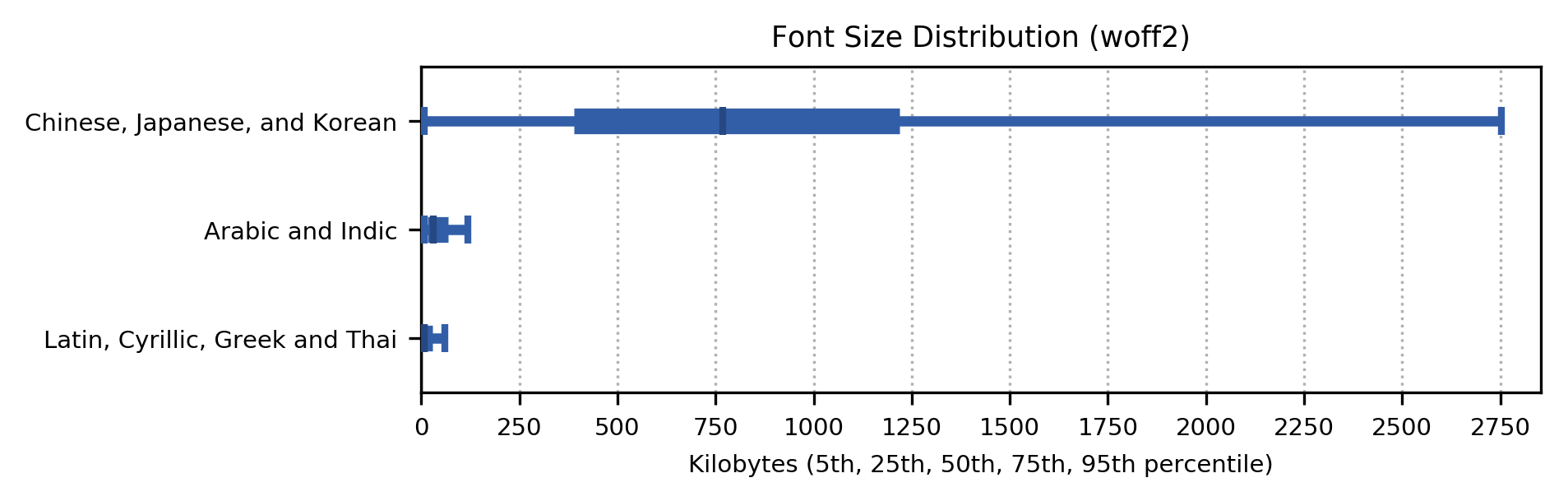
Note: because the preprocessor used to prepare fonts for the Range Request approach drops all hinting information, to make a fair comparison, the fonts used for the Patch Subset approach also had hintng information removed. There is nothing in either approach which precludes sending hinting information; this was just a limitation of some of the software used in this simulation.
Note: Because the additional table transforms in WOFF2 (and subsequent client-side table reconstitution) would have complicated the simulation, both Patch Subset and Range Request simulated serving the initial font as a TrueType or Opentype font (over HTTP/2), with Brotli used as HTTP Content Transfer Encoding. Ths means that the performance gains from the WOFF2 table transforms were not obtained in this simulation.
4.6 Codepoint Prediction
Because making many small requests is costly, it could be beneficial to send additional codepoints besides the ones actually requested. The hope is that they will be needed later, when the user visits a different page. This is a tradeoff, potentially increasing total download size (if the codepoints end up not being used) but potentially decreasing the number of separate requests. This is particularly valuable on network connections with longer round trip times.
Rather than sending random codepoints, it is best if the server tries to predict which unseen codepoints are statistically likely to occur in the future. This is called codepoint prediction.
In this study, an index of the Web was analyzed to determine the frequency of occurrence (percentage of documents in the index which include that codepoint at least once) for each codepoint. The index was segmented by script (using the same script subsets as are used for unicode-range subsetting by Google Fonts [Google script subsets]).
Each client request contains the font to enrich, the set of codepoints already downloaded, and the set of codepoints to be added.
The prediction algorithm in this study had two variables, which could be tuned to give different tradeoffs suitable for different network conditions: N is the number of predicted codepoints to add, and F is a minimum occurrence theshold. Codepoints which occur less frequently than F will not be sent (unless explicitly requested). The algorithm proceeded in four stages:
- Find all script subsets which intersect the set of codepoints the client wants to add
- Discard any of those script subsets which do not intersect the codepoint coverage of the font to be augmented
- Pick the top N codepoints by frequency which are
- in the font to be augmented
- not in the set of codepoints the client has, or wants
- in any of the subsets matched in steps 1 and 2
- above frequency threshold F
- Return the requested codepoints, plus the predicted codepoints.
The simulation was run with two or three different values for N and F, for each language type:
| Language Type | N (Max codepoints) | F (Frequency Threshold) |
|---|---|---|
| Latin, Greek Cyrillic, Thai | 87 | 0.005 |
| 37 | 0.005 | |
| Arabic + Indic | 109 | 0.005 |
| 55 | 0.00615 | |
| Chinese, Japanese, Korean | 1500 | 0.005 |
| 941 | 0.062 | |
| 24 | 0.999 |
The results [Codepoint Prediction] are summarized later in this report.
4.7 Simulation and analysis framework
The C++ and Python code used for the testing and analysis framework, plus instructions to build the software and run the tests, and the datafiles holding the Web corpus, are all available on GitHub to allow independent verification and further experimentation [ PFE-analysis repo ]
4.9 Out of scope
Because this was a pre-standarization experiment, details of wire protocols (which would certainly be needed for an interoperable standard) were not comparatively explored at this stage.
5. Analysis
The following four font transfer methods are reported:
- Whole font
- This is used as the performance baseline. The entire original font file (with hinting removed) is loaded directly, compressed as a woff2. In the graphs below, the gains or losses of other three methods are normalized such that whole font corresponds to 0%.
- Unicode range
- The fonts are split into multiple subsets, and woff2 compressed. Each subset is downloaded only if needed for a given page. The subset definitions used are those currently in use by the Google Fonts service [Google script subsets]. Unicode range is the current state of the art in partially transferring fonts and is in widespread use today. Segmentation is by glyph closure [Closure]. This subsetting can result in incorrect rendering, as noted earlier.
- Patch Subset
- Described above, this is a progressive font enrichment method where the client first requests a font which is transmitted with Brotli compression. The fonts is then subsequently extended to cover additional codepoints via a Brotli binary patch computed by the server.
- Range Request
- Described above, this is a progressive font enrichment method where the client first requests a pre-processed font which contains everything except for the glyf or CFF table. The fonts is transmitted with Brotli compression. Then the glyf or CFF table is filled in as needed by requesting pieces of it using HTTP/2 range requests.
In the graphs below, the performance distribution is represented by it’s 5th, 25th, 50th (median), 75th and 95th percentile. Portions of the distribution which reduced the number of bytes transferred or the loading cost are shaded green (which represents an improvement in performance), while portions of the distribution which increased the number of bytes or cost are shaded red (which represents a performance regression).
For those who wish to graph the results differently, the numerical raw data is available [PFE Results 07 Aug 2020] and CSV files of these results are on GitHub.
5.1 Analysis: Alphabetic
5.1.1 Bytes Transferred
For languages in the alphabetic group (using Latin, Cyrillic, Greek and Thai scripts), all three methods produced in increase in median performance for bytes transferred. The distribution of performance showed an increase over almost all of the range, with the two PFE methods showing a very small regression (less than 10%) for the 5% percentile on the slower networks.
Patch Subset shows the largest reduction in bytes transferred (a median improvement of 50% on the fastest networks, to 43% on the slowest) with Unicode Range close behind (a median improvement of around 43% on all networks). Range Request has much smaller reduction (a median improvement of around 21% on all networks).
