Annotations are typically used to convey information about a resource or associations between resources. Simple examples include a comment or tag on a single web page or image, or a blog post about a news article.
The Web Annotation Data Model specfication describes a structured model and format to enable annotations to be shared and reused across different hardware and software platforms. Common use cases can be modeled in a manner that is simple and convenient, while at the same time enabling more complex requirements, including linking arbitrary content to a particular data point or to segments of timed multimedia resources.
The specification provides both a conceptual model that accommodates these use cases, and the vocabulary of terms that represents it. A specific JSON format is recommended for ease of creation and consumption of the annotations.
Status of This Document
This section describes the status of this document at the time of its publication.
Other documents may supersede this document. A list of current W3C publications and the
latest revision of this technical report can be found in the W3C technical reports index at
http://www.w3.org/TR/.
This is a work in progress. No section should be considered final, and the absence of any content does not imply that such content is out of scope, or may not appear in the future. If you feel something should be covered, please tell us!
This specification was derived from the Open Annotation Community Group's outcomes, and details of the differences between the two are maintained in the Acknowledgement appendix.
This document was published by the Web Annotation Working Group as a First Public Working Draft.
This document is intended to become a W3C Recommendation.
If you wish to make comments regarding this document, please send them to
public-annotation@w3.org
(subscribe,
archives).
All comments are welcome.
Publication as a First Public Working Draft does not imply endorsement by the W3C
Membership. This is a draft document and may be updated, replaced or obsoleted by other
documents at any time. It is inappropriate to cite this document as other than work in
progress.
Annotating, the act of creating associations between distinct pieces
of information, is a pervasive activity online in many guises but currently lacks a structured approach.
Web citizens make comments about online resources using either tools built
in to the hosting web site, external web services, or the functionality
of an annotation client. Comments about photos on Flickr, videos on
YouTube, people's posts on Facebook, or mentions of resources on Twitter
could all be considered as annotations associated with the
resource being discussed. In addition, there are a plethora of closed and proprietary web-based
"sticky note" systems and stand-alone multimedia
annotation systems. The primary complaint about these types of systems is that
the user-created annotations cannot be shared or reused due to a deliberate "lock-in"
strategy within the environments where they were created. The minimum requirement for any solution
is a common approach to expressing these annotations.
The Web Annotation Data Model provides an extensible, interoperable framework for
expressing annotations such that they can easily be shared between
platforms, with sufficient richness of expression to satisfy complex
requirements while remaining simple enough to also allow for the most common use cases,
such as attaching a piece of text to a single web resource.
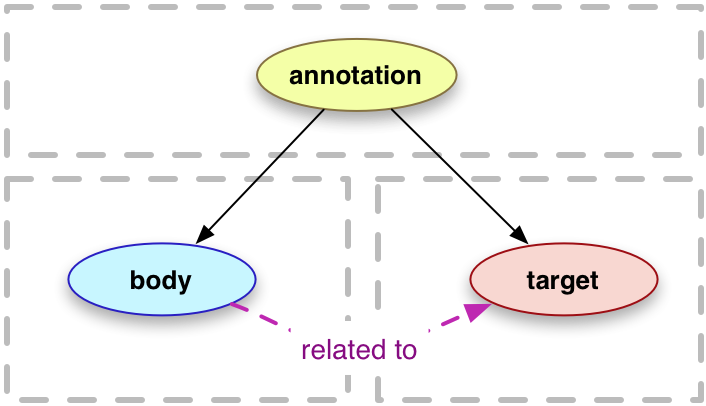
An annotation is considered to be a set of connected resources,
typically including a body and target, and conveys that the body is related to the target.
The exact nature of this relationship changes according to the intention of the annotation, but most frequently conveys
that the body is somehow "about" the target. Other possible relationships include that the body is an identifier for the target, provides a representation of the target, or classifies the target in some way.
This perspective results in a basic model with three parts, depicted below.
The full model supports additional functionality, enabling content to be embedded within the annotation,
selecting arbitrary segments of resources, choosing the appropriate representation of a
resource and providing styling hints for consuming clients. Annotations created by or intended
for machines are also considered to be in scope, ensuring that the Data Web is not ignored in
favor of only considering the human-oriented Document Web.
The Web Annotation Data Model does not
prescribe a transport protocol for creating, managing and retrieving annotations.
Instead it describes a web-centric method, promoting discovery and sharing of
annotations without clients or servers having to agree on a particular
set of network transactions to communicate those annotations.
A further specification will be written that standardizes the transport protocol, which may be adopted separately.
The specification is divided into the essential core plus distinct modules that add functionality.
The modules cover cases where the exact nature of the body or target cannot be sufficiently captured in a URI and
explicit semantics when annotating multiple resources.
1.1 Aims of the Model
The primary aim of the Web Annotation Data Model is to provide a
standard description model and format to enable annotations to be shared between
systems. This interoperability may be either for sharing with others,
or the migration of private annotations between devices. The shared
annotations must be able to be integrated into existing collections
and reused without loss of significant information. The model should
cover as many annotation use cases as possible, while keeping the simple
annotations easy and expanding from that baseline to make complex uses possible.
The Web Annotation Data Model is a single, consistent model that can be used by all interested parties.
All efforts have been made to keep the implementation costs for both producers
and consumers to a minimum. A single method of fulfilling a use case
is strongly preferred over multiple methods, unless there are existing
standards that need to be accommodated or there is a significant cost
associated with a method that is otherwise necessary.
1.2 Diagrams and Examples
The examples throughout the document are serialized primarily as [JSON-LD] using the Context given in Appendix B, and also as [Turtle] with the prefixes taken from the namespace declarations given in Appendix A. They do not represent specific use cases with real resources.
Note Well: The examples serialized in JSON-LD use keys in the style of body and target in place of the equivalent oa:hasBody and oa:hasTarget. This choice keeps the JSON representation simple and it is made possible by the application of the JSON-LD context, detailed in Appendix B.
The diagrams use the following style
Instances are depicted as colored ellipses.
Instances without a URI are depicted as colored ellipses with double lines.
Classes are depicted as white rectangles.
Literals are depicted as white lozenges.
Relationships and properties are depicted as straight, black lines.
Class instantiation is depicted as a straight black line with white arrow head.
Example instance identifiers are lowercase and end in a number. For example, anno1 is a specific instance of an Annotation, whereas oa:Annotation is a class.
Example literals follow the requirements for the model and, thus, must not be interpreted as the only possible value.
Lists are depicted as vertical braces with a gray background and '...' in the middle (regardless of if there are actually other items in the list or not).
Conceptual resource boundaries not explicit in the model, but considered important for understanding, are depicted as grey dashed boxes around the components. They are used to convey spatial parts of the diagrams and may be safely ignored.
1.3 Terminology
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in [rfc2119].
2. Web Annotation Principles
The Web Annotation Data Model is defined using the following basic principles:
An Annotation is a resource that represents the link between resources, or a selection within a resource.
There are two types of participating resources, Bodies and Targets.
Annotations have 0..n Bodies.
Annotations have 1..n Targets.
The content of the Body resources is related to, and typically "about", the content of the Target resources.
Annotations, Bodies and Targets may have their own properties and relationships, typically including provenance information and descriptive metadata.
The intent behind the creation of an Annotation is an important property, and is identified by a Motivation resource.
The following principles describe additional distinctions needed regarding the exact nature of Target and Body:
The Target or Body resource may be more specific than the entity identified by the resource's URI alone.
In particular,
The Target or Body resource may be a specific segment of a resource.
The Target or Body resource may be a resource with a specific style.
The Target or Body resource may be a resource in a specific context or container.
The Target or Body resource may be any combination of the above.
The identity of the specific resource is separate from the description of how to obtain the specific resource.
The specific resource is derived from a resource identified by a URI.
The following principles describe additional semantics regarding multiple resources:
A resource may be a choice between multiple resources.
A resource may be a unique, unordered set of resources.
A resource may be an ordered list of resources.
These resources may be used anywhere a resource may be used.
3. Core Annotation Framework
3.1 Annotation
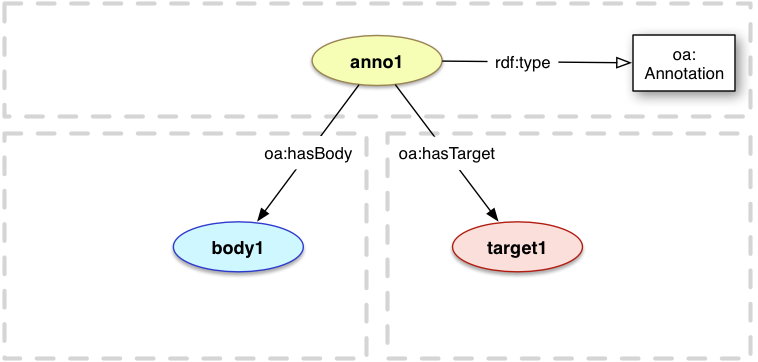
An Annotation is a web resource and SHOULD have an HTTP URI. All Annotations MUST be instances of the class oa:Annotation; additional subclassing is only recommended to address additional, community-specific requirements.
Typically an Annotation has a single Body, which is a comment or other descriptive resource, and a single Target that the Body is somehow "about". This "aboutness" may be further clarified or extended to notions such as classifying or identifying, discussed in more detail in the section on Motivations. Annotations may also have provenance information, such as who created them, as discussed in the section on Provenance.
This specification defines two relationships, oa:hasBody and oa:hasTarget,
to associate the Body and Target resources, respectively, with the Annotation. The Body and Target resources SHOULD have HTTP URIs, unless they are embedded within the Annotation.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:Annotation
Class
The class for Annotations
The oa:Annotation class MUST be associated with an Annotation.
oa:hasBody
Relationship
body
The relationship between an Annotation and the Body of the Annotation
There SHOULD be 1 or more oa:hasBody relationships associated with an Annotation but there MAY be 0.
oa:hasTarget
Relationship
target
The relationship between an Annotation and the Target of the Annotation
There MUST be 1 or more oa:hasTarget relationships associated with an Annotation.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <target1> .
3.2 Body and Target
3.2.1 Simple Textual Body
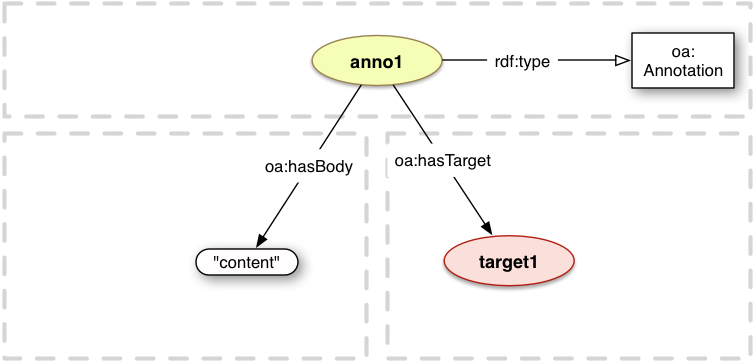
The simplest type of Body is a plain text note, without additional information or properties. This sort of Body MAY be represented by a string as the value of oa:hasBody, rather than as a resource with properties. However, there are several restrictions on when and how this may be used:
The string body MUST be an xsd:string and MUST NOT have a language associated with it.
The body MUST be interpreted as if it were the content of a resource with the media type text/plain to avoid the situation where clients would have to introspect on the content to determine the media type.
The body MUST NOT have any other properties, such as a recorded creator or creation time. When this form is used, these properties MUST NOT be inferred from similar properties on the Annotation resource.
The serialization in JSON MUST be a plain string literal.
When these requirements are not met, the annotation MUST use the Embedded Textual Body form instead.
Note Well: When the body is a string in the JSON-LD serialization, it is always a string literal. In order for body value to be a URI, it MUST be in the {"@id": "URI"} form, otherwise it will be considered a string literal. However, as targetMUST NOT be a string literal, it MAY be given as either a string or in the JSON object form. This is a side effect of allowing string literal bodies.
Vocabulary
No additional vocabulary items are introduced in this section.
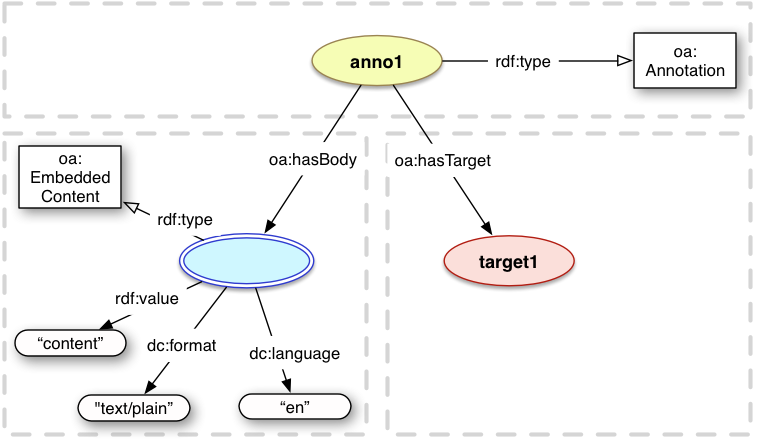
<anno1> a oa:Annotation ;
oa:hasBody "content" ;
oa:hasTarget <target1> .
