7. Web application APIs
7.1. Scripting
7.1.1. Introduction
Various mechanisms can cause author-provided executable code to run in the context of a document. These mechanisms include, but are probably not limited to:
-
Processing of
scriptelements. -
Navigating to
javascript:URLs. -
Event handlers, whether registered through the DOM using
addEventListener(), by explicit event handler content attributes, by event handler IDL attributes, or otherwise. -
Processing of technologies like SVG that have their own scripting features.
7.1.2. Enabling and disabling scripting
Scripting is enabled in a browsing context when all of the following conditions are true:
-
The user agent supports scripting.
-
The user has not disabled scripting for this browsing context at this time. (User agents may provide users with the option to disable scripting globally, or in a finer-grained manner, e.g. on a per-origin basis.)
-
The browsing context’s active document’s active sandboxing flag set does not have its sandboxed scripts browsing context flag set.
Scripting is disabled in a browsing context when any of the above conditions are false (i.e., when scripting is not enabled).
Scripting is enabled for a node if the node’s node document has a browsing context, and scripting is enabled in that browsing context.
Scripting is disabled for a node if there is no such browsing context, or if scripting is disabled in that browsing context.
7.1.3. Processing model
7.1.3.1. Definitions
A script is one of two possible structures. All scripts have:
- A settings object
-
An environment settings object, containing various settings that are shared with other scripts in the same context.
A classic script additionally has:
- A Source text
-
A string containing a block of executable code to be evaluated as a JavaScript Script.
- Optionally, a muted errors flag
-
A flag which, if set, means that error information will not be provided for errors in this script (used to mute errors for cross-origin scripts, since that can leak private information).
A module script additionally has:
- A module record
-
A Source Text Module Record representing the parsed module, ready to be evaluated.
- A base URL
-
A base URL used for resolving module specifiers when resolving a module specifier. This will either be the URL from which the script was obtained, for external module scripts, or the document base URL of the containing document, for inline module scripts.
- A credentials mode
-
A credentials mode used to fetch imported modules.
- A cryptographic nonce
-
A cryptographic nonce used to fetch imported modules.
- A parser state
-
The parser metadata used to fetch imported modules.
An environment settings object specifies algorithms for obtaining the following:
- A realm execution context
-
A JavaScript execution context shared by all
scriptelements that use this settings object, i.e. all scripts in a given JavaScript realm. When we run a classic script or run a module script, this execution context becomes the top of the JavaScript execution context stack, on top of which another execution context specific to the script in question is pushed. (This setup ensures ParseScript and ModuleEvaluation know which Realm to use.) - A module map
-
Used when importing JavaScript modules.
- A responsible browsing context
-
A browsing context that is assigned responsibility for actions taken by the scripts that use this environment settings object.
When a script creates and navigates a new top-level browsing context, the
openerattribute of the new browsing context’sWindowobject will be set to the responsible browsing context’sWindowProxyobject. - A responsible event loop
-
An event loop that is used when it would not be immediately clear what event loop to use.
- A responsible document
-
A
Documentthat is assigned responsibility for actions taken by the scripts that use this environment settings object.For example, the URL of the responsible document is used to set the URL of the
Documentafter it has been reset usingopen().If the responsible event loop is not a browsing context event loop, then the environment settings object has no responsible document.
- An API URL character encoding
-
A character encoding used to encode URLs by APIs called by scripts that use this environment settings object.
- An API base URL
-
An URL used by APIs called by scripts that use this environment settings object to parse URLs.
- An origin
-
An origin used in security checks.
- A creation URL
-
An absolute URL representing the location of the resource with which the environment settings object is associated. Note that this URL might be distinct from the responsible document’s URL, due to mechanisms such as
history.pushState(). - An HTTPS state
-
An HTTPS state value representing the security properties of the network channel used to deliver the resource with which the environment settings object is associated.
An environment settings object also has an outstanding rejected promises weak set and an about-to-be-notified rejected promises list, used to track unhandled promise rejections. The outstanding rejected promises weak set must not create strong references to any of its members, and implementations are free to limit its size, e.g., by removing old entries from it when new ones are added.
7.1.3.2. Fetching scripts
The various script-fetching algorithms below have two hooks that may be customized by their callers:
-
Set up the request, which takes a request which it may modify before the algorithm continues
-
Process the response, which takes a response and must either return
trueorfalseto indicate success or failure, respectively
Service Workers is an example of a specification that runs these algorithms with its own options for the hooks. [SERVICE-WORKERS]
To fetch a classic script for a script element element, given a url, a CORS setting, a cryptographic nonce, a parser state, a settings object, and a character encoding, run
these steps. The algorithm will asynchronously complete with either null (on failure) or a new classic script (on success).
-
Let request be the result of creating a potential-CORS request given url and CORS setting.
-
Set request’s client to settings object, its type to "
script", its destination to "script", its cryptographic nonce metadata to cryptographic nonce, and its parser metadata to parser state. -
If the caller specified custom steps to set up the request, perform them on request.
-
Fetch request.
-
Return from this algorithm, and run the remaining steps as part of the fetch’s process response for the response response.
response can be either CORS-same-origin or CORS-cross-origin. This only affects how error reporting happens.
-
If response’s type is "
error", or response’s status is not an ok status, asynchronously complete this algorithm with null, and abort these steps. -
If the caller specified custom steps to process the response, perform them on response. If they return false, complete this algorithm with null, and abort these steps.
-
If response’s Content-Type metadata, if any, specifies a character encoding, and the user agent supports that encoding, then set character encoding to that encoding (ignoring the passed-in value).
-
Let source text be the result of decoding response’s body to Unicode, using character encoding as the fallback encoding.
The decode algorithm overrides character encoding if the file contains a BOM.
-
Let script be the result of creating a classic script using source text and settings object.
If response was CORS-cross-origin, then pass the muted errors flag to the create a classic script algorithm as well.
-
Asynchronously complete this algorithm with script.
To fetch a classic worker script given a url, a referrer, a settings object, and a destination, run these steps. The algorithm will asynchronously complete with either null (on failure) or a new classic script (on success).
-
Let request be a new request whose url is url, client is settings object, type is "
script", destination is destination, referrer is referrer, mode is "same-origin", credentials mode is "same-origin", parser metadata is "not parser-inserted", and whose use-URL-credentials flag is set. -
If the caller specified custom steps to set up the request, perform them on request.
-
Fetch request.
-
Return from this algorithm, and run the remaining steps as part of the fetch’s process response for the response response.
-
If response’s type is "
error", or response’s status is not an ok status, asynchronously complete this algorithm with null, and abort these steps. -
If the caller specified custom steps to process the response, perform them on response. If they return false, complete this algorithm with null, and abort these steps.
-
Let source text be the result of UTF-8 decoding response’s body.
-
Let script be the result of creating a classic script using source text and settings object.
-
Asynchronously complete this algorithm with script.
To fetch a module script tree given a url, a credentials mode, a cryptographic nonce, a parser state, a destination, a fetch client settings object, and an optional ancestor list, run these steps. The algorithm will asynchronously complete with either null (on failure) or a new module script (on success).
-
If ancestor list is not given, let it be an empty list.
-
If module map settings object is not given, let it be fetch client settings object.
-
Fetch a single module script given url, credentials mode, cryptographic nonce, parser state, destination, and module map settings object. If the caller of this algorithm specified custom set up the request or process the response steps, pass those along while fetching a single module script.
-
Return from this algorithm and run the following steps when fetching a single module script asynchronously completes with result:
-
If result is null, asynchronously complete this algorithm with null and abort these steps.
-
Otherwise, result is a module script. Fetch the descendants of result given destination and an ancestor list obtained by appending url to ancestor list.
-
When fetching the descendants of a module script asynchronously completes with descendants result, asynchronously complete this algorithm with descendants result.
The following algorithms are used when fetching a module script tree, and are not meant to be used directly by other specifications (or by other parts of this specification).
To fetch the descendants of a module script module script, given a destination and an ancestor list, run these steps. The algorithm will asynchronously complete with either null (on failure) or with module script (on success).
-
Let record be module script’s module record.
-
If record.[[RequestedModules]] is empty, asynchronously complete this algorithm with module script.
-
Let urls be a new empty list.
-
For each string requested of record.[[RequestedModules]]:
-
Let url be the result of resolving a module specifier given module script and requested.
-
If the result is error:
-
Let error be a new
TypeErrorexception. -
Report the exception error for module script.
-
Abort this algorithm, and asynchronously complete it with null.
-
-
Otherwise, if url is not in ancestor list, add url to urls.
-
-
For each url in urls, fetch a module script tree given url, module script’s credentials mode, module script’s cryptographic nonce, module script’s parser state, destination, module script’s settings object, and ancestor list.
It is intentional that no custom set up the request or process the response steps are passed along here. Those hooks only apply to the top-level fetch at the root of the module script tree.
If any of the fetch a module script tree invocations asynchronously complete with null, the user agent may terminate any or all of the other fetches, and must then asynchronously complete this algorithm with null.
Once all of the fetch a module script tree invocations asynchronously complete with a module script, asynchronously complete this algorithm with module script.
To fetch a single module script, given a url, a credentials mode, a cryptographic nonce, a parser state, a destination, and a settings object, run these steps. The algorithm will asynchronously complete with either null (on failure) or a module script (on success).
-
Let module map be settings object’s module map.
-
If module map contains an entry with key url whose value is "
fetching", wait (in parallel) until that entry’s value changes, then proceed to the next step. -
If module map contains an entry with key url, asynchronously complete this algorithm with that entry’s value, and abort these steps.
-
Create an entry in module map with key url and value "
fetching". -
Let request be a new request whose url is url, destination is destination, type is "
script", mode is "cors", credentials mode is credentials mode, cryptographic nonce metadata is cryptographic nonce, parser metadata is parser state and client is settings object. -
If the caller specified custom steps to set up the request, perform them on request.
-
Fetch request.
-
Return from this algorithm, and run the remaining steps as part of the fetch’s process response for the response response.
response is always CORS-same-origin.
-
If any of the following conditions are met, set the value of the entry in module map whose key is url to null, asynchronously complete this algorithm with null, and abort these steps:
-
response’s type is "
error" -
The result of extracting a MIME type from response’s header list (ignoring parameters) is not a JavaScript MIME type.
For historical reasons, fetching a classic script does not include MIME type checking. In contrast, module scripts will fail to load if they are not of a correct MIME type.
-
The caller specified custom steps to process the response, which when performed on response return false.
-
-
Let source text be the result of UTF-8 decoding response’s body.
-
Let module script be the result of creating a module script given source text, settings object, response’s url, credentials mode, and cryptographic nonce.
-
Set the value of the entry in module map whose key is url to module script, and asynchronously complete this algorithm with module script.
It is intentional that the module map is keyed by the request URL, whereas the base URL for the module script is set to the response URL. The former is used to deduplicate fetches, while the latter is used for URL resolution.
7.1.3.3. Creating scripts
To create a classic script, given some script source, an environment settings object, and an optional muted errors flag:
-
Let script be a new classic script that this algorithm will subsequently initialize.
-
Set script’s settings object to the environment settings object provided.
-
If scripting is disabled for the given environment settings object’s responsible browsing context, set script’s source text to the empty string. Otherwise, set script’s source text to the supplied script source.
-
If the muted errors flag was set, then set script’s muted errors flag.
-
Return script.
To create a module script, given some script source, an environment settings object, a script base URL, a credentials mode, a cryptographic nonce, and a parser state:
-
Let script be a new module script that this algorithm will subsequently initialise.
-
Set script’s settings object to the environment settings object provided.
-
Let realm be the provided environment settings object’s Realm.
-
If scripting is disabled for the given environment settings object’s responsible browsing context, then let script source be the empty string. Otherwise, let script source be the provided script source.
-
Let result be ParseModule(script source, realm, script).
-
If result is a List of errors, report the exception given by the first element of result for script, return null, and abort these steps.
-
Set script’s module record to result.
-
Set script’s base URL to the script base URL provided.
-
Set script’s credentials mode to the credentials mode provided.
-
Set script’s cryptographic nonce to the cryptographic nonce provided.
-
Set script’s parser state to the parser state.
-
Return script.
7.1.3.4. Calling scripts
To run a classic script given a classic script s and an optional rethrow errors flag:
-
Let settings be the settings object of s.
-
Check if we can run script with settings. If this returns "do not run", then return undefined and abort these steps.
-
Let realm be settings’s Realm.
-
Prepare to run script with settings.
-
Let result be ParseScript(s’s source text, realm, s).
-
If result is a List of errors, set result to the first element of result and go to the step labeled error.
-
Let evaluationStatus be ScriptEvaluation(result).
-
If evaluationStatus is an abrupt completion, set result to evaluationStatus.[[value]] and go to the next step (labeled Error). If evaluationStatus is a normal completion, or if ScriptEvaluation does not complete because the user agent has aborted the running script, skip to the step labeled Cleanup.
-
Error: At this point result must be an exception. Perform the following steps:
-
If the rethrow errors flag is set and s’s muted errors flag is not set, rethrow result.
-
If the rethrow errors flag is set and s’s muted errors flag is set, throw a
NetworkErrorexception. -
If the rethrow errors flag is not set, report the exception given by result for the script s.
-
-
Cleanup: Clean up after running script with settings.
-
If evaluationStatus exists and is a normal completion, return evaluationStatus.[[value]]. Otherwise, script execution was unsuccessful, either because an error occurred during parsing, or an exception occurred during evaluation, or because it was aborted prematurely.
To run a module script given a module script s:
-
Let settings be the settings object of s.
-
Check if we can run script with settings. If this returns "do not run" then abort these steps.
-
Let record be s’s module record.
-
Let instantiationStatus be record.ModuleDeclarationInstantiation().
This step will recursively instantiate all of the module’s dependencies.
-
If instantiationStatus is an abrupt completion, report the exception given by instantiationStatus.[[Value]] for s and abort these steps.
-
Prepare to run script given settings.
-
Let evaluationStatus be record.ModuleEvaluation().
This step will recursively evaluate all of the module’s dependencies.
-
If evaluationStatus is an abrupt completion, report the exception given by evaluationStatus.[[Value]] for s. (Do not perform this step if ScriptEvaluation fails to complete as a result of the user agent aborting the running script.)
-
Clean up after running script with settings.
The steps to check if we can run script with an environment settings object settings are as follows. They return either "run" or "do not run".
-
If the global object specified by settings is a
Windowobject whoseDocumentobject is not fully active, then return "do not run" and abort these steps. -
If scripting is disabled for the responsible browsing context specified by settings, then return "do not run" and abort these steps.
-
Return "run".
The steps to prepare to run script with an environment settings object settings are as follows:
-
Increment settings’s realm execution context’s entrance counter by one.
-
Push settings’s realm execution context onto the JavaScript execution context stack; it is now the running JavaScript execution context.
The steps to clean up after running script with an environment settings object settings are as follows:
-
Assert: settings’s realm execution context is the running JavaScript execution context.
-
Decrement settings’s realm execution context’s entrance counter by one.
-
Remove settings’s realm execution context from the JavaScript execution context stack.
-
If the JavaScript execution context stack is now empty, run the global script clean-up jobs. (These cannot run scripts.)
-
If the JavaScript execution context stack is now empty, perform a microtask checkpoint. (If this runs scripts, these algorithms will be invoked reentrantly.)
These algorithms are not invoked by one script directly calling another, but they can be invoked reentrantly in an indirect manner, e.g., if a script dispatches an event which has event listeners registered.
The running script is the script in the [[HostDefined]] field in the ScriptOrModule component of the running JavaScript execution context.
Each unit of related similar-origin browsing contexts has a global script
clean-up jobs list, which must initially be empty. A global script clean-up job cannot run
scripts, and cannot be sensitive to the order in which other clean-up jobs are executed. The File
API uses this to release blob: URLs. [FILEAPI]
When the user agent is to run the global script clean-up jobs, the user agent must perform each of the jobs in the global script clean-up jobs list and then empty the list.
7.1.3.5. Realms, settings objects, and global objects
A global object is a JavaScript object that is the [[GlobalObject]] field of a JavaScript realm.
In this specification, all JavaScript realms are initialized with global objects that are either Window or WorkerGlobalScope objects.
There is always a 1:1:1 mapping between JavaScript realms, global objects, and environment settings objects:
-
A JavaScript realm has a [[HostDefined]] field, which contains the Realm’s settings object.