To put these byte savings in context, the median size of font used for alphabetic languages was 17,660 bytes (8,360 as WOFF2 ), so a reduction of 50% would make that 4,180 bytes. For a Content Distribution Network, servin very large numbers of fonts, this may be worthwhile saving in monthly bandwidth; for an individual Web page, the saving is modest, and the guarantee of not breaking rendering is more worthwhile.
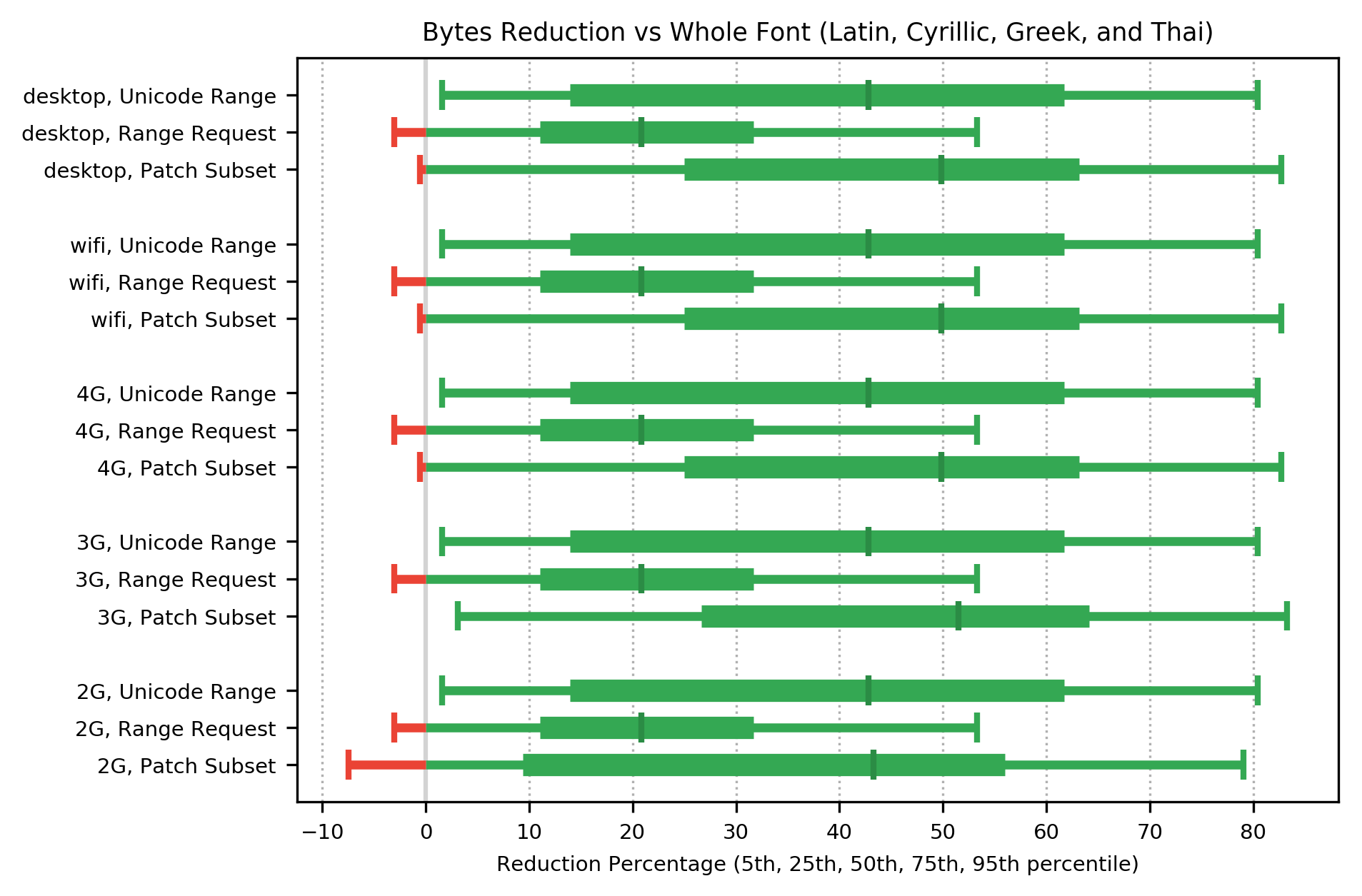
Applying these percentage byte savings to the worst case (95th percentile) font size for alphabetic fonts (184kb at TrueType or OpenType, 60kb as WOFF2), here are the total bytes transferred over a series of page views (not the amount transferred for a single page, which is smaller) for each network class. The 95th percentile is similar to the size of the complete WOFF2 font, while the median is half that size.