3.2.2 Body and Target Classes
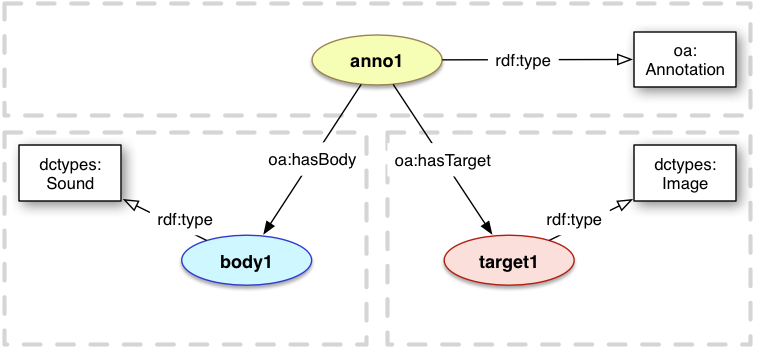
The Target MUST always be a resource with a URI. The Body SHOULD be a resource, with the only exception described in the previous section. Both Body, when it is a resource, and Target SHOULD have a class which describes the general content type (Text, Image, Audio, Video etc). This allows a consuming client to easily determine if and how it can render the resource without maintaining a long list of media types. For example, an [HTML5] based client could use the information that the Target resource is an image to generate a <img> element with the appropriate src attribute, rather than having to maintain a list of all of the possible image media types. The creator of the Annotation may also not know the media type of the representation of the Body or Target, but would typically be able to provide a general class. The Body or Target MAY also have other classes.
The Dublin Core Types [DC-TERMS] vocabulary is RECOMMENDED for expressing this information. The most common classes are listed in the table below, but other classes MAY also be used. Please note that the vocabulary's advice to encode images of text as dctypes:Text is NOT RECOMMENDED within the context of Web Annotation, as it does not help consuming clients to interpret or render the resource.
Vocabulary
Item
Type
JSON-LD Key
Description
dctypes:Dataset
Class
The class for a resource which encodes data in a defined structure
dctypes:Image
Class
The class for image resources, primarily intended to be seen
dctypes:MovingImage
Class
The class for video resources, with or without audio
dctypes:Sound
Class
The class for a resource primarily intended to be heard
dctypes:Text
Class
The class for a resource primarily intended to be read
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <target1> .
<body1> a dctypes:Sound .
<target1> a dctypes:Image .
3.2.3 Body and Target Metadata
The Body and Target resources MAY have additional metadata associated with them, and properties describing the media type and language of the representation are RECOMMENDED.
The representations of the Body and Target resources MAY be of any media type [rfc2045]. If known, the media type of the resource SHOULD be given using the
dc:format property, for example to distinguish between comments in plain text versus those encoded in HTML.
If known, the language of the resource SHOULD be given using the dc:language property.
Vocabulary
Item
Type
JSON-LD Key
Description
dc:format
Property
format
The media type of the content.
There SHOULD be exactly 1 dc:format property associated with the resource.
dc:language
Property
language
The language of the content, if known.
There MAY be 0 or more dc:language properties. Each language SHOULD be expressed according to [rfc5646]
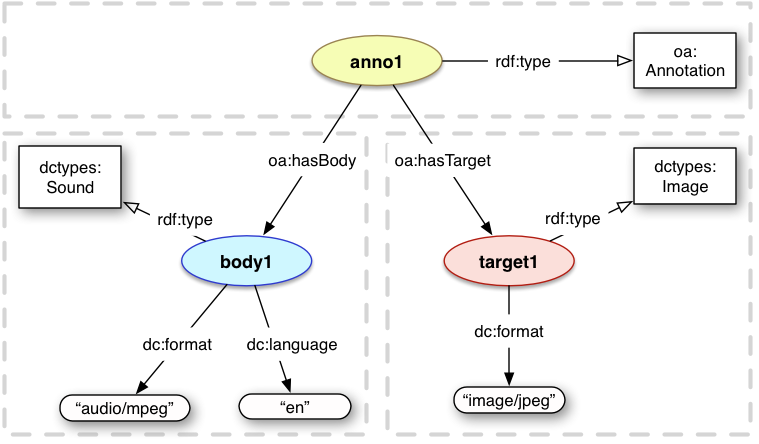
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <target1> .
<body1> a dctypes:Sound ;
dc:format "audio/mpeg" ;
dc:language "en" .
<target1> a dctypes:Image ;
dc:format "image/jpeg" .
3.2.4 Embedded Textual Body
If the requirements for a simple textual Body are not met, and the representation of the Body is to be embedded within the Annotation's serialization, then the Body MUST be a resource and MUST have the class oa:EmbeddedContent. The content of the Body is recorded as the value of the rdf:value property, and additional properties such as dc:format and dc:languageSHOULD be given if known.
Vocabulary
oa:EmbeddedContent
Class
A class assigned to the Body for embedding textual resources within the Annotation.
This class MUST be assigned to the Body.
rdf:value
Property
value
The character sequence of the content.
There MUST be exactly 1 rdf:value property associated with the ContentAsText resource.
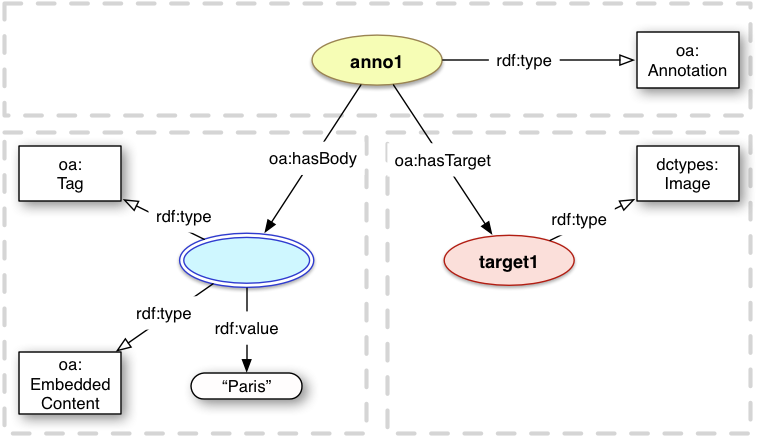
Tagging a resource with a short text string is a common use case for Annotation. Tags are typically keywords or labels, and used for organization, description or discovery of the resource being tagged.
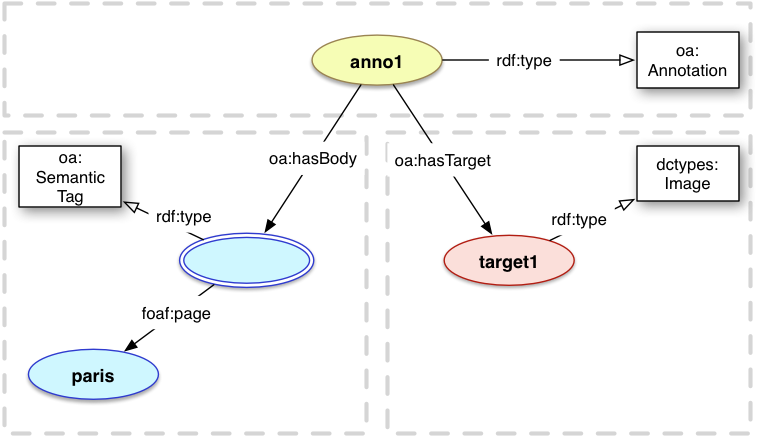
In the Web Annotation model, the tag is represented as the Body of the Annotation, and the resource being tagged is the Target. For example, one might wish to associate the textual tag "paris" with an image of the capital of France to describe what is being depicted. Similarly, "capital", "city", "photo", "stunning" might all be used as tags for the same image.
The embedded textual body pattern is used for tags. The Body resource MUST also have the oa:Tag class assigned to it, as applications render comments and tags in very different ways.
Annotations that tag resources SHOULD also have the oa:tagging motivation to make the intent of the Annotation more clear to applications, and MAY have other motivations as well.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:Tag
Class
A class assigned to the Body when it is a tag, such as a embedded text string
<anno1> a oa:Annotation ;
oa:hasTarget <target1> ;
oa:hasBody [
a oa:Tag, oa:EmbeddedContent ;
rdf:value "paris"
] .
<target1> a dctypes:Image .
3.2.6 Semantic Tags
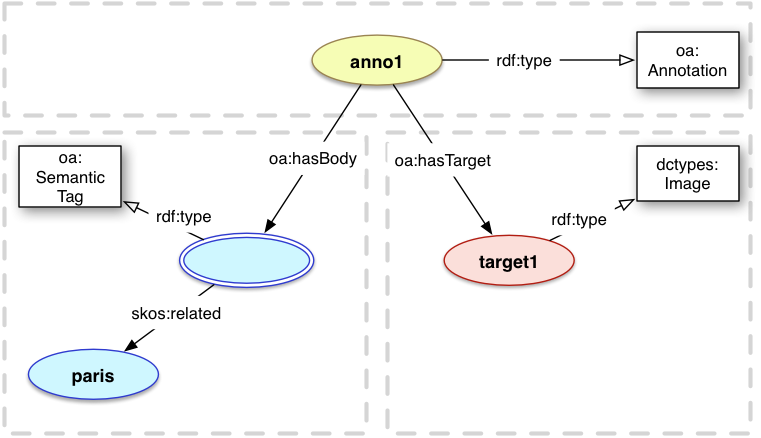
In the Linked Data paradigm, URIs are used instead of strings to avoid the issue of polysemy where one word has multiple meanings. In this situation, one would use two different URIs to refer to the cities of Paris, France and Paris, Texas. This type of body is termed a Semantic Tag.
For semantic tags, the Body is a resource with the class oa:SemanticTag and has a reference to the URI representing the concept of the tag. The Paris example might instead use the URI http://dbpedia.org/resource/Paris in place of the string, and is typically a term from a controlled vocabulary intended to be widely reused.
If the URI does not have a representation, and the URI thus truly identifies the concept itself rather than a document about the concept, then the skos:related property is used to refer from the Semantic Tag to the Concept. If the URI does have a representation, such as http://en.wikipedia.org/wiki/Paris, and the representation describes or somehow embodies the concept, then the foaf:page property is used to refer from the Semantic Tag to the Document.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:SemanticTag
Class
[subClass of oa:Tag] A class assigned to the Body when it is a semantic tagging resource; a URI that identifies a concept, rather than an embedded string, frequently a term from a controlled vocabulary
foaf:page
Relationship
page
The foaf:page relationship expresses the link between a Semantic Tag and the document that describes the tagging concept.
skos:related
Relationship
related
The skos:related relationship expresses the link between a Semantic Tag and its concept.
Example 16: Semantic Tag, referring to a Document (Turtle)
<anno1> a oa:Annotation ;
oa:hasTarget <target1> ;
oa:hasBody [
a oa:SemanticTag ;
foaf:page <http://en.wikipedia.org/wiki/Paris>
] .
<target1> a dctypes:Image .
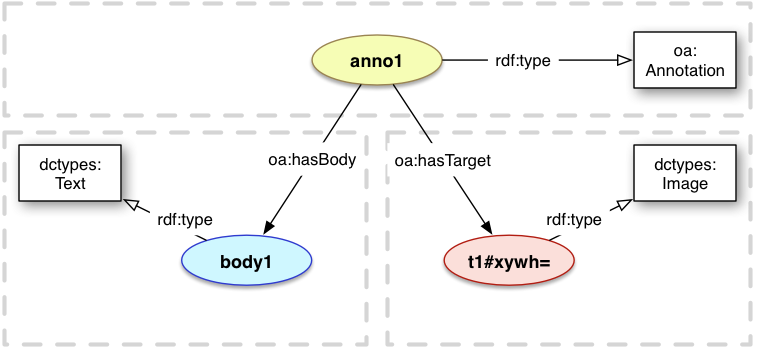
3.2.7 Fragment URIs
Many Annotations involve part of a resource, rather than its entirety.
In the Architecture of the World Wide Web [webarch], segments of resources are identified using URIs with a Fragment component that at the same time both describes how to extract the segment of interest from the resource, and identifies the extracted content. For simple annotations, it is valuable to be able to use these fragment URIs as the identifier of either Body or Target.
It is important to be aware of the consequences of using a Fragment URI for the purpose of identifying parts of a resource, and the restrictions that using them places on implementations.
Most fragments are defined with respect to individual media types, and not every media type has a fragment specification.
Even if a media type does have a fragment definition, it is often not possible to describe the segment of interest sufficiently precisely. For example, fragments for HTML cannot be used to describe an arbitrary range of text.
It is not possible to determine with certainty what is being identified without knowing the media type, as the same fragment string might be possible in different specifications. For example, the same fragment string could identify either a rectangular area in an image, or a strangely named section of an HTML document.
Fragment URIs are not compatible with other methods of describing the segment more specifically, described in the Specific Resources section of this specification. It is recognized that this additional level of description is not required in all scenarios.