-
A JavaScript realm has a [[GlobalObject]] field, which contains the Realm’s global object.
-
Each global object in this specification is created during the initialization of a corresponding JavaScript realm, known as the global object’s Realm.
-
Each global object in this specification is created alongside a corresponding environment settings object, known as its relevant settings object.
-
An environment settings object’s realm execution context’s Realm component is the environment settings object’s Realm.
-
An environment settings object’s Realm then has a [[GlobalObject]] field, which contains the environment settings object’s global object.
When defining algorithm steps throughout this specification, it is often important to indicate what JavaScript realm is to be used—or, equivalently, what global object or environment settings object is to be used. In general, there are at least four possibilities:
- Entry
-
This corresponds to the script that initiated the currently running script action: i.e., the function or script that the user agent called into when it called into author code.
- Incumbent
-
This corresponds to the most-recently-entered author function or script on the stack.
- Current
-
This corresponds to the currently-running function object, including built-in user-agent functions which might not be implemented as JavaScript. (It is derived from the current JavaScript realm.)
- Relevant
-
Every platform object has a relevant Realm. When writing algorithms, the most prominent platform object whose relevant Realm might be important is the
thisvalue of the currently-running function object. In some cases, there can be other important relevant Realms, such as those of any arguments.
Note how the entry, incumbent, and current concepts are usable without qualification, whereas the relevant concept must be applied to a particular platform object.
a.html being loaded in a browser window, b.html being loaded in an iframe as shown, and c.html and d.html omitted (they can simply be empty documents):
<!-- a/a.html --> <!DOCTYPE HTML> <html lang="en"> <title>Entry page</title> <iframe src="b.html"></iframe> <button onclick="frames[0].hello()">Hello</button> <!-- b.html --> <!DOCTYPE HTML> <html lang="en"> <title>Incumbent page</title> <iframe src="c.html" id="c"></iframe> <iframe src="d.html" id="d"></iframe> <script> const c = document.querySelector("#c").contentWindow; const d = document.querySelector("#d").contentWindow; window.hello = () => { c.print.call(d); }; </script>
Each page has its own browsing context, and thus its own JavaScript realm, global object, and environment settings object.
When the print() method is called in response to pressing the button in a.html, then:
-
The entry Realm is that of
a.html. -
The incumbent Realm is that of
b.html. -
The current Realm is that of
c.html(since it is theprint()method fromc.htmlwhose code is running). -
The relevant Realm of the object on which the
print()method is being called is that ofd.html.
The incumbent and entry concepts should not be used by new specifications, and we are considering whether we can remove almost all existing uses
Currently, the incumbent concept is used in some security checks, and the entry concept is sometimes used to obtain, amongst other things, the API base URL to parse a URL, used in scripts running in that unit of related similar-origin browsing contexts.
In general, the current concept is what should be used by specifications going forward. There is an important exception, however. If an algorithm is creating an object that is to be persisted and returned multiple times (instead of simply returned to author code right away, and never vended again), it should use the relevant concept with regard to the object on which the method in question is being executed. This prevents cross-realm calls from causing an object to store objects created in the "wrong" realm.
navigator.getBattery() method creates promises in the relevant Realm for
the Navigator object on which it is invoked. This has the following impact: [BATTERY-STATUS]
<!-- outer.html --> <!DOCTYPE html> <html lang="en"> <title>Relevant Realm demo: outer page</title> <script> function doTest() { const promise = navigator.getBattery.call(frames[0].navigator); console.log(promise instanceof Promise); // logs false console.log(promise instanceof frames[0].Promise); // logs true frames[0].hello(); } </script> <iframe src="inner.html" onload="doTest()"></iframe> <!-- inner.html --> <!DOCTYPE html> <html lang="en"> <title>Relevant Realm demo: inner page</title> <script> function hello() { const promise = navigator.getBattery(); console.log(promise instanceof Promise); // logs true console.log(promise instanceof parent.Promise); // logs false } </script>
If the algorithm for the getBattery() method had instead used the current
Realm, all the results would be reversed. That is, after the first call to getBattery() in outer.html, the Navigator object in inner.html would be permanently storing a Promise object created in outer.html’s JavaScript realm, and calls like that inside the hello() function would thus return a promise from the "wrong" realm. Since this is
undesirable, the algorithm instead uses the relevant Realm, giving the sensible results
indicated in the comments above.
The rest of this section deals with formally defining the entry, incumbent, current, and relevant concepts.
7.1.3.5.1. Entry
All realm execution contexts must contain, as part of their code evaluation state, an entrance counter value, which is initially zero. In the process of calling scripts, this value will be incremented and decremented.
With this in hand, we define the entry execution context to be the most recently pushed entry in the JavaScript execution context stack whose entrance counter value is greater than zero. The entry Realm is the entry execution context’s Realm component.
Then, the entry settings object is the environment settings object of the entry Realm.
Similarly, the entry global object is the global object of the entry Realm.
7.1.3.5.2. Incumbent
The incumbent settings object is determined as follows:
-
Let scriptOrModule be the result of JavaScript’s GetActiveScriptOrModule() abstract operation.
-
If scriptOrModule is null, abort these steps; there is no incumbent settings object.
-
Return the settings object of the
scriptin scriptOrModule’s [[HostDefined]] field.
Then, the incumbent Realm is the Realm of the incumbent settings object.
Similarly, the incumbent global object is the global object of the incumbent settings object.
7.1.3.5.3. Current
The JavaScript specification defines the current Realm Record, sometimes abbreviated to the "current Realm". [ECMA-262]
Then, the current settings object is the environment settings object of the current Realm Record.
Similarly, the current global object is the global object of the current Realm Record.
7.1.3.5.4. Relevant
The relevant settings object for a platform object is defined as follows:
- If the object is a global object
- Each global object in this specification is created alongside a corresponding environment settings object; that is its relevant settings object.
- Otherwise
-
The relevant settings object for a non-global platform object o is
the environment settings object whose global object is the global object of the global environment associated with o.
The "global environment associated with" concept is from the olden days, before the modern JavaScript specification and its concept of realms. We expect that as the Web IDL specification gets updated, every platform object will have a Realm associated with it, and this definition can be re-cast in those terms. [ECMA-262] [WEBIDL]
Then, the relevant Realm for a platform object is the Realm of its relevant settings object.
Similarly, the relevant global object for a platform object is the global object of its relevant settings object.
7.1.3.6. Killing scripts
Although the JavaScript specification does not account for this possibility, it’s sometimes
necessary to abort a running script.
This causes any ScriptEvaluation or ModuleEvaluation to cease immediately, emptying
the JavaScript execution context stack without triggering any of the normal mechanisms like finally blocks. [ECMA-262]
User agents may impose resource limitations on scripts, for example CPU quotas, memory limits,
total execution time limits, or bandwidth limitations. When a script exceeds a limit, the user
agent may either throw a QuotaExceededError exception, abort the script without an
exception, prompt the user, or throttle script execution.
<script> while (true) { /* loop */ } </script>
User agents are encouraged to allow users to disable scripting whenever the user is prompted
either by a script (e.g., using the window.alert() API) or because
of a script’s actions (e.g., because it has exceeded a time limit).
If scripting is disabled while a script is executing, the script should be terminated immediately.
User agents may allow users to specifically disable scripts just for the purposes of closing a browsing context.
For example, the prompt mentioned in the example above could also offer the
user with a mechanism to just close the page entirely, without running any unload event handlers.
7.1.3.7. Integration with the JavaScript job queue
The JavaScript specification defines the JavaScript job and job queue abstractions in order to specify certain invariants about how promise operations execute with a clean JavaScript execution context stack and in a certain order. However, as of the time of this writing the definition of EnqueueJob in that specification are not sufficiently flexible to integrate with HTML as a host environment. [ECMA-262]
This is not strictly true. It is in fact possible, by taking liberal advantage of the many "implementation defined" sections of the algorithm, to contort it to our purposes. However, the end result is a mass of messy indirection and workarounds that essentially bypasses the job queue infrastructure entirely, albeit in a way that is technically sanctioned within the bounds of implementation-defined behavior. We do not take this path, and instead introduce the following willful violation.
As such, user agents must instead use the following definition in place of that in the JavaScript specification. These ensure that the promise jobs enqueued by the JavaScript specification are properly integrated into the user agent’s event loops.
7.1.3.7.1. EnqueueJob(queueName, job, arguments)
When the JavaScript specification says to call the EnqueueJob abstract operation, the following algorithm must be used in place of JavaScript’s EnqueueJob:
-
Assert: queueName is
"PromiseJobs". ("ScriptJobs"must not be used by user agents.) -
Let settings be the settings object of job.[[Realm]]
-
Queue a microtask, on settings’s responsible event loop, to perform the following steps:
-
Check if we can run script with settings. If this returns "do not run" then abort these steps.
-
Prepare to run script with settings.
-
Let result be the result of performing the abstract operation specified by job, using the elements of arguments as its arguments.
-
Clean up after running script with settings.
-
If result is an abrupt completion, report the exception given by result.[[Value]].
-
7.1.3.8. Integration with the JavaScript module system
The JavaScript specification defines a syntax for modules, as well as some host-agnostic parts of
their processing model. This specification defines the rest of their processing model: how the
module system is bootstrapped, via the script element with type attribute set to
"module", and how modules are fetched, resolved, and executed. [ECMA-262]
Although the JavaScript specification speaks in terms of "scripts" versus
"modules", in general this specification speaks in terms of classic scripts versus module scripts, since both of them use the script element.
A module map is a map of absolute URLs to values that are either a module
script, null, or a placeholder value "fetching". Module maps are used to
ensure that imported JavaScript modules are only fetched, parsed, and evaluated once per Document or Worker.
To resolve a module specifier given a module script script and a string specifier, perform the following steps. It will return either an absolute URL or failure.
-
Apply the URL parser to specifier. If the result is not failure, return the result.
-
If specifier does not start with the character U+002F SOLIDUS (/), the two-character sequence U+002E FULL STOP, U+002F SOLIDUS (./), or the three-character sequence U+002E FULL STOP, U+002E FULL STOP, U+002F SOLIDUS (../), return failure and abort these steps.
This restriction is in place so that in the future we can allow custom module loaders to give special meaning to "bare" import specifiers, like
import "jquery"orimport "web/crypto". For now any such imports will fail, instead of being treated as relative URLs. -
Return the result of applying the URL parser to specifier with script’s base URL as the base URL.
7.1.3.8.1. HostResolveImportedModule(referencingModule, specifier)
JavaScript contains an implementation-defined HostResolveImportedModule abstract operation. User agents must use the following implementation: [ECMA-262]
-
Let referencing module script be referencingModule.[[HostDefined]].
-
Let module map be referencing module script’s settings object’s module map.
-
Let url be the result of resolving a module specifier given referencing module script and specifier. If the result is failure, throw a
TypeErrorexception and abort these steps. -
Let resolved module script be the value of the entry in module map whose key is url. If no such entry exists, or if the value is null or "
fetching", throw aTypeErrorexception and abort these steps. -
Return resolved module script’s module record.
7.1.3.9. Runtime script errors
When the user agent is required to report an error for a particular script script with a particular position line:col, using a particular target target, it must run these steps, after which the error is either handled or not handled:
-
If target is in error reporting mode, then abort these steps; the error is not handled.
-
Let target be in error reporting mode.
-
Let message be a user-agent-defined string describing the error in a helpful manner.
-
Let error object be the object that represents the error: in the case of an uncaught exception, that would be the object that was thrown; in the case of a JavaScript error that would be an
Errorobject. If there is no corresponding object, then the null value must be used instead. -
Let location be an absolute URL that corresponds to the resource from which script was obtained.
The resource containing the script will typically be the file from which the
Documentwas parsed, e.g., for inlinescriptelements or event handler content attributes; or the JavaScript file that the script was in, for external scripts. Even for dynamically-generated scripts, user agents are strongly encouraged to attempt to keep track of the original source of a script. For example, if an external script uses thedocument.write()API to insert an inlinescriptelement during parsing, the URL of the resource containing the script would ideally be reported as being the external script, and the line number might ideally be reported as the line with thedocument.write()call or where the string passed to that call was first constructed. Naturally, implementing this can be somewhat non-trivial.User agents are similarly encouraged to keep careful track of the original line numbers, even in the face of
document.write()calls mutating the document as it is parsed, or event handler content attributes spanning multiple lines. -
If script has muted errors, then set message to "
Script error.", set location to the empty string, set line and col to 0, and set error object to null. -
Let event be a new trusted
ErrorEventobject that does not bubble but is cancelable, and which has the event nameerror. -
Initialize event’s
messageattribute to message. -
Initialize event’s
filenameattribute to location. -
Initialize event’s
linenoattribute to line. -
Initialize event’s
colnoattribute to col. -
Initialize event’s
errorattribute to error object. -
Dispatch event at target.
-
Let target no longer be in error reporting mode.
-
If event was canceled, then the error is handled. Otherwise, the error is not handled.
Returning true cancels event per the event handler processing algorithm.
7.1.3.9.1. Runtime script errors in documents
When the user agent is to report an exception E, the user agent must report the error for the relevant script, with the problematic position (line number and column number) in the resource containing the script, using the global object specified by the script’s settings object as the target. If the error is still not handled after this, then the error may be reported to a developer console.
7.1.3.9.2. The ErrorEvent interface
[Constructor(DOMString type, optional ErrorEventInit eventInitDict), Exposed=(Window, Worker)] interface ErrorEvent : Event { readonly attribute DOMString message; readonly attribute DOMString filename; readonly attribute unsigned long lineno; readonly attribute unsigned long colno; readonly attribute any error; };
dictionary ErrorEventInit : EventInit { DOMString message = ""; DOMString filename = ""; unsigned long lineno = 0; unsigned long colno = 0; any error = null; };
The message attribute must return the value it
was initialized to. It represents the error message.
The filename attribute must return the value it
was initialized to. It represents the absolute URL of the script in which the error
originally occurred.
The lineno attribute must return the value it
was initialized to. It represents the line number where the error occurred in the script.
The colno attribute must return the value it
was initialized to. It represents the column number where the error occurred in the script.
The error attribute must return the value it
was initialized to. Where appropriate, it is set to the object representing the error
(e.g., the exception object in the case of an uncaught DOM exception).
7.1.3.10. Unhandled promise rejections
In addition to synchronous runtime script errors, scripts may experience asynchronous
promise rejections, tracked via the unhandledrejection and rejectionhandled events.
When the user agent is to notify about rejected promises on a given environment settings object settings object, it must run these steps:
-
Let list be a copy of settings object’s about-to-be-notified rejected promises list.
-
If list is empty, abort these steps.
-
Clear settings object’s about-to-be-notified rejected promises list.
-
Queue a task to run the following substep:
-
For each promise p in list:
-
If p’s [[PromiseIsHandled]] internal slot is true, continue to the next iteration of the loop.
-
Let event be a new trusted
PromiseRejectionEventobject that does not bubble but is cancelable, and which has the event nameunhandledrejection. -
Initialise event’s
promiseattribute to p. -
Initialise event’s
reasonattribute to the value of p’s [[PromiseResult]] internal slot. -
Dispatch event at settings object’s global object.
-
If the event was canceled, then the promise rejection is handled. Otherwise, the promise rejection is not handled.
-
If p’s [[PromiseIsHandled]] internal slot is false, add p to settings object’s outstanding rejected promises weak set.
-
-
This algorithm results in promise rejections being marked as handled or not handled. These concepts parallel handled and not handled script errors. If a rejection is still not handled after this, then the rejection may be reported to a developer console.
7.1.3.10.1. The HostPromiseRejectionTracker implementation
ECMAScript contains an implementation-defined HostPromiseRejectionTracker(promise, operation) abstract operation. User agents must use the following implementation: [ECMA-262]
-
Let script be the running script.
-
If script has muted errors, terminate these steps.
-
Let settings object be script’s settings object.
-
If operation is
"reject",-
Add promise to settings object’s about-to-be-notified rejected promises list.
-
-
If operation is
"handle",-
If settings object’s about-to-be-notified rejected promises list contains promise, remove promise from that list and abort these steps.
-
If settings object’s outstanding rejected promises weak set does not contain promise, abort these steps.
-
Remove promise from settings object’s outstanding rejected promises weak set.
-
Queue a task to run the following steps:
-
Let event be a new trusted
PromiseRejectionEventobject that does not bubble and is not cancelable, and which has the event namerejectionhandled. -
Initialise event’s
promiseattribute to promise. -
Initialise event’s
reasonattribute to the value of promise’s [[PromiseResult]] internal slot. -
Dispatch event at settings object’s global object.