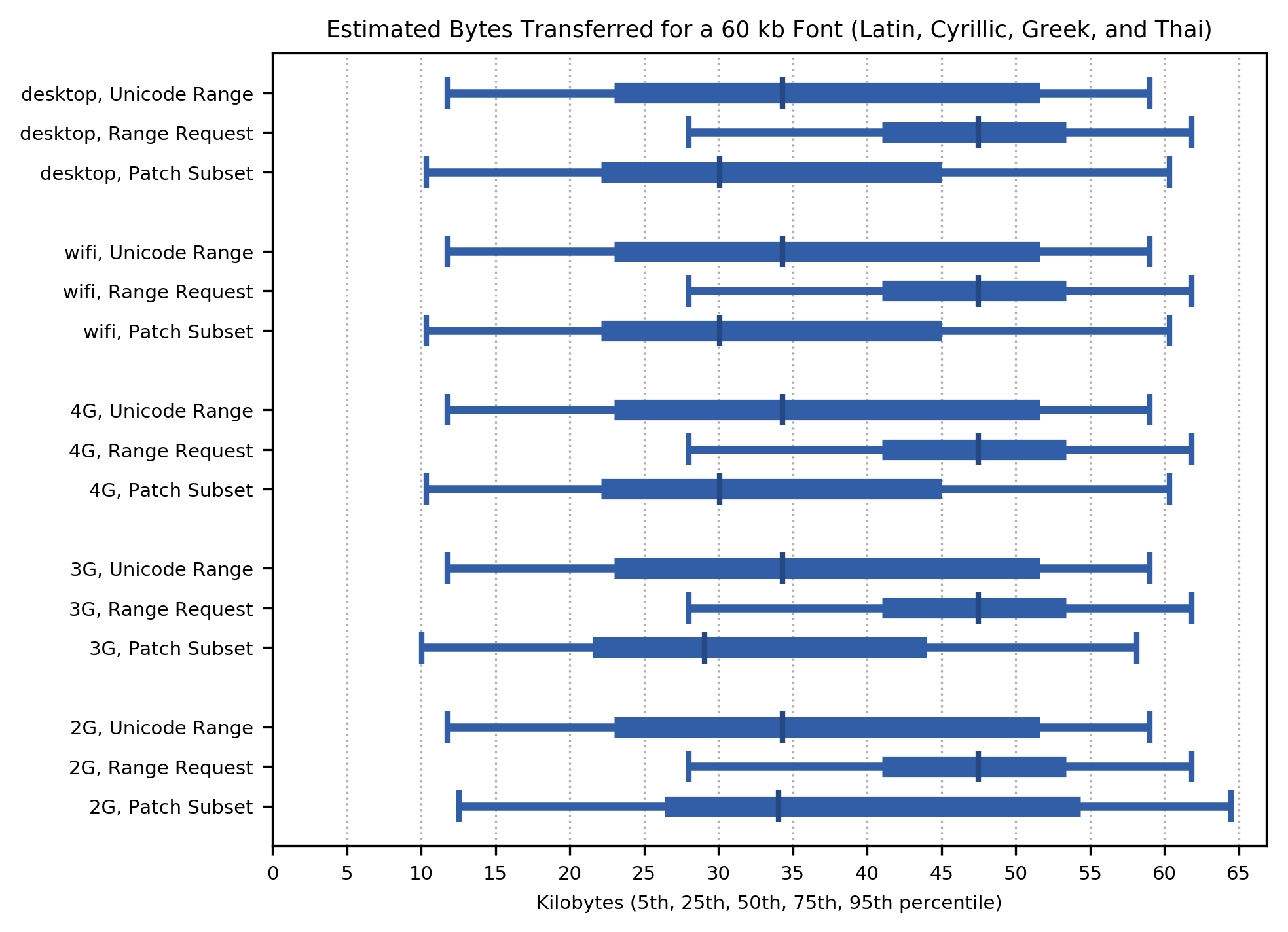
5.1.2 Cost
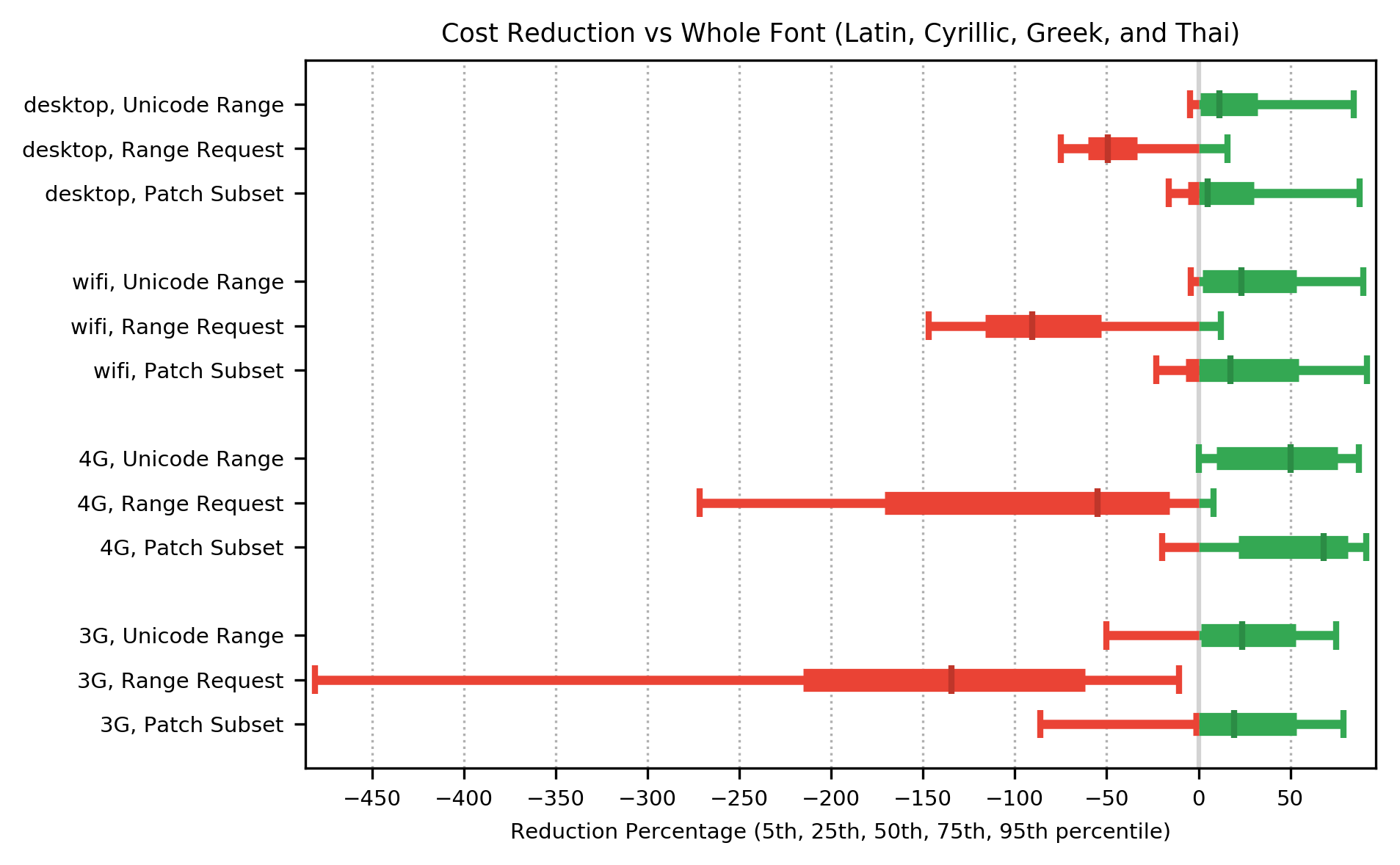
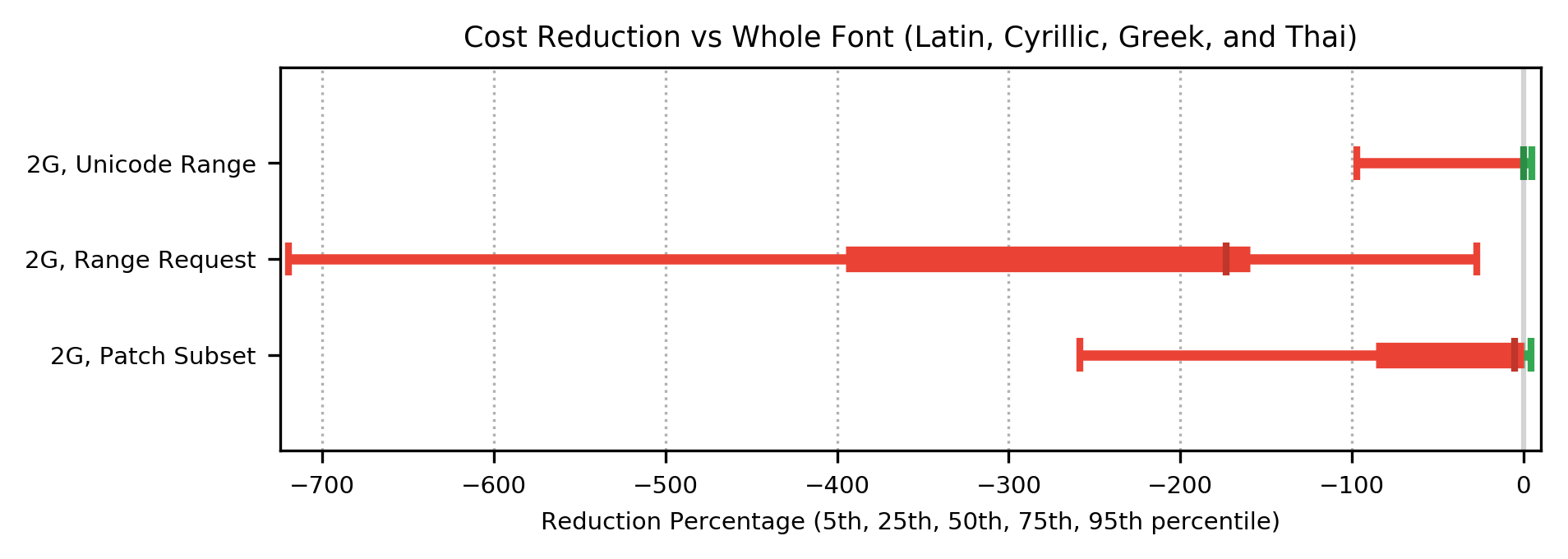
For languages in the alphabetic group, the cost function shows a median improvement over whole font for Unicode Range and Patch Subset, for networks in the 3G class or faster. The cost function for Range Request showed a consistent regression on all networks, ranging from a median 50% slower on the fastest network to median 175% slower on 2G networks. On 2G networks, for all methods, the performance regression in median cost function was sufficiently large that it is shown on a separate graph: note the different scale on the x-axis.
On 3G and 2G networks, Unicode Range and Patch Subset showed performance regression ranging from 50% slower to 250% slower, at the fifth percentile.