As URIs are considered to be opaque strings, annotation systems may not discover annotations with fragment URIs
when searching by means of the URI without the fragment. For example, an Annotation with the Target
http://example.com/image.jpg#xywh=1,1,1,1 would not be discovered in a simple search for
http://example.com/image.jpg, even though it is part of it.
For more information regarding fragments, please see
Best Practices for Fragment Identifiers and Media Type Definitions [fragid-best-practices].
For situations where these issues are not a concern, or would provide a significant burden to implementation,
Fragment URIs MAY be used as either the Body or Target of an Annotation. It is otherwise RECOMMENDED to use the
Selector mechanism described in the Specific Resources module, which includes
a transition mechanism (oa:FragmentSelector) to ensure compatibility with existing and future fragment specifications.
Vocabulary
No additional vocabulary items are introduced in this section.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <t1#xywh=100,100,300,300> .
<body1> a dctypes:Text .
<t1#xywh=100,100,300,300> a dctypes:Image .
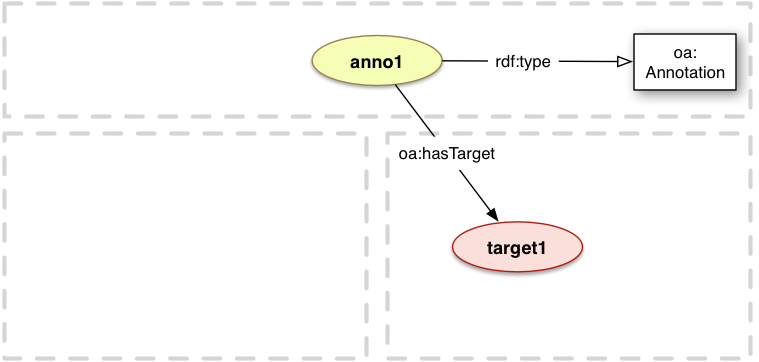
3.2.8 Annotations without a Body
A special case exists when the Annotation does not have a Body at all.
Examples of this sort of situation include bookmarking a particular resource, marking a point within a
resource, and highlighting a section of a resource without making a
comment about why it is being highlighted. A Body may be added to these
Annotations later, perhaps explaining the importance of the resource
and thus why it was bookmarked.
Vocabulary
No additional vocabulary items are introduced in this section.
<anno1> a oa:Annotation ;
oa:hasTarget <target1> .
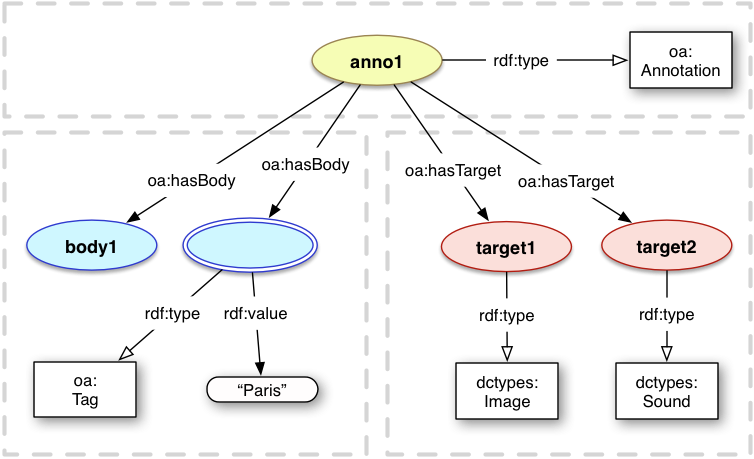
3.2.9 Multiple Bodies or Targets
It is also possible for an Annotation to have multiple Bodies and/or Targets.
Each Body is considered to be equally related to each Target individually, rather than the complete set of Targets.
This construction may be used so long as dropping any of the Bodies or Targets would not invalidate the Annotation's meaning. Thus in the figure below all of the following are individually true:
body1 is about target1
body1 is about target2
body2 is about target1
body2 is about target2
Example use cases include having multiple tags about a single image, or a single comment that applies to several web pages.
For situations when the Annotation needs different semantics for multiple Bodies or Targets,
such as when a comment is comparing or contrasting the Targets, and hence not about each equally and individually, it is necessary to use further constructions described in the Multiplicity section. It also allows the Bodies or Targets to be ordered, or for a choice to be made by the client on which one of the resources is most appropriate for the user. Alternatively, multiple Annotations may be created.
Vocabulary
No additional vocabulary items are introduced in this section.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasBody [ a oa:Tag ; rdf:value "paris" ] ;
oa:hasTarget <target1> ;
oa:hasTarget <target2> .
<target1> a dctypes:Image .
<target2> a dctypes:Sound .
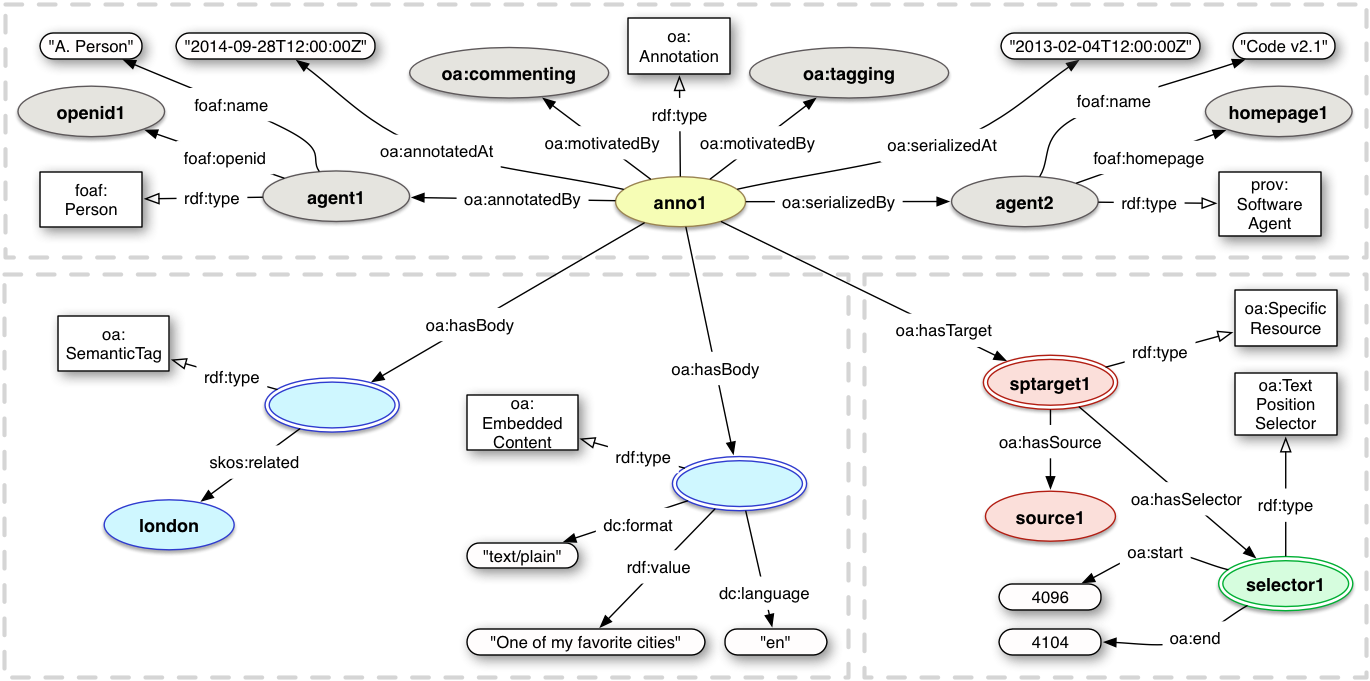
3.3 Provenance
It is important for consuming clients and services to
understand the context in which the Annotation was created. In
particular, the person, organization or machine responsible for the Annotation
deserves credit for their contribution, and the
time at which the Annotation was created is useful for
filtering out old, potentially irrelevant annotations. The creator of the Annotation is
also useful for determining the trustworthiness of the Annotation, potentially based on reputation models.
The software used to create and serialize the Annotation, along with when that activity occurred, is useful for
both advertising the software and debugging problems.
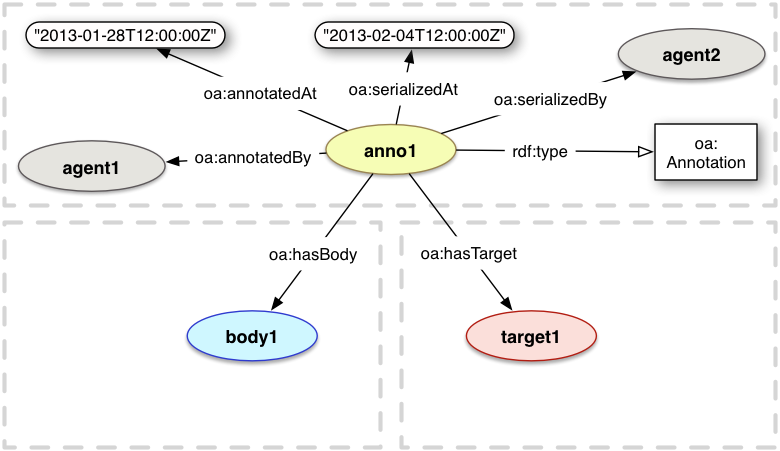
Provenance information can be attached to the Annotation, Body, Target or any other resource in the Annotation graph. Thus, the provenance information attached to an Annotation is not necessarily true for the Body or the Target resources. For instance, a PhD student in 2013 could be formalizing Charles Darwin's notebooks from 1836 as Annotations with textual comments, and so the student would be the author of the Annotation, while Darwin would be the author of the Body. Additional provenance information, such as Darwin as the creator of the Body, SHOULD be provided where possible, but it is considered out of scope for this specification to formalize further requirements. Existing vocabularies, such as Dublin Core Terms [DC-TERMS], SHOULD be used.
A complete mapping for the Annotation's provenance in the PROV [prov-o] model is provided
in Appendix D. Please note that the Annotation node primarily represents the concept of the Annotation, but for simplicity the model allows serialization level properties to be attached to it. If a model with distinct identifiers is required, then the expanded model described in Appendix D is RECOMMENDED.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:annotatedBy
Relationship
annotatedBy
[subProperty of
prov:wasAttributedTo] The object of the relationship is a resource that
identifies the agent responsible for creating the Annotation. This may be either a human or software agent.
There SHOULD be exactly 1 oa:annotatedBy relationship per Annotation,
but MAY be 0 or more than 1, as the Annotation's creator may wish to remain anonymous, or multiple
agents may have worked together on it.
oa:annotatedAt
Property
annotatedAt
The time at which the Annotation was created.
There SHOULD be exactly 1 oa:annotatedAt property per Annotation, and MUST NOT be more than 1.
The datetime MUST be expressed in the xsd:dateTime format, and SHOULD have a timezone specified.
oa:serializedBy
Relationship
serializedBy
[subProperty of
prov:wasAttributedTo] The object of the relationship is the agent responsible for generating the Annotation's serialization.
There MAY be 0 or more oa:serializedBy relationships per Annotation.
oa:serializedAt
Property
serializedAt
The time at which the agent referenced by oa:serializedBy generated the first serialization of the Annotation, and any subsequent substantially different one.
There MAY be exactly 1 oa:serializedAt property per Annotation, and MUST NOT be more than 1.
The datetime MUST be expressed in the xsd:dateTime format, and SHOULD have a timezone specified.
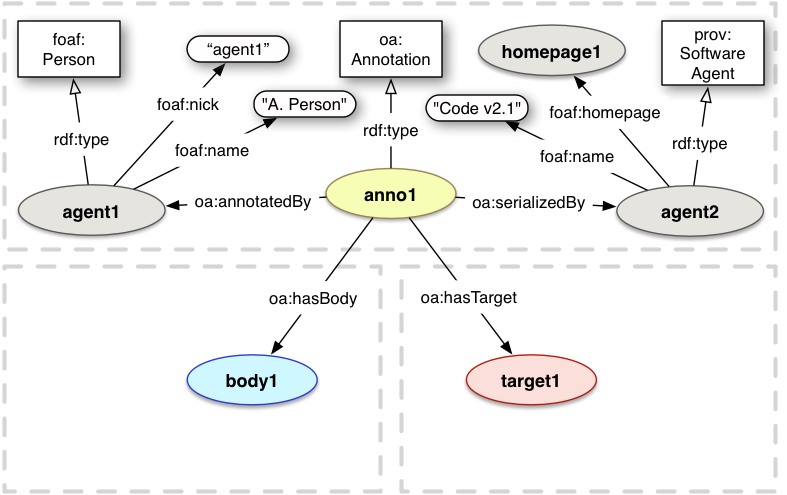
This section recommends best practices for recording information about the
agents involved in the Annotation, in particular the annotator and serializer.
The terms listed below are RECOMMENDED for use in describing
agents. Other terms from the FOAF [FOAF] vocabulary are also RECOMMENDED,
but not presented explicitly. Other more specific vocabularies MAY
also be used as required. The prov:SoftwareAgent class is used as FOAF does not define a class for software based agents.