-
-
7.1.3.10.2. The PromiseRejectionEvent interface
[Constructor(DOMString type, PromiseRejectionEventInit eventInitDict), Exposed=(Window,Worker)] interface PromiseRejectionEvent : Event { readonly attribute Promise<any> promise; readonly attribute any reason; };
dictionary PromiseRejectionEventInit : EventInit { required Promise<any> promise; any reason; };
The promise attribute must return
the value it was initialized to. It represents the promise which this notification is about.
The reason attribute must return
the value it was initialized to. It represents the rejection reason for the promise.
7.1.3.11. HostEnsureCanCompileStrings(callerRealm, calleeRealm)
JavaScript contains an implementation-defined HostEnsureCanCompileStrings(callerRealm, calleeRealm) abstract operation. User agents must use the following implementation: [ECMA-262]
-
Perform ? EnsureCSPDoesNotBlockStringCompilation(callerRealm, calleeRealm). [CSP3]
7.1.4. Event loops
7.1.4.1. Definitions
To coordinate events, user interaction, scripts, rendering, networking, and so forth, user agents
must use event loops as described in this section. There
are two kinds of event loops: those for browsing contexts, and those for workers.
There must be at least one browsing context event loop per user agent, and at most one per unit of related similar-origin browsing contexts.
When there is more than one event loop for a unit of related browsing contexts, complications arise when a browsing context in that group is navigated such that it switches from one unit of related similar-origin browsing contexts to another. This specification does not currently describe how to handle these complications.
A browsing context event loop always has at least one browsing context. If such an event loop’s browsing contexts all go away, then the event loop goes away as well. A browsing context always has an event loop coordinating its activities.
Worker event loops are simpler: each worker has one event loop, and the worker processing model manages the event loop’s lifetime.
An event loop has one or more task queues. A task queue is an ordered list of tasks, which are algorithms that are responsible for such work as:
- Events
-
Dispatching an
Eventobject at a particularEventTargetobject is often done by a dedicated task.Not all events are dispatched using the task queue, many are dispatched during other tasks.
- Parsing
-
The HTML parser tokenizing one or more bytes, and then processing any resulting tokens, is typically a task.
- Callbacks
-
Calling a callback is often done by a dedicated task.
- Using a resource
-
When an algorithm fetches a resource, if the fetching occurs in a non-blocking fashion then the processing of the resource once some or all of the resource is available is performed by a task.
- Reacting to DOM manipulation
-
Some elements have tasks that trigger in response to DOM manipulation, e.g., when that element is inserted into the document.
Each task in a browsing context event loop is associated with a Document;
if the task was queued in the context of an element, then it is the element’s node document; if the task was queued in the context of a browsing context, then it
is the browsing context’s active document at the time the task was queued; if the
task was queued by or for a script then the document is the responsible document specified by the script’s settings object.
A task is intended for a specific event loop: the event loop that is handling tasks for the task’s associated Document or Worker.
When a user agent is to queue a task, it must add the given task to one of the task queues of the relevant event loop.
Each task is defined as coming from a specific task source. All the tasks from
one particular task source and destined to a particular event loop (e.g., the
callbacks generated by timers of a Document, the events fired for mouse movements over that Document, the tasks queued for the parser of that Document) must always be added
to the same task queue, but tasks from different task sources may be placed
in different task queues.
For example, a user agent could have one task queue for mouse and key events (the user interaction task source), and another for everything else. The user agent could then give keyboard and mouse events preference over other tasks three quarters of the time, keeping the interface responsive but not starving other task queues, and never processing events from any one task source out of order.
Each event loop has a currently running task. Initially, this is null. It is used to handle reentrancy. Each event loop also has a performing a microtask checkpoint flag, which must initially be false. It is used to prevent reentrant invocation of the perform a microtask checkpoint algorithm.
7.1.4.2. Processing model
An event loop must continually run through the following steps for as long as it exists:
-
Select the oldest task on one of the event loop’s task queues, if any, ignoring, in the case of a browsing context event loop, tasks whose associated
Documents are not fully active. The user agent may pick any task queue. If there is no task to select, then jump to the Microtasks step below. -
Set the event loop’s currently running task to the task selected in the previous step.
-
Run: Run the selected task.
-
Set the event loop’s currently running task back to null.
-
Remove the task that was run in the Run step above from its task queue.
-
Microtasks: Perform a microtask checkpoint.
-
Update the rendering: If this event loop is a browsing context event loop (as opposed to a
Workerevent loop), then run the following substeps.-
Let now be the value that would be returned by the
Performanceobject’snow()method. [HR-TIME-2] -
Let docs be the list of
Documentobjects associated with the event loop in question, sorted arbitrarily except that the following conditions must be met:-
Any
DocumentB that is nested through aDocumentA must be listed after A in the list. -
If there are two documents A and B whose browsing contexts are both nested browsing contexts and their browsing context containers are both elements in the same
DocumentC, then the order of A and B in the list must match the relative tree order of their respective browsing context containers in C.
In the steps below that iterate over docs, each
Documentmust be processed in the order it is found in the list. -
-
If there is a top-level browsing context B that the user agent believes would not benefit from having its rendering updated at this time, then remove from docs all
Documentobjects whose browsing context’s top-level browsing context is B.Whether a top-level browsing context would benefit from having its rendering updated depends on various factors, such as the update frequency. For example, if the browser is attempting to achieve a 60 Hz refresh rate, then these steps are only necessary every 60th of a second (about 16.7ms). If the browser finds that a top-level browsing context is not able to sustain this rate, it might drop to a more sustainable 30Hz for that set of
Documents, rather than occasionally dropping frames. (This specification does not mandate any particular model for when to update the rendering.) Similarly, if a top-level browsing context is in the background, the user agent might decide to drop that page to a much slower 4Hz, or even less.Another example of why a browser might skip updating the rendering is to ensure certain tasks are executed immediately after each other, with only microtask checkpoints interleaved (and without, e.g., animation frame callbacks interleaved). For example, a user agent might wish to coalesce timer callbacks together, with no intermediate rendering updates.
-
If there are a nested browsing contexts B that the user agent believes would not benefit from having their rendering updated at this time, then remove from docs all
Documentobjects whose browsing context is in B.As with top-level browsing contexts, a variety of factors can influence whether it is profitable for a browser to update the rendering of nested browsing contexts. For example, a user agent might wish to spend less resources rendering third-party content, especially if it is not currently visible to the user or if resources are constrained. In such cases, the browser could decide to update the rendering for such content infrequently or never.
-
For each fully active
Documentin docs, run the resize steps for thatDocument, passing in now as the timestamp. [CSSOM-VIEW] -
For each fully active
Documentin docs, run the scroll steps for thatDocument, passing in now as the timestamp. [CSSOM-VIEW] -
For each fully active
Documentin docs, evaluate media queries and report changes for thatDocument, passing in now as the timestamp. [CSSOM-VIEW] -
For each fully active
Documentin docs, run CSS animations and send events for thatDocument, passing in now as the timestamp. [CSS3-ANIMATIONS] -
For each fully active
Documentin docs, run the fullscreen rendering steps for thatDocument, passing in now as the timestamp. [FULLSCREEN] -
For each fully active
Documentin docs, run the animation frame callbacks for thatDocument, passing in now as the timestamp. -
For each fully active
Documentin docs, update the rendering or user interface of thatDocumentand its browsing context to reflect the current state.
-
-
If this is a
Workerevent loop (i.e., one running for aWorkerGlobalScope), but there are no tasks in the event loop’s task queues and theWorkerGlobalScopeobject’s closing flag is true, then destroy the event loop, aborting these steps, resuming the run a worker steps. -
Return to the first step of the event loop.
Each event loop has a microtask queue. A microtask is a task that is originally to be queued on the microtask queue rather than a task queue. There are two kinds of microtasks: solitary callback microtasks, and compound microtasks.
This specification only has solitary callback microtasks. Specifications that use compound microtasks have to take extra care to wrap callbacks to handle spinning the event loop.
When an algorithm requires a microtask to be queued, it must be appended to the relevant event loop’s microtask queue; the task source of such a microtask is the microtask task source.
It is possible for a microtask to be moved to a regular task queue, if, during its initial execution, it spins the event loop. In that case, the microtask task source is the task source used. Normally, the task source of a microtask is irrelevant.
When a user agent is to perform a microtask checkpoint, if the performing a microtask checkpoint flag is false, then the user agent must run the following steps:
-
Let the performing a microtask checkpoint flag be true.
-
Microtask queue handling: If the event loop’s microtask queue is empty, jump to the Done step below.
-
Select the oldest microtask on the event loop’s microtask queue.
-
Set the event loop’s currently running task to the task selected in the previous step.
-
Run: Run the selected task.
This might involve invoking scripted callbacks, which eventually calls the clean up after running script steps, which call this perform a microtask checkpoint algorithm again, which is why we use the performing a microtask checkpoint flag to avoid reentrancy.
-
Set the event loop’s currently running task back to null.
-
Remove the microtask run in the step above from the microtask queue, and return to the Microtask queue handling step.
-
Done: For each environment settings object whose responsible event loop is this event loop, notify about rejected promises on that environment settings object.
-
Let the performing a microtask checkpoint flag be false.
If, while a compound microtask is running, the user agent is required to execute a compound microtask subtask to run a series of steps, the user agent must run the following steps:
-
Let parent be the event loop’s currently running task (the currently running compound microtask).
-
Let subtask be a new task that consists of running the given series of steps. The task source of such a microtask is the microtask task source. This is a compound microtask subtask.
-
Set the event loop’s currently running task to subtask.
-
Run subtask.
-
Set the event loop’s currently running task back to parent.
When an algorithm running in parallel is to await a stable state, the user agent must queue a microtask that runs the following steps, and must then stop executing (execution of the algorithm resumes when the microtask is run, as described in the following steps):
-
Run the algorithm’s synchronous section.
-
Resumes execution of the algorithm in parallel, if appropriate, as described in the algorithm’s steps.
Steps in synchronous sections are marked with ⌛.
When an algorithm says to spin the event loop until a condition goal is met, the user agent must run the following steps:
-
Let task be the event loop’s currently running task.
This might be a microtask, in which case it is a solitary callback microtask. It could also be a compound microtask subtask, or a regular task that is not a microtask. It will not be a compound microtask.
-
Let task source be task’s task source.
-
Let old stack be a copy of the JavaScript execution context stack.
-
Empty the JavaScript execution context stack.
-
Stop task, allowing whatever algorithm that invoked it to resume, but continue these steps in parallel.
This causes one of the following algorithms to continue: the event loop’s main set of steps, the perform a microtask checkpoint algorithm, or the execute a compound microtask subtask algorithm to continue.
-
Wait until the condition goal is met.
-
Queue a task to continue running these steps, using the task source task source. Wait until this new task runs before continuing these steps.
-
Replace the JavaScript execution context stack with the old stack.
-
Return to the caller.
Some of the algorithms in this specification, for historical reasons, require the user agent to pause while running a task until a condition goal is met. This means running the following steps:
-
If necessary, update the rendering or user interface of any
Documentor browsing context to reflect the current state. -
Wait until the condition goal is met. While a user agent has a paused task, the corresponding event loop must not run further tasks, and any script in the currently running task must block. User agents should remain responsive to user input while paused, however, albeit in a reduced capacity since the event loop will not be doing anything.
7.1.4.3. Generic task sources
The following task sources are used by a number of mostly unrelated features in this and other specifications.
- The DOM manipulation task source
-
This task source is used for features that react to DOM manipulations, such as things that happen in a non-blocking fashion when an element is inserted into the document.
- The user interaction task source
-
This task source is used for features that react to user interaction, for example keyboard or mouse input.
Events sent in response to user input (e.g.,
clickevents) must be fired using tasks queued with the user interaction task source. [UIEVENTS] - The networking task source
-
This task source is used for features that trigger in response to network activity.
- The history traversal task source
-
This task source is used to queue calls to
history.back()and similar APIs.
7.1.5. Events
7.1.5.1. Event handlers
Many objects can have event handlers specified. These act as non-capture event listeners for the object on which they are specified. [DOM]
An event handler has a name, which always starts with
"on" and is followed by the name of the event for which it is intended.
An event handler has a value, which is either null, or is a callback object, or is an internal raw uncompiled handler. The EventHandler callback function type describes how
this is exposed to scripts. Initially, an event handler’s value must be set to null.
Event handlers are exposed in one of two ways.
The first way, common to all event handlers, is as an event handler IDL attribute.
The second way is as an event handler content attribute. Event handlers on HTML elements and some of the event handlers on Window objects are exposed in this way.
An event handler IDL attribute is an IDL attribute for a specific event handler. The name of the IDL attribute is the same as the name of the event handler.
Event handler IDL attributes, on setting, must set the corresponding event handler to their new value, and on getting, must return the result of getting the current value of the event handler in question (this can throw an exception, in which case the getting propagates it to the caller, it does not catch it).
If an event handler IDL attribute exposes an event handler of an object that doesn’t exist, it must always return null on getting and must do nothing on setting.
This can happen in particular for event handler IDL attribute on body elements that do not have corresponding Window objects.
Certain event handler IDL attributes have additional requirements, in particular
the onmessage attribute of MessagePort objects.
An event handler content attribute is a content attribute for a specific event handler. The name of the content attribute is the same as the name of the event handler.
Event handler content attributes, when specified, must contain valid JavaScript code which, when parsed, would match the FunctionBody production after automatic semicolon insertion. [ECMA-262]
When an event handler content attribute is set, execute the following steps:
-
If the Should element’s inline behavior be blocked by Content Security Policy? algorithm returns "
Blocked" when executed upon the attribute’s element "script attribute", and the attribute’s value, then abort these steps. [CSP3] -
Set the corresponding event handler to an internal raw uncompiled handler consisting of the attribute’s new value and the script location where the attribute was set to this value.
When an event handler content attribute is removed, the user agent must set the corresponding event handler to null.
When an event handler H of an element or object T implementing the EventTarget interface is first set to a non-null value, the user agent must append an event listener to the list of event listeners associated with T with type set to the event handler event type corresponding to H and callback set to the event handler processing algorithm defined below. [DOM]
The callback is emphatically not the event handler itself. Every event handler ends up registering the same callback the algorithm defined below, which takes care of invoking the right callback, and processing the callback’s return value.
This only happens the first time the event
handler’s value is set. Since listeners are called in the order they were registered, the
order of event listeners for a particular event type will always be first the event listeners
registered with addEventListener() before
the first time the event handler was set to a non-null value,
then the callback to which it is currently set, if any, and finally the event listeners registered
with addEventListener() after the
first time the event handler was set to a non-null value.
<button>Start Demo</button> <script> var button = document.getElementById('test'); button.addEventListener('click', function () { alert('ONE') }, false); button.setAttribute('onclick', "alert('NOT CALLED')"); // event handler listener is registered here button.addEventListener('click', function () { alert('THREE') }, false); button.onclick = function () { alert('TWO'); }; button.addEventListener('click', function () { alert('FOUR') }, false); </script>
The interfaces implemented by the event object do not influence whether an event handler is triggered or not.
The event handler processing algorithm for an event handler H and an Event object E is as follows:
-
Let callback be the result of getting the current value of the event handler H.
-
If callback is null, then abort these steps.
-
Process the
Eventobject E as follows:- If E is an
ErrorEventobject and the event handler IDL attribute’s type isOnErrorEventHandler - Invoke callback with five arguments, the first one having the value of E’s
messageattribute, the second having the value of E’sfilenameattribute, the third having the value of E’slinenoattribute, the fourth having the value of E’scolnoattribute, the fifth having the value of E’serrorattribute, and with the callback this value set to E’scurrentTarget. Let return value be the callback’s return value. [WEBIDL] - Otherwise
- Invoke callback with one argument, the value of which is the
Eventobject E, with the callback this value set to E’scurrentTarget. Let return value be the callback’s return value. [WEBIDL]
In this step, invoke means to invoke the Web IDL callback function.
If an exception gets thrown by the callback, end these steps and allow the exception to propagate. (It will propagate to the DOM event dispatch logic, which will then report the exception.)
- If E is an
-
Process return value as follows:
- If the event type is
mouseover - If the event type is
errorand E is anErrorEventobject - If return value is a Web IDL boolean true value, then cancel the event.