For 3G and 2G networks, despite the reduction in bytes transferred, the cost function results indicate that for alphabetic languages, transferring the whole font in one network request will result in faster page rendering than Patch Subset.
For all network types, despite the reduction in bytes transferred, the cost function results indicate that for alphabetic languages, transferring the whole font in one network request will result in faster page rendering than Range Request.
5.2 Analysis: Glyph Shaping
5.2.1 Bytes Transferred
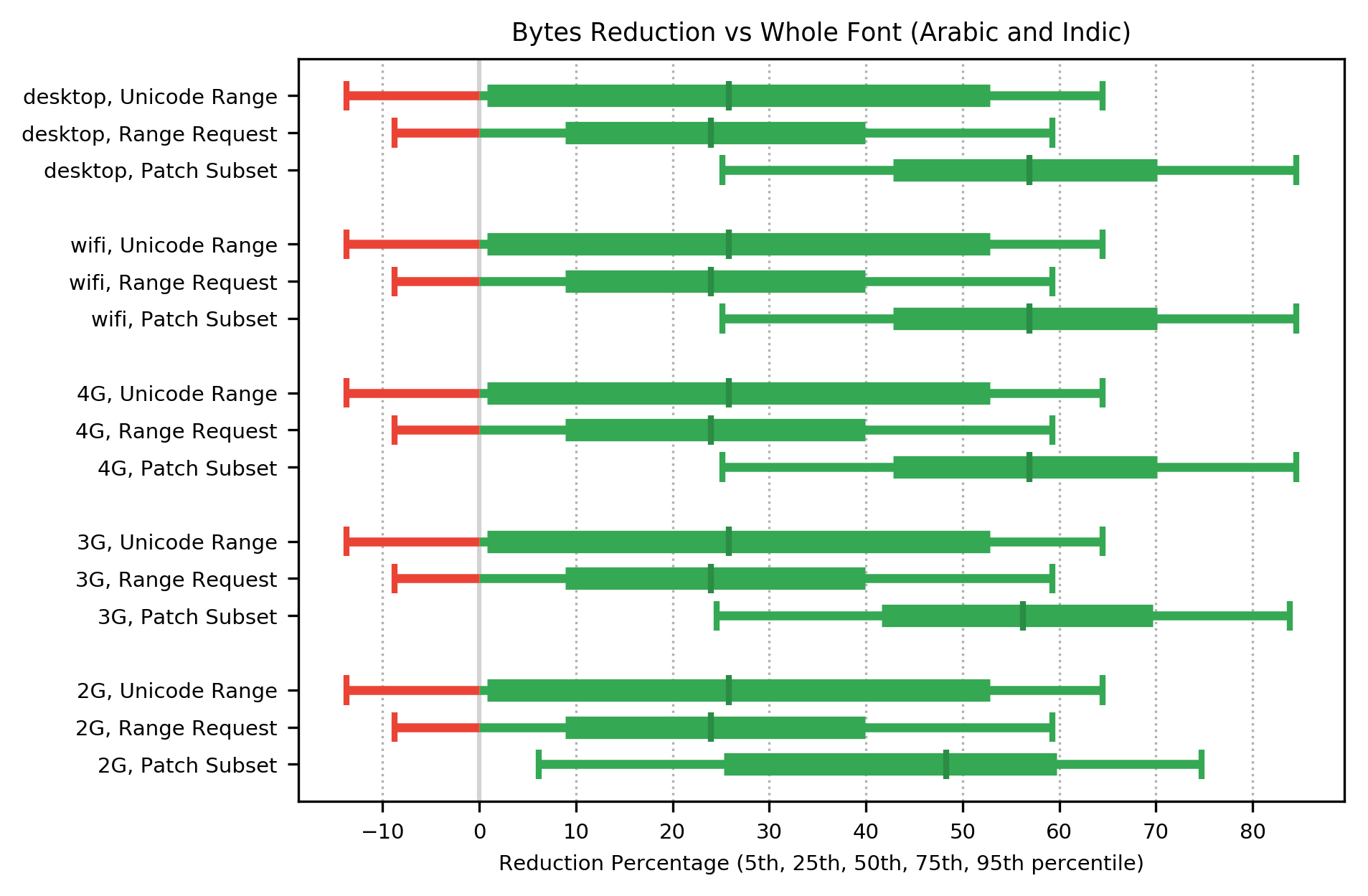
For languages in the shaping group (Arabic and Indic), all three methods produced in increase in median performance for bytes transferred. The distribution of performance showed an increase over almost all of the range, with the two PFE methods showing a fairly small regression (8 to 15%) for the 5% percentile on all networks.
Patch Subset shows the largest reduction in bytes transferred (a median improvement of 55% on all but the slowest networks, dropping to 48% on 2G). Unicode Range and Range Request showed smaller reductions (a median improvement of around 25% on all networks, for both methods). On all but 2G networks, the 5th percentile of Patch Subset was as good as the median performance of the other two methods.
To put these byte savings in context, the median size of font used for shaping languages was 93,588 bytes (30,332 as WOFF2 ), so a reduction of 55% would make that 13,649 bytes. For a Content Distribution Network, this is a worthwhile saving in monthly bandwidth. For an individual Web page, the saving is significant, but again the guarantee of not breaking rendering (which is a major drawback of Unicode Range for this language group) is a significant gain in functionality.
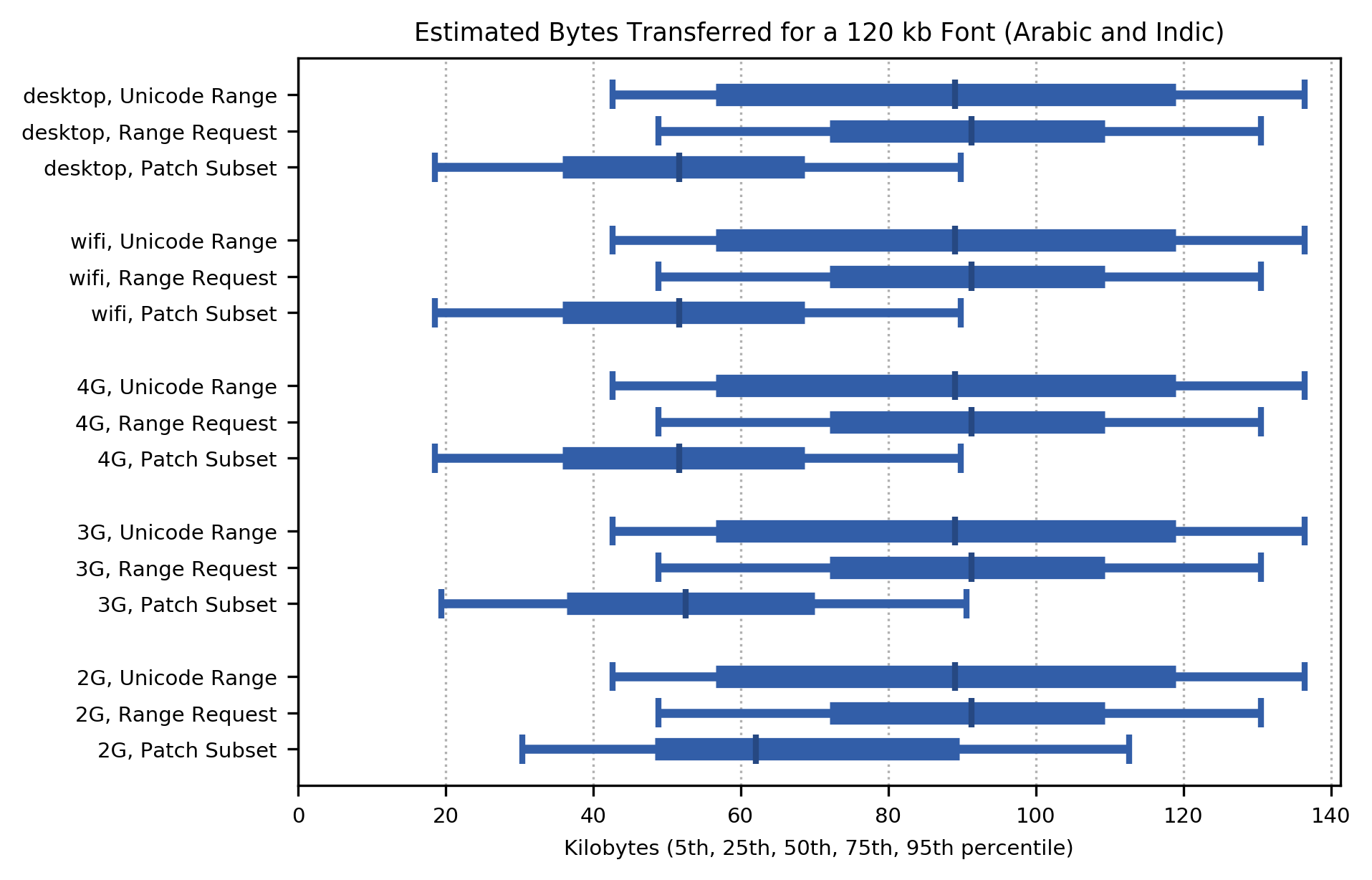
Applying these percentage byte savings to the worst case (95th percentile) font size for shaping fonts (460kb as TrueType or OpenType, 119kb as WOFF2), here are the total bytes transferred over a series of page views (not the amount transferred for a single page, which is smaller) for each network class. Unicode Range and Range Request have worst-case results that transfer more than the whole font as WOFF2. Except on 2G networks, Patch Subset has worst-case results around 60% the size of the whole font as WOFF2, and the median number of bytes transferred is around 42% of whle font, except on the 2G networks where it is a little worse.