Vocabulary
Item
Type
JSON-LD Key
Description
foaf:Person
Class
The class for a human agent, typically used as the class of the object of the oa:annotatedBy relationship
prov:SoftwareAgent
Class
The class for a software agent, typically used as the class of the object of the oa:serializedBy relationship. It might also be used for the object of the oa:annotatedBy for machine generated annotations.
foaf:Organization
Class
The class for an organization, as opposed to an individual. This might be used as the class of the object of the oa:annotatedBy relationship, for example.
foaf:name
Property
name
The name of the agent.
Each agent SHOULD have exactly 1 foaf:name property.
foaf:nick
Property
nick
The account name of the agent.
Each agent SHOULD have exactly 1 foaf:nick property.
foaf:mbox
Relationship
mbox
The email address associated with the agent, using the mailto: URI scheme.
Each agent MAY have 1 or more mailboxes
foaf:homepage
Relationship
homepage
The home page for the agent. Each agent MAY have 1 or more home pages.
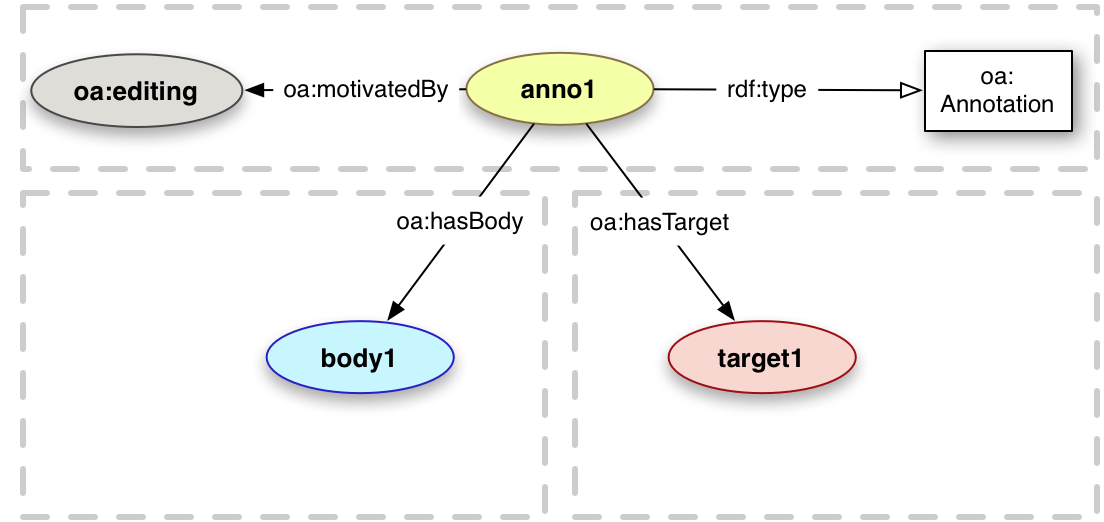
In many cases it is important to understand the reasons why the Annotation was created, not just the agents involved. While other annotation data models have subclassed a core Annotation class to convey these motivations, it was considered that a richer and better description could be obtained by using a SKOS Concept hierarchy [skos-reference].
Motivations are SKOS Concepts, and can be inter-related between communities with more meaningful distinctions than a simple class/subclass tree.
This frees up the use of subclassing for situations when it is desirable to be more explicit and prescriptive about the form an Annotation takes.
Each Annotation SHOULD have at least one oa:motivatedBy relationship to an instance of oa:Motivation, which is a subClass of skos:Concept.
A list of high level Motivations is presented below. For more information about how these can be inter-related and new Motivations created, please see this appendix.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:Motivation
Class
[subClass of skos:Concept] The Motivation for an Annotation is a reason for its creation, and might include things like Replying to another annotation, Commenting on a resource, or Linking to a related resource.
oa:motivatedBy
Relationship
motivation
The relationship between an Annotation and a Motivation.
There SHOULD be at least 1 Motivation for each Annotation, and MAY be more than 1.
Instances of oa:Motivation
oa:bookmarking
Instance
The motivation that represents the creation of a bookmark to the Target resources or recorded
point or points within one or more resources. For example, an Annotation that bookmarks the point in a text where the reader finished reading.
Bookmark Annotations may or may not have a Body resource.
oa:classifying
Instance
The motivation that represents the assignment of a classification type, typically from
a controlled vocabulary, to the Target resource(s). For example to classify an Image resource as a Portrait.
oa:commenting
Instance
The motivation that represents a commentary about or review of the Target resource(s).
For example to provide a commentary about a particular PDF.
oa:describing
Instance
The motivation that represents a description of the Target resource(s), as opposed to a
comment about them. For example describing the above PDF's contents, rather than commenting on their accuracy.
oa:editing
Instance
The motivation that represents a request for a modification or edit to the Target resource. For example,
an Annotation that requests a typo to be corrected.
oa:highlighting
Instance
The motivation that represents a highlighted section of the Target resource or segment.
For example to draw attention to the selected text that the annotator disagrees with.
A Highlight may or may not have a Body resource
oa:identifying
Instance
The motivation that represents the assignment of an identity to the Target resource(s). For example, annotating the name of a city in a string of text with the URI that identifies it.
oa:linking
Instance
The motivation that represents an untyped link to a resource related to the Target.
oa:moderating
Instance
The motivation that represents an assignment of value or quality to the Target resource(s).
For example annotating an Annotation to moderate it up in a trust network or threaded discussion.
oa:questioning
Instance
The motivation that represents asking a question about the Target resource(s).
For example to ask for assistance with a particular section of text, or question its veracity.
oa:replying
Instance
The motivation that represents a reply to a previous statement, either an Annotation or another resource.
For example providing the assistance requested in the above.
oa:tagging
Instance
The motivation that represents adding a Tag on the Target resource(s). Please see the sections on Tags and Semantic Tags for more information.
While it is possible using only the constructions in the core data model to create Annotations that reference parts of resources by using fragment URIs, there are many situations when this is not sufficient. For example, even a simple circular region of an image, or a diagonal line across it, are not possible. Selecting an arbitrary span of text in an HTML page, perhaps the simplest annotation concept, is also not supported by fragment URIs. This module of the specification introduces methods to identify and describe a segment of interest, how to obtain the correct representation of a resource, how to associate style information with an Annotation, and provide scoping information
for the Body and Target resources specific to the Annotation.
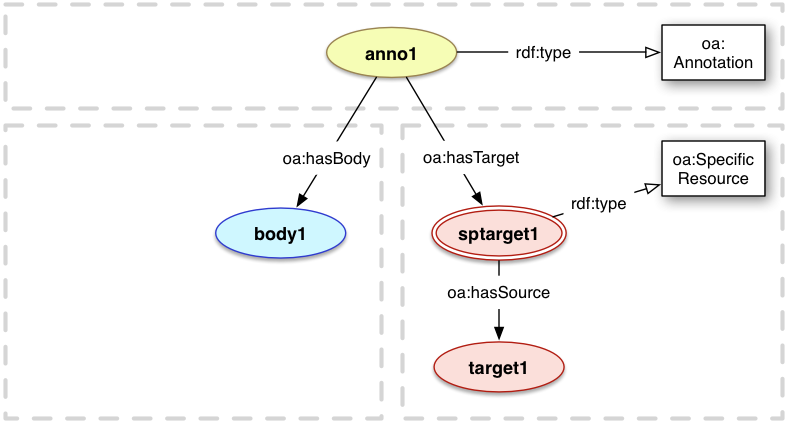
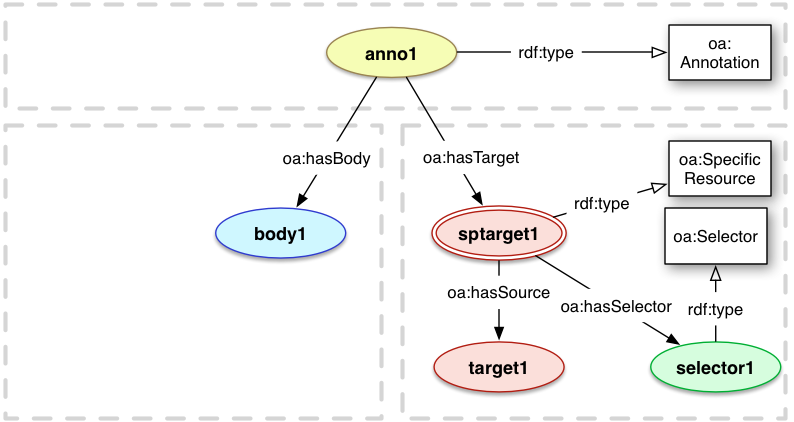
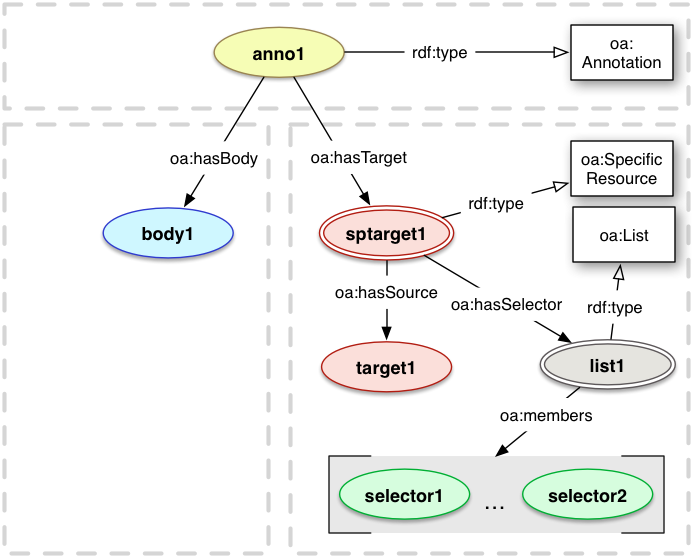
4.1 Specifiers and Specific Resources
Specifiers in the Web Annotation model are used to describe the contextual details of the resources that the Annotation refers to.
This could be by describing a particular segment of a resource, the applicable timestamp of a resource which frequently changes, or by providing style information for rendering.
In order to ensure that the segments have an identity that can be globally referenced, the model
introduces a Specific Resource class that is used to identify the resource, typically a segment, described by the Specifiers.
Specifiers are associated directly with each Specific Resource, which takes the role of either Body or Target in the Annotation.
In this context, the full resource is called the Source resource, and thus the Specifier describes how to determine the aspects
of the Source that constitute the Specific Resource. For example, a circular area of an image is identified by the Specific Resource,
described by a Specifier, and the complete image resource is the Source. The properties and relationships that can be expressed about Body and Target resources, such as type, format and provenance, should remain attached to the Source resource.
The Web Annotation Model defines two primary Specifier classes with different roles: oa:State and
oa:Selector. A State describes how to determine the correct representation of the Source resource,
and a Selector describes how to discover the correct segment of that representation. The Specific Resource may also have rendering information, associated with it via a Style, and information regarding other resources that provide a more definite scope for the resource, such as its appearance within another resource.
It is expected that if a State is present, it will be processed first to ensure the correct representation is retrieved. Then, if there is a Selector, it would be applied to determine the correct segment of the representation. Finally, if there is a Style, it would be applied to ensure the correct rendering or the resource or segment. As Scopes do not affect the rendering directly, they may be processed in any way deemed appropriate for the user interface or application.
States, Selectors and Styles are intended to be reusable by multiple Annotations, and are thus not linked directly to the Source resource.
For example, an instance of a Selector MAY be re-used to select the same segment of multiple resources, or an instance of a State MAY be re-used to ensure a consistent time or set of HTTP request headers. The Specific Resource MAY also be re-used if the information associated with it
is applicable in the new context, including any States, Selectors, Styles and Scopes.
The Specifier's description MAY be conveyed as an external or embedded resource, or as properties of the object. The description SHOULD use existing standards whenever possible. If the Specifier has an HTTP URI, then its
description, and only its description, MUST be returned when the URI is dereferenced.
If the Specific Resource has an HTTP URI, then the exact segment of the Source resource that it identifies, and only the segment,
MUST be returned when the URI is dereferenced. For example, if the segment of interest is a region of an image and the Specific
Resource has an HTTP URI, then dereferencing it MUST return the selected region of the image as it was at the time when the annotation was created. Typically this would be a burden to support, and thus the Specific Resource SHOULD be identified by a globally unique URI, such as a UUID URN. If it is not considered important to allow other Annotations or systems to refer to the Specific Resource, then a blank node MAY be used instead.
Note Well: The same Specifier classes are used for both Specific Target and Specific Body.
The diagrams and examples in this section only depict one of these, however the same model applies for both.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:SpecificResource
Class
The class for Specific Resources
The oa:SpecificResource class SHOULD be associated with a Specific Resource to be clear as to its role as a more specific region or state of another resource.
oa:hasSource
Relationship
source
The relationship between a Specific Resource and the resource that it is a more specific representation of.
There MUST be exactly 1 oa:hasSource relationship associated with a Specific Resource.