- If the event type is
beforeunload -
The event handler IDL attribute’s type is
OnBeforeUnloadEventHandler, and the return value will therefore have been coerced into either the value null or a DOMString.If the return value is null, then cancel the event.
Otherwise, if the
Eventobject E is aBeforeUnloadEventobject, and theEventobject E’sreturnValueattribute’s value is the empty string, then set thereturnValueattribute’s value to return value. - Otherwise
- If return value is a Web IDL boolean false value, then cancel the event.
- If the event type is
The EventHandler callback function type represents a callback used for event handlers. It is
represented in Web IDL as follows:
[TreatNonObjectAsNull] callback EventHandlerNonNull = any (Event event); typedef EventHandlerNonNull? EventHandler;
In JavaScript, any Function object implements this interface.
<body onload="alert(this)" onclick="alert(this)">
...leads to an alert saying "[object Window]" when the document is
loaded, and an alert saying "[object HTMLBodyElement]" whenever the
user clicks something in the page.
The return value of the function affects whether the event is canceled or not:
as described above, if the return value is false, the event is canceled (except for mouseover events, where the return value has to be true to cancel the event). With beforeunload events, the value is instead used to determine whether or not to prompt
about unloading the document.
For historical reasons, the onerror handler has different arguments:
[TreatNonObjectAsNull] callback OnErrorEventHandlerNonNull = any ((Event or DOMString) event, optional DOMString source, optional unsigned long lineno, optional unsigned long column, optional any error); typedef OnErrorEventHandlerNonNull? OnErrorEventHandler;
Similarly, the onbeforeunload handler has a different return value:
[TreatNonObjectAsNull] callback OnBeforeUnloadEventHandlerNonNull = DOMString? (Event event); typedef OnBeforeUnloadEventHandlerNonNull? OnBeforeUnloadEventHandler;
An internal raw uncompiled handler is a tuple with the following information:
-
An uncompiled script body
-
A location where the script body originated, in case an error needs to be reported
When the user agent is to get the current value of the event handler H, it must run these steps:
-
If H’s value is an internal raw uncompiled handler, run these substeps:
-
If H is an element’s event handler, then let element be the element, and document be the element’s node document.
Otherwise, H is a
Windowobject’s event handler: let element be null, and let document be theDocumentmost recently associated with thatWindowobject. -
If document does not have a browsing context, or if scripting is enabled for document’s browsing context, then return null.
-
Let body be the uncompiled script body in the internal raw uncompiled handler.
-
Let location be the location where the script body originated, as given by the internal raw uncompiled handler.
-
If element is not null and element has a form owner, let form owner be that form owner. Otherwise, let form owner be null.
-
Let script settings be the environment settings object created for the
Windowobject with which document is currently associated. -
If body is not parsable as FunctionBody or if parsing detects an early error, then follow these substeps:
-
Set H’s value to null.
-
Report the error for the appropriate script and with the appropriate position (line number and column number) given by location, using the global object specified by script settings as the target. If the error is still not handled after this, then the error may be reported to a developer console.
-
Return null.
-
-
If body begins with a Directive Prologue that contains a Use Strict Directive then let strict be true, otherwise let strict be false.
-
Let function be the result of calling FunctionCreate, with arguments:
- kind
-
Normal
- ParameterList
-
- If H is an
onerrorevent handler of aWindowobject - Let the function have five arguments, named
event,source,lineno,colno, anderror. - Otherwise
- Let the function have a single argument called
event.
- If H is an
- Body
-
The result of parsing body above.
- Scope
-
-
If H is an element’s event handler, then let Scope be the result of NewObjectEnvironment(document, the global environment).
Otherwise, H is a
Windowobject’s event handler: let Scope be the global environment. -
If form owner is not null, let Scope be NewObjectEnvironment(form owner, Scope).
-
If element is not null, let Scope be the NewObjectEnvironment(element, Scope).
-
- Strict
-
The value of strict.
-
Set H’s value to function.
-
-
Return H’s value.
7.1.5.2. Event handlers on elements, Document objects, and Window objects
The following are the event handlers (and their corresponding event handler event
types) that must be supported by all HTML elements, as both event handler content
attributes and event handler IDL attributes; and that must be supported by all Document and Window objects, as event handler IDL attributes:
| Event handler | Event handler event type |
|---|---|
onabort
| abort
|
onauxclick
| auxclick
|
oncancel
| cancel
|
oncanplay
| canplay
|
oncanplaythrough
| canplaythrough
|
onchange
| change
|
onclick
| click
|
onclose
| close
|
oncontextmenu
| contextmenu
|
oncuechange
| cuechange
|
ondblclick
| dblclick
|
ondrag
| drag
|
ondragend
| dragend
|
ondragenter
| dragenter
|
ondragexit
| dragexit
|
ondragleave
| dragleave
|
ondragover
| dragover
|
ondragstart
| dragstart
|
ondrop
| drop
|
ondurationchange
| durationchange
|
onemptied
| emptied
|
onended
| ended
|
oninput
| input
|
oninvalid
| invalid
|
onkeydown
| keydown
|
onkeypress
| keypress
|
onkeyup
| keyup
|
onloadeddata
| loadeddata
|
onloadedmetadata
| loadedmetadata
|
onloadend
| loadend
|
onloadstart
| loadstart
|
onmousedown
| mousedown
|
onmouseenter
| mouseenter
|
onmouseleave
| mouseleave
|
onmousemove
| mousemove
|
onmouseout
| mouseout
|
onmouseover
| mouseover
|
onmouseup
| mouseup
|
onwheel
| wheel
|
onpause
| pause
|
onplay
| play
|
onplaying
| playing
|
onprogress
| progress
|
onratechange
| ratechange
|
onreset
| reset
|
onseeked
| seeked
|
onseeking
| seeking
|
onselect
| select
|
onshow
| show
|
onstalled
| stalled
|
onsubmit
| submit
|
onsuspend
| suspend
|
ontimeupdate
| timeupdate
|
ontoggle
| toggle
|
onvolumechange
| volumechange
|
onwaiting
| waiting
|
The following are the event handlers (and their corresponding event handler event
types) that must be supported by all HTML elements other than body and frameset elements, as both event handler content attributes and event handler IDL attributes;
that must be supported by all Document objects, as event handler IDL attributes; and
that must be supported by all Window objects, as event handler IDL attributes on the Window objects themselves, and with corresponding event handler content attributes and event handler IDL attributes exposed on all body and frameset elements that are
owned by that Window object’s Documents:
| Event handler | Event handler event type |
|---|---|
onblur
| blur
|
onerror
| error
|
onfocus
| focus
|
onload
| load
|
onresize
| resize
|
onscroll
| scroll
|
The following are the event handlers (and their corresponding event handler event
types) that must be supported by Window objects, as event handler IDL attributes on
the Window objects themselves, and with corresponding event handler content attributes and event handler IDL attributes exposed on all body and frameset elements that are
owned by that Window object’s Documents:
| Event handler | Event handler event type |
|---|---|
onafterprint
| afterprint
|
onbeforeprint
| beforeprint
|
onbeforeunload
| beforeunload
|
onhashchange
| hashchange
|
onlanguagechange
| languagechange
|
onmessage
| message
|
onoffline
| offline
|
ononline
| online
|
onpagehide
| pagehide
|
onpageshow
| pageshow
|
onrejectionhandled
| rejectionhandled
|
onpopstate
| popstate
|
onstorage
| storage
|
onunhandledrejection
| unhandledrejection
|
onunload
| unload
|
The following are the event handlers (and their corresponding event handler event
types) that must be supported by all HTML elements, as both event handler content
attributes and event handler IDL attributes and that must be supported by all Document objects, as event handler IDL attributes:
| Event handler | Event handler event type |
|---|---|
oncut
| cut
|
oncopy
| copy
|
onpaste
| paste
|
The following are the event handlers (and their corresponding event handler event
types) that must be supported on Document objects as event handler IDL attributes:
| Event handler | Event handler event type |
|---|---|
onreadystatechange
| readystatechange
|
7.1.5.2.1. IDL definitions
[NoInterfaceObject] interface GlobalEventHandlers { attribute EventHandler onabort; attribute EventHandler onblur; attribute EventHandler oncancel; attribute EventHandler oncanplay; attribute EventHandler oncanplaythrough; attribute EventHandler onchange; attribute EventHandler onclick; attribute EventHandler onclose; attribute EventHandler oncontextmenu; attribute EventHandler oncuechange; attribute EventHandler ondblclick; attribute EventHandler ondrag; attribute EventHandler ondragend; attribute EventHandler ondragenter; attribute EventHandler ondragexit; attribute EventHandler ondragleave; attribute EventHandler ondragover; attribute EventHandler ondragstart; attribute EventHandler ondrop; attribute EventHandler ondurationchange; attribute EventHandler onemptied; attribute EventHandler onended; attribute OnErrorEventHandler onerror; attribute EventHandler onfocus; attribute EventHandler oninput; attribute EventHandler oninvalid; attribute EventHandler onkeydown; attribute EventHandler onkeypress; attribute EventHandler onkeyup; attribute EventHandler onload; attribute EventHandler onloadeddata; attribute EventHandler onloadedmetadata; attribute EventHandler onloadstart; attribute EventHandler onmousedown; [LenientThis] attribute EventHandler onmouseenter; [LenientThis] attribute EventHandler onmouseleave; attribute EventHandler onmousemove; attribute EventHandler onmouseout; attribute EventHandler onmouseover; attribute EventHandler onmouseup; attribute EventHandler onwheel; attribute EventHandler onpause; attribute EventHandler onplay; attribute EventHandler onplaying; attribute EventHandler onprogress; attribute EventHandler onratechange; attribute EventHandler onreset; attribute EventHandler onresize; attribute EventHandler onscroll; attribute EventHandler onseeked; attribute EventHandler onseeking; attribute EventHandler onselect; attribute EventHandler onshow; attribute EventHandler onstalled; attribute EventHandler onsubmit; attribute EventHandler onsuspend; attribute EventHandler ontimeupdate; attribute EventHandler ontoggle; attribute EventHandler onvolumechange; attribute EventHandler onwaiting; };
[NoInterfaceObject] interface WindowEventHandlers { attribute EventHandler onafterprint; attribute EventHandler onbeforeprint; attribute OnBeforeUnloadEventHandler onbeforeunload; attribute EventHandler onhashchange; attribute EventHandler onlanguagechange; attribute EventHandler onmessage; attribute EventHandler onoffline; attribute EventHandler ononline; attribute EventHandler onpagehide; attribute EventHandler onpageshow; attribute EventHandler onrejectionhandled; attribute EventHandler onpopstate; attribute EventHandler onstorage; attribute EventHandler onunhandledrejection; attribute EventHandler onunload; };
[NoInterfaceObject] interface DocumentAndElementEventHandlers { attribute EventHandler oncopy; attribute EventHandler oncut; attribute EventHandler onpaste; };
7.1.5.3. Event firing
Certain operations and methods are defined as firing events on elements. For example, the click() method on the HTMLElement interface is defined as firing a click event on the element. [UIEVENTS]
Firing a simple event named e means that a trusted event with the name e, which does not
bubble (except where otherwise stated) and is not cancelable (except where otherwise stated), and
which uses the Event interface, must be created and dispatched at the given target.
Firing a synthetic mouse event named e means that an event with the name e, which is trusted (except where otherwise
stated), does not bubble (except where otherwise stated), is not cancelable (except where
otherwise stated), and which uses the MouseEvent interface, must be created and dispatched at
the given target. The event object must have its screenX, screenY, clientX, clientY, and button attributes initialized to
0, its ctrlKey, shiftKey, altKey, and metaKey attributes initialized according to the current state of the key input
device, if any (false for any keys that are not available), its detail attribute
initialized to 1, its relatedTarget attribute initialized to null (except where
otherwise stated), and its view attribute initialized to the Window object of
the Document object of the given target node, if any, or else null. The getModifierState() method on the object must return values appropriately describing
the state of the key input device at the time the event is created.
Firing a click event means firing a synthetic mouse event named click, which bubbles and is cancelable.
The default action of these events is to do nothing except where otherwise stated.
7.1.5.4. Events and the Window object
When an event is dispatched at a DOM node in a Document in a browsing
context, if the event is not a load event, the user agent
must act as if, for the purposes of event dispatching,
the Window object is the parent of the Document object. [DOM]
7.2. The WindowOrWorkerGlobalScope mixin
The WindowOrWorkerGlobalScope mixin is for use of APIs that are to be exposed
on Window and WorkerGlobalScope objects.
Other specifications are encouraged to further extend it using partial interface along with an appropriate reference. WindowOrWorkerGlobalScope { … };
typedef (DOMString or Function) TimerHandler; [NoInterfaceObject, Exposed=(Window, Worker)] interface WindowOrWorkerGlobalScope { [Replaceable] readonly attribute USVString origin; // Base64 utility methods (WindowBase64) DOMString btoa(DOMString btoa); DOMString atob(DOMString atob); // Timers (WindowTimers) long setTimeout((Function or DOMString) handler, optional long timeout = 0, any... arguments); void clearTimeout(optional long handle = 0); long setInterval((Function or DOMString) handler, optional long timeout = 0, any... arguments); void clearInterval(optional long handle = 0); // ImageBitmap, Images (ImageBitmapFactories) Promise<ImageBitmap> createImageBitmap(ImageBitmapSource image); Promise<ImageBitmap> createImageBitmap(ImageBitmapSource image, long sx, long sy, long sw, long sh); }; Window implements WindowOrWorkerGlobalScope; WorkerGlobalScope implements WindowOrWorkerGlobalScope;
- origin = self . origin
- Returns the global object’s origin, serialized as string.
self.origin over location.origin. self.origin returns the origin of the
environment, while location.origin returns URL of the environment.
Imagine the following script executing in a document on https://example.com:
var frame = document.createElement("iframe")
frame.onload = function() {
var frameWin = frame.contentWindow
console.log(frameWin.location.origin) // "null"
console.log(frameWin.origin) // "https://example.com"
}
document.body.appendChild(frame)
self.origin is a more reliable security indicator.
The origin attribute’s getter must return this object’s relevant
setting object’s origin, serialized.
7.3. Base64 utility methods
The atob() and btoa() methods allow authors to transform content to and from
the base64 encoding.
In these APIs, for mnemonic purposes, the "b" can be considered to stand for "binary", and the "a" for "ASCII". In practice, though, for primarily historical reasons, both the input and output of these functions are Unicode strings.
- result = window .
btoa( data ) -
Takes the input data, in the form of a Unicode string containing only characters in the range U+0000 to U+00FF, each representing a binary byte with values 0x00 to 0xFF respectively, and converts it to its base64 representation, which it returns.
Throws an
InvalidCharacterErrorexception if the input string contains any out-of-range characters. - result = window .
atob( data ) -
Takes the input data, in the form of a Unicode string containing base64-encoded binary data, decodes it, and returns a string consisting of characters in the range U+0000 to U+00FF, each representing a binary byte with values 0x00 to 0xFF respectively, corresponding to that binary data.
Throws an
InvalidCharacterErrorexception if the input string is not valid base64 data.
The btoa() method must throw an InvalidCharacterError exception if the method’s first argument contains any character
whose code point is greater than U+00FF. Otherwise, the user agent must convert that argument to a
sequence of octets whose nth octet is the eight-bit representation of the code
point of the nth character of the argument, and then must apply the base64
algorithm to that sequence of octets, and return the result. [RFC4648]
The atob() method must run the following
steps to parse the string passed in the method’s first argument:
- Let input be the string being parsed.
- Let position be a pointer into input, initially pointing at the start of the string.
- Remove all space characters from input.
- If the length of input divides by 4 leaving no remainder, then: if input ends with one or two U+003D EQUALS SIGN (=) characters, remove them from input.
- If the length of input divides by 4 leaving a remainder of 1, throw an
InvalidCharacterErrorexception and abort these steps. -
If input contains a character that is not in the following list of characters and character ranges, throw an
InvalidCharacterErrorexception and abort these steps:- U+002B PLUS SIGN (+)
- U+002F SOLIDUS (/)
- Alphanumeric ASCII characters
- Let output be a string, initially empty.
- Let buffer be a buffer that can have bits appended to it, initially empty.
-
While position does not point past the end of input, run these substeps:
-
Find the character pointed to by position in the first column of the following table. Let n be the number given in the second cell of the same row.