Taking into account the freedom from shaping breakage, Patch Subset provides consistently better perforance and also higher typographic rendering quality.
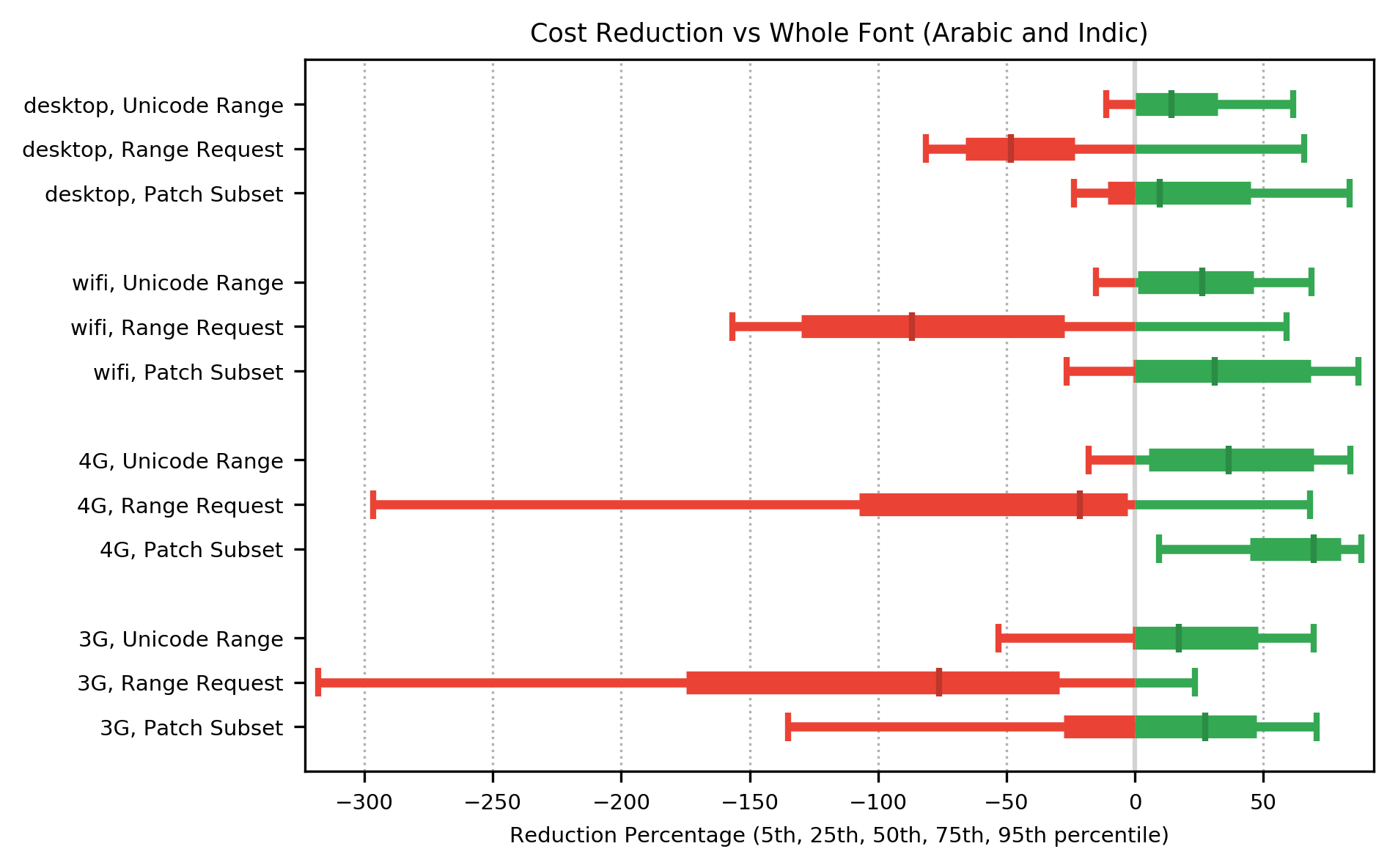
5.2.2 Cost
For languages in the shaping group, the cost function shows a median improvement over whole font for Unicode Range and Patch Subset, for networks in the 3G class or faster. The cost function for Range Request again showed a consistent regression on all networks, ranging from a median 50% slower on the fastest network to median 175% slower on 2G networks. Once again, for 2G networks, the performance regression in median cost function for all methods was sufficiently large that it is shown on a separate graph: note the different scale on the x-axis.