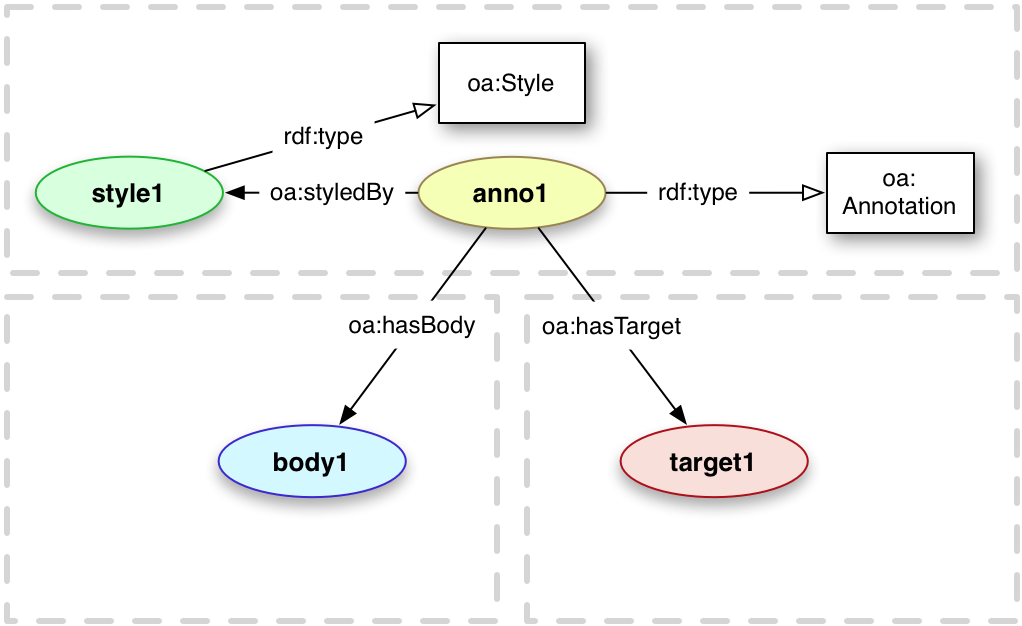
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <sptarget1> .
<sptarget1> a oa:SpecificResource ;
oa:hasSource <target1> .
4.2 Selectors
Many Annotations refer to part of a resource, rather than all of it, as the Target.
Examples include Annotations on an area within an image or video, a range of characters in text, a
time segment in an audio file or a slice of a dataset. Equally, the
segment may be the Body of the Annotation, where the comment is given
at a particular point in the video, or in a particular paragraph of
text.
A Selector is a Specifier which describes how to determine the
segment of interest from within the retrieved representation of the Source resource. The
nature of the Selector will be dependent on the type of the
representation for which the segment is conveyed. For example the
methods used to describe a section of an image will be very different
to the methods used to discover the correct paragraph of text, or the
correct slice of a dataset.
Only one Selector can be associated with a Specific Resource. If multiple Selectors are required,
either to express a choice between different optional, equivalent selectors, or a chain of selectors
that should all be processed, it is necessary to use the constructions described in the Multiplicity module.
Typically if all of the information needed to resolve the Selector (or other Specifier) is present within the graph, such as is the case for the FragmentSelector, TextQuoteSelector, TextPositionSelector and DataPositionSelector classes, then there is no need to have a resolvable resource that provides the same information. However for the SvgSelector any other Specifiers that have a representation with a life of its own, it may be easier or more efficient to have the [SVG] document resolvable separately from the Annotation via an HTTP URI.
It must also be noted that the model allows several equivalent expressions of the same segment of interest. For example, to describe a rectangular area, it is possible to use URIs with fragments directly (as in the Core document), the FragmentSelector class, or the SvgSelector. Similarly for plain text documents, either RFC 5147 or the Text Selectors could be used. While this is not optimal from an interoperability perspective, this could not be avoided at the same time as keeping the Web Annotation model flexible and compatible with existing specifications. It is RECOMMENDED that communities implement shared bridging strategies and follow the recommendations of the specification and any best practice documents wherever possible.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:Selector
Class
The super class for individual Selectors. This class is not used directly in Annotations, only its subclasses are.
oa:hasSelector
Relationship
selector
The relationship between a Specific Resource and a Selector.
There MUST be exactly 0 or 1 oa:hasSelector relationship associated with a Specific Resource.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <sptarget1> .
<sptarget1> a oa:SpecificResource ;
oa:hasSource <target1> ;
oa:hasSelector <selector1> .
<selector1> a oa:Selector .
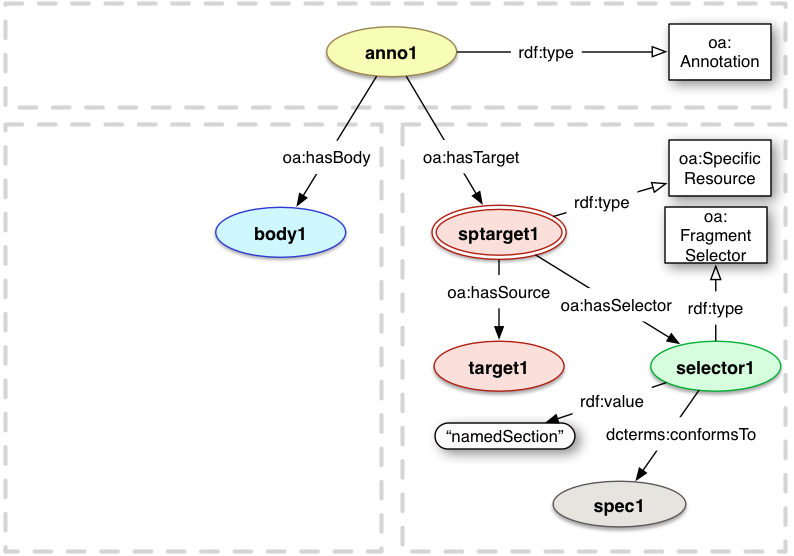
4.2.1 Fragment Selector
The web architecture defines a method of identifying a particular
segment of a resource, using the fragment part of the URI. This has
been used for media type specific fragments (such as XML and PDF) and
more recently for media fragments that are applicable to entire
classes of resources, such as Image and Video, regardless of their
exact media type.
The Web Annotation model defines a fragment-based Selector (oa:FragmentSelector) which allows
both existing and future fragment specifications to be used to describe the segment of interest.
The description of the segment is the syntax for the fragment identifier component
of the URI, and it is included in the Annotation graph via the rdf:value property.
Thus a fragment URI may be reconstructed by concatenating the
oa:hasSource resource's URI, plus a '#', plus the value.
For example, if the resource's URI was http://www.example.com/image.jpg
and the rdf:value property was "xywh=1,2,3,4", then the resulting URI would
be http://www.example.com/image.jpg#xywh=1,2,3,4.
It is RECOMMENDED to use oa:FragmentSelector rather than annotating the fragment URI directly, although consuming applications MUST be aware of both.
Publishing systems MAY rewrite fragment URIs into the corresponding oa:FragmentSelector form, except when the URI is for a Semantic Tag.
Clients MUST process the value of the FragmentSelector based on the standard that it conforms to, expressed using the
dcterms:conformsTo relationship. If that is not present, then the client should use the media
type of the Source resource to determine the meaning of the fragment. This is to prevent misinterpretation of the fragment
identifier component, which is by definition media type dependent. For example, it is possible to construct a fragment identifier
that looks like it conforms to the W3C Media Fragment specification
as part of an HTML anchor. Clients MUST therefore also use any State
information provided to be certain that the representation appropriate for the FragmentSelector is retrieved.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:FragmentSelector
Class
[subClass of
oa:Selector] A resource which describes the segment of interest in a
representation, through the use of the fragment identifier component of a URI.
rdf:value
Property
value
The contents of the
fragment identifier component of a URI that describes the segment of interest in the
resource.
The oa:FragmentSelector MUST have exactly 1 rdf:value property.
dcterms:conformsTo
Relationship
conformsTo
The Fragment Selector SHOULD have a dcterms:conformsTo relationship
with the object being the specification that defines the syntax of the fragment.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <sptarget1> .
<sptarget1> a oa:SpecificResource ;
oa:hasSelector <selector1> ;
oa:hasSource <target1> .
<selector1> a oa:FragmentSelector ;
dcterms:conformsTo <spec1> ;
rdf:value "namedSection" .
4.2.2 Range Selectors
There are several selectors that describe how to extract segments that have a start and end in linear data, such as extracting characters from text or bytes from data. Range selectors are also used to describe points within linear data, for example a cursor location for where to insert information into a web page. This is done by giving a 0 length selection.
Three Range Selectors are defined by the model, two for text and one for bitstreams.
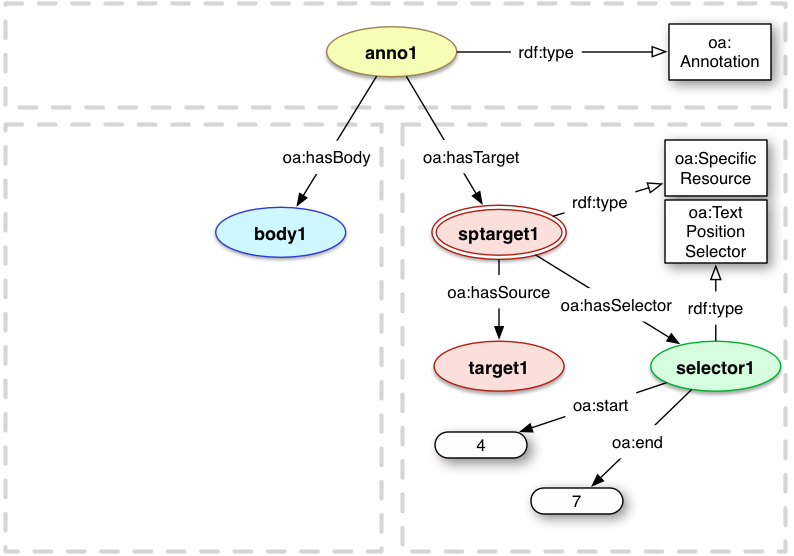
4.2.2.1 Text Position Selector
Any sublist of an ordered list of characters can be selected by starting at a particular point in the stream and reading forwards until an end point.
The start can be thought of as the position of a cursor in the list. Position 0 would be immediately before the first character, position 1 would be immediately before the second character, and so on. The start character is thus included in the list, but the end character is not as the cursor stops immediately before it.
For example, if the document was "abcdefghijklmnopqrstuvwxyz", the start was 4, and the end was 7, then the selection would be "efg".
The text MUST be normalized before counting characters.
HTML/XML tags should be removed, character entities should be replaced with the
character that they encode, unnecessary whitespace should be normalized, and so forth. The normalization routine may be performed automatically by a browser, and other clients should implement the DOM String Comparisons [DOM-Level-3-Core] method.
This allows the Selector to be used with different formats and still have the same semantics and utility. For a Selector that works from the bitstream rather than the rendered characters, please see the Data Position Selector.
The use of this Selector does not require text to be copied from the Source document into the
Annotation graph, unlike the Text Quote Selector, but is very brittle with regards to changes to the resource. Any edits may change the selection, and thus it is RECOMMENDED that a State
be additionally used to help identify the correct representation.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:TextPositionSelector
Class
[subClass of oa:Selector] The class for a Selector which describes a range of text based on its start and end positions.
oa:start
Property
start
The starting position of the segment of text. The first character in the full text is character position 0, and the character is included within the segment.
Each TextPositionSelector MUST have exactly 1 oa:start property.
oa:end
Property
end
The end position of the segment of text. The last character is not included within the segment.
Each TextPositionSelector MUST have exactly 1 oa:end property.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <sptarget1> .
<sptarget1> a oa:SpecificResource ;
oa:hasSource <target1> ;
oa:hasSelector <selector1> .
<selector1> a oa:TextPositionSelector ;
oa:start 4 ;
oa:end 7 .
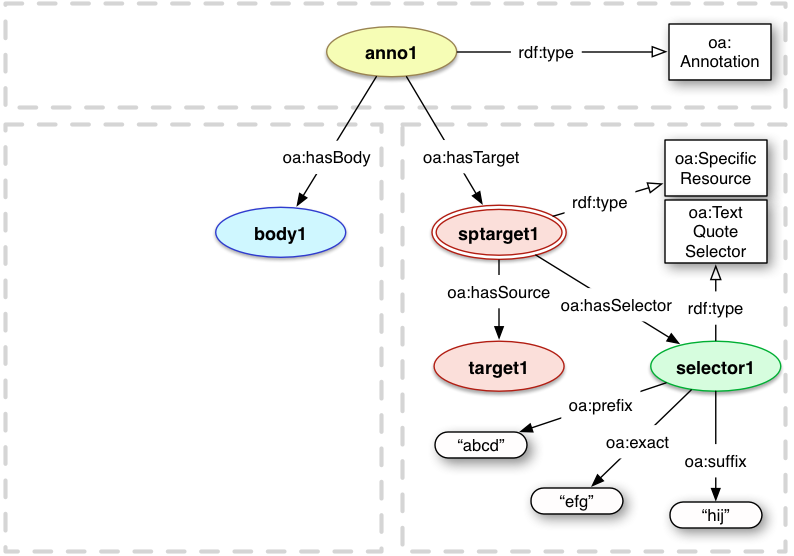
4.2.2.2 Text Quote Selector
This Selector describes a range of text by copying it, and including some range of text immediately before
and after it to distinguish between multiple copies of the same sequence of characters within the document.