Character Number A 0 B 1 C 2 D 3 E 4 F 5 G 6 H 7 I 8 J 9 K 10 L 11 M 12 N 13 O 14 P 15 Q 16 R 17 S 18 T 19 U 20 V 21 W 22 X 23 Y 24 Z 25 a 26 b 27 c 28 d 29 e 30 f 31 g 32 h 33 i 34 j 35 k 36 l 37 m 38 n 39 o 40 p 41 q 42 r 43 s 44 t 45 u 46 v 47 w 48 x 49 y 50 z 51 0 52 1 53 2 54 3 55 4 56 5 57 6 58 7 59 8 60 9 61 + 62 / 63 - Append to buffer the six bits corresponding to number, most significant bit first.
- If buffer has accumulated 24 bits, interpret them as three 8-bit big-endian numbers. Append the three characters with code points equal to those numbers to output, in the same order, and then empty buffer.
- Advance position by one character.
-
-
If buffer is not empty, it contains either 12 or 18 bits. If it contains 12 bits, discard the last four and interpret the remaining eight as an 8-bit big-endian number. If it contains 18 bits, discard the last two and interpret the remaining 16 as two 8-bit big-endian numbers. Append the one or two characters with code points equal to those one or two numbers to output, in the same order.
The discarded bits mean that, for instance,
atob("YQ")andatob("YR")both return "a". - Return output.
7.4. Dynamic markup insertion
APIs for dynamically inserting markup into the document interact with the parser, and thus their behavior varies depending on whether they are used with HTML documents (and the HTML parser) or XML documents (and the XML parser).
Document objects have a throw-on-dynamic-markup-insertion counter, which is used in
conjunction with the create an element for the token algorithm to prevent custom element constructors from being able to use document.open(), document.close(), and document.write() when they are
invoked by the parser. Initially, the counter must be set to zero.
7.4.1. Opening the input stream
The open() method comes in several variants with different numbers of arguments.
- document = document .
open( [ type [, replace ] ] ) -
Causes the
Documentto be replaced in-place, as if it was a newDocumentobject, but reusing the previous object, which is then returned.If the type argument is omitted or has the value "
text/html", then the resultingDocumenthas an HTML parser associated with it, which can be given data to parse usingdocument.write(). Otherwise, all content passed todocument.write()will be parsed as plain text.If the replace argument is present and has the value "
replace", the existing entries in the session history for theDocumentobject are removed.The method has no effect if the
Documentis still being parsed.Throws an "
InvalidStateError"DOMExceptionif theDocumentis an XML document. - window = document .
open( url, name, features [, replace ] ) - Works like the
window.open()method.
Document objects have an ignore-opens-during-unload counter, which is used to
prevent scripts from invoking the document.open() method (directly or
indirectly) while the document is being unloaded. Initially, the counter must be set to
zero.
When called with two arguments (or fewer), the document.open() method must act
as follows:
-
If the
Documentobject is an XML document, then throw an "InvalidStateError"DOMExceptionand abort these steps. -
If the
Documentobject is not an active document, then abort these steps. -
If the origin of the
Documentis not equal to the origin of the responsible document specified by the entry settings object, throw a "SecurityError"DOMExceptionand abort these steps. -
Let type be the value of the first argument.
-
If the second argument is an ASCII case-insensitive match for the value "
replace", then let replace be true.Otherwise, if the browsing context’s session history contains only one
Document, and that was theabout:blankDocumentcreated when the browsing context was created, and thatDocumenthas never had the unload a document algorithm invoked on it (e.g., by a previous call todocument.open()), then let replace be true.Otherwise, let replace be false.
-
If the
Documenthas an active parser whose script nesting level is greater than zero, then the method does nothing. Abort these steps and return theDocumentobject on which the method was invoked.This basically causes
document.open()to be ignored when it’s called in an inline script found during parsing, while still letting it have an effect when called from a non-parser task such as a timer callback or event handler. -
Similarly, if the
Document's ignore-opens-during-unload counter is greater than zero, then the method does nothing. Abort these steps and return theDocumentobject on which the method was invoked.This basically causes
document.open()to be ignored when it’s called from abeforeunloadpagehide, orunloadevent handler while theDocumentis being unloaded. -
Set the
Document's salvageable state to false. -
Prompt to unload the
Documentobject. If the user refused to allow the document to be unloaded, then abort these steps and return theDocumentobject on which the method was invoked. -
Unload the
Documentobject, with the recycle parameter set to true. -
Unregister all event listeners registered on the
Documentnode and its descendants. -
Remove any tasks associated with the
Documentin any task source. -
Remove all child nodes of the document, without firing any mutation events.
-
Call the JavaScript InitializeHostDefinedRealm() abstract operation with the following customizations:
-
For the global object, create a new
Windowobject window. -
For the global this value, use the current browsing context’s associated
WindowProxy. -
Let realm execution context be the created JavaScript execution context.
-
-
Set window’s associated
Documentto theDocument. -
Set up a browsing context environment settings object with realm execution context.
-
Replace the
Document's singleton objects with new instances of those objects, created in window’s Realm. (This includes in particular theHistoryandNavigatorobjects, the variousBarPropobjects, the twoStorageobjects, the variousHTMLCollectionobjects, and objects defined by other specifications, likeSelection. It also includes all the Web IDL prototypes in the JavaScript binding, including theDocumentobject’s prototype.) -
Change the document’s character encoding to UTF-8.
-
If the
Documentis ready for post-load tasks, then set theDocumentobject’s reload override flag and set theDocument's reload override buffer to the empty string. -
Set the
Document's salvageable state back to true. -
Change the document’s URL to the URL of the responsible document specified by the entry settings object.
-
If the
Document's iframe load in progress flag is set, set theDocument's mute iframe load flag. -
Create a new HTML parser and associate it with the document. This is a script-created parser (meaning that it can be closed by the
document.open()anddocument.close()methods, and that the tokenizer will wait for an explicit call todocument.close()before emitting an end-of-file token). The encoding confidence is irrelevant. -
Set the current document readiness of the document to "
loading". -
If type is an ASCII case-insensitive match for the string "
replace", then, for historical reasons, set it to the string "text/html".Otherwise:
If the type string contains a U+003B SEMICOLON character (;), remove the first such character and all characters from it up to the end of the string.
Strip leading and trailing white space from type.
-
If type is not now an ASCII case-insensitive match for the string "
text/html", then act as if the tokenizer had emitted a start tag token with the tag name "pre" followed by a single U+000A LINE FEED (LF) character, then switch the HTML parser’s tokenizer to the §8.2.4.5 PLAINTEXT state. -
Remove all the entries in the browsing context’s session history after the current entry. If the current entry is the last entry in the session history, then no entries are removed.
This doesn’t necessarily have to affect the user agent’s user interface.
-
Remove any tasks queued by the history traversal task source that are associated with any
Documentobjects in the top-level browsing context’s document family. -
Remove any earlier entries that share the same
Document. -
If replace is false, then add a new entry, just before the last entry, and associate with the new entry the text that was parsed by the previous parser associated with the
Documentobject, as well as the state of the document at the start of these steps. This allows the user to step backwards in the session history to see the page before it was blown away by thedocument.open()call. This new entry does not have aDocumentobject, so a new one will be created if the session history is traversed to that entry. -
Set the
Document's fired unload flag to false. (It could have been set to true during the unload step above.) -
Finally, set the insertion point to point at just before the end of the input stream (which at this point will be empty).
-
Return the
Documenton which the method was invoked.
The document.open() method does not affect whether a Document is ready for post-load tasks or completely loaded.
When called with four arguments, the open() method on the Document object must
call the open() method on the Window object of the Document object, with the
same arguments as the original call to the open() method, and return whatever that
method returned. If the Document object has no Window object, then the method must throw
an "InvalidAccessError" DOMException.
7.4.2. Closing the input stream
- document .
close() -
Closes the input stream that was opened by the
document.open()method.Throws an
InvalidStateErrorexception if theDocumentis an XML document.
The close() method must run the following steps:
-
If the
Documentobject is an XML document, then throw anInvalidStateErrorexception and abort these steps. -
If there is no script-created parser associated with the document, then abort these steps.
-
Insert an explicit "EOF" character at the end of the parser’s input stream.
-
If there is a pending parsing-blocking script, then abort these steps.
-
Run the tokenizer, processing resulting tokens as they are emitted, and stopping when the tokenizer reaches the explicit "EOF" character or spins the event loop.
7.4.3. document.write()
- document .
write(text...) -
In general, adds the given string(s) to the
Document’s input stream.This method has very idiosyncratic behavior. In some cases, this method can affect the state of the HTML parser while the parser is running, resulting in a DOM that does not correspond to the source of the document (e.g., if the string written is the string "
<plaintext>" or "<!--"). In other cases, the call can clear the current page first, as ifdocument.open()had been called. In yet more cases, the method is simply ignored, or throws an exception. To make matters worse, the exact behavior of this method can in some cases be dependent on network latency, which can lead to failures that are very hard to debug. For all these reasons, use of this method is strongly discouraged.This method throws an
InvalidStateErrorexception when invoked on XML documents.
Document objects have an ignore-destructive-writes counter, which is
used in conjunction with the processing of script elements to prevent external
scripts from being able to use document.write() to blow
away the document by implicitly calling document.open().
Initially, the counter must be set to zero.
The document.write(...) method must act as
follows:
-
If the method was invoked on an XML document, throw an
InvalidStateErrorexception and abort these steps. - If the
Documentobject is not an active document, then abort these steps. -
If the insertion point is undefined and either the
Document’s ignore-opens-during-unload counter is greater than zero or theDocument’s ignore-destructive-writes counter is greater than zero, abort these steps. -
If the insertion point is undefined, call the
open()method on thedocumentobject (with no arguments). If the user refused to allow the document to be unloaded, then abort these steps. Otherwise, the insertion point will point at just before the end of the (empty) input stream. -
Insert the string consisting of the concatenation of all the arguments to the method into the input stream just before the insertion point.
-
If the
Documentobject’s reload override flag is set, then append the string consisting of the concatenation of all the arguments to the method to theDocument’s reload override buffer. -
If there is no pending parsing-blocking script, have the HTML parser process the characters that were inserted, one at a time, processing resulting tokens as they are emitted, and stopping when the tokenizer reaches the insertion point or when the processing of the tokenizer is aborted by the tree construction stage (this can happen if a
scriptend tag token is emitted by the tokenizer).If the
document.write()method was called from script executing inline (i.e., executing because the parser parsed a set ofscripttags), then this is a reentrant invocation of the parser. -
Finally, return from the method.
7.4.4. document.writeln()
- document .
writeln(text...) -
Adds the given string(s) to the
Document’s input stream, followed by a newline character. If necessary, calls theopen()method implicitly first.This method throws an
InvalidStateErrorexception when invoked on XML documents.
The document.writeln(...) method, when
invoked, must act as if the document.write() method had
been invoked with the same argument(s), plus an extra argument consisting of a string containing a
single line feed character (U+000A).
7.5. Timers
The setTimeout() and setInterval() methods allow authors to schedule timer-based callbacks.
- handle = window .
setTimeout( handler [, timeout [, arguments... ] ] ) -
Schedules a timeout to run handler after timeout milliseconds. Any arguments are passed straight through to the handler.
- handle = window .
setTimeout( code [, timeout ] ) -
Schedules a timeout to compile and run code after timeout milliseconds.
- window .
clearTimeout( handle ) -
Cancels the timeout set with
setTimeout()orsetInterval()identified by handle. - handle = window .
setInterval( handler [, timeout [, arguments... ] ] ) -
Schedules a timeout to run handler every timeout milliseconds. Any arguments are passed straight through to the handler.
- handle = window .
setInterval( code [, timeout ] ) -
Schedules a timeout to compile and run code every timeout milliseconds.
- window .
clearInterval( handle ) -
Cancels the timeout set with
setInterval()orsetTimeout()identified by handle.
Timers can be nested; after five such nested timers, however, the interval is forced to be at least four milliseconds.
This API does not guarantee that timers will run exactly on schedule. Delays due to CPU load, other tasks, etc, are to be expected.
Objects that implement the WindowTimers interface have a list of active
timers. Each entry in this lists is identified by a number, which must be unique within the
list for the lifetime of the object that implements the WindowTimers interface.
The setTimeout() method must return
the value returned by the timer initialization steps, passing them the method’s
arguments, the object on which the method for which the algorithm is running is implemented (a Window or WorkerGlobalScope object) as the method
context, and the repeat flag set to false.
The setInterval() method must
return the value returned by the timer initialization steps, passing them the
method’s arguments, the object on which the method for which the algorithm is running is
implemented (a Window or WorkerGlobalScope object) as the method context, and the repeat flag set to true.
The clearTimeout() and clearInterval() methods must clear the
entry identified as handle from the list of active timers of the WindowTimers object on which the method was invoked, if any, where handle is the argument passed to the method. (If handle does
not identify an entry in the list of active timers of the WindowTimers object on which the method was invoked, the method does nothing.)
Because clearTimeout() and clearInterval() clear entries from the same
list, either method can be used to clear timers created by setTimeout() or setInterval().
The timer initialization steps, which are invoked with some method arguments, a method context, a repeat flag which can be true or false, and optionally (and only if the repeat flag is true) a previous handle, are as follows:
- Let method context proxy be method context if that
is a
WorkerGlobalScopeobject, or else theWindowProxythat corresponds to method context. - If previous handle was provided, let handle be previous handle; otherwise, let handle be a user-agent-defined integer that is greater than zero that will identify the timeout to be set by this call in the list of active timers.
- If previous handle was not provided, add an entry to the list of active timers for handle.
- Let callerRealm be the current Realm Record, and calleeRealm be method context’s JavaScript realm.
-
Let task be a task that runs the following substeps:
- If the entry for handle in the list of active timers has been cleared, then abort this task’s substeps.
-
Run the appropriate set of steps from the following list:
- If the first method argument is a
Function -
Invoke the
Function. Use the third and subsequent method arguments (if any) as the arguments for invoking theFunction. Use method context proxy as the Callback this value. [ECMA-262] - Otherwise
-
- Perform HostEnsureCanCompileStrings(callerRealm, calleeRealm). If this throws an exception, report the exception.
- Let script source be the first method argument.
- Let script language be JavaScript.
- Let settings object be method context’s environment settings object.
- Create a script using script source as the script source, the URL where script source can be found, scripting language as the scripting language, and settings object as the environment settings object.
- If the first method argument is a
- If the repeat flag is true, then call timer initialization steps again, passing them the same method arguments, the same method context, with the repeat flag still set to true, and with the previous handle set to handler.
- Let timeout be the second method argument.
- If the currently running task is a task that was created by this algorithm, then let nesting level be the task’s timer nesting level. Otherwise, let nesting level be zero.
- If nesting level is greater than 5, and timeout is less than 4, then increase timeout to 4.
- Increment nesting level by one.
- Let task’s timer nesting level be nesting level.
- Return handle, and then continue running this algorithm in parallel.
-
If method context is a
Windowobject, wait until theDocumentassociated with method context has been fully active for a further timeout milliseconds (not necessarily consecutively).Otherwise, method context is a
WorkerGlobalScopeobject; wait until timeout milliseconds have passed with the worker not suspended (not necessarily consecutively). -
Wait until any invocations of this algorithm that had the same method context, that started before this one, and whose timeout is equal to or less than this one’s, have completed.
Argument conversion as defined by Web IDL (for example, invoking
toString()methods on objects passed as the first argument) happens in the algorithms defined in Web IDL, before this algorithm is invoked. -
Optionally, wait a further user-agent defined length of time.
This is intended to allow user agents to pad timeouts as needed to optimize the power usage of the device. For example, some processors have a low-power mode where the granularity of timers is reduced; on such platforms, user agents can slow timers down to fit this schedule instead of requiring the processor to use the more accurate mode with its associated higher power usage.
-
Once the task has been processed, if the repeat flag is false, it is safe to remove the entry for handle from the list of active timers (there is no way for the entry’s existence to be detected past this point, so it does not technically matter one way or the other).
The task source for these tasks is the timer task source.
function doExpensiveWork() {var done = false; // ... // this part of the function takes up to five milliseconds // set done to true if we’re done // ... return done; } function rescheduleWork() { var handle = setTimeout(rescheduleWork, 0); // preschedule next iteration if (doExpensiveWork()) clearTimeout(handle); // clear the timeout if we don’t need it } function scheduleWork() { setTimeout(rescheduleWork, 0); } scheduleWork(); // queues a task to do lots of work
7.6. User prompts
7.6.1. Simple dialogs
- window .
alert(message) -
Displays a modal alert with the given message, and waits for the user to dismiss it.