On 3G and 2G networks, at the fifth percentile (worst case results), Unicode Range showed performance regression ranging from 50% slower to 100% slower, while Patch Subset was worse, showing performance regression ranging from 130% slower to 260% slower, and Range Request showed performance regression ranging from 310% slower to 650% slower
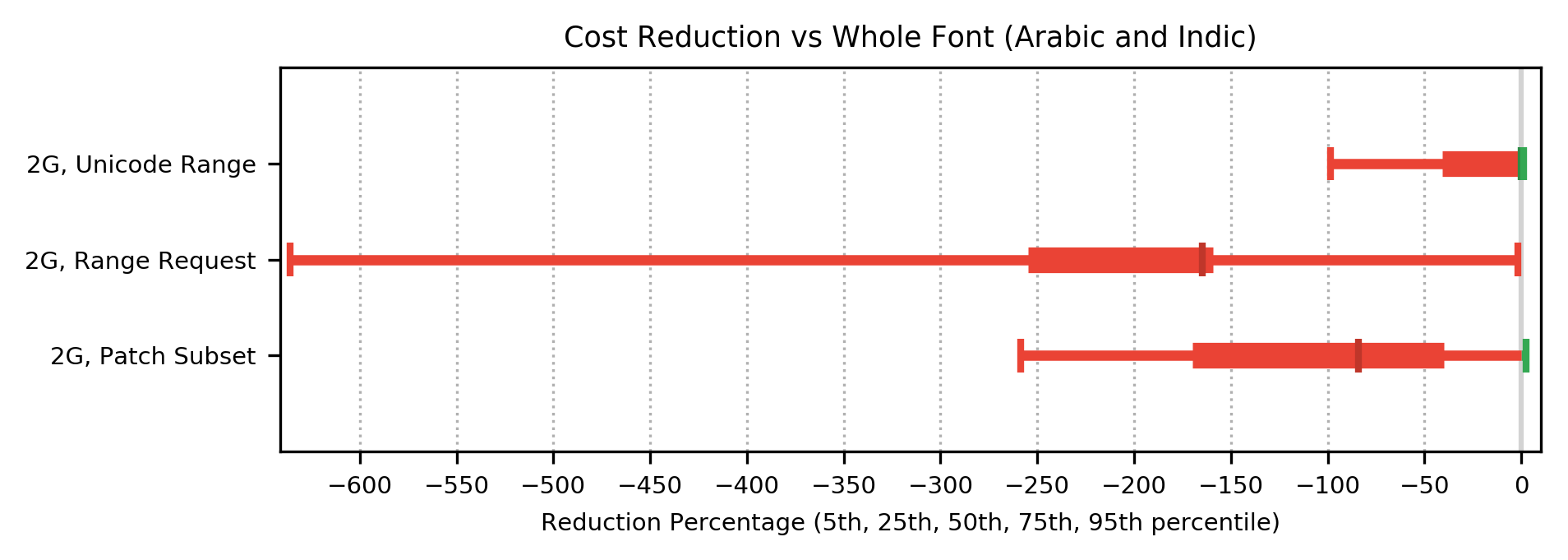
For 2G networks, despite the reduction in bytes transferred, the cost function results indicate that for shaping languages, transferring the whole font in one network request will result in faster page rendering than Patch Subset. For 3G networks, for shaping languages, Patch Subset will result in faster rendering much of the time but slower rendering sometimes.
For all network types, despite the reduction in bytes transferred, the cost function results indicate that for shaping languages, transferring the whole font in one network request will result in significantly faster page rendering than Range Request.
5.3 Analysis: CJK
5.3.1 Bytes Transferred
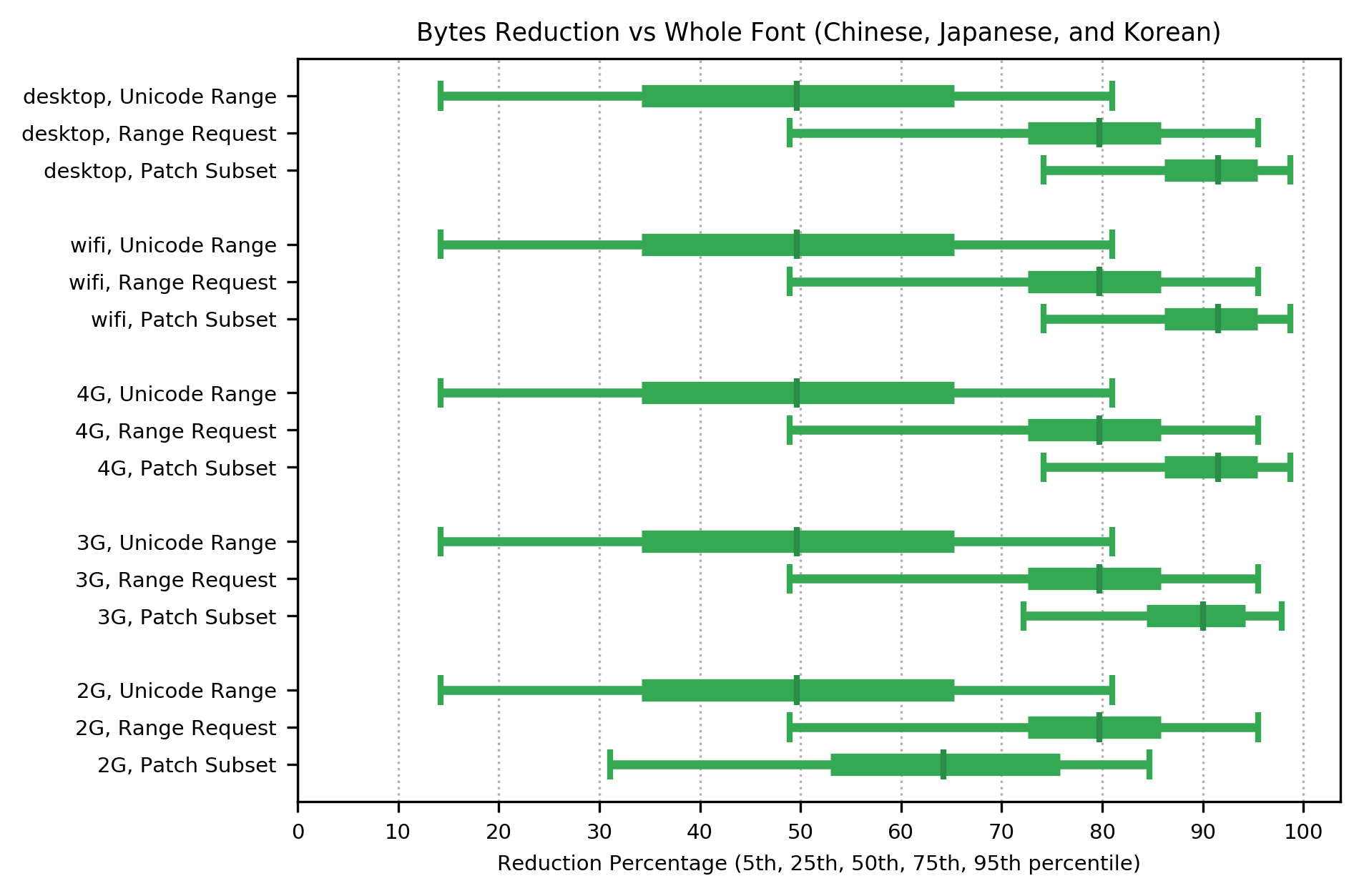
For languages in the CJK group, all three methods produced in increase in median performance for bytes transferred. Both Patch Subset and Range Request significantly outperformed Unicode Range. The distribution of performance showed an increase over the entire range, with no regression even at the 5th percentile, on all networks.
Patch Subset shows the largest reduction in bytes transferred (a median improvement of 90% on all but the slowest networks, dropping to 65% on 2G). Range Request also showed a very good reduction (a median improvement of around 80% on all but the slowest networks, dropping to 80% on 2G, where it outperformed Patch Subset). Unicode Range had a consistent but modest reduction, (a median improvement of 50%) on all networks.