The length of the prefix and suffix should be determined from the context of the document.
For example, if the document were again "abcdefghijklmnopqrstuvwxyz",
one could select "efg" by a prefix of "abcd", the quotation of "efg"
and a suffix of "hijk".
The text MUST be normalized before recording.
Thus HTML/XML tags should be removed, character entities should be replaced with the
character that they encode, unnecessary whitespace should be normalized, and so forth.
The normalization routine may be performed automatically by a browser, and other clients should implement the DOM String Comparisons method. This allows the Selector to be used with different encodings and still have the same semantics and utility.
If the content is under copyright, then this method of selecting text is potentially dangerous.
A user might select the entire text of the document to annotate, and a client naïvely copy
it into the Annotation and publish it openly on the web. For static texts with access and/or
distribution restrictions, the use of the Text Position Selector is perhaps more appropriate.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:TextQuoteSelector
Class
[subClass of oa:Selector] The class for a Selector that describes a textual segment by means of quoting it, plus passages before or after it.
oa:exact
Property
exact
A copy of the text which is being selected, after normalization.
Each TextQuoteSelector MUST have exactly 1 oa:exact property.
oa:prefix
Property
prefix
A snippet of text that occurs immediately before the text which is being selected.
Each TextQuoteSelector SHOULD have exactly 1 oa:prefix property, and MUST NOT have more than 1.
oa:suffix
Property
suffix
The snippet of text that occurs immediately after the text which is being selected.
Each TextQuoteSelector SHOULD have exactly 1 oa:suffix property, and MUST NOT have more than 1.
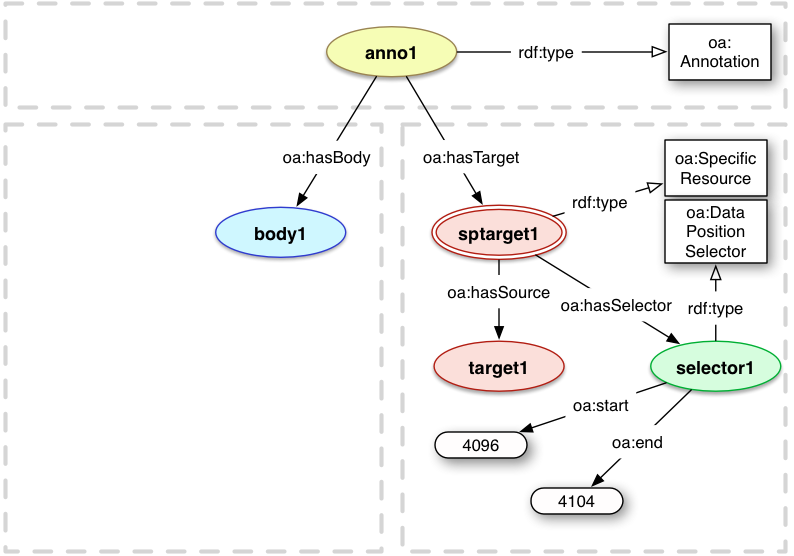
Very similar to the Text Position Selector, the Data Position Selector uses the same properties but works at the byte in bitstream level rather than the character in text level. This is useful, for example, for annotating segments of disk images for forensic purposes, or the part of a stream of data recorded from a sensor.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:DataPositionSelector
Class
[subClass of oa:Selector] The class for a Selector which describes a range of data based on its start and end positions within the byte stream.
oa:start
Property
start
The starting position of the segment of data. The first byte is character position 0.
Each DataPositionSelector MUST have exactly 1 oa:start property.
oa:end
Property
end
The end position of the segment of data. The last character is not included within the segment.
Each DataPositionSelector MUST have exactly 1 oa:end property.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <sptarget1> .
<sptarget1> a oa:SpecificResource ;
oa:hasSource <target1> ;
oa:hasSelector <selector1> .
<selector1> a oa:DataPositionSelector ;
oa:start 4096 ;
oa:end 4104 .
4.2.3 Area Selectors
Although simple rectangular areas can be described using media fragment selectors, it is often
useful to be able to describe circles, ellipses and arbitrary polygons.
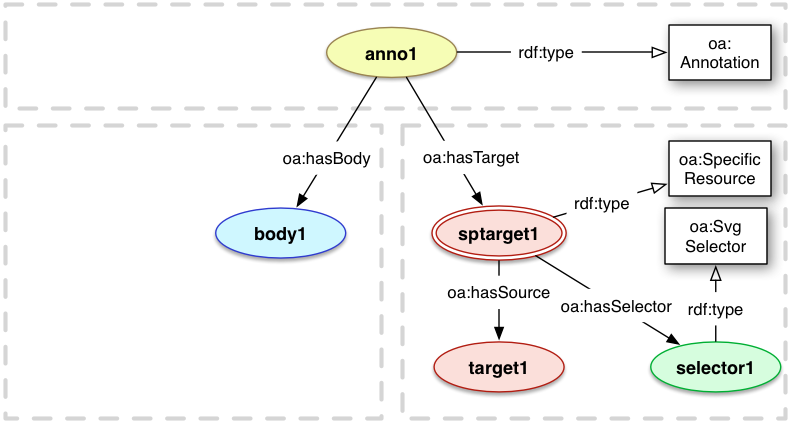
4.2.3.1 SVG Selector
An SvgSelector defines an area through the use of
the Scalable Vector Graphics
standard. The content of the Selector is a valid SVG document.
It is RECOMMENDED that the document contain only a single shape element and that element SHOULD be one
of: path, rect, circle, ellipse, polyline,
polygon or g. The g element SHOULD
be used only to construct a multi-element group, for example to define a
donut shape requiring an outer circle and a clipped inner circle.
The dimensions of both the shape and the SVG canvas MUST be relative to the dimensions of
the Source resource. For example, given an image which is 600 pixels
by 400 pixels, and the desired section is a circle of 100 pixel radius
at the center of the image, then the SVG element would be:
<circle cx="300" cy="200" r="100"/>
It is NOT RECOMMENDED to include style information within the SVG
element, nor Javascript, animation, text or other non-shape oriented
information. Clients SHOULD ignore such information if present.
The SVG document MAY be a separate resource, or embedded within the annotation's serialization.
In the first example below it is a separate resource and if the URI http://example.org/selector1 was dereferenced, it would return an SVG document. In the second example, the content of the SVG resource is embedded using the same pattern as embedding a Body.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:SvgSelector
Class
[subClass of oa:Selector] The class for a Selector which defines a shape using the SVG standard.
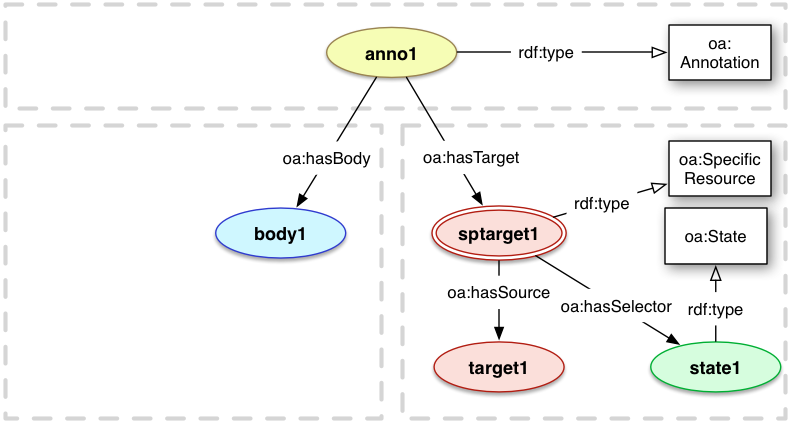
The State Specifier describes the intended state of a Body or Target resource as
applicable to the particular Annotation, and thus gives a consuming client
the information needed to retrieve the correct representation of that resource.
As web resources change over time, it might include a link to an
archived copy of the Source resource, or the timestamp at which the
Annotation applies to assist in discovering appropriate archived
representations. Resources may have
multiple representations in different formats, and the Annotation may only apply to one of
them, and thus the State could describe how to retrieve the
representation in the correct format directly from the Source. Other facets include fixity or checksum
information to determine whether the retrieved representation is the same as the annotated one,
whether the resource requires authentication to retrieve, the
user-agent string to send to the web server, and so forth.
Consuming clients MUST process a supplied State before processing any supplied Selector or style information.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:State
Class
A
resource which describes how to retrieve a representation
of the Source resource that is appropriate for the Annotation. This class is not used directly in Annotations, only its subclasses are.
oa:hasState
Relationship
state
The relationship
between a oa:SpecificResource and an oa:State resource.
There MAY be 0 or 1 oa:hasState relationship for each
SpecificResource.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <sptarget1> .
<sptarget1> a oa:SpecificResource ;
oa:hasState <state1> ;
oa:hasSource <target1> .
4.3.1 Time State
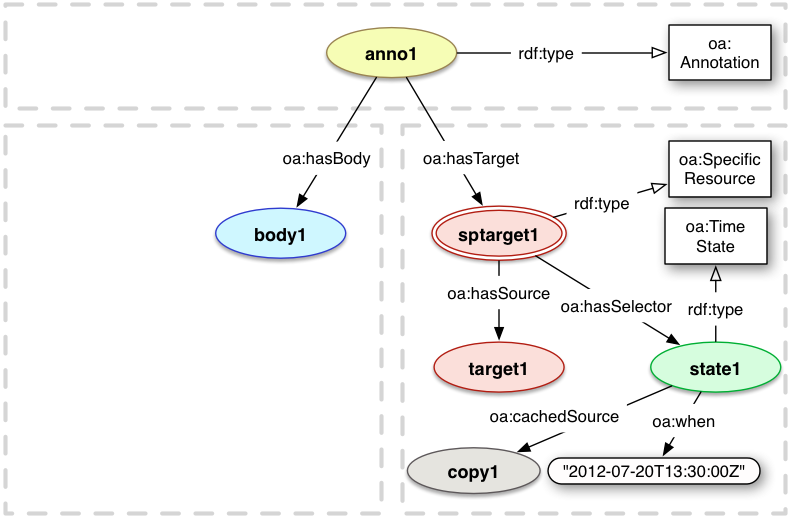
A Time State resource records the time at which the resource is appropriate for the Annotation, typically the time that the Annotation was created. Consuming applications can then use that information to discover an appropriate representation of the resource from that time, for example using the Memento [rfc7089] protocol. The State may also have a link directly to an appropriate cached or archived copy of the resource's representation from that time.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:TimeState
Class
A
resource which describes how to retrieve a representation
of the Source resource that is temporally appropriate for the Annotation.
oa:when
Property
when
The timestamp at which the
Source resource should be interpreted for the Annotation. The timestamp MUST be expressed in the xsd:dateTime format, and SHOULD have a timezone specified.
There MAY be 0 or more oa:when properties per TimeState, but there MUST be at least one of oa:when and oa:cachedSource. If there is more than 1, each gives an alternative timestamp at which the Source may be interpreted.
oa:cachedSource
Relationship
cached
A link to a copy of the Source resource's
representation, appropriate for the Annotation.
There MAY be 0 or more oa:cachedSource relationships per TimeState, but there MUST be at least one of oa:cachedSource and oa:when. If there is more than 1, each gives an alternative copy of the representation.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <sptarget1> .
<sptarget1> a oa:SpecificResource ;
oa:hasState <state1> ;
oa:hasSource <target1> .
<state1> a oa:TimeState ;
oa:cachedSource <copy1> ;
oa:when "2012-07-20T13:30:00Z" .
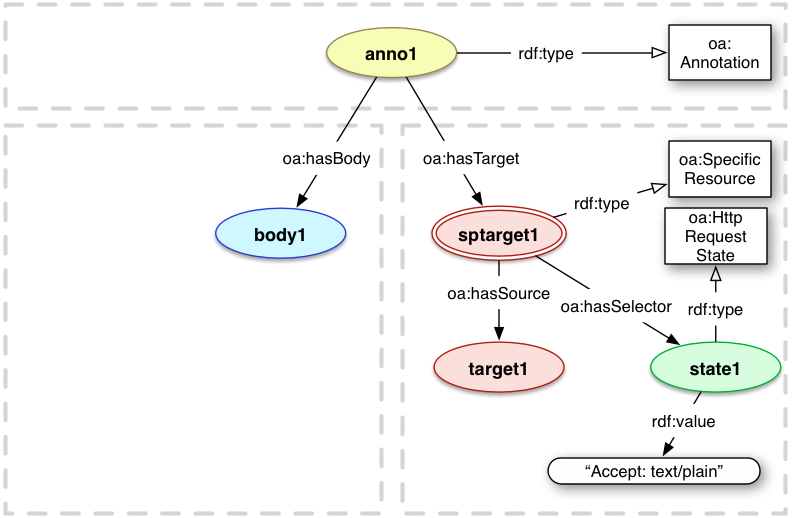
4.3.2 Request Header State
As there are potentially many representations that can be delivered from a resource with a single URI, and a
Specific Resource may only apply to one of them, it is important to be able to record the HTTP Request headers
that need to be sent to retrieve the correct representation. The HttpRequestState resource maintains a copy
of the headers to be replayed when obtaining the representation.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:HttpRequestState
Class
A
resource which describes how to retrieve an appropriate representation
of the Source resource for the Annotation, based on the HTTP Request headers to send to the server.
rdf:value
Property
value
The HTTP request headers as a single, complete string, exactly as they would appear in an HTTP request.