- result = window .
confirm(message) -
Displays a modal OK/Cancel prompt with the given message, waits for the user to dismiss it, and returns true if the user clicks OK and false if the user clicks Cancel.
- result = window .
prompt(message [, default] ) -
Displays a modal text field prompt with the given message, waits for the user to dismiss it, and returns the value that the user entered. If the user cancels the prompt, then returns null instead. If the second argument is present, then the given value is used as a default.
Logic that depends on tasks or microtasks, such as media elements loading their media data, are stalled when these methods are invoked.
To optionally truncate a simple dialog string s, return either s itself or some string derived from s that is shorter. User agents should not provide UI for displaying the elided portion of s, as this makes it too easy for abusers to create dialogs of the form "Important security alert! Click 'Show More' for full details!".
For example, a user agent might want to only display the first 100 characters of a message. Or, a user agent might replace the middle of the string with "…". These types of modifications can be useful in limiting the abuse potential of unnaturally large, trustworthy-looking system dialogs.
The alert(message) method, when invoked, must run the following steps:
- If the event loop’s termination nesting level is non-zero, optionally abort these steps.
- If the active sandboxing flag set of the active document of the responsible browsing context specified by the incumbent settings object has the sandboxed modals flag set, then abort these steps.
- Optionally, abort these steps. (For example, the user agent might give the user the option to ignore all alerts, and would thus abort at this step whenever the method was invoked.)
- If the method was invoked with no arguments, then let message be the empty string; otherwise, let message be the method’s first argument.
- Show the given message to the user.
- Optionally, pause while waiting for the user to acknowledge the message.
The confirm(message) method, when invoked, must run the following steps:
- If the event loop’s termination nesting level is non-zero, optionally abort these steps, returning false.
- If the active sandboxing flag set of the active document of the responsible browsing context specified by the incumbent settings object has the sandboxed modals flag set, then return false and abort these steps.
- Optionally, return false and abort these steps. (For example, the user agent might give the user the option to ignore all prompts, and would thus abort at this step whenever the method was invoked.)
- Set message to the result of optionally truncating message.
- Show message to the user, and ask the user to respond with a positive or negative response.
- Pause until the user responds either positively or negatively.
- If the user responded positively, return true; otherwise, the user responded negatively: return false.
The prompt(message, default) method, when invoked, must run the following steps:
- If the event loop’s termination nesting level is non-zero, optionally abort these steps, returning null.
- If the active sandboxing flag set of the active document of the responsible browsing context specified by the incumbent settings object has the sandboxed modals flag set, then return null and abort these steps.
- Optionally, return null and abort these steps. (For example, the user agent might give the user the option to ignore all prompts, and would thus abort at this step whenever the method was invoked.)
- Set message to the result of optionally truncating message.
- Set default to the result of optionally truncating default.
- Show message to the user, and ask the user to either respond with a string value or abort. The response must be defaulted to the value given by default.
- Pause while waiting for the user’s response.
- If the user aborts, then return null; otherwise, return the string that the user responded with.
7.6.2. Printing
- window .
print() -
Prompts the user to print the page.
When the print() method is invoked, if the Document is ready for post-load tasks, then the user agent must
run the printing steps in parallel. Otherwise, the user agent must only set the print when loaded flag on the Document.
User agents should also run the printing steps whenever the user asks for the opportunity to obtain a physical form (e.g., printed copy), or the representation of a physical form (e.g., PDF copy), of a document.
The printing steps are as follows:
-
The user agent may display a message to the user or abort these steps (or both).
For instance, a kiosk browser could silently ignore any invocations of the
print()method.For instance, a browser on a mobile device could detect that there are no printers in the vicinity and display a message saying so before continuing to offer a "save to PDF" option.
-
If the active sandboxing flag set of the active document of the responsible browsing context specified by the incumbent settings object has the sandboxed modals flag set, then abort these steps.
If the printing dialog is blocked by a
Document’s sandbox, then neither thebeforeprintnorafterprintevents will be fired. -
The user agent must fire a simple event named
beforeprintat theWindowobject of theDocumentthat is being printed, as well as any nested browsing contexts in it.The
beforeprintevent can be used to annotate the printed copy, for instance adding the time at which the document was printed. -
The user agent should offer the user the opportunity to obtain a physical form (or the representation of a physical form) of the document. The user agent may wait for the user to either accept or decline before returning; if so, the user agent must pause while the method is waiting. Even if the user agent doesn’t wait at this point, the user agent must use the state of the relevant documents as they are at this point in the algorithm if and when it eventually creates the alternate form.
-
The user agent must fire a simple event named
afterprintat theWindowobject of theDocumentthat is being printed, as well as any nested browsing contexts in it.The
afterprintevent can be used to revert annotations added in the earlier event, as well as showing post-printing UI. For instance, if a page is walking the user through the steps of applying for a home loan, the script could automatically advance to the next step after having printed a form or other.
7.7. System state and capabilities
7.7.1. The Navigator object
The navigator attribute of the Window interface must return an instance of the Navigator interface,
which represents the identity and state of the user agent (the client), and allows Web pages to
register themselves as potential protocol and content handlers:
interface Navigator { // objects implementing this interface also implement the interfaces given below }; Navigator implements NavigatorID; Navigator implements NavigatorLanguage; Navigator implements NavigatorOnLine; Navigator implements NavigatorContentUtils; Navigator implements NavigatorCookies; Navigator implements NavigatorPlugins;
These interfaces are defined separately so that other specifications can re-use parts of the Navigator interface.
7.7.1.1. Client identification
[NoInterfaceObject, Exposed=(Window, Worker)] interface NavigatorID { [Exposed=Window] readonly attribute DOMString appCodeName; // constant "Mozilla" readonly attribute DOMString appName; // constant "Netscape" readonly attribute DOMString appVersion; readonly attribute DOMString platform; [Exposed=Window]readonly attribute DOMString product; // constant "Gecko" readonly attribute DOMString userAgent; };
In certain cases, despite the best efforts of the entire industry, Web browsers have bugs and limitations that Web authors are forced to work around.
This section defines a collection of attributes that can be used to determine, from script, the kind of user agent in use, in order to work around these issues.
Client detection should always be limited to detecting known current versions; future versions and unknown versions should always be assumed to be fully compliant.
- window .
navigator.appCodeName - Returns the string "
Mozilla". - window .
navigator.appName - Returns the string "
Netscape". - window .
navigator.appVersion - Returns the version of the browser.
- window .
navigator.platform - Returns the name of the platform.
- window .
navigator.product - Returns the string "
Gecko". - window .
navigator.productSub() - Returns either the string "
20030107", or the string "20100101". - window .
navigator.userAgent - Returns the complete User-Agent header.
appCodeName, of type DOMString, readonly- Must return the string "
Mozilla". appName, of type DOMString, readonly- Must return the string "
Netscape". appVersion, of type DOMString, readonly- Must return either the string "
4.0" or a string representing the version of the browser in detail, e.g., "1.0 (VMS; en-US) Mellblomenator/9000". platform, of type DOMString, readonly- Must return either the empty string or a string representing the platform on which the
browser is executing, e.g., "
MacIntel", "Win32", "FreeBSD i386", "WebTV OS". product, of type DOMString, readonly- Must return the string "
Gecko". taintEnabled()- Must return false.
userAgent, of type DOMString, readonly- Must return the string used for the value of the "
User-Agent" header in HTTP requests, or the empty string if no such header is ever sent.
Any information in this API that varies from user to user can be used to profile the user. In fact, if enough such information is available, a user can actually be uniquely identified. For this reason, user agent implementors are strongly urged to include as little information in this API as possible.
7.7.1.2. Language preferences
[NoInterfaceObject, Exposed=(Window, Worker)] interface NavigatorLanguage { readonly attribute DOMString? language; readonly attribute DOMString[] languages; };
- window .
navigator.language - Returns a language tag representing the user’s preferred language.
- window .
navigator.languages - Returns an array of language tags representing the user’s preferred languages, with the most preferred language first.
The most preferred language is the one returned by
navigator.language.
A languagechange event is fired at the Window or WorkerGlobalScope object when the user agent’s understanding
of what the user’s preferred languages are changes.
language, of type DOMString, readonly, nullable- Must return a valid BCP 47 language tag representing either a plausible language or the user’s most preferred language. [BCP47]
languages, of type DOMString[], readonly-
Must return a read only array of valid BCP 47 language tags representing either one or more plausible languages, or the user’s preferred languages, ordered by preference with the most preferred language first. The same object must be returned until the user agent needs to return different values, or values in a different order. [BCP47]
Whenever the user agent needs to make the
navigator.languagesattribute of aWindoworWorkerGlobalScopeobject return a new set of language tags, the user agent must queue a task to fire a simple event namedlanguagechangeat theWindoworWorkerGlobalScopeobject and wait until that task begins to be executed before actually returning a new value.The task source for this task is the DOM manipulation task source.
To determine a plausible language, the user agent should bear in mind the following:
- Any information in this API that varies from user to user can be used to profile or identify the user.
- If the user is not using a service that obfuscates the user’s point of origin (e.g., the Tor anonymity network), then the value that is least likely to distinguish the user from other users with similar origins (e.g., from the same IP address block) is the language used by the majority of such users. [TOR]
- If the user is using an anonymizing service, then the value "
en-US" is suggested; if all users of the service use that same value, that reduces the possibility of distinguishing the users from each other.
To avoid introducing any more fingerprinting vectors, user agents should use the same list for
the APIs defined in this function as for the HTTP Accept-Language header.
7.7.1.3. Custom scheme and content handlers: the registerProtocolHandler() and registerContentHandler() methods
[NoInterfaceObject] interface NavigatorContentUtils { // content handler registration void registerProtocolHandler(DOMString scheme, DOMString url, DOMString title); void registerContentHandler(DOMString mimeType, DOMString url, DOMString title); DOMString isProtocolHandlerRegistered(DOMString scheme, DOMString url); DOMString isContentHandlerRegistered(DOMString mimeType, DOMString url); void unregisterProtocolHandler(DOMString scheme, DOMString url); void unregisterContentHandler(DOMString mimeType, DOMString url); };
The registerProtocolHandler() method
allows Web sites to register themselves as possible handlers for particular schemes. For example,
an online telephone messaging service could register itself as a handler of the sms: scheme, so that if the user clicks on such a link, he is given the
opportunity to use that Web site. Analogously, the registerContentHandler() method allows
Web sites to register themselves as possible handlers for content in a particular MIME
type. For example, the same online telephone messaging service could register itself as a
handler for text/vcard files, so that if the user has no native application capable
of handling vCards, his Web browser can instead suggest he use that site to view contact
information stored on vCards that he opens. [RFC5724] [RFC6350]
- window .
navigator.registerProtocolHandler(scheme, url, title) - window .
navigator.registerContentHandler(mimeType, url, title) -
Registers a handler for the given scheme or content type, at the given URL, with the given title.
The string "
%s" in the URL is used as a placeholder for where to put the URL of the content to be handled.Throws a "
SecurityError"DOMExceptionif the user agent blocks the registration (this might happen if trying to register as a handler for "http", for instance).Throws a "
SyntaxError"DOMExceptionif the "%s" string is missing in the URL.
User agents may, within the constraints described in this section, do whatever they like when the methods are called. A user agent could, for instance, prompt the user and offer the user the opportunity to add the site to a shortlist of handlers, or make the handlers his default, or cancel the request. user agents could provide such a UI through modal UI or through a non-modal transient notification interface. user agents could also simply silently collect the information, providing it only when relevant to the user.
User agents should keep track of which sites have registered handlers (even if the user has declined such registrations) so that the user is not repeatedly prompted with the same request.
The arguments to the methods have the following meanings and corresponding implementation requirements. The requirements that involve throwing exceptions must be processed in the order given below, stopping at the first exception thrown. (So the exceptions for the first argument take precedence over the exceptions for the second argument.)
- scheme (
registerProtocolHandler()only) -
A scheme, such as "
mailto" or "web+auth". The scheme must be compared in an ASCII case-insensitive manner by user agents for the purposes of comparing with the scheme part of URLs that they consider against the list of registered handlers.The scheme value, if it contains a colon (as in "
mailto:"), will never match anything, since schemes don’t contain colons.If the
registerProtocolHandler()method is invoked with a scheme that is neither a safelisted scheme nor a scheme whose value starts with the substring "web+" and otherwise contains only lowercase ASCII letters, and whose length is at least five characters (including the "web+" prefix), the user agent must throw a "SyntaxError"DOMException.The following schemes are the safelisted schemes:
bitcoingeoimircircsmagnetmailtommsnewsnntpopenpgp4fprsipsmssmstosshtelurnwebcalwtaixmpp
This list can be changed. If there are schemes that should be added, please send feedback.
This list excludes any schemes that could reasonably be expected to be supported inline, e.g., in an
iframe, such ashttpor (more theoretically)gopher. If those were supported, they could potentially be used in man-in-the-middle attacks, by replacing pages that have frames with such content with content under the control of the protocol handler. If the user agent has native support for the schemes, this could further be used for cookie-theft attacks. - mimeType (
registerContentHandler()only) -
A MIME type, such as
model/vnd.flatland.3dmlorapplication/vnd.google-earth.kml+xml. The MIME type must be compared in an ASCII case-insensitive manner by user agents for the purposes of comparing with MIME types of documents that they consider against the list of registered handlers.User agents must compare the given values only to the MIME type/subtype parts of content types, not to the complete type including parameters. Thus, if mimeType values passed to this method include characters such as commas or white space, or include MIME parameters, then the handler being registered will never be used.
The type is compared to the MIME type used by the user agent after the sniffing algorithms have been applied.
If the
registerContentHandler()method is invoked with a MIME type that is in the type blocklist or that the user agent has deemed a privileged type, the user agent must throw a "SecurityError"DOMException.The following MIME types are in the type blocklist:
application/x-www-form-urlencodedapplication/xhtml+xmlapplication/xmlimage/gifimage/jpegimage/pngimage/svg+xmlmultipart/x-mixed-replacetext/csstext/htmltext/pingtext/plaintext/vtttext/xml- All types that the user agent supports displaying natively in a browsing context during navigation, except for
application/rss+xmlandapplication/atom+xml
This list can be changed. If there are MIME types that should be added, please send feedback.
- url
-
A string used to build the URL of the page that will handle the requests.
User agents must throw a "
SyntaxError"DOMExceptionif the url argument passed to one of these methods does not contain the exact literal string "%s".User agents must throw a "
SyntaxError"DOMExceptionif parsing the url argument relative to the API base URL specified by the entry settings object is not successful.The resulting URL string would by definition not be a valid URL as it would include the string "
%s" which is not a valid component in a URL.User agents must throw a "
SecurityError"DOMExceptionif the resulting absolute URL has an origin that differs from the origin specified by the entry settings object.This is forcibly the case if the
%splaceholder is in the scheme, host, or port parts of the URL.The resulting URL string is the proto-URL. It identifies the handler for the purposes of the methods described below.
When the user agent uses this handler, it must replace the first occurrence of the exact literal string "
%s" in the url argument with an escaped version of the absolute URL of the content in question (as defined below), then parse the resulting URL, relative to the API base URL specified by the entry settings object at the time theregisterContentHandler()orregisterProtocolHandler()methods were invoked, and then navigate an appropriate browsing context to the resulting URL.To get the escaped version of the absolute URL of the content in question, the user agent must replace every character in that absolute URL that is not a character in the URL default encode set with the result of UTF-8 percent encoding that character.
If the user had visited a site athttps://example.com/that made the following call:navigator.registerContentHandler('application/x-soup', 'soup?url=%s', 'SoupWeb™')
...and then, much later, while visiting
https://www.example.net/, clicked on a link such as:<a href="chickenkïwi.soup">Download our Chicken Kïwi soup!</a>
...then, assuming this
chickenkïwi.soupfile was served with the MIME typeapplication/x-soup, the user agent might navigate to the following URL:https://example.com/soup?url=https://www.example.net/chickenk%C3%AFwi.soup
This site could then fetch the
chickenkïwi.soupfile and do whatever it is that it does with soup (synthesize it and ship it to the user, or whatever). - title
-
A descriptive title of the handler, which the user agent might use to remind the user what the site in question is.