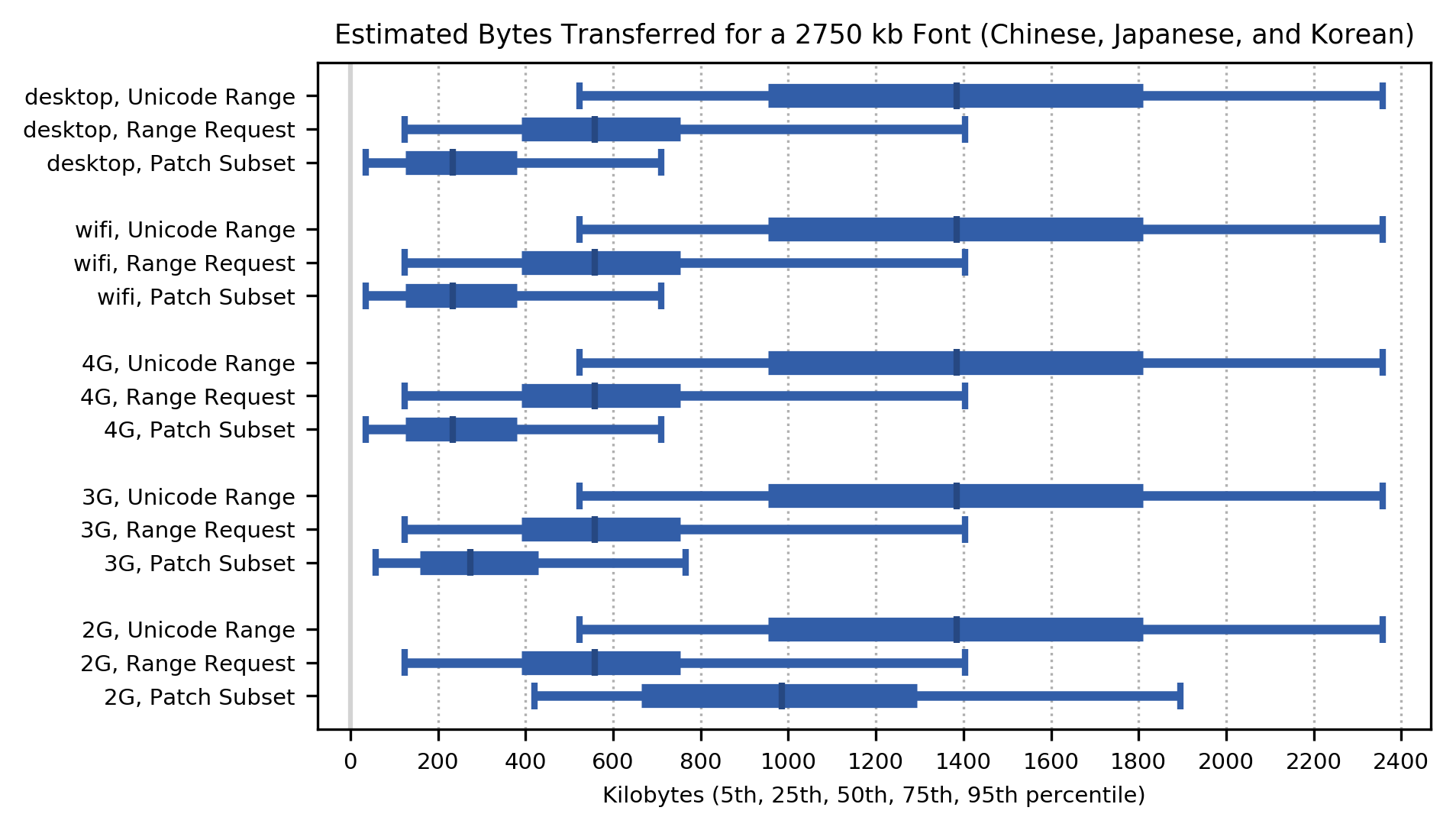
To put these byte savings in context, the median size of font used for CJK languages was 1.8 Megabytes, which is 769 kilobytes as WOFF2. The 75th percentile was 2.6 Megabytes, which is 1.2 Megabytes as WOFF2, while the 95th percentile was 5.2 Megabytes, which is 2.6 Megabytes as WOFF2. CJK fonts thus require a massive reduction in bytes transferred, to be usable as Webfonts.
For Patch Subset, a reduction of 90% would make the median font size 76.9 kilobytes and the 95th percentile 260 kilobytes. For Range Request, a reduction of 65% would make the median 269 kilobytes and the 95th percentile 910 kilobytes. Although those results are 4 to 5 times worse, if an active server extension is not an option, they might still be usable on fast networks.
For a Content Distribution Network, these are massive saving in monthly bandwidth. For an individual Web page, the savings are also vast, but still might not be enough.
Applying these percentage byte savings to the worst case (95th percentile) font size for CJK fonts (5.52Mb as TrueType or OpenType, 2.75Mb as WOFF2), here are the total bytes transferred over a series of page views (not the amount transferred for a single page, which is smaller) for each network class. Unicode Range transfers a median of 50% of the bytes for whole font as WOFF2, but is clearly outperformed by the two PFE methods. Of those, Patch Subset gives the strongest performance on all network types. On all but 2G, the median bytes transferred are 20% of whole font as WOFF2; for 2G, Range Request does better than Patch Subset.
5.3.2 Cost
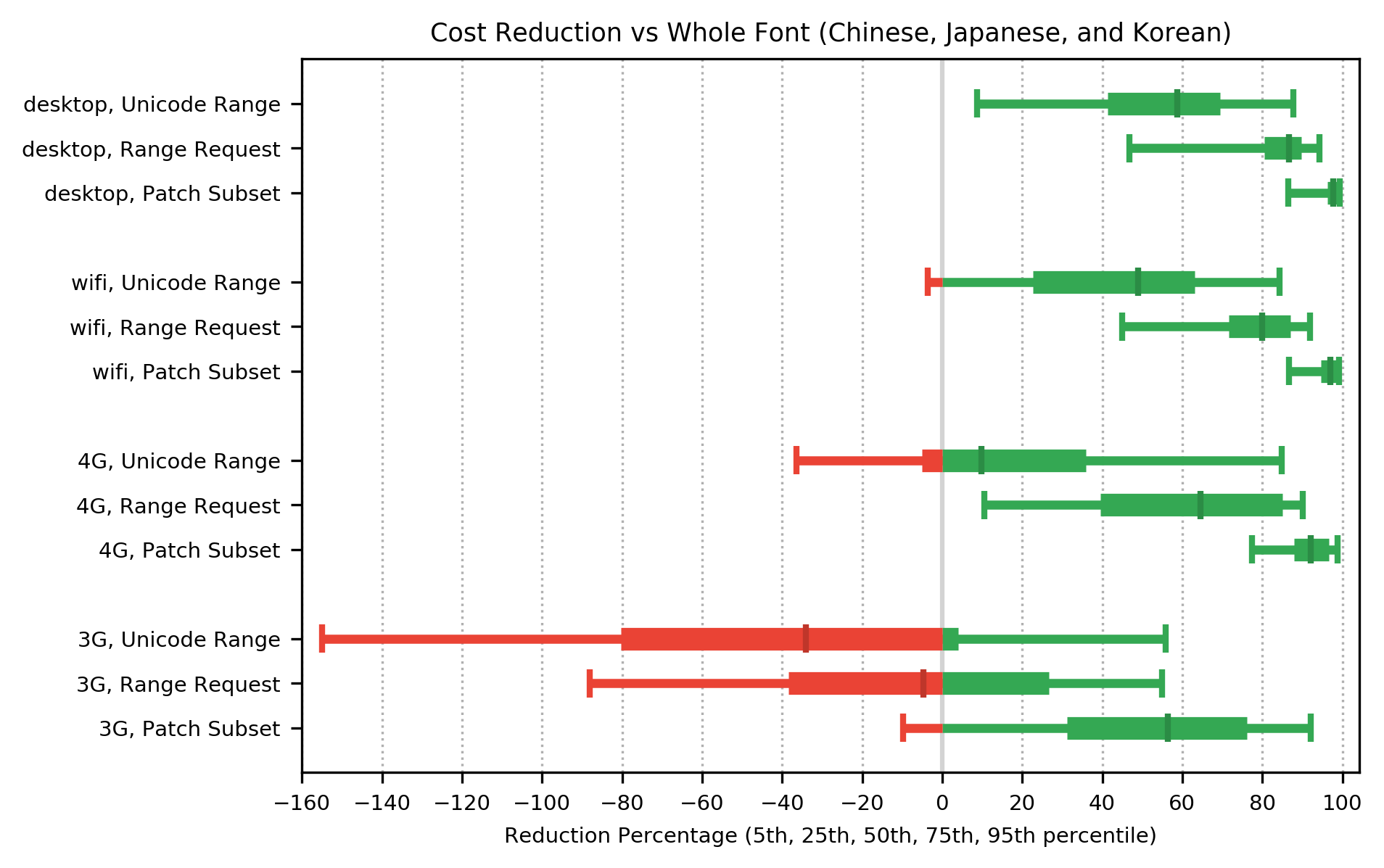
On 4G and faster networks, for languages in the CJK group, the cost function shows a median improvement over whole font for all methods.