There MUST be exactly 1 rdf:value property per HTTPRequestState.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <sptarget1> .
<sptarget1> a oa:SpecificResource ;
oa:hasState <state1> ;
oa:hasSource <target1> .
<state1> a oa:HttpRequestState ;
rdf:value "Accept: text/plain" .
4.4 Styles
The interpretation of a particular Annotation may rely on rendering
style being consistent between clients. For example, if the Body
refers to the part of an image highlighted in yellow, as compared to the red highlighted part,
then these colors need to be maintained. Equally, annotators
may convey information via the styling alone, perhaps only to
themselves. In order for this implicit information not to be lost between systems,
the styling needs to be consistently represented. For example, an annotator may
know that green highlights are intended to be referred back to, but
that they disagree with sections highlighted in red.
The Style resource is associated with the Annotation itself, and the content of the resource provides the rendering hints about the Annotation's constituent resources. Styles may also require additional information to be added to the Annotation graph for processing. If there are multiple Style resources that must be associated with the Annotation, then the use of the Multiplicity Constructs is RECOMMENDED.
Consuming applications MAY process these instructions, and publishing systems MUST NOT assume that they will be processed; they are only provided as hints rather than requirements. If a client cannot understand or act upon the style, then it MAY continue to render the selection or resource regardless.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:Style
Class
A
resource which describes the style in which the selection or resource
should be rendered. This class is not used directly in Annotations, only its subclasses are.
oa:styledBy
Relationship
stylesheet
The relationship between an Annotation and the oa:Style.
There MAY be 0 or 1 styledBy relationships for each Annotation.
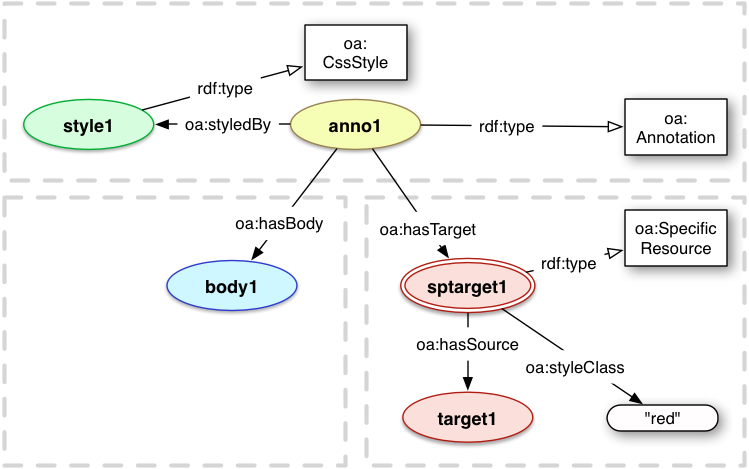
The standard style language for the web is the W3C's Cascading Style Sheets [CSS2]. It promotes the separation of presentation layer and the content layer for HTML and XML structured documents.
CSS is used in the Web Annotation model via the oa:CssStyle subClass of oa:Style. It uses the common approach of class-selectors and the class label is attached to a Specific Resource using the oa:styleClass property. This class label must only be attached to Specific Resources, as it is not universally true that the Source resource has that class.
Each block in the CSS resource has the format:
.classname { css-value }
And thus to associate the color red with a Specific Resource that has a class "red", one would use in the CSS:
.red { color: red }
And the Specific Resource (spres1) to be styled would have the property:
<spres1> oa:styleClass "red" .
When rendering a Specific Resource, consuming applications SHOULD check to see if it has a oa:styleClass property. If it does, then the application SHOULD attempt to locate the appropriate selector in the CSS document, and then apply the css-value block. If a Specific Resource has a styleClass, but no such class is described by a oa:CssStyle attached to the Annotation, then the oa:styleClassMUST be silently ignored.
The CSS resource MAY have its own dereferenceable URI that provides the information, or it may be embedded within the Annotation.
In the first example below, the CSS resource must be retrieved from its URI http://example.org/style1, whereas in the second example it is embedded within the annotation.
It bears repeating that the exact rendering of the Specific Body or Target is, ultimately, up to the user's client.
It is understood that not all consuming clients will include CSS parsers, and thus be unable to process the styling information.
The use of this Style does not preclude non-HTML based clients, although implementation may be more difficult even if the information can be parsed. It must be expected that such clients will not process all, or even any, of the styling hints provided in the CSS Style resource.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:CssStyle
Class
[subClass of oa:Style] A resource which describes styles for resources participating in
the Annotation using CSS.
oa:styleClass
Property
styleClass
The string name of the class used in the CSS description that should be applied to the Specific Resource.
There MAY be 0 or more styleClass properties on a Specific Resource.
{"@id":"http://example.org/anno1","@type":"oa:Annotation","stylesheet":{"@id":"http://example.org/style1","@type":["oa:CssStyle","oa:EmbeddedContent"],"value":".red { color: red }","format":"text/css"},"body":{"@id":"http://example.org/body1"},"target":{"@id":"http://example.org/sptarget1","@type":"oa:SpecificResource","source":"http://example.org/target1","styleClass":"red"}}
Example 56: CSS Style, embedded (Turtle)
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <sptarget1> ;
oa:styledBy <style1> .
<style1> a oa:CssStyle, oa:EmbeddedContent ;
dc:format "text/css" ;
rdf:value ".red { color: red }" .
<sptarget1> a oa:SpecificResource ;
oa:hasSource <target1> ;
oa:styleClass "red" .
4.5 Scope of a Resource
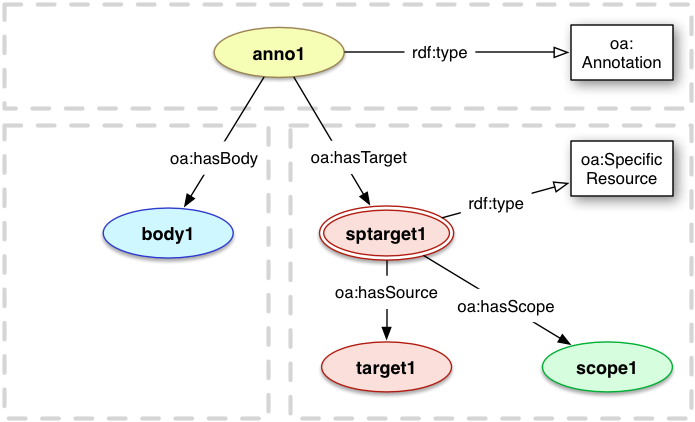
It is sometimes important for an Annotation to capture the context in which it was made, in terms of the resources that the annotator was viewing or using at the time. For example, it may be important to know that an annotation on a particular image was made in the context of one web page rather than another. This does not imply an assertion that the annotation is only valid for the image in the context of that page, it just records that the page was being viewed. This might also be useful for annotating a resource in the context of a particular collection.
As such scoping information is only true for a particular Annotation, it must be attached to a Specific Resource,
and not to the Source directly. This is true even if there is neither a Selector nor a State, as other Annotations that refer to the Source would otherwise incorrectly inherit this assertion. The object of the oa:hasScope relationship is the resource that somehow scopes or provides the context
for the resource in this Annotation.
For example, in the diagram below, the resource named "scope1" could be the webpage "http://www.example.com/index.html",
and the Source resource "target1" could be an image "http://www.example.com/images/logo.jpg", where the
Body is a comment that it should not be in that page.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:hasScope
Relationship
scope
The relationship between a Specific Resource and the resource that provides the scope or context for it in this Annotation.
There MAY be 0 or more hasScope relationships for each Specific Resource.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <sptarget1> .
<sptarget1> a oa:SpecificResource ;
oa:hasScope <scope1> ;
oa:hasSource <target1> .
5. Multiplicity
There are many use cases where an Annotation comprises multiple Bodies, Targets or both.
The semantics for multiple Bodies and Targets associated directly with the Annotation are
that each resource is related to the others individually, however this is not always the case. It is useful to
associate the Annotation with one resource from a group of alternatives, for example to have a comment that is
available in three different languages and for the user's client to display only the most appropriate one.
Or to annotate a set of resources where all of the resources are equally important, as is the case when comparing resources with each other. In this case, the comment does not apply individually to each resource, it applies to all of them together.
Finally, it is useful to consider ordering that set of resources, particularly for grouping Selectors that must be processed in the correct sequence to extract the intended segment.
The Web Annotation model includes three multiplicity constructs to fulfil these requirements:
oa:Choice, oa:Composite and oa:List respectively. These nodes are used as the object of the oa:hasBody, oa:hasTarget, oa:hasSelector, oa:hasState, oa:styledBy and oa:hasScope relationships. The resources that make up the multiplicity construct may either any type of resource, including further such multiplicity constructs. For example, a oa:Composite may have two items, one of which is a resource and the other an oa:Choice between two further resources.
Multiplicity Constructs SHOULD have a globally unique URI to identify them, such as a UUID URN. The URI MAY be resolvable, and if it is then the description of the construct MUST be returned when it is dereferenced. This identity recommendation is not typical for the equivalent classes of rdf:Alt, rdf:Bag and rdf:List, and further processing and modeling requirements based on those classes could not be asserted. The Constructs MAY not be given a URI if it is not considered important that they be referenced directly by other Annotations or systems.
The option of having a simple string literal for the body is NOT possible when using Multiplicity constructs, and the embedded textual body resource pattern MUST be used.
Note Well: All of the examples below display only a single construction at a single level,
however the same patterns follow for all of the relationships and structures composed of more than one grouping resource.
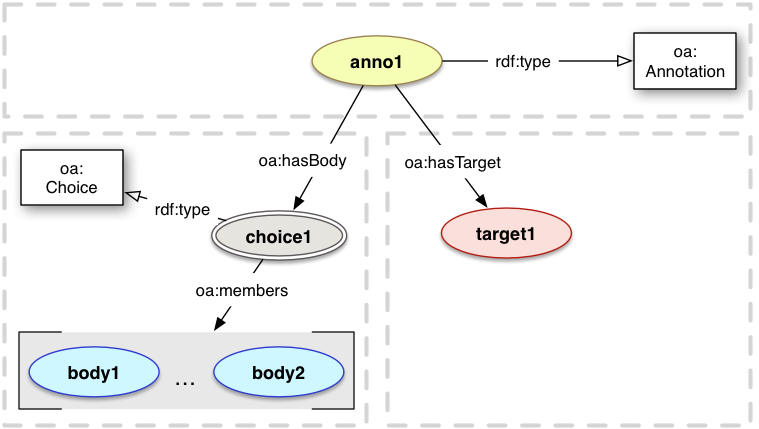
5.1 Choice
A Choice has an ordered list of resources from which an application that is consuming the Annotation should select only one to process or display. The order is given from the most preferable to least preferable. For Specifiers, the Client should choose one of the constituent resources to use, as they are somehow comparable or
equivalent. Clients MAY use any algorithm to determine which resource to choose, and SHOULD make use of the information present in the Annotation to do so automatically, or MAY present a list and require the user to make the decision.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:Choice
Class
A multiplicity construct that conveys to a consuming application that it should select one of the constituent resources to display to the user, and not render all of them. This construct is equivalent to the rdf:Alt container class.
oa:members
Relationship
members
An rdf:List giving the ordered list of resources to choose from.
<anno1> a oa:Annotation ;
oa:hasTarget <target1> ;
oa:hasBody [
a oa:Choice ;
oa:members (<body1><body2>)
] .
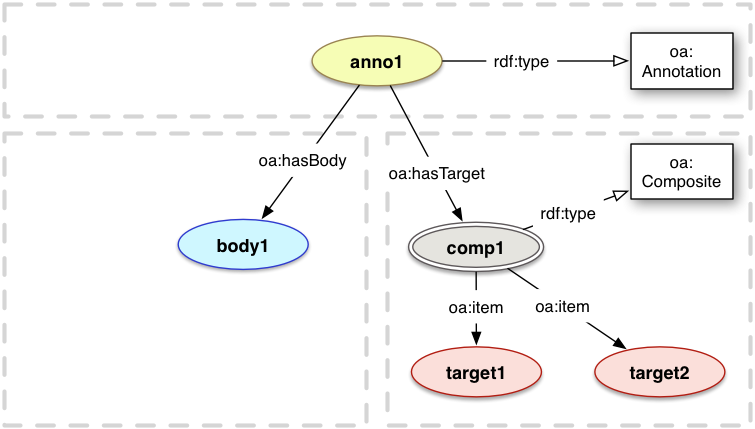
5.2 Composite
A Composite is a set of resources that are all required for an Annotation to be correctly interpreted.