This section does not define how the pages registered by these methods are used, beyond the requirements on how to process the url value (see above). To some extent, the processing model for navigating across documents defines some cases where these methods are relevant, but in general user agents may use this information wherever they would otherwise consider handing content to native plugins or helper applications.
user agents must not use registered content handlers to handle content that was returned as part of a non-GET transaction (or rather, as part of any non-idempotent transaction), as the remote site would not be able to fetch the same data.
In addition to the registration methods, there are also methods for determining if particular handlers have been registered, and for unregistering handlers.
- state = window .
navigator.isProtocolHandlerRegistered(scheme, url) - state = window .
navigator.isContentHandlerRegistered(mimeType, url) -
Returns one of the following strings describing the state of the handler given by the arguments:
new- Indicates that no attempt has been made to register the given handler (or that the handler has been unregistered). It would be appropriate to promote the availability of the handler or to just automatically register the handler.
registered- Indicates that the given handler has been registered or that the site is blocked from registering the handler. Trying to register the handler again would have no effect.
declined- Indicates that the given handler has been offered but was rejected. Trying to register the handler again may prompt the user again.
- window .
navigator.unregisterProtocolHandler(scheme, url) - window .
navigator.unregisterContentHandler(mimeType, url) -
Unregisters the handler given by the arguments.
The isProtocolHandlerRegistered() method must return the handler state string that most closely describes the current
state of the handler described by the two arguments to the method, where the first argument gives
the scheme and the second gives the string used to build the URL of the page that
will handle the requests.
The first argument must be compared to the schemes for which custom protocol handlers are registered in an ASCII case-insensitive manner to find the relevant handlers.
The second argument must be preprocessed as described below, and if that is successful, must then be matched against the proto-URLs of the relevant handlers to find the described handler.
The isContentHandlerRegistered() method must return the handler state string that most closely describes the current
state of the handler described by the two arguments to the method, where the first argument gives
the MIME type and the second gives the string used to build the URL of
the page that will handle the requests.
The first argument must be compared to the MIME types for which custom content handlers are registered in an ASCII case-insensitive manner to find the relevant handlers.
The second argument must be preprocessed as described below, and if that is successful, must then be matched against the proto-URLs of the relevant handlers to find the described handler.
The handler state strings are the following strings. Each string describes several situations, as given by the following list.
new- The described handler has never been registered for the given scheme or type.
- The described handler was once registered for the given scheme or type, but the site has since unregistered it. If the handler were to be reregistered, the user would be notified accordingly.
- The described handler was once registered for the given scheme or type, but the site has since unregistered it, but the user has indicated that the site is to be blocked from registering the type again, so the user agent would ignore further registration attempts.
registered- An attempt was made to register the described handler for the given scheme or type, but the user has not yet been notified, and the user agent would ignore further registration attempts. (Maybe the user agent batches registration requests to display them when the user requests to be notified about them, and the user has not yet requested that the user agent notify it of the previous registration attempt.)
- The described handler is registered for the given scheme or type (maybe, or maybe not, as the default handler).
- The described handler is permanently blocked from being (re)registered. (Maybe the user marked the registration attempt as spam, or blocked the site for other reasons.)
declined- An attempt was made to register the described handler for the given scheme or type, but the user has not yet been notified; however, the user might be notified if another registration attempt were to be made. (Maybe the last registration attempt was made while the page was in the background and the user closed the page without looking at it, and the user agent requires confirmation for this registration attempt.)
- An attempt was made to register the described handler for the given scheme or type, but the user has not yet responded.
- An attempt was made to register the described handler for the given scheme or type, but the user declined the offer. The user has not indicated that the handler is to be permanently blocked, however, so another attempt to register the described handler might result in the user being prompted again.
- The described handler was once registered for the given scheme or type, but the user has since removed it. The user has not indicated that the handler is to be permanently blocked, however, so another attempt to register the described handler might result in the user being prompted again.
The unregisterProtocolHandler() method must unregister the handler described by the two arguments to the method, where the first
argument gives the scheme and the second gives the string used to build the URL of
the page that will handle the requests.
The first argument must be compared to the schemes for which custom protocol handlers are registered in an ASCII case-insensitive manner to find the relevant handlers.
The second argument must be preprocessed as described below, and if that is successful, must then be matched against the proto-URLs of the relevant handlers to find the described handler.
The unregisterContentHandler() method must unregister the handler described by the two arguments to the method, where the first
argument gives the MIME type and the second gives the string used to build the URL of the page that will handle the requests.
The first argument must be compared to the MIME types for which custom content handlers are registered in an ASCII case-insensitive manner to find the relevant handlers.
The second argument must be preprocessed as described below, and if that is successful, must then be matched against the proto-URLs of the relevant handlers to find the described handler.
The second argument of the four methods described above must be preprocessed as follows:
-
If the string does not contain the substring "
%s", abort these steps. There’s no matching handler. -
Parse the string relative to the entry settings object. If this fails, then throw a "
SyntaxError"DOMException. -
If the resulting URL record’s origin is not the same origin as the origin specified by the entry settings object, throw a "
SecurityError"DOMException. -
Return the resulting URL string as the result of preprocessing the argument.
7.7.1.3.1. Security and privacy
These mechanisms can introduce a number of concerns, in particular privacy concerns.
Hijacking all Web usage. User agents should not allow schemes that are key to its normal operation, such as
httporhttps, to be rerouted through third-party sites. This would allow a user’s activities to be trivially tracked, and would allow user information, even in secure connections, to be collected.Hijacking defaults. User agents are strongly urged to not automatically change any defaults, as this could lead the user to send data to remote hosts that the user is not expecting. New handlers registering themselves should never automatically cause those sites to be used.
Registration spamming. User agents should consider the possibility that a site will attempt to register a large number of handlers, possibly from multiple domains (e.g., by redirecting through a series of pages each on a different domain, and each registering a handler for
video/mpeg— analogous practices abusing other Web browser features have been used by pornography Web sites for many years). User agents should gracefully handle such hostile attempts, protecting the user.Misleading titles. User agents should not rely wholly on the title argument to the methods when presenting the registered handlers to the user, since sites could easily lie. For example, a site
hostile.example.netcould claim that it was registering the "Cuddly Bear Happy Content Handler". User agents should therefore use the handler’s domain in any UI along with any title.Hostile handler metadata. User agents should protect against typical attacks against strings embedded in their interface, for example ensuring that markup or escape characters in such strings are not executed, that null bytes are properly handled, that over-long strings do not cause crashes or buffer overruns, and so forth.
Leaking Intranet URLs. The mechanism described in this section can result in secret Intranet URLs being leaked, in the following manner:
- The user registers a third-party content handler as the default handler for a content type.
- The user then browses his corporate Intranet site and accesses a document that uses that content type.
- The user agent contacts the third party and hands the third party the URL to the Intranet content.
No actual confidential file data is leaked in this manner, but the URLs themselves could contain confidential information. For example, the URL could be
https://www.corp.example.com/upcoming-aquisitions/the-sample-company.egf, which might tell the third party that Example Corporation is intending to merge with The Sample Company. Implementors might wish to consider allowing administrators to disable this feature for certain subdomains, content types, or schemes.Leaking secure URLs. User agents should not send HTTPS URLs to third-party sites registered as content handlers without the user’s informed consent, for the same reason that user agents sometimes avoid sending
Referer(sic) HTTP headers from secure sites to third-party sites.Leaking credentials. User agents must never send username or password information in the URLs that are escaped and included sent to the handler sites. User agents may even avoid attempting to pass to Web-based handlers the URLs of resources that are known to require authentication to access, as such sites would be unable to access the resources in question without prompting the user for credentials themselves (a practice that would require the user to know whether to trust the third-party handler, a decision many users are unable to make or even understand).
Interface interference. User agents should be prepared to handle intentionally long arguments to the methods. For example, if the user interface exposed consists of an "accept" button and a "deny" button, with the "accept" binding containing the name of the handler, it’s important that a long name not cause the "deny" button to be pushed off the screen.
Fingerprinting users. Since a site can detect if it has attempted to register a particular handler or not, whether or not the user responds, the mechanism can be used to store data. User agents are therefore strongly urged to treat registrations in the same manner as cookies: clearing cookies for a site should also clear all registrations for that site, and disabling cookies for a site should also disable registrations.
7.7.1.3.2. Sample user interface
This section is non-normative.
A simple implementation of this feature for a desktop Web browser might work as follows.
The registerContentHandler() method
could display a modal dialog box:
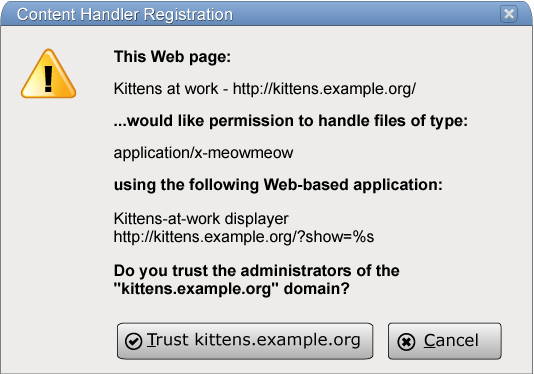
In this dialog box, "Kittens at work" is the title of the page that invoked the method,
"https://kittens.example.org/" is the URL of that page, "application/x-meowmeow" is the string that
was passed to the registerContentHandler() method as its first
argument (mimeType), "https://kittens.example.org/?show=%s" was the second
argument (url), and "Kittens-at-work displayer" was the third argument (title).
If the user clicks the Cancel button, then nothing further happens. If the user clicks the "Trust" button, then the handler is remembered.
When the user then attempts to fetch a URL that uses the "application/x-meowmeow" MIME type, then it might display a dialog as follows:
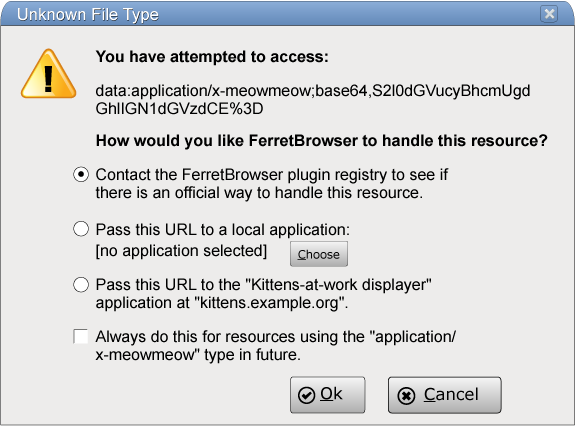
In this dialog, the third option is the one that was primed by the site registering itself earlier.
If the user does select that option, then the browser, in accordance with the requirements described in the previous two sections, will redirect the user to "https://kittens.example.org/?show=data%3Aapplication/x-meowmeow;base64,S2l0dGVucyBhcmUgdGhlIGN1dGVzdCE%253D".
The registerProtocolHandler() method
would work equivalently, but for schemes instead of unknown content types.
7.7.1.4. Cookies
[NoInterfaceObject] interface NavigatorCookies { readonly attribute boolean cookieEnabled; };
- window .
navigator.cookieEnabled - Returns false if setting a cookie will be ignored, and true otherwise.
The cookieEnabled attribute must
return true if the user agent attempts to handle cookies according to the cookie specification,
and false if it ignores cookie change requests. [COOKIES]
7.7.1.5. Plugins
[NoInterfaceObject] interface NavigatorPlugins { [SameObject] readonly attribute PluginArray plugins; [SameObject] readonly attribute MimeTypeArray mimeTypes; boolean javaEnabled(); };
interface PluginArray { void refresh(optional boolean reload = false); readonly attribute unsigned long length; getter Plugin? item(unsigned long index); getter Plugin? namedItem(DOMString name); };
interface MimeTypeArray { readonly attribute unsigned long length; getter MimeType? item(unsigned long index); getter MimeType? namedItem(DOMString name); };
interface Plugin { readonly attribute DOMString name; readonly attribute DOMString description; readonly attribute DOMString filename; readonly attribute unsigned long length; getter MimeType? item(unsigned long index); getter MimeType? namedItem(DOMString name); };
interface MimeType { readonly attribute DOMString type; readonly attribute DOMString description; readonly attribute DOMString suffixes; // comma-separated readonly attribute Plugin enabledPlugin; };
- window .
navigator.plugins.refresh( [ refresh ] ) - Updates the lists of supported plugins and MIME types for this page, and reloads the page if the lists have changed.
- window .
navigator.plugins.length - Returns the number of plugins, represented by
Pluginobjects, that the user agent reports. - plugin = window .
navigator.plugins.item(index) - window .
navigator.plugins[index] - Returns the specified
Pluginobject. - plugin = window .
navigator.plugins.item(name) - window .
navigator.plugins[name] - Returns the
Pluginobject for the plugin with the given name. - window .
navigator.mimeTypes.length - Returns the number of MIME types, represented by
MimeTypeobjects, supported by the plugins that the user agent reports. - mimeType = window .
navigator.mimeTypes.item(index) - window .
navigator.mimeTypes[index] - Returns the specified
MimeTypeobject. - mimeType = window .
navigator.mimeTypes.item(name) - window .
navigator.mimeTypes[name] - Returns the
MimeTypeobject for the given MIME type. - plugin .
name - Returns the plugin’s name.
- plugin .
description - Returns the plugin’s description.
- plugin .
filename - Returns the plugin library’s filename, if applicable on the current platform.
- plugin .
length - Returns the number of MIME types, represented by
MimeTypeobjects, supported by the plugin. - mimeType = plugin .
item(index) - plugin[index]
- Returns the specified
MimeTypeobject. - mimeType = plugin .
item(name) - plugin[name]
- Returns the
MimeTypeobject for the given MIME type. - mimeType .
type - Returns the MIME type.
- mimeType .
description - Returns the MIME type’s description.
- mimeType .
suffixes - Returns the MIME type’s typical file extensions, in a comma-separated list.
- mimeType .
enabledPlugin - Returns the
Pluginobject that implements this MIME type. - window .
navigator.javaEnabled() - Returns true if there’s a plugin that supports the MIME type "
application/x-java-vm".
The plugins attribute must
return a PluginArray object.
The mimeTypes attribute must
return a MimeTypeArray object.
A PluginArray object represents none, some, or all of the plugins supported by the user agent, each of which is represented by a Plugin object. Each of these Plugin objects may be hidden plugins. A can’t
be enumerated, but can still be inspected by using its name.
The fewer plugins are represented by the PluginArray object, and of those, the more that are , the more the user’s privacy will be protected. Each exposed plugin
increases the number of bits that can be derived for fingerprinting. Hiding a plugin helps, but
unless it is an extremely rare plugin, it is likely that a site attempting to derive the list of
plugins can still determine whether the plugin is supported or not by probing for it by name (the
names of popular plugins are widely known). Therefore not exposing a plugin at all is preferred.
Unfortunately, many legacy sites use this feature to determine, for example, which plugin to use
to play video. Not exposing any plugins at all might therefore not be entirely plausible.
The PluginArray objects created by a user agent must not be live. The
set of plugins represented by the objects must not change once an object is created, except when
it is updated by the refresh() method.
Each plugin represented by a PluginArray can support a number of MIME types. For each such plugin, the user agent must
pick one or more of these MIME types to be those that are explicitly supported.
The explicitly supported MIME types of
a plugin are those that are exposed through the Plugin and MimeTypeArray interfaces. As with plugins themselves, any variation between users regarding what is exposed
allows sites to fingerprint users. User agents are therefore encouraged to expose the same MIME types for all users of a plugin, regardless of the
actual types supported... at least, within the constraints imposed by compatibility with legacy
content.
The supported property indices of a PluginArray object are the
numbers from zero to the number of non- plugins represented by the object, if any.
The length attribute must return the
number of non- plugins represented by the object.
The item() method of a PluginArray object must return null if the argument is not one of the object’s supported property indices, and otherwise must return the result of running the
following steps, using the method’s argument as index:
- Let list be the
Pluginobjects representing the non- plugins represented by thePluginArrayobject. - Sort list alphabetically by the
nameof eachPlugin. - Return the indexth entry in list.
It is important for privacy that the order of plugins not leak additional information, e.g., the order in which plugins were installed.
The supported property names of a PluginArray object are the values
of the name attributes of all the Plugin objects represented by the PluginArray object. The
properties exposed in this way must be unenumerable.
The namedItem() method of a PluginArray object must return null if the argument is not one of the object’s supported property names, and otherwise must return the Plugin object, of those represented by the PluginArray object, that has a name equal to the method’s argument.