On 3G networks, Patch Subset was still providing a median improvement of 55% while Unicode Range and Range Request had shifted to a performance regression in page load times.
Once again, for 2G networks, the performance regression in median cost function for all methods was sufficiently large that it is shown on a separate graph: note the different scale on the x-axis. The cost function for CJK fonts on 2G networks showed a significant regression over whole font for all methods.
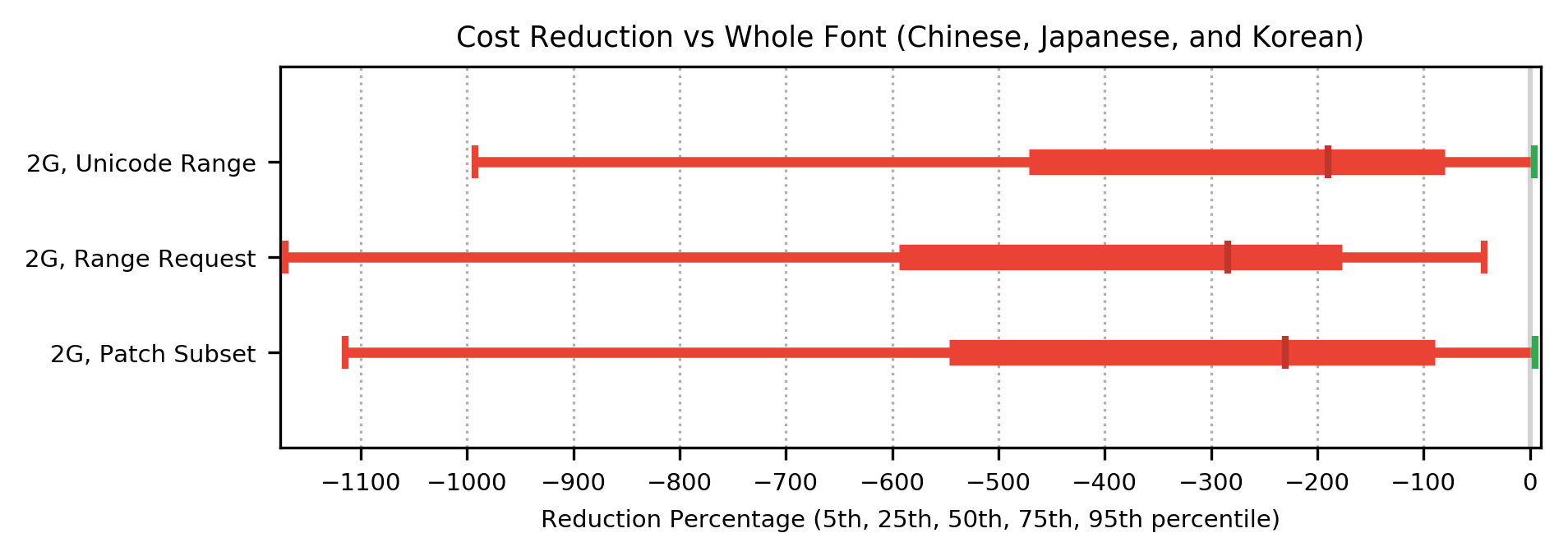
5.4 Analysis: Effect of Codepoint Prediction
The result of the simulations showed that for all three script categories, using codepoint prediction was able to lower costs enough to tie or beat existing transfer methods for all connection types other than Mobile 2G and the slowest variant of Mobile 3G. This comes at the cost of sending more bytes, but still sends less bytes than existing transfer methods.
CJK scripts benefited the least from prediction. Arabic, Indic, Latin, Cyrllic, Greek, and Thai saw more improvements. For those scripts, prediction closed the performance gap between existing font transfer methods for many connection types.
Prediction was not beneficial in all cases. For some script and network conditions combinations it increased overall cost. If prediction is to be used it should be selectively enabled based on the script and client network capabilities.
6. Conclusions
Two approaches to Progressive Font Enrichment were studied, Patch Subset and Range Request. Both gave significant reductions in the number of bytes transferred, compared to sending the whole font as WOFF2, or using the existing Unicode Range method.
Of these, Patch Subset requires servers to be upgraded, while Range Request does not. The 2019 Web Almanac found that 25% of Webfonts were self-hosted, the other 75% being served from a CDN [Web Almanac 2019: Fonts]. This shows both that the number of servers that would need to be upgraded is small, and also that there is demand for an easy, self-hosted solution.
The limiting factor when displaying content with Webfonts, especially on slower networks with longer round-trip times, is latency. The effect is increased when many requests are made. This was modelled as a cost function.
6.1 Conclusions: Alphabetic
The alphabetic group of languages (using Latin, Cyrillic, Greek and Thai scripts), is currently well served by existing Web font delivery methods, and is little affected by shaping failure from subsetting. The cost function data indicated that the Patch Subset approach would improve page load times, on 3G or faster networks. The Range Request approach would worsen page load times on Desktop and Mobile WiFi networks, and significantly worsen page load times on 4G, 3G and 2G networks. Therefore, for 2G networks, loading the entire font as a WOFF2 would be the best approach.
6.2 Conclusions: Shaping
The shaping group of languages (using Arabic and Indic scripts) is significantly impacted by subsetting-induced failure of shaping and other rendering failures. The cost function data indicated that the Patch Subset approach would improve page load times, on 4G or faster networks, while retaining the rendering fidelity of the whole font. Codepoint prediction improves page load times for the shaping group of languages. The Range Request approach would worsen page load times on Desktop networks, and significantly worsen page load times on Mobile WiFi, 4G, 3G and 2G networks. Therefore, for 3G and 2G networks, loading the entire font as a WOFF2 would be the best approach.
6.3 Conclusions: CJK
The Chinese, Japanese and Korean (CJK) group of languages is currently unable to use Webfonts due to the very large filesizes. A substantial reduction in filesize is needed, without a significant increase in page load times caused by multiple network requests.
For the first time, on 4G and faster networks, Patch Subset makes CJK Webfonts a realistic resource, rather than being completely unusable.
On 3G networks, Patch Subset may still be usable for CJK Webfonts (improving page load times in many but not all cases, while worsening them in others).
Note: a server implementing Patch Subset could be configured to automatically behave as whole font dependent on the network conditions. This would ensure that the worst case performance on slow networks would never show a performance regression.
If an active server extension cannot be used, then for 4G and faster networks, Range Request makes CJK Webfonts an expensive but usable resource.
On 2G networks, the byte savings from Range Request are outweighed by the massive cost increases of all methods. Relying on pre-installed fonts for CJK content on 2G networks remains the only viable solution, alas.
6.4 Conclusions: Further work
Further work is expected to refine the already impressive gains noted in this report:
- The simulation skipped the first stage of WOFF2 compression (table rearrangement), which should give improved results.
- Codepoint prediction could be further refined, and the dependence on network type further investigated.
- Additional sorting functions and fitness functions in the streaming font preprocessor could be investigated
- HTTP/2 POST requests bypasses Web caches; a solution which works with existing Web caches should be investigated.
- Pushing Patch Subset to give better than 90% bye reductions on CJK fonts will improve the chance of significant uptake.
- Requesting a PFE-enabled font would likely require changes to CSS, perhaps a new format string on the src descriptor.
The simulation performed here is entirely theoretical. Testing in actual browsers on real networks should be performed using proof of concept implementations of Range Request and Patch Subset. This will give more accurate assessments of the performance of these two transfer methods and validate the results reported here.
The impressive results from this simulation study clearly indicate that standardization-track work to refine and develop Progressive Font Enrichment should be undertaken immediately. This is expected to extend the geographically localized success of Webfonts to the Global Web.