Examples include an Annotation that compares the differences between two resources, or an Annotation where the
Body consists of both a human readable review and a necessary structured data file. These are different
from individual Bodies and Targets, as each would individually annotate or be annotated. It is also important
to be able to combine Specifiers, such as using two Selectors where one gives the time range in a video,
and a second gives a non-rectangular area to plot over that time range.
The data model defines a class oa:Composite and the oa:item relationship to each of the resources in the set. Each Composite MUST have two or more constituent resources, and there is no order given between them.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:Composite
Class
[subClass of rdf:Bag] A multiplicity construct that conveys to a consuming application that all of the constituent resources are required for the Annotation to be correctly interpreted. This construct is equivalent to the container class rdf:Bag.
oa:item
Relationship
item
[subProperty of rdfs:member] The relationship between a Composite and its constituent resources.
A Composite MUST have 1 or more items.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget [
a oa:Composite ;
oa:item <target1> ;
oa:item <target2>
] .
5.3 List
A List is a multiplicity construct that provides an order to its constituent resources in the context of the Annotation.
Examples of use are particularly strong for Selectors, where a processing application must first make one selection then another,
and if it did it in the other order, the result would be incorrect. This includes situations like first referencing a
particular page in a book that does not have its own URI, and then doing a text selection within that page. Another use case would be to assign order to a set of Styles to give precedence to the definition of classes within them.
Vocabulary
Item
Type
JSON-LD Key
Description
oa:List
Class
[subClass of oa:Composite] A multiplicity construct that conveys to a consuming application that all of the constituent resources are required for the Annotation to be correctly interpreted, and in a particular order.
<anno1> a oa:Annotation ;
oa:hasBody <body1> ;
oa:hasTarget <sptarget1> .
<sptarget1> a oa:SpecificResource ;
oa:hasSource <target1> ;
oa:hasSelector [
a oa:List ;
oa:members ( <selector1><selector2> )
] .
A. Namespaces
The Web Annotation Data Model defines a namespace for its classes and properties, and uses several others as listed below.
The namespace URI will always remain the same, even if the data model changes.
The following namespaces are used in this specification:
The RECOMMENDED serialization format is [JSON-LD]. This is to enable web-browser based implementations to easily consume Annotations using tools and methods familiar to developers.
The Context presented below is RECOMMENDED to ensure consistency between implementations, and can be
referenced as http://www.w3.org/xxx/yyy.
The following is a Context description that is RECOMMENDED for use in systems that implement the Web Annotation data model. Its use results in serializations in the style of the examples in this document.
{"@id":"http://example.org/anno1","@type":"oa:Annotation","motivation":["oa:tagging","oa:commenting"],"annotatedBy":{"@id":"http://example.org/agent1","@type":"foaf:Person","name":"A. Person","nick":"agent1"},"serializedBy":{"@id":"http://example.org/agent2","@type":"prov:SoftwareAgent","name":"Code v2.1","homepage":"http://example.org/agent2/homepage1"},"body":[{"@type":"oa:SemanticTag","related":"http://dbpedia.org/resource/London"},{"@type":"oa:EmbeddedContent","value":"One of my favorite cities","format":"text/plain","language":"en"}],"target":{"@id":"http://example.org/sptarget1","@type":"oa:SpecificResource","source":"http://example.org/source1","selector":{"@id":"http://example.org/selector1","@type":"oa:TextPositionSelector","start":4096,"end":4104}}}
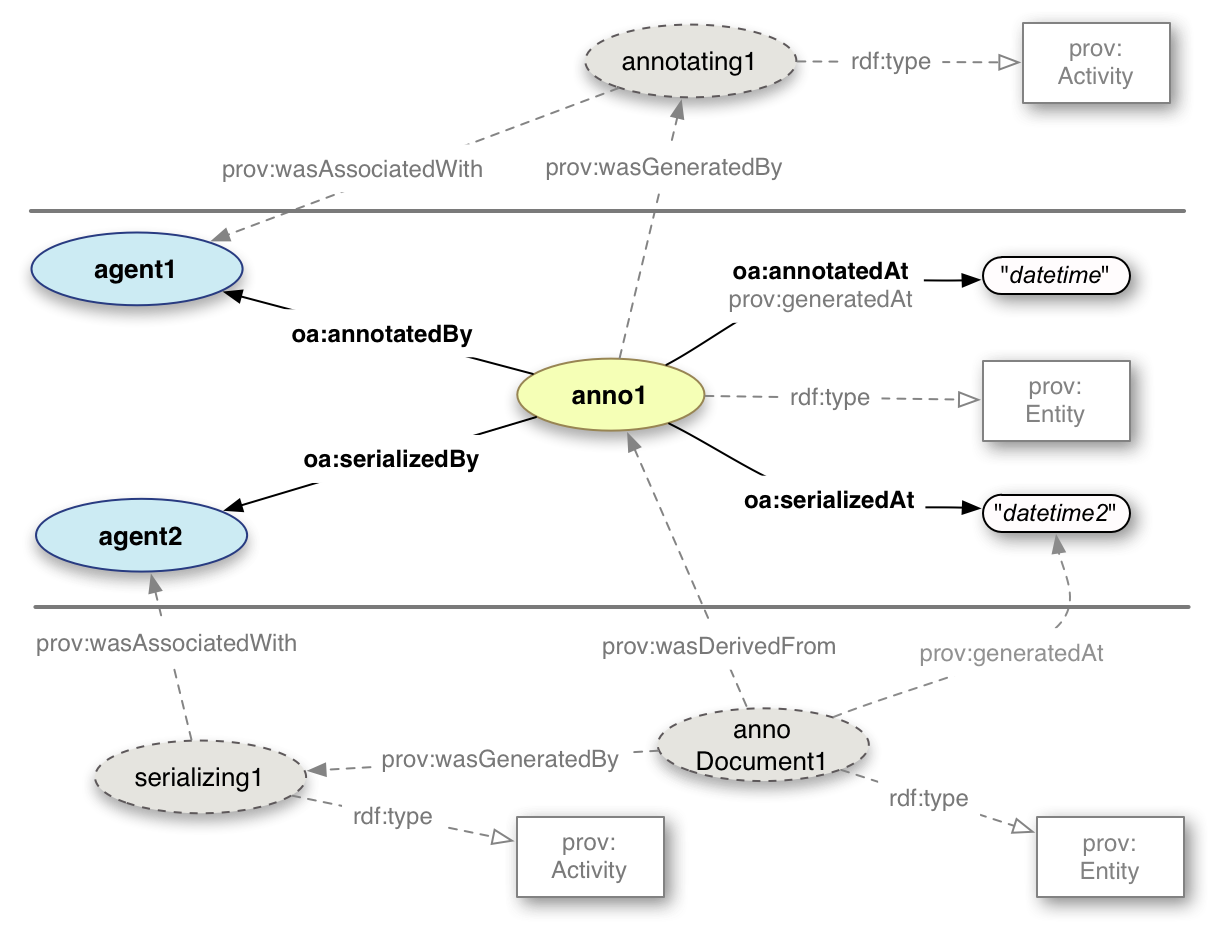
The Web Annotation data model specifies a very simple method of expressing the provenance of an Annotation.
This is able to be mapped into the richer and more complex PROV [prov-o] model.
The PROV model is expressed in terms of Activities and Entities consumed or produced by those Activities.
There are two Entities in the Web Annotation model, which for expediency and simplicity are collapsed into just oa:Annotation.
These are the Annotation document, and the concept that the Annotation embodies or describes.
This is the distinction between oa:annotatedBy and oa:annotatedAt,
versus oa:serializedBy and oa:serializedAt. In the PROV model we have to split these apart again.
We use the oa:Annotation for the concept, and thus still require an Annotation document.
There are also two Activities, Annotating and Serializing, which produce these Entities.
In this case, Annotating is the process of annotating a resource, and should not be confused or conflated
with the Motivation of the same name. Serializing is the process by which the Annotation Document is created.
The Annotation document is derived from the concept, which necessarily comes first.
The concept was produced as the outcome of the Annotating process, which was performed by an Agent,
the object of oa:annotatedBy. The Annotation document was produced as the outcome of the Serializing process,
which was also performed by an Agent, the object of oa:serializedBy. Both of these processes happened at a
particular point in time, oa:annotatedAt and oa:serializedAt, respectively.
Fig. 32Provenance Mapping
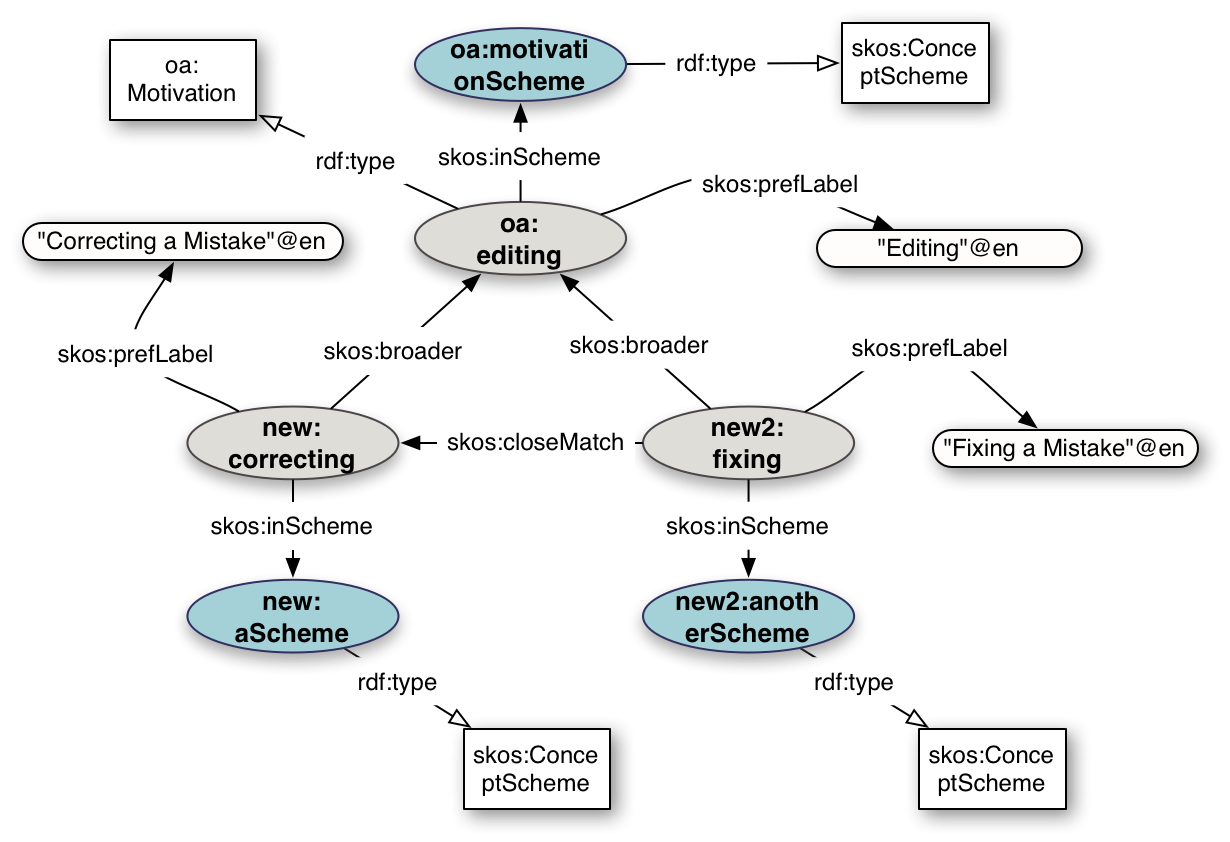
E. Extending Motivations
Although the list of Motivations in the specification is derived from an extensive survey of the annotation landscape,
there are many situations where more exact definitions of Motivation are required or desirable.
In these cases it is RECOMMENDED to create a new Motivation resource and relate it to one or more that already exist.
New Motivations MUST be instances of oa:Motivation, which is a subClass of skos:Concept.
The skos:broader relationship SHOULD be asserted between the new Motivation and at least one existing Motivation, if there are any that are broader in scope. Other relationships, such as skos:relatedMatch, skos:exactMatch and skos:closeMatch, SHOULD also be asserted to concepts created by other communities.
Vocabulary
Fig. 33Extending Motivations
F. Acknowledgements
The Web Annotation Working Group gratefully acknowledges the contributions of the Open Annotation Community Group. The output of the Community Group was fundamental to the current data model.
Changes in this specification from the Community Group's model are:
Allow a string literal as the body
Replace the ContentAsText construction which was not taken through the standardization process
Align Semantic Tags, and ensure that the class is not associated with arbitrary URIs
Use intuitive and memorable names for the JSON-LD keys
Improve the Choice and List constructions by not multi-classing rdf:List, and instead reference one.
Defer embedded graphs until post FPWD
Remove equivalence as a much broader problem than just annotation
Ian Hickson; Robin Berjon; Steve Faulkner; Travis Leithead; Erika Doyle Navara; Edward O'Connor; Silvia Pfeiffer. HTML5. 28 October 2014. W3C Recommendation. URL: http://www.w3.org/TR/html5/