The refresh() method of the PluginArray object of a Navigator object, when invoked, must check to
see if any plugins have been installed or reconfigured since the user
agent created the PluginArray object. If so, and the method’s argument is true, then
the user agent must act as if the location.reload() method was called instead. Otherwise, the user agent must update the PluginArray object and MimeTypeArray object created for attributes of that Navigator object, and the Plugin and MimeType objects created
for those PluginArray and MimeTypeArray objects, using the same Plugin objects for cases where the name is the same, and the same MimeType objects for
cases where the type is the same, and creating new objects
for cases where there were no matching objects immediately prior to the refresh() call. Old Plugin and MimeType objects must continue to return the same values that they had prior to
the update, though naturally now the data is stale and may appear inconsistent (for example, an
old MimeType entry might list as its enabledPlugin a Plugin object that no longer lists that MimeType as a supported MimeType).
A MimeTypeArray object represents the MIME types explicitly supported by plugins supported by the user
agent, each of which is represented by a MimeType object.
The MimeTypeArray objects created by a user agent must not be live.
The set of MIME types represented by the objects must not change once an object is created, except
when it is updated by the PluginArray object’s refresh() method.
The supported property indices of a MimeTypeArray object are the
numbers from zero to the number of MIME types explicitly
supported by non- plugins represented by the corresponding PluginArray object, if
any.
The length attribute must return the
number of MIME types explicitly supported by non- plugins represented by the
corresponding PluginArray object, if any.
The item() method of a MimeTypeArray object must return null if the argument is not one of the object’s supported property indices, and otherwise must return the result of running the
following steps, using the method’s argument as index:
- Let list be the
MimeTypeobjects representing the MIME types explicitly supported by non- plugins represented by the correspondingPluginArrayobject, if any. - Sort list alphabetically by the
typeof eachMimeType. - Return the indexth entry in list.
It is important for privacy that the order of MIME types not leak additional information, e.g., the order in which plugins were installed.
The supported property names of a MimeTypeArray object are the values
of the type attributes of all the MimeType objects represented by the MimeTypeArray object. The properties exposed in this way
must be unenumerable.
The namedItem() method of a MimeTypeArray object must return null if the argument is not one of the object’s supported property names, and otherwise must return the MimeType object
that has a type equal to the method’s argument.
A Plugin object represents a plugin. It has
several attributes to provide details about the plugin, and can be enumerated to obtain the list
of MIME types that it explicitly
supports.
The Plugin objects created by a user agent must not be live. The set of MIME types represented by the objects, and the values of the
objects' attributes, must not change once an object is created, except when updated by the PluginArray object’s refresh() method.
The reported MIME types for a Plugin object are the MIME types explicitly supported by the corresponding plugin when this object was last created or updated by PluginArray.refresh(), whichever happened most
recently.
The supported property indices of a Plugin object
are the numbers from zero to the number of reported MIME types.
The length attribute must return the number
of reported MIME types.
The item() method of a Plugin object must return null if the argument is not one of the
object’s supported property indices, and otherwise must return the result of running
the following steps, using the method’s argument as index:
- Let list be the
MimeTypeobjects representing the reported MIME types. - Sort list alphabetically by the
typeof eachMimeType. - Return the indexth entry in list.
It is important for privacy that the order of MIME types not leak additional information, e.g., the order in which plugins were installed.
The supported property names of a Plugin object
are the values of the type attributes of the MimeType objects representing the reported MIME types. The properties
exposed in this way must be unenumerable.
The namedItem() method of a Plugin object must return null if the argument is not one of the
object’s supported property names, and otherwise must return the MimeType object that has a type equal to the
method’s argument.
The name attribute must return the plugin’s name.
The description and filename attributes must return user-agent-defined
(or, in all likelihood, plugin-defined) strings. In each case, the same string must
be returned each time, except that the strings returned may change when the PluginArray.refresh() method updates the object.
If the values returned by the description or filename attributes vary between versions of a plugin, they can be used both as a fingerprinting vector and, even more importantly,
as a trivial way to determine what security vulnerabilities a plugin (and thus a
browser) may have. It is thus highly recommended that the description attribute just return the same value as the name attribute, and that the filename attribute return the empty string.
A MimeType object represents a MIME type that is, or was, explicitly supported by a plugin.
The MimeType objects created by a user agent must not be live. The
values of the objects' attributes must not change once an object is created, except when updated
by the PluginArray object’s refresh() method.
The type attribute must return the valid MIME type with no parameters describing the MIME type.
The description and suffixes attributes must return
user-agent-defined (or, in all likelihood, plugin-defined) strings. In each case, the
same string must be returned each time, except that the strings returned may change when the PluginArray.refresh() method updates the object.
If the values returned by the description or suffixes attributes vary between versions of a plugin, they can be used both as a fingerprinting vector and, even more importantly,
as a trivial way to determine what security vulnerabilities a plugin (and thus a
browser) may have. It is thus highly recommended that the description attribute just return the same value as the type attribute, and that the suffixes attribute return the empty string.
Commas in the suffixes attribute are
interpreted as separating subsequent filename extensions, as in "htm,html".
The enabledPlugin attribute must
return the Plugin object that represents the plugin that explicitly supported the MIME type that this MimeType object represents when this object was last created or updated by PluginArray.refresh(), whichever happened most
recently.
The javaEnabled() attribute
must return true if the user agent supports a plugin that supports the MIME
type "application/x-java-vm"; otherwise it must return false.
7.8. Images
[Exposed=(Window, Worker)] interface ImageBitmap { readonly attribute unsigned long width; readonly attribute unsigned long height; }; typedef (HTMLImageElement or HTMLVideoElement or HTMLCanvasElement or Blob or ImageData or CanvasRenderingContext2D or ImageBitmap) ImageBitmapSource;
An ImageBitmap object represents a bitmap image that can be painted to a canvas
without undue latency.
The exact judgement of what is undue latency of this is left up to the implementer, but in general if making use of the bitmap requires network I/O, or even local disk I/O, then the latency is probably undue; whereas if it only requires a blocking read from a GPU or system RAM, the latency is probably acceptable.
- promise = Window .
createImageBitmap(image [, sx, sy, sw, sh ] ) -
Takes image, which can be an
imgelement,video, orcanvaselement, aBlobobject, anImageDataobject, aCanvasRenderingContext2Dobject, or anotherImageBitmapobject, and returns a promise that is resolved when a newImageBitmapis created.If no
ImageBitmapobject can be constructed, for example because the provided image data is not actually an image, then the promise is rejected instead.If sx, sy, sw, and sh arguments are provided, the source image is cropped to the given pixels, with any pixels missing in the original replaced by transparent black. These coordinates are in the source image’s pixel coordinate space, not in CSS pixels.
Rejects the promise with an
InvalidStateErrorexception if the source image is not in a valid state (e.g., animgelement that hasn’t finished loading, or aCanvasRenderingContext2Dobject whose bitmap data has zero length along one or both dimensions, or anImageDataobject whose data isdataattribute has been neutered). Rejects the promise with a "SyntaxError"DOMExceptionif the script is not allowed to access the image data of the source image (e.g., avideothat is CORS-cross-origin, or acanvasbeing drawn on by a script in a worker from another origin). - imageBitmap .
width -
Returns the intrinsic width of the image, in CSS pixels.
- imageBitmap .
height -
Returns the intrinsic height of the image, in CSS pixels.
An ImageBitmap object always has associated bitmap data, with a width and a height.
However, it is possible for this data to be corrupted. If an ImageBitmap object’s
media data can be decoded without errors, it is said to be fully decodable.
An ImageBitmap object’s bitmap has an origin-clean flag, which indicates whether the
bitmap is tainted by content from a different origin. The flag is initially set to
true and may be changed to false by the steps of createImageBitmap().
An ImageBitmap object can be obtained from a variety of different objects, using
the createImageBitmap() method. When invoked, the method must act as follows:
- If image is an
imgelement -
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
IndexSizeErrorexception and abort these steps. - If the
imgelement is not completely available, then return a promise rejected with anInvalidStateErrorexception and abort these steps. - If the
imgelement’s media data is not a bitmap (e.g., it’s a vector graphic), then return a promise rejected with anInvalidStateErrorexception and abort these steps. - Create a new
ImageBitmapobject. - Let the
ImageBitmapobject’s bitmap data be a copy of theimgelement’s media data, cropped to the source rectangle. If this is an animated image, theImageBitmapobject’s bitmap data must only be taken from the default image of the animation (the one that the format defines is to be used when animation is not supported or is disabled), or, if there is no such image, the first frame of the animation. - If the origin of the
imgelement’s image is not the same origin as the origin specified by the entry settings object, then set the origin-clean flag of theImageBitmapobject’s bitmap to false. - Return a new promise, but continue running these steps in parallel.
- Resolve the promise with the new
ImageBitmapobject as the value.
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
- If image is a
videoelement -
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
IndexSizeErrorexception and abort these steps. - If the
videoelement’snetworkStateattribute isNETWORK_EMPTY, then return a promise rejected with anInvalidStateErrorexception and abort these steps. - If the
videoelement’sreadyStateattribute is eitherHAVE_NOTHINGorHAVE_METADATA, then return a promise rejected with anInvalidStateErrorexception and abort these steps. - Create a new
ImageBitmapobject. - Let the
ImageBitmapobject’s bitmap data be a copy of the frame at the current playback position, at the media resource’s intrinsic width and intrinsic height (i.e., after any aspect-ratio correction has been applied), cropped to the source rectangle. - If the origin of the
videoelement’s image is not the same origin as the origin specified by the entry settings object, then set the origin-clean flag of theImageBitmapobject’s bitmap to false. - Return a new promise, but continue running these steps in parallel.
- Resolve the promise with the new
ImageBitmapobject as the value.
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
- If image is a
canvaselement -
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
IndexSizeErrorexception and abort these steps. - If the
canvaselement’s bitmap has either a horizontal dimension or a vertical dimension equal to zero, then return a promise rejected with anInvalidStateErrorexception and abort these steps. - Create a new
ImageBitmapobject. - Let the
ImageBitmapobject’s bitmap data be a copy of thecanvaselement’s bitmap data, cropped to the source rectangle. - Set the origin of the
ImageBitmapobject’s bitmap to the same value as the origin-clean flag of thecanvaselement’s bitmap. - Return a new promise, but continue running these steps in parallel.
- Resolve the promise with the new
ImageBitmapobject as the value.
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
- If image is a
Blobobject -
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
IndexSizeErrorexception and abort these steps. - If image is closed, then return a promise rejected with an
InvalidStateErrorexception and abort these steps. - Return a new promise, but continue running these steps in parallel.
- Read the
Blobobject’s data. If an error occurs during reading of the object, then reject the promise with null, and abort these steps. - Apply the image sniffing rules to
determine the file format of the image data, with MIME type of the
Blob(as given by theBlobobject’stypeattribute) giving the official type. - If the image data is not in a supported file format (e.g., it’s not actually an image at all), or if the image data is corrupted in some fatal way such that the image dimensions cannot be obtained, then reject the promise with null, and abort these steps.
- Create a new
ImageBitmapobject. - Let the
ImageBitmapobject’s bitmap data be the image data read from theBlobobject, cropped to the source rectangle. If this is an animated image, theImageBitmapobject’s bitmap data must only be taken from the default image of the animation (the one that the format defines is to be used when animation is not supported or is disabled), or, if there is no such image, the first frame of the animation. - Resolve the promise with the new
ImageBitmapobject as the value.
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
- If image is an
ImageDataobject -
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
IndexSizeErrorexception and abort these steps. - If the image object’s
dataattribute has been neutered, return a promise rejected with anInvalidStateErrorexception and abort these steps. - Create a new
ImageBitmapobject. - Let the
ImageBitmapobject’s bitmap data be the image data given by theImageDataobject, cropped to the source rectangle. - Return a new promise, but continue running these steps in parallel.
- Resolve the promise with the new
ImageBitmapobject as the value.
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
- If image is a
CanvasRenderingContext2Dobject -
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
IndexSizeErrorexception and abort these steps. - If the
CanvasRenderingContext2Dobject’s scratch bitmap has either a horizontal dimension or a vertical dimension equal to zero, then return a promise rejected with anInvalidStateErrorexception and abort these steps. - Create a new
ImageBitmapobject. - Let the
ImageBitmapobject’s bitmap data be a copy of theCanvasRenderingContext2Dobject’s scratch bitmap, cropped to the source rectangle. - Set the origin-clean flag of the
ImageBitmapobject’s bitmap to the same value as the origin-clean flag of theCanvasRenderingContext2Dobject’s scratch bitmap - Return a new promise, but continue running these steps in parallel.
- Resolve the promise with the new
ImageBitmapobject as the value.
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
- If image is an
ImageBitmapobject -
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
IndexSizeErrorexception and abort these steps. - Create a new
ImageBitmapobject. - Let the
ImageBitmapobject’s bitmap data be a copy of the image argument’s bitmap data, cropped to the source rectangle. - Set the origin-clean flag of the
ImageBitmapobject’s bitmap to the same value as the origin-clean flag of the bitmap of the image argument. - Return a new promise, but continue running these steps in parallel.
- Resolve the promise with the new
ImageBitmapobject as the value.
- If either the sw or sh arguments are specified
but zero, return a promise rejected with an
- Let input be the image data being cropped.
- If the sx, sy, sw, and sh arguments are omitted, return input.
- Place input on an infinite transparent black grid plane, positioned so that it’s top left corner is at the origin of the plane, with the x-coordinate increasing to the right, and the y-coordinate increasing down, and with each pixel in the input image data occupying a cell on the plane’s grid.
-
Let output be the rectangle on the plane denoted by the rectangle whose
corners are the four points (sx, sy), (sx+sw, sy), (sx+sw, sy+sh), (sx, sy+sh).
If either sw or sh are negative, then the top-left corner of this rectangle will be to the left or above the (sx, sy) point. If any of the pixels on this rectangle are outside the area where the input bitmap was placed, then they will be transparent black in output.
- Return output.
The width attribute must return the ImageBitmap object’s
width, in CSS pixels.
The height attribute must return the ImageBitmap object’s
height, in CSS pixels.
var sprites = {}; function loadMySprites() { var image = new Image(); image.src = 'mysprites.png'; var resolver; var promise = new Promise(function (arg) { resolver = arg }); image.onload = function () { resolver(Promise.all( createImageBitmap(image, 0, 0, 40, 40).then(function (image) { sprites.woman = image }), createImageBitmap(image, 40, 0, 40, 40).then(function (image) { sprites.man = image }), createImageBitmap(image, 80, 0, 40, 40).then(function (image) { sprites.tree = image }), createImageBitmap(image, 0, 40, 40, 40).then(function (image) { sprites.hut = image }), createImageBitmap(image, 40, 40, 40, 40).then(function (image) { sprites.apple = image }), createImageBitmap(image, 80, 40, 40, 40).then(function (image) { sprites.snake = image }), )); }; return promise; } function runDemo() { var canvas = document.querySelector('canvas#demo'); var context = canvas.getContext('2d'); context.drawImage(sprites.tree, 30, 10); context.drawImage(sprites.snake, 70, 10); } loadMySprites().then(runDemo);
7.9. Animation Frames
Each Document associated with a top-level browsing context has a list of animation frame callbacks, which must be initially empty,
and an animation frame callback identifier, which is a number which must
initially be zero.
When the requestAnimationFrame() method is called, the user agent must run the following steps:
-
Increment document’s animation frame callback identifier by one.
-
Append the method’s argument to document’s list of animation frame callbacks, associated with document’s animation frame callback identifier’s current value
-
Return document’s animation frame callback identifier’s current value
When the cancelAnimationFrame() method is called, the user agent must run the following steps:
-
Find the entry in document’s list of animation frame callbacks that is associated with the value given by the method’s argument handle
-
If there is such an entry, remove it from document’s list of animation frame callbacks
When the user agent is to run the animation frame callbacks for a Document document with a timestamp now, it must
run the following steps:
-
If the value returned by the document object’s
hiddenattribute is true, abort these steps. [PAGE-VISIBILITY] -
Let callbacks be a list of the entries in document’s list of animation frame callbacks, in the order in which they were added to the list.
-
Set document’s list of animation frame callbacks to the empty list.
-
For each entry in callbacks, in order: invoke the Web IDL callback function, passing now as the only argument, and if an exception is thrown, report the exception. [WEBIDL]